A Transfer Learning Method for Meteorological Visibility Estimation Based on Feature Fusion Method




Abstract
:Featured Application
Abstract
1. Introduction
2. Methodology
2.1. Database Construction
2.2. Method Overview
2.2.1. Image Preprocessing
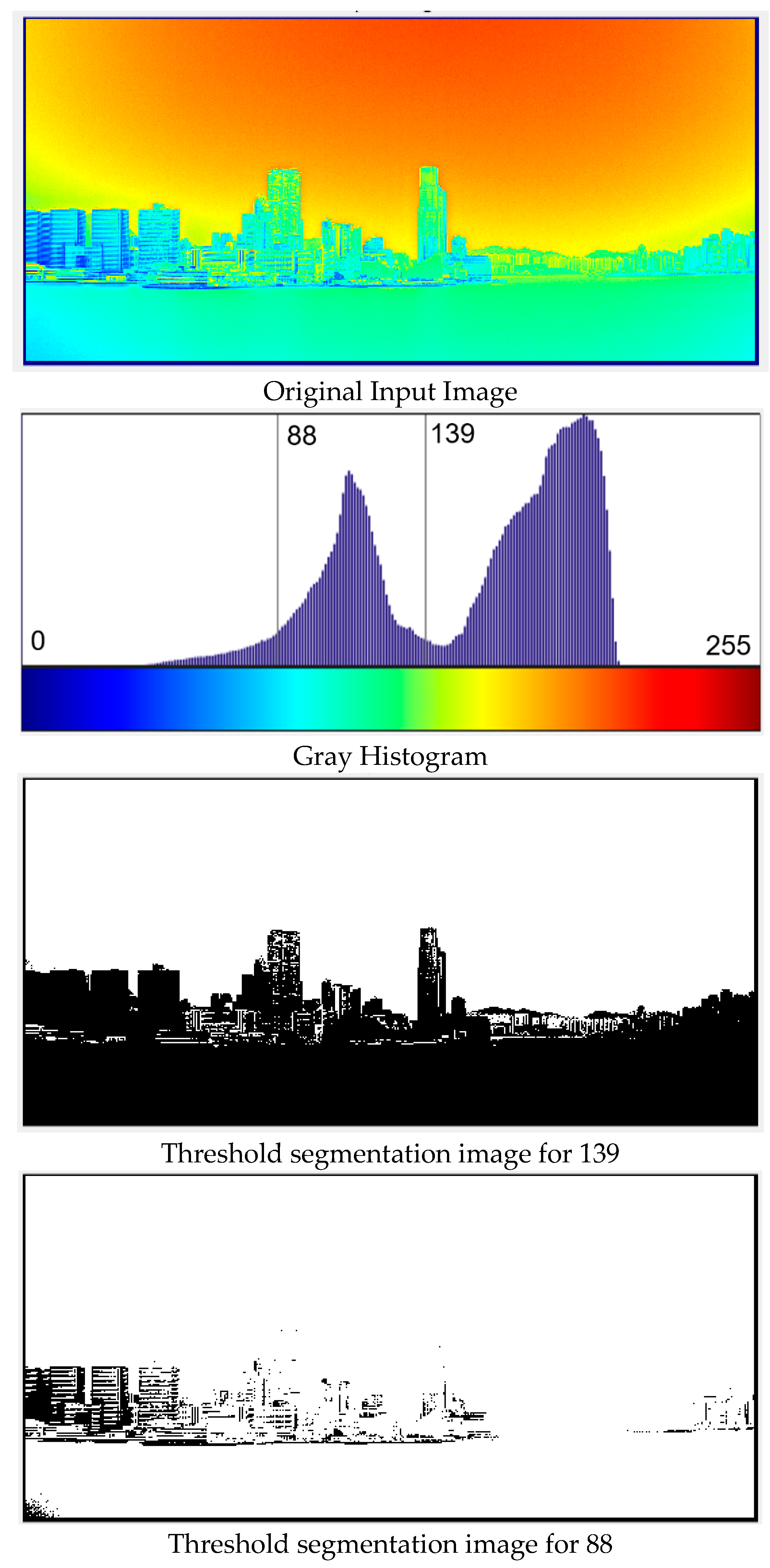
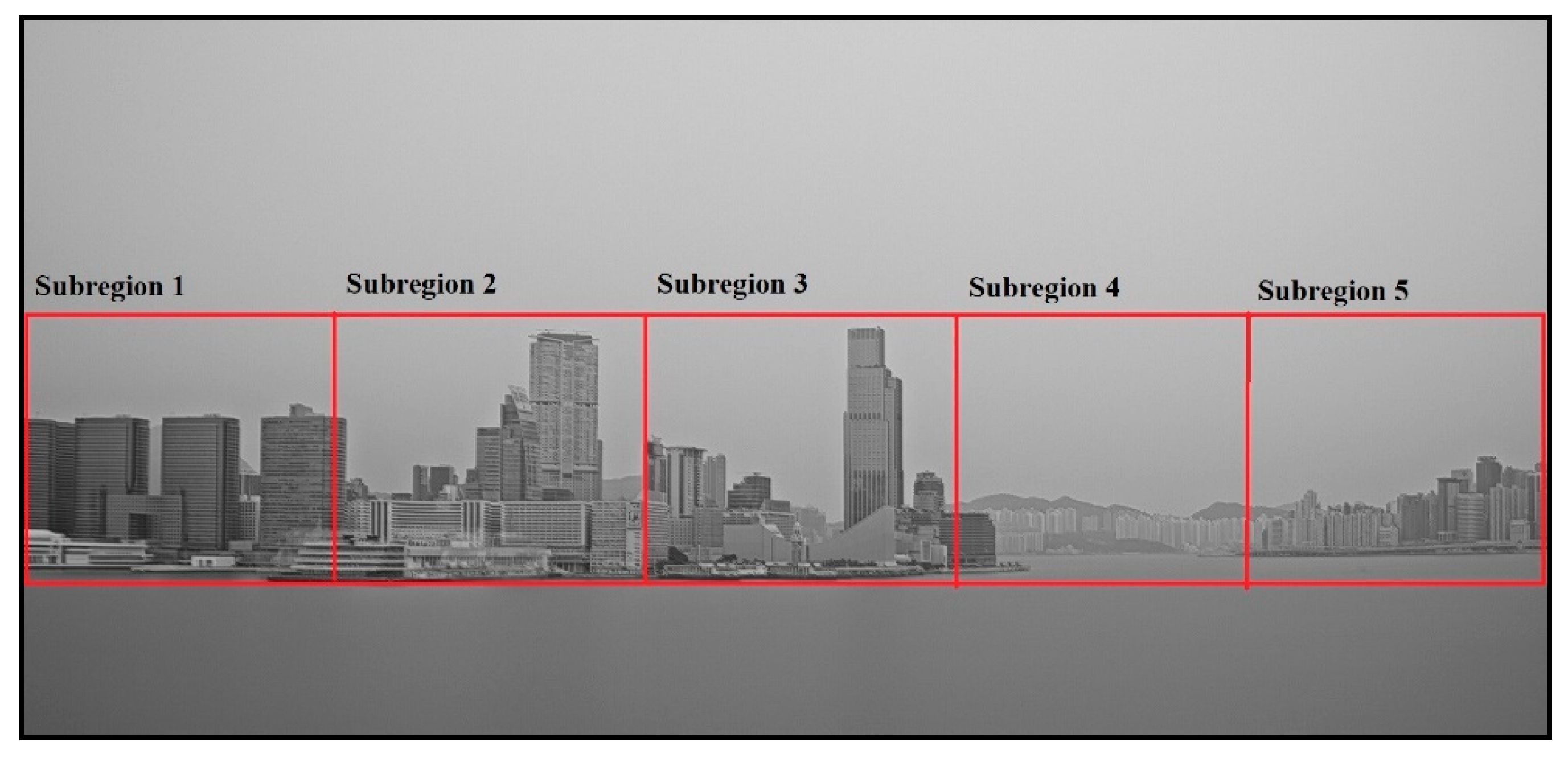
2.2.2. Subregion Segmentation
- Apply gray-level averaging to all the images in the database to derive the comprehensive image.
- Gaussian blur algorithm was applied to the image to obtain the grayscale distribution of the image.
- Apply the adaptive threshold segmentation algorithm to find the threshold value.
- According to the threshold value found in step 3, the images in the database were then segmented into sub-region images with x-y coordinates.
- Effective subregions are then extracted from the results of step 4.
2.2.3. Subregion Feature Extraction and Visibility Evaluation
2.2.4. Comprehensive Visibility Evaluation
3. Experiment Results and Analysis
3.1. Experiment Platform
3.2. Result and Analysis
- (1)
- Analysis of different effective areas
- (2)
- Performance of different feature extraction networks
- (3)
- Different fusion method
- (4)
- Comparison of different methods in other paper
4. Discussion and Summary
- Each effective subregion Ri contains some static landmark objects at certain distances from observer location. Suppose Ri contains a nearest static object at distance xi. If visibility is below xi, all the objects in Ri cannot be observed and the whole region will be appeared as a uniform gray region as outline edges of the objects cannot be seen in this visibility range. Variations of image characteristics (e.g., gray level, and image sharpness of static objects) are observable for visibility range greater xi and Ri can provide useful image feature information for visibility estimation in a visibility range above xi.
- The weather images in this paper were collected in order of time sequence. Taking the hull as an example, the same hull will appear in different positions in the images. The entire image sequence records the moving trajectory of the hull from appearance to departure. Theoretically, a dynamic object must have a mean position from entering to departure. So long as the moving objects does not remain stationary at a certain position for a long time. These objects usually could be removed after the gray averaging process.
- The proposed method is even more effective for removing the natural moving objects in the nature such as moving clouds or sea waves. The area for the sky or the sea will become a uniform gray region after the gray averaging process. Therefore, after carrying out the proposed gray level averaging process, dynamic objects and natural moving objects could be removed in the image, leaving only the static objects in the image for subsequent region selection and feature extraction.
- In this case, if we perform the gray level averaging for the image dataset with visibilities higher than xi. All static objects at distance less than xi in Ri will be appeared as clear objects with sharp outline edges. Furthermore, dynamic objects (e.g., moving cloud and sea) will be filtered out if the total number of images is sufficiently large.
- In summary, performing gray level average on the entire image database could find static objects observable in different visibility ranges and locate the coordinates of the effective sub-regions. Combining with the threshold segmentation method, the gray level averaging can be used to detect observable static objects for different visibility ranges.
- The Feature Extraction and Regression model proposed in this paper is based on effective subregions selection, feature extraction by deep learning neural network, multiple support vector regression (SVR) models and weight fusion model for visibility estimation. Each support vector regression (SVR) model provide piecewise approximation for the overall complex mapping between visibility and image features.
- Different from other fusion methods as proposed in [21], the fusion in this paper aims to exclude invalid areas, reduce the amount of calculation and maintain the accuracy of visibility evaluation. Actually, the fusion approach in [21] does not exclude invalid regions, while the proposed method in this paper does not restrict the size and location of the subregions. It determines the segmentation of image according to the content of static objects in the whole image.
- In case the image contains no static objects in a particular visibility distance, visibility value at this range is estimated based on the interpolation (or fusion) of visibility values from other subregions.
- In summary, the proposed method can reduce the processing time of image features as only the selected regions are analyzed instead of the whole image. It can improve the estimation accuracy by using fusion for the estimates from different subregions. The proposed method shows good performance and results for the practical visibility data provided by HKO. Experimental results show that the accuracy of visibility estimation reaches more than 90%. This method did not need to define a large-scale visual annotation set, and had high robustness and effectiveness. This method also eliminates the interference of invalid regions and reductant features on the visibility estimation, and reduced the complexity and operations of the estimation process.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
List of Abbreviation
| ADAS | Advanced Driver Assistance Systems |
| ASM | Atmospheric scattering model |
| CCTV | Closed-Circuit Television |
| CNN | Convolutional Neural Networks |
| DCNN | Deep Convolutional Neural Networks |
| DHCNN | Deep Hybrid Convolutional Neural Network |
| FCM | Fuzzy C-means algorithm |
| FE-V | Feature encoding visibility detection network |
| FOVI | Foggy Outdoor Visibility images dataset (CCTV images) |
| FROSI | Foggy Road Sign Images dataset (synthetic images) |
| GRNN | Generalized Regression Neural Network |
| HKO | Hong Kong Observatory |
| MOR | Meteorological Optical Range |
| RBF | Radial Basis Function |
| RNN | Recurrent Neural Networks |
| SVM | Support Vector Machine |
Appendix B. Summary of Weighted Fusion Method
References
- Khademi, S.; Rasouli, S.; Hariri, E. Measurement of the atmospheric visibility distance by imaging a linear grating with sinusoidal amplitude and having variable spatial period through the atmosphere. J. Earth Space Phys. 2016, 42, 449–458. [Google Scholar]
- Zhuang, Z.; Tai, H.; Jiang, L. Changing Baseline Lengths Method of Visibility Measurement and Evaluation. Acta Opt. Sin. 2016, 36, 0201001. [Google Scholar] [CrossRef]
- Song, H.; Chen, Y.; Gao, Y. Visibility estimation on road based on lane detection and image inflection. J. Comput. Appl. 2012, 32, 3397–3403. [Google Scholar] [CrossRef]
- Liu, N.; Ma, Y.; Wang, Y. Comparative Analysis of Atmospheric Visibility Data from the Middle Area of Liaoning Province Using Instrumental and Visual Observations. Res. Environ. Sci. 2012, 25, 1120–1125. [Google Scholar]
- Minnis, P.; Doelling, D.R.; Nguyen, L.; Miller, W.F.; Chakrapani, V. Assessment of the Visible Channel Calibrations of the VIRS on TRMM and MODIS on Aqua and Terra. J. Atmos. Ocean. Technol. 2008, 25, 385–400. [Google Scholar] [CrossRef] [Green Version]
- Chattopadhyay, P.; Ray, A.; Damarla, T. Simultaneous tracking and counting of targets in a sensor network. J. Acoust. Soc. Am. 2016, 139, 2108. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, G.Y.; Sun, G.F.; Su, S.; Zhang, J.L. Calibration Method for Standard Scattering Plate Calibration System Used in Calibrating Visibility Meter. Acta Photonica Sin. 2017, 46, 312003. [Google Scholar] [CrossRef]
- Huang, S.C.; Chen, B.H.; Wang, W.J. Visibility Restoration of Single Hazy Images Captured in Real-World Weather Conditions. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 1814–1824. [Google Scholar] [CrossRef]
- Farhan, H.; Jechang, J. Visibility Enhancement of Scene Images Degraded by Foggy Weather Conditions with Deep Neural Networks. J. Sens. 2016, 2016, 3894832. [Google Scholar]
- Ling, Z.; Fan, G.; Gong, J.; Guo, S. Learning deep transmission network for efficient image dehazing. Multimed. Tools Appl. 2019, 78, 213–236. [Google Scholar] [CrossRef]
- Ju, M.; Gu, Z.; Zhang, D.; Qin, H. Visibility Restoration for Single Hazy Image Using Dual Prior Knowledge. Math. Probl. Eng. 2017, 2017, 8190182. [Google Scholar] [CrossRef] [Green Version]
- Zhu, L.; Zhu, G.; Han, L.; Wang, N. The Application of Deep Learning in Airport Visibility Forecast. Atmos. Clim. Sci. 2017, 7, 314–322. [Google Scholar] [CrossRef] [Green Version]
- Li, S.Y.; Fu, H.; Lo, W.L. Meteorological Visibility Evaluation on Webcam Weather Image Using Deep Learning Features. Int. J. Comput. Theory Eng. 2017, 9, 455–461. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.H.; Huang, S.C.; Li, C.Y.; Kuo, S.Y. Haze Removal Using Radial Basis Function Networks for Visibility Restoration Applications. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 3828–3838. [Google Scholar] [PubMed]
- Chaabani, H.; Werghi, N.; Kamoun, F.; Taha, B.; Outay, F. Estimating meteorological visibility range under foggy weather conditions: A deep learning approach. Procedia Comput. Sci. 2018, 141, 478–483. [Google Scholar] [CrossRef]
- Palvanov, A.; Cho, Y.I. DHCNN for Visibility Estimation in Foggy Weather Conditions. In Proceedings of the 2018 Joint 10th International Conference on Soft Computing and Intelligent Systems (SCIS) and 19th International Symposium on Advanced Intelligent Systems (ISIS), Toyama, Japan, 5–8 December 2018. [Google Scholar]
- You, Y.; Lu, C.; Wang, W.; Tang, C.K. Relative CNN-RNN: Learning Relative Atmospheric Visibility from Images. IEEE Trans. Image Process. 2018, 28, 45–55. [Google Scholar] [CrossRef]
- Choi, Y.; Choe, H.G.; Choi, J.Y.; Kim, K.T.; Kim, J.B.; Kim, N.I. Automatic Sea Fog Detection and Estimation of Visibility Distance on CCTV. J. Coast. Res. 2018, 85, 881–885. [Google Scholar] [CrossRef]
- Ren, W.; Pan, J.; Zhang, H.; Cao, X.; Yang, M.H. Single Image Dehazing via Multi-scale Convolutional Neural Networks with Holistic Edges. Int. J. Comput. Vis. 2019, 128, 240–259. [Google Scholar] [CrossRef]
- Lu, Z.; Lu, B.; Zhang, H.; Fu, Y.; Qiu, Y.; Zhan, T. A method of visibility forecast based on hierarchical sparse representation. J. Vis. Commun. Image Represent. 2019, 58, 160–165. [Google Scholar] [CrossRef]
- Li, Q.; Tang, S.; Peng, X.; Ma, Q. A Method of Visibility Detection Based on the Transfer Learning. J. Atmos. Ocean. Technol. 2019, 36, 1945–1956. [Google Scholar] [CrossRef]
- Outay, F.; Taha, B.; Chaabani, H.; Kamoun, F.; Werghi, N. Estimating ambient visibility in the presence of fog: A deep convolutional neural network approach. Pers. Ubiquitous Comput. 2019. [Google Scholar] [CrossRef]
- Zhang, C.; Wu, M.; Chen, J.; Chen, K.; Zhang, C.; Xie, C.; Huang, B.; He, Z. Weather Visibility Prediction Based on Multimodal Fusion. IEEE Access 2019, 7, 74776–74786. [Google Scholar] [CrossRef]
- Palvanov, A.; Cho, Y. VisNet: Deep Convolutional Neural Networks for Forecasting Atmospheric Visibility. Sensors 2019, 19, 1343. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lo, W.L.; Zhu, M.; Fu, H. Meteorology Visibility Estimation by Using Multi-Support Vector Regression Method. J. Adv. Inf. Technol. 2020, 11, 40–47. [Google Scholar]
- Malm, W.; Cismoski, S.; Prenni, A.; Peters, M. Use of cameras for monitoring visibility impairment. Atmos. Environ. 2018, 175, 167–183. [Google Scholar] [CrossRef]
- De Bruine, M.; Krol, M.C.; van Noije, T.P.C.; Le Sager, P.; Röckmann, T. The impact of precipitation evaporation on the atmospheric aerosol distribution in EC-Earth v3.2.0. Geosci. Model Dev. Discuss. 2017, 11, 1443–1465. [Google Scholar] [CrossRef] [Green Version]
- Hautiére, N.; Tarel, J.P.; Lavenant, J.; Aubert, D. Automatic fog detection and estimation of visibility distance through use of an onboard camera. Mach. Vis. Appl. 2006, 17, 8–20. [Google Scholar] [CrossRef]
- Yang, W.; Liu, J.; Yang, S.; Guo, Z. Scale-Free Single Image Deraining Via Visibility-Enhanced Recurrent Wavelet Learning. IEEE Trans. Image Process. 2019, 28, 2948–2961. [Google Scholar] [CrossRef]
- Cheng, X.; Yang, B.; Liu, G.; Olofsson, T.; Li, H. A variational approach to atmospheric visibility estimation in the weather of fog and haze. Sustain. Cities Soc. 2018, 39, 215–224. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, T.; Pedrycz, W.; Zhao, C.; Miao, D. Improved Adaptive Image Retrieval with the Use of Shadowed Sets. Pattern Recognit. 2019, 90, 390–403. [Google Scholar] [CrossRef]
- Chaabani, H.; Kamoun, F.; Bargaoui, H.; Outay, F. A Neural network approach to visibility range estimation under foggy weather conditions. Procedia Comput. Sci. 2017, 113, 466–471. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Evaluation Range (m) | Advantages | Disadvantages |
|---|---|---|---|
| The pre-trained Convolutional Neural Networks (CNN) model (AlexNet) was used to perform feature extraction on the image, and the proposed Generalized Regression Neural Network (GRNN) is used for the evaluation of image visibility. Finally, visibility of webcam weather images was classified [13]. | 0–35,000 |
|
|
| Quickly bridge Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN). Use CNN-RNN for visibility learning, and relative Support Vector Machine (SVR) for regression analysis [17]. | 300–800 |
|
|
| Using a novel deep integrated convolutional neural networks (VisNet) method to estimate images visibility by using webcam weather images. Three deeply integrated convolutional neural network streams were connected in parallel in the VisNet. Evaluate the model’s performance, by using three different datasets of images, each with different visibility ranges and a different number of classes [24]. |
|
|
|
| Using a feature encoding visibility detection network (FE-V network) without reference image to extract features from the image. Using deep convolutional neural networks (DCNN) for transfer learning. Using Support Vector Regression (SVR) and fusion to estimate visibility [21]. | 0–20,000 |
|
|
| Using a novel Multiple Support Vector Regression (MSVR) model based on deep learning method for predicting weather visibility for different ranges. Extracting different subregions according to prescribed landmarks information from the whole images. Uses the VGG16 network to extract features. Subregions images were divided into different classes according to visibility range. Features are imported into different SVM for visibility estimation [25]. | 0–50,000 |
|
|
| Item | Configuration |
|---|---|
| Operating System | Linux |
| Memory Capacity | 32GB memory |
| Central Processing Unit | 2.6 GHz Intel CPU i7-8700 |
| Graphics Processing Unit | NVIDIA GeForce GTX 1060 Ti |
| Software platform | Python 3.6 |
| Deep Learning Library | Keras |
| Image database | Hong Kong Observatory (HKO) |
| Image Database of Hong Kong Observatory | Visibility Range (km) | |||||
|---|---|---|---|---|---|---|
| 0–10 | 11–20 | 21–30 | 31–40 | 40–50 | Total | |
| No. of training set sample images | 432 | 1271 | 762 | 726 | 439 | 3630 |
| No. of test set sample images | 144 | 424 | 254 | 242 | 146 | 1210 |
| Total | 576 | 1695 | 1016 | 968 | 585 | 4841 |
| No. of Effective Subregion | No.1 | No.2 | No.3 | No.4 | No.5 |
|---|---|---|---|---|---|
| Estimated visibility | 16.44 | 13.77 | 15.81 | 14.97 | 13.07 |
| Fusion Weight | 0.12 | 0.23 | 0.25 | 0.18 | 0.22 |
| Fusion of Effective Subregion | |||
|---|---|---|---|
| No. of Effective subregion | No.1 | No.1, No.3, No.5 | No.1, No.2, No.3, No.4, No.5 |
| Accuracy (%) | 67.83 | 83.1 | 91.2 |
| Deep Learning Network | Visibility Range (km) | |||||
|---|---|---|---|---|---|---|
| 0–10 | 11–20 | 21–30 | 31–40 | 41–50 | Total | |
| VGG-16 (%) | 84.36 | 91.31 | 89.16 | 87.45 | 87.22 | 88.26 |
| VGG-19 (%) | 85.61 | 91.66 | 89.32 | 87.96 | 87.52 | 88.32 |
| DenseNet (%) | 89.41 | 93.22 | 92.31 | 88.51 | 88.10 | 90.52 |
| ResNet_50 (%) | 89.11 | 94.58 | 91.51 | 88.62 | 88.33 | 91.20 |
| Fusion Method | Visibility Range (km) | |||||
|---|---|---|---|---|---|---|
| 0–10 | 11–20 | 21–30 | 31–40 | 41–50 | Total | |
| Random fusion (%) | 55.62 | 57.16 | 69.55 | 69.21 | 68.71 | 67.48 |
| Average fusion (%) | 78.39 | 80.95 | 88.79 | 87.46 | 86.58 | 84.53 |
| Weight fusion (%) | 86.12 | 93.61 | 92.25 | 92.21 | 91.60 | 90.32 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Lo, W.L.; Fu, H.; Chung, H.S.H. A Transfer Learning Method for Meteorological Visibility Estimation Based on Feature Fusion Method. Appl. Sci. 2021, 11, 997. https://doi.org/10.3390/app11030997
Li J, Lo WL, Fu H, Chung HSH. A Transfer Learning Method for Meteorological Visibility Estimation Based on Feature Fusion Method. Applied Sciences. 2021; 11(3):997. https://doi.org/10.3390/app11030997
Chicago/Turabian StyleLi, Jiaping, Wai Lun Lo, Hong Fu, and Henry Shu Hung Chung. 2021. "A Transfer Learning Method for Meteorological Visibility Estimation Based on Feature Fusion Method" Applied Sciences 11, no. 3: 997. https://doi.org/10.3390/app11030997
APA StyleLi, J., Lo, W. L., Fu, H., & Chung, H. S. H. (2021). A Transfer Learning Method for Meteorological Visibility Estimation Based on Feature Fusion Method. Applied Sciences, 11(3), 997. https://doi.org/10.3390/app11030997