
CORE-ReID V2: Advancing the Domain Adaptation for Object Re-Identification with Optimized Training and Ensemble Fusion

 ,
,  ,
,
Abstract
1. Introduction
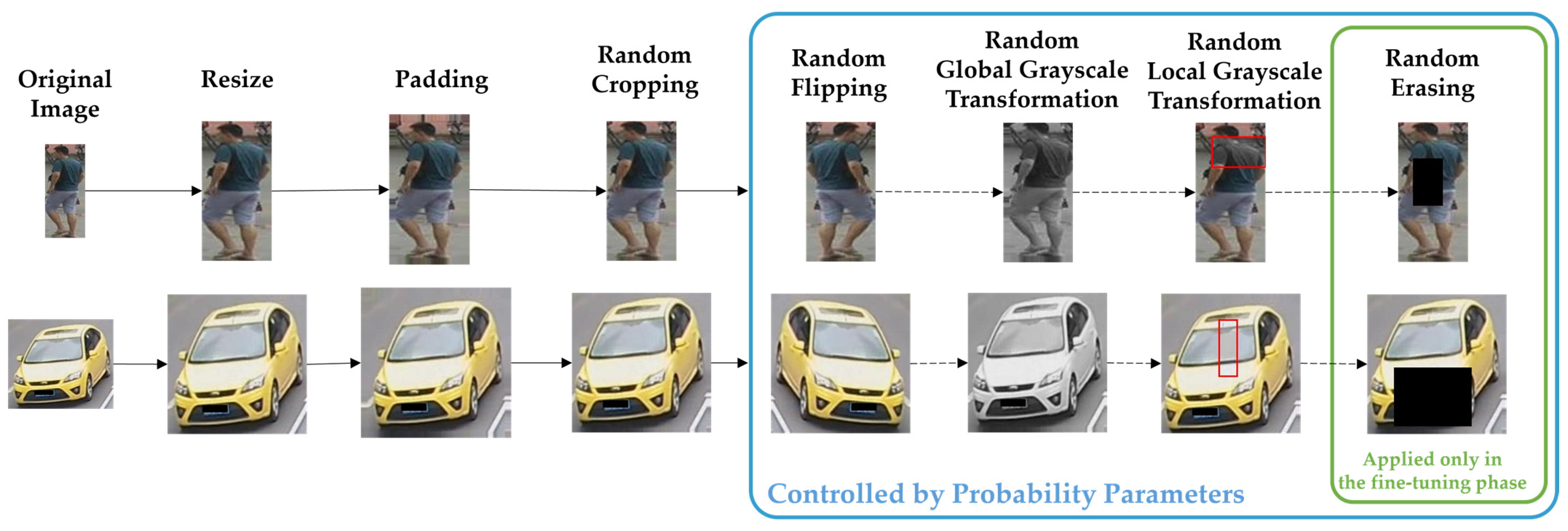
- Advanced data augmentation techniques: the framework integrates novel data augmentation strategies, such as Local Grayscale Patch Replacement and Random Image-to-Grayscale Conversion for the UDA task. These methods introduce diversity in the training data, enhancing the model’s stability.
- Dynamic and flexible backbone support: CORE-ReID V2 extends compatibility to smaller backbone architectures, including ResNet18 and ResNet34, without compromising performance. This flexibility allows for deployment in resource-constrained environments while maintaining high accuracy.
- Expansion to vehicle and further object ReID: unlike its predecessor, which focused solely on person re-identification, CORE-ReID V2 extends its scope to vehicle re-identification and further general object re-identification. This expansion demonstrates its versatility and adaptability across various domains.
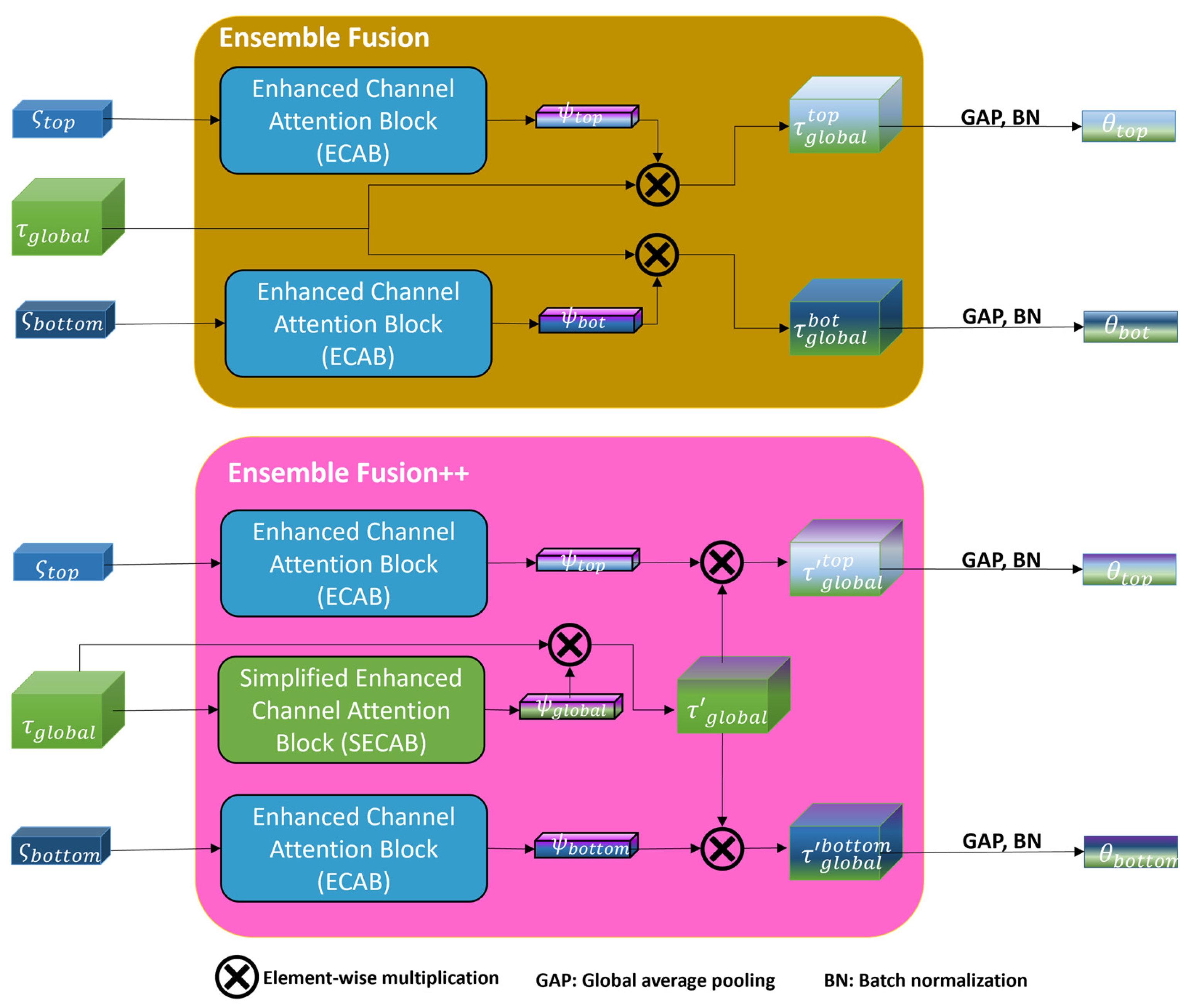
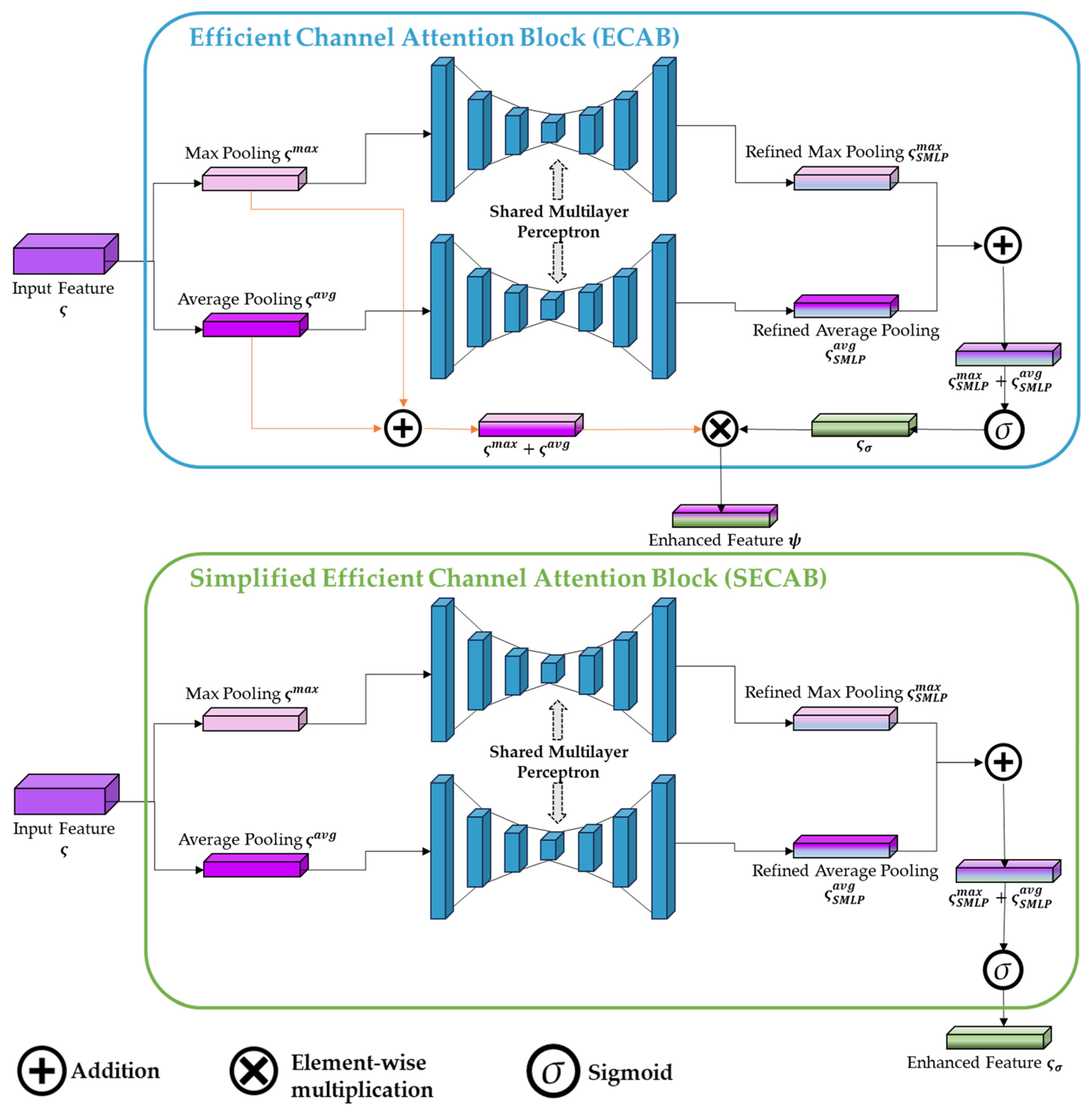
- Introduction of ensemble fusion++: the framework incorporates the SECAB into the global feature extraction pipeline to enhance feature representation by dynamically emphasizing informative channels, thereby improving discrimination between instances.
2. Related Work
2.1. UDA for Object ReID
2.2. Knowledge Transfer
2.3. Feature Fusion
3. Materials and Methods
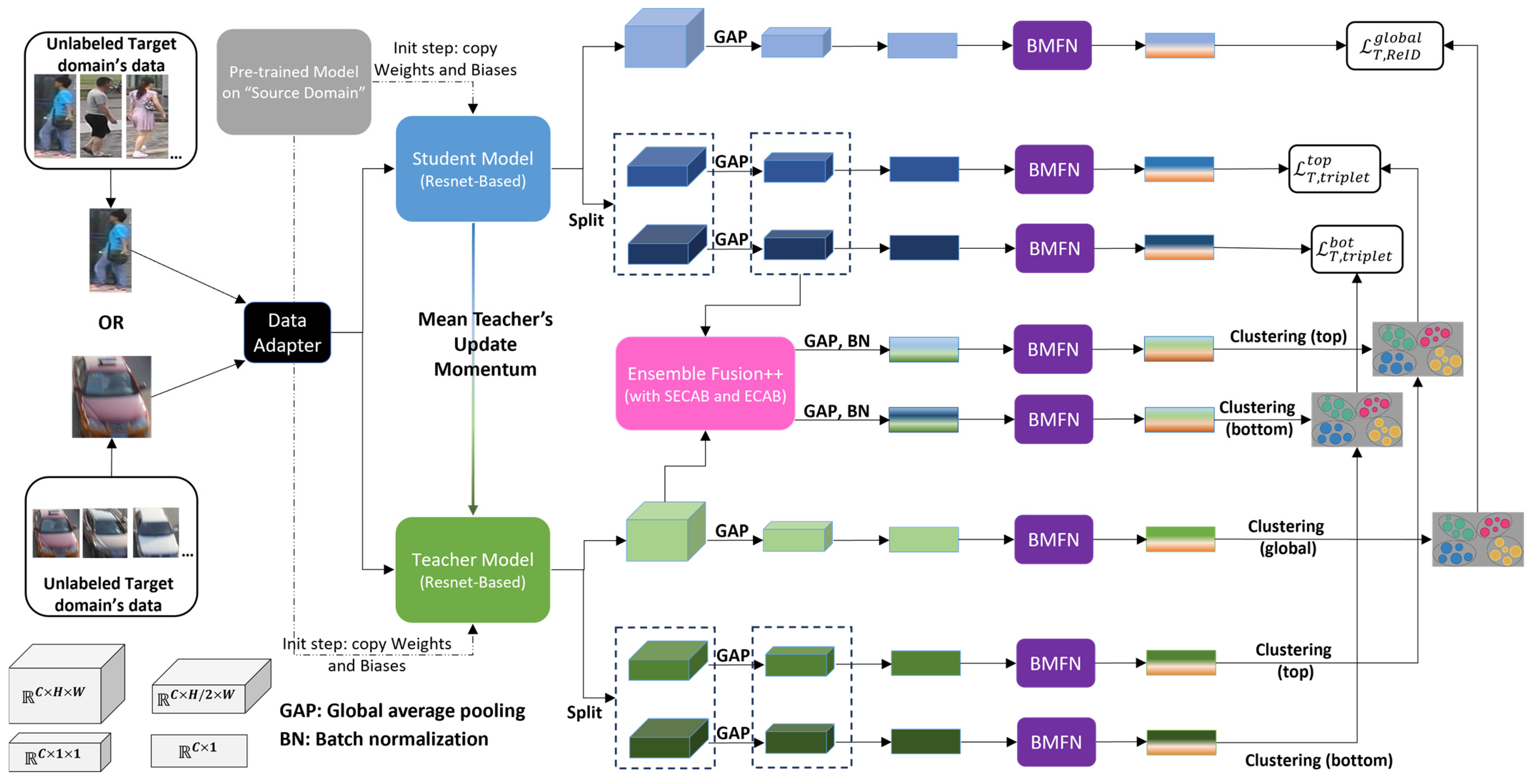
3.1. Overview
3.1.1. CORE-ReID V1 and CORE-ReID V2
- Limited application domain: the framework was specifically designed for Person ReID, restricting its applicability to other ReID tasks such as vehicle ReID and object ReID.
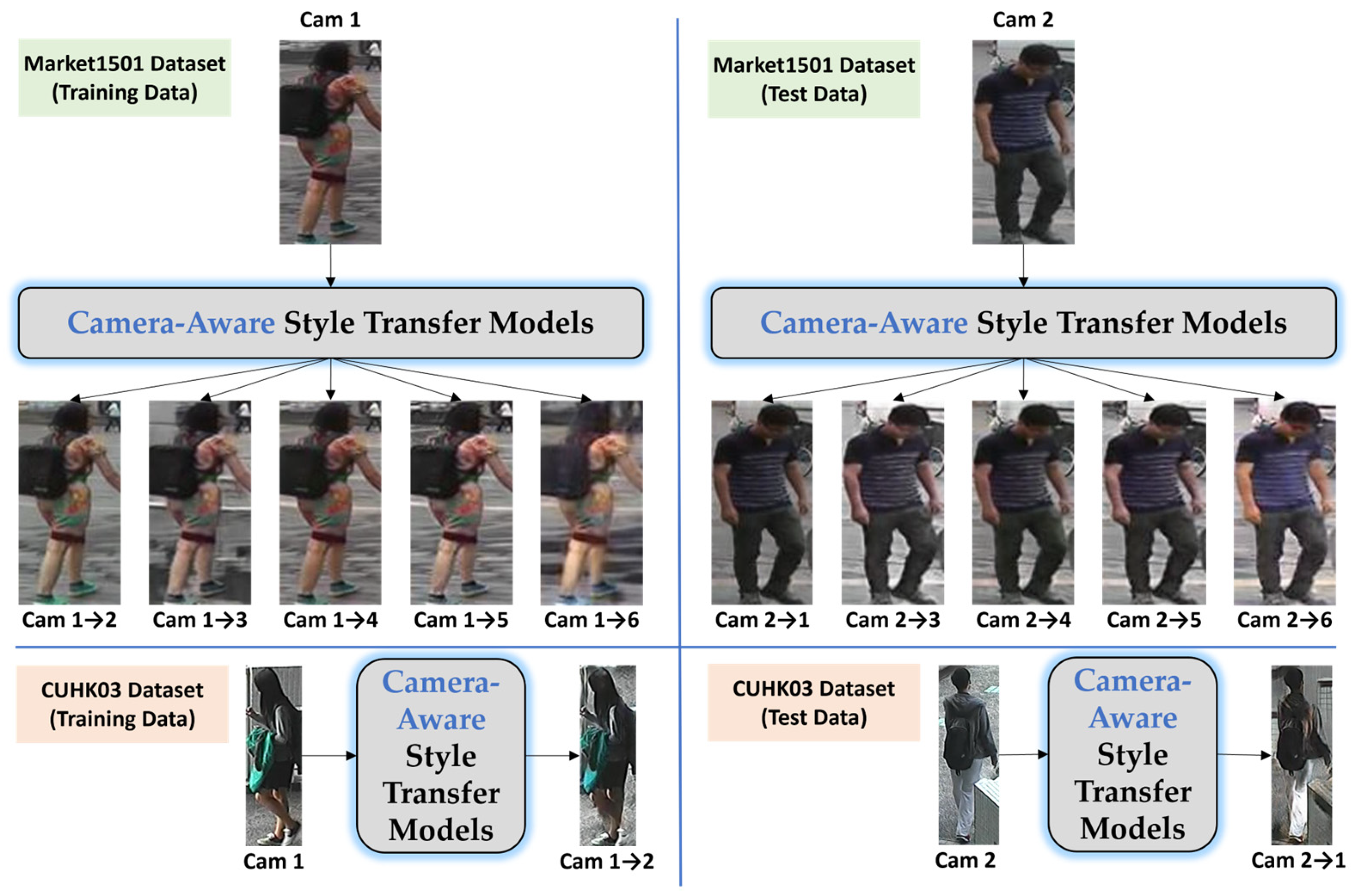
- Synthetic-data generation challenge: the camera-aware style transfer method relied on predefined camera information, making it ineffective when the number of cameras was unspecified.
- Inefficient data augmentation: The Random Grayscale Patch Replacement technique only operated locally, limiting its effectiveness in learning color-invariant features.
- Clustering limitations: the K-means clustering used random centroid initialization, leading to poor centroid placement, slow convergence, high variance in clustering results, and imbalanced cluster sizes.
- Feature fusion issue: the ECAB module enhanced only local features, neglecting improvements to global representations.
- Restricted backbone support: the framework exclusively supported deep networks such as ResNet50, ResNet101, and ResNet152, making it computationally expensive and unsuitable for lightweight applications.
- Expanded application scope: unlike CORE-ReID V1, which was restricted to person ReID, CORE-ReID V2 extends its applicability to vehicle ReID and object ReID, making it a versatile framework for various ReID tasks.
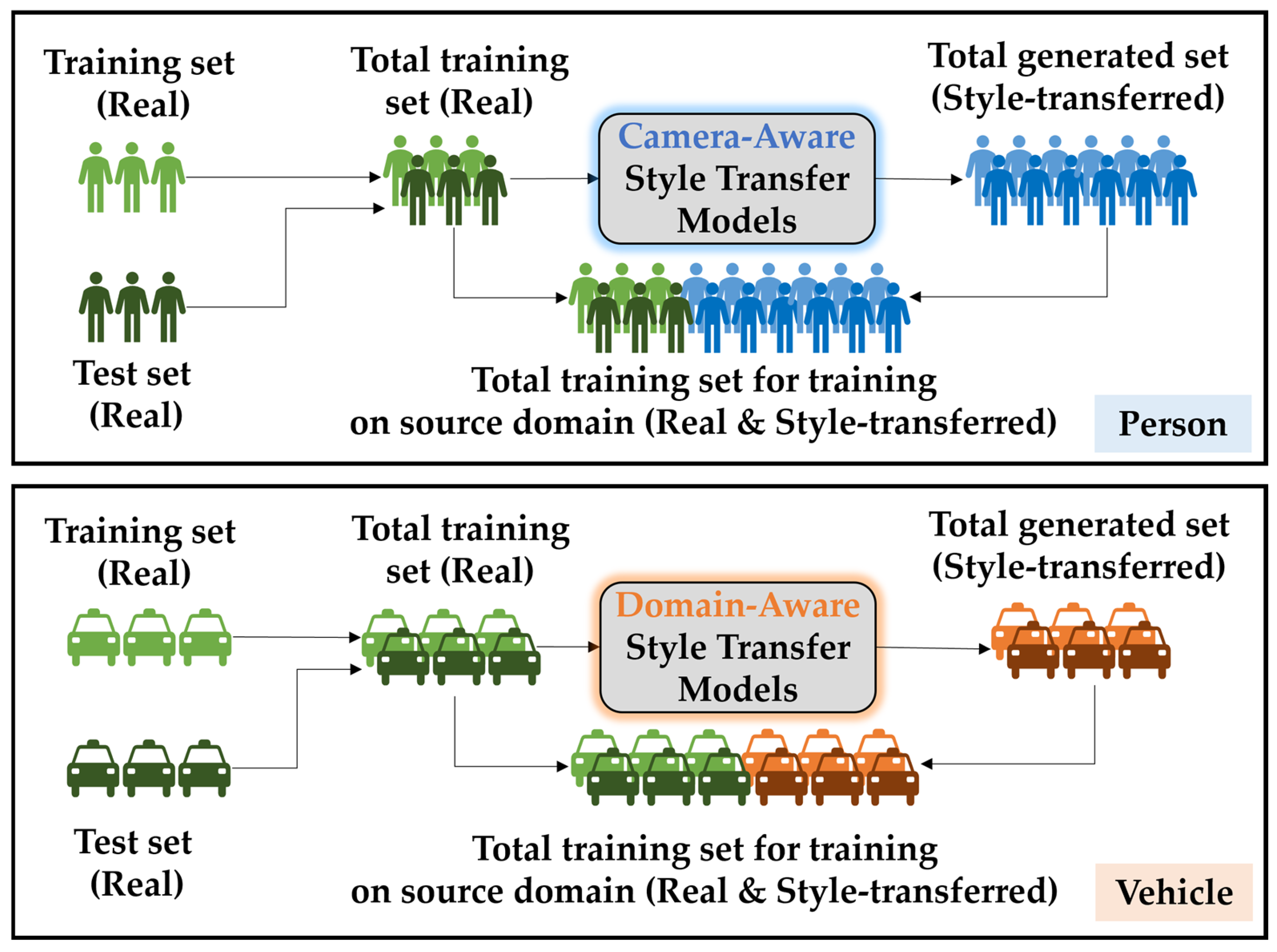
- Advanced synthetic data generation: CORE-ReID V2 incorporates both camera-aware style transfer and domain-aware style transfer, allowing effective synthetic data generation even when the number of cameras is unknown.
- Improved data augmentation: a new grayscale patch-replacement strategy considers both local grayscale transformation and global grayscale conversion, leading to better feature generalization across domains.
- Enhanced clustering with greedy K-means++: instead of relying on random initialization, CORE-ReID V2 employs greedy K-means++, which selects optimized centroids to improve cluster spread; minimizes redundancy, requiring fewer iterations; enhances stability and consistency, reducing randomness; ensures better centroid distribution, leading to improved clustering performance.
- Ensemble fusion++ for Comprehensive Feature Enhancement: CORE-ReID V2 introduces ensemble fusion++, which integrates both ECAB and SECAB, ensuring that global features are enhanced alongside local features, leading to a more balanced and comprehensive feature representation.
- Flexible backbone support: CORE-ReID V2 broadens its applicability by supporting lightweight networks such as ResNet18 and ResNet34, alongside ResNet50, ResNet101, and ResNet152. This allows deployment in computationally constrained environments, such as real-time and edge-based applications.
3.1.2. Problem Definition and Methodology
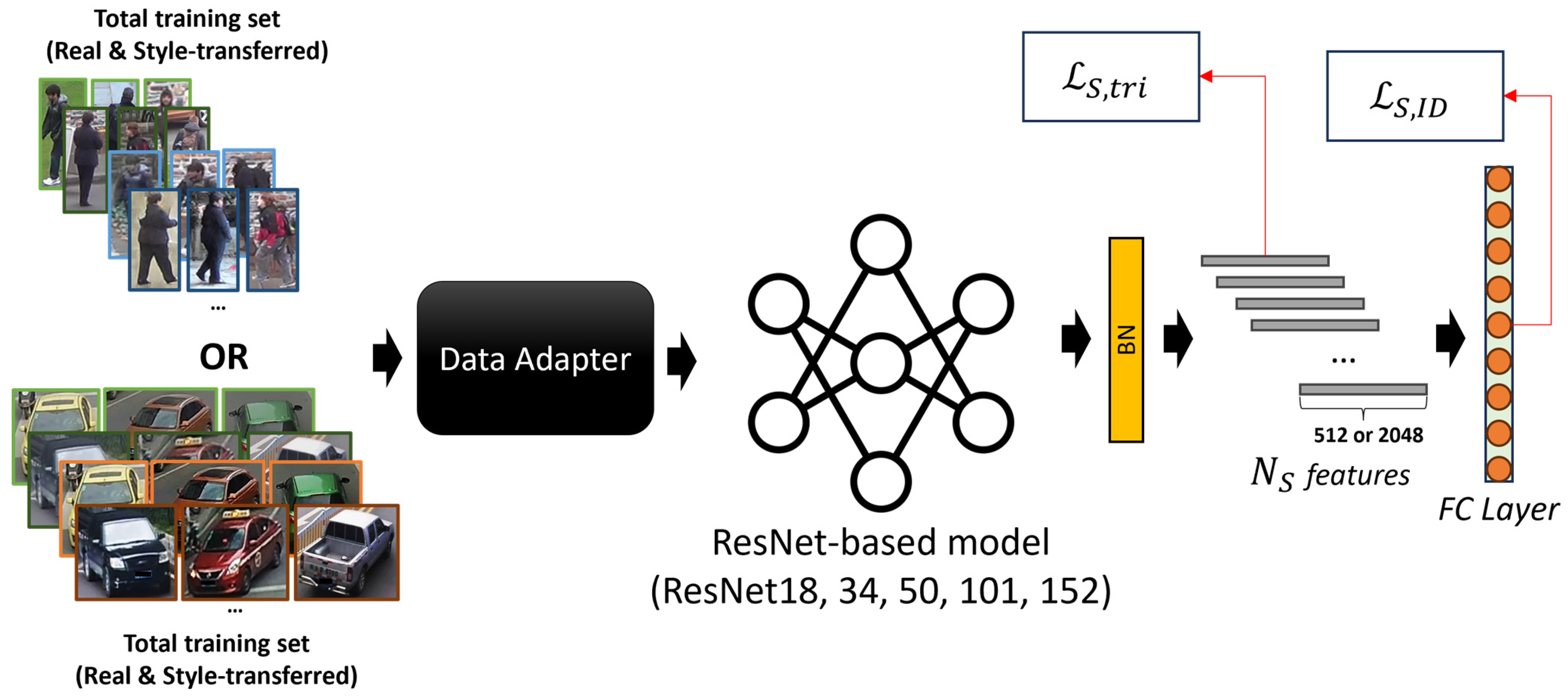
3.2. Source-Domain Pre-Training
3.2.1. Image-to-Image Translation
3.2.2. Fully Supervised Pre-Training
| Algorithm 1: Global Grayscale Transformation | |
| Input: Input image I; Grayscale transformation probability pglobal | |
| . | |
| . | |
| 1: | then |
| 2: | . |
| 3: | else |
| 4: | . |
| 5: | . |
| 6: | end |
| Algorithm 2: Local Grayscale Transformation | |
. | |
| . | |
| ; ; . | |
| 1: | then |
| 2: | ; . |
| 3: | else |
| 4: | do |
| 5: | ; |
| 6: | ; |
| 7: | ; |
| 8: | ; |
| 9: | then |
| 10: | ; |
| 11: | ; |
| 12: | ; |
| 13: | . |
| 14: | end |
| 15: | end |
| 16: | end |
3.2.3. Implementation Details
3.3. Target-Domain Fine-Tuning
3.3.1. Overall Algorithm
3.3.2. Ensemble Fusion++ Component
3.3.3. SECAB
3.3.4. Greedy K-Means++
| Algorithm 3: Greedy K-means++ seeding | |
| ; ; . | |
| . | |
| . | |
| 1: | . |
| 2: | do |
| 3: | independently; |
| 4: | ; |
| 5: | ; |
| 6: | . |
| 7: | |
3.3.5. Detailed Implementation
4. Results
4.1. Dataset Description
4.2. Evaluation Metrics
4.3. Benchmark on Person ReID
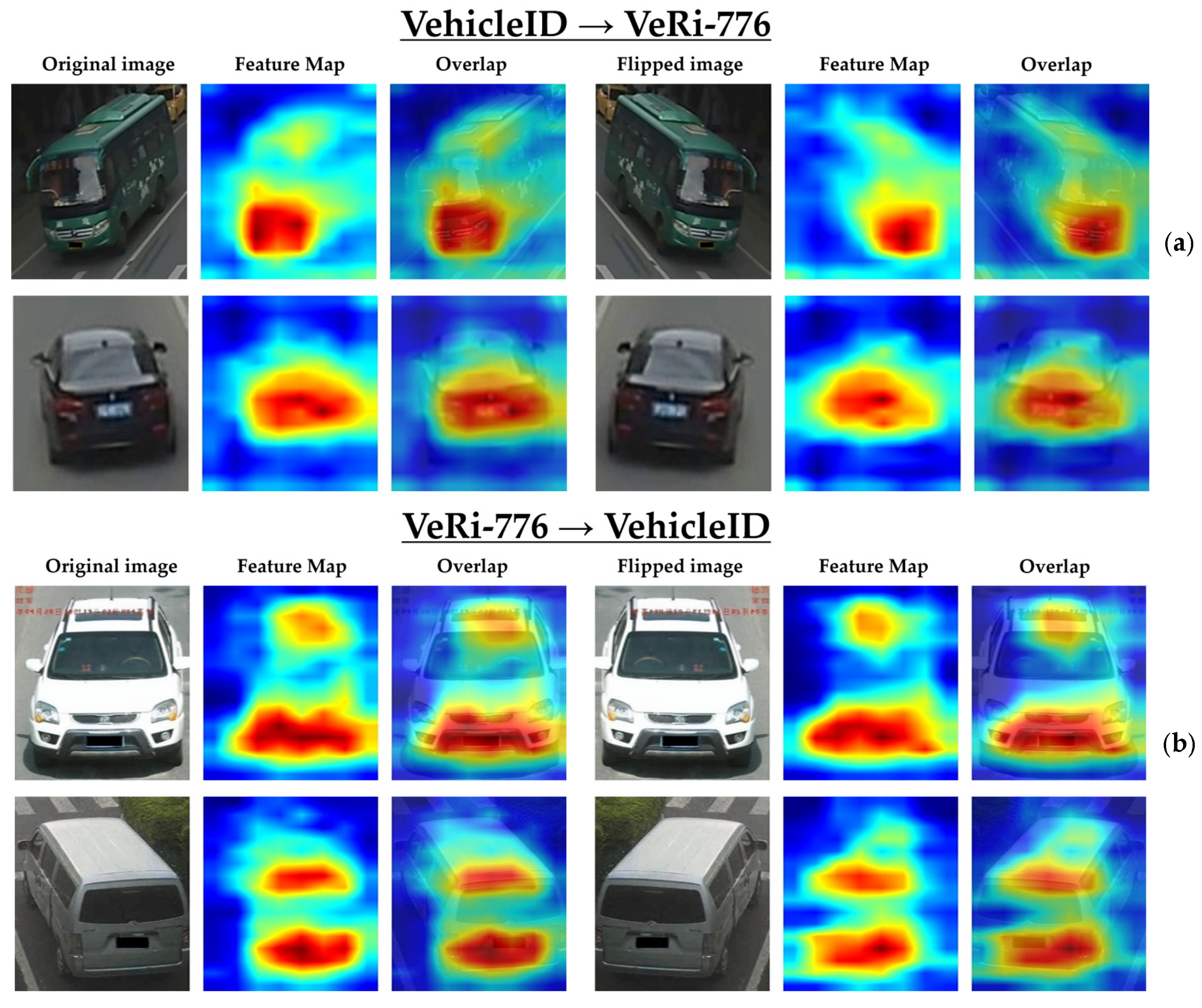
4.4. Benchmark on Vehicle ReID
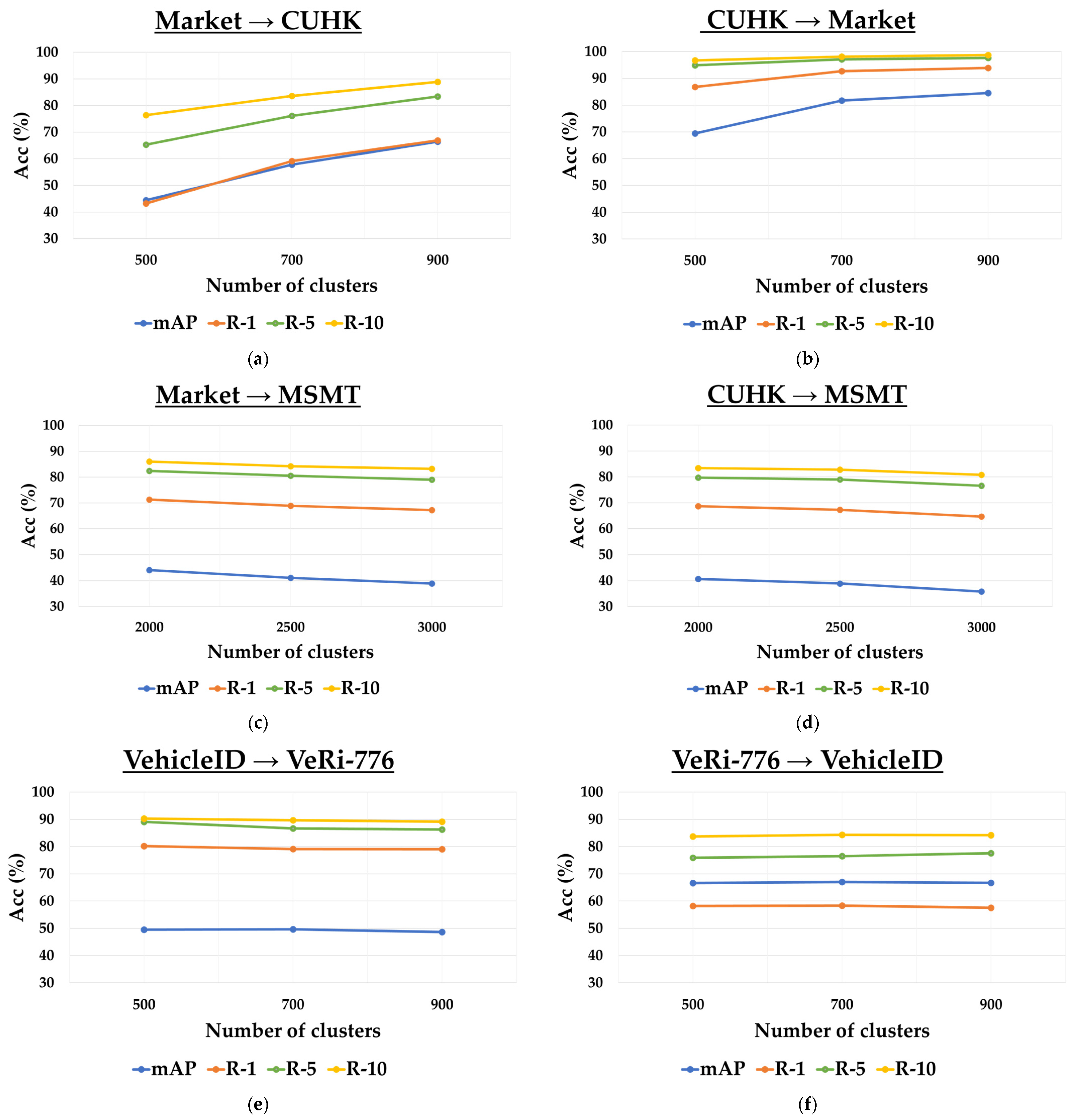
4.5. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ECAB | Efficient Channel Attention Block |
| BMFN | Bidirectional Mean Feature Normalization |
| CBAM | Convolutional Block Attention Module |
| CNN | Convolutional neural network |
| CORE-ReID V1 | Comprehensive optimization and refinement through ensemble fusion in domain adaptation for person re-identification |
| HHL | Hetero-Homogeneous Learning |
| MMFA | Multi-task Mid-level Feature Alignment |
| MMT | Mutual Mean-Teaching |
| Object ReID | object re-identification |
| SECAB | Simplified Efficient Channel Attention Block |
| SOTA | State-of-the-srt |
| SSG | Self-Similarity Grouping |
| UDA | Unsupervised domain adaptation |
| UNRN | Uncertainty-Guided Noise-Resilient Network |
References
- Liu, X.; Liu, W.; Mei, T.; Ma, H. A Deep Learning-Based Approach to Progressive Vehicle Re-identification for Urban Surveillance. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 869–884. [Google Scholar]
- Liu, X.; Liu, W.; Mei, T.; Ma, H. PROVID: Progressive and Multimodal Vehicle Reidentification for Large-Scale Urban Surveillance. IEEE Trans. Multimed. 2018, 20, 645–658. [Google Scholar] [CrossRef]
- Wang, Z.; He, L.; Tu, X.; Zhao, J.; Gao, X.; Shen, S. Robust Video-Based Person Re-Identification by Hierarchical Mining. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 8179–8191. [Google Scholar] [CrossRef]
- Zheng, L.; Yang, Y.; Hauptmann, A.G. Person Re-identification: Past, Present and Future. arXiv 2016, arXiv:1610.02984. [Google Scholar]
- Chang, Z.; Zheng, S. Revisiting Multi-Granularity Representation via Group Contrastive Learning for Unsupervised Vehicle Re-identification. arXiv 2024, arXiv:2410.21667. [Google Scholar]
- Luo, H.; Jiang, W.; Gu, Y.; Liu, F.; Liao, X.; Lai, S. A Strong Baseline and Batch Normalization Neck for Deep Person Re-Identification. IEEE Trans. Multimed. 2020, 22, 2597–2609. [Google Scholar] [CrossRef]
- Sharma, C.; Kapil, S.R.; Chapman, D. Person Re-Identification with a Locally Aware Transformer. arXiv 2021, arXiv:2106.03720. [Google Scholar]
- Chen, W.; Xu, X.; Jia, J.; Luo, H.; Wang, Y.; Wang, F. Beyond Appearance: A Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 15050–15061. [Google Scholar]
- Almeida, E.; Silva, B.; Batista, J. Strength in Diversity: Multi-Branch Representation Learning for Vehicle Re-Identification. In Proceedings of the 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC), Bilbao, Spain, 24–28 September 2023; pp. 4690–4696. [Google Scholar]
- Li, J.; Gong, X. Prototypical Contrastive Learning-based CLIP Fine-tuning for Object Re-identification. arXiv 2023, arXiv:2310.17218. [Google Scholar]
- Nguyen, T.Q.; Prima, O.D.A.; Hotta, K. CORE-ReID: Comprehensive Optimization and Refinement through Ensemble Fusion in Domain Adaptation for Person Re-Identification. Software 2024, 3, 227–249. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jegou, H. Training Data-efficient Image Transformers & Distillation Through Attention. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Song, L.; Wang, C.; Zhang, L.; Du, B.; Zhang, Q.; Huang, C.; Wang, X. Unsupervised Domain Adaptive Re-identification: Theory and Practice. Pattern Recognit. 2020, 102, 107173. [Google Scholar] [CrossRef]
- Ge, Y.; Chen, D.; Li, H. Mutual Mean-Teaching: Pseudo Label Refinery for Unsupervised Domain Adaptation on Person Re-identification. arXiv 2020, arXiv:2001.01526. [Google Scholar]
- Fu, Y.; Wei, Y.; Wang, G.; Zhou, Y.; Shi, H.; Uiuc, U. Self-Similarity Grouping: A Simple Unsupervised Cross Domain Adaptation Approach for Person Re-Identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 6111–6120. [Google Scholar]
- Ding, J.; Zhou, X. Learning Feature Fusion for Unsupervised Domain Adaptive Person Re-identification. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 2613–2619. [Google Scholar]
- Zhou, R.; Wang, Q.; Cao, L.; Xu, J.; Zhu, X.; Xiong, X.; Zhang, H.; Zhong, Y. Dual-Level Viewpoint-Learning for Cross-Domain Vehicle Re-Identification. Electronics 2024, 13, 1823. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. K-means++: The Advantages of Careful Seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Zhang, Y.; Xiang, T.; Hospedales, T.M.; Lu, H. Deep Mutual Learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4320–4328. [Google Scholar]
- Zhai, Y.; Ye, Q.; Lu, S.; Jia, M.; Ji, R.; Tian, Y. Multiple Expert Brainstorming for Domain Adaptive Person Re-identification. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 594–611. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean Teachers Are Better Role Models: Weight-averaged Consistency Targets Improve Semi-supervised Deep Learning Results. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1195–1204. [Google Scholar]
- Brown, L.M. View independent vehicle/person classification. In Proceedings of the ACM 2nd International Workshop on Video Surveillance & Sensor Networks, New York, NY, USA, 15 October 2004; pp. 114–123. [Google Scholar]
- Yue, J.X.S. Mimicking visual searching with integrated top down cues and low-level features. Neurocomput 2014, 133, 1–17. [Google Scholar] [CrossRef]
- Wei, L.; Liu, X.; Li, J.; Zhang, S. VP-ReID: Vehicle and Person Re-Identification System. In Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval, Yokohama, Japan, 11–14 June 2018; pp. 501–504. [Google Scholar]
- Chen, X.; Sui, H.; Fang, J.; Feng, W.; Zhou, M. Vehicle Re-Identification Using Distance-Based Global and Partial Multi-Regional Feature Learning. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1276–1286. [Google Scholar] [CrossRef]
- Lin, X.; Li, R.; Zheng, X.; Peng, P.; Wu, Y.; Huang, F. Aggregating Global and Local Visual Representation for Vehicle Re-IDentification. IEEE Trans. Multimed. 2020, 23, 3968–3977. [Google Scholar] [CrossRef]
- Akbarian, S.; Seyyed-Kalantari, L.; Khalvati, F.; Dolatabadi, E. Evaluating Knowledge Transfer in Neural Network for Medical Images. IEEE Access 2023, 11, 85812–85821. [Google Scholar] [CrossRef]
- Chen, S.; Wang, Y.; Shi, Y.; Yan, K.; Geng, M.; Tian, Y. Deep Transfer Learning for Person Re-Identification. In Proceedings of the 2018 IEEE Fourth International Conference on Multimedia Big Data (BigMM), Xi’an, China, 13–16 September 2018. [Google Scholar]
- Zhao, G.; Zhang, X.; Tang, H.; Shen, J.; Qian, X. Domain-Oriented Knowledge Transfer for Cross-Domain Recommendation. IEEE Trans. Multimed. 2024, 26, 9539–9550. [Google Scholar] [CrossRef]
- Wang, Q.; Qian, X.; Li, B.; Fu, Y.; Xue, X. Image-Text-Image Knowledge Transferring for Lifelong Person Re-Identification with Hybrid Clothing States. arXiv 2024, arXiv:2405.16600. [Google Scholar]
- Saenko, K.; Kulis, B.; Fritz, M.; Darrell, T. Adapting Visual Category Models to New Domains. In Proceedings of the Computer Vision—ECCV 2010, Berlin/Heidelberg, Germany, 5–11 September 2010; pp. 213–226. [Google Scholar]
- Gong, B.; Shi, Y.; Sha, F.; Grauman, K. Geodesic Flow Kernel for Unsupervised Domain Adaptation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2066–2073. [Google Scholar]
- Fernando, B.; Habrard, A.; Sebban, M.; Tuytelaars, T. Unsupervised Visual Domain Adaptation Using Subspace Alignment. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 2960–2967. [Google Scholar]
- Sun, B.; Feng, J.; Saenko, K. Return of Frustratingly Easy Domain Adaptation. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12 February 2016; pp. 2058–2065. [Google Scholar]
- Zhou, L.; Ye, M.; Li, X.; Zhu, C.; Liu, Y.; Li, X. Disentanglement Then Reconstruction: Unsupervised Domain Adaptation by Twice Distribution Alignments. Expert Syst. Appl. 2024, 237, 121498. [Google Scholar] [CrossRef]
- Zhang, X.; Ge, Y.; Qiao, Y.; Li, H. Refining Pseudo Labels with Clustering Consensus over Generations for Unsupervised Object Re-identification. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 3435–3444. [Google Scholar]
- Bousmalis, K.; Silberman, N.; Dohan, D.; Erhan, D.; Krishnan, D. Unsupervised Pixel–Level Domain Adaptation with Generative Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 95–104. [Google Scholar]
- Wei, L.; Zhang, S.; Gao, W.; Tian, Q. Person Transfer GAN to Bridge Domain Gap for Person Re-Identification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 79–88. [Google Scholar]
- Huang, Y.; Wu, Q.; Xu, J.; Zhong, Y. SBSGAN: Suppression of Inter-Domain Background Shift for Person Re-Identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 27 October–2 November 2019; pp. 9526–9535. [Google Scholar]
- Liu, M.-Y.; Tuzel, O. Coupled Generative Adversarial Networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 469–477. [Google Scholar]
- Fan, H.; Yan, L.Z.C.; Yang, Y. Unsupervised Person Re-identification: Clustering and Fine-tuning. ACM Trans. Multimed. Comput. Commun. Appl. 2018, 14, 1–18. [Google Scholar] [CrossRef]
- Lin, Y.; Dong, X.; Zheng, L.; Yan, Y.; Yang, Y. A Bottom-Up Clustering Approach to Unsupervised Person Re-Identification. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; AAAI Press: Washington, DC, USA, 2019; pp. 8738–8745. [Google Scholar]
- Ge, Y.; Zhu, F.; Chen, D.; Zhao, R.; Li, H. Self-paced Contrastive Learning with Hybrid Memory for Domain Adaptive Object Re-ID. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6 December 2020; pp. 11309–11321. [Google Scholar]
- Zheng, K.; Lan, C.; Zeng, W.; Zhang, Z.; Zha, Z.-J. Exploiting Sample Uncertainty for Domain Adaptive Person Re-Identification. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI), Virtual Event, 2–9 February 2021. [Google Scholar]
- Sun, Q.-S.; Zeng, S.-G.; Liu, Y.; Heng, P.-A.; Xia, D.-S. A new method of feature fusion and its application in image recognition. Pattern Recognit. 2005, 38, 2437–2448. [Google Scholar] [CrossRef]
- Sudha, D.; Ramakrishna, M. Comparative Study of Features Fusion Techniques. In Proceedings of the 2017 International Conference on Recent Advances in Electronics and Communication Technology (ICRAECT), Bangalore, India, 16–17 March 2017; pp. 235–239. [Google Scholar]
- Tian, Y.; Zhang, W.; Zhang, Q.; Lu, G.; Wu, X. Selective Multi-Convolutional Region Feature Extraction based Iterative Discrimination CNN for Fine-Grained Vehicle Model Recognition. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 3279–3284. [Google Scholar]
- Lu, L.; Yi, Y.; Huang, F.; Wang, K.; Wang, Q. Integrating Local CNN and Global CNN for Script Identification in Natural Scene Images. IEEE Access 2019, 7, 52669–52679. [Google Scholar] [CrossRef]
- He, Z.; Nan, F.; Li, X.; Lee, S.-J.; Yang, Y. Traffic Sign Recognition by Combining Global and Local Features Based on Semi-supervised Classification. IET Intell. Transp. Syst. 2019, 14, 323–330. [Google Scholar] [CrossRef]
- Suh, S.; Lukowicz, P.; Lee, Y.O. Fusion of Global-Local Features for Image Quality Inspection of Shipping Label. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 2643–2649. [Google Scholar]
- Li, Z.; Yang, L.; Zhou, F. FSSD: Feature Fusion Single Shot Multibox Detector. arXiv 2017, arXiv:1712.00960. [Google Scholar]
- Cong, R.; Yang, N.; Li, C.; Fu, H.; Zhao, Y.; Huang, Q. Global-and-Local Collaborative Learning for Co-Salient Object Detection. IEEE Trans. Cybern. 2023, 53, 1920–1931. [Google Scholar] [CrossRef]
- Li, T.; Zhang, Z.; Zhu, M.; Cui, Z.; Wei, D. Combining Transformer Global and Local Feature Extraction for Object Detection. Complex Intell. Syst. 2024, 10, 4897–4920. [Google Scholar] [CrossRef]
- Wei, J.; Wang, S.; Huang, Q. F3Net: Fusion, Feedback and Focus for Salient Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12321–12328. [Google Scholar]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Zhuge, M.; Fan, D.-P.; Liu, N.; Zhang, D.; Xu, D.; Shao, L. Salient Object Detection via Integrity Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 3738–3752. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, X.; Peng, C.; Xue, X.; Sun, J. ExFuse: Enhancing Feature Fusion for Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 269–284. [Google Scholar]
- Dai, Y.; Gieseke, F.; Oehmcke, S.; Wu, Y.; Barnard, K. Attentional Feature Fusion. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 3559–3568. [Google Scholar]
- Yang, X.; Li, S.; Chen, Z.; Chanussot, J.; Jia, X.; Zhang, B.; Li, B.; Chen, P. An Attention-Fused Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery. ISPRS J. Photogramm. Remote Sens. 2021, 177, 238–262. [Google Scholar] [CrossRef]
- Tian, Q.; Zhao, F.; Zhang, Z.; Qu, H. GLFFNet: A Global and Local Features Fusion Network with Biencoder for Remote Sensing Image Segmentation. Appl. Sci. 2023, 13, 8725. [Google Scholar] [CrossRef]
- Zhou, X.; Zhou, L.; Zhang, H.; Ji, W.; Zhou, B. Local–Global Multiscale Fusion Network for Semantic Segmentation of Buildings in SAR Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 7410–7421. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- He, S.; Luo, H.; Wang, P.; Wang, F.; Li, H.; Jiang, W. TransReID: Transformer-based Object Re-Identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 15013–15022. [Google Scholar]
- Chen, Y.; Zhu, X.; Gong, S. Instance-Guided Context Rendering for Cross-Domain Person Re-Identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 232–242. [Google Scholar]
- Deng, W.; Zheng, L.; Ye, Q.; Kang, G.; Yang, Y.; Jiao, J. Image-Image Domain Adaptation with Preserved Self-Similarity and Domain-Dissimilarity for Person Re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 994–1003. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; March, M.; Lempitsky, V. Domain-Adversarial Training of Neural Networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Motiian, S.; Piccirilli, M.; Adjeroh, D.A.; Doretto, G. Unified Deep Supervised Domain Adaptation and Generalization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5716–5726. [Google Scholar]
- Tang, Y.; Yang, X.; Wang, N.; Song, B.; Gao, X. CGAN-TM: A Novel Domain-to-Domain Transferring Method for Person Re-Identification. IEEE Trans. Image Process. 2020, 29, 5641–5651. [Google Scholar] [CrossRef]
- Dai, Y.; Liu, J.; Sun, Y.; Tong, Z.; Zhang, C.; Duan, L.-Y. IDM: An Intermediate Domain Module for Domain Adaptive Person Re-ID. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 11844–11854. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning Transferable Features with Deep Adaptation Networks. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 97–105. [Google Scholar]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.-Y.; Isola, P.; Saenko, K.; Efros, A.; Darrell, T. CyCADA: Cycle-Consistent Adversarial Domain Adaptation. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1989–1998. [Google Scholar]
- Gretton, A.; Borgwardt, K.M.; Rasch, M.J.; Schölkopf, B.; Smola, A. A Kernel Two-Sample Test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Gao, R.; Liu, F.; Zhang, J.; Han, B.; Liu, T.; Niu, G.; Sugiyama, M. Maximum Mean Discrepancy Test is Aware of Adversarial Attacks. arXiv 2020, arXiv:2010.11415. [Google Scholar]
- Zhang, W.; Ouyang, W.; Li, W.; Xu, D. Collaborative and Adversarial Network for Unsupervised Domain Adaptation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3801–3809. [Google Scholar]
- Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M. Domain-Adversarial Neural Networks. arXiv 2014, arXiv:1412.4446. [Google Scholar]
- Jiang, Y.; Chen, W.; Sun, X.; Shi, X.; Wang, F.; Li, H. Exploring the Quality of GAN Generated Images for Person Re-Identification. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 4146–4155. [Google Scholar]
- Pan, H.; Chen, Y.; He, Y.; Li, X.; He, Z. How Image Generation Helps Visible-to-Infrared Person Re-Identification? arXiv 2022, arXiv:2210.01585. [Google Scholar]
- Xie, H.; Luo, H.; Gu, J.; Jiang, W. Unsupervised Domain Adaptive Person Re-Identification via Intermediate Domains. Appl. Sci. 2022, 12, 6990. [Google Scholar] [CrossRef]
- Hu, C.; Li, X.; Liu, D.; Wu, H.; Chen, X.; Wang, J.; Liu, X. Teacher-Student Architecture for Knowledge Learning: A Survey. arXiv 2022, arXiv:2210.17332. [Google Scholar]
- Passalis, N.; Tefas, A. Learning Deep Representations with Probabilistic Knowledge Transfer. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 268–284. [Google Scholar]
- Laine, S.; Aila, T. Temporal Ensembling for Semi-Supervised Learning. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable Person Re-identification: A Benchmark. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Liu, H.; Tian, Y.; Wang, Y.; Pang, L.; Huang, T. Deep Relative Distance Learning: Tell the Difference between Similar Vehicles. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2167–2175. [Google Scholar]
- Ju, Y.; Jia, S.; Cai, J.; Guan, H.; Lyu, S. GLFF: Global and Local Feature Fusion for AI-synthesized Image Detection. IEEE Trans. Multimed. 2024, 26, 4073–4085. [Google Scholar] [CrossRef]
- Polyak, B.T.; Juditsky, A. Acceleration of Stochastic Approximation by Averaging. SIAM J. Control Optim. 1992, 30, 838–855. [Google Scholar] [CrossRef]
- Zou, Y.; Yang, X.; Yu, Z.; Kumar, B.V.K.V.; Kautz, J. Joint Disentangling and Adaptation for Cross-Domain Person Re-Identification. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 87–104. [Google Scholar]
- Gong, Y.; Huang, L.; Chen, L. Eliminate Deviation with Deviation for Data Augmentation and a General Multi-modal Data Learning Method. arXiv 2021, arXiv:2101.08533. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Grunau, C.; Özüdoğru, A.A.; Rozhoň, V.; Tětek, J. A Nearly Tight Analysis of Greedy K-means++. In Proceedings of the 2023 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), Florence, Italy, 22–25 January 2023; pp. 1012–1070. [Google Scholar]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. DeepReID: Deep Filter Pairing Neural Network for Person Re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 152–159. [Google Scholar]
- Lou, Y.; Bai, Y.; Liu, J.; Wang, S.; Duan, L. VERI-Wild: A Large Dataset and a New Method for Vehicle Re-Identification in the Wild. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3230–3238. [Google Scholar]
- Zhong, Z.; Zheng, L.; Cao, D.; Li, S. Re-ranking Person Re-identification with k-Reciprocal Encoding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3652–3661. [Google Scholar]
- Jin, X.; Lan, C.; Zeng, W.; Chen, Z.; Zhang, L. Style Normalization and Restitution for Generalizable Person Re-Identification. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3140–3149. [Google Scholar]
- Liao, S.; Shao, L. Interpretable and Generalizable Person Re-identification with Query-Adaptive Convolution and Temporal Lifting. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Zhao, Y.; Zhong, Z.; Yang, F.; Luo, Z.; Lin, Y.; Li, S.; Sebe, N. Learning to Generalize Unseen Domains via Memory-based Multi-Source Meta-Learning for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Choi, S.; Kim, T.; Jeong, M.; Park, H.; Kim, C. Meta Batch-Instance Normalization for Generalizable Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Yang, F.; Zhong, Z.; Luo, Z.; Li, S.; Sebe, N. Federated and Generalized Person Re-identification through Domain and Feature Hallucinating. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Xu, B.; Liang, J.; He, L.; Sun, Z. Mimic Embedding via Adaptive Aggregation: Learning Generalizable Person Re-identification. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 372–388. [Google Scholar]
- Zhang, P.; Dou, H.; Yu, Y.; Li, X. Adaptive Cross-Domain Learning for Generalizable Person Re-Identification. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Li, H.; Wang, Y.; Zhu, L.; Wang, W.; Yin, K.; Li, Y.; Yin, G. Weakly Supervised Cross-Domain Person Re-Identification Algorithm Based on Small Sample Learning. Electronics 2023, 12, 4186. [Google Scholar] [CrossRef]
- Mao, Y.; Huafeng, L.; Yafei, Z. Unsupervised Domain Adaptation for Cross-Regional Scenes Person Re-identification. J. Shanghai Jiao Tong Univ. 2023, 1–26. [Google Scholar] [CrossRef]
- Sun, J.; Li, Y.; Chen, L.; Chen, H.; Peng, W. Multiple Integration Model for Single-source Domain Generalizable Person Re-identification. J. Vis. Commun. Image Represent 2024, 98, 104037. [Google Scholar] [CrossRef]
- Li, Q.; Gong, S. Mitigate Domain Shift by Primary-Auxiliary Objectives Association for Generalizing Person ReID. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2024; pp. 393–402. [Google Scholar]
- Zhao, F.; Liao, S.; Xie, G.-S.; Zhao, J.; Zhang, K.; Shao, L. Unsupervised Domain Adaptation with Noise Resistible Mutual-Training for Person Re-identification. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 526–544. [Google Scholar]
- Dai, Y.; Liu, J.; Bai, Y.; Tong, Z.; Duan, L.-Y. Dual-Refinement: Joint Label and Feature Refinement for Unsupervised Domain Adaptive Person Re-Identification. IEEE Trans. Image Process. 2020, 30, 7815–7829. [Google Scholar] [CrossRef]
- Bai, Z.; Wang, Z.; Wang, J.; Hu, D.; Ding, E. Unsupervised Multi-Source Domain Adaptation for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 12914–12923. [Google Scholar]
- Wang, Y.; Liang, X.; Liao, S. Cloning Outfits from Real-World Images to 3D Characters for Generalizable Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 4890–4899. [Google Scholar]
- Tay, C.-P.; Yap, K.-H. Collaborative learning mutual network for domain adaptation in person re-identification. Neural Comput. Appl. 2022, 34, 12211–12222. [Google Scholar] [CrossRef]
- Zhou, H.; Kong, J.; Jiang, M.; Liu, T. Heterogeneous dual network with feature consistency for domain adaptation person re-identification. Int. J. Mach. Learn. Cyber 2023, 14, 1951–1965. [Google Scholar] [CrossRef]
- Yun, X.; Wang, Q.; Cheng, X.; Song, K.; Sun, Y. Discrepant mutual learning fusion network for unsupervised domain adaptation on person re-identification. Appl. Intell. 2023, 53, 2951–2966. [Google Scholar] [CrossRef]
- Lee, G.; Lee, S.; Kim, D.; Shin, Y.; Yoon, Y.; Ham, B. Camera-Driven Representation Learning for Unsupervised Domain Adaptive Person Re-identification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 1453–11462. [Google Scholar]
- Rami, H.; Giraldo, J.H.; Winckler, N.; Lathuilière, S. Source-Guided Similarity Preservation for Online Person Re-Identification. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2024; pp. 1700–1709. [Google Scholar]
- Zhang, B.; Wu, D.; Lu, X.; Li, Y.; Gu, Y.; Li, J.; Wang, J. A domain generalized person re-identification algorithm based on meta-bond domain alignment. J. Vis. Commun. Image Represent 2024, 98, 2913–2933. [Google Scholar] [CrossRef]
- Tian, Q.; Cheng, Y.; He, S.; Sun, J. Unsupervised multi-source domain adaptation for person re-identification via feature fusion and pseudo-label refinement. Comput. Electr. Eng 2024, 113, 109029. [Google Scholar] [CrossRef]
- Bashir, R.M.S.; Shahzad, M.; Fraz, M.M. VR-PROUD: Vehicle Re-identification using Progressive Unsupervised Deep Architecture. Pattern Recognit. 2019, 90, 52–65. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Luo, Z.; Li, S.; Yang, Y. Invariance Matters: Exemplar Memory for Domain Adaptive Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 598–607. [Google Scholar]
- Peng, J.; Wang, Y.; Wang, H.; Zhang, Z.; Fu, X.; Wang, M. Unsupervised Vehicle Re-identification with Progressive Adaptation. In Proceedings of the International Joint Conference on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 913–919. [Google Scholar]
- Wang, H.; Peng, J.; Jiang, G.; Fu, X. Learning Multiple Semantic Knowledge For Cross-Domain Unsupervised Vehicle Re-Identification. In Proceedings of the IEEE International Conference on Multimedia and Expo, Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Wang, Y.; Peng, J.; Wang, H.; Wang, M. Progressive learning with multi-scale attention network for cross-domain vehicle re-identification. Sci. China Inf. Sci. 2022, 65, 160103. [Google Scholar] [CrossRef]
- Zhang, F.; Zhang, L.; Zhang, H.; Ma, Y. Image-to-image domain adaptation for vehicle re-identification. Multimed. Tools Appl. 2023, 82, 40559–40584. [Google Scholar] [CrossRef]
- Zhan, G.; Wang, Q.; Min, W.; Han, Q.; Zhao, H.; Wei, Z. Unsupervised Vehicle Re-Identification Based on Cross-Style Semi-Supervised Pre-Training and Feature Cross-Division. Electronics 2023, 12, 2931. [Google Scholar] [CrossRef]
- Zhang, X.; Ling, Y.; Li, K.; Zhou, W.S.Z. Multimodality Adaptive Transformer and Mutual Learning for Unsupervised Domain Adaptation Vehicle Re-Identification. IEEE Trans. Intell. Transport. Syst. 2024, 25, 20215–20226. [Google Scholar] [CrossRef]
- Ding, Y.; Fan, H.; Xu, M.; Yang, Y. Adaptive Exploration for Unsupervised Person Re-identification. ACM Trans. Multimed. Comput. Commun. Appl. 2020, 16, 1–19. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Yan, C.; Pang, G.; Wang, L.; Jiao, J.; Feng, X.; Shen, C.; Li, J. BV-Person: A Large-Scale Dataset for Bird-View Person Re-Identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 10943–10952. [Google Scholar]
- Yildiz, S.; Kasim, A.N. ENTIRe-ID: An Extensive and Diverse Dataset for Person Re-Identification. In Proceedings of the 2024 IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG), Istanbul, Turkiye, 27–31 May 2024; pp. 1–5. [Google Scholar]
- Li, X.; Yuan, M.; Jiang, Q.; Li, G. VRID-1: A Basic Vehicle Re-identification Dataset for Similar Vehicles. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–8. [Google Scholar]
- Wang, P.; Jiao, B.; Yang, L.Y.Y.; Zhang, S.; Wei, W. Vehicle Re-identification in Aerial Imagery: Dataset and Approach. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October 2019–2 November 2019; pp. 460–469. [Google Scholar]
- Oliveira, I.O.D.; Laroca, R.; Menotti, D.; Fonseca, K.V.O.; Minetto, R. Vehicle-Rear: A New Dataset to Explore Feature Fusion for Vehicle Identification Using Convolutional Neural Networks. IEEE Access 2021, 9, 101065–101077. [Google Scholar] [CrossRef]
- Wang, H.; Yuan, X.; Cai, Y.; Chen, L.; Li, Y. V2I-CARLA: A Novel Dataset and a Method for Vehicle Reidentification-Based V2I Environment. IEEE Trans. Instrum. Meas. 2022, 71, 1–9. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | CORE-ReID V1 | CORE-ReID V2 | |
|---|---|---|---|
| Current Status | Drawbacks/Issues | ||
| Applied Domain | Person ReID | Only support person ReID. | Expansion from person ReID to vehicle ReID and further object ReID. |
| Synthetic Data Generation | Camera-aware style transfer | Do not work in case the number of cameras is not specified. | Camera-aware style transfer and domain-aware style transfer (in the case where the number of cameras is not specified). |
| Data Augmentation | Random gray scale patch replacement | Only replace a random gray scale patch in the image locally. | Locally gray scale patch replacement and global gray scale conversion. |
| K-means Clustering | Random initialization | Problems from random initialization: (1) Poor centroid placement; (2) Slow convergence; (3) Stuck in local minima; (4) High variance in results; (5) Imbalanced cluster sizes. | Greedy K-means++ initialization helps (1) Select centroids with optimized spread; (2) Minimize redundancy, requiring fewer iterations; (3) Improve initialization stability; (4) Reduce randomness and to provide consistent clusters; (5) Ensure better centroid distribution. |
| Ensemble Fusion | Ensemble fusion with ECAB | Only the local features are enhanced in the ensemble fusion. | Ensemble fusion++ (with ECAB and SECAB) helps enhance both local and global features. |
| Supported Backbones | ResNet50, 101, 152 | Do not support small backbones such as ResNet18, 34. | ResNet18, 34, 50, 101, 152 |
| Aspect | ECAB | SECAB |
|---|---|---|
| Target Use | Local feature vectors | Global feature map |
| Pooling | Adaptive max + avg pooling | Adaptive max + avg pooling |
| Attention Core | Shared Multilayer Perceptron | Same Shared Multilayer Perceptron |
| Output Processing | Attention map × (max + avg feature) | Attention map only |
| Residual Information Fusion (Later) | With refined global features | With original global features |
| Computational Cost | Higher (due to residual and additional element-wise operations) | Lower (no fusion step, lightweight on GPU) |
| Deployment Stage | Local-level features refinement | Global-level features refinement |
| Used in Ensemble Fusion | Yes | No |
| Used in Ensemble Fusion++ | Yes | Yes |
| Category | Dataset | Cameras | Training Set (ID/Image) | Test Set (ID/Image) | |
|---|---|---|---|---|---|
| Gallery | Query | ||||
| Person ReID | Market-1501 | 6 | 751/12,936 | 750/19,732 | 750/3368 |
| CUHK03 | 2 | 767/7365 | 700/5332 | 700/1400 | |
| MSMT17 | 15 | 1401/32,621 | 3060/82,161 | 3060/11,659 | |
| Vehicle ReID | VeRi-776 | 20 | 576/37,778 | 200/11,579 | 200/1678 |
| VehicleID | - | 13,134/110,178 | Test800: 800/800 | Test800: 800/6532 | |
| Test1600: 1600/1600 | Test1600: 1600/11,395 | ||||
| Test2400: 2400/2400 | Test2400: 2400/17,638 | ||||
| VERI-Wild | 174 | 30,671/277,794 | Test3000: 3000/38,816 | Test3000: 3000/3000 | |
| Test5000: 5000/64,389 | Test5000: 5000/5000 | ||||
| Test10000: 10,000/128,517 | Test10000: 10,000/10,000 | ||||
| Market ➝ CUHK | CUHK ➝ Market | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | Reference | mAP | R-1 | R-5 | R-10 | mAP | R-1 | R-5 | R-10 |
| SNR a [96] | CVPR 2020 | 17.5 | 17.1 | - | - | 52.4 | 77.8 | - | - |
| UDAR [14] | PR 2020 | 20.9 | 20.3 | - | - | 56.6 | 77.1 | - | - |
| QAConv50 a [97] | ECCV 2020 | 32.9 | 33.3 | - | - | 66.5 | 85.0 | - | - |
| M3L a [98] | CVPR 2021 | 35.7 | 36.5 | - | - | 62.4 | 82.7 | - | - |
| MetaBIN a [99] | CVPR 2021 | 43.0 | 43.1 | - | - | 67.2 | 84.5 | - | - |
| DFH-Baseline [100] | CVPR 2022 | 10.2 | 11.2 | - | - | 13.2 | 31.1 | - | - |
| DFH a [100] | CVPR 2022 | 27.2 | 30.5 | - | - | 31.3 | 56.5 | - | - |
| META a [101] | ECCV 2022 | 47.1 | 46.2 | - | - | 76.5 | 90.5 | - | - |
| ACL a [102] | ECCV 2022 | 49.4 | 50.1 | - | - | 76.8 | 90.6 | - | - |
| RCFA [103] | Electronics 2023 | 17.7 | 18.5 | 33.6 | 43.4 | 34.5 | 63.3 | 78.8 | 83.9 |
| CRS [104] | JSJTU 2023 | - | - | - | - | 65.3 | 82.5 | 93.0 | 95.9 |
| MTI [105] | JVCIR 2024 | 16.3 | 16.2 | - | - | - | - | - | - |
| PAOA+ a [106] | WACV 2024 | 50.3 | 50.9 | - | - | 77.9 | 91.4 | - | - |
| Baseline (CORE-ReID) [11] | Software 2024 | 62.9 | 61.0 | 79.6 | 87.2 | 83.6 | 93.6 | 97.3 | 98.7 |
| Direct Transfer | Ours | 23.9 | 24.6 | 40.3 | 48.9 | 35.5 | 63.3 | 77.8 | 83.2 |
| CORE-ReID V2 Tiny (ResNet18) | Ours | 33.0 | 31.9 | 48.9 | 59.1 | 60.3 | 83.4 | 91.8 | 94.7 |
| CORE-ReID V2 | Ours | 66.4 | 66.9 | 83.4 | 88.9 | 84.5 | 93.9 | 97.6 | 98.7 |
| Market ➝ MSMT | CUHK ➝ MSMT | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | Reference | mAP | R-1 | R-5 | R-10 | mAP | R-1 | R-5 | R-10 |
| NRMT [107] | ECCV 2020 | 19.8 | 43.7 | 56.5 | 62.2 | - | - | - | - |
| DG-Net++ [87] | ECCV 2020 | 22.1 | 48.4 | - | - | - | - | - | - |
| MMT [15] | ICLR 2020 | 22.9 | 52.5 | - | - | 13.5 b | 30.9 b | 44.4 b | 51.1 b |
| UDAR [14] | PR 2020 | 12.0 | 30.5 | - | - | 11.3 | 29.6 | - | - |
| Dual-Refinement [108] | ArXiv 2020 | 25.1 | 53.3 | 66.1 | 71.5 | - | - | - | - |
| SNR a [96] | CVPR 2020 | - | - | - | - | 7.7 | 22.0 | - | - |
| QAConv50 a [97] | ECCV 2020 | - | - | - | - | 17.6 | 46.6 | - | - |
| M3L a [98] | CVPR 2021 | - | - | - | - | 17.4 | 38.6 | - | - |
| MetaBIN a [99] | CVPR 2021 | - | - | - | - | 18.8 | 41.2 | - | - |
| RDSBN [109] | CVPR 2021 | 30.9 | 61.2 | 73.1 | 77.4 | - | - | - | - |
| ClonedPerson [110] | CVPR 2022 | 14.6 | 41.0 | - | - | 13.4 | 42.3 | - | - |
| META a [101] | ECCV 2022 | - | - | - | - | 24.4 | 52.1 | - | - |
| ACL a [102] | ECCV 2022 | - | - | - | - | 21.7 | 47.3 | - | - |
| CLM-Net [111] | NCA 2022 | 29.0 | 56.6 | 69.0 | 74.3 | - | - | - | - |
| CRS [104] | JSJTU 2023 | 22.9 | 43.6 | 56.3 | 62.7 | 22.2 | 42.5 | 55.7 | 62.4 |
| HDNet [112] | IJMLC 2023 | 25.9 | 53.4 | 66.4 | 72.1 | - | - | - | - |
| DDNet [113] | AI 2023 | 28.5 | 59.3 | 72.1 | 76.8 | - | - | - | - |
| CaCL [114] | ICCV 2023 | 36.5 | 66.6 | 75.3 | 80.1 | - | - | - | - |
| PAOA+ a [106] | WACV 2024 | - | - | - | - | 26.0 | 52.8 | - | - |
| OUDA [115] | WACV 2024 | 20.2 | 46.1 | - | - | - | - | - | - |
| M-BDA [116] | VCIR 2024 | 26.7 | 51.4 | 64.3 | 68.7 | - | - | - | - |
| UMDA [117] | VCIR 2024 | 32.7 | 62.4 | 72.7 | 78.4 | - | - | - | - |
| Baseline (CORE-ReID) [11] | Software 2024 | 41.9 | 69.5 | 80.3 | 84.4 | 40.4 | 67.3 | 79.0 | 83.1 |
| Direct Transfer | Ours | 11.7 | 30.2 | 42.9 | 48.0 | 35.5 | 63.3 | 77.8 | 82.7 |
| CORE-ReID V2 Tiny (ResNet18) | Ours | 35.8 | 64.7 | 76.6 | 80.8 | 18.8 | 44.2 | 57.1 | 62.3 |
| CORE-ReID V2 | Ours | 44.1 | 71.3 | 82.4 | 86.0 | 40.7 | 68.7 | 79.7 | 83.4 |
| VehicleID ➝ VeRi-776 | |||||
|---|---|---|---|---|---|
| Method | Reference | mAP | R-1 | R-5 | R-10 |
| FACT [1] | ECCV 2016 | 18.75 | 52.21 | 72.88 | - |
| PUL [42] | ACM 2018 | 17.06 | 55.24 | 67.34 | - |
| SPGAN [66] | CVPR 2018 | 16.4 | 57.4 | 70.0 | 75.6 |
| VR-PROUD [118] | PR 2019 | 22.75 | 55.78 | 70.02 | - |
| ECN [119] | CVPR 2019 | 20.06 | 57.41 | 70.53 | - |
| MMT [15] | ICLR 2020 | 35.3 | 74.6 | 82.6 | - |
| SPCL [44] | NIPS 2020 | 38.9 | 80.4 | 86.8 | - |
| PAL [120] | IJCAI 2020 | 42.04 | 68.17 | 79.91 | - |
| UDAR [14] | PR 2020 | 35.80 | 76.90 | 85.80 | 89.00 |
| ML [121] | ICME 2021 | 36.90 | 77.80 | 85.50 | - |
| PLM [122] | Sci.China 2022 | 47.37 | 77.59 | 87.00 | - |
| VDAF [123] | MTA 2023 | 24.86 | 46.32 | 55.17 | - |
| CSP+FCD [124] | Elec 2023 | 45.60 | 74.30 | 83.70 | - |
| MGR-GCL [5] | ArXiv 2024 | 48.73 | 79.29 | 87.95 | - |
| MATNet+DMDU [125] | ArXiv 2024 | 49.25 | 79.13 | 88.97 | - |
| Baseline | Ours | 47.70 | 78.12 | 86.23 | 88.14 |
| Direct Transfer | Ours | 22.71 | 62.04 | 71.79 | 76.32 |
| CORE-ReID V2 Tiny (ResNet18) | Ours | 40.17 | 73.00 | 81.41 | 85.40 |
| CORE-ReID V2 | Ours | 49.50 | 80.15 | 89.05 | 90.29 |
| VehicleID ➝ VERI-Wild | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Test3000 | Test5000 | Test10000 | |||||||||||
| Method | Reference | mAP | R-1 | R-5 | R-10 | mAP | R-1 | R-5 | R-10 | mAP | R-1 | R-5 | R-10 |
| SPGAN [66] | CVPR 2018 | 24.1 | 59.1 | 76.2 | - | 21.6 | 55.0 | 74.5 | - | 17.5 | 47.4 | 66.1 | - |
| ECN [119] | CVPR 2019 | 34.7 | 73.4 | 88.8 | - | 30.6 | 68.6 | 84.6 | - | 24.7 | 61.0 | 78.2 | - |
| MMT [15] | ICLR 2020 | 27.7 | 55.6 | 77.4 | - | 23.6 | 47.7 | 71.5 | - | 18.0 | 40.2 | 65.0 | - |
| SPCL [44] | NIPS 2020 | 25.1 | 48.8 | 72.8 | - | 21.5 | 42.0 | 66.1 | - | 16.6 | 32.7 | 55.7 | - |
| UDAR [14] | PR 2020 | 30.0 | 68.4 | 85.3 | - | 26.2 | 62.5 | 81.8 | - | 20.8 | 53.7 | 73.9 | - |
| AE [126] | CCA 2020 | 29.9 | 67.0 | 88.5 | - | 26.2 | 61.8 | 81.5 | - | 20.9 | 53.1 | 73.7 | - |
| DLVL [18] | Elec 2024 | 31.4 | 59.9 | 80.7 | - | 27.3 | 51.9 | 74.9 | - | 21.7 | 41.8 | 65.8 | - |
| Baseline | Ours | 39.8 | 75.2 | 89.3 | 91.6 | 34.5 | 69.6 | 81.7 | 88.7 | 26.8 | 61.1 | 79.6 | 81.3 |
| Direct Transfer | Ours | 20.9 | 48.2 | 64.3 | 70.7 | 18.9 | 44.3 | 60.9 | 66.9 | 15.6 | 38.0 | 53.3 | 59.8 |
| CORE-ReID V2 Tiny (ResNet18) | Ours | 28.6 | 56.5 | 74.9 | 80.2 | 23.1 | 52.1 | 70.6 | 78.4 | 19.9 | 48.1 | 66.3 | 74.6 |
| CORE-ReID V2 | Ours | 40.2 | 76.6 | 90.2 | 92.1 | 34.9 | 70.2 | 86.2 | 89.3 | 27.8 | 62.1 | 79.8 | 82.3 |
| VeRi-776 ➝ VehicleID Test800 | VeRi-776 ➝ VehicleID Test1600 | VeRi-776 ➝ VehicleID Test2400 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | Reference | mAP | R-1 | R-5 | R-10 | mAP | R-1 | R-5 | R-10 | mAP | R-1 | R-5 | R-10 |
| FACT [1] | ECCV 2016 | - | 49.53 | 67.96 | - | - | 44.63 | 64.19 | - | - | 39.91 | 60.49 | - |
| Mixed Diff+CCL [84] | CVPR 2016 | - | 49.00 | 73.50 | - | - | 42.80 | 66.80 | - | - | 38.20 | 61.60 | - |
| PUL [42] | ACM 2018 | 43.90 | 40.03 | 56.03 | - | 37.68 | 33.83 | 49.72 | - | 34.71 | 30.90 | 47.18 | - |
| PAL [120] | IJCAI 2020 | 53.50 | 50.25 | 64.91 | - | 48.05 | 44.25 | 60.95 | - | 45.14 | 41.08 | 59.12 | - |
| UDAR [14] | PR 2020 | 59.60 | 54.00 | 66.10 | 72.01 | 55.30 | 48.10 | 64.10 | 70.20 | 52.90 | 45.20 | 62.60 | 69.14 |
| ML [121] | ICME 2021 | 61.60 | 54.80 | 69.20 | - | 48.70 | 40.30 | 57.70 | - | 45.00 | 36.50 | 54.10 | - |
| PLM [122] | Sci.China 2022 | 54.85 | 51.23 | 67.11 | - | 49.41 | 45.40 | 63.37 | - | 46.00 | 41.73 | 60.94 | - |
| CSP+FCD [124] | Elec 2023 | 51.90 | 54.40 | 67.40 | - | 46.50 | 52.70 | 65.60 | - | 42.70 | 45.90 | 60.30 | - |
| VDAF [123] | MTA 2023 | - | - | - | - | - | 47.03 | 64.86 | - | - | 43.69 | 61.76 | - |
| MGR-GCL [5] | ArXiv 2024 | 55.24 | 52.38 | 75.29 | - | 50.56 | 45.88 | 67.65 | - | 47.59 | 42.83 | 64.36 | - |
| DMDU [125] | TITS 2024 | 61.83 | 55.61 | 68.25 | - | 56.73 | 53.28 | 63.56 | - | 53.97 | 47.59 | 61.85 | - |
| Baseline | Ours | 64.28 | 56.16 | 74.55 | 81.15 | 60.02 | 51.84 | 71.62 | 78.08 | 56.15 | 47.85 | 66.89 | 75.27 |
| Direct Transfer | Ours | 61.28 | 53.50 | 69.81 | 76.13 | 57.23 | 48.57 | 67.05 | 73.77 | 52.31 | 44.04 | 61.08 | 68.60 |
| CORE-ReID V2 Tiny (ResNet18) | Ours | 63.87 | 55.18 | 73.43 | 81.11 | 59.69 | 50.05 | 70.88 | 77.75 | 55.14 | 45.99 | 65.07 | 73.54 |
| CORE-ReID V2 | Ours | 67.04 | 58.32 | 76.51 | 84.32 | 63.02 | 53.49 | 74.36 | 81.85 | 57.99 | 48.62 | 68.30 | 77.11 |
| Person ReID | Market → CUHK | CUHK → Market | ||||||
|---|---|---|---|---|---|---|---|---|
| Number of Clusters | mAP | R-1 | R-5 | R-10 | mAP | R-1 | R-5 | R-10 |
| 44.4 | 43.2 | 65.3 | 76.4 | 69.4 | 86.8 | 94.9 | 96.7 | |
| 57.8 | 59.1 | 76.1 | 83.6 | 81.7 | 92.7 | 97.1 | 98.1 | |
| 66.4 | 66.9 | 83.4 | 88.9 | 84.5 | 93.9 | 97.6 | 98.7 | |
| Person ReID | Market → MSMT | CUHK → MSMT | ||||||
| Number of Clusters | mAP | R-1 | R-5 | R-10 | mAP | R-1 | R-5 | R-10 |
| 44.1 | 71.3 | 82.4 | 86.0 | 40.68 | 68.66 | 79.74 | 83.36 | |
| 41.1 | 68.9 | 80.5 | 84.2 | 38.91 | 67.26 | 78.97 | 82.80 | |
| 38.9 | 67.2 | 79.0 | 83.2 | 35.8 | 64.7 | 76.6 | 80.8 | |
| Vechile ReID | VehicleID → VeRi-776 | VeRi-776 → VehicleID Small | ||||||
| Number of Clusters | mAP | R-1 | R-5 | R-10 | mAP | R-1 | R-5 | R-10 |
| 49.50 | 80.15 | 89.05 | 90.29 | 66.60 | 58.20 | 75.90 | 83.70 | |
| 49.63 | 79.14 | 86.65 | 89.69 | 67.04 | 58.32 | 76.51 | 84.32 | |
| 48.61 | 79.02 | 86.29 | 89.15 | 66.70 | 57.50 | 77.60 | 84.20 | |
| Person ReID | ||||||||
|---|---|---|---|---|---|---|---|---|
| Method | mAP | R-1 | R-5 | R-10 | mAP | R-1 | R-5 | R-10 |
| Ours (Random) | 63.6 | 63.8 | 80.9 | 87.8 | 83.8 | 93.6 | 97.4 | 98.6 |
| Ours (Greedy Initialization) | 66.4 | 66.9 | 83.4 | 88.9 | 84.5 | 93.9 | 97.6 | 98.7 |
| Person ReID | ||||||||
| Method | mAP | R-1 | R-5 | R-10 | mAP | R-1 | R-5 | R-10 |
| Ours (Random) | 42.2 | 69.7 | 80.2 | 84.9 | 40.5 | 67.6 | 78.8 | 83.1 |
| Ours (Greedy Initialization) | 44.1 | 71.3 | 82.4 | 86.0 | 40.7 | 68.7 | 79.7 | 83.4 |
| Vehicle ReID | ||||||||
| Method | mAP | R-1 | R-5 | R-10 | mAP | R-1 | R-5 | R-10 |
| Ours (Random) | 47.72 | 78.23 | 86.56 | 88.26 | 65.79 | 56.14 | 75.95 | 83.56 |
| Ours (Greedy Initialization) | 49.50 | 80.15 | 89.05 | 90.29 | 67.04 | 58.32 | 76.51 | 84.32 |
| Person ReID | ||||||||
|---|---|---|---|---|---|---|---|---|
| Method | mAP | R-1 | R-5 | R-10 | mAP | R-1 | R-5 | R-10 |
| Ours (without SECAB) | 65.0 | 65.1 | 82.6 | 87.6 | 83.9 | 93.7 | 97.4 | 98.6 |
| Ours (with SECAB) | 66.4 | 66.9 | 83.4 | 88.9 | 84.5 | 93.9 | 97.6 | 98.7 |
| Person ReID | ||||||||
| Method | mAP | R-1 | R-5 | R-10 | mAP | R-1 | R-5 | R-10 |
| Ours (without SECAB) | 43.2 | 70.3 | 81.8 | 85.2 | 40.5 | 68.0 | 79.2 | 83.1 |
| Ours (with SECAB) | 44.1 | 71.3 | 82.4 | 86.0 | 40.7 | 68.7 | 79.7 | 83.4 |
| Vehicle ReID | ||||||||
| Method | mAP | R-1 | R-5 | R-10 | mAP | R-1 | R-5 | R-10 |
| Ours (without SECAB) | 48.03 | 78.92 | 87.61 | 88.93 | 65.14 | 57.02 | 75.56 | 82.97 |
| Ours (with SECAB) | 49.50 | 80.15 | 89.05 | 90.29 | 67.04 | 58.32 | 76.51 | 84.32 |
| Person ReID | ||||||||
|---|---|---|---|---|---|---|---|---|
| Method | mAP | R-1 | R-5 | R-10 | mAP | R-1 | R-5 | R-10 |
| Ours (Top-local: ECAB, Bottom-Local: ECAB, Global: ECAB) | 64.3 | 64.9 | 81.6 | 84.3 | 83.2 | 92.6 | 97.3 | 98.6 |
| Ours (Top-local: SECAB, Bottom-Local: SECAB, Global: SECAB) | 62.3 | 63.2 | 80.2 | 82.8 | 81.0 | 89.6 | 94.5 | 95.1 |
| Ours (Top-local: ECAB, Bottom-Local: ECAB, Global: SECAB) | 66.4 | 66.9 | 83.4 | 88.9 | 84.5 | 93.9 | 97.6 | 98.7 |
| Person ReID | ||||||||
|---|---|---|---|---|---|---|---|---|
| Method | mAP | R-1 | R-5 | R-10 | mAP | R-1 | R-5 | R-10 |
| Ours (ResNet18) | 33.0 | 31.9 | 48.9 | 59.1 | 60.3 | 83.4 | 91.8 | 94.7 |
| Ours (ResNet34) | 38.8 | 38.4 | 55.9 | 64.7 | 64.4 | 85.9 | 93.7 | 95.4 |
| Ours (ResNet50) | 64.9 | 64.1 | 81.3 | 87.9 | 83.7 | 93.8 | 97.6 | 98.5 |
| Ours (ResNet101) | 66.4 | 66.9 | 83.4 | 88.9 | 84.5 | 93.9 | 97.6 | 98.7 |
| Ours (ResNet152) | 65.2 | 65.1 | 82.1 | 87.9 | 83.5 | 93.2 | 97.5 | 98.1 |
| Vehicle ReID | VehicleID → VeRi-776 | VeRi-776 → VehicleID Small | ||||||
| Method | mAP | R-1 | R-5 | R-10 | mAP | R-1 | R-5 | R-10 |
| Ours (ResNet18) | 40.17 | 73.00 | 81.41 | 85.40 | 63.87 | 55.18 | 73.43 | 81.11 |
| Ours (ResNet34) | 46.62 | 75.92 | 83.73 | 87.49 | 63.80 | 54.80 | 73.60 | 80.30 |
| Ours (ResNet50) | 48.11 | 78.84 | 86.71 | 89.81 | 67.02 | 58.30 | 77.00 | 83.90 |
| Ours (ResNet101) | 49.50 | 80.15 | 89.05 | 90.29 | 67.04 | 58.32 | 76.51 | 84.32 |
| Ours (ResNet152) | 48.07 | 78.26 | 86.73 | 89.96 | 66.97 | 58.23 | 76.49 | 83.86 |
| CORE-ReID V2 with Backbone | Parameters (Millions) | GFLOPs (per Image) | Image Size | FPS (Using 1 Quadro RTX 8000 GPU) |
|---|---|---|---|---|
| ResNet-18 | 12.97 M | 1.18 | 128 × 256 | 254 |
| ResNet-34 | 23.08 M | 2.35 | 128 × 256 | 185 |
| ResNet-50 | 46.62 M | 5.10 | 128 × 256 | 144 |
| ResNet-101 | 65.61 M | 7.58 | 128 × 256 | 87 |
| ResNet-152 | 81.26 M | 10.61 | 128 × 256 | 61 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, T.Q.; Prima, O.D.A.; Irfan, S.A.; Purnomo, H.D.; Tanone, R. CORE-ReID V2: Advancing the Domain Adaptation for Object Re-Identification with Optimized Training and Ensemble Fusion. AI Sens. 2025, 1, 4. https://doi.org/10.3390/aisens1010004
Nguyen TQ, Prima ODA, Irfan SA, Purnomo HD, Tanone R. CORE-ReID V2: Advancing the Domain Adaptation for Object Re-Identification with Optimized Training and Ensemble Fusion. AI Sensors. 2025; 1(1):4. https://doi.org/10.3390/aisens1010004
Chicago/Turabian StyleNguyen, Trinh Quoc, Oky Dicky Ardiansyah Prima, Syahid Al Irfan, Hindriyanto Dwi Purnomo, and Radius Tanone. 2025. "CORE-ReID V2: Advancing the Domain Adaptation for Object Re-Identification with Optimized Training and Ensemble Fusion" AI Sensors 1, no. 1: 4. https://doi.org/10.3390/aisens1010004
APA StyleNguyen, T. Q., Prima, O. D. A., Irfan, S. A., Purnomo, H. D., & Tanone, R. (2025). CORE-ReID V2: Advancing the Domain Adaptation for Object Re-Identification with Optimized Training and Ensemble Fusion. AI Sensors, 1(1), 4. https://doi.org/10.3390/aisens1010004