
FSH-DETR: An Efficient End-to-End Fire Smoke and Human Detection Based on a Deformable DEtection TRansformer (DETR)

Abstract
:1. Introduction
- (1)
- We propose FSH-DETR for the precise and rapid detection of fire, smoke, and humans. In response to complex and dynamic fire environments, we introduce ConvNeXt to enhance the algorithm’s ability to extract features of varying scales.
- (2)
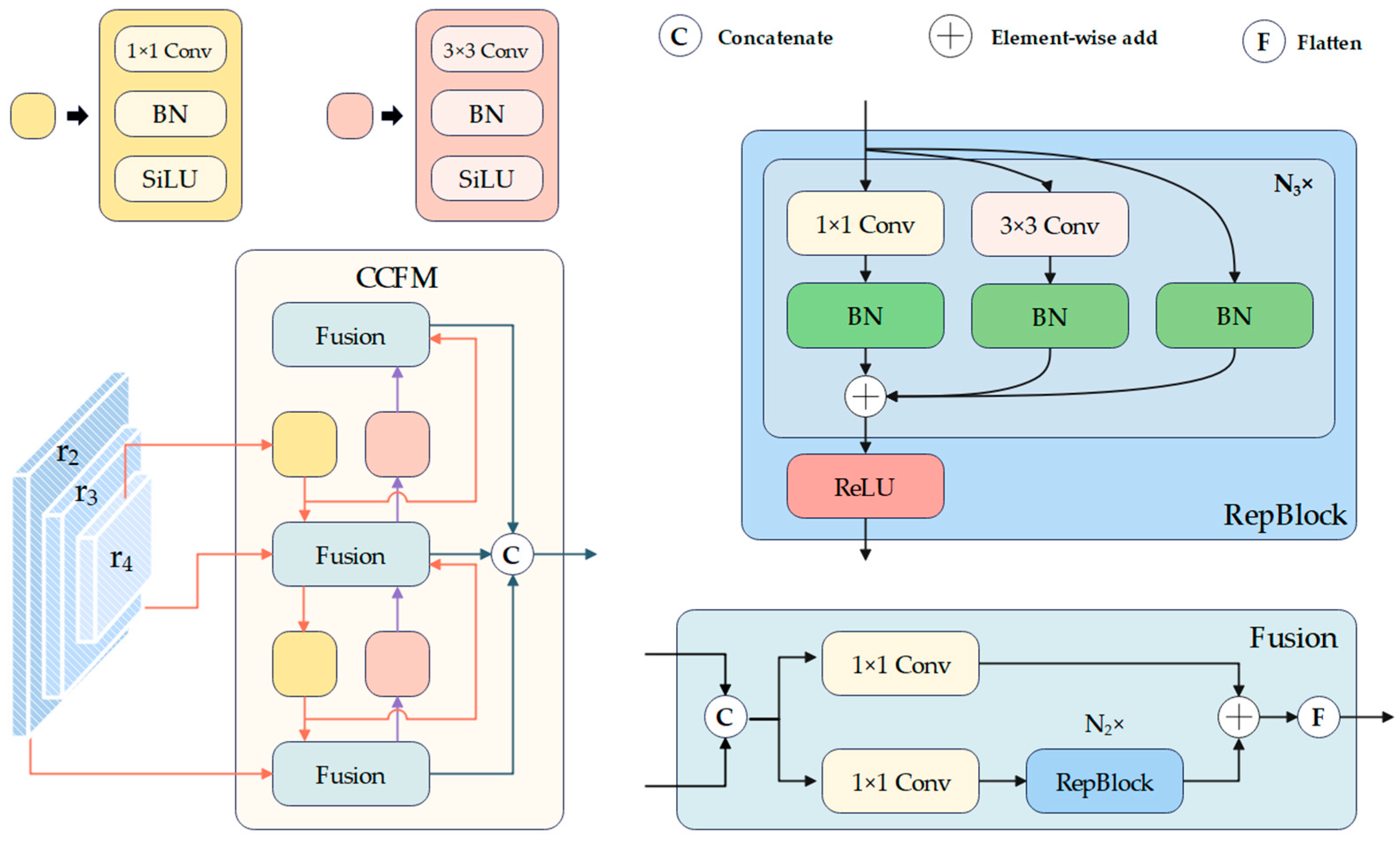
- To improve detection precision and significantly reduce computational costs, we propose the Mixed Encoder, which integrates SSFI (Separate Single-scale Feature Interaction Module) and CCFM (CNN-based Cross-scale Feature Fusion Module) [31].
- (3)
- To solve the issue of slow convergence and improve the model’s stability in complex fire scenarios, we introduce PIoU v2 as the loss function.
- (4)
- Extensive experiments on the public dataset have demonstrated that our model achieves superior detection precision with less computational cost compared to the baseline.
2. Related Works
3. Methodology
3.1. Overall Architecture of FSH-DETR
3.2. ConvNeXt Backbone
3.3. Mixed Encoder
3.3.1. Separable Single-Scale Feature Interaction
3.3.2. CNN-Based Cross-Scale Feature-Fusion Module
3.4. IoU-Based Loss Function
Powerful IoU
4. Experiment Settings
4.1. Image Dataset
4.2. Evaluation Metrics
4.3. Experimental Environment
4.4. Optimization Method and Other Details
5. Result Analysis
5.1. Effectiveness of Backbone
5.2. Effectiveness of PIoU v2
5.3. Comparison with Other Models
5.4. Ablation Experiments
- (1)
- The results of the first and second groups of experiments indicate that ConvNeXt significantly reduces the number of parameters in comparison to the other models while improving , , and .
- (2)
- The results of the first and third groups of experiments indicate that upgrading the original encoder to the Mixed Encoder reduces the computational cost but increases the number of parameters and reduces and slightly.
- (3)
- The results of the sixth and seventh groups of experiments indicate that although the Mixed Encoder is the main reason for the increase in the model parameter count, it also ensures the improvement in the model’s precision in detecting fires and humans, as well as .
- (4)
- The results of the first and fourth experimental groups indicate that using PIoU v2 as the loss function slightly improves the detection precision of the algorithm but has almost no effect on the parameter and computational cost.
5.5. Visualization
6. Discussion
6.1. Limitions
6.2. Potential Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shelby, H.; Evarts, B. Fire Loss in the United States during 2021; National Fire Protection Association (NFPA): Quincy, MA, USA, 2022. [Google Scholar]
- Wang, Z.; Wang, Z.; Zou, Z.; Chen, X.; Wu, H.; Wang, W.; Su, H.; Li, F.; Xu, W.; Liu, Z.; et al. Severe Global Environmental Issues Caused by Canada’s Record-Breaking Wildfires in 2023. Adv. Atmos. Sci. 2023, 41, 565–571. [Google Scholar] [CrossRef]
- Nguyen, M.D.; Vu, H.N.; Pham, D.C.; Choi, B.; Ro, S. Multistage Real-Time Fire Detection Using Convolutional Neural Networks and Long Short-Term Memory Networks. IEEE Access 2021, 9, 146667–146679. [Google Scholar] [CrossRef]
- Çetin, A.E.; Dimitropoulos, K.; Gouverneur, B.; Grammalidis, N.; Günay, O.; Habiboǧlu, Y.H.; Töreyin, B.U.; Verstockt, S. Video fire detection–review. Digit. Signal Process. 2013, 23, 1827–1843. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; IEEE: New York, NY, USA, 2005; Volume 1. [Google Scholar]
- Borges, P.; Izquierdo, E.; Mayer, J. Efficient visual fire detection applied for video retrieval. In Proceedings of the 2008 16th European Signal Processing Conference, Lausanne, Switzerland, 25–29 August 2008; pp. 1–5. [Google Scholar]
- Habiboğlu, Y.H.; Günay, O.; Cetin, A.E. Flame detection method in video using covariance descriptors. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 1817–1820. [Google Scholar] [CrossRef]
- Pu, L.; Zhao, W. Image fire detection algorithms based on convolutional neural networks. Case Stud. Therm. Eng. 2020, 19, 100625. [Google Scholar]
- Dunnings, A.J.; Breckon, T.P. Experimentally Defined Convolutional Neural Network Architecture Variants for Non-Temporal Real-Time Fire Detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 1558–1562. [Google Scholar]
- Huang, J.; Zhou, J.; Yang, H.; Liu, Y.; Liu, H. A Small-Target Forest Fire Smoke Detection Model Based on Deformable Transformer for End-to-End Object Detection. Forests 2023, 14, 162. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Baik, S.W. Early fire detection using convolutional neural networks during surveillance for effective disaster management. Neurocomputing 2018, 288, 30–42. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS—Improving object detection with one line of code. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Joseph, R.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Joseph, R.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Alexey, B.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef] [PubMed]
- Ross, G. Fast r-cnn. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef] [PubMed]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse r-cnn: End-to-end object detection with learnable proposals. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Zhao, L.; Zhi, L.; Zhao, C.; Zheng, W. Fire-YOLO: A Small Target Object Detection Method for Fire Inspection. Sustainability 2022, 14, 4930. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Computer Vision—ECCV 2020, Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26 April–1 May 2020. [Google Scholar]
- Hu, Y.; Zhan, J.; Zhou, G.; Chen, A.; Cai, W.; Guo, K.; Hu, Y.; Li, L. Fast forest fire smoke detection using MVMNet. Knowl.-Based Syst. 2022, 241, 108219. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Lv, W.; Zhao, Y.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. arXiv 2023, arXiv:2304.08069. [Google Scholar]
- Nguyen, H.H.; Ta, T.N.; Nguyen, N.C.; Pham, H.M.; Nguyen, D.M. Yolo based real-time human detection for smart video surveillance at the edge. In Proceedings of the 2020 IEEE Eighth International Conference on Communications and Electronics (ICCE), Phu Quoc Island, Vietnam, 13–15 January 2021; IEEE: New York, NY, USA, 2021. [Google Scholar]
- Yakhyokhuja, V.; Abdusalomov, A.; Cho, Y.I. Automatic fire and smoke detection method for surveillance systems based on dilated CNNs. Atmosphere 2020, 11, 1241. [Google Scholar] [CrossRef]
- Mukhriddin, M.; Abdusalomov, A.B.; Cho, J. A wildfire smoke detection system using unmanned aerial vehicle images based on the optimized YOLOv5. Sensors 2022, 22, 9384. [Google Scholar] [CrossRef] [PubMed]
- Saydirasulovich, S.N.; Mukhiddinov, M.; Djuraev, O.; Abdusalomov, A.; Cho, Y.I. An improved wildfire smoke detection based on YOLOv8 and UAV images. Sensors 2023, 23, 8374. [Google Scholar] [CrossRef]
- Ergasheva, A.; Akhmedov, F.; Abdusalomov, A.; Kim, W. Advancing Maritime Safety: Early Detection of Ship Fires through Computer Vision, Deep Learning Approaches, and Histogram Equalization Techniques. Fire 2024, 7, 84. [Google Scholar] [CrossRef]
- Jin, P.; Ou, X.; Xu, L. A collaborative region detection and grading framework for forest fire smoke using weakly supervised fine segmentation and lightweight faster-RCNN. Forests 2021, 12, 768. [Google Scholar] [CrossRef]
- Feng, Q.; Xu, X.; Wang, Z. Deep learning-based small object detection: A survey. Math. Biosci. Eng. 2023, 20, 6551–6590. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Xiong, F.; Sun, P.; Hu, L.; Li, B.; Yu, G. Double anchor R-CNN for human detection in a crowd. arXiv 2019, arXiv:1909.09998. [Google Scholar]
- Barmpoutis, P.; Dimitropoulos, K.; Kaza, K.; Grammalidis, N. Fire Detection from Images Using Faster R-CNN and Multidimensional Texture Analysis. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8301–8305. [Google Scholar]
- Chaoxia, C.; Shang, W.; Zhang, F. Information-guided flame detection based on faster R-CNN. IEEE Access 2020, 8, 58923–58932. [Google Scholar] [CrossRef]
- Duan, K.; Xie, L.; Qi, H.; Bai, S.; Huang, Q.; Tian, Q. Corner proposal network for anchor-free, two-stage object detection. In Computer Vision—ECCV 2020, Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhao, M.; Ning, K.; Yu, S.; Liu, L.; Wu, N. Quantizing oriented object detection network via outlier-aware quantization and IoU approximation. IEEE Signal Process. Lett. 2020, 27, 1914–1918. [Google Scholar] [CrossRef]
- Lin, M.; Li, C.; Bu, X.; Sun, M.; Lin, C.; Yan, J.; Ouyang, W.; Deng, Z. Detr for crowd pedestrian detection. arXiv 2020, arXiv:2012.06785. [Google Scholar]
- Li, Y.; Zhang, W.; Liu, Y.; Jing, R.; Liu, C. An efficient fire and smoke detection algorithm based on an end-to-end structured network. Eng. Appl. Artif. Intell. 2022, 116, 105492. [Google Scholar] [CrossRef]
- Konstantina, M.; Vretos, N.; Daras, P. Transformer-based fire detection in videos. Sensors 2023, 23, 3035. [Google Scholar] [CrossRef] [PubMed]
- Meng, D.; Chen, X.; Fan, Z.; Zeng, G.; Li, H.; Yuan, Y.; Sun, L.; Wang, J. Conditional DETR for fast training convergence. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Liu, S.; Li, F.; Zhang, H.; Yang, X.; Qi, X.; Su, H.; Zhu, J.; Zhang, L. DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Li, F.; Zeng, A.; Liu, S.; Zhang, H.; Li, H.; Zhang, L.; Ni, L.M. Lite DETR: An interleaved multi-scale encoder for efficient DETR. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Mehta, S.; Rastegari, M. Separable self-attention for mobile vision transformers. arXiv 2022, arXiv:2206.02680. [Google Scholar]
- Liu, C.; Wang, K.; Li, Q.; Zhao, F.; Zhao, K.; Ma, H. Powerful-IoU: More straightforward and faster bounding box regression loss with a nonmonotonic focusing mechanism. Neural Netw. 2024, 170, 276–284. [Google Scholar] [CrossRef]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Zhora, G. SIoU loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding box regression loss with dynamic focusing mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 2019 International Conference on Machine Learning PMLR, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Kweon, I.S.; Xie, S. Convnext v2: Co-designing and scaling convnets with masked autoencoders. In Proceedings of the the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34. [Google Scholar]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. Rtmdet: An empirical study of designing real-time object detectors. arXiv 2022, arXiv:2212.07784. [Google Scholar]
- Chen, Q.; Chen, X.; Wang, J.; Zhang, S.; Yao, K.; Feng, H.; Han, J.; Ding, E.; Zeng, G.; Wang, J. Group DETR: Fast DETR training with group-wise one-to-many assignment. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Images | Fire Objects | Smoke Objects | Human Objects |
|---|---|---|---|---|
| Train | 20,016 | 21,809 | 14,896 | 11,568 |
| Evaluation | 5004 | 8135 | 4000 | 2175 |
| Total | 25,020 | 29,944 | 18,896 | 13,743 |
| Parameter Name | Parameter Value |
|---|---|
| epoch | 100 |
| batch size | 16 |
| optimizer | AdamW |
| learning rate | 0.0002 |
| weight decay | 0.0001 |
| Backbone | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| ResNet-50 | 65.5 | 84.0 | 63.7 | 45.1 | 53.7 | 70.6 | 126.0 | 41.1 | 25.1 |
| EfficientNet-b0 | 64.9 | 81.6 | 63.3 | 35.6 | 53.4 | 69.8 | 71.3 | 16.4 | 18.9 |
| ConvNeXtv2-A | 60.2 | 74.4 | 60.1 | 27.2 | 49.4 | 65.2 | 74.4 | 41.9 | 19.6 |
| ConvNeXt-tiny | 66.1 | 84.3 | 65.2 | 53.6 | 53.1 | 71.6 | 70.8 | 40.8 | 29.8 |
| IoU Loss Function | Total Training Time (h) | ||||||
|---|---|---|---|---|---|---|---|
| GIoU | 65.5 | 84.0 | 63.7 | 45.1 | 53.7 | 70.6 | 23.2 |
| DIoU | 65.4 | 82.8 | 63.8 | 39.1 | 52.4 | 70.6 | 19.2 |
| CIoU | 65.6 | 83.8 | 64.4 | 43.2 | 54.3 | 70.8 | 18.0 |
| SIoU | 65.5 | 83.6 | 64.6 | 41.1 | 53.1 | 70.6 | 19.2 |
| PIoUv1 | 65.2 | 83.3 | 64.5 | 48.7 | 51.7 | 70.5 | 18.9 |
| PIoUv2 | 65.6 | 83.6 | 64.8 | 48.2 | 52.8 | 70.7 | 19.5 |
| Model | Backbone | |||||||
|---|---|---|---|---|---|---|---|---|
| YOLOv3 | DarkNet-53 | 57.2 | 78.3 | 59.4 | 36.7 | 47.0 | 62.3 | 68.5 |
| YOLOv5 | YOLOv5-n | 63.9 | 79.5 | 63.1 | 24.5 | 52.7 | 68.8 | 92.5 |
| YOLOv7 | YOLOv7-tiny | 65.2 | 81.3 | 63.2 | 33.8 | 54.8 | 69.6 | 93.9 |
| YOLOv8 | YOLOv8-n | 64.9 | 79.0 | 63.2 | 33.5 | 55.3 | 69.0 | 64.6 |
| RTMDet | RTMDet-tiny | 65.2 | 79.8 | 64.1 | 59.8 | 55.1 | 69.3 | 42.2 |
| DETR | R-50 | 62.6 | 81.9 | 62.6 | 17.3 | 46.8 | 68.7 | 34.1 |
| Deformable DETR | R-50 | 65.5 | 84.0 | 63.7 | 45.1 | 53.7 | 70.6 | 25.1 |
| Conditional DETR | R-50 | 64.2 | 82.6 | 63.7 | 27.7 | 50.2 | 70.2 | 30.8 |
| DAB-DETR | R-50 | 65.1 | 83.1 | 65.2 | 25.1 | 52.4 | 70.6 | 24.9 |
| Group-DETR | R-50 | 65.6 | 83.2 | 64.3 | 43.5 | 51.9 | 71.1 | 19.3 |
| Ours | ConvNeXt | 66.7 | 84.2 | 65.3 | 50.2 | 54.0 | 71.6 | 28.4 |
| Improved Methods | Evaluation Metrics | |||||||
|---|---|---|---|---|---|---|---|---|
| ConvNeXt | Mixed Encoder | Loss Function | ||||||
| × | × | × | 65.5 | 96.89 | 73.97 | 79.88 | 126.0 | 41.1 |
| √ | × | × | 66.1 | 97.50 | 80.48 | 80.17 | 70.8 | 40.8 |
| × | √ | × | 65.8 | 98.01 | 73.27 | 79.99 | 75.5 | 46.3 |
| × | × | √ | 65.6 | 97.21 | 76.91 | 78.62 | 123.0 | 40.1 |
| √ | √ | × | 66.6 | 98.05 | 78.09 | 78.89 | 77.5 | 50.1 |
| √ | × | √ | 66.2 | 97.62 | 80.75 | 79.40 | 79.8 | 40.8 |
| √ | √ | √ | 66.7 | 98.05 | 78.78 | 80.22 | 77.5 | 50.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, T.; Zeng, G. FSH-DETR: An Efficient End-to-End Fire Smoke and Human Detection Based on a Deformable DEtection TRansformer (DETR). Sensors 2024, 24, 4077. https://doi.org/10.3390/s24134077
Liang T, Zeng G. FSH-DETR: An Efficient End-to-End Fire Smoke and Human Detection Based on a Deformable DEtection TRansformer (DETR). Sensors. 2024; 24(13):4077. https://doi.org/10.3390/s24134077
Chicago/Turabian StyleLiang, Tianyu, and Guigen Zeng. 2024. "FSH-DETR: An Efficient End-to-End Fire Smoke and Human Detection Based on a Deformable DEtection TRansformer (DETR)" Sensors 24, no. 13: 4077. https://doi.org/10.3390/s24134077
APA StyleLiang, T., & Zeng, G. (2024). FSH-DETR: An Efficient End-to-End Fire Smoke and Human Detection Based on a Deformable DEtection TRansformer (DETR). Sensors, 24(13), 4077. https://doi.org/10.3390/s24134077