1. Introduction
Let
Y be a discrete variable with
generic outcomes
and corresponding probabilities
such that
Expressed in terms of the natural logarithm, the Shannon entropy attributed to
Y in connection with
is [
1]
For convenience let
represent the original form defined in terms of the base-2 logarithm.
is bound according to
The maximum is generated only when all outcomes are equally probable.
vanishes in the limit as some
approaches unity, which represents a completely predetermined outcome.
Because it emerges naturally from the basic principles of encoded compression, the discrete Shannon entropy is widely recognized as an informatic measure. Specifically, consider a message
consisting of
symbols from a generalized alphabet
. Let
represent the total number of occurrences of a particular symbol
within
. In the limit as
N becomes infinitely large suppose that each
approaches a certain constant
that is characteristic to the “language” in which
is composed. For sufficiently large
N we therefore have
. The total number
I of likely messages of length
N is consequently fixed by
according to
The right side of Equation (
5) is simply the inverse of the probability for finding any one particular
among all messages of length
N subject to
. The inventory of likely messages could be encoded as
I different integers. The number
β of bits required to register the encoded inventory is given by
, and we therefore have the average compression rate
Notwithstanding its significance, Equation (
6) represents only a particular example of the expansive utility of the discrete Shannon entropy. Interpreted most broadly, and in accordance with the purpose for which it was derived,
measures the indeterminacy in a random selection from among
n different options with corresponding probabilities
[
1]. It is therefore appropriate to attribute a quantity of entropy
to a discrete variable with probabilities
.
Consider a variable Y whose allowed outcomes are governed by some such that is near . The nearly maximal entropy implies that Y exhibits no significant statistical preference toward any particular outcome or group of outcomes among . Consequently an ideal observer who studied the behavior of Y could develop a successful model only to predict the most trivial details about future outcomes. Stated alternatively, the degree to which Y behaves deterministically is minimal. In contrast suppose that is much smaller than . The nearly minimal entropy implies a strong statistical preference for some comparatively small number of . As such Y would exhibit an appreciable degree of deterministic behavior. A successful, non-trivial predictive model could be therefore developed from observations of Y.
It is important to emphasize that H is a rigorous measure of indeterminacy in a variable only insofar as the indeterminacy depends on alone. Let X be a discrete variable whose n allowed outcomes are D-dimensional real vectors, i.e. for . The elements of every one-dimensional are implicitly listed in ascending order throughout the following. Analogously to the real nature of , the real nature of endows the outcomes of X with definite spatial attributes in which non-trivial deterministic behaviors could manifest. Consequently, as illustrated in the following two examples, H is not generally sufficient as a measure of indeterminacy in real-valued discrete variables.
Consider two variables and whose outcomes are confined to the real axis. Let the allowed outcomes of be equally probable and equally spaced, hence the subscript “”, and let the allowed outcomes of be equally probable but randomly spaced, hence the subscript “”. More formally, the allowed outcomes of are of the form , which is defined for to be a set of n equally spaced points on the real axis. Let γ represent the arbitrary spacing in a given . For convenience we also define for a given n to represent a set of equal probabilities. The allowed outcomes of are of the form , which is defined for to be indistinguishable from a set of n points distributed randomly over some simple finite segment of the real axis. The intrinsic spatial structure of effects a commensurate degree of deterministic behavior in . For instance, the difference between successive outcomes of is always an integer multiple of γ, and is therefore significantly more predictable than the difference between successive outcomes of . Because and differ only in the spatial arrangement of their allowed outcomes, would behave more deterministically. By definition a smaller quantity of entropy should be therefore attributed to . The discrete Shannon entropy attributed to both variables, however, would be identically maximal.
Consider next a complementary scenario in which the allowed outcomes are identically valued but the respective probabilities differ. Let and be two variables with one-dimensional allowed outcomes of the form . The set of probabilities governing is of the form , which is defined generally to be indistinguishable from n randomly selected positive real numbers, subsequently normalized to unity and listed in random order. The spatial assignment of through would be globally isotropic but locally irregular, despite the intrinsic structure of . The outcomes of are matched to a set of probabilities of the form , which is defined generally to be indistinguishable from n randomly selected positive real numbers, subsequently normalized to unity and listed in ascending order. The ordered arrangement of effects a non-trivial deterministic bias favoring progressively larger outcomes in . Note that the specific form of in this example could be constructed simply by sorting the elements of , in which case would behave more deterministically but and would be identical.
The problems raised in the previous two paragraphs do not imply any flaw in
H. The discrete Shannon entropy was formulated only to measure indeterminacy effected by a given
in a generic discrete variable. The net indeterminacy in a real-valued discrete variable, however, depends on the respective intrinsic characteristics of
and
, and on the manner in which
and
are matched. A special measure is therefore required for discrete real variables. Note that Equation (
6) is insensitive to the nature of
, and the present considerations are therefore irrelevant in the context of the coding theorems. To be precise, the role of
in Equation (
6) is not truly as a measure of indeterminacy.
Although it included no special provisions for discrete real variables, Shannon’s seminal paper introduced a separate formulation for the entropy of a continuous real variable. Let
be a probabilistically determined variable whose allowed outcomes span a continuum of real vectors within some region
. Let the probability density
be defined such that
gives the probability for an outcome of
to lie within an infinitesimal element
centered on
x, where
is an independent variable and
represents implicitly the product of the differentials of each vector component of
. We therefore require
to vanish for all
. The normalization of
ρ is accordingly
Henceforth any integration is understood to span
in the absence of explicit limits. The entropy
attributed to
in connection with
ρ is [
1]
where
is defined to vanish for
. The measure in Equation (
8) is known as the
differential (Shannon) entropy.
In contrast to
H a single quantity of
is subject to no finite bounds. Consequently a simple comparison between
H and
is not meaningful. For instance, the differential entropy of a normalized Gaussian
is
. For
ν equal to
the entropy vanishes, which signifies a predetermined outcome in the context of discrete real variables. Furthermore in the limit as
ν becomes infinitely large
behaves as a
D-dimensional delta-distribution
, which describes a single predetermined real outcome.
, however, decreases without bound as
ν approaches infinity.
The apparent inconsistencies between
H and
are reconciled in the following manner. As a generalization of
let
be some well-behaved, unity-normalized function that becomes
in the limit as the positive, real parameter
ν becomes infinitely large. In association with an arbitrary
X, with
n allowed outcomes
and corresponding probabilities
, let the probability density
be defined such that
and thus
where
is the appropriate normalization coefficient for a given
ν, and
and
span
and
respectively. The symbol “∼” is used in Equation (
10) and throughout, where convenient, to signify asymptotic equality as
ν approaches infinity. The right side of Equation (
11) describes the probabilistic behavior of
X. Consider an originally continuous test variable
whose outcomes are governed by
. The entropy attributed to
is
, which behaves asymptotically as
When
ν is finite but very large the behavior of
is a hybrid of the continuous traits of
and the discrete traits of
and
. In the limit as
the two sets of traits become completely disassociated from one another, and
is characterized only by
and
. The entropy associated with the probabilistic behavior of
X should be therefore given by the asymptote of
. From Equation (
12) we readily obtain
thereby recovering
H from
.
Although the analysis leading to Equation (
13) may be instructive,
is asymptotically independent of
and could not produce the desired new measure for discrete real variables. It is reasonable to suspect that some additional quantity of the form
could be considered in conjunction with
to provide the required asymptotic sensitivity to both
and
. In order to be meaningful, however, the additional measure should be intrinsically related to
.
Within the paradigm of wave mechanics two distinct quantities of differential entropy are naturally associated with a given
ρ. More precisely, two separate probability density functions are naturally associated with a given probability amplitude
, namely
and the spectral density
where
is the Fourier-conjugate of
ψ and
is an independent variable. We may interpret
as the probability density governing the outcomes of a variable
that is the conjugate of the variable
governed by
ρ. The entropy attributed to
in connection with
is
. The total differential entropy attributed to the conjugated pair is therefore
A more formal derivation of
follows from the total phase-space distribution [
9]
which is subject to the normalization
where
for any given
x and
k. Because
f is simply a probability density in a
-dimensional vector space, it is appropriate to attribute a quantity of differential entropy
to the conjugated pair.
The total differential entropy
S has been the subject of extensive research. (See, for instance, [
2,
3,
4,
5,
6,
7,
8]). It is worthwhile to mention here two general characteristics that distinguish
S as a fundamentally important measure. Because
f is dimensionless
S, like the relative entropy, is free from a potentially serious flaw to which the differential Shannon entropy is otherwise vulnerable [
10]. Furthermore, whereas
and
may become infinitely negative,
S is subject to the lower bound [
2]
Perhaps uniquely, a Gaussian amplitude generates the minimal
S allowed by Equation (
20) [
2].
The purpose of this article is to demonstrate that a measure of indeterminacy for discrete real variables that is sensitive to both
and
emerges from the total differential entropy of
and its conjugate in the limit as
ν diverges. Specifically, the conjugated analogue of Equation (
13) includes an additional measure
, expressed most generally in terms of an integral, that behaves naturally as a measure of indeterminacy in the spatial configuration of
and
. Furthermore the conjugate is universally eliminated in the limit as
becomes discrete and the entire residual entropy
, named
η is therefore attributed to X.
Section 2 contains a derivation of
η. The general characteristics of
η are examined in
Section 3.
Section 4 presents a quantitative study demonstrating the basic behaviors of
η as a measure of indeterminacy for discrete real variables. The primary conclusions are summarized and interpreted in
Section 5.
2. Derivation of η
The terms defined in
Section 1 retain their definitions throughout the following. Let
be the conjugate of a given
. The probability density
governing the outcomes of
is formulated presently. Let
be defined such that
. The total differential entropy of the conjugated pair is thus
. This section contains a derivation of the asymptotic form of
expressed analogously to Equation (
13).
The first step is to formulate
. Following the standard wave-mechanical prescription, and in accordance with natural law, we attribute to each allowed outcome a separate amplitude [
11]. The total amplitude is simply the sum of the individual amplitude waveforms multiplied by an appropriate normalization coefficient. Let the probability amplitude
be therefore defined such that
,
i.e.,
The waveform assigned to each
is
and the total amplitude is accordingly
where
is defined such that
is unity-normalized for all
ν. Because the real part of
becomes ever more sharply peaked with increasing
ν, the cross terms
in
are negligible for sufficiently large
ν and vanish asymptotically. We therefore have
which is equivalent to Equation (
10). Note that
The next step is to determine the respective forms of the conjugate amplitude
and density
. Let
represent the conjugate of
, and let the associated density
be defined as
. It follows from Equation (
15), with
substituted for
x, that
where
is the conjugate of a given
. We therefore have
and thus
where
An equivalent expression for
following from the Euler identity is
For convenience we define
such that
.
The asymptotic behavior of
is ascertained readily from the explicit form of
in Equation (
15) with
expressed as
for all non-vanishing
. It follows from the behavior ascribed to
that
which is independent of
k. Because
must remain unity-normalized
must vanish everywhere asymptotically. As
increasingly resembles
the real part of
must either increase or decrease without bound, which ensures that the right side of Equation (
31) vanishes. Consequently
and
vanish asymptotically for all
k.
It is also worthwhile to note that, because
and
are both unity-normalized for all
ν, Equations (
28) and (
30) imply
where
is the expected value of any
averaged against
. Equation (
32) may be understood as a consequence of the asymptotic uniformity of
in conjunction with the usual trigonometric property
In the limit as
ν diverges
becomes simply the average of
ζ over all space, which we denote by
, and thus vanishes term-by-term in accordance with Equation (
34). Expressed more generally,
Returning to the derivation proper, the next step is to evaluate
in the limit as
ν approaches infinity. It follows from Equations (
25) and (
28) that
Substituting
for
τ in the left-most term on the right side of Equation (
36) produces
Although
decreases without bound it does so with asymptotic uniformity, hence
for any
. The middle term on the right side of Equation (
37) is therefore asymptotically proportional to
and thus vanishes. Equation (
37) accordingly becomes
The asymptotic form of the right-most term in Equation (
39) is
Because
τ is periodic
is identical to the average value of
taken over some finite region
spanning one period in each dimension. We therefore have
where
An analytical expression for
is possible only for a few rudimentary configurations of
and
, and Equation (
41) is thus critical for quantifying Ξ.
Finally, Equation (
39) may be expressed in terms of a proper limit as
analogously to Equation (
13). Combining Equations (
13) and (
43) produces the central result
where
The nature and behavior of
are examined in the following Sections.
3. General Characteristics of η
By definition measures the net indeterminacy in the conjugated pair and . In the limit as ν becomes infinitely large, however, the pair is characterized completely by and , independently of . The entropy attributed asymptotically to the pair is therefore η. Furthermore as becomes discrete vanishes everywhere and becomes therefore a “ghost” variable, doomed to exist without ever generating an outcome. The indeterminacy measured by η must be therefore evident in the probabilistic behaviors of X. Because X and its ghost conjugate together are indistinguishable from X alone we conclude that η is a generally valid measure of indeterminacy in discrete real variables.
Given that Ξ is the asymptotic form of its attribution to X is perhaps counterintuitive, despite the elimination of the conjugate. In particular and are typically anti-correlated among different ρ of a given generalized form. Recall, however, that is asymptotically insensitive to and therefore is not generally correlated to in any appreciable manner among different . Not only is sensitive to both and , it is also naturally correlated to the intrinsic indeterminacy effected by the definite spatial attributes of . Stated most generally, greater spatial regularity in the configuration of and effects greater harmonic regularity in the spatial arrangement of the peaks in , for . Greater harmonic regularity in implies greater localization in the associated Fourier spectrum, which accordingly generates a smaller , for a given . In order to isolate the effects associated with and we exclude the contribution from . In that manner Ξ measures the deterministic effects of real allowed outcomes.
Lower bounds on
η and Ξ follow directly from the universal lower bound on
S. Specifically, both
and
are subject to Equation (
20) for all
ν. We therefore have
and thus
Regardless of the degree of spatial structure in the configuration of
and
, no variable could behave more deterministically than a fixed real number. Equation (
46) is therefore consistent with the attribution of zero entropy to a predetermined outcome.
Upper bounds on
η and Ξ may be obtained by writing Equation (
41) as
where the right-most term has been reduced using
which is a consequence of Equation (
34). The integral on the right side of Equation (
48) is simply the differential Shannon entropy associated with a normalized density
τ/
k0 defined over
. Furthermore log(
k0) is the maximal differential Shannon entropy that could be associated with
. Equation (
48) therefore implies
hence
The upper bound on
η is consistent with the basic expectations about the predictive utility of real outcomes. Consider some
X that has been “disguised” by mapping the
n allowed outcomes in
to a set of
n generic outcomes, while keeping the corresponding probabilities
fixed. An ideal observer who studied only the generic outcomes could form a predictive model only to the extent allowed by
. Suppose that such an observer were subsequently allowed to study the real outcomes. The numeric details could never detract from the observer’s capability to develop a predictive model because, at very least, the outcomes from any
could be interpreted simply as non-numeric symbols. The entropy attributed to
X, therefore, should not be greater than the entropy attributed to the generic analogue, which is precisely what Equation (
51) ensures.
For any
,
H and
η should be similar when the degree of deterministic structure within
is negligible. We therefore expect
which is validated in the following section. Among variables with spatially randomized outcomes, indeterminacy depends primarily on the intrinsic characteristics of
, hence Equation (
52). Conversely, among variables with equally probable outcomes, indeterminacy depends only on x. In that manner
η(
e, x) measures the intrinsic indeterminacy in the spatial configuration of x. It is therefore fitting, as explicitly evident in Equation (
30), that
τ is sensitive to each of the
n(
n − 1)/2 uniquely defined positive intervals
xl −
xj within a given x.
Because there is no preferred region within
, any meaningful measure of indeterminacy for discrete real variables must be invariant under spatial transformations of the form
for any finite
. By inspecting either Equation (
29) or Equation (
30) we readily find that
τ is translationally invariant, hence
Similarly transformations of the form
, where
is a
D-dimensional unitary rotation matrix, could not change the indeterminacy in any
X. Consequently the entropy attributed to
X must be rotationally invariant as well. The effects of such a rotation would be equivalent to replacing the original
with
, which we may write as
after the variable substitution
. The rotation therefore amounts to nothing more than a cosmetic change of variables, which does not affect the average value of
—whether taken over all space or taken over a finite region spanning a period in each dimension of
. We therefore have
For the same reasons we also have
for any non-vanishing
, where
. Contrary to Equation (
55), suppose that the entropy of a real discrete variable were to increase under transformations of the form
for
. Consider applying such transformations successively to the allowed outcomes of some non-trivial
X. Given that the entropy must never exceed
H the effects of the transformations must become negligible at some point, which would imply the existence of some preferred spatial scale for a given
and
. The indeterminacy, however, could not be sensitive to such a scale. The scale-invariance expressed in Equation (
55) is therefore necessary for any meaningful measure of indeterminacy in discrete real variables.
4. Quantitative Study
This section presents the results of numerical calculations of η chosen to validate the identification of η as the entropy of a discrete real variable and to demonstrate the utility of Ξ as a probe of deterministic structure in sequences of real numbers or non-numeric symbols. For convenience this introductory study is restricted to scenarios where ; the conclusions are readily generalized to higher-dimensional spaces. In each calculation of η reported here the period-averaged value of −τlog(τ) was obtained from 25 ⌊ κ0/κ*⌋ samples, where κ* = 2 π/(xn − x1) represents the finest periodicity in τ. Note that xn − x1 is always the largest positive interval within a one-dimensional x. All computations were precise to 15 significant figures. The accuracy, in comparison to the “true” value of η produced by an infinite number of samples, is always better than η.
The first sets of calculations examined below involve the basic types of
and
introduced in
Section 1, matched in various instructive combinations. Each
was constructed from
n different real numbers with 15 significant figures selected randomly from
, and subsequently normalized. Each
was constructed by randomly selecting
n different integers from
. This produces approximately the same effect as using the full range available with 15 significant figures, but dramatically reduces processing requirements. For each calculation involving
a corresponding calculation involving
is performed, and each
is constructed by sorting the elements of the corresponding
. Finally, each reported quantity of
η involving a randomly generated parameter is the average of 100 separate calculations with different randomizations.
Let us begin by examining how
η measures indeterminacy effected through different types of p.
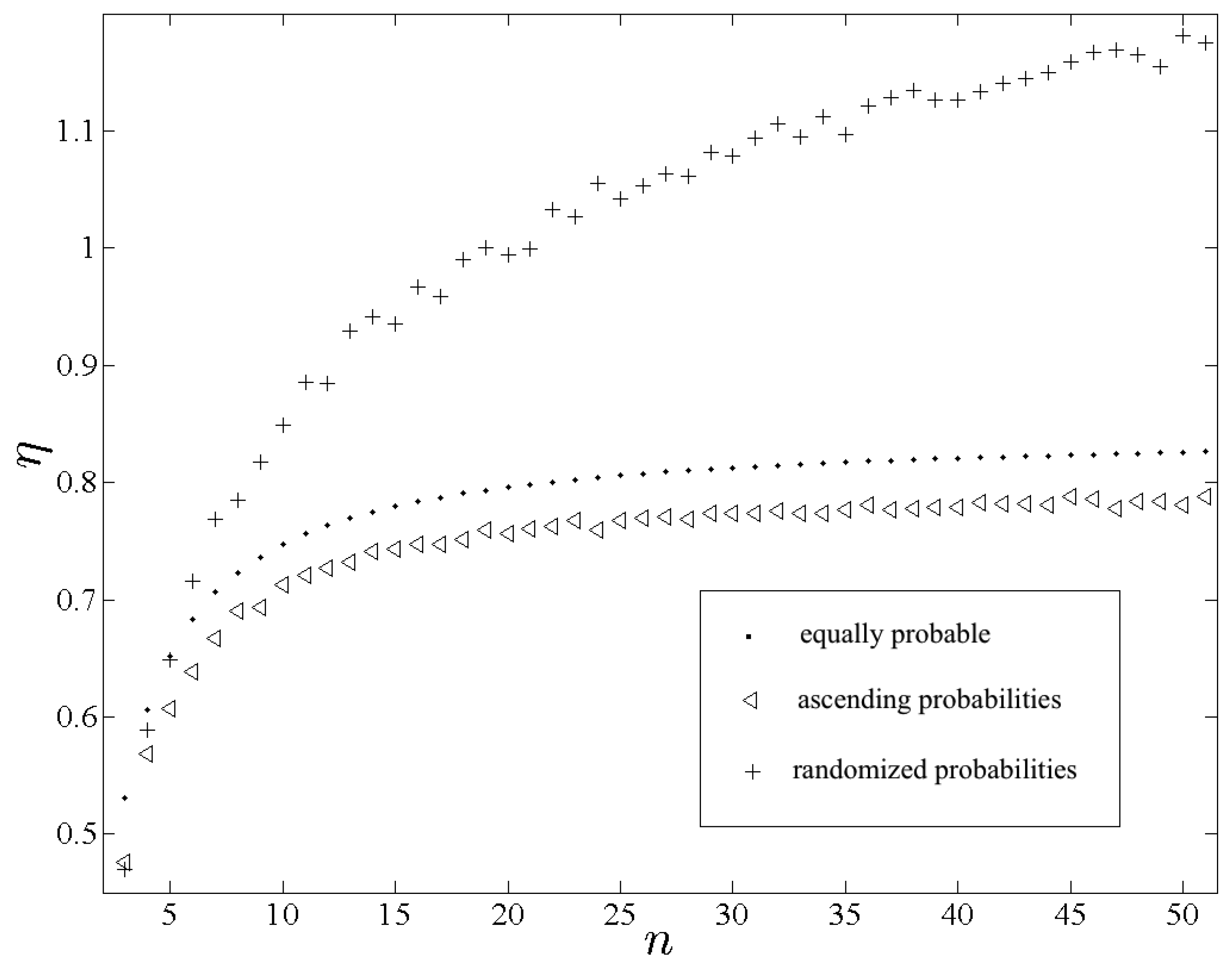
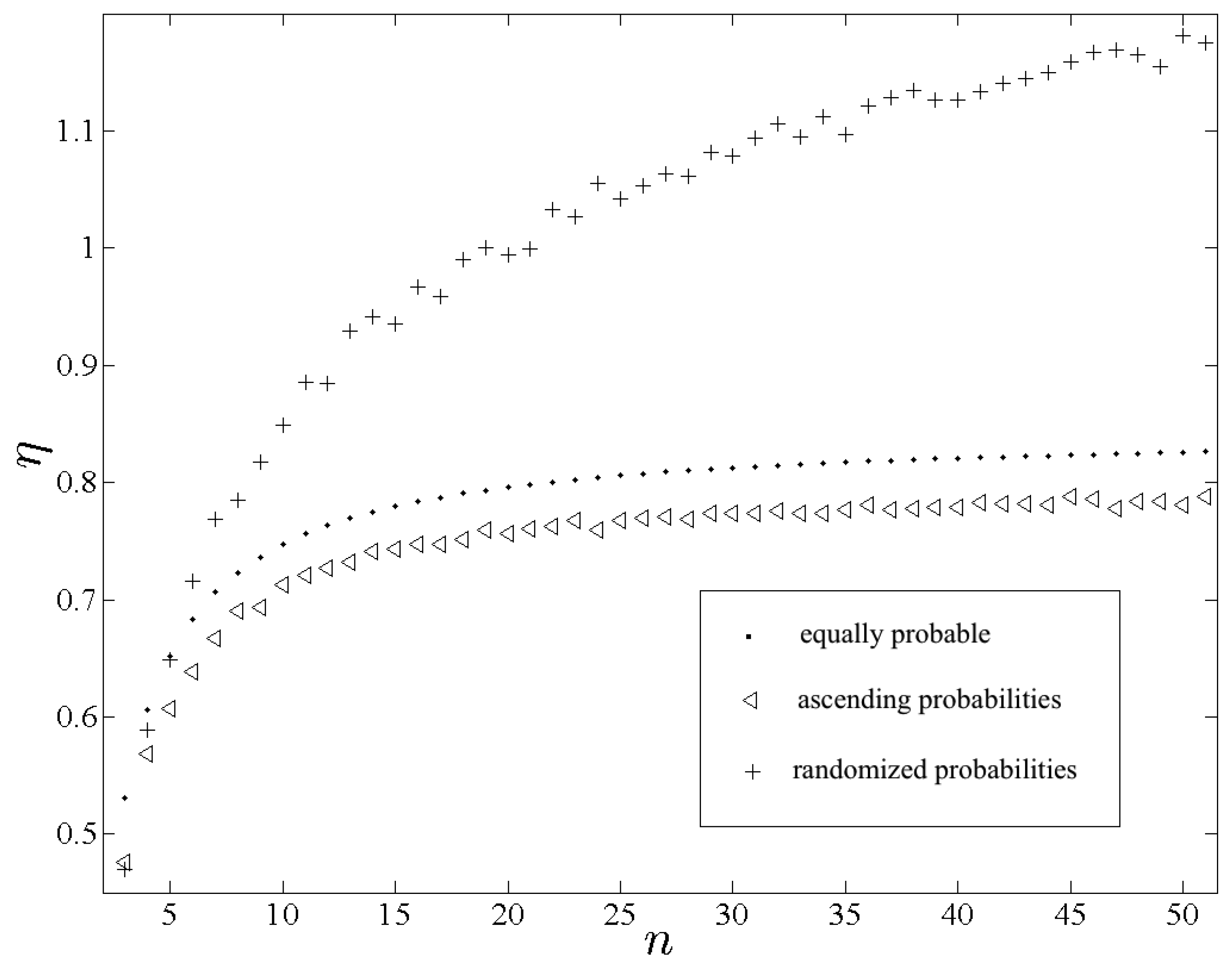
Figure 1 displays calculations of
η(p
e, x
e),
η(p
a, x
e) and
η(p
r, x
e) plotted as functions of
n. Recall that
η(p
r, x
e) and
η(p
a, x
e) should behave respectively as quantities of entropy attributed to the variables
Xre and
Xae examined in
Section 1. We find that
η(p
r, x
e) is appreciably greater than
η(p
a, x
e) for all but trivially small
n, which is consistent with the expected result. Because the only difference between each p
a and p
r is the order of their respective terms, the differences between the associated quantities of entropy are entirely due to the contribution from Ξ.
Perhaps more importantly, and in opposition to the behavior of H alone, we find that is also appreciably greater than for all non-trivial n. Among generic discrete variables any non-uniformity in is a benefit to predictability, hence . Among real-valued discrete variables, however, the predictive benefit of non-uniformities in depends on the manner in which the probabilities are spatially assigned. In the case of the indeterminacy effected by the irregular spatial assignment of evidently outweighs the intrinsic predictive benefit of , which implies that behaves more deterministically than . Though not necessarily expected a priori, that implication is not surprising.
Figure 1.
Plots of , and using the respective symbols “•” , “◃” and “+”.
Figure 1.
Plots of , and using the respective symbols “•” , “◃” and “+”.
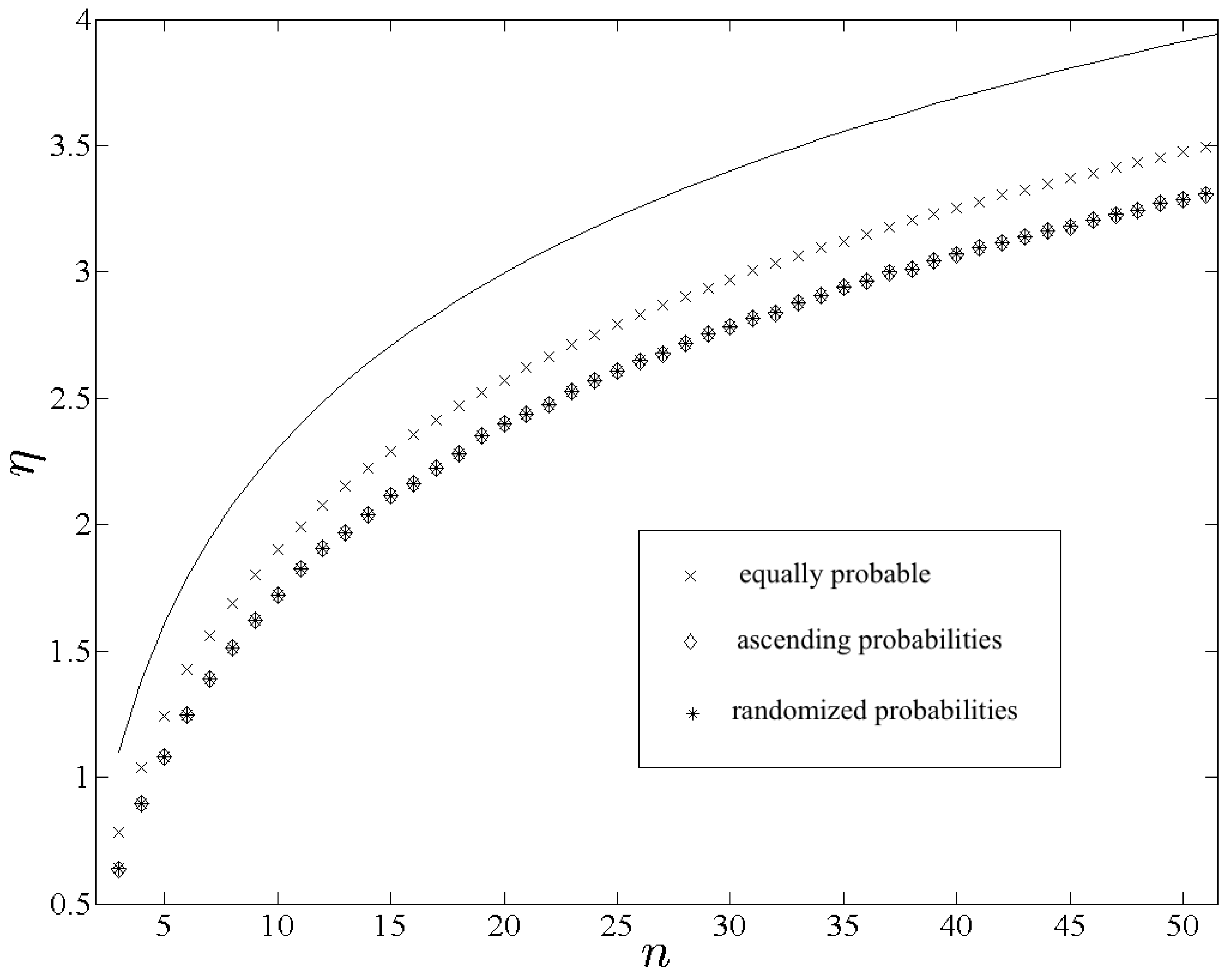
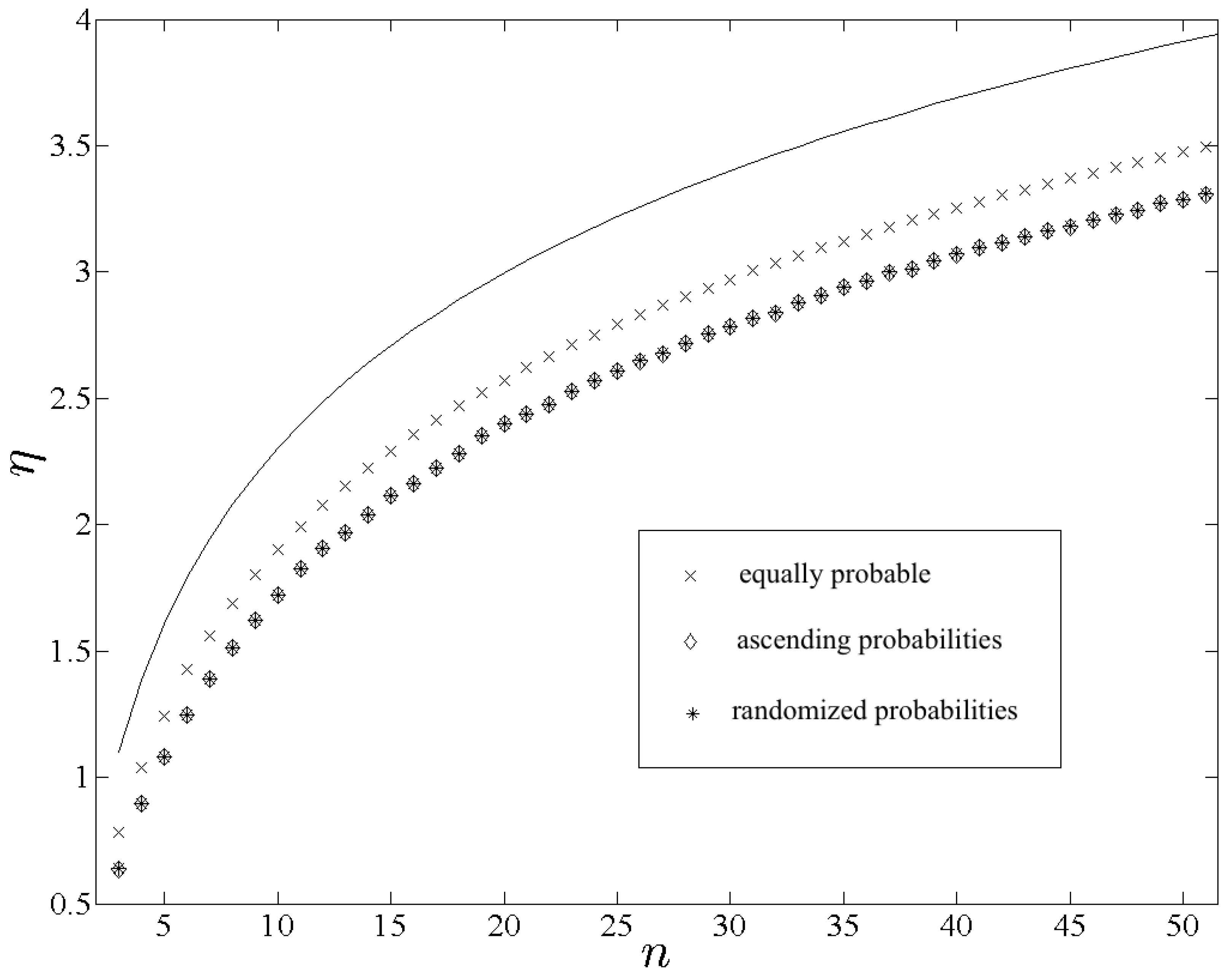
As a complement to the previous scenario it is instructive to compare the effects of the three types of probabilities when matched to spatially randomized outcomes.
Figure 2 displays calculations of
,
and
plotted as functions of
n. Note that
and
nearly coincide for each
n, and the symbols “⋄” and “*” are always superimposed in
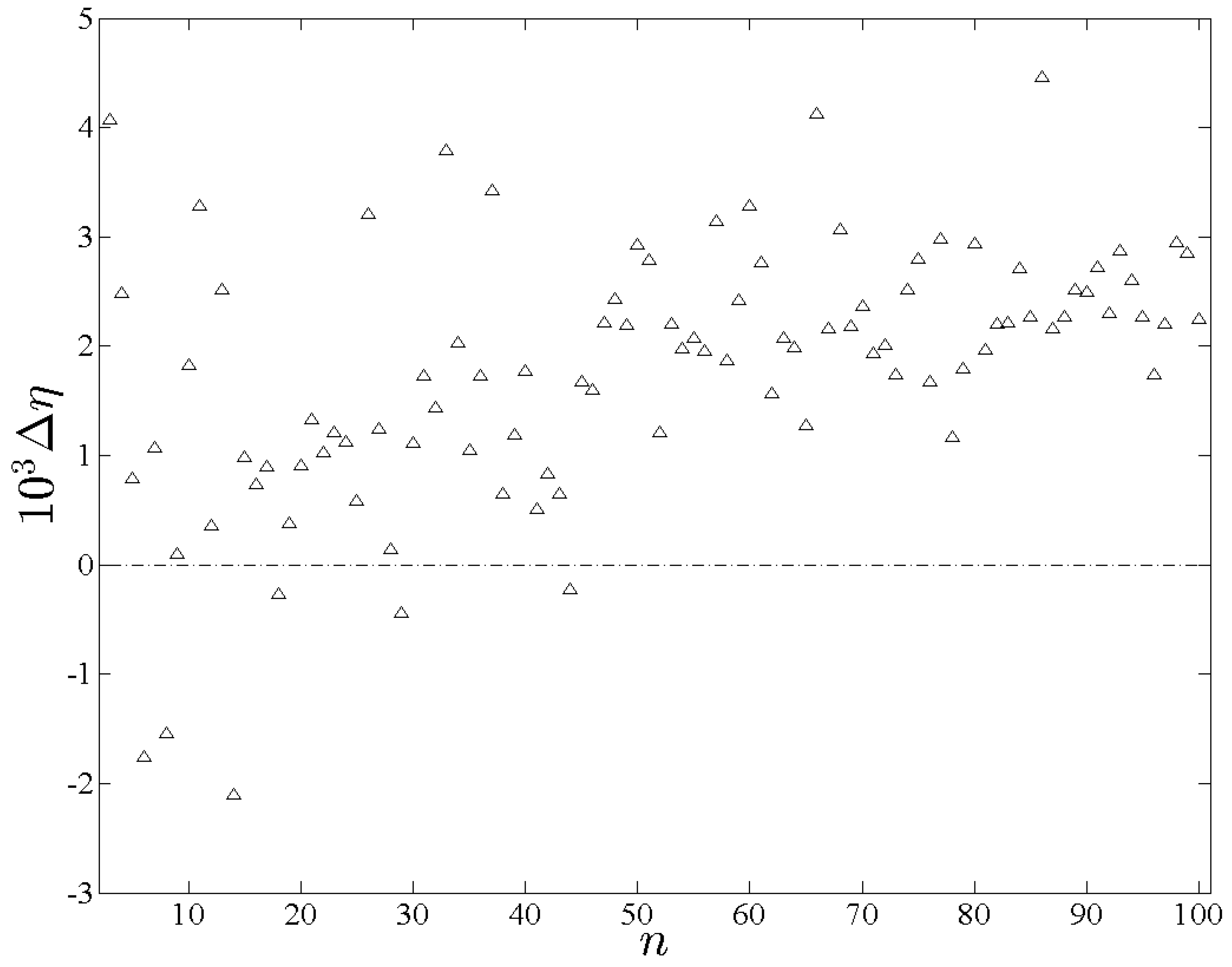
Figure 2. The entropy-difference
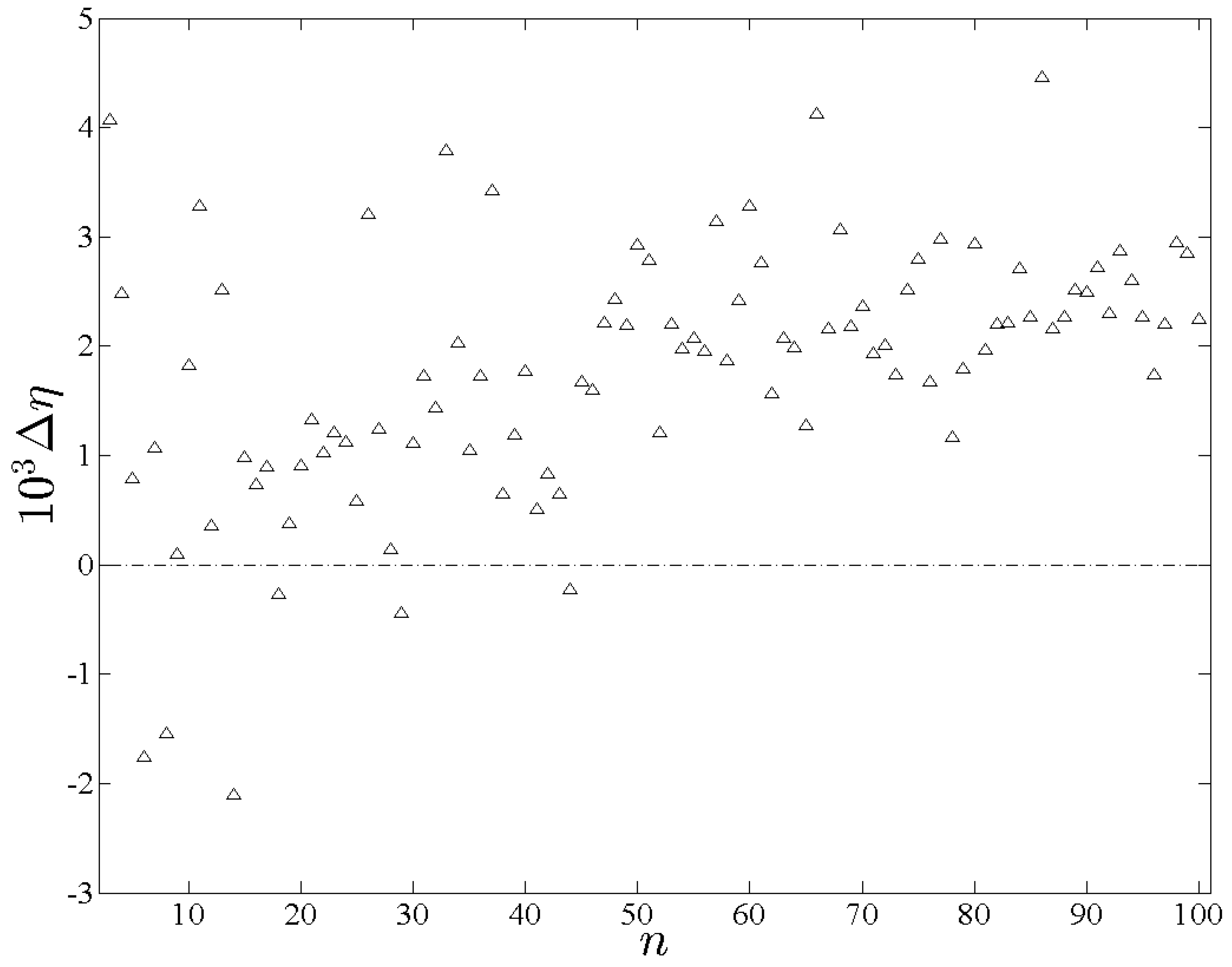
is shown in
Figure 3. In contrast to the previous scenario
consistently effects the largest entropy among the three, which is expected from Equation (
52) given that
is maximal. Note that
would be even closer to
had the randomness of
not been restricted for the sake of computational feasibility. The similarity between
and
is also expected from Equation (
52) given that
. Furthermore insofar as
and
differ the former should be typically greater for sufficiently large
n, which is confirmed in
Figure 3.
Let us next examine calculations demonstrating how
η measures indeterminacy effected through x, which is perhaps the most significant attribute of
η. The most basic comparison corresponds to the scenario involving
and
in
Section 1. It is immediately evident from
Figure 1 and
Figure 2 that
is considerably larger than
for all
n, which is expected.
Figure 2.
Plots of , and , using the respective symbols “×”, “⋄” and “*”. The solid line follows a plot of for reference.
Figure 2.
Plots of , and , using the respective symbols “×”, “⋄” and “*”. The solid line follows a plot of for reference.
Figure 3.
The entropy difference Δη plotted here is η(pr,xr) - η.(pa, xr).
Figure 3.
The entropy difference Δη plotted here is η(pr,xr) - η.(pa, xr).
In order to test the sensitivity of
η to more subtle differences in spatial structure the following additional sets of type
are defined. For a given
n let x
p consist of the first
n prime numbers. It follows from the Prime Number Theorem (PNT) that the local average gap in the vicinity of a given
xj ∈ x
p varies as log(
j) for sufficiently large
j. The term gap is used throughout in reference to a positive interval between consecutive terms in any given one-dimensional
and is defined such that the
j-th gap is
The global anisotropy associated with the PNT constitutes an intrinsic deterministic spatial characteristic. For a more pronounced anisotropy of the same kind, let
be defined for a given
n such that its sequence of gaps consists of the first
n − 1 prime gaps arranged in ascending order. As an example, for
n = 6 we have
. Let
be defined for a given
n such that its sequence of gaps consists of the first
n − 1 prime gaps ordered randomly, with the exception that the first gap in
is always 1. Finally let
be defined such that its sequence of gaps is
, where
is the
j-th prime gap. In other words, the sequence of gaps in
is constructed simply by alternating the order of
and
for all even
i no greater than
n − 2. Consequently every even-numbered element of
is guaranteed to be identical to the corresponding prime. As an example we have
for
n = 8. Note that the average gap in the vicinity of some
differs only negligibly from the corresponding average gap in the primes, and
therefore exhibits the same global anisotropy inherent to x
p.
Consider four variables with
allowed outcomes
,
,
and
, respectively, all of which are equally probable. As
is the least deterministically configured among the four,
should be largest. Furthermore, given that the sequence of gaps in
ascends uniformly, the deterministic nature of the associated anisotropy is significantly greater than in
and
. We therefore expect
to be the smallest entropy among the four.
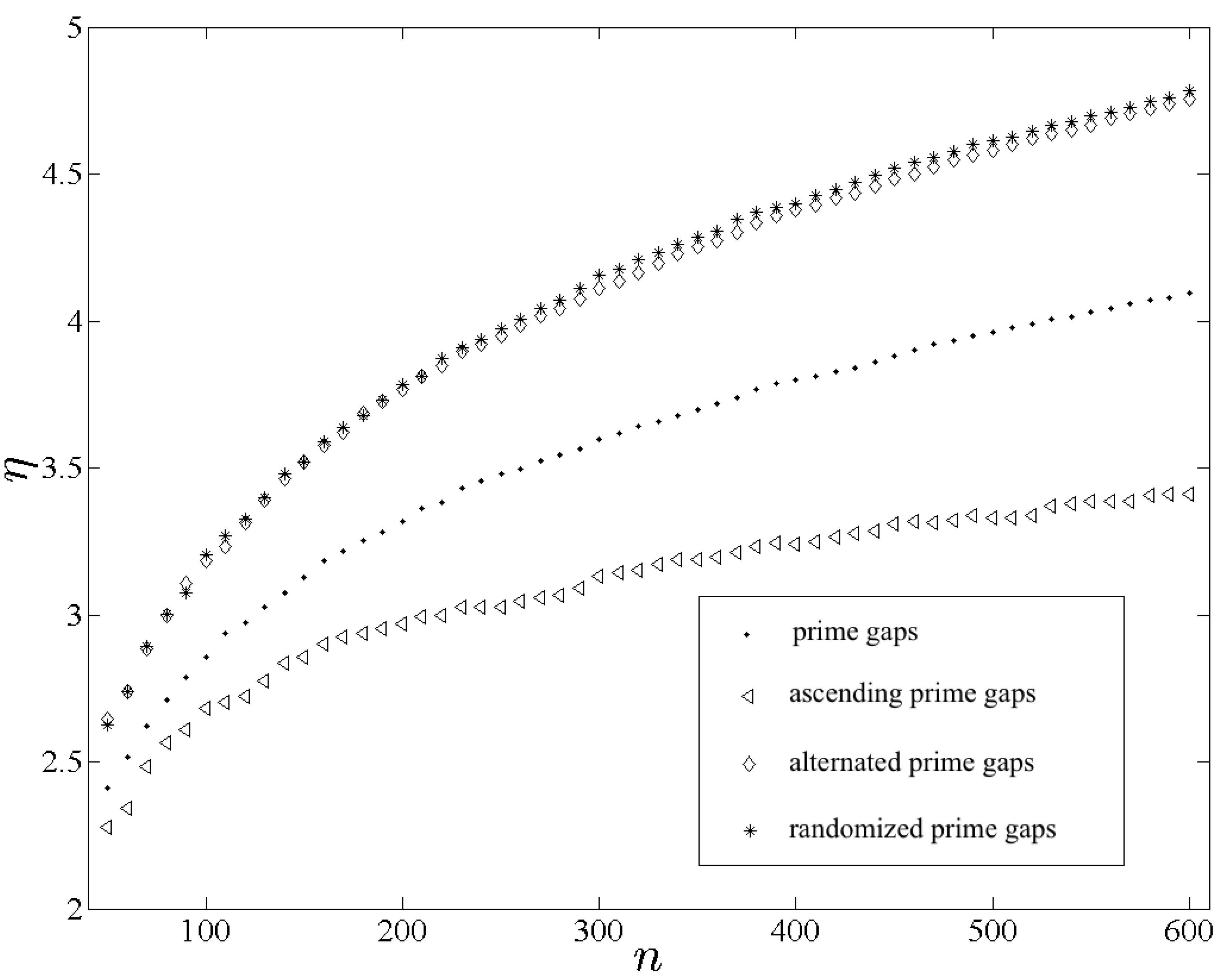
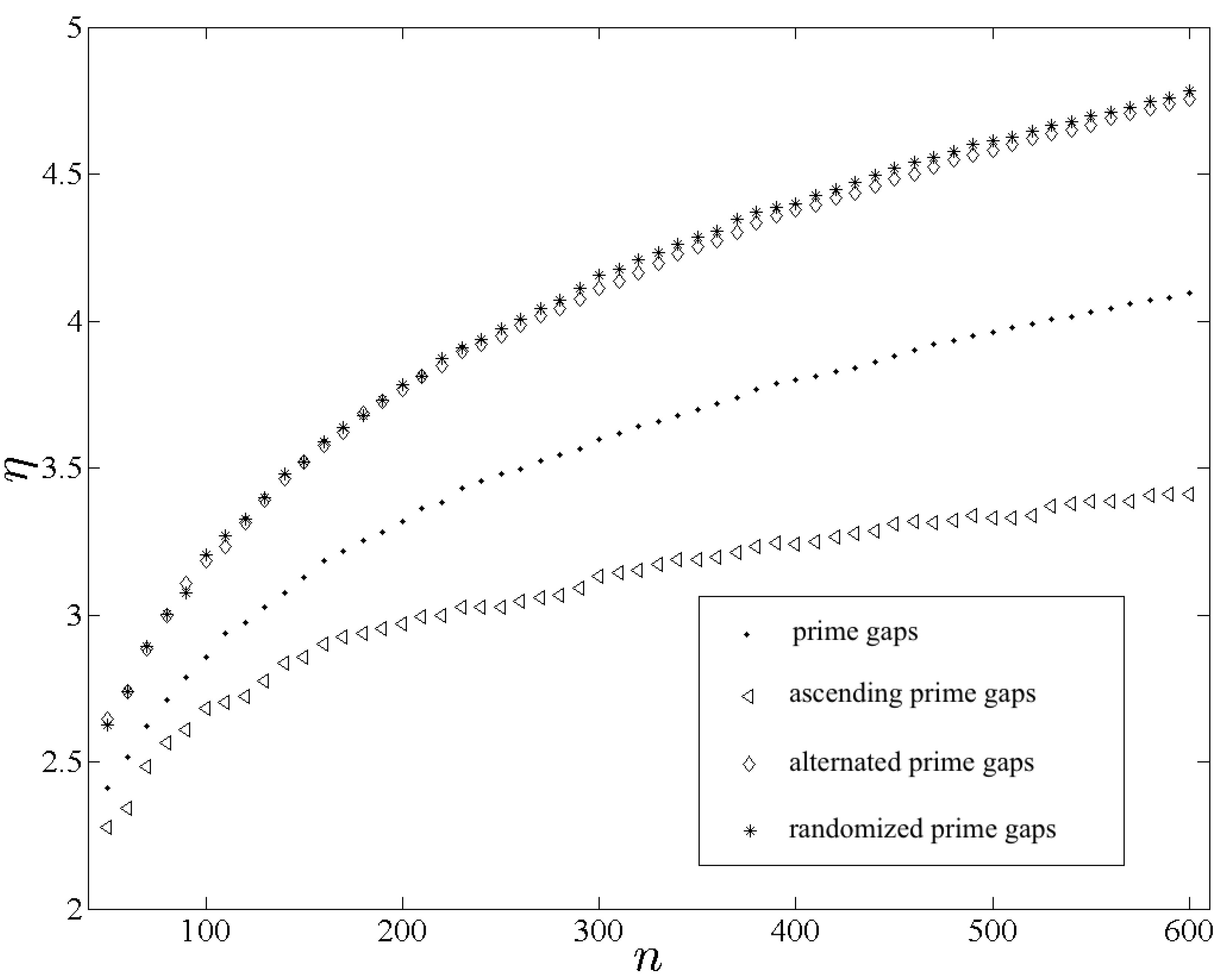
Figure 4 shows
,
,
and
plotted as functions of
n. Although
and
differ only negligibly for
n smaller than approximately 200, for all larger
n the entropy due to
is the greatest among the four. The small but non-negligible difference between
and
for large
n is attributed to the global anisotropy in
. The entropy due to
is the smallest among the four. The behavior of
η in these calculations is therefore consistent with the stated expectations.
The dramatic difference between
and
is noteworthy and unexpected. The smaller entropy due to
implies a greater degree of intrinsic determinacy in the arrangement of
along the real axis. Note that the implied deterministic structure could not be associated with the PNT. A detailed analysis of this finding is beyond the present scope and has become the subject of a separate investigation [
12]. For the present purposes it is sufficient to mention, as the reader may verify readily, that the number of positive intervals of a given size
d among the first
primes is strongly correlated to the largest primordial factor of
d [
12]. That regularity could represent the deterministic property intimated by
.
Figure 4.
Plots of , , and , shown with “•”, “◃”, “⋄” and “*”, respectively, measuring intrinsic structure in the primes and in three variants constructed by changing the order of the first even prime gaps.
Figure 4.
Plots of , , and , shown with “•”, “◃”, “⋄” and “*”, respectively, measuring intrinsic structure in the primes and in three variants constructed by changing the order of the first even prime gaps.
5. Summary and Conclusions
For finite ν the entropy attributed to the variable governed by is simply . In the limit as , however, becomes a discrete variable X whose behavior is insensitive to the function from which is constructed. The entropy attributed asymptotically to X is therefore , which recovers the discrete Shannon entropy. Similarly when ν is finite a quantity of entropy is attributed to the conjugated pair and . The nature of the pair, however, is asymptotically insensitive to . The entropy attributed to the pair in the limit as ν diverges is therefore , whose asymptotic form is defined as η. Furthermore because the conjugate is asymptotically eliminated η must be attributed to X alone.
As
H is a function only of
, the existence of some
-dependent contribution to the entropy of a discrete real variable is expected independently of the introduction of Ξ. Whereas the form of
H uniquely exhibits the properties required for a self-consistent measure of indeterminacy effected by
[
1], the complete set of requirements for a measure of indeterminacy effected by
and
is not readily ascertained
a priori. Among those required properties are certainly translational invariance, scale-invariance, rotational invariance, non-negativity and being bound from above by
H, all of which were proven for
η Section 3. Furthermore the calculations presented in
Section 4 demonstrate that
η behaves in the expected manner over a broad range of different configurations of
and
.
The somewhat counterintuitive role of Ξ is a natural consequence of the relationship between a given wave-mechanical probability density and the corresponding spectral density. More broadly interpreted, the wave-mechanical origin of
η may be understood as a natural consequence of a fundamental unity between information theory and quantum theory. Such an interpretation is well-motivated given the profound connections already known. For instance, the bounds on
S lead to an uncertainty relation that is stronger than the most general form of the Heisenberg Uncertainty Principle [
2]. Even more striking, the basic precepts of quantum theory have been derived from informatic principles [
13].It is important to specify, however, that the validity of
η is contingent upon no quantum-mechanical premise.
The distinctive feature of
η is its dependence on x, which is necessary for a complete measure of indeterminacy in discrete real variables. Because of the generality of its form,
η can be readily manipulated to probe intrinsic organization in sequences of real numbers.
Section 4 presented calculations demonstrating the novel capability of
η in such applications. Future investigations will explore additional applications of
η.

{kind=link}
{kind=link}
{kind=link}
{kind=link}