

A Novel Stock Price Prediction and Trading Methodology Based on Active Learning Surrogated with CycleGAN and Deep Learning and System Engineering Integration: A Case Study on TSMC Stock Data


Abstract
1. Introduction
- This study employs CycleGAN to elucidate the joint effect of stock price and trading volume, demonstrating the capability of this DL model to capture their joint effect;
- It cascades the outcomes of CycleGAN into subsequent DL models for stock price prediction, evaluating and contrasting the predicting accuracies of ResNet and LSTM;
- The research methodology fuses an SE Model with predictive analytics for a short-term stock price prediction. It also compares the derived trading signals and RoI against those obtained from Bollinger Band alone and the proposed approach;
- AL strategies are applied to augment the dataset, thereby mitigating risks of overfitting or underfitting in DL models. This approach also encompasses the utilization of active learning with experimental design techniques, sometimes called Design of Experiment (DoE), to optimize the system’s hyperparameters;
- Data from Taiwan Semiconductor Manufacturing Company (TSMC) are utilized to train and validate the active learning-based system, with the aim of enhancing decision-making processes in stock market investments.
2. A Literature Review
2.1. Technical Analysis on Stock Market
2.1.1. Technical Analysis and Joint Effect of Stock Price and Trading Volume
2.1.2. Sentimental Analysis of Political and Economic Factors
2.1.3. Capital Asset Pricing Model, Sharp Ration, and Information Ratio
- Subtract the benchmark return from the portfolio return;
- Divide the result by the tracking error.
2.2. Cyclic GAN (CycleGAN)
2.3. Architecture and Functionality of Convolution Neuron Network (CNN)
2.4. Deconvolutional Networks
2.5. Residual Neural Network (ResNet)
2.6. Long Short-Term Memory (LSTM)
- (1)
- The input gate protects the unit from irrelevant input events;
- (2)
- The forget gate helps the unit forget previous memory contents [41];
- (3)
- The output gate exposes the contents of the memory cell (or not) at the output of the LSTM block.
2.7. Image of Time Series by GADF
2.8. System Engineering (SE) and Dynamic Behavior
- Mass: When considering Newton’s second law, the mass M relates to the formula:
- 2.
- Damper (friction force): f = Dv; D is the friction constant, and v is the speed.
- 3.
- Spring (spring force): Accounting for spring pushback force (R). A spring is an element that stores mechanical potential energy through elastic deformation.
2.9. Active Learning and Design of Experiment (DoE)
2.9.1. Surrogate Function and Active Learning
2.9.2. DoE and Taguchi Method
2.10. Bollinger Bands
- (1)
- Middle band
- (2)
- Upper band: Standard deviation of the middle band + K × N time period;
- (3)
- Lower band: Middle track-standard deviation of K × N time period;
- (4)
- Extended index—%b index: The position of the closing price in the Bollinger Bands is presented in digital form as a key indicator for trading decisions. The formula is
2.11. Evaluation and Experimental Results
- MSE (Mean Squared Error): This model computes the mean of the squares of the differences between actual and predicted values. MSE serves dual purposes; it evaluates the model’s accuracy and optimizes the gradient for neural network convergence. Under a consistent learning rate, a lower MSE correlates with a smaller gradient, indicating improved model performance [3,7];
- (1)
- Accuracy: Defined as the proportion of true results; i.e., both true positives and true negatives) among the total number of cases examined. It is calculated as (TP + TN)/(TP + FP + FN + TN). However, accuracy may be misleading, especially in cases of class imbalance;
- (2)
- Precision: This measures the ratio of true positives to the total prediction positives, calculated as TP/(TP + FP). Precision, sometimes conflated with accuracy, specifically refers to the consistency of repeated measurements under unchanged conditions;
- (3)
- Recall (sensitivity): Also known as the true positive rate, recall evaluates the model’s ability to correctly identify positive instances. The F1 Score, derived as 2TP/(2TP + FP + FN), is the harmonic mean of precision and recall, ranging from 0.0 (worst) to 1.0 (best). It is especially useful in scenarios where both recall and precision are crucial;
- (4)
- Return on Investment (ROI): ROI quantifies the efficiency of an investment, calculating the proportionate return relative to the investment cost [25]. In predictive modeling, ROI helps assess the financial benefit yielded by models like Bollinger Bands.
3. Research Method
3.1. Development Framework
3.2. Data Set
- Data Source: TWSE;
- Stock data: TSMC (2330.TW);
- Historical data: closing price and trading volume on each trading day;
- Data interval: January 2012 to December 2022, a total of ten years of trading day data;
- Training data: the first 90% of the total data is used as the training set, and 10% of the total data is used as the validation set;
- Test data: the last 10% of the total data.
3.3. Active Learning and DoE
- Learning rate (CycleGAN GAN, ): CycleGAN Model Learning Rate;
- Learning rate (Prediction, ): Learning Rate of the Prediction Model;
- λcls: Tuning the hyperparameters of Lcls in CycleGAN;
- λres: Tuning the hyperparameters of Lres in CycleGan;
- T: Represents the variation in data from the past T days utilized for predictions by model P;
- D: Indicates the data prediction D days into the future.
3.4. Data Pre-Processing
3.4.1. Normalization of Stock Prices and Trading Volumes
3.4.2. Direct Normalization
3.5. Training/Validation/Test Data
3.6. Deep Learning Architecture
3.6.1. Design of CycleGAN
3.6.2. Stock Price Prediction Models
- (1)
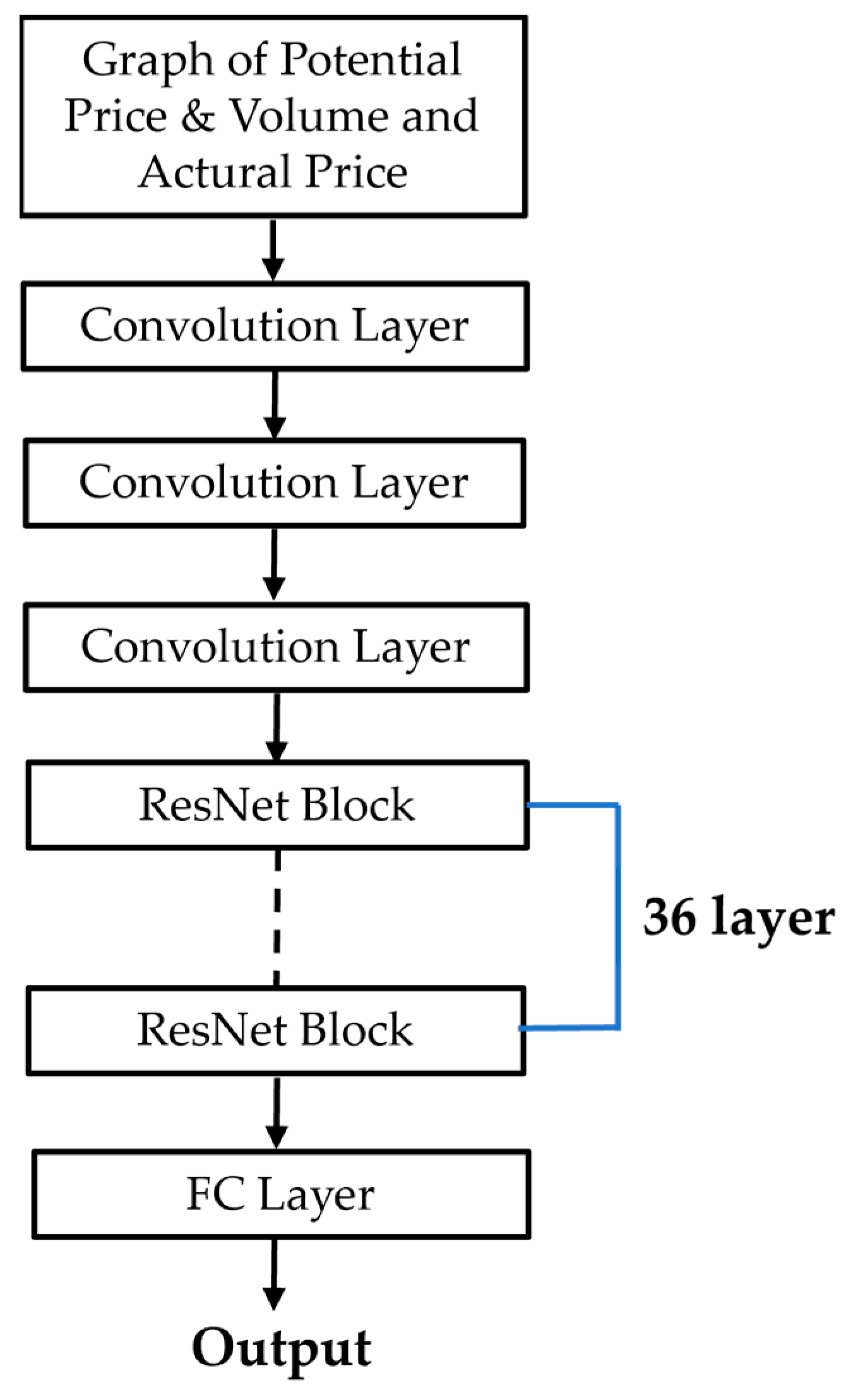
- CNN + ResNet Architecture: This approach integrates CNN for eigenvalue extraction with a ResNet framework. Specifically, the model utilizes a 36-day stock price reduction period, determined by the DoE, to inform the architecture of the ResNet. Consequently, the ResNet is structured with 36 layers, a design choice illustrated in Figure 12;
- (2)
- LSTM Model: The LSTM model is employed to reconstruct time series data related to stock prices. In this configuration, a five-day period (also determined by the DoE) encompassing stock price and trading volume data is utilized. The LSTM model is accordingly designed with four layers, as depicted in Figure 13.
3.7. System Engineering and Dynamics
- (1)
- Force (F): Computed as the product of market value (M) and the displacement value predicted by the model. F represents the external capital’s influence on market value. The input variables, Xt and Yt, are derived from the potential and current stock prices and trading volumes, respectively. These variables simulate the energy thrust of the market;
- (2)
- Market Value (M): Calculated as the product of closing stock price and the number of issued stocks. A change in market value reflects how capital inflows affect stock price growth rates across different market capitalizations;
- (3)
- Friction (f): Represented as a function of transaction tax (set at 3% in Taiwan), calculated from the product of trading volume, stock price, and the tax rate. It represents the resistance encountered during stock transactions.
- (4)
- Resilience (R): Based on the stock’s previous day’s performance, resilience correlates with the potential energy stored in the stock price movement. It is modeled to reflect the principle of the Bollinger Bands, with the rebound force increasing as the stock price deviates from its average;
- (5)
- Acceleration (a): Derived using a distance formula, assuming an initial velocity of zero. It is calculated based on the stock price at a specified future time point.
3.8. Design of Bollinger Band
- (1)
- Upper band: middle band + standard deviation of K × N time period;
- (2)
- Lower band: Middle band-standard deviation of K × N time period.
- (3)
- Extended Indicator—%b Indicator: The %b value, a numerical metric, quantifies the closing price’s relative position within the Bollinger Bands, thereby serving as a critical index for informed trading decisions. Specifically, a %b value of 0.5, or 50% in percentage terms, indicates that the closing price is precisely at the midpoint of the Bollinger Bands. The value of %b is calculated as
- (1)
- Select the closing price of the day;
- (2)
- The three-band setting parameter K is obtained by experimenting with Bollinger Bands. Two experiments are used to obtain the K that can make it have the best average reporting rate;
- (3)
- The closing price fluctuates between the upper and lower bands, with its magnitude occasionally surpassing the band range (0 to 1). Consequently, the %b value does not possess a definite boundary. When there is an upward trend break, and the closing price situates above the upper band, the %b value exceeds 1; inversely, during a downward trend break with the closing price below the lower band, the %b value is less than 0. By scrutinizing and analyzing the ‘%b Indicator’, investors can gain insights to inform their trading decisions based on the indicator’s prevailing momentum. The three-band setting parameter N is also obtained through experimental Bollinger bands, experiments 5~35, interval 5, and the parameter N that can make it have the best average reporting rate is obtained;
- (4)
- When setting the %b indicator ≥ 1, the stock should be sold (if it has not been bought before, it will not be sold). The stock should be bought when the %b index ≤ 0. The research methodology was implemented using PyTorch.
4. Results of the Experiments and Evaluation
4.1. Parameter Selection
4.2. Single Stock Prediction of Semiconductor Industry
4.3. Multi-Stock Forecasting in the Semiconductor Industry
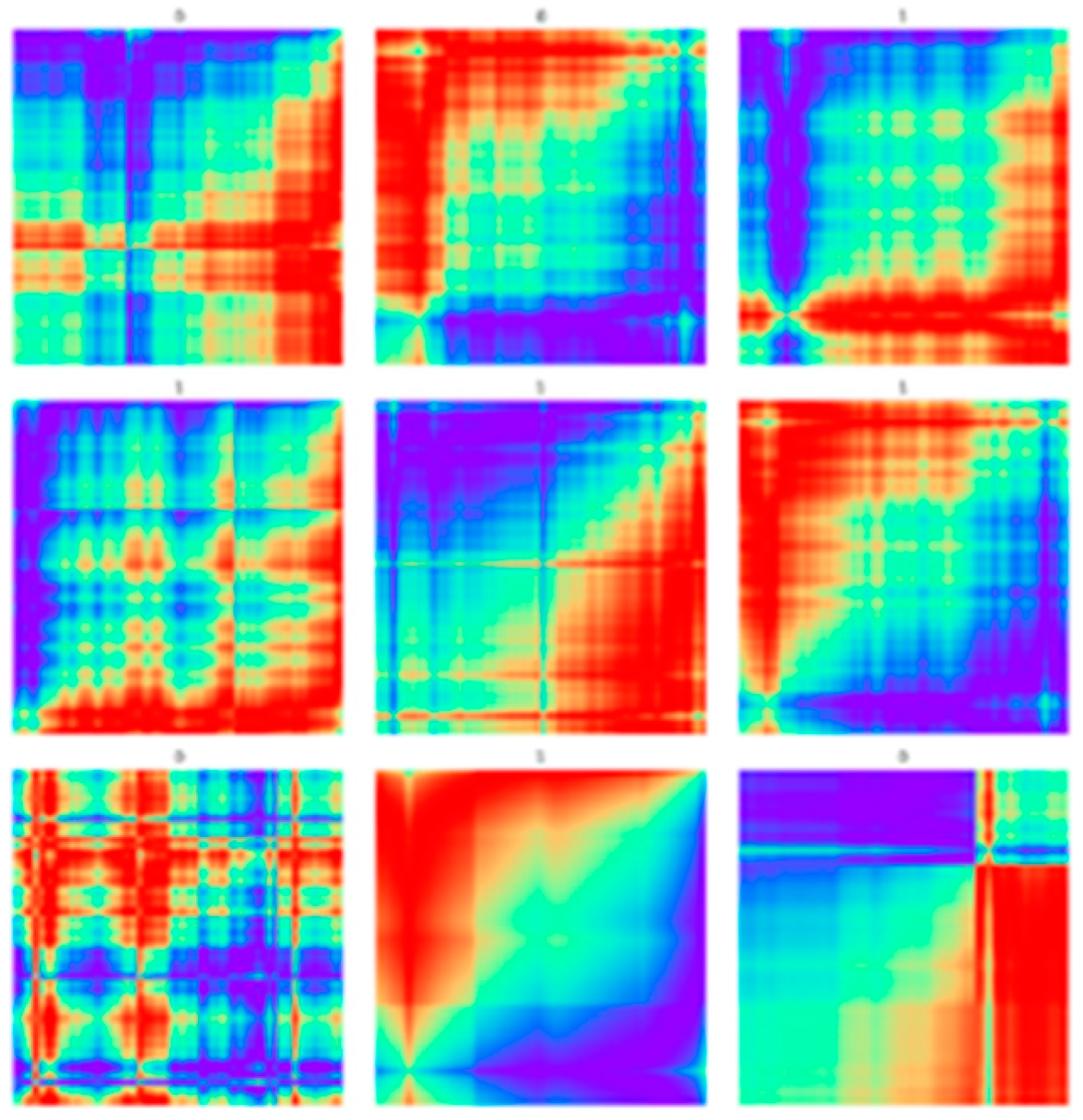
4.4. Results of Experiment of Learning Joint Effect of Stock Price and Trading Volume with CycleGAN
4.5. Performance of the Prediction of the Stock Price
Validation of Predictive Model
4.6. Performance of Stock Price Prediction by Using Normalization
4.7. Performance of Stock Price Prediction Integrating of Dynamic SE Simulation
- (1)
- Within the dynamic SE simulation, ResNet demonstrates enhanced learning for normalized target data, outperforming LSTM. Conversely, in scenarios lacking normalization, LSTM exhibits better performance;
- (2)
- Excluding the dynamic SE simulation, normalized target data lead to lower training losses but increased validation and test losses, adversely affecting ResNet’s outcomes more than LSTM;
- (3)
- Overall, when combined with dynamic SE simulation, LSTM outshines ResNet, displaying more consistent losses across training, validation, and test stages, with an average loss of 4.1958684 compared to ResNet’s 4.235332. Without simulation integration, ResNet matches LSTM’s performance, showing little variation in loss metrics;
- (4)
- Ultimately, ResNet, when used without simulation of system engineering and non-normalized target data, achieves the most accurate stock price prediction with the least deviation, marking a superior result of 3.464465.
4.8. Trading Signals and the ROI Prediction by Bollinger Band
4.8.1. Trading Signal of Bollinger Band
4.8.2. ROI
5. Conclusions
- This pioneering research uses CycleGAN with ResNet and CNN to analyze the stock price–volume joint effect, demonstrating its effectiveness in estimating potential prices and volumes. A notable reduction in cycle loss was achieved, with the lowest loss recorded for the 25-day stock price and trading volume determined by DoE;
- The optimal configuration, comprising a 25-day data interval for CycleGAN and a five-day prediction period, determined by DoE, led to superior outcomes, evidenced by elevated accuracy and F1 scores. In stock price prediction, ResNet surpassed LSTM in terms of accuracy and precision;
- This study investigates the incorporation of the outcomes from CycleGAN learning and predictive DL models into system engineering based on the assumption that future trading volume and price differing from current values will impact subsequent stock prices. This concept was tested within a system engineering framework. The analysis suggests that using the predictive model for future price and volume trends and integrating these into the system engineering framework enhances the accuracy of stock price predictions, as indicated by a lower error rate in the latter method compared to the former;
- Further research evaluated the effectiveness of combining stock price prediction with Bollinger Bands over a five-day span. The findings show that Bollinger Bands, enriched with predictive model data, outperform those based solely on historical information. This approach led to a reduced frequency of trading signals and a 30% increase in average ROI, highlighting the potential of system engineering in resolving challenges in the stock market domain and contributing to the field.
- In terms of DL, this study utilized ResNet within CycleGAN for stock price prediction. Future research should expand this approach by incorporating Inception as well as DenseNet, even potentially an ensemble of the above three DL tools, i.e., ResNet, Inception, and DenseNet, into CycleGAN and stock price predictions. Additional parameters may also be integrated to improve this model’s performance;
- Surprisingly, ResNet’s stock price prediction performance surpasses that of LSTM, which is traditionally used for time series analysis, such as stock price prediction. Consequently, future investigations could explore the use of Gated Recurrent Units (GRU) as an alternative to LSTM for enhanced stock price prediction;
- Regarding trading strategies, the current reliance on Bollinger Bands and the %b index as trading signals should evolve. Future strategies will incorporate diverse trading signals, including frequency analysis through Wavelet, to synergize with stock price predictions;
- Although coupling DL with system engineering improves stock price prediction with higher accuracy and expected ROI, the impact of system engineering regarding precision is not consistently significant. This may be due to CycleGAN’s learning the joint effects of stock price and volume, reflecting stock market dynamics. Stock trading is often viewed through the lens of cash flow dynamics. Therefore, future models may benefit from adopting a fluid mechanics perspective rather than the current solid body approach to better simulate the flow of financial assets;
- Starting from collecting foreign stock data to compare whether the Taiwanese domestic and foreign markets have the same effect or the domestic stocks with lower trading volume to further verify the versatility of this method.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- DeMark, T.R. The New Science of Technical Analysis; John Wiley and Sons, Inc.: Hoboken, NJ, USA, 1984. [Google Scholar]
- ADAM HAYES. Technical Analysis Definition. Available online: https://www.investopedia.com/terms/t/technicalanalysis.asp (accessed on 1 January 2022).
- Chiang, J.K.; Gu, H.Z.; Hwang, K.R. Stock Price Prediction based on Financial Statement and Industry Status using Multi-task Transfer Learning. In Proceedings of the International Conference on Information Management (ICIM), Taipei, Taiwan, 27–29 March 2020. [Google Scholar]
- Chen, S.W.; Wei, C.Z. The Nonlinear Causal Relationship between Price and Volume of Taiwanese Stock and Currency Market. J. Econ. Manag. 2006, 2, 21–51. [Google Scholar]
- Ying, C.C. Stock Market Prices and Volumes of Sales. Econometrica 1966, 34, 676–685. [Google Scholar] [CrossRef]
- Karpoff, J.M. The relation between price changes and trading volume: A survey. J. Financ. Quant. Anal. 1987, 22, 109–126. [Google Scholar] [CrossRef]
- Sri, L.M.; Yogesh, K.; Subramanian, V. Deep Learning with PyTorch 1.x, 2nd ed.; Packt Pub: Birmingham, UK, 2019. [Google Scholar]
- Gibson, A.; Patterson, J. Deep Learning, 1st ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2016. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Aaron, C.; Bengion, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Wikipedia. Generative Adversarial Network. 2021. Available online: https://en.wikipedia.org/wiki/Generative_adversarial_network (accessed on 15 January 2022).
- Bruner, J. Generative Adversarial Networks for Beginners. 2023. Available online: https://github.com/jonbruner/generative-adversarial-networks/blob/master/gan-notebook.ipynb (accessed on 15 January 2022).
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Hiemstra, C.; Jones, J.D. Testing for linear and nonlinear Granger causality in the stock price-volume relation. J. Financ. 1994, 49, 1639–1664. [Google Scholar]
- Seely, S. An Introduction to Engineering Systems; Pergamon Press Inc.: Tarrytown, NY, USA, 1972. [Google Scholar]
- MBA Knowledge Encyclopedia, System Dynamics. Available online: https://wiki.mbalib.com/zh-tw/%E7%B3%BB%E7%BB%9F%E5%8A%A8%E5%8A%9B%E5%AD%A6 (accessed on 1 October 2020).
- Taiwan’s TSMC controlled 60% of Foundry Market in Q1. Available online: https://www.taiwannews.com.tw/en/news/4917619 (accessed on 15 January 2022).
- Taiwan Economy Grows Fastest Since 2010 as TSMC Gives Boost. Available online: https://www.bloomberg.com/news/articles/2022-01-27/tsmc-s-40-billion-spree-may-tip-the-scales-on-taiwan-s-growth#xj4y7vzk (accessed on 1 January 2022).
- Yu, I.-Y. A Study on the Causal Relationship between Stock Prices and Trading Volume—Empirical Evidence from the Taiwan Stock Market. Master Thesis, Yoshimori University, Tokyo, Japan, 2021. [Google Scholar]
- Crouch, R.L. The volume of transactions and price changes on the New York Stock Exchange. Financ. Anal. J. 1970, 26, 104–109. [Google Scholar] [CrossRef]
- Stickel, S.E.; Verrecchia, R.E. Evidence that trading volume sustains stock price changes. Financ. Anal. J. 1994, 50, 57–67. [Google Scholar] [CrossRef]
- Sheu, H.J.; Wu, S.; Ku, K.P. Cross-sectional relationships between stock returns and market beta, trading volume, and sales-to-price in Taiwan. Int. Rev. Financ. Anal. 1998, 7, 1–18. [Google Scholar] [CrossRef]
- Tu, Y.P. The Relationship between Price and Volume under Taiwan’s Eight Major Stock indexes. Master Thesis, National Chengchi University, Taipei, Taiwan, 2016. [Google Scholar]
- Chiang, J.K.; Lin, C.L.; Chiang, Y.F.; Su, Y. Optimization of the spectrum splitting and auction for 5th generation mobile networks to enhance quality of services for IoT from the perspective of inclusive sharing economy. Electronics 2021, 11, 3. [Google Scholar] [CrossRef]
- Chiang, J.K.; Chen, C.C. Sentimental analysis on Big Data–on case of financial document text mining to predict sub-index trend. In Proceedings of the 2015 5th International Conference on Computer Sciences and Automation Engineering (ICCSAE 2015), Sanya, China, 14–15 November 2015; Atlantis Press: Paris, France, 2016; pp. 423–428. [Google Scholar]
- Sharpe, W.F. Capital Asset Prices: A Theory of Market Equilibrium under Conditions of Risk. J. Financ. 1964, 19, 425–442. [Google Scholar]
- Froot, K.A.; Perold, A.; Stein, J.C. Shareholder Trading Practices and Corporate Investment Horizons. Working Paper (No. 3638), National Bureau of Economic Research, February 1991. Available online: https://www.nber.org/papers/w3638 (accessed on 1 January 2022).
- Goodwin, T.H. The Information Ratio. Financ. Anal. J. 1998, 54, 34–43. [Google Scholar] [CrossRef]
- Chiang, J.K.; Lin, Y.S. Research into Optimization of Profit with Hedging for Stock Investment by Constructing Capital Asset Model with Simulated Annealing Method- with Example of 50 Stocks of 0050. In Proceedings of the International Conference of Information Management, Bandung, Indonesia, 13–14 August 2020. [Google Scholar]
- Zheng, Q.; Delingette, H.; Duchateau, N.; Ayache, N. 3D consistent biventricular myocardial segmentation using deep learning for mesh generation. arXiv 2018, arXiv:1803.11080. [Google Scholar]
- Wang, A. Backpropagation (BP). 2023. Available online: https://www.brilliantcode.net/1326/backpropagation-1-gradient-descent-chain-rule/ (accessed on 20 January 2022).
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Wikipedia. Convolutional Neural Network. 2022. Available online: https://en.wikipedia.org/wiki/Convolutional_neural_network (accessed on 15 January 2022).
- Zhang, L.; Aggarwal, C.; Qi, G.J. Stock price prediction via discovering multi-frequency trading patterns. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 2141–2149. [Google Scholar]
- Granger, C.W.; Morgenstern, O. Spectral analysis of New York stock market prices 1. Kyklos 1963, 16, 1–27. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Townsend, J.T. Theoretical analysis of an alphabetic confusion matrix. Percept. Psychophys. 1971, 9, 40–50. [Google Scholar] [CrossRef]
- Sundermeyer, M.; Schlüter, R.; Ney, H. LSTM neural networks for language modeling. In Proceedings of the Thirteenth Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef] [PubMed]
- de Vitry, L. Encoding Time Series as Images-Gramian Angular Field Imaging. Analytics Vidhya, 15 October 2018. Available online: https://medium.com/analytics-vidhya/encoding-time-series-as-images-b043becbdbf3 (accessed on 1 January 2023).
- Guo, S. An Introduction to Surrogate Modeling, Part I: Fundamentals; Data Sci: Toronto, ON, Canada, 2020. [Google Scholar]
- Liu, H.; Cai, J.; Ong, Y.S. An adaptive sampling approach for Kriging metamodeling by maximizing expected prediction error. Comput. Chem. Eng. 2017, 106, 171–182. [Google Scholar] [CrossRef]
- Forrester, A.; Sobester, A.; Keane, A. Engineering Design via Surrogate Modelling: A Practical Guide; John Wiley & Sons: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Plastics Industry Development Center of Taiwan, Quality Engineering. 2008. Available online: https://www.pidc.org.tw/safety.php?id=124 (accessed on 6 October 2022).
- Lee, H.H. Taguchi Methods: Principles and Practices of Quality Design, 4th ed.; Gao-Li Pub., 2022; Available online: https://www.studocu.com/tw/document/national-formosa-university/department-of-mechanical-and-computer-aided-engineering/taguchi-method-course/7369020 (accessed on 6 October 2022).
- Pan, Y.H. Application of the Taguchi Method in Neural Network Input Parameter Design—A Case Study on the Development of a Rapid Response System Model for Retailers. Master Thesis, Yoshimori University, Taiwan, 2003. [Google Scholar]
- Taguchi Quality Engineering, CH 9, Institute of Industry Engineering and Management. National Yunlin University of Science and Technology. Available online: https://www.iem.yuntech.edu.tw/lab/qre/public_html/Courses/1/AQM-1/files/CH9%20%E7%94%B0%E5%8F%A3%E6%96%B9%E6%B3%95.pdf (accessed on 6 October 2022).
- Bollinger, J. Using Bollinger Bands. Stock. Commod. 1992, 10, 47–51. [Google Scholar]
- CMoney. What is Bolinger Band. 2021. Available online: https://www.cmoney.tw/learn/course/technicals/topic/1216 (accessed on 6 October 2022).



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Stock Price Is Rising | Predicted Stock Price Is Falling | |
|---|---|---|
| Actual Stock Price is rising | True Positive (TP) | False Negative (FN) |
| Actual Stock Price is falling | False Positive (FP) | True Negative (TN) |
|
|
|
|
|
|
| Level | T | D | ||||
|---|---|---|---|---|---|---|
| 1 | 25 day | 1 day | 0.8 | 250 | 0.001 | 0.001 |
| 2 | 30 day | 5 day | 1 | 200 | 0.0005 | 0.0005 |
| No. of Experiments | T | D | ||||
|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 2 | 1 | 1 | 1 | 2 | 2 | 2 |
| 3 | 1 | 2 | 2 | 1 | 1 | 2 |
| 4 | 1 | 2 | 2 | 2 | 2 | 1 |
| 5 | 2 | 1 | 2 | 1 | 2 | 1 |
| 6 | 2 | 1 | 2 | 2 | 1 | 2 |
| 7 | 2 | 2 | 1 | 1 | 2 | 2 |
| 8 | 2 | 2 | 1 | 2 | 1 | 1 |
| Trading Volume | Closing Price | |
|---|---|---|
| 1 | 0.0840 | 0.0084 |
| 2 | 0.0838 | 0.0080 |
| 3 | 0.0964 | 0.0171 |
| 4 | 0.0937 | 0.0167 |
| 5 | 0.0884 | 0.0085 |
| 6 | 0.0865 | 0.0081 |
| 7 | 0.0976 | 0.0161 |
| 8 | 0.0936 | 0.0175 |
| Test Group | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| SN Ratio | 41.51 | 41.94 | 35.34 | 35.55 | 41.41 | 41.83 | 35.86 | 35.14 |
| T | D | |||||
|---|---|---|---|---|---|---|
| Level 1 | 38.59 | 41.67 | 38.61 | 38.53 | 38.46 | 38.40 |
| Level 2 | 38.56 | 35.47 | 38.53 | 38.62 | 38.69 | 38.74 |
| Contribution (max–min) | 0.03 | 6.2 | 0.08 | 0.09 | 0.23 | 0.34 |
| Factor importance ranking | 6 | 1 | 5 | 4 | 3 | 2 |
| Decision Level | 1 | 1 | 1 | 2 | 2 | 2 |
| T | D | ||||
|---|---|---|---|---|---|
| 25 | 1 | 0.8 | 200 | 0.0005 | 0.0005 |
| Trading Volume | Closing Price |
|---|---|
| 0.0805 | 0.0077 |
| Trading Volume | Closing Price |
|---|---|
| 0.0816 | 0.0056 |
| Transaction Volume | Opening Price | Highest Price | Lowest Price | Closing Price |
|---|---|---|---|---|
| 0.0426 | 0.0042 | 0.0045 | 0.0037 | 0.0047 |
| Test Group | g | Trading Volume | Closing Price | |
|---|---|---|---|---|
| 1 | - | - | 0.0805 | 0.0077 |
| 2 | 1 | 0.01 | 0.0773 | 0.0073 |
| 3 | 1 | 0.04 | 0.0732 | 0.0068 |
| 4 | 1 | 0.05 | 0.0735 | 0.0067 |
| 5 | 1 | 0.06 | 0.0747 | 0.0067 |
| 6 | 1 | 0.07 | 0.0768 | 0.0066 |
| 7 | 1 | 0.08 | 0.0792 | 0.0067 |
| 8 | 1 | 0.09 | 0.0822 | 0.0067 |
| 9 | 1 | 0.1 | 0.0860 | 0.0068 |
| Test Group | g | Trading Volume | Closing Price | |
|---|---|---|---|---|
| 1 | - | - | 0.0816 | 0.0056 |
| 2 | 1 | 0.01 | 0.0786 | 0.0053 |
| 3 | 1 | 0.04 | 0.0748 | 0.0048 |
| 4 | 1 | 0.05 | 0.0748 | 0.0047 |
| 5 | 1 | 0.06 | 0.0756 | 0.0047 |
| 6 | 1 | 0.07 | 0.0775 | 0.0047 |
| 7 | 1 | 0.08 | 0.0800 | 0.0047 |
| 8 | 1 | 0.09 | 0.0830 | 0.0048 |
| 9 | 1 | 0.1 | 0.0864 | 0.0049 |
| Days | Training Cycle Loss | Valid Cycle Loss | Testing Cycle Loss |
|---|---|---|---|
| 20 | 0.031995635 | 0.038789876 | 0.036866438 |
| 25 | 0.016229397 | 0.016477194 | 0.015846474 |
| 30 | 0.0015571207 | 0.031062838 | 0.030280465 |
| Training | Validation | Testing | Average | |
|---|---|---|---|---|
| ResNet, no SE and Normalization | 1.951394 | 3.345 | 5.097 | 3.464465 |
| ResNet, with SE, no Normalization | 3.211395 | 4.104 | 5.3906 | 4.235332 |
| ResNet, no SE, with and Normalization | 1.9069737 | 3.9998 | 5.3466 | 3.37511246 |
| ResNet, with SE and Normalization | 15.592605 | 9.153 | 12.2104 | 12.318668 |
| Training | Validation | Testing | Average | |
|---|---|---|---|---|
| LSTM no SE and Normalization | 1.995237 | 3.38 | 5.0802 | 3.485146 |
| LSTM, with SE, no Normalization | 3.5186053 | 3.7602 | 5.3088 | 4.1958684 |
| LSTM no SE, and Normalization | 2.002026 | 3.356 | 5.073 | 3.477009 |
| LSTM, with SE and Normalization | 11.24382 | 13.5698 | 18.6598 | 14.49114 |
| Method. | Training | Validation | Testing | Total Average |
|---|---|---|---|---|
| Bolinger Band | 0.140962 | 0.20709 | 0.121204 | 0.155066 |
| Prediction by LSTM combined with SE and Bolling Band | 0.191472 | 0.227625 | 0.123423 | 0.19198 |
| Prediction by ResNet combined with SE and Bolling Band | 0.209931 | 0.228786 | 0.123423 | 0.203827 |
| Prediction by LSTM combined with Bolling Band, no SE | 0.156184 | 0.229696 | 0.124331 | 0.1698 |
| Prediction by ResNet combined with Bolling Band, no SE | 0.17589 | 0.262105 | 0.124331 | 0.189294 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chiang, J.K.; Chi, R. A Novel Stock Price Prediction and Trading Methodology Based on Active Learning Surrogated with CycleGAN and Deep Learning and System Engineering Integration: A Case Study on TSMC Stock Data. FinTech 2024, 3, 427-459. https://doi.org/10.3390/fintech3030024
Chiang JK, Chi R. A Novel Stock Price Prediction and Trading Methodology Based on Active Learning Surrogated with CycleGAN and Deep Learning and System Engineering Integration: A Case Study on TSMC Stock Data. FinTech. 2024; 3(3):427-459. https://doi.org/10.3390/fintech3030024
Chicago/Turabian StyleChiang, Johannes K., and Renhe Chi. 2024. "A Novel Stock Price Prediction and Trading Methodology Based on Active Learning Surrogated with CycleGAN and Deep Learning and System Engineering Integration: A Case Study on TSMC Stock Data" FinTech 3, no. 3: 427-459. https://doi.org/10.3390/fintech3030024
APA StyleChiang, J. K., & Chi, R. (2024). A Novel Stock Price Prediction and Trading Methodology Based on Active Learning Surrogated with CycleGAN and Deep Learning and System Engineering Integration: A Case Study on TSMC Stock Data. FinTech, 3(3), 427-459. https://doi.org/10.3390/fintech3030024