Real-Time 3D Printing Remote Defect Detection (Stringing) with Computer Vision and Artificial Intelligence



Abstract
1. Introduction
1.1. Computer Vision and Object Detection
1.2. Applications on Additive Manufacturing
1.3. Common Defects in 3D printing
2. Methodology
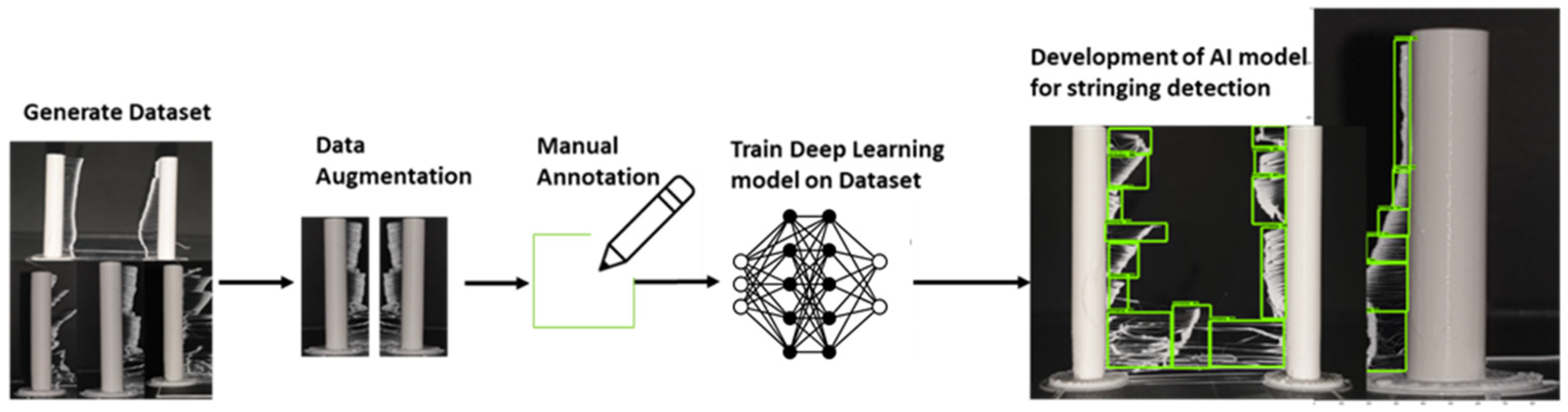
2.1. Data Collection and Annotation
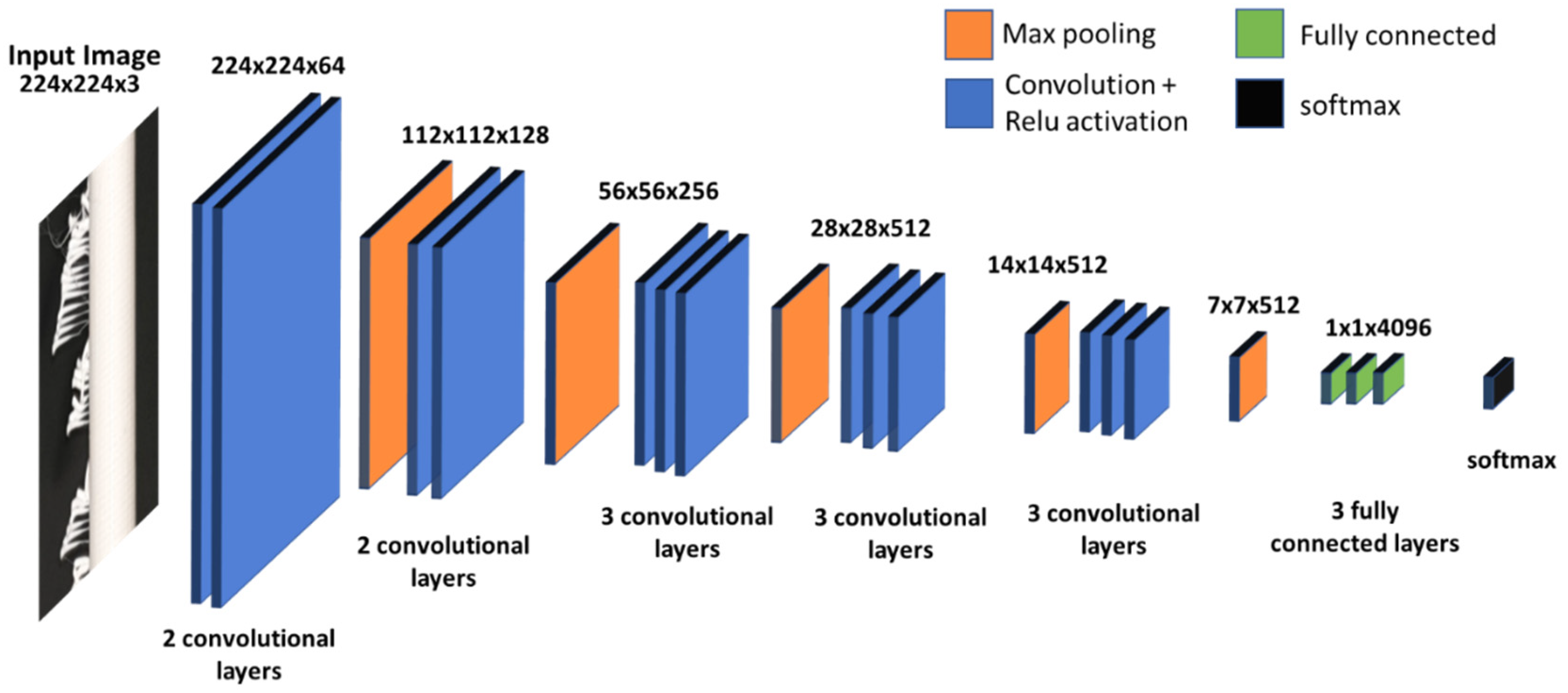
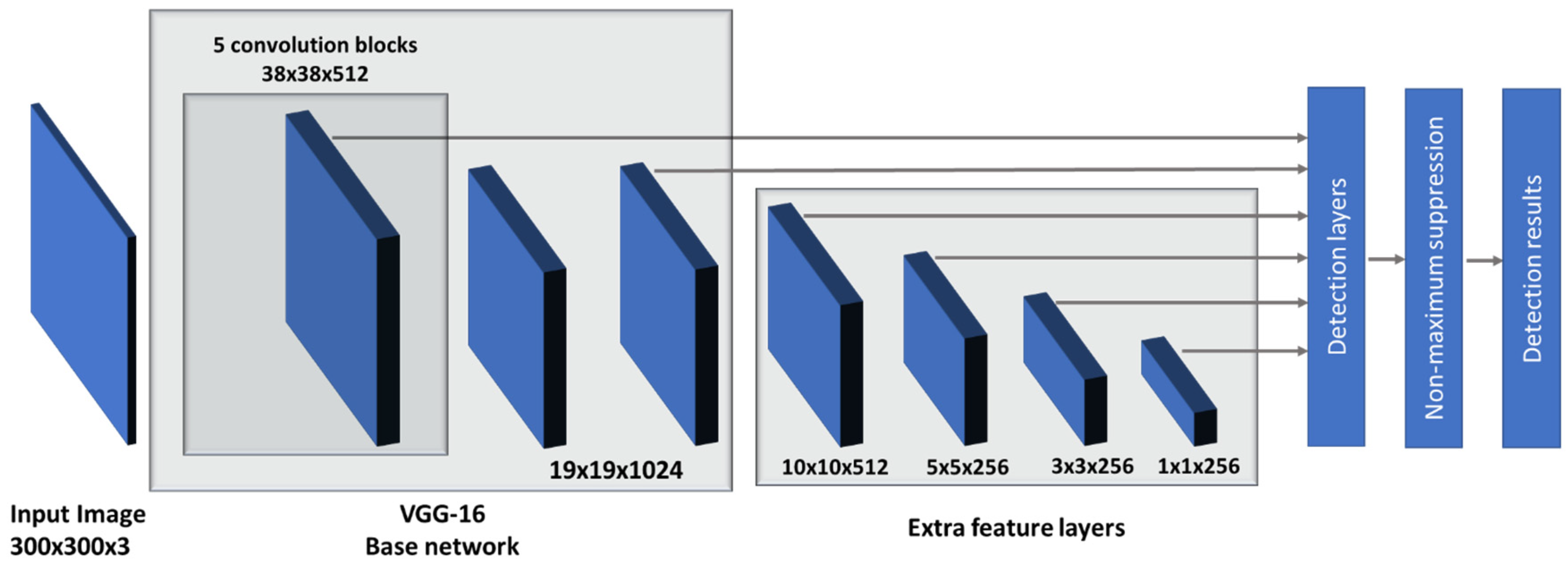
2.2. Model Selection and Training
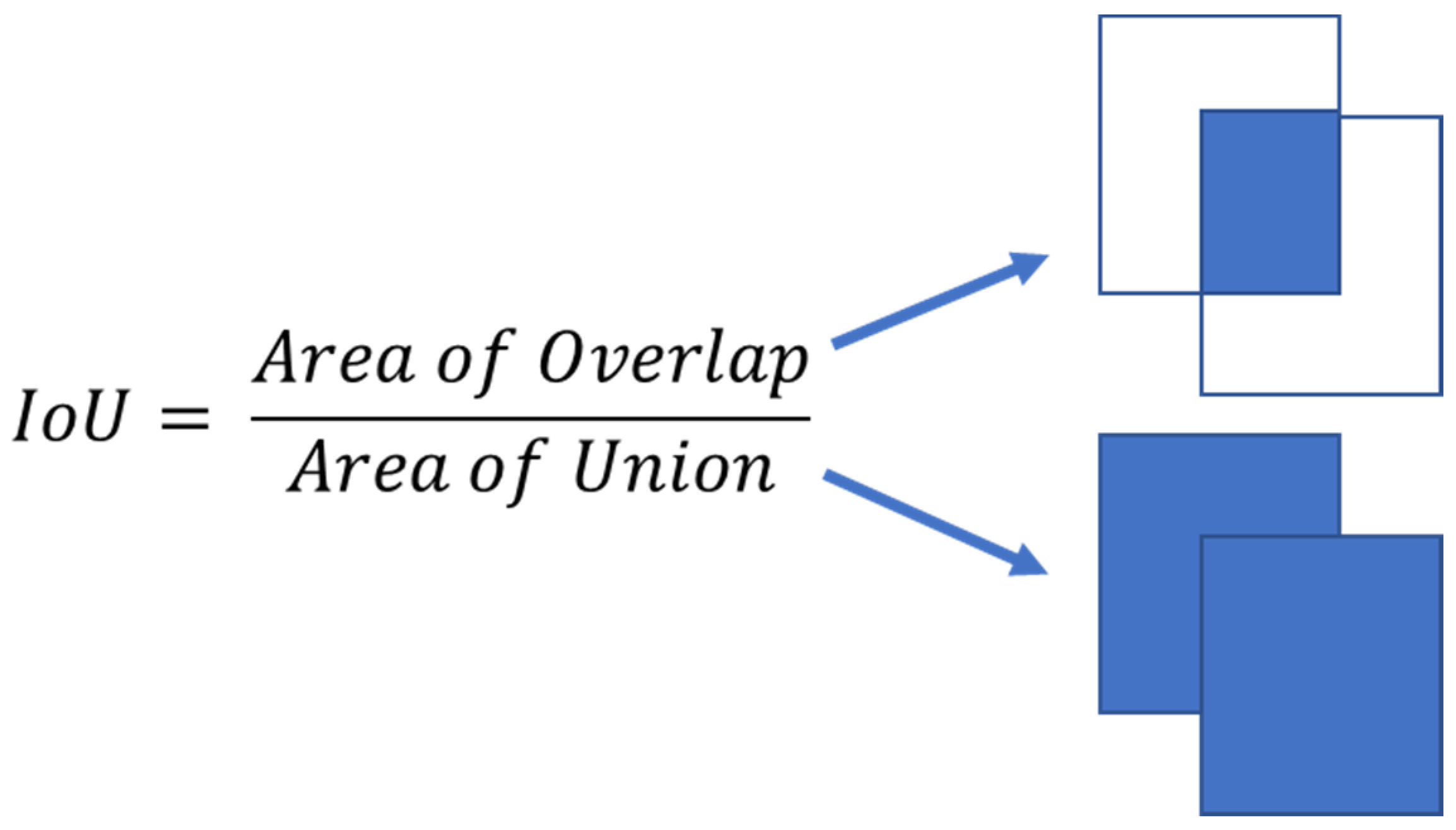
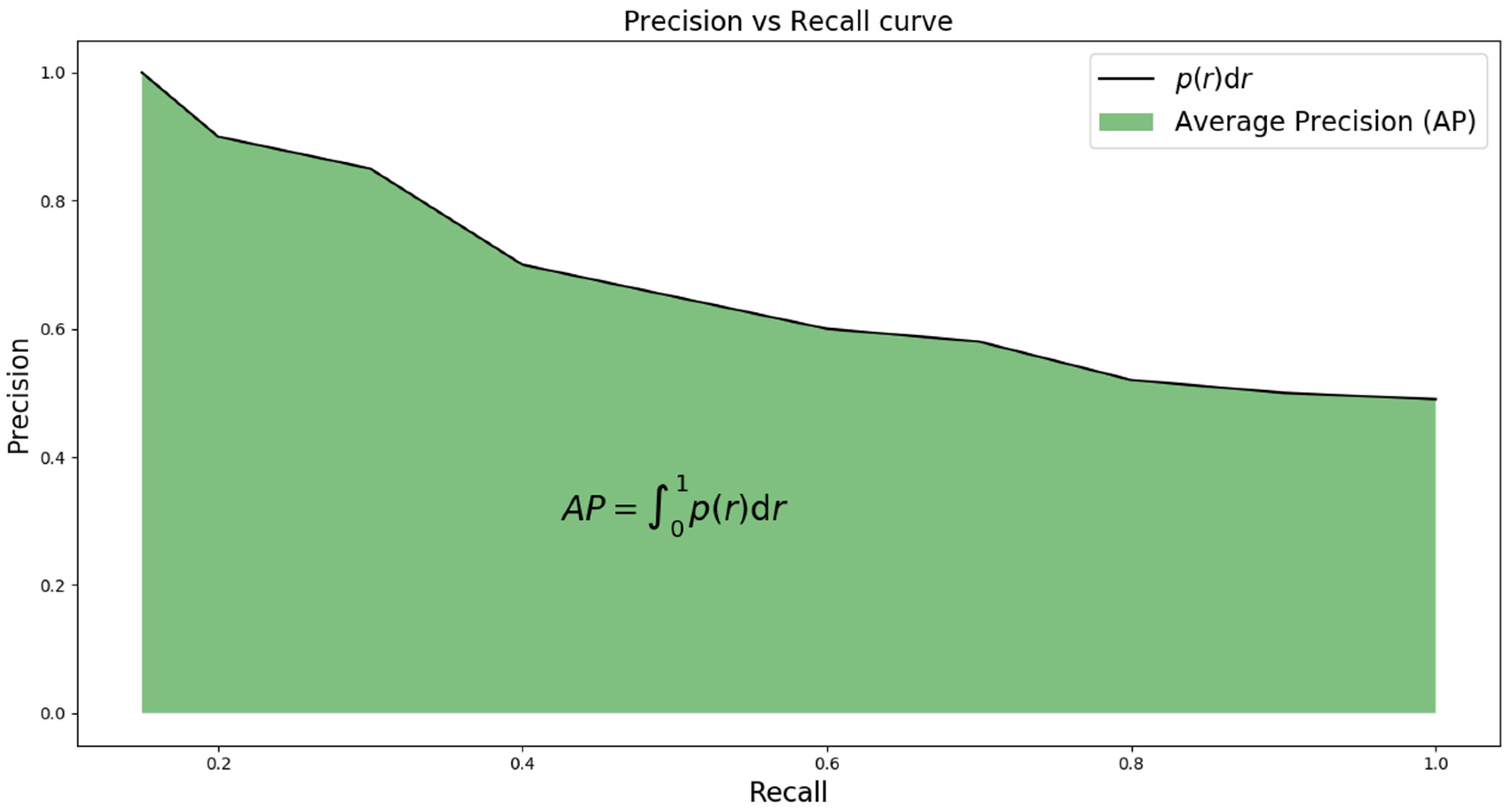
2.3. Evaluation Metrics Principles
3. Results and Live Deployment
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer Science & Business Media: Amsterdam, The Netherlands, 2010. [Google Scholar]
- El-Dahshan, E.-S.A.; Hosny, T.; Salem, A.-B.M. Hybrid intelligent techniques for MRI brain images classification. Digit. Signal Process. 2010, 20, 433–441. [Google Scholar] [CrossRef]
- Starner, T.; Auxier, J.; Ashbrook, D.; Gandy, M. The gesture pendant: A self-illuminating, wearable, infrared computer vision system for home automation control and medical monitoring. In Proceedings of the Digest of Papers. Fourth International Symposium on Wearable Computers, IEEE, Atlanta, GA, USA, 21 October 2000. [Google Scholar]
- Agin, G. Computer Vision Systems for Industrial Inspection and Assembly. Computer 1980, 13, 11–20. [Google Scholar] [CrossRef]
- Kurada, S.; Bradley, C. A review of machine vision sensors for tool condition monitoring. Comput. Ind. 1997, 34, 55–72. [Google Scholar] [CrossRef]
- Menze, M.; Geiger, A. Object scene flow for autonomous vehicles. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 12 June 2015; pp. 3061–3070. [Google Scholar]
- Hou, Y.-L.; Pang, G.K.H. People Counting and Human Detection in a Challenging Situation. IEEE Trans. Syst. Man Cybern. 2014 Part A Syst. Humans 2010, 41, 24–33. [Google Scholar] [CrossRef]
- Scime, L.; Beuth, J. Anomaly detection and classification in a laser powder bed additive manufacturing process using a trained computer vision algorithm. Addit. Manuf. 2018, 19, 114–126. [Google Scholar] [CrossRef]
- Baumgartl, H.; Tomas, J.; Buettner, R.; Merkel, M. A deep learning-based model for defect detection in laser-powder bed fusion using in-situ thermographic monitoring. Prog. Addit. Manuf. 2020, 5, 1–9. [Google Scholar] [CrossRef]
- Cui, W.; Zhang, Y.; Zhang, X.; Li, L.; Liou, F. Metal Additive Manufacturing Parts Inspection Using Convolutional Neural Network. Appl. Sci. 2020, 10, 545. [Google Scholar] [CrossRef]
- Jin, Z.; Zhang, Z.; Gu, G.X. Automated Real-Time Detection and Prediction of Interlayer Imperfections in Additive Manufacturing Processes Using Artificial Intelligence. Adv. Intell. Syst. 2020, 2, 1900130. [Google Scholar] [CrossRef]
- Nuchitprasitchai, S.; Roggemann, M.; Pearce, J.M. Factors effecting real-time optical monitoring of fused filament 3D printing. Prog. Addit. Manuf. 2017, 2, 133–149. [Google Scholar] [CrossRef]
- Petsiuk, A.; Pearce, J.M. Open source computer vision-based layer-wise 3D printing analysis. arXiv 2003, arXiv:05660. [Google Scholar] [CrossRef]
- All3dp. Available online: https://all3dp.com/2/ender-3-filament-sensor-runout/ (accessed on 13 October 2020).
- Re3dp. Available online: https://re3d.org/gigabot/ (accessed on 13 October 2020).
- Langeland, S.A.K. Automatic Error Detection in 3D Pritning using Computer Vision. Master’s Thesis, The University of Bergen, Bergen, Norway, 2020. [Google Scholar]
- OpenCV. Available online: https://opencv.org/ (accessed on 13 October 2020).
- Baumann, F.; Roller, D. Vision based error detection for 3D printing processes. MATEC Web Conf. 2016, 59, 06003. [Google Scholar] [CrossRef]
- Lyngby, R.A.; Wilm, J.; Eiríksson, E.R.; Nielsen, J.B.; Jensen, J.N.; Aanæs, H.; Pedersen, D.B. In-Line 3D Print Failure Detection Using Computer Vision; euspen: Leuven, Belgium, 2017. [Google Scholar]
- Makagonov, N.G.; Blinova, E.M.; Bezukladnikov, I.I. Development of Visual Inspection Systems for 3D Printing. In Proceedings of the 2017 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus), Moscow, Russia, 1–3 February 2017. [Google Scholar]
- Karayannis, P.; Petrakli, F.; Gkika, A.; Koumoulos, E. 3D-Printed Lab-on-a-Chip Diagnostic Systems-Developing a Safe-by-Design Manufacturing Approach. Micromachines 2019, 10, 825. [Google Scholar] [CrossRef] [PubMed]
- OctoPrint. Available online: https://octoprint.org/ (accessed on 13 October 2020).
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Tzutalin, L. Git Code. 2015. Available online: https://github.com/tzutalin/labelImg (accessed on 13 October 2020).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- TensorFlow. Available online: https://www.tensorflow.org/ (accessed on 13 October 2020).
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Zhang, H.; Kyaw, Z.; Chang, S.F.; Chua, T.S. Visual Translation Embedding Network for Visual Relation Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5532–5540. [Google Scholar]
- He, X.; Peng, Y.; Zhao, J. Fine-Grained Discriminative Localization Via Saliency-Guided Faster R-CNN. In Proceedings of the 25th ACM International Conference on Multimedia, New York, NY, USA, 23–27 October 2017; pp. 627–635. [Google Scholar]
- Halstead, M.; McCool, C.; Denman, S.; Perez, T.; Fookes, C. Fruit quantity and quality estimation using a robotic vision system. arXiv 2018, arXiv:1801.05560. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November; pp. 9627–9636.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach Category | Pros | Cons |
|---|---|---|
| Comparison of final printed object with reconstruction of 3D printed model [12] |
|
|
| Combination of conventional Image processing techniques (layer-wise) [13,16] |
|
|
| Advanced Image Processing [18,19] |
|
|
| Batch_Size | 24 |
|---|---|
| initial_learning_rate | 0.004 |
| decay_steps | 800 |
| decay_factor | 0.95 |
| momentum_optimizer_value | 0.9 |
| decay | 0.9 |
| epsilon | 1.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paraskevoudis, K.; Karayannis, P.; Koumoulos, E.P. Real-Time 3D Printing Remote Defect Detection (Stringing) with Computer Vision and Artificial Intelligence. Processes 2020, 8, 1464. https://doi.org/10.3390/pr8111464
Paraskevoudis K, Karayannis P, Koumoulos EP. Real-Time 3D Printing Remote Defect Detection (Stringing) with Computer Vision and Artificial Intelligence. Processes. 2020; 8(11):1464. https://doi.org/10.3390/pr8111464
Chicago/Turabian StyleParaskevoudis, Konstantinos, Panagiotis Karayannis, and Elias P. Koumoulos. 2020. "Real-Time 3D Printing Remote Defect Detection (Stringing) with Computer Vision and Artificial Intelligence" Processes 8, no. 11: 1464. https://doi.org/10.3390/pr8111464
APA StyleParaskevoudis, K., Karayannis, P., & Koumoulos, E. P. (2020). Real-Time 3D Printing Remote Defect Detection (Stringing) with Computer Vision and Artificial Intelligence. Processes, 8(11), 1464. https://doi.org/10.3390/pr8111464