Just Don’t Fall: An AI Agent’s Learning Journey Towards Posture Stabilisation



Abstract

1. Introduction
2. Material and Methods
2.1. Biomechanic Simulation Environment
2.2. Artificial Neural Network Model
2.3. Reinforcement Training Procedure
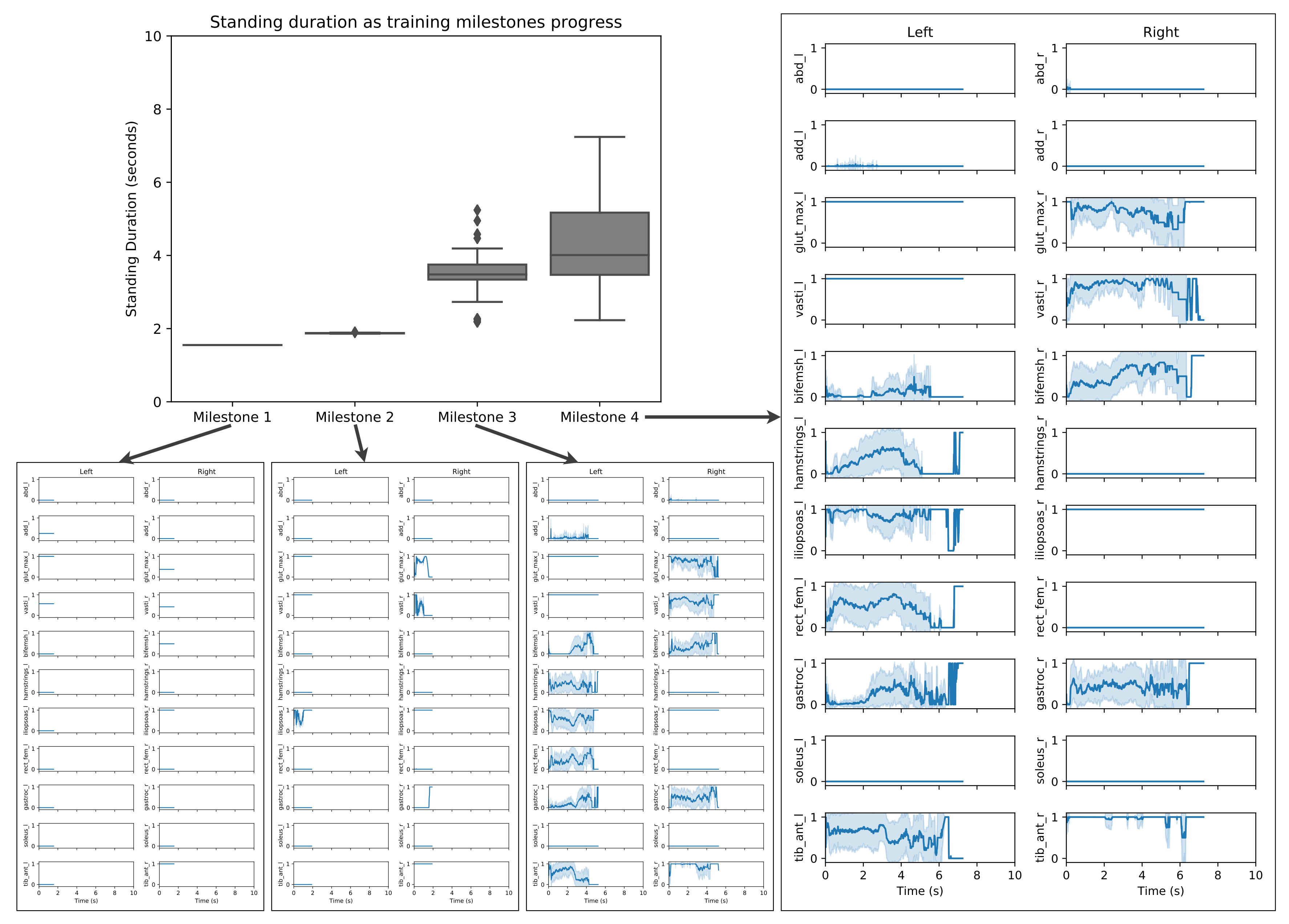
3. Results
- identify the importance of centre of gravity (COG); and
- identify and exploit the dominant leg concept.
4. Discussion
4.1. An Interesting Behaviour
4.2. Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| AGI | Artificial General Intelligence |
| ANN | Artificial Neural Network |
| COG/COM | Centre of Gravity/Mass |
| D4PG | Distributed Distributional Deep Deterministic Policy Gradient |
| DDPG | Deep Deterministic Policy Gradient |
| DoF | Degree of Freedom |
| DRL | Deep Reinforcement Learning |
| LSTM | Long-Short-Term-Memory |
| MLP | Multi-layer Perceptron |
| NEAT | Neuro-Evolution of Augmenting Topology |
| RL | Reinforcement Learning |
| XAI | Explainable Artificial Intelligence |
| ZMP | Zero Moment Point |
References
- Pua, Y.H.; Ong, P.H.; Clark, R.A.; Matcher, D.B.; Lim, E.C.W. Falls efficacy, postural balance, and risk for falls in older adults with falls-related emergency department visits: Prospective cohort study. BMC Geriatr. 2017, 17, 291. [Google Scholar] [CrossRef] [PubMed]
- Alonso, A.C.; Brech, G.C.; Bourquin, A.M.; Greve, J.M.D. The influence of lower-limb dominance on postural balance. Sao Paulo Med J. 2011, 129, 410–413. [Google Scholar] [CrossRef] [PubMed]
- Riemann, B.L.; Guskiewicz, K.M. Contribution of the Peripheral Somatosensory System to Balance and Postural Equilibrium; Human Kinetics: Champaign, IL, USA, 2000; pp. 37–51. [Google Scholar]
- Novacheck, T.F. The biomechanics of running. Gait Posture 1998, 7, 77–95. [Google Scholar] [CrossRef]
- Winter, D.A.; Quanbury, A.O.; Reimer, G.D. Analysis of instantaneous energy of normal gait. J. Biomech. 1976, 9, 253–257. [Google Scholar] [CrossRef]
- Miller, C.A.; Verstraete, M.C. A mechanical energy analysis of gait initiation. Gait Posture 1999, 9, 158–166. [Google Scholar] [CrossRef]
- Inman, V.T.; Ralston, H.J.; Todd, F. Human Walking; Williams & Wilkins: Philadelphia, PA, USA, 1981. [Google Scholar]
- Devine, J. The versatility of human locomotion. Am. Anthropol. 1985, 87, 550–570. [Google Scholar] [CrossRef]
- Winter, D.A. Biomechanics and Motor Control of Human Movement; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Bohannon, R.W. Comfortable and maximum walking speed of adults aged 20–79 years: Reference values and determinants. Age Ageing 1997, 26, 15–19. [Google Scholar] [CrossRef]
- Serra-AÑó, P.; López-Bueno, L.; García-Massó, X.; Pellicer-Chenoll, M.T.; González, L.M. Postural control mechanisms in healthy adults in sitting and standing positions. Percept. Mot. Skills 2015, 121, 119–134. [Google Scholar] [CrossRef]
- Park, E.; Reimann, H.; Schöner, G. Coordination of muscle torques stabilizes upright standing posture: An UCM analysis. Exp. Brain Res. 2016, 234, 1757–1767. [Google Scholar] [CrossRef]
- Barroso, F.O.; Torricelli, D.; Molina-Rueda, F.; Alguacil-Diego, I.M.; Cano-de-la Cuerda, R.; Santos, C.; Moreno, J.C.; Miangolarra-Page, J.C.; Pons, J.L. Combining muscle synergies and biomechanical analysis to assess gait in stroke patients. J. Biomech. 2017, 63, 98–103. [Google Scholar] [CrossRef]
- Seth, A.; Hicks, J.L.; Uchida, T.K.; Habib, A.; Dembia, C.L.; Dunne, J.J.; Ong, C.F.; DeMers, M.S.; Rajagopal, A.; Millard, M.; et al. OpenSim: Simulating musculoskeletal dynamics and neuromuscular control to study human and animal movement. PLoS Comput. Biol. 2018, 14, e1006223. [Google Scholar] [CrossRef]
- Raabe, M.E.; Chaudhari, A.M. An investigation of jogging biomechanics using the full-body lumbar spine model: Model development and validation. J. Biomech. 2016, 49, 1238–1243. [Google Scholar] [CrossRef] [PubMed]
- Delp, S.L.; Anderson, F.C.; Arnold, A.S.; Loan, P.; Habib, A.; John, C.T.; Guendelman, E.; Thelen, D.G. OpenSim: Open-source software to create and analyze dynamic simulations of movement. IEEE Trans. Biomed. Eng. 2007, 54, 1940–1950. [Google Scholar] [CrossRef] [PubMed]
- Reinbolt, J.A.; Seth, A.; Delp, S.L. Simulation of human movement: Applications using OpenSim. Procedia IUTAM 2011, 2, 186–198. [Google Scholar] [CrossRef]
- Iskander, J.; Hossny, M.; Nahavandi, S. Using biomechanics to investigate the effect of VR on eye vergence system. Appl. Ergon. 2019, 81, 102883. [Google Scholar] [CrossRef]
- Iskander, J.; Hossny, M.; Nahavandi, S.; Del Porto, L. An Ocular Biomechanic Model for Dynamic Simulation of Different Eye Movements. J. Biomech. 2018, 71, 208–216. [Google Scholar] [CrossRef]
- Nahavandi, D.; Iskander, J.; Hossny, M.; Haydari, V.; Harding, S. Ergonomic effects of using Lift Augmentation Devices in mining activities. In Proceedings of the 2016 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Budapest, Hungary, 9–12 October 2016. [Google Scholar]
- Abobakr, A.; Nahavandi, D.; Hossny, M.; Iskander, J.; Attia, M.; Nahavandi, S.; Smets, M. RGB-D ergonomic assessment system of adopted working postures. Appl. Ergon. 2019, 80, 75–88. [Google Scholar] [CrossRef] [PubMed]
- Hossny, M.; Nahavandi, D.; Nahavandi, S.; Haydari, V.; Harding, S. Musculoskeletal analysis of mining activities. In Proceedings of the 2015 IEEE International Symposium on Systems Engineering (ISSE), Rome, Italy, 28–30 September 2015; pp. 184–189. [Google Scholar]
- Dorn, T.W.; Wang, J.M.; Hicks, J.L.; Delp, S.L. Predictive simulation generates human adaptations during loaded and inclined walking. PLoS ONE 2015, 10, e0121407. [Google Scholar] [CrossRef]
- DeMers, M.S.; Hicks, J.L.; Delp, S.L. Preparatory co-activation of the ankle muscles may prevent ankle inversion injuries. J. Biomech. 2017, 52, 17–23. [Google Scholar] [CrossRef]
- Halilaj, E.; Rajagopal, A.; Fiterau, M.; Hicks, J.L.; Hastie, T.J.; Delp, S.L. Machine learning in human movement biomechanics: Best practices, common pitfalls, and new opportunities. J. Biomech. 2018, 81, 1–11. [Google Scholar] [CrossRef]
- Haarnoja, T.; Ha, S.; Zhou, A.; Tan, J.; Tucker, G.; Levine, S. Learning to walk via deep reinforcement learning. arXiv 2018, arXiv:1812.11103. [Google Scholar]
- Hebbel, M.; Kosse, R.; Nistico, W. Modeling and learning walking gaits of biped robots. In Proceedings of the Workshop on Humanoid Soccer Robots of the IEEE-RAS International Conference on Humanoid Robots, Genova, Italy, 4–6 December 2006; pp. 40–48. [Google Scholar]
- Kober, J.; Bagnell, J.A.; Peters, J. Reinforcement learning in robotics: A survey. Int. J. Robot. Res. 2013, 32, 1238–1274. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Introduction to Reinforcement Learning; MIT Press: Cambridge, MA, USA, 1998; Volume 2. [Google Scholar]
- Kidziński, Ł.; Ong, C.; Mohanty, S.P.; Hicks, J.; Carroll, S.; Zhou, B.; Zeng, H.; Wang, F.; Lian, R.; Tian, H.; et al. Artificial Intelligence for Prosthetics: Challenge Solutions. In The NeurIPS’18 Competition; Springer: Berlin/Heidelberg, Germany, 2020; pp. 69–128. [Google Scholar]
- Kidziński, Ł.; Mohanty, S.P.; Ong, C.F.; Hicks, J.L.; Carroll, S.F.; Levine, S.; Salathé, M.; Delp, S.L. Learning to run challenge: Synthesizing physiologically accurate motion using deep reinforcement learning. In The NIPS’17 Competition: Building Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2018; pp. 101–120. [Google Scholar]
- Kidziński, Ł.; Mohanty, S.P.; Ong, C.F.; Huang, Z.; Zhou, S.; Pechenko, A.; Stelmaszczyk, A.; Jarosik, P.; Pavlov, M.; Kolesnikov, S.; et al. Learning to Run challenge solutions: Adapting reinforcement learning methods for neuromusculoskeletal environments. In The NIPS’17 Competition: Building Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2018; pp. 121–153. [Google Scholar]
- Jaśkowski, W.; Lykkebø, O.R.; Toklu, N.E.; Trifterer, F.; Buk, Z.; Koutník, J.; Gomez, F. Reinforcement Learning to Run… Fast. In The NIPS’17 Competition: Building Intelligent Systems; Springer: Berlin/Heidelberg, Germany, 2018; pp. 155–167. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Schulman, J.; Moritz, P.; Levine, S.; Jordan, M.; Abbeel, P. High-dimensional continuous control using generalized advantage estimation. arXiv 2015, arXiv:1506.02438. [Google Scholar]
- Levine, S.; Finn, C.; Darrell, T.; Abbeel, P. End-to-end training of deep visuomotor policies. J. Mach. Learn. Res. 2016, 17, 1334–1373. [Google Scholar]
- Duan, Y.; Chen, X.; Houthooft, R.; Schulman, J.; Abbeel, P. Benchmarking deep reinforcement learning for continuous control. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1329–1338. [Google Scholar]
- Pilotto, A.; Boi, R.; Petermans, J. Technology in geriatrics. Age Ageing 2018, 47, 771–774. [Google Scholar] [CrossRef]
- Lee, S.; Lee, K.; Park, M.; Lee, J. Scalable Muscle-actuated Human Simulation and Control. ACM Trans. Graph. 2019, 37. [Google Scholar] [CrossRef]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. Openai gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Delp, S.L.; Loan, J.P.; Hoy, M.G.; Zajac, F.E.; Topp, E.L.; Rosen, J.M. An interactive graphics-based model of the lower extremity to study orthopaedic surgical procedures. IEEE Trans. Biomed. Eng. 1990, 37, 757–767. [Google Scholar] [CrossRef]
- Ong, C.F.; Geijtenbeek, T.; Hicks, J.L.; Delp, S.L. Predictive simulations of human walking produce realistic cost of transport at a range of speeds. In Proceedings of the 16th International Symposium on Computer Simulation in Biomechanics, Gold Coast, Australia, 20–22 July 2017; pp. 19–20. [Google Scholar]
- Arnold, E.M.; Ward, S.R.; Lieber, R.L.; Delp, S.L. A model of the lower limb for analysis of human movement. Ann. Biomed. Eng. 2010, 38, 269–279. [Google Scholar] [CrossRef]
- Thelen, D.G. Adjustment of muscle mechanics model parameters to simulate dynamic contractions in older adults. J. Biomech. Eng. 2003, 125, 70–77. [Google Scholar] [CrossRef] [PubMed]
- Hunt, K.; Crossley, F. Coefficient of Restitution Interpreted as Damping in Vibroimpact. J. Appl. Mech. 1975, 42, 440–445. [Google Scholar] [CrossRef]
- Stanley, K.O.; Miikkulainen, R. Evolving Neural Networks through Augmenting Topologies. Evol. Comput. 2002, 10, 99–127. [Google Scholar] [CrossRef] [PubMed]
- Stanley, K.O. Neuroevolution: A different kind of deep learning. O’Reilly 2017, 27, 2019. [Google Scholar]
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-Learning in Neural Networks: A Survey. arXiv 2020, arXiv:cs.LG/2004.05439. [Google Scholar]
- Grondman, I.; Busoniu, L.; Lopes, G.A.; Babuska, R. A survey of actor-critic reinforcement learning: Standard and natural policy gradients. IEEE Trans. Syst. Man, Cybern. Part C Appl. Rev. 2012, 42, 1291–1307. [Google Scholar] [CrossRef]
- Konda, V.R.; Tsitsiklis, J.N. Actor-critic algorithms. Adv. Neural Inf. Process. Syst. 2000, 1008–1014. [Google Scholar]
- Ghassabian, A.; Sundaram, R.; Bell, E.; Bello, S.C.; Kus, C.; Yeung, E. Gross Motor Milestones and Subsequent Development. Pediatrics 2016, 138, e20154372. [Google Scholar] [CrossRef]
- Forbes, P.A.; Chen, A.; Blouin, J.S. Sensorimotor control of standing balance. In Handbook of Clinical Neurology; Elsevier: Amsterdam, The Netherlands, 2018; Volume 159, pp. 61–83. [Google Scholar]
- Spry, S.; Zebas, C.; Visser, M. What is Leg Dominance? ISBS-Conference Proceedings Archive. 1993. Available online: https://ojs.ub.uni-konstanz.de/cpa/article/view/1700 (accessed on 15 June 2012).
- Dragicevic, P. Fair Statistical Communication in HCI. In Modern Statistical Methods for HCI; Springer: Berlin/Heidelberg, Germany, 2016; pp. 291–330. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. arXiv 2018, arXiv:cs.LG/1801.01290. [Google Scholar]
- Barth-Maron, G.; Hoffman, M.W.; Budden, D.; Dabney, W.; Horgan, D.; TB, D.; Muldal, A.; Heess, N.; Lillicrap, T. Distributed Distributional Deterministic Policy Gradients. arXiv 2018, arXiv:cs.LG/1804.08617. [Google Scholar]
- Hossny, M.; Iskander, J.; Attia, M.; Saleh, K. Refined Continuous Control of DDPG Actors via Parametrised Activation. arXiv 2020, arXiv:cs.LG/2006.02818. [Google Scholar]
- Abobakr, A.; Hossny, M.; Nahavandi, S. A Skeleton-Free Fall Detection System From Depth Images Using Random Decision Forest. IEEE Syst. J. 2018, 12, 1–12. [Google Scholar] [CrossRef]
- Rahwan, I.; Cebrian, M.; Obradovich, N.; Bongard, J.; Bonnefon, J.F.; Breazeal, C.; Crandall, J.W.; Christakis, N.A.; Couzin, I.D.; Jackson, M.O.; et al. Machine behaviour. Nature 2019, 568, 477–486. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
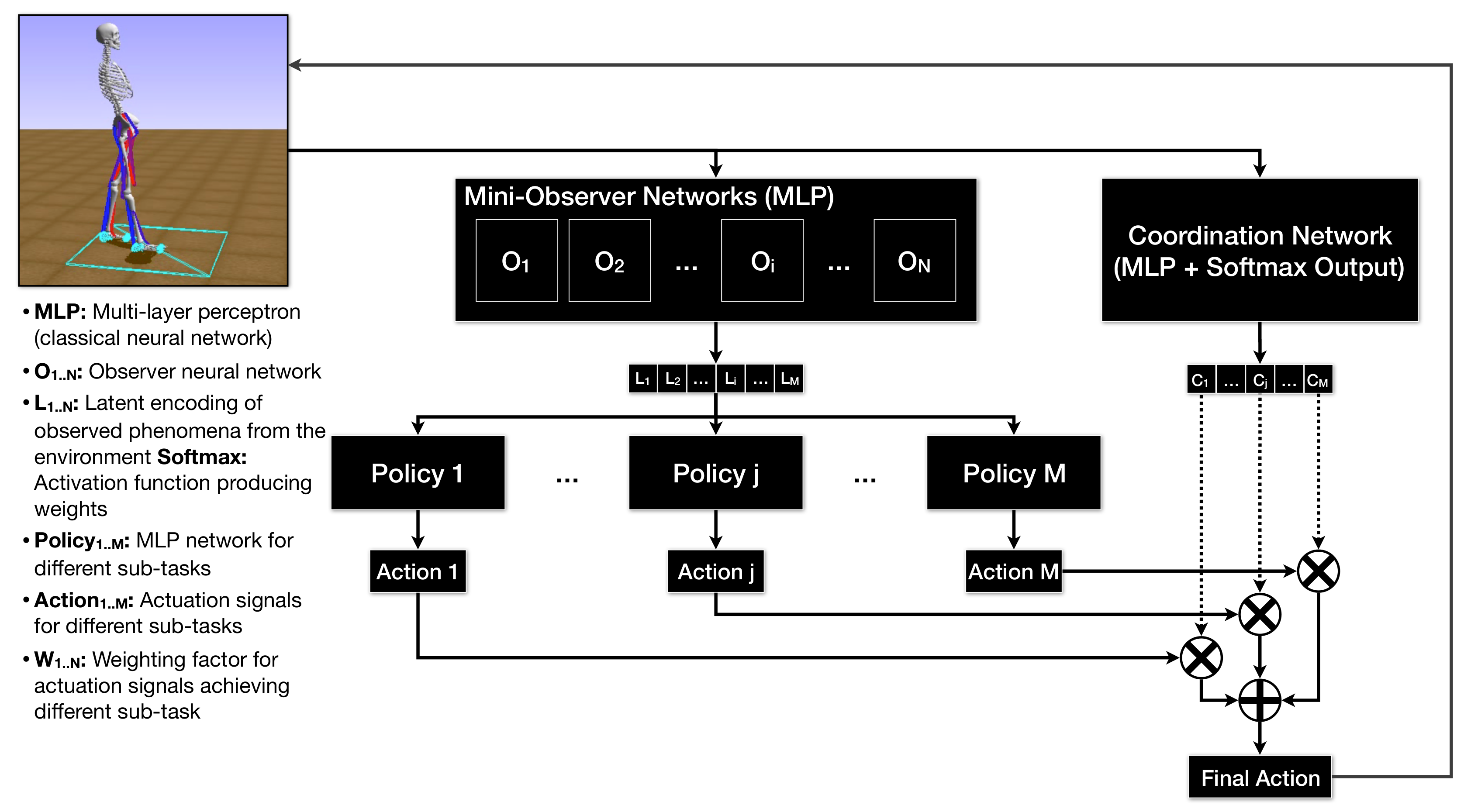{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Observation | Size | Notation (in Score fn.) | Comments |
|---|---|---|---|
| Ground Reaction Forces | 6 | 3 per foot | |
| Pelvis Orientation/Linear/Angular Velocity | 9 | ||
| Joint Angles | 8 | 4 per leg | |
| Change in Joint Angles | 8 | 4 per leg | |
| Muscle Actuation | 22 | 11 per leg | |
| Muscle Force | 22 | 11 per leg | |
| Muscle Length | 22 | 11 per leg | |
| Random Values | 3 | velocity vector field [30] |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hossny, M.; Iskander, J. Just Don’t Fall: An AI Agent’s Learning Journey Towards Posture Stabilisation. AI 2020, 1, 286-298. https://doi.org/10.3390/ai1020019
Hossny M, Iskander J. Just Don’t Fall: An AI Agent’s Learning Journey Towards Posture Stabilisation. AI. 2020; 1(2):286-298. https://doi.org/10.3390/ai1020019
Chicago/Turabian StyleHossny, Mohammed, and Julie Iskander. 2020. "Just Don’t Fall: An AI Agent’s Learning Journey Towards Posture Stabilisation" AI 1, no. 2: 286-298. https://doi.org/10.3390/ai1020019
APA StyleHossny, M., & Iskander, J. (2020). Just Don’t Fall: An AI Agent’s Learning Journey Towards Posture Stabilisation. AI, 1(2), 286-298. https://doi.org/10.3390/ai1020019