1. Introduction
Transfer entropy (TE) is an information-theoretic statistic measurement, which aims to measure an amount of time-directed information between two dynamical systems. Given the past time evolution of a dynamical system
, TE from another dynamical system
to the first system
is the amount of Shannon uncertainty reduction in the future time evolution of
when including the knowledge of the past evolution of
. After its introduction by Schreiber [
1], TE obtained special attention in various fields, such as neuroscience [
2–
8], physiology [
9–
11], climatology [
12] and others, such as physical systems [
13–
17].
More precisely, let us suppose that we observe the output
Xi ∈ ℝ,
i ∈ ℤ, of some sensor connected to
. If the sequence
X is supposed to be an
m-th order Markov process,
i.
e., if considering subsequences
, the probability measure
(defined on measurable subsets of real sequences) attached to
X fulfills the
m-th order Markov hypothesis:
then the past information
(before time instant
i + 1) is sufficient for a prediction of
Xi+k, k ≥ 1, and can be considered as an
m-dimensional state vector at time
i (note that, to know from X the hidden dynamical evolution of
, we need a one-to-one relation between
and the physical state of
at time
i). For the sake of clarity, we introduce the following notation:
,
i = 1, 2, …,
N, is an independent and identically distributed (IID) random sequence, each term following the same distribution as a random vector (
Xp, X−, Y−) ∈ ℝ
1+m+n whatever
i (in
Xp,
X−,
Y−, the upper indices “p” and “-” correspond to “predicted” and “past”, respectively). This notation will substitute for the notation
,
i = 1, 2, …,
N, and we will denote by
,
,
and
the spaces in which (
Xp, X−, Y−), (
Xp, X−), (
X−, Y−) and
X− are respectively observed.
Now, let us suppose that a causal influence exists from
on
and that an auxiliary random process
Yi ∈ ℝ,
i ∈ ℤ, recorded from a sensor connected to
, is such that, at each time
i and for some
n > 0,
is an image (not necessarily one-to-one) of the physical state of
. The negation of this causal influence implies:
If
Equation (2) holds, it is said that there is an absence of information transfer from
to
. Otherwise, the process
X can be no longer considered strictly a Markov process. Let us suppose the joint process (
X,
Y) is Markovian,
i.
e., there exist a given pair (
m′,
n′), a transition function f and an independent random sequence
ei,
i ∈ ℤ, such that
, where the random variable
ei+1 is independent of the past random sequence (
Xj, Yj, ej),
j ≤
i, whatever
i. As
where
g is clearly a non-injective function, the pair
,
i ∈ ℤ, corresponds to a hidden Markov process, and it is well known that this observation process is not generally Markovian.
The deviation from this assumption can be quantified using the Kullback pseudo-metric, leading to the general definition of TE at time
i:
where the ratio in
Equation (3) corresponds to the Radon–Nikodym derivative [
18,
19] (
i.
e., the density) of the conditional measure
with respect to the conditional measure
Considering “log” as the natural ogarithm, information is measured in natural (nats). Now, given two observable scalar random time series
X and
Y with no
a priori given model (as is generally the case), if we are interested in defining some causal influence from
Y to
X through TE analysis, we must specify the dimensions of the past information vectors
X− and
Y−,
i.
e.,
m and
n. Additionally, even if we impose them, it is not evident that all of the coordinates in
and
will be useful. To deal with this issue, variable selection procedures have been proposed in the literature, such as uniform and non-uniform embedding algorithms [
20,
21].
If the joint probability measure
is derivable with respect to the Lebesgue measure
µn+m+1 in ℝ
1+m+n (
i.
e., if
is absolutely continuous with respect to
µn++m+1), then the pdf (joint probability density function)
and also the pdf for each subset of
exist, and TE
Y→X,i can then be written (see
Appendix A):
or:
where
(
U) denotes the Shannon differential entropy of a random vector
U. Note that, if the processes
Y and
X are assumed to be jointly stationary, for any real function
g : ℝ
m+n+1 → ℝ, the expectation
does not depend on
i. Consequently, TE
Y→X,i does not depend on
i (and so can be simply denoted by TE
Y→X), nor all of the quantities defined in
Equations (3) to
(5). In theory, TE is never negative and is equal to zero if and only if
Equation (2) holds.
According to Definition
(3), TE is not symmetric, and it can be regarded as a conditional mutual information (CMI) [
3,
22] (sometimes also named partial mutual information (PMI) in the literature [
23]). Recall that mutual information between two random vectors
X and
Y is defined by:
and TE can be also written as:
Considering the estimation
of TE, TE
Y→X, as a function defined on the set of observable occurrences (
xi, yi),
i = 1, …,
N, of a stationary sequence (
Xi, Yi),
i = 1, …,
N, and
Equation (5), a standard structure for the estimator is given by (see
Appendix B):
where
U1,
U2,
U3 and
U4 stand respectively for (
X−,
Y−), (
Xp,
X−), (
Xp,
X−,
Y−) and
X−. Here, for each
n,
is an estimated value of log (
pU (
un)) computed as a function
fn (
u1, …,
uN) of the observed sequence
un,
n = 1, …,
N. With the
k-NN approach addressed in this study,
fn (
u1, …,
uN) depends explicitly only on
un and on its
k nearest neighbors. Therefore, the calculation of
definitely depends on the chosen estimation functions
fn. Note that if, for
N fixed, these functions correspond respectively to unbiased estimators of log (
p (
un)), then
is also unbiased; otherwise, we can only expect that
is asymptotically unbiased (for
N large). This is so if the estimators of log (
pU (
un)) are asymptotically unbiased.
Now, the theoretical derivation and analysis of the most currently used estimators
for the estimation of
generally suppose that u1, …, uN are N independent occurrences of the random vector U, i.e., u1, …, uN is an occurrence of an independent and identically distributed (IID) sequence U1, …, UN of random vectors
. Although the IID hypothesis does not apply to our initial problem concerning the measure of TE on stationary random sequences (that are generally not IID), the new methods presented in this contribution are extended from existing ones assuming this hypothesis, without relaxing it. However, the experimental section will present results not only on IID observations, but also on non-IID stationary autoregressive (AR) processes, as our goal was to verify if some improvement can be nonetheless obtained for non-IID data, such as AR data.
If we come back to mutual information (MI) defined by
Equation (6) and compare it with
Equations (5), it is obvious that estimating MI and TE shares similarities. Hence, similarly to
Equation (8) for TE, a basic estimation
of
from a sequence (
xi, yi),
i = 1, …,
N, of
N independent trials is:
In what follows, when explaining the links among the existing methods and the proposed ones, we refer to
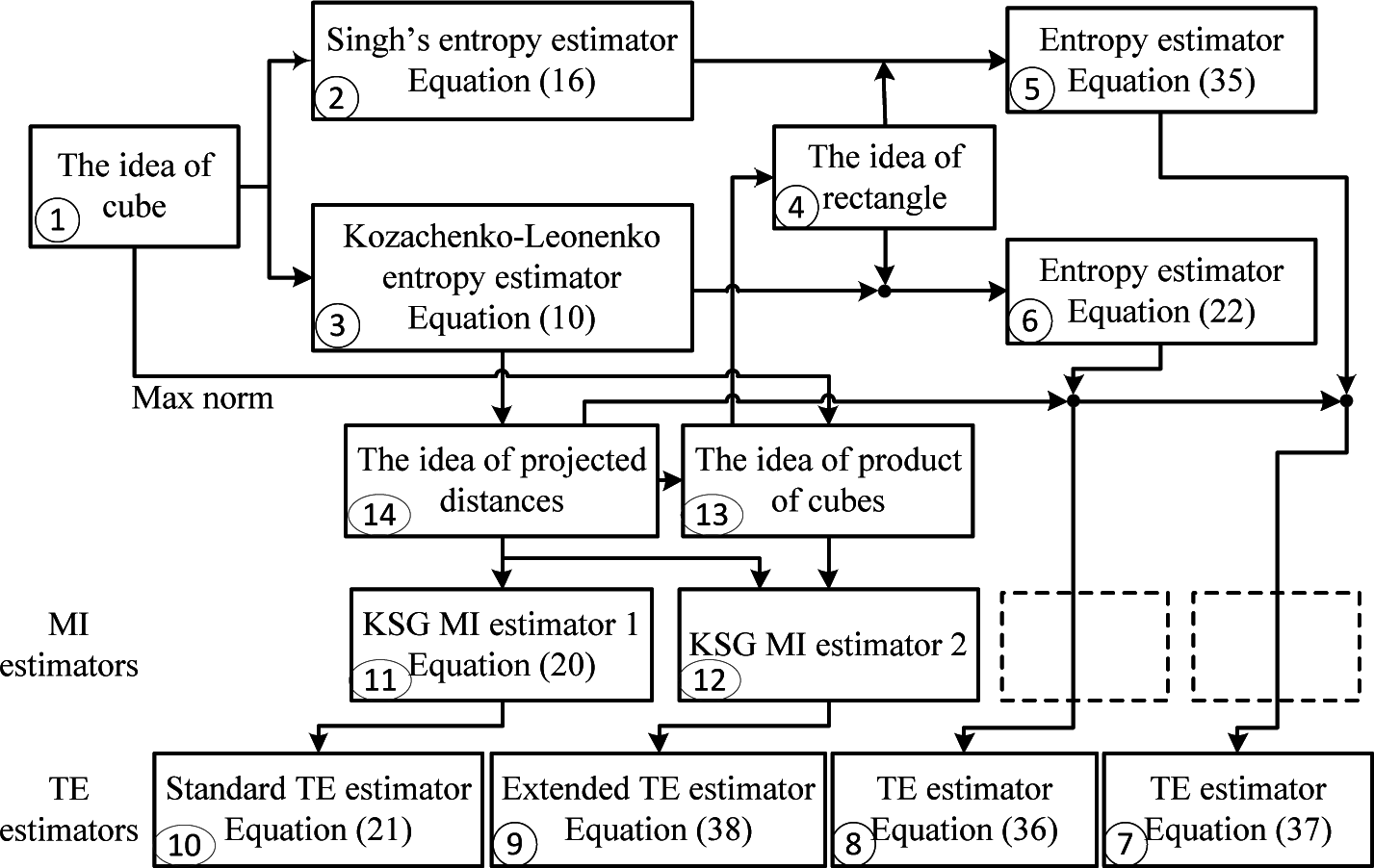
Figure 1. In this diagram, a box identified by a number
k in a circle is designed by box ⓚ.
Improving performance (in terms of bias and variance) of TE and MI estimators (obtained by choosing specific estimation functions
) in
Equations (8) and
(9), respectively) remains an issue when applied on short-length IID (or non-IID) sequences [
3]. In this work, we particularly focused on bias reduction. For MI, the most widely-used estimator is the Kraskov–Stögbauer–Grassberger (KSG) estimator [
24,
31], which was later extended to estimate transfer entropy, resulting in the
k-NN TE estimator [
25–
27,
32–
35] (adopted in the widely-used TRENTOOL open source toolbox, Version 3.0). Our contribution originated in the Kozachenko–Leonenko entropy estimator summarized in [
24] and proposed beforehand in the literature to get an estimation
of the entropy
of a continuously-distributed random vector
X, from a finite sequence of independent outcomes
xi,
i = 1, …,
N. This estimator, as well as another entropy estimator proposed by Singh
et al. in [
36] are briefly described in Section 2.1, before we introduce, in Section 4, our two new TE estimators based on both of them. In Section 2.2, Kraskov MI and standard TE estimators derived in literature from the Kozachenko–Leonenko entropy estimator are summarized, and the passage from a square to rectangular neighboring region to derive new entropy estimation is detailed in Section 3. Our methodology is depicted in
Figure 1.
3. From a Square to a Rectangular Neighboring Region for Entropy Estimation
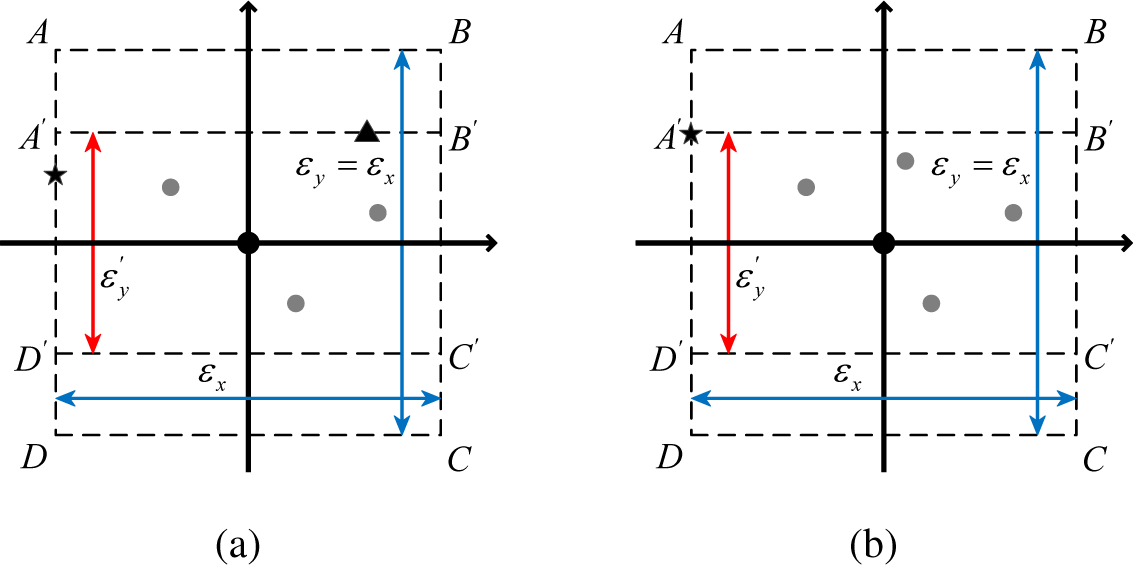
In [
24], to estimate MI, as illustrated in
Figure 2, Kraskov
et al. discussed two different techniques to build the neighboring region to compute
: in the standard technique (square
ABCD in
Figure 2a,b), the region determined by the first
k nearest neighbors is a (hyper-)cube and leads to
Equation (20), and in the second technique (rectangle
A′
B′
C′
D′ in
Figure 2a,b), the region determined by the first
k nearest neighbors is a (hyper-)rectangle. Note that the TE estimator mentioned in the previous section (
Equation (21)) is based on the first situation (square
ABCD in
Figure 2a or
2b). The introduction of the second technique by Kraskov
et al. was to circumvent the fact that
Equation (15) was not applied rigorously to obtain the terms
ψ(
nX,i+1) or
ψ(
nY,i+1) in
Equation (20). As a matter of fact, for one of these terms, no point
xi (or
yi) falls exactly on the border of the (hyper-)cube
(or
) obtained by the distance projection from the
space. As clearly illustrated in
Figure 2 (rectangle
A′
B′
C′
D′ in
Figure 2a,b), the second strategy prevents that issue, since the border of the (hyper-)cube (in this case, an interval of ℝ) after projection from
space to
space (or
space) contains one point. When the dimensions of
and
are larger than one, this strategy leads to building an (hyper-)rectangle equal to the product of two (hyper-)cubes, one of them in
and the other one in
. If the maximum distance of the
k-th NN in
is obtained in one of the directions in
, this maximum distance, after multiplying by two, fixes the size of the (hyper-)cube in
. To obtain the size of the second (hyper-)cube (in
), the
k neighbors in
are first projected on
, and then, the largest of the distances calculated from these projections fixes the size of this second (hyper-)cube.
In the remainder of this section, for an arbitrary dimension
d, we propose to apply this strategy to estimate the entropy of a single multidimensional variable
X observed in ℝ
d. This leads to introducing a d-dimensional (hyper-)rectangle centered on
xi having a minimal volume and including the set
of neighbors. Hence, the rectangular neighboring is built by adjusting its size separately in each direction in the space
. Using this strategy, we are sure that, in any of the
d directions, there is at least one point on one of the two borders (and only one with probability one). Therefore, in this approach, the (hyper-)rectangle, denoted by
, where the sizes
ε1, …,
εd in the respective
d directions are completely specified from the neighbors set
, is substituted for the basic (hyper-)square
. It should be mentioned that the central symmetry of the (hyper-)rectangle around the center point allows for reducing the bias in the density estimation [
38] (
cf.
Equation (11) or
(18)). Note that, when
k <
d, there must exist neighbors positioned on some vertex or edges of the (hyper-)rectangle. With
k <
d, it is impossible that, for any direction, one point falls exactly inside a face (
i.
e., not on its border). For example, with
k = 1 and
d > 1, the first neighbor will be on a vertex, and the sizes of the edges of the reduced (hyper-)rectangle will be equal to twice the absolute value of its coordinates, whatever the direction.
Hereafter, we propose to extend the entropy estimators by Kozachenko–Leonenko and Singh using the above strategy before deriving the corresponding TE estimators and comparing their performance.
3.1. Extension of the Kozachenko–Leonenko Method
As indicated before, in [
24], Kraskov
et al. extended the Kozachenko–Leonenko estimator (
Equations (10) and
(15)) using the rectangular neighboring strategy to derive the MI estimator. Now, focusing on entropy estimation, after some mathematical developments (see
Appendix D), we obtain another estimator of
, denoted by
(Box ⑥ in
Figure 1),
Here,
vi is the volume of the minimum volume (hyper-)rectangle around the point
xi. Exploiting this entropy estimator, after substitution in
Equation (8), we can derive a new estimation of TE.
3.2. Extension of Singh’s Method
We propose in this section to extend Singh’s entropy estimator by using a (hyper-)rectangular domain, as we did for the Kozachenko–Leonenko estimator extension introduced in the preceding section. Considering a
d-dimensional random vector
X ∈ ℝ
d continuously distributed according to a probability density function
pX, we aim at estimating the entropy
(
X) from the observation of a
pX distributed IID random sequence
Xi,
i = 1, …,
N. For any specific data point
xi and a fixed number
k (1 ≤
k ≤
N), the minimum (hyper-)rectangle (rectangle
A′B′C′D′ in
Figure 2) is fixed, and we denote this region by
and its volume by
vi. Let us denote
ξi (1 ≤
ξi ≤ min(
k, d)) the number of points on the border of the (hyper-)rectangle that we consider as a realization of a random variable Ξ
i. In the situation described in
Figure 2a,b,
ξi = 2 and
ξi = 1, respectively. According to [
39] (Chapter 6, page 269), if
corresponds to a ball (for a given norm) of volume
vi, an unbiased estimator of
pX(
xi) is given by:
This implies that the classical estimator
is biased and that presumably
is also a biased estimation of (
pX(
xi)) for
N large, as shown in [
39].
Now, in the case
, is the minimal (i.e., with minimal (hyper-)volume) (hyper-)rectangle
, including
, more than one point can belong to the border, and a more general estimator
of
pX(
xi) can be
a priori considered:
where
is some given function of
k and
ξi. The corresponding estimation of
is then:
with:
ti being realizations of random variables
Ti and
being realizations of random variables
. We have:
Our goal is to derive
for N large to correct the asymptotic bias of
, according to Steps (1) to (3), explained in Section 2.1.3. To this end, we must consider an asymptotic approximation of the conditional probability distribution
before computing the asymptotic difference between the expectation E [T1] = E [E [T1|X1 = x1, Ξ1 = ξ1]] and the true entropy
.
Let us consider the random Lebesgue measure
V1 of the random minimal (hyper-)rectangle
((
ϵ1, …,
ϵd) denotes the random vector for which (
ε1, …,
εd) ∈ ℝ
d is a realization) and the relation
. For any
r > 0, we have:
where
, since, conditionally to Ξ
1 =
ξ1, we have
.
The Poisson approximation (when
N →
∞ and
vr → 0) of the binomial distribution summed in
Equation (29) leads to a parameter
λ = (
N −
ξ1 − 1)
pX(
x1)
vr. As
N is large compared to
ξ1 + 1, we obtain from
Equation (26):
and we get the approximation:
Since
, we can get the density function of
T1, noted
, by deriving
. After some mathematical developments (see
Appendix F), we obtain:
and consequently (see
Appendix G for details),
Therefore, with the definition of differential entropy
(
X1) =
E[−log (
pX(
X1))], we have:
Thus, the estimator expressed by
Equation (25) is asymptotically biased. Therefore, we consider a modified version, denoted by
, obtained by subtracting an estimation of the bias
given by the empirical mean
(according to the large numbers law), and we obtain, finally (Box ⑤ in
Figure 1):
In comparison with the development of
Equation (22), we followed here the same methodology, except we take into account (through a conditioning technique) the influence of the number of points on the border.
We observe that, after cancellation of the asymptotic bias, the choice of the function of
k and
ξi to define
in
Equation (24) does not have any influence on the final result. In this way, we obtain an expression for
, which simply takes into account the values
ξi that could
a priori influence the entropy estimation.
Note that, as for the original Kozachenko–Leonenko (
Equation (10)) and Singh (
Equation (16)) entropy estimators, both new estimation functions (
Equation (22) and
(35)) hold for any value of
k, such that
k ≪
N, and we do not have to choose a fixed
k while estimating entropy in lower dimensional spaces. Therefore, under the framework proposed in [
24], we built two different TE estimators using
Equations (22) and
(35), respectively.
3.3. Computation of the Border Points Number and of the (Hyper-)Rectangle Sizes
We explain more precisely hereafter how to determine the numbers of points
ξi on the border. Let us denote
j = 1,…,
k, the
k nearest neighbors of
, and let us consider the
d ×
k array
Di, such that for any (
p,
j) ∈ {1, …,
d} × {1,…,
k},
is the distance (in R) between the
p-th component
of
and the
p-th component
xi(
p) of
xi. For each
p, let us introduce
Ji(
p) ∈ {1, …,
k} defined by
Di(
p, Ji(
p)) = max (
Di(
p, 1), …,
Di(
p, k)) and which is the value of the column index of
Di for which the distance
Di(
p, j) is maximum in the row number
p. Now, if there exists more than one index
Ji(
p) that fulfills this equality, we select arbitrarily the lowest one, hence avoiding the max(
·) function to be multi-valued. The MATLAB implementation of the max function selects such a unique index value. Then, let us introduce the
d × k Boolean array
Bi defined by
Bi(
p, j) = 1 if
j =
Ji(
p) and
Bi(
p, j) = 0, otherwise. Then:
The d sizes εp, p = 1, …, d of the (hyper-)rectangle
xi are equal respectively to εp = 2Di(p, Ji(p)), p = 1, …, d.
We can define
ξi as the number of non-null column vectors in
Bi. For example, if the
k-th nearest neighbor
is such that ∀
j ≠
k,
i.
e., when the
k-th nearest neighbor is systematically the farthest from the central point
xi for each of the
d entries directions, then all of the entries in the last column of
Bi are equal to one, while all other are equal to zero: we have only one column including values different from zero and, so, only one point on the border (
ξi = 1), which generalizes the case depicted in
Figure 2b for
d = 2.
N.B.: this determination of
ξi may be incorrect when there exists a direction
p, such that the number of indices
j for which
Di(
p, j) reaches the maximal value is larger than one: the value of
ξi obtained with our procedure can then be underestimated. However, we can argue that, theoretically, this case occurs with a probability equal to zero (because the observations are continuously distributed in the probability) and, so, it can be
a priori discarded. Now, in practice, the measured quantification errors and the round off errors are unavoidable, and this probability will differ from zero (although remaining small when the aforesaid errors are small): theoretically distinct values
Di(
p, j) on the row
p of
Di may be erroneously confounded after quantification and rounding. However, the max(
·) function then selects on row
p only one value for
Ji(
p) and, so, acts as an error correcting procedure. The fact that the maximum distance in the concerned
p directions can then be allocated to the wrong neighbor index has no consequence for the correct determination of
ξi.
4. New Estimators of Transfer Entropy
From an observed realization
,
i = 1, 2, …,
N of the IID random sequence
,
i = 1, 2, …,
N and a number
k of neighbors, the procedure could be summarized as follows (distances are from the maximum norm):
similarly to the MILCA [
31] and TRENTOOL toolboxes [
34], normalize, for each
i, the vectors
,
and
;
in joint space
, for each point
, calculate the distance
between
and its k-th neighbor, then construct the (hyper-)rectangle with sizes ε1, …, εd (d is the dimension of the vectors
), for which the (hyper-)volume is
and the border contains
points;
for each point
in subspace
, count the number
of points falling within the distance
, then find the smallest (hyper-)rectangle that contains all of these points and for which
and
are respectively the volume and the number of points on the border; repeat the same procedure in subspaces
and
.
From
Equation (22) (modified to
k not constant for
,
and
), the final TE estimator can be written as (Box ⑧ in
Figure 1):
where
,
,
, and with
Equation (35), it yields to (Box ⑦ in
Figure 1):
In
Equations (36) and
(37), the volumes
,
,
,
are obtained by computing, for each of them, the product of the edges lengths of the (hyper-)rectangle,
i.
e., the product of
d edges lengths,
d being respectively equal to
,
,
and
. In a given subspace and for a given direction, the edge length is equal to twice the largest distance between the corresponding coordinate of the reference point (at the center) and each of the corresponding coordinates of the
k nearest neighbors. Hence a generic formula is
, where
U is one of the symbols (
Xp, X−), (
X−, Y−), (
Xp, X−, Y−) and
X− and the
εUj are the edge lengths of the (hyper-)rectangle.
The new TE estimator
(Box ⑧ in
Figure 1) can be compared with the extension of
, the TE estimator proposed in [
27] (implemented in the JIDT toolbox [
30]). This extension [
27], included in
Figure 1 (Box ⑨), is denoted here by
. The main difference with our
estimator is that our algorithm uses a different length for each sub-dimension within a variable, rather than one length for all sub-dimensions within the variable (which is the approach of the extended algorithm). We introduced this approach to make the tightest possible (hyper-)rectangle around the
k nearest neighbors.
is expressed as follows:
In the experimental part, this estimator is marked as the “extended algorithm”. It differs from
Equation (36) in two ways. Firstly, the first summation on the right hand-side of
Equation (36) does not exist. Secondly, compared with
Equation (36), the numbers of neighbors
,
and
included in the rectangular boxes, as explained in Section 3.1, are replaced respectively with
,
and
, which are obtained differently. More precisely, Step (2) in the above algorithm becomes:
(2′) For each point
in subspace
,
is the number of points falling within a (hyper-)rectangle equal to the Cartesian product of two (hyper-)cubes, the first one in
and the second one in
, whose edge lengths are equal, respectively, to
and
, i.e.,
. Denote by
the volume of this (hyper-)rectangle. Repeat the same procedure in subspaces
and
.
Note that the important difference between the construction of the neighborhoods used in
and is
is that, for the first case, the minimum neighborhood, including the k neighbors, is constrained to be a Cartesian product of (hyper-)cubes and, in the second case, this neighborhood is a (hyper-)rectangle whose edge lengths can be completely different.
6. Discussion and Summary
In the computation of
k-NN based estimators, the most time-consuming part is the procedure of nearest neighbor searching. Compared to
Equations (10) and
(16),
Equations (22) and
(35) involve supplementary information, such as the maximum distance of the first
k-th nearest neighbor in each dimension and the number of points on the border. However, most currently used neighbor searching algorithms, such as
k-d tree (
k-dimensional tree) and ATRIA (A TRiangle Inequality based Algorithm) [
40], provide not only information on the
k-th neighbor, but also on the first (
k − 1) nearest neighbors. Therefore, in terms of computation cost, there is no significant difference among the three TE estimators (Boxes ⑦, ⑧, ⑨, ⑩ in
Figure 1).
In this contribution, we discussed TE estimation based on
k-NN techniques. The estimation of TE is always an important issue, especially in neuroscience, where getting large amounts of stationary data is problematic. The widely-used
k-NN technique has been proven to be a good choice for the estimation of information theoretical measurement. In this work, we first investigated the estimation of Shannon entropy based on the
k-NN technique involving a rectangular neighboring region and introduced two different
k-NN entropy estimators. We derived mathematically these new entropy estimators by extending the results and methodology developed in [
24] and [
36]. Given the new entropy estimators, two novel TE estimators have been proposed, implying no extra computation cost compared to existing similar
k-NN algorithm. To validate the performance of these estimators, we considered different simulated models and compared the new estimators with the two TE estimators available in the free TRENTOOL and JIDT toolboxes, respectively, and which are extensions of two Kraskov–Stögbauer–Grassberger (KSG) MI estimators, based respectively on (hyper-)cubic and (hyper-)rectangular neighborhoods.
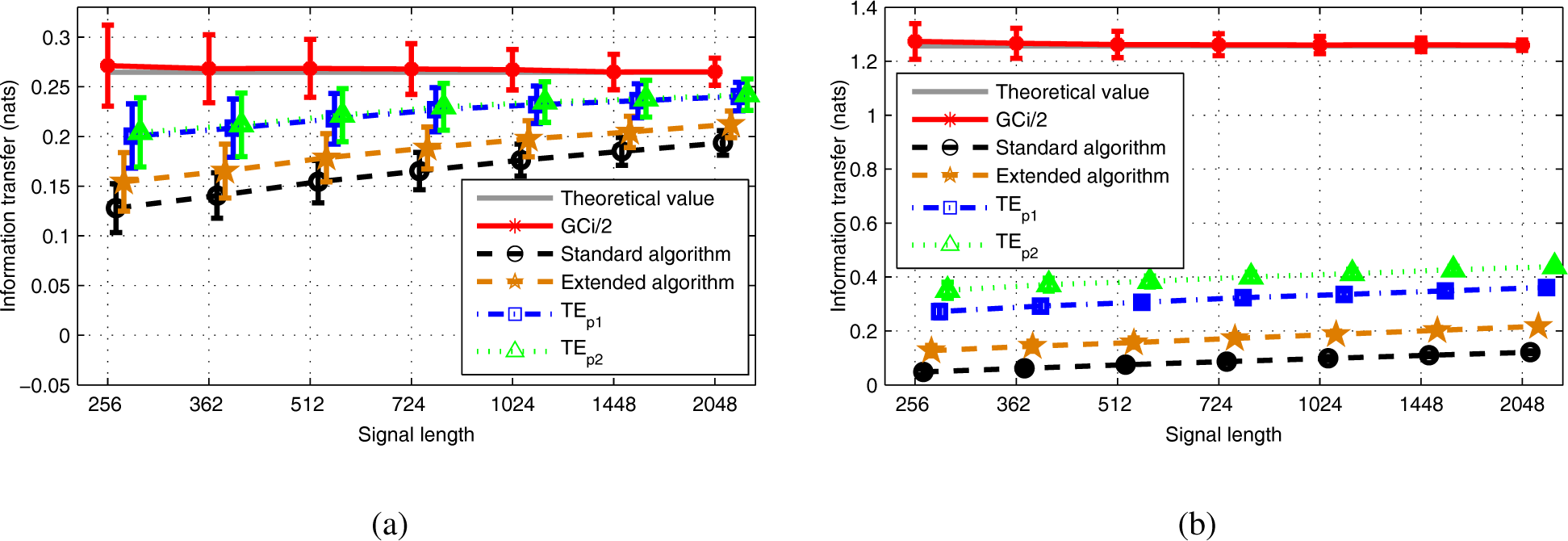
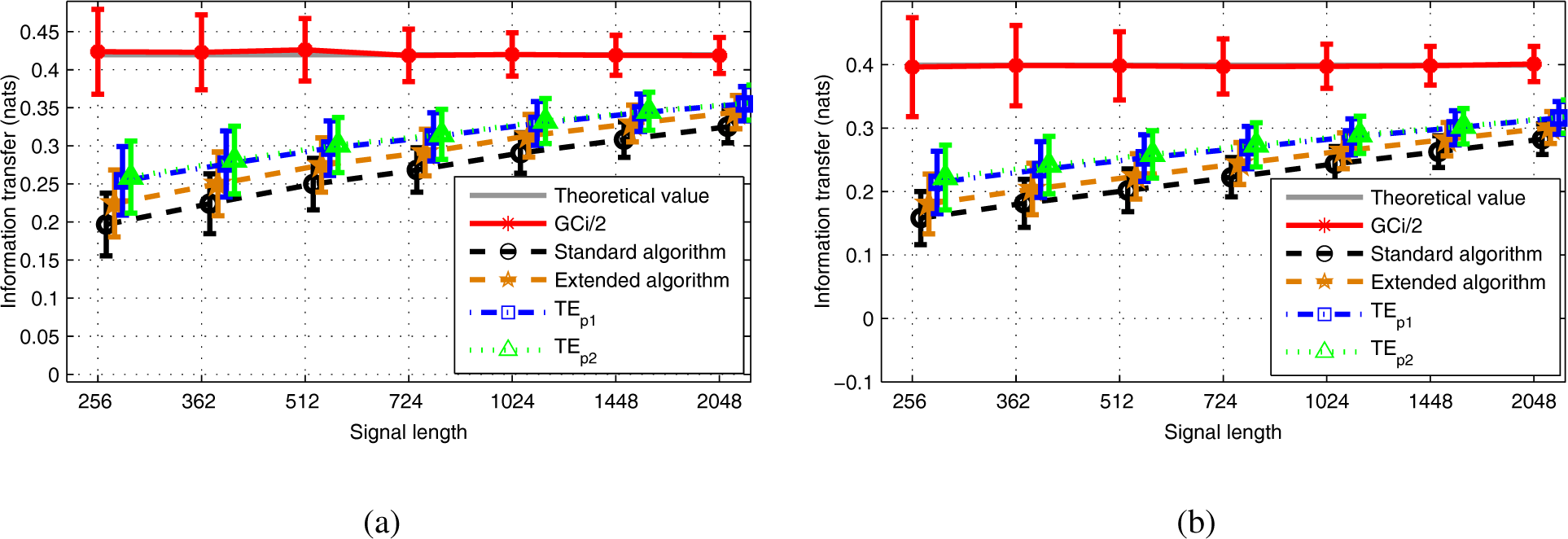
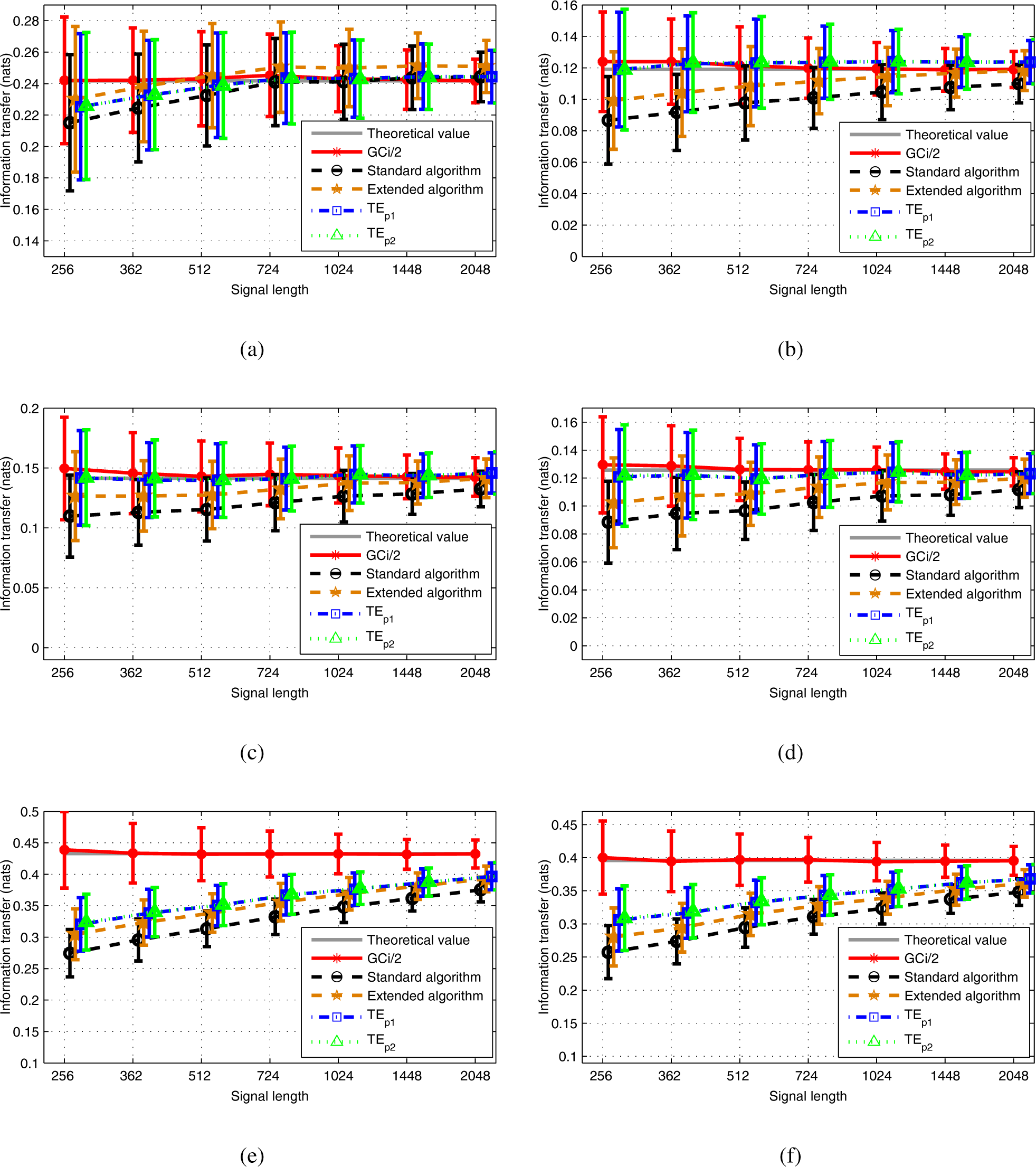
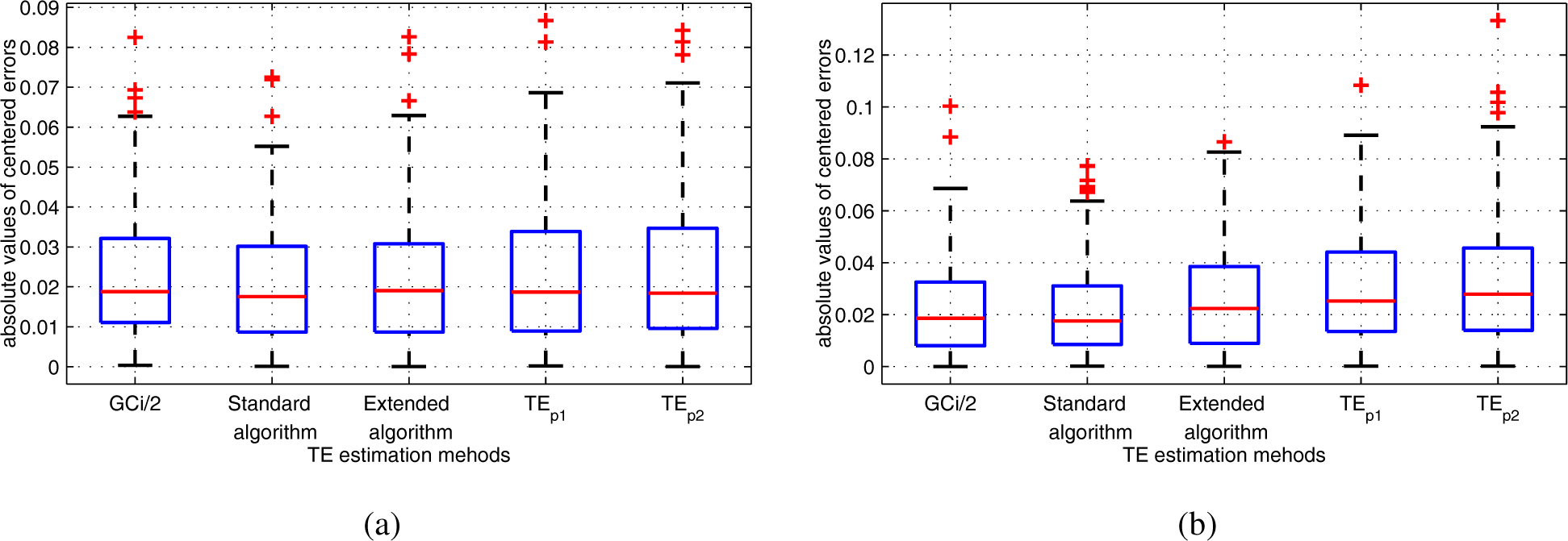
Under the Gaussian assumption, experimental results showed the effectiveness of the new estimators under the IID assumption, as well as for time-correlated AR signals in comparison with the standard KSG algorithm estimator. This conclusion still holds when comparing the new algorithms with the extended KSG estimator. Globally, all TE estimators satisfactorily converge to the theoretical TE value, i.e., to half the value of the Granger causality, while the newly proposed TE estimators showed lower bias for k sufficiently large (in comparison with the reference TE estimators) with comparable variances estimation errors.
As the variance remains relatively stable when the number of neighbors falls from eight to three, in this case, the extended algorithm, which displays a slightly lower bias, may be preferred.
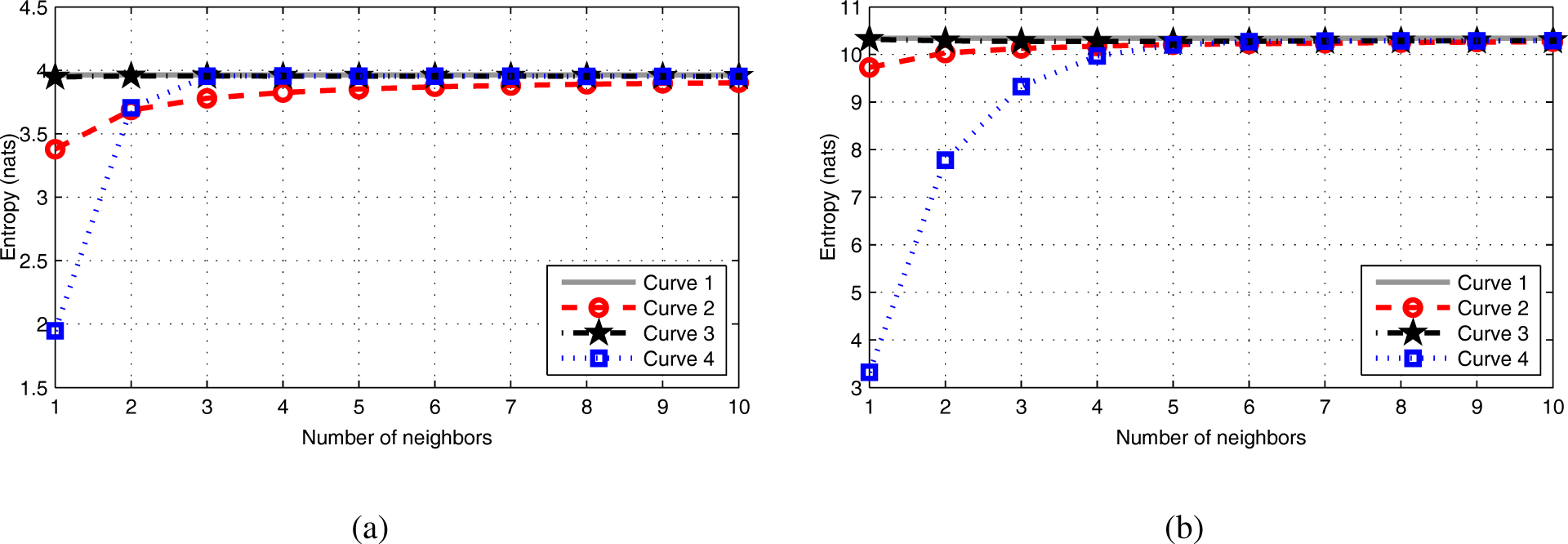
Now, one of the new TE estimators suffered from noticeable error when the number of neighbors was small. Some experiments allowed us to verify that this issue already exists when estimating the entropy of a random vector: when the number of neighbors
k falls below the dimension
d, then the bias drastically increases. More details on this phenomenon are given in
Appendix I.
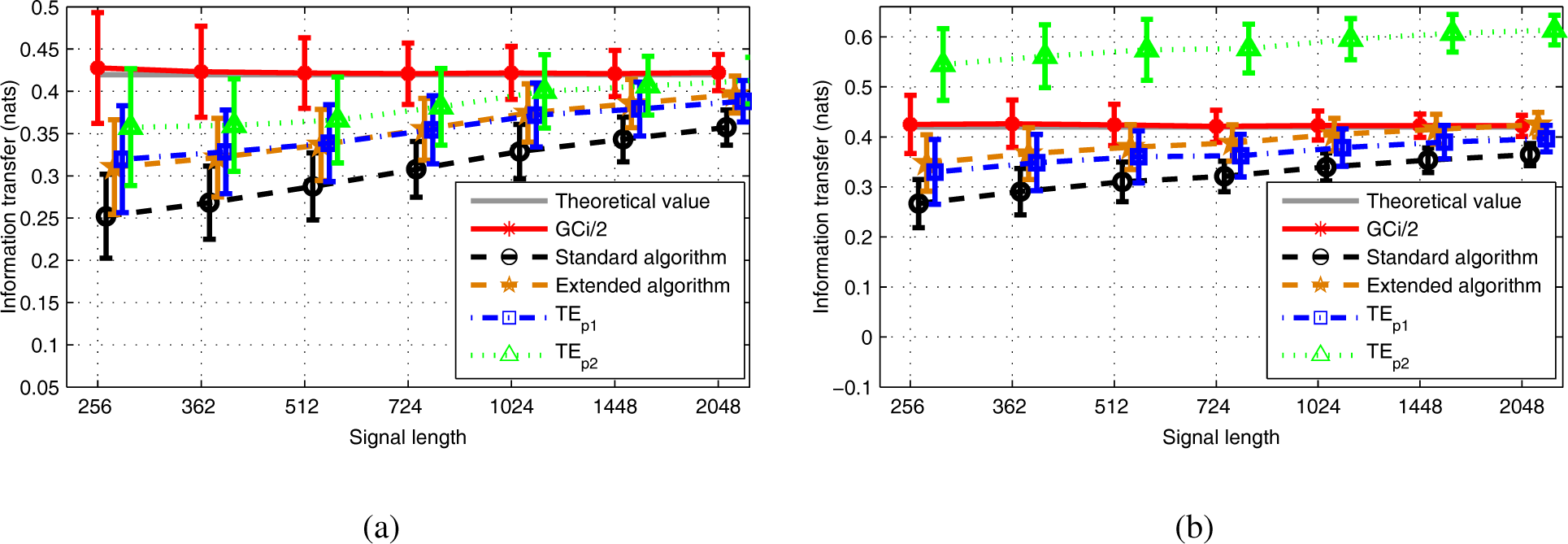
As expected, experiments with Model 1 showed that all three TE estimators under examination suffered from the “curse of dimensionality”, which made it difficult to obtain accurate estimation of TE with high dimension data. In this contribution, we do not present the preliminary results that we obtained when simulating a nonlinear version of Model 1, for which the three variables
Xt,
Yt and
Zt were scalar and their joint law was non-Gaussian, because a random nonlinear transformation was used to compute
Xt from
Yt,
Zt. For this model, we computed the theoretical TE (numerically, with good precision) and tuned the parameters to obtain a strong coupling between
Xt and
Zt. The theoretical Granger causality index was equal to zero. We observed the same issue as that pointed out in [
41],
i.
e., a very slow convergence of the estimator when the number of observations increases, and noticed that the four estimators
,
,
and
, revealed very close performance. In this difficult case, our two methods do not outperform the existing ones. Probably, for this type of strong coupling, further improvement must be considered at the expense of an increasing computational complexity, as that proposed in [
41].
This work is a first step in a more general context of connectivity investigation for neurophysiological activities obtained either from nonlinear physiological models or from clinical recordings. In this context, partial TE has also to be considered, and future work would address a comparison of the techniques presented in this contribution in terms of bias and variance. Moreover, considering the practical importance to know statistical distributions of the different TE estimators for independent channels, this point should be also addressed.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







