
Modeling and Forecasting Cryptocurrency Closing Prices with Rao Algorithm-Based Artificial Neural Networks: A Machine Learning Approach


Abstract
:1. Introduction
- We are designing an efficient ANN forecast for the nearly precise prediction of cryptocurrencies such as Bitcoin, Litecoin, Ethereum, CMC 200, Tether, and Ripple.
- Suitable tuning of ANN parameters (i.e., weight and bias) by RA, thus forming a hybrid model (i.e., RA + ANN) to overcome the limitations of derivative-based optimization techniques.
- We are evaluating the performance of the RA + ANN forecast through two performance metrics, MAPE and ARV.
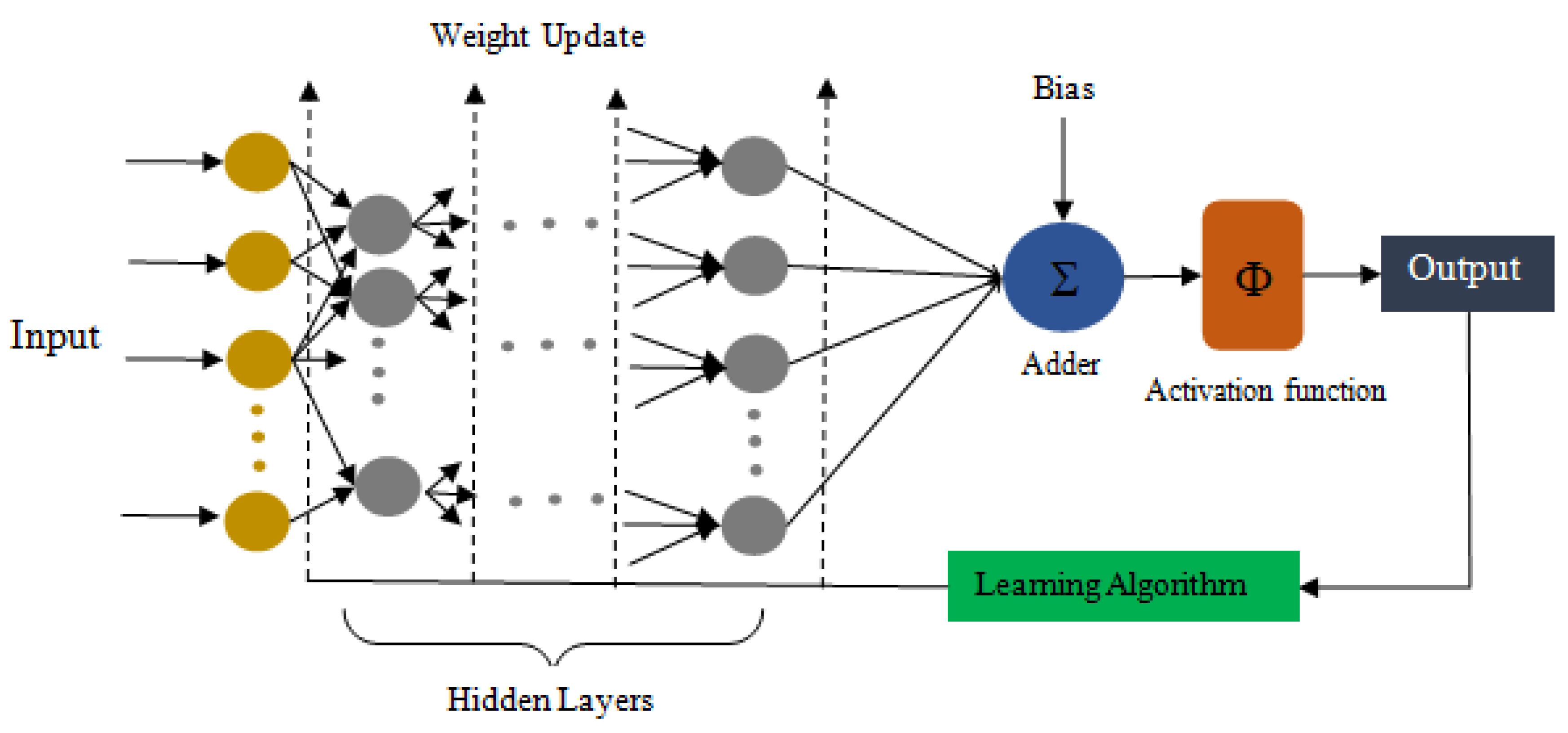
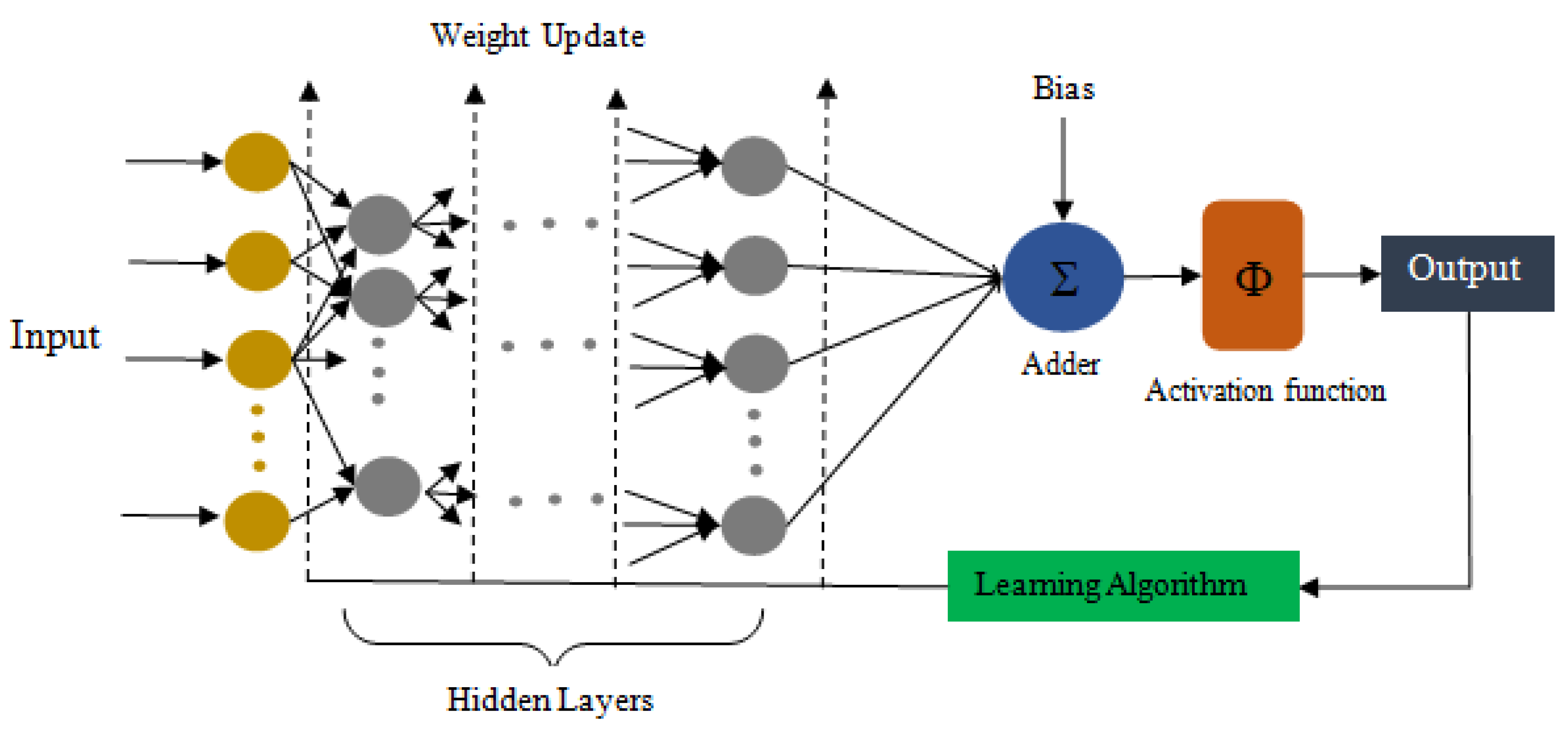
2. Artificial Neural Network
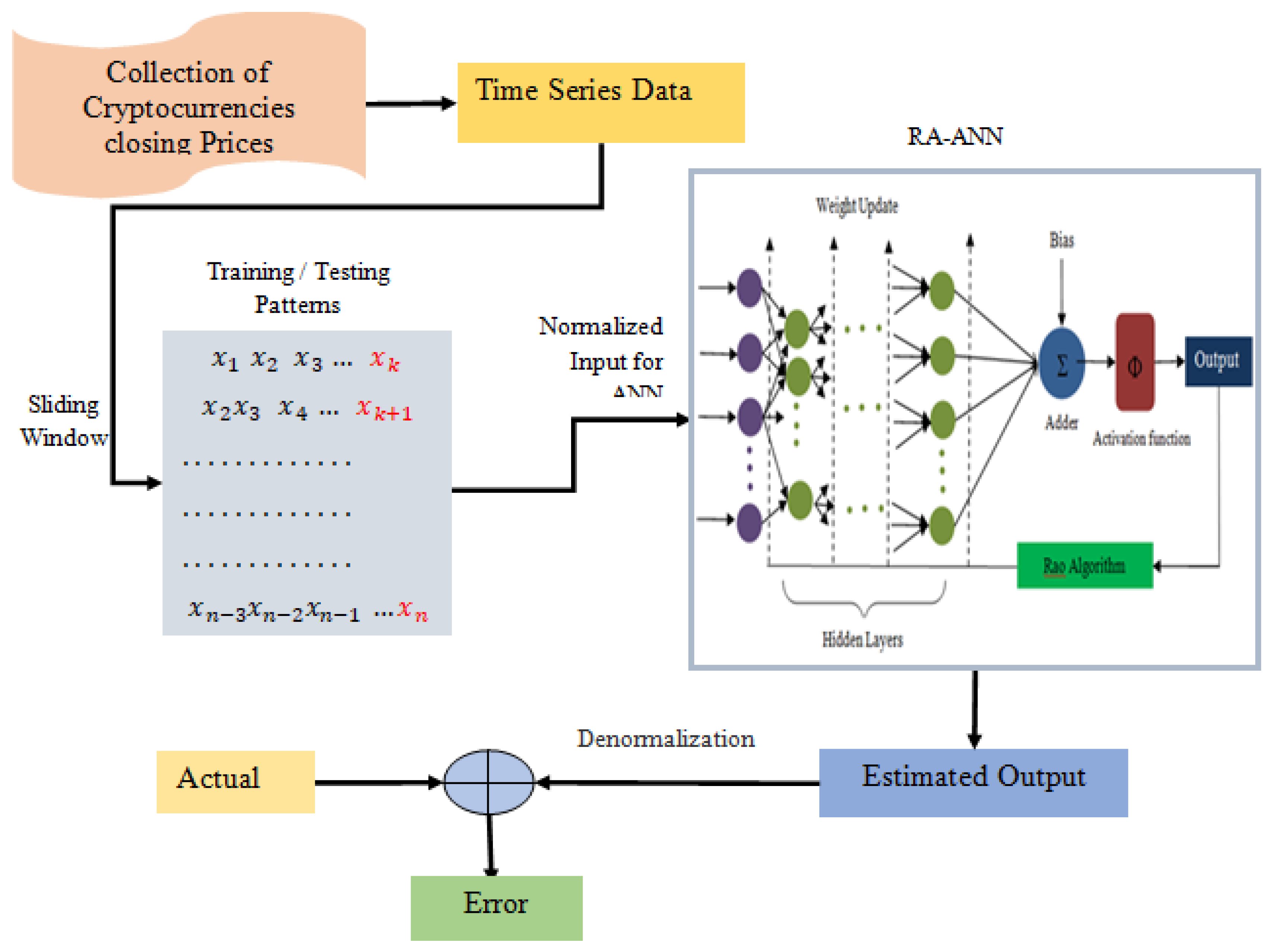
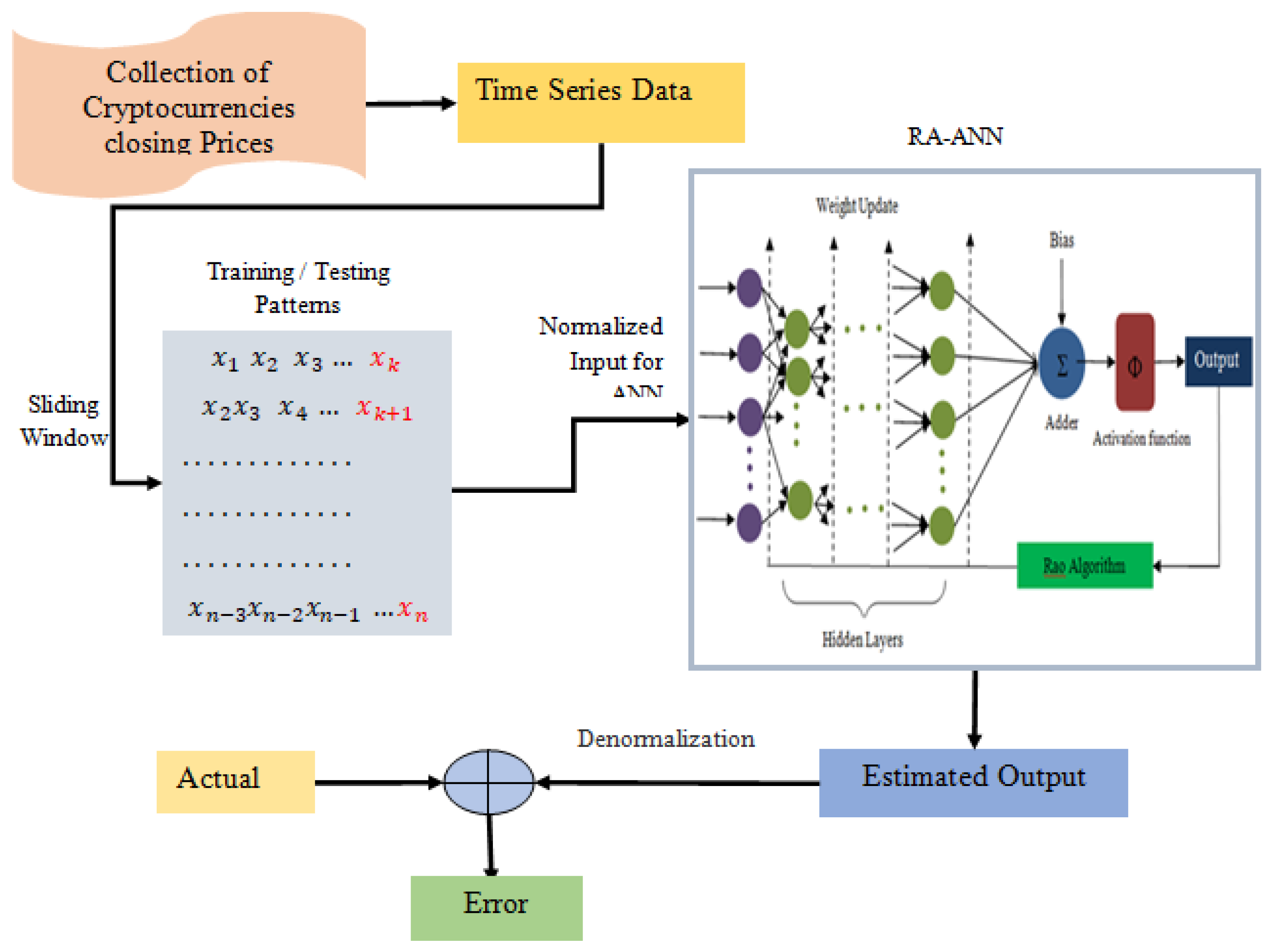
3. Proposed RA + ANN Based Forecasting
- = the value of variable of solution () at iteration.
- = the modified value of variable of solution () at iteration.
- = variable value of the best solution in iteration.
- = variable value of the worst solution iteration.
- and are two random values in [0,1].
| Algorithm 1: RA + ANN-based forecasting. |
| 1. Set population size (n), No. of design variables (m), and Termination criteria. 2. Initialization of population. 3. Set training and test data using sliding window. 4. Normalization of training and test data. /* Model Training */ 5. While (! = termination criteria) For each candidate solution (W) in the population. Supply train data and W to ANN. Compute ANN output. Error = expected output–estimated output Fitness = accumulated error. End Identify best and worst solution. Update population using any Equations (8)–(10). 6. End /* Model Testing */ 7. Feed test data and best solution to ANN. Calculate the model output error value. 8. Reiterate Steps 2–6 for all training and test patterns and preserve total error. |
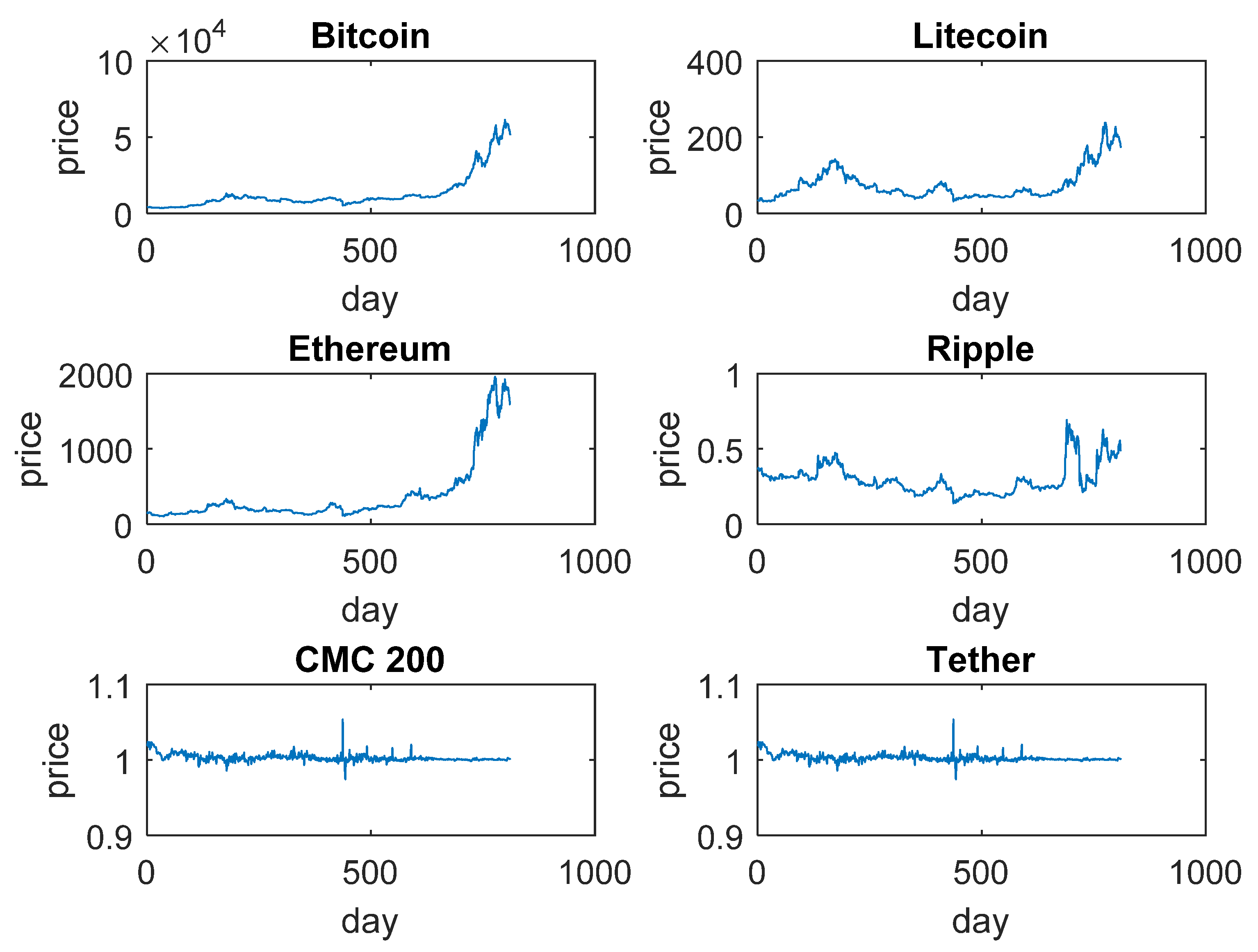
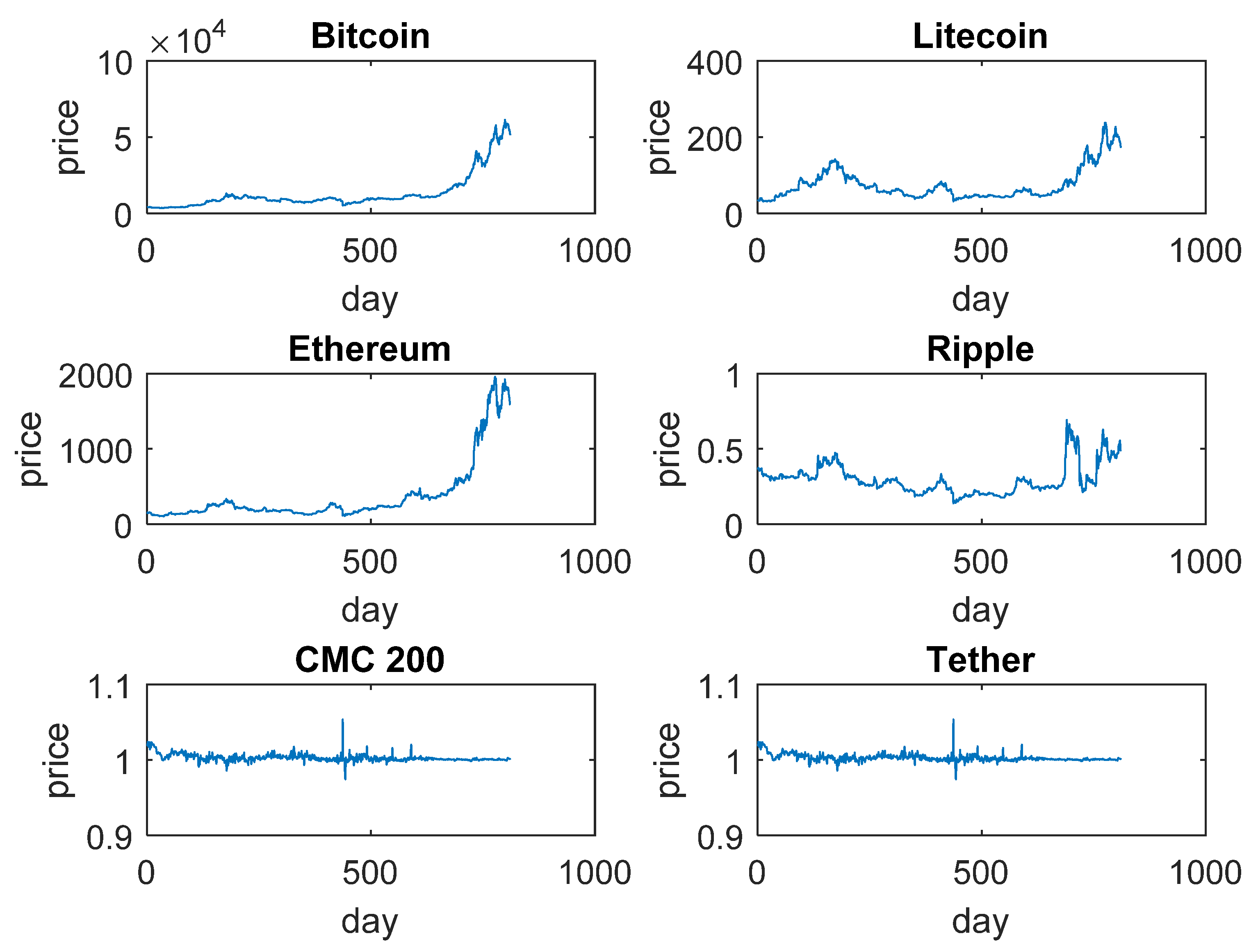
4. Cryptocurrency Data
5. Experimental Results and Analysis
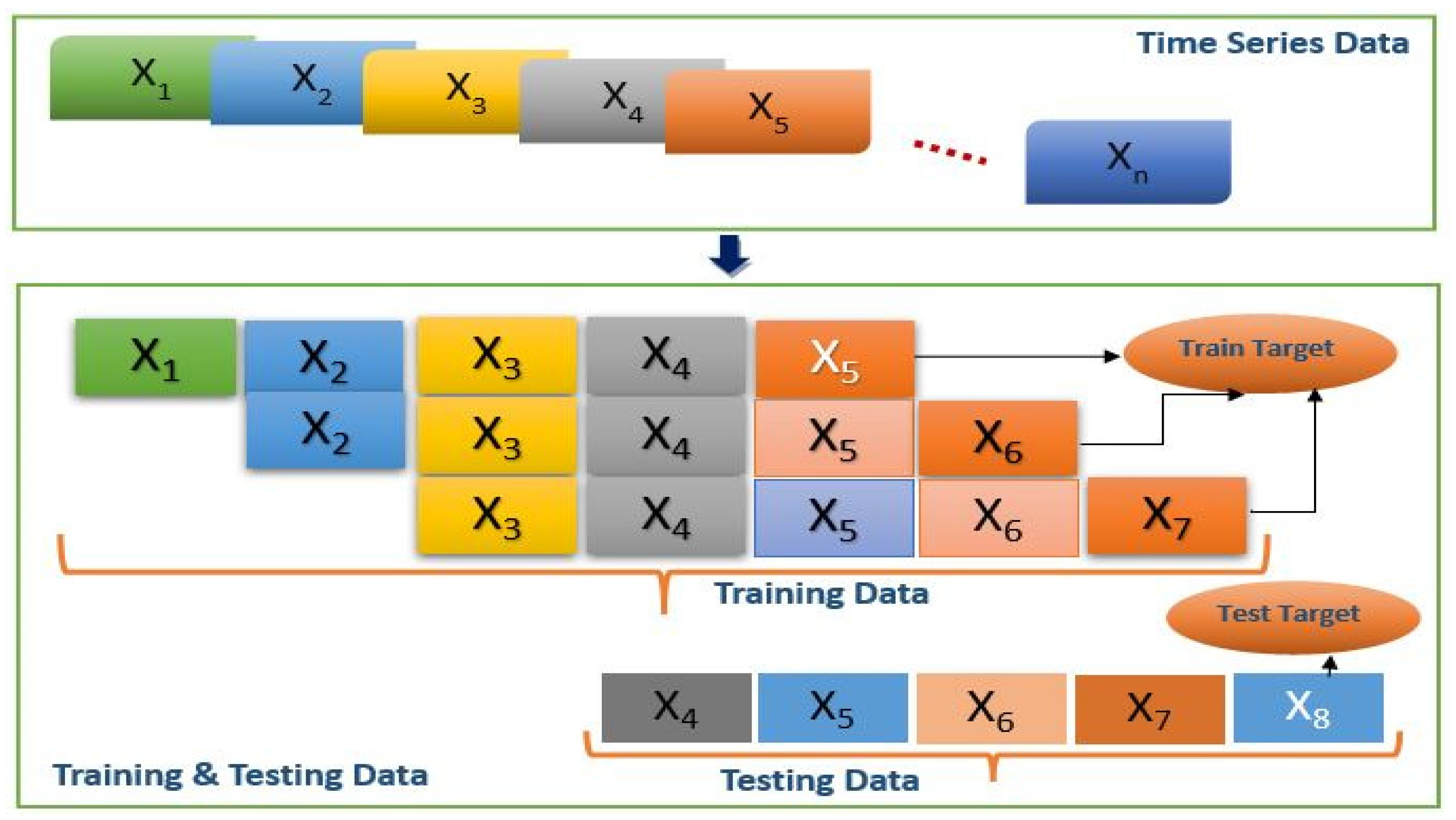
5.1. Model Input Selection and Normalization
5.2. Performance Evaluation Metrics
5.3. Experimental Setting
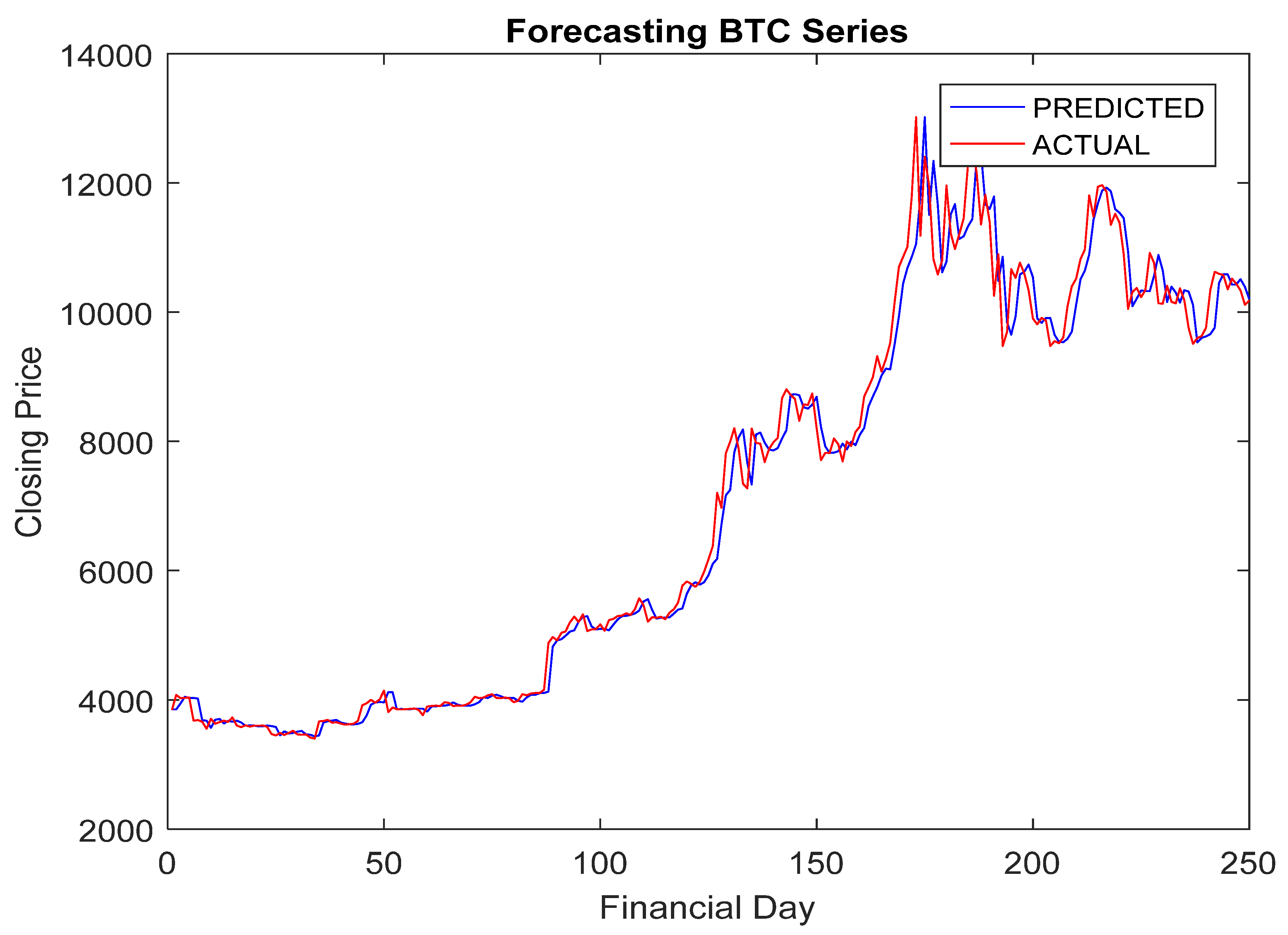
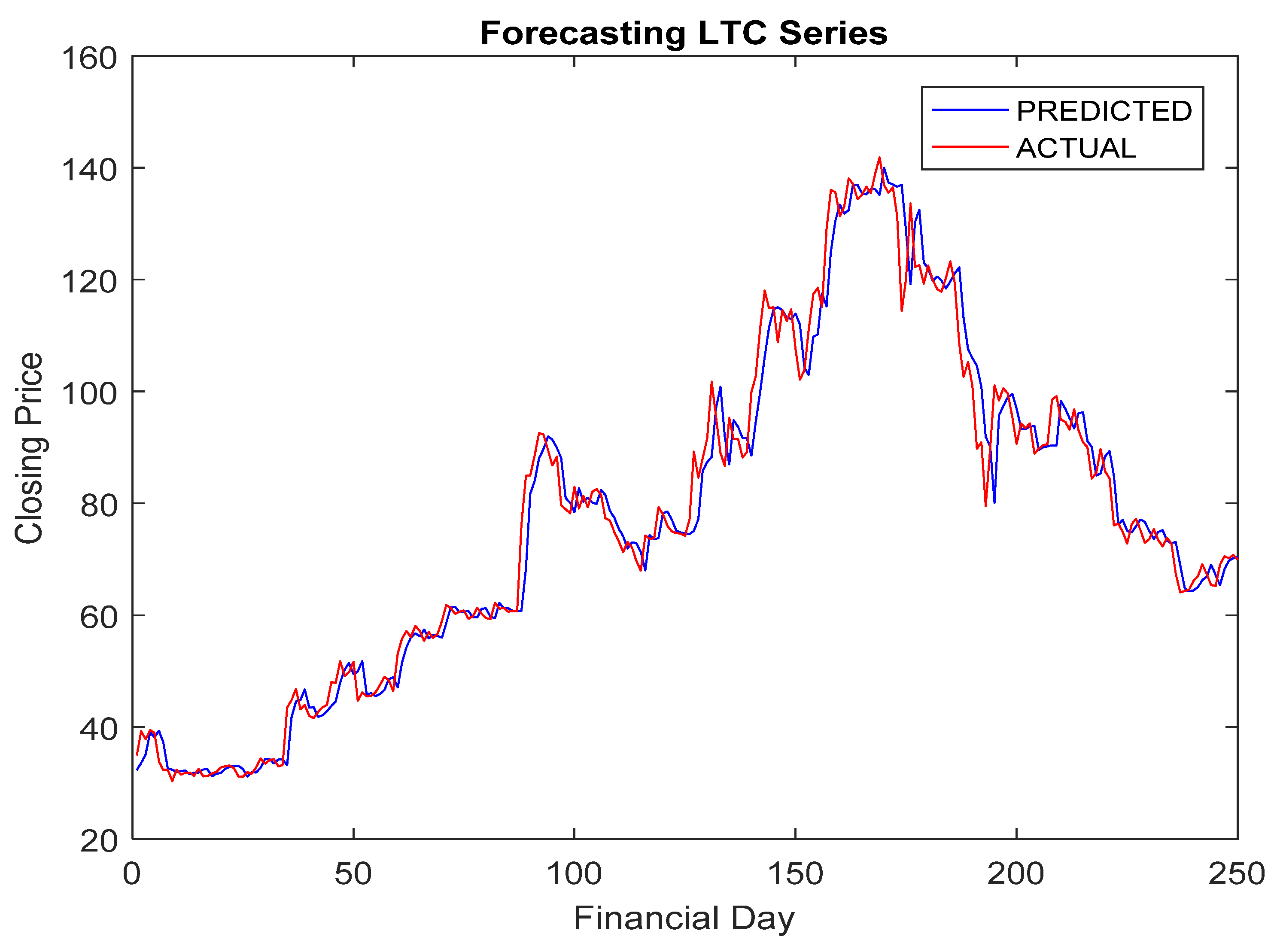
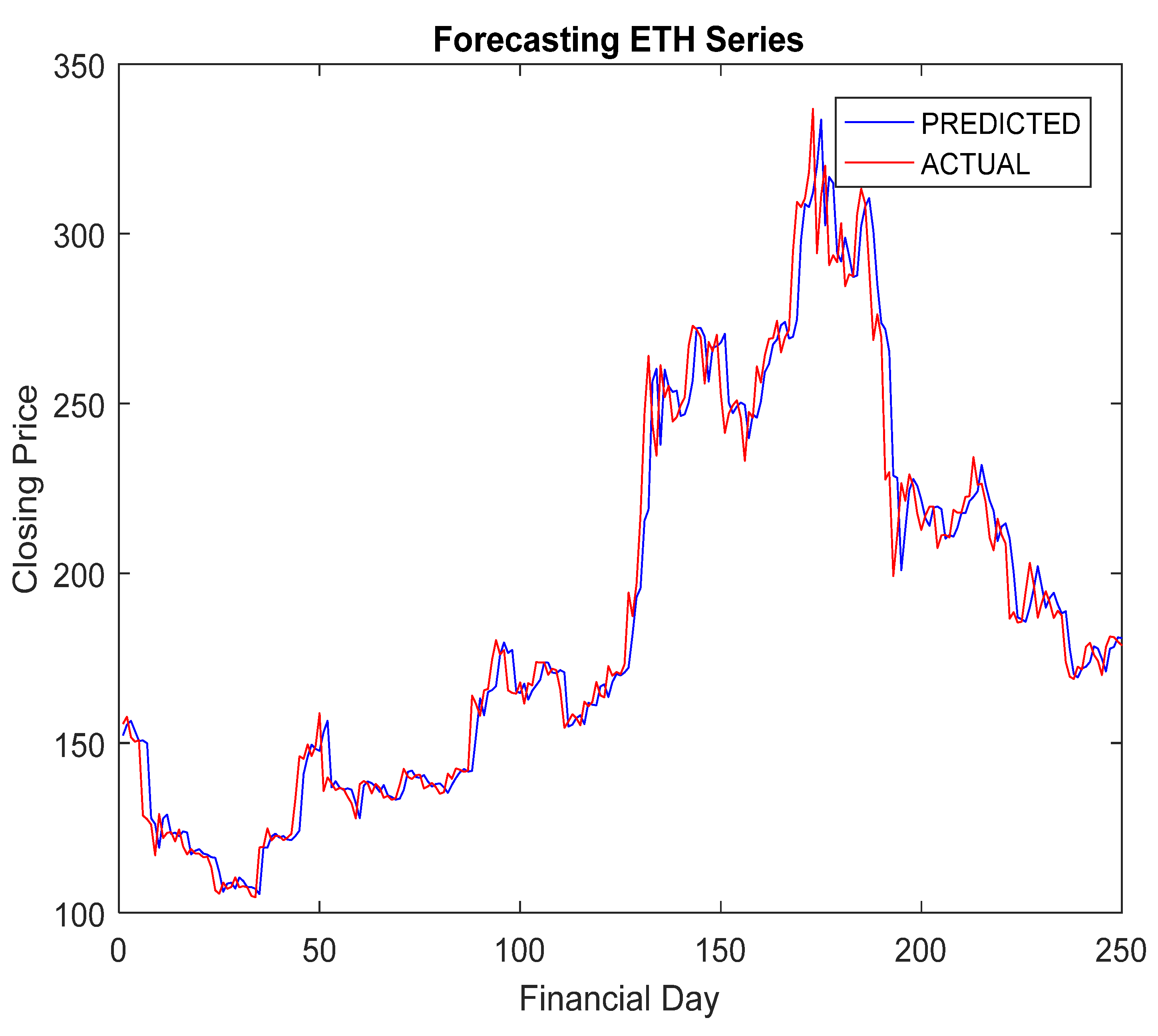
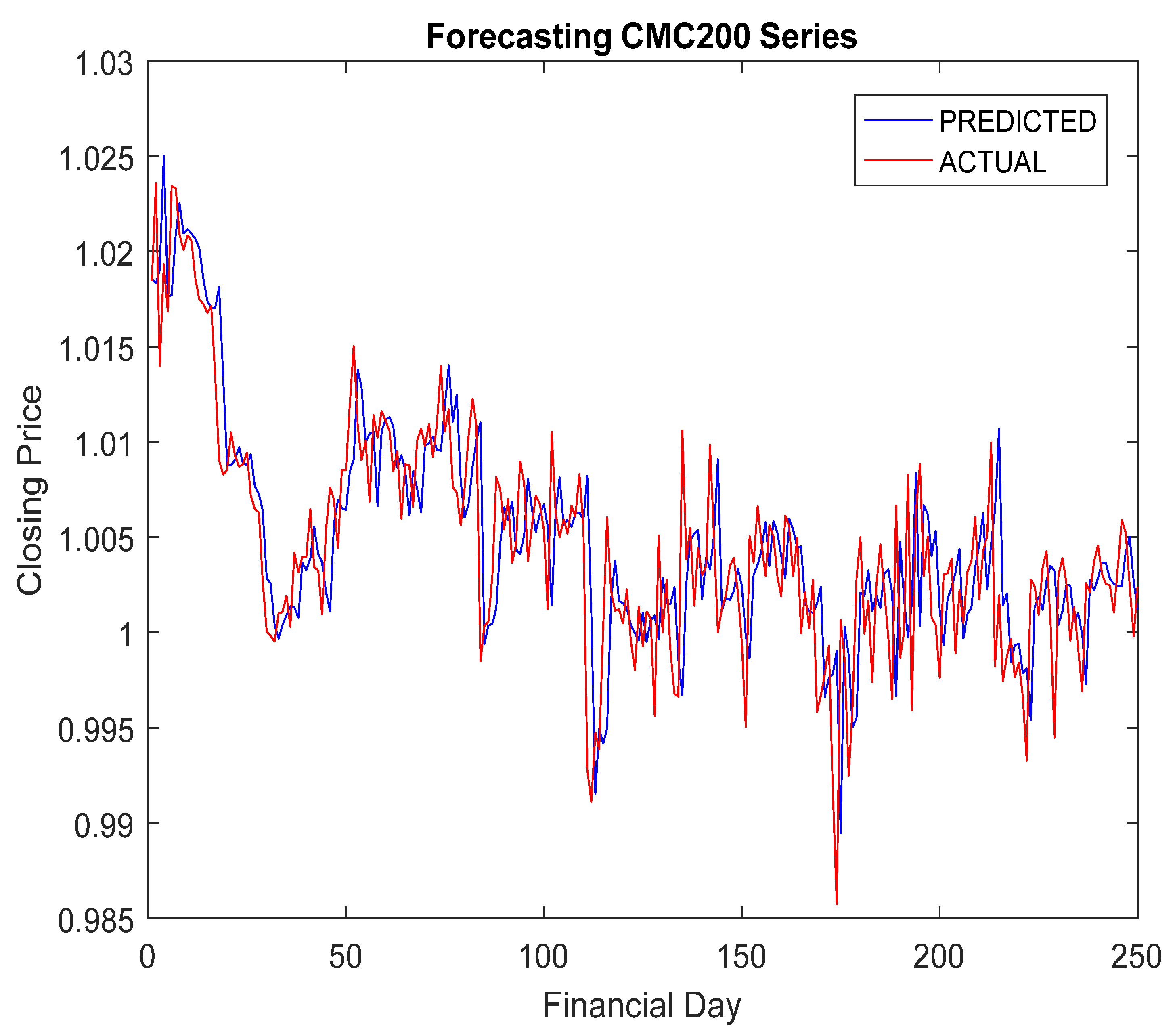
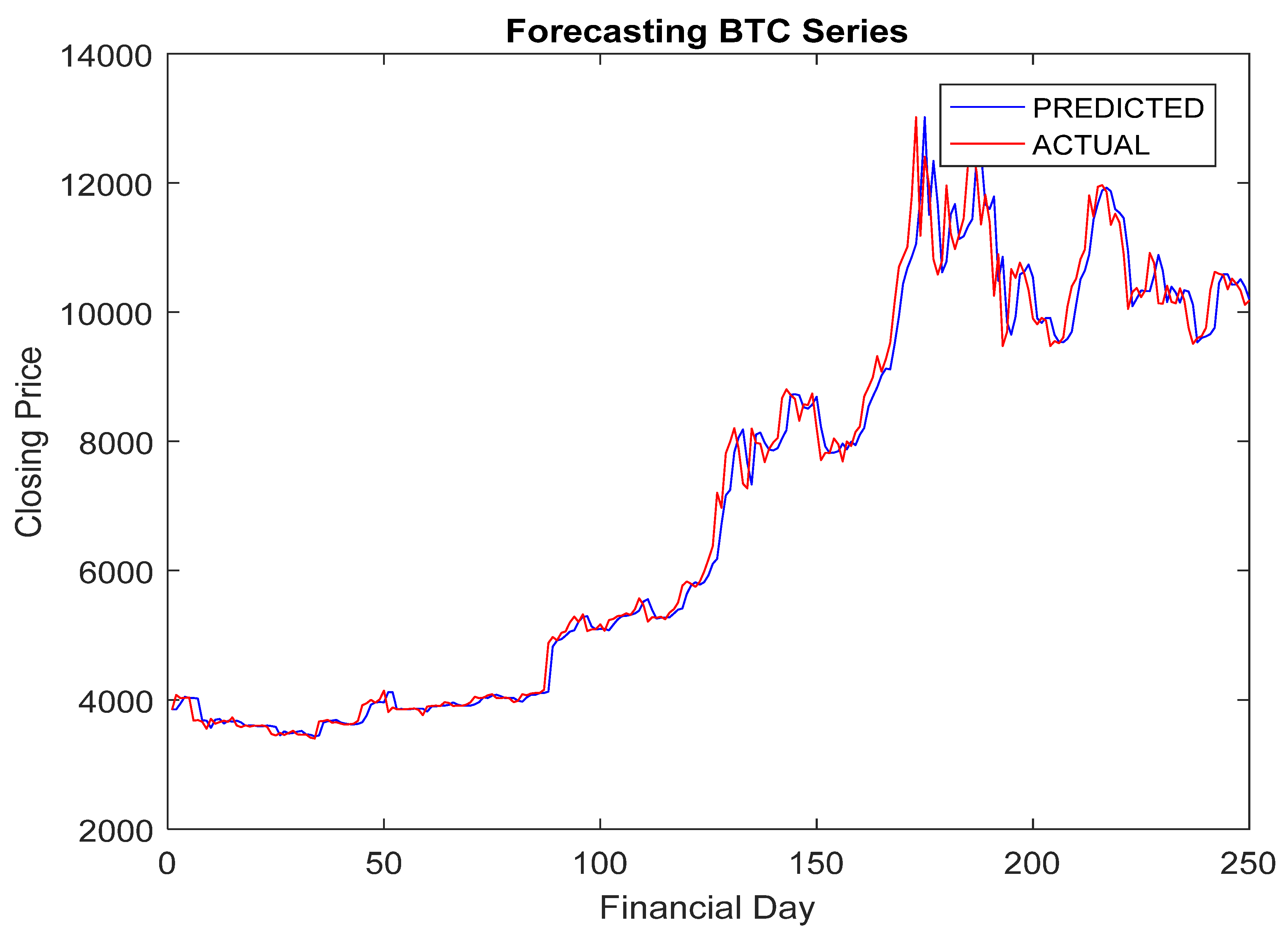
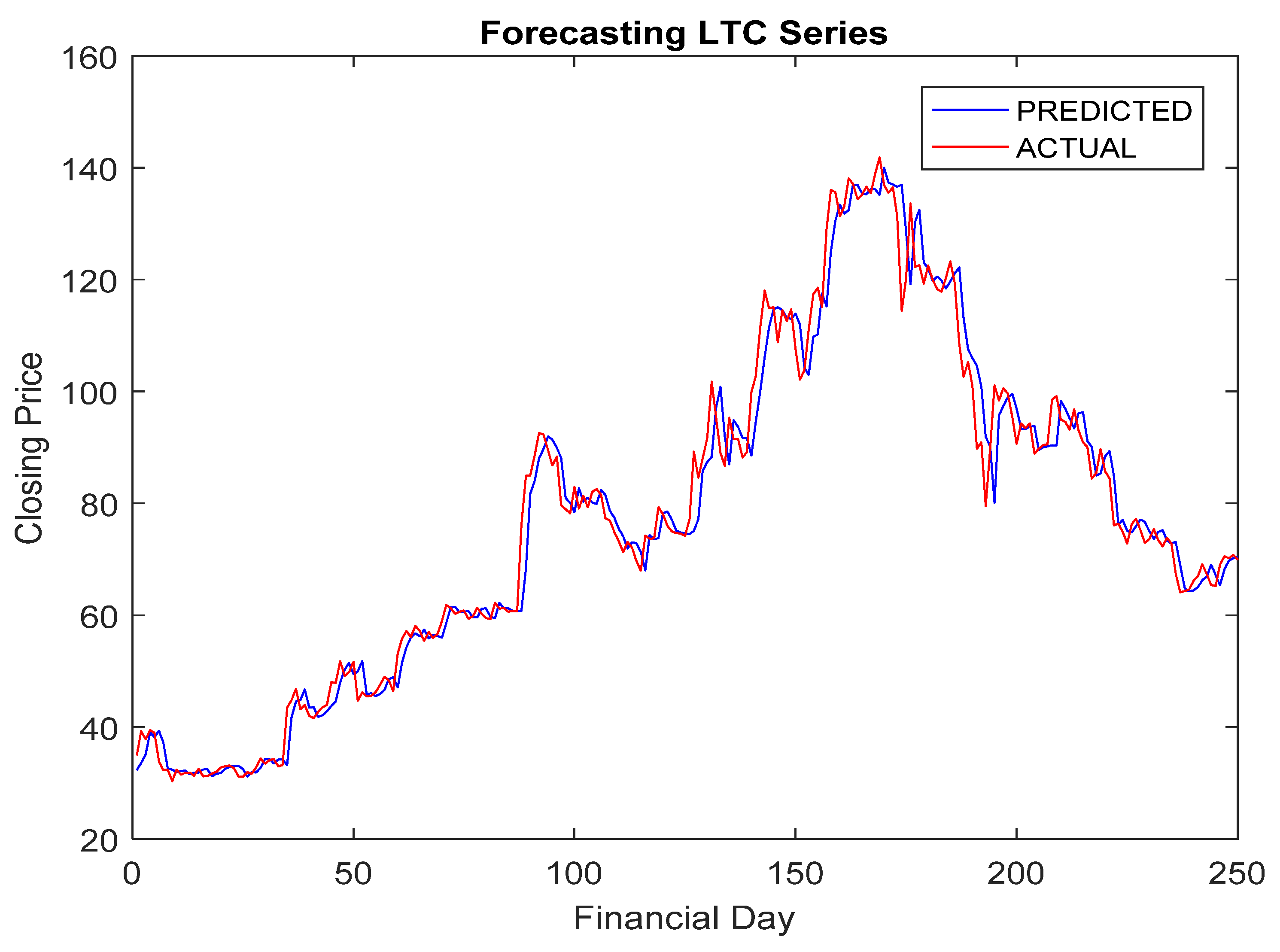
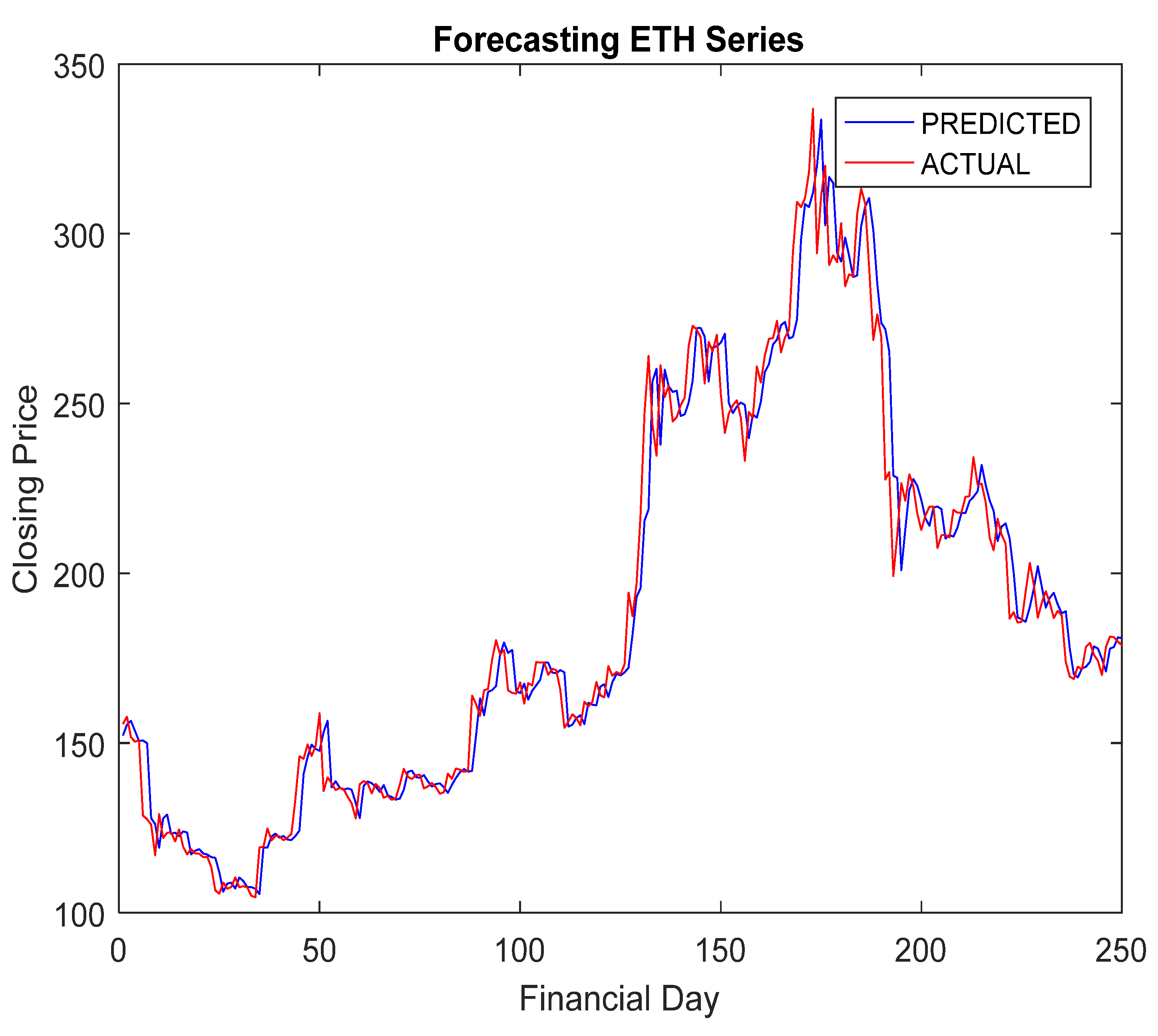
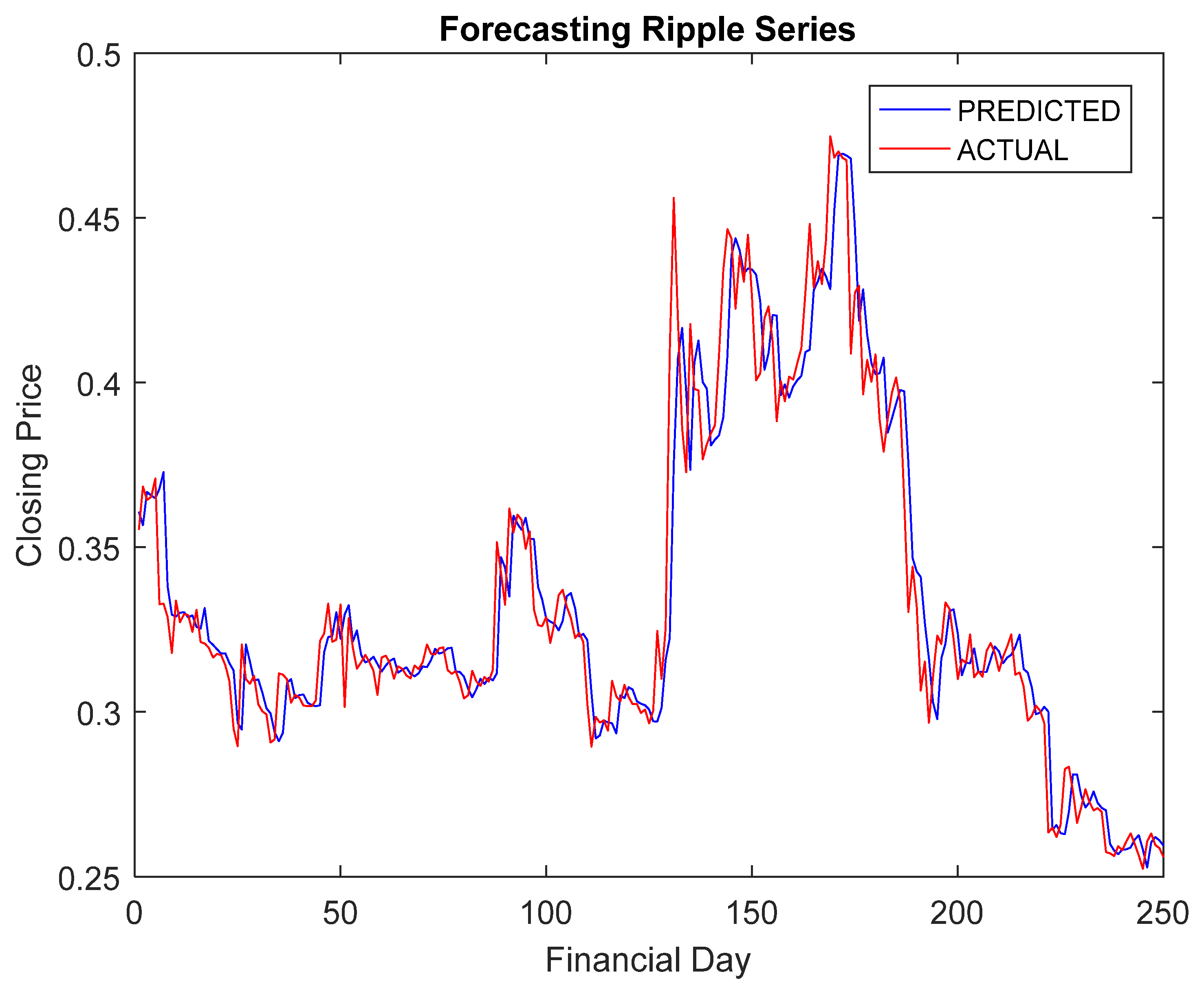
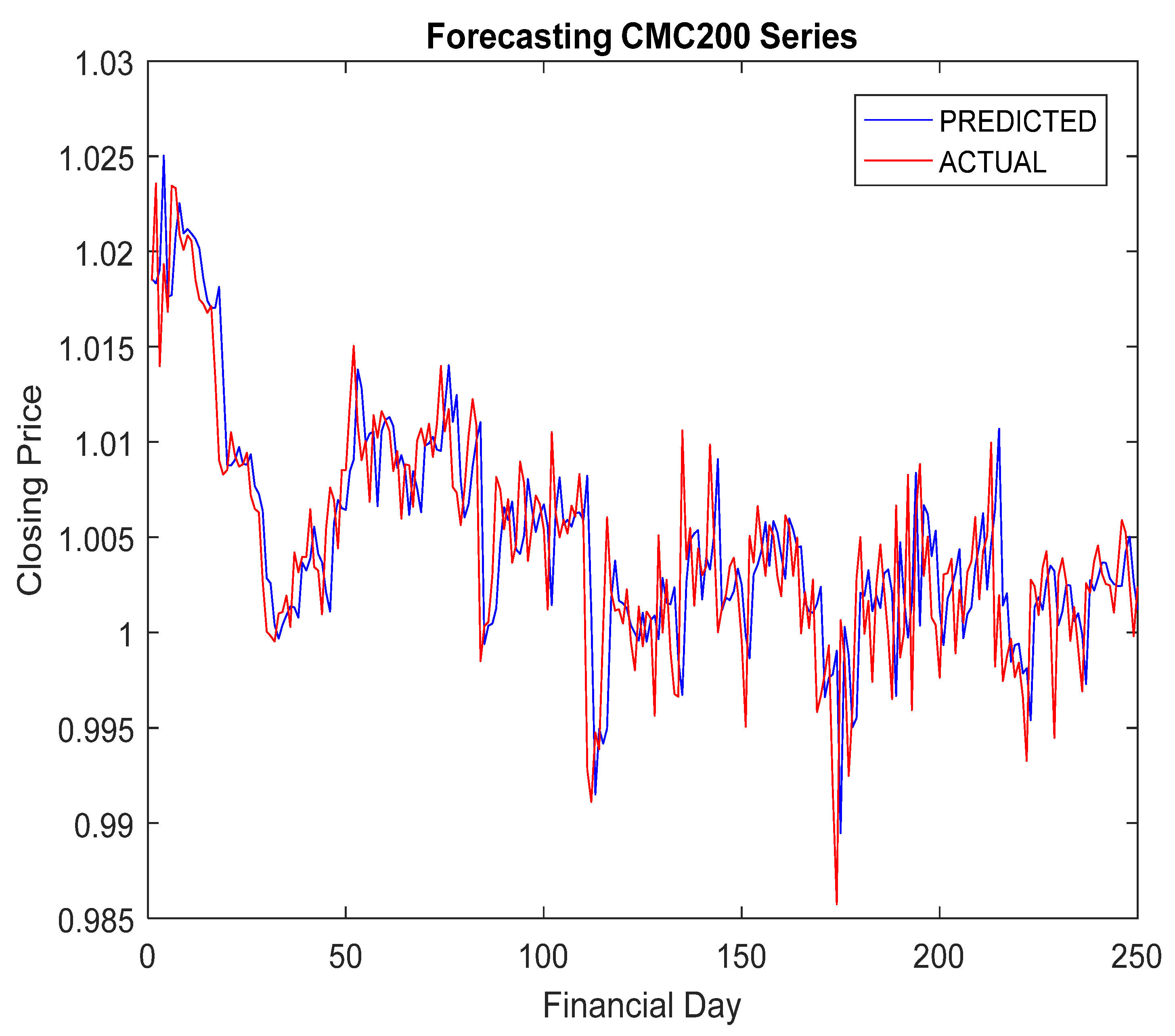
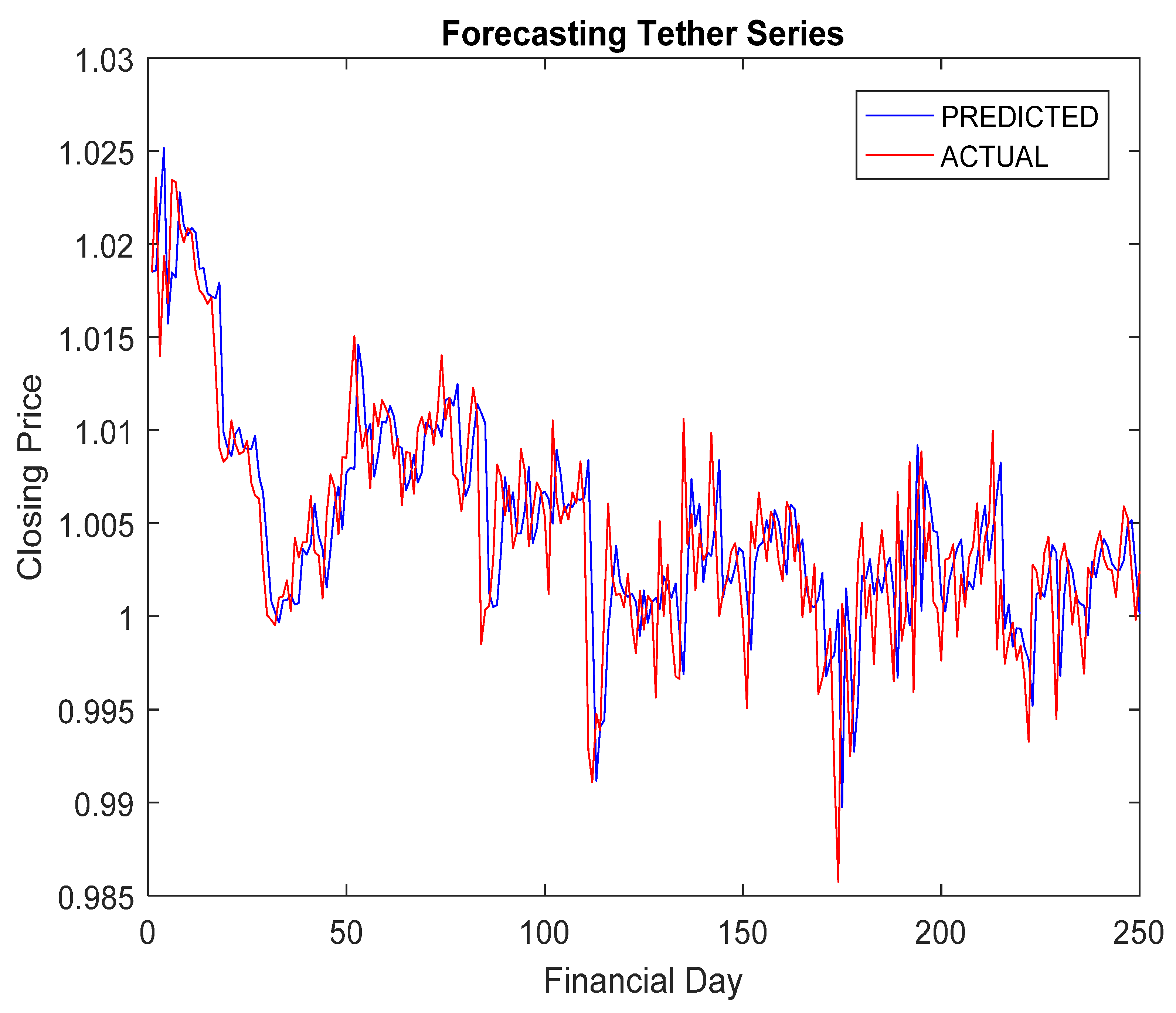
5.4. Simulation Results and Discussion
- The RA + ANN-based forecast was found quite capable in capturing the inherent dynamism and uncertainties associated with cryptocurrency data.
- The hybridization of RA and ANN achieved improved forecasting accuracy compared to others.
- The outcomes from the statistical test justified the significant difference between RA + ANN and others.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lansky, J. Possible state approaches to cryptocurrencies. J. Syst. Integr. 2018, 9, 19–31. [Google Scholar] [CrossRef]
- Nakamoto, S. Bitcoin: A peer-to-peer electronic cash system. Decentralized Bus. Rev. 2019, 21260. Available online: https://www.debr.io/article/21260.pdf (accessed on 26 March 2021).
- Kyriazis, N.A. A survey on efficiency and profitable trading opportunities in cryptocurrency markets. J. Risk Financ. Manag. 2019, 12, 67. [Google Scholar] [CrossRef] [Green Version]
- Mukhopadhyay, U.; Skjellum, A.; Hambolu, O.; Oakley, J.; Yu, L.; Brooks, R. A brief survey of cryptocurrency systems. In Proceedings of the 2016 14th annual conference on privacy, security and trust (PST), Auckland, New Zealand, 12–14 December 2016; pp. 745–752. [Google Scholar]
- Ferreira, M.; Rodrigues, S.; Reis, C.I.; Maximiano, M. Blockchain: A tale of two applications. Appl. Sci. 2018, 8, 1506. [Google Scholar] [CrossRef] [Green Version]
- Grinberg, R. Bitcoin: An innovative alternative digital currency. Hastings Sci. Technol. Law J. 2012, 4, 159. [Google Scholar]
- Mai, F.; Shan, Z.; Bai, Q.; Wang, X.; Chiang, R.H. How does social media impact Bitcoin value? A test of the silent majority hypothesis. J. Manag. Inf. Syst. 2018, 35, 19–52. [Google Scholar] [CrossRef]
- Sapuric, S.; Kokkinaki, A. Bitcoin Is Volatile! Isn’t That Right? Proceedings of the International Conference on Business Information Systems, Larnaca, Cyprus, 22–23 May 2014; Springer: Cham, Switzerland, 2014; pp. 255–265. [Google Scholar]
- Corelli, A. Cryptocurrencies and exchange rates: A relationship and causality analysis. Risk 2018, 6, 111. [Google Scholar] [CrossRef] [Green Version]
- Trabelsi, N. Are there any volatility spill-over effects among cryptocurrencies and widely traded asset classes? J. Risk Financ. Manag. 2018, 11, 66. [Google Scholar] [CrossRef] [Green Version]
- Billah, M.; Waheed, S.; Hanifa, A. Stock market prediction using an improved training algorithm of neural network. In Proceedings of the 2016 2nd International Conference on Electrical, Computer & Telecommunication Engineering (ICECTE), Rajshahi, Bangladesh, 8–10 December 2016; pp. 1–4. [Google Scholar]
- Nayak, S.C.; Misra, B.B.; Behera, H.S. An adaptive second order neural network with genetic-algorithm-based training (ASONN-GA) to forecast the closing prices of the stock market. Int. J. Appl. Metaheuristic Comput. (IJAMC) 2016, 7, 39–57. [Google Scholar] [CrossRef]
- Nayak, S.C.; Misra, B.B.; Behera, H.S. Efficient forecasting of financial time-series data with virtual adaptive neuro-fuzzy inference system. Int. J. Bus. Forecast. Mark. Intelligence 2016, 2, 379–402. [Google Scholar] [CrossRef]
- Rebane, J.; Karlsson, I.; Papapetrou, P.; Denic, S. Seq2Seq RNNs and ARIMA models for cryptocurrency prediction: A comparative study. In Proceedings of the SIGKDD Fintech’18, London, UK, 19–23 August 2018. [Google Scholar]
- White, H. Economic prediction using neural networks: The case of IBM daily stock returns. In Proceedings of the IEEE 1988 International Conference on Neural Networks, San Diego, CA, USA, 24–27 July 1988; Volume 2, pp. 451–458. [Google Scholar]
- Sureshkumar, K.K.; Elango, N.M. Performance analysis of stock price prediction using artificial neural network. Glob. J. Comput. Sci. Technol. 2012. [Google Scholar]
- Misnik, A.; Krutalevich, S.; Prakapenka, S.; Borovykh, P.; Vasiliev, M. Impact Analysis of Additional Input Parameters on Neural Network Cryptocurrency Price Prediction. In Proceedings of the 2019 XXI International Conference Complex Systems: Control and Modeling Problems (CSCMP), Samara, Russia, 3–6 September 2019; pp. 163–167. [Google Scholar]
- Jay, P.; Kalariya, V.; Parmar, P.; Tanwar, S.; Kumar, N.; Alazab, M. Stochastic neural networks for cryptocurrency price prediction. IEEE Access 2020, 8, 82804–82818. [Google Scholar] [CrossRef]
- Akyildirim, E.; Goncu, A.; Sensoy, A. Prediction of cryptocurrency returns using machine learning. Ann. Oper. Res. 2020, 297, 3–36. [Google Scholar] [CrossRef]
- Yazdinejad, A.; HaddadPajouh, H.; Dehghantanha, A.; Parizi, R.M.; Srivastava, G.; Chen, M.Y. Cryptocurrency malware hunting: A deep recurrent neural network approach. Appl. Soft Comput. 2020, 96, 106630. [Google Scholar] [CrossRef]
- Alessandretti, L.; ElBahrawy, A.; Aiello, L.M.; Baronchelli, A. Anticipating cryptocurrency prices using machine learning. Complexity 2018, 2018, 8983590. [Google Scholar] [CrossRef]
- Corbet, S.; Lucey, B.; Urquhart, A.; Yarovaya, L. Cryptocurrencies as a financial asset: A systematic analysis. Int. Rev. Financ. Anal. 2019, 62, 182–199. [Google Scholar] [CrossRef] [Green Version]
- McNally, S.; Roche, J.; Caton, S. Predicting the price of bitcoin using machine learning. In Proceedings of the 2018 26th Euromicro International Conference on Parallel, Distributed and Network-Based Processing (PDP), Cambridge, UK, 21–23 March 2018; pp. 339–343. [Google Scholar]
- Nakano, M.; Takahashi, A.; Takahashi, S. Bitcoin technical trading with artificial neural network. Phys. A Stat. Mech. Its Appl. 2018, 510, 587–609. [Google Scholar] [CrossRef]
- Rao, R. Rao algorithms: Three metaphor-less simple algorithms for solving optimization problems. Int. J. Ind. Eng. Comput. 2020, 11, 107–130. [Google Scholar] [CrossRef]
- Caesarendra, W.; Pratama, M.; Kosasih, B.; Tjahjowidodo, T.; Glowacz, A. Parsimonious network based on a fuzzy inference system (PANFIS) for time series feature prediction of low speed slew bearing prognosis. Appl. Sci. 2018, 8, 2656. [Google Scholar] [CrossRef] [Green Version]
- Helfer, G.A.; Barbosa, J.L.; Alves, D.; da Costa, A.B.; Beko, M.; Leithardt, V.R. Multispectral cameras and machine learning integrated into portable devices as clay prediction technology. J. Sens. Actuator Netw. 2021, 10, 40. [Google Scholar] [CrossRef]
- Alazeb, A.; Panda, B.; Almakdi, S.; Alshehri, M. Data Integrity Preservation Schemes in Smart Healthcare Systems That Use Fog Computing Distribution. Electronics 2021, 10, 1314. [Google Scholar] [CrossRef]
- Nayak, S.C.; Misra, B.B.; Behera, H.S. On developing and performance evaluation of adaptive second order neural network with ga-based training (asonn-ga) for financial time series prediction. In Advancements in Applied Metaheuristic Computing; IGI Global: Hershey, PA, USA, 2018; pp. 231–263. [Google Scholar]
- Nayak, S.C.; Misra, B.B.; Behera, H.S. Efficient financial time series prediction with evolutionary virtual data position exploration. Neural Comput. Appl. 2019, 31, 1053–1074. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Hatamlou, A. Multi-verse optimizer: A nature-inspired algorithm for global optimization. Neural Comput. Appl. 2016, 27, 495–513. [Google Scholar] [CrossRef]
- Nayak, S.C.; Das, S.; Misra, B.B. Development and Performance Analysis of Fireworks Algorithm-Trained Artificial Neural Network (FWANN): A Case Study on Financial Time Series Forecasting. In Handbook of Research on Fireworks Algorithms and Swarm Intelligence; IGI Global: Hershey, PA, USA, 2020; pp. 176–194. [Google Scholar]
- Tan, Y.; Zhu, Y. Fireworks Algorithm for Optimization. In Proceedings of the International Conference in Swarm Intelligence, Beijing, China, 12–15 June 2010; Springer: Berlin, Germany, 2010; pp. 355–364. [Google Scholar]
- Alatas, B. ACROA: Artificial chemical reaction optimization algorithm for global optimization. Expert Syst. Appl. 2011, 38, 13170–13180. [Google Scholar] [CrossRef]
- Nayak, S.C.; Misra, B.B. A chemical-reaction-optimization-based neuro-fuzzy hybrid network for stock closing price prediction. Financ. Innov. 2019, 5, 38. [Google Scholar] [CrossRef]
- Rao, R.V.; Savsani, V.J.; Vakharia, D.P. Teaching–learning-based optimization: An optimization method for continuous non-linear large scale problems. Inf. Sci. 2012, 183, 1–15. [Google Scholar] [CrossRef]
- Rao, R. Jaya: A simple and new optimization algorithm for solving constrained and unconstrained optimization problems. Int. J. Ind. Eng. Comput. 2016, 7, 19–34. [Google Scholar]
- Rao, R.V.; Pawar, R.B. Constrained design optimization of selected mechanical system components using Rao algorithms. Appl. Soft Comput. 2020, 89, 106141. [Google Scholar] [CrossRef]
- Rao, R.V.; Pawar, R.B. Self-adaptive multi-population Rao algorithms for engineering design optimization. Appl. Artif. Intell. 2020, 34, 187–250. [Google Scholar] [CrossRef]
- Premkumar, M.; Babu, T.S.; Umashankar, S.; Sowmya, R. A new metaphor-less algorithms for the photovoltaic cell parameter estimation. Optik 2020, 208, 164559. [Google Scholar] [CrossRef]
- Wang, L.; Wang, Z.; Liang, H.; Huang, C. Parameter estimation of photovoltaic cell model with Rao-1 algorithm. Optik 2020, 210, 163846. [Google Scholar] [CrossRef]
- Jabir, H.A.; Kamel, S.; Selim, A.; Jurado, F. Optimal Coordination of Overcurrent Relays Using Metaphor-less Simple Method. In Proceedings of the 2019 21st International Middle East Power Systems Conference (MEPCON), Cairo, Egypt, 17–19 December 2019; pp. 1063–1067. [Google Scholar]
- Haykin, S. Neural Networks and Learning Machines 3/E; Pearson Educ: Delhi, India, 2010. [Google Scholar]
- Nayak, S.C.; Misra, B.B.; Behera, H.S. Impact of data normalization on stock index forecasting. Int. J. Comput. Inf. Syst. Ind. Manag. Appl. 2014, 6, 257–269. [Google Scholar]
- Nayak, S.C.; Misra, B.B. Extreme learning with chemical reaction optimization for stock volatility prediction. Financ. Innov. 2020, 6, 16. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistic | Bitcoin | Litecoin | Ethereum | Ripple | CMC 200 | Tether |
|---|---|---|---|---|---|---|
| Minimum | 68.4300 | 1.1600 | 0.4348 | 0.0028 | 0.9742 | 0.9742 |
| Mean | 1.4826 × 103 | 20.4966 | 147.7843 | 0.0984 | 1.0029 | 1.0029 |
| Median | 482.8100 | 3.9100 | 12.0200 | 0.0079 | 1.0017 | 1.0017 |
| Variance | 8.7535 × 106 | 2.2240 × 103 | 6.9765 × 104 | 0.1028 | 2.5621 × 10−5 | 2.5621 × 10−5 |
| Maximum | 1.9497 × 104 | 358.3400 | 1.3964 × 103 | 3.3800 | 1.0536 | 1.0536 |
| Standard deviation | 2.9593 × 103 | 47.1594 | 264.1308 | 0.3206 | 0.0051 | 0.0051 |
| Skewness | 3.5394 | 4.1627 | 2.3844 | 5.8039 | 1.9417 | 1.9417 |
| Kurtosis | 15.9671 | 21.5925 | 8.5122 | 42.9469 | 19.3797 | 19.3797 |
| Correlation coefficient | 0.00130 | 0.00211 | −0.0052 | 0.0027 | 0.0039 | 0.0035 |
| MODEL | BITCOIN | RIPPLE | EHTEREUM | LITECOIN | CMC200 | TETHER | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAPE | ARV | MAPE | ARV | MAPE | ARV | MAPE | ARV | MAPE | ARV | MAPE | ARV | |
| RA + ANN | 0.0300 | 0.0057 | 0.0397 | 0.0051 | 0.0385 | 0.0039 | 0.0322 | 0.0054 | 0.0275 | 0.0027 | 0.0065 | 0.0055 |
| GA + ANN | 0.0322 | 0.0075 | 0.0457 | 0.0143 | 0.0495 | 0.0057 | 0.0454 | 0.0058 | 0.0299 | 0.0053 | 0.0087 | 0.0173 |
| PSO + ANN | 0.0454 | 0.0061 | 0.0473 | 0.0053 | 0.0439 | 0.0063 | 0.0394 | 0.0079 | 0.0287 | 0.0164 | 0.0082 | 0.0094 |
| SVM | 0.0394 | 0.0065 | 0.0476 | 0.0068 | 0.0463 | 0.0059 | 0.0837 | 0.0060 | 0.0428 | 0.0342 | 0.0093 | 0.0107 |
| MLP | 0.0472 | 0.0077 | 0.0497 | 0.0174 | 0.0593 | 0.0467 | 0.1726 | 0.0246 | 0.0479 | 0.0277 | 0.0329 | 0.0637 |
| ARIMA | 0.0606 | 0.0083 | 0.0828 | 0.0163 | 0.0758 | 0.0193 | 0.0940 | 0.0095 | 0.1327 | 0.0336 | 0.0852 | 0.2953 |
| LSE | 0.0946 | 0.1005 | 0.0876 | 0.1373 | 0.2557 | 0.0736 | 0.2163 | 0.0266 | 0.5283 | 0.2734 | 0.1086 | 0.4066 |
| Proposed Forecast | Comparative Forecast | p and h Values from Wilcoxon Signed Test | ||||
|---|---|---|---|---|---|---|
| NASDAQ | BSE | DJIA | HSI | NIKKEI | ||
| RA + ANN | GA + ANN | 2.5034 × 10−5 (h = 1) | 3.1432 × 10−4 (h = 1) | 2.2441 × 10−3 (h = 1) | 3.0134 × 10−5 (h = 1) | 2.2763 × 10−4 (h = 1) |
| PSO + ANN | 3.1362 × 10−3 (h = 1) | 4.2634 × 10−5 (h = 1) | 4.3004 × 10−3 (h = 1) | 6.2515 × 10−3 (h = 1) | 1.7253 × 10−2 (h = 1) | |
| SVM | 4.2418 × 10−4 (h = 1) | 2.1505 × 10−3 (h = 1) | 3.3410 × 10−2 (h = 1) | 2.990152 (h = 0) | 1.6728 × 10−1 (h = 1) | |
| MLP | 1.5728 × 10−3 (h = 1) | 0.008524 (h = 0) | 6.2803 × 10−2 (h = 1) | 7.2095 × 10−2 (h = 1) | 4.2021 × 10−3 (h = 1) | |
| ARIMA | 4.3007 × 10−4 (h = 1) | 3.7726 × 10−2 (h = 1) | 1.7362 × 10−5 (h = 1) | 3.3282 × 10−3 (h = 1) | 1.7062 × 10−4 (h = 1) | |
| LSE | 1.5338 × 10−3 (h = 1) | 0.01821 (h = 0) | 6.2033 × 10−2 (h = 1) | 7.0025 × 10−2 (h = 1) | 3.2521 × 10−3 (h = 1) | |
| p and h values from Diebold–Mariano test | ||||||
| GA + ANN | 2.09755 (h = 1) | 2.34220 (h = 1) | 2.0007 (h = 1) | 1.9820 (h = 1) | 2.2037 (h = 1) | |
| PSO + ANN | 2.22043 (h = 1) | 2.36020 (h = 1) | 1.9873 (h = 1) | 1.9815 (h = 1) | −1.9900 (h = 1) | |
| SVM | 2.36105 (h = 1) | 1.99247 (h = 1) | 1.97695 (h = 1) | 1.98577 (h = 1) | 1.9792 (h = 1) | |
| MLP | 2.7329 (h = 1) | 1.9800 (h = 1) | −3.05263 (h = 1) | −1.99265 (h = 1) | 2.52655 (h = 1) | |
| ARIMA | 1.9909 (h = 1) | 2.61227 (h = 1) | −3.40582 (h = 1) | 1.96035 (h = 0) | 2.45884 (h = 1) | |
| LSE | 2.0728 × 10−3 (h = 1) | 2.88524 (h = 1) | 3.2800 × 10−2 (h = 1) | 5.1095 × 10−2 (h = 1) | 4.32171 × 10−3 (h = 1) | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nayak, S.K.; Nayak, S.C.; Das, S. Modeling and Forecasting Cryptocurrency Closing Prices with Rao Algorithm-Based Artificial Neural Networks: A Machine Learning Approach. FinTech 2022, 1, 47-62. https://doi.org/10.3390/fintech1010004
Nayak SK, Nayak SC, Das S. Modeling and Forecasting Cryptocurrency Closing Prices with Rao Algorithm-Based Artificial Neural Networks: A Machine Learning Approach. FinTech. 2022; 1(1):47-62. https://doi.org/10.3390/fintech1010004
Chicago/Turabian StyleNayak, Sanjib Kumar, Sarat Chandra Nayak, and Subhranginee Das. 2022. "Modeling and Forecasting Cryptocurrency Closing Prices with Rao Algorithm-Based Artificial Neural Networks: A Machine Learning Approach" FinTech 1, no. 1: 47-62. https://doi.org/10.3390/fintech1010004
APA StyleNayak, S. K., Nayak, S. C., & Das, S. (2022). Modeling and Forecasting Cryptocurrency Closing Prices with Rao Algorithm-Based Artificial Neural Networks: A Machine Learning Approach. FinTech, 1(1), 47-62. https://doi.org/10.3390/fintech1010004