
Bayesian Mixture Copula Estimation and Selection with Applications


Abstract
:1. Introduction
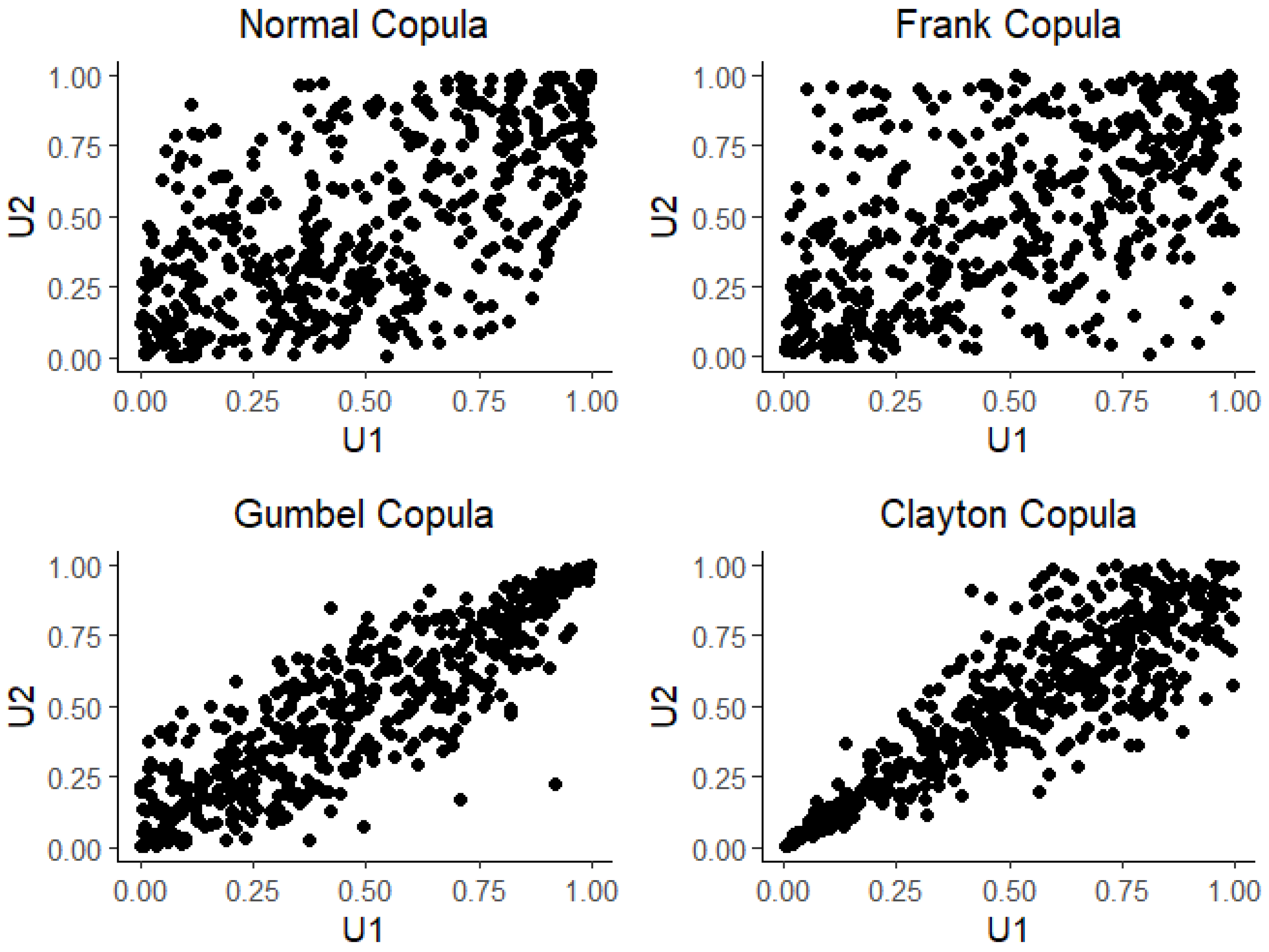
2. Parametric Copula Families
2.1. Elliptical Copulas
2.2. Archimedean Copulas
3. Estimation and Selection
3.1. Markov Chain Monte Carlo
- Setting initial values .
- Denote the current round to be t, iteratively updating such thatfor using Gibbs procedure; this can be sampled from the multinomial distribution with with .
- For all , we propose where is updated every 50 iterations from the sample variance of previously accepted points. We accept the with the acceptance rate
- Update .
- Repeat steps 2–4 until the stopping criteria are reached, for example, after 10,000 iterations. The MCMC method would be sufficient for our purpose. However, by setting up the EM method for the posterior mode, we can bridge between the Bayesian methods and the penalized likelihood methods discussed in [16,17]. In addition, if the gradient information of the copula is available, it would be faster to work with the EM to get the parameter estimations.
3.2. EM Algorithm
4. Numerical Simulations
4.1. Markov Chain Monte Carlo
4.2. Expectaion Maximization
4.3. Higer Dimensional Cases
5. Real Data Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- McNeil, A.J.; Frey, R.; Embrechts, P. Quantitative Risk Management: Concepts, Techniques and Tools-Revised Edition; Princeton University Press: Princeton, NJ, USA, 2015. [Google Scholar]
- Sklar, M. Fonctions de repartition an dimensions et leurs marges. Publ. Inst. Statist. Univ. Paris 1959, 8, 229–231. [Google Scholar]
- Embrechts, P. Copulas: A personal view. J. Risk Insur. 2009, 76, 639–650. [Google Scholar] [CrossRef]
- McLachlan, G.J.; Lee, S.X.; Rathnayake, S.I. Finite mixture models. Annu. Rev. Stat. Its Appl. 2019, 6, 355–378. [Google Scholar] [CrossRef]
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Dunson, D.B.; Vehtari, A.; Rubin, D.B. Bayesian Data Analysis; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Hu, L. Dependence patterns across financial markets: A mixed copula approach. Appl. Financ. Econ. 2006, 16, 717–729. [Google Scholar] [CrossRef]
- Arakelian, V.; Karlis, D. Clustering dependencies via mixtures of copulas. Commun. Stat.-Simul. Comput. 2014, 43, 1644–1661. [Google Scholar] [CrossRef]
- Vrac, M.; Billard, L.; Diday, E.; Chédin, A. Copula analysis of mixture models. Comput. Stat. 2012, 27, 427–457. [Google Scholar] [CrossRef] [Green Version]
- Liu, G.; Long, W.; Yang, B.; Cai, Z. Semiparametric estimation and model selection for conditional mixture copula models. Scand. J. Stat. 2022, 49, 287–330. [Google Scholar] [CrossRef]
- Huard, D.; Evin, G.; Favre, A.C. Bayesian copula selection. Comput. Stat. Data Anal. 2006, 51, 809–822. [Google Scholar] [CrossRef]
- Silva, R.d.S.; Lopes, H.F. Copula, marginal distributions and model selection: A Bayesian note. Stat. Comput. 2008, 18, 313–320. [Google Scholar] [CrossRef]
- Wu, J.; Wang, X.; Walker, S.G. Bayesian nonparametric inference for a multivariate copula function. Methodol. Comput. Appl. Probab. 2014, 16, 747–763. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Wang, X.; Walker, S.G. Bayesian nonparametric estimation of a copula. J. Stat. Comput. Simul. 2015, 85, 103–116. [Google Scholar] [CrossRef]
- Rousseau, J.; Mengersen, K. Asymptotic behaviour of the posterior distribution in overfitted mixture models. J. R. Stat. Soc. Ser. B Stat. Methodol. 2011, 73, 689–710. [Google Scholar] [CrossRef] [Green Version]
- Wang, X. Selection of Mixed Copulas and Finite Mixture Models with Applications in Finance. Ph.D. Thesis, The University of North Carolina at Charlotte, Charlotte, NC, USA, 2008. [Google Scholar]
- Cai, Z.; Wang, X. Selection of mixed copula model via penalized likelihood. J. Am. Stat. Assoc. 2014, 109, 788–801. [Google Scholar] [CrossRef]
- Smith, M.S.; Loaiza-Maya, R. Implicit copula variational inference. J. Comput. Graph. Stat. 2022, 2022, 1–28. [Google Scholar] [CrossRef]
- Ang, A.; Chen, J. Asymmetric correlations of equity portfolios. J. Financ. Econ. 2002, 63, 443–494. [Google Scholar] [CrossRef]
- Smith, M.S.; Gan, Q.; Kohn, R.J. Modelling dependence using skew t copulas: Bayesian inference and applications. J. Appl. Econom. 2012, 27, 500–522. [Google Scholar] [CrossRef]
- Wei, Z.; Kim, S.; Choi, B.; Kim, D. Multivariate skew normal copula for asymmetric dependence: Estimation and application. Int. J. Inf. Technol. Decis. Mak. 2019, 18, 365–387. [Google Scholar] [CrossRef]
- Nelsen, R.B. An Introduction to Copulas; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Genest, C.; Ghoudi, K.; Rivest, L.P. “Understanding relationships using copulas,” by Edward Frees and Emiliano Valdez, January 1998. North Am. Actuar. J. 1998, 2, 143–149. [Google Scholar] [CrossRef]
- Joe, H. Multivariate Models and Multivariate Dependence Concepts; CRC Press: Boca Raton, FL, USA, 1997. [Google Scholar]
- Frank, M.J. On the simultaneous associativity of F(x,y) and x+y-F(x,y). Aequationes Math. 1979, 19, 194–226. [Google Scholar] [CrossRef]
- Feng, Z.D.; McCulloch, C.E. Using bootstrap likelihood ratios in finite mixture models. J. R. Stat. Soc. Ser. B Methodol. 1996, 58, 609–617. [Google Scholar] [CrossRef]
- Smith, M.S. Implicit copulas: An overview. Econom. Stat. 2021, in press. [CrossRef]
- Patton, A.J. A review of copula models for economic time series. J. Multivar. Anal. 2012, 110, 4–18. [Google Scholar] [CrossRef] [Green Version]
- Fan, J.; Li, R. Variable selection via nonconcave penalized likelihood and its oracle properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Smith, M.S. Bayesian approaches to copula modelling. arXiv 2011, arXiv:1112.4204. [Google Scholar] [CrossRef] [Green Version]

{kind=link}
| Copula Type | Range | |
|---|---|---|
| Frank | ||
| Gumbel | ||
| Clayton |
| True Copula (Param) | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| MCMC Estimation | |||||||||
| Clayton | Gumbel | Normal | Frank | ||||||
| Normal (0.5) | 400 | 0.089 (0.088) | 1.568 (1.670) | 0.047 (0.036) | 3.801 (2.750) | 0.839 (0.105) | 0.444 (0.046) | 0.025 (0.032) | −0.029 (0.994) |
| 800 | 0.0439 (0.066) | 1.173 (1.586) | 0.007 (0.011) | 2.494 (1.370) | 0.940 (0.066) | 0.514 (0.026) | 0.009 (0.014) | 0.113 (0.916) | |
| 2000 | 0.039 (0.049) | 1.363 (1.424) | 0.028 (0.034) | 3.087 (1.968) | 0.913 (0.063) | 0.494 (0.024) | 0.020 (0.038) | 0.043 (1.120) | |
| Clayton (5) | 400 | 0.990 (0.011) | 4.914 (0.246) | 0.005 (0.010) | 2.490 (1.612) | 0.003 (0.005) | 0.526 (0.224) | 0.002 (0.003) | 0.012 (0.965) |
| 800 | 0.992 (0.009) | 4.876 (0.185) | 0.003 (0.006) | 2.641 (1.774) | 0.003 (0.005) | 0.488 (0.207) | 0.002 (0.004) | 0.037 (0.944) | |
| 2000 | 0.996 (0.003) | 5.091 (0.133) | 0.001 (0.002) | 2.411 (1.569) | 0.001 (0.002) | 0.568 (0.205) | 0.001 (0.001) | −0.198 (0.983) | |
| Gumbel (2.5) | 400 | 0.017 (0.027) | 1.676 (1.505) | 0.957 (0.038) | 2.486 (0.105) | 0.022 (0.033) | 0.530 (0.210) | 0.004 (0.007) | 0.080 (1.002) |
| 800 | 0.002 (0.004) | 1.480 (1.593) | 0.991 (0.009) | 2.701 (0.071) | 0.004 (0.007) | 0.545 (0.210) | 0.002 (0.005) | 0.070 (1.051) | |
| 2000 | 0.006 (0.008) | 1.442 (1.268) | 0.988 (0.014) | 2.470 (0.048) | 0.005 (0.011) | 0.533 (0.194) | 0.001 (0.002) | −0.091 (0.968) | |
| Frank (5) | 400 | 0.061 (0.083) | 1.903 (1.512) | 0.030 (0.041) | 2.386 (2.115) | 0.875 (0.087) | 0.647 (0.038) | 0.033 (0.047) | 0.416 (1.037) |
| 800 | 0.058 (0.041) | 3.774 (2.751) | 0.019 (0.039) | 2.324 (2.043) | 0.899 (0.055) | 0.603 (0.031) | 0.024 (0.031) | 0.280 (0.984) | |
| 2000 | 0.007 (0.012) | 1.358 (1.223) | 0.004 (0.007) | 2.255 (1.394) | 0.205 (0.055) | 0.790 (0.041) | 0.784 (0.058) | 4.408 (0.285) | |
| 0.5 Gumbel (2.5) + 0.5 Clayton (5) | 400 | 0.439 (0.057) | 6.079 (0.761) | 0.533 (0.059) | 2.756 (0.242) | 0.024 (0.036) | 0.569 (0.207) | 0.004 (0.007) | 0.176 (1.003) |
| 800 | 0.567 (0.034) | 5.332 (0.390) | 0.429 (0.040) | 2.328 (0.143) | 0.002 (0.004) | 0.514 (0.210) | 0.002 (0.004) | 0.126 (0.976) | |
| 2000 | 0.509 (0.034) | 5.111 (0.356) | 0.480 (0.032) | 2.505 (0.076) | 0.005 (0.008) | 0.523 (0.200) | 0.006 (0.007) | 0.182 (1.005) | |
| 0.5 Clayton (5) + 0.5 Normal (0.5) | 400 | 0.513 (0.087) | 5.150 (1.054) | 0.061 (0.070) | 2.606 (2.353) | 0.383 (0.095) | 0.554 (0.080) | 0.044 (0.067) | 0.280 (1.036) |
| 800 | 0.573 (0.041) | 4.107 (0.336) | 0.165 (0.079) | 1.833 (0.534) | 0.191 (0.144) | 0.410 (0.126) | 0.069 (0.086) | 0.365 (1.028) | |
| 2000 | 0.456 (0.035) | 5.500 (0.372) | 0.069 (0.046) | 2.750 (0.788) | 0.473 (0.035) | 0.466 (0.035) | 0.002 (0.003) | −0.105 (0.941) | |
| True Copula (Param) | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| MCMC Estimation | |||||||||
| Clayton | Gumbel | Normal | Frank | ||||||
| Normal (0.5) | 400 | 0.003 (0.005) | 1.637 (1.785) | 0.114 (0.125) | 2.015 (1.073) | 0.878 (0.124) | 0.590 (0.038) | 0.005 (0.009) | 0.064 (0.993) |
| 800 | 0.08 (0.08) | 1.543 (1.321) | 0.008 (0.011) | 2.569 (1.758) | 0.886 (0.102) | 0.568 (0.033) | 0.026 (0.037) | 0.246 (1.054) | |
| 2000 | 0.025 (0.039) | 0.845 (1.039) | 0.021 (0.021) | 1.740 (0.786) | 0.952 (0.048) | 0.541 (0.022) | 0.002 (0.004) | −0.072 (0.951) | |
| Clayton(5) | 400 | 0.987 (0.015) | 4.856 (0.240) | 0.006 (0.014) | 2.648 (1.718) | 0.004 (0.007) | 0.530 (0.204) | 0.002 (0.004) | 0.061 (0.929) |
| 800 | 0.994 (0.006) | 4.733 (0.185) | 0.003 (0.005) | 2.957 (1.793) | 0.001 (0.002) | 0.499 (0.226) | 0.001 (0.003) | −0.050 (1.023) | |
| 2000 | 0.996 (0.004) | 5.423 (0.130) | 0.002 (0.004) | 3.438 (2.236) | 0.001 (0.002) | 0.539 (0.197) | 0.001 (0.001) | −0.088 (0.959) | |
| Gumbel (2.5) | 400 | 0.009 (0.018) | 1.589 (1.533) | 0.971 (0.034) | 2.830 (0.122) | 0.018 (0.031) | 0.554 (0.190) | 0.002 (0.004) | −0.104 (1.088) |
| 800 | 0.005 (0.007) | 2.293 (2.862) | 0.981 (0.021) | 2.652 (0.084) | 0.012 (0.019) | 0.484 (0.199) | 0.002 (0.003) | 0.076 (0.931) | |
| 2000 | 0.004 (0.008) | 2.295 (2.647) | 0.993 (0.008) | 2.530 (0.044) | 0.001 (0.001) | 0.522 (0.216) | 0.002 (0.004) | 0.156 (0.962) | |
| Frank (5) | 400 | 0.012 (0.016) | 2.220 (2.809) | 0.096 (0.099) | 2.333 (1.019) | 0.005 (0.010) | 0.532 (0.197) | 0.887 (0.094) | 4.533 (0.376) |
| 800 | 0.147 (0.044) | 4.664 (1.414) | 0.006 (0.011) | 2.430 (1.634) | 0.836 (0.048) | 0.599 (0.028) | 0.011 (0.018) | 0.145 (1.028) | |
| 2000 | 0.005 (0.007) | 2.334 (3.135) | 0.050 (0.028) | 2.659 (0.833) | 0.016 (0.024) | 0.453 (0.208) | 0.929 (0.023) | 5.107 (0.281) | |
| 0.5 Gumbel (2.5) + 0.5 Clayton (5) | 400 | 0.551 (0.085) | 4.327 (0.556) | 0.363 (0.129) | 2.586 (0.276) | 0.080 (0.135) | 0.603 (0.206) | 0.006 (0.009) | 0.072 (1.071) |
| 800 | 0.413 (0.046) | 5.149 (0.526) | 0.538 (0.060) | 2.645 (0.167) | 0.050 (0.050) | 0.558 (0.211) | 0.003 (0.007) | −0.031 (1.136) | |
| 2000 | 0.531 (0.030) | 4.792 (0.270) | 0.464 (0.031) | 2.500 (0.089) | 0.004 (0.008) | 0.508 (0.197) | 0.001 (0.002) | 0.104 (1.026) | |
| 0.5 Clayton (5) + 0.5 Normal (0.5) | 400 | 0.502 (0.082) | 4.871 (0.992) | 0.044 (0.077) | 2.376 (1.230) | 0.450 (0.109) | 0.488 (0.077) | 0.005 (0.009) | −0.122 (0.960) |
| 800 | 0.526 (0.042) | 5.321 (0.461) | 0.015 (0.020) | 2.841 (1.888) | 0.444 (0.054) | 0.485 (0.048) | 0.015 (0.026) | 0.065 (1.021) | |
| 2000 | 0.534 (0.034) | 4.725 (0.325) | 0.106 (0.058) | 1.751 (0.353) | 0.351 (0.070) | 0.512 (0.060) | 0.009 (0.011) | 0.015 (0.966) | |
| True Copula (Param) | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| EM Estimations | |||||||||
| Clayton | Gumbel | Normal | Frank | ||||||
| Normal (0.5) | 200 | 0.020 (0.060) | 1.137 (0.435) | 0.035 (0.110) | 1.957 (0.135) | 0.947 (0.117) | 0.509 (0.030) | 0 (0) | 0.5 (0) |
| 400 | 0.031 (0.078) | 1.479 (1.661) | 0.050 (0.12) | 2.031 (0.351) | 0.921 (0.129) | 0.506 (0.042) | 0 (0) | 0.5 (0) | |
| 800 | 0.031 (0.068) | 1.021 (0.134) | 0 (0) | 2 (0) | 0.969 (0.068) | 0.485 (0.021) | 0 (0) | 0.5 (0) | |
| Clayton (5) | 200 | 1 (0) | 4.955 (0.525) | 0 (0) | 2 (0) | 0 (0) | 0.5 (0) | 0 (0) | 0.5 (0) |
| 400 | 0.989 (0.035) | 4.972 (0.246) | 0.012 (0.036) | 2.628 (1.985) | 0 (0) | 0.5 (0) | 0 (0) | 0.5 (0) | |
| 800 | 1 (0) | 4.988 (0.162) | 0 (0) | 2 (0) | 0 (0) | 0.5 (0) | 0 (0) | 0.5 (0) | |
| Gumbel (2.5) | 200 | 0 (0) | 1 (0) | 1 (0) | 2.486 (0.177) | 0 (0) | 0.5 (0) | 0 (0) | 0.5 (0) |
| 400 | 0 (0) | 1 (0) | 1 (0) | 2.500 (0.088) | 0 (0) | 0.5 (0) | 0 (0) | 0.5 (0) | |
| 800 | 0 (0) | 1 (0) | 0.979 (0.038) | 2.562 (0.081) | 0.02 (0.04) | 0.513 (0.058) | 0 (0) | 0.5 (0) | |
| Frank (5) | 200 | 0.117 (0.138) | 2.182 (1.415) | 0.155 (0.268) | 2.016 (0.118) | 0.723 (0.244) | 0.557 (0.102) | 0.010 (0.030) | 0.498 (0.007) |
| 400 | 0.054 (0.087) | 1.619 (1.075) | 0.184 (0.187) | 2.283 (0.383) | 0.764 (0.228) | 0.555 (0.080) | 0 (0) | 0.5 (0) | |
| 800 | 0.075 (0.085) | 2.201 (1.456) | 0.060 (0.103) | 2.249 (0.498) | 0.840 (0.089) | 0.608 (0.047) | 0.030 (0.050) | 0.517 (0.029) | |
| True Copula (Param) | |||||||
|---|---|---|---|---|---|---|---|
| MCMC Estimations | |||||||
| n | Comp1 | Comp2 | Comp3 | ||||
| Normal (0.7, −0.7, −0.6) | 400 | 0.815 (0.160) | 0.691 (0.031), −0.676 (0.042), −0.602 (0.048) | 0.173 (0.152) | 0.685 (0.212), −0.658 (0.278), −0.430 (0.342) | 0.019 (0.016) | 0.414 (0.306), −0.050 (0.539), −0.152 (0.413) |
| 800 | 0.991 (0.014) | 0.680 (0.017), −0.715 (0.015), −0.604 (0.023) | 0.007 (0.012) | 0.371 (0.429),−0.435 (0.318),−0.413 (0.571) | 0.002 (0.003) | 0.312 (0.445),−0.341 (0.377),−0.308 (0.566) | |
| 2000 | 0.992 (0.007) | 0.70 (0.009),−0.699 (0.010),−0.612 (0.012) | 0.007 (0.007) | 0.154 (0.350),−0.362 (0.498),−0.336 (0.252) | 0.001 (0.001) | −0.225 (0.283),0.303 (0.445),−0.230 (0.239) | |
| 0.7 Normal (0.6, 0.6, 0.6) + 0.3 Normal (−0.7, −0.7, 0.7) | 400 | 0.609 (0.097) | 0.679 (0.069), 0.616 (0.048), 0.602 (0.043) | 0.289 (0.047) | −0.595 (0.310), −0.592 (0.327), 0.713 (0.066)’ | 0.102 (0.085) | −0.224 (0.387), −0.170 (0.452), 0.468 (0.141) |
| 800 | 0.656 (0.074) | 0.567 (0.035), 0.599 (0.042), 0.576 (0.038) | 0.216 (0.042) | −0.535 (0.326), −0.594 (0.252), 0.687 (0.076) | 0.128 (0.054) | −0.331 (0.392), −0.450 (0.342), 0.724 (0.087) | |
| 2000 | 0.663 (0.030) | 0.636 (0.017), 0.607 (0.021), 0.603 (0.014) | 0.310 (0.020) | −0.677 (0.030), −0.690 (0.029), 0.740 (0.020) | 0.026 (0.027) | 0.190 (0.320), 0.138 (0.319), 0.257 (0.193) | |
| SSEC | HSI | SP500 | SSEC | HSI | SP500 | |
|---|---|---|---|---|---|---|
| Pearson Correlation | Spearman Correlation | |||||
| SSEC | 1 | 0.699 | 0.18 | 1 | 0.679 | 0.173 |
| HSI | 0.699 | 1 | 0.25 | 0.679 | 1 | 0.224 |
| SP500 | 0.18 | 0.25 | 1 | 0.173 | 0.224 | 1 |
| SSEC-HSI | SSEC-SP500 | HSI-SP500 | ||
|---|---|---|---|---|
| Clayton | w | 0.280 (0.144, 0.372) | 0.685 (0.508, 0.814) | 0 |
| 2.53 (1.65, 3.65) | 0.168 (0.069, 0.247) | |||
| Gumbel | w | 0 | 0 | 0.104 (0.015, 0.257) |
| 1.484 (1.130, 2.368) | ||||
| Normal | w | 0.668 (0.587, 0.785) | 0.222 (0.062, 0.350) | 0.528 (0.350, 0.672) |
| 0.722 (0.681, 0.764) | 0.366 (0.190, 0.563) | 0.400 (0.269, 0.561) | ||
| Frank | w | 0 | 0 | 0.33 (0.201, 0.542) |
| −0.534 (−1.557, 0.509) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Xie, D.; Yu, S. Bayesian Mixture Copula Estimation and Selection with Applications. Analytics 2023, 2, 530-545. https://doi.org/10.3390/analytics2020029
Liu Y, Xie D, Yu S. Bayesian Mixture Copula Estimation and Selection with Applications. Analytics. 2023; 2(2):530-545. https://doi.org/10.3390/analytics2020029
Chicago/Turabian StyleLiu, Yujian, Dejun Xie, and Siyi Yu. 2023. "Bayesian Mixture Copula Estimation and Selection with Applications" Analytics 2, no. 2: 530-545. https://doi.org/10.3390/analytics2020029
APA StyleLiu, Y., Xie, D., & Yu, S. (2023). Bayesian Mixture Copula Estimation and Selection with Applications. Analytics, 2(2), 530-545. https://doi.org/10.3390/analytics2020029