1. Introduction
Neural networks [
1] have emerged as a central pillar of machine learning [
2], capable of detecting nuanced patterns in complex, large-scale datasets by emulating certain structural and functional characteristics of the human brain. Constructed from interconnected computational elements analogous to biological neurons, these networks excel in processing and relaying information across multiple layers. Crucially, the depth, configuration, and number of these layers significantly influence a network’s capacity to generalize and perform effectively in myriad real-world tasks.
This remarkable flexibility and performance have positioned neural networks as indispensable tools in diverse fields, including autonomous vehicles [
3], healthcare [
4], robotics [
5], and telecommunications [
6]. Despite their extensive applicability, deploying neural networks on resource-constrained platforms remains a formidable challenge, largely due to their high computational and memory requirements. These limitations can hinder their efficiency and broad adoption, particularly when rapid inference or low power consumption is demanded.
In addressing these computational constraints, researchers have increasingly focused on reconfigurable architectures [
7], which offer a compelling balance between adaptability and performance. By enabling post-manufacturing modifications, reconfigurable systems provide hardware-level flexibility akin to that of software environments, allowing design parameters such as throughput, latency, and resource utilization to be fine-tuned to specific application demands. This adaptability is particularly well-suited for optimizing the performance of neural networks while minimizing hardware overhead.
Recent efforts to implement neural networks on Field-Programmable Gate Arrays (FPGAs) highlight the promise of reconfigurable solutions. For instance, [
8] introduces a pragmatic method for shrinking hardware-based neural networks by employing adaptable layers in Artificial Neural Networks, wherein each layer can execute two distinct functions. This approach achieves a remarkable 41% reduction in the FPGA footprint compared with alternative designs and demonstrates a straightforward, Verilog-based implementation on the Altera Arria 10 GX FPGA. Concurrently, ref. [
9] proposes an adaptive parallelism strategy for Binary Neural Networks (BNNs) on a Xilinx XCZU7EV FPGA, thereby streamlining resource usage while preserving high throughput across varying BNN layers. This dynamic allocation of computational parallelism enables a substantial improvement in area–speed efficiency relative to previous FPGAs and VLSI accelerators, which is especially pertinent for real-time inference on edge devices.
Along similar lines, ref. [
10] demonstrated a fully reconfigurable multilayer perceptron on a Cyclone IV FPGA that supports run-time adjustment of key network parameters, including number of inputs, neurons per layer, total layers, bias inclusion, and choice of activation function, entirely without re-synthesis. Their architecture reuses a fixed bank of 20 hardware neurons as virtual layers under the control of a finite-state machine, and replaces vendor-specific DSP blocks with custom VEDIC multipliers to ensure portability to ASIC implementations. Although the design operates at a lower peak clock rate (approximately 77 MHz), it achieves competitive performance, achieving 99.3% accuracy on the Iris classification task in 1.16 µs and sub-microsecond latency on function approximation, while consuming only 37% of logic elements and 1% of memory bits on the FPGA.
Prior FPGA-based accelerators have typically optimized only one or two metrics. For example, ref. [
8] achieved a 41% reduction in footprint, ref. [
9] reported a 24% improvement in area–speed efficiency, and [
10] enabled per-task reconfiguration. In contrast, NeuroAdaptiveNet employs per-input reconfiguration to achieve simultaneous improvements in power consumption, hardware resource utilization, and classification accuracy.
At runtime, NeuroAdaptiveNet evaluates each input and switches to the most suitable compact neural model, resulting in up to 24.5% lower power consumption, up to 52.85% lower resource utilization, and up to 4.31% higher classification accuracy compared with the best static design. Unlike prior designs that use a fixed single network or adapt only at the task level, NeuroAdaptiveNet’s input-level flexibility incurs only microseconds of overhead while delivering maximum accuracy with minimal hardware and energy requirements. Its efficient performance and high accuracy make it an ideal solution for Edge AI systems constrained by limited power and resources. The primary goal of this study is to introduce a novel FPGA-based neural network implementation that departs from the conventional static design.
The remainder of this paper is structured as follows.
Section 2 details the dynamic classifier selection framework,
Section 3 explains the FPGA design,
Section 4 reports accuracy, resource-use, power, and latency results,
Section 5 analyzes trade-offs and future work, and
Section 6 concludes the paper.
3. NeuroAdaptiveNet Design
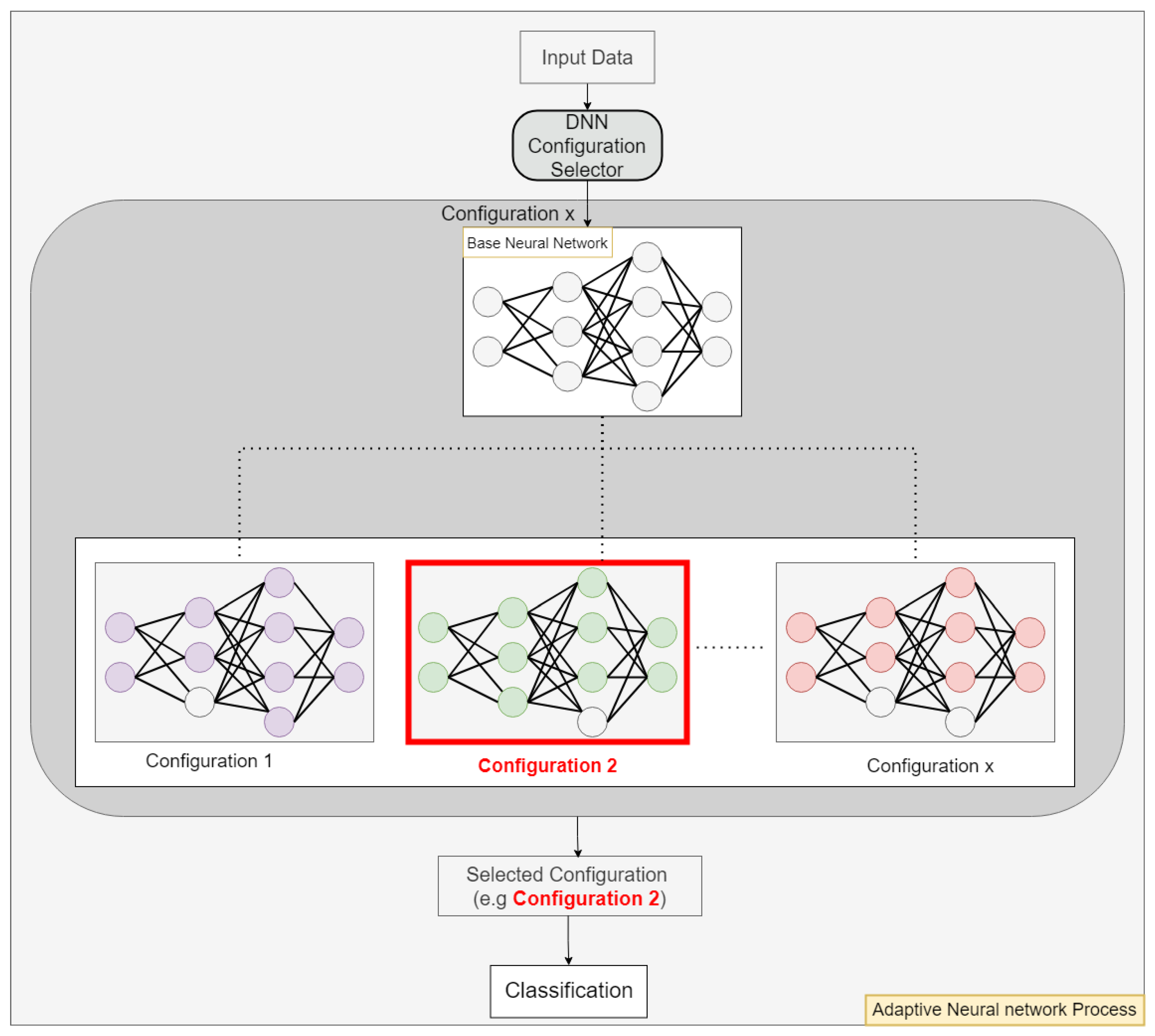
We implemented the design using Verilog, creating two primary modules as depicted in
Figure 3: the DNN Configuration Selector module and the DNN Accelerator module.
The DNN Configuration Selector module incorporates a Squared Euclidean Distance Unit that efficiently computes the distances between the input data vector and pre-stored centroids as shown in
Figure 4. This computation is achieved through a pipeline of parallel subtractors, multipliers, and an accumulator.
Initially, parallel subtractors calculate the differences between each feature of the input vector and the corresponding features of a centroid. These differences are then squared by the multipliers and the resulting squared values are aggregated by the accumulator to yield the squared Euclidean distance for the centroid. The computation adheres to the formula shown in Equation (
1), enabling precise distance measurement while optimizing hardware performance.
where
and
are the individual features of the input vector and centroid.
After completing the centroid evaluations, the computed distances are temporarily stored in a buffer. A comparator examines these distances, identifies the smallest value, and retrieves its corresponding label to determine the most suitable neural network configuration. This selection process is facilitated by a lookup table, represented as the “configurations” block in
Figure 3, which maps each closest centroid to its optimal neural network model configuration. This association ensures that each input data point is processed by the configuration best suited for accurate classification.
The Control Unit serves as a critical component, managing the data flow and overseeing all computational tasks within the system. It directs the neural network module to deploy the specific configuration identified by the DNN Configuration Selector, ensuring smooth operation and accurate classification.
In our FPGA architecture, each processing element mimics the function of a traditional neuron by carrying out Multiply-Accumulate operations followed by ReLU activation. Each processing element multiplies input vector elements by their corresponding weights W and adds a bias term b. This is mathematically represented as follows:
The implementation of the ReLU activation function is achieved using a comparator along with a 2:1 Multiplexer. This setup allows the activation function to be expressed mathematically as follows:
This implementation allows each processing element to efficiently handle all necessary calculations and activation steps, closely mimicking the behavior of neurons in traditional neural network models. The architecture accommodates variable neuron counts and supports multiple layers. In a static implementation, the design instantiates as many processing elements as the size of the largest hidden layer. For NeuroAdaptiveNet, we instantiate processing elements equal to the maximum hidden-layer size across all configurations in the ensemble. This arrangement ensures that all neurons within each layer execute in parallel, while layers are processed sequentially.
In the output stage, the commonly used softmax activation is replaced by the argmax function to better align with our focus on maximizing classification accuracy. The argmax function identifies the neuron with the highest output and converts this information into a one-hot encoded vector, circumventing the need for complete class probability distributions. This streamlined approach reduces computational overhead, simplifies hardware complexity, and accelerates inference.
4. Results
4.1. Dataset and Pre-Processing
We evaluate the NeuroAdaptiveNet system, implemented on an FPGA, using four distinct datasets from the UCI repository: Pima Indian Diabetes, Vehicle Silhouettes, Connect-4, and German Credit. These datasets vary in complexity and classification tasks, with Pima Indian Diabetes and German Credit tailored for binary classification and Vehicle Silhouettes and Connect-4 involving multiclass classification.
To maintain uniformity across these heterogeneous datasets, we adopt an 85–15 split for data partitioning. Specifically, 85% of each dataset is used both to train the models and to compute centroids. The remaining 15% of the data is held out for testing and performance evaluation, enabling a comprehensive assessment of the system’s accuracy and robustness.
The design is implemented on an Ultra96v2 board featuring the Zynq UltraScale+ MPSoC. Our FPGA implementations employ a 16-bit fixed-point format for all input vectors, weights, biases, and centroids.
We run scikit-learn’s KMeans multiple times to generate different centroid initializations, then select the initialization that performs best on a validation subset of the training data.
4.2. Configurations
We employ a small ensemble of compact neural networks that differ in both their training data and their architecture. To create this ensemble, we partition the full training set into two subsets and train half of our network configurations on the first subset and the other half on the second. Each configuration also varies the number of neurons per layer. Although this ensemble is not intended to represent the optimal combination of models, it demonstrates that selecting from a diverse collection of smaller networks for each individual input can achieve a more resource and energy-efficient adaptive implementation than relying on a single, statically configured network.
Table 1 lists the network configurations that make up the NeuroAdaptiveNet ensemble for each dataset. Each configuration is defined by its layer-wise neuron counts, ensuring a diverse set of model. At runtime, the DNN Configuration Selector chooses the configuration best suited to the current input and the accelerator dynamically loads its corresponding weights, biases, and neuron-count settings before performing inference.
Upon receiving an input sample, the selector identifies the optimal network configuration, which is defined by its layer-wise neuron counts, weight matrices, and bias vectors. The accelerator then loads these parameters and performs inference by processing exactly the specified neurons in each layer. We train each network configuration in Python 3.8 and export its weights and bias vectors into memory initialization files.
4.3. Accuracy Results
With the ensemble configurations defined, we now evaluate the classification accuracy of NeuroAdaptiveNet against static network designs.
Determining the optimal number of centroids C is critical. This parameter has a critical impact on accuracy. To identify the best value, we ran a series of experiments varying the number of centroids from 10 to 100 for smaller datasets and from 10 to 200 for larger ones.
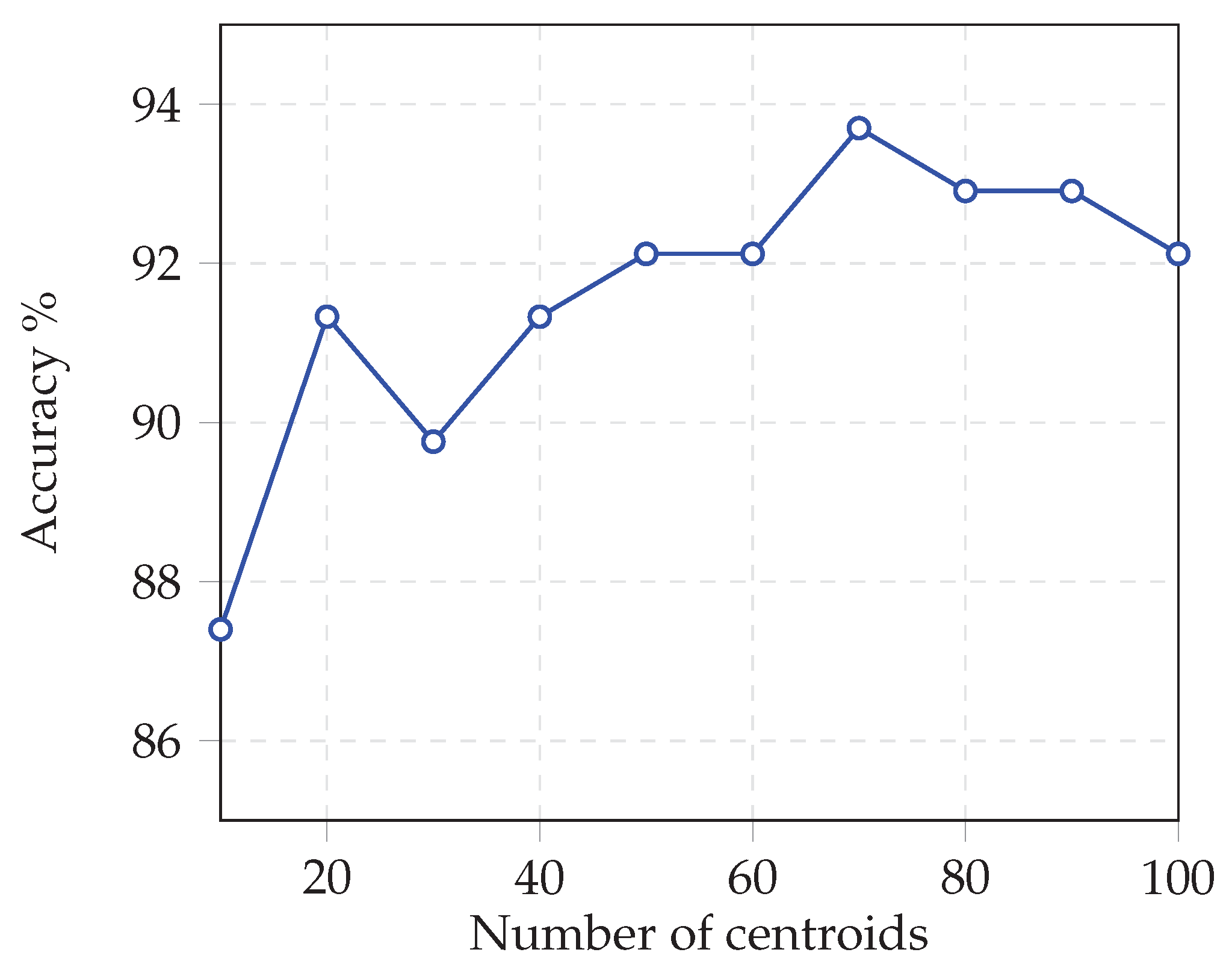
Figure 5 shows how accuracy on the Vehicle dataset improves as the number of centroids increases.
Figure 5 clearly shows that increasing the number of centroids from 10 to 70 raises classification accuracy from 87.40% to 93.70%. This improvement occurs because each additional centroid refines the partitioning of the feature space, creating more regions in which a specialized network can operate.
Following comprehensive experiments to determine each dataset’s optimal centroid count, we evaluate NeuroAdaptiveNet performance against static neural network models with larger, denser architectures, as shown in
Table 2.
The results indicate that the NeuroAdaptiveNet system outperforms the traditional models in all tested datasets, achieving up to 4.31% more accuracy. The NeuroAdaptiveNet showed higher accuracy compared to several larger networks employing the standard approach. This pattern of enhanced performance was consistent across all datasets, with the NeuroAdaptiveNet system demonstrating a clear advantage over the traditional setups.
For the Vehicle Silhouettes and German Credit datasets, the best configuration was achieved with 70 centroids. In contrast, the Diabetes dataset reached optimal performance with a different centroid count of 50, while the Connect-4 dataset required 180 centroids for the best results.
4.4. Resource Utilization and Power Analysis
Resource usage is a key indicator of FPGA designs efficiency. In this analysis, we compare how much hardware different neural network models use for all datasets. This helps us understand which designs are most efficient for specific applications.
Across all four benchmarks, as shown in
Table 3,
Table 4,
Table 5 and
Table 6, NeuroAdaptiveNet delivers consistent FPGA resource savings: LUT utilization decreases by roughly 4% to 15%, FF usage by approximately 19% to 51%, and DSP consumption by about 25% to 53%. These results demonstrate that NeuroAdaptiveNet effectively minimizes hardware utilization without sacrificing accuracy. These resource reductions result from NeuroAdaptiveNet’s dynamic use of compact networks, each of which requires fewer processing elements than a single, larger fixed design.
We observed that NeuroAdaptiveNet uses more LUTRAM than a single static design. This increase results from storing multiple parameter sets, including each configuration’s weights and biases, as well as the centroid feature vectors required by the DNN Configuration Selector.
To assess the energy efficiency of our adaptive architecture, we performed post-implementation power estimation in Xilinx Vivado, targeting the programmable logic of an Ultra96-V2 board (Zynq UltraScale+ MPSoC). NeuroAdaptiveNet was configured with the centroid counts that maximize classification accuracy for each dataset, and its PL dynamic power consumption was compared against the highest-performing static Neural network implementation. The results are summarized in
Table 7.
Table 7 presents the dynamic PL power consumption of NeuroAdaptiveNet when configured with the centroid counts (C) that yielded the highest classification accuracy on each dataset, compared against the corresponding neural networks (120, 120, 64) for Connect-4, (16, 16) for Diabetes, (60, 60, 30) for Vehicle, and (32, 32) for German-Credit, NeuroAdaptiveNet achieves power savings of 10.1%, 24.5%, 1.5%, and 18.2%, respectively. These findings confirm that NeuroAdaptiveNet consistently reduces FPGA power consumption compared to conventional fixed neural networks, achieving substantial energy savings without sacrificing accuracy.
4.5. Latency Analysis
Inference latency is a key metric for real-time neural network applications.
Table 8 presents the measured maximum clock frequencies and inference latencies for NeuroAdaptiveNet.
The integration of the DNN Configuration Selector for centroid evaluation adds only a small latency overhead. Inference latency increases by 0.67 µs on Connect-4, 0.32 µs on Diabetes, 0.23 µs on Vehicle, and 0.40 µs on German-Credit.
6. Conclusions
The NeuroAdaptiveNet system represents a novel approach to FPGA-based neural networks, offering dynamic adaptability and high accuracy for real-time and edge computing scenarios. Experimental results across diverse datasets confirm its effectiveness in adjusting neural network configurations on a per-input basis, thus balancing hardware resource management and classification performance.
By capitalizing on an adaptive architecture that reconfigures its parameters in response to incoming data, NeuroAdaptiveNet showcases significant benefits over static neural network models, particularly in terms of efficiency and response time. This ability to select the most suitable neural configuration for each input greatly enhances its applicability in resource-limited environments where computational demands and power constraints are paramount.
Looking ahead, the integration of dimensionality reduction techniques and specialized distance metrics offers promising avenues to counteract the limitations posed by high-dimensional data. These enhancements have the potential to reinforce the adaptability of NeuroAdaptiveNet, further increasing its performance in a wide range of real-time and edge computing applications. Ultimately, the system’s flexibility and efficiency mark a meaningful step forward in developing next-generation, FPGA-optimized neural network solutions.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}