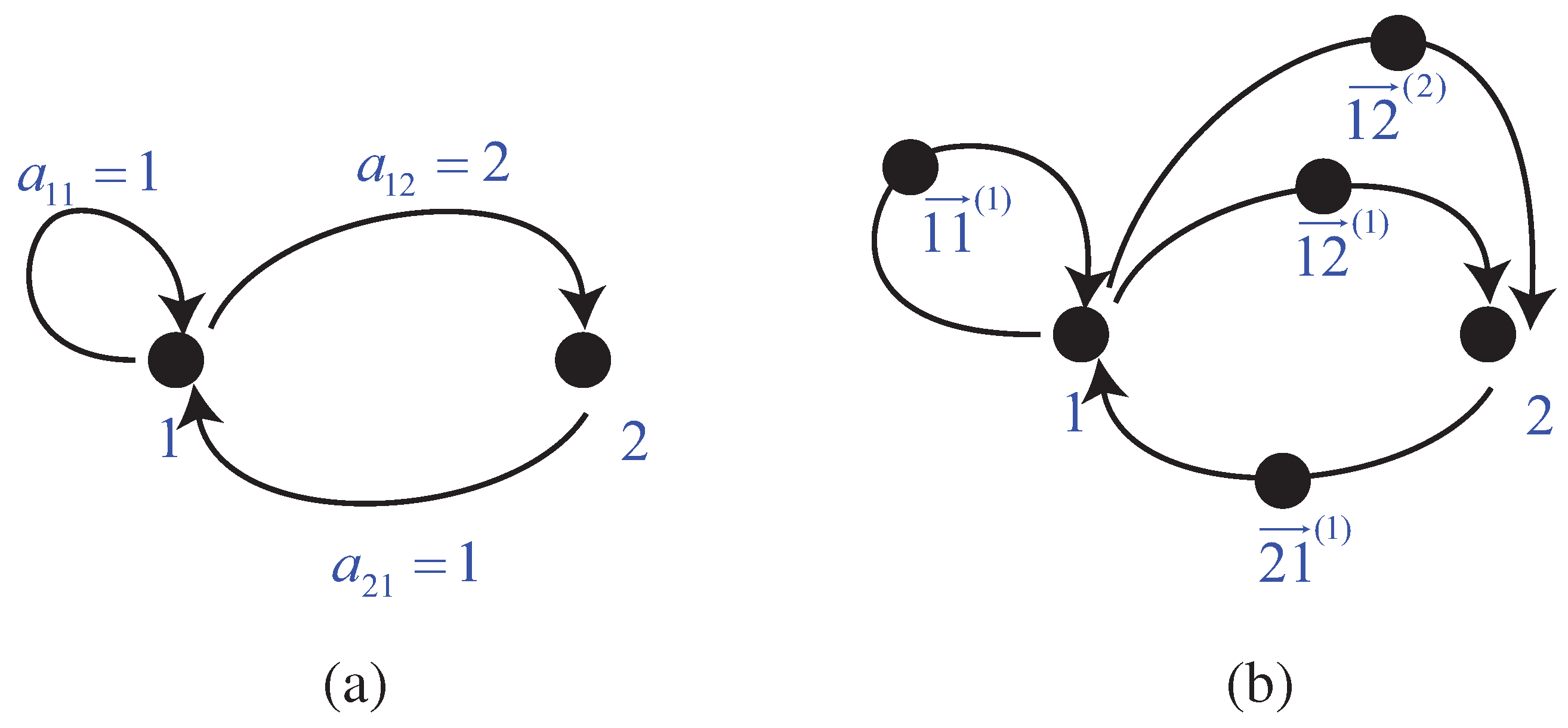1. Introduction
The main concern of this paper is to relate eigenvalue estimates to the Kolmogorov-Sinai entropy for Markov shifts. We shall begin with the definition of the Kolmogorov-Sinai entropy. Let
be an irreducible nonnegative matrix. By an irreducible matrix
, we mean for each
, there exists positive integer
k such that
. A matrix
is said to be a
stochastic matrix compatible with , if
satisfies
if ,
if ,
, for all .
We denote by
the set of all stochastic matrices compatible with
. By Perron-Frobenius Theorem, it is easily seen that every stochastic matrix
has a unique left eigenvector
corresponding to eigenvalue 1 with
. Here we say
is the
stationary probability vector associated with
. For a transition matrix
,
i.e.,
or 0 for each
, the
subshift of finite type generated by
is defined by
and the shift map on
is defined by
. A cylinder of
is the set
for any
. Disjoint unions of cylinders form an algebra which generates the Borel
σ-algebra of
. For any
and its associated stationary probability vector
, the Markov measure of a cylinder may then be defined by
Here
is an invariant measure under the shift map
(see e.g., [
8]). The
Kolmogorov-Sinai entropy (or called the
measure theoretic entropy) of
under the invariant measure
is defined by
where
and the convention
is adopted. The notion of the Kolmogorov-Sinai entropy was first studied by Kolmogorov in 1958 on the problems arising from information theory and dimension of functional spaces, that measures the uncertainty of the dynamical systems (see e.g., [
6,
7]). It is shown in [
8] (p. 221) that
where the summation in (1) is taken over all
with
. On the other hand, it is shown by Parry [
9] (Theorems 6 and 7) that the Kolmogorov-Sinai entropy of
has an upper bound
.
Theorem 1.1 (
Parry’s Theorem)
. Let be an irreducible transition matrix. Then for any and its associated stationary probability vector , we havewhere denotes the dominant eigenvalue of . Moreover, if is regular ( for some ), the equality in (2) holds for some unique and the stationary probability vector associated with . Parry’s Theorem shows the Kolmogorov-Sinai entropy for a Markov shift is less than or equal to its topological entropy (that is,
) and exactly one of the Markov measures on
maximizes the Kolmogorov-Sinai entropy of
provided it is topological mixing. This is also a crucial lemma for showing the Variational Property of Entropy [
8] (Proposition 8.1) in the ergodic theory. However, from the viewpoint of eigenvalue problems, combination of (1) and (2) gives a lower bound for the dominant eigenvalue of the transition matrix
. In this paper, we generalize Parry’s Theorem to general
irreducible nonnegative matrices. Toward this end, we extend the entropy of irreducible nonnegative matrices by
It is easily seen that
.
Theorem 1.2 (
Main Result 1: The Generalized Parry’s Theorem)
. Let an irreducible nonnegative matrix. Let and be a stationary probability vector associated with , then we havewhere the summation is taken over all with . Moreover, the equality in (3) holds whenandwhere and are, respectively, the right and left eigenvectors of corresponding to the eigenvalue . Here, denotes the diagonal matrix with on its diagonal, denotes the vector , and denotes the transpose of the column vector . Lower bound estimates for the dominant eigenvalue of a symmetric irreducible nonnegative matrix play an important role in various fields, e.g., the complexity of a symbolic dynamical system [
5], synchronization problem of coupled systems [
10], or the ground state estimates of Schrödinger operators [
2]. A usual way to estimate the lower bound for
is the Rayleigh quotient
It is also well-known that (see e.g., [
4] (Theorem 8.1.26)),
provided that
is nonnegative and
is positive. Comparing the lower bound estimate (3) with (4) as well as with the Rayleigh quotient, we have the following result.
Corollary 1.3.
Let be a symmetric, irreducible nonnegative matrix. Suppose be positive. Then the matrix is in and is the stationary probability vector associated with . In addition,andHere, each equality holds if and only if is the eigenvector of corresponding to the eigenvalue . Here we remark that for any arbitrary irreducible nonnegative matrix , the entropy involves the left eigenvector of . Hence, the lower bound estimate (3) is merely a formal expression. However, for a symmetric irreducible nonnegative matrix and chosen as in Corollary 1.3, the vector can be explicitly expressed. Therefore, can be written in an explicit form. We shall further show in Proposition 2.6 that where .
Considering symmetric nonnegative
and its perturbation
, it is easily seen that
, where
is the normalized eigenvector of
corresponding to
. This gives a trivial lower bound for the gap of
and
. Upper bound estimates for the gap are well studied in the perturbation theory [
4,
11]. By considering
as a low rank perturbation of
, the interlace structure of eigenvalues of
and of
is studied by [
1,
3]. In the second result of this paper, we give a nontrivial lower bound for
.
Theorem 1.4 (
Main Result 2)
. Let be an irreducible nonnegative matrix and be the eigenvector of corresponding to with . Suppose is symmetric. Then for any nonnegative , we havewhereHere . Furthermore, the equality in (5) holds if and only if . This paper is organized as follows. In
Section 2, we prove the generalized Parry’s Theorem in three steps. First, we prove the case in which the matrix
has only integer entries. Next we show that Theorem 1.2 is true for nonnegative matrices with rational entries. Finally we show that it holds true for all irreducible nonnegative matrices. The proof of Corollary 1.3 is given at the end of this section. In
Section 3, we give the proof of Theorem 1.4. We conclude this paper in
Section 4.
Throughout this paper, we use the boldface alphabet (or symbols) to denote matrices (or vectors). For , the Hadamard product of and is their elementwise product which is denoted by . The notation denotes the diagonal matrix with on its diagonal. A matrix is said to be a transition matrix if or 0 for all . denotes the dominant eigenvalue of a nonnegative matrix .
2. Proof of the Generalized Parry’s Theorem and Corollary 1.3
In this section, we shall prove the generalized Parry’s Theorem and Corollary 1.3. To prove inequality (3), we proceed in three steps.
Step 1: Inequality (3) is true for all irreducible nonnegative matrices with integer entries.
Let
be an irreducible nonnegative matrix with integer entries. To adopt Parry’s Theorem, we shall construct a transition matrix
corresponding to
for which
. To this end, we define the sets of indexes:
Let
and
. The transition matrix
corresponding to
with index set
is defined as follows
It is easily seen that
can be written in the block form:
where
and
are, respectively, the zero matrices in
and
,
and
.
Proposition 2.1.
.
Proof.
From (7), we see that
From (6a) and (6b), for each
with
, we have
Using (8), together with (6c), we have
From (9) we see that
. Hence
. On the other hand,
is a nonnegative matrix. From Perron-Frobenius Theorem, its dominant eigenvalue is nonnegative. The assertion follows. ☐
Remark 2.1. In the language of graph theory,
represents the number of directed edges from vertex
i to vertex
j. Hence
equals to the number of all possible routes of length
,
i.e.,
For the construction of
, we add an additional vertex on every edge from vertex
i to vertex
j (See Figure 2.1 for the illustration). Hence, each route that obeys the rule defined by
,
now becomes one of the following routes according to the rule defined by
:
where
,
. However, a route of the form in (11) is equivalent to the form in (10) but its length is doubled. Hence
.
Figure 1.
Illustration for Remark 2.1 with the example .
Figure 1.
Illustration for Remark 2.1 with the example .
Now, let
be given and
be its associated stationary probability vector. We shall accordingly define a stochastic matrix
and its associated stationary probability vector
. The stochastic matrix
is defined as follows:
From (6) and (12), it is easily seen that
is a stochastic matrix compatible with
. Let the vector
be defined by
and
Proposition 2.2.
is the stationary probability vector associated with .
Proof.
We first show that
is a left eigenvector of
with the corresponding eigenvalue 1. For any
, using (12b), (13b), and the fact that
, we have
On the other hand, using (12a) and (13a), for all
with
and
, we have
In (14), we have proved
. Now we show that the total sum of entries of
is 1. Using the fact
we conclude that
The proof is complete. ☐
From the construction of the transition matrix , it is easily seen that is irreducible. In (12) and Proposition 2.2, we show that and the vector defined by (13) is its associated stationary probability vector. Hence the Kolmogorov-Sinai entropy is well-defined. Now we give the relationship between the quantities and defined in Equation (3).
Proof.
We note that by (12b),
if
. Using the definition of
and
in (12) and (13), as well as the entropy formula (1), we have
The proof is complete. ☐
Using Proposition 2.3, 2.1, and Parry’s Theorem 1.1, it follows that
Step 2: Inequality (3) is true for all irreducible nonnegative matrices with rational entries.
Any nonnegative matrix with all entries that are rational can be written as where is a nonnegative matrix with integer entries and n is an positive integer. Suppose is irreducible and . Note that . Letting be a stationary probability vector associated with , inequality (3) for follows from the following proposition.
Proof.
From the definition of
, we see that
On the other hand, since
and
, we have
Substituting (17) into (16) and using the result (15) in
Step 1, we have
☐
Step 3: Inequality (3) is true for all irreducible nonnegative matrices.
It remains to show (3) holds for all nonnegative with irrational entries. The assertion follows from Step 2 and the continuous dependence of eigenvalues with respect to the matrix.
Now, we give the proof of the second assertion of Theorem 1.2.
Proposition 2.5.
The equality in (3) holds when one choosesandwhere and are, respectively, the right and left eigenvectors of corresponding to eigenvalue . Proof.
By setting
, we may write
To ease the notation, set
. Hence, we have
The proof of Theorem 1.2 is complete. ☐
In the following, we give the proof of Corollary 1.3. We first prove the following useful proposition. It will be used in
Section 3 as well.
Proposition 2.6.
Let be an irreducible nonnegative matrix. Suppose is symmetric and be positive. If and , where , then From Proposition 2.5, we see that the matrix in Proposition 2.5 is a stochastic matrix compatible with and is its associated stationary probability vector. Hence, the entropy is well defined. Now, we give the proof of this Proposition.
Proof. Since
is irreducible and
, it follows
, and hence,
is well-defined. It is easily seen that
if and only if
. However,
. This shows that
. On the other hand, since
is symmetric, we see that
. Hence
We have proved the first assertion of this proposition. By the definition of
in (3), we have
This completes the proof. ☐
Now, we are in a proposition to give the proof of Corollary 1.3.
Proof of Corollary 1.3.
For convenience, we let
. Hence
and
. Using Proposition 2.6, we have
Here inequality (19) follows from Jensen’s inequality (see e.g., [
12] (Theorem 7.35)) for
and the fact that
. Similarly, using Proposition 2.6 and the monotonicity of log, we also see that
This proves the first assertion of Corollary 1.3. It is easily seen that if
is an eigenvector corresponding to
, then both equalities in (19) and (20) hold. From the assumption that
is irreducible and
, it follows that
also. This implies there are
N terms in (18). Hence equality in (19) or in (20) holds only if
, for all
, are constant. That is,
. Here
λ is some eigenvalue of
. However,
. From Perron-Frobenius Theorem it follows
. The proof is complete. ☐

{kind=link}