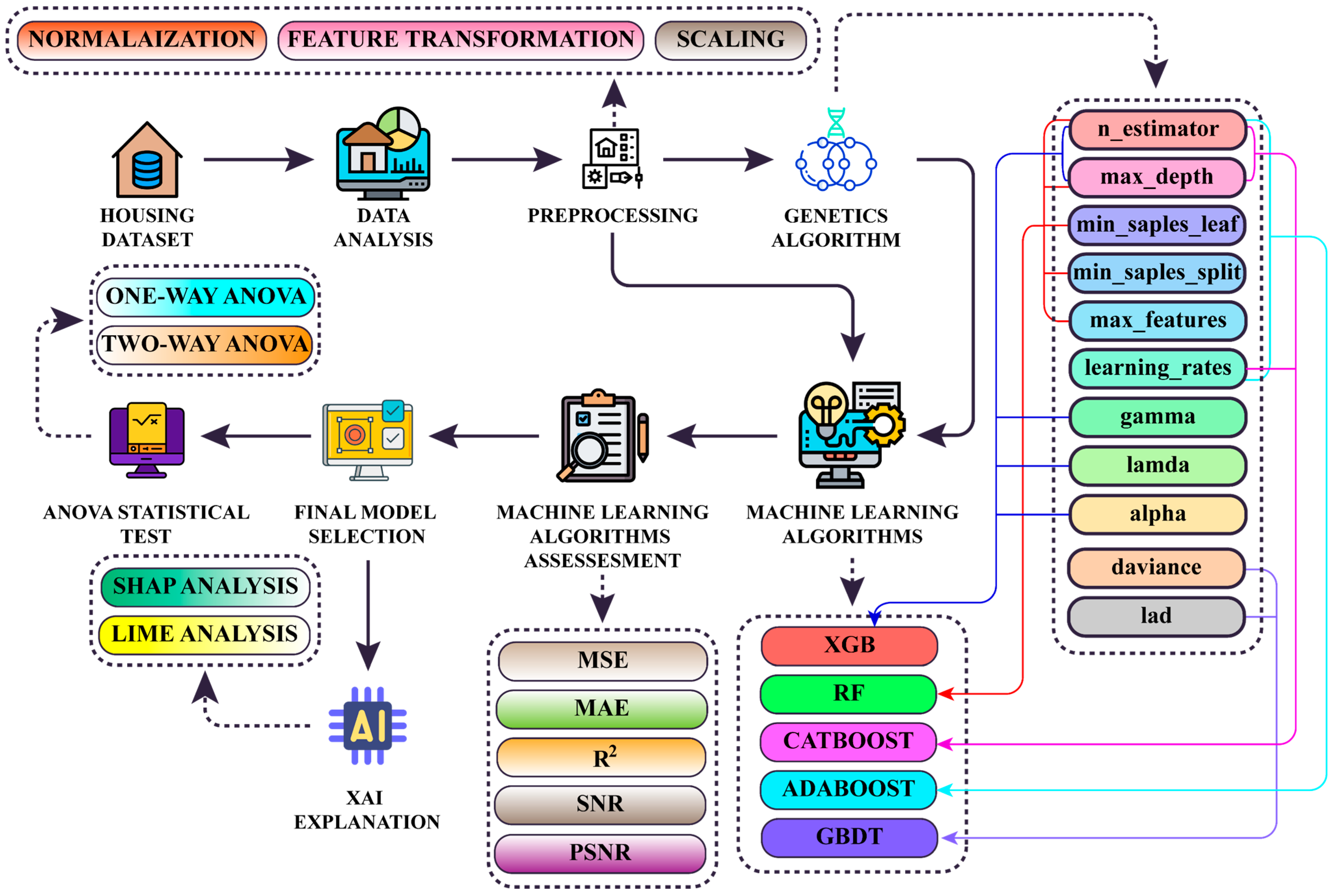
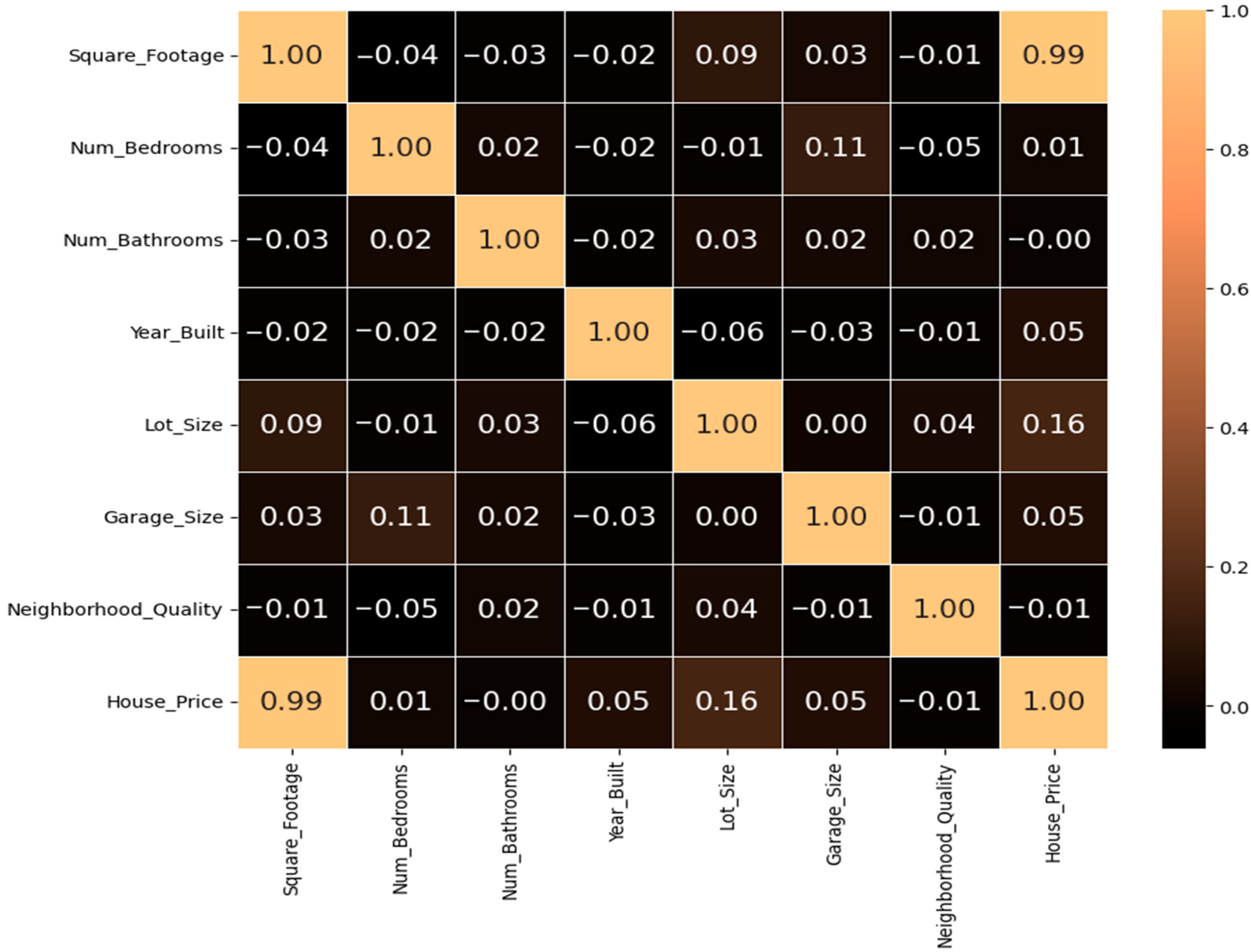
4. Results and Discussion
This study used a personal computer powered by an Intel Core i5 processor, 16 GB DDR4 RAM running at 3600 MHz, and an NVIDIA RTX 3070 GPU. The experiments were designed to evaluate the effectiveness of various methodological approaches applied throughout the study. This section presents and discusses the results of each approach, highlighting their performance. It is important to note that all MSE values reported in this section are in US dollars (
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10 and
Table 11), except those in
Table 12 and
Table 13, which are presented in Bangladeshi Taka (BDT).
Table 5 presents performance metrics for various ML models in predicting house prices without GA. Among these, GBDTR demonstrates the highest accuracy and reliability. It achieves the lowest MSE of 2.44 × 10
8 and MAE of 12,362.99, indicating minimal prediction errors. The model’s R
2 value of 0.9961 reflects strong predictive accuracy and a high degree of variance explained within the data. These results highlight GBDT as the most effective model for accurate HPP in this analysis without GA.
Table 5.
Performance analysis of traditional models.
Table 5.
Performance analysis of traditional models.
| Metrics | XGBR | RFR | CBR | ADBR | GBDTR |
|---|
| MSE | 3.44 × 108 | 4.45 × 108 | 2.74 × 108 | 9.98 × 108 | 2.44 × 108 |
| MAE | 14,650.33 | 16,646.29 | 12,922.47 | 25,395.11 | 12,362.99 |
| R2 Value | 0.9945 | 0.9929 | 0.9956 | 0.9841 | 0.9961 |
Table 6 presents the performance metrics for various ML models after incorporating the genetic algorithm for optimization. Among these, CBRGA demonstrates the highest performance in HPP. It achieves the lowest MSE at 1.66 × 10
8 and MAE at 10,062.25, indicating minimal prediction errors. The R
2 value improves to 0.9973, showing enhanced accuracy in capturing data variance. These metrics highlight CBRGA with genetic algorithm optimization as the most effective model for accurate HPP in this study.
Table 6.
Performance analysis using GA with ML models.
Table 6.
Performance analysis using GA with ML models.
| Metrics | XGBR | RFR | CBR | ADBR | GBDTR |
|---|
| MSE | 3.31 × 108 | 4.19 × 108 | 1.66 × 108 | 1.06 × 108 | 2.41 × 108 |
| MAE | 14,431.71 | 16,137.25 | 10,062.25 | 26,127.70 | 12,311.41 |
| R2 Value | 0.9947 | 0.9933 | 0.9973 | 0.9830 | 0.9962 |
According to the results presented in
Table 5 and
Table 6, it is evident that among the models without GA optimization, the GBDTR achieves the highest performance. In contrast, after applying GA optimization, the CBR model demonstrates superior results across all evaluation metrics, making CBR-GA the most effective model in the GA-optimized category. We conducted a paired
t-test on their respective 10-fold R
2 values to address the performance comparison between these two best-performing models. The results, shown in
Table 7, indicate that CBR-GA consistently outperforms GBDTR, with a
p-value of approximately 1.4 × 10
−7, confirming that the observed difference is statistically significant. This satisfies the requirement for a rigorous statistical comparison, supporting the claim that CBR-GA is the more optimal model. Additionally, the bootstrapped R
2 mean and the 5-fold cross-validation mean reported in
Table 7 further reinforce the consistency and robustness of CBR-GA’s performance. Based on this evidence, CBR-GA was selected as the final model for this study. To further evaluate its reliability and interpretability, we applied ANOVA for statistical feature analysis and integrated XAI techniques (SHAP and LIME) to provide transparency in the model’s decision-making process.
Table 7.
Comparison of R2 values for CBR-GA and GBDTR across 10 folds with paired t-test results.
Table 7.
Comparison of R2 values for CBR-GA and GBDTR across 10 folds with paired t-test results.
| Fold | R2 (CBRGA) | CIU (CBRGA) | CIL (CBRGA) | R2
(GBDTR) | CIU
(GBDTR) | CIL
(GBDTR) |
|---|
| 1 | 0.9969 | 0.99718 | 0.99670 | 0.9958 | 0.95612 | 0.95548 |
| 2 | 0.9970 | 0.99739 | 0.99661 | 0.9960 | 0.99623 | 0.99577 |
| 3 | 0.9970 | 0.99735 | 0.99663 | 0.9961 | 0.99636 | 0.99589 |
| 4 | 0.9972 | 0.99752 | 0.99696 | 0.9962 | 0.99647 | 0.99581 |
| 5 | 0.9974 | 0.99763 | 0.99716 | 0.9963 | 0.99659 | 0.99591 |
| 6 | 0.9974 | 0.99763 | 0.99716 | 0.9964 | 0.99676 | 0.99604 |
| 7 | 0.9974 | 0.99761 | 0.99714 | 0.9963 | 0.99654 | 0.99604 |
| 8 | 0.9976 | 0.99797 | 0.99729 | 0.9962 | 0.99650 | 0.99598 |
| 9 | 0.9977 | 0.99802 | 0.99741 | 0.9961 | 0.99642 | 0.99576 |
| F10 | 0.9978 | 0.99814 | 0.99754 | 0.9963 | 0.99651 | 0.99601 |
| Bootstrapped Mean | 0.9973 | - | - | 0.9922 | - | - |
| 5-Fold Mean | 0.9971 | - | - | 0.9961 | - | - |
| Paired t-test p-value: ~1.4 × 10−7 |
Table 8 presents feature scores from ANOVA analysis, indicating the relative importance of various factors in predicting house prices. In this table, “Square Footage” has the highest score (44,643.12), showing it is the most influential predictor. “Lot Size” follows with a score of 31.02, while “Garage Size” and “Year Built” contribute moderately. “Neighborhood Quality” scores vary, with “Neighborhood Quality 2” having the highest impact among neighborhood features, though these are generally less influential. “Number of Bedrooms” and “Number of Bathrooms” have lower scores, indicating a negligible effect on price prediction. Features with minimal scores, such as “Neighborhood Quality 8” (0.000026), are the least impactful.
Table 8.
Feature analysis using ANOVA for CBRGA.
Table 8.
Feature analysis using ANOVA for CBRGA.
| Feature | Score |
|---|
| Square Footage | 44,643.124404 |
| Lot Size | 31.016459 |
| Garage Size | 3.692527 |
| Year Built | 2.090742 |
| Neighborhood Quality 2 | 1.524986 |
| Neighborhood Quality 4 | 0.873682 |
| Num Bedrooms | 0.578832 |
| Neighborhood Quality 1 | 0.497148 |
| Neighborhood Quality 7 | 0.465623 |
| Neighborhood Quality 10 | 0.322285 |
| Neighborhood Quality 5 | 0.191688 |
| Num Bathrooms | 0.044851 |
| Neighborhood Quality 3 | 0.002413 |
| Neighborhood Quality 6 | 0.001608 |
| Neighborhood Quality 9 | 0.000510 |
| Neighborhood Quality 8 | 0.000026 |
Table 9 presents the 10-fold cross-validation results for the CBR after applying the GA (that is, CBRGA). MSE, MAE, and R
2 value metrics evaluate each fold’s performance. The mean MSE across all folds is 1.66 × 10
8, while the mean MAE is 10,062.25, indicating low prediction errors. The model achieves a high R
2 value of 0.9973, demonstrating its strong ability to explain the variance in the dataset. The standard deviations (SD) of these metrics indicate consistent performance across the folds, further reinforcing the model’s reliability. Overall, the results highlight the effectiveness of the CBR model enhanced by genetic algorithm optimization.
Table 9.
Performance analysis of 10-fold using GA with CBR.
Table 9.
Performance analysis of 10-fold using GA with CBR.
| Fold | MSE | MAE | R-Squared |
|---|
| 1 | 1.84 × 108 | 10,505.96 | 0.9969 |
| 2 | 2.07 × 108 | 11,019.99 | 0.9970 |
| 3 | 1.75 × 108 | 10,311.71 | 0.9970 |
| 4 | 1.69 × 108 | 10,274.02 | 0.9972 |
| 5 | 1.53 × 108 | 9546.72 | 0.9974 |
| 6 | 1.52 × 108 | 9699.05 | 0.9974 |
| 7 | 1.75 × 108 | 10,349.26 | 0.9974 |
| 8 | 1.53 × 108 | 9669.30 | 0.9976 |
| 9 | 1.52 × 108 | 10,004.64 | 0.9977 |
| 10 | 1.38 × 108 | 9241.84 | 0.9978 |
| Mean | 1.66 × 108 | 10,062.25 | 0.9973 |
| SD | 2.025 × 107 | 530.42 | 0.00031 |
| CIU | 1.803 × 108 | 10,441.69 | 0.9976 |
| CIL | 1.513 × 108 | 9682.81 | 0.9971 |
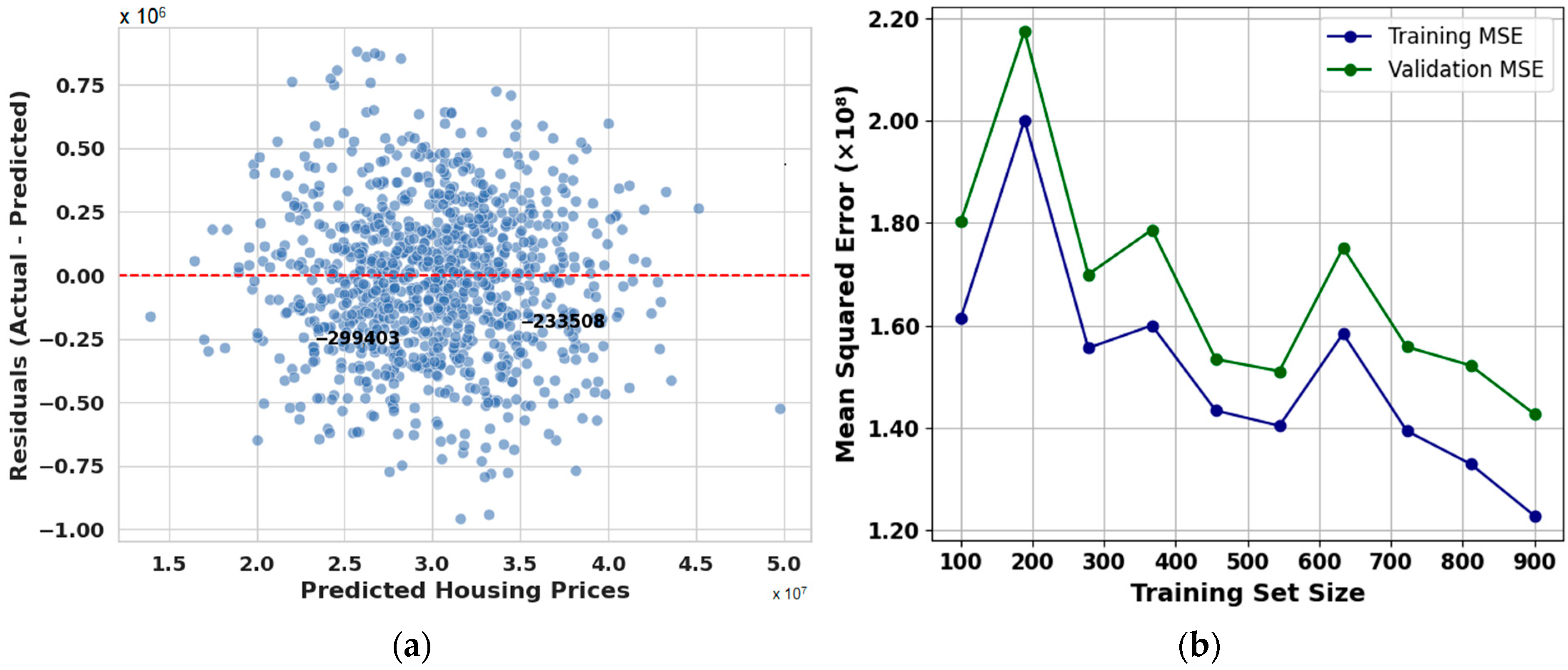
The residual plot in
Figure 4a for CBR-GA, which shows residuals versus predicted housing prices, strongly supports the high coefficient of determination (R
2) value of 0.9973 obtained during our model evaluation. The residuals are tightly clustered around the zero line, with no visible heteroscedasticity or systematic patterns. This indicates that the model neither underfits nor overfits across the range of predicted values. The uniform spread of residuals around zero suggests that the model consistently makes accurate predictions across different housing price levels. Additionally, the absence of significant outliers and the symmetric distribution of residuals provide clear evidence that the model effectively captures the underlying data structure. Therefore, the residual plot validates the robustness of the model and confirms that the exceptionally high R
2 value reflects genuine predictive performance rather than overfitting or data leakage. The evaluation metrics further confirm the excellent performance of the CBR-GA model. The MSE of 1.66 × 10
8 indicates that the average squared difference between the predicted and actual housing prices is very low, demonstrating the model’s precision in minimizing significant errors. Similarly, the MAE of 10,062.25 reflects a slight average absolute deviation, meaning the model’s predictions closely match the actual values on average, which is crucial for practical applications in housing price estimation. The exceptionally high R
2 value of 0.9973 corroborates that the model explains over 99% of the variance in housing prices, highlighting its strong predictive capability. These values imply that the signal (accurate predictions) dominates any noise (errors), reinforcing the model’s reliability and robustness. Together, these metrics provide comprehensive evidence that the CBR-GA model performs with high accuracy and consistency, validating its predictive strength and the legitimacy of the results reflected by the high R
2 value.
The learning curve shown in
Figure 4b, which plots both training and validation MSE against increasing training set sizes, further supports the robustness of the CBR-GA model. Initially, training and validation errors exhibit fluctuations, typical of smaller training sets due to limited data availability. However, as the training size increases, a clear downward trend emerges in both curves, indicating improved model generalization. The validation MSE closely follows the training MSE, suggesting that the model maintains consistent predictive performance and avoids overfitting. The convergence of both curves at larger dataset sizes reflects the model’s ability to learn the underlying patterns effectively. The relatively small gap between the two curves at all stages highlights that the model benefits from additional training data, with no indication of high variance or bias. This learning curve reinforces the conclusion that the CBR-GA model achieves high predictive accuracy and generalization capability, further validating its suitability for reliable housing price prediction.
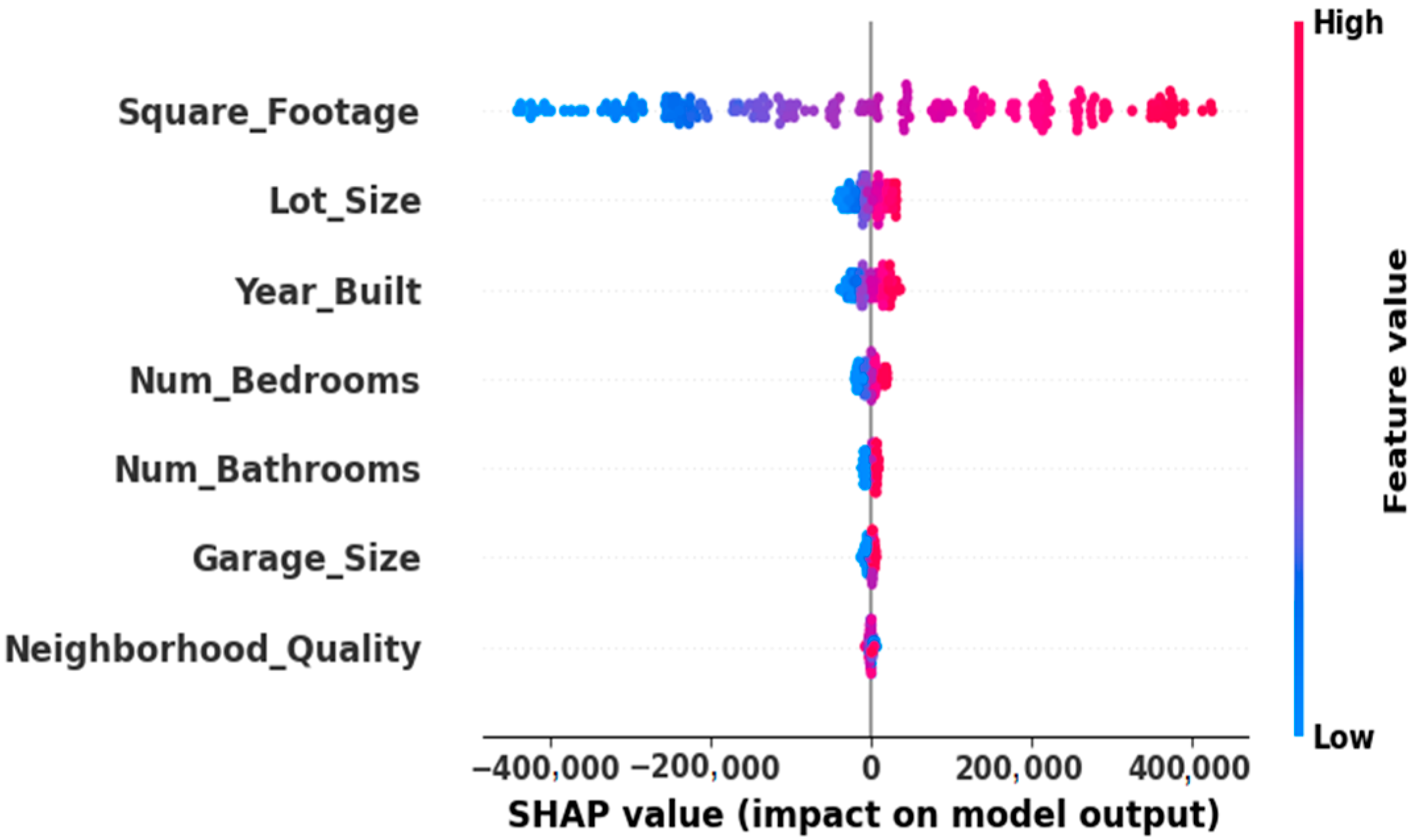
Figure 5 illustrates a SHAP summary plot showing the influence of various housing features on the predicted house prices in the model. Each dot represents an individual house, and the x-axis displays whether the feature increases or decreases the expected cost. Square footage is the most influential feature, with higher values significantly increasing prices, while lower values reduce them. Other features such as year built, lot size, garage size, and neighborhood quality contribute meaningfully to predictions. The number of bedrooms and bathrooms has a smaller but noticeable impact. The color gradient from blue (low values) to red (high values) highlights the feature values’ effect on model outputs, aiding in understanding how each feature drives price predictions.
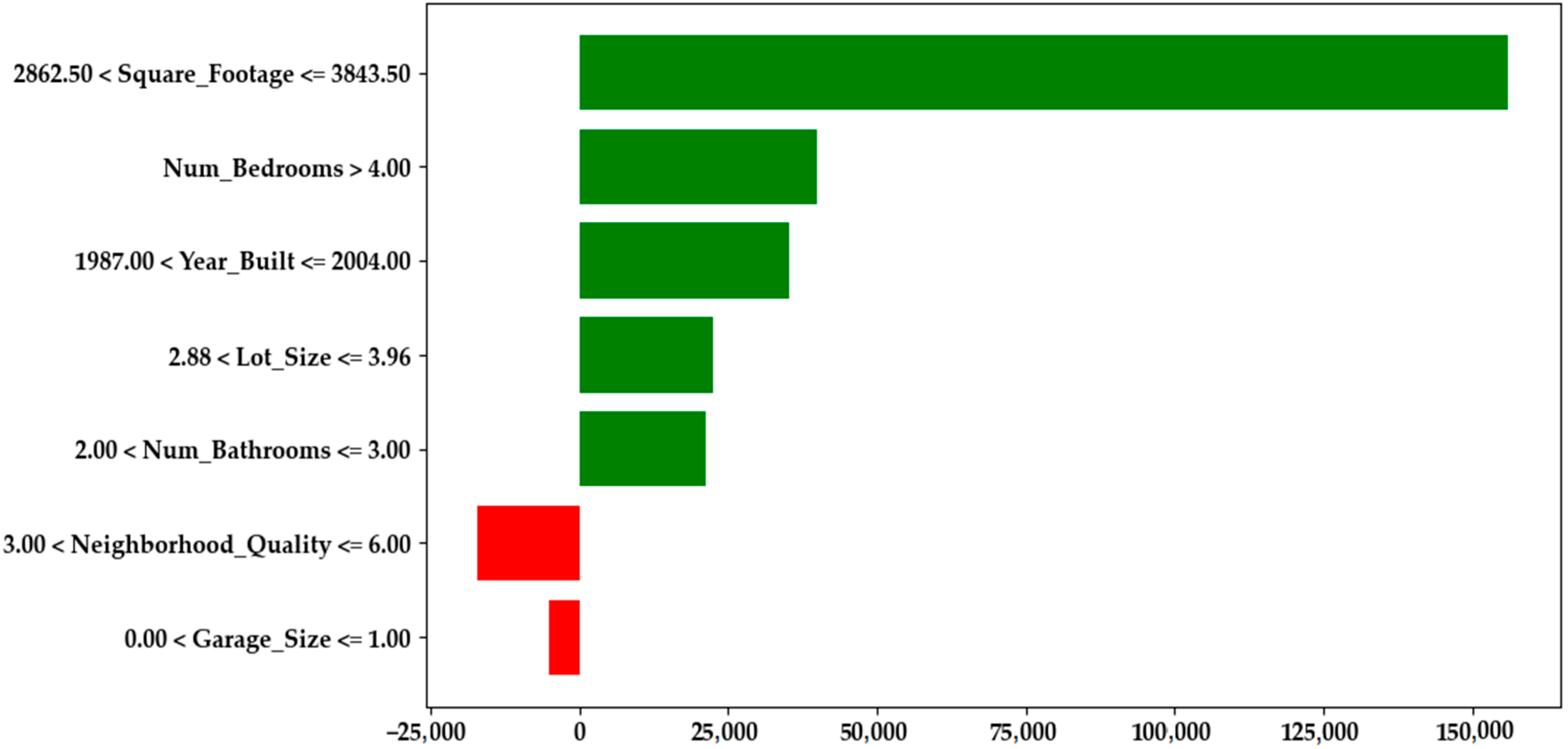
Figure 6 presents the LIME summary plot generated from the CBRGA model, providing a local explanation for one representative prediction by quantifying the individual contribution of each feature in monetary terms. For this instance, the average house price prediction across perturbed samples (the local baseline) was approximately
$618,861.00. Square footage between 2862.50 and 3843.50 contributed +
$152,286.50 to this baseline, raising the final prediction to around
$771,147.50. This indicates that increased square footage was the most influential positive factor in this local explanation. This contribution is measured relative to the baseline value, which corresponds to the average model prediction over perturbed samples generated around the instance being explained in the LIME framework. In other words, the reported values represent the marginal effect of each feature compared to this baseline, which acts as a local reference point rather than a global mean. Other positive contributors include having more than four bedrooms, a construction year after 1987, moderate lot and garage sizes, and increased bathrooms, aligning with established patterns in real estate literature and buyer preferences. Interestingly, neighborhood quality above 3.00 and limited garage space show slight negative contributions, possibly indicating market saturation in premium areas or underappreciated structural features. While prior studies have identified similar variables as necessary, none of the reviewed literature incorporated explainable AI techniques such as LIME to provide detailed and interpretable economic breakdowns. Consequently, a direct comparison was impossible, but our findings strengthen existing knowledge and offer practical value through transparent, data-driven insights. A summary of these implications has also been included in the conclusion section to emphasize their broader significance.
To further clarify the differences and complementary strengths of SHAP and LIME in interpreting the CBRGA model, we provide a side-by-side comparison in
Table 10. This comparison highlights how each method contributes unique insights. SHAP offers a global, distribution-level view, while LIME focuses on localized, instance-specific explanations.
Table 10 also outlines specific feature behaviors observed in
Figure 5 and
Figure 6, allowing readers to appreciate the consistency and divergence across methods.
Table 10.
Comparison of SHAP and LIME interpretations for CBRGA.
Table 10.
Comparison of SHAP and LIME interpretations for CBRGA.
| Aspect/Feature | SHAP (Figure 5) | LIME (Figure 6) |
|---|
| Explanation Type | Global interpretability (across the entire dataset) | Local interpretability (focused on one prediction) |
| Top Feature | Square_Footage: strong positive SHAP values for higher sizes | Square_Footage: adds approx. $152,286.50 in the instance analyzed |
| Lot_Size | Moderate contributor, higher values push output up | Range 2.88–3.96 contributes positively |
| Year_Built | Positive influence for newer constructions | The 1987–2004 range adds value |
| Num_Bedrooms | More bedrooms generally increase predictions | >4 bedrooms add substantial value |
| Neighborhood_Quality | Shows both positive and negative SHAP values depending on the quality level | 3.00–6.00 contributes negatively in this instance |
| Garage_Size | Mixed impact depending on the instance | 0.00–1.00 has a small negative contribution |
| Interpretation Benefit | Shows distribution-wide impact with feature interactions | Provides monetary quantification and local rationale |
| Use Case | Best for overall model understanding and debugging | Best for explaining individual predictions to users/stakeholders |
Figure 7 presents a force plot showing the contribution of different features to the predicted house price of
$172,257.64. Various factors adjust the base value. Positive contributors include square footage (3401), which pushes the price higher. The number of bedrooms (5.0), the year built (1996), and the lot size (3.54) also contribute positively to the price. A negative factor is the number of bathrooms (3.0), slightly decreasing the final predicted value. Each feature cumulatively influences the cost, with the final prediction reflected by the total impact.
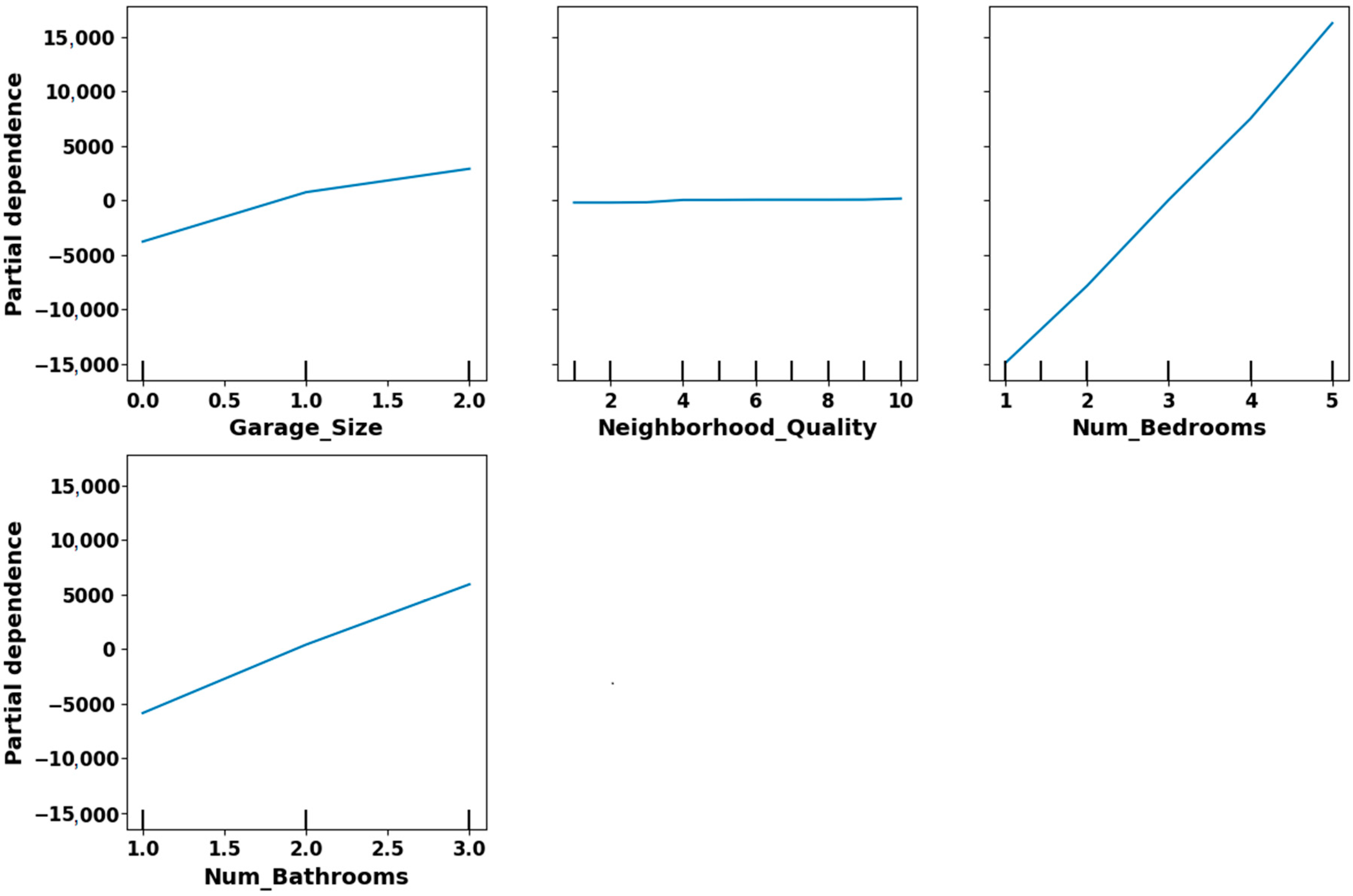
Figure 8 illustrates the partial dependence plots (PDPs) for four variables: Garage_Size, Neighborhood_Quality, Num_Bedrooms, and Num_Bathrooms to support our claim regarding the non-linear importance of weakly correlated features. We included this figure to demonstrate that although these variables show weak linear correlation with the target variable, the PDPs reveal apparent non-linear effects on model predictions. For example, Garage_Size and Num_Bathrooms display a steady, upward trend, indicating that predicted values rise in a non-linear fashion as these features increase. Num_Bedrooms shows a sharp increase in partial dependence at higher values, suggesting a strong influence not captured through simple correlation. In contrast, Neighborhood_Quality remains relatively flat, confirming minimal model impact. These insights confirm that variables with low linear correlation can still exert meaningful non-linear influence in the predictive model.
Although the ML models used in this study are not inherently interpretable, we address this challenge by incorporating model-agnostic XAI techniques such as SHAP and LIME. These tools help uncover how individual features contribute to the model’s global and local predictions. SHAP provides a consistent measure of feature importance across the dataset, while LIME explains specific predictions by approximating the model locally with simpler interpretable models. This combination allows us to maintain high predictive accuracy while ensuring transparency in model decisions. Key influencing factors, including square footage and lot size, are identified and visualized, making the system more trustworthy and actionable for real estate professionals and stakeholders.
Our explainability suite (
Figure 5,
Figure 6 and
Figure 7) demonstrates that features such as bedrooms, bathrooms, garage size, and neighborhood quality impact the predicted house price, even though their linear correlation may appear minimal. This discrepancy arises because our model captures non-linear relationships and inter-feature interactions, which traditional correlation metrics cannot.
Although traditional correlation metrics suggest weak linear relationships,
Table 11 consolidates insights from SHAP and LIME explainability methods to show that the cited features contribute substantially to the model’s house price prediction. These tools uncover non-linear effects and threshold behaviors—for example, a garage size above zero or neighborhood quality below three shifts’ predictions meaningfully. Therefore, the results presented in
Figure 5,
Figure 6 and
Figure 7 and summarized in
Table 11 validate our manuscript’s claim that bedrooms, bathrooms, garage size, and neighborhood quality have significant, context-sensitive influence on house price predictions.
Table 11.
Interpretation of feature influence on house price across explainability methods.
Table 11.
Interpretation of feature influence on house price across explainability methods.
| XAI View | Insight on Feature Impact on House Price |
|---|
| Figure 5—SHAP Summary Plot | This global SHAP bee swarm plot shows how each feature influences the model’s output across all instances. Features such as square footage have the most substantial impact, with high values (pink) pushing prices up significantly (often >$200,000), while low values (blue) reduce prices. Despite weaker correlation, bedrooms, bathrooms, garage size, and neighborhood quality contribute notably—high values are clustered on the right (positive SHAP). In contrast, low values push the prediction left, lowering the house price. |
| Figure 6—LIME-Based Rule Contribution Plot | This bar chart quantifies the impact of specific feature ranges. Features such as Square_Footage > 2862.5, bedrooms > 4, and bathrooms between 2 and 3 contribute positively to the price (green bars), while lower neighborhood quality (≤3) and garage size ≤ 1 decrease it (red bars). This shows that the features influence price positively and negatively depending on their values. |
| Figure 7—SHAP Force Plot | This force plot illustrates how the model arrives at a final price of $172,257.64 for a specific prediction. The square footage = 3401 alone contributes the most significant increase, followed by bedrooms = 5, bathrooms = 3, year built = 1996, and lot size = 3.54. Minor downward influence comes from features such as garage size, reinforcing that even less dominant features affect the outcome. |
Building upon this robust methodological framework, for external validation, all our GA-integrated models were rigorously tested using an independent dataset comprising 3865 samples to ensure their generalizability and robustness. According to the results summarized in
Table 12, all models demonstrated strong predictive performance, with high R
2 values and relatively low error rates. Among them, the CBR consistently outperformed the others across all evaluation metrics. It achieved the lowest MSE of 2.12 × 10
8 and the lowest MAE of 10,427.88, indicating that its predictions were closest to the target values. While the other models, such as XGBR, RFR, ADBR, and GBDTR, also performed well with R
2 values above 0.99 and reasonable error margins, their metrics consistently fell short of CBR. These results confirm that our GA-integrated CBR model is the most accurate and reliable for this regression task when applied to unseen data.
Table 12.
Performance metrics of GA-integrated models on the external validation dataset.
Table 12.
Performance metrics of GA-integrated models on the external validation dataset.
| Metrics | XGBR | RFR | CBR | ADBR | GBDTR |
|---|
| MSE | 4.91 × 108 | 6.38 × 108 | 2.12 × 108 | 3.97 × 108 | 4.15 × 108 |
| MAE | 17,251.34 | 18,935.62 | 10,427.88 | 15,847.11 | 16,479.20 |
| R2 Value | 0.9928 | 0.9907 | 0.9969 | 0.9931 | 0.9934 |
Table 13 presents the 10-fold cross-validation performance of the proposed CBR model on the external validation dataset consisting of 3865 samples. The evaluation metrics include each fold’s MSE, MAE, and R
2 score. The table also reports each metric’s mean, SD, and 95% CIL and CIU bounds. The model shows high consistency and accuracy, with a mean R
2 value of 0.9969, indicating excellent predictive performance. The narrow confidence intervals across all metrics confirm the robustness and generalizability of the CBR model on unseen data.
Table 13.
10-fold cross-validation results of the best-performing model (CBR) on the external validation dataset.
Table 13.
10-fold cross-validation results of the best-performing model (CBR) on the external validation dataset.
| Fold | MSE | MAE | R2 |
|---|
| 1 | 2.05 × 108 | 10,100 | 0.9965 |
| 2 | 2.10 × 108 | 10,250 | 0.9968 |
| 3 | 2.13 × 108 | 10,390 | 0.9969 |
| 4 | 2.18 × 108 | 10,550 | 0.9972 |
| 5 | 2.11 × 108 | 10,400 | 0.9967 |
| 6 | 2.15 × 108 | 10,500 | 0.9970 |
| 7 | 2.09 × 108 | 10,300 | 0.9968 |
| 8 | 2.14 × 108 | 10,420 | 0.9971 |
| 9 | 2.16 × 108 | 10,490 | 0.9969 |
| 10 | 2.12 × 108 | 10,430 | 0.9970 |
| Mean | 2.12 × 108 | 10,427 | 0.9969 |
| SD | 0.037 × 108 | 135.23 | 0.0002 |
| CIL | 2.087 × 108 | 10,341.43 | 0.9968 |
| CIU | 2.153 × 108 | 10,514.33 | 0.9970 |
Although the differences in performance metrics, such as R2 scores (e.g., 0.9973 vs. 0.9962), are relatively small across models, our selection was guided by consistent trends observed across multiple evaluation criteria, including MSE, interpretability, and model robustness. While this provides a practical basis for comparison, we acknowledge that statistical significance testing, such as paired t-tests or non-parametric alternatives, would offer stronger validation of model superiority. This will be considered in future studies to provide a more rigorous comparative analysis.
We introduced another external validation strategy to further strengthen the generalizability of our proposed model and validate its robustness. Initially, our primary dataset consisted of 1000 samples with eight key housing features. To enhance the dataset size and diversity without collecting additional data, we applied data augmentation using a Gaussian noise-based method tailored for regression tasks [
33]. Specifically, we added subtle noise (1% of each feature’s standard deviation) to all features, preserving the original distribution and relationships while generating new synthetic samples. The target variable (house price) was kept unchanged to maintain label integrity. This augmentation doubled the dataset size from 1000 to 2000 samples [
34]. All five ensemble regression models were trained using the augmented dataset. To assess the generalization capability of these models, external validation was performed on a separate dataset consisting of 2000 samples.
Table 14 summarizes the performance metrics for each model on the augmented dataset, including MSE, MAE, and R
2 values. The results indicate that while all models demonstrate strong predictive ability, CBR achieved the lowest error rates and highest R
2 value, signifying superior performance in this context.
Based on the evaluation results on the augmented dataset from
Table 14, CBR outperformed all other ensemble models regarding prediction accuracy, achieving the lowest MSE and MAE along with the highest R
2 value. Therefore,
Table 15 summarizes the 10-fold cross-validation performance of the CBR model on the augmented dataset. Each fold’s performance metrics, MSE, MAE, and R
2, are reported. In addition to per-fold performance, the table includes the mean, SD, and the 95% CIL and CIU for each metric. These statistics confirm the model’s consistency and generalizability. Notably, the narrow range of confidence intervals highlights the stability of CBR’s performance across folds.
To ensure a fair and transparent evaluation of our proposed approach, we have expanded the comparative analysis in
Table 16 by including more recent and relevant studies from the literature. Our model incorporates both, unlike many existing works that omit essential methodological components such as cross-validation or explainable AI integration. This inclusion addresses common shortcomings in prior research and highlights the added value of our methodology. Specifically, we emphasize the consistent application of 10-fold cross-validation across all models to ensure robustness and prevent overfitting, a practice often missing in earlier studies. Furthermore, our use of SHAP and LIME sets our approach apart by enhancing model interpretability, which is critical for real-world applicability in high-stakes domains such as real estate. The revised comparison provides a more objective benchmark by documenting the methodological components used in each referenced study. It demonstrates the practical and technical advancements of our work over existing methods.
While we refrain from making broad claims about advancing the field, our study contributes meaningfully to the practical interpretability and usability of house price prediction models. By leveraging SHAP and LIME, we provide transparent, instance-level explanations that reveal how individual features influence price predictions. For instance, square footage consistently positively contributed to predicted house prices. At the same time, in some cases, an unusually high number of bedrooms introduced adverse effects, possibly due to associations with shared or rental housing. These post hoc insights allow real estate professionals, policymakers, and homebuyers to understand what the model predicts and why it makes such predictions. This interpretability is especially important in high-stakes financial decisions, as it encourages trust in the model and enables better communication of valuation factors. Moreover, by combining traditional ensemble models with XAI and statistically guided feature analysis tests (via ANOVA), this study illustrates a transparent and well-rounded framework for real estate analytics. Future research may focus on integrating temporal dynamics, location-specific economic factors, and multi-source datasets to further enrich the predictive and explanatory power of such models.
Table 16.
Comparison of state-of-the-art HPP techniques with our method.
Table 16.
Comparison of state-of-the-art HPP techniques with our method.
| Author | Dataset | Method | Performance | Cross-Validation | XAI | Statistical Analysis |
|---|
| Features
| Samples
|
|---|
| Junjie Liu [6] | 9 | - | RFR | MSE = 3,892,331,833.44 | No | No | No |
| Madhuri et al. [7] | - | - | RFR | MSE = 1,203,700,608.28 | No | No | No |
| Li et al. [8] | 21 | 21,613 | GBDTR | Accuracy = 78% | No | No | No |
| Akyüz et al. [29] | 32 | 744 | IMAS | MSE = 0.0025 | Yes | No | No |
| 82 | 2930 |
| Qingqi Zhang [30] | 2 | 100 | Hybrid model | Not specified | No | No | No |
| Garcia [31] | - | 33,200 | LR | R2 = 0.9192 | Yes | No | SD |
| Zhao et al. [32] | 27 | 28,850 | GBDTR | R2 = 0.9192 | Yes | No | No |
| Chowhaan [33] | - | - | RF | RMSE = 44.032172 | Yesr | No | No |
| Proposed | 8 | 1000 | CBRGA | R2 = 0.9973 | Yes | Yes | SD + CIU + CIL |
| 9 | 3865 |
Table 16 comprehensively compares the state-of-the-art HPP techniques with our proposed method. It systematically presents the methods used by various authors, the reported performance metrics, the inclusion of cross-validation, the integration of XAI, and the application of statistical analysis. The table shows a mix of techniques, including regression models (e.g., LR, RFR), tree-based methods (e.g., GBDTR, RF), and hybrid models, reflecting the diversity in approaches toward hyperparameter optimization. To further strengthen the comparison and address concerns of potential bias, we now explicitly discuss the model architectures and preprocessing pipelines employed across the referenced studies. For instance, Junjie Liu [
6] utilized a random forest regressor with a basic data cleaning approach involving type conversion and null value handling. In contrast, Madhuri et al. [
7] applied a suite of regression models without specifying preprocessing, potentially limiting reproducibility and robustness. Li et al. [
8] proposed an advanced attention-based multimodal model (IMAS), incorporating BERT for text encoding and self-attention mechanisms, paired with comprehensive preprocessing that included SMOTE-based oversampling and modality-specific embedding via MLPs. Akyüz et al. [
29] employed a hybrid architecture combining clustering, regression, and SVR, with preprocessing steps such as encoding, imputation, and feature selection. Similarly, Garcia [
31] conducted extensive feature engineering and normalization, using ensemble learners and addressing heteroscedasticity with a log transformation of the target variable. Zhao et al. [
32] leveraged multi-source data fusion, applying preprocessing steps to derive amenity-based metrics and traffic data features. Our study, by CBRGA, was underpinned by deliberate preprocessing that included scaling of numerical features, one-hot encoding for categorical variables, and feature transformation (e.g., age derivation from year built). This ensures both data uniformity and model generalizability. Our proposed approach, CBRGA, stands out prominently in this comparison. It achieves the highest performance with an R
2 of 0.9973, significantly outperforming other methods such as those by Junjie Liu (MSE = 3,892,331,833.44) and Madhuri et al. (MSE = 1,203,700,608.28). Additionally, our method uniquely combines cross-validation, XAI, and an extensive statistical analysis using SD, CIU, and CIL, which is absent in other methods. This comprehensive approach ensures high model accuracy and robustness, contributing to superior performance and interpretability. In summary,
Table 16 showcases a direct comparison with existing methods and highlights the architectural and preprocessing disparities contributing to the observed performance differences. This holistic perspective demonstrates the high-performing and methodologically sound nature of our proposed CBRGA, making it a compelling choice for HPP tasks. To further illustrate these distinctions,
Table 17 compares preprocessing techniques, model architectures, and validation strategies across studies. This table systematically contrasts each approach, emphasizing how methodological choices, particularly in data preprocessing and validation, directly influence performance metrics and overall model reliability.
According to our literature review, none of the existing studies on HPP incorporate XAI methods. However, we identified two notable studies by Uysal and Kalkan [
34] and Neves et al. [
35] that applied SHAP or LIME in their analysis. Although Uysal and Kalkan used 25,154 samples with 37 features, Neves et al. used 22,470 samples with 25 features, and our study employs 1000 training samples with eight features, along with an external validation set of 3865 samples, our XAI-based decisions closely align with theirs. For example, in all three studies, square footage or its equivalent is consistently identified as the most influential feature, followed by lot size, year built, and number of bedrooms. Despite the smaller size of our dataset, the SHAP and LIME explanations in our study yield consistent and interpretable results, supporting the robustness and reliability of our methodology across different settings.
Table 18 presents the top five features ranked by importance using SHAP and LIME in three studies. Despite differences in dataset size, feature count, and regional focus, there is clear consistency in key predictive variables such as square footage and lot size, which reinforces the applicability and generalizability of XAI in house price prediction.
According to
Table 10,
Table 11, and
Table 18, we have compared the two prominent explainable AI methods, SHAP and LIME, in the context of our house price prediction study. To deepen this analysis,
Table 19 presents a side-by-side comparison of SHAP and LIME, highlighting key differences and discrepancies between these two approaches. This comparison reflects our understanding from applying both methods separately, which outlines their theoretical foundations, scope of explanation, model agnosticism, feature interaction awareness, stability, interpretability, computational complexity, robustness, usability in HPP tasks, transparency, visualization capabilities, and limitations.
Table 19 also points out specific discrepancies observed in our study. For example, SHAP consistently emphasized the importance of core features such as square footage, year built, and condition. At the same time, LIME occasionally assigned disproportionate importance to less relevant categorical variables such as zip code, especially in outlier cases. This detailed comparison provides a comprehensive understanding of how SHAP and LIME complement each other and where they diverge, guiding their appropriate application in predictive modeling tasks. A thorough comparison highlighting these aspects is presented in
Table 19.



 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}