Abstract
Although the market for Head-Mounted Display Virtual Reality (HMD VR) devices has been growing along with the metaverse trend, the product has not been as widespread as initially expected. As each user has different purposes for use and prefers different features, various factors are expected to influence customer evaluations. Therefore, the present study aims to: (1) analyze customer reviews of hands-on HMD VR devices, provided with new user experience (UX), using text mining, and artificial neural network techniques; (2) comprehensively examine variables that affect user evaluations of VR devices; and (3) suggest major implications for the future development of VR devices. The research procedure consisted of four steps. First, customer reviews on HMD VR devices were collected from Amazon.com. Second, candidate variables were selected based on a literature review, and sentiment scores were extracted. Third, variables were determined through topic modeling, in-depth interviews, and a review of previous studies. Fourth, an artificial neural network analysis was performed by setting customer evaluation as a dependent variable, and the influence of each variable was checked through feature importance. The results indicate that feature importance can be derived from variables, and actionable implications can be identified, unlike in general sentiment analysis.
1. Introduction
Since Google first released Cardboard in 2014, many global companies, such as Samsung, Facebook, Microsoft, and Apple, have taken an interest in Virtual Reality (VR) devices with Head-Mounted Displays (HMDs). Bloomberg projected that the HMD VR device market would grow to over USD 87 billion [1]. The technical features of VR have rapidly evolved, from primitive early types to realistic motion-sensitive VR, and VR has also begun to adopt a variety of content genres, from computer games to industrial tools. More recently, borderline research has been conducted to transfer real-world experiences into VR [2] and to bring experiences in VR environments into the real world [3,4].
Despite the increased interest and popularity of HMD VR devices, surprisingly little research has been conducted to understand users’ preferences for their features and quality. There could be several reasons for this. First, HMD VR devices have ‘experience-type’ aspects that are not fully understood until they are actually used, and due to the high price of the devices, it is not easy to obtain research samples (users). Second, unlike with other existing IT products, it is difficult to generalize the results from research that is limited to a specific VR device when there are more than 20 types of VR devices, and the differences in quality and features are significant. Third, HMD technology has rapidly upgraded and evolved over the years, making it challenging for researchers to capture the most general HMD VR device until now. Therefore, the basic practical research stream on HMD VR has not been realized, and the theoretical understanding of this new IT device and its use is far from complete.
Over the past few years, the technical specifications of HMD VR devices have become well-defined and generalized, and more users have begun to share their reviews online. This has made the current time an appropriate opportunity to conduct exploratory research on the like/dislike propensity of users for HMD VR devices.
The research objective of this study is to identify the most significant factors affecting users’ preference from dimensional sentiment score for HMD VR devices. To do this, we set up the following research question.
- Research question: Can multi-dimensional sentiment scoring of online user reviews predict and provide explanation for review ratings?
To answer this research question, this study uses the following methods: research models from previous research, in-depth interviews, and topic modeling. These were combined to find the most important factors determining user preference for HMD VR. An artificial neural network analysis with sentiment scores based on Shapley Additive Explanations (SHAPs) was conducted to identify the feature importance of the research factors that were significant based on customer ratings.
This study includes a comprehensive outline that includes a conceptual background, methods, experiment, discussion, and conclusion. The conceptual background discusses key concepts and literature, while the Methods section details the study procedure. The Experiment section describes the data collection and findings, followed by a discussion of the results and their limitations. The paper ends with a conclusion that discusses both the academic and practical implications of the study.
Researchers directly studying HMD VR devices or practitioners developing products will be able to directly use the results of this study. In particular, product evaluations based on users’ selective attention will be linked to direct business implications and will aid in prioritization and decision making. In addition, although this study was conducted on reviews of HMD VR devices, the research methodology and research procedures will be useful for all researchers and practitioners who want to analyze various emotions through online reviews.
2. Conceptual Background
2.1. HMD VR Device
Virtual Reality (VR) is defined by Boas [5] as an immersive experience that allows users to interact with a simulated environment using specific devices that provide feedback to make the experience as real as possible. Based on Boas’ definition, this study defines Head-Mounted Display (HMD) VR devices as pieces of equipment worn on the head that enable users to immerse themselves in and interact with a simulated environment.
Examples of HMD VR devices include Samsung’s Gear VR, Facebook’s Oculus Rift, and Google’s Cardboard. Users of HMD VR devices can experience an entirely new type of user experience that is different from anything they have experienced before. When using HMD VR devices, users feel as though they are disconnected from the outside world, as their surroundings change as they move, and they feel as though they are truly inside the virtual world. According to Park and Lee [6], HMD VR devices provide the closest experience to what people would expect from VR.
A study by John [7] predicted that the HMD VR device market will experience a compound annual growth rate of over 54.01% by 2022. The size of the market is 211% of the corporate value of Samsung (USD 379 billion) and 121% of Google (USD 656 billion), according to Forbes [8]. Market and Market, a global market research company, projected that the domestic market for HMD VR would grow from KRW 676.8 billion to KRW 6 trillion between 2014 and 2020 [9].
A study by Korolov [10] reported that, currently, entry-level HMD VR devices based on smartphones account for around 98% of total sales, whereas standalone premium HMD VR devices account for only about 2%. The HMD VR market is currently in the early stages of technology adoption, where innovators are adopting the technology, and users who have purchased and used entry-level devices are looking to upgrade to standalone premium devices for a better user experience.
This is similar to when PDAs were developed and partially adopted by the industry before smartphones became popular. Just as smartphones overcame many of the technical and UX challenges of PDAs to become popular, so too will HMD VR devices be able to overcome their limitations.
With the announcement of Apple’s Vision Pro, as the industry and user base expand from VR to Mixed Reality (MR), it is critical to examine customer response to HMD VR devices. Nevertheless, there is a serious lack of research on user perceptions or evaluations of HMD VR devices compared to other VR technologies.
2.2. Customer Reviews and Ratings in E-Commerce
Online customer reviews can be described as product evaluations created by customers and shared on either the company’s own or third-party e-commerce platforms [11]. E-commerce is short for electronic commerce [12]. This means that e-commerce is a platform where tangible goods or services are offered online. Since you cannot see the product or experience the service in person, you need to gather a lot of information to make a purchase decision. A typical example is a review rating, which we will discuss with customer reviews. On an e-commerce platform, review rating is the rating of a user’s final satisfaction with a product or service they have purchased, for example, on a scale of 1 to 5.
Before the development of big data analytics techniques, review data were limited to simple technical statistics or simple sentiment analysis of positive or negative reviews. However, as shown in Figure 1, users may be positive about the quality of a particular product but negative about its technical usability, such as software. With the sophistication of text-mining techniques, it is now possible to analyze complex user responses like these.
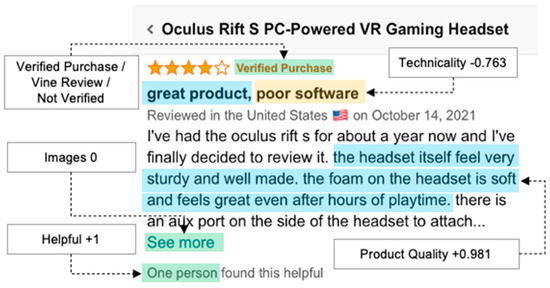
Figure 1.
Example of multi–dimensional sentiment from review.
Furthermore, interaction can occur between user reviews in the context of e-commerce. An attentively written review may receive helpful votes from multiple users, thus representing the opinion of many individuals despite being one review. These different characteristics suggest that we can take a different approach than the traditional approach of treating all text as having the same sentiment quotient.
In this study, we will also consider the complex features of user reviews.
2.3. Text Mining and Sentiment Analysis: A Big Data Perspective
The term big data refers to large datasets that are large in size and complexity and contain diverse and complex structures. These datasets pose challenges in terms of storage, analysis, and visualization for subsequent processing or results [13]. Big data are characterized by variety, velocity, and volume (3Vs) [13]. This is because a large amount of diverse data need to be analyzed quickly. In particular, user review data are text data and require a different approach to data analysis than the data analysis techniques that have been used through existing structured data. This is where text-mining techniques from natural language processing come in.
Text mining generally involves the extraction of insights or knowledge from unstructured text documents [14]. For example, sentiment analysis derives a sentiment score from text that indicates positivity and negativity. This allows a human to determine whether a sentence or piece of text is positive or negative based on the score alone, without having to read it.
In the financial sector, there has been extensive research into the use of sentiment analysis to build predictive models [15,16]. For instance, text related to a particular issue is filtered from the entire text, and the filtered text is classified as good news or bad news to predict stock prices [17]. However, similar attempts are rarely made in end-user reviews of products such as HMD VR devices. Unlike the financial sector’s simple classification of good news and bad news, end-user reviews contain various types of sentiments. Existing approaches, however, disregard various aspects of sentiments and simply deduce positive or negative sentiment scores for use in the analysis.
For instance, sentiment analysis was performed on specific public opinions on Twitter, and each score was examined from one dimension of positivity or negativity [17,18,19,20]. However, the overall text contains a complex mixture of sentiments, and capturing such a complex mixture of sentiments helps understand the phenomenon from multiple dimensions by disassembling sentiment scores that are partially exposed.
An attempt to apply text mining in a more diverse way, including multidimensional sentiment analysis, is shown in Table 1.

Table 1.
Literature review of text mining and sentiment analysis.
Mudambi and Schuff used an information economics model to analyze 1587 Amazon.com customer reviews. Their results indicate that review depth, extremity, and product type significantly affect review helpfulness, with depth being more influential for search goods and extremity being less beneficial for experience goods [11]. Jo and Oh developed the Aspect and Sentiment Unification Model (ASUM) to identify evaluated aspects and associated sentiments in user reviews. The ASUM, tested on a large set of reviews from Amazon and Yelp, demonstrated strong sentiment classification capabilities that rival supervised methods, all without using sentiment labels [21]. Ahmed and Rodríguez-Díaz used sentiment analysis and machine learning to assess the online reputation of airlines from TripAdvisor reviews. They found geographic and low-cost strategy differences in service quality. They identified 295 significant tags associated with overall ratings [22]. Lucini et al. used text-mining techniques on over 55,000 online reviews from 170 countries, representing over 400 airlines. They discovered that ‘cabin personnel’, ‘onboard service’, and ‘value for money’ were the most influential factors in predicting airline recommendations [23]. Kuyucuk and ÇALLI analyzed 104,313 complaints about freight companies during the COVID-19 outbreak. Using multi-label classification and word-based labeling methods, they found that package delivery delays were the most common problem. Despite the pandemic, hygiene complaints were minimal. Their findings underscore the importance of timely complaint review and problem identification for customer satisfaction [24]. Çallı used text mining and machine learning to analyze 21,526 online reviews of Turkish mobile banking services. Applying LDA, Random Forest, and Naive Bayes algorithms, 11 key themes emerged. Usefulness, convenience, and time-saving were critical for app ratings, while seven topics pertained to technical and security issues [25]. Çallı used Latent Dirichlet Allocation to analyze 10,594 airline complaints during the COVID-19 pandemic. Their study revealed primary triggers for customer complaints and proposed a decision support system for identifying significant service failures. [26]
In this study, we performed model-based feature selection, as in a study by Mudambi and Schuff [11], but we supplemented it with LDA-based topic modeling to examine whether the features fully reflect the entire text.
3. Methods
3.1. Research Design
The conceptual framework for this study is shown in Figure 2.
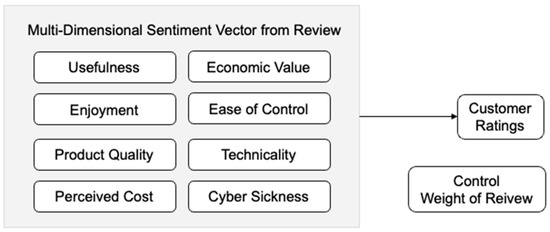
Figure 2.
Conceptual framework.
Initially, sentiment keywords that can be used to assign weights to reviews are selected through VAM, LDA-topic modeling, and in-depth interviews. These selected keywords are then utilized for generating the MDSV.
The reviews are collected using data crawling and refined in the form of tabular data. The refined data are utilized as the basic data for generating MDSV.
Sentiment scores are computed for each review using NLTK and added to the structured data. The weight of the sentiment scores for each review is determined based on the sentiment keywords present in the review, and MDSV is derived accordingly. The derived MDSV finally predicts customer ratings through a deep learning model, reflecting the weight of the review as a control variable in the process.
Previous studies on dimensional sentiment analysis of online review data have focused on the sentiment decomposition stage. However, there are few studies that go beyond the sentiment decomposition stage to the stage of building a predictive model using deep learning and interpreting the model using XAI. We conducted such a research design to understand users more deeply and derive action items using AI.
3.2. Research Process
The research process of this study is illustrated in Figure 3. First, online reviews of HMD VR devices are collected and refined. Second, variables are deduced from previous studies, and then appropriate keyword candidates for the deduced variables are selected. Topic modeling is conducted to examine whether the deduced variables sufficiently represent all the reviews, and other variables are added if necessary. Third, an in-depth interview is conducted through a survey to examine whether the selected variables and keywords are properly reflected in the reviews and whether any inappropriate items are removed. Fourth, the Natural Language Toolkit (NLTK), an open-source library, is used to deduce the sentiment score of each measured item in a sentence unit. Fifth, the multi-dimensional sentiment vector (MDSV) of the reviews is created based on the sentiment scores deduced in a sentence unit. Sixth, the review rating is predicted through regression using a deep neural network based on the MDSV as input data. The generated MDSV is used as input in the input layer of a deep neural network, and the prediction results are compared against the ground truth to calculate metrics, such as mean absolute error (MAE), mean square error (MSE), and root mean squared error (RMSE), which are visualized.
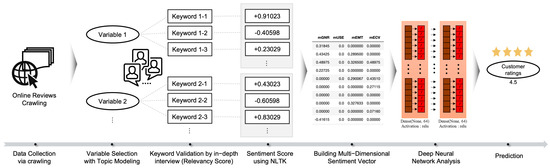
Figure 3.
Process of feature engineering and analysis.
Subsequently, a SHAP analysis is conducted using the model and test dataset, independent of the metric evaluation of the model. The SHAP analysis identifies the sentiment indices with the most significant impact, and relevant variables are sorted for analysis of the results.
3.3. Exploratory Feature Selection
3.3.1. Value-Based Adoption Model
This study utilized the VAM model proposed by Kim et al. [27] for exploratory feature selection. According to Zeithaml [28], when adopting new technologies, users consider not only the benefits but also the time and effort required. While conventional TAM models only consider benefits, Zeithaml’s approach [28] also takes into account the aspect of sacrifice.
This approach assumes that users consider both benefits and sacrifices in adopting new technologies before making a final decision. It aligns well with sentiment analysis, which can identify both positive and negative aspects of user reviews.
3.3.2. Topic Modeling
Topic modeling is a text-mining method that aims to identify latent topics from a collection of documents [29,30]. Unlike traditional word frequency analysis, topic modeling considers the co-occurrence of words within and across documents to extract topics. Latent Dirichlet Allocation (LDA), which is a popular technique in topic modeling, assumes that documents are generated from a mixture of topics, and each topic is a distribution over words. Through LDA, topics can be identified based on the connection between words across documents [31,32]. In this study, we examine whether there are topics that are missed by the variables selected in the previous studies using the Intertopic Distance Map derived from topic modeling.
3.3.3. In-Depth Interview for Keyword Filtering
The in-depth interview is an interview method that allows for a deeper understanding of a particular topic by capturing the interviewee’s point of view [33]. It can be used in conjunction with quantitative techniques to compensate for their limitations and was used in this study to verify the appropriateness of keywords. Specifically, a questionnaire of reviews, keywords, and metrics was then administered to assess keyword appropriateness.
Interview participants were selected based on their understanding of the metrics in the research methodology. Prior to the interview, participants were informed of the purpose of the study. The seven interviewees were asked to review the relevancy of the keywords through a questionnaire to determine if the measurement items reflect the variables and if the variables are correctly represented by the reviews. In order to avoid respondent fatigue, the interviewees assessed 700 randomly sampled reviews of about 150 characters each, for the relevancy of the selected keywords. After the evaluation, we had a free-flowing discussion about why we assigned keyword relevance scores.
3.3.4. Weight of Review
Most e-commerce platforms have various systems that allow customers to assess product reviews. Amazon also has a similar system where users can vote for reviews written by other users as “helpful,” and reviewers with a large number of votes become influencers. These votes are an effective indicator of how the public perceives and supports each review [34]. Since even customers who do not typically write reviews can vote, user feedback that has rarely been analyzed in previous studies on review text analysis can be analyzed. Furthermore, communication can be actively carried out through user reviews, during which images are also used in addition to text. The reviews also indicate the status of the purchase to demonstrate their legitimacy.
This study assumes that users’ participation in reviews affects a product’s rating. In other words, reviews with more user participation will be considered more significant than those with less user participation.
3.4. Sentiment Score Using NLTK
Sentiment analysis is a technique that aims to analyze people’s opinions and subjectivity in text [5]. This analysis method has been widely used in many previous studies, mostly through SentiWords, to measure social media users’ sentiment, to understand semantic relations by assessing positivity/negativity, and to draw a network map by making inferences from a semantic network.
In this study, the Natural Language Toolkit (NLTK) is used to derive a sentiment score from the given text based on the bag-of-words model. More specifically, the sentiment word dictionary is used to count the number of words representing positivity and negativity in the text, and +1 point is given if the text is close to positivity and −1 point if it is close to negativity.
This analytical technique has been particularly useful when analyzing large amounts of text. For example, in a study by Kim [35], user reviews were examined using sentiment analysis, utilizing hotel user reviews for the sentiment analysis, whereas Choi [36] analyzed the effects of the sentiment level of service quality index on hospital evaluations.
The present study aims to deduce sentiment scores based on the NLTK and predict review ratings accordingly.
3.5. Multi-Dimensional Sentiment Vector (MDSV)
A multi-dimensional sentiment vector (MDSV) is used to predict user reviews, which incorporates the weight of each review as well as the interactions among users. From the data representation aspect, MDSV consists of one vector for each user review, sentiment score using nltk and review rating score.
Here, each dimension is composed of features derived from the exploratory feature selection. For example, the Enjoyment feature consists of the following metrics: Surprise of VR experience (EMT01), Interest of VR experience (EMT02), and Diversity of VR content (EMT03). The mean of the sentiment score for each metric is then derived and used as the sentiment score for the enjoyment feature (mEMT). The review matrix derived by this procedure is expressed as a set of MDSVs, as shown in Figure 4.
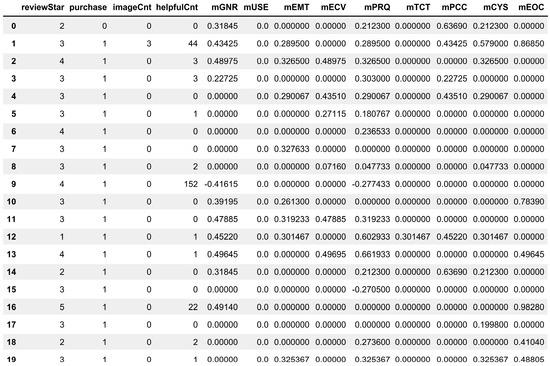
Figure 4.
Sample of multi–dimensional sentiment vector.
3.6. Deep Learning Model with SHAP
Shapley Additive Explanations (SHAPs) [37] are an explainable AI (XAI) technique that helps explain the prediction results of a model. It does so by calculating the degree of influence of each variable or feature to explain how they contribute to the prediction results. Specifically, SHAP uses the Shapley value to calculate the level of contribution of variables. The Shapley value is a concept derived from game theory that measures the winning contribution of each player in a game. SHAP is useful for explaining the prediction results since it calculates the influence of each variable on the prediction results.
There are various methods to calculate the level of contribution of each variable, and permutation is one of them. The permutation method involves eliminating each variable from a deep learning model that has been trained and then recalculating the model’s prediction results. The difference from the previous results is then calculated to measure the level of contribution of each variable. Another method called Tree SHAP can be used in a decision tree model to examine how a variable contributes to a decision tree through which path. This study aims to explain the model by deducing the importance of each feature through SHAP, using the method described above.
To perform the SHAP analysis, a Python package provided by Lundberg and Lee [37] was utilized. The analytical tools provided by the SHAP analysis package mainly target structured data; therefore, graphs were generated using only the SHAP values to express the SHAP analysis results for MDSV. Regression was applied using a dense layer to form an optimal neural network, with neural architecture search performed using Keras and TensorFlow as backend. The analysis results were saved by measuring MAE and MSE for each epoch, and all evaluation metrics were saved for both the training and validation datasets. The effect of the sentiment index was analyzed and represented as results.
4. Experiment
4.1. Data Collection
The product review data were collected in the form of a JSON file consisting of 2,027,283 lines. After excluding 17,434 lines having a null value, the remaining data included 1,369,653 string values and 426,796 number values, totaling up to 1,903,148 data values. To collect user review data from Amazon.com, data crawling was applied. In the first step of data crawling, Python was used to search for products using “VR” as a keyword. This resulted in the collection of review data for 106,698 products. The collected data items included URL, date, customer ratings, and status of purchase for the reviews accumulated until 26 October 2022.
Results were filtered based on the Amazon Standard Identification Number (ASIN) value, which is a unique product identifier, to remove duplicated products published under different product titles on the Amazon website for A/B tests or customized target marketing. In addition, only products with at least 200 reviews were selected to avoid those from sellers who abuse the service to ensure their products are exposed at the top of a webpage. Certain accessories such as 360-degree cameras or controllers were excluded to limit the analysis target to HMD VR devices. All ASIN values were inspected through the URL to confirm whether each product was a VR device or an accessory. Data validation was also tested by checking whether the number of user reviews matched the review content.
As a result of this process, a total of 19,402 reviews consisting of 79,566 sentences were collected.
4.2. Data Pre-Processing
To prepare for the analysis, sentiment scores were deduced from the selected reviews using NLTK. However, non-English reviews were excluded as NLTK only supports English. Reviews that were too short or could not have their sentiment scores properly deduced were also excluded from the training dataset. The training dataset ultimately consisted of 10,083 reviews.
According to Google Cloud [38], a minimum of “50× the number of features” is suggested for a neural network regression model for tabular data in general. The model used in this study had 12 features, requiring at least 600 reviews for training. As the pre-processed dataset had 10,083 reviews, there were sufficient data.
Prior to training, the data underwent pre-processing by data type. Categorical data, such as the “Status of Purchase” feature, underwent one-hot encoding to ensure there were no issues with feeding data into the neural network.
Additionally, the data were randomly split into training (80%) and validation (20%) sets for cross-validation.
To account for the differences in the effects of each feature due to their varying scales, normalization of each feature was performed using the mean and standard deviation values deduced from the training dataset.
4.3. Result of Feature Selection
To select the features for this study, the following procedure was employed.
First, the VAM model proposed by Kim et al. [27] was consulted to identify applicable variables for HMD VR devices, including Usefulness, Enjoyment, Technicality, and Perceived Cost. Then, variables that specifically fit the HMD VR device context, such as Ease of Control [39,40], Product Quality [28], and Economic Value [28], were chosen based on previous research. Venkatesh, V. and Suh, K.S. stated that Ease of Use is important in the technology acceptance model [39,40], and in this study, the measure item is divided into hardware and software aspects. Zeithaml stated that price and quality should be considered together in consumer perceptions of a product, and since HMD VR devices are becoming standalone, expensive, and wearable devices, the influence on product quality will be large. Second, additional variables were identified using topic modeling. The R programming language-based LDAvis technique [41] was used to visualize the results of LDA-based topic modeling in a Cartesian quadrant through principal component analysis (PCA) to generate clusters. Each topic has a total topic token percent, which shows how much weight is given to the topic in the entire document.
As a pre-processing step for topic modeling, SMART option in R was used to remove 571 stopwords that are not typically used in topic modeling. Figure 5 is a visualization of the Intertopic Distance Map generated as a result of topic modeling [41,42]. In the Intertopic Distance Map, each dot represents a topic, and the distance between the dots shows how semantically similar the topics are. This visualization is useful when dealing with large textual data because it allows you to see which topics are missing. The MCMC and model tuning parameters were set to K = 20, G = 5000, alpha = 0.02, eta = 0.02, and lambda = 1.00.
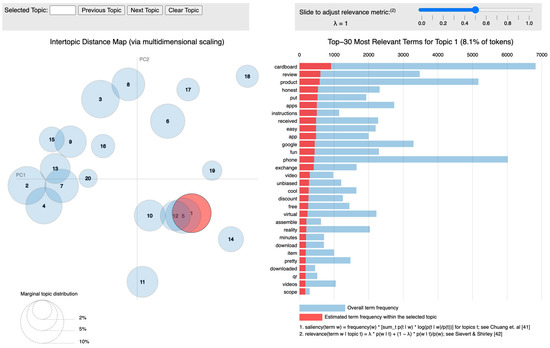
Figure 5.
Intertopic Distance Map.
The topic modeling results showed that “dizziness” was frequently mentioned in user reviews. Consequently, cybersickness specialized for the domain of HMD VR devices was identified as a variable, and the variable and keywords were defined as shown in Table 1 based on previous studies.
Third, measurement items were extracted that were defined to suit the HMD VR devices and keywords, representing the measurement items. The keywords were used to select reviews, and those with a high misclassification rate were excluded after evaluating their relevance in in-depth interviews. Out of 106 keywords, 36 were eliminated because they did not meet the minimum requirement of 10 reviews for the relevancy assessment survey. A Likert 7 scale was used to eliminate six inadequate keywords that scored 1–3 points in the relevancy assessment survey from the analysis. During the process, the VR content diversity (EMT03) item was removed due to the lack of keywords. Finally, 64 keywords were selected, and the results of the relevancy test are shown in detail in Table 2, based on which the final measurement items were selected.
Table 2.
Relevancy of measurement items.
Fourth, features used for the weight of review feature consisted of four measured items: the length of the review, the status of purchase, the number of helpful votes, and the number of images. These items are metadata of reviews that reflect the responses of other users.
Table 3 lists the features selected through the above process.
Table 3.
Resulting feature selection and definition.
4.4. Result of Deep Neural Network Analysis
The programming was implemented using TensorFlow 1.15.0 as the backend and Keras as the high-level API. To design an appropriate neural network architecture, the hyperparameters, including the type and number of layers, activation function, and optimizer, were determined through hyperparameter tuning. The performance of each model pipeline was measured to select the optimal configuration. A feedforward artificial neural network architecture composed of one input layer, two hidden layers, and one output layer was utilized. The activation function used for each hidden layer was ReLU, and the optimizer used was Adam, with a learning rate of 0.001.
The loss function used was Mean Squared Error (MSE), and both MSE and Mean Absolute Error (MAE) were used as evaluation metrics. Initially, the number of epochs was set to 1000 to visualize the results and identify the point at which overfitting occurred. Figure 6 shows the epoch history plot where the MAE/MSE scores are presented for the training and validation sets. As overfitting was observed between 0 and 200 epochs, a patience value of 10 was set as the Early Stopping option in the callback function of Keras. The loss value was monitored in the validation set to determine the appropriate time to stop training.
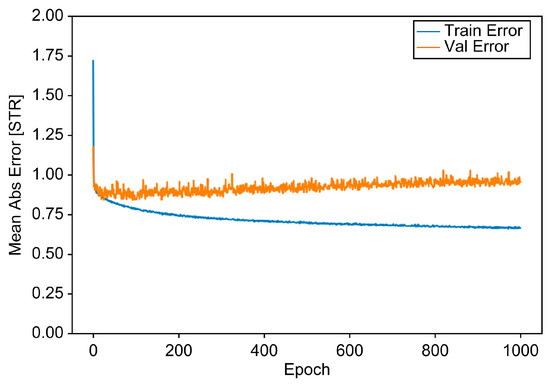
Figure 6.
MAE score vs. epoch for training and validation sets.
The monitoring results revealed that overfitting occurred between 20 and 30 epochs. Therefore, training was terminated, and evaluation was conducted using the testing set. As shown in Figure 7, the results showed that the final MAE and MSE values were 0.8879 and 1.3826, respectively. This indicates that the model built using only review data predicted the review rating with an average error of 0.8879.
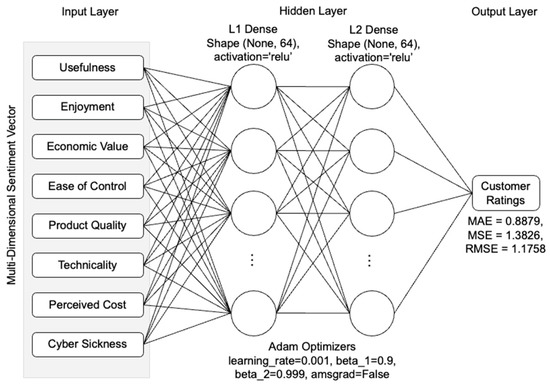
Figure 7.
Deep neural network architecture and result.
For the SHAP analysis, 2015 pieces of test data were used to simulate the model and extract the SHAP values. Figure 8 and Figure 9 illustrate the impact of the sentiment score of each SHAP value, as determined by the SHAP analysis results.
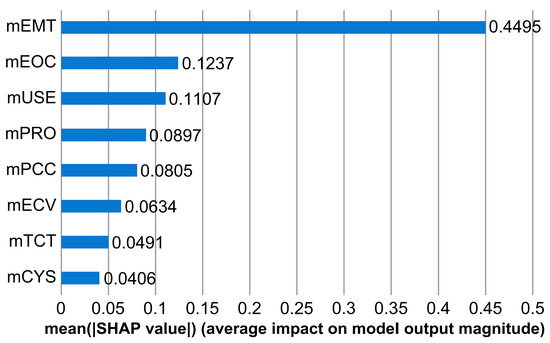
Figure 8.
Global Feature Importance of Sentiment Score.
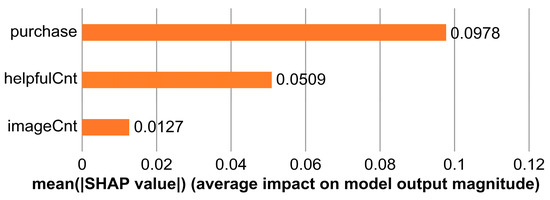
Figure 9.
Global feature importance of the reviews’ metadata.
In Figure 8, the sentiment scores are presented in descending order of impact. The impact order is as follows: (1) enjoyment of using HMD VR device (0.4495), (2) ease of control (0.1237), (3) usefulness (0.1107), (4) product quality (0.0897), (5) perceived cost (0.08805), (6) economic value (0.0634), (7) technicality (0.0491), and (8) cybersickness (0.0406). The sentiment score of enjoyment was found to be significantly higher than all other sentiment scores, whereas ease of control and usefulness had only 1/4 of the impact compared to enjoyment. This result suggests that users consider “easy enjoyment” as the most important factor when purchasing HMD VR devices.
In addition, product quality and perceived cost formed the third group, with a difference of 0.03–0.04, whereas cybersickness and technicality formed the group with the lowest impact. The results indicate that users may be satisfied if the experience offers enjoyment, even if the device is technically challenging and causes slight dizziness. This result can be interpreted as the “selective attention” phenomenon [47], where people pay less attention to other things when there is an object to focus on. This was also confirmed in a study by Cohen et al. [48], in which 95% of the field of view of a user wearing an HMD VR device was changed from color to black and white, but many people did not notice the change.
These findings are expected to contribute to improvements in HMD VR devices in the future. Reducing dizziness by improving hardware performance is time-consuming and costly, and since the industry is based on manufacturing, it is very difficult to secure a competitive advantage without innovation activities such as technology transfer of advanced technologies [49]. If it is difficult to have a solid hardware advantage over competitors; it may be possible to reduce vertigo by bundling content that users can immerse themselves in and enjoy or by providing coupons for discounts.
Figure 9 displays a schematic diagram of the impact of review metadata. The status of purchase had the highest impact (0.09789), whereas the recommendation of other users (helpfulCnt: 0.0509) had only half of the impact. Lastly, the number of images (imageCnt: 0.0127) had the lowest impact among metadata, and even when sentiment scores were taken into consideration, it had minimal impact on reviews.
Figure 10 shows a graph that represents the magnitude of the impact of sentiment index with respect to the intensity of sentiment index. Enjoyment (mEMT) has a positive correlation with the SHAP value. Similarly, ease of control (mEOC), usefulness (mUSE), and product quality (mPRQ) also have a positive correlation. This means that if users experience enjoyment and usefulness when using an HMD VR device that is easy to use and of high quality, they will give a good overall evaluation. On the other hand, economic value (mECV), technicality (mTCT), and cybersickness (mCYS) do not have a clear positive or negative correlation with SHAP scores. This means that if a user has already purchased an HMD VR device, price, technical difficulties, and cybersickness do not have a significant impact on their evaluation.
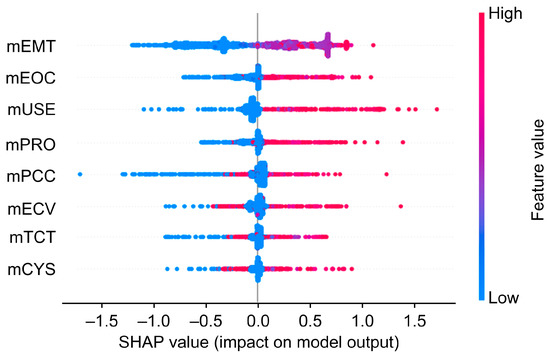
Figure 10.
Global feature importance.
5. Discussion and Limitations
The study demonstrated that review ratings can be accurately predicted using deep learning when a sentiment index is employed to express user reviews. The results were consistent and did not show fluctuations, even after the process was repeated. However, there are additional factors that influence review ratings, beyond sentiment index and review metadata.
For instance, there may be new words or usages that cannot be expressed through sentiment index and subtle nuances in sentences that can also impact review ratings. As the current analysis method relies solely on the use of sentiment words, it may be inadequate in accounting for all the factors explained above.
While the explicit sentiment factors analyzed in this study represent an improvement over previous studies [50,51,52,53,54,55,56,57,58,59,60,61] that relied on various sentence and word analyses through deep neural networks, this approach may still be insufficient because x-factors hidden in sentences are not considered.
To predict review ratings in the future, while taking these x-factors into account, the sentiment index used in this study can serve as the main analysis subject, whereas features extracted from sentences can be input to the intermediate input layer of a neural network for additional analysis.
In addition, the analytical techniques used in this study have been used in many other studies but not in the same way as in this study. Therefore, it is necessary to perform the analysis with newly modified data and different algorithms with sufficient follow-up studies to ensure the validity and reliability of the research method. For example, a more sophisticated research design would be possible by using a different method that supports consistency of the sentiment score from the existing simple sentiment score derivation. In addition, it is expected that academic reproducibility will be improved by designing a single software library that can integrate the current relatively complex analysis procedures for smooth application in follow-up studies.
6. Conclusions
This study has the following academic implications.
First, the use of text analysis based on social science studies enabled the researchers to identify variables that might have been overlooked and analyze customer reviews on HMD VR devices on Amazon.com, a platform used by more than 50% of the global population.
Second, topic modeling was used as a means of exploratory variable finding. While previous studies have used topic modeling primarily for analyzing the main interests using K-fold cross-validation, research field status, or word clouds with the selected topics, this study used topic modeling to confirm the selection of variables through in-depth interviews.
Third, the analysis of reviews on HMD VR devices was conducted to expand conventional online customer review research. It is expected that this approach can be applied not only to HMD VR devices but also to other areas for which data can be accessed online.
Fourth, we found that there is a phenomenon of selective attention in the area of consumer behavior of HMD VR devices. Customers of HMD VR devices have shown that they do not mind cybersickness, high prices, and technical difficulties, as long as they find the experience enjoyable and useful enough.
Lastly, unstructured data frequently used in text analysis were transformed into structured data through social science analysis. As a result, structured data analyses, for which more analytical techniques and knowledge are available, can now be applied to text analysis. This study has a particular implication in that unstructured data were converted to structured data with meaning, which was not the case in previous methods.
This study has the following practical implications.
First, the results of the user review analysis can suggest concrete strategic directions for hands-on HMD VR device manufacturers. The research can be used by HMD VR device manufacturing companies to set strategic priorities based on the analysis results.
Second, the analysis method proposed in this study can be used to perform preliminary market research on hands-on devices. If the items of exploratory feature selection are appropriately performed for each domain, the analysis method used in this study can be applied to general hands-on devices, not just HMD VR devices. To perform market research for new types of hands-on devices, numerous previously written reviews can be interpreted from a multi-dimensional perspective.
Lastly, hidden user needs that were not previously disclosed can be discovered, leading to the development of differentiation strategies. In previous methods that merely deduced sentiment scores, the overall impression of customers was discovered using the sentiment score of the entire text, which hindered the perception of detailed content. However, with an MDSV-based analysis, the SHAP results allow for the analysis of more detailed content for providing a guide.
It is often said, “You never know the worth of water till the well is dry.” Most users of HMD VR devices have, so far, enjoyed the content and, as a result, had a generally positive evaluation. However, a different story may emerge if user experiences are examined in more detail. Users’ negative emotional experiences hidden in enjoyment are a signal that the well is drying up. If the findings of this study are used to make improvements and focus is placed on customers, product differentiation will be just one step away.
Author Contributions
Conceptualization, Y.M.; methodology, Y.M. and C.C.L.; software, Y.M.; validation, Y.M.; formal analysis, Y.M.; investigation, Y.M.; resources, Y.M.; data curation, Y.M.; writing—original draft preparation, Y.M.; writing—review and editing, C.C.L. and H.Y.; visualization, Y.M.; supervision, C.C.L. and, H.Y.; project administration, Y.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data will be available if requested by the corresponding author for sufficient reasons.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Bloomberg, Virtual Reality Market Size Worth $87.0 Billion by 2030: Grand View Research, Inc. 2022. Available online: https://www.bloomberg.com/press-releases/2022-07-07/virtual-reality-market-size-worth-87-0-billion-by-2030-grand-view-research-inc (accessed on 15 March 2023).
- Ahmed, N.; De Aguiar, E.; Theobalt, C.; Magnor, M.; Seidel, H.-P. Automatic generation of personalized human avatars from multi-view video. In Proceedings of the ACM Symposium on Virtual Reality Software and Technology, Monterey, CA, USA, 7–9 November 2005; pp. 257–260. [Google Scholar]
- Hee Lee, J.; Shvetsova, O.A. The impact of VR application on student’s competency development: A comparative study of regular and VR engineering classes with similar competency scopes. Sustainability 2019, 11, 2221. [Google Scholar] [CrossRef]
- Horváth, I. An analysis of personalized learning opportunities in 3D VR. Front. Comput. Sci. 2021, 3, 673826. [Google Scholar] [CrossRef]
- Boas, Y. Overview of Virtual Reality Technologies. Available online: https://static1.squarespace.com/static/537bd8c9e4b0c89881877356/t/5383bc16e4b0bc0d91a758a6/1401142294892/yavb1g12_25879847_finalpaper.pdf (accessed on 1 March 2022).
- Park, M.J.; Lee, B.J. The features of VR (virtual reality) communication and the aspects of its experience. J. Commun. Res. 2004, 41, 29–60. [Google Scholar]
- John, J. Global (VR) Virtual Reality Market Size Forecast to Reach. Available online: https://www.globenewswire.com/news-release/2018/05/01/1494026/0/en/Global-VR-Virtual-Reality-Market-Size-Forecast-to-Reach-USD-26-89-Billion-by-2022.html (accessed on 27 February 2023).
- Badenhausen, K. Apple and Microsoft Head the World’s Most Valuable Brands 2015. Available online: http://www.forbes.com/sites/kurtbadenhausen/2015/05/13/apple-and-microsoft-head-the-worlds-most-valuable-brands-2015/#2d0ce65a2875 (accessed on 1 March 2022).
- Rohan, Virtual Reality Market Worth $15.89 Billion by 2020. Available online: https://www.marketsandmarkets.com/PressReleases/ar-market.asp (accessed on 27 February 2023).
- Korolov, M. 98% of VR Headsets Sold This Year Are for Mobile Phones–Hypergrid Business. 2016. Available online: https://www.hypergridbusiness.com/2016/11/report-98-of-vr-headsets-sold-this-year-are-for-mobile-phones/ (accessed on 27 February 2023).
- Mudambi, S.M.; Schuff, D. Research note: What makes a helpful online review? A study of customer reviews on Amazon. com. MIS Q. 2010, 34, 185–200. [Google Scholar] [CrossRef]
- Burt, S.; Sparks, L. E-commerce and the retail process: A review. J. Retail. Consum. Serv. 2003, 10, 275–286. [Google Scholar] [CrossRef]
- Sagiroglu, S.; Sinanc, D. Big data: A review. In Proceedings of the 2013 International Conference on Collaboration Technologies and Systems (CTS), San Diego, CA, USA, 20–24 May 2013; pp. 42–47. [Google Scholar]
- Tan, A.-H. Text mining: The state of the art and the challenges. In Proceedings of the Pakdd 1999 Workshop on Knowledge Disocovery from Advanced Databases, Beijing, China, 26–28 April 1999; pp. 65–70. [Google Scholar]
- Mishev, K.; Gjorgjevikj, A.; Vodenska, I.; Chitkushev, L.T.; Trajanov, D. Evaluation of sentiment analysis in finance: From lexicons to transformers. IEEE Access 2020, 8, 131662–131682. [Google Scholar] [CrossRef]
- Ferreira, F.G.D.C.; Gandomi, A.H.; Cardoso, R.T.N. Artificial intelligence applied to stock market trading: A review. IEEE Access 2017, 9, 30898–30917. [Google Scholar] [CrossRef]
- Imran, A.S.; Daudpota, S.M.; Kastrati, Z.; Batra, R. Cross-cultural polarity and emotion detection using sentiment analysis and deep learning on COVID-19 related tweets. IEEE Access 2020, 8, 181074–181090. [Google Scholar] [CrossRef]
- Jianqiang, Z.; Xiaolin, G. Comparison research on text pre-processing methods on twitter sentiment analysis. IEEE Access 2017, 5, 2870–2879. [Google Scholar] [CrossRef]
- Zhao, Z.; Hao, Z.; Wang, G.; Mao, D.; Zhang, B.; Zuo, M.; Yen, J.; Tu, G. Sentiment Analysis of Review Data Using Blockchain and LSTM to Improve Regulation for a Sustainable Market. J. Theor. Appl. Electron. Commer. Res. 2022, 17, 1–19. [Google Scholar] [CrossRef]
- Pezoa-Fuentes, C.; García-Rivera, D.; Matamoros-Rojas, S. Sentiment and Emotion on Twitter: The Case of the Global Consumer Electronics Industry. J. Theor. Appl. Electron. Commer. Res. 2023, 18, 39. [Google Scholar] [CrossRef]
- Jo, Y.; Oh, A.H. Aspect and sentiment unification model for online review analysis. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2011; pp. 815–824. [Google Scholar]
- Zaki Ahmed, A.; Rodríguez-Díaz, M. Analyzing the online reputation and positioning of airlines. Sustainability 2020, 12, 1184. [Google Scholar] [CrossRef]
- Lucini, F.R.; Tonetto, L.M.; Fogliatto, F.S.; Anzanello, M.J. Text mining approach to explore dimensions of airline customer satisfaction using online customer reviews. J. Air Transp. Manag. 2020, 83, 101760. [Google Scholar] [CrossRef]
- Kuyucuk, T.; ÇALLI, L. Using Multi-Label Classification Methods to Analyze Complaints Against Cargo Services during the COVID-19 Outbreak: Comparing Survey-Based and Word-Based Labeling. Sak. Univ. J. Comput. Inf. Sci. 2022, 5, 371–384. [Google Scholar] [CrossRef]
- Çallı, L. Exploring mobile banking adoption and service quality features through user-generated content: The application of a topic modeling approach to Google Play Store reviews. Int. J. Bank Mark. 2023, 41, 428–454. [Google Scholar] [CrossRef]
- Çallı, L.; Çallı, F. Understanding airline passengers during COVID-19 outbreak to improve service quality: Topic modeling approach to complaints with latent dirichlet allocation algorithm. Transp. Res. Rec. 2023, 2677, 656–673. [Google Scholar] [CrossRef]
- Kim, H.W.; Chan, H.C.; Gupta, S. Value-based Adoption of Mobile Internet: An empirical investigation. Decis. Support Syst. 2007, 43, 111–126. [Google Scholar] [CrossRef]
- Zeithaml, V.A. Consumer Perceptions of Price, Quality, and Value: A Means-End Model and Synthesis of Evidence. J. Mark. 1988, 52, 2–22. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Griffiths, T.; Steyvers, M. Finding scientific topics. Proc. Natl. Acad. Sci. USA 2004, 101, 9. [Google Scholar] [CrossRef]
- Yang, C.; Wu, L.; Tan, K.; Yu, C.; Zhou, Y.; Tao, Y.; Song, Y. Online user review analysis for product evaluation and improvement. J. Theor. Appl. Electron. Commer. Res. 2021, 16, 90. [Google Scholar] [CrossRef]
- Yang, Y.; Ma, Y.; Wu, G.; Guo, Q.; Xu, H. The Insights, “Comfort” Effect and Bottleneck Breakthrough of “E-Commerce Temperature; during the COVID-19 Pandemic. J. Theor. Appl. Electron. Commer. Res. 2022, 17, 1493–1511. [Google Scholar]
- Legard, R.; Keegan, J.; Ward, K. In-depth interviews. Qual. Res. Pract. A Guide Soc. Sci. Stud. Res. 2003, 6, 138–169. [Google Scholar]
- Nadeem, W.; Juntunen, M.; Shirazi, F.; Hajli, N. Consumers’ value co-creation in sharing economy: The role of social support, consumers’ ethical perceptions and relationship quality. Technol. Forecast. Soc. Chang. 2020, 151, 119786. [Google Scholar] [CrossRef]
- Kim, G. Developing Theory-Based Text Mining Framework to Evaluate Service Quality: In the Context of Hotel Customers’ Online Reviews. Master’s Thesis, Yonsei University, Seoul, Republic of Korea, 2016. [Google Scholar]
- Choi, J. Analysis of the Impact of Sentiment Level of Service Quality Indicators on Hospital Evaluation: Using Text Mining Techniques. Master’s Thesis, Yonsei University, Seoul, Republic of Korea, 2016. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4765–4774. [Google Scholar]
- Google Cloud. Best Practices for Creating Tabular Training Data|Vertex AI|. Available online: https://cloud.google.com/vertex-ai/docs/tabular-data/bp-tabular#how-many-rows (accessed on 1 March 2023).
- Suh, K.S.; Chang, S. User interfaces and consumer perceptions of online stores: The role of telepresence. Behav. Inf. Technol. 2006, 25, 99–113. [Google Scholar] [CrossRef]
- Venkatesh, V. Determinants of perceived ease of use: Integrating control, intrinsic motivation, and emotion into the technology acceptance model. Inf. Syst. Res. 2000, 11, 342–365. [Google Scholar] [CrossRef]
- Sievert, C.; Shirley, K.E. LDAvis: A method for visualizing and interpreting topics. In Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces, Baltimore, MD, USA, 27 June 2014; pp. 63–70. [Google Scholar]
- Chuang, J.; Manning, C.D.; Heer, J. Termite: Visualization techniques for assessing textual topic models. In Proceedings of the International Working Conference on Advanced Visual Interfaces, Capri Island, Italy, 21–25 May 2012; pp. 74–77. [Google Scholar]
- Lee, C.; Yun, H.; Lee, C.; Lee, C.C. Factors Affecting Continuous Intention to Use Mobile Wallet: Based on Value-based Adoption Model. J. Soc. e-Bus. Stud. 2015, 20, 117–135. [Google Scholar] [CrossRef]
- Suh, K.S.; Lee, Y.E. The effects of virtual reality on consumer learning: An empirical investigation. MIS Q. 2005, 29, 673–697. [Google Scholar] [CrossRef]
- LaViola, J.J., Jr. A discussion of cybersickness in virtual environments. ACM SIGCHI Bull. 2000, 32, 47–56. [Google Scholar] [CrossRef]
- McCauley, M.E.; Sharkey, T.J. Cybersickness: Perception of Self-Motion in Virtual Environments. Presence Teleoperators Virtual Environ. 1992, 1, 311–318. [Google Scholar] [CrossRef]
- Simons, D.J.; Chabris, C.F. Gorillas in our midst: Sustained inattentional blindness for dynamic events. Perception 1999, 28, 1059–1074. [Google Scholar] [CrossRef]
- Cohen, M.A.; Botch, T.L.; Robertson, C.E. The limits of color awareness during active, real-world vision. Proc. Natl. Acad. Sci. USA 2020, 117, 13821–13827. [Google Scholar] [CrossRef]
- Lee, S.; Shvetsova, O.A. Optimization of the technology transfer process using Gantt charts and critical path analysis flow diagrams: Case study of the korean automobile industry. Processes 2019, 7, 917. [Google Scholar] [CrossRef]
- Balakrishnan, V.; Shi, Z.; Law, C.L.; Lim, R.; Teh, L.L.; Fan, Y. A deep learning approach in predicting products’ sentiment ratings: A comparative analysis. J. Supercomput. 2022, 78, 7206–7226. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z. Yelp Review Rating Prediction: Machine Learning and Deep Learning Models. arXiv 2020, arXiv:2012.06690. [Google Scholar] [CrossRef]
- Conneau, A.; Schwenk, H.; Barrault, L.; Lecun, Y. Very deep convolutional networks for text classification. arXiv 2016, arXiv:1606.01781. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the EMNLP 2014-2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 26–28 October 2014; pp. 1746–1751. [Google Scholar] [CrossRef]
- Sharma, A.K.; Chaurasia, S.; Srivastava, D.K. Sentimental Short Sentences Classification by Using CNN Deep Learning Model with Fine Tuned Word2Vec. Procedia Comput. Sci. 2020, 167, 1139–1147. [Google Scholar] [CrossRef]
- Khan, Z.Y.; Niu, Z.; Sandiwarno, S.; Prince, R. Deep learning techniques for rating prediction: A survey of the state-of-the-art. Artif. Intell. Rev. 2021, 54, 95–135. [Google Scholar] [CrossRef]
- Ullah, K.; Rashad, A.; Khan, M.; Ghadi, Y.; Aljuaid, H.; Nawaz, Z. A Deep Neural Network-Based Approach for Sentiment Analysis of Movie Reviews. Complexity 2022, 2022, 5217491. [Google Scholar] [CrossRef]
- Shirani-mehr, H. Applications of Deep Learning to Sentiment Analysis of Movie Reviews. In Technical Report 2014; Stanford University: Stanford, CA, USA, 2014. [Google Scholar]
- Abarja, R.A.; Wibowo, A. Movie rating prediction using convolutional neural network based on historical values. Int. J. 2020, 8, 2156–2164. [Google Scholar] [CrossRef]
- Ning, X.; Yac, L.; Wang, X.; Benatallah, B.; Dong, M.; Zhang, S. Rating prediction via generative convolutional neural networks based regression. Pattern Recognit. Lett. 2020, 132, 12–20. [Google Scholar] [CrossRef]
- Pouransari, H.; Ghili, S. Deep Learning for Sentiment Analysis of Movie Reviews. In CS224N Proj; pp. 1–8. Available online: https://cs224d.stanford.edu/reports/PouransariHadi.pdf (accessed on 1 March 2022).
- Gogineni, S.; Pimpalshende, A. Predicting IMDB Movie Rating Using Deep Learning. In Proceedings of the 2020 5th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 10–12 June 2020; pp. 1139–1144. [Google Scholar] [CrossRef]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).