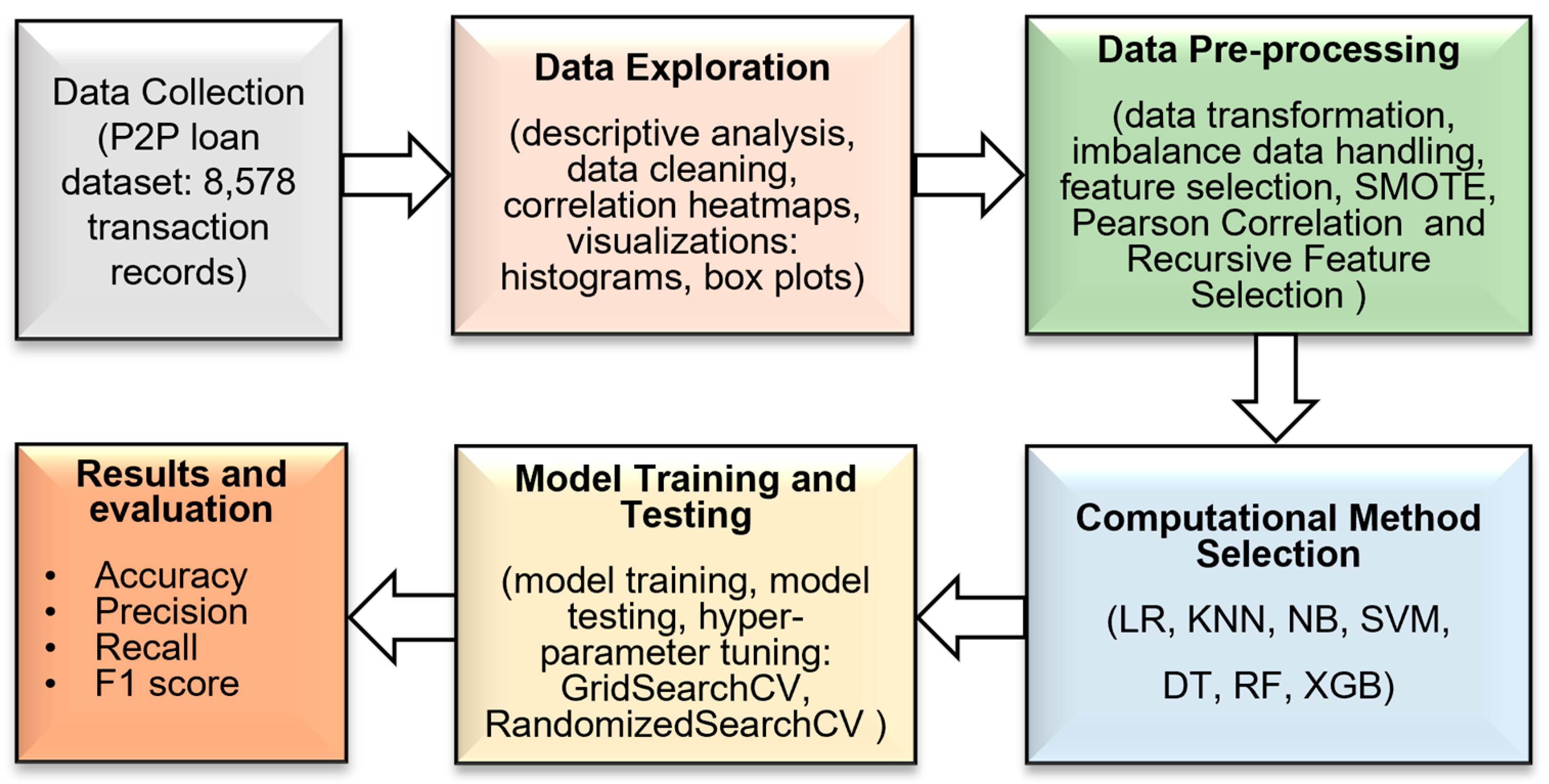
4.1. Process of Data Exploration
The dataset is explored, beginning with the essential step of importing the necessary libraries and packages. The read_csv() function is employed to bring in the dataset, followed by an exploration using the info(), describe(), is_null(), and duplicated() functions to extract comprehensive insights from the dataset.
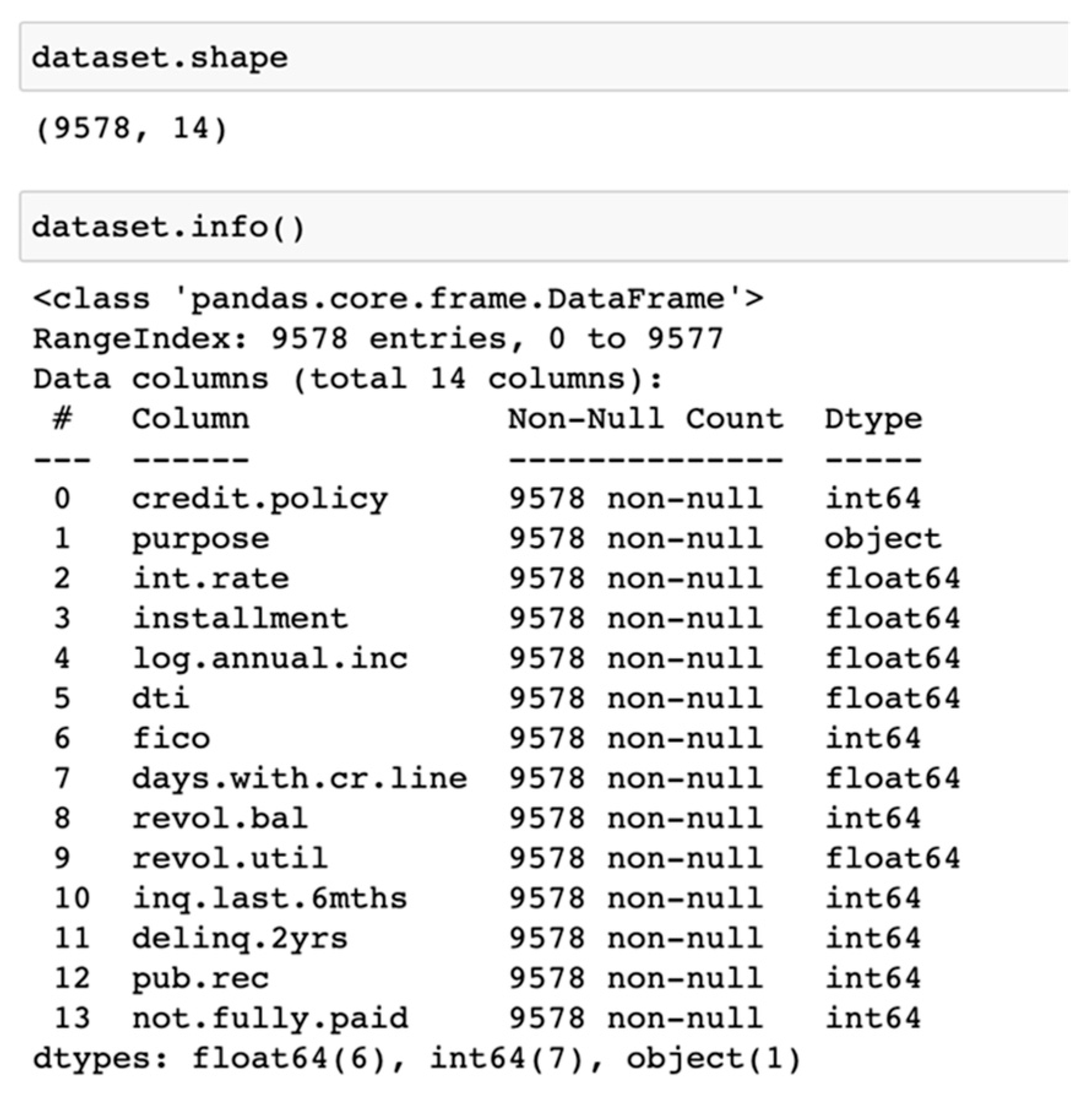
Figure 8 presents a summary of the dataset’s structure and attribute types. The dataset consists of 9578 rows and 14 columns, where “purpose” is the only categorical attribute, and the remaining attributes are numerical. The class attribute in the dataset is designated as “not_fully_paid.” Notably, the dataset has no null values or duplicated values, facilitating a streamlined data-cleaning process.
In the subsequent analysis, attention is directed towards the class attribute, followed by the examination of the categorical attribute and, subsequently, an exploration of the numerical attributes and their correlations with the target variable.
The distribution of the class attribute not_fully_paid, was determined. It was found that fully paid clients account for 84% of the dataset, while not fully paid clients make up 16%. This indicates a significant class imbalance within the dataset.
The lone categorical attribute in the dataset is “purpose.”
Figure 9 provides an overview of its various values along with their respective quantities. It is noteworthy that “Debt_consolidation” and “credit_card” emerge as the most prevalent purposes for borrowing money.
Following this, the connection between the “purpose” variable and the class variable is visualized using a stacked bar chart. The chart illustrates the percentage of loans that are either fully paid or not fully paid based on their respective purposes (refer to
Figure 10). Notably, the category “small_business” exhibits the highest rate of not fully paid loans, implying that small businesses often confront more substantial financial challenges compared to other borrowers. This suggests that generating profits in their business might not be attainable within a short timeframe, potentially leading to loan default.
On the other hand, individuals who borrow for a “major_purchase” or to pay off “credit_card” debt appear to have a higher likelihood of repaying their loans compared to other purposes. These insights can prove valuable for informed loan approval decision-making.
A correlation heatmap was generated to investigate the relationships among numeric variables (
Figure 11). It is worth noting that there are not many robust correlations between these attributes. The most pronounced correlation exists between “fico” and “int_rate” (corr = −0.71), as anticipated, indicating that individuals with lower FICO scores tend to have higher interest rates on their loans.
Figure 12 illustrates the correlations between the class attribute and other attributes, which, in general, do not exhibit specifically powerful relationships. Notably, “revol_util” “int_rate”, “credit_policy”, “inq_last_6mths” and “fico”, exhibit the strongest connections to “not_fully_paid”.
Subsequently, in
Figure 13, histograms were constructed to visualize the distribution of numerical variables. Significantly, it is apparent that “log_annual_income” (representing the borrower’s income, transformed applying log scaling) is the only feature showcasing a normal distribution, whereas others exhibit notable skewness. To address this skewness, logarithmic transformation was employed for the other attributes.
Furthermore, it is worth observing that the distributions of the “fully paid” and “not fully paid” target customer groups seem similar. This produces concerns regarding the potential absence of a distinct pattern that machine learning algorithms can discern to differentiate between these two groups.
Afterward, it delved into a detailed exploration of the numeric attributes that exhibit strong correlations with the class attribute, specifically “fico”, “credit_policy”, “inq_last_6mths”, “int_rate”, and “revol_util”. Box plots are used to visualize the distributions of these attributes in relation to fully paid and not fully paid customers to gain insights.
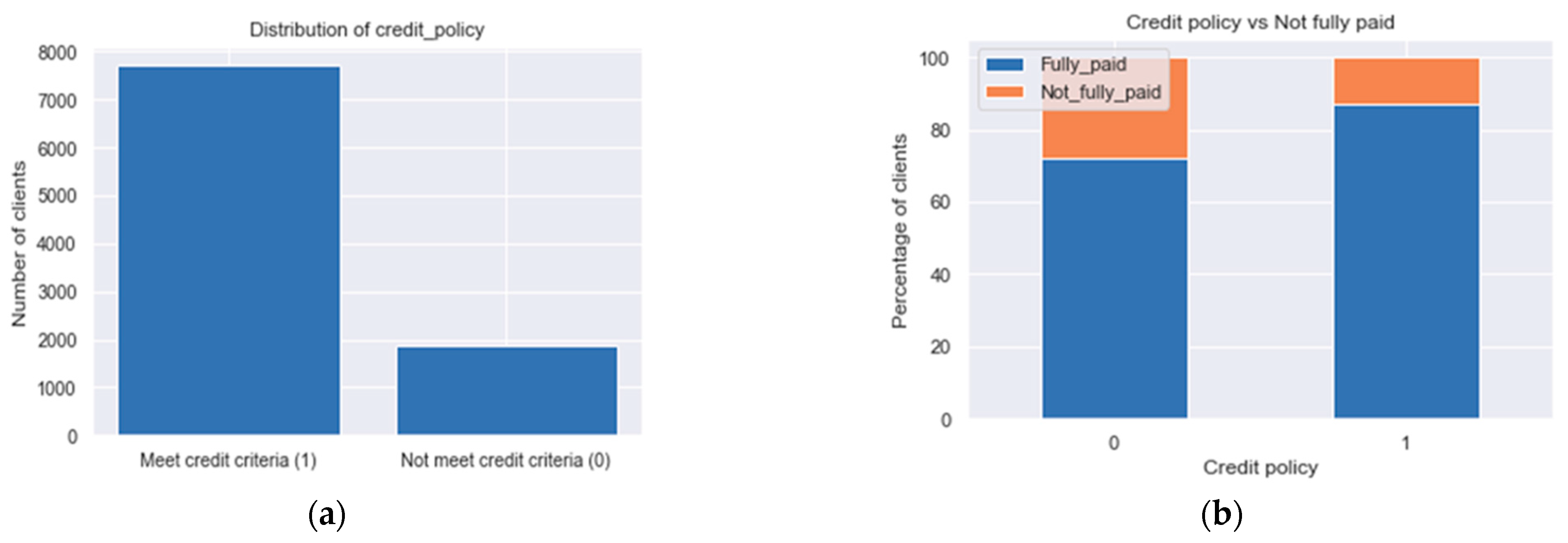
Commencing with “credit_policy” (as depicted in
Figure 14), it is evident that clients who fail to meet the credit criteria have a higher probability of becoming loan defaulters. However, it is noteworthy that around 13% of individuals who meet the credit criteria still end up as defaulters. This raises concerns regarding the credit approval process. Lenders may need to reassess their credit policy to ensure that individuals meeting the criteria are more likely to fulfill their loan obligations.
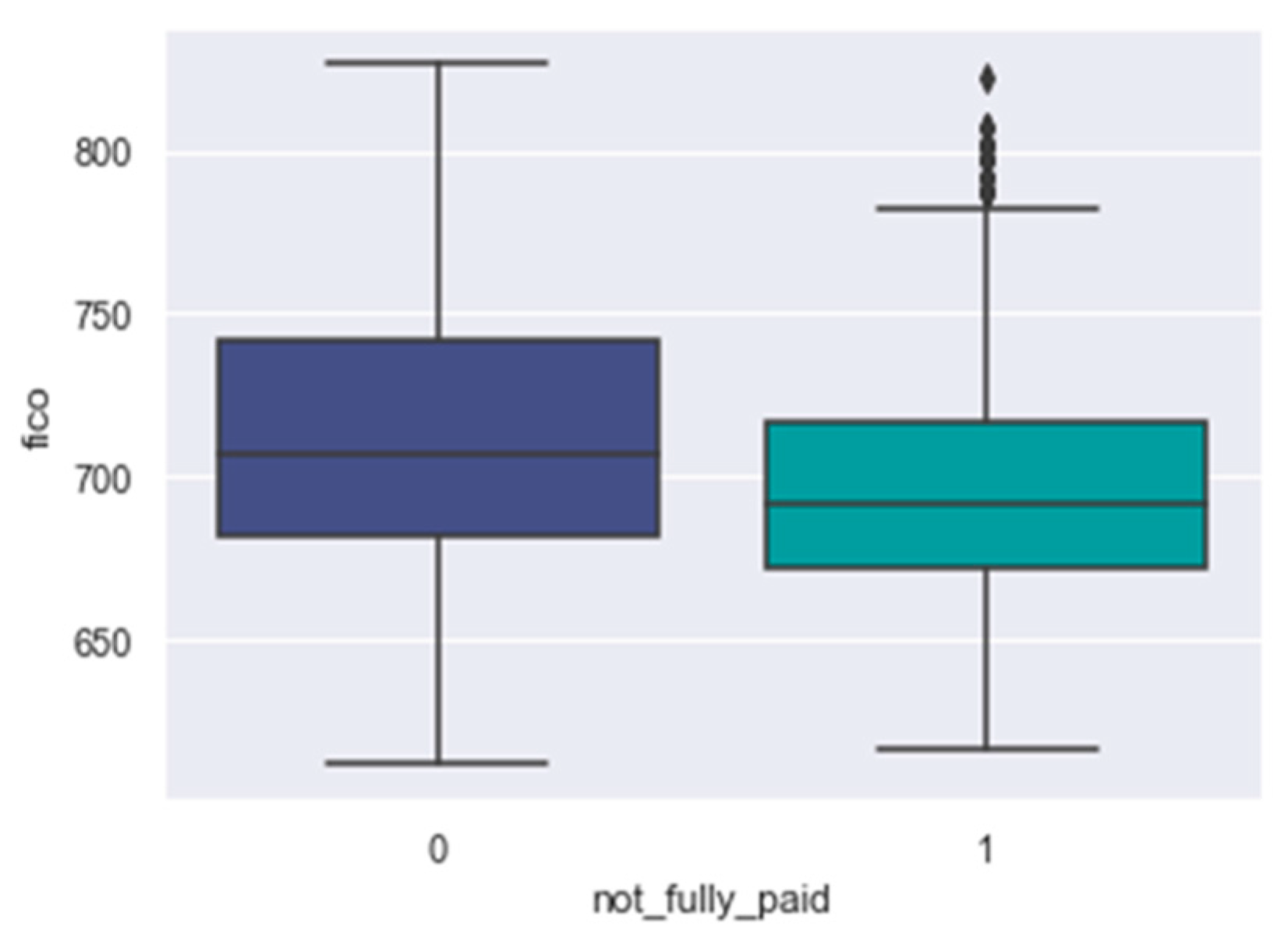
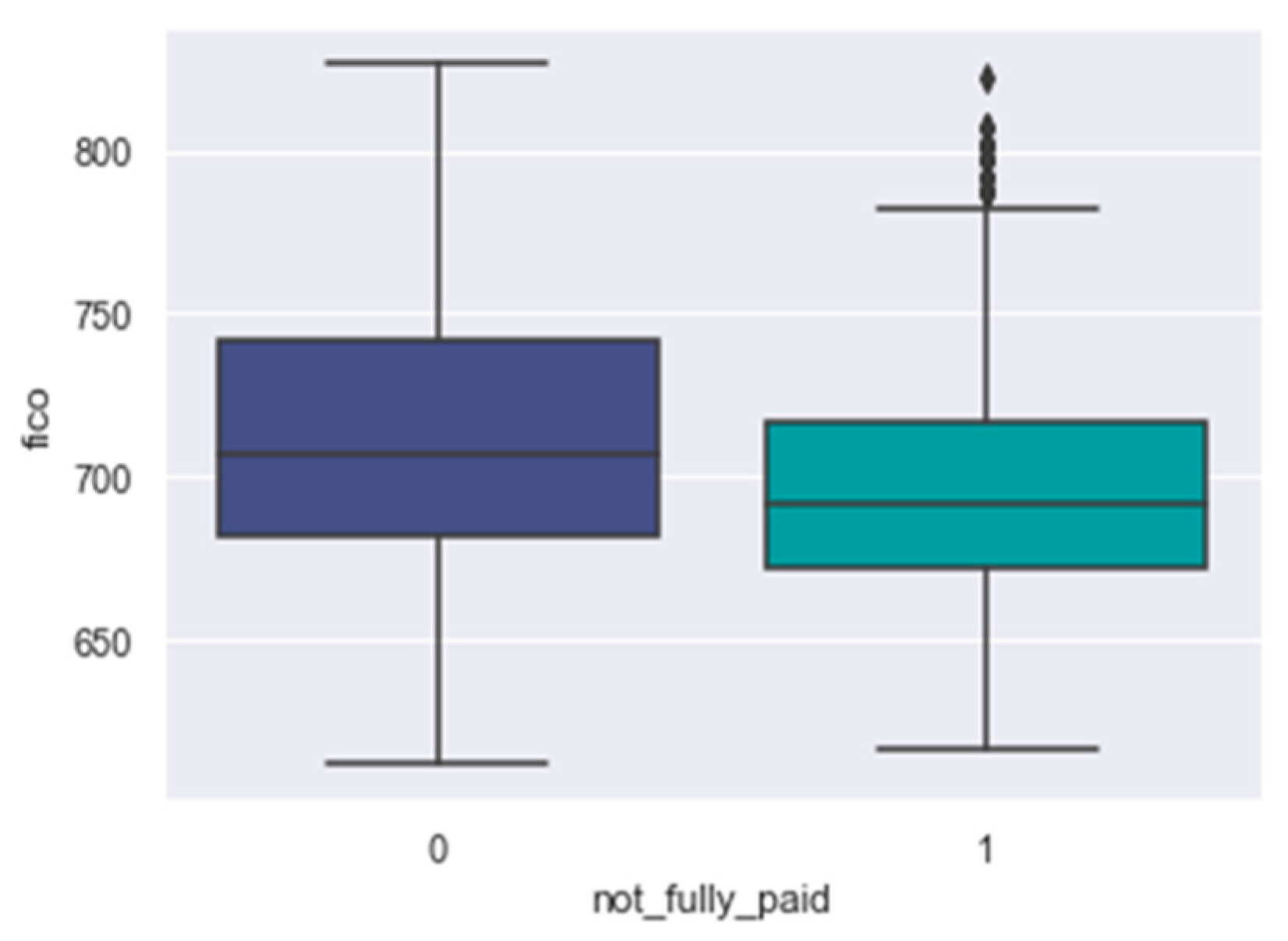
fico: Figure 15 reveals that the FICO scores of defaulters tend to be lower compared to those of borrowers with good repayment records.
Int_rate: Figure 16 showcases that loans not fully paid usually come with higher interest rates when contrasted with fully paid loans.
Inq_last_6mths:
Figure 17 shows that defaulters typically have more inquiries during the previous six months. A notable portion (26%) of customers, characterized by having more than 2 inquiries (third quantile of the “inq_last_6mth” attribute) in the last 6 months, eventually become defaulters.
The correlation between the interest rate and FICO scores is depicted for both customer groups (fully paid and not fully paid) presented in
Figure 18. The figure demonstrates that individuals with high FICO scores and low interest rates are less prone to default on their loans.
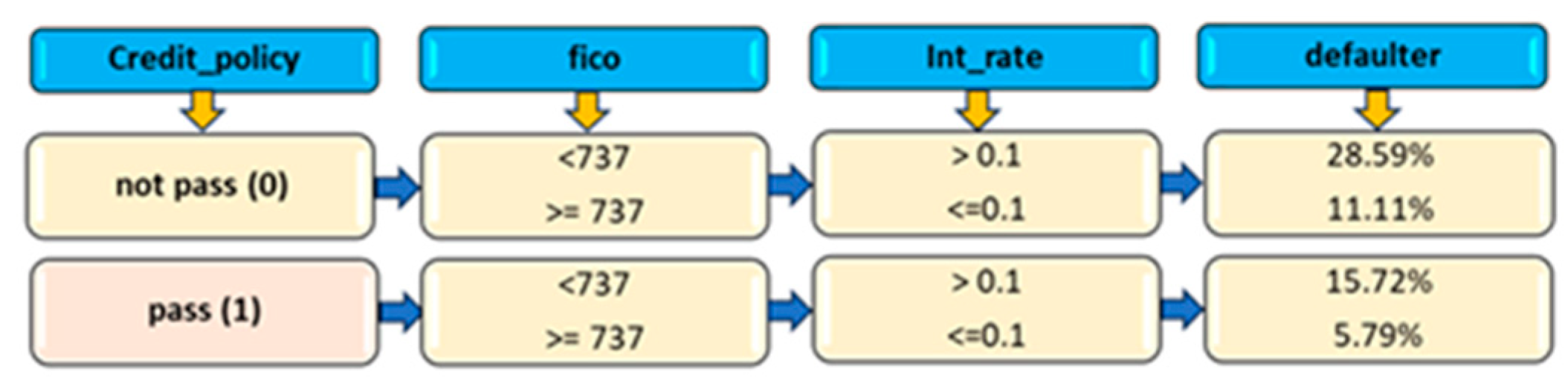
Figure 19 shows borrowers who satisfy or do not satisfy the credit policy criteria, possessing both an interest rate below 0.1 (first quantile of “int_rate”) and a FICO score exceeding 737 (third quantile of “fico”). Remarkably, 6% of borrowers meeting the credit policy criteria end up as loan defaulters. In stark contrast, a considerably higher proportion, amounting to 29%, of clients who do not meet the credit policy criteria, with interest rates surpassing 0.1 and FICO scores falling below 737, fail to repay their loans.
To sum up, our comprehensive data exploration has yielded valuable insights into client behavior. Specifically, loans that end up not being fully paid are typically unable to meet the credit policy, come with extreme interest rates, and have lower FICO scores. These loans also tend to have a higher number of recent inquiries within the last 6 months. Furthermore, when considering the purpose of borrowing, the proportion of defaulters is notably higher in the “small business” category compared to other customer groups.
Moving forward, the insights gained from this exploratory data analysis (EDA) were integrated with a feature selection algorithm to build an effective model for predicting loan defaulters.
4.2. Data Pre-Processing
This process encompasses several steps, including Train Test split, Logarithmic Transformation, Feature Scaling, SMOTE, and Feature Selection. Logarithmic transformation was employed primarily to address skewness in specific numeric attributes closely associated with the class attribute, specifically “instalment”, “fico”, and “day_with_credit_line”. Other attributes do not undergo log transformation as they do not exhibit a log-normal distribution. Notably, Feng et al. [
51] have noticed that applying log transformation to right-skewed data can sometimes result in a distribution that is even more skewed than the original one.
Figure 20 portrays the distribution of numeric attributes following log transformation. A comparison between
Figure 12 and
Figure 19 reveals a slight reduction in the skewness of these features.
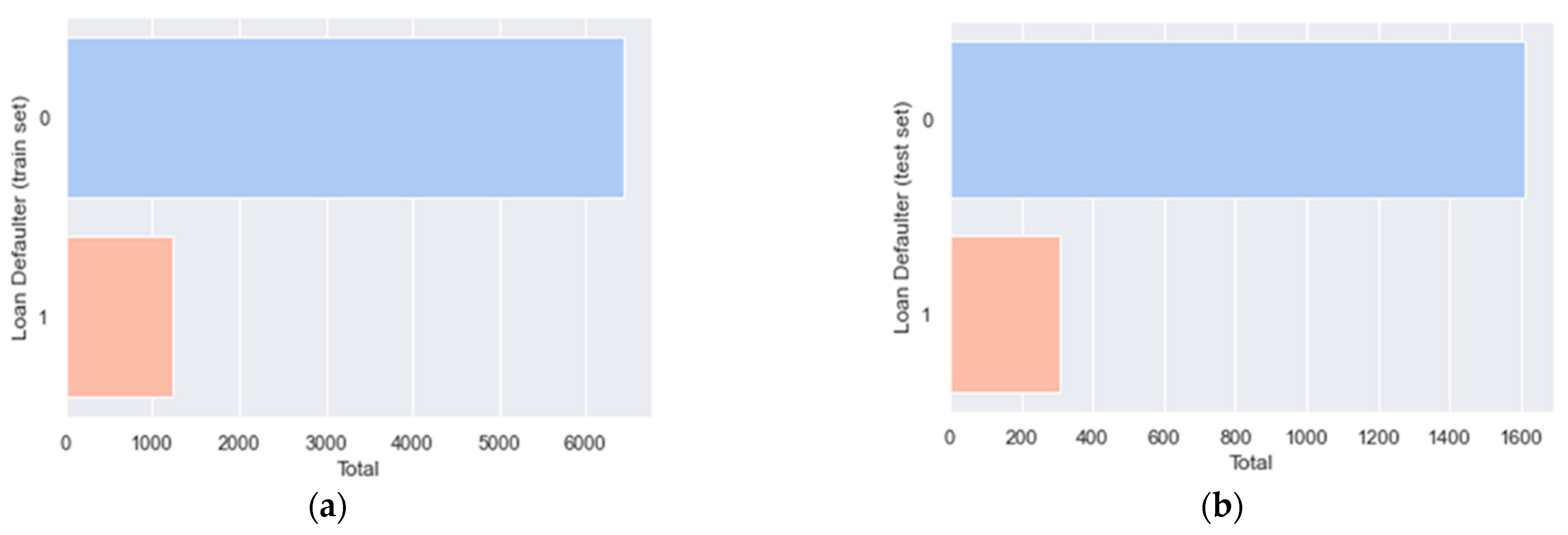
The dataset is divided into training and testing sets, employing a stratified split approach with a test size of 0.2. This ensures that both sets maintain an equal ratio of defaulters and non-defaulters. The respective counts of defaulters and non-defaulters in the training set (a) and testing set (b) are presented in
Figure 21.
Given the dataset’s significant class imbalance, where the proportion of defaulters to non-defaulters is roughly 19%, SMOTE is employed to oversample the minority class (defaulters) within the training dataset. This is a crucial step, as utilizing a highly imbalanced dataset could result in machine learning models being biased toward the majority class [
32]. Importantly, there is no need to apply SMOTE to the test data to prevent data leakage.
Figure 22 illustrates the counts of defaulters (1) and non-defaulters (0) in the training set after SMOTE has been applied.
Feature scaling is a critical step that standardizes all features to the same scale, preventing any single feature from dominating others. If one feature becomes overly dominant, machine learning models may overlook the significance of other features. Standardization, where values are centered around the mean and possess a standard deviation of one, is chosen for feature scaling in this project for its resilience against outliers [
13].
For feature selection, Recursive Feature Elimination (RFE) is utilized with Logistic Regression (LR) as the base algorithm. In alignment with the insights from Exploratory Data Analysis (EDA), the decision is made to retain 12 features. As a result of the RFE process, the selected features include credit_policy, encoded purposes, fico, revol_ball, log_annual_income, inq_last_6mths and installment. Interestingly, this outcome aligns with the findings from the EDA. Although a correlation exists between “int_rate” and the “class attribute”, the relatively high correlation coefficient between “fico” and “int_rate” (0.71) may explain why “int_rate” was not selected by RFE.
4.3. Result Achieved by Various ML Algorithms
4.3.1. Logistic Regression
Initially, the machine learning model is trained using Logistic Regression on the training dataset, utilizing the LogisticRegression library from Scikit-Learn [
52]. Subsequently, the constructed model is tested, and the outcomes are elaborated upon in
Table 3.
The performance of the LR model appears to be relatively modest, yielding an accuracy of 64% and a macro average recall of 62%. The LR correctly predicts 59% of loan defaults, but out of all the loans predicted to be defaulted by the model, only 24% turn out to be defaults, resulting in a precision of 24% for class 1.
To enhance the algorithm’s performance, parameter tuning is conducted, focusing on three parameters: solver, penalty, and C. The GridSearchCV() method is employed to search for the optimal parameter values, which are determined to be ‘C’: 0.01, ‘penalty’: ‘l2’, and ‘solver’: ‘saga’. Subsequently, the model is retrained and tested using these parameter values, and the results are presented in
Table 4.
It is evident that parameter tunning did not yield any notable improvement, as the accuracy and recall scores remain at 64% and 62%, respectively.
4.3.2. K-Nearest Neighbors
The KNN algorithm is used to train the ML model on the training dataset, utilizing the
KNeighborsClassifier library from Scikit Learn. Subsequently, the constructed model is put to the test, and the outcomes are detailed in
Table 5.
The performance of the model appears to be modest, with an accuracy of 67% and a macro average recall of 54%. KNN outperforms LR in identifying good lenders, achieving a recall of 73%, a precision of 85%, and an F1 score of 79%. However, its performance in identifying defaulters is relatively weak.
KNN classifies new data by considering its proximity to neighbors. However, as noted in the exploratory data analysis (EDA), the distribution of the two classes in the target variable is quite similar. This similarity could possibly account for the suboptimal performance [
53].
To enhance its performance,
parameter tuning is carried out, focusing on three parameters, weight_options, k_range, and metrics. The GridSearchCV() method is employed to search for the best parameter set, resulting in the selection of ‘n_neighbors’: 20, ‘metric’: ‘euclidean’, and ‘weights’: ‘distance’. The model is subsequently retrained and tested using these parameters, and the results are presented (
Table 6).
Table 7 and
Table 8 reveal a marginal performance improvement, with accuracy increasing from 67% to 69% and recall rising from 54% to 56%.
4.3.3. Support Vector Machine (SVM)
The machine learning model is trained using kernel Support Vector Machine (SVM) on the training dataset, utilizing the SVC library from Scikit-Learn. Subsequently, the constructed model is put to the test, and
Table 7 shows the results.
The performance achieved indicates a higher accuracy of 78% compared to KNN and LR. But compared to LR, the recall is less. In addition, SVM struggles to detect defaulters; recall, precision, and f1_score are all below 30%. Nonetheless, SVM excels in predicting non-defaulters, correctly identifying 88% of them.
In addition, parameter tuning is carried out, focusing on three parameters: kernel, C, and gamma. Instead of GridSearchCV(), RandomizedSearchCV() is employed to search for the optimal parameter set, thereby saving time and computational resources. The resulting parameters are ‘C’: 1, ‘gamma’: 1, and ‘kernel’: ‘rbf’. The model is then retrained and tested using kernel SVM, and the results are given in
Table 8.
A minor decline in performance is noticeable when compared to
Table 8. The drawback of SVM lies in its tuning process, which is notably time- and resource-intensive.
4.3.4. Naïve Bayes
The ML model is trained using NB with the
GausianNB library from Scikit learn on the training dataset. Subsequently, the generated model is put to the test, and the outcomes are presented in
Table 9.
The performance of the NB model closely resembles that of SVM, achieving an accuracy of 71% and a macro-average recall of 58%. NB excels in predicting good loans, with a precision of 87% for non-defaulters.
To enhance its performance, parameter tuning is conducted. GridSearchCV() is employed to search for the optimal parameter value, resulting in ‘var_smoothing’: 2.848. Subsequently, the model is retrained and tested using this parameter value, and the results are presented in
Table 10.
No improvement is observed following parameter tuning, as both the recall and accuracy scores persist at 56% and 71%, respectively.
4.3.5. Decision Tree
The ML model is trained using DT with the
DecisionTreeClassifier library from Scikit-Learn on the training dataset. Subsequently, the generated model is put to the test, and the outcomes are presented in
Table 11.
The DT algorithm demonstrates enhanced accuracy at 73% in contrast to other algorithms, yet it exhibits lower recall at 53%. Notably, the strength of DT lies in effectively recognizing non-defaulters, achieving a recall of 0.83 and a precision of 85%. However, it demonstrates inefficiency in detecting defaulters, with a recall of 23% and precision of 21%.
4.3.6. Random Forest
The ML model is trained using RF with the
RandomForestClassifier library from Scikit-Learn on the training dataset. Subsequently, the generated model is put to the test, and the outcomes are presented in
Table 12.
There is a substantial improvement in accuracy compared to other algorithms, reaching 82%. This can be attributed to RF’s capability to amalgamate predictions from various trees to formulate the ultimate prediction for each input. Notably, RF excels in identifying non-defaulters, achieving a recall of 97% and precision of 85%. However, its detection of defaulters is notably deficient, with a recall of 7%.
4.3.7. XGBoost
The XGBoost classifier from the XGBClassifier library is utilized to train the machine learning model. Subsequently, the constructed model undergoes testing, and the outcomes are detailed in
Table 13.
The highest accuracy (83%) is achieved in comparison to other algorithms, albeit with a reasonably low recall of 53%. XGBoost also demonstrates strong performance in correctly identifying non-defaulters, with a 97% accuracy rate. However, it struggles to detect defaulters, with a recall of just 9% for class 1.
Parameter tuning was conducted to enhance model performance. Instead of GridSearchCV, RandomizedSearchCV was employed to save time and computational resources. This search resulted in the following optimal parameter values: ‘subsample’: 0.5, ‘‘gamma’: 0.2, objective’: ‘binary:logistic’, ‘min_child_weight’: 5, ‘n_estimators’: 800, ‘max_depth’: 7, and ‘colsample_bytree’: 0.8. The model was subsequently retrained and evaluated using these tuned parameters. However, the results presented in
Table 14 indicate that the parameter tuning process did not yield any improvements in model performance.
4.4. Performance Comparison and Analysis
In this section, the performance of various algorithms is assessed to select the most suitable model for our dataset. Subsequently, additional techniques have been implemented to enhance its performance further.
Upon reviewing the confusion matrices and classification reports, it becomes evident that all models exhibit superior performance in the majority class (non-defaulters) compared to the minority class (defaulters). Notably, the tree-based models, such as XGBoost, Decision Trees (DT), and Random Forest (RF), excel in identifying non-defaulters but fall short in accurately identifying defaulters, which is the primary focus of this project.
As previously discussed in Chapter 3 (
Section 3.5), given our objective of identifying loan defaulters, the primary metric for assessing the performance of different ML algorithms is recall.
Table 15 provides a comparison of recall (macro average) and accuracy for all models, presented as percentages and sorted in descending order of recall values. Notably, LR emerges as the top performer, followed by NB and KNN. LR surpasses other algorithms, including more complex ones like XGBoost and RF, in effectively predicting defaulters. This reaffirms the robustness and applicability of LR in various binary classification scenarios [
54]. The systematic experiments conducted in our research work have demonstrated that minimal to no significant improvement was achieved through parameter tuning. Furthermore, in the assessment of algorithmic accuracy, it is observed that XGBoost (XGB) achieves the highest accuracy at 83%, followed by Random Forest (RF) at 82%, and Decision Tree (DT) at 73%.
Considering the high recall achieved by LR, potential methods were investigated to enhance its recall for the minority class. Typically, Logistic Regression (LR) categorizes a data point by assessing its probability of being True, utilizing a default threshold set at 0.5. For instance, if the probability surpasses 0.5, the data point is classified as a defaulter; otherwise, it is classified as a non-defaulter. To enhance predictions in class 1 (defaulters), one could consider reducing the decision threshold, especially if it does not significantly impact precision [
55]. To explore that,
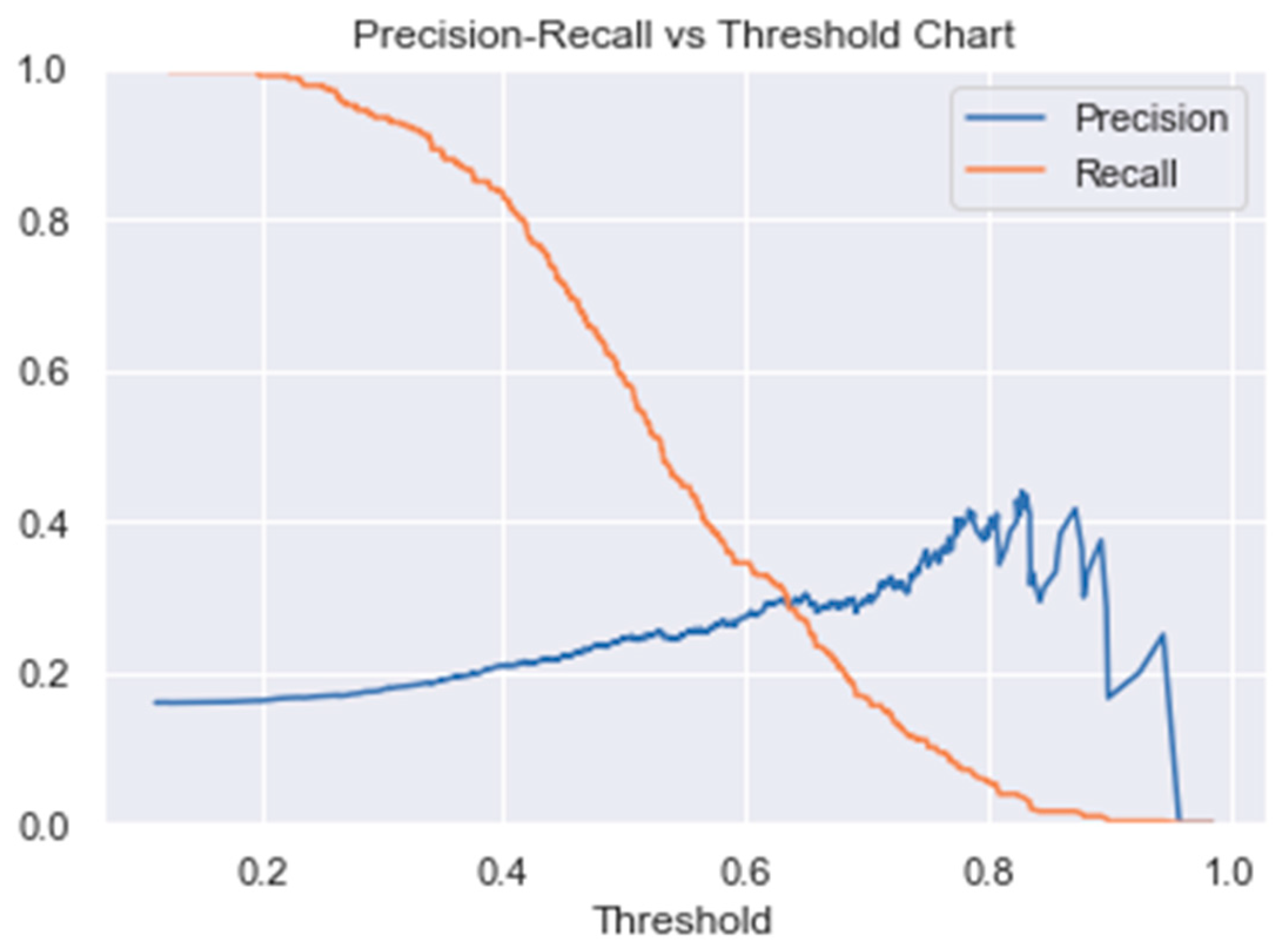
Figure 23 displays recall and precision scores across various threshold values.
Interestingly, it becomes evident that when reducing the threshold, the recall increases at a notably faster rate than precision. For instance, lowering the threshold from 0.5 to 0.4 results in a substantial increase in recall, from 0.58 to 0.83 (an increase of 0.25), while precision experiences only a slight reduction, from 0.24 to 0.21 (a decrease of 0.03).
To delve more profoundly into the analysis, a model is trained and tested with a threshold set at 0.4, employing identical training and testing datasets. The outcomes are outlined in
Table 16. It is essential to note that the trade-off between recall and precision implies that by reducing the threshold, there is a risk of rejecting many good customers, as the model may classify them as defaulters and decline their applications. Therefore, it is crucial to exercise caution when considering a significant reduction in the threshold value.
4.5. Critical Analysis of the Study
4.5.1. Strengths of this Proposed Study
By thoroughly exploring data, we pinpoint the financial traits associated with loans that are not repaid. It becomes evident that instances of repayment failure typically involve individuals who do not adhere to the credit policy, carry higher interest rates coupled with lower FICO scores, and exhibit a higher frequency of inquiries in the last 6 months. Furthermore, our analysis has revealed other valuable insights that should be taken into account when making decisions regarding loan applications. These insights include:
Customers who borrow funds for small businesses pose a higher risk.
The likelihood of a client becoming a defaulter significantly rises when the interest rate exceeds 0.1, and their FICO score falls below 737. Specifically, 28.59% of clients in this category are unlikely to repay their loans, in contrast to a mere 5.79% of clients with interest rates below 0.1 and FICO scores above 737 who are inclined to become loan defaulters.
A significant number of individuals who met the credit policy criteria have not fully repaid their loans, indicating a need for the lending institute to review and potentially tighten its credit policy criteria.
In summary, our hypothesis that lenders can predict the likelihood of non-full repayment from clients based solely on their financial information has been validated. ML models were effectively trained for this prediction task. In terms of overall accuracy, XGBoost and RF demonstrated strong performance. However, LR stood out as the top performer for predicting defaulters. LR achieved an 83% correct prediction rate for defaulters with only a minor impact on precision by adjusting its decision threshold to 0.4. Therefore, it is affirmed that lending organizations can derive substantial advantages from utilizing the proposed model as a supportive tool for predicting loan defaulters.
4.5.2. Limitations of the Study
In its present state, the performance of the model slightly falls short of the desired level, as it overlooks the classification of a notable number of loans as defaulters, even though they may actually be repaid. Consequently, it is not recommended for use as an automated loan approval system. Alternatively, it should be utilized to offer additional insights to decision-makers involved in the loan approval process.
The lower accuracy of the model could be attributed to the highly imbalanced dataset, which may cause the models to exhibit a bias towards the majority class, e.g., non-defaulters. Additionally, since the aim is to avoid using personal data, the limited selection of features may have a notable impact on the model’s accuracy.
4.5.3. Comparison with Similar Existing Studies
In comparison to previous ML studies that utilized datasets with a similarly limited number of features (listed in
Table 17) and as depicted in
Figure 24, our current study demonstrates a significant improvement in the identification of defaulters. The recall, without any threshold adjustments, stands at 0.62, which notably surpasses the recall values of 0.39, 0.45 and 0.19 in previous studies.
By adjusting the decision threshold to 0.4, the recall experiences a substantial improvement, reaching 0.83. Despite our model’s low accuracy when compared to other studies, it is important to note that accuracy is not the most critical metric in this research due to the high degree of imbalance present in all datasets. Additionally, it is worth considering that the primary objective of all aforementioned studies is to identify loan defaults, which represent a relatively rare occurrence when compared to the total number of loans. Hence, prioritizing the reduction of false negatives (instances where loan defaulters are not identified) is considerably more critical than minimizing false positives (identifying non-defaulters as defaulters), given the substantially higher cost associated with false negatives. It is important to highlight that, as this project seeks to refrain from utilizing personal data, the results are not directly comparable to those studies that incorporate personal data, as previously mentioned in the literature review.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}