
Predicting Final User Satisfaction Using Momentary UX Data and Machine Learning Techniques



Abstract
:1. Introduction
2. Literature Review
2.1. User Experience (UX)
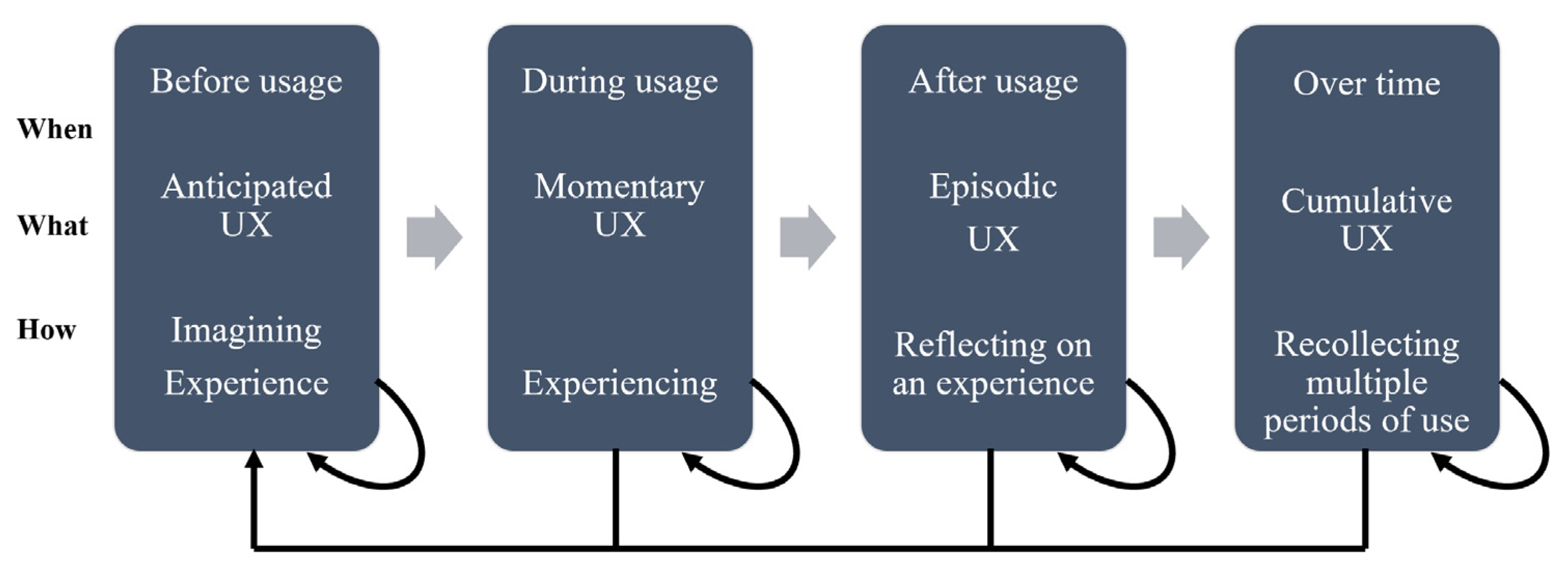
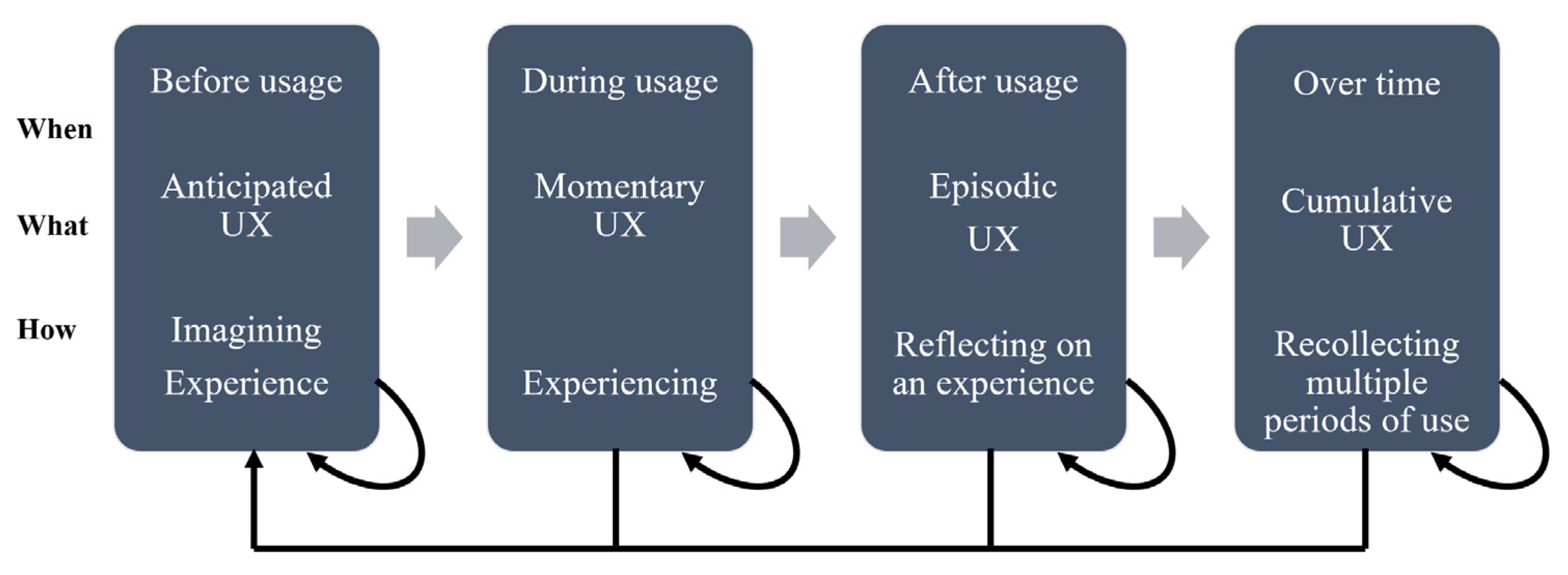
2.2. UX Evaluation Method (UXE)
- Before usage (prior to interacting with products/services);
- Momentary (a snapshot, e.g., perceptions, emotions);
- Single (a single episode in which a user explores design features to address a task goal);
- Typical test session (e.g., 100 min in which a user performs a specific task).
- Long-term (e.g., interacting with products/services in everyday life).
2.3. Classification Techniques
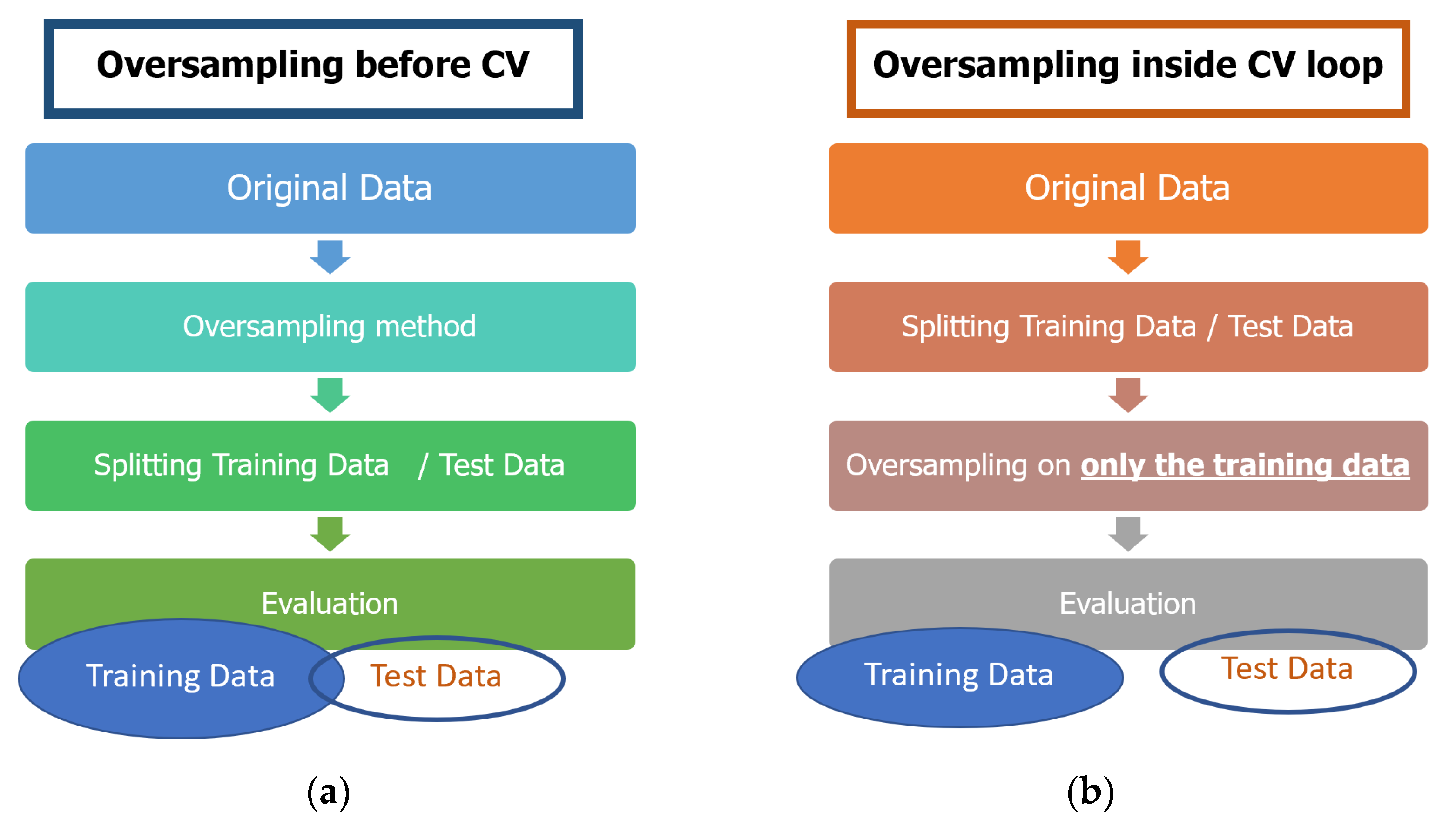
2.4. Sampling Techniques
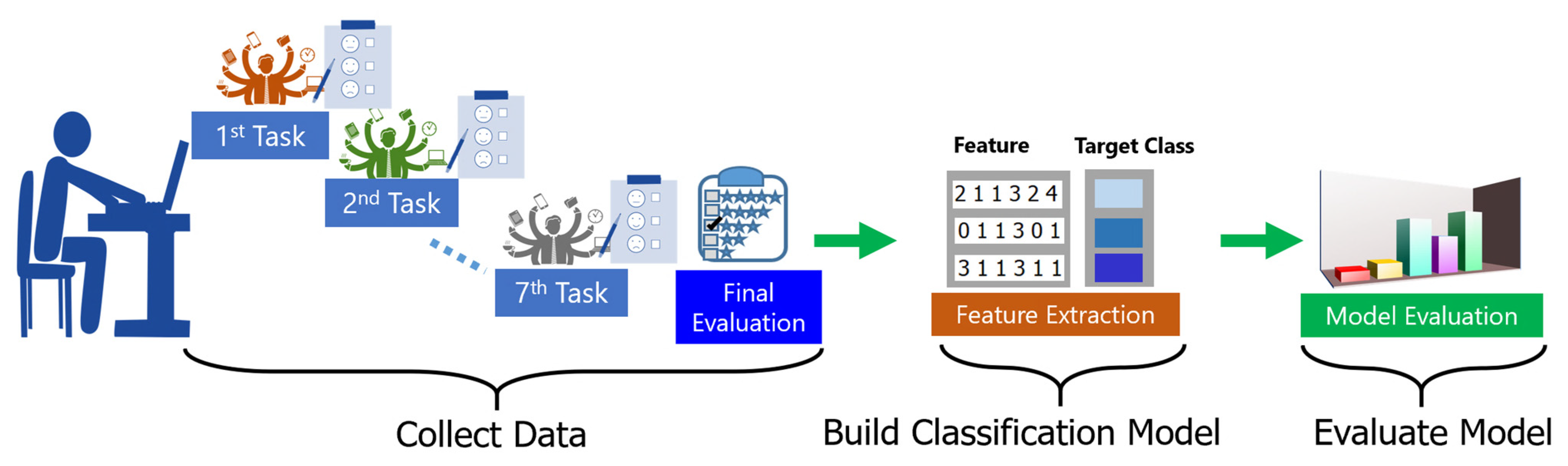
3. Methods
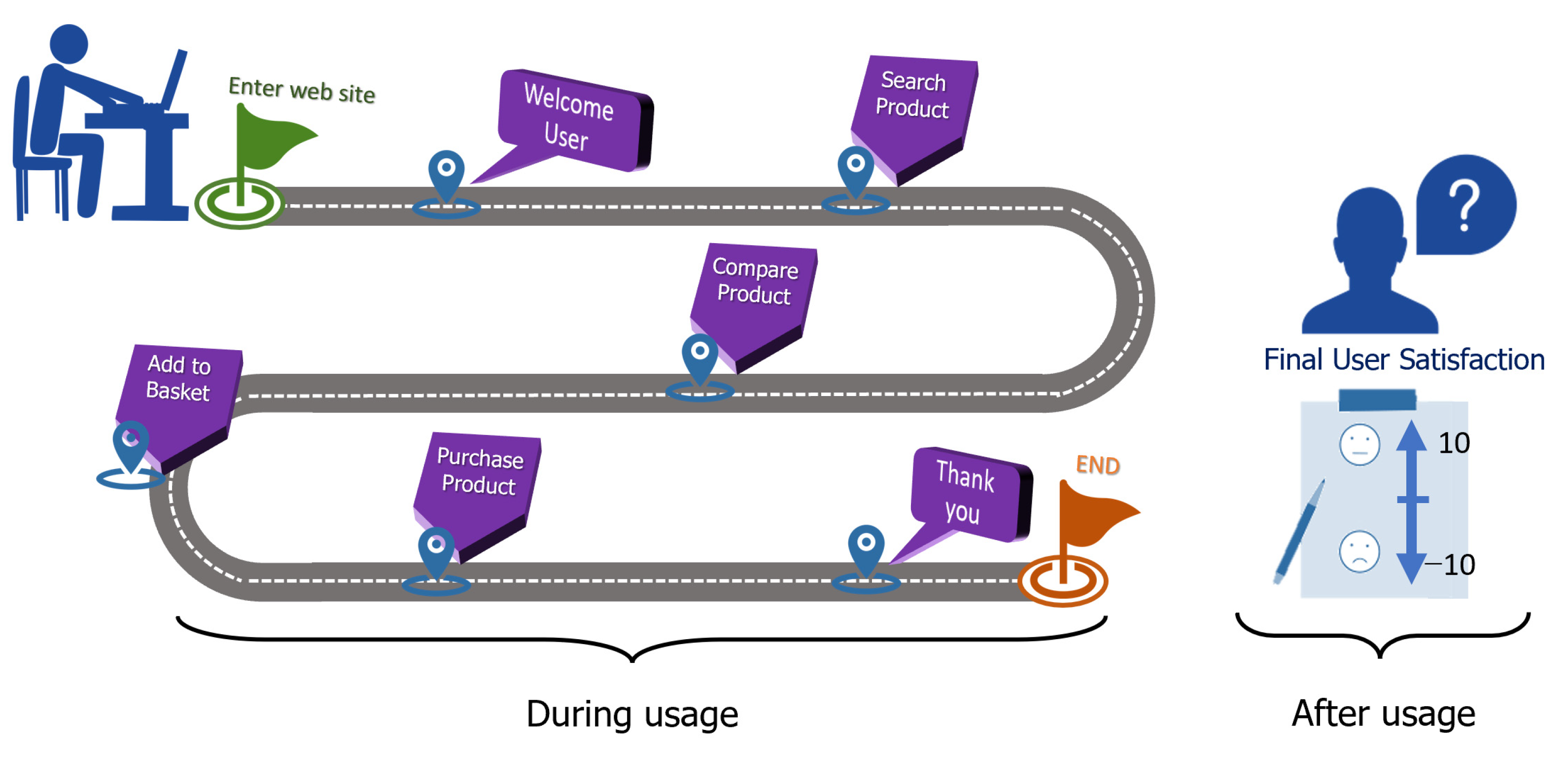
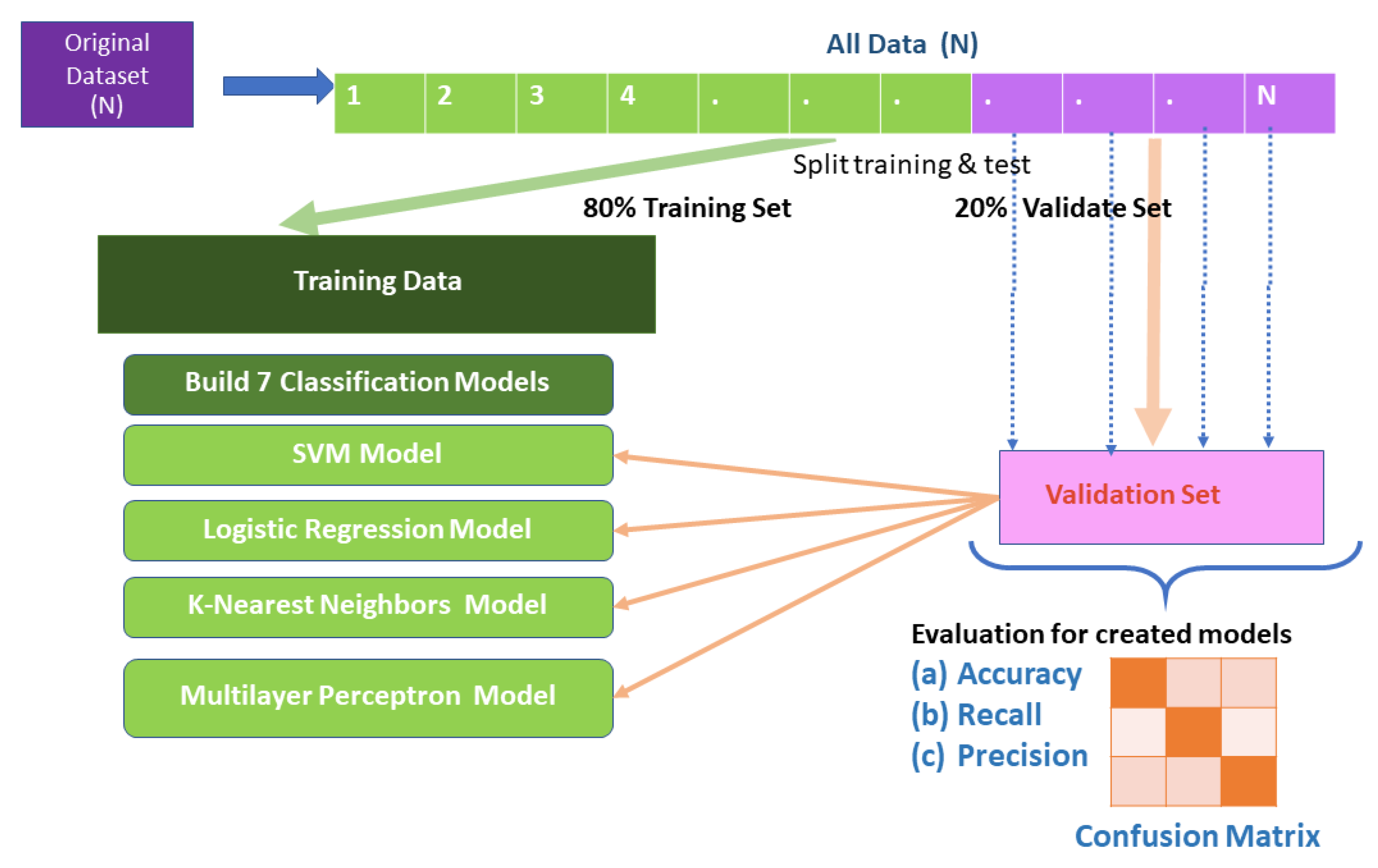
3.1. Proposed Framework
3.2. Experiments
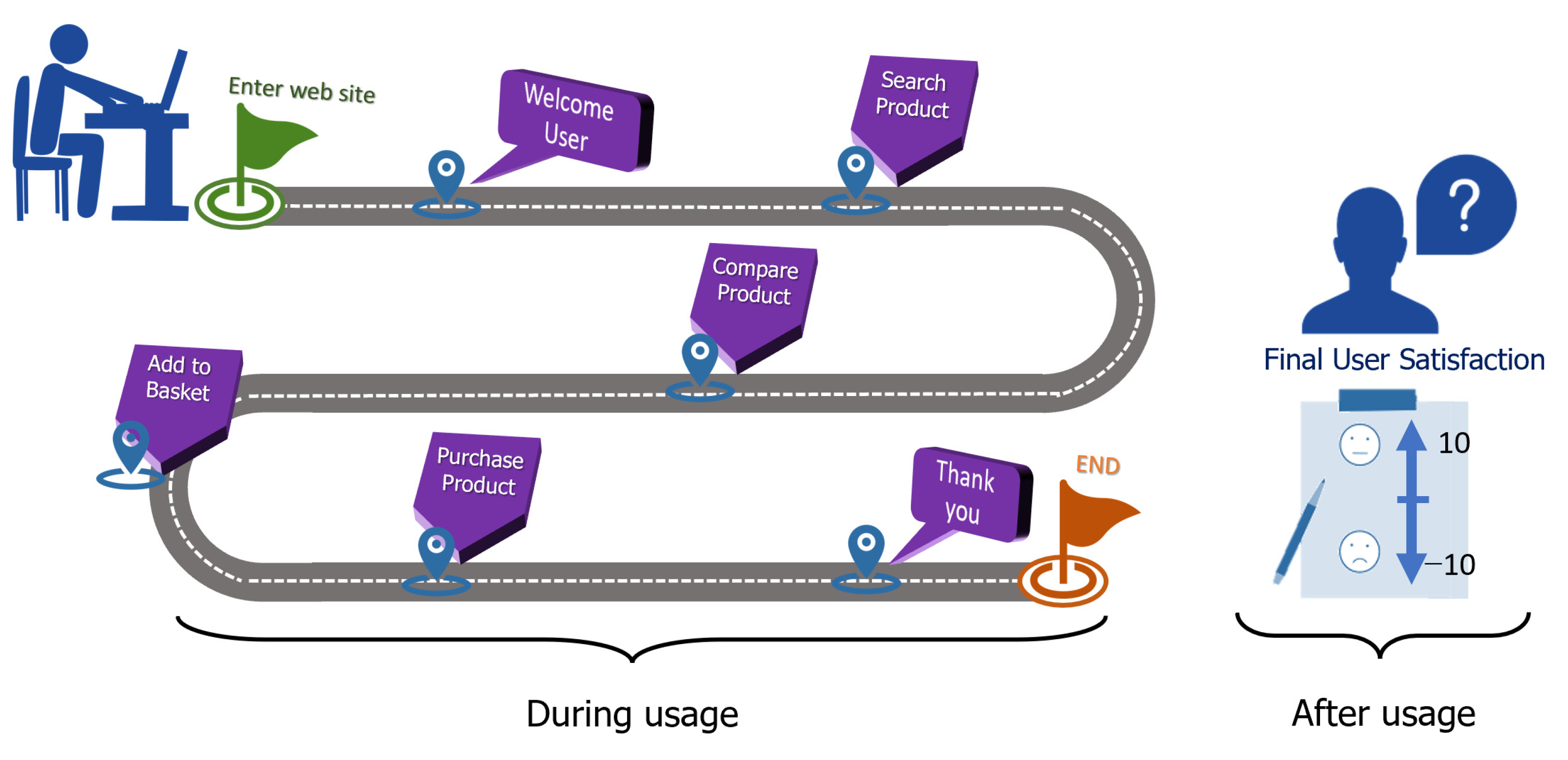
3.2.1. Travel Agency Website (Service Group)
3.2.2. Google Nest Mini (Product Group)
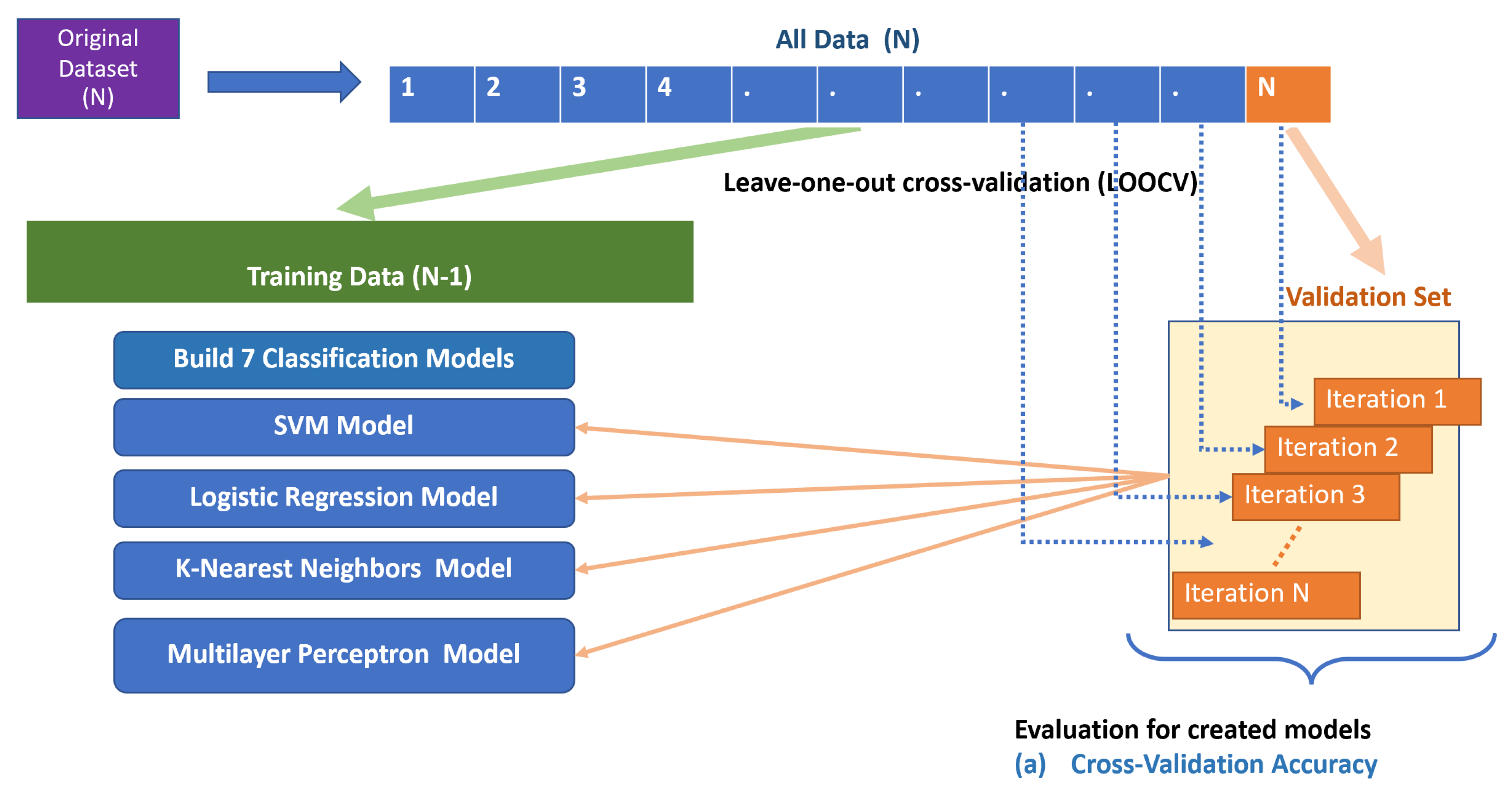
3.3. Evaluation
4. Results
4.1. Results from Experiment I: Service Usage with Travel Agency Site
4.2. Results from Experiment II: Product Usage with Google Nest Mini
5. Discussion
5.1. Experiment I: Service Usage with Travel Agency Site
5.2. Experiment II: Product Usage with Google Nest Mini
5.3. Findings
6. Conclusions
6.1. Theoretical Implications
6.2. Practical Implications
6.3. Limitations and Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Law, E.L.-C.; van Schaik, P.; Roto, V. Attitudes towards user experience (UX) measurement. Int. J. Hum.-Comput. Stud. 2014, 72, 526–541. [Google Scholar] [CrossRef] [Green Version]
- Balasubramoniam, V.; Tungatkar, N. Study of user experience (UX) and UX evaluation methods. Int. J. Adv. Res. Comput. Eng. Technol. 2013, 2, 1214–1219. [Google Scholar]
- Kurosu, M.; Hashizume, A.; Ueno, Y.; Tomida, T.; Suzuki, H. UX Graph and ERM as Tools for Measuring Kansei Experience. In Proceedings of the 18th International Conference on Human-Computer Interaction, Theory, Design, Development and Practice, Toronto, ON, Canada, 17–22 July 2016; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9731, pp. 331–339. [Google Scholar] [CrossRef]
- Barari, M.; Ross, M.; Surachartkumtonkun, J. Negative and positive customer shopping experience in an online context. J. Retail. Consum. Serv. 2020, 53, 101985. [Google Scholar] [CrossRef]
- Vall-Llosera, L.; Linares-Mustarós, S.; Bikfalvi, A.; Coenders, G. A Comparative Assessment of Graphic and 0–10 Rating Scales Used to Measure Entrepreneurial Competences. Axioms 2020, 9, 21. [Google Scholar] [CrossRef] [Green Version]
- Carneiro, J.; Santos, R.; Marreiros, G.; Novais, P. Understanding decision quality through satisfaction. In Proceedings of the International Conference on Practical Applications of Agents and Multi-Agent Systems, Salamanca, Spain, 4–6 June 2014; Springer: Cham, Switzerland, 2014; pp. 368–377. [Google Scholar]
- Roto, V.; Law, E.; Vermeeren, A.; Hoonhout, J. User experience white paper: Bringing clarity to the concept of user experience. In Proceedings of the Dagstuhl Seminar on Demarcating User Experience, Wadern, Germany, 15–17 September 2011; p. 12. [Google Scholar]
- Marti, P.; Iacono, I. Anticipated, momentary, episodic, remembered: The many facets of User eXperience. In Proceedings of the 2016 Federated Conference on Computer Science and Information Systems (FedCSIS), Gdansk, Poland, 11–14 September 2016; pp. 1647–1655. [Google Scholar]
- Hashizume, A.; Kurosu, M. UX Graph Tool for Evaluating the User Satisfaction. Int. J. Comput. Sci. Issue 2016, 13, 86–93. [Google Scholar] [CrossRef]
- Badran, O.; Al-Haddad, S. The Impact of Software User Experience on Customer Satisfaction. J. Manag. Inf. Decis. Sci. 2018, 21, 1–20. [Google Scholar]
- Matsuda, Y.; Fedotov, D.; Takahashi, Y.; Arakawa, Y.; Yasumoto, K.; Minker, W. EmoTour: Estimating Emotion and Satisfaction of Users Based on Behavioral Cues and Audiovisual Data. Sensors 2018, 18, 3978. [Google Scholar] [CrossRef] [Green Version]
- Cavalcante Siebert, L.; Bianchi Filho, J.F.; da Silva Júnior, E.J.; Kazumi Yamakawa, E.; Catapan, A. Predicting customer satisfaction for distribution companies using machine learning. Int. J. Energy Sect. Manag. 2019, 15, 743–764. [Google Scholar] [CrossRef]
- Kumar, S.; Zymbler, M. A machine learning approach to analyze customer satisfaction from airline tweets. J. Big Data 2019, 6, 62. [Google Scholar] [CrossRef] [Green Version]
- Bolger, N.; Davis, A.; Rafaeli, E. Diary Methods: Capturing Life as it is Lived. Annu. Rev. Psychol. 2003, 54, 579–616. [Google Scholar] [CrossRef] [Green Version]
- Klotins, E. Usability and User Experience: Measurement Model; School of Computing, Blekinge Institue of Technology: Karlskrona, Sweden, 2011. [Google Scholar]
- Feng, L.; Wei, W. An empirical study on user experience evaluation and identification of critical UX issues. Sustainability 2019, 11, 2432. [Google Scholar] [CrossRef] [Green Version]
- Körber, M.; Bengler, K. Measurement of momentary user experience in an automotive context. In Proceedings of the 5th International Conference on Automotive User Interfaces and Interactive Vehicular Applications, Eindhoven, The Netherlands, 28–30 October 2013; pp. 194–201. [Google Scholar]
- Sánchez-Adame, L.M.; Urquiza-Yllescas, J.F.; Mendoza, S. Measuring Anticipated and Episodic UX of Tasks in Social Networks. Appl. Sci. 2020, 10, 8199. [Google Scholar] [CrossRef]
- Hassan, R.S.; Nawaz, A.; Lashari, M.N.; Zafar, F. Effect of Customer Relationship Management on Customer Satisfaction. Procedia Econ. Financ. 2015, 23, 563–567. [Google Scholar] [CrossRef] [Green Version]
- Tao, F. Customer Relationship Management based on Increasing Customer Satisfaction. Int. J. Bus. Soc. Sci. 2014, 5, 255. [Google Scholar] [CrossRef]
- Sulaiman, S.M. Customer Relationship Management, Customer Satisfaction and Its Impact on Customer Loyalty; SciTePress: Setúbal, Portugal, 2018; Volume 2, pp. 692–698. [Google Scholar] [CrossRef]
- Angamuthu, B. Impact of customer relationship management on customer satisfaction and its role towards customer loyalty and retention practices in the hotel sector. BVIMSR J. Manag. Res. 2015, 7, 43–52. [Google Scholar]
- Rahimi, R.; Kozak, M. Impact of Customer Relationship Management on Customer Satisfaction: The Case of a Budget Hotel Chain. J. Travel Tour. Mark. 2017, 34, 40–51. [Google Scholar] [CrossRef] [Green Version]
- Taufik, M.; Renaldi, F.; Umbara, F.R. Implementing Online Analytical Processing in Hotel Customer Relationship Management. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1115, 12040. [Google Scholar] [CrossRef]
- Gharaibeh, N.K. Enhancing crm business intelligence applications by web user experience model. Int. J. Adv. Comput. Sci. Appl. 2015, 6, 1–6. [Google Scholar]
- Koonsanit, K.; Nishiuchi, N. Classification of User Satisfaction Using Facial Expression Recognition and Machine Learning. In Proceedings of the 2020 IEEE Region 10 Conference (Tencon), Osaka, Japan, 16–19 November 2020; pp. 561–566. [Google Scholar] [CrossRef]
- Kaul, D. Customer Relationship Management (CRM), Customer Satisfaction and Customer Lifetime Value in Retail. Rev. Prof. Manag.-A J. New Delhi Inst. Manag. 2017, 15, 55. [Google Scholar] [CrossRef]
- Shankar, V.; Winer, R.S. When customer relationship management meets data mining. J. Interact. Mark. 2006, 20, 2–4. [Google Scholar] [CrossRef]
- Libai, B.; Bart, Y.; Gensler, S.; Hofacker, C.F.; Kaplan, A.; Kötterheinrich, K.; Kroll, E.B. Brave New World? On AI and the Management of Customer Relationships. J. Interact. Mark. 2020, 51, 44–56. [Google Scholar] [CrossRef]
- Nielsen Norman Group the Definition of User Experience (UX). Available online: https://www.nngroup.com/articles/definition-user-experience/ (accessed on 17 June 2021).
- Vermeeren, A.P.; Law, E.L.-C.; Roto, V.; Obrist, M.; Hoonhout, J.; Väänänen-Vainio-Mattila, K. User experience evaluation methods: Current state and development needs. In Proceedings of the 6th Nordic Conference on Human-Computer Interaction: Extending Boundaries, Reykjavik, Iceland, 16–20 October 2010; pp. 521–530. [Google Scholar]
- Kujala, S.; Roto, V.; Väänänen-Vainio-Mattila, K.; Karapanos, E.; Sinnelä, A. UX Curve: A method for evaluating long-term user experience. Interact Comput 2011, 23, 473–483. [Google Scholar] [CrossRef]
- Schilling, K.; Applegate, R. Best methods for evaluating educational impact: A comparison of the efficacy of commonly used measures of library instruction. J. Med. Libr. Assoc. 2012, 100, 258–269. [Google Scholar] [CrossRef] [PubMed]
- Karapanos, E.; Martens, J.; Hassenzahl, M. On the retrospective assessment of users’ experiences over time: Memory or actuality? In Proceedings of the CHI ‘10: CHI Conference on Human Factors in Computing Systems, Atlanta, GA, USA, 10–15 April 2010; p. 4080. [Google Scholar] [CrossRef]
- Wawre, S.V.; Deshmukh, S.N. Sentiment classification using machine learning techniques. Int. J. Sci. Res. 2016, 5, 819–821. [Google Scholar]
- Schölkopf, B.; Smola, A.J.; Williamson, R.C.; Bartlett, P.L. New support vector algorithms. Neural Comput. 2000, 12, 1207–1245. [Google Scholar] [CrossRef]
- Senechal, T.; McDuff, D.; Kaliouby, R. Facial action unit detection using active learning and an efficient non-linear kernel approximation. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 10–18. [Google Scholar]
- Torres-Valencia, C.; Álvarez-López, M.; Orozco-Gutiérrez, Á. SVM-based feature selection methods for emotion recognition from multimodal data. J. Multimodal User Interfaces 2017, 11, 9–23. [Google Scholar] [CrossRef]
- Zhang, M.-L.; Zhou, Z.-H. A k-nearest neighbor based algorithm for multi-label classification. In Proceedings of the 2005 IEEE International Conference on Granular Computing, Beijing, China, 25–27 July 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 2, pp. 718–721. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Kinha, Y. An Easy Guide to Choose the Right Machine Learning Algorithm. KDnuggets. 2020. Available online: https://www.kdnuggets.com/2020/05/guide-choose-right-machine-learning-algorithm.html (accessed on 13 June 2021).
- Haykin, S.S. Neural Networks and Learning Machines; Prentice Hall: New York, NY, USA, 2009. [Google Scholar]
- Khondoker, M.; Dobson, R.; Skirrow, C.; Simmons, A.; Stahl, D. A comparison of machine learning methods for classification using simulation with multiple real data examples from mental health studies. Stat. Methods Med. Res. 2016, 25, 1804–1823. [Google Scholar] [CrossRef] [Green Version]
- Beleites, C.; Neugebauer, U.; Bocklitz, T.; Krafft, C.; Popp, J. Sample size planning for classification models. Anal. Chim. Acta 2013, 760, 25–33. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Oppong, S.H. The problem of sampling in qualitative research. Asian J. Manag. Sci. Educ. 2013, 2, 202–210. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Longadge, R.; Dongre, S. Class imbalance problem in data mining review. Int. J. Comput. Sci. Netw. 2013, 2, 1–6. [Google Scholar]
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning. J. Mach. Learn. Res. 2017, 18, 559–563. [Google Scholar]
- Nguyen, H.M.; Cooper, E.W.; Kamei, K. Borderline over-sampling for imbalanced data classification. Int. J. Knowl. Eng. Soft Data Paradig. 2011, 3, 4–21. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1322–1328. [Google Scholar]
- Batista, G.E.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Akinbi, A.; Berry, T. Forensic Investigation of Google Assistant. SN Comput. Sci. 2020, 1, 272. [Google Scholar] [CrossRef]
- Stover-Wright, E. Snowball Sampling: An Alternate Approach to Obtaining Consumer Satisfaction Responses. J. Rehabil. Adm. 2013, 37, 103–107. [Google Scholar]
- Precourt, G. What Do We Know about Peer-to-Peer Marketing? J. Advert. Res. 2014, 124–125. [Google Scholar] [CrossRef]
- Spool, J. Is Design Metrically Opposed? Available online: https://www.uie.com/wp-assets/transcripts/is_design_metrically_opposed.html (accessed on 21 June 2021).
- DJokić, I. The Use of Semantic Differential in Function of Measuring Image of the Company. Econ. Anal. 2017, 1, 50–61. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. Linear Regression. In An Introduction to Statistical Learning: With Applications in R; James, G., Witten, D., Hastie, T., Tibshirani, R., Eds.; Springer Texts in Statistics; Springer: New York, NY, USA, 2013; pp. 59–126. ISBN 978-1-4614-7138-7. [Google Scholar] [CrossRef]
- Meng, M.; Zhao, C. Application of support vector machines to a small-sample prediction. Adv. Pet. Explor. Dev. 2015, 10, 72–75. [Google Scholar]
- Raikwal, J.S.; Saxena, K. Performance evaluation of SVM and k-nearest neighbor algorithm over medical data set. Int. J. Comput. Appl. 2012, 50, 2. [Google Scholar]
- Paper, D. Scikit-Learn Classifier Tuning from Simple Training Sets. In Hands-On Scikit-Learn for Machine Learning Applications; Apress: Berkeley, CA, USA, 2020; pp. 137–163. ISBN 978-1-4842-5373-1. [Google Scholar]
- Santos, M.S.; Soares, J.P.; Abreu, P.H.; Araujo, H.; Santos, J. Cross-Validation for Imbalanced Datasets: Avoiding Overoptimistic and Overfitting Approaches. IEEE Comput. Intell. Mag. 2018, 13, 59–76. [Google Scholar] [CrossRef]
- Ng, A.Y. Preventing" overfitting" of cross-validation data. In Proceedings of the ICML, Nashville, TN, USA, 8–12 July 1997; Carnegie Mellon University: Pittsburgh, PA, USA, 1997; Volume 97, pp. 245–253. [Google Scholar]
- Raschka, S. Model Evaluation, Model Selection, and Algorithm Selection in Machine Learning. arXiv 2018, arXiv:1811.12808. [Google Scholar]
- Subramanian, J.; Simon, R. Overfitting in prediction models–is it a problem only in high dimensions? Contemp. Clin. Trials 2013, 36, 636–641. [Google Scholar] [CrossRef] [PubMed]
- Cahyana, N.; Khomsah, S.; Aribowo, A.S. Improving Imbalanced Dataset Classification Using Oversampling and Gradient Boosting. In Proceedings of the 2019 5th International Conference on Science in Information Technology (ICSITech), Yogyakarta, Indonesia, 23–24 October 2019; pp. 217–222. [Google Scholar] [CrossRef]
- Ben-Hur, A.; Weston, J. A user’s guide to support vector machines. In Data Mining Techniques for the Life Sciences; Springer: Berlin/Heidelberg, Germany, 2010; pp. 223–239. [Google Scholar]


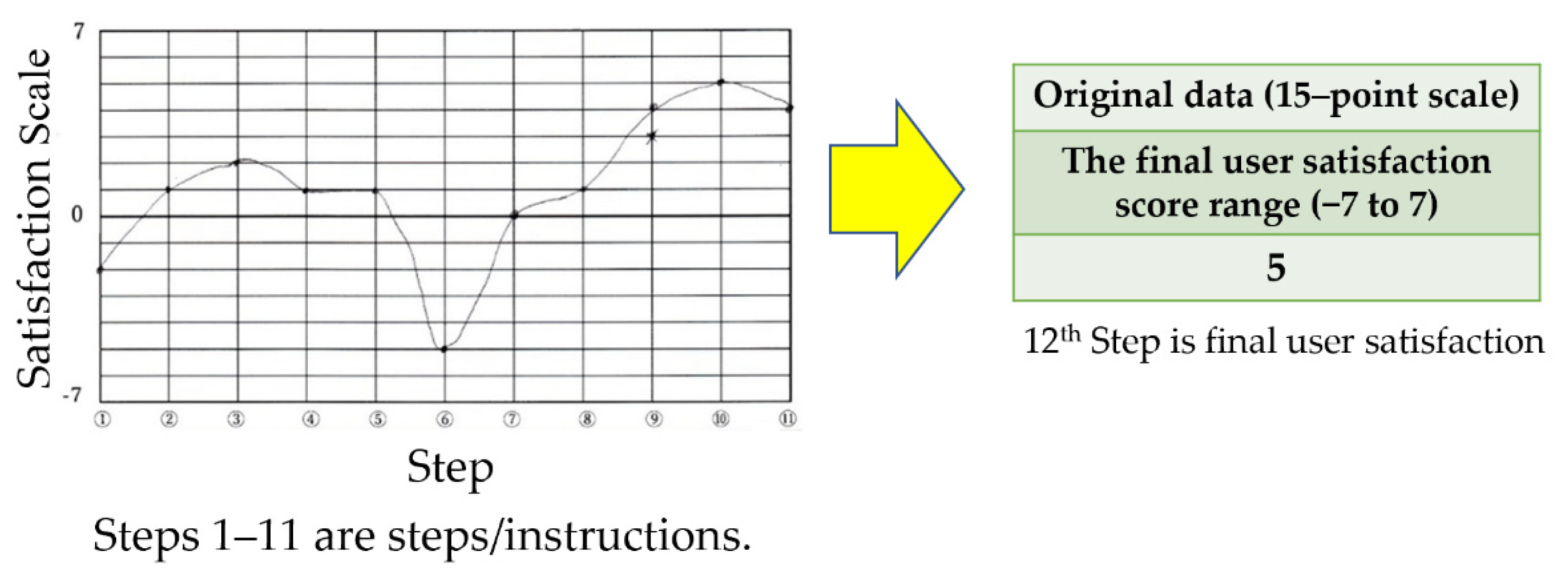
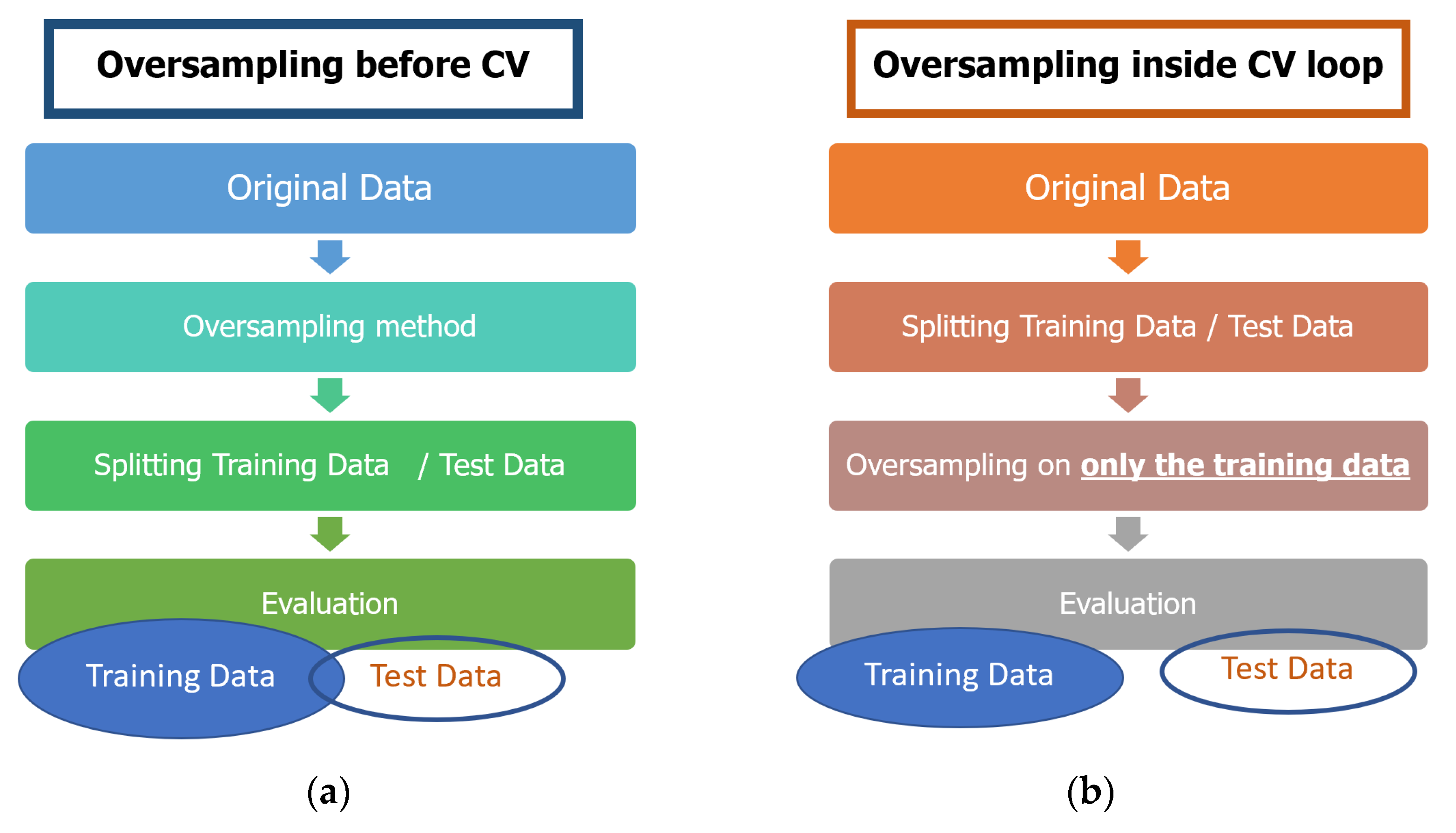
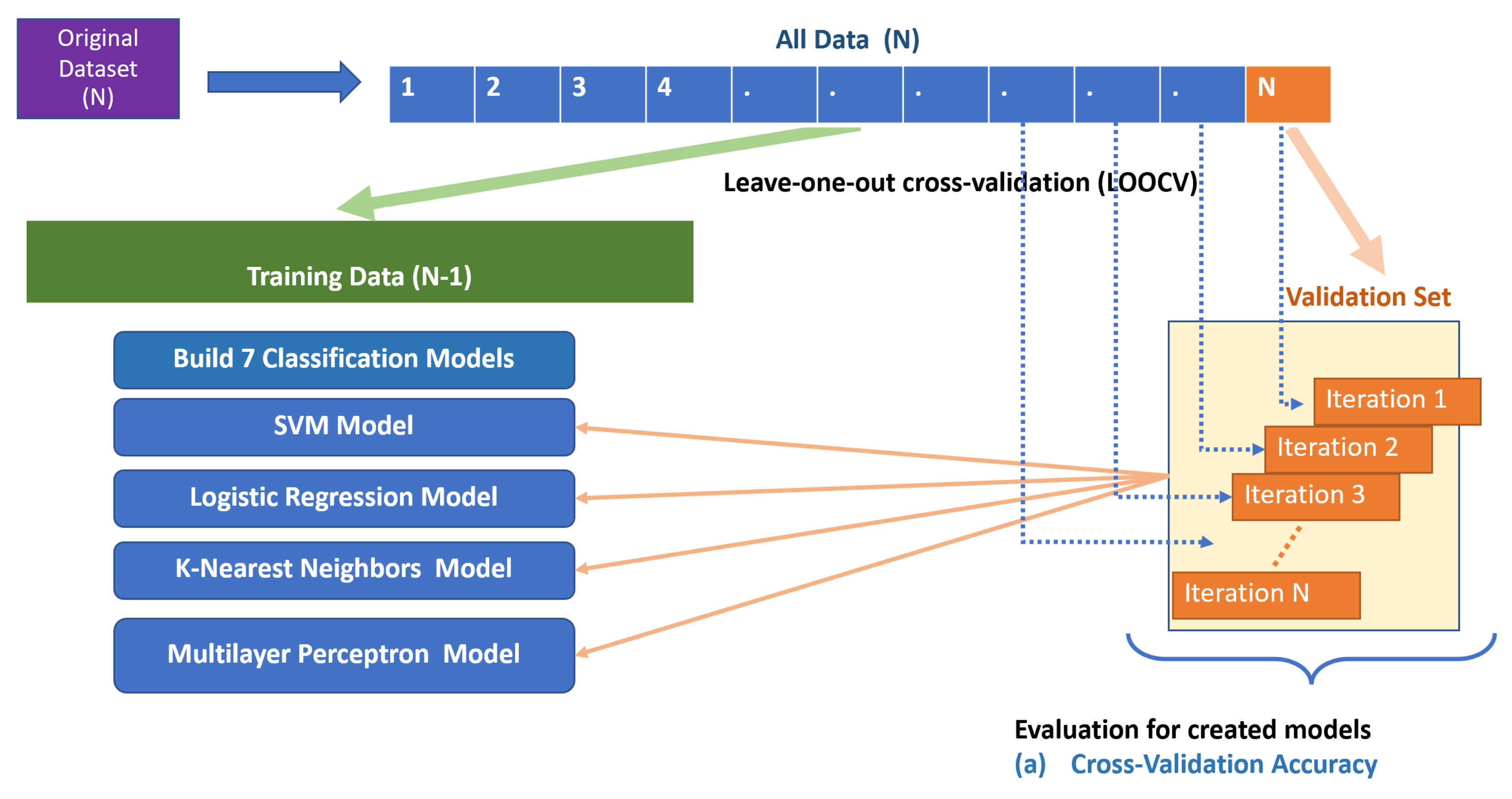
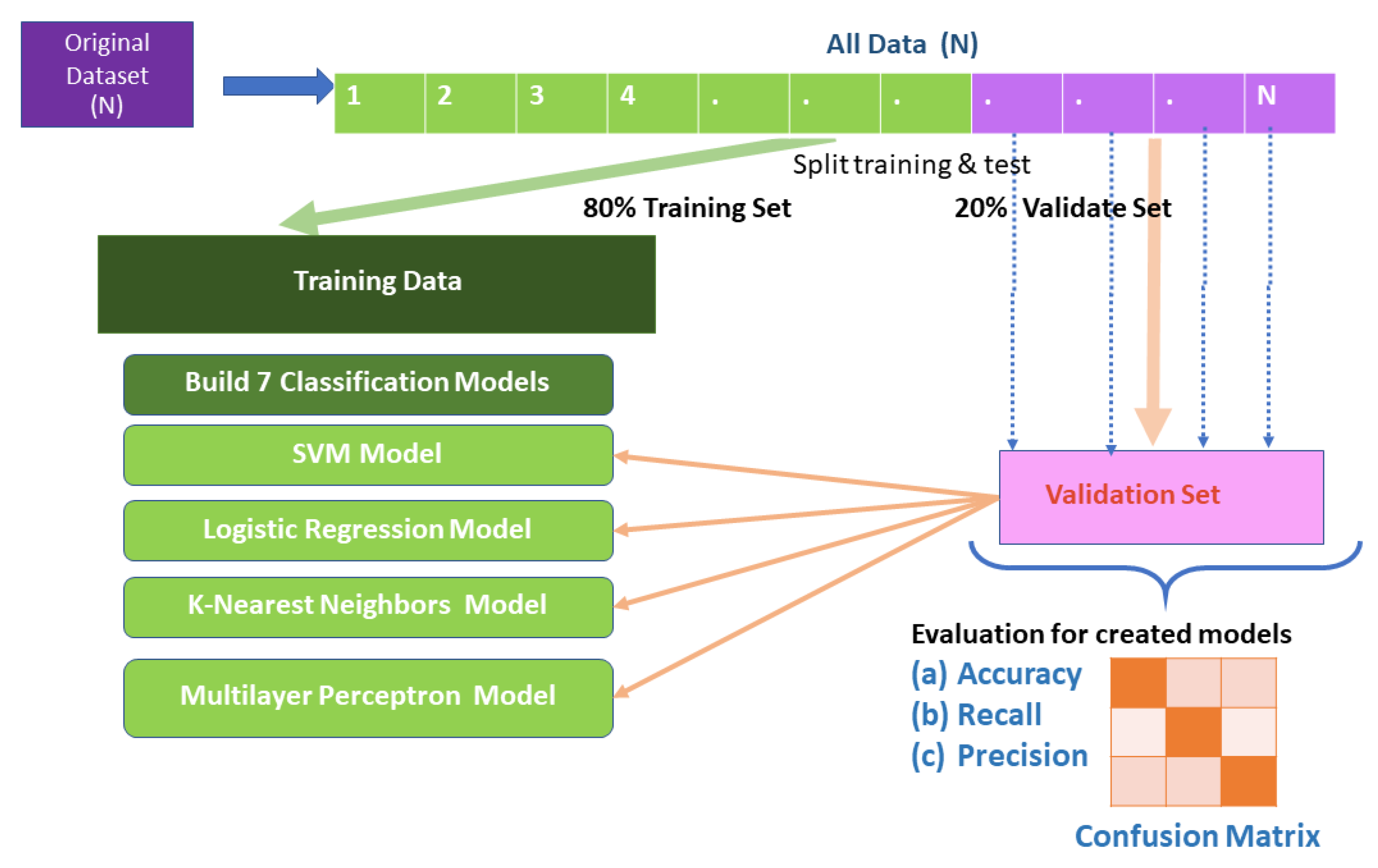

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach. | Description |
|---|---|
| UX Curve [32] | UX Curve is a tool for drawing a timeline and a horizontal line that splits positive and negative experiences. |
| UX Graph [3,22] | UX Graph is a tool for drawing the degree of satisfaction on a time scale. It is an improved version of the conventional UX Curve. |
| iScale [34] | iScale is a tool for the backward-looking expression of long-term user experience data. |
| Approaches | Description |
|---|---|
| Support Vector Machine with Polynomial Kernel Function | The SVM algorithm uses the best line to separate n-dimensional space into classes by the hyperplane. The learning of the hyperplane is processed by transforming the problem using Polynomial Function [40]. |
| Support Vector Machine with Radial Basis Kernel Function | SVM models classify data by optimizing a hyperplane that separates the classes using Radial Basis Kernel Function [40]. |
| Support Vector Machine with Linear Kernel Function | This classifier is formally defined by a separating line. The learning of the hyperplane is processed by transforming the problem using linear algebra [40]. |
| Support Vector Machine with Sigmoid Kernel Function | SVM models process data points by drawing decision boundaries with the Sigmoid Kernel Function [40]. |
| K-Nearest Neighbors | K-Nearest Neighbors uses the label of data points surrounding a target data point to define the class label by a plurality vote of its neighbors [39]. |
| Logistic Regression | Linear Regression is a technique to predict a continuous output value from a linear relationship. However, the output of Logistic Regression will provide a value between 0 and 1, a probability [40]. |
| Multilayer Perceptron | A multilayer perceptron (MLP) is a technique to classify the class label. It is the same structure as a single layer perceptron with one or more hidden layers. It can only classify separable cases with a binary target (1, 0) [42]. |
| Steps | Directions |
|---|---|
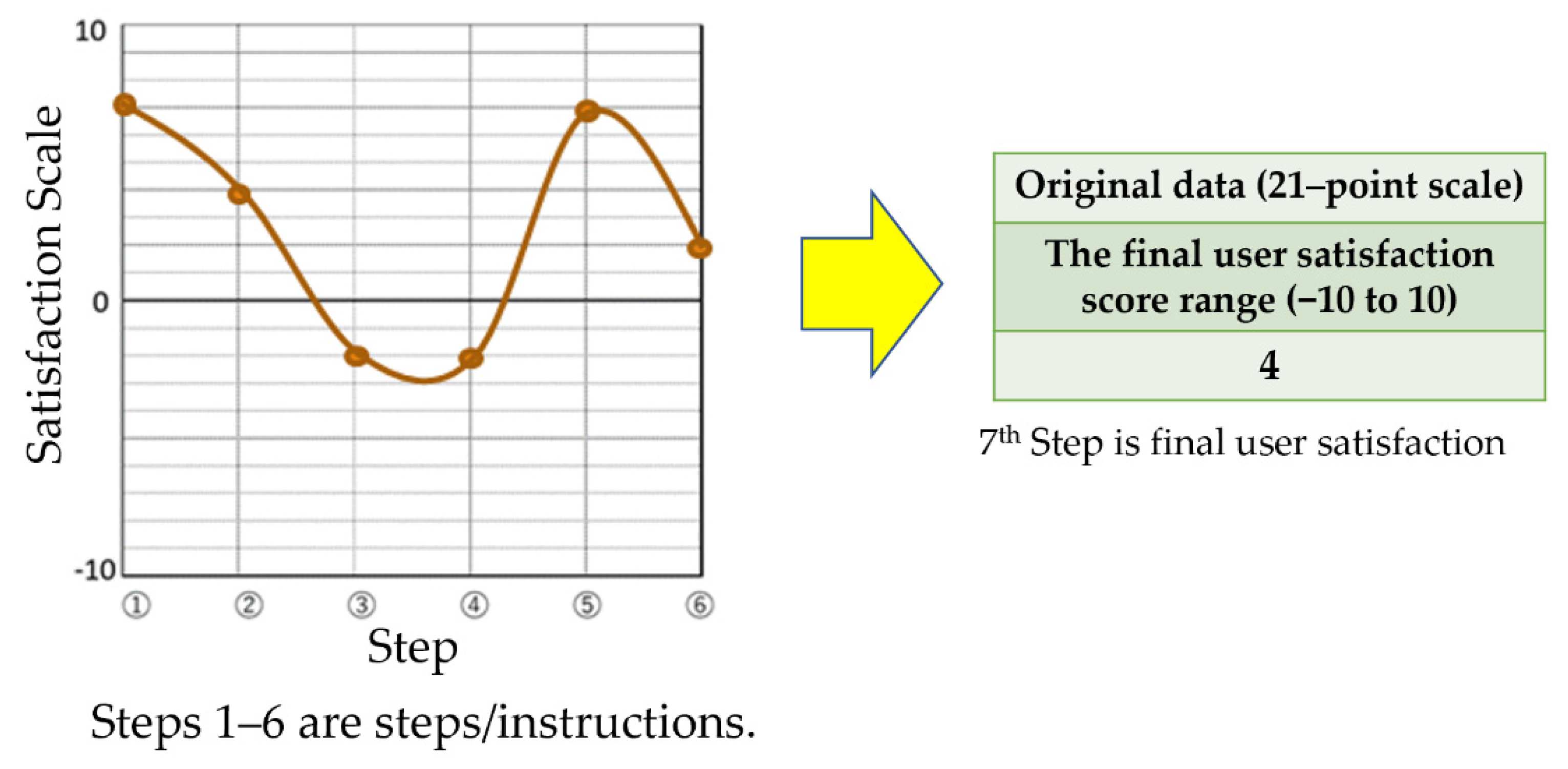
| 1st | Find where you want to visit once in your life. Then, evaluate user satisfaction. |
| 2nd | Find the country of interest. Then, evaluate user satisfaction. |
| 3rd | Visit the homepage of the travel agency website. Then, evaluate user satisfaction. |
| 4th | View information on the travel agency website. Then, evaluate user satisfaction. |
| 5th | Select a tour in which you are interested. Then, evaluate user satisfaction. |
| 6th | Select and then purchase a favorite tour. Then, evaluate user satisfaction. |
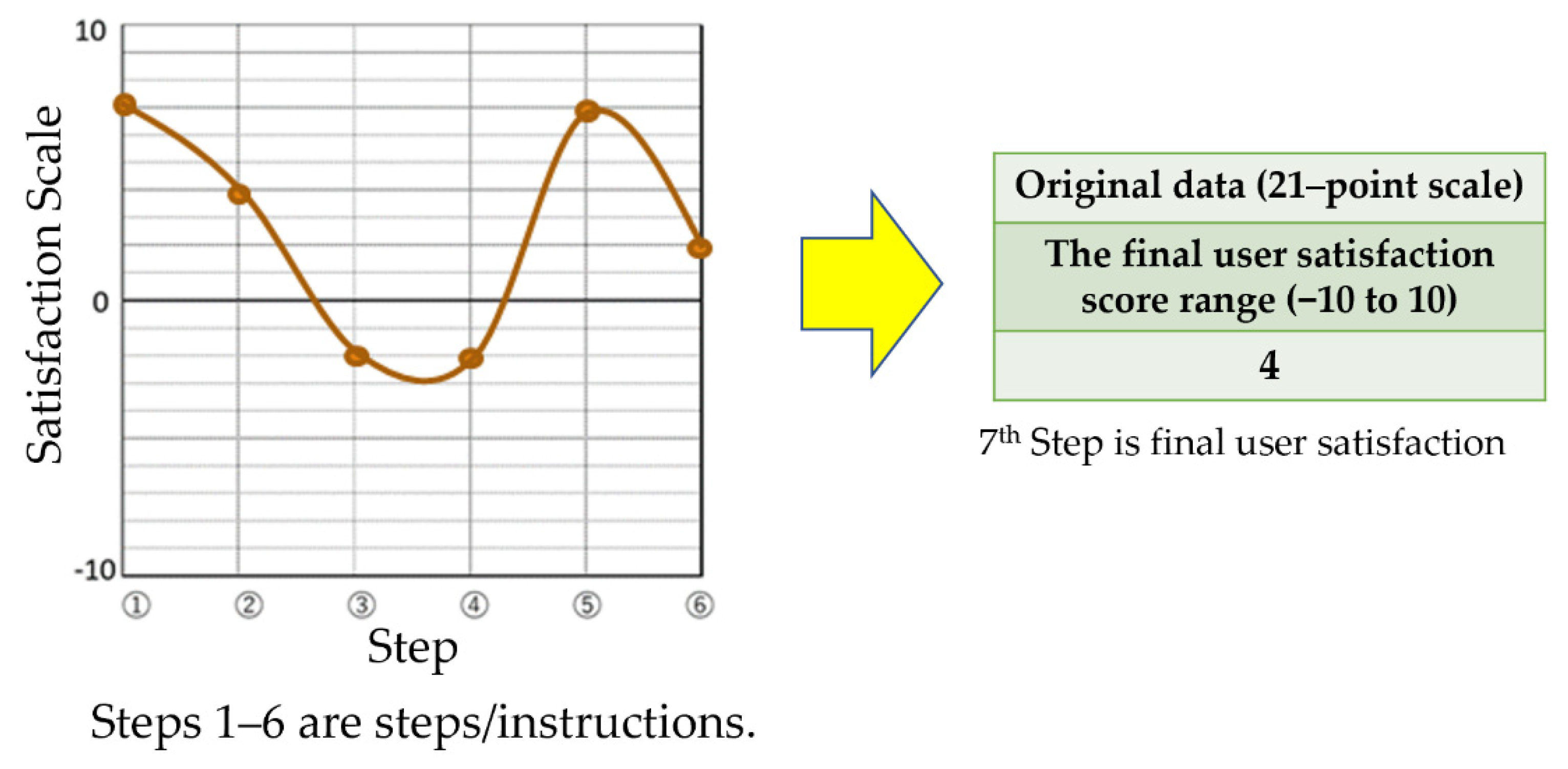
| 7th | Evaluate your final user satisfaction with the travel agency website. |
| Meaning of Satisfaction Rating | Dataset I | Meaning of Satisfaction Rating | Dataset II | ||
|---|---|---|---|---|---|
| Original Data | After Shrinking | Original Data | After Shrinking | ||
| Extremely satisfied | 10 | 3 | Extremely satisfied | 10 | 2 |
| 9 | 9 | ||||
| 8 | 8 | ||||
| Satisfied | 7 | 2 | 7 | ||
| 6 | 6 | ||||
| 5 | Satisfied | 5 | 1 | ||
| 4 | 4 | ||||
| Slightly satisfied | 3 | 1 | 3 | ||
| 2 | 2 | ||||
| 1 | 1 | ||||
| Neutral | 0 | 0 | Neutral | 0 | 0 |
| Slightly unsatisfied | −1 | −1 | Unsatisfied | −1 | −1 |
| −2 | −2 | ||||
| −3 | −3 | ||||
| Unsatisfied | −4 | −2 | −4 | ||
| −5 | −5 | ||||
| −6 | Extremely unsatisfied | −6 | −2 | ||
| −7 | −7 | ||||
| Extremely unsatisfied | −8 | −3 | −8 | ||
| −9 | −9 | ||||
| −10 | −10 | ||||
| Steps | Directions |
|---|---|
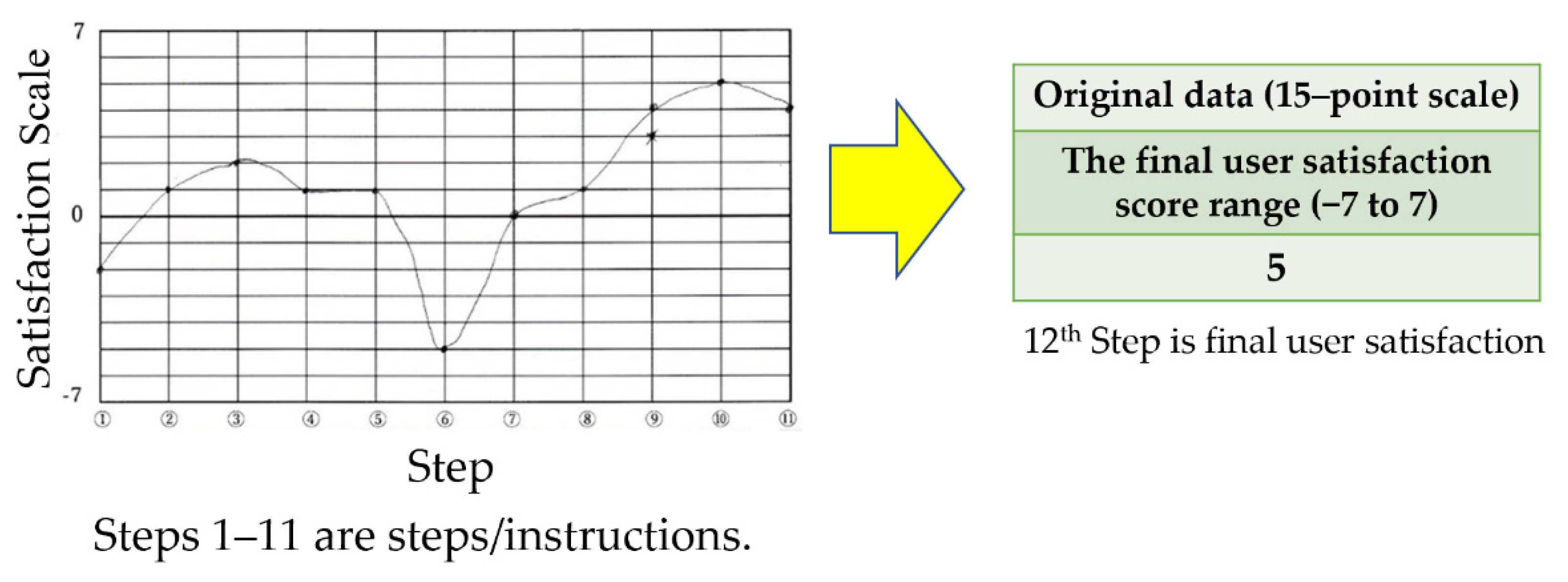
| 1st | Browse nest mini on Google Store. |
| 2nd | Open the box, take out the smart speaker. |
| 3rd | Read the instructions, turn on the smart speaker. |
| 4th | Install the Google app on your smartphone, select an account. |
| 5th | Connect apps and smart speakers using Wi-Fi connection with smartphone location information and router. |
| 6th | Open a Wi-Fi connection between the smart speaker and router using the app. |
| 7th | Follow the instructions in the app and using voice recognition on the smart speaker. |
| 8th | Connect and set various setting services in the app. |
| 9th | Play music on a smart speaker that has been set up. |
| 10th | Set alarm timers with smart speakers. |
| 11th | Listen to weather forecasts with smart speakers. |
| 12th | Evaluate your final user satisfaction with the Google Nest Mini. |
| Meaning of Satisfaction Rating | Dataset I | Meaning of Satisfaction Rating | Dataset II | ||
|---|---|---|---|---|---|
| Original Data | After Shrinking | Original Data | After Shrinking | ||
| Extremely satisfied | 7 | 3 | Extremely satisfied | 7 | 2 |
| 6 | 6 | ||||
| Satisfied | 5 | 2 | 5 | ||
| 4 | Satisfied | 4 | 1 | ||
| Slightly satisfied | 3 | 1 | 3 | ||
| 2 | 2 | ||||
| 1 | 1 | ||||
| Neutral | 0 | 0 | Neutral | 0 | 0 |
| Slightly unsatisfied | −1 | −1 | Unsatisfied | −1 | −1 |
| −2 | −2 | ||||
| −3 | −3 | ||||
| Unsatisfied | −4 | −2 | −4 | ||
| −5 | Extremely unsatisfied | −5 | −2 | ||
| Extremely unsatisfied | −6 | −3 | −6 | ||
| −7 | −7 | ||||
| Scores | Dataset | SVM Poly | SVM RBF | SVM Linear | SVM Sigmoid | KNN | LR | MLP | |
|---|---|---|---|---|---|---|---|---|---|
| LOOCV | Cross-Validation Accuracy | I (7 Classes) | 0.93 | 0.79 | 0.80 | 0.50 | 0.84 | 0.72 | 0.80 |
| II (5 Classes) | 0.90 | 0.87 | 0.88 | 0.45 | 0.80 | 0.87 | 0.84 | ||
| Split for training/test (80/20) | Accuracy | I (7 Classes) | 0.87 | 0.60 | 0.73 | 0.33 | 0.73 | 0.60 | 0.67 |
| II (5 Classes) | 0.93 | 0.93 | 0.86 | 0.54 | 0.86 | 0.89 | 0.93 | ||
| Recall | I (7 Classes) | 0.87 | 0.60 | 0.73 | 0.33 | 0.73 | 0.60 | 0.67 | |
| II (5 Classes) | 0.93 | 0.93 | 0.86 | 0.54 | 0.86 | 0.89 | 0.93 | ||
| Precision | I (7 Classes) | 0.90 | 0.64 | 0.85 | 0.21 | 0.75 | 0.70 | 0.65 | |
| II (5 Classes) | 0.96 | 0.95 | 0.87 | 0.42 | 0.88 | 0.90 | 0.93 | ||
| Model Performance | Dataset I: 7 Classes (7-Point Scale Data) | Dataset II: 5 Classes (5-Point Scale Data) | |||
|---|---|---|---|---|---|
| Score | Polynomial Kernel SVM | Polynomial Kernel SVM with Oversampling into the Cross-Validation Step | Polynomial Kernel SVM | Polynomial Kernel SVM with Oversampling into the Cross-Validation Step | |
| LOOCV | Cross-Validation Accuracy | 0.48 | 0.93 | 0.72 | 0.90 |
| Split for training/test (80/20) | Accuracy | 0.40 | 0.87 | 0.70 | 0.93 |
| Recall | 0.40 | 0.87 | 0.70 | 0.93 | |
| Precision | 0.65 | 0.90 | 0.61 | 0.96 | |
| Scores | Dataset | SVM Poly | SVM RBF | SVM Linear | SVM Sigmoid | KNN | LR | MLP | |
|---|---|---|---|---|---|---|---|---|---|
| LOOCV | Cross-Validation Accuracy | I (7 Classes) | 0.60 | 0.52 | 0.52 | 0.16 | 0.52 | 0.44 | 0.40 |
| II (5 Classes) | 0.76 | 0.68 | 0.64 | 0.32 | 0.68 | 0.68 | 0.48 | ||
| Split for training/test (80/20) | Accuracy | I (7 Classes) | 0.88 | 0.80 | 0.80 | 0.20 | 0.40 | 0.20 | 0.60 |
| II (5 Classes) | 0.86 | 0.60 | 0.80 | 0.40 | 0.40 | 0.40 | 0.60 | ||
| Recall | I (7 Classes) | 0.88 | 0.80 | 0.80 | 0.20 | 0.40 | 0.20 | 0.60 | |
| II (5 Classes) | 0.86 | 0.60 | 0.80 | 0.40 | 0.40 | 0.40 | 0.60 | ||
| Precision | I (7 Classes) | 0.92 | 0.87 | 0.80 | 0.60 | 0.37 | 0.20 | 0.67 | |
| II (5 Classes) | 0.89 | 0.60 | 0.85 | 0.53 | 0.53 | 0.53 | 0.87 | ||
| Model Performance | Dataset I: 7 Classes (7-Point Scale Data) | Dataset II: 5 Classes (5-Point Scale Data) | |||
|---|---|---|---|---|---|
| Score | Polynomial Kernel SVM | Polynomial Kernel SVM with Oversampling into the Cross-Validation Step | Polynomial Kernel SVM | Polynomial Kernel SVM with Oversampling into the Cross-Validation Step | |
| LOOCV | Cross-Validation Accuracy | 0.52 | 0.60 | 0.60 | 0.76 |
| Split for training/test (80/20) | Accuracy | 0.60 | 0.88 | 0.60 | 0.86 |
| Recall | 0.60 | 0.88 | 0.60 | 0.86 | |
| Precision | 0.50 | 0.92 | 0.80 | 0.89 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koonsanit, K.; Nishiuchi, N. Predicting Final User Satisfaction Using Momentary UX Data and Machine Learning Techniques. J. Theor. Appl. Electron. Commer. Res. 2021, 16, 3136-3156. https://doi.org/10.3390/jtaer16070171
Koonsanit K, Nishiuchi N. Predicting Final User Satisfaction Using Momentary UX Data and Machine Learning Techniques. Journal of Theoretical and Applied Electronic Commerce Research. 2021; 16(7):3136-3156. https://doi.org/10.3390/jtaer16070171
Chicago/Turabian StyleKoonsanit, Kitti, and Nobuyuki Nishiuchi. 2021. "Predicting Final User Satisfaction Using Momentary UX Data and Machine Learning Techniques" Journal of Theoretical and Applied Electronic Commerce Research 16, no. 7: 3136-3156. https://doi.org/10.3390/jtaer16070171
APA StyleKoonsanit, K., & Nishiuchi, N. (2021). Predicting Final User Satisfaction Using Momentary UX Data and Machine Learning Techniques. Journal of Theoretical and Applied Electronic Commerce Research, 16(7), 3136-3156. https://doi.org/10.3390/jtaer16070171