
Deep Learning-Based Superpixel Texture Analysis for Crack Detection in Multi-Modal Infrastructure Images




Abstract
:1. Introduction
- We aim to assess the performance of the proposed method in accurately detecting cracks under conditions of limited data availability. Through this investigation, we endeavor to contribute to the advancement of non-destructive testing methodologies for structural integrity assessment and defect identification.
- The proposed approach involves a multi-step process, beginning with the segmentation of images using a deep learning-based super-pixel method. Subsequently, we apply texture analysis techniques using the Mahotas Python library to identify cracks present in the images.
- Additionally, we aim to investigate the effectiveness of accurate segmentation on crack detection performance. By evaluating the influence of precise segmentation on the effectiveness of our detection method, we seek to understand the importance of segmentation quality in defect identification and localization.
- Furthermore, we explore the feasibility of utilizing thermal and visible image fusion as part of our detection strategy. This investigation aims to determine whether fusion images offer advantages over individual modalities in terms of crack-detection accuracy and reliability. By integrating thermal and visible images, we seek to enhance the robustness and versatility of our detection method, particularly in scenarios characterized by limited training data.
2. Literature Review
3. Materials and Methods
3.1. Deep Learning-Based Super-Pixel Segmentation Phase
3.1.1. Learning Super-Pixels on a Regular Grid
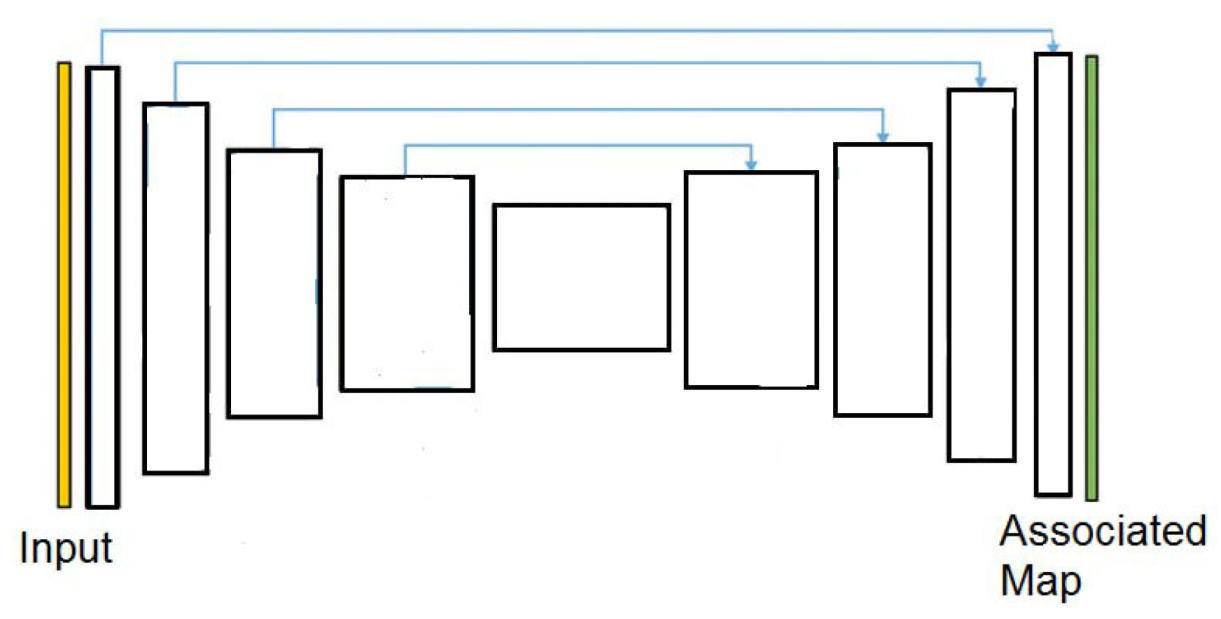
3.1.2. Deep Learning-Based Super-Pixel Architecture
3.2. Deep Learning-Based Super-Pixel Texture Analysis Phase
| Algorithm 1 Deep learning-based Super-pixel Texture Analysis for Crack Detection |
|
Mathematical Analysis
3.3. Mathematical Analysis for Mean Threshold
3.4. Mathematical Analysis for Variance Threshold
4. Results and Discussions
4.1. Dataset
4.2. Results of Image Segmentation Phase
4.2.1. Implementation Details
4.2.2. Results of Deep Learning-Based Super-Pixel Segmentation Phase
4.2.3. Comparative Analysis of Proposed Method with SLIC Method
4.3. Results of Crack Detection Phase
4.3.1. Implementation Details
4.3.2. Crack Detection Using Visible Images
4.3.3. Performance Metrics
4.3.4. Qualitative Analysis
4.4. Multi-Modal Images for Crack Detection
4.5. Effectiveness of Fusion Images
4.6. Comparative Analysis
4.7. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| NDT | non-destructive testing |
| CNN | convolutional neural network |
| SLIC | simple linear iterative clustering |
| ReLU | leaky rectified linear units |
| SHM | structural health monitoring |
References
- Sfarra, S.; Cicone, A.; Yousefi, B.; Ibarra-Castanedo, C.; Perilli, S.; Maldague, X. Improving the detection of thermal bridges in buildings via on-site infrared thermography: The potentialities of innovative mathematical tools. Energy Build. 2019, 182, 159–171. [Google Scholar] [CrossRef]
- Maldague, X. Applications of infrared thermography in nondestructive evaluation. Trends Opt. Nondestruct. Test. 2000, 591–609. [Google Scholar] [CrossRef]
- Ghiass, R.S.; Arandjelović, O.; Bendada, H.; Maldague, X. A unified framework for thermal face recognition. In Neural Information Processing, Proceedings of the 21st International Conference, ICONIP 2014, Kuching, Malaysia, 3–6 November 2014, Proceedings, Part II; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 335–343. [Google Scholar]
- Qu, Z.; Ju, F.R.; Guo, Y.; Bai, L.; Chen, K. Concrete surface crack detection with the improved pre-extraction and the second percolation processing methods. PloS ONE 2018, 13, e0201109. [Google Scholar] [CrossRef] [PubMed]
- Lins, R.G.; Sidney, N.G. Automatic crack detection and measurement based on image analysis. IEEE Trans. Instrum. Meas. 2016, 65, 583–590. [Google Scholar] [CrossRef]
- Shan, B.; Zheng, S.; Ou, J. A stereovision-based crack width detection approach for concrete surface assessment. KSCE J. Civ. Eng. 2016, 20, 803–812. [Google Scholar] [CrossRef]
- Salman, M.; Mathavan, S.; Kamal, K.; Rahman, M. Pavement crack detection using the Gabor filter. In Proceedings of the 16th International IEEE Conference on Intelligent Transportation Systems (ITSC), The Hague, The Netherlands, 6–9 October 2013; pp. 2039–2044. [Google Scholar]
- Broberg, P. Surface crack detection in welds using thermography. NDT E Int. 2013, 57, 69–73. [Google Scholar] [CrossRef]
- Liu, Y.; Yao, J.; Lu, X.; Xie, R.; Li, L. DeepCrack: A deep hierarchical feature learning architecture for crack segmentation. Neurocomputing 2019, 338, 139–153. [Google Scholar] [CrossRef]
- Escalona, U.; Arce, F.; Zamora, E.; Sossa, A. Fully convolutional networks for automatic pavement crack segmentation. Comput. Sist. 2019, 23, 451–460. [Google Scholar] [CrossRef]
- Jenkins, M.D.; Carr, T.A.; Iglesias, M.I.; Buggy, T.; Morison, G. A Deep Convolutional Neural Network for Semantic Pixel-Wise Segmentation of Road and Pavement Surface Cracks. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 2120–2124. [Google Scholar]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic Pixel-Level Crack Detection and Measurement Using Fully Convolutional Network. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Fan, Z.; Li, C.; Chen, Y.; Wei, J.; Loprencipe, G.; Chen, X.; Di Mascio, P. Automatic Crack Detection on Road Pavements Using Encoder-Decoder Architecture. Materials 2020, 13, 2960. [Google Scholar] [CrossRef] [PubMed]
- König, J.; Jenkins, M.D.; Barrie, P.; Mannion, M.; Morison, G. A Convolutional Neural Network for Pavement Surface Crack Segmentation Using Residual Connections and Attention Gating. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019. [Google Scholar]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar]
- Xue, H.; Chen, X.; Zhang, R.; Wu, P.; Li, X.; Liu, Y. Deep learning-based maritime environment segmentation for unmanned surface vehicles using superpixel algorithms. J. Mar. Sci. Eng. 2021, 9, 1329. [Google Scholar] [CrossRef]
- Yuan, X.; Shi, J.; Gu, L. A review of deep learning methods for semantic segmentation of remote sensing imagery. Expert Syst. Appl. 2021, 169, 114417. [Google Scholar] [CrossRef]
- Tuceryan, M.; Jain, A. Texture analysis. In Handbook of Pattern Recognition and Computer Vision; World Scientific Publishing: Singapore, 1993; pp. 235–276. [Google Scholar]
- Chen, Y.; Ding, Y.; Zhao, F.; Zhang, E.; Wu, Z.; Shao, L. Surface defect detection methods for industrial products: A review. Appl. Sci. 2021, 11, 7657. [Google Scholar] [CrossRef]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Susstrun, S. Slic superpixels. Technical Report 149300 EPFL, June 2010. [Google Scholar]
- Yang, F.; Sun, Q.; Jin, H.; Zhou, Z. Superpixel segmentation with fully convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 13964–13973. [Google Scholar]
- Yu, Y.; Wang, C.; Fu, Q.; Kou, R.; Huang, F.; Yang, B.; Yang, T.; Gao, M. Techniques and challenges of image segmentation: A review. Electronics 2023, 12, 1199. [Google Scholar] [CrossRef]
- Neupane, B.; Horanont, T.; Aryal, J. Deep learning-based semantic segmentation of urban features in satellite images: A review and meta-analysis. Remote Sens. 2021, 13, 808. [Google Scholar] [CrossRef]
- Khooriphan, W.; Niwitpong, S.A.; Niwitpong, S. Confidence Intervals for the Ratio of Variances of Delta-Gamma Distributions with Applications. Axioms 2022, 11, 689. [Google Scholar] [CrossRef]
- Mehrtash, A.; Wells, W.M.; Tempany, C.M.; Abolmaesumi, P.; Kapur, T. Confidence calibration and predictive uncertainty estimation for deep medical image segmentation. IEEE Trans. Med. Imaging 2020, 39, 3868–3878. [Google Scholar] [CrossRef] [PubMed]
- Shahsavarani, S.; Lopez, F.; Ibarra-Castanedo, C.; Maldague, X. Semantic Segmentation of Defects in Infrastructures through Multi-modal Images. In Thermosense: Thermal Infrared Applications XLV; SPIE: Bellingham, WA, USA, 2024. [Google Scholar]
- Liu, K.; Han, X.; Chen, B.M. Deep learning based automatic crack detection and segmentation for unmanned aerial vehicle inspections. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; IEEE: New York, NY, USA, 2019. [Google Scholar]
- Liu, F.; Liu, J.; Wang, L. Asphalt pavement crack detection based on convolutional neural network and infrared thermography. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22145–22155. [Google Scholar] [CrossRef]
- Liu, F.; Liu, J.; Wang, L. Deep learning and infrared thermography for asphalt pavement crack severity classification. Autom. Constr. 2022, 140, 104383. [Google Scholar] [CrossRef]
- Shahsavarani, S.; Lopez, F.; Maldague, X. Multi-modal image processing pipeline for NDE of structures and industrial assets. In Thermosense: Thermal Infrared Applications XLV; SPIE: Bellingham, WA, USA, 2023; Volume 12536, pp. 255–264. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample | Method | Intersection of Union (IOU) | Precision | Recall |
|---|---|---|---|---|
| Sample 1 | Proposed Method | 93.72 | 93.81 | 99.90 |
| SLIC10 | 92.13 | 92.20 | 99.91 | |
| SLIC15 | 92.98 | 92.44 | 99.92 | |
| SLIC20 | 92.98 | 93.05 | 99.92 | |
| Sample 2 | Proposed Method | 94.02 | 94.08 | 99.93 |
| SLIC10 | 93.47 | 93.58 | 99.88 | |
| SLIC15 | 92.44 | 92.48 | 99.95 | |
| SLIC20 | 92.73 | 92.74 | 96.22 | |
| Sample 3 | Proposed Method | 94.02 | 94.08 | 99.93 |
| SLIC10 | 93.47 | 93.58 | 99.83 | |
| SLIC15 | 93.28 | 93.32 | 99.95 | |
| SLIC20 | 93.88 | 93.93 | 99.95 | |
| Sample 4 | Proposed Method | 94.08 | 94.08 | 99.93 |
| SLIC10 | 92.16 | 92.21 | 99.93 | |
| SLIC15 | 92.34 | 92.37 | 99.95 | |
| SLIC20 | 93.40 | 93.44 | 99.94 | |
| Sample 5 | Proposed Method | 92.79 | 92.83 | 99.96 |
| SLIC10 | 90.81 | 90.87 | 99.92 | |
| SLIC15 | 90.42 | 90.49 | 99.92 | |
| SLIC20 | 91.80 | 91.85 | 99.94 |
| Sample | Image Spectrum | Intersection of Union (IOU) | Precision | Recall |
|---|---|---|---|---|
| Sample 2 | Visible | 97.15 | 99.12 | 79.99 |
| Fusion | 99.60 | 99.99 | 99.60 | |
| Sample 3 | Visible | 99.67 | 99.82 | 99.84 |
| Fusion | 98.93 | 99.56 | 99.36 |
| Sample | Image Spectrum | Intersection of Union (IOU) | Precision | Recall |
|---|---|---|---|---|
| Sample 1 | Visible | 73.56 | 98.87 | 98.66 |
| Fusion | 95.51 | 99.99 | 95.55 | |
| Sample 2 | Visible | 76.15 | 99.12 | 79.99 |
| Fusion | 99.60 | 99.99 | 99.60 | |
| Sample 3 | Visible | 75.67 | 99.82 | 76.84 |
| Fusion | 98.93 | 99.56 | 99.36 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shahsavarani, S.; Ibarra-Castanedo, C.; Lopez, F.; Maldague, X.P.V. Deep Learning-Based Superpixel Texture Analysis for Crack Detection in Multi-Modal Infrastructure Images. NDT 2024, 2, 128-142. https://doi.org/10.3390/ndt2020008
Shahsavarani S, Ibarra-Castanedo C, Lopez F, Maldague XPV. Deep Learning-Based Superpixel Texture Analysis for Crack Detection in Multi-Modal Infrastructure Images. NDT. 2024; 2(2):128-142. https://doi.org/10.3390/ndt2020008
Chicago/Turabian StyleShahsavarani, Sara, Clemente Ibarra-Castanedo, Fernando Lopez, and Xavier P. V. Maldague. 2024. "Deep Learning-Based Superpixel Texture Analysis for Crack Detection in Multi-Modal Infrastructure Images" NDT 2, no. 2: 128-142. https://doi.org/10.3390/ndt2020008
APA StyleShahsavarani, S., Ibarra-Castanedo, C., Lopez, F., & Maldague, X. P. V. (2024). Deep Learning-Based Superpixel Texture Analysis for Crack Detection in Multi-Modal Infrastructure Images. NDT, 2(2), 128-142. https://doi.org/10.3390/ndt2020008