In this section, our methods are introduced. Firstly, we describe the features used in our study. Then, the methods for unsupervised link prediction, feature representation and DBN-based link prediction are introduced. Then, we introduce the learning strategy of how to build up models for these three methods and finally, the generalization across datasets.
4.1. Features
The features of a node in an SSN can be roughly divided into two classes. One class contains the features based on the node’s self-degrees, such as in-degree and out-degree; the other class contains the features based on the node’s interactions with its neighbors, such as the common neighbor number and the number of neighbors who share certain opinions.
The first class contains the following features. For each edge in
E, which connects two nodes, we collect information from the two node themselves. Denote the edge’s start node as
u and end node as
v. Then, count the out-degree with a positive sign value of node
u denoted as
, while
stands for the out-degree with a negative sign value for node
u. Furthermore, count the in-degree with a positive sign value and a negative sign value of
u as
and
. At the same time, collect the same features from node
v as
,
,
and
. There are a total of 8 kinds of features, which form the self-degree features, and the details are shown in
Algorithm 1.
The second class contains the following features. For each edge in
E, which connects
u and
v, collect information from two nodes’ edges with their neighbors. Denote
Ne(
u) as the set of
u’s neighbor nodes, which directly connect with
u, and
Ne(
v) as
v’s directly connected neighbor set.
CNe(
u,
v) =
Ne(
u) ∩
Ne(
v) is the common neighbor set of
u and
v. There are two methods to count nodes in
CNe(
u,
v), by nodes and by edges. This is caused by the fact that there may be more than one edge from
u and
v to a common neighbor
w. Counting by nodes means counting every common neighbor only once, no matter how many edges are between them, while counting by edges means counting the number of edges from
u and
v to a common neighbor. Denoting
as counting by the node method’s result and
as counting by the edge method’s result. After counting the common neighbors, we select any node
w from
CNe(
u,
v), whose edges could have any direction with any sign value connected with
u and
v. For example, denote
as the number of nodes who get positive links from both
u and
v. There are 2 directions and 2 kinds of sign values, so the relationships of
u,
v and
w can be divided into 16 kinds. When collecting the 16 kinds of features, each node in
CNe(
u,
v) is only counted once in each kind, but a node can appear in more than one kind. The details are shown in
Algorithm 1, and there are a total of 18 features that form the neighbor features.
Algorithm 1.
Algorithm for extracting features from an signed social network (SSN).
Algorithm 1.
Algorithm for extracting features from an signed social network (SSN).
![Entropy 17 02140f8]() |
The algorithms to extract the above features are shown in
Algorithm 1. The input is the graph of the SSN saved by a set of links as (
start node u,
end node v,
link value s), and the output is the List
Features that contains each link’s features saved in an Array. The main strategy of the algorithm is based on scanning the graph by links two times: the first time, the NodeLinks Structure Array
Networks contains the whole structure of which the graph is built; the second time, each link’s features are extracted and added to the List
Features. In order to speed up the procedure of extracting features, the data structure NodeLinks with four Lists are used to save links for each node. Those lists contain both links that started from this node and ended with that node and separated by positive and negative values. For example,
Networks[
u].
posLinksTo saves all of the positive links starting with node
u, and
Networks[
v].
negLinksFrom saves all of the negative links ending with
v. Therefore, this algorithm needs 2 ×
n(
n =
number of links) random access memory (RAM) to save the graph
Networks and
O(
n) time to build the Array
Networks. However, the storage cost makes it possible to count the 8 degree features in linear
O(
n) time, because it does not need to scan the whole graph to find all of the links ending with a node, and it would cost
O(
n2) if only the links that started from this node were saved. When counting the 18 neighbor features, the time cost is
O(
n +
m2)(
m =
max number of neighbors for each node), because the algorithm needs
m ×
m steps to find all kinds of common neighbors that are shared by two nodes. As a result, the total time cost of this algorithm is
O(
n +
m2), and it needs 2 ×
n RAM space.
4.2. Unsupervised Link Prediction
Hinton and Salakhutdinov show the ability of DBN-based autoencoders in [
28]. They get two-dimensional codes of images by a 784-1000-500-250-2 (DBN with 4 RBMs and their dimensions (visible × hidden) as 1st (784 × 1000), 2nd (1000 × 500), 3rd (500 × 250) and 4th (250 × 2)) autoencoder and two-dimensional codes of documents by a 2000-500-250-125-2 (DBN with 4 RBMs and their dimensions (visible × hidden) as 1st (2000 × 500), 2nd (500 × 250), 3rd (250 × 125) and 4th (125 × 2)) autoencoder. The visualization results show that the autoencoder works better than using PCA (principal components analysis) to reduce the dimensionality of data, and the results are like the ones by the clustering method. That inspired us to use DBN to encode the link feature’s for link prediction and to use the code as the “value” of that link.
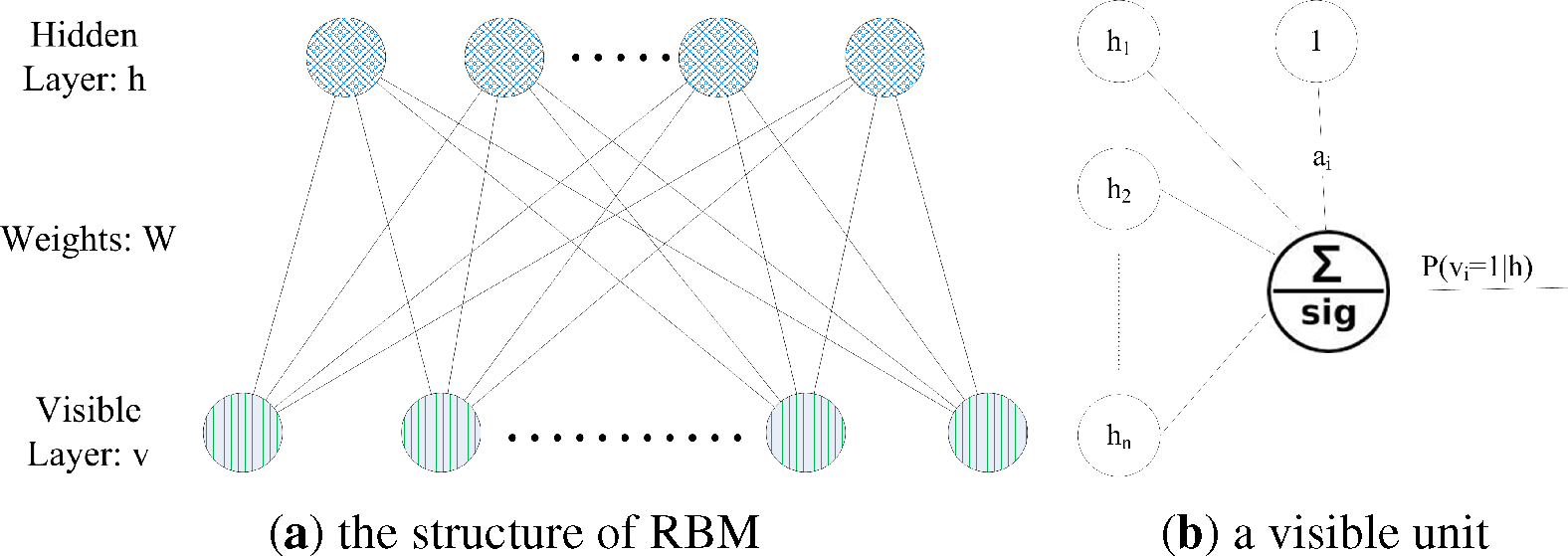
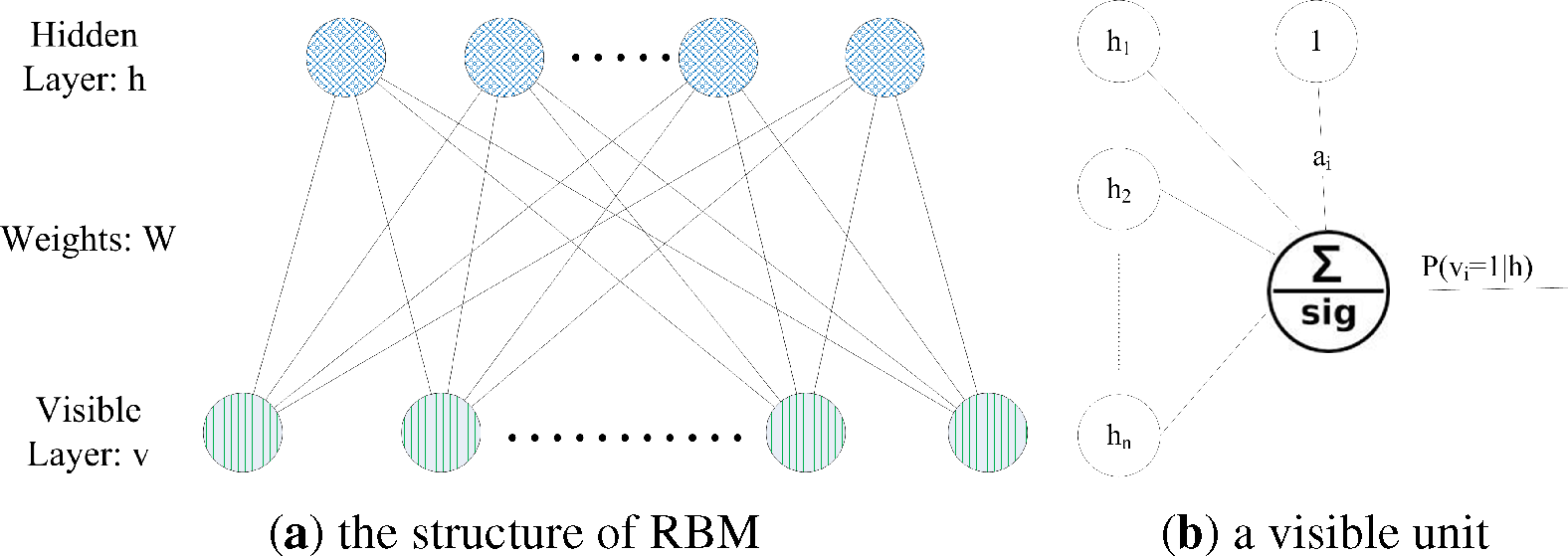
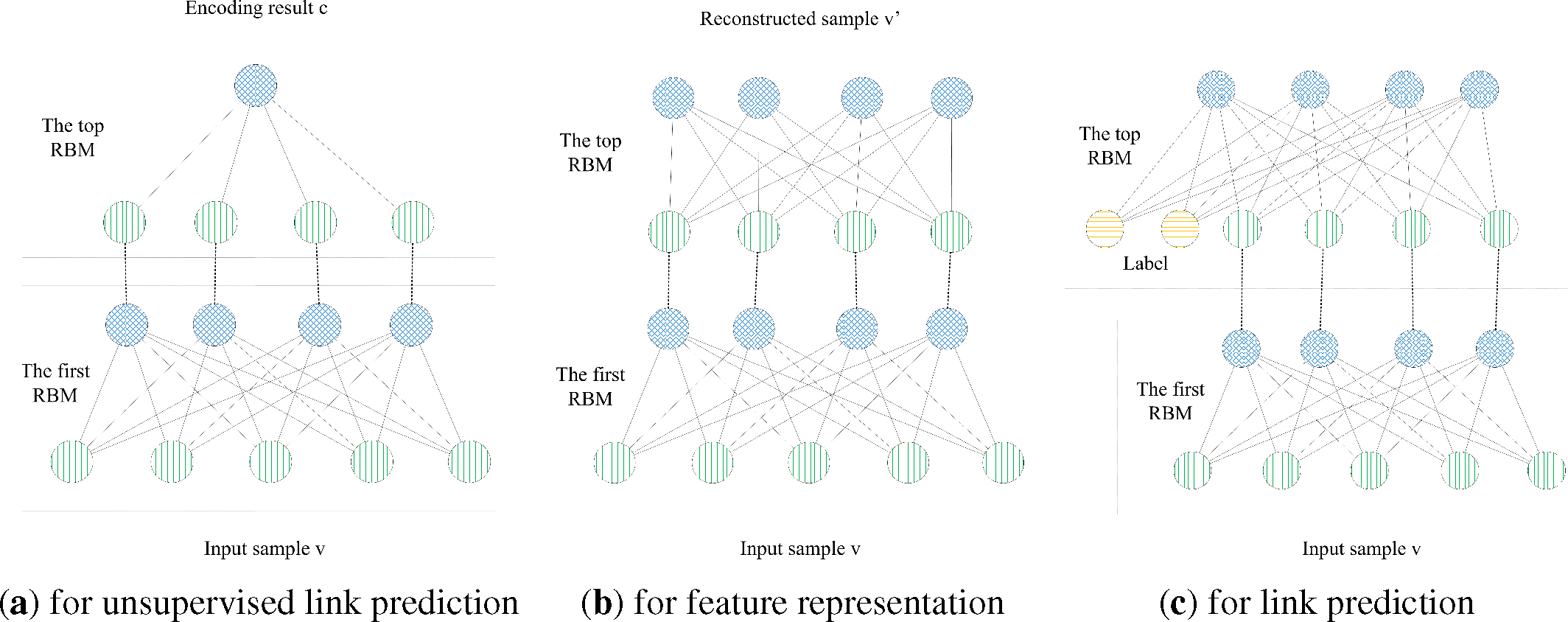
To train a model for unsupervised link prediction, We use a DBN with the structure as shown in
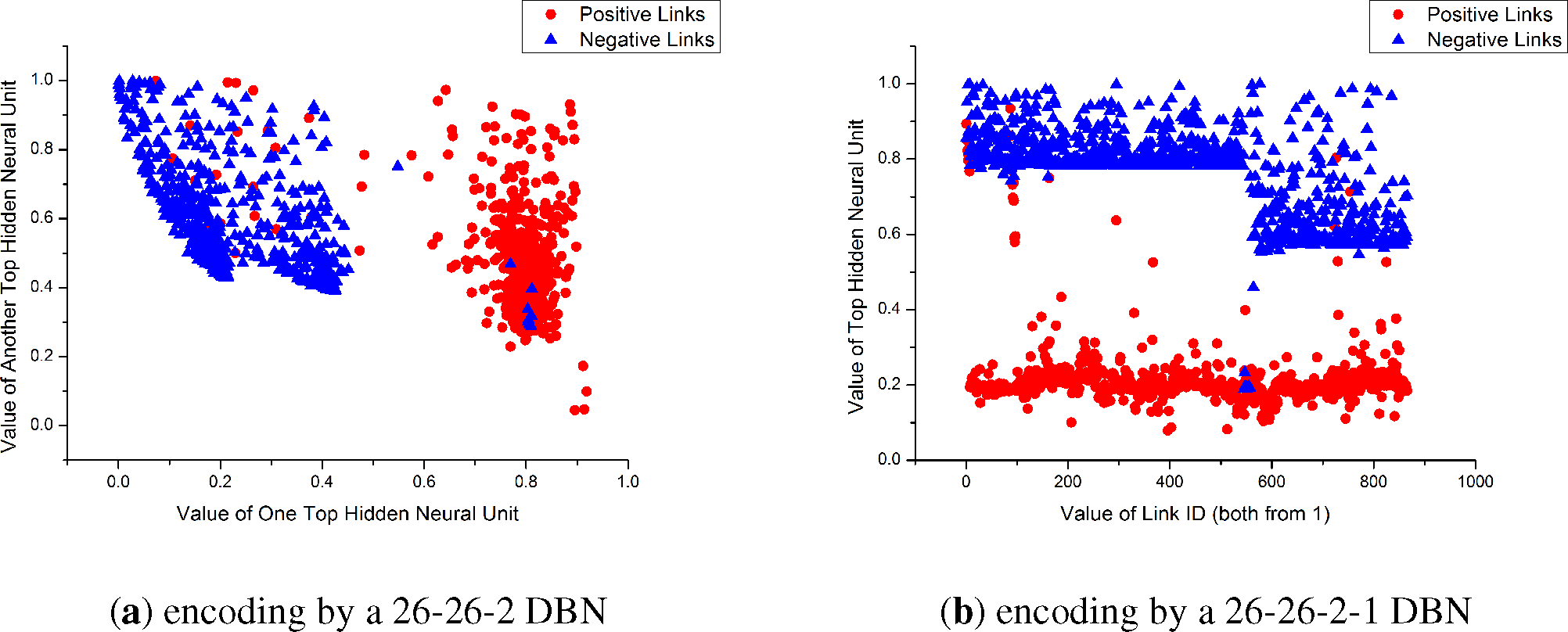
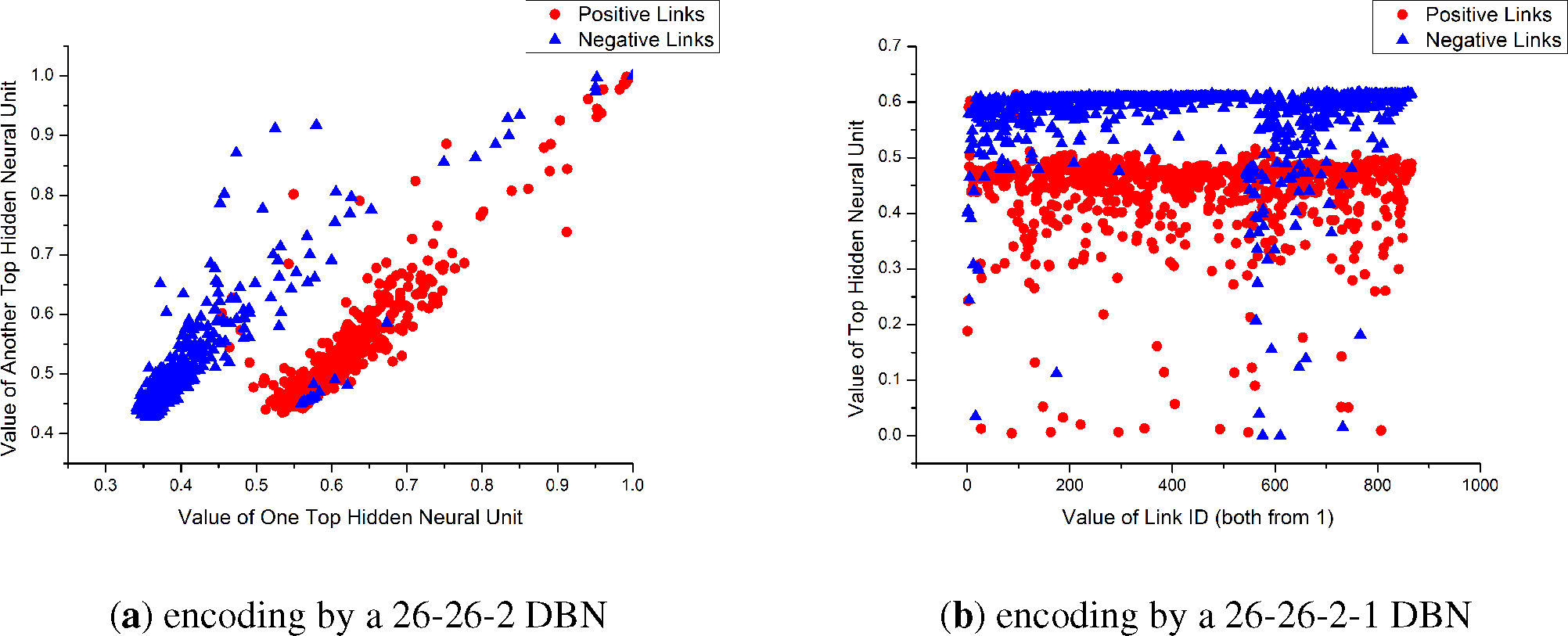
Figure 4a. Through all RBMs, the dimension of the input sample vector is decreased. Though a 26-26-2 DBN with 2 RBMs—1st (26 × 26) and 2nd (26 × 2)—as shown in
Figure 5a, we found that the two-dimensional code from the DBN could represent the “meaning” of samples properly. Because there are two classes of link values (positive and negative) in our problem, we try to use one-dimension to represent the sample’s label. If the last hidden layer has one neuron, whose output (one-dimensional code) could be treated as a probability value to be zero or one, we can take the probability value as how it belongs to a class label. Such a method is similar to Hinton’s, so the one-dimensional code could stand for the “value” of the link sample, by which the code is generated.
With a continuous value, the one-dimensional code could represent the abstracted label of the input sample. This method works like a clustering method that “clustering” each sample to a real value in [0, 1], and the value means to which class the sample should belongs. As shown in
Figure 5b, samples with different kinds of links have different top hidden unit values. The details of this method are shown in
Algorithm 2. In order to get one one-dimensional code, the
DimHidden = [
26,
1] and
TrainTimes = [50,50]. The code of each sample in
tstFeatureSet is saved in
EnTstFeatureSet. Then, we normalize the code values in
EnTstFeatureSet by a sigmoid function and make the evaluations.
Algorithm 2.
Algorithm of building a deep belief network (DBN) for unsupervised link prediction.
Algorithm 2.
Algorithm of building a deep belief network (DBN) for unsupervised link prediction.
![Entropy 17 02140f9]() |
4.3. Feature Representation
Well-trained RBMs have high representation power. Bengio and Courville suggest training the representation of features by deep networks firstly for several tasks in [
27]. That inspired us to use RBMs to represent the link prediction features and to use the represented features as the input for training another classifier.
We use the DBN as shown in
Figure 4b to represent the link prediction features. The original feature vectors are used as the first RBM’s visible units’ input. Then, we activate each layer of the network and use the top RBM’s hidden units’ output as the represented feature vectors. After this process, we use the represented features to train a logistic regression model introduced by Jeffrey Whitaker [
38] to classify link values.
The details of this method are shown in
Algorithm 3. The original features are saved in
trnFeatureSet and
tstFeatureSet, and the features that are represented by the DBN are saved in
repTrnFeatureSet and
repTstFeatureSet. Then, the samples in
repTrnFeatureSet are used as the dataset to train a logistic regression model, and the
repTstFeatureSet is used as the test dataset to evaluate the method’s performance.
4.4. DBN-Based Link Prediction
A DBN is used to recognize handwritten digit images with high accuracy in [
17]. The DBN with RBMs forms a very good generative model that represents the joint distribution of handwritten digit images and their labels. That inspired us to use a similar method to get the joint distribution of link samples and their sign values.
Algorithm 3.
Algorithm for building a DBN for feature representation.
Algorithm 3.
Algorithm for building a DBN for feature representation.
![Entropy 17 02140f10]() |
We use a DBN as shown in
Figure 4c. In order to get the input vector for the top RBM’s visible layer shown in
Figure 4c, we need to construct a vector that combines a link’s sample and its label. Firstly, we transform the link value label to a binary class label vector. The dimension of each label vector is the same as the many classes we have in the dataset. The detail is setting all label vector bits to “0”, then only setting the
i-th bit to “1”, if the sample belongs to the
i-th class. At the same time, we represent the samples by the above feature representation method. Then, we join the represented sample vector with that sample’s binary class label vector as the input visible vector for training the top RBM. Because the RBM can learn the distribution of all input visible vectors, the top RBM could model the joint distribution of represented link samples and their labels. When predicting a sample’s label, we use the following method.
After training the top RBM, a represented sample is joined with each possible binary class label vector as the input for the top RBM, and we get a set of free energy for each combination by:
where
vi is the value of visible unit
i and
ai is
vi’s bias;
hj is calculated by
Equation (1)For example, there is a sample
s. We firstly get the representation of the sample
s by the bottom RBMs and denote that vector as
v. Then, we combine
v with each binary class label {
c1,
c2…
ci…} and get a set of possible combine vectors as {
vc1,
vc2, …
vci….}. After inputting each of them into the top RBM, a set of free energy {
F(
vc1),
F(
vc2), …
F(
vci)…} for these possible combined vectors can be obtained by
Equation (3). Then, we can use a SoftMax method as:
to get the log probability of which class label the vector
v (sample
s) should have.
The details of this method are shown in
Algorithm 4. The
repTrnFeatureSet and
repTstFeatureSet contain the represented samples. As shown in
Algorithm 4, Lines 7–17, use
repTrnFeatureSet to make the training dataset
trainDataset for the top RBM and use
repTstFeatureSet to make the possible test datasets
assumePosTestDataset and
assumeNegTestDataset. Then, use the trained top RBM to get all free energy with the test datasets by
Equation (3) in
Algorithm 4, Lines 20–26 and save them assuming as a positive class
assumePosFreeEnergySet and assuming as a negative one
assumeNegFreeEnergySet. Finally, use
assumePosFreeEnergySet and
assumeNegFreeEnergySet to get the probability for each sample’s class label by
Equation (4).
4.5. Training Strategy
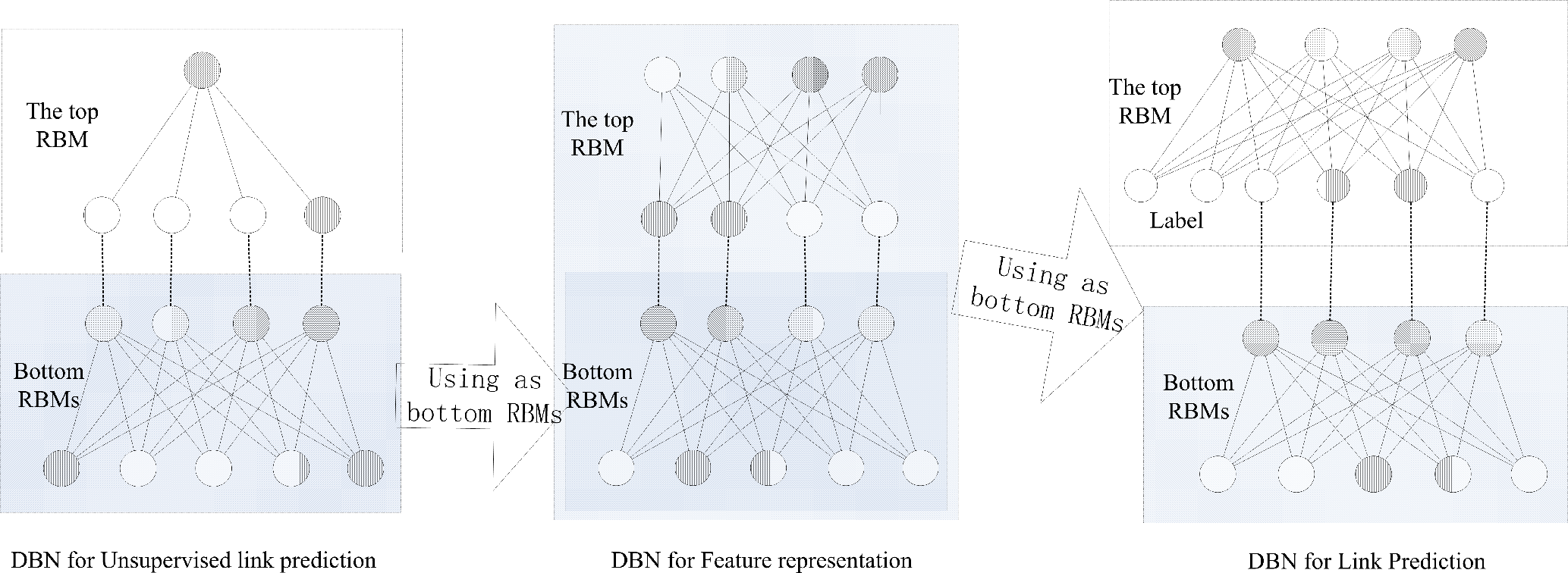
Training the DBN is a time-consuming task, because a well-trained RBM needs lots of iterations before convergence. If we train DBNs for more than three tasks independently, it would cost a lot of time and we would have to check whether all RBMs are well trained. We design a strategy to reuse RBMs as shown in
Figure 6. Such a learning strategy can save a lot of training time and allow us to check whether these methods are suitable for the problem early on by the experiment results of the first methods.
Algorithm 4.
Algorithm for building a DBN for DBN-based link prediction.
Algorithm 4.
Algorithm for building a DBN for DBN-based link prediction.
![Entropy 17 02140f11]() |
Firstly, we have no trained RBMs, so we build the DBN for unsupervised link prediction with newly-trained RBMs. We train each RBM individually; the first RBM is trained by the original features. After finishing training of the first RBM, the second RBM is trained by the output of the first RBM’s hidden vectors, which are generated by the original features. Repeat this process until finishing the training of the top RBM. Therefore, the DBN is trained for unsupervised link prediction. Secondly, we start to build up the DBN for the feature representation method. Except the top RBM, we take the bottom RBMs trained for unsupervised link prediction as the bottom RBMs in the DBN for feature representation. Then, we train the top RBM by the hidden vectors’ activities from the bottom RBMs. Thirdly, when we build up the DBN for DBN-based link prediction method, we take the whole DBN for feature representation as the bottom RBMs. Additionally, we train the top RBM by the method introduced in Section 4.4.
By reusing the trained DBN’s RBMs, the cost of building the next DBN only requires the time cost of training a new top RBM. Anyway, those methods are more suitable for a static environment than an online environment. The main reason is that the DBNs need to be trained step by step with enough balance samples at the beginning. As introduced in Section 3.2, the RBM is trained by an unsupervised process. If the samples are not balanced, it would cause modeling the larger prediction error at the beginning. Additionally, the error would be difficult to fix, for the learning process is unsupervised. In an online environment, it would be very difficult to keep the balance of samples with different labels at the beginning. As a result, we advise building up these DBNs in a static environment; then, one can use it for some online systems. When one wants to update these models for later usage, we also advise rebuilding these DBNs with new samples and replacing the old DBNs.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}