

A Review of Synthetic Image Data and Its Use in Computer Vision



Abstract
:1. Introduction
2. Computer Vision and Synthetic Image Data
3. Types of Synthetic Imagery for Computer Vision
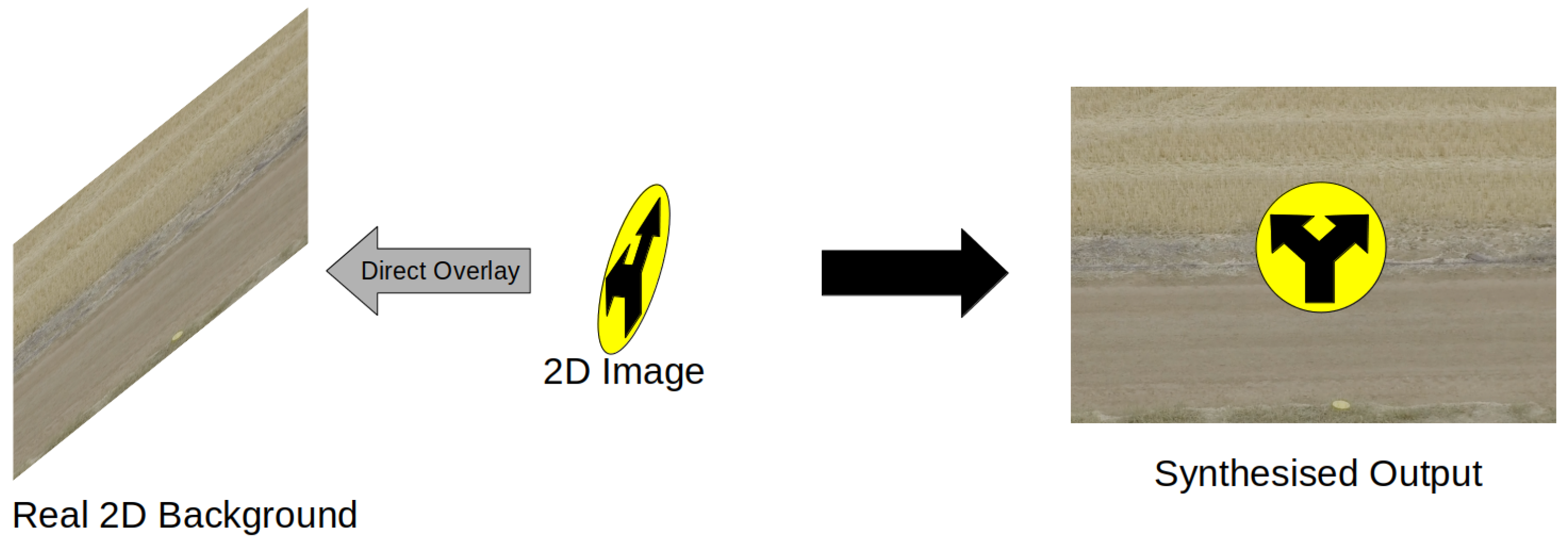
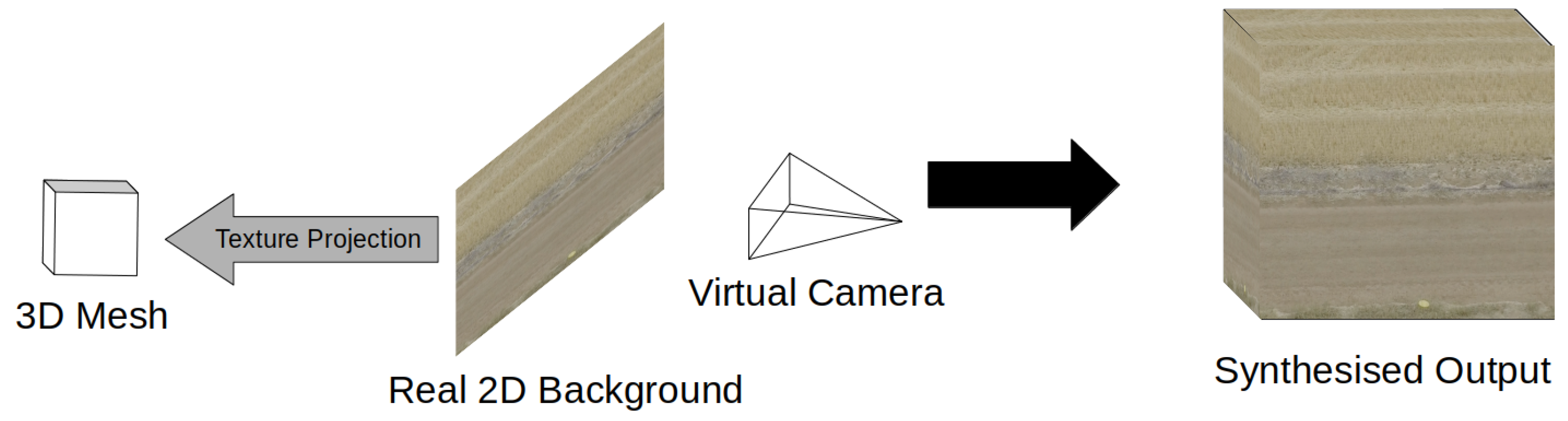
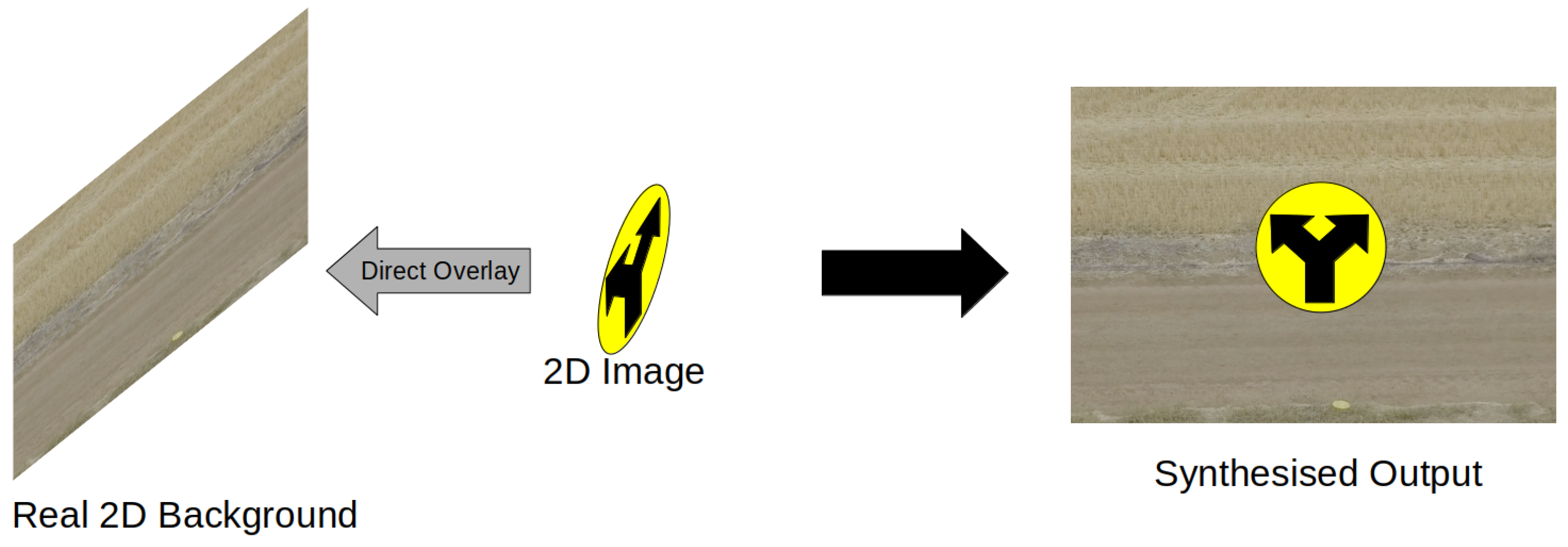
3.1. Synthetic Composite Imagery
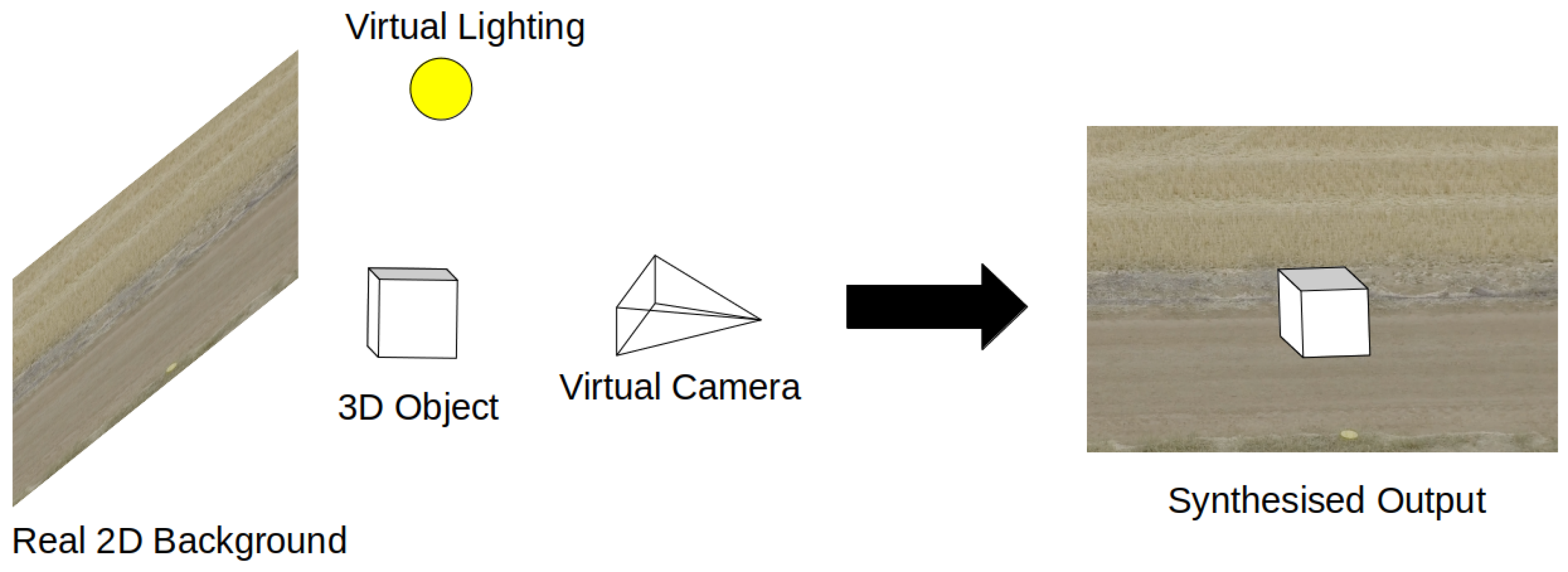
3.2. Virtual Synthetic Data
4. Methods of Data Synthesis
4.1. Manual Generation
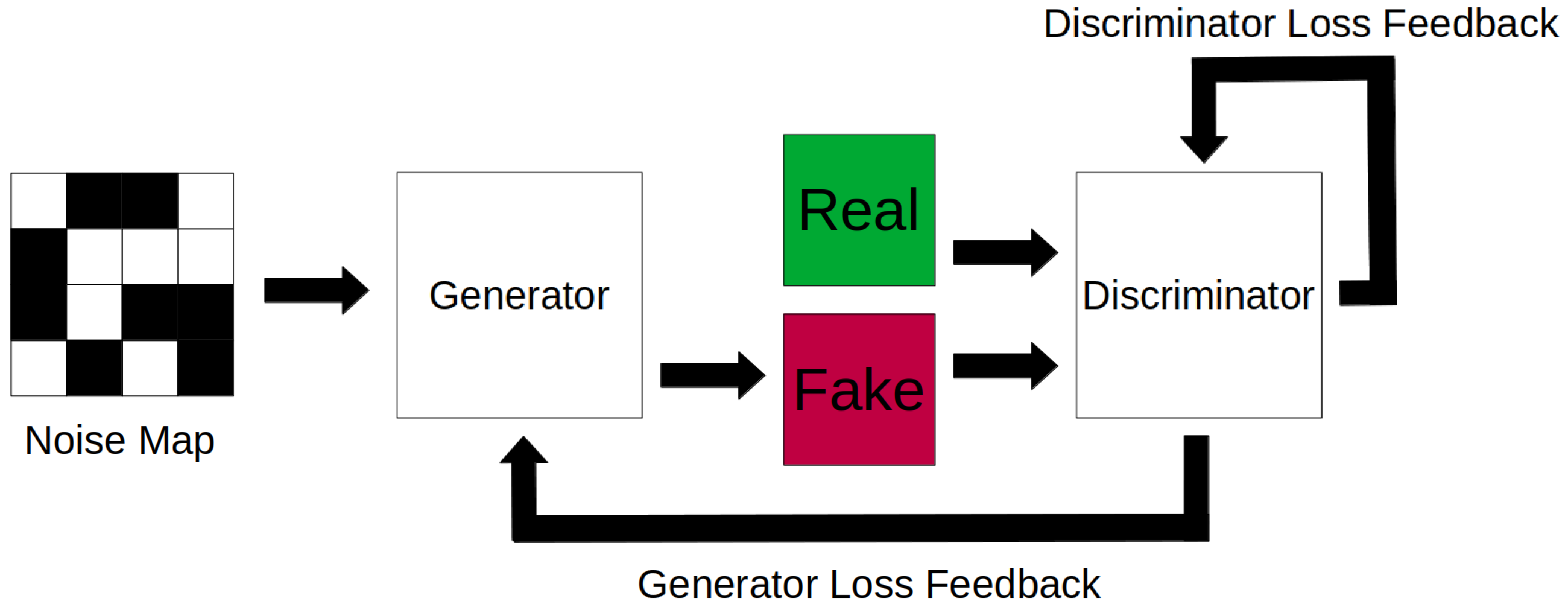
4.2. Generative Adversarial Networks, Variational Autoencoders, and Hybrid Networks
4.3. 3D Morphable Models and Parametric Models
4.4. Games, Game Engines and 3D Modelling Software
4.5. Other Methodologies
5. Performance of Synthetic Data
6. Applications of Synthetic Data
6.1. Object Recognition and Classification
6.2. Face Recognition and Analysis
6.3. Medical Applications
6.4. Drone and Aerial Vision and Vehicle Automation
6.5. Environmental Condition Synthesis
6.6. Human Detection, Crowd Counting and Action Recognition
6.7. Depth Perception and Semantic Segmentation Tasks
7. Research Gaps and Challenges
7.1. Domain Gap
7.2. Data Diversity
7.3. Photorealism
7.4. Computational Resource Requirements
7.5. Synthetic Data Benchmark
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional neural network |
| 3DMM | 3D morphable models |
| FID | Frechet Inception Distance |
| GAN | Generative adversarial network |
| GPU | Graphics Processing Unit |
| GTA5 | Grand Theft Auto V |
| IS | Inception Score |
| VAE | Variational Autoencoder |
References
- Atapour-Abarghouei, A.; Breckon, T.P. Real-time monocular depth estimation using synthetic data with domain adaptation via image style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2800–2810. [Google Scholar]
- Sakaridis, C.; Dai, D.; Van Gool, L. Semantic foggy scene understanding with synthetic data. Int. J. Comput. Vis. 2018, 126, 973–992. [Google Scholar] [CrossRef] [Green Version]
- Hattori, H.; Lee, N.; Boddeti, V.N.; Beainy, F.; Kitani, K.M.; Kanade, T. Synthesizing a scene-specific pedestrian detector and pose estimator for static video surveillance. Int. J. Comput. Vis. 2018, 126, 1027–1044. [Google Scholar] [CrossRef]
- Tripathi, S.; Chandra, S.; Agrawal, A.; Tyagi, A.; Rehg, J.M.; Chari, V. Learning to generate synthetic data via compositing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 461–470. [Google Scholar]
- Ekbatani, H.K.; Pujol, O.; Segui, S. Synthetic Data Generation for Deep Learning in Counting Pedestrians. In Proceedings of the ICPRAM, Porto, Portugal, 24–26 February 2017; pp. 318–323. [Google Scholar]
- Rogez, G.; Schmid, C. Image-based synthesis for deep 3D human pose estimation. Int. J. Comput. Vis. 2018, 126, 993–1008. [Google Scholar] [CrossRef] [Green Version]
- Behl, H.S.; Baydin, A.G.; Gal, R.; Torr, P.H.; Vineet, V. Autosimulate:(quickly) learning synthetic data generation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 255–271. [Google Scholar]
- Martinez-Gonzalez, P.; Oprea, S.; Garcia-Garcia, A.; Jover-Alvarez, A.; Orts-Escolano, S.; Garcia-Rodriguez, J. Unrealrox: An extremely photorealistic virtual reality environment for robotics simulations and synthetic data generation. Virtual Real. 2020, 24, 271–288. [Google Scholar] [CrossRef] [Green Version]
- Müller, M.; Casser, V.; Lahoud, J.; Smith, N.; Ghanem, B. Sim4cv: A photo-realistic simulator for computer vision applications. Int. J. Comput. Vis. 2018, 126, 902–919. [Google Scholar] [CrossRef] [Green Version]
- Poucin, F.; Kraus, A.; Simon, M. Boosting Instance Segmentation With Synthetic Data: A Study To Overcome the Limits of Real World Data Sets. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 11–17 October 2021; pp. 945–953. [Google Scholar]
- Jaipuria, N.; Zhang, X.; Bhasin, R.; Arafa, M.; Chakravarty, P.; Shrivastava, S.; Manglani, S.; Murali, V.N. Deflating dataset bias using synthetic data augmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 772–773. [Google Scholar]
- Jiang, C.; Qi, S.; Zhu, Y.; Huang, S.; Lin, J.; Yu, L.F.; Terzopoulos, D.; Zhu, S.C. Configurable 3d scene synthesis and 2d image rendering with per-pixel ground truth using stochastic grammars. Int. J. Comput. Vis. 2018, 126, 920–941. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Gao, J.; Lin, W.; Yuan, Y. Pixel-wise crowd understanding via synthetic data. Int. J. Comput. Vis. 2021, 129, 225–245. [Google Scholar] [CrossRef]
- Wang, Q.; Gao, J.; Lin, W.; Yuan, Y. Learning from synthetic data for crowd counting in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 8198–8207. [Google Scholar]
- Kortylewski, A.; Schneider, A.; Gerig, T.; Egger, B.; Morel-Forster, A.; Vetter, T. Training deep face recognition systems with synthetic data. arXiv 2018, arXiv:1802.05891. [Google Scholar]
- Tsirikoglou, A.; Eilertsen, G.; Unger, J. A survey of image synthesis methods for visual machine learning. In Proceedings of the Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2020; Volume 39, pp. 426–451. [Google Scholar]
- Seib, V.; Lange, B.; Wirtz, S. Mixing Real and Synthetic Data to Enhance Neural Network Training–A Review of Current Approaches. arXiv 2020, arXiv:2007.08781. [Google Scholar]
- Gaidon, A.; Lopez, A.; Perronnin, F. The reasonable effectiveness of synthetic visual data. Int. J. Comput. Vis. 2018, 126, 899–901. [Google Scholar] [CrossRef] [Green Version]
- Frolov, S.; Hinz, T.; Raue, F.; Hees, J.; Dengel, A. Adversarial text-to-image synthesis: A review. Neural Netw. 2021, 144, 187–209. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Varol, G.; Romero, J.; Martin, X.; Mahmood, N.; Black, M.J.; Laptev, I.; Schmid, C. Learning from Synthetic Humans. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 June 2017. [Google Scholar]
- Shermeyer, J.; Hossler, T.; Van Etten, A.; Hogan, D.; Lewis, R.; Kim, D. Rareplanes: Synthetic data takes flight. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2021; pp. 207–217. [Google Scholar]
- Khadka, A.R.; Oghaz, M.; Matta, W.; Cosentino, M.; Remagnino, P.; Argyriou, V. Learning how to analyse crowd behaviour using synthetic data. In Proceedings of the 32nd International Conference on Computer Animation and Social Agents, Paris, France, 1–3 July 2019; pp. 11–14. [Google Scholar]
- Allken, V.; Handegard, N.O.; Rosen, S.; Schreyeck, T.; Mahiout, T.; Malde, K. Fish species identification using a convolutional neural network trained on synthetic data. ICES J. Mar. Sci. 2019, 76, 342–349. [Google Scholar] [CrossRef]
- Rosen, S.; Holst, J.C. DeepVision in-trawl imaging: Sampling the water column in four dimensions. Fish. Res. 2013, 148, 64–73. [Google Scholar] [CrossRef]
- Alhaija, H.A.; Mustikovela, S.K.; Mescheder, L.; Geiger, A.; Rother, C. Augmented reality meets computer vision: Efficient data generation for urban driving scenes. Int. J. Comput. Vis. 2018, 126, 961–972. [Google Scholar] [CrossRef] [Green Version]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Marcu, A.; Costea, D.; Licaret, V.; Pîrvu, M.; Slusanschi, E.; Leordeanu, M. SafeUAV: Learning to estimate depth and safe landing areas for UAVs from synthetic data. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Gaidon, A.; Wang, Q.; Cabon, Y.; Vig, E. Virtual worlds as proxy for multi-object tracking analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4340–4349. [Google Scholar]
- Tremblay, J.; Prakash, A.; Acuna, D.; Brophy, M.; Jampani, V.; Anil, C.; To, T.; Cameracci, E.; Boochoon, S.; Birchfield, S. Training deep networks with synthetic data: Bridging the reality gap by domain randomization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 969–977. [Google Scholar]
- Qiu, H.; Yu, B.; Gong, D.; Li, Z.; Liu, W.; Tao, D. SynFace: Face Recognition with Synthetic Data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 11–17 October 2021; pp. 10880–10890. [Google Scholar]
- Tang, Z.; Naphade, M.; Birchfield, S.; Tremblay, J.; Hodge, W.; Kumar, R.; Wang, S.; Yang, X. Pamtri: Pose-aware multi-task learning for vehicle re-identification using highly randomized synthetic data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 211–220. [Google Scholar]
- Shen, B.; Li, B.; Scheirer, W.J. Automatic Virtual 3D City Generation for Synthetic Data Collection. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision Workshops (WACVW), Seoul, Korea, 11–17 October 2021; pp. 161–170. [Google Scholar]
- Richardson, E.; Sela, M.; Kimmel, R. 3D face reconstruction by learning from synthetic data. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 460–469. [Google Scholar]
- Loing, V.; Marlet, R.; Aubry, M. Virtual training for a real application: Accurate object-robot relative localization without calibration. Int. J. Comput. Vis. 2018, 126, 1045–1060. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Im Im, D.; Ahn, S.; Memisevic, R.; Bengio, Y. Denoising criterion for variational auto-encoding framework. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Meng, Q.; Catchpoole, D.; Skillicom, D.; Kennedy, P.J. Relational autoencoder for feature extraction. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 364–371. [Google Scholar]
- Ballé, J.; Minnen, D.; Singh, S.; Hwang, S.J.; Johnston, N. Variational image compression with a scale hyperprior. arXiv 2018, arXiv:1802.01436. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Hindupur, A. The GAN Zoo. 2018. Available online: https://github.com/hindupuravinash/the-gan-zoo (accessed on 26 September 2022).
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 7354–7363. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale GAN training for high fidelity natural image synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. Adv. Neural Inf. Process. Syst. 2016, 29, 2226–2234. [Google Scholar]
- Wu, Y.; Donahue, J.; Balduzzi, D.; Simonyan, K.; Lillicrap, T. Logan: Latent optimisation for generative adversarial networks. arXiv 2019, arXiv:1912.00953. [Google Scholar]
- Han, S.; Srivastava, A.; Hurwitz, C.L.; Sattigeri, P.; Cox, D.D. not-so-biggan: Generating high-fidelity images on a small compute budget. arXiv 2020, arXiv:2009.04433. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–29 June 2016; pp. 3213–3223. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 1125–1134. [Google Scholar]
- Kaneko, T.; Kameoka, H. Cyclegan-vc: Non-parallel voice conversion using cycle-consistent adversarial networks. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 2100–2104. [Google Scholar]
- Kaneko, T.; Kameoka, H.; Tanaka, K.; Hojo, N. Cyclegan-vc2: Improved cyclegan-based non-parallel voice conversion. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6820–6824. [Google Scholar]
- Kaneko, T.; Kameoka, H.; Tanaka, K.; Hojo, N. Cyclegan-vc3: Examining and improving cyclegan-vcs for mel-spectrogram conversion. arXiv 2020, arXiv:2010.11672. [Google Scholar]
- Harms, J.; Lei, Y.; Wang, T.; Zhang, R.; Zhou, J.; Tang, X.; Curran, W.J.; Liu, T.; Yang, X. Paired cycle-GAN-based image correction for quantitative cone-beam computed tomography. Med. Phys. 2019, 46, 3998–4009. [Google Scholar] [CrossRef]
- Engin, D.; Genç, A.; Kemal Ekenel, H. Cycle-dehaze: Enhanced cyclegan for single image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 825–833. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8789–8797. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-shot text-to-image generation. In Proceedings of the International Conference on Machine Learning PMLR, Virtual, 18–24 July 2021; pp. 8821–8831. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Dayma, B.; Patil, S.; Cuenca, P.; Saifullah, K.; Abraham, T.; Lê Khac, P.; Melas, L.; Ghosh, R. DALL·E Mini. 2021. Available online: https://github.com/borisdayma/dalle-mini (accessed on 27 September 2022).
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis With Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022; pp. 10684–10695. [Google Scholar]
- Yu, J.; Xu, Y.; Koh, J.Y.; Luong, T.; Baid, G.; Wang, Z.; Vasudevan, V.; Ku, A.; Yang, Y.; Ayan, B.K.; et al. Scaling autoregressive models for content-rich text-to-image generation. arXiv 2022, arXiv:2206.10789. [Google Scholar]
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.; Ghasemipour, S.K.S.; Ayan, B.K.; Mahdavi, S.S.; Lopes, R.G.; et al. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. arXiv 2022, arXiv:2205.11487. [Google Scholar]
- Mansimov, E.; Parisotto, E.; Ba, J.L.; Salakhutdinov, R. Generating images from captions with attention. arXiv 2015, arXiv:1511.02793. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. In Proceedings of the International Conference on Machine Learning PMLR, Baltimore, MD, USA, 18–23 July 2016; pp. 1060–1069. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning PMLR, Virtual, 13–14 August 2021; pp. 8748–8763. [Google Scholar]
- Esser, P.; Rombach, R.; Ommer, B. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 12873–12883. [Google Scholar]
- Yu, J.; Li, X.; Koh, J.Y.; Zhang, H.; Pang, R.; Qin, J.; Ku, A.; Xu, Y.; Baldridge, J.; Wu, Y. Vector-quantized image modeling with improved vqgan. arXiv 2021, arXiv:2110.04627. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Raffel, C.; Luong, M.T.; Liu, P.J.; Weiss, R.J.; Eck, D. Online and linear-time attention by enforcing monotonic alignments. In Proceedings of the International Conference on Machine Learning PMLR, Sydney, Australia, 6–11 August 2017; pp. 2837–2846. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Karras, T.; Aittala, M.; Laine, S.; Härkönen, E.; Hellsten, J.; Lehtinen, J.; Aila, T. Alias-Free Generative Adversarial Networks. In Proceedings of the NeurIPS, Virtual, 6–14 December 2021. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Srivastava, A.; Valkov, L.; Russell, C.; Gutmann, M.U.; Sutton, C. Veegan: Reducing mode collapse in gans using implicit variational learning. Adv. Neural Inf. Process. Syst. 2017, 30, 3310–3320. [Google Scholar]
- Donahue, J.; Krähenbühl, P.; Darrell, T. Adversarial feature learning. arXiv 2016, arXiv:1605.09782. [Google Scholar]
- Larsen, A.B.L.; Sønderby, S.K.; Larochelle, H.; Winther, O. Autoencoding beyond pixels using a learned similarity metric. In Proceedings of the International Conference on Machine Learning PMLR, New York, NY, USA, 20–22 June 2016; pp. 1558–1566. [Google Scholar]
- Bao, J.; Chen, D.; Wen, F.; Li, H.; Hua, G. CVAE-GAN: Fine-grained image generation through asymmetric training. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2745–2754. [Google Scholar]
- Shang, W.; Sohn, K.; Tian, Y. Channel-recurrent autoencoding for image modeling. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 4–8 January 2018; pp. 1195–1204. [Google Scholar]
- Wang, Z.; Zheng, H.; He, P.; Chen, W.; Zhou, M. Diffusion-GAN: Training GANs with Diffusion. arXiv 2022, arXiv:2206.02262. [Google Scholar]
- Ben-Cohen, A.; Klang, E.; Raskin, S.P.; Soffer, S.; Ben-Haim, S.; Konen, E.; Amitai, M.M.; Greenspan, H. Cross-modality synthesis from CT to PET using FCN and GAN networks for improved automated lesion detection. Eng. Appl. Artif. Intell. 2019, 78, 186–194. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Little, J.J. Sports camera calibration via synthetic data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Chen, R.J.; Lu, M.Y.; Chen, T.Y.; Williamson, D.F.; Mahmood, F. Synthetic data in machine learning for medicine and healthcare. Nat. Biomed. Eng. 2021, 5, 1–5. [Google Scholar] [CrossRef]
- Sankaranarayanan, S.; Balaji, Y.; Jain, A.; Lim, S.N.; Chellappa, R. Learning from synthetic data: Addressing domain shift for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3752–3761. [Google Scholar]
- Salian, I. Nvidia Research Achieves AI Training Breakthrough. 2021. Available online: https://blogs.nvidia.com/blog/2020/12/07/neurips-research-limited-data-gan/ (accessed on 27 September 2022).
- Wu, J.; Zhang, C.; Xue, T.; Freeman, B.; Tenenbaum, J. Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Marriott, R.T.; Romdhani, S.; Chen, L. A 3d gan for improved large-pose facial recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13445–13455. [Google Scholar]
- Pumarola, A.; Agudo, A.; Martinez, A.M.; Sanfeliu, A.; Moreno-Noguer, F. Ganimation: Anatomically-aware facial animation from a single image. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 818–833. [Google Scholar]
- Mirzaei, M.S.; Meshgi, K.; Frigo, E.; Nishida, T. Animgan: A spatiotemporally-conditioned generative adversarial network for character animation. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 2286–2290. [Google Scholar]
- Wu, X.; Zhang, Q.; Wu, Y.; Wang, H.; Li, S.; Sun, L.; Li, X. F3A-GAN: Facial Flow for Face Animation With Generative Adversarial Networks. IEEE Trans. Image Process. 2021, 30, 8658–8670. [Google Scholar] [CrossRef] [PubMed]
- Lin, C.Z.; Lindell, D.B.; Chan, E.R.; Wetzstein, G. 3D GAN Inversion for Controllable Portrait Image Animation. arXiv 2022, arXiv:2203.13441. [Google Scholar]
- Blanz, V.; Vetter, T. A morphable model for the synthesis of 3D faces. In Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques, New York, NY, USA, 8–13 August 1999; pp. 187–194. [Google Scholar]
- Egger, B.; Smith, W.A.; Tewari, A.; Wuhrer, S.; Zollhoefer, M.; Beeler, T.; Bernard, F.; Bolkart, T.; Kortylewski, A.; Romdhani, S.; et al. 3d morphable face models—past, present, and future. ACM Trans. Graph. 2020, 39, 1–38. [Google Scholar] [CrossRef]
- Wood, E.; Baltrusaitis, T.; Hewitt, C.; Dziadzio, S.; Cashman, T.J.; Shotton, J. Fake It Till You Make It: Face analysis in the wild using synthetic data alone. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 11–17 October 2021; pp. 3681–3691. [Google Scholar]
- Kortylewski, A.; Egger, B.; Schneider, A.; Gerig, T.; Morel-Forster, A.; Vetter, T. Analyzing and reducing the damage of dataset bias to face recognition with synthetic data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Qi, X.; Chen, Q.; Jia, J.; Koltun, V. Semi-parametric image synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8808–8816. [Google Scholar]
- Qiu, W.; Yuille, A. Unrealcv: Connecting computer vision to unreal engine. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2016; pp. 909–916. [Google Scholar]
- Qiu, W.; Zhong, F.; Zhang, Y.; Qiao, S.; Xiao, Z.; Kim, T.S.; Wang, Y. Unrealcv: Virtual worlds for computer vision. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1221–1224. [Google Scholar]
- Hatay, E.; Ma, J.; Sun, H.; Fang, J.; Gao, Z.; Yu, H. Learning To Detect Phone-Related Pedestrian Distracted Behaviors With Synthetic Data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 2981–2989. [Google Scholar]
- Acharya, P.; Lohn, D.; Ross, V.; Ha, M.; Rich, A.; Sayyad, E.; Hollerer, T. Using Synthetic Data Generation To Probe Multi-View Stereo Networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 11–17 October 2021; pp. 1583–1591. [Google Scholar]
- Saleh, F.S.; Aliakbarian, M.S.; Salzmann, M.; Petersson, L.; Alvarez, J.M. Effective use of synthetic data for urban scene semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 84–100. [Google Scholar]
- Riegler, G.; Urschler, M.; Ruther, M.; Bischof, H.; Stern, D. Anatomical landmark detection in medical applications driven by synthetic data. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 12–16. [Google Scholar]
- Fabbri, M.; Brasó, G.; Maugeri, G.; Cetintas, O.; Gasparini, R.; Osep, A.; Calderara, S.; Leal-Taixe, L.; Cucchiara, R. MOTSynth: How Can Synthetic Data Help Pedestrian Detection and Tracking? In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 11–17 October 2021; pp. 10849–10859. [Google Scholar]
- Yi, X.; Adams, S.; Babyn, P.; Elnajmi, A. Automatic catheter and tube detection in pediatric x-ray images using a scale-recurrent network and synthetic data. J. Digit. Imag. 2020, 33, 181–190. [Google Scholar] [CrossRef]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30, 6629–6640. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City UT, USA, 18–23 June 2018. [Google Scholar]
- Gokay, D.; Simsar, E.; Atici, E.; Ahmetoglu, A.; Yuksel, A.E.; Yanardag, P. Graph2Pix: A Graph-Based Image to Image Translation Framework. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 11–17 October 2021; pp. 2001–2010. [Google Scholar]
- Bergman, A.W.; Kellnhofer, P.; Wang, Y.; Chan, E.R.; Lindell, D.B.; Wetzstein, G. Generative Neural Articulated Radiance Fields. arXiv 2022, arXiv:2206.14314. [Google Scholar]
- Chan, E.R.; Lin, C.Z.; Chan, M.A.; Nagano, K.; Pan, B.; Mello, S.D.; Gallo, O.; Guibas, L.; Tremblay, J.; Khamis, S.; et al. Efficient Geometry-aware 3D Generative Adversarial Networks. In Proceedings of the CVPR, New Orleans, LA, USA, 18–22 June 2022. [Google Scholar]
- Chan, A.B.; Liang, Z.S.J.; Vasconcelos, N. Privacy preserving crowd monitoring: Counting people without people models or tracking. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–7. [Google Scholar]
- Chen, K.; Loy, C.C.; Gong, S.; Xiang, T. Feature mining for localised crowd counting. In Proceedings of the BMVC, Surrey, UK, 3–7 September 2012; Volume 1, p. 3. [Google Scholar]
- Ferryman, J.; Shahrokni, A. Pets2009: Dataset and challenge. In Proceedings of the 2009 Twelfth IEEE International Workshop on Performance Evaluation of Tracking and Surveillance, Snowbird, UT, USA, 13–17 June 2009; pp. 1–6. [Google Scholar]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-image crowd counting via multi-column convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 23–26 June 2016; pp. 589–597. [Google Scholar]
- Schröder, G.; Senst, T.; Bochinski, E.; Sikora, T. Optical flow dataset and benchmark for visual crowd analysis. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 June 2018; pp. 1–6. [Google Scholar]
- Shao, S.; Zhao, Z.; Li, B.; Xiao, T.; Yu, G.; Zhang, X.; Sun, J. Crowdhuman: A benchmark for detecting human in a crowd. arXiv 2018, arXiv:1805.00123. [Google Scholar]
- Zhang, Q.; Lin, W.; Chan, A.B. Cross-view cross-scene multi-view crowd counting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 557–567. [Google Scholar]
- Liu, M.Y.; Tuzel, O. Coupled generative adversarial networks. Adv. Neural Inf. Process. Syst. 2016, 29, 469–477. [Google Scholar]
- Dumoulin, V.; Belghazi, I.; Poole, B.; Mastropietro, O.; Lamb, A.; Arjovsky, M.; Courville, A. Adversarially learned inference. arXiv 2016, arXiv:1606.00704. [Google Scholar]
- Dahmen, T.; Trampert, P.; Boughorbel, F.; Sprenger, J.; Klusch, M.; Fischer, K.; Kübel, C.; Slusallek, P. Digital reality: A model-based approach to supervised learning from synthetic data. AI Perspect. 2019, 1, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Frid-Adar, M.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. Synthetic data augmentation using GAN for improved liver lesion classification. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 289–293. [Google Scholar]
- Waheed, A.; Goyal, M.; Gupta, D.; Khanna, A.; Al-Turjman, F.; Pinheiro, P.R. Covidgan: Data augmentation using auxiliary classifier gan for improved COVID-19 detection. IEEE Access 2020, 8, 91916–91923. [Google Scholar] [CrossRef] [PubMed]
- Mariani, G.; Scheidegger, F.; Istrate, R.; Bekas, C.; Malossi, C. Bagan: Data augmentation with balancing gan. arXiv 2018, arXiv:1803.09655. [Google Scholar]
- Huang, S.W.; Lin, C.T.; Chen, S.P.; Wu, Y.Y.; Hsu, P.H.; Lai, S.H. Auggan: Cross domain adaptation with gan-based data augmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 718–731. [Google Scholar]
- Zhou, Y.; Giffard-Roisin, S.; De Craene, M.; Camarasu-Pop, S.; D’Hooge, J.; Alessandrini, M.; Friboulet, D.; Sermesant, M.; Bernard, O. A framework for the generation of realistic synthetic cardiac ultrasound and magnetic resonance imaging sequences from the same virtual patients. IEEE Trans. Med. Imaging 2017, 37, 741–754. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Prakash, C.D.; Karam, L.J. It GAN DO better: GAN-based detection of objects on images with varying quality. IEEE Trans. Image Process. 2021, 30, 9220–9230. [Google Scholar] [CrossRef]
- Barbu, A.; Mayo, D.; Alverio, J.; Luo, W.; Wang, C.; Gutfreund, D.; Tenenbaum, J.; Katz, B. Objectnet: A large-scale bias-controlled dataset for pushing the limits of object recognition models. Adv. Neural Inf. Process. Syst. 2019, 32, 9448–9458. [Google Scholar]
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 international interdisciplinary PhD workshop (IIPhDW), Swinoujscie, Poland, 9–12 May 2018; pp. 117–122. [Google Scholar]
- Liu, L.; Muelly, M.; Deng, J.; Pfister, T.; Li, L.J. Generative modeling for small-data object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6073–6081. [Google Scholar]
- Balaji, Y.; Min, M.R.; Bai, B.; Chellappa, R.; Graf, H.P. Conditional GAN with Discriminative Filter Generation for Text-to-Video Synthesis. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; Volume 1, p. 2. [Google Scholar]
- Liu, M.Y.; Huang, X.; Yu, J.; Wang, T.C.; Mallya, A. Generative adversarial networks for image and video synthesis: Algorithms and applications. arXiv 2020, arXiv:2008.02793. [Google Scholar] [CrossRef]
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments. In Proceedings of the Workshop on faces in ‘Real-Life’ Images: Detection, Alignment, and Recognition, Marseille, France, 17–20 October 2008. [Google Scholar]
- Huang, R.; Zhang, S.; Li, T.; He, R. Beyond face rotation: Global and local perception gan for photorealistic and identity preserving frontal view synthesis. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2439–2448. [Google Scholar]
- Shen, Y.; Luo, P.; Yan, J.; Wang, X.; Tang, X. Faceid-gan: Learning a symmetry three-player gan for identity-preserving face synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 821–830. [Google Scholar]
- Yin, X.; Yu, X.; Sohn, K.; Liu, X.; Chandraker, M. Towards large-pose face frontalization in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3990–3999. [Google Scholar]
- Deng, J.; Cheng, S.; Xue, N.; Zhou, Y.; Zafeiriou, S. Uv-gan: Adversarial facial uv map completion for pose-invariant face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7093–7102. [Google Scholar]
- Liu, W.; Piao, Z.; Min, J.; Luo, W.; Ma, L.; Gao, S. Liquid warping gan: A unified framework for human motion imitation, appearance transfer and novel view synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 5904–5913. [Google Scholar]
- Liu, W.; Piao, Z.; Tu, Z.; Luo, W.; Ma, L.; Gao, S. Liquid warping gan with attention: A unified framework for human image synthesis. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5114–5132. [Google Scholar] [CrossRef]
- Men, Y.; Mao, Y.; Jiang, Y.; Ma, W.Y.; Lian, Z. Controllable person image synthesis with attribute-decomposed gan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 4–9 June 2020; pp. 5084–5093. [Google Scholar]
- Khanam, F.T.Z.; Al-Naji, A.; Chahl, J. Remote monitoring of vital signs in diverse non-clinical and clinical scenarios using computer vision systems: A review. Appl. Sci. 2019, 9, 4474. [Google Scholar] [CrossRef] [Green Version]
- Khanam, F.T.Z.; Chahl, L.A.; Chahl, J.S.; Al-Naji, A.; Perera, A.G.; Wang, D.; Lee, Y.; Ogunwa, T.T.; Teague, S.; Nguyen, T.X.B.; et al. Noncontact sensing of contagion. J. Imaging 2021, 7, 28. [Google Scholar] [CrossRef]
- Condrea, F.; Ivan, V.A.; Leordeanu, M. In Search of Life: Learning from Synthetic Data to Detect Vital Signs in Videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Virtual, 4–9 June 2020; pp. 298–299. [Google Scholar]
- Dao, P.D.; Liou, Y.A.; Chou, C.W. Detection of flood inundation regions with Landsat/MODIS synthetic data. In Proceedings of the International Symposium on Remote Sensing, Berlin, Germany, 11–15 May 2015. [Google Scholar]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Ling, H.; Hu, Q.; Nie, Q.; Cheng, H.; Liu, C.; Liu, X.; et al. Visdrone-det2018: The vision meets drone object detection in image challenge results. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y.; et al. VisDrone-DET2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Munich, Germany, 8–14 September 2019. [Google Scholar]
- Fan, H.; Du, D.; Wen, L.; Zhu, P.; Hu, Q.; Ling, H.; Shah, M.; Pan, J.; Schumann, A.; Dong, B.; et al. Visdrone-mot2020: The vision meets drone multiple object tracking challenge results. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 713–727. [Google Scholar]
- Cao, Y.; He, Z.; Wang, L.; Wang, W.; Yuan, Y.; Zhang, D.; Zhang, J.; Zhu, P.; Van Gool, L.; Han, J.; et al. VisDrone-DET2021: The vision meets drone object detection challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 11–17 October 2021; pp. 2847–2854. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 23–29 June 2020; pp. 11621–11631. [Google Scholar]
- Weyand, T.; Araujo, A.; Cao, B.; Sim, J. Google landmarks dataset v2-a large-scale benchmark for instance-level recognition and retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 23–29 June; pp. 2575–2584.
- Kelly, G.; McCabe, H. A survey of procedural techniques for city generation. ITB J. 2006, 14, 342–351. [Google Scholar]
- Kishore, A.; Choe, T.E.; Kwon, J.; Park, M.; Hao, P.; Mittel, A. Synthetic data generation using imitation training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 11–17 October 2021; pp. 3078–3086. [Google Scholar]
- Chen, Y.; Pan, Y.; Yao, T.; Tian, X.; Mei, T. Mocycle-gan: Unpaired video-to-video translation. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 22–29 October 2019; pp. 647–655. [Google Scholar]
- Handa, A.; Patraucean, V.; Badrinarayanan, V.; Stent, S.; Cipolla, R. Understanding real world indoor scenes with synthetic data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 22–26 June 2016; pp. 4077–4085. [Google Scholar]
- Mayer, N.; Ilg, E.; Fischer, P.; Hazirbas, C.; Cremers, D.; Dosovitskiy, A.; Brox, T. What makes good synthetic training data for learning disparity and optical flow estimation? Int. J. Comput. Vis. 2018, 126, 942–960. [Google Scholar] [CrossRef] [Green Version]
- Xue, Y.; Guo, Y.C.; Zhang, H.; Xu, T.; Zhang, S.H.; Huang, X. Deep image synthesis from intuitive user input: A review and perspectives. Comput. Vis. Media 2022, 8, 3–31. [Google Scholar] [CrossRef]
- Luo, S. A Survey on Multimodal Deep Learning for Image Synthesis: Applications, methods, datasets, evaluation metrics, and results comparison. In Proceedings of the 2021 the 5th International Conference on Innovation in Artificial Intelligence, Xiamen, China, 5–9 March 2021; pp. 108–120. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Output Resolution | Training Cost | Generation Cost (50k Images) | FID Score [106] (fid50k) |
|---|---|---|---|---|
| Pix2Pix [50] | 256 × 256 | N/A @ 1xTitan X | N/A @ 1xTitan X | 112.01 |
| Pix2PixHD [107] | 256 × 256 | N/A @ 1xTitan X | N/A @ 1xTitan X | 23.89 |
| CycleGAN [48] | 256 × 256 | N/A @ 1xTitan X | N/A @ 1xTitan X | 19.35 |
| Graph2Pix [108] | 256 × 256 | N/A @ 1xTitan X | N/A @ 1xTitan X | 19.29 |
| GNARF [109] | 256 × 256 | N/A | N/A | 7.9 |
| EG3D [110] | 512 × 512 | 8d 12h @ 8xTesla V100 | N/A @ RTX 3090 | 4.7 |
| StyleGAN-1 [72] | 1024 × 1024 | 6d 14h @ 8xTesla V100 | 16m @ 1xTesla V100 | 4.41 |
| StyleGAN-2 [73] | 1024 × 1024 | 9d 18h @ 8xTesla V100 | 22m @ 1xTesla V100 | 2.84 |
| StyleGAN-3-T [74] | 1024 × 1024 | 8d 5h @ 8xTesla V100 | Up to 1h @ 1xTesla V100 | 2.79 |
| StyleGAN-3-R [74] | 1024 × 1024 | 1d 17h @ 8xTesla V100 | Up to 1h @ 1xTesla V100 | 3.07 |
| Method | Output Resolution | Dataset Size | Scene Locations | Pedestrian Instances |
|---|---|---|---|---|
| UCSD [111] (Real) | 238 × 158 | 2000 images | 1 | 49,885 |
| Mall [112] (Real) | 640 × 480 | 2000 images | 1 | >60,000 |
| PETS2009 [113] (Real) | 576 × 768 | 875 images | 1 | 4307 |
| ShanghaiTech [114] (Real) | 576 × 768 | 1198 images | N/A | 330,000 |
| CrowdFlow [115] (Synthetic) | 1280 × 720 | 3200 images | 5 | <1451 |
| CrowdHuman [116] (Real) | <1400 × 800 | 24,370 images | N/A | 470,000 |
| GCC [14] (Synthetic) | 1920 × 1080 | 15,212 images | 100 | 7,625,843 |
| GCC [117] (Synthetic) | 1920 × 1080 | 280,000 images | 31 | ∼38,000,000 |
| Method | Resolution | Training Cost | Generation Cost | % Turkers Labeled Real |
|---|---|---|---|---|
| CoGAN [118] | 512 × 512 | N/A | N/A | 0.6 ± 0.5% |
| BiGAN/ALI [77,119] | 512 × 512 | N/A | N/A | 2.1 ± 1% |
| CycleGAN [48] | 512 × 512 | N/A | N/A | 26.8 ± 2.8% |
| Method | Resolution | Training Cost | Generation Cost | Per-Pixel Accuracy |
|---|---|---|---|---|
| BiGAN/ALI [77,119] | N/A | N/A | N/A | 0.41 |
| CoGAN [118] | N/A | N/A | N/A | 0.45 |
| CycleGAN [48] | N/A | N/A | N/A | 0.58 |
| Pix2Pix [50] | 256 × 256 | N/A | N/A | 0.85 |
| Pix2PixHD [107] | 2048 × 1024 | N/A | N/A | 0.83 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Man, K.; Chahl, J. A Review of Synthetic Image Data and Its Use in Computer Vision. J. Imaging 2022, 8, 310. https://doi.org/10.3390/jimaging8110310
Man K, Chahl J. A Review of Synthetic Image Data and Its Use in Computer Vision. Journal of Imaging. 2022; 8(11):310. https://doi.org/10.3390/jimaging8110310
Chicago/Turabian StyleMan, Keith, and Javaan Chahl. 2022. "A Review of Synthetic Image Data and Its Use in Computer Vision" Journal of Imaging 8, no. 11: 310. https://doi.org/10.3390/jimaging8110310
APA StyleMan, K., & Chahl, J. (2022). A Review of Synthetic Image Data and Its Use in Computer Vision. Journal of Imaging, 8(11), 310. https://doi.org/10.3390/jimaging8110310