An Effective BERT-Based Pipeline for Twitter Sentiment Analysis: A Case Study in Italian




Abstract
1. Introduction
- A pre-processing phase is carried out to transform Twitter jargon, including emojis and emoticons, into plain text, using language-independent conversion techniques that are general and applicable also to different languages.
- A language model is used, namely BERT, but in its version pre-trained on plain text instead of tweets. There are two reasons for this choice: firstly, the pre-trained models are widely available in many languages, avoiding the time-consuming and resource-intensive model training directly on tweets from scratch, allowing to focus only on their fine-tuning; secondly, available plain text corpora are larger than tweet-only ones, allowing for better performance.
2. Background and Related Works
2.1. Techniques for Sentiment Analysis
2.1.1. Word Embedding
2.1.2. Deep Neural Networks
2.2. Pre-Processing Techniques for Sentiment Analysis
2.3. Sentiment Analysis in the Italian Language
3. Methods
3.1. Pre-Processing Procedures
^([0-2][0-9]|(3)[0-1])(\/)(((0)[0-9])|((1)[0-2]))(\/)\d{4}$→<date>
(\w+@\w+.[\w+]{2,4}$)→<email>
(^\d∗(\.\d{1,2})?$)→<money>
^[0-9]∗$→<number>
\d+(\%|\s\bpercent\b)→<percentage>
([(][\d]{3}[)][ ]?[\d]{3}-[\d]{4})→<phone>
^([0-1][0-9]|[2][0-3]):([0-5][0-9])$→<time>
(\w+:\/\/\S+) → url
(@[A-Za-z0-9]+) → @user
(#S+) → < tokenize(S+) >
#serviziopubblico: La ’buona scuola’ dev’essere: fondata sul lavoro…allora i politici tutti ripetenti? Si, Mastella prima di tuttihttp://a.co/344555

(#publicservice: The ’good school’ must be: based on work…then politicians all repeating? Yes, Mastella above allhttp://a.co/344555)

<servizio pubblico>: La ’buona scuola’ dev’essere: fondata sul lavoro…allora i politici tutti ripetenti? Si, Mastella prima di tutti Faccina Con Un Gran Sorriso url
(<public service>: The ’good school’ must be: based on work…then politicians all repeating? Yes, Mastella above all Grinning Face url).
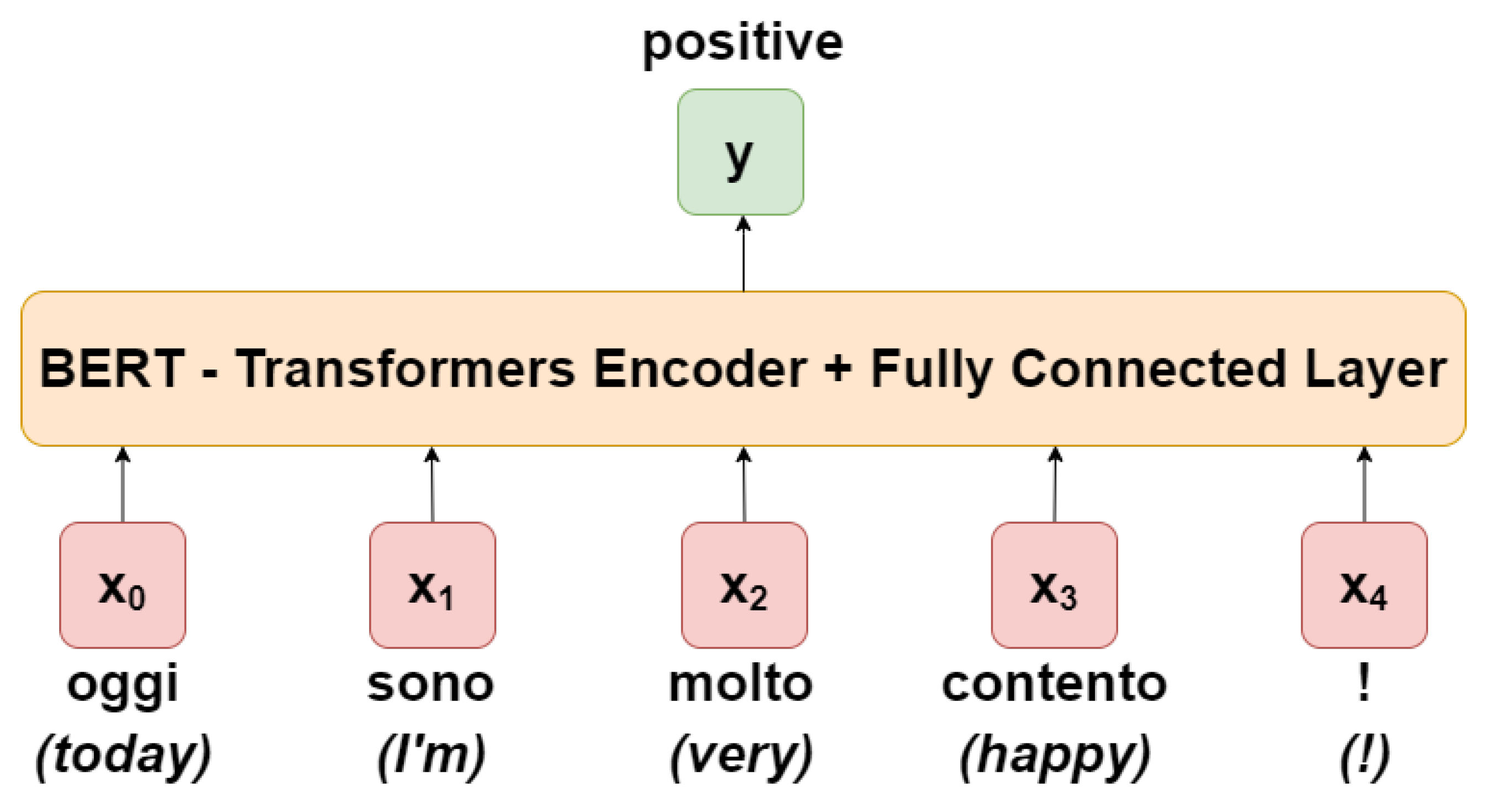
3.2. Bert System Architecture
Transformer
3.3. Model Training
4. Experimental Design
4.1. Data Set
- Task 1: Subjectivity Classification. It was intended to verify the subjectivity and objectivity of tweets.
- Task 2: Polarity Classification. Its purpose was to verify positivity, negativity and neutrality (and their mixes) in tweets. This paper focuses on this task.
- Task 3: Irony Detection. It aimed to verify whether tweets are ironic or not.
4.2. Metrics
4.3. Experiments Execution
5. Results and Discussion
Alla ’Buona scuola’ noi rispondiamo con la ’Vera scuola’! #noallabuonascuola #laverascuola
(To the ’Good school’ we respond with the ’True school’! #noallabuonascuola #laverascuola)
Alla ’Buona scuola’ noi rispondiamo con la ’Vera scuola’! <no alla buona scuola> <la vera scuola>
(To the ’Good school’ we respond with the ’True school’! <no to good school> <the real school>)
#AndreaColletti #M5S: #Riforma della #prescrizione https://t.co/iRMQ3x5rwf #Incalza #TuttiInGalera #ersistema #terradeifuochi
(#AndreaColletti #M5S: #Reformation of the #prescription https://t.co/iRMQ3x5rwf #Pressing #AllInJail #thesystem #fireland)
<Andrea Colletti> <M5S>: <Riforma> della <prescrizione> url <Incalza> <Tutti In Galera> <er sistema> <terra dei fuochi>
(<Andrea Colletti> <M5S>: <Reformation> of the <prescription> url <Pressing> <All In Jail> <the system> <fire land>)
#Roma #PiazzaDiSpagna pochi minuti fa. #NoComment #RomaFeyenoord http://t.co/2F1YtLNc8z

(#Roma #PiazzaDiSpagna few minutes ago. #NoComment #RomaFeyenoord http://t.co/2F1YtLNc8z)

<Roma> <Piazza Di Spagna> pochi minuti fa Faccina Arrabbiata. <No Comment> <Roma Feyenoord> url
(<Rome> <Piazza Di Spagna> a few minutes ago Angry Face. <No Comment> <Roma Feyenoord> url)
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Araque, O.; Corcuera-Platas, I.; Sánchez-Rada, J.F.; Iglesias, C.A. Enhancing deep learning sentiment analysis with ensemble techniques in social applications. Expert Syst. Appl. 2017, 77, 236–246. [Google Scholar] [CrossRef]
- Becken, S.; Stantic, B.; Chen, J.; Alaei, A.R.; Connolly, R.M. Monitoring the environment and human sentiment on the Great Barrier Reef: Assessing the potential of collective sensing. J. Environ. Manag. 2017, 203, 87–97. [Google Scholar] [CrossRef] [PubMed]
- Thet, T.T.; Na, J.; Khoo, C.S.G. Aspect-based sentiment analysis of movie reviews on discussion boards. J. Inf. Sci. 2010, 36, 823–848. [Google Scholar] [CrossRef]
- Bakshi, R.K.; Kaur, N.; Kaur, R.; Kaur, G. Opinion mining and sentiment analysis. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 452–455. [Google Scholar]
- Liu, B. Sentiment Analysis and Subjectivity. In Handbook of Natural Language Processing, 2nd ed.; Indurkhya, N., Damerau, F.J., Eds.; Chapman and Hall/CRC: New York, NY, USA, 2010; pp. 627–666. [Google Scholar]
- Hutto, C.J.; Gilbert, E. VADER: A Parsimonious Rule-Based Model for Sentiment Analysis of Social Media Text. In Proceedings of the Eighth International Conference on Weblogs and Social Media, ICWSM 2014, Ann Arbor, MI, USA, 1–4 June 2014; Adar, E., Resnick, P., Choudhury, M.D., Hogan, B., Oh, A.H., Eds.; The AAAI Press: Palo Alto, CA, USA, 2014. [Google Scholar]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Chen, T.; Xu, R.; He, Y.; Wang, X. Improving sentiment analysis via sentence type classification using BiLSTM-CRF and CNN. Expert Syst. Appl. 2017, 72, 221–230. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1, pp. 4171–4186. [Google Scholar] [CrossRef]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to Fine-Tune BERT for Text Classification? In Chinese Computational Linguistics-18th China National Conference, CCL 2019, Kunming, China, 18–20 October 2019; Lecture Notes in Computer Science; Sun, M., Huang, X., Ji, H., Liu, Z., Liu, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11856, pp. 194–206. [Google Scholar] [CrossRef]
- Azzouza, N.; Akli-Astouati, K.; Ibrahim, R. TwitterBERT: Framework for Twitter Sentiment Analysis Based on Pre-trained Language Model Representations. In Emerging Trends in Intelligent Computing and Informatics-Data Science, Intelligent Information Systems and Smart Computing, International Conference of Reliable Information and Communication Technology, IRICT 2019, Johor, Malaysia, 22–23 September 2019; Saeed, F., Mohammed, F., Gazem, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; Volume 1073, pp. 428–437. [Google Scholar] [CrossRef]
- Nguyen, D.Q.; Vu, T.; Nguyen, A.T. BERTweet: A pre-trained language model for English Tweets. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, EMNLP 2020-Demos, Online, 16–20 November 2020; Liu, Q., Schlangen, D., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 9–14. [Google Scholar]
- Polignano, M.; Basile, P.; de Gemmis, M.; Semeraro, G.; Basile, V. AlBERTo: Italian BERT Language Understanding Model for NLP Challenging Tasks Based on Tweets. In Proceedings of the Sixth Italian Conference on Computational Linguistics, Bari, Italy, 13–15 November 2019; Bernardi, R., Navigli, R., Semeraro, G., Eds.; Volume 2481. [Google Scholar]
- González, J.; Moncho, J.A.; Hurtado, L.; Pla, F. ELiRF-UPV at TASS 2020: TWilBERT for Sentiment Analysis and Emotion Detection in Spanish Tweets. In Proceedings of the Iberian Languages Evaluation Forum (IberLEF 2020) co-located with 36th Conference of the Spanish Society for Natural Language Processing (SEPLN 2020), Málaga, Spain, 23 September 2020; Cumbreras, M.Á.G., Gonzalo, J., Cámara, E.M., Martínez-Unanue, R., Rosso, P., Zafra, S.M.J., Zambrano, J.A.O., Miranda, A., Zamorano, J.P., Gutiérrez, Y., et al., Eds.; Volume 2664, pp. 179–186. [Google Scholar]
- Ángel González, J.; Hurtado, L.F.; Pla, F. TWilBert: Pre-trained deep bidirectional transformers for Spanish Twitter. Neurocomputing 2020. [Google Scholar] [CrossRef]
- Thakkar, G.; Pinnis, M. Pretraining and Fine-Tuning Strategies for Sentiment Analysis of Latvian Tweets. In Human Language Technologies—The Baltic Perspective-Proceedings of the Ninth International Conference Baltic HLT 2020; IOS Press: Kaunas, Lithuania, 2020; pp. 55–61. [Google Scholar] [CrossRef]
- Barbieri, F.; Basile, V.; Croce, D.; Nissim, M.; Novielli, N.; Patti, V. Overview of the Evalita 2016 SENTIment POLarity Classification Task. In Proceedings of the Third Italian Conference on Computational Linguistics (CLiC-it 2016) & Fifth Evaluation Campaign of Natural Language Processing and Speech Tools for Italian. Final Workshop (EVALITA 2016), Napoli, Italy, 5–7 December 2016; Basile, P., Corazza, A., Cutugno, F., Montemagni, S., Nissim, M., Patti, V., Semeraro, G., Sprugnoli, R., Eds.; Volume 1749. [Google Scholar]
- Liu, B.; Zhang, L. A Survey of Opinion Mining and Sentiment Analysis. In Mining Text Data; Aggarwal, C.C., Zhai, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 415–463. [Google Scholar] [CrossRef]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment Classification using Machine Learning Techniques. In Proceedings of the 2002 Conference on Empirical Methods in Natural Language Processing, EMNLP 2002, Philadelphia, PA, USA, 6–7 July 2002; pp. 79–86. [Google Scholar] [CrossRef]
- Mukherjee, S.; Joshi, S. Author-Specific Sentiment Aggregation for Polarity Prediction of Reviews. In Proceedings of the Ninth International Conference on Language Resources and Evaluation, LREC 2014, Reykjavik, Iceland, 26–31 May 2014; Calzolari, N., Choukri, K., Declerck, T., Loftsson, H., Maegaard, B., Mariani, J., Moreno, A., Odijk, J., Piperidis, S., Eds.; pp. 3092–3099. [Google Scholar]
- Diamantini, C.; Mircoli, A.; Potena, D. A Negation Handling Technique for Sentiment Analysis. In Proceedings of the 2016 International Conference on Collaboration Technologies and Systems, CTS 2016, Orlando, FL, USA, 31 October–4 November 2016; Smari, W.W., Natarian, J., Eds.; pp. 188–195. [Google Scholar] [CrossRef]
- Perikos, I.; Hatzilygeroudis, I. Aspect based sentiment analysis in social media with classifier ensembles. In Proceedings of the 16th IEEE/ACIS International Conference on Computer and Information Science, ICIS 2017, Wuhan, China, 24–26 May 2017; Zhu, G., Yao, S., Cui, X., Xu, S., Eds.; pp. 273–278. [Google Scholar] [CrossRef]
- Pota, M.; Esposito, M.; Pietro, G.D. A Forward-Selection Algorithm for SVM-Based Question Classification in Cognitive Systems. In Proceedings of the Intelligent Interactive Multimedia Systems and Services 2016, KES IIMSS 2016, Puerto de la Cruz, Tenerife, Spain, 15–17 June 2016; Pietro, G.D., Gallo, L., Howlett, R.J., Jain, L.C., Eds.; pp. 587–598. [Google Scholar] [CrossRef]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar] [CrossRef]
- Berger, A.L.; Pietra, S.D.; Pietra, V.J.D. A Maximum Entropy Approach to Natural Language Processing. Comput. Linguistics 1996, 22, 39–71. [Google Scholar]
- Pota, M.; Fuggi, A.; Esposito, M.; Pietro, G.D. Extracting Compact Sets of Features for Question Classification in Cognitive Systems: A Comparative Study. In Proceedings of the 10th International Conference on P2P, Parallel, Grid, Cloud and Internet Computing, 3PGCIC 2015, Krakow, Poland, 4–6 November 2015; Xhafa, F., Barolli, L., Messina, F., Ogiela, M.R., Eds.; pp. 551–556. [Google Scholar] [CrossRef]
- Thelwall, M.; Buckley, K.; Paltoglou, G.; Cai, D.; Kappas, A. Sentiment in short strength detection informal text. J. Assoc. Inf. Sci. Technol. 2010, 61, 2544–2558. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of the Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 3111–3119. [Google Scholar]
- Ali, F.; El-Sappagh, S.H.A.; Islam, S.M.R.; Ali, A.; Attique, M.; Imran, M.; Kwak, K. An intelligent healthcare monitoring framework using wearable sensors and social networking data. Future Gener. Comput. Syst. 2021, 114, 23–43. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; Moschitti, A., Pang, B., Daelemans, W., Eds.; pp. 1532–1543. [Google Scholar] [CrossRef]
- Cao, K.; Rei, M. A Joint Model for Word Embedding and Word Morphology. In Proceedings of the 1st Workshop on Representation Learning for NLP, Rep4NLP@ACL 2016, Berlin, Germany, 11 August 2016; Blunsom, P., Cho, K., Cohen, S.B., Grefenstette, E., Hermann, K.M., Rimell, L., Weston, J., Yih, S.W., Eds.; pp. 18–26. [Google Scholar] [CrossRef]
- Li, Y.; Pan, Q.; Yang, T.; Wang, S.; Tang, J.; Cambria, E. Learning Word Representations for Sentiment Analysis. Cogn. Comput. 2017, 9, 843–851. [Google Scholar] [CrossRef]
- Yu, L.; Wang, J.; Lai, K.R.; Zhang, X. Refining Word Embeddings Using Intensity Scores for Sentiment Analysis. IEEE ACM Trans. Audio Speech Lang. Process. 2018, 26, 671–681. [Google Scholar] [CrossRef]
- Hao, Y.; Mu, T.; Hong, R.; Wang, M.; Liu, X.; Goulermas, J.Y. Cross-Domain Sentiment Encoding through Stochastic Word Embedding. IEEE Trans. Knowl. Data Eng. 2020, 32, 1909–1922. [Google Scholar] [CrossRef]
- Ali, F.; Kwak, D.; Khan, P.; El-Sappagh, S.H.A.; Ali, A.; Ullah, S.; Kim, K.; Kwak, K.S. Transportation sentiment analysis using word embedding and ontology-based topic modeling. Knowl. Based Syst. 2019, 174, 27–42. [Google Scholar] [CrossRef]
- Yadav, A.; Vishwakarma, D.K. Sentiment analysis using deep learning architectures: A review. Artif. Intell. Rev. 2020, 53, 4335–4385. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., von Luxburg, U., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R., Eds.; pp. 5998–6008. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar] [CrossRef]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A Convolutional Neural Network for Modelling Sentences. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 22–27 June 2014; pp. 655–665. [Google Scholar] [CrossRef]
- Pota, M.; Esposito, M.; Pietro, G.D.; Fujita, H. Best Practices of Convolutional Neural Networks for Question Classification. Appl. Sci. 2020, 10, 4710. [Google Scholar] [CrossRef]
- Pota, M.; Esposito, M. Question Classification by Convolutional Neural Networks Embodying Subword Information. In Proceedings of the 2018 International Joint Conference on Neural Networks, Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Pota, M.; Esposito, M.; Palomino, M.A.; Masala, G.L. A Subword-Based Deep Learning Approach for Sentiment Analysis of Political Tweets. In Proceedings of the 32nd International Conference on Advanced Information Networking and Applications Workshops, AINA 2018 Workshops, Krakow, Poland, 16–18 May 2018; pp. 651–656. [Google Scholar] [CrossRef]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Li, D.; Qian, J. Text sentiment analysis based on long short-term memory. In Proceedings of the 2016 First IEEE International Conference on Computer Communication and the Internet (ICCCI), Wuhan, China, 13–15 October 2016; pp. 471–475. [Google Scholar]
- Baziotis, C.; Pelekis, N.; Doulkeridis, C. DataStories at SemEval-2017 Task 4: Deep LSTM with Attention for Message-level and Topic-based Sentiment Analysis. In Proceedings of the 10th International Workshop on Semantic Evaluation, SemEval@NAACL-HLT 2016, San Diego, CA, USA, 16–17 June 2016; pp. 747–754. [Google Scholar] [CrossRef]
- Alayba, A.M.; Palade, V.; England, M.; Iqbal, R. A Combined CNN and LSTM Model for Arabic Sentiment Analysis. In Proceedings of the Machine Learning and Knowledge Extraction-Second IFIP TC 5, TC 8/WG 8.4, 8.9, TC 12/WG 12.9 International Cross-Domain Conference, CD-MAKE 2018, Hamburg, Germany, 27–30 August 2018; Holzinger, A., Kieseberg, P., Tjoa, A.M., Weippl, E.R., Eds.; Volume 11015, pp. 179–191. [Google Scholar] [CrossRef]
- Howard, J.; Ruder, S. Universal Language Model Fine-tuning for Text Classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018, Melbourne, Australia, 15–20 July 2018; Gurevych, I., Miyao, Y., Eds.; Volume 1, pp. 328–339. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://openai.com/blog/language-unsupervised/ (accessed on 1 October 2020).
- Nozza, D.; Bianchi, F.; Hovy, D. What the [MASK]? Making Sense of Language-Specific BERT Models. arXiv 2020, arXiv:2003.02912. [Google Scholar]
- Song, Y.; Wang, J.; Liang, Z.; Liu, Z.; Jiang, T. Utilizing BERT Intermediate Layers for Aspect Based Sentiment Analysis and Natural Language Inference. arXiv 2020, arXiv:2002.04815. [Google Scholar]
- Dashtipour, K.; Gogate, M.; Li, J.; Jiang, F.; Kong, B.; Hussain, A. A hybrid Persian sentiment analysis framework: Integrating dependency grammar based rules and deep neural networks. Neurocomputing 2020, 380, 1–10. [Google Scholar] [CrossRef]
- Ombabi, A.H.; Ouarda, W.; Alimi, A.M. Deep learning CNN-LSTM framework for Arabic sentiment analysis using textual information shared in social networks. Soc. Netw. Anal. Min. 2020, 10, 53. [Google Scholar] [CrossRef]
- Boiy, E.; Hens, P.; Deschacht, K.; Moens, M. Automatic Sentiment Analysis in On-line Text. In Proceedings of the 11th International Conference on Electronic Publishing, Vienna, Austria, 13–15 June 2007; pp. 349–360. [Google Scholar]
- Danisman, T.; Alpkocak, A. Feeler: Emotion classification of text using vector space model. In Proceedings of the AISB 2008 Symposium on Affective Language in Human and Machine, Aberdeen, Scotland, UK, 1–4 April 2008; pp. 53–59. [Google Scholar]
- Agrawal, A.; An, A. Unsupervised Emotion Detection from Text Using Semantic and Syntactic Relations. In Proceedings of the 2012 IEEE/WIC/ACM International Conferences on Web Intelligence, WI 2012, Macau, China, 4–7 December 2012; pp. 346–353. [Google Scholar] [CrossRef]
- Han, B.; Baldwin, T. Lexical Normalisation of Short Text Messages: Makn Sens a #twitter. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Proceedings of the Conference, Portland, OR, USA, 19–24 June 2011; Lin, D., Matsumoto, Y., Mihalcea, R., Eds.; pp. 368–378. [Google Scholar]
- Saif, H.; Fernández, M.; He, Y.; Alani, H. On Stopwords, Filtering and Data Sparsity for Sentiment Analysis of Twitter. In Proceedings of the Ninth International Conference on Language Resources and Evaluation, LREC 2014, Reykjavik, Iceland, 26–31 May 2014; Calzolari, N., Choukri, K., Declerck, T., Loftsson, H., Maegaard, B., Mariani, J., Moreno, A., Odijk, J., Piperidis, S., Eds.; pp. 810–817. [Google Scholar]
- Angiani, G.; Ferrari, L.; Fontanini, T.; Fornacciari, P.; Iotti, E.; Magliani, F.; Manicardi, S. A Comparison between Preprocessing Techniques for Sentiment Analysis in Twitter. In Proceedings of the 2nd International Workshop on Knowledge Discovery on the WEB, KDWeb 2016, Cagliari, Italy, 8–10 September 2016; Armano, G., Bozzon, A., Cristani, M., Giuliani, A., Eds.; Volume 1748. [Google Scholar]
- Zhao, J.; Gui, X. Comparison Research on Text Pre-processing Methods on Twitter Sentiment Analysis. IEEE Access 2017, 5, 2870–2879. [Google Scholar] [CrossRef]
- Strohm, F. The Impact of Intensifiers, Diminishers and Negations on Emotion Expressions; Universitätsbibliothek der Universität Stuttgart: Stuttgart, Germany, 2017. [Google Scholar]
- Gratian, V.; Haid, M. BrainT at IEST 2018: Fine-tuning Multiclass Perceptron For Implicit Emotion Classification. In Proceedings of the 9th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, WASSA@EMNLP 2018, Brussels, Belgium, 31 October 2018; Balahur, A., Mohammad, S.M., Hoste, V., Klinger, R., Eds.; pp. 243–247. [Google Scholar] [CrossRef]
- Pecar, S.; Farkas, M.; Simko, M.; Lacko, P.; Bieliková, M. NL-FIIT at IEST-2018: Emotion Recognition utilizing Neural Networks and Multi-level Preprocessing. In Proceedings of the 9th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, WASSA@EMNLP 2018, Brussels, Belgium, 31 October 2018; Balahur, A., Mohammad, S.M., Hoste, V., Klinger, R., Eds.; pp. 217–223. [Google Scholar] [CrossRef]
- Symeonidis, S.; Effrosynidis, D.; Arampatzis, A. A comparative evaluation of pre-processing techniques and their interactions for twitter sentiment analysis. Expert Syst. Appl. 2018, 110, 298–310. [Google Scholar] [CrossRef]
- Kim, Y.; Lee, H.; Jung, K. AttnConvnet at SemEval-2018 Task 1: Attention-based Convolutional Neural Networks for Multi-label Emotion Classification. In Proceedings of the 12th International Workshop on Semantic Evaluation, SemEval@NAACL-HLT 2018, New Orleans, LA, USA, 5–6 June 2018; Apidianaki, M., Mohammad, S.M., May, J., Shutova, E., Bethard, S., Carpuat, M., Eds.; pp. 141–145. [Google Scholar] [CrossRef]
- Berardi, G.; Esuli, A.; Marcheggiani, D.; Sebastiani, F. ISTI@TREC Microblog Track 2011: Exploring the Use of Hashtag Segmentation and Text Quality Ranking. In Proceedings of the Twentieth Text REtrieval Conference, TREC 2011, Gaithersburg, MD, USA, 15–18 November 2011. [Google Scholar]
- Patil, C.G.; Patil, S.S. Use of Porter stemming algorithm and SVM for emotion extraction from news headlines. Int. J. Electron. Commun. Soft Comput. Sci. Eng. 2013, 2, 9. [Google Scholar]
- Rose, S.L.; Venkatesan, R.; Pasupathy, G.; Swaradh, P. A lexicon-based term weighting scheme for emotion identification of tweets. Int. J. Data Anal. Tech. Strateg. 2018, 10, 369–380. [Google Scholar] [CrossRef]
- Seal, D.; Roy, U.K.; Basak, R. Sentence-level emotion detection from text based on semantic rules. In Information and Communication Technology for Sustainable Development; Springer: Berlin/Heidelberg, Germany, 2020; pp. 423–430. [Google Scholar]
- Pradha, S.; Halgamuge, M.N.; Vinh, N.T.Q. Effective Text Data Preprocessing Technique for Sentiment Analysis in Social Media Data. In Proceedings of the 11th International Conference on Knowledge and Systems Engineering, KSE 2019, Da Nang, Vietnam, 24–26 October 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Sohrabi, M.K.; Hemmatian, F. An efficient preprocessing method for supervised sentiment analysis by converting sentences to numerical vectors: A twitter case study. Multim. Tools Appl. 2019, 78, 24863–24882. [Google Scholar] [CrossRef]
- Alam, S.; Yao, N. The impact of preprocessing steps on the accuracy of machine learning algorithms in sentiment analysis. Comput. Math. Organ. Theory 2019, 25, 319–335. [Google Scholar] [CrossRef]
- Babanejad, N.; Agrawal, A.; An, A.; Papagelis, M. A Comprehensive Analysis of Preprocessing for Word Representation Learning in Affective Tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 5799–5810. [Google Scholar]
- Pota, M.; Esposito, M.; Pietro, G.D. Convolutional Neural Networks for Question Classification in Italian Language. In New Trends in Intelligent Software Methodologies, Tools and Techniques-Proceedings of the 16th International Conference, SoMeT_17, Kitakyushu City, Japan, 26–28 September 2017; Fujita, H., Selamat, A., Omatu, S., Eds.; IOS Press: Amsterdam, The Netherlands, 2017; Volume 297, pp. 604–615. [Google Scholar] [CrossRef]
- Vassallo, M.; Gabrieli, G.; Basile, V.; Bosco, C. The Tenuousness of Lemmatization in Lexicon-based Sentiment Analysis. In Proceedings of the Sixth Italian Conference on Computational Linguistics, Bari, Italy, 13–15 November 2019; Bernardi, R., Navigli, R., Semeraro, G., Eds.; Volume 2481. [Google Scholar]
- Deriu, J.; Cieliebak, M. Sentiment Detection using Convolutional Neural Networks with Multi-Task Training and Distant Supervision. In Proceedings of the Third Italian Conference on Computational Linguistics (CLiC-it 2016) & Fifth Evaluation Campaign of Natural Language Processing and Speech Tools for Italian. Final Workshop (EVALITA 2016), Napoli, Italy, 5–7 December 2016; Basile, P., Corazza, A., Cutugno, F., Montemagni, S., Nissim, M., Patti, V., Semeraro, G., Sprugnoli, R., Eds.; Volume 1749. [Google Scholar]
- Attardi, G.; Sartiano, D.; Alzetta, C.; Semplici, F. Convolutional Neural Networks for Sentiment Analysis on Italian Tweets. In Proceedings of the Third Italian Conference on Computational Linguistics (CLiC-it 2016) & Fifth Evaluation Campaign of Natural Language Processing and Speech Tools for Italian. Final Workshop (EVALITA 2016), Napoli, Italy, 5–7 December 2016; Basile, P., Corazza, A., Cutugno, F., Montemagni, S., Nissim, M., Patti, V., Semeraro, G., Sprugnoli, R., Eds.; Volume 1749. [Google Scholar]
- Castellucci, G.; Croce, D.; Basili, R. Context-aware Convolutional Neural Networks for Twitter Sentiment Analysis in Italian. In Proceedings of the Third Italian Conference on Computational Linguistics (CLiC-it 2016) & Fifth Evaluation Campaign of Natural Language Processing and Speech Tools for Italian. Final Workshop (EVALITA 2016), Napoli, Italy, 5–7 December 2016; Basile, P., Corazza, A., Cutugno, F., Montemagni, S., Nissim, M., Patti, V., Semeraro, G., Sprugnoli, R., Eds.; Volume 1749. [Google Scholar]
- Cimino, A.; Dell’Orletta, F. Tandem LSTM-SVM Approach for Sentiment Analysis. In Proceedings of the Third Italian Conference on Computational Linguistics (CLiC-it 2016) & Fifth Evaluation Campaign of Natural Language Processing and Speech Tools for Italian. Final Workshop (EVALITA 2016), Napoli, Italy, 5–7 December 2016; Basile, P., Corazza, A., Cutugno, F., Montemagni, S., Nissim, M., Patti, V., Semeraro, G., Sprugnoli, R., Eds.; Volume 1749. [Google Scholar]
- Mattei, L.D.; Cimino, A.; Dell’Orletta, F. Multi-Task Learning in Deep Neural Network for Sentiment Polarity and Irony classification. In Proceedings of the 2nd Workshop on Natural Language for Artificial Intelligence (NL4AI 2018) co-located with 17th International Conference of the Italian Association for Artificial Intelligence (AI*IA 2018), Trento, Italy, 22–23 November 2018; Basile, P., Basile, V., Croce, D., Dell’Orletta, F., Guerini, M., Eds.; Volume 2244, pp. 76–82. [Google Scholar]
- Magnini, B.; Lavelli, A.; Magnolini, S. Comparing Machine Learning and Deep Learning Approaches on NLP Tasks for the Italian Language. In Proceedings of the 12th Language Resources and Evaluation Conference, LREC 2020, Marseille, France, 11–16 May 2020; pp. 2110–2119. [Google Scholar]
- Pires, T.; Schlinger, E.; Garrette, D. How Multilingual is Multilingual BERT? In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 28 July–2 August 2019; Volume 1, pp. 4996–5001. [Google Scholar] [CrossRef]
- Petrolito, R.; Dell’Orletta, F. Word Embeddings in Sentiment Analysis. In Proceedings of the Fifth Italian Conference on Computational Linguistics (CLiC-it 2018), Torino, Italy, 10–12 December 2018; Volume 2253. [Google Scholar]
- Joshi, S.; Deshpande, D. Twitter Sentiment Analysis System. Int. J. Comput. Appl. 2018, 180, 35–39. [Google Scholar] [CrossRef]
- Eisner, B.; Rocktäschel, T.; Augenstein, I.; Bosnjak, M.; Riedel, S. emoji2vec: Learning Emoji Representations from their Description. Proceedings of The Fourth International Workshop on Natural Language Processing for Social Media, SocialNLP@EMNLP 2016, Austin, TX, USA, 1 November 2016; Ku, L., Hsu, J.Y., Li, C., Eds.; pp. 48–54. [Google Scholar] [CrossRef]
- Novak, P.K.; Smailovic, J.; Sluban, B.; Mozetic, I. Sentiment of Emojis. PLoS ONE 2015, 10, e0144296. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Bridging Nonlinearities and Stochastic Regularizers with Gaussian Error Linear Units. CoRR 2016. Available online: https://openreview.net/pdf?id=Bk0MRI5lg (accessed on 1 October 2020).
- Basile, V.; Andrea, B.; Malvina, N.; Patti, V.; Paolo, R. Overview of the Evalita 2014 SENTIment POLarity Classification Task. In 4th Evaluation Campaign of Natural Language Processing and Speech tools for Italian (EVALITA’14); Pisa University Press: Pisa, Italy, 2014; pp. 50–57. [Google Scholar]
- Stranisci, M.; Bosco, C.; Farías, D.I.H.; Patti, V. Annotating Sentiment and Irony in the Online Italian Political Debate on #labuonascuola. In Proceedings of the Tenth International Conference on Language Resources and Evaluation LREC 2016, Portorož, Slovenia, 23–28 May 2016. [Google Scholar]
- Basile, V.; Nissim, M. Sentiment analysis on Italian tweets. In Proceedings of the 4th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Atlanta, Georgia, 14 June 2013; pp. 100–107. [Google Scholar]
- Basile, P.; Caputo, A.; Gentile, A.L.; Rizzo, G. Overview of the EVALITA 2016 Named Entity rEcognition and Linking in Italian Tweets (NEEL-IT) Task. In Proceedings of the Third Italian Conference on Computational Linguistics (CLiC-it 2016) & Fifth Evaluation Campaign of Natural Language Processing and Speech Tools for Italian. Final Workshop (EVALITA 2016), Napoli, Italy, 5–7 December 2016; Volume 1749. [Google Scholar]



{kind=link}
{kind=link}
| Symbol | English | Italian |
|---|---|---|
| :) :-) 8-) :-] :-)) | Happy | Felice |
| :-( :( :-\ | Sad | Triste |
| :-P x-p | Joking | Scherzo |
| <3 < 3 :∗ | Love | Amore |
| Emoji | Meaning | Italian |
|---|---|---|
 | Crying Face | Faccina Che Piange |
 | Grinning Face | Faccina Con Un Gran Sorriso |
 | Heart With Arrow | Cuore Con Freccia |
 | Pouting Face | Faccina Arrabbiata |
| Hyperparameter | Value |
|---|---|
| Attention heads | 12 |
| Batch size | 8 |
| Epochs | 5 |
| Gradient accumulation steps | 16 |
| Hidden size | 768 |
| Hidden layers | 12 |
| Learning rate | 0.00003 |
| Maximum sequence length | 128 |
| Parameters | 110 M |
| Characteristic | Train | Test |
|---|---|---|
| Emoji | 157 | 145 |
| Emoticon | 320 | 20 |
| Hashtag | 5417 | 2180 |
| Mention | 3138 | 1564 |
| Other | 1468 | 464 |
| URL | 2314 | 956 |
| Combination | Resulting Sentiment | Train | Test | |
|---|---|---|---|---|
| oneg | opos | |||
| 0 | 0 | Neutral | 2816 | 914 |
| 0 | 1 | Positive | 1611 | 316 |
| 1 | 0 | Negative | 2543 | 734 |
| 1 | 1 | Mixed | 440 | 36 |
| System | F | ||
|---|---|---|---|
| Proposed System | 0.7381 | 0.7620 | 0.7500 |
| AlBERTo | 0.7155 | 0.7291 | 0.7223 |
| LSTM-based [81] | 0.6600 | 0.7360 | 0.6980 |
| CNN-based [77] | 0.6529 | 0.7128 | 0.6828 |
| UniPI.2.c | 0.6850 | 0.6426 | 0.6638 |
| Unitor.1.u | 0.6354 | 0.6885 | 0.6620 |
| Unitor.2.u | 0.6312 | 0.6838 | 0.6575 |
| ItaliaNLP.1.c | 0.6265 | 0.6743 | 0.6504 |
| Multilingual BERT [82] | - | - | 0.5217 |
| Model | |||||||
|---|---|---|---|---|---|---|---|
| BERT | 0.9172 | 0.8871 | 0.9019 | 0.5419 | 0.6250 | 0.5805 | 0.7412 |
| Pre-processing + BERT | 0.9262 | 0.8618 | 0.8928 | 0.5125 | 0.6780 | 0.5833 | 0.7381 |
| Model | |||||||
| BERT | 0.7639 | 0.9285 | 0.8382 | 0.8257 | 0.5416 | 0.6541 | 0.7461 |
| Pre-processing + BERT | 0.7759 | 0.9295 | 0.8458 | 0.8358 | 0.5710 | 0.6782 | 0.7620 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pota, M.; Ventura, M.; Catelli, R.; Esposito, M. An Effective BERT-Based Pipeline for Twitter Sentiment Analysis: A Case Study in Italian. Sensors 2021, 21, 133. https://doi.org/10.3390/s21010133
Pota M, Ventura M, Catelli R, Esposito M. An Effective BERT-Based Pipeline for Twitter Sentiment Analysis: A Case Study in Italian. Sensors. 2021; 21(1):133. https://doi.org/10.3390/s21010133
Chicago/Turabian StylePota, Marco, Mirko Ventura, Rosario Catelli, and Massimo Esposito. 2021. "An Effective BERT-Based Pipeline for Twitter Sentiment Analysis: A Case Study in Italian" Sensors 21, no. 1: 133. https://doi.org/10.3390/s21010133
APA StylePota, M., Ventura, M., Catelli, R., & Esposito, M. (2021). An Effective BERT-Based Pipeline for Twitter Sentiment Analysis: A Case Study in Italian. Sensors, 21(1), 133. https://doi.org/10.3390/s21010133