
TipScreener: A Framework for Mining Tips for Online Review Readers


Abstract
1. Introduction
2. Literature Review
2.1. Methods to Extract Information from User-Generated Content
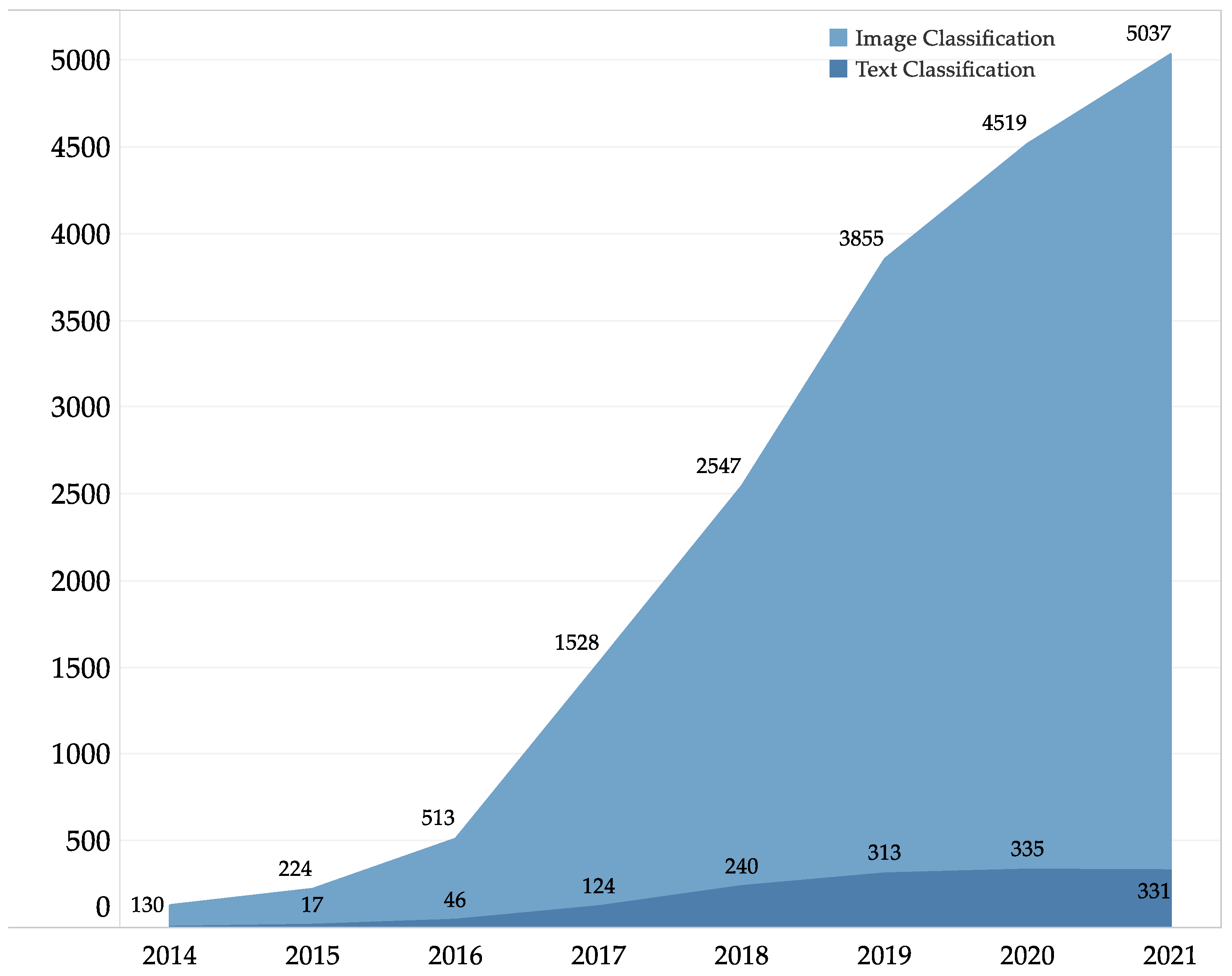
2.2. Text Classification and Deep Learning
3. The TipScreener Framework
3.1. Identification of Similar Businesses
3.2. Identifying Information Tokens
- Named entities: named entities are the names of pre-defined categories such as mentions of persons (e.g., Jack, Rose), organizations (e.g., World Health Organization, World Trade Organization), locations (e.g., New York, Hannover), businesses (e.g., Hugendubel, Block James), etc. [61,62,63,64]. In the experiment of our research, name entities such as the name of dishes are very important tokens. Our study applies the named entity recognition system of the StanfordCoreNLP.
- Compound nouns: collocations such as “power adapter” and “towel hanging” are composed of multiple nouns, which will become two different items if they are considered independent words separately. We extract compound nouns from the whole review corpus we obtained using the method in [10].
3.3. Matching Token and Opinion Words
3.4. Review Data Preprocessing and Preliminary Review Sentence Filtering
3.5. Secondary Filtering of Review Sentences—A CNN Classifier
3.5.1. Stage 1. Data Processing
3.5.2. Stage 2. Training Word Embeddings
3.5.3. Stage 3. Training a CNN Classifier and Filtering Uninformative Sentences
3.6. Finding the Most Informative Collection of High-Quality Tip Sentences
3.7. Enhance the Readability of the Final Tips-Set
4. The Application of TipScreener in the Catering Industry
Data
- Avocado on toast, many kinds of coffee preparations (flat white, Italian varieties), a little patio outside, wifi, friendly (if shy) staff.
- There’s some less hectic seating downstairs, featuring a comfy couch, an old fireplace, a few tables, and the best part—a pair of power outlets anywhere you might sit, in addition to the free (secure) WIFI.
- Great coffee and coconut porridge, nata tarts and avocado mash on bread.
- Friendly staff, nice cakes, nice coffee, average prices, nice decor, lots of individual seating.
- Espresso was fine but the panino was really poor essentially while the bread was ok but the ingredients in this case tomato and mozzarella were minimal and totally inadequate.
- The environment is unique with a beautiful art gallery downstairs.
5. Evaluation
5.1. Evaluation of the Usefulness and Novelty of Tips
5.1.1. Study A1
5.1.2. Study A2
5.2. Evaluation of Matching Accuracy of Token-Opinion Words
5.3. Comparison with The Baseline Algorithm
5.3.1. Evaluating Tokens Identification
5.3.2. Evaluating Tip Informativeness
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
| Algorithm A1. TipScreener |
| 1. Input: set of businesses , set of customer reviews composed of subsets ,, similarity function 2. Output: two sets of tips ( and ) for each business . 3. for do 4. #The set of similar businesses 5. Find token set 6. Find opinion words set 7. = ReviewFilterOne(, ) #To filter sentences containing no token and remove duplicates. 8. = ReviewFilterTwo() #To filter unhelpful sentences despitecontaining tokens. 9. = { }#A“{token:frequency}” dictionary for 10. = { } #A“{sentence:tokens-list}” dictionary for 11. for in do 12. for token in do 13. .append() #If in , add t to the current tokenlist of 14. = .get(,0) +1 #Add 1 to the current count of 15. for b ∈ B do 16. , 17. = SentenceSelector(, , ) 18. #A unique token set 19. = SentenceSelector(, , ) #Final unique tip-set 20. = #Final general tip-set 21. Return , , |
References
- Qi, J.; Zhang, Z.; Jeon, S.; Zhou, Y. Mining customer requirements from online reviews: A product improvement perspective. Inf. Manag. 2016, 53, 951–963. [Google Scholar] [CrossRef]
- Hu, N.; Zhang, T.; Gao, B.; Bose, I. What do hotel customers complain about? Text analysis using structural topic model. Tour. Manag. 2019, 72, 417–426. [Google Scholar] [CrossRef]
- Chevalier, J.A.; Mayzlin, D. The Effect of word of mouth on sales: Online book reviews. J. Mark. Res. 2006, 43, 345–354. [Google Scholar] [CrossRef]
- Awad, N.F.; Ragowsky, A. Establishing trust in electronic commerce through online word of mouth: An examination across genders. J. Manag. Inf. Syst. 2008, 24, 101–121. [Google Scholar] [CrossRef]
- Local Consumer Review Survey 2022. Available online: https://www.brightlocal.com/learn/local-sonsumer-review-survey/ (accessed on 17 October 2022).
- Consumer Review Survey. Available online: https://www.brightlocal.com/research/local-consumer-review-survey/ (accessed on 17 October 2022).
- Guy, I.; Mejer, A.; Nus, A.; Raiber, F. Extracting and ranking travel tips from user-generated reviews. In Proceedings of the 26th International Conference on World Wide Web, Perth, WA, Australia, 3–7 April 2017. [Google Scholar]
- Zhu, D.; Lappas, T.; Zhang, J. Unsupervised tip-mining from customer reviews. Decis. Support Syst. 2018, 107, 116–124. [Google Scholar] [CrossRef]
- Kumar, S.; Chowdary, C.R. Semantic Model to extract tips from hotel reviews. Electron. Commer. Res. 2020, 22, 1059–1077. [Google Scholar] [CrossRef]
- Timoshenko, A.; Hauser, J.R. Identifying customer needs from user-generated content. Mark. Sci. 2019, 38, 1–20. [Google Scholar] [CrossRef]
- Baccianella, S.; Esuli, A.; Sebastiani, F. Multi-facet rating of product reviews. In Advances in Information Retrieval; Boughanem, M., Berrut, C., Mothe, J., Soule-Dupuy, C., Eds.; Springer Berlin Heidelberg: Berlin, Germany, 2009; Volume 5478, pp. 461–472. [Google Scholar]
- Chou, Y.-C.; Chen, H.-Y.; Liu, D.-R.; Chang, D.-S. Rating prediction based on merge-CNN and concise attention review mining. IEEE Access 2020, 8, 190934–190945. [Google Scholar] [CrossRef]
- Wu, C.; Wu, F.; Liu, J.; Huang, Y.; Xie, X. ARP: Aspect-aware neural review rating prediction. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019. [Google Scholar]
- Mahadevan, A.; Arock, M. Review rating prediction using combined latent topics and associated sentiments: An empirical review. Serv. Oriented Comput. Appl. 2020, 14, 19–34. [Google Scholar] [CrossRef]
- Mahadevan, A.; Arock, M. Integrated topic modeling and sentiment analysis: A review rating prediction approach for recommender systems. Turk. J. Electr. Eng. Comput. Sci. 2020, 28, 107–123. [Google Scholar] [CrossRef]
- McAuley, J.; Leskovec, J. Hidden factors and hidden topics: Understanding rating dimensions with review text. In Proceedings of the 7th ACM Conference on Recommender Systems, Hong Kong, China, 12 October 2013. [Google Scholar]
- Wang, B.; Chen, B.; Ma, L.; Zhou, G. User-personalized review rating prediction method based on review text content and user-item rating matrix. Information 2018, 10, 1. [Google Scholar] [CrossRef]
- Lee, J.Y.-H.; Yang, C.-S.; Chen, S.-Y. Understanding customer opinions from online discussion forums: A design science framework. Eng. Manag. J. 2017, 29, 235–243. [Google Scholar] [CrossRef]
- John, D.L.; Kim, E.; Kotian, K.; Ong, K.Y.; White, T.; Gloukhova, L.; Woodbridge, D.M.; Ross, N. Topic modeling to extract information from nutraceutical product reviews. In Proceedings of the 2019 16th IEEE Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 11–14 January 2019. [Google Scholar]
- Kim, S.-M.; Pantel, P.; Chklovski, T.; Pennacchiotti, M. Automatically assessing review helpfulness. In Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing, Sydney, NSW, Australia, 22–23 July 2006. [Google Scholar]
- Liu, J.; Cao, Y.; Lin, C.-Y.; Huang, Y.; Zhou, M. Low-quality product review detection in opinion summarization. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Prague, Czech, 28–30 June 2007. [Google Scholar]
- Zhang, Z.; Varadarajan, B. Utility scoring of product reviews. In Proceedings of the 15th ACM International Conference on Information and Knowledge Management, Arlington, Virginia, USA, 6–11 November 2006. [Google Scholar]
- Ghose, A.; Ipeirotis, P.G. Estimating the helpfulness and economic impact of product reviews: Mining text and reviewer characteristics. IEEE Trans. Knowl. Data Eng. 2011, 23, 1498–1512. [Google Scholar] [CrossRef]
- Liu, Y.; Huang, X.; An, A.; Yu, X. Modeling and predicting the helpfulness of online reviews. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008. [Google Scholar]
- Tsur, O.; Rappoport, A. Revrank: A fully unsupervised algorithm for selecting the most helpful book reviews. In Proceedings of the International AAAI Conference on Web and Social Media, San Jose, CA, USA, 17–20 March 2009. [Google Scholar]
- Lu, Y.; Tsaparas, P.; Ntoulas, A.; Polanyi, L. Exploiting social context for review quality Prediction. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010. [Google Scholar]
- Cremonesi, P.; Facendola, R.; Garzotto, F.; Guarnerio, M.; Natali, M.; Pagano, R. Polarized review summarization as decision making tool. In Proceedings of the 2014 International Working Conference on Advanced Visual Interfaces—AVI′ 14, Como, Italy, 27–29 May 2014. [Google Scholar]
- Gong, Y.; Liu, X. Generic text summarization using relevance measure and latent semantic analysis. In Proceedings of the 24th annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New Orleans, LA, USA, 9–13 September 2001. [Google Scholar]
- Mihalcea, R.; Tarau, P. Textrank: Bringing order into text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004. [Google Scholar]
- Erkan, G.; Radev, D.R. LexRank: Graph-based lexical centrality as salience in text summarization. J. Artif. Intell. Res. 2004, 22, 457–479. [Google Scholar] [CrossRef]
- Luhn, H.P. The automatic creation of literature abstracts. IBM J. Res. Dev. 1958, 2, 159–165. [Google Scholar] [CrossRef]
- Edmundson, H.P. New methods in automatic extracting. J. ACM 1969, 16, 264–285. [Google Scholar] [CrossRef]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the 2004 ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 22–25 August 2004. [Google Scholar]
- Rapacz, S.; Chołda, P.; Natkaniec, M. A method for fast selection of machine-learning classifiers for spam filtering. Electronics 2021, 10, 2083. [Google Scholar] [CrossRef]
- Michalopoulos, D.; Mavridis, I.; Jankovic, M. GARS: Real-time system for identification, assessment and control of cyber grooming attacks. Comput. Secur. 2014, 42, 177–190. [Google Scholar] [CrossRef]
- Xiong, X.; Liu, Y. Application of quadratic dimension reduction method based on LSA in classification of the Chineselegal text. Chin. Electron. Meas. Technol. 2007, 10, 111–114. [Google Scholar]
- Social-media-based public policy informatics: Sentiment and network analyses of U.S. immigration and border security. J. Assoc. Inf. Sci. Technol. 2017, 68, 2847. [CrossRef]
- Figueira, O.; Hatori, Y.; Liang, L.; Chye, C.; Liu, Y. Understanding COVID-19 public sentiment towards public health policies using social media data. In Proceedings of the 2021 IEEE Global Humanitarian Technology Conference, Seattle, WA, USA, 19–23 October 2021. [Google Scholar]
- Gallagher, C.; Furey, E.; Curran, K. The application of sentiment analysis and text analytics to customer experience reviews to understand what customers are really saying. Int. J. Data Warehous. Min. 2019, 15, 21–47. [Google Scholar] [CrossRef]
- Luo, J.; Qiu, S.; Pan, X.; Yang, K.; Tian, Y. Exploration of spa leisure consumption sentiment towards different holidays and different cities through online reviews: Implications for customer segmentation. Sustainability 2022, 14, 664. [Google Scholar] [CrossRef]
- Geetha, M.; Singha, P.; Sinha, S. Relationship between customer sentiment and online customer ratings for hotels—An empirical analysis. Tour. Manag. 2017, 61, 43–54. [Google Scholar] [CrossRef]
- Jiang, S.; Pang, G.; Wu, M.; Kuang, L. An improved K-Nearest-Neighbor algorithm for text categorization. Expert Syst. Appl. 2012, 39, 1503–1509. [Google Scholar] [CrossRef]
- Tago, K.; Takagi, K.; Kasuya, S.; Jin, Q. Analyzing influence of emotional tweets on user relationships using naive bayes and dependency parsing. World Wide Web 2019, 22, 1263–1278. [Google Scholar] [CrossRef]
- Sánchez-Franco, M.J.; Navarro-García, A.; Rondán-Cataluña, F.J. A naive bayes strategy for classifying customer satisfaction: A study based on online reviews of hospitality services. J. Bus. Res. 2019, 101, 499–506. [Google Scholar] [CrossRef]
- Moraes, R.; Valiati, J.F.; Gavião Neto, W.P. Document-level sentiment classification: An empirical comparison between SVM and ANN. Expert Syst. Appl. 2013, 40, 621–633. [Google Scholar] [CrossRef]
- Kowsari, K.; Jafari Meimandi, K.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text classification algorithms: A survey. Information 2019, 10, 150. [Google Scholar] [CrossRef]
- Li, P.; Wang, D.; Wang, L.; Lu, H. Deep visual tracking: Review and experimental comparison. Pattern Recognit. 2018, 76, 323–338. [Google Scholar] [CrossRef]
- Zhang, Y.; Wallace, B. A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Taipei, Taiwan, 27 November–1 December; Asian Federation of Natural Language Processing: Taipei, Taiwan, 2015. [Google Scholar]
- Nguyen, T.H.; Grishman, R. Relation extraction: Perspective from convolutional neural networks. In Proceedings of the 2015 Conference North American Chapter Association Computer Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015. [Google Scholar]
- Chiu, J.P.; Nichols, E. Named entity recognition with bidirectional LSTM-CNNs. Trans. Assoc. Comput. Linguist. 2016, 4, 357–370. [Google Scholar] [CrossRef]
- Dos Santos, C.N.; Gatti, M. Deep convolutional neural networks for sentiment analysis of short texts. In Proceedings of the 25th International Conference Computer Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014. [Google Scholar]
- Zhu, Q.; Jiang, X.; Ye, R. Sentiment analysis of review text based on BiGRU-attention and hybrid CNN. IEEE Access 2021, 9, 149077–149088. [Google Scholar] [CrossRef]
- Mottaghinia, Z.; Feizi-Derakhshi, M.-R.; Farzinvash, L.; Salehpour, P. A review of approaches for topic detection in twitter. J. Exp. Theor. Artif. Intell. 2021, 33, 747–773. [Google Scholar] [CrossRef]
- Jacob, M.S.; Selvi Rajendran, P. Fuzzy artificial bee colony-based CNN-LSTM and semantic feature for fake product review classification. Concurr. Comput. Pract. Exp. 2022, 34, e6539. [Google Scholar] [CrossRef]
- He, Y.; Sun, S.; Niu, F.; Li, F. A deep learning model enhanced with emotion semantics for microblog sentiment analysis. Chin. J. Comput. 2017, 40, 773–790. [Google Scholar]
- Zhou, Y.; Zhang, Y.; Cao, Y.; Huang, H. Sentiment analysis based on piecewise convolutional neural network combined with features. Comput. Eng. Des. 2019, 40, 3009–3013+3029. [Google Scholar]
- Meyer, D.; Leisch, F.; Hornik, K. The support vector machine under test. Neurocomputing 2003, 55, 169–186. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Harris, Z.S. Distributional structure. WORD 1954, 10, 146–162. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26. [Google Scholar] [CrossRef]
- Grishman, R.; Sundheim, B.M. Message understanding conference-6: A brief history. In Proceedings of the 16th International Conference on Computational Linguistics, Copenhagen, Denmark, 5–9 August 1996. [Google Scholar]
- Pasca, M.; Lin, D.; Bigham, J.; Lifchits, A.; Jain, A. Organizing and searching the world wide web of facts-step one: The one-million fact extraction challenge. In Proceedings of the 21st National Conference on Artificial Intelligence, Boston, MA, USA, 16–20 July 2006. [Google Scholar]
- Nadeau, D.; Sekine, S. A survey of named entity recognition and classification. Lingvisticæ Investig. 2007, 30, 3–26. [Google Scholar] [CrossRef]
- Nothman, J.; Ringland, N.; Radford, W.; Murphy, T.; Curran, J.R. Learning multilingual named entity recognition from Wikipedia. Artif. Intell. 2013, 194, 151–175. [Google Scholar] [CrossRef]
- Grimmer, J.; Stewart, B.M. Text as data: The promise and pitfalls of automatic content analysis methods for political texts. Political Anal. 2013, 21, 267–297. [Google Scholar] [CrossRef]
- Charniak, E. Statistical parsing with a context-free grammar and word statistics. In Proceedings of the Fourteenth NATIONAL Conference on Artificial Intelligence and Ninth Conference on Innovative Applications of Artificial Intelligence, Providence, RI, USA, 27–31 July 1997. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 26–28 August 2014. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Frequency of | Frequency of Other Tokens | Row Total | |
|---|---|---|---|
| Column total |
| Name | Location | Coordinates | The Distance from Mihbaj | Average Price per Person (£) | Cuisines |
|---|---|---|---|---|---|
| Mihbaj Cafe and Kitchen | 153 Praed Street What3words, London | (51.5161602, −0.1744095) | 0.0 | 9.72 | Lebanese, Arabic |
| Cookhouse Joe | 55 Berwick Street, London | (51.515617305, −0.1364719) | 1.64 | 8.18 | Lebanese, Mediterranean |
| Maroush Express | 68 Edgware Road, London | (51.5151339, −0.1627560) | 0.51 | 16.48 | Lebanese, Mediterranean, Middle Eastern |
| Noura | 16 Hobart Place, London | (51.4981821, −0.1477896) | 1.69 | 25.65 | Lebanese, Mediterranean, Grill, Middle Eastern |
| Unique tokens | sandwich, pastry, muffin, aubergine salad, soy milk, music, croissant, garden, snack, back yard, nata tart, pastel nata custard tart, art gallery, bean, cake, shakshuka, downstairs, coconut porridge, smoking area, toilet, chocolate, chocolate milkshake, mushroom, toast, eggs benedict, espresso, avocado, avocado mash, scone, guacamole, pancake, barista, gallery, flat white, feta cheese, almond, almond croissant, tart, pecan tart, panino, orange juice, sourdough, cappuccino, patio, paprika, prawn Kabseh, mozzarella, blueberry, aesthetic, couch, charging point, lactose, fireplace, power outlet |
| General tokens | food, service, coffee, atmosphere, price, drink, juice, salad, menu, bread, decor, decoration, table, tomato, serving, vibe, sauce, hummus, mint tea, chicken, sausage, manager, kitchen, cheese, wrap, WIFI, halloumi, staff, environment, waitress, falafel, chai latte, leaf, interior design, prawn, water, seat, pecan pie, chef, cookie, tea, milk, pie, latte, egg, seating, interior |
| Name | Cuisines | Coordinates | Similar Entities (Coordinates) |
|---|---|---|---|
| 215 Hackney | middle eastern, cafe | (51.5633018, −0.0733957) | New London Cafe (51.5469438, −0.098291) |
| Blighty Cafe (51.5639806, −0.1029146) | |||
| Piebury Corner (51.5509858, −0.1104161) | |||
| Roxie Steak | 803 Fulham Road Fulham, London | (51.4758293, −0.2052097) | Macellaio RC South Kensington (51.4926256, −0.1774369) |
| Roxie Steak—Putney (51.4599947, −0.2125896) | |||
| Gordon Ramsay Bar and Grill—Park Walk (51.4859695, −0.1799002) | |||
| Sinabro | 28 Battersea Rise, London | (51.4610708, −0.1644541) | Augustine Kitchen (51.4781781, −0.1694937) |
| Chez Bruce (51.4459466, −0.1655742) | |||
| Restaurant Gordon Ramsay (51.4853968, −0.1620078) | |||
| 28–50 Wine Workshop and Kitchen Chelsea (51.4858753, −0.1732108) |
| Coefficient | Standardized Coefficient | t | Significance | ||
|---|---|---|---|---|---|
| B | SE | Beta | |||
| (constant) | 2.397 | 0.108 | 22.211 | 0.000 | |
| type of sentence a | 0.789 | 0.153 | 0.251 | 5.169 | 0.000 |
| Coefficient | Standardized Coefficient | t | Significance | ||
|---|---|---|---|---|---|
| B | SE | Beta | |||
| (constant) | 3.151 | 0.109 | 28.784 | 0.000 | |
| type of sentence a | 0.658 | 0.155 | 0.209 | 4.252 | 0.000 |
| Err = 0 | Err = 1 | Err = 2 | Err = 3 | Err = 4 | Err = 5 | Err = 6 | |
|---|---|---|---|---|---|---|---|
| 30 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 27 | 2 | 1 | 0 | 0 | 0 | 0 | |
| 27 | 2 | 1 | 0 | 0 | 0 | 0 | |
| 26 | 3 | 1 | 0 | 0 | 0 | 0 | |
| 28 | 2 | 0 | 0 | 0 | 0 | 0 | |
| 29 | 1 | 0 | 0 | 0 | 0 | 0 |
| Name | Difference Set of Tokens | Example Tips |
|---|---|---|
| Mihbaj | staff, coffee, drink, etc. | The staff were very respectful and coordinated well. Good coffee and excellent healthy smoothie drinks. |
| 215 Hackney | food, vegan, gluten free, etc. | The food was really fresh, well presented and delicious. If you’re vegan, gluten free or looking for a healthy meal, this place is for you! |
| Roxie Steak | burger, pudding, etc. | Our nine-year-old girls took the adult sized burger which was fine for them. It was good except the pudding let it down. |
| Sinabro | food, take away service, etc. | The food is French in technique but very modern in interpretation. We have tested their new take away service doubting it would be easy to take away the chef and quality of the service. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, H.; Song, W.; Zhou, W. TipScreener: A Framework for Mining Tips for Online Review Readers. J. Theor. Appl. Electron. Commer. Res. 2022, 17, 1716-1740. https://doi.org/10.3390/jtaer17040087
Luo H, Song W, Zhou W. TipScreener: A Framework for Mining Tips for Online Review Readers. Journal of Theoretical and Applied Electronic Commerce Research. 2022; 17(4):1716-1740. https://doi.org/10.3390/jtaer17040087
Chicago/Turabian StyleLuo, Hanyang, Wugang Song, and Wanhua Zhou. 2022. "TipScreener: A Framework for Mining Tips for Online Review Readers" Journal of Theoretical and Applied Electronic Commerce Research 17, no. 4: 1716-1740. https://doi.org/10.3390/jtaer17040087
APA StyleLuo, H., Song, W., & Zhou, W. (2022). TipScreener: A Framework for Mining Tips for Online Review Readers. Journal of Theoretical and Applied Electronic Commerce Research, 17(4), 1716-1740. https://doi.org/10.3390/jtaer17040087