
Fragment Library of Colombian Natural Products: Generation and Comparative Chemoinformatic Analysis


 , ,
, ,  and
and 
Abstract
1. Introduction
2. Results and Discussion
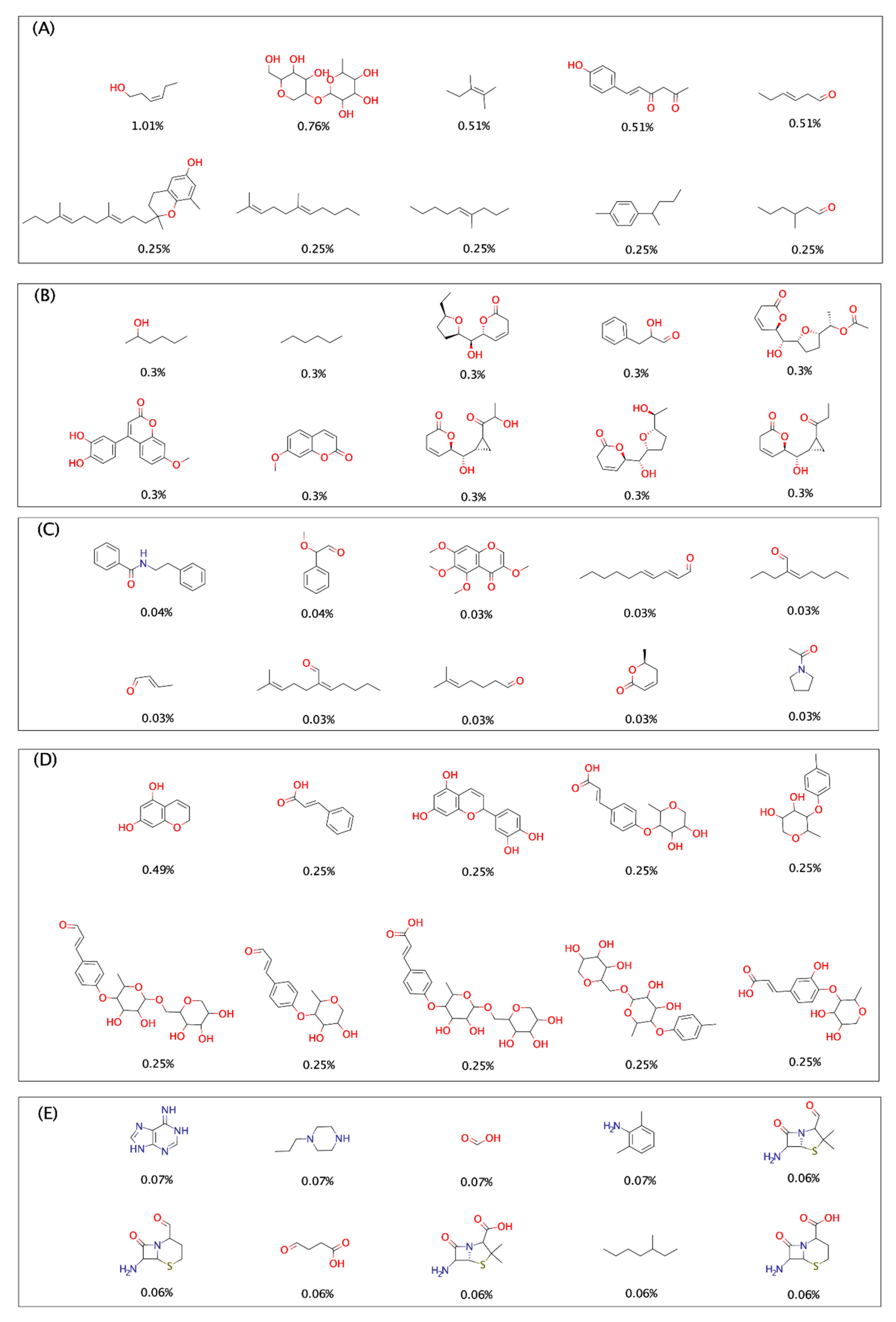
2.1. Unique and Overlapping Compounds and Fragments
2.2. Fragment Analysis
2.3. Structural Content, Composition, and Complexity of the Compound and Fragment Libraries
Structural Complexity
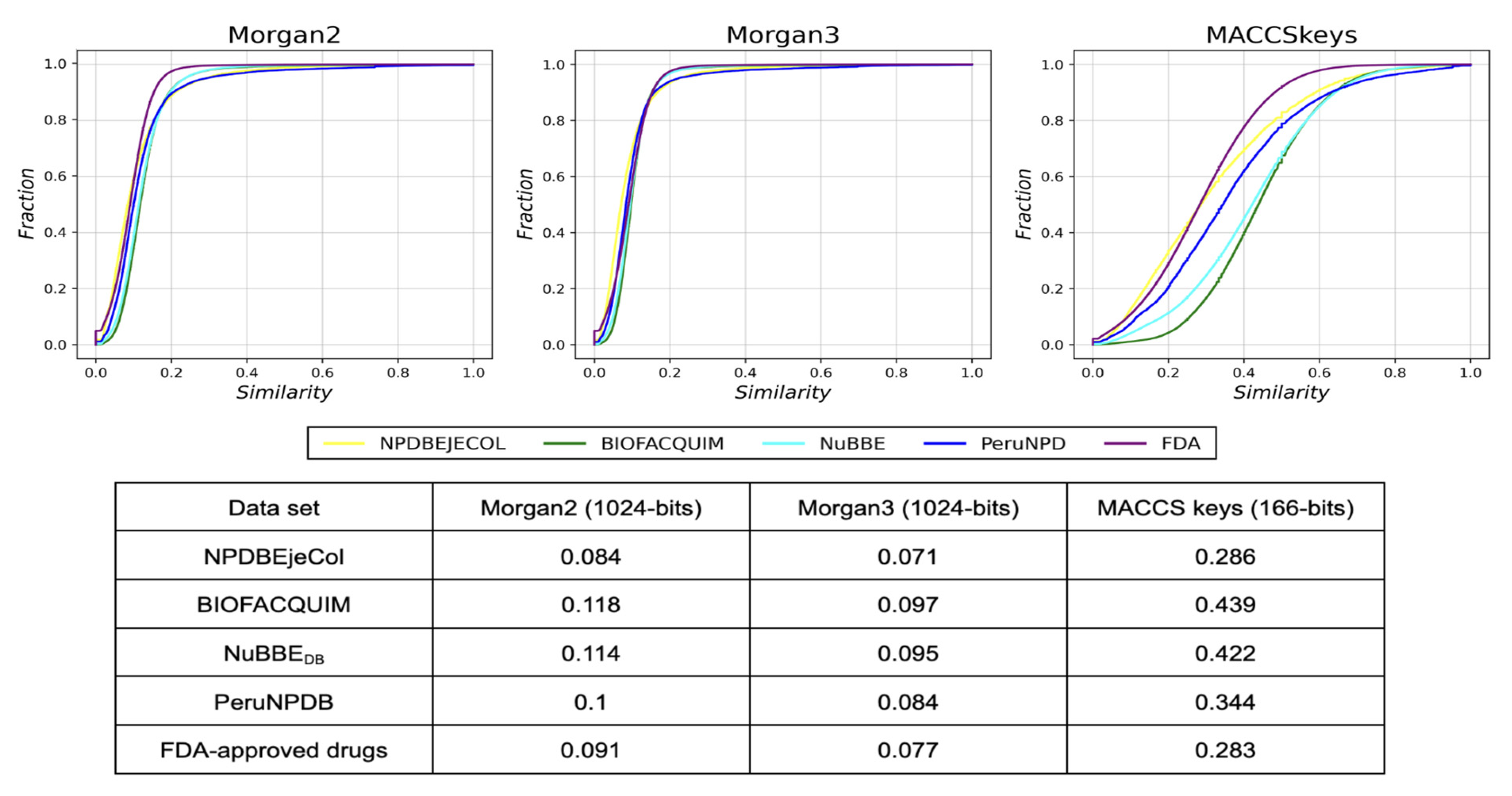
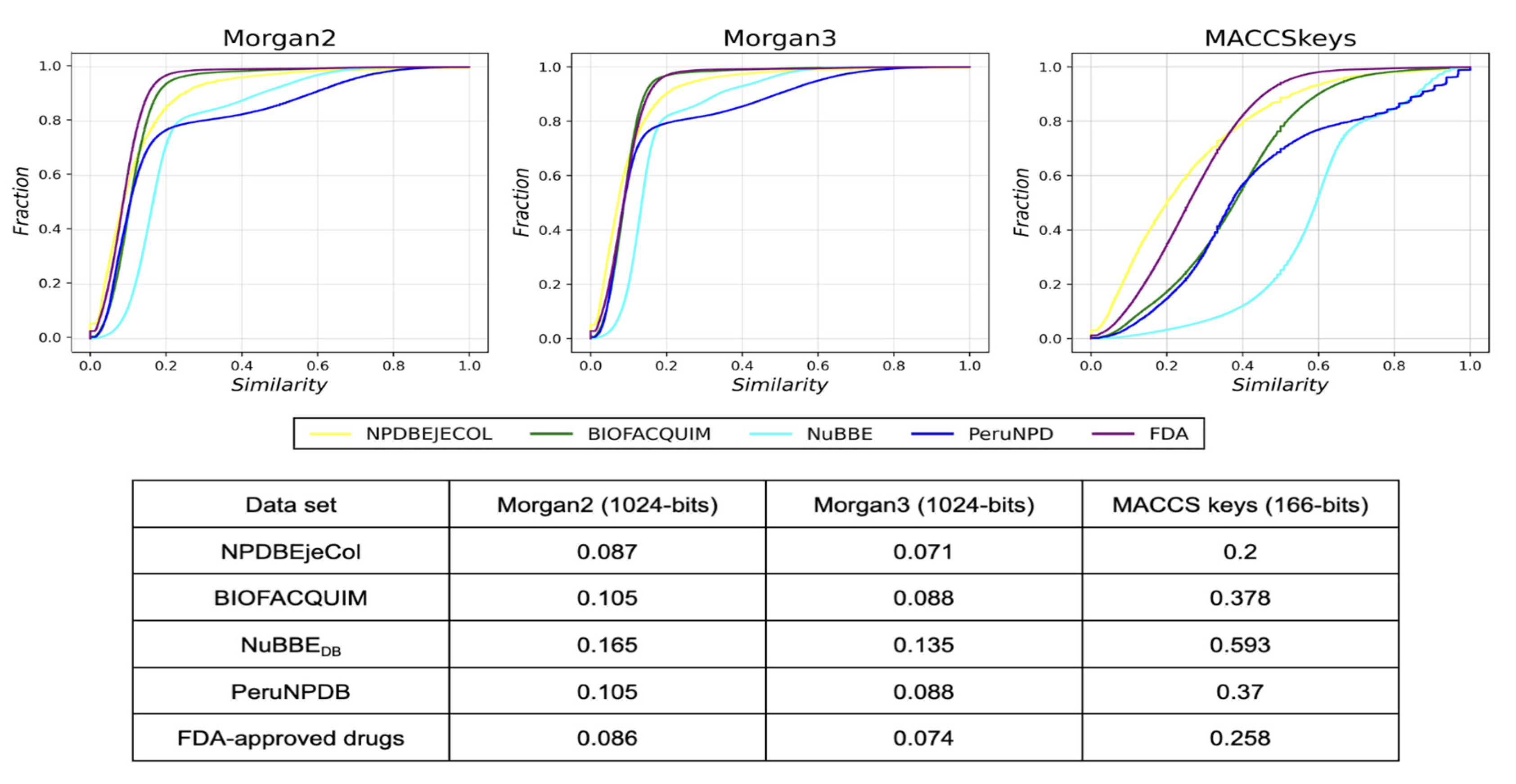
2.4. Structural Diversity
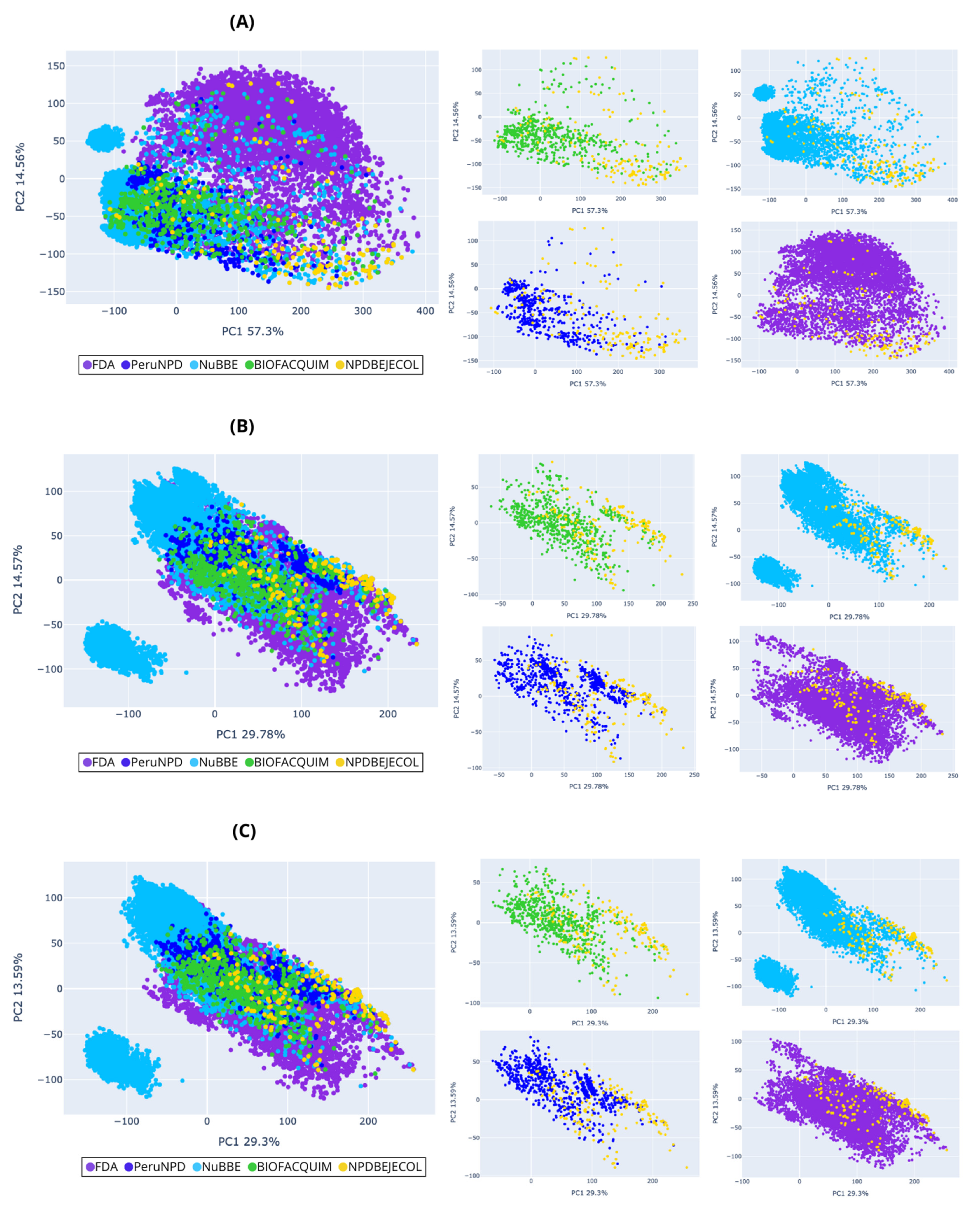
2.5. Visual Representation of the Chemical Space and Chemical Multiverse
3. Materials and Methods
3.1. Data Set Standardization
3.2. Fragment Analysis
3.3. Structural Diversity and Complexity
3.4. Chemical Space and Chemical Multiverse
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Newman, D.J.; Cragg, G.M. Natural Products as Sources of New Drugs over the Nearly Four Decades from 01/1981 to 09/2019. J. Nat. Prod. 2020, 83, 770–803. [Google Scholar] [CrossRef] [PubMed]
- Atanasov, A.G.; Zotchev, S.B.; Dirsch, V.M.; International Natural Product Sciences Taskforce; Supuran, C.T. Natural products in drug discovery: Advances and opportunities. Nat. Rev. Drug Discov. 2021, 20, 200–216. [Google Scholar] [CrossRef] [PubMed]
- Grigalunas, M.; Brakmann, S.; Waldmann, H.J. Chemical Evolution of Natural Product Structure. Am. Chem. Soc. 2022, 144, 3314–3329. [Google Scholar] [CrossRef] [PubMed]
- Chávez-Hernández, A.L.; Sánchez-Cruz, N.; Medina-Franco, J.L. A Fragment Library of Natural Products and its Comparative Chemoinformatic Characterization. Mol. Inform. 2020, 39, e2000050. [Google Scholar] [CrossRef] [PubMed]
- Chávez-Hernández, A.L.; Sánchez-Cruz, N.; Medina-Franco, J.L. Fragment Library of Natural Products and Compound Databases for Drug Discovery. Biomolecules 2020, 10, 1518. [Google Scholar] [CrossRef]
- Chen, Y.; Kirchmair, J. Cheminformatics in Natural Product-based Drug Discovery. Mol. Inform. 2020, 39, e2000171. [Google Scholar] [CrossRef]
- Sorokina, M.; Merseburger, P.; Rajan, K.; Yirik, M.A.; Steinbeck, C.J. COCONUT online: Collection of Open Natural Products database. J. Cheminformatics 2021, 13, 2. [Google Scholar] [CrossRef]
- Gallo, K.; Kemmler, E.; Goede, A.; Becker, F.; Dunkel, M.; Preissner, R.; Banerjee, P. SuperNatural 3.0—a database of natural products and natural product-based derivatives. Nucleic Acids Res. 2023, 51, D654–D659. [Google Scholar] [CrossRef]
- Gu, J.; Gui, Y.; Chen, L.; Yuan, G.; Lu, H.-Z.; Xu, X. Use of Natural Products as Chemical Library for Drug Discovery and Network Pharmacology. PLoS ONE 2013, 8, e62839. [Google Scholar] [CrossRef]
- Karageorgis, G.; Foley, D.J.; Laraia, L.; Brakmann, S.; Waldmann, H. Pseudo Natural Products-Chemical Evolution of Natural Product Structure. Angew. Chem. Int. Ed Engl. 2021, 60, 15705–15723. [Google Scholar] [CrossRef]
- Catálogo de Plantas y Líquenes de Colombia. Available online: https://ipt.biodiversidad.co/sib/resource?r=catalogo_plantas_liquenes (accessed on 22 April 2024).
- Rodríguez-Pérez, J.R.; Valencia-Sanchez, H.A.; Mosquera-Martinez, O.M.; Gómez-García, A.; Medina-Franco, J.L.; Cortes-Hernandez, H.F. Fragment Library of Colombian Natural Products: Generation and Comparative Chemoinformatic Analysis. ChemRxiv 2024. [Google Scholar] [CrossRef]
- Pilón-Jiménez, B.A.; Saldívar-González, F.I.; Díaz-Eufracio, B.I.; Medina-Franco, J.L. BIOFACQUIM: A Mexican Compound Database of Natural Products. Biomolecules 2019, 9, 31. [Google Scholar] [CrossRef] [PubMed]
- Barazorda-Ccahuana, H.L.; Ranilla, L.G.; Candia-Puma, M.A.; Cárcamo-Rodriguez, E.G.; Centeno-Lopez, A.E.; Davila-Del-Carpio, G.; Medina-Franco, J.L.; Chávez-Fumagalli, M.A. PeruNPDB: The Peruvian Natural Products Database for in silico drug screening. Sci. Rep. 2023, 13, 7577. [Google Scholar] [CrossRef] [PubMed]
- Pilon, A.C.; Valli, M.; Dametto, A.C.; Pinto, M.E.F.; Freire, R.T.; Castro-Gamboa, I.; Andricopulo, A.D.; Bolzani, V.S. NuBBEDB: An updated database to uncover chemical and biological information from Brazilian biodiversity. Sci. Rep. 2017, 7, 7215. [Google Scholar] [CrossRef]
- Wishart, D.S.; Knox, C.; Guo, A.C.; Shrivastava, S.; Hassanali, M.; Stothard, P.; Chang, Z.; Woolsey, J. DrugBank: A comprehensive resource for in silico drug discovery and exploration. Nucleic Acids Res. 2006, 34, D668–D672. [Google Scholar] [CrossRef]
- Weininger, D.; Weininger, A.; Weininger, J.L. SMILES. 2. Algorithm for generation of unique SMILES notation. J. Chem. Inf. Comput. Sci. 1989, 29, 97–101. [Google Scholar] [CrossRef]
- RDKit. Available online: https://www.rdkit.org (accessed on 8 January 2022).
- MolVS. Available online: https://molvs.readthedocs.io/en/latest/ (accessed on 8 January 2022).
- Sánchez-Cruz, N.; Pilón-Jiménez, B.A.; Medina-Franco, J.L. Functional group and diversity analysis of BIOFACQUIM: A Mexican natural product database. F1000Research 2019, 8, 2071. [Google Scholar] [CrossRef]
- Lewell, X.Q.; Judd, D.B.; Watson, S.P.; Hann, M.M. RECAP—retrosynthetic combinatorial analysis procedure: A powerful new technique for identifying privileged molecular fragments with useful applications in combinatorial chemistry. J. Chem. Inf. Comput. Sci. 1998, 38, 511–522. [Google Scholar] [CrossRef]
- Jaccard, P. étude Comparative de la distribuition florale dans une portion des Alpes et des Jura. Bull. Soc. Vaud. Sci. Nat. 1901, 37, 547–579. [Google Scholar]
- Rogers, D.; Hahn, M.J. Extended-Connectivity Fingerprints. Chem. Inf. Model. 2010, 50, 742–754. [Google Scholar] [CrossRef]
- Durant, J.L.; Leland, B.A.; Henry, D.R.; Nourse, J.G. Reoptimization of MDL keys for use in drug discovery. J. Chem. Inf. Comput. Sci. 2002, 42, 1273–1280. [Google Scholar] [CrossRef] [PubMed]
- Virshup, A.M.; Contreras-García, J.; Wipf, P.; Yang, W.; Beratan, D.N. Stochastic Voyages into Uncharted Chemical Space Produce a Representative Library of All Possible Drug-Like Compounds. J. Am. Chem. Soc. 2013, 135, 7296–7303. [Google Scholar] [CrossRef] [PubMed]
- Medina-Franco, J.L.; Chávez-Hernández, A.L.; López-López, E.; Saldívar-González, F.I. Chemical multiverse: An expanded view of chemical space. Mol. Inform. 2022, 41, e2200116. [Google Scholar] [CrossRef] [PubMed]
- Van der Maaten, L.; Hinton, G.J. Visualizing High-Dimensional Data Using t-SNE. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Wei, W.; Cherukupalli, S.; Jing, L.; Liu, X.; Zhan, P. Fsp3: A new parameter for drug-likeness. Drug Discov. Today 2020, 25, 1839–1845. [Google Scholar] [CrossRef]
- Clemons, P.A.; Bodycombe, N.E.; Carrinski, H.A.; Wilson, J.A.; Shamji, A.F.; Wagner, B.K.; Koehler, A.N.; Schreiber, S.L. Small molecules of different origins have distinct distributions of structural complexity that correlate with protein-binding profiles. Proc. Natl. Acad. Sci. USA 2010, 107, 18787–18792. [Google Scholar] [CrossRef]
- Lovering, F. Escape from Flatland 2: Complexity and promiscuity. Med. Chem. Commun. 2013, 4, 515–519. [Google Scholar] [CrossRef]
- Oprea, T.I.; Bologa, C.J. Molecular Complexity: You Know It When You See It. Med. Chem. 2023, 66, 12710–12714. [Google Scholar] [CrossRef]
- Jirasek, M.; Sharma, A.; Bame, J.R.; Mehr, S.H.M.; Bell, N.; Marshall, S.M.; Mathis, C.; MacLeod, A.; Cooper, G.J.T.; Swart, M.; et al. Investigating and Quantifying Molecular Complexity Using Assembly Theory and Spectroscopy. ACS Cent. Sci. 2024; in press. [Google Scholar] [CrossRef]
- Lovering, F.; Bikker, J.; Humblet, C.J. Escape from flatland: Increasing saturation as an approach to improving clinical success. Med. Chem. 2009, 52, 6752–6756. [Google Scholar] [CrossRef]
- Lachance, H.; Wetzel, S.; Kumar, K.; Waldmann, H.J. Charting, navigating, and populating natural product chemical space for drug discovery. Med. Chem. 2012, 55, 5989–6001. [Google Scholar] [CrossRef] [PubMed]
- Brinkhaus, H.O.; Rajan, K.; Schaub, J.; Zielesny, A.; Steinbeck, C. Open data and algorithms for open science in AI-driven molecular informatics. Curr. Opin. Struct. Biol. 2023, 79, 102542. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | NPDBEjeCol | BIOFACQUIM | NuBBEDB | PeruNPDB | FDA-Approved Drugs |
|---|---|---|---|---|---|
| Carbon atoms | 13.96 | 21.74 | 20.60 | 20.19 | 18.53 |
| Oxygen atoms | 2.78 | 5.88 | 4.95 | 5.73 | 4.05 |
| Nitrogen atoms | 0.12 | 0.15 | 0.24 | 0.27 | 2.44 |
| Fraction of carbon | 0.87 | 0.79 | 0.81 | 0.78 | 0.68 |
| Fraction of oxygen | 0.12 | 0.20 | 0.18 | 0.20 | 0.17 |
| Fraction of nitrogen | 0.01 | 0.01 | 0.01 | 0.01 | 0.09 |
| Fraction of sp3 carbon | 0.63 | 0.49 | 0.50 | 0.53 | 0.45 |
| Fraction of chiral carbon | 0.09 | 0.15 | 0.14 | 0.17 | 0.10 |
| Molecular weight | 234.77 | 386.43 | 357.55 | 367.22 | 376.56 |
| Heavy atoms | 16.88 | 27.80 | 25.83 | 26.27 | 25.92 |
| Rings | 1.69 | 3.26 | 3.19 | 2.79 | 2.66 |
| Aliphatic rings | 1.11 | 1.96 | 1.87 | 1.63 | 1.18 |
| Aromatic rings | 0.58 | 1.30 | 1.32 | 1.15 | 1.48 |
| Heterocycles | 0.45 | 1.27 | 1.13 | 0.98 | 1.19 |
| Aliphatic heterocycles | 0.36 | 0.98 | 0.80 | 0.74 | 0.70 |
| Aromatic heterocycles | 0.58 | 1.30 | 1.32 | 1.15 | 1.48 |
| Spiro atoms | 0.02 | 0.10 | 0.12 | 0.07 | 0.03 |
| Bridgehead atoms | 0.41 | 0.23 | 0.19 | 0.09 | 0.18 |
| Data Set | NPDBEjeCol | BIOFACQUIM | NuBBEDB | PeruNPDB | FDA-Approved Drugs |
|---|---|---|---|---|---|
| Carbon atoms | 9.98 | 17.28 | 24.86 | 22.26 | 15.99 |
| Oxygen atoms | 1.80 | 4.87 | 8.70 | 6.18 | 3.71 |
| Nitrogen atoms | 0.26 | 0.15 | 0.38 | 0.03 | 1.95 |
| Fraction of Carbons | 0.83 | 0.77 | 0.74 | 0.78 | 0.72 |
| Fraction of Oxygens | 0.15 | 0.22 | 0.25 | 0.22 | 0.16 |
| Fraction of nitrogen | 0.02 | 0.01 | 0.01 | 0.00 | 0.09 |
| Fraction of sp3 carbon | 0.63 | 0.54 | 0.63 | 0.61 | 0.50 |
| Fraction of chiral carbon | 0.08 | 0.18 | 0.30 | 0.17 | 0.13 |
| Molecular weight | 168.31 | 311.16 | 475.69 | 399.90 | 317.27 |
| Heavy atoms | 12.04 | 22.32 | 33.95 | 28.47 | 22.16 |
| Rings | 0.94 | 2.48 | 3.84 | 1.54 | 2.19 |
| Aliphatic rings | 0.53 | 1.61 | 2.89 | 0.95 | 1.00 |
| Aromatic rings | 0.40 | 0.87 | 0.95 | 0.60 | 1.19 |
| Heterocycles | 0.33 | 0.94 | 1.88 | 0.67 | 1.14 |
| Aliphatic Heterocycles | 0.20 | 0.65 | 1.45 | 0.57 | 0.58 |
| Aromatic Heterocycles | 0.40 | 0.87 | 0.95 | 0.60 | 1.19 |
| Spiro atoms | 0.03 | 0.07 | 0.55 | 0.05 | 0.03 |
| Bridgehead atoms | 0.07 | 0.30 | 1.37 | 0.05 | 0.15 |
| Data Set | Initial Number of Compounds | Compounds After Curation | Compounds Fragmented a | Number of Fragments Generated | Reference |
|---|---|---|---|---|---|
| NPDBEjeCol (natural products from Colombia). | 236 | 236 | 231 | 200 | [12] |
| BIOFACQUIM (natural products from Mexico). | 605 | 600 | 581 | 815 | [13] |
| NuBBEDB (natural products from Brazil). | 2101 | 2099 | 2097 | 16,048 | [14] |
| PeruNPDB (natural products from Peru). | 280 | 242 | 242 | 1103 | [15] |
| FDA-approved drugs. | 2769 | 2547 | 2471 | 9228 | [16] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chávez-Hernández, A.L.; Rodríguez-Pérez, J.R.; Cortés-Hernández, H.F.; Valencia-Sanchez, H.A.; Chávez-Fumagalli, M.Á.; Medina-Franco, J.L. Fragment Library of Colombian Natural Products: Generation and Comparative Chemoinformatic Analysis. Drugs Drug Candidates 2024, 3, 736-750. https://doi.org/10.3390/ddc3040042
Chávez-Hernández AL, Rodríguez-Pérez JR, Cortés-Hernández HF, Valencia-Sanchez HA, Chávez-Fumagalli MÁ, Medina-Franco JL. Fragment Library of Colombian Natural Products: Generation and Comparative Chemoinformatic Analysis. Drugs and Drug Candidates. 2024; 3(4):736-750. https://doi.org/10.3390/ddc3040042
Chicago/Turabian StyleChávez-Hernández, Ana L., Johny R. Rodríguez-Pérez, Héctor F. Cortés-Hernández, Hoover A. Valencia-Sanchez, Miguel Á. Chávez-Fumagalli, and José L. Medina-Franco. 2024. "Fragment Library of Colombian Natural Products: Generation and Comparative Chemoinformatic Analysis" Drugs and Drug Candidates 3, no. 4: 736-750. https://doi.org/10.3390/ddc3040042
APA StyleChávez-Hernández, A. L., Rodríguez-Pérez, J. R., Cortés-Hernández, H. F., Valencia-Sanchez, H. A., Chávez-Fumagalli, M. Á., & Medina-Franco, J. L. (2024). Fragment Library of Colombian Natural Products: Generation and Comparative Chemoinformatic Analysis. Drugs and Drug Candidates, 3(4), 736-750. https://doi.org/10.3390/ddc3040042