1. Introduction
Bridges, power generation systems, aircrafts, buildings and rotating machinery are only few instances of structural and mechanical systems which play an essential role in the modern society, even if the majority of them are approaching the end of their original design life [
1]. Taking into account that their replacement would be unsustainable from an economic standpoint, alternative strategies for early damage detection have been actively developed so to extend the basis service life of those infrastructures. Furthermore, the advent of novel materials whose long-term behaviour is still not fully understood drives the effort for effective Structural Health Monitoring (SHM), resulting in a saving of human lives and resources [
1].
SHM consists of three fundamental steps: (i) measurement, at regular intervals, of the dynamic response of the system; (ii) selection of damage-sensitive features from the acquired data; (iii) statistical analysis of those attributes to assess the current health state of the structure. To characterize the damage state of a system, the method relying on hierarchical phases, originally proposed by [
2] represents the currently adopted standard. The latter prescribes several consecutive identification phases (to be tackled in order), namely: check the existence of the damage, the location of the damage, its type, extent and the system’s prognosis. Damaged states are identified by comparison with a reference condition, assumed to be undamaged. The detection of the damage location relies upon a wider awareness of the structural behaviour and the way in which it is influenced by damage. This information, along with the knowledge of how the observed features are altered by different kinds of damage, allows to determine the type of damage. The last two phases require an accurate estimation of the damage mechanisms in order to classify its severity and to estimate the Remaining Useful Life (RUL).
All the steps mentioned above rely on continuous data acquisition and processing to obtain information about the current health condition of a system. In the last few years, the concept of Digital Twin has emerged, combining data assimilation, machine learning and physics-based numerical Simulations [
1], the latter being essential to completely understand the physics of the structure and damage mechanisms. A suitable tool able to extract main dominant features from a set of data is represented by neural networks [
3], especially generative models such as Generative Adversarial Networks (GANs) [
4] and Variational Autoencoders (VAEs) [
5].
In this paper, an application of the generative neural network RepGAN, proposed by [
6], is presented in the context of SHM.
Section 2 provides an overview on existing works. In
Section 3, the application of RepGAN to Structural Health Monitoring is presented. In
Section 4, extensive numerical results are illustrated, while
Section 5 gathers some concluding remarks.
2. Related Work
Generative Adversarial Networks [
4] are well known due to their generative capability. Given a multidimensional random variable
, where
denotes the probabilistic space with
-algebra
and probability measure
, whose samples are collected in the data set
, with probability density function
, the GAN generator attempts to reproduce synthetic samples
, sampled according to the probability density function
as similar as possible to the original data, i.e., a GAN trains over data samples in order to match
with
.
maps a lower dimension manifold
(with
in general) into the physics space
. In doing so,
learns to pass the critic test, undergoing the judgement of a discriminator
, simultaneously trained to recognize
counterfeits. The adversarial training scheme relies on the following two-players Minimax game:
In practice,
is represented by a neural network
and
D by a neural network
, with trainable weights and biases
and
, respectively. Moreover,
is approximated by the Empirical Risk function
, depending on the data set
, defined as:
with
sampled from a known latent space probability distribution
(for instance the normal distribution
). The generator
induces a sampling probability
so that, when optimized, passes the critic test, with
D being unable to distinguish between
and
(i.e.,
). In other words,
and
can be associated with the value of a categorical variable
C, with two possible values: class “
d” (data) and class “
g” (generated).
and
can be therefore sampled with the mixture probability density
“
g” with
being the indicator function and
[
7]. The optimum solution of the Minimax game in Equation (
2) induces a mixture probability distribution
[
4]. The saddle point of
corresponds to the minimum (with the respect to to
D) of the conditional Shannon’s entropy
(see
Appendix A). Moreover, minimizing the conditional Shannon’s entropy
corresponds to the maximization of the Mutual Information
(see
Appendix B), i.e., it corresponds to extract
samples
or
that are indistinguishable (belonging to same class), with an uninformative mapping
.
GANs proved useful in various applications such as generation of artificial data for data-set augmentation, filling gaps in corrupted images and image processing. Especially, deep convolutional generative adversarial networks (DCGANs) [
8] proved useful in the field of unsupervised learning. SHM could benefit from GANs as they improve the generalisation performance of models, extracting general features from data, as well as their semantics (damage state, frequency content, etc). However, the adversarial training scheme in
Appendix C does not grant a bijective mapping
(decoder) and
(encoder), which is crucial in order to obtain a unique representation of the data into the latent manifold. Autoencoders have been developed for image reconstruction so to learn the identity operator
. One can leverage the encoder
representation power to sample points
belonging to the latent manifold
and the decoder
to sample points
belonging to the latent manifold
(see Equation (
1)). In order to make the learning process of GANs stable across a range of data-sets and to realize higher resolution and deeper generative models, Convolutional Neural Networks (CNNs) are employed to define
,
and the discriminators.
and
induce sampling probability density functions
and
, respectively.
is usually unknown (depending on the data-set at stake), but
can be chosen ad hoc (such as, for instance,
) in order to get a powerful generative tool for realistic data samples
. A particular type of Autoencoders, called Variational Autoencoders (VAEs) was introduced by [
5], consisting in a probabilistic and generative version of the standard Autoencoder, where the encoder
infers the mean
and variance
of the latent manifold. However, the main contribution provided by VAEs is the straightforward approach that allows to reorganize the gradient computation and reduce variance in the gradients labelled reparametrization trick.
Adversarial Autoencoders (AAEs) [
9] employ the adversarial learning framework in Equation (
1), replacing
by
and adding to the adversarial GAN loss the Mean Square Loss
as an optimization penalty, in order to assure a good reconstruction of the original signal. However, AAEs do not assure a bijective mapping between
and
. In order to achieve the bijection (in a probabilistic sense) between
and
samples, the distance between the joint probability distributions
and
[
10], with the posteriors
and
must be minimized. A suitable distance operator for probability distributions is the so called Jensen–Shannon distance
, defined as [
10]:
with
being the Kullback–Leibler divergence (see
Appendix B) and
being the mixture probability distribution [
7], i.e., the probability of extracting
or
from a mixed data set, with
and the entropy of the mixture probability
.
can be rewritten as:
The adversarial optimization problem expressed in Equation (
1) can be seen as a minimization of the Jensen–Shannon distance for
:
that can be combined with the Autoencoder model in order to obtain the following expression [
10,
11]:
In this context,
learns to map data into a disentangled latent space, generally following the normal distribution, a good reconstruction is not ensured unless the cross-entropy between
and
is minimized too [
12].
Another crucial aspect of generative models is the semantics of the latent manifold. Most of the standard GAN models trained according to Equation (
1) employs a simple factored continuous input latent vector
and does not enforce any restrictions on the way the generator treats it. The individual dimensions of
do not correspond to semantic features of the data (uninformative latent manifolds) and
cannot be effectively used in order to perform meaningful topological operations in the latent manifold (e.g., describing neighborhoods) and to associate meaningful labels to it. An information-theoretic extension to GANs, called InfoGAN [
13] is able to learn a meaningful and disentangled representations in a completely unsupervised manner: a Gaussian noise
is associated with a latent code
to capture the characteristic features of the data distribution (for classification purposes). As a consequence, the generator becomes
and the corresponding probability distribution
, whose Mutual Information with the respect to to the latent codes
, namely
. The latter is forced to be high, penalizing the GAN loss in Equation (
1) with the variational lower bound
L(
G,Q), defined by:
with
being the probability distribution approximating the real unknown posterior probability distribution
(and represented by the neural network
).
can be easily approximated via Monte Carlo simulation, and maximized with the respect to to
and
via reparametrization trick [
13].
3. Methods
With the purpose of learning a semantically meaningful and disentangled representation of the SHM time-histories, we adopted in this study the architecture called RepGAN, originally proposed in [
6]. RepGAN is based on an encoder-decoder structure (both represented by deep CNNs made of stacked 1D convolutional blocks), with a latent space
.
a categorical variable representing the damage class(es), with
which is generally chosen as a categorical distribution over
classes, i.e.,
.
is a continuous variable of dimension
, with
, generally
or the uniform distribution
. Finally,
is a random noise of
independent components, with
, generally
. RepGAN adopts the conceptual frameworks of VAEs and InfoGAN, combining the learning of two representations
and
, respectively. The
scheme must learn to map multiple data instances
into their images (via encoder
) in a latent manifold
and back into a distinct instance in data space
(via decoder
), providing satisfactory results in reconstruction.
maps multiple data latent instances into the same data representation, in order to guarantee impressive generation and clustering performance. Combining the two surjective mappings, in RepGAN the two learning tasks
and
are performed together with shared parameters in order to obtain a bijective mapping
. In practice, the training of
is iterated five times more than the
. This ability to learn a bidirectional mapping between the input space and the latent space is achieved through a symmetric adversarial process. The Empirical Loss function can be written as:
with the terms:
are introduced in order to constrain a deterministic and injective encoding mapping (see
Appendix B). On the other hand, the term
.
penalizes the learning scheme, in order to minimize the conditional entropy , i.e., in order to grant a good reconstruction.
Following the original RepGAN formulation:
is enforced penalizing the -norm ;
corresponds to the InfoGAN
penalty, and it is maximized via the reparametrization trick (structuring the
branch of the encoder-decoder structure as a VAE, see [
5]).
Finally,
is maximized in a supervised way, considering the actual class of labeled signals
:
corresponding to a damaged structure and
to an undamaged one, respectively. RepGAN provides an informative and disentangled latent space associated with the damage class
. The most significant aspect of the approach is the efficiency in generating reasonable signals for different damage states only on the basis of undamaged recorded or simulated structural responses. Both generators
,
and discriminators
,
,
and
are parametrized via 1D CNN (and strided 1D CNN), following [
8]. Our RepGAN model has been designed using the Keras API, and trained employing a Nvidia Tesla K40 GPU (on the supercomputer
Ruche, the cluster of the Mésocentre Moulon of Paris Saclay University).
4. Results and Discussion
In the following, a case study is considered in order to prove the ability of the new architecture to achieve the three fundamental tasks of semantic generation, clustering and reconstruction. The reference example is a shear building subject to an earthquake ground motion whose signals are taken from the STEAD seismic database [
14]. STEAD [
14] is a high-quality, large-scale, and global data set of local earthquake and non-earthquake signals recorded by seismic instruments. In this work, local earthquake wave forms (recorded at local distances within 350 km of earthquakes) have been considered. Seismic data are constituted by three wave forms of 60 s duration, recorded in east–west, north–south, and up-dip directions, respectively. The structure is composed of 39 storeys. The mass and the stiffness of each floor, in undamaged conditions, are, respectively,
m = 625 × 10
kg and
k = 1 × 10
. Damage is simulated through the degradation of stiffness. In the present case, the stiffness reduction has been set equal to 50% of the above mentioned value. The structural response of the system is evaluated considering one degree-of-freedom (dof) per floor. To take into account damping effects, a Rayleigh damping model has been considered.
The following results have been obtained considering 100 signals in both undamaged and damaged conditions for a total of 200 samples, with separated training and validation data sets. Each signal is composed of 2048 time steps with dt = 0.04 s. The training process has been performed over 2000 epochs. The reconstruction capability of the proposed network has been evaluated through the Goodness-of-Fit (GoF) criteria [
15] where both the fit in Envelope (EG) and the fit in Phase (FG) are measured. An example is shown in
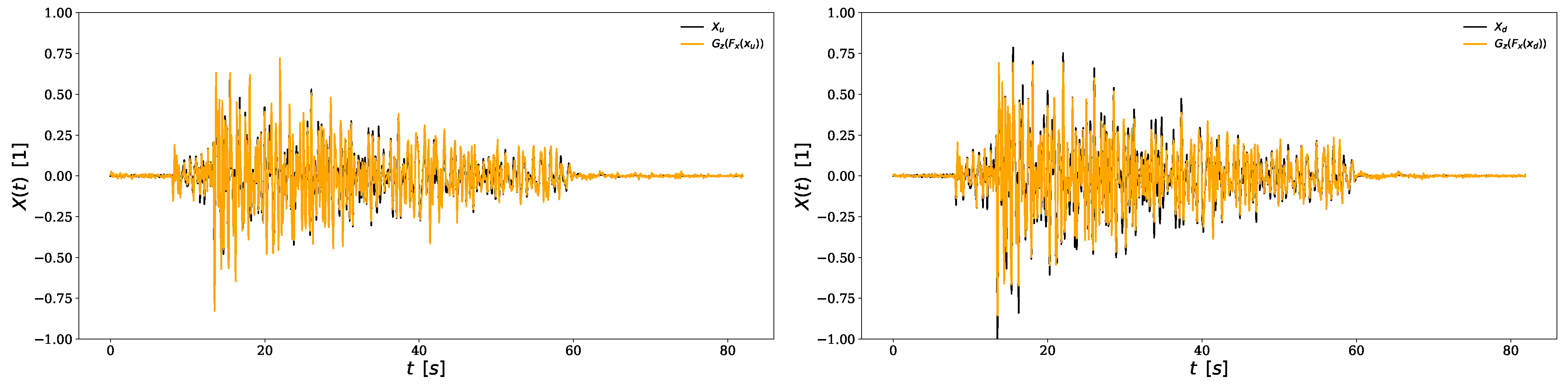
Figure 1. The values 9.17 and 9.69, respectively, related to EG and PG testify the excellent reconstruction quality.
The capability of reproducing signals for different damage scenarios can be appreciated from
Figure 2 which presents the original structural response (black) and the corresponding generated one (orange) in both undamaged (left panel in
Figure 2) and damaged (right panel in
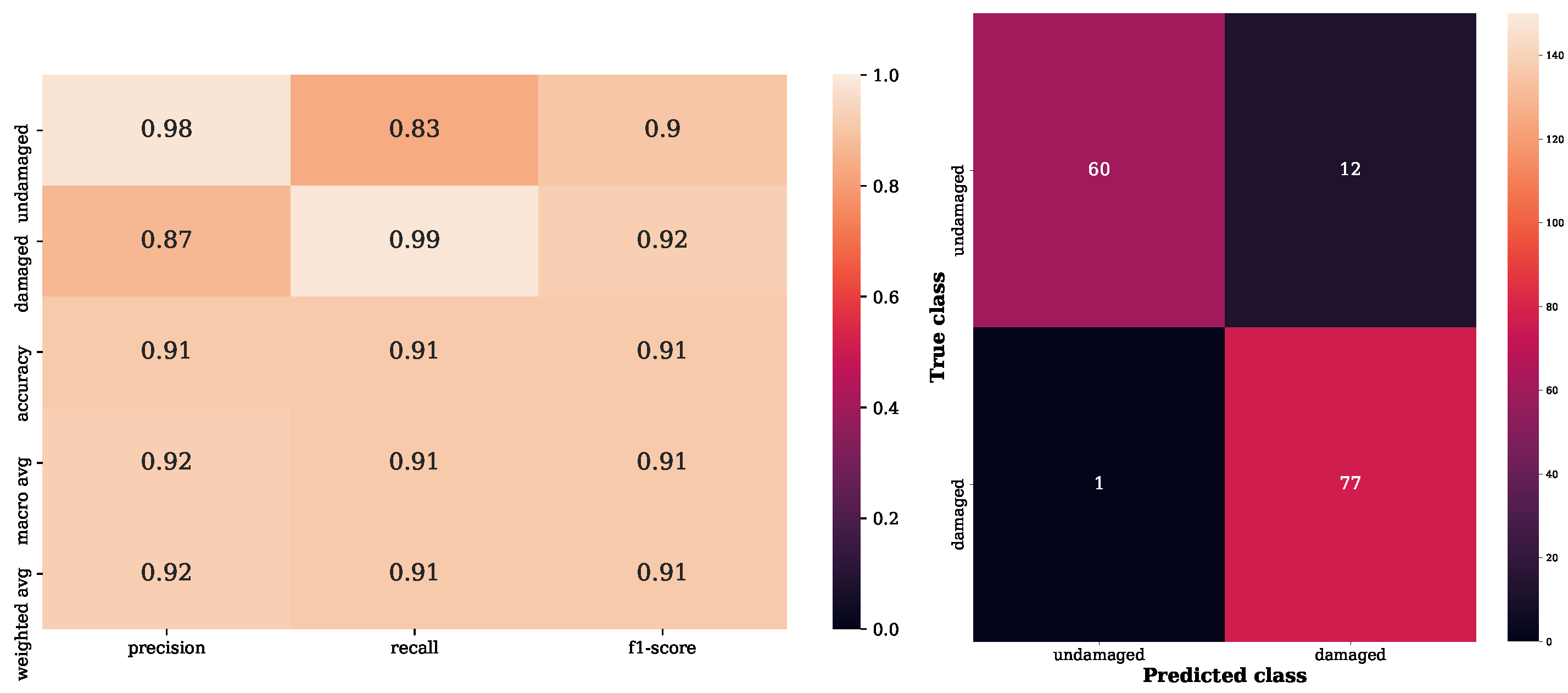
Figure 2) conditions. Regarding the classification capability, the classification report and the confusion matrix in
Figure 3 highlight the fact that the model is able to correctly assign the damage class to the considered time histories.


 ,
, 


{kind=link}
{kind=link}
{kind=link}