
Cochleogram-Based Speech Emotion Recognition with the Cascade of Asymmetric Resonators with Fast-Acting Compression Using Time-Distributed Convolutional Long Short-Term Memory and Support Vector Machines

Abstract
1. Introduction
2. Related Studies
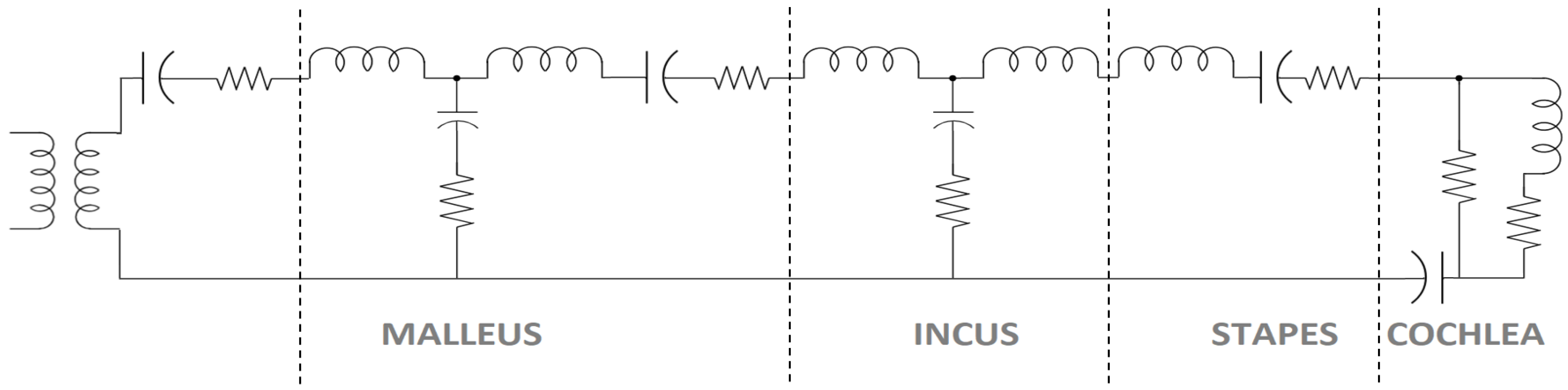
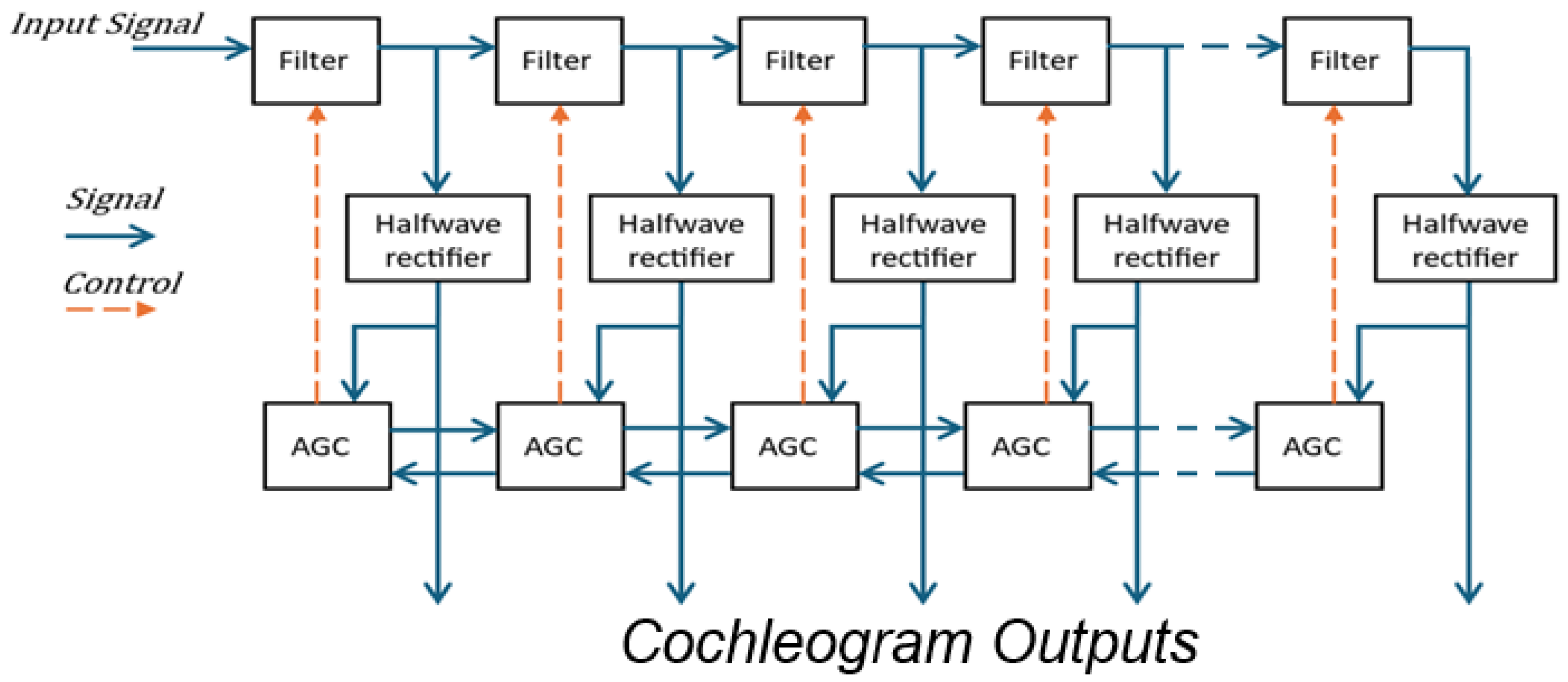
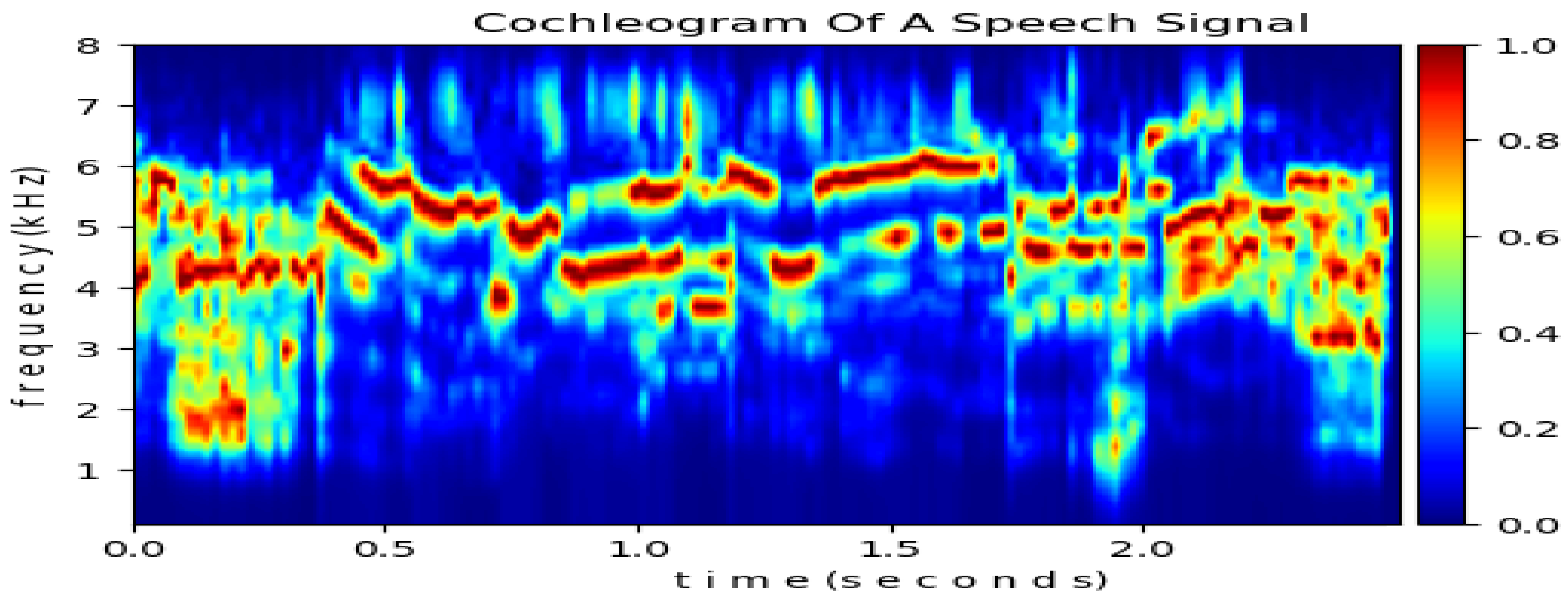
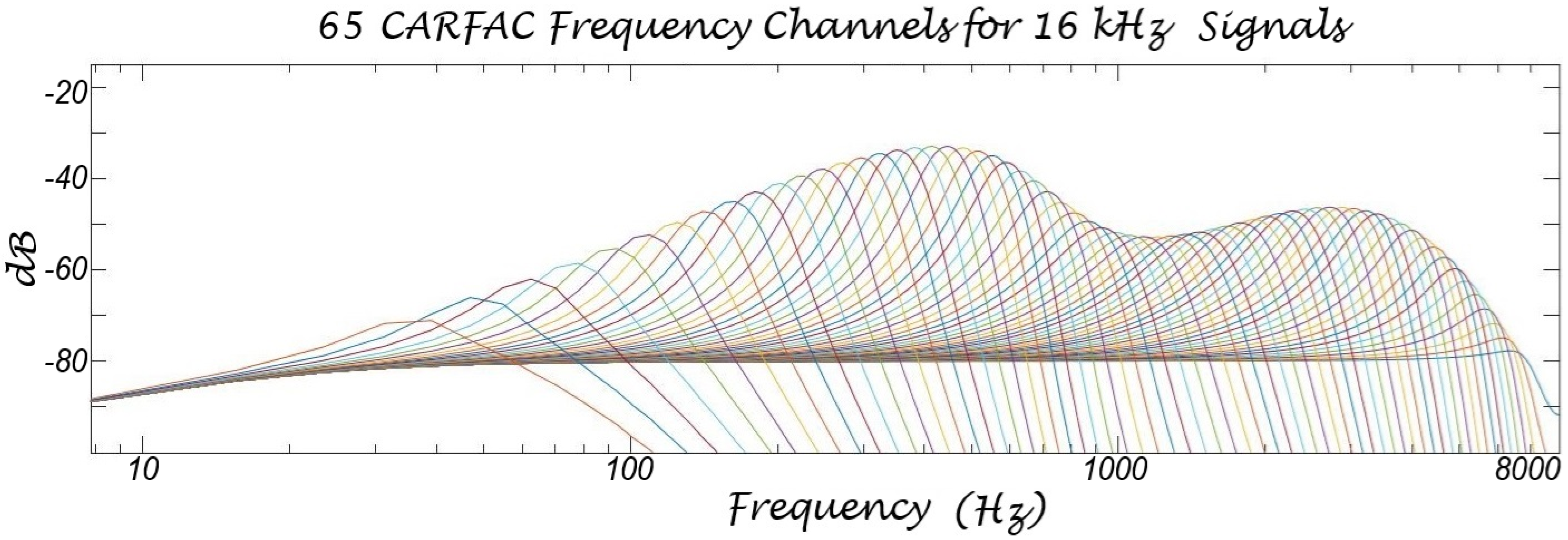
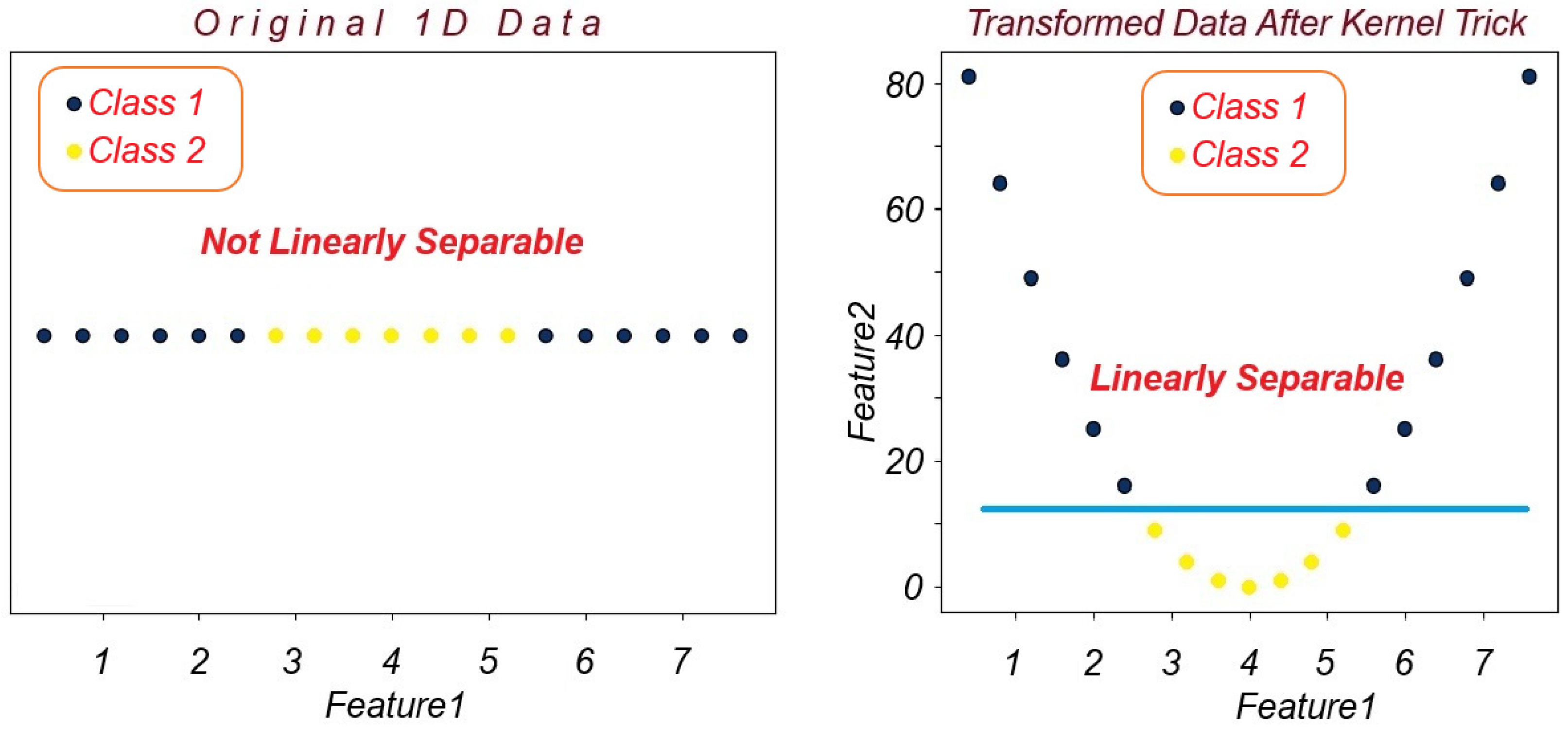
3. Proposed Approach
4. Experimental Design
4.1. Datasets
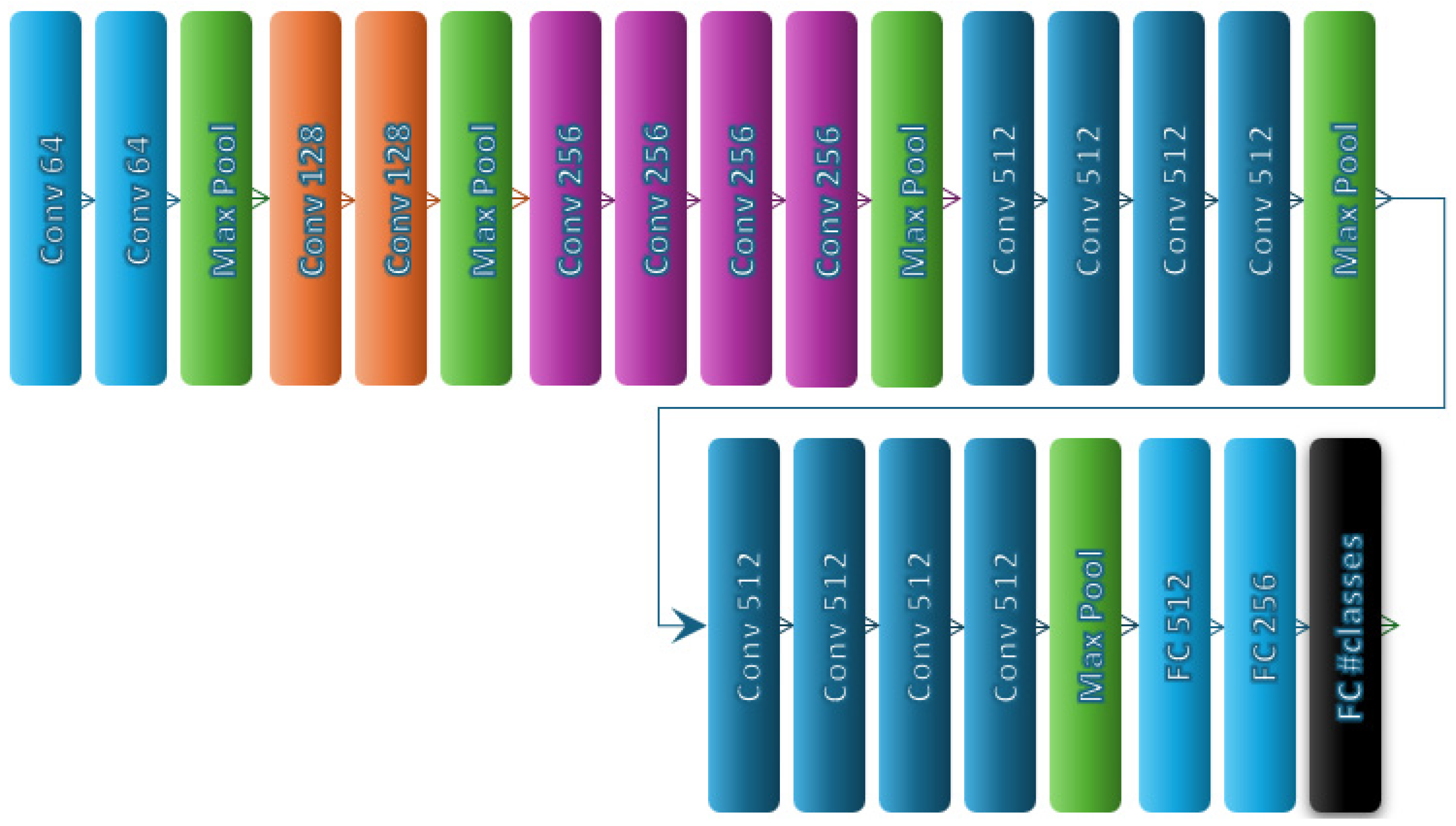
4.2. Deep Learning Architectures Used in the Experiments
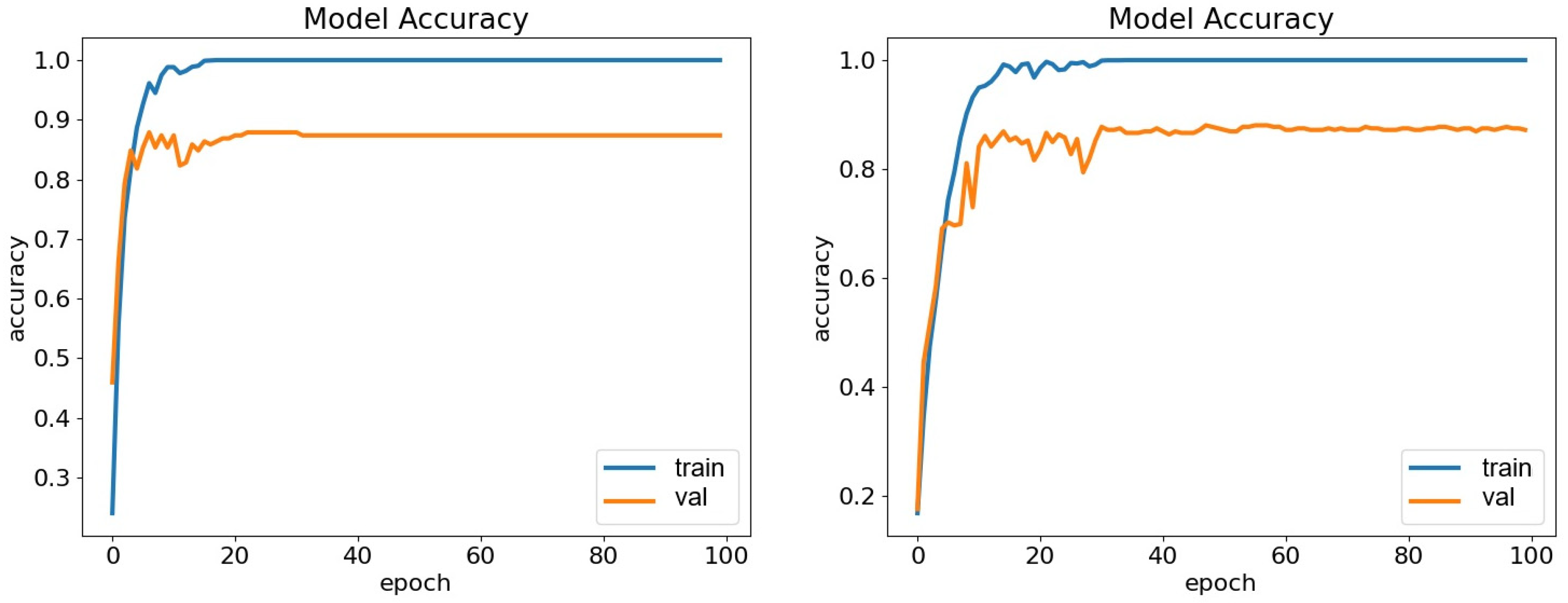
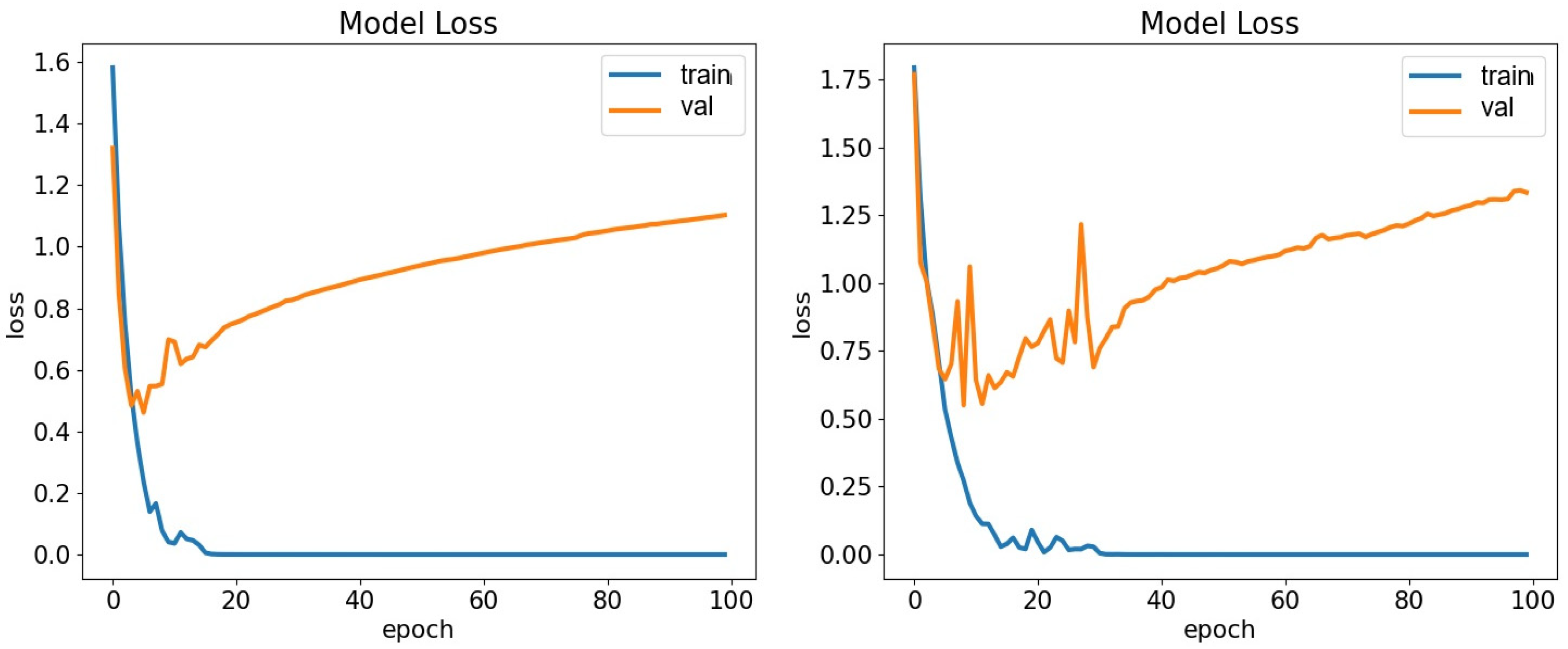
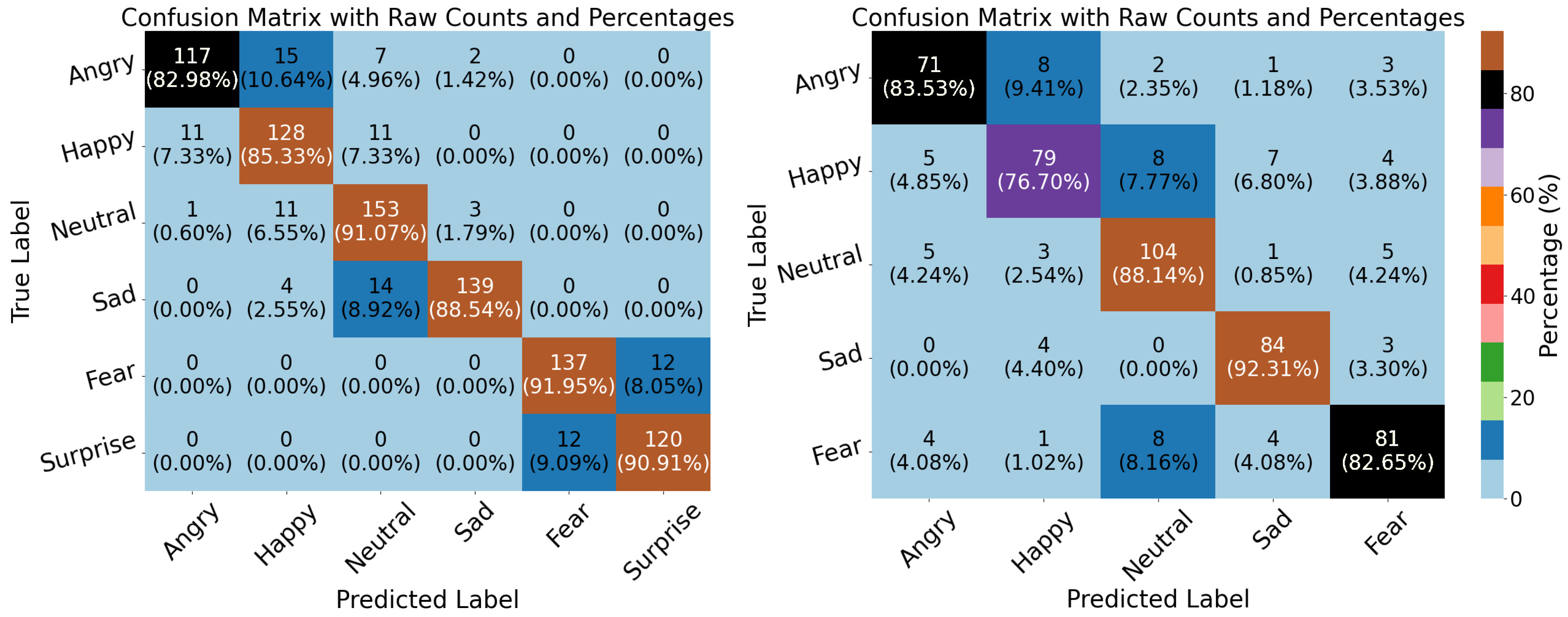
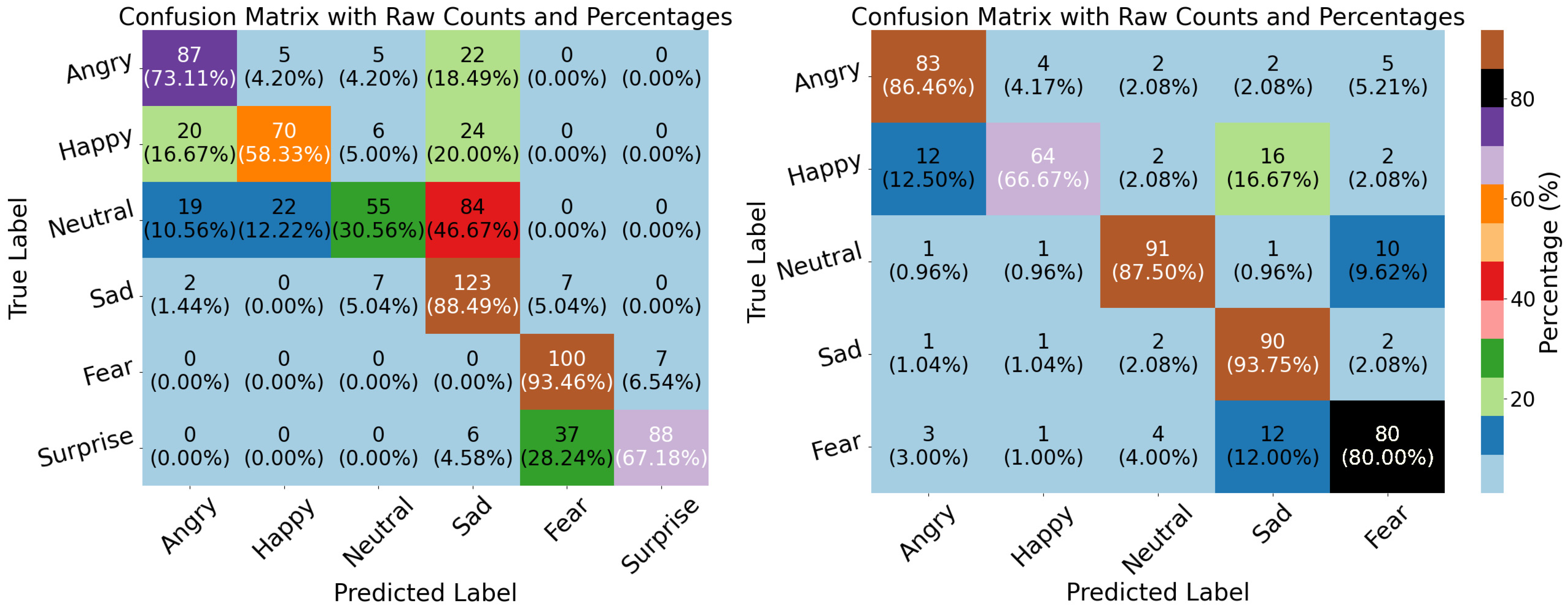
5. Results
6. Limitations of CARFAC 24 System
- CARFAC 24 outperforms traditional methods.
- Time-Distributed Convolutional LSTM models achieve high accuracy.
- SVM-SMO is quite successful when used in tandem with RBF kernel.
7. Discussions
8. Conclusions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ADAM | Adaptive Moment |
| AGC | Automatic Gain Control |
| ASED | Amharic Speech Emotion Dataset |
| CARFAC | Cascade of Asymmetric Resonators with Fast-Acting Compression |
| DCT | Discrete Cosine Transform |
| FFT | Fast Fourier Transform |
| FPGA | Field Programmable Gate Array |
| HWR | Half Wave Rectifier |
| IHC | Inner Hair Cell |
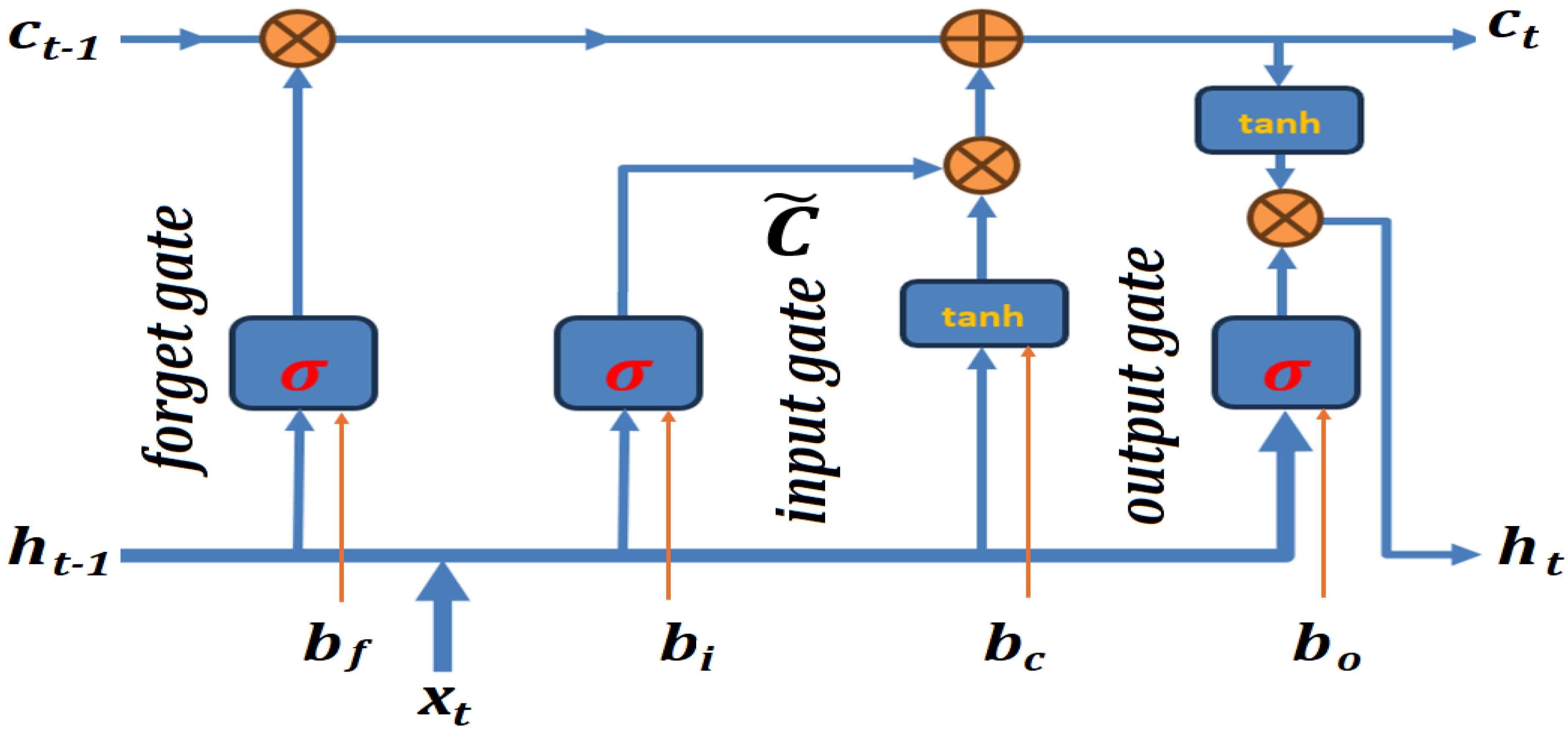
| LSTM | Long Short Term Memory |
| MFCC | Mel Frequency Cepstral Coefficients |
| OHC | Outer Hair Cell |
| PZFC | Pole-Zero Filter Cascade |
| RBF | Radial Basis Functions |
| ResNet | Residual Network |
| SER | Speech Emotion Recognition |
| SM | Scala Media |
| ST | Scala Tympani |
| SV | Scala Vestibuli |
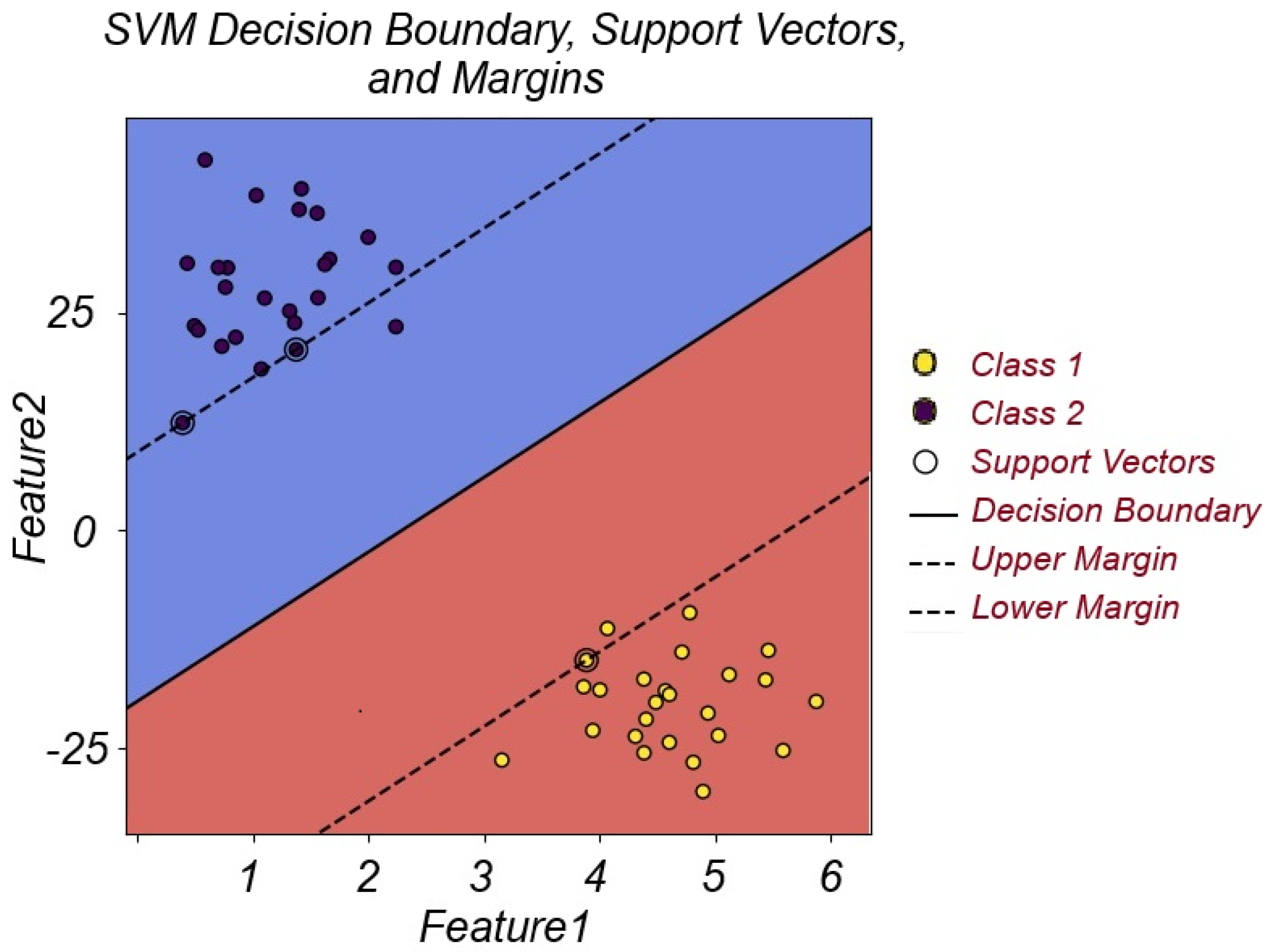
| SVM | Support Vector Machines |
| SMO | Sequential Minimal Optimization |
| TDConvLSTM | Time Distributed Convolutional LSTM |
| Weka | Waikato Environment for Knowledge Analysis |
| VGG | Visual Geometry Group |
References
- Lyon, R.F. Human and Machine Hearing: Extracting Meaning from Sound; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar]
- Stevens, S.S.; Volkmann, J.; Newman, E.B. A scale for the measurement of the psychological magnitude pitch. J. Acoust. Soc. Am. 1937, 8, 185–190. [Google Scholar] [CrossRef]
- Lyon, R.F. A computational model of filtering, detection and compression in the cochlea. In Proceedings of the ICASSP’82. IEEE International Conference on Acoustics, Speech, and Signal Processing, Paris, France, 3–5 May 1982; pp. 1282–1285. [Google Scholar]
- Hermansky, H. Perceptual linear predictive (PLP) analysis of speech. J. Acoust. Soc. Am. 1990, 87, 1738–1752. [Google Scholar] [CrossRef] [PubMed]
- Johannesma, P.I.M. The pre-response stimulus ensemble of neurons in the cochlear nucleus. In Symposium on Hearing Theory; IPO: Eindhoven, The Netherlands, 1972; pp. 58–69. [Google Scholar]
- Glasberg, B.R.; Moore, B. Derivation of auditory filter shapes from notched-noise data. Hear. Res. 1990, 47, 103–138. [Google Scholar] [CrossRef]
- Seneff, S. A joint synchrony/mean-rate model of auditory speech processing. J. Phon. 1988, 16, 55–76. [Google Scholar] [CrossRef]
- Meddis, R. An evaluation of eight computer models of the mammalian Inner Hair Cell Function. J. Acoust. Soc. Am. 1988, 90, 904–917. [Google Scholar]
- Bruce, C.; Erfani, Y.; Zilany, M.S.R. A phenomenological model of the synapse between the inner hair cell and auditory nerve: Implications of limited neurotransmitter release sites. Hear. Res. 2018, 360, 40–54. [Google Scholar] [CrossRef] [PubMed]
- Hohmann, V. Frequency analysis and synthesis using a gammatone filterbank. Acta Acust. United Acoust. 2002, 88, 433–442. [Google Scholar]
- King, A.; Varnet, L.; Lorenzi, C. Accounting for masking of frequency modulation by amplitude modulation with the modulation filter-bank concept. J. Acoust. Soc. Am. 2019, 145, 2277–2293. [Google Scholar] [CrossRef]
- Relaño-Iborra, H.; Zaar, J.; Dau, T. A speech-based computational auditory signal processing and perception model. J. Acoust. Soc. Am. 2019, 146, 3306–3317. [Google Scholar] [CrossRef]
- Jepsen, M.; Ewert, S.; Dau, T. A computational model of human auditory signal processing and perception. J. Acoust. Soc. Am. 2008, 124, 422–438. [Google Scholar] [CrossRef]
- Verhulst, S.; Altoè, A.; Vasilkov, V. Functional modeling of the human auditory brainstem response to broadband stimulation. Hear. Res. 2018, 360, 55–75. [Google Scholar] [CrossRef]
- Zilany, M.S.A.; Bruce, I.C.; Carney, L.H. Updated parameters and expanded simulation options for a model of the auditory periphery. J. Acoust. Soc. Am. 2014, 135, 283–286. [Google Scholar] [CrossRef] [PubMed]
- Jackson, B.S.; Carney, L.H. The spontaneous rate histogram of the auditory nerve can be explained by only two or three spontaneous rates and long-range dependence. J. Assoc. Res. Otolaryngol. 2005, 6, 148–159. [Google Scholar] [CrossRef]
- Gutkin, A. Eidos: An open-source auditory periphery modeling toolkit and evaluation of cross-lingual phonemic contrasts. In Proceedings of the 1st Joint Workshop on Spoken Language Technologies for Under-Resourced Languages (SLTU) and Collaboration and Computing for Under-Resourced Languages (CCURL); European Language Resources Association: Marseille, France, 2020; pp. 9–20. [Google Scholar]
- Masetto, S.; Spaiardi, P.; Johnson, S.J. Signal Transmission by Auditory and Vestibular Hair Cells. In Recent Advances in Audiological and Vestibular Research; IntechOpen: Rijeka, Croatia, 2022. [Google Scholar]
- Moser, T.; Karagulyan, N.; Neef, J.; Jaime Tobón, L.M. Diversity matters-extending sound intensity coding by inner hair cells via heterogeneous synapses. EMBO J. 2023, 42, e114587. [Google Scholar] [CrossRef] [PubMed]
- Ashmore, J. Cochlear outer hair cell motility. Physiol. Rev. 2008, 88, 173–210. [Google Scholar] [CrossRef] [PubMed]
- Feher, J.J. Quantitative Human Physiology: An introduction; Academic Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Qing, Z.; Mao-Li, D. Anatomy and physiology of peripheral auditory system and common causes of hearing loss. J. Otol. 2009, 4, 7–14. [Google Scholar] [CrossRef]
- Lord, R.M.; Abel, E.W.; Wang, Z.; Mills, R.P. Effects of draining cochlear fluids on stapes displacement in human middle-ear models. J. Acoust. Soc. Am. 2001, 110, 3132–3139. [Google Scholar] [CrossRef]
- Parent, P.; Allen, J.B. Time-domain “wave” model of the human tympanic membrane. Hear. Res. 2010, 263, 152–167. [Google Scholar] [CrossRef]
- Parent, P.; Allen, J.B. Wave model of the cat tympanic membrane. J. Acoust. Soc. Am. 2007, 122, 918–931. [Google Scholar] [CrossRef]
- Naghibolhosseini, M.; Long, G.R. Fractional-order modelling and simulation of human ear. Int. J. Comput. Math. 2018, 95, 1257–1273. [Google Scholar] [CrossRef]
- Pastras, C.J.; Gholami, N.; Jennings, S.; Zhu, H.; Zhou, W.; Brown, D.J.; Curthoys, I.S.; Rabbitt, R.D. A mathematical model for mechanical activation and compound action potential generation by the utricle in response to sound and vibration. Front. Neurol. 2023, 14, 1109506. [Google Scholar] [CrossRef] [PubMed]
- Kuokkanen, P. Modelling the Activity of the Auditory Nerve After Hearing Loss. Master’s Thesis, Department of Physics, University of Jyväskylä, Jyväskylä, Finland, 2005. [Google Scholar]
- Weremczuk, A.; Rusinek, R. Dynamics of the middle ear with an implantable hearing device: An improved electromechanical model. Nonlinear Dyn. 2024, 112, 2219–2235. [Google Scholar] [CrossRef]
- De Paolis, A.; Bikson, M.; Nelson, J.T.; de Ru, J.A.; Packer, M.; Cardoso, L. Analytical and numerical modeling of the hearing system: Advances towards the assessment of hearing damage. Hear. Res. 2017, 349, 111–128. [Google Scholar] [CrossRef]
- Zablotni, R.; Tudruj, S.; Latalski, J.; Szymanski, M.; Kucharski, A.; Zając, G.; Rusinek, R. Sound-Induced Round Window Vibration—Experiment and Numerical Simulations of Energy Transfer Through the Cochlea of the Human Ear. Appl. Sci. 2025, 15, 301. [Google Scholar] [CrossRef]
- Chen, J.; Sprigg, J.; Castle, N.; Matson, C.; Hedjoudje, A.; Dai, C. A Virtual Inner Ear Model Selects Ramped Pulse Shapes for Vestibular Afferent Stimulation. Bioengineering 2023, 10, 1436. [Google Scholar] [CrossRef]
- Schurzig, D.; Fröhlich, M.; Raggl, S.; Scheper, V.; Lenarz, T.; Rau, T.S. Uncoiling the human cochlea-Physical scala tympani models to study pharmacokinetics inside the inner ear. Life 2021, 11, 373. [Google Scholar] [CrossRef]
- Xu, Y.; Afshar, S.; Wang, R.; Cohen, G.; Singh Thakur, C.; Hamilton, T.J.; van Schaik, A. A biologically inspired sound localisation system using a silicon cochlea pair. Appl. Sci. 2021, 11, 1519. [Google Scholar] [CrossRef]
- Xu, Y.; Thakur, C.S.; Singh, R.K.; Hamilton, T.J.; Wang, R.M.; Van Schaik, A. A FPGA implementation of the CAR-FAC cochlear model. Front. Neurosci. 2018, 12, 198. [Google Scholar] [CrossRef]
- Lyon, R.F. Cascades of two-pole–two-zero asymmetric resonators are good models of peripheral auditory function. J. Acoust. Soc. Am. 2011, 130, 3893–3904. [Google Scholar] [CrossRef]
- Scarpiniti, M.; Parisi, R.; Lee, Y.C. A Scalogram-based CNN approach for audio classification in construction sites. Appl. Sci. 2023, 14, 90. [Google Scholar] [CrossRef]
- Davis, S.; Mermelstein, P. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Acoust. Speech Signal Process. 1980, 28, 357–366. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25. [Google Scholar]
- Schroeder, M.R. An integrable model for the basilar membrane. J. Acoust. Soc. Am. 1973, 53, 429–434. [Google Scholar] [CrossRef] [PubMed]
- Zweig, G.; Lipes, R.; Pierce, J.R. The cochlear compromise. J. Acoust. Soc. Am. 1976, 59, 975–982. [Google Scholar] [CrossRef] [PubMed]
- Slaney, M. Lyon’s Cochlear Model; Apple Computer, Advanced Technology Group: Cupertino, CA, USA, 1988; Volume 13. [Google Scholar]
- Duda, R.O.; Lyon, R.F.; Slaney, M. Correlograms and the separation of sounds. In Proceedings of the 1990 Conference Record Twenty-Fourth Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 5 October–7 November 1990; IEEE Computer Society: Washington, DC, USA, 1990; Volume 2, pp. 457–461. [Google Scholar]
- Lyon, R.F.; Schonberger, R.; Slaney, M.; Velimirović, M.; Yu, H. The CARFAC v2 Cochlear Model in Matlab, NumPy, and JAX. arXiv 2024, arXiv:2404.17490. [Google Scholar]
- Ahmed, N.; Natarajan, T.; Rao, K.R. Discrete cosine transform. IEEE Trans. Comput. 1974, 100, 90–93. [Google Scholar] [CrossRef]
- Christop, I. nEMO: Dataset of Emotional Speech in Polish. arXiv 2024, arXiv:2404.06292. [Google Scholar]
- Retta, E.A.; Sutcliffe, R.; Mahmood, J.; Berwo, M.A.; Almekhlafi, E.; Khan, S.A.; Chaudhry, S.A.; Mhamed, M.; Feng, J. Cross-Corpus Multilingual Speech Emotion Recognition: Amharic vs. Other Languages. Appl. Sci. 2023, 13, 12587. [Google Scholar] [CrossRef]
- Skowroński, K.; Gałuszka, A.; Probierz, E. Polish Speech and Text Emotion Recognition in a Multimodal Emotion Analysis System. Appl. Sci. 2024, 14, 10284. [Google Scholar] [CrossRef]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of German emotional speech. In Proceedings of the Ninth European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005; pp. 1517–1520. [Google Scholar]
- Livingstone, S.R.; Russo, F.A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef]
- Latif, S.; Qayyum, A.; Usman, M.; Qadir, J. Cross lingual speech emotion recognition: Urdu vs. western languages. In Proceedings of the 2018 International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, 17–19 December 2018; pp. 88–93. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Schmidhuber, J.; Hochreiter, S. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar]
- Liu, W.; Wang, J.; Li, Z.; Lu, Q. A Hybrid Improved Dual-Channel and Dual-Attention Mechanism Model for Water Quality Prediction in Nearshore Aquaculture. Electronics 2025, 14, 331. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Support Vector method. In Artificial Neural Networks—ICANN’97; Lecture Notes in Computer Science; Gerstner, W., Germond, A., Hasler, M., Nicoud, J.D., Eds.; Springer: Berlin/Heidelberg, Germany, 1997; Volume 1327. [Google Scholar] [CrossRef]
- Platt, J.C. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines; Microsoft Research Technical Report; Microsoft: Redmond, WA, USA, 1998. [Google Scholar]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Majdak, P.; Hollomey, C.; Baumgartner, R. AMT 1.x: A toolbox for reproducible research in auditory modeling. Acta Acust. 2022, 6, 19. [Google Scholar] [CrossRef]
- Chollet, F.; Anonymous. Keras. GitHub. Available online: https://github.com/fchollet/keras (accessed on 1 January 2024).
- Kingma, P.D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Badshah, A.M.; Ahmad, J.; Rahim, N.; Baik, S.W. Speech emotion recognition from spectrograms with deep convolutional neural network. In Proceedings of the 2017 International Conference on Platform Technology and Service (PlatCon), Busan, Republic of Korea, 13–15 February 2017; pp. 1–5. [Google Scholar]
- Rudd, D.H.; Huo, H.; Xu, G. Leveraged Mel spectrograms using harmonic and percussive components in speech emotion recognition. In Advances in Knowledge Discovery and Data Mining, Pacific-Asia Conference on Knowledge Discovery and Data Mining, Chengdu, China, May 16–19, 2022; Springer International Publishing: Cham, Switzerland; pp. 392–404.
- Glackin, C.; Wall, J.; Chollet, G.; Dugan, N.; Cannings, N. TIMIT and NTIMIT phone recognition using convolutional neural networks. In Pattern Recognition Applications and Methods, 7th International Conference, ICPRAM 2018, Funchal, Madeira, Portugal, 16–18 January 2018; Revised Selected Papers 7; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 89–100. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Output Shape | #Parameters |
|---|---|---|
| Input | (None, 1, 44, 66, 1) | 0 |
| Time Distributed Conv2D (256, (3 × 3), “relu”) | (None, 1, 44, 66, 256) | 2560 |
| Time Distributed Conv2D (256, (3 × 3), “relu”) | (None, 1, 44, 66, 256) | 590,080 |
| Time Distributed MaxPool (2, 2) | (None, 1, 22, 33, 256) | 0 |
| Time Distributed (Flatten) | (None, 1, 185,856) | 0 |
| LSTM (512) | (None, 1, 512) | 381,683,712 |
| LSTM (256) | (None, 1, 256) | 787,456 |
| LSTM (128) | (None, 128) | 197,120 |
| Drop Out (0.25) | (None, 128) | 0 |
| Flatten | (None, 128) | 0 |
| Dense (512) | (None, 512) | 66,048 |
| Drop Out (0.5) | (None, 512) | 0 |
| Dense (#classes) | (None, 6) | 3078 |
| ACC | Precision | Recall | F1 | Kappa | |
|---|---|---|---|---|---|
| SVM-SMO | 84.51 | 84.60 | 84.51 | 84.51 | - |
| TDConvLSTM | 84.64 | 84.59 | 84.64 | 84.56 | 80.74 |
| VGG19 | 84.24 | 84.87 | 84.24 | 84.23 | 80.25 |
| LSTM | 83.23 | 83.37 | 83.23 | 83.18 | 78.99 |
| ACC | Precision | Recall | F1 | Kappa | |
|---|---|---|---|---|---|
| SVM-SMO | 86.72 | 86.90 | 86.72 | 86.80 | - |
| TDConvLSTM | 88.51 | 88.83 | 88.51 | 88.57 | 86.19 |
| VGG19 | 88.40 | 88.46 | 88.40 | 88.35 | 86.07 |
| LSTM | 82.60 | 84.33 | 82.60 | 82.55 | 79.14 |
| ACC | Precision | Recall | F1-Score | Kappa | |
|---|---|---|---|---|---|
| SVM-SMO | 85.97 | 86.70 | 86.00 | 85.90 | - |
| TDConvLSTM | 82.93 | 83.77 | 82.93 | 82.77 | 78.66 |
| VGG19 | 79.67 | 81.60 | 79.67 | 79.39 | 74.58 |
| LSTM | 82.11 | 84.10 | 82.11 | 82.06 | 77.64 |
| ACC | Precision | Recall | F1-Score | Kappa | |
|---|---|---|---|---|---|
| SVM-SMO | 64.07 | 67.40 | 64.07 | 63.60 | - |
| TDConvLSTM | 65.70 | 70.95 | 65.70 | 64.41 | 58.98 |
| VGG19 | 60.67 | 64.18 | 60.67 | 60.26 | 52.92 |
| LSTM | 64.45 | 65.11 | 64.45 | 63.86 | 57.33 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Parlak, C. Cochleogram-Based Speech Emotion Recognition with the Cascade of Asymmetric Resonators with Fast-Acting Compression Using Time-Distributed Convolutional Long Short-Term Memory and Support Vector Machines. Biomimetics 2025, 10, 167. https://doi.org/10.3390/biomimetics10030167
Parlak C. Cochleogram-Based Speech Emotion Recognition with the Cascade of Asymmetric Resonators with Fast-Acting Compression Using Time-Distributed Convolutional Long Short-Term Memory and Support Vector Machines. Biomimetics. 2025; 10(3):167. https://doi.org/10.3390/biomimetics10030167
Chicago/Turabian StyleParlak, Cevahir. 2025. "Cochleogram-Based Speech Emotion Recognition with the Cascade of Asymmetric Resonators with Fast-Acting Compression Using Time-Distributed Convolutional Long Short-Term Memory and Support Vector Machines" Biomimetics 10, no. 3: 167. https://doi.org/10.3390/biomimetics10030167
APA StyleParlak, C. (2025). Cochleogram-Based Speech Emotion Recognition with the Cascade of Asymmetric Resonators with Fast-Acting Compression Using Time-Distributed Convolutional Long Short-Term Memory and Support Vector Machines. Biomimetics, 10(3), 167. https://doi.org/10.3390/biomimetics10030167