1. Introduction
Generative models have become a cornerstone of modern machine learning, offering powerful methods for synthesizing high-quality data across various domains such as image and video synthesis [
1,
2,
3], natural language processing [
4,
5,
6,
7], audio generation [
8,
9], and molecular structures and general 3D shapes [
10,
11,
12,
13], to name a few. These models transform an initial distribution, which is simple to sample from, into one that approximates the data distribution. Among these, diffusion-based models designed through the lenses of Stochastic Differential Equations (SDEs) [
14,
15,
16] have gained popularity due to their ability to generate realistic and diverse data samples through a series of stochastic transformations.
In such models, the data generation process, as described by a substantial body of empirical research [
17,
18,
19], appears to develop according to distinct stages: high-level semantics emerge first, followed by the incorporation of low-level details, culminating in a refinement (denoising) phase. Despite ample evidence, a comprehensive theoretical framework for modeling these dynamics remains underexplored.
Indeed, despite recent work on SDE-based generative models, refs. [
20,
21,
22,
23] shedding new light on such models, they fall short of explicitly investigating the emergence of abstract representations in the generative process. We address this gap by establishing a new framework for elucidating how generative models construct and leverage latent abstractions, approached through the paradigm of NLF [
24,
25,
26].
NLF is used across diverse engineering domains [
24], as it provides robust methodologies for the estimation and prediction of a system’s state amidst uncertainty and noise. NLF enables the inference of dynamic latent variables that define the system state based on observed data, offering a Bayesian interpretation of state evolution and the ability to incorporate stochastic system dynamics. The problem we consider is the following: an
unobservable random variable
X is measured through a noisy continuous-time process
, wherein the influence of
X on the noisy process is described by an observation function
H, with the noise component modeled as a Brownian motion term. The goal is to estimate the a posteriori measure
of the variable
X given the entire historical trajectory of the measurement process
.
In this work, we establish a connection between SDE-based generative models and NLF by observing that they can be interpreted as simulations of NLF dynamics. In our framework, the latent abstraction, which corresponds to certain real-world properties within the scope of classical nonlinear filtering and remains unaffected in a causal manner by the posterior process , is implicitly simulated and iteratively refined. We explore the connection between latent abstractions and the a posteriori process, through the concept of filtrations—broadly defined as collections of progressively increasing information sets—and offer a rigorous theory to study the emergence and influence of latent abstractions throughout the data generation process. To ground the reader’s intuition in a concrete example, our experimental validation considers a scenario where latent abstractions correspond to scene descriptions—such as color, shape, and object size—that are subsequently rendered using a computer program.
Our theoretical contributions unfold as follows. In
Section 2 we show how to reformulate classical NLF results such that the measurement process is the only available information, and derive the corresponding dynamics of both the latent abstraction and the measurement process. These results are summarized in Theorems 2 and 3.
Given the new dynamics, in Theorem 4, we show how to estimate the a posteriori measure of the NLF model and present a novel derivation to compute the mutual information between the measurement process and random variables derived from a transformation of the latent abstractions in Theorem 5. Finally, we show in Theorem 6 that the a posteriori measure is a sufficient statistic for any random variable derived from the latent abstractions when only having access to the measurement process.
Building on these general results, in
Section 3 we present a novel perspective on continuous-time score-based diffusion models, which is summarised in Equation (
10). We propose to view such generative models as NLF simulators that progress in two stages: first, our model updates the a posteriori measure representing sufficient statistics of the latent abstractions; second, it uses a projection of the a posteriori measure to update the measurement process. Such intuitive understanding is the result of several fundamental steps. In Theorems 7 and 8, we show that the common view of score-based diffusion models by which they evolve according to forward (noising) and backward (generative) dynamics is compatible with the NLF formulation, in which there is no need to distinguish between such phases. In other words, the NLF perspective of Equation (
10) is a valid generative model. In
Appendix H, we provide additional results (see Lemma A1), focusing on the specific case of linear diffusion models, which are the most popular instance of score-based generative models in use today. In
Section 4, we summarize the main intuitions behind our NLF framework.
Our results explain, by means of a theoretically sound framework, the emergence of latent abstractions that has been observed by a large body of empirical work [
17,
18,
19,
27,
28,
29,
30,
31,
32,
33]. The closest research to our findings are discussed in [
34,
35,
36], albeit from a different mathematical perspective. To root our theoretical results in additional empirical evidence, we conclude our work in
Section 5 with a series of experiments on score-based generative models [
14], where we (1) validate existing probing techniques to measure the emergence of latent abstractions, (2) compute the mutual information as derived in our framework and show that it is a suitable approach to measure the relation between the generative process and latent abstractions, and (3) introduce a new measurement protocol to further confirm the connections between our theory and how practical diffusion-based generative models operate.
2. Nonlinear Filtering
Consider two random variables
and
X, corresponding to a stochastic
measurement process (
) of some underlying
latent abstraction (
X). We construct our universe sample space
as the combination of the space of continuous functions in the interval
(i.e.,
with
), and of a complete separable metric space
, i.e.,
. On this space, we consider the joint
canonical process
for all
, with
. In this work, we indicate with
sigma-algebras. Consider the growing filtration naturally induced by the canonical process
(a short-hand for
), and define
. We build the probability triplet
, where the probability measure
is selected such that the process
has the following SDE representation
where
is a Brownian motion with initial value 0 and
is an
observation process. All standard technical assumptions are available in
Appendix A.
Next, we provide the necessary background on NLF, to pave the way for understanding its connection with the generative models of interest. The most important building block of the NLF literature is represented by the conditional probability measure (notice the reduced filtration ), which summarizes, a posteriori, the distribution of X given observations of the measurement process until time t, that is, .
Theorem 1 (Thm 2.1 [
24]).
Consider the probability triplet , the metric space and its Borel sigma-algebra . There exists a (probability measure valued ) process , with a progressively measurable modification, such that for all , the conditional probability measure is well defined and is equal to . The conditional probability measure is extremely important, as the fundamental goal of nonlinear filtering is the solution to the following problem. Here, we introduce the quantity , which is a random variable derived from the latent abstractions X.
Problem 1. For any fixed bounded and measurable, given knowledge of the measurement process , compute . This amounts to computing In simple terms, Problem 1 involves studying the existence of the a posteriori measure and the implementation of efficient algorithms for its update, using the flowing stream of incoming information
. We first focus our attention on the existence of an analytic expression for the value of the a posteriori expected measure
. Then, we quantify the interaction dynamics between observable measurements and
, through the lenses of mutual information
, which is an extension of the problems considered in [
37,
38,
39,
40].
2.1. Technical Preliminaries
We set the stage of our work by revisiting the measurement process
, and express it in a way that does not require access to unobservable information. Indeed, while
is naturally adapted with reference to its own filtration
, and consequently to any other growing filtration
such
, the representation in Equation (
1) is in general not adapted, letting aside degenerate cases.
Let us consider the family of growing filtrations
, where
. Intuitively,
allows to modulate between the two extreme cases of knowing only the initial conditions of the SDE, that is
, to the case of complete knowledge of the whole latent abstraction
X, and anything in between. As shown hereafter, the original process
associated with the space
which solves Equation (
1), also solves Equation (
4), which is adapted on the reduced filtration
. This allows us to reason about the partial observation of the latent abstraction (
vs.
), without incurring in the problem of the measurement process
being statistically dependent of the whole latent abstraction
X.
Armed with such representation, we study under which change of measure the process behaves as a Brownian motion (Theorem 3). This serves the purpose of simplifying the calculation of the expected value of given , as described in Problem 1. Indeed, if is a Brownian motion independent of , its knowledge does not influence our best guess for , i.e., the conditional expected value. Moreover, our alternative representation is instrumental for the efficient and simple computation of the mutual information , where the different measures involved in the Radon–Nikodym derivatives will be compared against the same reference Brownian measures.
The first step to define our representation is provided by the following
Theorem 2. [Appendix B] Consider the the probability triplet , the process in Equation (1) defined on it, and the growing filtration . Define a new stochastic processThen, is a Brownian motion. Notice that if , then . Following Theorem 2, the process
has SDE representation
Next, we derive the change of measure necessary for the process
to be a Brownian motion with reference to to the filtration
. To carry this out, we apply the Girsanov theorem [
41] to
, which, in general, admits a
-adapted representation
.
Theorem 3. [Appendix C] Define the new probability space via the measure , for , whereand Then, the stochastic process is a Brownian motion on the space .
A direct consequence of Theorem 3 is that the process is independent of any measurable random variable under the measure . Moreover, it holds that for all , .
2.2. A Posteriori Measure and Mutual Information
As in
Section 2 for the process
, here, we introduce a new process
, which represents the conditional law of
X given the filtration
. More precisely, for all
, the conditional probability measure
is well defined and is equal to
. Moreover, for any
bounded and measurable,
. Notice that if
then
reduces to
.
Armed with Theorem 3, we are ready to derive the expression for the a posteriori measure and the mutual information between observable measurements and the unavailable information about the latent abstractions, that materialize in the random variable .
Theorem 4. [Appendix D] The measure-valued process solves in weak sense (see Appendix D for a precise definition) the following SDE
where the initial condition satisfies for all . When
, Equation (
6) is the well-known Kushner–Stratonovitch (or Fujisaki—Kallianpur–Kunita) equation (see, e.g., [
24]). A proof for uniqueness of the solution of Equation (
6) can be approached by considering the strategies in [
42], but is outside the scope of this work. The (recursive) expression in Equation (
6) is particularly useful for engineering purposes since, in general, it is usually not known in which variables
, representing latent abstractions, we could be interested in. Keeping track of the
whole distribution at time
t is the most cost-effective solution, as we will show later.
Our next goal is to quantify the interaction dynamics between observable measurements and latent abstractions that materialize through the variable (from now on, we write only for the sake of brevity); in Theorem 5, we derive the mutual information .
Theorem 5. [Appendix E] The mutual information between observable measurements and ϕ is defined as:It holds that such quantity is equal to , with , which can be simplified as follows: The mutual information computed by Equation (
8) is composed of two elements: first, the mutual information between the initial measurements
and
, which is typically zero by construction. The second term quantifies how much the best prediction of the observation function
H is influenced by the extra knowledge of
, in addition to the measurement history
. By adhering to the premise that the conditional expectation of a stochastic variable constitutes the optimal estimator given the conditioning information, the integral on the right-hand side quantifies the expected squared difference between predictions, having access to measurements only (
) and those incorporating additional information (
).
Even though a precise characterization for general observation functions and and variables
is typically out of reach, a
qualitative analysis is possible. First, the mutual information between
and the measurements depends on (
i) how much the amplitude of
H is impacted by knowledge of
and (
ii) the
number of elements of
H that are impacted (informally, how much localized vs. global is the impact of
). Second, it is possible to define a hierarchical interpretation about the emergence of the various latent factors: a variable with a local impact can “
appear”, in an information theoretic sense, only if the impact of other global variables is resolved; otherwise, the remaining uncertainty of the global variables makes knowledge of the local variable irrelevant. In classical diffusion models, this is empirically known [
17,
18,
19], and corresponds to the phenomenon where
semantics emerges before details (global vs. local details in our language). For instance, as shown in
Section 5, during the generative dynamics, latent abstractions which correspond to high level properties such as color and geometric aspect ratio emerge in very early stages of the process.
Now, consider any measurable random variable , defined as a mapping to a generic measurable space , which means it can also be seen as a process. The data processing inequality states that the mutual information between such and will be smaller than the mutual information between the original measurement process and . However, it can be shown that all the relevant information about the random variable contained in is equivalently contained in the filtering process at time instant t, that is . This is not trivial, since is a -measurable quantity, i.e., . In other words, we show that is a sufficient statistic for any measurable random variable when starting from the measurement process.
Theorem 6. [Appendix F] For any measurable random variable , the following inequality holds: For a given , the measurement process and X are conditionally-independent given . This implies that . Then, (i.e., Equation (9) is attained with equality). While
contains all the relevant information about
, the same cannot be said about the conditional expectation, i.e., the particular case
. Indeed, from Equation (
2),
is obtained as a
transformation of
and thus can be interpreted as a
measurable quantity subject to the constraint of Equation (
9). As a particular case, the quantity
, of central importance in the construction of generative models
Section 3, carries, in general, less information about
than the un-projected
.
3. Generative Modeling
We are interested in
generative models for a given
-measurable random variable
V. An intuitive illustration of how data generation works according to our framework is as follows. Consider, for example, the image domain, and the availability of a rendering engine that takes as an input a computer program describing a scene (coordinates of objects, textures, light sources, auxiliary labels, etc...) and that produces an output image of the scene. In a similar vein, a generative model learns how to use latent variables (which are not explicitly provided in input, but rather implicitly learned through training) to generate an image. For such a model to work, one valid strategy is to consider an SDE in the form of Equation (
1) where the following holds (from a strictly technical point of view, Assumption 1 might be incompatible with other assumptions in
Appendix A, or proving compatibility could require particular effort. Such details are discussed in
Appendix G).
Assumption 1. The stochastic process satisfies
Then, we could numerically simulate the dynamics of Equation (
1) until time
T. Indeed, starting from initial conditions
, we could obtain
that, under Assumption 1, is precisely
V. Unfortunately, such a simple idea requires
explicit access to
X, as it is evident from Equation (
1). In mathematical terms, Equation (
1) is adapted to the filtration
. However, we have shown how to reduce the available information to account only for historical values of
. Then, we can combine the result in Theorem 4 with Theorem 2 and re-interpret Equation (
4), which is a valid generative model, as
where
H denotes
. Explicit simulation of Equation (
10) only requires knowledge of the whole history of the measurement process: provided Assumption 1 holds, it allows generation of a sample of the random variable
V.
Although the discussion in this work includes a large class of observation functions, we focus on the particular case of generative diffusion models [
14]. Typically, such models are presented through the lenses of a forward noising process and backward (in time) SDEs, following the intuition of Anderson [
43]. Next, according to the framework we introduce in this work, we reinterpret such models from the perspective of enlargement of filtrations.
Consider the
reversed process
defined on
and the corresponding filtration
. The measure
is selected such that the process
has a
-adapted expression
where
is a Brownian motion. Then, Assumption 1 is valid since
. Note that Equation (
11), albeit with a different notation, is reminiscent of the forward SDE that is typically used as the starting point to illustrate score-based generative models [
14]. In particular,
corresponds to the drift term of such a diffusion SDE.
Equation (
11) is equivalent to
, which is an expression for the process
, which is adapted to
. This constitutes the first step to derive an equivalent backward (generative) process according to the traditional framework of score-based diffusion models. Note that such an equivalent representation is not useful for simulation purposes: the goal of the next step is to transform it such that it is adapted to
. Indeed, using simple algebra, it holds that
where the last term in the parentheses is equal to
.
Note that
. Since
, we can apply the result in [
44] (Thm 2.2) to claim the following:
is a Brownian motion adapted to
, where this time
. Then, [
44].
Theorem 7. Consider the stochastic process which solves Equation (11). The same stochastic process also admits a -adapted representation Equation (
12) corresponds to the backward diffusion process from [
14] and, because it is adapted to the filtration
, it represents a valid, and easy-to-simulate, measurement process.
By now, it is clear how to go from an -adapted filtration to a -adapted one. We also showed that a -adapted filtration can be linked to the reverse, -adapted process induced by a forward diffusion SDE. What remains to be discussed is the connection that exists between the -adapted filtration, and its enlarged version . In other words, we have shown that a forward, diffusion SDE admits a backward process which is compatible with our generative model that simulates a NLF process having access only to measurements, but we need to make sure that such process admits a formulation that is compatible with the standard NLF framework in which latent abstractions are available.
To carry this out, we can leverage existing results about Markovian bridges [
22,
45] (and further work [
46,
47,
48,
49] on filtration enlargement). This requires assumptions about the existence and well-behaved nature of densities
of the SDE process, defined by the logarithm of the Radon–Nikodym derivative of the instantaneous measure
with reference to the Lebesgue measure in
,
(the analysis of the existence of the process adapted to
is considered in the time interval
[
50]; see also
Appendix G).
Theorem 8. Suppose that on , the Markov stochastic process satisfieswhere is a Brownian motion and F satisfies the requirements for existence and well definition of the stochastic integral [51]. Moreover, let Assumption 1 hold. Then, the same process admits -adapted representationwhere is the density with reference to the Lebesgue measure of the probability , and is a Brownian motion. The connection between time reversal of diffusion processes and enlarged filtrations is finalized with the result of Al-Hussaini and Elliott [
52], Thm. 3.3, where it is proved how the
term of Equation (
13) is a Brownian motion, using the techniques of time reversals of SDEs.
Since
, the enlarged filtration version of Equation (
12) reads
Note that the dependence of on the latent abstractions X is implicitly defined by conditioning the score term by , which is the “rendering” of X into the observable data domain.
Clearly, Equation (
14) can be reverted to the starting generative Equation (
12) by mimicking the results which allowed us to go from Equation (
1) to Equation (
4), by noticing that
(informally, this is obtained since
).
It is also important to notice that we can derive the expression for the mutual information between the measurement process and a sample from the data distribution, as follows
Mutual information is tightly related to the classical loss function of generative diffusion models.
Furthermore, by casting the result of Equation (
8) according to the forms of Equations (
12) and (
14), we obtain the simple and elegant expression
In
Appendix H, we present a specialization of our framework for the particular case of linear diffusion models, recovering the expressions for the variance-preserving and variance-exploding SDEs that are the foundations of score-based generative models [
14].
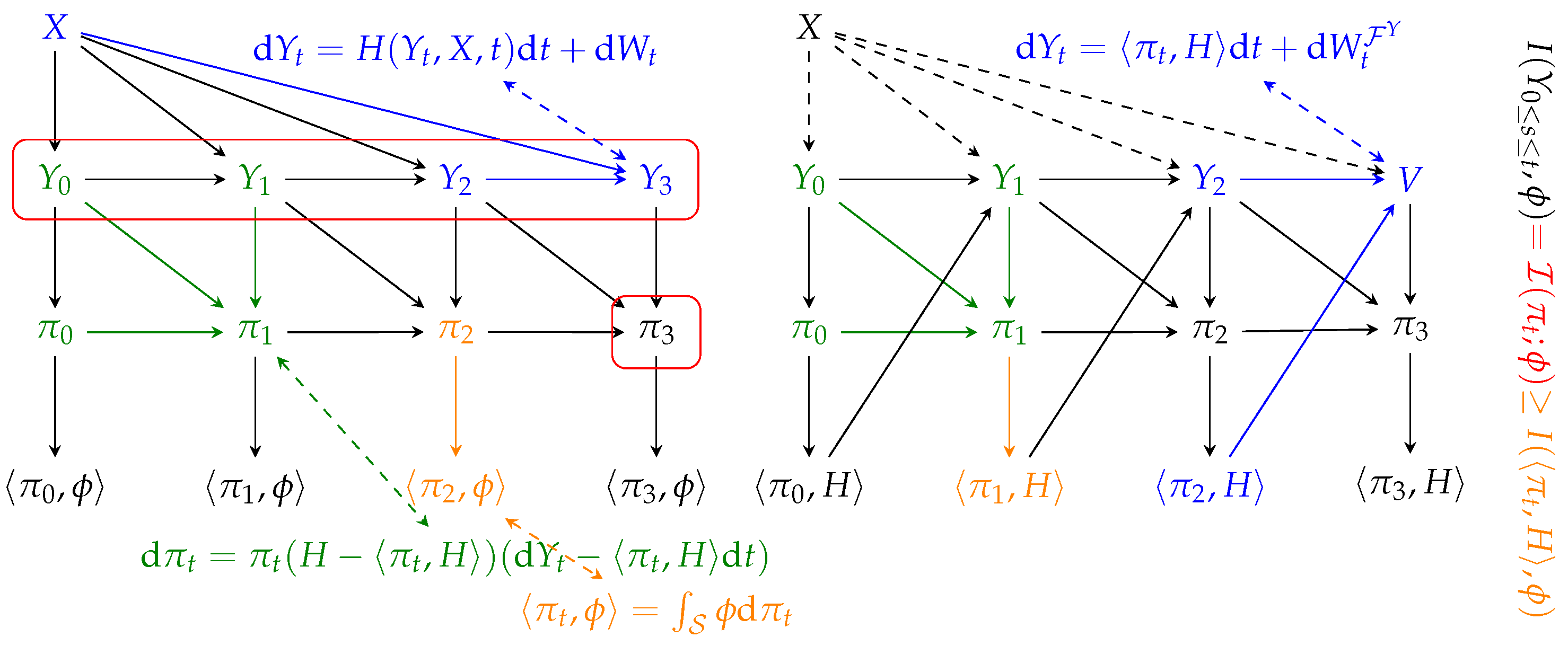
4. An Informal Summary of the Results
We shall now take a step back from the rigor of this work, and provide an intuitive summary of our results, using
Figure 1 as a reference.
We begin with an illustration of NLF, shown on the left of the figure. We consider an observable latent abstraction
X and the measurement process
, which, for ease of illustration, we consider evolving in discrete time, i.e.,
, and whose joint evolution is described by Equation (
1). Such an interaction is shown in blue:
depends on its immediate past
and the latent abstraction
X.
The a posteriori measure process
is updated in an iterative fashion by integrating the flux of information. We show this in green:
is obtained by updating
with
(the equivalent of
). This evolution is described by Kushner’s equation, which has been derived informally from the result of Equation (
6). The a posteriori process is a sufficient statistic for the latent abstraction
X: for example,
contains the same information about
as the whole
(red boxes). Instead, in general, a projected statistic
contains less information than the whole measurement process (this is shown in orange, for time instant 2). The mutual information between all these variables is proven in Theorem 6, whereas the actual value of
is shown in Theorem 5.
Next, we focus on generative modeling. As per our definition, any stochastic process satisfying Assumption 1 (
, in the figure) can be used for generative purposes. Since the latent abstraction is by definition not available, it is not possible to simulate directly the dynamics using Equation (
1) (dashed lines from
X to
). Instead, we derive a version of the process adapted to the history of
alone, together with the update of the projection
, which amounts to simulating Equation (
10). In [
36], diffusion models are shown to solve a “self-consistency” equation akin to a mean-field fixed point. Our framework aligns with this view by revealing how SDE-based generative processes implicitly enforce self-consistency between latent abstractions and measurements.
The update of the upper part of Equation (
10), which is a particular case of Equation (
6), can be
interpreted as the composition of two steps: (1) (green) the update of the a posteriori measure given new available measurements, and, (2) (orange) the projection of the whole
into the statistic of interest. The update of the measurement process, i.e., the lower part of Equation (
10), is color-coded in blue. This is in stark contrast to the NLF case, as the update of, e.g.,
does not depend
directly on
X. The system in Equation (
10) and its simulation describes the emergence of latent world representations in SDE-based generative models:
![Entropy 27 00371 i001]()
The theory developed in this work guarantees that the mutual information between measurements and any statistics
grows as described by Theorem 5. Our framework offers a new perspective, according to which, the dynamics of SDE-based generative models [
14] implicitly mimic the two steps procedure described in the box above. We claim that this is the reason why it is possible to dissect the parametric drift of such generative models and find a
representation of the abstract state distribution
, encoded into their activations. Next, we set to root our theoretical findings in experimental evidence.
Generality of Our Framework
While previous works studied latent abstraction emergence specifically within diffusion-based generative models, our current theoretical framework deliberately transcends this scope. Indeed, the results presented in this paper can be interpreted as a generalization of the results contained in [
53] (see also Equation (
A10)) and apply broadly to any generative model satisfying Assumption 1. Such generality includes a wide variety of generative modeling techniques, such as Neural Stochastic Differential Equations (neural SDEs) [
54], Schrödinger Bridges [
55], and Stochastic Normalizing Flows [
56]. In all these cases, our results on latent abstractions still hold; thus, the insights provided by our framework pave the way for deeper theoretical understanding and wider applicability across generative modeling paradigms.
5. Empirical Evidence
We complement existing empirical studies [
17,
18,
19,
30,
31,
32,
33,
34] that first measured the interactions between the generative process of diffusion models and latent abstractions, by focusing on a particular dataset that allows for a fine-grained assessment of the influence of latent factors.
Dataset. We use the Shapes3D [
57] dataset, which is a collection of
ray-tracing generated images, depicting simple 3D scenes, with an object (a sphere, cube,...) placed in a space, described by several attributes (color, size, orientation). Attributes have been derived from the computer program that the ray-tracing software executed to generate the scene: these are transformed into labels associated with each image. In our experiments, such labels are the materialization of the latent abstractions
X we consider in this work (see
Appendix J.1 for details).
Measurement Protocols. For our experiments, we use the base NCSPP model described by [
14]: specifically, our denoising score network corresponds to a U-NET [
58]. We train the unconditional version of this model from scratch using a score-matching objective. Detailed hyper-parameters and training settings are provided in
Appendix J.2. Next, we summarize three techniques to measure the emergence of latent abstractions through the lenses of the labels associated with each image in our dataset. For all such techniques, we use a specific “measurement” subset of our dataset, which we partition in 246 training, 150 validation, and 371 test examples. We use a multi-label stratification algorithm [
59,
60] to guarantee a balanced distribution of labels across all dataset splits.
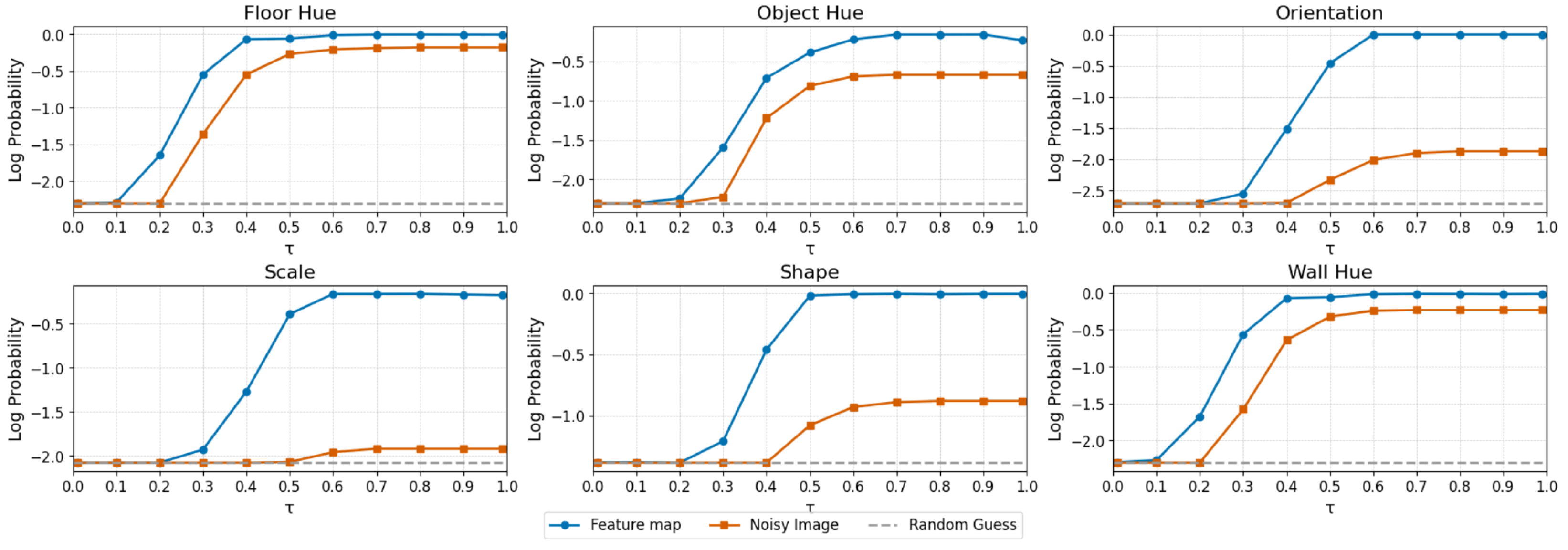
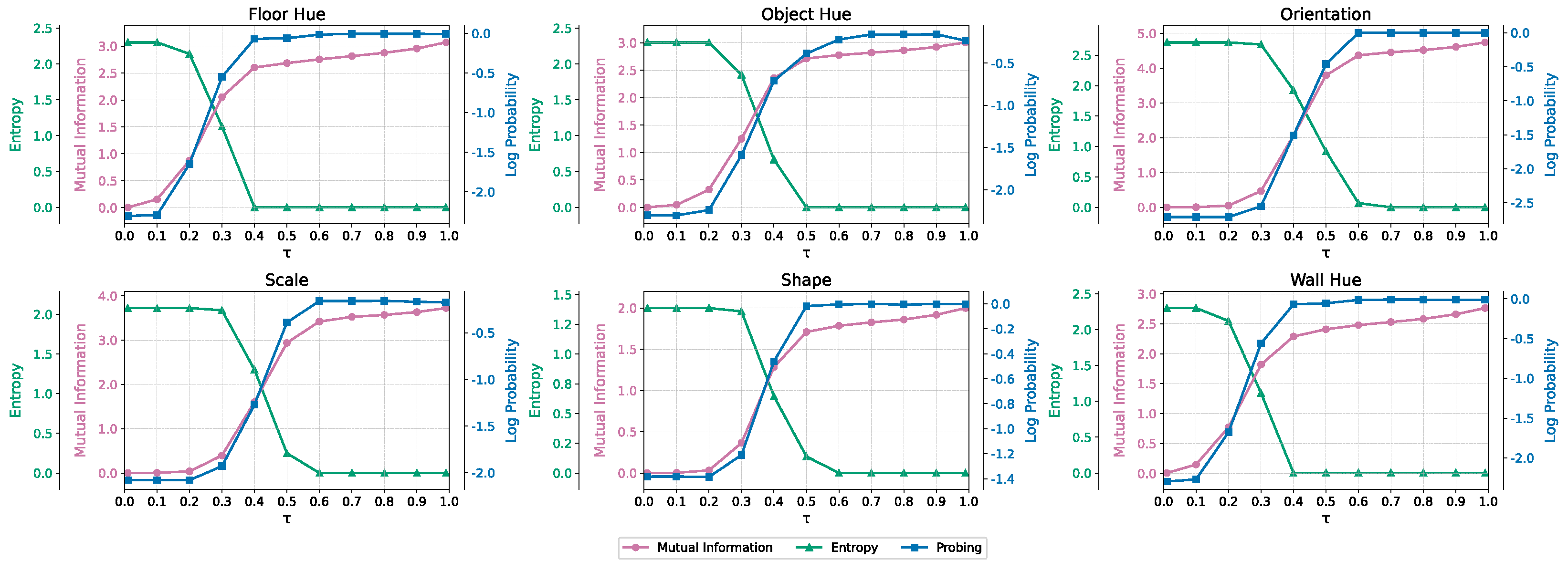
Linear probing. Each image in the measurement subset is perturbed with noise, using a variance-exploding schedule [
14], with noise levels decreasing from
to
in steps of 0.1, as shown in
Figure 2. Intuitively, each time value
can be linked to a different signal-to-noise ratio (
), ranging from
to
. We extract several feature maps from all the linear and convolutional layers of the denoising score network, for each perturbed image, resulting in a total of 162 feature map sets for each noise level. This process yields 11 different datasets per layer, which we use to train a linear classifier (our probe) for each of these datasets, using the training subset. In these experiments, we use a batch size of 64 and adjust the learning rate based on the noise level (see
Appendix J.3). Classifier performance is optimized by selecting models based on their log-probability accuracy observed on the validation subset. The final evaluation of each classifier is conducted on the test subset. Classification accuracy, measured by the model log likelihood, is a proxy of latent abstraction emergence [
17].
Mutual information estimation. We estimate mutual information between the labels and the outputs of the diffusion model across varying diffusion times, using Equation (
A10) (which is a specialized version of our theory for linear diffusion models; see
Appendix H) and adopt the same methodology discussed by Franzese et al. [
53] to learn conditional and unconditional score functions and to approximate the mutual information. The training process uses a randomized conditioning scheme: 33% of training instances are conditioned on all labels, 33% on a single label, and the remaining 33% are trained unconditionally. See
Appendix J.4 for additional details.
Forking. We propose a new technique to measure at which stage of the generative process, image features described by our labels emerge. Given an initial noise sample, we proceed with numerical integration of the backward SDE [
14] up to time
. At this point, we fork
k replicas of the backward process and continue the
k generative pathways independently until numerical integration concludes. We use a simple classifier (a pre-trained ResNet50 [
61] with an additional linear layer trained from scratch) to verify that labels are coherent across the
k forks. Coherency is measured using the entropy of the label distribution output by our simple classifier on each latent factor for all the
k branches of the fork. Intuitively, if we fork the process at time
, and the
k forks all end up displaying a cube in the image (entropy equals 0), this implies that the object shape is a latent abstraction that has already emerged by time
. Conversely, lack of coherence implies that such a latent factor has not yet influenced the generative process. Details of the classifier training and sampling procedure are provided in
Appendix J.5.
Results. We present our results in
Figure 3. We note that some attributes like
floor hue,
wall hue and
shape emerge earlier than others, which corroborates the hierarchical nature of latent abstractions, a phenomenon that is related to the spatial extent of each attribute in pixel space. This is evident from the results of linear probing, where we evaluate the performance of linear probes trained on features maps extracted from the denoiser network, and from the mutual information measurement strategy and the measured entropy of the predicted labels across forked generative pathways. Entropy decreases with
, which marks the moment in which the generative process proceeds along
k forks. When generative pathways converge to a unique scene with identical predicted labels (entropy reaches zero), this means that the model has committed to a specific set of latent factors (breaking some of the symmetries in the language of [
36]). This coincides with the same noise level corresponding to high accuracy for the linear probe, and high-values of mutual information. Further ablation experiments are presented in
Appendix J.6.
7. Conclusions
Despite their tremendous success in many practical applications, a deep understanding of how SDE-based generative models operate remained elusive. A particularly intriguing aspect of several empirical investigations was to uncover the capacity of generative models to create entirely new data by combining latent factors learned from examples. To the best of our knowledge, there exists no theoretical framework that attempts to describe such a phenomenon.
In this work, we closed this gap, and presented a novel theory—which builds on the framework of NLF—to describe the implicit dynamics allowing SDE-based generative models to tap into latent abstractions and guide the generative process. Our theory, which required advancing the standard NLF formulation, culminates in a new system of joint SDEs that fully describes the iterative process of data generation. Furthermore, we derived an information-theoretic measure to study the influence of latent abstractions, which provides a concrete understanding of the joint dynamics.
To root our theory into concrete examples, we collected experimental evidence by means of novel (and established) measurement strategies that corroborate our understanding of diffusion models. Latent abstractions emerge according to an implicitly learned hierarchy and can appear early on in the data generation process, much earlier than what is visible in the data domain. Our theory is especially useful as it allows analyses and measurements of generative pathways, opening up opportunities for a variety of applications, including image editing, and improved conditional generation.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}