1. Introduction
Drug-target affinity prediction (DTA) plays an important role in drug efficacy prediction, toxicity assessment, and drug metabolism research [
1]. Experimentally, affinity is typically measured using dissociation constants, inhibition constants, or half-maximal inhibitory concentration. However, traditional methods for obtaining DTA in the laboratory are often time-consuming and resource-intensive. Researchers may spend decades and significant resources classifying, screening, and experimenting with drugs [
2,
3,
4]. Therefore, the development of accurate computational methods for predicting DTA would provide valuable insights for drug discovery, guiding the optimization and improvement of drug molecules, enhancing their selectivity, potency, and safety, and thus significantly accelerating the drug discovery process.
Methods for predicting DTA are categorized into the following three major groups: structure-focused methods, machine learning approaches, and deep learning-driven techniques [
5]. Conventional structure-driven DTA prediction approaches mainly involve molecular docking [
6] and molecular dynamics simulations [
7], both of which rely on high-precision 3D structural data of the drug and protein to model their interactions. Although these methods have yielded promising results in terms of predictive performance, they require highly accurate structural information of both molecules and proteins, and consume substantial computational resources, which limits their large-scale application.
To tackle these problems, machine learning (ML)-based techniques have gained prominence [
8,
9,
10]. These approaches do not require high-precision structural information of the drug and protein, but instead use textual information from the drug and protein sequences for DTA prediction. Specifically, they extract primary features from the drug and protein sequences and input these features into classifiers, such as decision trees [
11] or support vector machines [
12], for training, to obtain drug–protein interaction models, which are then used for prediction. Some classical methods include kernel-based methods like KronRLS [
13] and similarity-based methods like SimBoost [
14]. However, these early machine learning approaches often require significant domain expertise to construct complex feature engineering.
Currently, deep learning-based prediction methods have demonstrated significant advantages in DTA prediction [
15,
16,
17]. Predicting DTA requires consideration of the complex molecular structures and interactions of both the drug and protein. Deep learning can process large volumes of high-dimensional biological data, efficiently managing this complexity by automatically learning and extracting features, without the need for manual feature extraction or precise predictions. This approach reduces information loss and improves the robustness and generalization ability of prediction models. For example, DeepDTA [
18] uses convolutional neural networks (CNNs) to separately extract representations of drug and protein, then concatenates these representations and passes them through FC layers to obtain predictions of the drug–protein binding affinity. WideDTA [
19] extends DeepDTA by adding two additional CNNs to model the interaction strength between individual protein substructures and drug substructure pairs. TransformerCPI [
20] utilizes transformers [
21] to capture sequence data from both drugs and proteins. Although deep learning models have demonstrated strong effectiveness in drug-target affinity prediction, several issues remain, such as the following: On the one hand, these sequence-based convolutional methods require equal lengths for input sequences, which necessitates truncating drug and protein sequences to a unified length, potentially leading to loss of information from both the drug and protein. On the other hand, atoms in distant regions of a drug molecule or amino acid residues in close proximity within a protein sequence may be spatially close in reality, but the spatial structural features of drug compounds and protein structures cannot be captured by these deep learning models.
To address these challenges, more researchers are adopting graph neural network (GNN)-based approaches for drug-target affinity prediction [
22,
23,
24]. GNNs offer unique advantages in DTA prediction, as both drugs and receptor proteins can be treated as complex graph structures, with interactions between the drug and protein modeled as interactions within a complex graph. GNNs are able to effectively capture the intricate molecular structures of drug molecules and protein molecules, as well as the interactions between them. For example, GraphDTA [
25] constructs a drug molecular graph, with atoms representing the nodes and the bonds between atoms serving as the edges, thus enriching the representation of drug molecules. DGraphDTA [
26] further builds a protein graph using contact map methods. It treats amino acid residues as nodes and considers them to be connected if the distance between them is below a certain threshold.
Although the aforementioned DTA prediction methods have achieved good results, they primarily focus on the features of individual drug and protein molecules while neglecting the relationships between drugs and proteins. For instance, HGRL-DTA [
27] integrates drug–protein interactions into the features of drugs and proteins but overlooks drug–drug and protein–protein relationships. MSF-DTA [
28] only considers protein–protein relationships, ignoring the relationships between drug–drug and drug–protein. To address these issues, this paper proposes an end-to-end DTA prediction method, DynHeter-DTA, that makes several contributions, which are as follows:
First, a mechanism was designed to dynamically adjust the connection strengths between drug–drug, protein–protein, and drug–protein interactions, constructing a variable heterogeneous graph structure in order to deeply explore drug-target interactions.
Furthermore, a model leveraging Graph Isomorphism Networks (GIN) and Self-Attention Graph Pooling (SAGPooling) techniques for drug-target interaction forecasting was introduced, improving both prediction efficiency and accuracy.
Finally, comprehensive experiments were conducted on the Davis, KIBA, and Human public datasets, comparing multiple baseline models. The proposed model’s superior performance was validated, providing a new approach for drug affinity prediction.
2. Results and Discussion
2.1. Settings
In this study, the dataset was divided into training and test sets with a ratio of 5:1, and fivefold cross-validation was applied to the training set. The proposed model DynHeter-DTA and comparison methods were trained using the training set and validated on the test set. Experiments were carried out on a machine equipped with 16 GB of VRAM on an NVIDIA MSI 4080 GPU and an Intel 11400f CPU, all from Nanjing, Jiangsu, China. The model was implemented with PyTorch 2.4.1, torch-geometric 2.6.1, and RDKit 2024.3.5, trained with the Adam optimizer at a fixed learning rate of 0.0005 and a batch size of 512. All hyperparameters, including the number of training epochs used in our experiments, are specified in
Table 1.
2.2. Metrics
Mean squared error (
) is used to quantify the discrepancy between the model’s predicted values and the ground truth, thereby evaluating DynHeter-DTA’s prediction performance. The formula is as follows:
where
is the size of the test set, and
and
are the actual and predicted values of the test sample, respectively.
The Concordance Index (
CI) is applied to evaluate the model’s accuracy and consistency in predicting the ranking of outcomes. The formula is as follows:
where
is a normalization constant and
is the step function.
The Relative Coefficient of Determination (
) is an indicator used to assess the relative goodness-of-fit of a regression model. It is a modified version of the coefficient of determination, considering the number of independent variables used in the model. The formula for the Relative Coefficient of Determination is as follows:
where
and
are the squared correlation coefficients with and without an intercept, respectively.
These above three evaluation metrics enable us to thoroughly assess the model’s performance and its predictive power in practical applications.
For the binary classification task of drug-target interaction (DTI), the following evaluation metrics are used in this study:
Here, , , and represent the number of true positives, false positives, and false negatives, respectively. In addition to accuracy and recall, the proposed model is also evaluated using the area under the receiver operating characteristic curve (AUROC) and the area under the precision-recall curve (AUPR).
2.3. Model Performance
To evaluate DynHeter-DTA’s performance, it was compared with baseline models, including KronRLS [
13], SimBoost [
14], DeepDTA [
18], WideDTA [
19], GraphDTA [
25], MGraphDTA [
29], GEFA [
30], WGNN-DTA [
31], and DGraphDTA [
26]. A detailed comparison and analysis of each model’s performance on different datasets was conducted. The performance results and a summary of the comparison with the baseline methods are presented in
Table 2 and
Table 3.
As demonstrated in
Table 3, DynHeter-DTA exceeds the performance of other methods on the Davis dataset, achieving values of 0.130, 0.923, and 0.828 in MSE, CI, and
, respectively. Compared to the second-best model, DGraphDTA, our model improves these metrics by 7.2%, 1.9%, and 12.8%, respectively. As shown in
Table 4, DynHeter-DTA also has a strong performance on the KIBA dataset, achieving values of 0.123, 0.908, and 0.821 in MSE, CI, and
, respectively. In comparison to the second-best model, DGraphDTA, DynHeter-DTA improves these metrics by 0.3%, 0.4%, and 4.0%, respectively.
For the DTI task, as is shown
Table 4, the proposed model is compared to GCN [
32], GanDTI [
33], GraphCPI [
34], MGraphDTA [
29], and TransformerCPI [
20]. DynHeter-DTA achieves AUC, Precision, Recall, and F1 scores of 0.988, 0.956, 0.961, and 0.951, respectively, which show improvements of 0.5%, 2.2%, 1.4%, and 0.8% over the best-performing model, MGraphDTA. These results demonstrate that DynHeter-DTA has a high performance and potential within the domain of drug–protein affinity prediction.
2.4. Binding Affinity Prediction on Testing Data
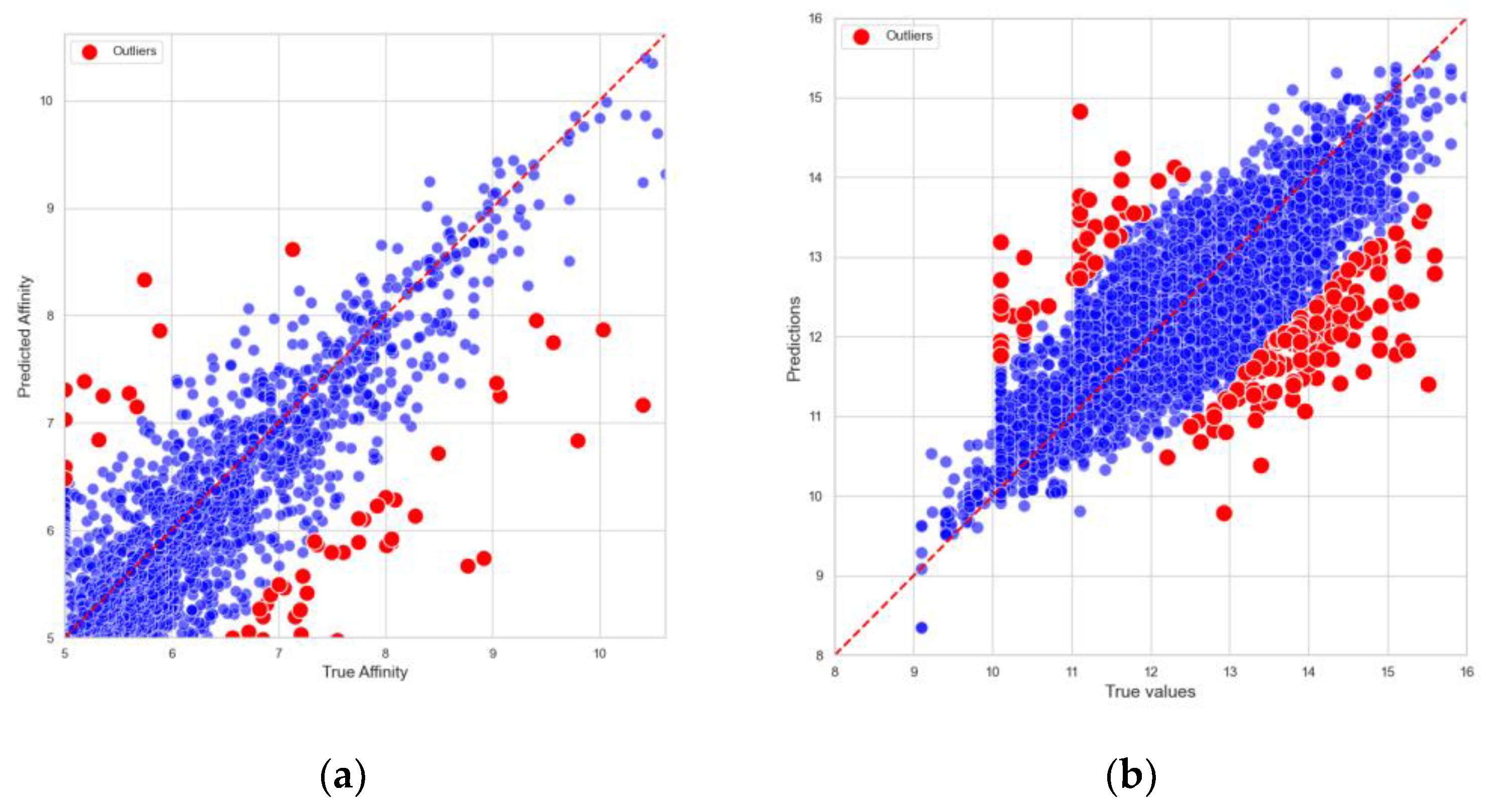
To further assess the reliability of the predictions, predicted binding affinities were compared to the actual binding affinities from the Davis and KIBA datasets on the test set. As shown in
Figure 1, DynHeter-DTA demonstrates an impressive performance. The predicted values exhibit a strong correlation with the true values, with the data points in the scatter plot closely distributed around the ideal prediction line, indicating that the model fits the actual data very well. This further validates the accuracy and stability of the model.
In order to systematically investigate the origins of outliers, this study analyzed the data points in the Davis and KIBA datasets whose prediction errors ranked in the top 5%. The results show that the average absolute errors for the entire datasets were 0.178 and 0.159, respectively, whereas these outliers (accounting for about 5.01% of the samples) exhibited average absolute errors of 1.233 and 0.1124, which are significantly higher than the overall levels. This finding indicates that utilizing the 95th percentile threshold effectively captures the high-error tail, which substantially deviates from the mean.
Within the context of drug–protein binding prediction, grouping outliers by compounds and proteins revealed that most anomalies originated on the compound side rather than the protein side. Notably, compounds 11,409,972, 11,984,591, 16,038,120, 126,565, and 11,409,972 displayed average errors exceeding 1 across multiple targets. For instance, compound 16,038,120 not only showed a large deviation with AK (2.14), but also with BMPR1B (1.82), TSSK1B (1.80), TRKB (1.57), and CHEK1 (1.49). Similarly, compound 11,409,972 showed high errors for EPHB6 (2.31), MET (1.90), LOK (1.66), and TNK1 (1.65). These findings suggest that such compounds do not merely “fail” on a single target, but rather exhibit consistently high errors across multiple targets.
To further elucidate the underlying causes, an in-depth analysis of the structures and physicochemical properties of these compounds was conducted. The results indicate that their scaffolds and substructures differ markedly (low Tanimoto similarity), implying that they are not derivatives of a single series that might cause systematic bias. However, at the macroscopic level of physicochemical features, these compounds commonly exhibit high molecular weights (>500 Da), elevated LogP values (>4), and multiple aromatic rings and hydrogen-bonding sites, collectively manifesting as “complex, lipophilic, and high-molecular-weight” attributes.
2.5. Ablation Study
To examine the key determinants of the DynHeter-DTA’s predictive capability, ablation experiments were executed using different variants of the model. The subsequent numbered lists illustrate
Without heterogeneous graph, using GCN instead of GIN and SAGPooling;
Without heterogeneous graph, using GIN and SAGPooling;
Using dynamic heterogeneous graph with GIN and SAGPooling.
Through these ablation experiments, it was found that the key factors affecting the model’s predictive performance are the use of heterogeneous graphs and the application of GIN and SAGPooling. On the Davis and KIBA datasets, the model performed the worst when the heterogeneous graph was not used and GCN replaced GIN and SAGPooling. When GIN and SAGPooling were used without the heterogeneous graph, the model performance improved. However, the best performance across all metrics was achieved when the dynamic heterogeneous graph was used in conjunction with GIN and SAGPooling. This result demonstrates that the introduction of the dynamic heterogeneous graph and the synergistic effect of GIN and SAGPooling significantly enhanced the model’s predictive capabilities, highlighting the critical role these components play in improving model performance. The experimental results are shown in
Table 5 and
Table 6.
2.6. Visual Explanation
2.6.1. Visualization of the Dynamic Heterogeneous Graph
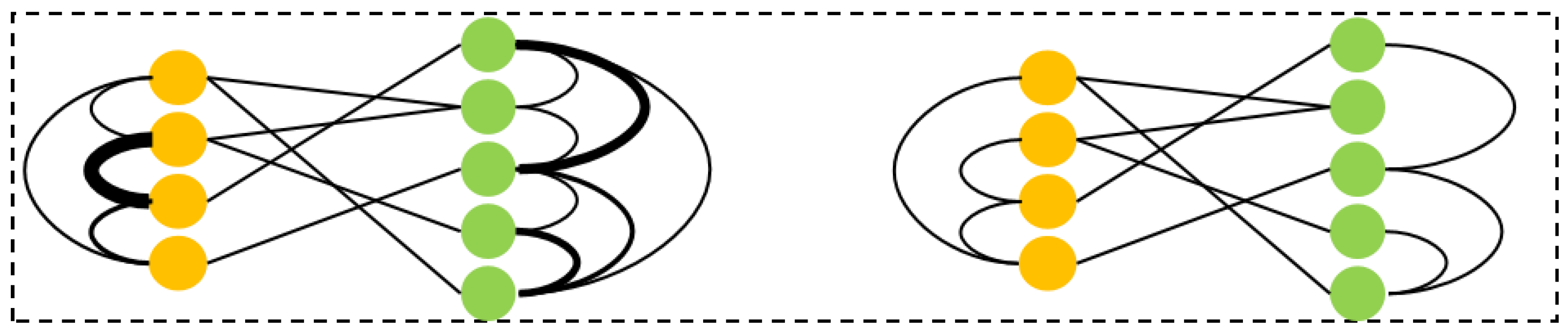
To better understand the proposed variable heterogeneous graph prediction model, a visual analysis of the constructed drug–protein heterogeneous graph is conducted. In traditional static graph structures, the edges are usually based on predefined similarity or interaction strength. However, in our model, the edges are adaptively optimized according to the features of the nodes. This dynamic adjustment mechanism allows the graph structure to continuously evolve during training, providing a more accurate reflection of the affinity relationship between drugs and proteins.
As shown in
Figure 2, the nodes in the graph are divided into the following two categories: drug nodes and protein nodes. The edges between drug nodes represent drug-to-drug similarity, the edges between protein nodes represent protein-to-protein similarity, and the edges between drug and protein nodes represent their interaction relationship. This heterogeneous graph structure enables us to capture the multi-level relationships between drugs and proteins comprehensively.
To further illustrate the dynamic changes in the graph, several drug molecules and protein molecules were selected to form a heterogeneous graph for dynamic adjustment. The comparison between the initial graph structure and the dynamically adjusted graph structure is displayed in
Figure 3. The initial graph provides the basic interactions between drugs and proteins, while the dynamically adjusted graph highlights the interactions that the model considers more important by optimizing the edge weights. This optimization not only enhances the expressive power of the graph, but also improves the model’s ability to adapt to complex data, providing more effective information support for drug–protein affinity prediction.
2.6.2. Visualization of GIN and SAGPooling
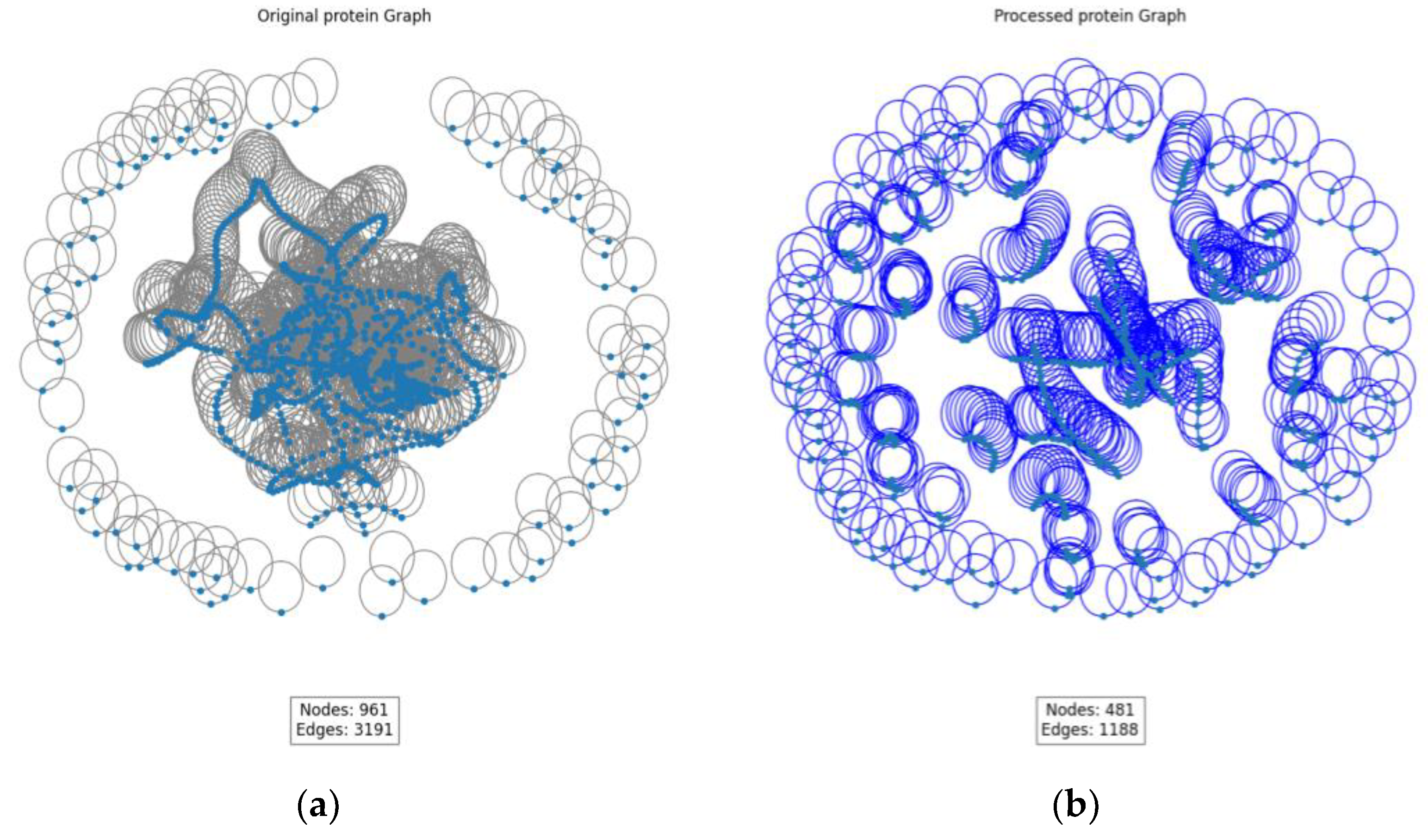
As shown in
Figure 4, a visual analysis of GIN and SAGPooling was conducted. The left side presents the original graph, while the right side displays the processed graph. By comparing the two graphs, significant changes in the graph structure and feature representation after applying GIN and SAGPooling are clearly observable.
GIN significantly enhances the node feature representations through its unique feature aggregation mechanism. Specifically, GIN aggregates the features of neighboring nodes by weighted summation at each layer and applies a multi-layer perceptron (MLP) for non-linear transformation. This ensures that the feature representation of each node contains not only its own information, but also the features of its neighboring nodes. This method effectively captures subtle relationships in the graph, ensuring that information is fully propagated across the graph structure.
In the original graph, the number of nodes is denoted as 961 and the number of edges as 3191. After the pooling operation, the number of nodes is reduced to 481 and the number of edges to 1188. This reduction is a result of the SAGPooling operation, which selects and retains the most important nodes based on an attention mechanism. GIN enhances the feature representations of the nodes during feature extraction, making it more effective in identifying and retaining critical nodes during the pooling process. This combination of GIN and SAGPooling significantly improves the node feature representations in the model while reducing irrelevant information and redundant nodes and edges. As a result, the model can more efficiently learn the affinity relationships between drugs and proteins.
2.6.3. Visualization of Drug–Protein Binding
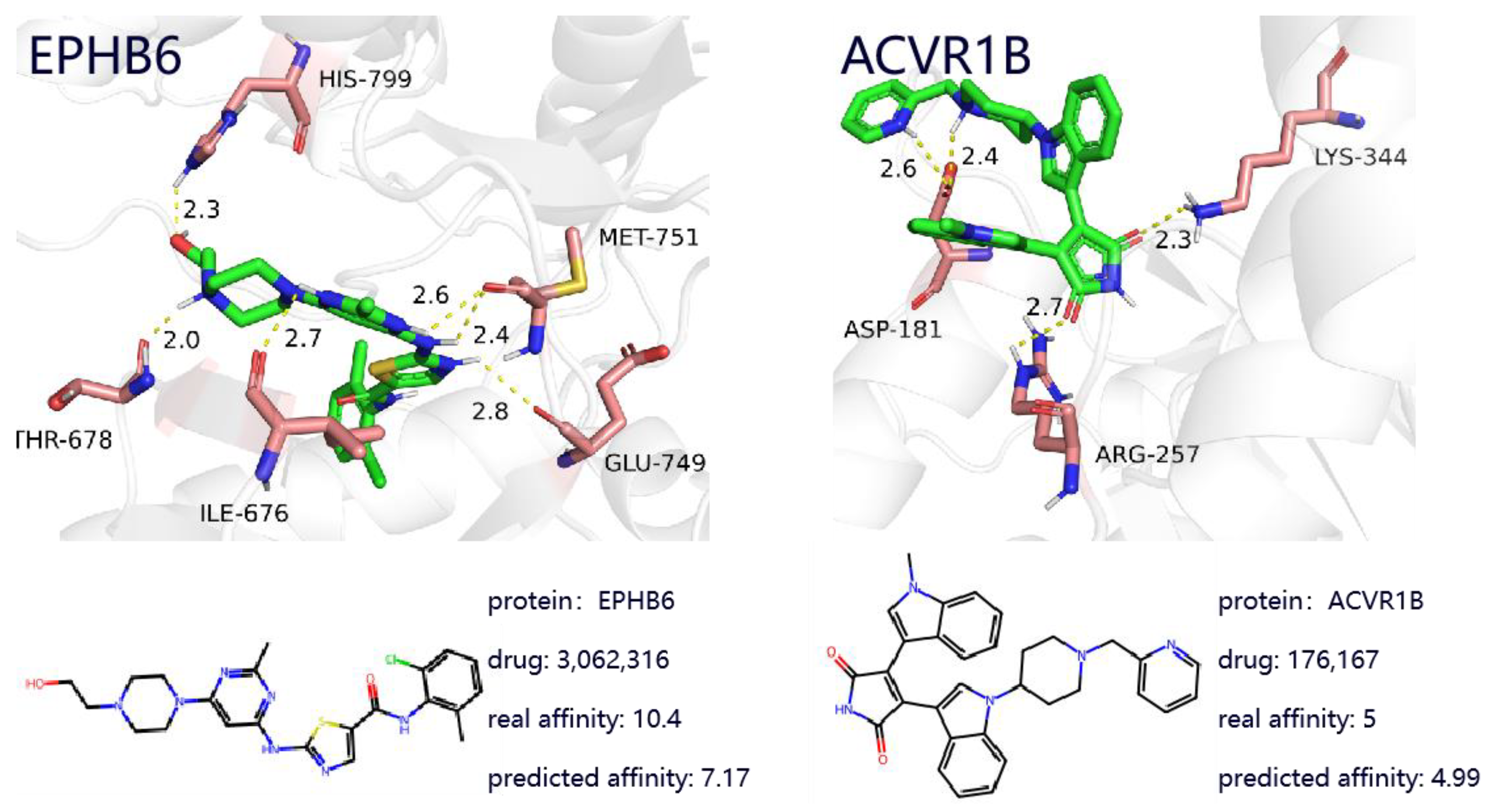
To further investigate the effectiveness of the proposed method, this study presents two case studies of drug-target complexes, which provide deeper insight into DTA prediction and contribute to understanding the potential mechanisms behind protein-target-based drug discovery. As shown in
Figure 5, the left panel illustrates the complex between the targeted drug Dasatinib and the gene EPHB6, while the right panel shows the complex between the targeted drug Enzastaurin and the target ACVR1B. By utilizing known drug-target binding examples, the effectiveness and practicality of the proposed model in real-world applications are validated.
2.7. Discussion
In this study, we propose a drug-target affinity prediction model trained on the DAVIS and KIBA datasets, demonstrating broad potential for real-world applications. While the model exhibits a limited performance on certain complex, lipophilic compounds of high molecular weight that contain multiple aromatic rings and hydrogen-bonding sites, it effectively predicts the binding affinities between novel drug molecules and their target proteins in most other cases. This capability assists in identifying lead compounds during drug discovery and offers valuable insights for drug development. Furthermore, it can uncover previously unknown protein–drug interactions and supports the identification of new therapeutic targets.
Although the model may require further optimization for more complex tasks, such as multi-target drug design, its methodological framework exhibits strong scalability. In the future, it could be applied to other areas, such as protein–protein interaction prediction, drug–drug interaction analysis, and protein–antibody interaction prediction, showing considerable potential for expansion in these fields.
3. Materials and Methods
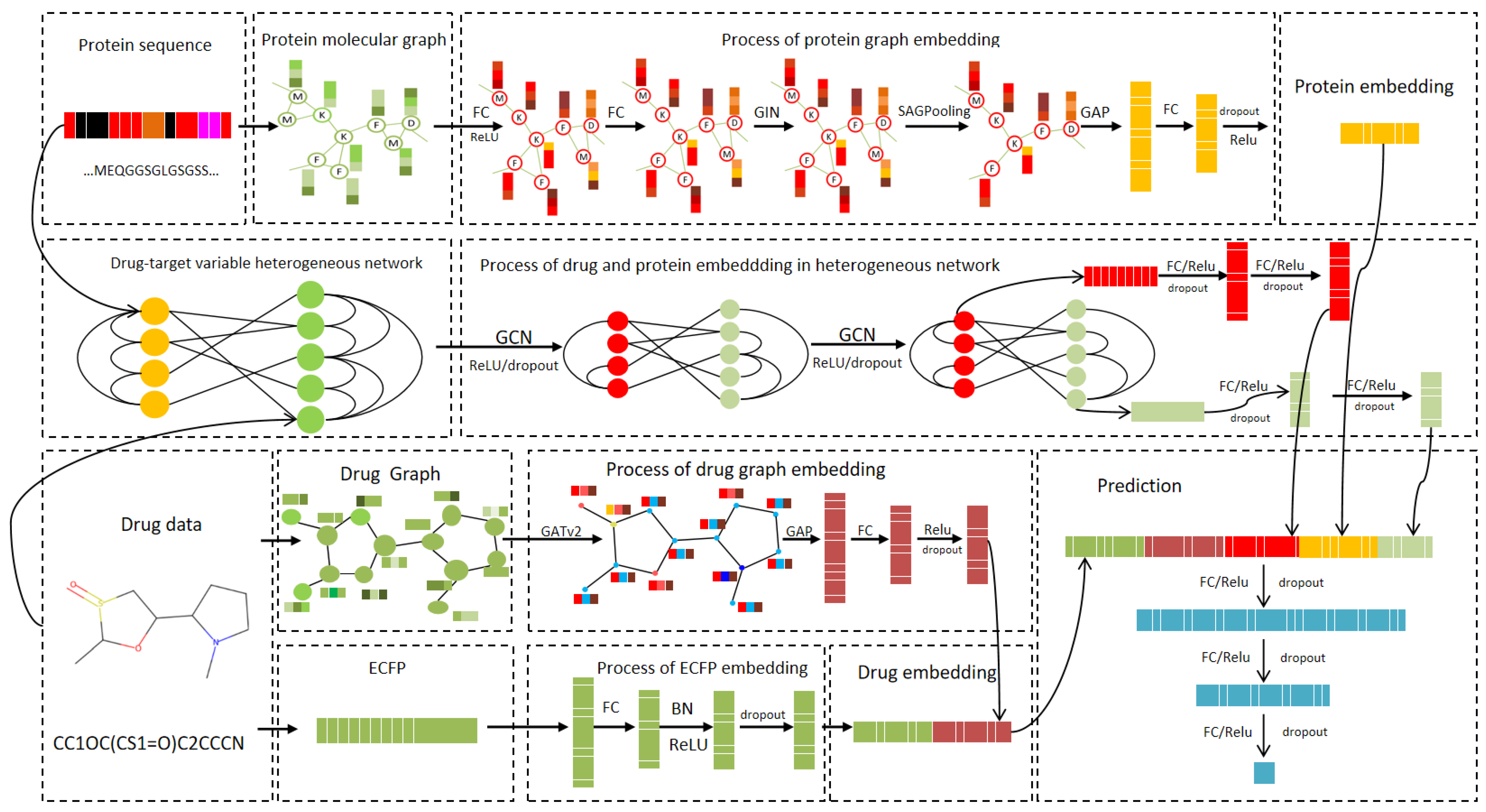
In this section, a dynamic heterogeneous graph representation learning model, DynHeter-DTA, for DTA prediction is proposed. The model’s input includes the drug and protein sequences, and the overall architecture is divided into the following two parts: feature extraction and relationship modeling.The entire model framework is illustrated in
Figure 6.
In the feature extraction part, for drug embedding, the drug’s Morgan fingerprints (ECFP) [
35] are first computed using the RDKit library, and the fingerprint embedding is extracted through an FC layer. The drug’s SMILES sequence is then converted into a molecular graph, and its features are extracted using a Graph Attention Network (GAT). The results are passed through an FC layer to generate the molecular graph embedding. These two embeddings are then concatenated to form the drug embedding. For protein sequences, the method proposed by Jiang et al. [
26] is adopted, which transforms the protein sequence into a protein residue graph. GINs are employed to extract features, and a SAGPooling layer is applied to remove irrelevant nodes. The protein embedding is generated through global pooling.
In the relationship modeling part, a dynamic heterogeneous graph is constructed based on drug and protein data, integrating drug–drug and protein–protein similarities, and the complex interactions between drugs and proteins. A two-layer GCN is employed to extract global features for both the drug and protein. These global features are then fused with the previously extracted drug and protein embeddings and processed through FC layers. The final output is the predicted binding affinity score.
3.1. Database
The Davis [
36] and KIBA [
37] datasets are two important resources for studying drug–protein interactions and are essential for drug discovery and progress in the biomedical field. The Davis dataset is based on experimentally determined drug–protein interaction data, containing detailed records of drug molecules, their associated protein targets, and their binding affinities, typically represented by Kd values. This dataset provides essential information about drug–protein interactions. On the other hand, the KIBA dataset focuses on the interactions between kinase inhibitors and protein kinases. It includes data on kinase inhibitor molecules and their binding affinities with kinase proteins, assisting in the prediction of potential kinase inhibitors’ effectiveness. The Davis and KIBA datasets are employed to evaluate the model in comparison to other baseline models. In addition, this paper also introduces the Human [
38] dataset to evaluate the proposed model, which includes 3369 positive samples and 3359 negative samples.
Table 7 summarizes the specific details of these three datasets.
In the Davis, KIBA, and Human datasets, drug molecules are represented by a structured SMILES notation. SMILES encodes the structure of a drug molecule as a string, where atoms and bonds are represented by specific characters. RDKit is a machine learning software library that assists in solving challenges related to chemical information; PyTorch is a free, open-source platform for deep learning applications and machine learning tasks. PyG is a graph neural network library built on top of PyTorch. The RDKit [
39] library is employed to construct node and edge features for drug molecules, while the drug graph structure is built using PyG [
40]. The model is developed using PyTorch [
41].
In all datasets, proteins are represented by their sequences. The one-dimensional representation of protein sequences provides basic information about proteins, but it often neglects the critical role of spatial structure in protein functionality [
42]. On the other hand, the three-dimensional structural representation of proteins is highly complex and is typically represented as a point cloud to capture the protein’s spatial conformation. While this representation can capture spatial information, it incurs significant computational cost [
43]. To balance the consideration of spatial structure with computational efficiency, Jiang et al. [
26] proposed a method to construct protein graph representations by predicting contact maps. In this representation, a protein is viewed as a graph, where nodes represent amino acids and edges indicate interactions between amino acids.
3.2. Drug–Protein Dynamic Heterogeneous Graph
The heterogeneous graph is an effective representation of the relationship between drugs and proteins. The heterogeneous graph is denoted as
, where
is the feature matrix and
is the adjacency matrix. The entire heterogeneous graph consists of the feature matrix as well as the edge weight matrix. The initial adjacency matrix is
where
is the drug–drug similarity matrix;
is the drug–protein binding affinity matrix, and
is its transpose; and
is the protein–protein similarity matrix.
represents an adjacency matrix where each node has a self-loop. The matrices
and
are obtained using the following Tanimoto coefficients and global alignment methods, while
is provided by the dataset.
Here, the Tanimoto coefficient is used to measure drug–drug similarity [
44]. Each drug is represented by its Morgan fingerprints to capture the local environmental information of its molecular structure, effectively describing the structural features of the molecule. Subsequently, the Tanimoto coefficient [
43] is used to measure the resemblance between two drugs. The formula can be expressed as follows [
44]:
where
and
represent the fingerprint vectors of two drug molecules. Furthermore, the value of the Tanimoto coefficient varies between 0 and 1; a value approaching 1 suggests greater structural similarity of the two molecules, and vice versa.
The Needleman–Wunsch (NW) global alignment algorithm [
45] is used in this study to calculate protein–protein similarity. The NW algorithm is a classical dynamic programming approach designed to globally align two sequences and determine their optimal matching. It constructs a matrix to incrementally compute the similarity scores between the two sequences, and ultimately identifies the best alignment path through a backtracking procedure. During matrix filling, the algorithm considers match, mismatch, and gap insertions, ultimately producing a similarity score that reflects the global alignment between the sequences. The calculated similarity is denoted as
in this study.
To capture the features of drug–protein interaction affinity in the heterogeneous graph, Graph Convolutional Networks (GCN) are utilized. This method uses the feature matrix and adjacency matrix of nodes as inputs. By performing convolution operations on the graph, it captures the feature relationships between nodes and their neighbors. The general learning process of GCN can be expressed as follows [
32]:
where
is the adjacency matrix with added self-loops,
is the identity matrix,
is the degree matrix of
A,
σ is the non-linear activation function (ReLU used in our study),
is the trainable weight matrix of the
-th layer, and
is the node feature matrix at the
-th layer, which is derived from the one-hot encoding of the drug and protein, along with their similarity and binding relationships.
By incorporating drug–drug similarity and protein–protein similarity into the heterogeneous graph, and designing a dynamic edge weight adjustment method, a variable heterogeneous graph for the drug–protein similarity affinity is constructed. The update of the heterogeneous graph is integrated with the model training. The model can more comprehensively capture the similarity and interaction information between drugs and proteins. This enhanced heterogeneous graph can dynamically learn the optimal graph structure, improving both the graph’s expressiveness and the model’s flexibility and adaptability. This, in turn, provides more effective informational support for drug–protein affinity prediction.
To further achieve this, two transformations to the heterogeneous graph adjacency matrix and node feature matrix are exerted, respectively, which result in the following dynamic heterogeneous graph learning process:
The adjacency matrix of the designed variable heterogeneous graph with self-loops is
where
and
directly affect the edge structure retained in the graph and are updated through back propagation.
The feature matrix of the designed variable heterogeneous graph is
where
is obtained by marking all non-zero elements in matrix
as 1. This is
where
is the one-hot encoding of drugs and proteins.
3.3. Drug Graph and Protein Graph Embedding Representation
A Graph Attention Network (GAT) is leveraged to learn the embedding from the drug graph [
46]. For a node
in the drug graph
and its neighboring nodes
, the attention coefficient is
where
and
are the features of nodes
and
;
is the trainable attention weight vector;
is the trainable weight matrix used for linear transformation; and
represents the importance of node
to node
.
To facilitate a comparison between different adjacent nodes, the Softmax function is used over the neighbors.
where
is the neighborhood of node
in the graph.
Then, by calculating the weighted sum of the features based on the normalized attention coefficients of each node, the output features are derived, as follows:
where
is the non-linear activation function (ReLU in the model) and
represents the processed feature of the drug graph after applying GAT.
A Graph Isomorphism Network (GIN) is used to extract the embedding of the protein graph [
47]. For a node in the protein graph and its neighboring nodes, the operation on the graph can be expressed by the following formula:
where
denotes the set of neighboring nodes of node
in the protein graph, and
and
are the feature vectors of nodes
and
in the protein graph at the
h-th layer, respectively. Additionally,
is a learnable parameter and
refers to the protein graph after processing with GIN.
SAGPooling [
48] is a node feature aggregation technique based on the self-attention approach, capable of adaptively learning the importance weights of each node, and thus effectively distinguishing which nodes should be retained and which can be discarded. The process is as follows. First, calculate the importance score
where
and
represent the feature matrix and adjacency matrix of the protein graph after processing with GIN, respectively. Then, select the top
K highest-scoring nodes
Finally, the node features and the adjacency matrix are updated according to the following rules:
3.4. Information Fusion
The node features in the heterogeneous graph are subsequently fused with the information from the drug graph and the protein graph, respectively. Specifically, given the feature
of the drug node
in the heterogeneous graph, the processed molecular graph
, and the processed drug ECPR representation
, the enhanced embedding of the drug node can be defined as follows:
where
represents the concatenation process and GAP refers to global average pooling.
Similarly, given a protein node
in the heterogeneous graph, with the feature
and the processed protein graph
, the fused representation of the protein node can be defined as
3.5. DTA Prediction
In the model, predicting the drug–protein binding affinity is treated as a regression problem. By concatenating the representation
of drug
and the representation
of protein
, the final prediction is made through three fully connected layers. This approach effectively integrates the features of both drug and protein, enhancing the model’s prediction accuracy. The formula is as follows:
The regression loss function, mean squared error (MSE), quantifies the difference between the predicted values and the ground truth. The formula is as follows:
where
is the true binding affinity.
4. Conclusions
For drug–protein binding prediction, this paper addresses two main issues. The first issue is how to effectively utilize the connections between drugs and proteins. To tackle this, we propose a dynamic heterogeneous graph structure. It can adaptively learn the optimal graph structure and dynamically adjust the connection strengths between drug–drug, protein–protein, and drug–protein interactions, thereby more effectively capturing complex interaction relationships.
The second issue is that in reality, the number of drugs is much smaller than the number of proteins, and in the protein–drug binding process, there are likely many irrelevant or weakly influential nodes on the protein. To address this, we combine GIN and SAGPooling techniques to accurately extract the important node features from proteins, simplify the protein graph structure, and enhance both prediction efficiency and accuracy.
Experiments on the Davis, KIBA and Human datasets were conducted to evaluate the performance of DynHeter-DTA. The model demonstrated substantial improvements over existing methods in both prediction accuracy and its ability to capture complex relationships. The comparison between predicted and true binding affinities showed a high correlation, validating the effectiveness of our approach. An ablation study was conducted to evaluate the contribution of each component of the model, revealing that both the dynamic graph structure and the feature extraction techniques (GIN and SAGPooling) are crucial for enhancing performance. Moreover, a visual explanation of the model’s decision-making process further confirmed that DynHeter-DTA successfully identifies important drug-target interaction features, offering insights into the underlying binding mechanisms. These results emphasize the potential of DynHeter-DTA as a powerful tool for drug affinity prediction.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}