
EGNet: 3D Semantic Segmentation Through Point–Voxel–Mesh Data for Euclidean–Geodesic Feature Fusion


Abstract
1. Introduction
2. Related Work
2.1. Method Based on Euclidean Feature
2.2. Method Based on Geodesic Feature
2.3. Method Based on Geodesic Features and Euclidean Features
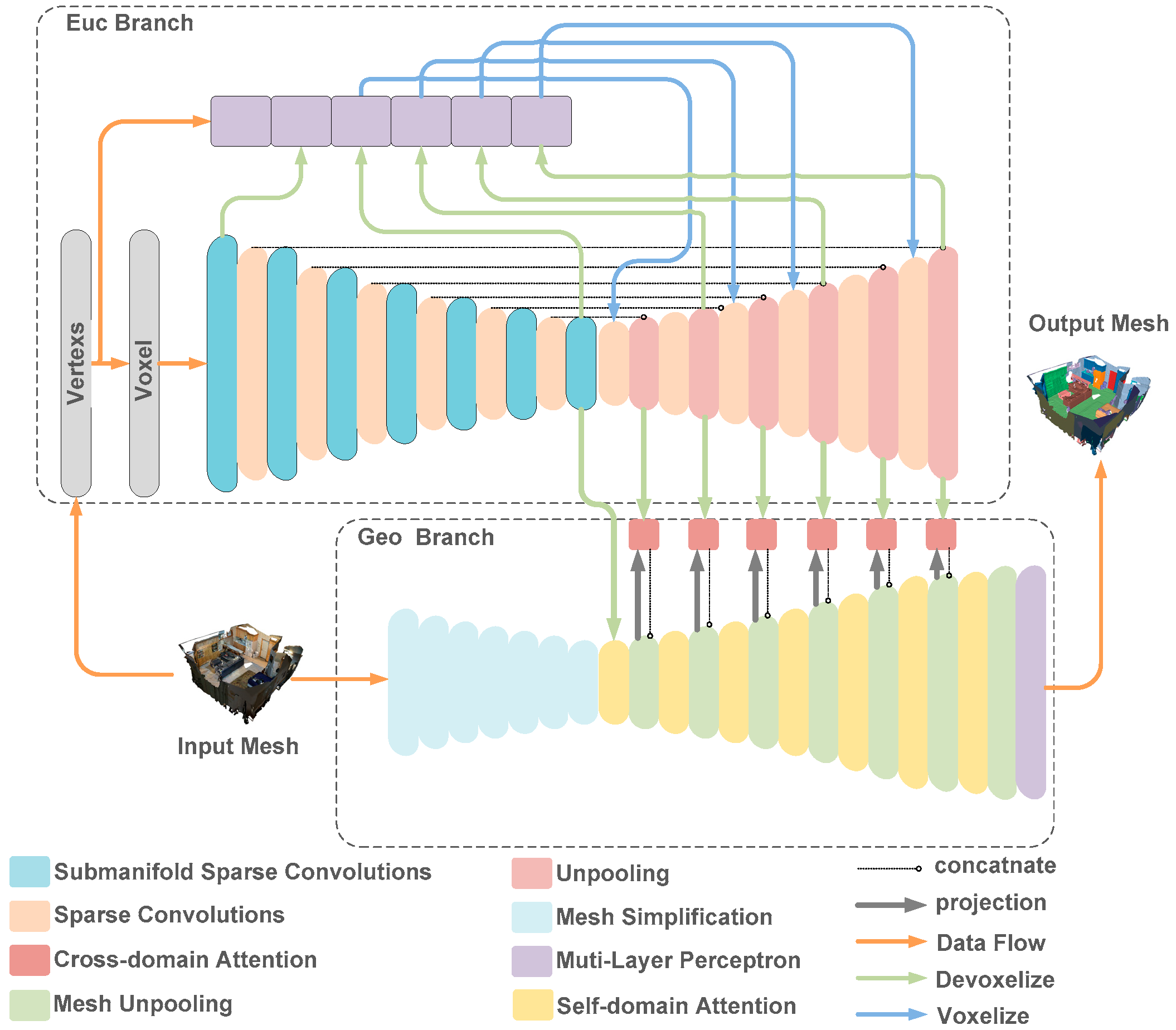
3. Methodology
3.1. Euclidean Branch
- (1)
- MLP based on point: Sparse voxel branches cannot model fine single-point features effectively. Inspired by the work of H. Tang [9], we improve the method for combining point features and voxel features of point cloud data. The MLP is used to extract the features of a single point and achieve high-resolution point information to compensate for the missing information based on coarse-grained voxels. We employ voxelization and devoxelization to achieve data consolidation during fusion.
- (2)
- Voxelization: The point cloud tensor is expressed as C = ({Pc, Fc}), where Pc = (xi, yi, zi) defines the 3D coordinates of the point cloud and Fc represents the feature vector of the points [21]. The sparse tensor is described as S = ({Ps, Fs}, v), where Ps is the ratio of the 3D coordinates of the point cloud to the voxel size, Fs is the feature tensor of the grid, and v is the voxel resolution.
- (3)
- Devoxelization: In the devoxelization process, inspired by [17], we use trilinear interpolation at each layer to transform the eight neighboring voxel rasters into a point cloud tensor. The features of each point are interpolated using the features of the eight neighboring voxels. Note that, for the de-voxelization process, if we use the voxelized data converted to point cloud data, these point cloud data will generate a rough 3D mesh, causing information loss. To avoid this, one option is to increase the voxel mesh resolution; however, this method will cause memory overflow. Therefore, we use the original 3D point cloud as nodes based on the approach for model inference used in [17]. For each point , we define a random variable to denote the relationship between data categories (semantic information). We also define to be the scores (logits) associated with the probability distribution of , where is operated as shown in Equation (3):
- (4)
- Combination of sparse convolution and submanifold sparse convolution: Generally, the sparse tensors are convolved in a certain access order. However, the conventional convolution operation is not adjusted to suit the sparsity of the input data, resulting in the “submanifold dilation problem”. Submanifold sparse convolution (SSC) [20] addresses the limitation of submanifold dilation by restricting the convolutional output to a group of active input regions to ensure the sparsity stays constant across multiple layers. However, SSC causes each pixel to be processed separately, which limits the network’s ability to extract the correlation with neighborhood information. Therefore, our method combines the SC (m, n, f, s = 2) and SSC (m, n, f, s = 1) to create convolution networks based on U-Net, where m is the input features, n is the output features, f is the filter size, and s is the step size. The size of the output feature map is (l − f + s)/s.
3.2. Geodesic Branch
- (1)
- MLP based on point cloud data: Mesh simplification primarily minimizes the number of triangular meshes while preserving the model’s geometric details and texture components. Developed methods for mesh simplification include VC [24], edge collapse quadratic error metric (QEM) [25], wavelet discretization [26], and a combination of VC and QEM [19]. Our experiments compare these methods, revealing that edge collapse yields optimal performance. Although the literature [19] shows that direct application of the QEM method produces high-frequency noise signals and that combining clustering and edge folding methods is optimal, we have already extracted the high-frequency features from the point cloud data using the MLP network in the Euclidean branching. Therefore, we do not need the high-resolution features embedded in the gridded data prior to simplification. Instead, we employ an attentional mechanism during feature aggregation to select the high-frequency features that best match the geodetic features of the gridded data. This mechanism filters the high-frequency noise in the gridded data, achieving an effect similar to that of the VC method. Because we only extract the geodesic features from the gridded data, we also do not need to consider whether the collapsed edges depend on a specific task [27].
- (2)
- Self-domain Attention: The adjacency matrix describes graph G, while the diagonal matrix D is defined as , where denotes the degree of vertex . The formula represents the graph features of the geodesic branch or the graph features of the Euclidean branch.
- (3)
- Cross-domain Attention Module: To fuse mesh data features and features extracted by Euclidean branch, we designed the cross-domain attention module, which mirrors the structure of the self-domain attention module. The difference is the input features. First, when calculating the attention weight matrix , we use the Euclidean feature to calculate , identifying Euclidean features that correspond to the current geodesic features. The formula is as follows:
4. Experiment Results and Analyses
4.1. Datasets
4.2. Implementation Detail
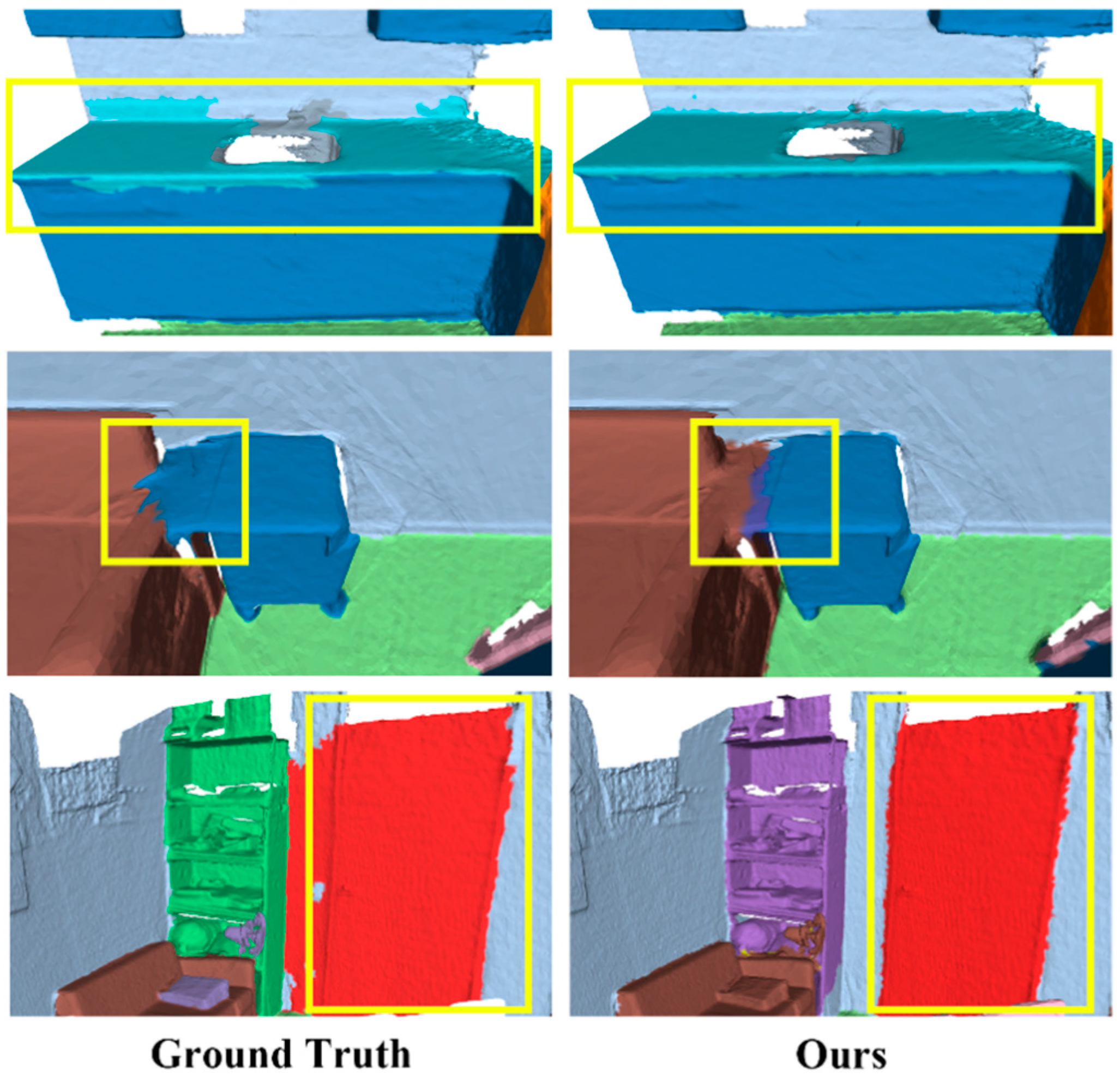
4.3. Experimental Results and Analysis
4.4. Ablation Study
4.5. Model Efficiency
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ding, R.; Yang, J.; Xue, C.; Zhang, W.; Bai, S.; Qi, X. Lowis3d: Language-driven open-world instance-level 3D scene understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 8517–8533. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Gan, V.J.L. Multi-view stereo for weakly textured indoor 3D reconstruction. Comput.-Aided Civ. Infrastruct. Eng. 2024, 39, 1469–1489. [Google Scholar] [CrossRef]
- Li, S.; Li, H. Regional-to-local point-voxel transformer for large-scale indoor 3D point cloud semantic segmentation. Remote Sens. 2023, 15, 4832. [Google Scholar] [CrossRef]
- Jhaldiyal, A.; Chaudhary, N. Semantic segmentation of 3D lidar data using deep learning: A review of projection-based methods. Appl. Intell. 2023, 53, 6844–6855. [Google Scholar] [CrossRef]
- Liu, Z.; Tang, H.; Lin, Y.; Han, S. Point-voxel cnn for efficient 3D deep learning. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates Inc.: Red Hook, NY, USA, 2019; pp. 965–975. [Google Scholar]
- Chang, A.; Dai, A.; Funkhouser, T.; Halber, M.; Niessner, M.; Savva, M.; Song, S.; Zeng, A.; Zhang, Y. Matterport3D: Learning from RGB-D Data in Indoor Environments. arXiv 2017, arXiv:1709.06158. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 5105–5114. [Google Scholar]
- Jiang, M.; Wu, Y.; Zhao, T.; Zhao, Z.; Lu, C. Pointsift: A sift-like network module for 3D point cloud semantic segmentation. arXiv 2018, arXiv:1807.00652. [Google Scholar]
- Tang, H.; Liu, Z.; Zhao, S.; Lin, Y.; Lin, J.; Wang, H.; Han, S. Searching efficient 3D architectures with sparse point-voxel convolution. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 685–702. [Google Scholar]
- Xu, M.; Ding, R.; Zhao, H.; Qi, X. Paconv: Position adaptive convolution with dynamic kernel assembling on point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3172–3181. [Google Scholar] [CrossRef]
- Wu, X.; Lao, Y.; Jiang, L.; Liu, X.; Zhao, H. Point transformer v2: Grouped vector attention and partition-based pooling. Adv. Neural Inf. Process. Syst. 2022, 35, 33330–33342. [Google Scholar]
- Wu, P.; Gu, L.; Yan, X.; Xie, H.; Wang, F.L.; Cheng, G.; Wei, M. PV-RCNN++: Semantical point-voxel feature interaction for 3D object detection. Vis. Comput. 2023, 39, 2425–2440. [Google Scholar] [CrossRef]
- Park, J.; Kim, C.; Kim, S.; Jo, K. PCSCNet: Fast 3D semantic segmentation of LiDAR point cloud for autonomous car using point convolution and sparse convolution network. Expert Syst. Appl. 2023, 212, 118815. [Google Scholar] [CrossRef]
- Agathos, A.; Azariadis, P. Optimal Point-to-Point geodesic path generation on point clouds. Comput.-Aided Des. 2023, 162, 103552. [Google Scholar] [CrossRef]
- Shao, Y.; Chen, J.; Gu, X.; Lu, J.; Du, S. A novel curved surface profile monitoring approach based on geometrical-spatial joint feature. J. Intell. Manuf. 2024, 1–23. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, J.; Ma, X.; Wang, G.; Bhatti, U.A.; Huang, M. Interactive medical image annotation using improved Attention U-net with compound geodesic distance. Expert. Syst. Appl. 2024, 237, 121282. [Google Scholar] [CrossRef]
- Tchapmi, L.; Choy, C.; Armeni, I.; Gwak, J.; Savarese, S. Segcloud: Semantic segmentation of 3D point clouds. In Proceedings of the International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 537–547. [Google Scholar] [CrossRef]
- Schult, J.; Engelmann, F.; Kontogianni, T.; Leibe, B. Dualconvmesh-net: Joint geodesic and euclidean convolutions on 3D meshes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8609–8619. [Google Scholar] [CrossRef]
- Hu, Z.; Bai, X.; Shang, J.; Zhang, R.; Dong, J.; Wang, X.; Sun, G.; Fu, H.; Tai, C.L. Vmnet: Voxel-mesh network for geodesic-aware 3D semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 15468–15478. [Google Scholar] [CrossRef]
- Graham, B.; Engelcke, M.; Maaten, L. 3D semantic segmentation with submanifold sparse convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9224–9232. [Google Scholar] [CrossRef]
- Maturana, D.; Scherer, S. Voxnet: A 3D convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, Hamburg, Germany, 28 September–3 October 2015; Volume 2015, pp. 922–928. [Google Scholar] [CrossRef]
- Choy, C.; Gwak, J.; Savarese, S. 4D spatio-temporal convnets: Minkowski convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3070–3079. [Google Scholar] [CrossRef]
- Tang, H.; Liu, Z.; Li, X.; Lin, Y.; Han, S. TorchSparse: Efficient point cloud inference engine. Proc. Mach. Learn. Syst. 2022, 4, 302–315. [Google Scholar]
- Yang, H.; Huang, S.; Wang, R. Efficient roof vertex clustering for wireframe simplification based on the extended multiclass twin support vector machine. IEEE Geosci. Remote Sens. Lett. 2024, 21, 6501405. [Google Scholar] [CrossRef]
- Li, J.; Chen, D.; Hu, F.; Wang, Y.; Li, P.; Peethambaran, J. Shape-preserving mesh decimation for 3D building modeling. Int. J. Appl. Earth Obs. Geoinf. 2024, 126, 103623. [Google Scholar] [CrossRef]
- Eldar, Y.C.; Bolcskei, H. Block-sparsity: Coherence and efficient recovery. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; Volume 2009, pp. 2885–2888. [Google Scholar] [CrossRef]
- Hanocka, R.; Hertz, A.; Fish, N.; Giryes, R.; Fleishman, S.; Cohen-Or, D. Meshcnn: A network with an edge. ACM Trans. Graph. 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Shi, Y.; Huang, Z.; Feng, S.; Zhong, H.; Wang, W.; Sun, Y. Masked label prediction: Unified message passing model for semi-supervised classification. arXiv 2020, arXiv:2009.03509. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Niessner, M. Scannet: Richly-annotated 3D reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2432–2443. [Google Scholar] [CrossRef]
- Dai, A.; Nießner, M. 3dmv: Joint 3D-multi-view prediction for 3D semantic scene segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 458–474. [Google Scholar] [CrossRef]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. Pointcnn: Convolution on x-transformed points. In Proceedings of the 32nd International Conference on Neural Information Processing Systems (NIPS’18), Montréal, QC, Canada, 3–8 December 2018; Curran Associates Inc.: Red Hook, NY, USA, 2018; pp. 828–838. [Google Scholar]
- Wang, J.; Sun, B.; Lu, Y. Mvpnet: Multi-view point regression networks for 3D object reconstruction from a single image. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8949–8956. [Google Scholar] [CrossRef]
- Wu, W.; Qi, Z.; Fuxin, L. Pointconv: Deep convolutional networks on 3D point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9613–9622. [Google Scholar] [CrossRef]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6410–6419. [Google Scholar] [CrossRef]
- Lei, H.; Akhtar, N.; Mian, A. Spherical kernel for efficient graph convolution on 3D point clouds. arXiv 2019, arXiv:1909.09287. [Google Scholar]
- Gong, J.; Xu, J.; Tan, X.; Song, H.; Qu, Y.; Xie, Y.; Ma, L. Omni-supervised point cloud segmentation via gradual receptive field component reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11673–11682. [Google Scholar]
- Yue, G.; Xiao, R.; Zhao, Z.; Li, C. AF-GCN: Attribute-fusing graph convolution network for recommendation. IEEE Trans. Big Data 2022, 9, 597–607. [Google Scholar] [CrossRef]
- Wang, C.; Jiang, L.; Wu, X.; Tian, Z.; Peng, B.; Zhao, H.; Jia, J. Groupcontrast: Semantic-aware self-supervised representation learning for 3D understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 4917–4928. [Google Scholar] [CrossRef]
- Wu, X.; Jiang, L.; Wang, P.S.; Liu, Z.; Liu, X.; Qiao, Y.; Ouyang, W.; He, T.; Zhao, H. Point transformer V3: Simpler faster stronger. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 4840–4851. [Google Scholar] [CrossRef]
- Su, H.; Jampani, V.; Sun, D.; Maji, S.; Kalogerakis, E.; Yang, M.H.; Kautz, J. Splatnet: Sparse lattice networks for point cloud processing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2530–2539. [Google Scholar] [CrossRef]
- Dai, A.; Ritchie, D.; Bokeloh, M.; Reed, S.; Sturm, J.; Niessner, M. Scancomplete: Large-scale scene completion and semantic segmentation for 3D scans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4578–4587. [Google Scholar] [CrossRef]
- Tatarchenko, M.; Park, J.; Koltun, V.; Zhou, Q.Y. Tangent convolutions for dense prediction in 3D. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3887–3896. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Year | Val | Test |
|---|---|---|---|
| PointNet++ [7] | 2017 | 53.5 | 55.7 |
| 3DMV [30] | 2018 | - | 48.4 |
| PointCNN [31] | 2018 | - | 45.8 |
| SparseConvNet [20] | 2018 | 69.3 | 72.5 |
| MVPNet [32] | 2019 | - | 64.1 |
| PointConv [33] | 2019 | 61.0 | 66.6 |
| KPConv [34] | 2019 | 69.2 | 68.6 |
| MinkowskiNet [22] | 2019 | 72.2 | 73.6 |
| SPH3D-GCN [35] | 2019 | - | 61.8 |
| DCM-Net [18] | 2020 | - | 65.8 |
| RFCR+KPConv [36] | 2021 | - | 70.3 |
| PointTransformer V2 [11] | 2022 | 75.4 | 74.2 |
| AF-GCN [37] | 2023 | 73.4 | 71.8 |
| GroupContrast [38] | 2024 | 75.7 | |
| PointTransformer V3 [39] | 2024 | 77.5 | 77.9 |
| Ours | 2024 | 73.3 | 74.1 |
| Method | mAP | ||
|---|---|---|---|
| MinkowskiNet [22] | 72.8 | 56.9 | 36.0 |
| PointTransformer V2 [11] | 76.3 | 60.0 | 38.3 |
| Ours | 76.1 | 60.7 | 40.2 |
| Method | PointNet++ [7] | SplatNet [40] | ScanComplete [41] | TangentConv [42] | 3DMV [30] | DCM-Net [18] | VMNet [19] | Ours |
|---|---|---|---|---|---|---|---|---|
| omAcc | 43.8 | 26.7 | 44.9 | 46.8 | 56.1 | 66.2 | 67.2 | 67.5 |
| Wall | 80.1 | 90.8 | 79.0 | 56.0 | 79.6 | 78.4 | 85.9 | 84.6 |
| Floor | 81.3 | 95.7 | 95.9 | 87.7 | 95.5 | 93.6 | 94.4 | 93.8 |
| Cab | 34.1 | 30.3 | 31.9 | 41.5 | 59.7 | 64.5 | 56.2 | 56.1 |
| Bed | 71.8 | 19.9 | 70.4 | 73.6 | 82.3 | 89.5 | 89.5 | 89.5 |
| Chair | 59.7 | 77.6 | 68.7 | 60.7 | 70.5 | 70.0 | 83.7 | 83.5 |
| Sofa | 63.5 | 36.9 | 41.4 | 69.3 | 73.3 | 85.3 | 70.0 | 69.7 |
| Table | 58.1 | 19.8 | 35.1 | 38.1 | 48.5 | 46.1 | 54.0 | 53.2 |
| Door | 49.6 | 33.6 | 32.0 | 55.0 | 64.3 | 81.3 | 76.7 | 75.4 |
| Wind | 28.7 | 15.8 | 37.5 | 30.7 | 55.7 | 63.4 | 63.2 | 63.1 |
| Bookshelf | 1.1 | 15.7 | 17.5 | 33.9 | 8.3 | 43.7 | 44.6 | 45.0 |
| Image | 34.3 | 0 | 27.0 | 50.6 | 55.4 | 73.2 | 72.1 | 72 |
| Counter | 10.1 | 0 | 37.2 | 38.4 | 34.8 | 39.9 | 29.1 | 30.2 |
| Desk | 0 | 0 | 11.8 | 19.7 | 2.4 | 47.9 | 38.4 | 48.3 |
| Window | 68.8 | 12.3 | 50.4 | 48.0 | 80.1 | 60.3 | 79.7 | 67.7 |
| Ceiling | 79.3 | 75.7 | 97.6 | 45.1 | 94.8 | 89.3 | 94.5 | 82 |
| Refrigerator | 0 | 0 | 0.1 | 22.6 | 4.7 | 65.8 | 47.6 | 64.7 |
| Bathtub | 29.0 | 0 | 15.7 | 35.9 | 54.0 | 43.7 | 80.1 | 83.5 |
| Toilet | 70.4 | 10.4 | 74.9 | 50.7 | 71.1 | 86.0 | 85.0 | 77.5 |
| Sink | 29.4 | 4.1 | 44.4 | 49.3 | 47.5 | 49.6 | 49.2 | 51.0 |
| Shower | 62.1 | 20.3 | 53.5 | 56.4 | 76.7 | 87.5 | 88.0 | 83.4 |
| Other Furniture | 8.5 | 1.7 | 21.8 | 16.6 | 19.9 | 31.1 | 29.0 | 43.4 |
| Model Part | Result | |||||
|---|---|---|---|---|---|---|
| Point | Self-Domain | Cross-Domain | mIou | mAcc | OA | |
| Euc Only | 68.3 | 77.2 | 88.6 | |||
| Euc Point | ✓ | 70.1 | 78.6 | 89 | ||
| Geo Only | 69.6 | 77.9 | 88.9 | |||
| Geo Self | ✓ | 70.9 | 79.3 | 89.4 | ||
| Ours | ✓ | ✓ | ✓ | 73.3 | 80.4 | 90.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Q.; Song, Y.; Jin, X.; Wu, Y.; Zhang, H.; Zhao, D. EGNet: 3D Semantic Segmentation Through Point–Voxel–Mesh Data for Euclidean–Geodesic Feature Fusion. Sensors 2024, 24, 8196. https://doi.org/10.3390/s24248196
Li Q, Song Y, Jin X, Wu Y, Zhang H, Zhao D. EGNet: 3D Semantic Segmentation Through Point–Voxel–Mesh Data for Euclidean–Geodesic Feature Fusion. Sensors. 2024; 24(24):8196. https://doi.org/10.3390/s24248196
Chicago/Turabian StyleLi, Qi, Yu Song, Xiaoqian Jin, Yan Wu, Hang Zhang, and Di Zhao. 2024. "EGNet: 3D Semantic Segmentation Through Point–Voxel–Mesh Data for Euclidean–Geodesic Feature Fusion" Sensors 24, no. 24: 8196. https://doi.org/10.3390/s24248196
APA StyleLi, Q., Song, Y., Jin, X., Wu, Y., Zhang, H., & Zhao, D. (2024). EGNet: 3D Semantic Segmentation Through Point–Voxel–Mesh Data for Euclidean–Geodesic Feature Fusion. Sensors, 24(24), 8196. https://doi.org/10.3390/s24248196