
Overview of Training LLMs on One Single GPU †
Abstract
1. Introduction
2. Related Works
3. Methodology
3.1. Model Fine-Tuning and Optimization Techniques
- Parameter-Efficient Fine-Tuning (PEFT): This includes methods such as LoRA (Low-Rank Adaptation) [15] which is used to reduce considerably the number of trainable parameters making memory less loaded for training when adapting Large Language models to downstream tasks;
- 8-bit Adam Optimizer [16]: This is utilized to reduce memory usage during optimization while maintaining training stability and convergence;
- Mixed-Precision Training: We employed both FP16 and BF16 [5] to accelerate computation and reduce memory overhead;
- Gradient Checkpointing: This was implemented to trade-off computation memory, enabling the training of larger models within limited GPU memory;
- Effective Batch Size: The batch size was set to powers of two (2^N) to align with hardware optimizations and ensure efficient memory utilization [17].
3.2. Dataset and Training Configuration
3.3. Collected Metrics
- Peak GPU Usage: The maximum GPU memory utilization value during training measured in MB;
- Training Time: Total time taken to complete the fine-tuning process;
- Iteration Speed: The number of iterations completed per second, reflecting computational throughput;
- Training Loss: The final loss value, monitoring convergence and model performance.
4. Results
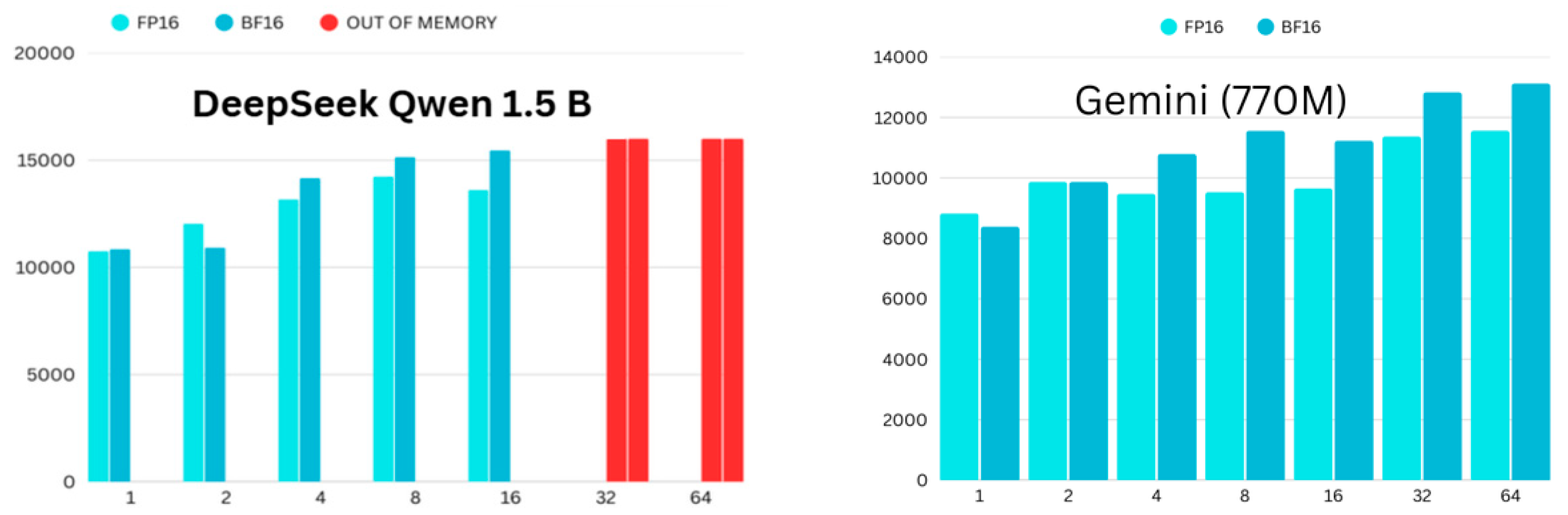
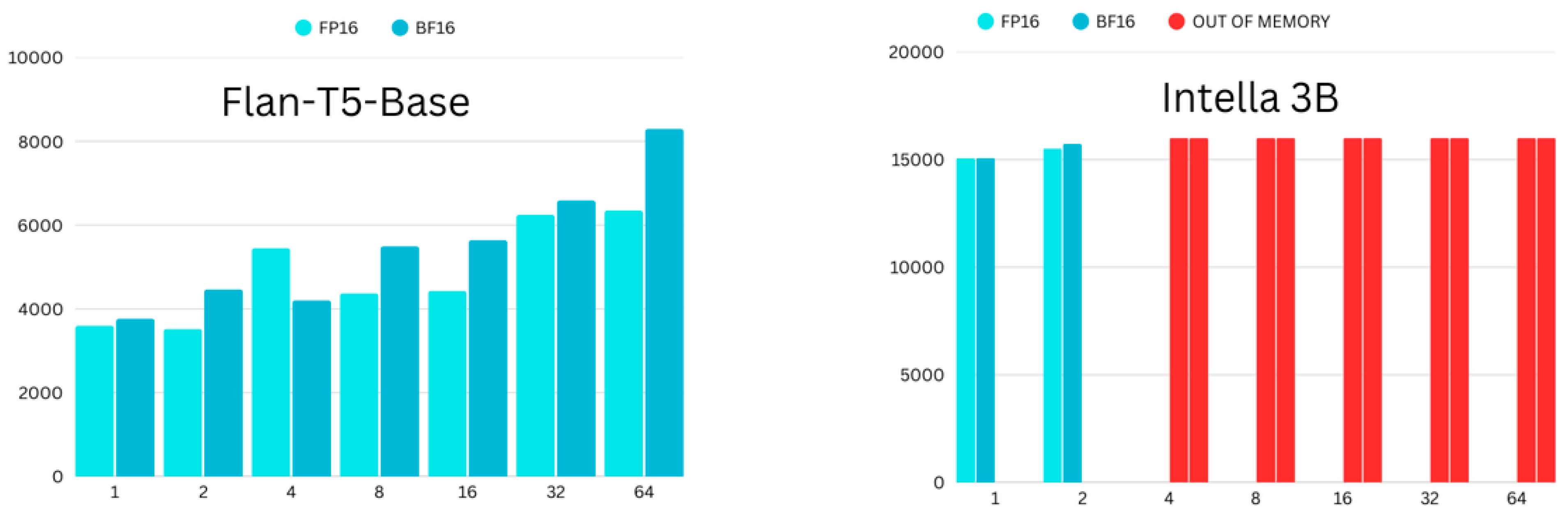
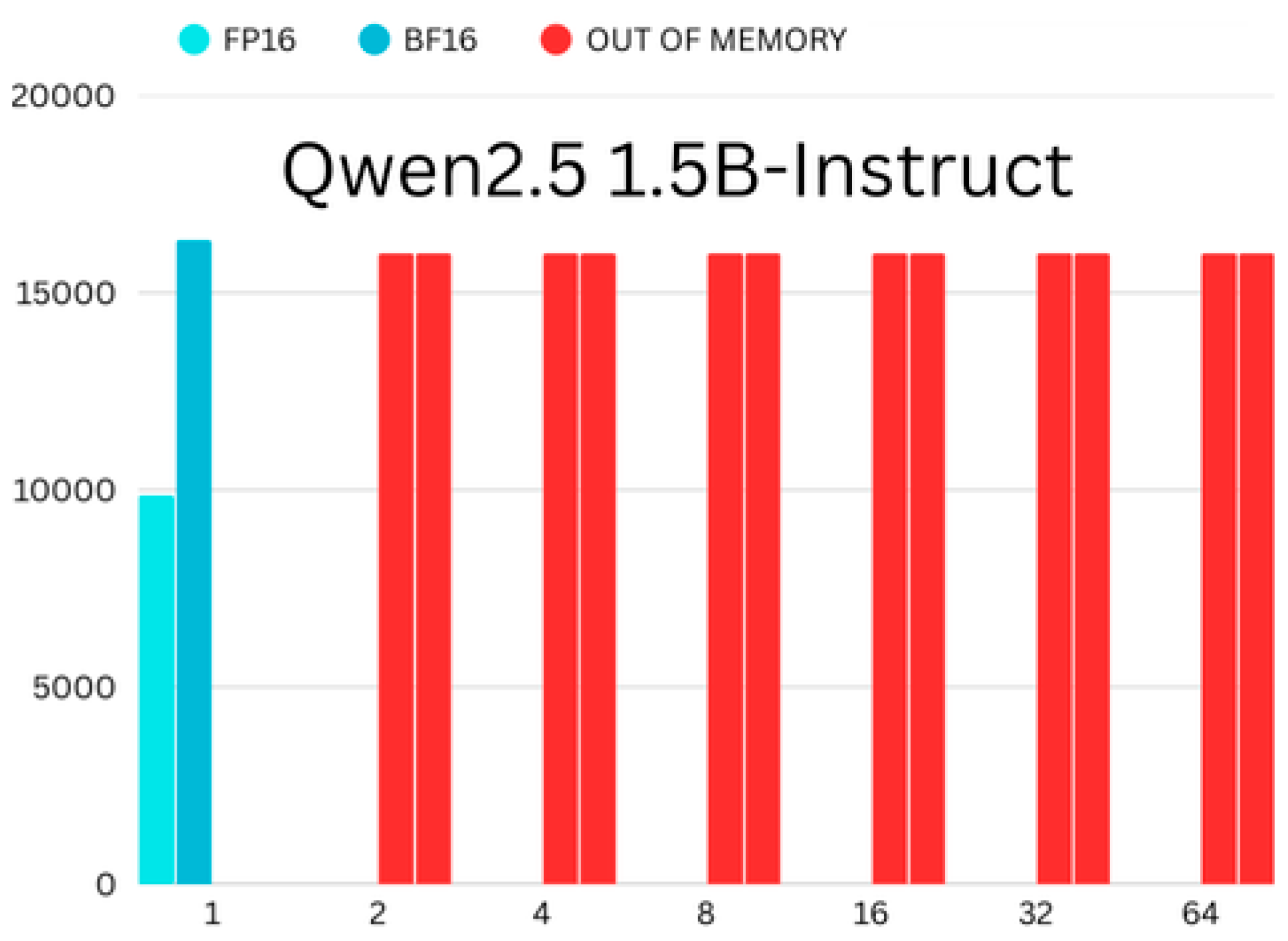
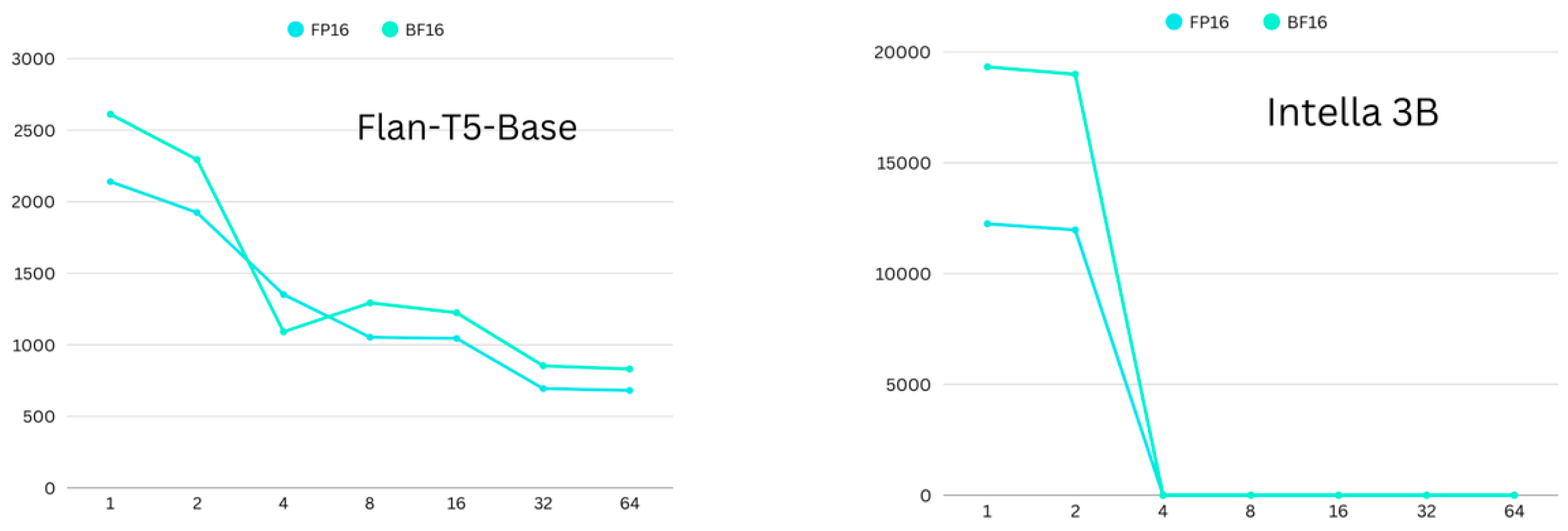
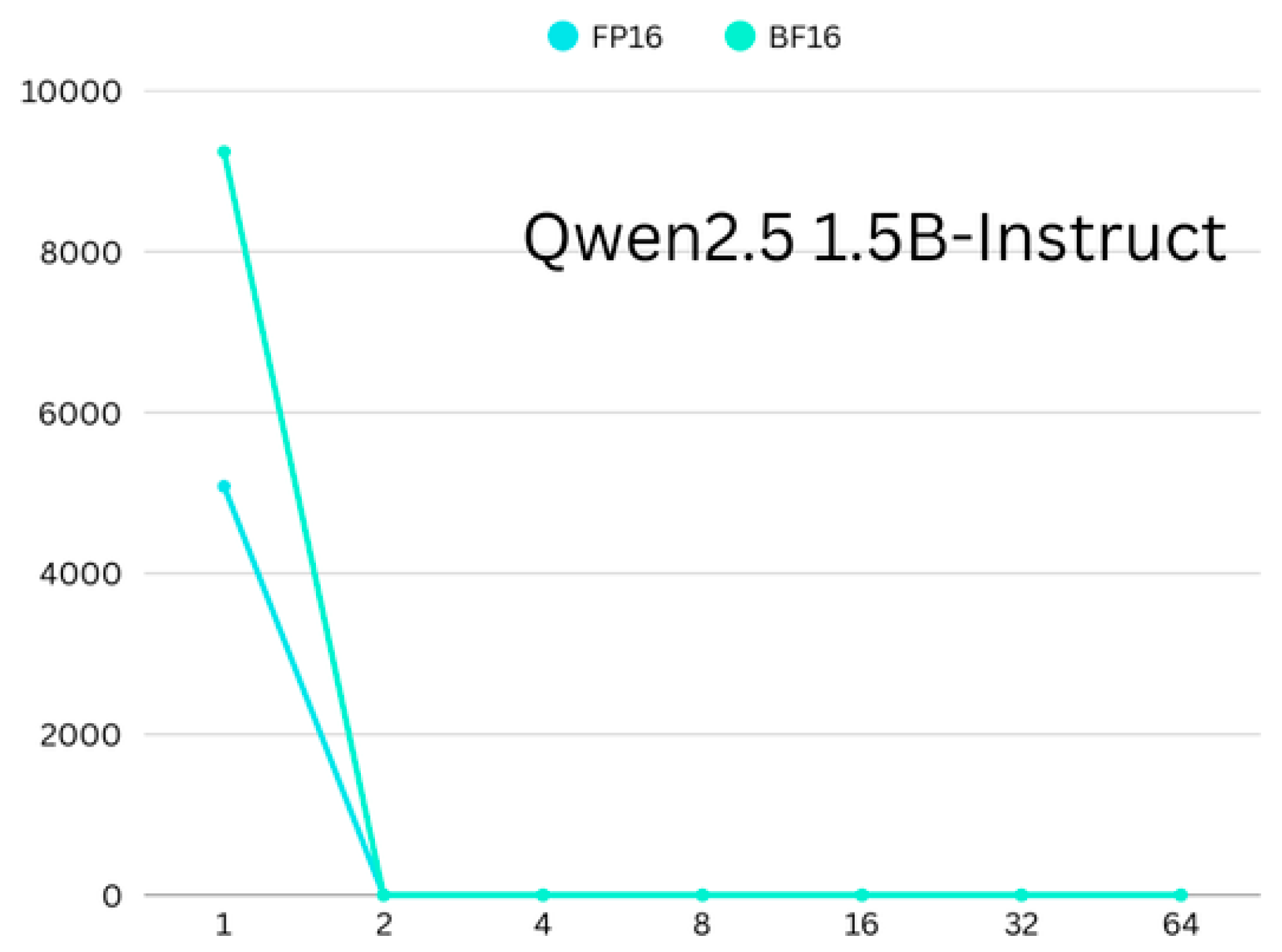
4.1. Memory Consumption
4.2. Time Consumption
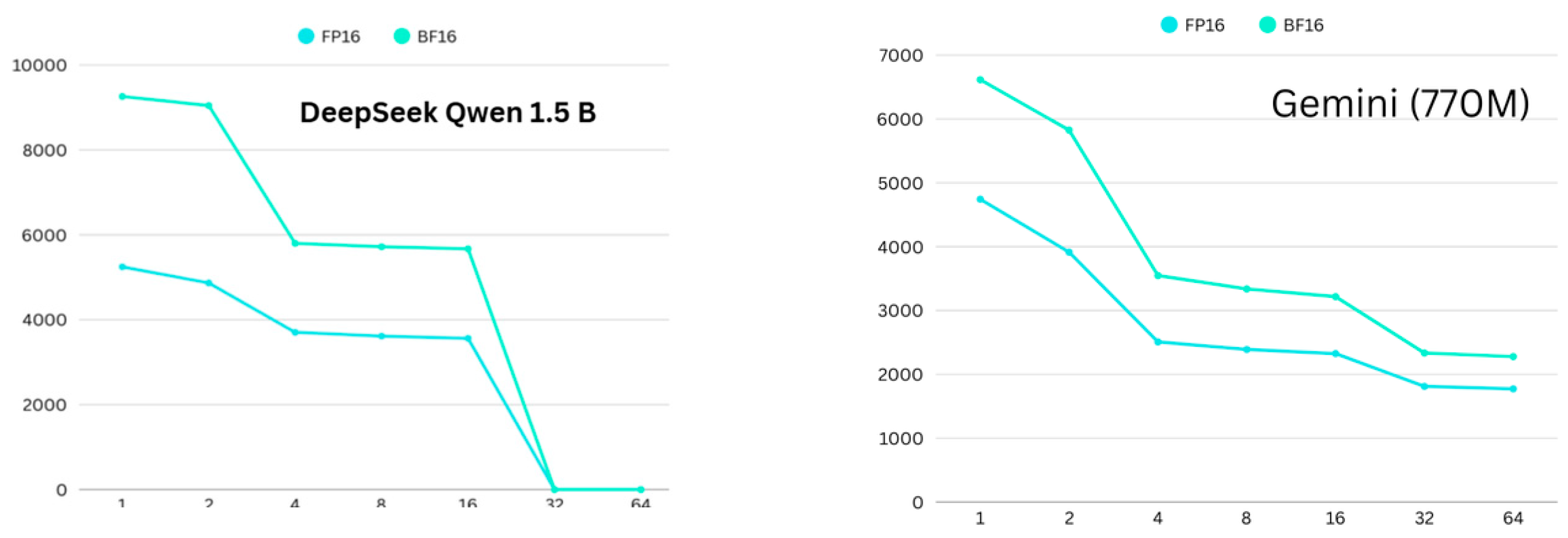
4.3. Convergence Differences
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- DeepSeek-AI. DeepSeek-V3 Technical Report. arXiv 2025, arXiv:2412.19437. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 5 January 2025).
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv 2020, arXiv:1910.10683. [Google Scholar]
- Micikevicius, P.; Narang, S.; Alben, J.; Diamos, G.; Elsen, E.; Garcia, D.; Ginsburg, B.; Houston, M.; Kuchaiev, O.; Venkatesh, G.; et al. Mixed Precision Training. arXiv 2018, arXiv:1710.03740. [Google Scholar]
- Chen, T.; Xu, B.; Zhang, C.; Guestrin, C. Training Deep Nets with Sublinear Memory Cost. arXiv 2016, arXiv:1604.06174. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W.J. Learning both Weights and Connections for Efficient Neural Networks. arXiv 2015, arXiv:1506.02626. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Hugging Face’s Transformers: State-of-the-Art Natural Language Processing. arXiv 2020, arXiv:1910.03771. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Reddi, V.J.; Cheng, C.; Kanter, D.; Mattson, P.; Schmuelling, G.; Wu, C.-J.; Anderson, B.; Breughe, M.; Charlebois, M.; Chou, W.; et al. MLPerf Inferrence Bechmark. arXiv 2020, arXiv:1911.02549. [Google Scholar]
- Coleman, C.; Narayanan, D.; Kang, D.; Zhao, T.; Zhang, J.; Nardi, L.; Bailis, P.; Olukotun, K.; Ré, C.; Zaharia, M. DAWNBench: SMASH: One-shot Model Architecture Search through HYperNetworks. arXiv 2017, arXiv:1708.05344. [Google Scholar]
- NVIDIA. NVIDIA T4 GPU Architecture. 2020. Available online: https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/tesla-t4/t4-tensor-core-datasheet-951643.pdf (accessed on 10 January 2025).
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Dettmers, T.; Lewis, M.; Belkada, Y.; Zettlemoyer, L. 8-bit Adam Optimizer Via Block-Wise Quantization. arXiv 2022, arXiv:2110.02861. [Google Scholar]
- NVIDIA. 2023. Available online: https://docs.nvidia.com/deeplearning/performance/index.html (accessed on 15 January 2025).
- Alyafeai, Z.; Almubarak, K.; Ashraf, A.; Alnuhait, D.; Alshahrani, S.; Abdulrahman, G.A.Q.; Ahmed, G.; Gawah, Q.; Saleh, Z.; Ghaleb, M.; et al. CIDAR: Culturally Relevant Instruction Dataset for Arabic. arXiv 2024, arXiv:2402.03177. [Google Scholar]
- Chen, L.; Li, S.; Yan, J.; Wang, H.; Gunaratna, K.; Yadav, V.; Tang, Z.; Srinivasan, V.; Zhou, T.; Huang, H.; et al. ALPAGASUS: Training a better ALPACA with fewer data. arXiv 2024, arXiv:2307.08701. [Google Scholar]
- Narayanan, D.; Shoeybi, M.; Casper, J.; LeGresley, P.; Patwary, M.; Korthikanti, V.; Vainbrand, D.; Kashinkunti, P.; Bernauer, J.; Catanzaro, B.; et al. Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM. arXiv 2021, arXiv:2104.04473. [Google Scholar]
- Hoffmann, J.; Borgeaud, S.; Mensch, A.; Buchatskaya, E.; Cai, T.; Rutherford, E.; de Las Casas, D.; Hendricks, L.A.; Welbl, J.; Clark, A.; et al. Training Compute-Optimal Large Language Models. arXiv 2022, arXiv:2203.15556. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | DeepSeek | Gemini | Flan-T5 | Instella | Qwen |
|---|---|---|---|---|---|
| Highest (FP16) | 1 h 27 m 32 s | 1 h 19 m 04 s | 35 m 40 s | 3 h 24 m 09 s | 1 h 24 m 43 s |
| Highest (BF16) | 2 h 34 m 19 s | 1 h 50 m 15 s | 43 m 32 s | 5 h 22 m 10 s | 2 h 37 m 03 s |
| Lowest (FP16) | 59 m 22 s | 29 m 33 s | 11 m 21 s | 3 h 19 m 31 s | 1 h 24 m 43 s |
| Lowest (BF16) | 1 h 34 m 30 s | 37 m 58 s | 13 m 51 s | 5 h 16 m 39 s | 2 h 37 m 03 s |
| Model | DeepSeek | Gemini | Flan-T5 | Instella | Qwen |
|---|---|---|---|---|---|
| Effective size 1 | 2.5252 | 0.009 | 0.0063 | 1.0631 | 1.6211 |
| Effective size 2 | 5.3273 | 0.0119 | 0.0721 | 1.0945 | None |
| Effective size 4 | 5.5068 | 0.161 | 0.0116 | None | None |
| Effective size 8 | 11.7354 | 0.0256 | 0.0188 | None | None |
| Effective size 16 | 24.3662 | 0.0376 | 0.0257 | None | None |
| Effective size 32 | None | 0.0624 | 0.0329 | None | None |
| Effective size 64 | None | 0.128 | 0.0749 | None | None |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ben jouad, M.; Elaachak, L. Overview of Training LLMs on One Single GPU. Comput. Sci. Math. Forum 2025, 10, 14. https://doi.org/10.3390/cmsf2025010014
Ben jouad M, Elaachak L. Overview of Training LLMs on One Single GPU. Computer Sciences & Mathematics Forum. 2025; 10(1):14. https://doi.org/10.3390/cmsf2025010014
Chicago/Turabian StyleBen jouad, Mohamed, and Lotfi Elaachak. 2025. "Overview of Training LLMs on One Single GPU" Computer Sciences & Mathematics Forum 10, no. 1: 14. https://doi.org/10.3390/cmsf2025010014
APA StyleBen jouad, M., & Elaachak, L. (2025). Overview of Training LLMs on One Single GPU. Computer Sciences & Mathematics Forum, 10(1), 14. https://doi.org/10.3390/cmsf2025010014