
Drone vs. Bird Detection: Deep Learning Algorithms and Results from a Grand Challenge

 ,
,  ,
, 

 ,
,  ,
,  , , , ,
, , , ,
Abstract
1. Introduction
2. Drone vs. Bird Detection Challenge 2020
2.1. Dataset
2.2. Evaluation Protocol
2.3. Participation
3. Related Work
3.1. Drone Datasets
3.2. Drone Detection
4. Gradiant Team
4.1. Methodology
4.2. Datasets Used
4.3. Experimental Evaluation
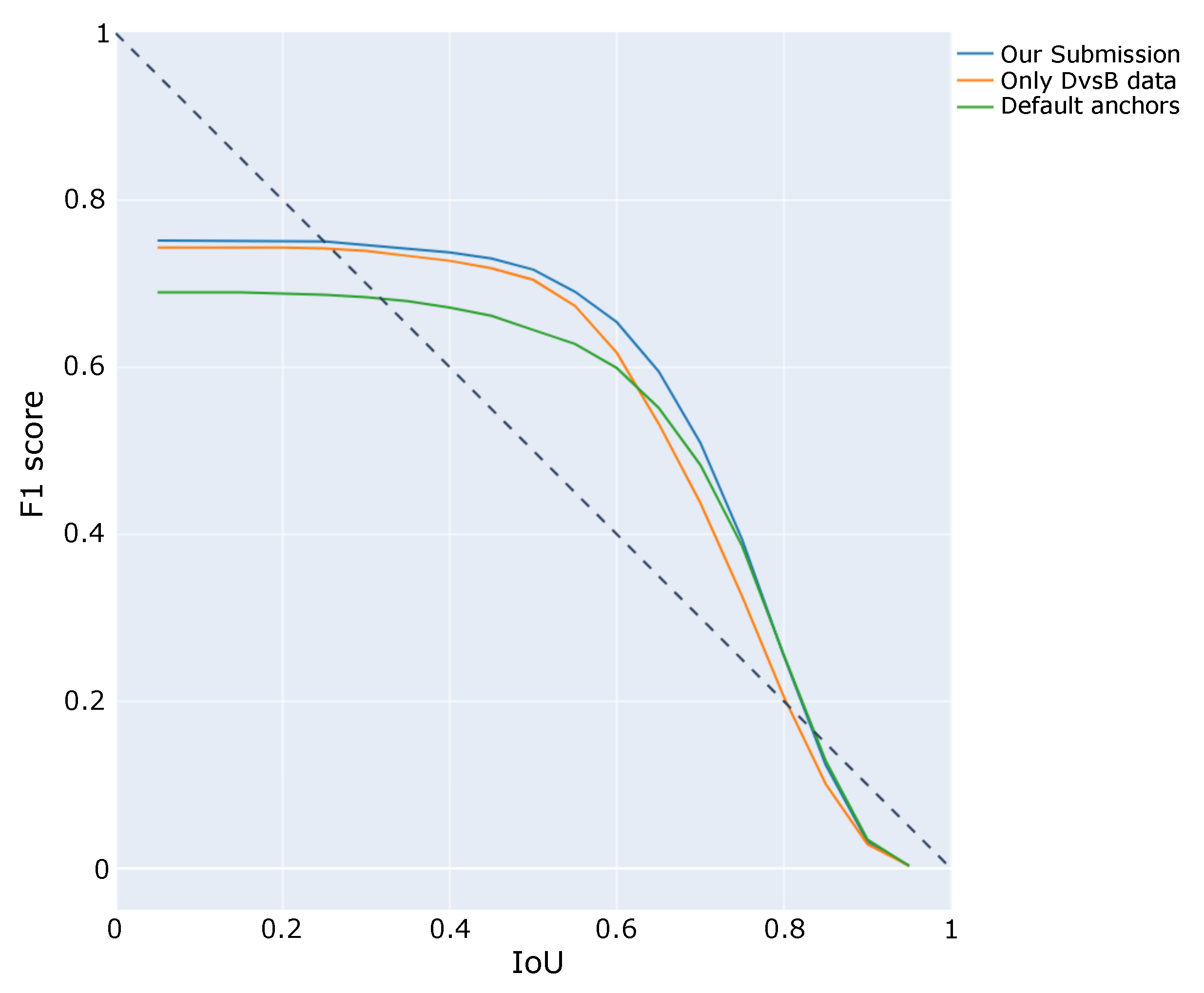
4.4. Discussion
5. EagleDrone Team
5.1. Methodology
5.2. Datasets Used
5.3. Experimental Evaluation
5.4. Discussion
6. Alexis Team
6.1. Methodology
6.2. Datasets Used
6.3. Experimental Evaluation
6.4. Discussion
7. Performance Comparison
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Elloumi, M.; Dhaou, R.; Escrig, B.; Idoudi, H.; Saidane, L.A. Monitoring road traffic with a UAV-based system. In Proceedings of the 2018 IEEE Wireless Communications and Networking Conference (WCNC), Barcelona, Spain, 15–18 April 2018. [Google Scholar]
- Tokekar, P.; Hook, J.V.; Mulla, D.; Isler, V. Sensor Planning for a Symbiotic UAV and UGV System for Precision Agriculture. IEEE Trans. Robot. 2016, 32, 1498–1511. [Google Scholar] [CrossRef]
- Shakhatreh, H.; Sawalmeh, A.H.; Al-Fuqaha, A.; Dou, Z.; Almaita, E.; Khalil, I.; Othman, N.S.; Khreishah, A.; Guizani, M. Unmanned Aerial Vehicles (UAVs): A Survey on Civil Applications and Key Research Challenges. IEEE Access 2019, 7, 48572–48634. [Google Scholar] [CrossRef]
- Humphreys, T. Statement on the Security Threat Posed by Unmanned Aerial Systems and Possible Countermeasures; Oversight and Management Efficiency Subcommittee, Homeland Security Committee: Washington, DC, USA, 2015. [Google Scholar]
- El-Sayed, A.F. Bird Strike in Aviation: Statistics, Analysis and Management; John Wiley & Sons: Hoboken, NJ, USA, 2019. [Google Scholar]
- Anderson, A.; Carpenter, D.S.; Begier, M.J.; Blackwell, B.F.; DeVault, T.L.; Shwiff, S.A. Modeling the cost of bird strikes to US civil aircraft. Transp. Res. Part D Transp. Environ. 2015, 38, 49–58. [Google Scholar] [CrossRef]
- Coluccia, A.; Fascista, A.; Ricci, G. Online Estimation and Smoothing of a Target Trajectory in Mixed Stationary/moving Conditions. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Coluccia, A.; Fascista, A.; Ricci, G. A k-nearest neighbors approach to the design of radar detectors. Signal Process. 2020, 174, 107609. [Google Scholar] [CrossRef]
- Coluccia, A.; Fascista, A.; Ricci, G. Robust CFAR Radar Detection Using a K-nearest Neighbors Rule. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), (Held as Virtual Event), Barcelona, Spain, 4–8 May 2020; pp. 4692–4696. [Google Scholar] [CrossRef]
- Coluccia, A.; Fascista, A.; Ricci, G. A novel approach to robust radar detection of range-spread targets. Signal Process. 2020, 166, 107223. [Google Scholar] [CrossRef]
- Coluccia, A.; Fascista, A.; Ricci, G. CFAR Feature Plane: A Novel Framework for the Analysis and Design of Radar Detectors. IEEE Trans. Signal Process. 2020, 68, 3903–3916. [Google Scholar] [CrossRef]
- Schumann, A.; Sommer, L.; Müller, T.; Voth, S. An image processing pipeline for long range UAV detection. Emerging Imaging and Sensing Technologies for Security and Defence III; and Unmanned Sensors, Systems, and Countermeasures. Int. Soc. Opt. Photon. 2018, 10799, 107990T. [Google Scholar]
- Samaras, S.; Diamantidou, E.; Ataloglou, D.; Sakellariou, N.; Vafeiadis, A.; Magoulianitis, V.; Lalas, A.; Dimou, A.; Zarpalas, D.; Votis, K.; et al. Deep learning on multi sensor data for counter UAV applications—A systematic review. Sensors 2019, 19, 4837. [Google Scholar] [CrossRef] [PubMed]
- Coluccia, A.; Fascista, A.; Ricci, G. Spectrum sensing by higher-order SVM-based detection. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruna, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar] [CrossRef]
- De Cubber, G.; Shalom, R.; Coluccia, A. The SafeShore System for the Detection of Threat Agents in a Maritime Border Environment. In Proceedings of the IARP Workshop on Risky Interventions and Environmental Surveillance, Les Bons Villers, Belgium, 18–19 May 2017. [Google Scholar]
- Coluccia, A.; Ghenescu, M.; Piatrik, T.; De Cubber, G.; Schumann, A.; Sommer, L.; Klatte, J.; Schuchert, T.; Beyerer, J.; Farhadi, M.; et al. Drone vs. Bird detection challenge at IEEE AVSS2017. In Proceedings of the 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 Agust–1 September 2017; pp. 1–6. [Google Scholar]
- Coluccia, A.; Fascista, A.; Schumann, A.; Sommer, L.; Ghenescu, M.; Piatrik, T.; De Cubber, G.; Nalamati, M.; Kapoor, A.; Saqib, M.; et al. Drone vs. Bird Detection Challenge at IEEE AVSS2019. In Proceedings of the 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, Taiwan, 18–21 September 2019. [Google Scholar]
- Aksoy, M.C.; Orak, A.S.; Özkan, H.M.; Selimoglu, B. Drone Dataset: Amateur Unmanned Air Vehicle Detection. 2019. Available online: https://data.mendeley.com/datasets/zcsj2g2m4c/4 (accessed on 16 April 2021).
- Bosquet, B.; Mucientes, M.; Brea, V. STDnet: A ConvNet for Small Target Detection. In Proceedings of the 29th British Machine Vision Conference, Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Li, J.; Ye, D.H.; Chung, T.; Kolsch, M.; Wachs, J.; Bouman, C. Multi-target detection and tracking from a single camera in Unmanned Aerial Vehicles (UAVs). In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 4992–4997. [Google Scholar]
- Rozantsev, A.; Lepetit, V.; Fua, P. Flying objects detection from a single moving camera. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4128–4136. [Google Scholar]
- Pawełczyk, M.; Wojtyra, M. Real World Object Detection Dataset for Quadcopter Unmanned Aerial Vehicle Detection. IEEE Access 2020, 8, 174394–174409. [Google Scholar] [CrossRef]
- Anti-UAV Challenge. Available online: https://anti-uav.github.io/ (accessed on 14 April 2021).
- Li, J.; Murray, J.; Ismaili, D.; Schindler, K.; Albl, C. Reconstruction of 3D flight trajectories from ad-hoc camera networks. arXiv 2020, arXiv:2003.04784. [Google Scholar]
- Sommer, L.; Schumann, A.; Müller, T.; Schuchert, T.; Beyerer, J. Flying object detection for automatic UAV recognition. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Müller, T. Robust drone detection for day/night counter-UAV with static VIS and SWIR cameras. In Proceedings of the Ground/Air Multisensor Interoperability, Integration, and Networking for Persistent ISR VIII. International Society for Optics and Photonics, Anaheim, CA, USA, 10–13 April 2017; Volume 10190, p. 1019018. [Google Scholar]
- Schumann, A.; Sommer, L.; Klatte, J.; Schuchert, T.; Beyerer, J. Deep cross-domain flying object classification for robust UAV detection. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. 2015. Available online: arXiv:cs.CV/1506.01497 (accessed on 14 April 2021).
- Craye, C.; Ardjoune, S. Spatio-Temporal Semantic Segmentation for Drone Detection. In Proceedings of the 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, Taiwan, 18–21 September 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical image com-puting and computer-assisted intervention (MICCAI), Munich, Germany, 5–9 October 2015. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Saqib, M.; Daud Khan, S.; Sharma, N.; Blumenstein, M. A study on detecting drones using deep convolutional neural networks. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Nalamati, M.; Kapoor, A.; Saqib, M.; Sharma, N.; Blumenstein, M. Drone Detection in Long-Range Surveillance Videos. In Proceedings of the 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, Taiwan, 18–21 September 2019; pp. 1–6. [Google Scholar]
- Aker, C.; Kalkan, S. Using deep networks for drone detection. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. 2016. Available online: arXiv:cs.CV/1612.08242 (accessed on 14 April 2021).
- Liu, H.; Qu, F.; Liu, Y.; Zhao, W.; Chen, Y. A drone detection with aircraft classification based on a camera array. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Shanghai, China, 28–29 December 2017; Volume 322, p. 052005. [Google Scholar]
- Unlu, E.; Zenou, E.; Riviere, N.; Dupouy, P.E. Deep learning-based strategies for the detection and tracking of drones using several cameras. IPSJ Trans. Comput. Vis. Appl. 2019, 11, 1–13. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. 2018. Available online: arXiv:cs.CV/1804.02767 (accessed on 14 April 2021).
- Magoulianitis, V.; Ataloglou, D.; Dimou, A.; Zarpalas, D.; Daras, P. Does Deep Super-Resolution Enhance UAV Detection? In Proceedings of the 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, Taiwan, 18–21 September 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Yamanaka, J.; Kuwashima, S.; Kurita, T. Fast and Accurate Image Super Resolution by Deep CNN with Skip Connection and Network in Network. In Proceedings of the International Conference on Neural Information Processing (ICONIP), Guangzhou, China, 14–18 November 2017. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Oksuz, K.; Can Cam, B.; Akbas, E.; Kalkan, S. Localization recall precision (LRP): A new performance metric for object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 504–519. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Loy, C.C.; Qiao, Y.; Tang, X. ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks. 2018. Available online: arXiv:cs.CV/1809.00219 (accessed on 14 April 2021).
- Kemker, R.; McClure, M.; Abitino, A.; Hayes, T.; Kanan, C. Measuring Catastrophic Forgetting in Neural Networks. 2017. Available online: arXiv:cs.AI/1708.02072 (accessed on 14 April 2021).
- Jocher, G.; Kwon, Y.; Guigarfr Veitch-Michaelis, J.; Perry0418; Ttayu; Marc; Bianconi, G.; Baltacı, F.; Suess, D.; et al. Ultralytics YOLOv3. 2020. Available online: https://zenodo.org/record/3785397 (accessed on 16 April 2021).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Wang, J.; Fu, X.; Yu, T.; Guo, Y.; Wang, R. DC-SPP-YOLO: Dense connection and spatial pyramid pooling based YOLO for object detection. arXiv 2020, arXiv:1903.08589. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft Coco: Common Objects in Context; European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. arXiv 2019, arXiv:1911.08287. [Google Scholar] [CrossRef]
- Dwibedi, D.; Misra, I.; Hebert, M. Cut, paste and learn: Surprisingly easy synthesis for instance detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1301–1310. [Google Scholar]
- Unel, F.O.; Ozkalayci, B.; Cigla, C. The Power of Tiling for Small Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Buslaev, A.; Parinov, A.; Khvedchenya, E.; Iglovikov, V.I.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. arXiv 2018, arXiv:1809.06839. [Google Scholar]
- Jackson, P.T.; Atapour-Abarghouei, A.; Bonner, S.; Breckon, T.P.; Obara, B. Style Augmentation: Data Augmentation via Style Randomization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 83–92. [Google Scholar]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics/Tile Size (px) | 320 | 480 | 640 |
|---|---|---|---|
| Known sequence AP (%) | 91.3 | 92.9 | 89.1 |
| Unknown sequence AP (%) | 56.1 | 57.8 | 44.3 |
| Processing time per image (ms) | 195 | 169 | 125 |
| Training | AP (%) |
|---|---|
| DvB | 52.2 |
| DvB + synthetic | 55.6 |
| DvB + synthetic + style augmentation | 57.8 |
| Sequence | AP (%) |
|---|---|
| Known | 93.55 ± 0.6 |
| Unknown | 66.0 ± 13.5 |
| Submission | Alexis [%] | Eagledrone [%] | Gradiant [%] |
|---|---|---|---|
| Run 1 | 79.8 | 66.8 | 80.0 |
| Run 2 | 79.4 | ✗ | 72.9 |
| Run 3 | ✗ | ✗ | 75.2 |
| Sequence | Static | Alexis [%] | Eagledrone [%] | Gradiant [%] |
|---|---|---|---|---|
| GOPR5843_004 | ✓ | 97.7 | ||
| GOPR5845_002 | ✓ | |||
| GOPR5847_001 | ✓ | |||
| dji_matrice_210_midrange_cruise | ✓ | |||
| dji_mavick_mountain_cross | ✗ | |||
| dji_phantom_mountain | ✓ | |||
| dji_phantom_close | ✓ | |||
| two_parrot_2 | ✓ | |||
| parrot_disco_long_session_2_1m | ✗ | |||
| 2019_08_19_C0001_27_46_solo_1m | ✓ | |||
| 2019_08_19_C0001_57_00_inspire_1m | ✓ | |||
| 2019_09_02_C0002_11_18_solo | ✓ | |||
| 2019_10_16_C0003_52_30_mavic | ✗ | |||
| 2019_11_14_C0001_11_23_inspire_1m | ✓ | |||
| Overall |
| Sequence | #GT | Alexis | Eagledrone | Gradiant | |||
|---|---|---|---|---|---|---|---|
| #Det | Recall | #Det | Recall | #Det | Recall | ||
| GOPR5843_004 | 438 | 1381 | 97.5 | 368 | 77.2 | 447 | 98.2 |
| GOPR5845_002 | 544 | 1330 | 99.4 | 577 | 96.7 | 836 | 99.8 |
| GOPR5847_001 | 318 | 443 | 70.4 | 217 | 62.3 | 427 | 66.0 |
| dji_matrice_210_midrange_cruise | 1469 | 1853 | 99.9 | 1498 | 98.5 | 1499 | 99.9 |
| dji_mavick_mountain_cross | 1551 | 3528 | 91.1 | 1453 | 83.0 | 2223 | 81.8 |
| dji_phantom_mountain | 1663 | 2668 | 84.0 | 1245 | 56.2 | 1774 | 69.5 |
| dji_phantom_close | 1193 | 1307 | 99.6 | 1195 | 99.6 | 1188 | 98.9 |
| two_parrot_2 | 2789 | 2951 | 96.0 | 2990 | 96.2 | 2783 | 95.1 |
| parrot_disco_long_session_2_1m | 789 | 2585 | 43.3 | 1479 | 55.1 | 2151 | 68.7 |
| 2019_08_19_C0001_27_46_solo_1m | 926 | 10,625 | 92.9 | 727 | 59.7 | 10,394 | 92.9 |
| 2019_08_19_C0001_57_00_inspire_1m | 1219 | 8178 | 90.4 | 1052 | 81.9 | 6338 | 93.1 |
| 2019_09_02_C0002_11_18_solo | 626 | 8152 | 89.1 | 676 | 94.4 | 4284 | 95.4 |
| 2019_10_16_C0003_52_30_mavic | 733 | 57,005 | 40.2 | 478 | 44.1 | 1188 | 68.8 |
| 2019_11_14_C0001_11_23_inspire_1m | 368 | 16,928 | 68.2 | 1156 | 64.9 | 21,898 | 56.8 |
| Overall | 14,626 | 118,934 | 87.4 | 15,102 | 72.9 | 57,430 | 87.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Coluccia, A.; Fascista, A.; Schumann, A.; Sommer, L.; Dimou, A.; Zarpalas, D.; Méndez, M.; de la Iglesia, D.; González, I.; Mercier, J.-P.; et al. Drone vs. Bird Detection: Deep Learning Algorithms and Results from a Grand Challenge. Sensors 2021, 21, 2824. https://doi.org/10.3390/s21082824
Coluccia A, Fascista A, Schumann A, Sommer L, Dimou A, Zarpalas D, Méndez M, de la Iglesia D, González I, Mercier J-P, et al. Drone vs. Bird Detection: Deep Learning Algorithms and Results from a Grand Challenge. Sensors. 2021; 21(8):2824. https://doi.org/10.3390/s21082824
Chicago/Turabian StyleColuccia, Angelo, Alessio Fascista, Arne Schumann, Lars Sommer, Anastasios Dimou, Dimitrios Zarpalas, Miguel Méndez, David de la Iglesia, Iago González, Jean-Philippe Mercier, and et al. 2021. "Drone vs. Bird Detection: Deep Learning Algorithms and Results from a Grand Challenge" Sensors 21, no. 8: 2824. https://doi.org/10.3390/s21082824
APA StyleColuccia, A., Fascista, A., Schumann, A., Sommer, L., Dimou, A., Zarpalas, D., Méndez, M., de la Iglesia, D., González, I., Mercier, J.-P., Gagné, G., Mitra, A., & Rajashekar, S. (2021). Drone vs. Bird Detection: Deep Learning Algorithms and Results from a Grand Challenge. Sensors, 21(8), 2824. https://doi.org/10.3390/s21082824