

Cart-State-Aware Discovery of E-Commerce Visitor Journeys with Process Mining



Abstract
1. Introduction
- RQ1: What is the most important process structuredness factor, and what are the other significant factors?
- RQ2: What are the most frequent e-commerce visitor journeys that can be observed using clickstream data?
- RQ3: What is the end-to-end e-commerce journey?
2. Background, Related Work, and Contributions
2.1. Background of Web Usage Mining
2.2. Related Work on Web Usage Mining
2.3. Definitions Related to Process Mining and Techniques Used
2.4. Process Mining Applications in E-Commerce
2.5. Evaluating Process Structuredness
2.6. Main Contributions
- We developed an empirical process structuredness measure using expert knowledge.
- We proposed a methodology for structuring the outcomes of e-commerce visitor journeys and tested it with real-life data.
- By treating the cases with an account balance approach that is applied similarly in accounting, we calculated the cart status at the beginning and end of a journey and used this information for grouping the sessions.
- We identified three levels of e-commerce visitor journeys and explained them.
- By using cart statuses at the beginning and end of these journeys, we obtained a high-level end-to-end e-commerce journey.
- We proposed new metrics to evaluate online user journeys and to benchmark e-commerce journey design success success.
3. Materials and Methods
- DDDDDAAAACBBBDDDDDAACCDDDAABBDD
- DDDDDAAAACBBB
- DDDDDAACCDDDAABB
- DD
4. Evaluation and Results
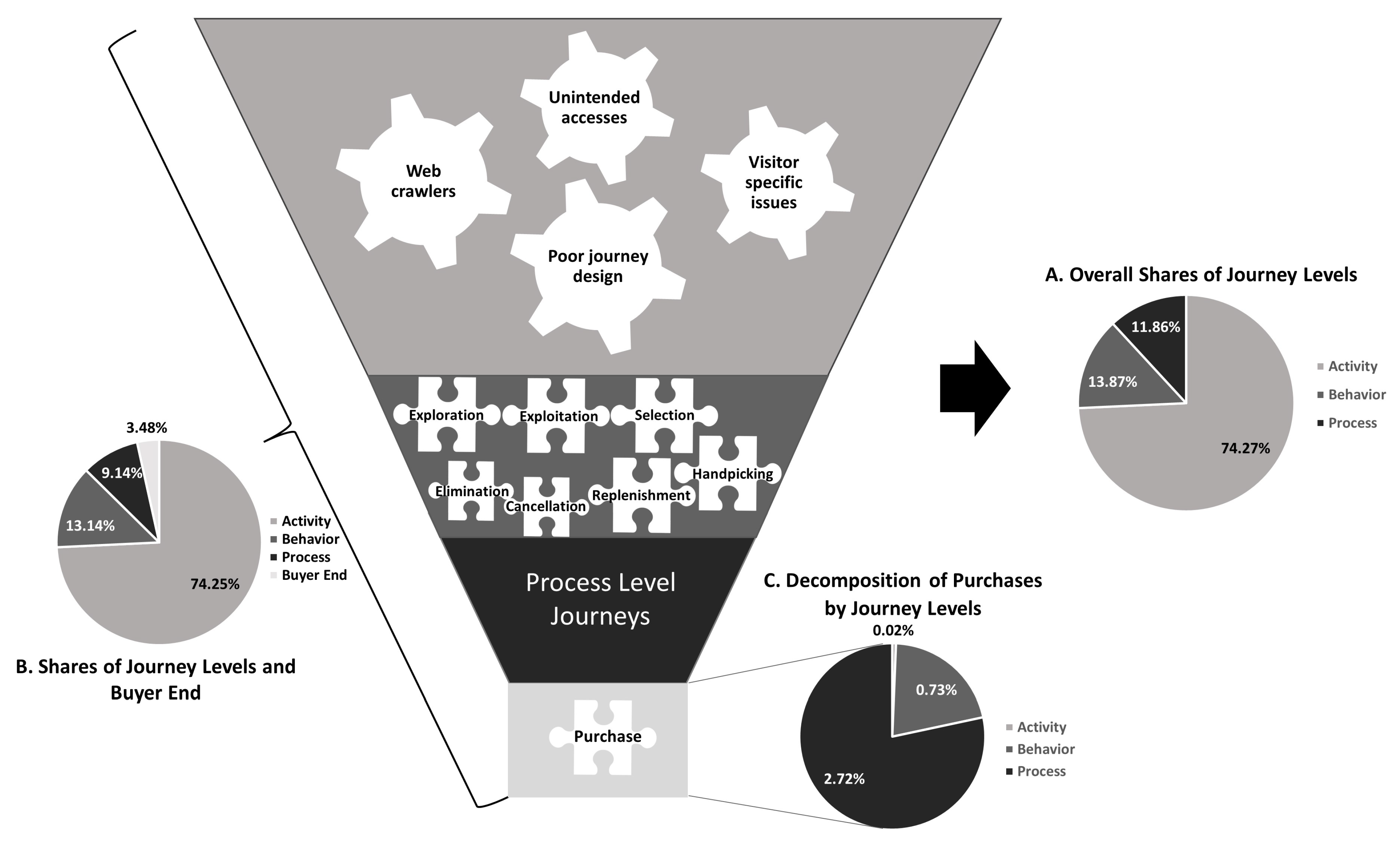
- Step 1—Filtering Activity Level Journeys: An algorithm was developed to process the dataset in line with the methodology described in the Section 3. “Purchase” was considered to be the last activity in the customer journey. Each purchase in the dataset was shown as a separate event in the dataset; because of this, consecutive purchases in the same case were kept together to prevent one-activity cases. Cases without any “Purchase” activities were not changed. Following this, cases with just one or two events were removed from the dataset and saved in another file for further analysis as the activity-level journeys.
- Step 2—Event Log Enrichment and Repair: After the initial dataset examination, it was decided that activity types in the dataset did not reflect the intentions of the visitors. For data enrichment purposes, activity types in Appendix C were created with an algorithm. Since cart status information was not readily available in the web logs used in this research, cart statuses were calculated and start and end nodes in line with cart status were added to each case as explained in Table 3.
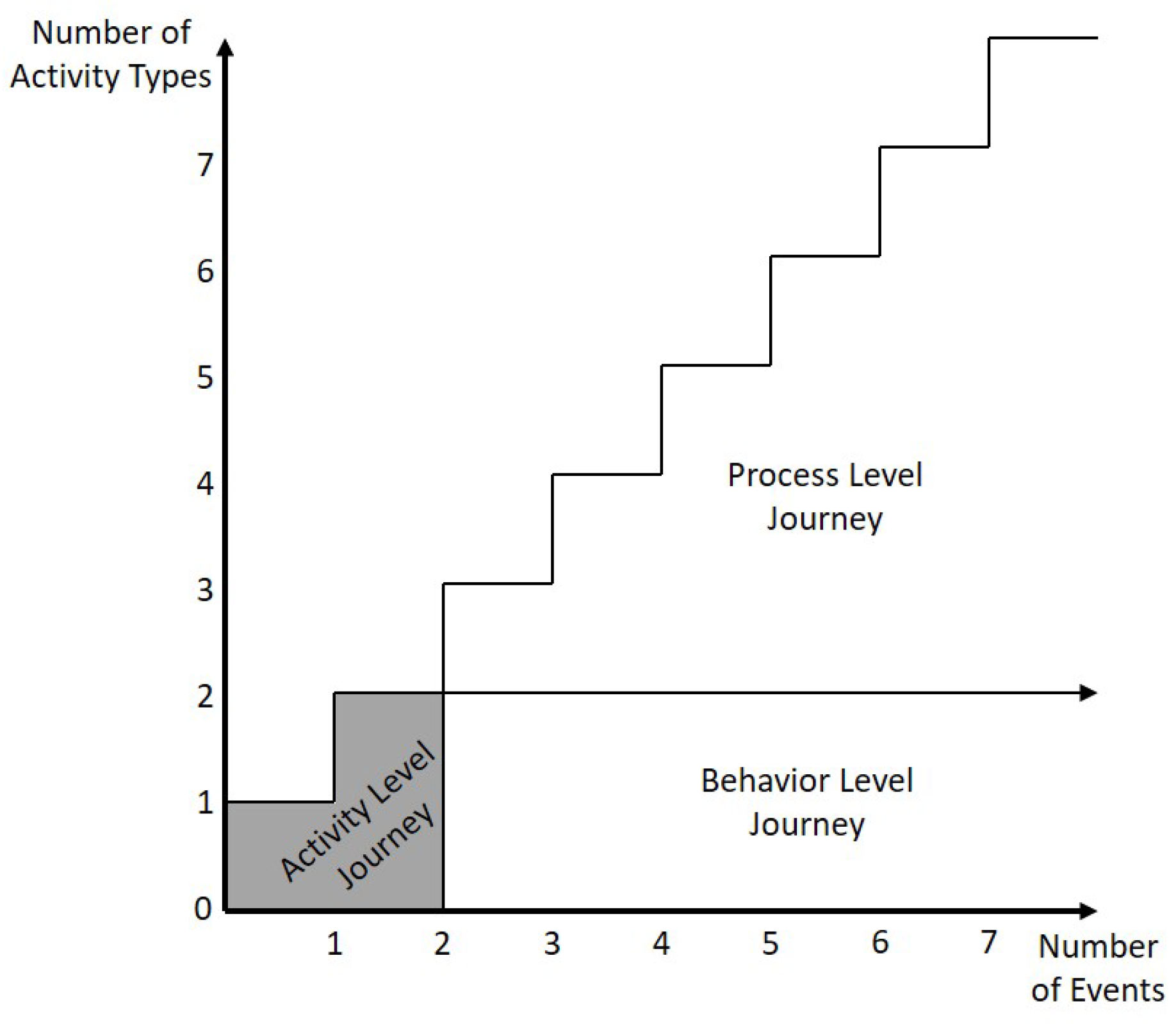
- Step 3—Filtering Behavior Level Journeys: In line with Figure 3, we created an algorithm that filtered out behavior-level journeys regardless of the session length but at a maximum of two activity types. Then, each combination of activities was saved in separate files for analyzing these behavior-level journeys.
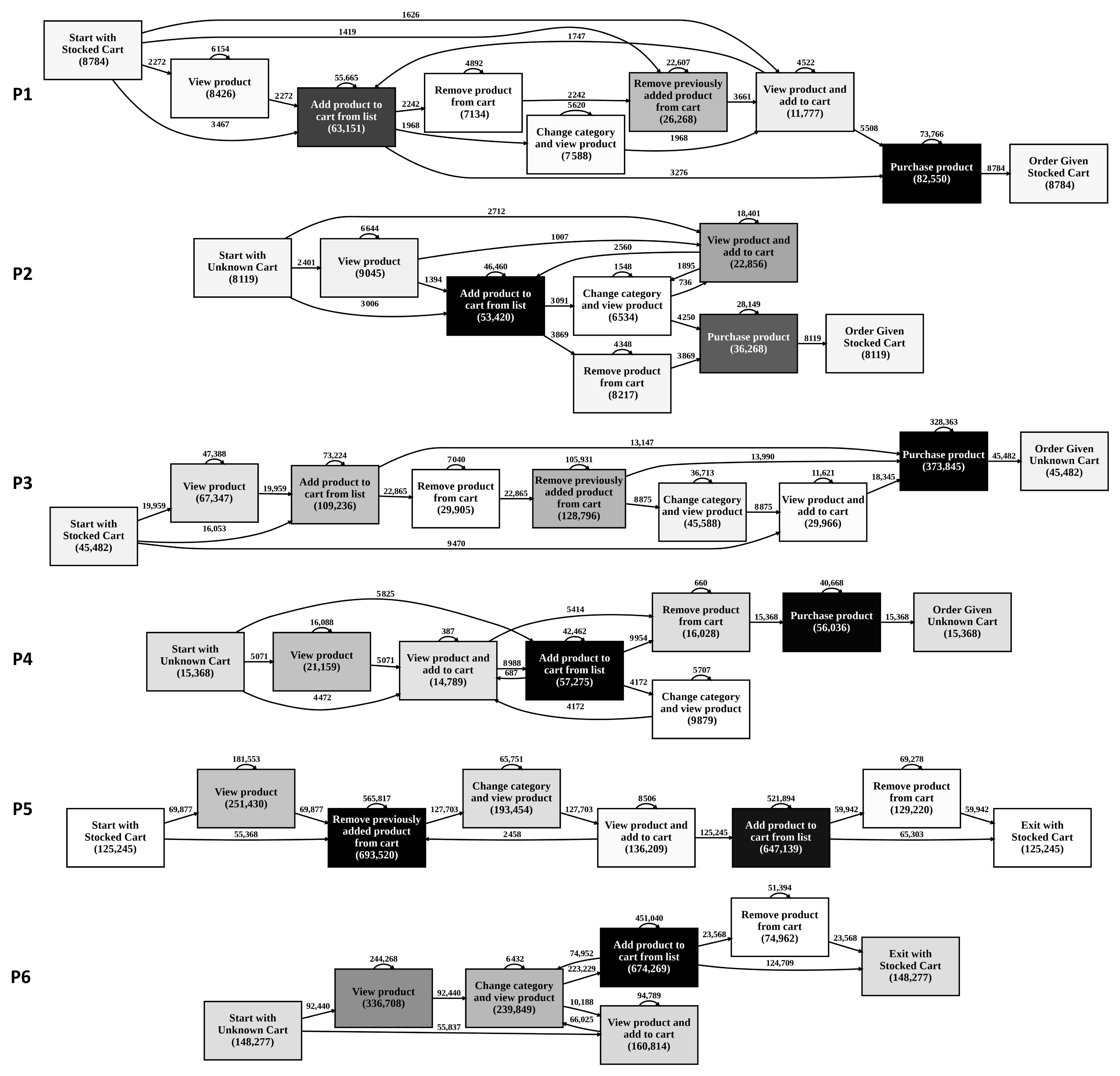
- Step 4—Process Level Journey Classification: In order to decrease the number of variants, first of all, “Purchase-Previously-Carted” activities were converted back to “Purchase”. Then, a case grouping was made with start and end nodes, as in Table 4, and eight groups were identified. Following that, each group was processed with the algorithm illustrated in Figure 4. Structuredness for the processes of each resulting cluster were tested using the empirical measure developed in this study.
4.1. Activity Level E-Commerce Visitor Journeys
4.2. Behavior Level E-Commerce Visitor Journeys
- Exploitation: Visiting product pages only in a specific category. In Table 5, the joint occurrence of each behavior with other behaviors is also given. At the behavior level, this kind of journey was observed in 59.92% of cases without taking any other action, and in 40.08% of the cases, other behaviors were detected.
- Exploration: Visiting product pages in at least two categories.
- Selection: Adding products to the cart without visiting related product pages.
- Handpicking: After visiting a product page, adding that product to the cart and sometimes viewing another product in the same category and adding it to the cart.
- Elimination: Removing products from cart which were added in previous sessions or in the current session after visiting a product page. This behavior was always observed with other behaviors.
- Cancellation: Removing products from cart that were added in previous sessions or in the current session. This behavior is identical to the invalidation of purchase requests in corporate procurement processes.
- Replenishment: Removing products from the cart that were added in previous sessions before or after adding new products to the cart from a list. This behavior was always observed with other behaviors.
- Purchase: Purchasing products that were added to the cart in the previous sessions or in the current session.
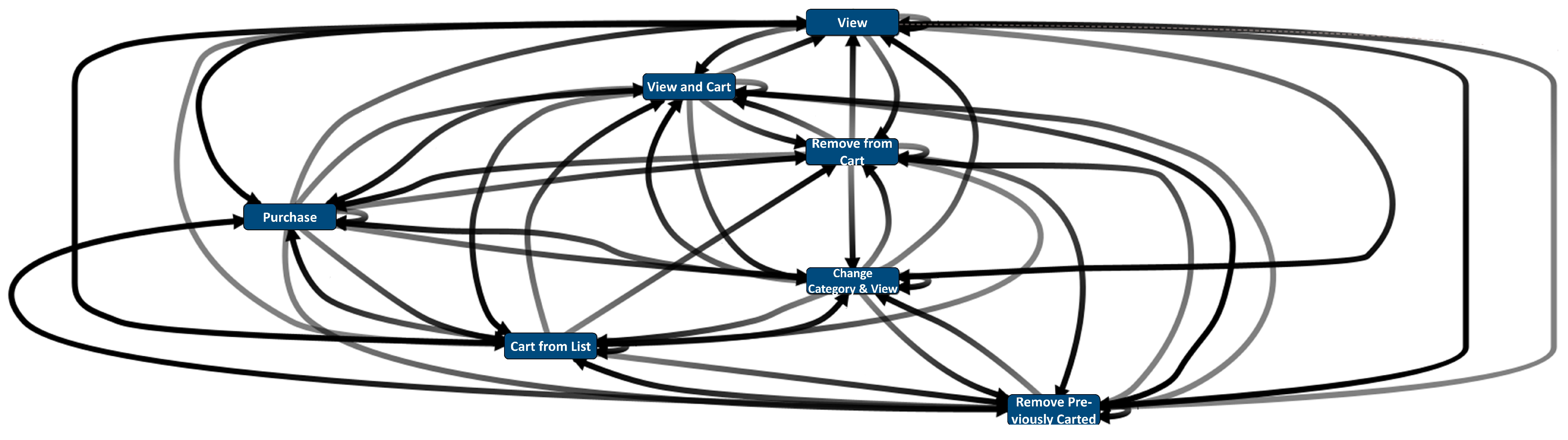
4.3. Process Level E-Commerce Visitor Journeys
5. Discussion
- RQ1: In the existing studies in the literature, the number of arcs in a diagram was considered to be an important factor for the process structuredness [61]. In this study, it was revealed that process experts do not consider self-loops of the nodes, and Arcs per Node Excluding Self Loops is the most significant factor for process structuredness, as shown in Table A3. Moreover, Number of Nodes is a factor influencing process structuredness; however, it is not as significant as Arcs per Node Excluding Self Loops.
- RQ2: By applying the four-step methodology, we identified that activity level e-commerce visitor journeys were the most common journey type and that they carried importance for e-commerce journey design. After these, at the behavior level, Exploitation and Exploration were the most common journeys, and it was revealed that journeys with Exploration behavior had significantly lower CR. We think that for prediction and recommendation in e-commerce, researchers and e-practitioners can benefit from analyzing and studying on these behaviors. Lastly, at the process level, P5 and P6 were the most common journeys which needed to be focused on for higher CR.
- RQ3: To our knowledge, for the first time in the e-commerce literature, we mapped an end-to-end process of an e-commerce journey, which is given in Figure 6. This journey map is the top-level process, and most common lower-level processes are shown in Figure 7. In line with the research objective, these processes are structured, and they provided many insights for the dataset analyzed. The implications of these are discussed in the following subsections.
5.1. Implications for E-Commerce Visitor Journeys
- To enhance e-commerce journey design and thus convert activity-level journeys to more advanced journeys;
- To obtain a KPI to measure competition by filtering web crawler sessions;
- To evaluate advertisement efficiency by reporting access points.
5.2. Implications for Structuredness Measure
5.3. Limitations and Validity
5.4. Future Research Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CR | Conversion Rate |
| DFG | Directly Follows Graph |
| RQ | Research Question |
| SEPM | Sequential Event Pattern Mining |
| HRNNs | Hierarchical Recurrent Neural Networks |
| HNNs | Hopfield Neural Networks |
| QoS | Quality of Service |
| LTL | Linear Temporal Logic |
| CPA-PM | Cloud Pattern API-Process Mining |
| CNC | Coefficient of Network Connectivity |
| CNCX | Coefficient of Network Connectivity Excluding Self Loops |
| ACD | Average Connector Degree |
| 7PMG | Seven Process Modeling Guidelines |
| BPMN | Business Process Modeling Notation |
| IoT | Internet of Things |
| ERP | Enterprise Resource Planning |
| CRM | Customer Relationship Management |
| KPI | Key Performance Indicator |
| AUC | Area Under Curve |
| MAP | Mean Average Precision |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Reference | Main Focus | Contribution | Findings |
|---|---|---|---|---|
| 1 | Poggi et al. [9] | Process discovery | Knowledge-based Miner algorithm which was also capable of using prior knowledge; first e-commerce research with process mining; and transforming URLs to activities | General customer behavior with different algorithms |
| 2 | Padidem and Nalini [46] | Process discovery | Four shopper types assumed, expected behaviors guessed and then two of the types were discovered as processes; expected shopper types verified and behavior of shopper types analyzed | |
| 3 | Ghavamipoor et al. [47] | Quality of Service (QoS) sensitive customer behavior model graph discovery | Proposed a Customer Behavior Model Graph that was sensitive to the QoS provided to customers during their navigation to formulate QoS-aware offers to them | Customer Behavior Model Graphs for buyer and visitor customer types were analyzed |
| 4 | Hernández et al. [48] | Analysis of customers’ purchasing behavior | LTL-based model checking approach to analyze customer behavior with declarative modeling was developed | Purchasing rates were found to be differing for different categories |
| 5 | Terragni and Hassani [49] | Analyzing customer journeys to make recommendations | Used process mining on the web logs to explore the customer journey; predicted their activities and recommended actions that maximize particular KPIs | Attribute (mobile and non-mobile) based customer journeys discovered and analyzed |
| 6 | Terragni and Hassani [50] | Analyzing customer journeys to make recommendations | Data-driven customer journey mapping and recommendations using the mapped journey | General customer journey map obtained |
| 7 | Goossens et al. [51] | Order aware recommendations | Used a process model to do predictions and recommendations within the customer journey; explicitly used the order of events during predictions and recommendations and optimized recommendations for any chosen KPI | No information |
| 8 | Filipowska et al. [52] | Usability | Proposed a model for improving usability of the website taking into account dynamic aspects of user’s activity on the portal | No information |
| 9 | Nguyen et al. [53] | Customer Journey Management | Proposed an approach for designing and deploying a customer journey management system | No information |
| 10 | El-Gharib and Amyot [54] (2022) | Data preprocessing | A data preprocessing method (CPA-PM) for event logs generated by cloud-based information systems, with an emphasis on clickstream data | No information |
| # | Industry | # of Events | Tool | Notation | Algorithm | Prediction | Recommendation | Metrics |
|---|---|---|---|---|---|---|---|---|
| 1 | Online Travel and Booking | 4 million+ | Business Process Insights (BPI) | DFG | Knowledge-based Miner, Heuristic Miner, Fuzzy miner | No | No | None |
| 2 | No information | No information | No information | Petri Nets | No information | No | No | None |
| 3 | Supermarket | 200,000 | ProM | Dependency Frequency Diagram | Heuristic Miner | Transition probabilities calculated | No | Average Absolute Error |
| 4 | Gift Shop | 8,607,625 | Model Checker | Declarative Model | No information | Behavioral patterns occurrence | No | No information |
| 5 | Advertising | 10 million | Disco | DFG | Fuzzy Miner | Next activity prediction | Product pages recommended to the visitors | AUC (Area Under Curve) |
| 6 | Advertising | 10 million | Disco | DFG | Fuzzy Miner | No | Product pages recommended to the visitors | MAP@5 and AUC |
| 7 | Online Ticket Sales | 141,510 | Disco | DFG | Fuzzy Miner | Next activity prediction | Recommendations were made for new sales to customers | F1 Score |
| 8 | No information | 76,975 | ProM | No information | No information | No | No | No information |
| 9 | Software | 18,077 | PM4Py | Petri Nets | Fuzzy Miner, Alpha Algorithm, Heuristic Miner, Inductive Miner | No | No | Fitness and Simplicity |
| 10 | Software | 1,602,438 and 2,144,210 | Disco and ProM | DFG | Fuzzy Miner | No | No | None |
Appendix B
- Can you follow the flow in the diagram and read it as a process?
- How much effort is needed to turn the process diagram into a more structured one?
- As a process analysis expert, is this diagram acceptable from a customer centric perspective?
- Structured: Without any hesitation, the process diagram can be tagged as structured.
- More or Less Structured: There are a few parts complicating the process, and by easily lining these parts, the process can be turned into a structured process.
- Rather Structured: It is possible to partially understand the flow; however, it is difficult to determine whether it is structured. If it is possible to make it structured with less effort according to the reviewer, then this tag is assigned.
- Close to Unstructured: It is possible to partially understand the flow; however, it is difficult to determine whether it is structured. If the required effort is expected to be high by the reviewer, then this tag is assigned.
- Unstructured: There is no block structure in the process; it is very difficult to follow the flow, and visually, it is spaghetti-like without any hesitation. From a practical point of view, this type of output is not acceptable by a customer.
- Extremely Unstructured: It is impossible to follow or understand the flow. This type of output cannot be produced manually.
- Number of Nodes (Size);
- Number of Arcs;
- Total Number of Elements (including all nodes and arcs);
- Number of Self Loops (Arcs starting and ending at the same node);
- Percentage of All Possible Journeys (Density);
- Arcs per Node (CNC: Coefficient of Network Connectivity);
- Arcs per Node Excluding Self Loops (CNCX: Coefficient of Network Connectivity Excluding Self Loops).
| Input Variable | Wald’s Test | p-Value | Coefficient |
|---|---|---|---|
| (Intercept) | 320.453 | <0.001 | −4.993 |
| CNCX | 264.367 | <0.001 | 1.632 |
| Size | 36.838 | <0.001 | 0.072 |
| Number of Self Loops | 0.67 | 0.682 | Insignificant |
Appendix C
- Changing Category: All “view” activities after an event with a different category than the previous event were converted to “Change-Category-and-View” activity. In this way, visitors moving to another category were identified.
- Adding to Cart: As the “cart” activity type did not cover the actual visitor experience, adding a product to the cart after viewing that specific product page was named “View-and-Cart”. If the visitor added a product without viewing its product page, then this activity was considered “Cart-from-list”, meaning that after searching, the visitor directly added that product from a search list or used a similar functionality.
- Removing Carted Products: After examining the dataset, it was observed that in some cases, the user was removing a product that was not added to the cart in that session. These activities were renamed “Remove-Previously-Carted”. If a product was added to the cart and removed in the same session, no modifications were needed.
- Purchasing: Similar to removing from cart, it was observed that some products were purchased that were not added to cart in a specific session. These activities were renamed “Purchase-Previously-Carted”. If a product was added to the cart and purchased in the same session, no modifications were needed.
Appendix D
| Node | P1 | P2 | P3 | P4 | P5 | P6 | P7 | P8 |
|---|---|---|---|---|---|---|---|---|
| START | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Start with Unknown Cart | X | ✓ | X | ✓ | X | ✓ | X | ✓ |
| Start with Stocked Cart | ✓ | X | ✓ | X | ✓ | X | ✓ | X |
| VIEW | 84% | 81% | 78% | 83% | 91% | 99% | 87% | 98% |
| View | 71% | 63% | 67% | 68% | 77% | 89% | 83% | 86% |
| Change Category and View | 73% | 60% | 60% | 57% | 75% | 85% | 78% | 51% |
| CART | ✓ | ✓ | 92% | ✓ | ✓ | ✓ | 47% | ✓ |
| View and Cart | 68% | 75% | 54% | 72% | 56% | 69% | 17% | 51% |
| Cart from List | 96% | 87% | 76% | 78% | 90% | 82% | 32% | 63% |
| REMOVE | 91% | 64% | 82% | 51% | ✓ | 25% | ✓ | ✓ |
| Remove from Cart | 77% | 64% | 53% | 51% | 63% | 25% | 43% | ✓ |
| Remove from Previous Cart | 82% | X | 74% | X | ✓ | X | ✓ | X |
| PURCHASE | ✓ | ✓ | ✓ | ✓ | X | X | X | X |
| Purchase | 99% | ✓ | 88% | ✓ | X | X | X | X |
| Purchase Previously Carted | 69% | X | 82% | X | X | X | X | X |
| END | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Exit with Unknown Cart | X | X | X | X | X | X | ✓ | ✓ |
| Exit with Stocked Cart | X | X | X | X | ✓ | ✓ | X | X |
| Order given Stocked Cart | ✓ | ✓ | X | X | X | X | X | X |
| Order given Unknown Cart | X | X | ✓ | ✓ | X | X | X | X |
References
- Available online: https://www.retaildogma.com/conversion-rate/ (accessed on 30 August 2024).
- Available online: https://www.oberlo.com/statistics/average-ecommerce-conversion-rate (accessed on 31 August 2024).
- Bucklin, R.E.; Sismeiro, C. Click here for Internet insight: Advances in clickstream data analysis in marketing. J. Interact. Mark. 2009, 23, 35–48. [Google Scholar] [CrossRef]
- Alawadh, M.; Barnawi, A. A Consumer Behavior Analysis Framework toward Improving Market Performance Indicators: Saudi’s Retail Sector as a Case Study. J. Theor. Appl. Electron. Commer. Res. 2024, 19, 152–171. [Google Scholar] [CrossRef]
- Schiffman, L.; O’Cass, A.; Paladino, A.; Carlson, J. Consumer Behaviour, 6th ed.; Pearson Higher Education: Melbourne, VIC, Australia, 2013; pp. 1–71. [Google Scholar]
- Zhang, X.; Guo, F.; Chen, T.; Pan, L.; Beliakov, G.; Wu, J. A Brief Survey of Machine Learning and Deep Learning Techniques for E-Commerce Research. J. Theor. Appl. Electron. Commer. Res. 2023, 18, 2188–2216. [Google Scholar] [CrossRef]
- Stalidis, G.; Karaveli, I.; Diamantaras, K.; Delianidi, M.; Christantonis, K.; Tektonidis, D.; Katsalis, A.; Salampasis, M. Recommendation Systems for e-Shopping: Review of Techniques for Retail and Sustainable Marketing. Sustainability 2023, 15, 16151. [Google Scholar] [CrossRef]
- Al-Hasan, T.M.; Sayed, A.N.; Bensaali, F.; Himeur, Y.; Varlamis, I.; Dimitrakopoulos, G. From Traditional Recommender Systems to GPT-Based Chatbots: A Survey of Recent Developments and Future Directions. Big Data Cogn. Comput. 2024, 8, 36. [Google Scholar] [CrossRef]
- Poggi, N.; Muthusamy, V.; Carrera, D.; Khalaf, R. Business process mining from e-commerce web logs. In Proceedings of the Business Process Management: 11th International Conference, BPM 2013, Beijing, China, 26–30 August 2013; pp. 65–80. [Google Scholar]
- Kakalejčík, L.; Bucko, J.; Vejačka, M. Differences in buyer journey between high-and low-value customers of e-commerce business. J. Theor. Appl. Electron. Commer. Res. 2019, 14, 47–58. [Google Scholar] [CrossRef]
- Van der Aalst, W.M.P. Process Mining: Data Science in Action, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2016; pp. 125–153, 387–420. [Google Scholar]
- Halvorsrud, R.; Mannhardt, F.; Prillard, O.; Boletsis, C. Customer journeys and process mining–challenges and opportunities. In Proceedings of the ITM Web of Conferences, International Conference on Exploring Service Science (IESS 2.4), Brno, Czech Republic, 8–9 February 2024. [Google Scholar]
- Van der Aalst, W.M.P.; Carmona, J. Process Mining Handbook, 1st ed.; Springer Nature: Berlin/Heidelberg, Germany, 2022; pp. 37–76, 125–153. [Google Scholar]
- Hair, J.F.; William, C.B.; Barry, J.; Rolph, E.A. Multivariate Data Analysis, 7th ed.; Pearson: Edinburgh Gate, UK, 2009; pp. 313–341. [Google Scholar]
- Moe, W.W. Buying, searching, or browsing: Differentiating between online shoppers using in-store navigational clickstream. J. Consum. Psychol. 2003, 13, 29–39. [Google Scholar] [CrossRef]
- Kumar, B.; Roy, S.; Sinha, A.; Iwendi, C.; Strážovská, L. E-Commerce Website Usability Analysis Using the Association Rule Mining and Machine Learning Algorithm. Mathematics 2022, 11, 25. [Google Scholar] [CrossRef]
- Kumar, A.; Singh, R.K. Web mining overview, techniques, tools and applications: A survey. Int. Res. J. Eng. Technol. 2016, 3, 1543–1547. [Google Scholar]
- Mughal, M.J.H. Data mining: Web data mining techniques, tools and algorithms: An overview. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 208–215. [Google Scholar] [CrossRef]
- Eirinaki, M.; Vazirgiannis, M. Web mining for web personalization. ACM Trans. Internet Technol. 2003, 3, 1–27. [Google Scholar] [CrossRef]
- Hu, X.; Cercone, N. A data warehouse/online analytic processing framework for web usage mining and business intelligence reporting. Int. J. Intell. Syst. 2004, 19, 585–606. [Google Scholar] [CrossRef]
- Rosário, A.; Raimundo, R. Consumer Marketing Strategy and E-Commerce in the Last Decade: A Literature Review. J. Theor. Appl. Electron. Commer. Res. 2021, 16, 3003–3024. [Google Scholar] [CrossRef]
- McDowell, W.C.; Wilson, R.C.; Kile, C.O., Jr. An examination of retail website design and conversion rate. J. Bus. Res. 2016, 69, 4837–4842. [Google Scholar] [CrossRef]
- Tueanrat, Y.; Papagiannidis, S.; Alamanos, E. Going on a journey: A review of the customer journey literature. J. Bus. Res. 2021, 125, 336–353. [Google Scholar] [CrossRef]
- Anderl, E.; Becker, I.; Wangenheim, F.V.; Schumann, J.H. Mapping the customer journey: A graph-based framework for online attribution modeling. SSRN 2014. [Google Scholar] [CrossRef]
- Park, Y.H.; Fader, P.S. Modeling browsing behavior at multiple websites. Mark. Sci. 2004, 23, 280–303. [Google Scholar] [CrossRef]
- Liu, F.; Wang, R.; Zhang, P.; Zuo, M. A Typology of Online Window Shopping Consumers. In Proceedings of the PACIS, Ho Chi Minh City, Vietnam, 11–15 July 2012; p. 128. [Google Scholar]
- Wei, J.; Shen, Z.; Sundaresan, N.; Ma, K.L. Visual cluster exploration of web clickstream data. In Proceedings of the 2012 IEEE Conference on Visual Analytics Science and Technology (VAST), Seattle, WA, USA, 14–19 October 2012; pp. 3–12. [Google Scholar]
- Schellong, D.; Kemper, J.; Brettel, M. Clickstream Data as a Source to Uncover Consumer Shopping Types in a Large-Scale Online Setting. In Proceedings of the Twenty-Fourth European Conference on Information Systems (ECIS) AISeL (2016), Istanbul, Turkiye, 15 June 2016. [Google Scholar]
- Raphaeli, O.; Goldstein, A.; Fink, L. Analyzing online consumer behavior in mobile and PC devices: A novel web usage mining approach. Electron. Commer. Res. Appl. 2017, 26, 1–12. [Google Scholar] [CrossRef]
- Park, C.H. Online purchase paths and conversion dynamics across multiple websites. J. Retail. 2017, 93, 253–265. [Google Scholar] [CrossRef]
- Lin, W.; Milic-Frayling, N.; Zhou, K.; Ch’ng, E. Predicting outcomes of active sessions using multi-action motifs. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence, Thessaloniki, Greece, 14–17 October 2019; pp. 9–17. [Google Scholar]
- Kanaan, M.; Cazabet, R.; Kheddouci, H. Temporal pattern mining for e-commerce dataset. Trans.-Large-Scale-Data-Knowl.-Centered Syst. 2020, XLVI, 67–90. [Google Scholar]
- Li, J.; Abbasi, A.; Cheema, A.; Abraham, L.B. Path to purpose? How online customer journeys differ for hedonic versus utilitarian purchases. J. Mark. 2020, 84, 127–146. [Google Scholar] [CrossRef]
- Ho, H.F. A novel approach for exploring channel dependence of consumers’ latent shopping intent and the related behaviors by visualizing browsing patterns. Data Technol. Appl. 2021, 55, 715–733. [Google Scholar] [CrossRef]
- Kukar-Kinney, M.; Scheinbaum, A.C.; Orimoloye, L.O.; Carlson, J.R.; He, H. A model of online shopping cart abandonment: Evidence from e-tail clickstream data. J. Acad. Market. Sci. 2022, 50, 961–980. [Google Scholar] [CrossRef]
- Hammer, M. The Agenda: What Every Business Must Do to Dominate the Decade, 1st ed.; Crown Business: New York, NY, USA, 2003; pp. 1–68. [Google Scholar]
- IEEE Task Force on Process Mining. Process Mining Manifesto. In Proceedings of the BPM 2011 International Workshops, Clermont-Ferrand, France, 29 August 2011; pp. 169–194. [Google Scholar]
- Garcia, C.d.S.; Meincheim, A.; Junior, E.R.F.; Dallagassa, M.R.; Sato, D.M.V.; Carvalho, D.R.; Santos, E.A.P.; Scalabrin, E.E. Process mining techniques and applications–A systematic mapping study. Expert Syst. Appl. 2019, 133, 260–295. [Google Scholar] [CrossRef]
- Lorenz, R.; Senoner, J.; Sihn, W.; Netland, T. Using process mining to improve productivity in make-to-stock manufacturing. Int. J. Prod. Res. 2021, 59, 4869–4880. [Google Scholar] [CrossRef]
- Pereira Detro, S.; Santos, E.A.P.; Panetto, H.; Loures, E.D.; Lezoche, M.; Cabral Moro Barra, C. Applying process mining and semantic reasoning for process model customisation in healthcare. Enterp. Inf. Syst. 2019, 14, 983–1009. [Google Scholar] [CrossRef]
- Teinemaa, I.; Dumas, M.; Rosa, M.L.; Maggi, F.M. Outcome-oriented predictive process monitoring: Review and benchmark. ACM Trans. Knowl. Discov. Data 2019, 13, 1–57. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning, 1st ed.; Springer: New York, NY, USA, 2013; pp. 130–210. [Google Scholar]
- Sharma, S. Applied Multivariate Techniques, 1st ed.; John Wiley & Sons, Inc.: Upper Saddle River, NJ, USA, 1995; pp. 317–342. [Google Scholar]
- Wilbik, A.; Kaymak, U. Linguistic Summarization of Processes–a research agenda. In Proceedings of the 2015 Conference of the International Fuzzy Systems Association and the European Society for Fuzzy Logic and Technology (IFSA-EUSFLAT-15), Gijón, Spain, 30 June–3 July 2015; pp. 1636–1643. [Google Scholar]
- Grisold, T.; Kremser, W.; Mendling, J.; Recker, J.; Vom Brocke, J.; Wurm, B. Generating impactful situated explanations through digital trace data. J. Inf. Technol. 2024, 39, 2–18. [Google Scholar] [CrossRef]
- Padidem, D.K.; Nalini, D.C. Process Mining Approach to Discover Shopping Behavior Process Model In Ecommerce Web Sites Using Click Stream Data. Int. J. Civ. Eng. Technol. 2017, 8, 948–955. [Google Scholar]
- Ghavamipoor, H.; Hashemi Golpayegani, S.A.; Shahpasand, M. A QoS-sensitive model for e-commerce customer behavior. J. Res. Interact. Mark. 2017, 11, 380–397. [Google Scholar] [CrossRef]
- Hernández, S.; Álvarez, P.; Fabra, J.; Ezpeleta, J. Using Model Checking to Identify Customers Purchasing Behaviour in an E-Commerce. In Proceedings of the ATAED@ Petri Nets/ACSD, Zaragoza, Spain, 25–30 June 2017; pp. 158–164. [Google Scholar]
- Terragni, A.; Hassani, M. Analyzing customer journey with process mining: From discovery to recommendations. In Proceedings of the 2018 IEEE 6th International Conference on Future Internet of Things and Cloud (FiCloud), Barcelona, Spain, 6–8 August 2018; pp. 224–229. [Google Scholar]
- Terragni, A.; Hassani, M. Optimizing customer journey using process mining and sequence-aware recommendation. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, Limassol, Cyprus, 8–12 April 2019; pp. 57–65. [Google Scholar]
- Goossens, J.; Demewez, T.; Hassani, M. Effective steering of customer journey via order-aware recommendation. In Proceedings of the 2018 IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 17–20 November 2018; pp. 828–837. [Google Scholar]
- Filipowska, A.; Kałużny, P.; Skrzypek, M. Improving user experience in e-commerce by application of process mining techniques. Zesz. Nauk. Politech. CzęStochowskiej ZarząDzanie 2019, 33, 30–40. [Google Scholar] [CrossRef]
- Nguyen Chan, N.; Nguyen Vo, D.L.; Pham-Nguyen, C.; Le Dinh, T.; Dam, N.A.K.; Pham Thi, T.T.; Vu Thi, M.H. Design and deployment of a customer journey management system: The CJMA approach. In Proceedings of the 5th International Conference on Future Networks & Distributed Systems, Dubai, United Arab Emirates, 15–16 December 2021; pp. 8–16. [Google Scholar]
- El-Gharib, N.M.; Amyot, D. Data preprocessing method and API for mining processes from cloud-based application event logs. Algorithms 2022, 15, 180. [Google Scholar] [CrossRef]
- Augusto, A.; Conforti, R.; Dumas, M.; La Rosa, M.; Bruno, G. Automated discovery of structured process models from event logs: The discover-and-structure approach. Data Knowl. Eng. 2018, 117, 373–392. [Google Scholar] [CrossRef]
- Diamantini, C.; Genga, L.; Potena, D. Behavioral process mining for unstructured processes. J. Intell. Inf. Syst. 2016, 47, 5–32. [Google Scholar] [CrossRef]
- Veiga, G.M.; Ferreira, D.R. Understanding spaghetti models with sequence clustering for ProM. In Proceedings of the Business Process Management Workshops: BPM 2009 International Workshops, Ulm, Germany, 7 September 2009; pp. 92–103. [Google Scholar]
- Augusto, A.; Mendling, J.; Vidgof, M.; Wurm, B. The connection between process complexity of event sequences and models discovered by process mining. Inf. Sci. 2022, 598, 196–215. [Google Scholar] [CrossRef]
- Van der Aalst, W.M.P. Process mining: Overview and opportunities. ACM Trans. Manag. Inf. Syst. 2012, 3, 7.1–7.17. [Google Scholar] [CrossRef]
- Van der Aalst, W.M.P. Process mining: Discovering and improving Spaghetti and Lasagna processes. In Proceedings of the 2011 IEEE Symposium on Computational Intelligence and Data Mining (CIDM), Paris, France, 11–15 April 2011; pp. 1–7. [Google Scholar]
- Mendling, J.; Reijers, H.A.; Cardoso, J. What makes process models understandable? In Proceedings of the Business Process Management: 5th International Conference, BPM 2007, Brisbane, Australia, 24–28 September 2007; pp. 48–63. [Google Scholar]
- Reijers, H.A.; Mendling, J. A study into the factors that influence the understandability of business process models. IEEE Trans. Syst. Man. Cybern. Part A Syst. Hum. 2010, 41, 449–462. [Google Scholar] [CrossRef]
- Mendling, J.; Reijers, H.A.; Van der Aalst, W.M.P. Seven process modeling guidelines (7PMG). Inf. Softw. Technol. 2010, 52, 127–136. [Google Scholar] [CrossRef]
- Martin, N.; Fischer, D.A.; Kerpedzhiev, G.D.; Goel, K.; Leemans, S.J.; Röglinger, M.; Aalst, W.M.P.v.; Dumas, M.; Rosa, M.L.; Wynn, M.T. Opportunities and challenges for process mining in organizations: Results of a Delphi study. Bus. Inf. Syst. Eng. 2021, 63, 511–527. [Google Scholar] [CrossRef]
- Calders, T.; Günther, C.W.; Pechenizkiy, M.; Rozinat, A. Using minimum description length for process mining. In Proceedings of the 2009 ACM Symposium on Applied Computing, Honolulu, HI, USA, 12 March 2009; pp. 1451–1455. [Google Scholar]
- Dumas, M.; La Rosa, M.; Mendling, J.; Mäesalu, R.; Reijers, H.A.; Semenenko, N. Understanding business process models: The costs and benefits of structuredness. In Proceedings of the Advanced Information Systems Engineering: 24th International Conference, CAiSE 2012, Gdansk, Poland, 25–29 June 2012; pp. 31–46. [Google Scholar]
- Sánchez-González, L.; Ruiz, F.; García, F.; Piattini, M. Improving quality of business process models. In Proceedings of the Evaluation of Novel Approaches to Software Engineering: 6th International Conference, ENASE 2011, Beijing, China, 8–11 June 2011; pp. 130–144. [Google Scholar]
- Avila, D.T.; dos Santos, R.I.; Mendling, J.; Thom, L.H. A systematic literature review of process modeling guidelines and their empirical support. Bus. Process Manag. J. 2020, 27, 1–23. [Google Scholar] [CrossRef]
- Vidgof, M.; Wurm, B.; Mendling, J. The Impact of Process Complexity on Process Performance: A Study Using Event Log Data. Lect. Notes Comput. Sci. 2023, 14159, 413–429. [Google Scholar]
- Marin-Castro, H.M.; Tello-Leal, E. Event log preprocessing for process mining: A review. Appl. Sci. 2021, 11, 10556. [Google Scholar] [CrossRef]
- Van Zelst, S.J.; Mannhardt, F.; de Leoni, M.; Koschmider, A. Event abstraction in process mining: Literature review and taxonomy. Granul. Comput. 2020, 6, 719–736. [Google Scholar] [CrossRef]
- Bose, R.J.C.; Van der Aalst, W.M.P. Context aware trace clustering: Towards improving process mining results. In Proceedings of the 2009 SIAM International Conference on Data Mining, Denver, CO, USA, 6–8 July 2009; pp. 401–412. [Google Scholar]
- Fang, H.; Liu, W.; Wang, W.; Zhang, S. Discovery of process variants based on trace context tree. Connect. Sci. 2023, 35, 2190499. [Google Scholar] [CrossRef]
- Kaggle. Ecommerce Events History in Cosmetics Shop. Kaggle Dataset, Provided by the REES46 Marketing Platform (Kechinov, M.). Available online: https://www.kaggle.com/mkechinov/ecommerce-events-history-in-cosmetics-shop (accessed on 15 December 2022).
- Liu, B.; Zhang, H.; Kong, L.; Niu, D. Factorizing historical user actions for next-day purchase prediction. ACM Trans. Web 2021, 16, 1–26. [Google Scholar] [CrossRef]
- McInerney, J.; Lacker, B.; Hansen, S.; Higley, K.; Bouchard, H.; Gruson, A.; Mehrotra, R. Explore, exploit, and explain: Personalizing explainable recommendations with bandits. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 31 August 2018; pp. 31–39. [Google Scholar]
- Diba, K.; Remy, S.; Pufahl, L. Compliance and performance analysis of procurement processes using process mining. In Proceedings of the International Conference on Process Mining, Aachen, Germany, 24–26 June 2019. [Google Scholar]
- Ferreira, D.R. A primer on Process Mining: Practical Skills with Python and Graphviz, 2nd ed.; Springer International Publishing: Cham, Switzerland, 2017; pp. 1–93. [Google Scholar]
- Luque, A.; Carrasco, A.; Martín, A.; de Las Heras, A. The impact of class imbalance in classification performance metrics based on the binary confusion matrix. Pattern Recognit. 2019, 91, 216–231. [Google Scholar] [CrossRef]
- Bose, R.J.C.; Van der Aalst, W.M.P. Trace clustering based on conserved patterns: Towards achieving better process models. In Proceedings of the Business Process Management Workshops: BPM 2009 International Workshops, Ulm, Germany, 7 September 2009; pp. 170–181. [Google Scholar]


| Consumer Purchase Behavior | Corporate Procurement Process |
|---|---|
| Unclear start and end | Clear start and end |
| Undefined process activities | Defined process activities |
| Flows in random order | Defined flow order |
| No rules | Defined rules |
| High number of process variants | Low number of process variants |
| Hard to understand process diagrams | Understandable process diagrams |
| Events are logged if possible | Events are mostly logged |
| Case ID | Activity | Timestamp | Price | Product |
|---|---|---|---|---|
| abcd45 | Add to Chart | 2024-08-08 13:05:01:034 | ||
| abcd45 | Add to Chart | 2024-08-08 13:05:03:055 | 150 | |
| abcd45 | Purchase | 2024-08-08 13:05:04:077 | 210 | |
| abcd45 | View | 2024-08-08 13:05:05:066 | Lipstick | |
| bcda71 | Add to Chart | 2024-08-08 13:05:06:041 | 500 | |
| bcda71 | Remove from Chart | 2024-08-08 13:05:10:064 | 350 | |
| bcda71 | Purchase | 2024-08-08 13:05:11:094 |
| Case ID | Order | Activity Type | Product ID | New Activity Type |
|---|---|---|---|---|
| bcda45 | 1 | Remove-from-Cart | 12345 | Remove-Previously-Carted |
| bcda45 | 2 | Cart | 12346 | Cart-from-List |
| bcda45 | 3 | Cart | 12347 | Cart-from-List |
| bcda45 | 4 | Cart | 12347 | Cart-from-List |
| bcda45 | 5 | Remove-from-Cart | 12347 | Remove-from-Cart |
| bcda45 | 6 | Remove-from-Cart | 12348 | Remove-Previously-Carted |
| bcda45 | 7 | Purchase | 12346 | Purchase |
| bcda45 | 8 | Purchase | 12349 | Purchase-Previously-Carted |
| Group | Start Node | End Node |
|---|---|---|
| 1 | Start-with-Stocked-Cart | Order-Given-Stocked-Cart |
| 2 | Start-with-Unknown-Cart | Order-Given-Stocked-Cart |
| 3 | Start-with-Stocked-Cart | Order-Given-Unknown-Cart |
| 4 | Start-with-Unknown-Cart | Order-Given-Unknown-Cart |
| 5 | Start-with-Stocked-Cart | Exit-with-Stocked-Cart |
| 6 | Start-with-Unknown-Cart | Exit-with-Stocked-Cart |
| 7 | Start-with-Stocked-Cart | Exit-with-Unknown-Cart |
| 8 | Start-with-Unknown-Cart | Exit-with-Unknown-Cart |
| Behavior | Share % | Median Duration (mins) | Joint Occurrence % |
|---|---|---|---|
| Exploitation | 38.82 | 3.42 | 4.08 |
| Exploration | 28.21 | 6.45 | 16.69 |
| Selection | 24.46 | 4.04 | 67.88 |
| Handpicking | 2.01 | 1.79 | 51.60 |
| Elimination | 3.22 | 3.00 | 100.00 |
| Cancellation | 9.41 | 1.78 | 66.93 |
| Replenishment | 0.77 | 1.50 | 100.00 |
| Purchase | 5.27 | 2.35 | 53.47 |
| Metric | P1 | P2 | P3 | P4 | P5 | P6 | P7 | P8 |
|---|---|---|---|---|---|---|---|---|
| Explained Cases % | 35.68 | 60.31 | 69.94 | 73.10 | 64.63 | 81.18 | 57.48 | 43.87 |
| Median Duration (minutes) | 16.80 | 28.00 | 17.60 | 12.40 | 13.40 | 10.70 | 7.30 | 4.20 |
| Structuredness % | 12.05 | 14.62 | 10.26 | 12.25 | 8.49 | 10.36 | 26.07 | 20.28 |
| Product Pages Visited | 1.82 | 1.92 | 2.48 | 2.02 | 3.55 | 3.89 | 6.39 | 2.20 |
| Product Categories Visited | 1.86 | 1.80 | 2.00 | 1.64 | 2.54 | 2.62 | 3.80 | 1.00 |
| Product Pages Visited per Category | 0.98 | 1.06 | 1.24 | 1.23 | 1.40 | 1.49 | 1.68 | 2.20 |
| Net Products Added to Cart in The Session | 7.72 | 8.38 | 2.40 | 3.65 | 5.22 | 5.13 | 0.00 | 0.00 |
| Net Cart Change | 4.73 | 8.38 | −0.43 | 3.65 | −0.31 | 5.13 | −7.47 | 0.00 |
| Purchases from The Session | [0.00, 6.72] | 4.47 | 2.40 | 3.65 | 0.00 | 0.00 | 0.00 | 0.00 |
| Purchases from Previous Session(s) | [2.68, 9.40] | 0.00 | 5.82 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Purchase per Session | 9.40 | 4.47 | 8.22 | 3.65 | 0.00 | 0.00 | 0.00 | 0.00 |
| Products Stocked for Upcoming Session(s) | [1.00, 7.72] | 3.92 | 0.00 | 0.00 | 5.22 | 5.13 | 0.00 | 0.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Topaloglu, B.; Oztaysi, B.; Dogan, O. Cart-State-Aware Discovery of E-Commerce Visitor Journeys with Process Mining. J. Theor. Appl. Electron. Commer. Res. 2024, 19, 2851-2879. https://doi.org/10.3390/jtaer19040138
Topaloglu B, Oztaysi B, Dogan O. Cart-State-Aware Discovery of E-Commerce Visitor Journeys with Process Mining. Journal of Theoretical and Applied Electronic Commerce Research. 2024; 19(4):2851-2879. https://doi.org/10.3390/jtaer19040138
Chicago/Turabian StyleTopaloglu, Bilal, Basar Oztaysi, and Onur Dogan. 2024. "Cart-State-Aware Discovery of E-Commerce Visitor Journeys with Process Mining" Journal of Theoretical and Applied Electronic Commerce Research 19, no. 4: 2851-2879. https://doi.org/10.3390/jtaer19040138
APA StyleTopaloglu, B., Oztaysi, B., & Dogan, O. (2024). Cart-State-Aware Discovery of E-Commerce Visitor Journeys with Process Mining. Journal of Theoretical and Applied Electronic Commerce Research, 19(4), 2851-2879. https://doi.org/10.3390/jtaer19040138