1. Introduction
Age-related macular degeneration (AMD) is a spectrum of retinal diseases that pose the threat of irreversible vision loss in older adults, especially among Caucasians [
1]. In late AMD, which includes advanced forms of geographic atrophy (also known as dry AMD) and/or neovascular types (wet AMD), there is significant damage to the retina, particularly the macula. This damage leads to a loss of central vision, which is crucial for tasks such as reading, driving, and recognizing faces. In geographic atrophy, there is a progressive loss of retinal pigment epithelium and photoreceptors, leading to blind spots in central vision. In neovascular AMD, abnormal blood vessels grow under the retina and leak fluid or blood, causing scarring and rapid vision loss.
While treatments exist to slow the progression of neovascular AMD, such as anti-VEGF (vascular endothelial growth factor) injections [
2], these treatments cannot reverse the damage that has already occurred. Similarly, there are no effective treatments for reversing vision loss in geographic atrophy. Therefore, early diagnosis, accurate prognosis, and preventive therapies can accordingly slow the progression of vision loss and minimize patient cost. Both retinal images and genetic variants serve as key factors in clinical diagnosis and prognosis of advanced AMD. The increasing number of AMD patients has outpaced the capacity for manual diagnosis and prognosis. Consequently, automated approaches are needed to help slow disease progression to late-stage AMD.
On the one side, deep learning algorithms have developed rapidly to successfully address numerous machine learning tasks, including image classification. In the past decade, based on deep CNN models such as Inception-V3, ResNet, etc., researchers diagnosed different stages of AMD [
3,
4,
5,
6] and detected more specific AMD-related endophenotypes [
7,
8] from color fundus photographs (CFPs). Besides diagnosis of AMD-related characteristics, researchers also investigated prediction of AMD progression using longitudinal CFPs in the Inception-V3 framework [
9]. A time-dependent Cox survival neural network was also proposed to predict survival probability beyond a given time point using longitudinal fundus images [
10]. Meanwhile, with the rapid advancements in self-supervised learning techniques in computer vision over the past two years, such as the development of masked autoencoders [
11], foundation models have emerged across various fields. These models offer promising image representation vectors for downstream task-specific analyses. In the domain of retinal diseases, a notable foundation model pretrained on 1.6 million retinal images was introduced in 2023, facilitating more advanced downstream retinal disease analysis [
12].
On the other side, AMD is one of the diseases that genetic factors serve as an essential role. A total of 52 SNPs from 34 loci were found to be independently associated with late AMD from a large genome-wide association study (GWAS) with 16,144 patients and 17,832 controls [
13]. Based on those 34 loci, researchers modeled genetic risk of advanced AMD as a quantitative score to predict time-to-late AMD in survival analysis [
14]. It has also been shown that marginally weak SNPs in GWAS can facilitate prediction of late AMD appearance [
15]. Moreover, multimodal deep neural networks of genotypes and phenotypes have been investigated to enhance prediction of AMD progression [
16,
17]. In 2020, a CNN model was proposed for the first time to predict future AMD risk utilizing both fundus images from a single visit and AMD-associated genetic variants [
18], marking a significant advancement in the predictive modeling of AMD progression.
In this work, we extend AMD prognosis prediction using both longitudinal fundus images and genetic variants associated with late AMD in an LSTM architecture [
19]. Furthermore, we introduce a novel variation of the LSTM model, time-varied LSTM, which allows an uneven length of time intervals between adjacent input visits so that more data can be utilized for training and the model can be more generalizable. Recent multimodal works relevant to our study include those by Ganjdanesh et al. [
16,
17] and Yan et al. [
18], who employed multimodal genotype and fundus image data integration for AMD prediction, albeit using single fundus images rather than longitudinal sequences. While these approaches effectively integrated imaging and genetic data, our model is the first specifically designed to leverage both longitudinal fundus images and SNP data with irregular time intervals, enhancing predictive precision for AMD progression. Other recent multimodal approaches, such as those by Venugopalan et al. [
20], Cao and Long [
21], and Li et al. [
22], have demonstrated potential in combining imaging and genetic data in other diseases like Alzheimer’s and Parkinson’s; however, these models are not specifically tailored for AMD, and adapting them would require extensive tuning. Comparative analyses with existing methods demonstrate that our proposed TV-LSTM model provides superior or comparable performance, emphasizing its methodological novelty and clinical applicability.
The key contributions of this study include (1) introducing a novel time-varied LSTM (TV-LSTM) method tailored for longitudinal fundus imaging data with irregular time intervals; (2) integrating transformer-based retinal image embeddings and genetic variants for improved AMD progression prediction; and (3) demonstrating the clinical relevance and efficacy of our approach through comprehensive experiments and rigorous validation using a large-scale dataset.
2. Methods and Materials
In this section, we describe the methodology for predicting late AMD progression using both longitudinal fundus images and genetic variants. We first outline the approach under the regular LSTM setting and then introduce our proposed time-varied LSTM (TV-LSTM) setting, which accounts for irregular time intervals in longitudinal data. Additionally, we provide detailed information on the model training and evaluation settings, including loss functions and performance metrics. We also describe the dataset used in this study and the steps taken for data preprocessing and partitioning.
2.1. Regular LSTM
The Long Short-Term Memory (LSTM) network is a type of recurrent neural network (RNN) designed to overcome the limitations of traditional RNNs, particularly in learning long-term dependencies. In principle, LSTM models do not inherently require equal time intervals between observations. However, they do assume consistent time differences between training and testing to effectively learn temporal patterns and generalize them to new data. In practice, researchers often use equal time intervals to simplify the modeling process and enhance prediction accuracy. Equal intervals provide a uniform temporal structure, making it easier for the LSTM to capture sequential dependencies.
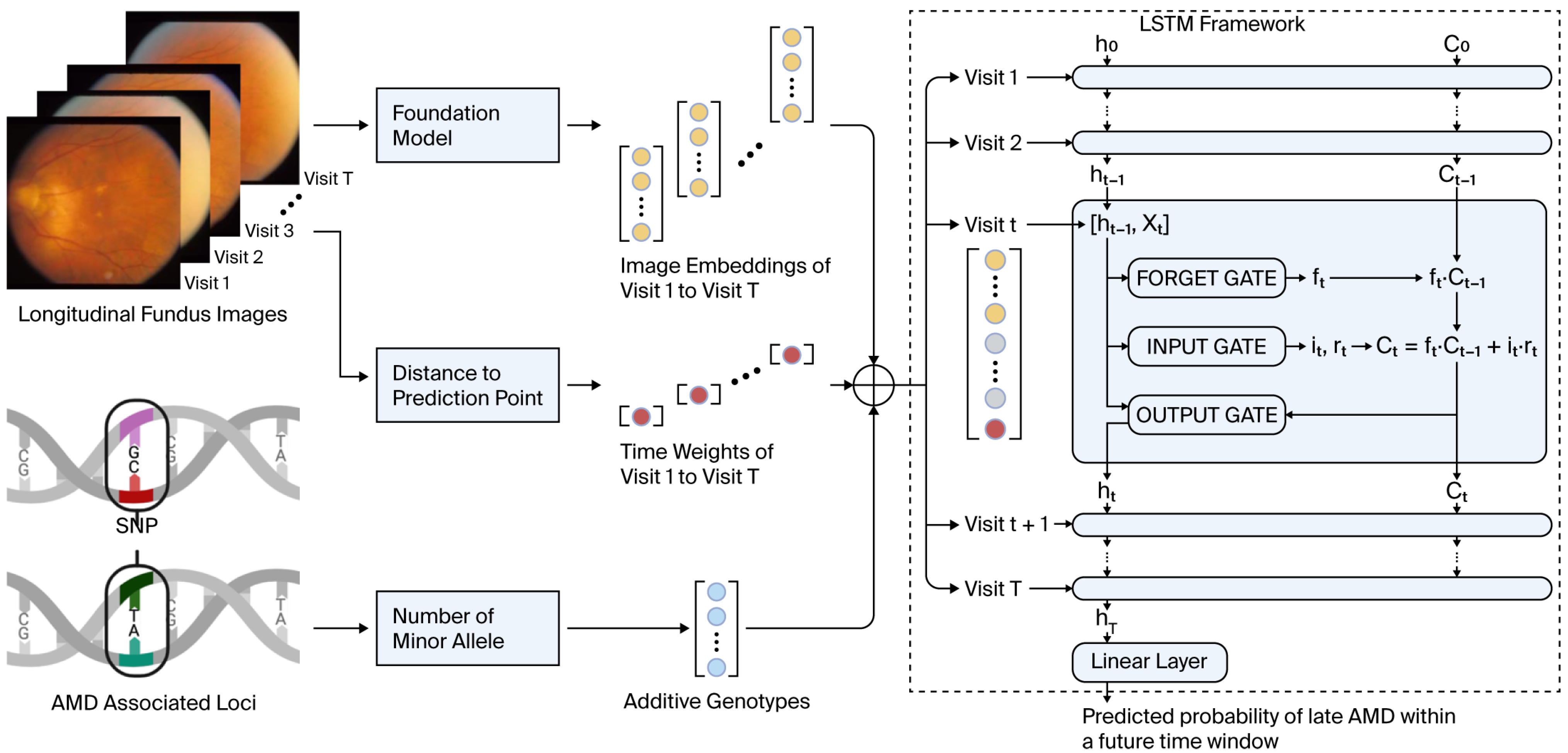
In the regular LSTM model, which assumes equal time intervals, the input consists of longitudinal data
for each observation, where
is a vector containing the subject’s information at time
. This information can include image embeddings and SNP data. Each image embedding is derived from the output of the retinal foundation model, RetFound, introduced by Zhou et al. [
12] and has the dimension of 1024. RetFound was pretrained on 1.6 million unlabeled retinal images through self-supervised learning, in which the model learned how to reconstruct partially masked images and gained the ability of extracting image global and local information. Downstream analysis using image representations from the retinal foundation model has been demonstrated to outperform most task-specific models. Hence, using the output of the foundation model is reasonable for further analysis in this work. The 52 selected genetic variants for each observation are from the largest GWAS of AMD to date [
13] and are represented in an additive manner based on the minor allele.
The core component of the LSTM network is the memory cell, which can maintain its state over time and is denoted as
. As shown in
Figure 1, an LSTM contains sequential blocks with similar structure. Each block comprises three gates: the forget gate, the input gate, and the output gate. These gates regulate the flow of information into, out of, and within the block.
Forget Gate: The forget gate controls the extent to which the information from the previous cell state
should be retained or forgotten. It uses a sigmoid activation function to produce a gating signal,
, in range of
, which modulates the previous cell state.
where
is the hidden state from the previous block,
is the weights that needs to be trained in the forget gate, and
is a bias term.
Input Gate: The input gate determines how much of the new information from the current input and the previous hidden state should be added to the cell state. It consists of a hyperbolic tangent function that outputs candidate cell state
representing the new memory update vector. In the meantime, a sigmoid activation function outputs
as a filter that determines to what extent the new update is worth retaining. After that, the new memory cell state
is derived as below.
Output Gate: The output gate decides how much of the cell state
should be exposed to the next hidden state,
. This gate uses a combination of the cell state and a sigmoid activation function to produce the next hidden state as follows:
where
,
, and
are the input, forget, and output gates, respectively.
is the candidate cell state,
is the cell state, and
is the hidden state.
The final hidden state
is the output after the last block and serves as a summary of the entire sequence. The hidden state
is passed through one fully connected layer, which helps to map the information from the LSTM’s output to the desired probabilities of 2 classes (late AMD or no late AMD in our study).
2.2. Time-Varied LSTM
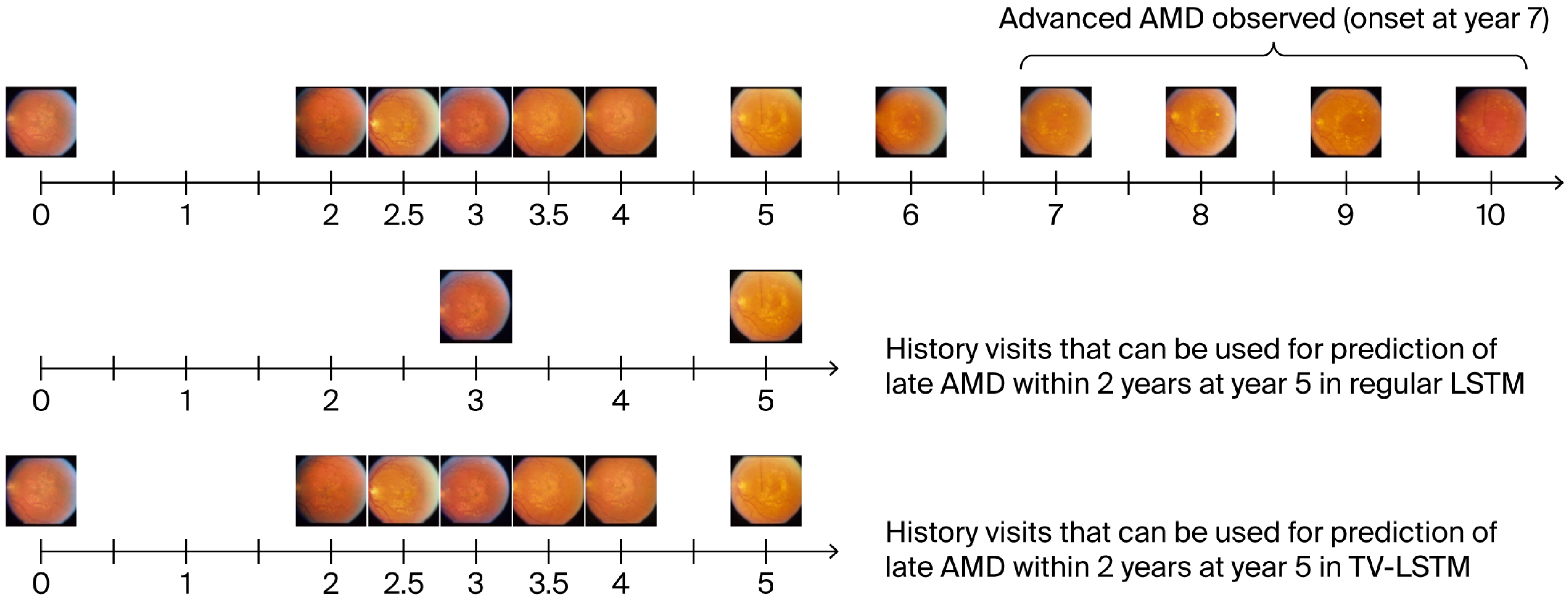
Traditional Long Short-Term Memory (LSTM) models are well-suited for handling sequential data but typically assume that time intervals between data points are consistent. This assumption, however, is rarely valid in real-world clinical settings, where patient visits occur at irregular intervals. As a result, traditional LSTM models may struggle to fully leverage the timing and sequence of clinical data, restricting the sample size and limiting the model’s generalizability. To address this limitation, we propose a novel variation, time-varied Long Short-Term Memory (TV-LSTM), which accommodates varying lengths of time intervals between longitudinal fundus images. In TV-LSTM, the interval between each visit and the prediction time point is normalized as a time weight,
, and incorporated into the input data
. The time weight takes a value between 0 and 1, indicating how close the current time point is to the predicted time point.
where
is the time weight for subject
at time
,
is the time of the earliest visit used for prediction for subject
, and
is the prediction time point for subject
. Data points closer to the prediction point are assigned a heavier time weight.
To clarify, the proposed time weight method fundamentally differs from interpolation, which involves estimating additional data points between observed intervals. Instead, our approach reweights existing observations based on their temporal proximity to the prediction point without creating new, artificial data points. By normalizing observed intervals to a [0, 1] range, we emphasize more recent observations, thus effectively utilizing the available data without interpolation.
Apart from the incorporation of the time weight into the input, all other components and mechanisms of TV-LSTM remain the same as those in a regular LSTM model, including the architecture of the forget gate, input gate, and output gate. Architecture and Workflow of time-varied LSTM are shown in
Figure 1. This design preserves the well-established strengths of LSTM in capturing sequential dependencies while enhancing its flexibility in handling irregular time intervals.
This approach not only increases the available sample size for training but also allows the inclusion of more temporally relevant visits, thereby improving the model’s adaptability and robustness in real-world analysis, as shown in
Figure 2.
2.3. Model Training and Evaluation
Training the LSTM and TV-LSTM models involves minimizing a cross-entropy loss function
to quantify the difference between predicted and actual AMD progression risk.
where
is the loss,
is the number of samples,
is the actual label, and
is the predicted probability.
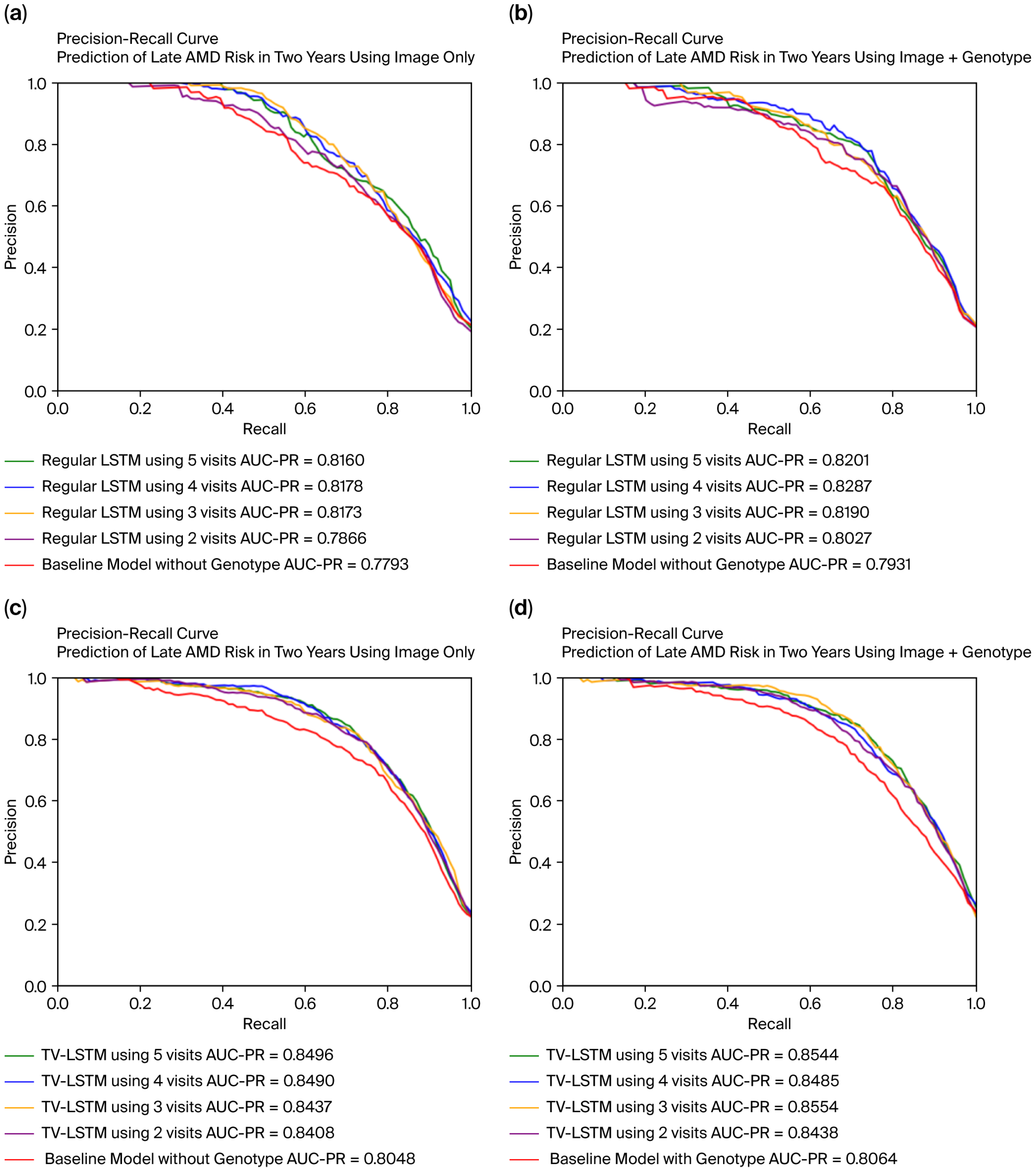
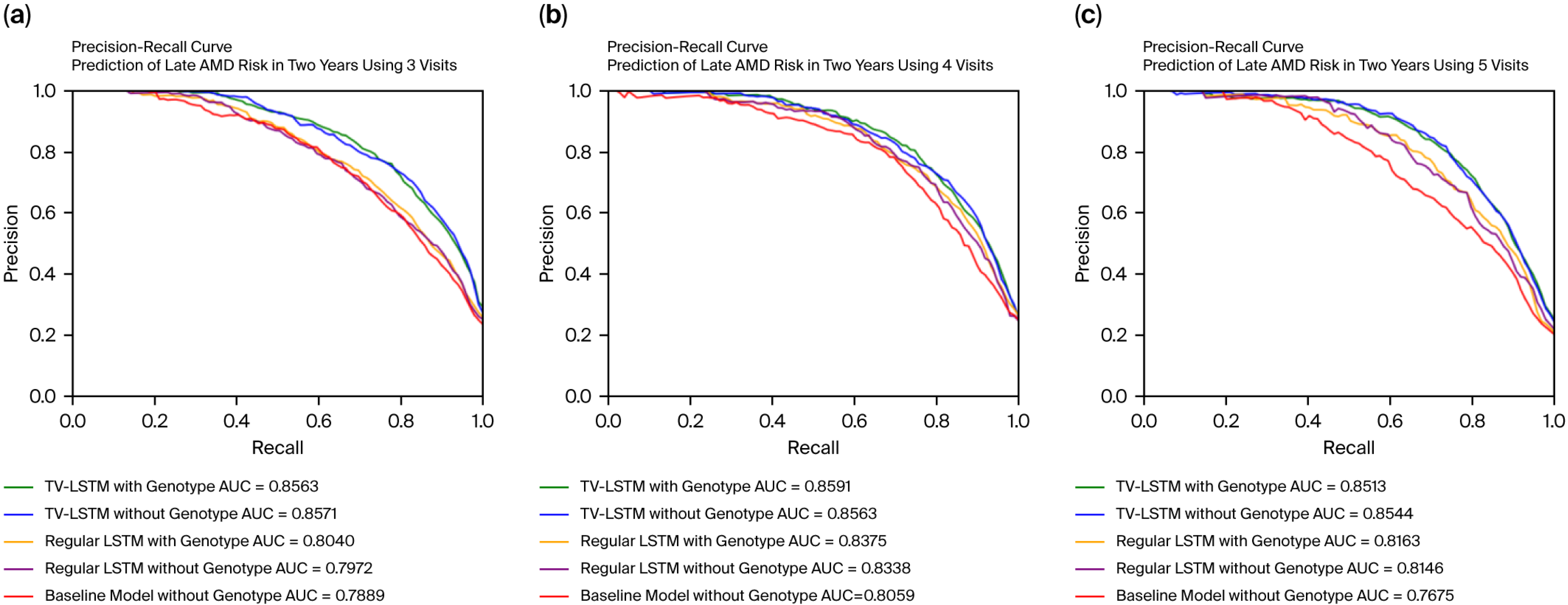
The model parameters are optimized using the Adam optimizer, which dynamically adjusts the learning rate during training. For model evaluation, we used the AUC-PR (Area Under the Precision–Recall Curve) metric, which is particularly suitable for our imbalanced dataset where fewer individuals progress to late AMD. The AUC-PR emphasizes precision and recall, providing a clearer reflection of how well the model identifies true positives, whereas AUC-ROC was not prioritized since it may remain high due to the large number of negative cases, masking poor performance in predicting the minority positive class.
Hyperparameters, including learning rates and batch sizes, were optimized via grid search using the validation set. The optimal learning rate identified was 1 × 10−4, with a batch size of 32, selected based on minimal validation loss. All experiments were performed using one NVIDIA A100 GPU with PyTorch 1.8.1, scikit-learn 0.24.2, NumPy 1.19.5, and pandas 0.25.3 (more details of package versions can be found on GitHub, see section Data Availability Statement).
2.4. Dataset Preprocessing, Partitioning, and Instrument Setup
The National Eye Institute (NEI) Age-Related Eye Disease Study (AREDS) (phs000001.v3.p1 in dbGaP) is a large-scale, long-term prospective clinical trial of age-related macular degeneration (AMD) and age-related cataract. A total of 187,996 color fundus images of 4628 subjects and corresponding eye-level phenotypes are covered in AREDS. Additionally, 2521 out of 4628 subjects have genotypes available. One subject could have up to 13 years of follow-up visits since the baseline.
All stereoscopic fundus images in the AREDS were captured using Zeiss FF450 Plus fundus cameras with a 30-degree field of view. These images were acquired under standardized imaging protocols across all participating sites, as detailed in AREDS Report No. 6 [
23]. In this study, we focused on Field 2 (centered slightly above the fovea), which targets the macula—an essential region for assessing AMD progression. Although individual imaging parameters such as flash intensity and exposure time are not available in the dataset, uniform imaging standards and centralized manual grading ensured high image consistency and quality across sites.
We selected Field 2 since this angle focuses on the most important region related to AMD (macula) and holds the largest sample size in the AREDS. Meanwhile, for most eyes given any visit, both left-side and right-side fundus of the stereoscopic pair images are available for each eye. We randomly picked all left-side images of the stereoscopic pair of all eyes to avoid redundant information and boost training speed. The overall image quality of fundus images in AREDS is acceptable for the following grading and research. Only 0.6% of images of 48,998 eyes were ungradable through the first 10 years of the AREDS.
We cropped each color fundus photograph (CFP) to a square region encompassing the macula and resized it to a resolution of 224 × 224 pixels. We first discarded all ungradable images. Subsequently, we reclassified the manually graded labels in the AREDS. All questionable classes in the AREDS were treated as absent. For the AMD status label at each visit, we recategorized the 9-step AMD severity scale into two classes: steps 1–8 were categorized as no/early/intermediate AMD, while steps 9–12 were categorized as late AMD.
The total number of participants varies in different tasks. The greater the number of visits included in the model, the smaller the number of participants we are able to include in the task, as shown in
Table 1. For each task, we randomly divide the AREDS dataset into three parts for each task: the training set plus validation set include 90% of participants, of which 90% belongs to the training set and 10% belongs to the validation set; the testing set includes 10% of participants. Participants in the training, validation, and testing sets were randomly picked from the AREDS and mutually exclusive.
The architecture of our approach, as shown in
Figure 1, demonstrates how longitudinal fundus images and genotype data can be integrated into a single processing pipeline to predict the risk of future late AMD. This framework could be adapted in a clinical setting where newly captured images from instruments like the Zeiss FF450 Plus are immediately processed and analyzed.
Figure 1 conceptually outlines the measurement and computation flow, from raw imaging input through embedding generation and genotype integration, to prediction output via the TV-LSTM model.
4. Discussion
Our architecture incorporates the encoder part of a transformer-based autoencoder (RetFound) to extract embeddings from retinal images, leveraging the transformer’s powerful representation capabilities. Subsequently, we use LSTM networks for sequence modeling due to their inherent suitability for capturing temporal dependencies, particularly with irregularly spaced clinical data. Unlike transformers alone, LSTM networks efficiently handle datasets with irregular temporal intervals and require fewer computational resources, making them ideal for clinical retinal imaging scenarios characterized by irregular follow-up intervals and limited observations. This hybrid approach combines the strengths of transformers in image embedding extraction with LSTM networks’ robustness against irregular temporal spacing.
In clinical scenarios involving prediction of late AMD progression, misdiagnoses primarily occur as false positives or false negatives. False-positive predictions, in which the model incorrectly anticipates disease progression in patients who remain stable, can lead to unnecessary psychological distress, heightened healthcare costs due to unwarranted interventions, and exposure to potential adverse treatment effects. Conversely, false-negative predictions, where the model fails to identify patients who later progress to late AMD, have more severe implications, including delayed interventions, irreversible retinal damage, and permanent vision loss. Consequently, the accurate distinction between progressing and stable cases is paramount for clinical efficacy. To rigorously evaluate our model’s predictive performance, we utilized both the Area Under the Receiver Operating Characteristic Curve (AUC-ROC) and the Area Under the Precision–Recall Curve (AUC-PR). While the AUC-ROC measures overall discriminatory ability independent of class prevalence, it can sometimes provide overly optimistic results in highly imbalanced datasets like ours due to the abundance of true negatives. This could mask critical performance issues in correctly identifying the minority group at genuine risk of disease progression. On the other hand, the AUC-PR metric is specifically designed for imbalanced datasets, directly assessing the balance between precision (correct positive predictions out of all positive predictions) and recall (accurately identifying most true progression cases). A high AUC-PR value indicates robust model performance in reliably identifying actual cases of AMD progression, thereby substantially increasing clinical trust in model outputs. Our proposed TV-LSTM model achieved an impressive AUC-PR of 0.8591, underscoring its reliability and potential clinical utility. Given these considerations, emphasizing AUC-PR alongside AUC-ROC provides a clearer and clinically more meaningful evaluation of our model, ensuring accurate identification of AMD progression cases essential for timely and effective patient care.
A major challenge for the time-varied LSTM model proposed in this paper is the lack of independent cohorts that can be used to validate our model. It is difficult to find suitable datasets that provide phenotypes, genotypes, and longitudinal fundus images available for at least three visits at the same time. For example, the UK Biobank (UKB) [
26] is another large-scale cohort that includes 85,728 subjects and 175,546 fundus images across three visits. Genotypic data is also available in UKB. However, the image quality in the UKB dataset is significantly lower than that in AREDS, and phenotypes were collected through questionnaires, which contain a large amount of missing data, unlike the manual grading process used in AREDS. Only 1695 images with definite AMD diagnoses from questionnaires are available, of which only 6 images are readable, have corresponding genotypes, and show progression to late AMD at the last visit from a non-late AMD status.
In this study, longitudinal fundus photographs were utilized to predict the progression of age-related macular degeneration (AMD). Emerging imaging techniques such as Optical Coherence Tomography (OCT) [
27] and Adaptive Optics (AO) [
28] offer significant potential for advancing retinal disease analysis. OCT captures high-resolution, cross-sectional images of the retina, enabling precise tracking of structural changes such as retinal thickness or fluid accumulation, which are critical in diseases like AMD and diabetic retinopathy. AO provides cellular-level imaging, offering detailed insights into photoreceptor integrity and other cellular dynamics, which are essential for understanding retinal health and pathology. The integration of Long Short-Term Memory (LSTM) networks with OCT and AO datasets could revolutionize the prediction and monitoring of retinal diseases. LSTM models excel at capturing temporal patterns, making them well-suited for analyzing sequential imaging data to detect subtle, progressive changes in retinal structures or cellular features. By leveraging OCT and AO data, LSTM models could provide early detection of disease progression, predict treatment outcomes, and enhance personalized treatment strategies. The combination of these advanced imaging modalities within a deep learning framework represents a promising step forward in retinal disease modeling, with the potential to improve clinical decision-making and patient care significantly. Future research should address challenges like data heterogeneity and the need for extensive annotated datasets to maximize the clinical impact of these technologies.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}