

A Petri Net and LSTM Hybrid Approach for Intrusion Detection Systems in Enterprise Networks

 , , ,
, , ,  and
and
Abstract
1. Introduction
- A ML-based approach to identify and discard malicious traffic in a real-time fashion is proposed. The proposed algorithm encompasses an LSTM network that acts as an IDS and is able to catch the time correlation of the network packets flowing through the corporate network and identify incoming dangerous packet sequences;
- A PN to check the packet flow throughout the network and choose whether to accept or block a packet is modeled. Firstly, the PN acts as a buffer by storing a predefined bunch of packets. Then, it predicts the next packet, acting as an IPS, and decides to discard or let through the whole buffer according to the output of the LSTM-based IDS;
- The combination of the two strategies constitutes a high-performance IDS-IPS framework that is able to identify and block malicious packet sequences in real-time and drastically lower the risk of compromising the corporate network. This combination is not extensively explored in the current literature.
2. Related Work
2.1. Deep Learning Methods in Intrusion Detection
2.2. Recurrent Neural Networks (RNNs) in Intrusion Detection
2.3. Petri Nets (PNs) in Intrusion Detection
2.4. Graph Learning and Federated Learning in Intrusion Detection
3. Materials and Methods
- First, the data are preprocessed by loading the dataset, balancing benign and attack packets, handling missing or infinite values, and standardizing features. Highly correlated features are removed, and Principal Component Analysis (PCA) is applied to reduce dimensionality.
- The preprocessed data are then prepared for LSTM training by converting them into sequences of window size 50 and splitting them into training, validation, and test sets.
- An LSTM model is defined, compiled with binary cross-entropy loss and the Adam optimizer, and trained using the training and validation data. The trained model is evaluated on the test set to assess its accuracy and precision.
- A Petri Net is defined with places representing packet states and transitions controlling packet flow based on LSTM predictions. The network structure includes connections between places and transitions to model decision-making.
- The Petri Net executes by simulating packet arrival and utilizing LSTM predictions to decide whether packets are benign or malicious. The packets are either stored in a non-blocked list (if benign) or a blocked list (if malicious), and the process is repeated for multiple sets of data.
| Algorithm 1 LSTM and Petri Net Workflow for IDS |
|
3.1. Balanced Dataset
3.2. Data Analysis
- 0: if the target feature is “Benign”;
- 1: if the target feature is different from “Benign”.
3.3. Normalization
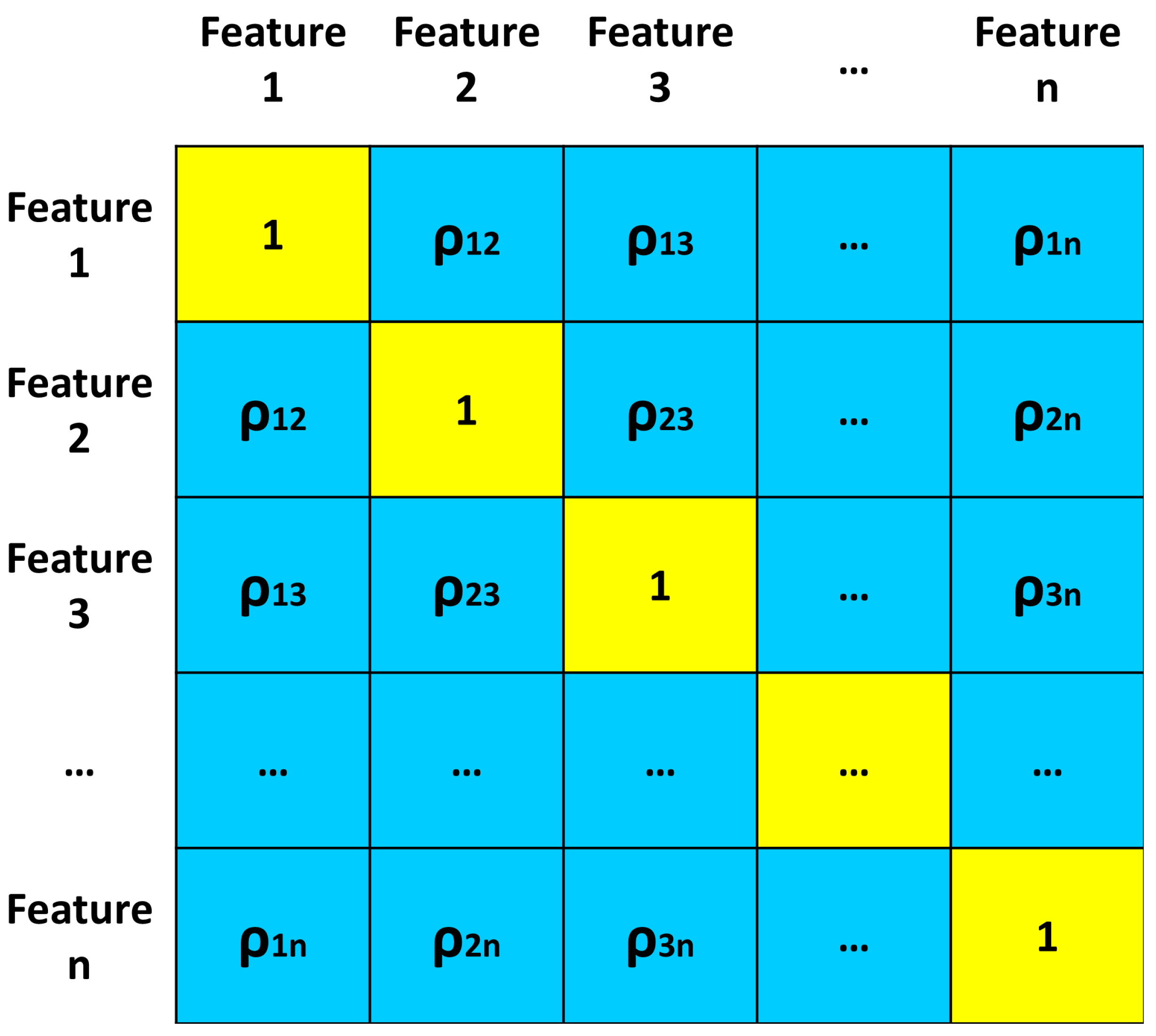
3.4. Correlation Matrix
- Main diagonal: the elements are all equal to 1. For the illustrated work, these coefficients are not useful for the analysis and therefore are not considered;
- Upper right triangle: it contains the correlation coefficients of each feature with the others;
- Lower left triangle: the same and identical correlation coefficients of the upper right triangle are contained.
3.5. Principal Component Analysis
3.6. LSTM
- Forget gate → through the sigmoid, it is decided which information will be discarded from the cell state. If the value of ft is equal to 1, then the information is kept, while if the value of ft is equal to 0, the information is discarded.
- Input gate → determines what information will be stored in the cell state. The sigmoid determines which information it to update. The tanh creates a vector of t values. Then, multiplying it and t, the new cell state ct is received.
- Output gate → the sigmoid determines the parts of the cell state to be brought to output (ot). The tanh processes the cell state ct. Then, multiply the two values obtained.
3.7. Petri Net
- Token: a place that contains tokens indicates that the condition corresponding to the place is met;
- Marking: a function that associates a non-negative number to each place. M is also defined by a vector containing the number of tokens for each place. In other words, it is the distribution of tokens in places in the system and corresponds to the state of the PN;
- Initial marking : the initial marking present at the beginning of the observation of the system.
- Enabling rule: when an input place to a transition has the required number of tokens, the transition is enabled.
- State transition rule: only when a transition is enabled, it can fire and one or more tokens are removed from each input place (as many as the weight of its input edges) and one or more tokens are placed in each output place (as many as the weight of its output edges).
- The enabling condition is met if
- The state condition leads to the creation of a new marking after the occurence of transition at the marking :
4. Implementation
- DATA PREPROCESSING: the “IDS 2018 Intrusion CSVs” datasets are imported, related to 16 February 2018 [15]. These data are preprocessed using different methodologies, including normalization, correlation matrix, and Principal Component Analysis;
- LSTM MODEL: the LSTM model is created to allow the binary classification of data into “malign” and “benign”. Model fit is performed using data from the training set. Then, the model is validated using the data from the valid set. Subsequently, the model is evaluated on the test dataset, with a prediction phase.
- PN: the IDS is made functional by building a PN. The main classes that compose the net and the methods to allow its operation are defined. Next, the network is assembled and run, showing the performance of the IDS.
4.1. Data Analysis
4.2. Petri Net
- Place: for the definition of the characteristics of a place in the PN. It is characterized by name and number of tokens;
- Transition: for the definition of the characteristics of a PN transition. It is characterized by a name, a set of input arcs, and a set of output arcs;
- Net: for the definition of the characteristics of the PN. It is characterized by name, current marking, a set of transitions, and global_var. The global_var attribute is composed as follows:
- −
- global_var[0]: contains the entire preprocessed data-frame;
- −
- global_var[1]: contains the index (randomly extracted) of the first packet of the 50 packet flow to be considered for the prediction of the 51st;
- −
- global_var[2]: contains the “df_bloc” data-frame in which all blocked packets are kept track of;
- −
- global_var[3]: contains the “df_not_bloc” data-frame where all unblocked packets are tracked
- −
- add_place(self, pl): with this method, a place is added within the network with its number of tokens;
- −
- add_transition(self, trans): with this method, a transition is added inside the network, with the input and output arcs;
- −
- add_input(self, trans, pl, weight = 1): with this method, an arc and its weight are inserted at the entrance to a transition and at the exit from a place;
- −
- add_output(self, trans, pl, weight = 1): with this method, an arc and its weight are inserted out of a transition and into a place;
- −
- fire(self, trans): with this method, the transition rule and enabling rule are implemented. In particular, for the transition t2, which has the predict_attack() and predict_benign() functions as output arc weights, the respective predict functions are executed.
- Number of total blocked packets in place A;
- Number of total NOT blocked packets present in place N;
- Percentage of blocked attack packets;
- Percentage of blocked benign packets;
- Percentage of unblocked attack packets;
- Percentage of unblocked benign packages.
- All places in the network are defined and added to it using the “add_place” method of the Net class.
- All transitions of the network are defined, which are added through the method of the Net class “add_transition”.
- All arcs of the network are defined. For each transition, the arcs entering it (with the “add_input” function) and the arcs leaving it (with the “add_output” function) are defined. In particular, the arc leaving transition t2 and entering P2 has the weight of the string predict_attack(net.global_var), whose function it represents is executed as soon as the fire() function is activated on this transition. In the same way, the arc leaving transition t2 and entering P3 has the weight of the string predict_benign(net.global_var), whose function it represents is executed as soon as the fire() function is activated on this transition.
5. Case Study
Dataset Analysis
- 3 January 2018;
- 3 February 2018;
- 14 February 2018;
- 15 February 2018;
- 16 February 2018;
- 20 February 2018;
- 21 February 2018;
- 22 February 2018;
- 23 February 2018;
- 28 February 2018.
- Benign: the relative packet is not considered an attack, but it is judged as innocuous by the university’s IDS;
- Brute-force: tend to hack accounts with weak username and password combinations;
- Heartbleed: exploitation of a security bug for the theft of passwords and sensitive data;
- Botnet: a representation of a set of devices connected to each other, which, if infected with malware, can be used for the distribution of malicious programs;
- DoS: exhausting system resources by flooding it with illegitimate service requests;
- DDoS: Distributed Denial of Service. They are similar to DoS attacks but occur on a much larger scale as requests arrive from multiple sources at the same time;
- Web attacks: the website is scanned to find its vulnerabilities. Then, attacks are conducted on the site, such as SQL injection, command injection, and unlimited file upload;
- Infiltration of the network from inside: a malicious file is sent by e-mail to the victim and an application vulnerability is exploited. After the exploitation, the victim’s computer is used to scan the internal network and find other vulnerable computers.
- Zero if label is ”Benign;”
- One if label is different from “Benign.”
- Bwd PSH Flags;
- Fwd URG Flags;
- Bwd URG Flags;
- CWE Flag Count;
- Fwd Byts/b Avg;
- Fwd Pkts/b Avg;
- Fwd Blk Rate Avg;
- Bwd Byts/b Avg;
- Bwd Pkts/b Avg;
- Bwd Blk Rate Avg.
- X: containing, for each row of the data-frame (except the last 50), a set of 50 packets, of which 49 successive packets and the packet in question;
- y: containing all the labels of the data-frame, except for the first 50 rows.
6. Results
- Loss for training set: 0.0158.
- Loss for validation set: 0.0167.
- Accuracy for training set: 0.9970.
- Accuracy for validation set: 0.9968.
- Percentage of blocked attack packets: 91.5%.
- Percentage of blocked benign packets: 8.5%.
- Percentage of unblocked attack packets: 20.1%.
- Percentage of unblocked benign packets: 79.9%.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Steingartner, W.; Galinec, D.; Kozina, A. Threat Defense: Cyber Deception Approach and Education for Resilience in Hybrid Threats Model. Symmetry 2021, 13, 597. [Google Scholar] [CrossRef]
- Safaei Pour, M.; Nader, C.; Friday, K.; Bou-Harb, E. A Comprehensive Survey of Recent Internet Measurement Techniques for Cyber Security. Comput. Secur. 2023, 128, 103123. [Google Scholar] [CrossRef]
- Zhao, R.; Mu, Y.; Zou, L.; Wen, X. A Hybrid Intrusion Detection System Based on Feature Selection and Weighted Stacking Classifier. IEEE Access 2022, 10, 71414–71426. [Google Scholar] [CrossRef]
- Oleiwi, H.W.; Mhawi, D.N.; Al-Raweshidy, H. MLTs-ADCNs: Machine Learning Techniques for Anomaly Detection in Communication Networks. IEEE Access 2022, 10, 91006–91017. [Google Scholar] [CrossRef]
- Zhang, J.; Li, Y.; Xiao, W.; Zhang, Z. Non-iterative and Fast Deep Learning: Multilayer Extreme Learning Machines. J. Frankl. Inst. 2020, 357, 8925–8955. [Google Scholar] [CrossRef]
- Nocera, F.; Abascià, S.; Fiore, M.; Shah, A.A.; Mongiello, M.; Di Sciascio, E.; Acciani, G. Cyber-Attack Mitigation in Cloud-Fog Environment Using an Ensemble Machine Learning Model. In Proceedings of the 2022 7th International Conference on Smart and Sustainable Technologies (SpliTech), Split, Croatia, 5–8 July 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Ali, M.H.; Jaber, M.M.; Abd, S.K.; Rehman, A.; Awan, M.J.; Damaševičius, R.; Bahaj, S.A. Threat Analysis and Distributed Denial of Service (DDoS) Attack Recognition in the Internet of Things (IoT). Electronics 2022, 11, 494. [Google Scholar] [CrossRef]
- Santhosh, S.; Sambath, M.; Thangakumar, J. Detection Of DDOS Attack using Machine Learning Models. In Proceedings of the 2023 International Conference on Networking and Communications (ICNWC), Chennai, India, 5–6 April 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Nocera, F.; Demilito, S.; Ladisa, P.; Mongiello, M.; Shah, A.A.; Ahmad, J.; Di Sciascio, E. A User Behavior Analytics (UBA)- based solution using LSTM Neural Network to mitigate DDoS Attack in Fog and Cloud Environment. In Proceedings of the 2022 2nd International Conference of Smart Systems and Emerging Technologies (SMARTTECH), Riyadh, Saudi Arabia, 9–11 May 2022; pp. 74–79. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Muhuri, P.S.; Chatterjee, P.; Yuan, X.; Roy, K.; Esterline, A. Using a Long Short-Term Memory Recurrent Neural Network (LSTM-RNN) to Classify Network Attacks. Information 2020, 11, 243. [Google Scholar] [CrossRef]
- Weerakody, P.B.; Wong, K.W.; Wang, G.; Ela, W. A review of irregular time series data handling with gated recurrent neural networks. Neurocomputing 2021, 441, 161–178. [Google Scholar] [CrossRef]
- Syed, S.N.; Lazaridis, P.I.; Khan, F.A.; Ahmed, Q.Z.; Hafeez, M.; Ivanov, A.; Poulkov, V.; Zaharis, Z.D. Deep Neural Networks for Spectrum Sensing: A Review. IEEE Access 2023, 11, 89591–89615. [Google Scholar] [CrossRef]
- Krishna, A.; Lal, M.A.A.; Mathewkutty, A.J.; Jacob, D.S.; Hari, M. Intrusion Detection and Prevention System Using Deep Learning. In Proceedings of the 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 2–4 July 2020; pp. 273–278. [Google Scholar] [CrossRef]
- IDS 2018 Intrusion CSVs (CSE-CIC-IDS2018). Available online: https://www.kaggle.com/datasets/solarmainframe/ids-intrusion-csv (accessed on 9 September 2024).
- Anderson, J.P. Computer Security Threat Monitoring and Surveillance; Technical Report; James P. Anderson Company: Danbury, CT, USA, 1980. [Google Scholar]
- Ali, L.; Zhu, C.; Zhou, M.; Liu, Y. Early diagnosis of Parkinson’s disease from multiple voice recordings by simultaneous sample and feature selection. Expert Syst. Appl. 2019, 137, 22–28. [Google Scholar] [CrossRef]
- Ali, L.; Khan, S.U.; Golilarz, N.A.; Yakubu, I.; Qasim, I.; Noor, A.; Nour, R. A Feature-Driven Decision Support System for Heart Failure Prediction Based on χ2 Statistical Model and Gaussian Naive Bayes. Comput. Math. Methods Med. 2019, 2019, 6314328. [Google Scholar] [CrossRef] [PubMed]
- Park, S.B.; Jo, H.J.; Lee, D.H. G-IDCS: Graph-Based Intrusion Detection and Classification System for CAN Protocol. IEEE Access 2023, 11, 39213–39227. [Google Scholar] [CrossRef]
- Kandhro, I.A.; Alanazi, S.M.; Ali, F.; Kehar, A.; Fatima, K.; Uddin, M.; Karuppayah, S. Detection of Real-Time Malicious Intrusions and Attacks in IoT Empowered Cybersecurity Infrastructures. IEEE Access 2023, 11, 9136–9148. [Google Scholar] [CrossRef]
- Boahen, E.K.; Bouya-Moko, B.E.; Qamar, F.; Wang, C. A Deep Learning Approach to Online Social Network Account Compromisation. IEEE Trans. Comput. Soc. Syst. 2023, 10, 3204–3216. [Google Scholar] [CrossRef]
- Boahen, E.K.; Frimpong, S.A.; Ujakpa, M.M.; Sosu, R.N.A.; Larbi-Siaw, O.; Owusu, E.; Appati, J.K.; Acheampong, E. A Deep Multi-architectural Approach for Online Social Network Intrusion Detection System. In Proceedings of the 2022 IEEE World Conference on Applied Intelligence and Computing (AIC), Sonbhadra, India, 17–19 June 2022; pp. 919–924. [Google Scholar] [CrossRef]
- Tao, L.; Xueqiang, M. Hybrid Strategy Improved Sparrow Search Algorithm in the Field of Intrusion Detection. IEEE Access 2023, 11, 32134–32151. [Google Scholar] [CrossRef]
- Fadhil, O.M. Fuzzy Rough Set Based Feature Selection and Enhanced KNN Classifier for Intrusion Detection. J. Kerbala Univ. 2016, 12, 72–86. [Google Scholar]
- Kim, J.; Kim, H. Applying Recurrent Neural Network to Intrusion Detection with Hessian Free Optimization. In Information Security Applications, Proceedings of the WISA 2015, Jeju Island, Republic of Korea, 20–22 August 2015; Kim, H.W., Choi, D., Eds.; Springer: Cham, Switzerland, 2016; pp. 357–369. [Google Scholar]
- Tang, T.A.; Mhamdi, L.; McLernon, D.; Zaidi, S.A.R.; Ghogho, M. Deep Recurrent Neural Network for Intrusion Detection in SDN-based Networks. In Proceedings of the 2018 4th IEEE Conference on Network Softwarization and Workshops (NetSoft), Montreal, QC, Canada, 25–29 June 2018; pp. 202–206. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Kim, J.; Kim, J.; Thi Thu, H.L.; Kim, H. Long Short Term Memory Recurrent Neural Network Classifier for Intrusion Detection. In Proceedings of the 2016 International Conference on Platform Technology and Service (PlatCon), Jeju, Republic of Korea, 15–17 February 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Fu, Y.; Lou, F.; Meng, F.; Tian, Z.; Zhang, H.; Jiang, F. An Intelligent Network Attack Detection Method Based on RNN. In Proceedings of the 2018 IEEE Third International Conference on Data Science in Cyberspace (DSC), Guangzhou, China, 18–21 June 2018; pp. 483–489. [Google Scholar]
- Staudemeyer, R.C. Applying long short-term memory recurrent neural networks to intrusion detection. S. Afr. Comput. J. 2015, 56, 136–154. [Google Scholar] [CrossRef]
- Le, T.T.H.; Kim, J.; Kim, H. An Effective Intrusion Detection Classifier Using Long Short-Term Memory with Gradient Descent Optimization. In Proceedings of the 2017 International Conference on Platform Technology and Service (PlatCon), Busan, Republic of Korea, 13–15 February 2017; pp. 1–6. [Google Scholar]
- Imrana, Y.; Xiang, Y.; Ali, L.; Abdul-Rauf, Z. A bidirectional LSTM deep learning approach for intrusion detection. Expert Syst. Appl. 2021, 185, 115524. [Google Scholar] [CrossRef]
- Liu, M.; Zhang, Q.; Hong, Z.; Yu, D. Network Security Situation Assessment Based on Data Fusion. In Proceedings of the First International Workshop on Knowledge Discovery and Data Mining (WKDD 2008), Adelaide, Australia, 23–24 January 2008; pp. 542–545. [Google Scholar]
- Khoury, H.; Laborde, R.; Barrère, F.; Abdelmalek, B.; Maroun, C. A specification method for analyzing fine grained network security mechanism configurations. In Proceedings of the 2013 IEEE Conference on Communications and Network Security (CNS), National Harbor, MD, USA, 14–16 October 2013; pp. 483–487. [Google Scholar] [CrossRef]
- Hwang, H.U.; Kim, M.S.; Noh, B.N. Expert System Using Fuzzy Petri Nets in Computer Forensics. In Advances in Hybrid Information Technology, Proceedings of the First International Conference, Jeju Island, Republic of Korea, 9–11 November 2006; Szczuka, M.S., Howard, D., Ślȩzak, D., Kim, H.-K., Kim, T.-H., Ko, I.-S., Lee, G., Sloot, P.M.A., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 312–322. [Google Scholar]
- Voron, J.B.; Démoulins, C.; Kordon, F. Adaptable Intrusion Detection Systems Dedicated to Concurrent Programs: A Petri Net-Based Approach. In Proceedings of the 2010 10th International Conference on Application of Concurrency to System Design, Braga, Portugal, 21–25 June 2010; pp. 57–66. [Google Scholar]
- Balaz, A.; Vokorokos, L. Intrusion detection system based on partially ordered events and patterns. In Proceedings of the 2009 International Conference on Intelligent Engineering Systems, Barbados, 16–18 April 2009; pp. 233–238. [Google Scholar] [CrossRef]
- Jianping, W.; Guangqiu, Q.; Chunming, W.; Weiwei, J.; Jiahe, J. Federated learning for network attack detection using attention-based graph neural networks. Sci. Rep. 2024, 14, 19088. [Google Scholar] [CrossRef] [PubMed]
- Tran, D.H.; Park, M. FN-GNN: A novel graph embedding approach for enhancing graph neural networks in network intrusion detection systems. Appl. Sci. 2024, 14, 6932. [Google Scholar] [CrossRef]
- Lin, P.; Ye, K.; Xu, C.Z. Dynamic Network Anomaly Detection System by Using Deep Learning Techniques. In Cloud Computing—CLOUD 2019, Proceedings of the 12th International Conference, Held as Part of the Services Conference Federation, San Diego, CA, USA, 25–30 June 2019; Da Silva, D., Wang, Q., Zhang, L.J., Eds.; Springer: Cham, Switzerland, 2019; pp. 161–176. [Google Scholar]
- Kim, J.; Shin, Y.; Choi, E. An Intrusion Detection Model based on a Convolutional Neural Network. J. Multimed. Inf. Syst. 2019, 6, 165–172. [Google Scholar] [CrossRef]
- Kanimozhi, V.; Jacob, T.P. Artificial Intelligence based Network Intrusion Detection with Hyper-Parameter Optimization Tuning on the Realistic Cyber Dataset CSE-CIC-IDS2018 using Cloud Computing. In Proceedings of the 2019 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 4–6 April 2019; pp. 33–36. [Google Scholar] [CrossRef]
- Karatas, G.; Demir, O.; Sahingoz, O.K. Increasing the Performance of Machine Learning-Based IDSs on an Imbalanced and Up-to-Date Dataset. IEEE Access 2020, 8, 32150–32162. [Google Scholar] [CrossRef]
- Kim, J.; Kim, J.; Kim, H.; Shim, M.; Choi, E. CNN-Based Network Intrusion Detection against Denial-of-Service Attacks. Electronics 2020, 9, 916. [Google Scholar] [CrossRef]
- Dey, A. Deep IDS: A deep learning approach for Intrusion detection based on IDS 2018. In Proceedings of the 2020 2nd International Conference on Sustainable Technologies for Industry 4.0 (STI), Dhaka, Bangladesh, 19–20 December 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Ayachi, Y.; Mellah, Y.; Berrich, J.; Bouchentouf, T. Increasing the Performance of an IDS using ANN model on the realistic cyber dataset CSE-CIC-IDS2018. In Proceedings of the 2020 International Symposium on Advanced Electrical and Communication Technologies (ISAECT), Marrakech, Morocco, 25–27 November 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Gopalan, S.S.; Ravikumar, D.; Linekar, D.; Raza, A.; Hasib, M. Balancing Approaches towards ML for IDS: A Survey for the CSE-CIC IDS Dataset. In Proceedings of the 2020 International Conference on Communications, Signal Processing, and Their Applications (ICCSPA), Sharjah, United Arab Emirates, 16–18 March 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Xu, H.; Deng, Y. Dependent Evidence Combination Based on Shearman Coefficient and Pearson Coefficient. IEEE Access 2018, 6, 11634–11640. [Google Scholar] [CrossRef]
- Jolliffe, I. Principal Component Analysis. In Wiley StatsRef: Statistics Reference Online; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2014. [Google Scholar] [CrossRef]
- Hasnain, M.; Pasha, M.F.; Ghani, I.; Mehboob, B.; Imran, M.; Ali, A. Benchmark Dataset Selection of Web Services Technologies: A Factor Analysis. IEEE Access 2020, 8, 53649–53665. [Google Scholar] [CrossRef]
- Hu, Z.; Zhao, Y.; Khushi, M. A Survey of Forex and Stock Price Prediction Using Deep Learning. Appl. Syst. Innov. 2021, 4, 9. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef]
- Zhang, L.; Yan, H.; Zhu, Q. An Improved LSTM Network Intrusion Detection Method. In Proceedings of the 2020 IEEE 6th International Conference on Computer and Communications (ICCC), Chengdu, China, 11–14 December 2020; pp. 1765–1769. [Google Scholar] [CrossRef]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 9 September 2024).
- Murata, T. Petri nets: Properties, analysis and applications. Proc. IEEE 1989, 77, 541–580. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Contribution | Shortcoming |
|---|---|---|
| Lin et al. [40] | Dynamic network anomaly detection system using LSTM and Attention Mechanisms for traffic classification. | Class imbalance, training complexity, real-time detection capability, feature selection. |
| Kim et al. [41] | Development of a CNN-based IDS and comparison with prebuilt RNN techniques. | Dataset dependence, preprocessing overhead, model complexity, performance on imbalanced data, feature selection. |
| Kanimozhi et al. [42] | Artificial Intelligence-based approach to detect botnet attacks. | Hyper-parameter optimization complexity, scalability issues, dataset limitations, real-time detection capability. |
| Karatas et al. [43] | Comparison of six ML-based IDSs by using K Nearest Neighbor, Random Forest, Gradient Boosting, Adaboost, Decision Tree, and Linear Discriminant Analysis algorithms; application of Synthetic Minority Oversampling Technique to balance the dataset. | Data imbalance handling, feature selection, dataset limitations, evaluation metrics, generalization. |
| Kim et al. [44] | Deep learning-based IDS focused on Denial of Service attacks. Usage of Convolutional Neural Networks and Recurrent Neural Networks. | Dataset limitation, class imbalance, generalization, comparison with limited models, hyper-parameter optimization, real-time implementation. |
| Dey [45] | Deep learning technique based on CNN and LSTM. | Dataset dependency, imbalanced data handling, generalization, adaptability. |
| Ayachi et al. [46] | Usage of adapted hyper-parameters in an artificial neural network to improve the general accuracy. | Preprocessing overhead, model complexity, generalization. |
| Gopalan et al. [47] | Analysis of balancing approaches using ML and definition of a taxonomy of the supervised ML techniques applied to train models for classification. | Dataset dependence, preprocessing overhead, imbalanced data handling, generalization, adaptability. |
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| Dst Port | −0.962971 | −0.962060 | −0.962971 | −0.960196 | −0.962971 |
| Protocol | −193,135,070 | 0.003857 | −193,135,070 | 354,091,889 | −193,135,070 |
| Flow Duration | 15,824,719 | −0.113343 | 15,824,721 | −0.422853 | 15,824,708 |
| Fwd Pkt Len Min | −0.001147 | −0.001147 | −0.001147 | 871,499,283 | −0.001147 |
| Flow Byts/s | −0.097724 | 0.055520 | −0.097724 | 79,437,217 | −0.097724 |
| Flow Pkts/s | −0.130869 | −0.128415 | −0.130869 | 0.432200 | −0.130869 |
| Bwd IAT Min | −0.447516 | −0.436038 | −0.447516 | −0.447516 | −0.447516 |
| Fwd PSH Flags | −0.002295 | −0.002295 | −0.002295 | −0.002295 | −0.002295 |
| FIN Flag Cnt | −0.034175 | −0.034175 | −0.034175 | −0.034175 | −0.034175 |
| RST Flag Cnt | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| PSH Flag Cnt | −0.137693 | 7,262,515 | −0.137693 | −0.137693 | −0.137693 |
| URG Flag Cnt | −0.174805 | −0.174805 | −0.174805 | −0.174805 | −0.174805 |
| ECE Flag Cnt | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Down/Up Ratio | −0.267129 | −0.267129 | −0.267129 | 3,319,988 | −0.267129 |
| Fwd Seg Size Min | −55,238,334 | 0.046221 | −55,238,334 | −41,417,195 | −55,238,334 |
| Active Mean | −0.011527 | −0.011527 | −0.011527 | −0.011527 | −0.011527 |
| Active Std | −0.002351 | −0.002351 | −0.002351 | −0.002351 | −0.002351 |
| Idle Std | 0.004111 | −0.002575 | −0.001406 | −0.002575 | 0.001306 |
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 5,074,604 | 0.173635 | 5,071,693 | 2,598,003 | 5,073,123 |
| 1 | 0.162982 | 4,461,345 | 0.163206 | 120,839,396 | 0.163096 |
| 2 | 37,948,500 | −1,053,695 | 37,948,894 | −69,087,613 | 37,948,694 |
| 3 | −83,421,649 | 0.692999 | −83,421,672 | 171,341,563 | −83,421,662 |
| 4 | −116,180,270 | −0.736592 | −116,180,261 | 830,636,674 | −116,180,265 |
| 5 | −22,494,404 | −1,279,925 | −22,494,358 | 123,686,500 | −22,494,383 |
| 6 | 6,406,088 | −0.020321 | 6,406,177 | 7,649,916 | 6,406,132 |
| 7 | 6,521,164 | −0.516545 | 6,523,266 | 14,324,288 | 6,522,233 |
| 8 | −79,378,003 | −0.632227 | −79,378,146 | −217,569,203 | −79,378,071 |
| 9 | −1,263,564 | 0.455594 | −1,263,568 | −12,495,999 | −1,263,565 |
| 10 | 104,454,578 | −0.646437 | 104,453,856 | 292,079,718 | 104,454,214 |
| 11 | 21,091,575 | −0.109694 | 21,093,984 | 60,465,977 | 21,092,801 |
| 12 | 0.653150 | −3,806,546 | 0.652938 | −22,163,114 | 0.653048 |
| Label | 0 | 0 | 0 | 0 | 0 |
| Parameter | Value |
|---|---|
| Input layer size | 50 |
| Output layers size | 1 (binary) |
| Activation function | Sigmoid |
| Number of Hidden Layers | 6 |
| Hidden layers size | 80 |
| Number of Dropout Layers | 6 |
| Drop probability | 0.3 |
| Feature | Description |
|---|---|
| dst_port | Destination port of connection |
| protocol | Protocol used during connection |
| fl_dur | Flow duration |
| tot_l_bw_pkt | Total size of packet in backward direction |
| fw_pkt_l_min | Minimum size of packet in forward direction |
| fl_byt_s | flow byte rate, which is number of packets transferred per second |
| fl_pkt_s | flow packets rate, which is number of packets transferred per second |
| bw_iat_min | Minimum time between two packets sent in the backward direction |
| fw_psh_flag | Number of times the PSH flag was set in packets traveling in the forward direction (0 for UDP) |
| bw_pkt_s | Number of backward packets per second |
| fin_cnt | Number of packets with FIN |
| rst_cnt | Number of packets with RST |
| pst_cnt | Number of packets with PUSH |
| urg_cnt | Number of packets with URG |
| down_up_ratio | Download and upload ratio |
| fw_seg_min | Minimum segment size observed in the forward direction |
| atv_avg | Mean time a flow was active before becoming idle |
| atv_std | Standard deviation time a flow was active before becoming idle |
| idl_std | Standard deviation time a flow was idle before becoming active |
| Paper | Best Achieved Accuracy | Model |
|---|---|---|
| Lin et al. [40] | 96.2% | LSTM and Attention Mechanism |
| Kim et al. [41] | 75% | CNN |
| Kanimozhi et al. [42] | 99.97% | Artificial Neural Network |
| Karatas et al. [43] | 99.69% | Adaboost algorithm |
| 99.66% | Decision Tree | |
| 99.21% | Random Forest | |
| 98.52% | K-Nearest Neighbor | |
| 99.11% | Gradient Boosting | |
| 90.80% | Linear Discriminant Analysis | |
| Kim et al. [44] | 91.5% | CNN |
| Dey [45] | 99.98% | Attention-based LSTM |
| Ayachi et al. [46] | 99.91% | Artificial Neural Networks with adapted hyper-parameters |
| Proposed approach | 99.71% | LSTM and Petri Net |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Volpe, G.; Fiore, M.; la Grasta, A.; Albano, F.; Stefanizzi, S.; Mongiello, M.; Mangini, A.M. A Petri Net and LSTM Hybrid Approach for Intrusion Detection Systems in Enterprise Networks. Sensors 2024, 24, 7924. https://doi.org/10.3390/s24247924
Volpe G, Fiore M, la Grasta A, Albano F, Stefanizzi S, Mongiello M, Mangini AM. A Petri Net and LSTM Hybrid Approach for Intrusion Detection Systems in Enterprise Networks. Sensors. 2024; 24(24):7924. https://doi.org/10.3390/s24247924
Chicago/Turabian StyleVolpe, Gaetano, Marco Fiore, Annabella la Grasta, Francesca Albano, Sergio Stefanizzi, Marina Mongiello, and Agostino Marcello Mangini. 2024. "A Petri Net and LSTM Hybrid Approach for Intrusion Detection Systems in Enterprise Networks" Sensors 24, no. 24: 7924. https://doi.org/10.3390/s24247924
APA StyleVolpe, G., Fiore, M., la Grasta, A., Albano, F., Stefanizzi, S., Mongiello, M., & Mangini, A. M. (2024). A Petri Net and LSTM Hybrid Approach for Intrusion Detection Systems in Enterprise Networks. Sensors, 24(24), 7924. https://doi.org/10.3390/s24247924