
The Quest for Efficient ASCON Implementations: A Comprehensive Review of Implementation Strategies and Challenges


Abstract
1. Introduction
- Security. The algorithm had to demonstrate robust security properties through proofs and third-party analyses. Considerations such as nonce-misuse resistance, the effects of state recovery, and the release of unverified plaintext (RUP) were also taken into account.
- Efficient Implementation. The algorithm needed to be deployable within resource-constrained platforms, whether hardware- or software-oriented. It was expected to outperform existing standards such as AES-GCM and SHA-2 in both performance and cost and exhibit enough flexibility to meet application-specific needs.
- Ease of Protection. The design had to facilitate the incorporation of protections against side-channel and fault attacks. Countermeasures needed to impose minimal performance and cost overhead.
- Royalty-Free. The resulting standard needed to be freely implementable, without licensing fees.
Our Contribution
2. Preliminaries
2.1. ASCON Design
ASCON Permutation
- Outer part (): Consists of r bits, known as the rate and is the maximum number of data bits that an invocation of permutation will process.
- Inner part (): Consists of c bits (), known as the capacity.
- Round Constant Addition . In this layer, a 1-byte round constant is XORed with the least significant bits of register . The round constant value depends on the round index and ensures differential and linear cryptanalysis resistance (Table 2).
- Substitution Layer . Updates ASCON state by applying in a column-wise fashion (Figure 2, down) a 5 bit S-Box (Figure 2, up). Each bit position in the five state words is updated simultaneously. This step introduces non-linearity and vertical diffusion across the state.The S-box design was inspired by the mapping used in Keccak [21]. This choice offers multiple advantages:
- High efficiency on 64 bit processors, allowing parallel execution.
- Avoidance of lookup tables, mitigating cache-timing attacks in software implementations.
- Algebraic simplicity (degree 2), facilitating first- and higher-order side-channel protection using masking or sharing-based countermeasures.
| Algorithm 1 ASCON Permutation over 320 bit State |
Input: Five 64-bit registers (big-endian order) Output: The updated state after applying the permutation for to rounds do ▹ Step 1: - Addition of Round Constant ▹ Step 2: - Substitution Layer if then ▹ Apply the ASCON S-Box transformation using LUT for to 63 do end for end if if then ▹ Apply the ASCON S-Box transformation using AFN for to 63 do end for end if ▹ Step 3: - Linear Diffusion Layer end for |
2.2. ASCON Suite
2.2.1. ASCON AEAD
- Initialization phase. In this phase, the 320 bit state is split into five 64 bit registers to , as shown in Table 5. The IV encodes the key length, rate, and round numbers, ensuring separation between different primitives. The state undergoes the permutation, acting as a non-invertible key derivation function (KDF), followed by an XOR with the secret key.
- Processing Associate Data. The input A is padded if its length is not a multiple of r, using a single ‘1’ followed by ‘0’s as necessary. Each resulting block is XORed with the first r bits of the internal state , followed by an invocation of the permutation. To ensure separation from the next phase, the resultant state is then XORed with ‘1’.
- Processing plaintext. The plaintext P is padded and split into r bit blocks using the same padding rule as for A. Each plaintext block is XORed with and the result is stored as a ciphertext block . The state undergoes the permutation after each block. The final ciphertext block is truncated to match the length of the last unpadded plaintext block.
- Finalization. This phase ensures message authentication. The state is XORed with the key K and undergoes the permutation, acting as a Tag-Generating Function (TGF). The 128 bit authentication tag T is extracted from the resulting state, authenticating both the associated data and the encrypted message.
| Algorithm 2 ASCON AEAD Encryption Algorithm |
|
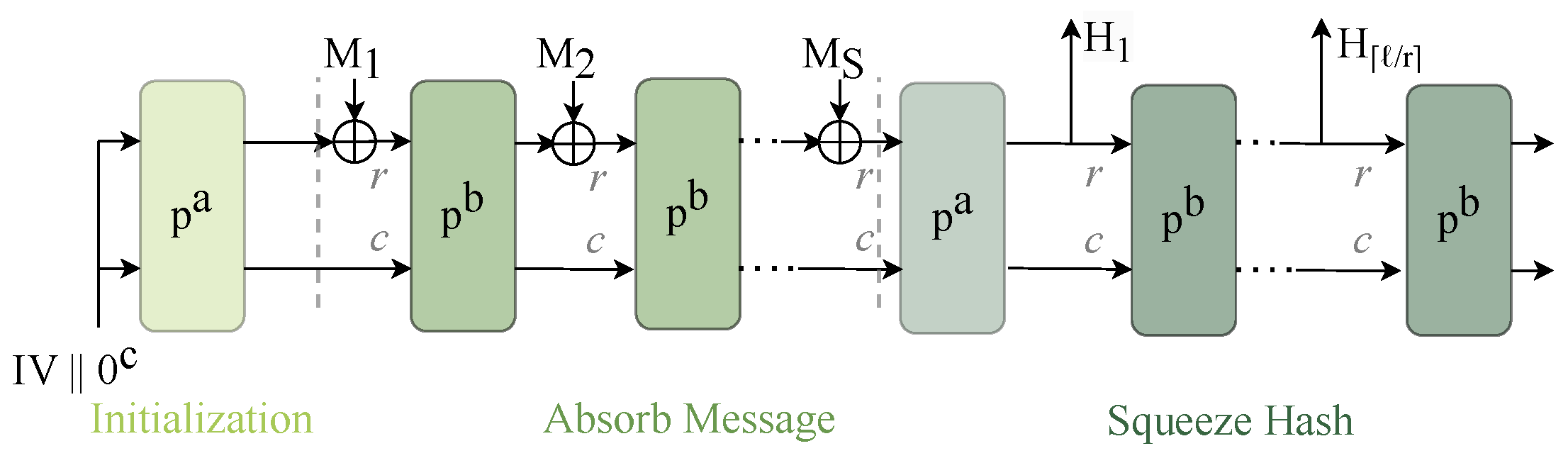
2.2.2. ASCON Hash and XOF
- Initialization: The 320 bit initial state is defined by r, a, and h. The permutation is applied to this state. Since the initial state is fixed, its transformation can be precomputed for efficiency.
- Message Absorption: ASCON-Hash and ASCON-XOF process the message M in r bit blocks. The same padding rule as ASCON-AEAD is used: a ‘1’ followed by the minimal number of ‘0’s to align the message length to a multiple of r. The padded message is split into blocks , each XORed with the first r bits of the state , followed by a permutation.
- Squeezing: The Hash output is extracted in r bit blocks until the requested output length is reached. After each extraction, S undergoes another permutation.
2.3. Side Channel Attacks
3. ASCON HW Accelerators
- Serialized Implementation. The aim of this approach is to obtain a compact accelerator. For this purpose, the S-Box implementation is reduced to process one bit per clock cycle. Obviously, registers are needed to store intermediate results.
- Unrolled Implementation. This implementation is used to obtain high throughput. The allocated hardware is repeated n times to increase throughput at the cost of area. In the fully unrolled version, the encryption and decryption are executed in one clock cycle. Since the updated state is directly fed to the next round, in this version, no registers are needed. Of course, for each unrolling degree, the critical path and, hence, the delay, will increase due to the additional combinational logic.
- Round-based Implementation. This approach offers the best trade-off between throughput and area. The hardware is re-utilized to execute m permutations (or rounds in one clock cycle). Therefore, differently from the previous technique, only the resources required by the permutation are repeated. Obviously, the higher m, the higher the area occupation and delay. In this case, the intermediate state must be stored.
- Stand-alone IPs: The accelerator works independently, despite the system it is integrated in.
- Coprocessors: Although interfaced with the CPU, they exploit their own registers.
- Instruction Set Extensions (ISEs): The hardware is directly integrated within the CPU microarchitecture and has direct access to the internal registers.
3.1. Low Area
3.2. Low Energy and Power
3.3. High Throughput
3.4. Comparative Analysis
4. Protected ASCON Implementations
4.1. Passive Attacks on ASCON

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | ASCON Implementation | FPGA/MCU | Freq [MHz] | SCA Workstation | Attack Strategy | SR = 1 | |
|---|---|---|---|---|---|---|---|
| Board | Oscilloscope | ||||||
| [47] | AEAD (ASCON-128) one-round-per-cycle HW implementation | Spartan-6 XC6SLX75 | 48 | SAKURA-G | Lecroy Waverunner z610i (500 MSample/s) | DPA on Hamming weight of the S-box output | ∼50 k traces |
| [48] | AEAD (ASCON-128) SW optimized for ARMv7-M | STM32F4 ARM Cortex-M4 | 7.37 | ChipWhisperer Lite | Integrated 8 bit oscilloscope | CPA on S-box output (8 bit at a time) | ∼8 k traces with unprotected, unsuccessful with first-order protected |
| [52] | AEAD of ASCON-128 (single S-box, 64 cycles/round) | Artix-7 | n.d. | NewAE CW305 board | PicoScope 5000 (125 Samples/clk) | Self-supervised deep learning SCA on power traces | ∼24 k traces |
4.2. ASCON Side-Channel Countermeasures
5. Takeaways for Designers and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AEAD | Authenticated Encryption with Associated Data |
| ASIC | Application-Specific Integrated Circuit |
| DLSCA | Deep Learning Side-Channel Attacks |
| DOM | Domain-Oriented Masking |
| FPGA | Field-Programmable Gate Array |
| LWC | Lightweight Cryptography |
| MAC | Message Authentication Code |
| NIST | National Institute of Standards and Technology |
| PPA | Power, Performance, and Area |
| PRF | Pseudorandom function |
| SCA | Side-Channel Attacks |
| UMA | Unified Masking Approach |
| XOF | Extendable Output Function |
References
- Rijmen, V.; Daemen, J. Advanced encryption standard. In Federal Information Processing Standards Publications; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2001; Volume 19, p. 22. [Google Scholar]
- Dworkin, M.J. Recommendation for Block Cipher Modes of Operation: Galois/Counter Mode (GCM) and GMAC; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2007.
- Information Technology Laboratory. Secure Hash Standard (SHS); Fips Pub 108; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2012.
- Grover, L.K. A fast quantum mechanical algorithm for database search. In Proceedings of the Twenty-Eighth Annual ACM Symposium on Theory of Computing, Philadelphia, PA, USA, 22–24 May 1996. [Google Scholar]
- Turan, M.S.; McKay, K.; Chang, D.; Kang, J.; Waller, N.; Kelsey, J.M.; Bassham, L.E.; Hong, D. Status Report on the Final Round of the NIST Lightweight Cryptography Standardization Process; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2023. [CrossRef]
- Mohajerani, K.; Beckwith, L.; Abdulgadir, A.; Ferrufino, E.; Kaps, J.; Gaj, K. SCA evaluation and benchmarking of finalists in the NIST lightweight cryptography standardization process. Cryptol. ePrint Arch. 2023. [Google Scholar]
- Sreehari, B.; Sankar, V.; Lopez, R.S.; Vaishnav, K.S.; Stuart, C.M. A review on fpga implementation of lightweight cryptography for wireless sensor network. In Proceedings of the 2023 International Conference on Power, Instrumentation, Control and Computing (PICC), Thrissur, India, 19–21 April 2023. [Google Scholar]
- Dobraunig, C.; Eichlseder, M.; Mendel, F.; Schläffer, M. Ascon v1. 2: Lightweight authenticated encryption and hashing. J. Cryptol. 2021, 34, 33. [Google Scholar] [CrossRef]
- Chari, S.; Jutla, C.S.; Rao, J.R.; Rohatgi, P. Towards sound approaches to counteract power-analysis attacks. In Advances in Cryptology—CRYPTO’99, Proceedings of the 19th Annual International Cryptology Conference, Santa Barbara, CA, USA, 15–19 August 1999; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Nikova, S.; Rechberger, C.; Rijmen, V. Threshold implementations against side-channel attacks and glitches. In Proceedings of the International Conference on Information and Communications Security, Raleigh, NC, USA, 4–7 December 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 529–545. [Google Scholar]
- Martín-González, M.; Tena-Sanchez, E.; Ordóñez, F.E.P.; Acosta, A.J. Hardware implementations, SCA/FIA attacks, and countermeasures for the ASCON AEAD cipher: A review. In Proceedings of the 2024 39th Conference on Design of Circuits and Integrated Systems (DCIS), Catania, Italy, 13–15 November 2024; pp. 1–6. [Google Scholar]
- Kaur, J.; Canto, A.C.; Kermani, M.M.; Azarderakhsh, R. A comprehensive survey on the implementations, attacks, and countermeasures of the current NIST lightweight cryptography standard. arXiv 2023, arXiv:2304.06222. [Google Scholar]
- Dobraunig, C.; Eichlseder, M.; Mendel, F.; Schläffer, M. Ascon PRF, MAC, and Short-Input MAC; Springer: Cham, Switherland, 2024; Cryptology ePrint Archive, Paper 2021/1574, 2021. [Google Scholar] [CrossRef]
- CAESAR, C. Competition for Authenticated Encryption: Security, Applicability, and Robustness. April 2013. Available online: https://competitions.cr.yp.to/caesar.html (accessed on 27 February 2025).
- Bertoni, G.; Daemen, J.; Peeters, M.; Van Assche, G. Permutation-based encryption, authentication and authenticated encryption. Dir. Authenticated Ciphers 2012, 159–170. [Google Scholar]
- Andreeva, E.; Daemen, J.; Mennink, B.; Assche, G.V. International Workshop on Fast Software Encryption. In Security of Keyed Sponge Constructions Using a Modular Proof Approach; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Bertoni, G.; Daemen, J.; Peeters, M.; Assche, G.V. Duplexing the sponge: Single-pass authenticated encryption and other applications. In Proceedings of the Selected Areas in Cryptography: 18th International Workshop, Toronto, ON, Canada, 11–12 August 2011. [Google Scholar]
- Paillier, P.; Verbauwhede, I. (Eds.) PRESENT: An Ultra-Lightweight Block Cipher; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Beaulieu, R.; Shors, D.; Smith, J.; Treatman-Clark, S.; Weeks, B.; Wingers, L. The SIMON and SPECK Families of Lightweight Block Ciphers; Association for Computing Machinery: New York, NY, USA, 2013. [Google Scholar]
- Banik, S.; Pandey, S.K.; Peyrin, T.; Sasaki, Y.; Sim, S.M.; Todo, Y. GIFT: A Small Present. In Proceedings of the Cryptographic Hardware and Embedded Systems—CHES 2017, Taipei, Taiwan, 25–28 September 2017; Fischer, W., Homma, N., Eds.; Springer: Cham, Switherland, 2017; pp. 321–345. [Google Scholar]
- Bertoni, G.; Daemen, J.; Peeters, M.; Van Assche, G. Keccak. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Athens, Greece, 26–30 May 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 313–314. [Google Scholar]
- Kelsey, J.; Chang, S.J.; Perlner, R. SHA-3 Derived Functions: cSHAKE, KMAC, TupleHash and ParallelHash; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2016. [CrossRef]
- O’flynn, C.; Chen, Z. Chipwhisperer: An open-source platform for hardware embedded security research. In Proceedings of the Constructive Side-Channel Analysis and Secure Design: 5th International Workshop, COSADE 2014, Paris, France, 13–15 April 2014; Revised Selected Papers 5. Springer: Cham, Switherland, 2014; pp. 243–260. [Google Scholar]
- Schneider, T.; Moradi, A. Leakage assessment methodology: Extended version. J. Cryptogr. Eng. 2016, 6, 85–99. [Google Scholar] [CrossRef]
- Kocher, P.; Jaffe, J.; Jun, B.; Rohatgi, P. Introduction to differential power analysis. J. Cryptogr. Eng. 2011, 1, 5–27. [Google Scholar] [CrossRef]
- Goubin, L.; Matsui, M. (Eds.) Cryptographic Hardware and Embedded Systems—CHES 2006, Proceedings of the 8th International Workshop, Yokohama, Japan, 10–13 October 2006, Proceedings; Lecture Notes in Computer Science; Springer: Cham, Switherland, 2006; Volume 4249. [Google Scholar] [CrossRef]
- Khan, S.; Lee, W.K.; Hwang, S.O. Evaluating the Performance of Ascon Lightweight Authenticated Encryption for AI-Enabled IoT Devices. In Proceedings of the 2022 TRON Symposium (TRONSHOW), Tokyo, Japan, 7–9 December 2022; pp. 1–6. [Google Scholar]
- Khan, S.; Lee, W.K.; Hwang, S.O. Scalable and Efficient Hardware Architectures for Authenticated Encryption in IoT Applications. IEEE Internet Things J. 2021, 8, 11260–11275. [Google Scholar] [CrossRef]
- Khan, S.; Inayat, K.; Muslim, F.B.; Shah, Y.A.; Atif Ur Rehman, M.; Khalid, A.; Imran, M.; Abdusalomov, A. Securing the IoT ecosystem: ASIC-based hardware realization of Ascon lightweight cipher. Int. J. Inf. Secur. 2024, 23, 3653–3664. [Google Scholar] [CrossRef]
- Mandal, K.; Saha, D.; Sarkar, S.; Todo, Y. Sycon: A New Milestone in Designing ASCON-like Permutations. J. Cryptogr. Eng. 2022, 12, 305–327. [Google Scholar] [CrossRef]
- Alharbi, A.R.; Aljaedi, A.; Aljuhni, A.; Alghuson, M.K.; Aldawood, H.; Jamal, S.S. Evaluating Ascon Hardware on 7-Series FPGA Devices. IEEE Access 2024, 12, 149076–149089. [Google Scholar] [CrossRef]
- Athanasiou, G.S.; Boufeas, D.; Konstantopoulou, E. A Robust ASCON Cryptographic Coprocessor for Secure IoT Applications. In Proceedings of the 2024 Panhellenic Conference on Electronics & Telecommunications (PACET), Thessaloniki, Greece, 28–29 March 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Nguyen, K.D.; Dang, T.K.; Kieu-Do-Nguyen, B.; Le, D.H.; Pham, C.K.; Hoang, T.T. ASIC Implementation of ASCON Lightweight Cryptography for IoT Applications. IEEE Trans. Circuits Syst. II Express Briefs 2025, 72, 278–282. [Google Scholar] [CrossRef]
- Steinegger, S.; Primas, R. A Fast and Compact RISC-V Accelerator for Ascon and Friends. In Proceedings of the Smart Card Research and Advanced Applications: 19th International Conference, CARDIS 2020, Virtual Event, 18–19 November 2020; Revised Selected Papers. Springer: Berlin/Heidelberg, Germany, 2020; pp. 53–67. [Google Scholar] [CrossRef]
- Roussel, N.; Potin, O.; Di Pendina, G.; Dutertre, J.M.; Rigaud, J.B. CMOS/STT-MRAM Based Ascon LWC: A Power Efficient Hardware Implementation. In Proceedings of the 2022 29th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Glasgow, UK, 24–26 October 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Raj, K.; Bodapati, S. FPGA Based Light Weight Encryption of Medical Data for IoMT Devices using ASCON Cipher. In Proceedings of the 2022 IEEE International Symposium on Smart Electronic Systems (iSES), Warangal, India, 18–22 December 2022; pp. 196–201. [Google Scholar] [CrossRef]
- Wei, X.; El-Hadedy, M.; Mosanu, S.; Zhu, Z.; Hwu, W.M.; Guo, X. RECO-HCON: A High-Throughput Reconfigurable Compact ASCON Processor for Trusted IoT. In Proceedings of the 2022 IEEE 35th International System-on-Chip Conference (SOCC), Belfast, UK, 5–8 September 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Khan, S.; Lee, W.K.; Karmakar, A.; Mera, J.M.B.; Majeed, A.; Hwang, S.O. Area-time Efficient Implementation of NIST Lightweight Hash Functions Targeting IoT Applications. IEEE Internet Things J. 2022, 10, 8083–8095. [Google Scholar]
- Tran, S.N.; Hoang, V.T.; Bui, D.H. A Hardware Architecture of NIST Lightweight Cryptography Applied in IPSec to Secure High-Throughput Low-Latency IoT Networks. IEEE Access 2023, 11, 89240–89248. [Google Scholar] [CrossRef]
- Ahmet, M. High-Performance FPGA Implementations of Lightweight ASCON-128 and ASCON-128a with Enhanced Throughput-to-Area Efficiency. In Proceedings of the 2024 17th International Conference on Information Security and Cryptology (ISCTürkiye), Ankara, Turkiye, 16–17 October 2024; pp. 1–7. [Google Scholar] [CrossRef]
- Pallavi, L.; Singh, P.; Patnaik, B.; Acharya, B. High frequency architecture of lightweight authenticated cipher ASCON-128 for resource-constrained IoT devices. In Proceedings of the 2023 OITS International Conference on Information Technology (OCIT), Raipur, India, 13–15 December 2023; pp. 405–410. [Google Scholar] [CrossRef]
- Cheng, H.; Großschädl, J.; Marshall, B.; Page, D.; Pham, T. RISC-V Instruction Set Extensions for Lightweight Symmetric CryptographyNov. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2022, 2023, 193–237. [Google Scholar] [CrossRef]
- Elsadek, I.; Tawfik, E.Y. Efficient Programable Architecture for LWC NIST FIPS Standard ASCON. In Proceedings of the 2024 12th International Symposium on Digital Forensics and Security (ISDFS), San Antonio, TX, USA, 29–30 April 2024; pp. 1–5. [Google Scholar] [CrossRef]
- Xu, D.; Wang, X.; Hao, Q.; Wang, J.; Cui, S.; Liu, B. A High-Performance Transparent Memory Data Encryption and Authentication Scheme Based on Ascon Cipher. IEEE Trans. Very Large Scale Integr. VLSI Syst. 2024, 32, 925–937. [Google Scholar] [CrossRef]
- Verhamme, C.; Cassiers, G.; Standaert, F.X. Analyzing the leakage resistance of the NIST’s lightweight crypto competition’s finalists. In Proceedings of the International Conference on Smart Card Research and Advanced Applications, Birmingham, UK, 7–9 November 2022; Springer: Cham, Switherland, 2022; pp. 290–308. [Google Scholar]
- Liu, Z.; Schaumont, P. Root-Cause Analysis of the Side Channel Leakage from ASCON Implementations; NIST Computer Security Resource Center: Gaithersburg, MD, USA, 2022.
- Samwel, N.; Daemen, J. DPA on hardware implementations of Ascon and Keyak. In Proceedings of the Computing Frontiers Conference, Siena, Italy, 15–17 May 2017; pp. 415–424. [Google Scholar]
- Weissbart, L.; Picek, S. Lightweight but not easy: Side-channel analysis of the ascon authenticated cipher on a 32-bit microcontroller. Cryptol. ePrint Arch. 2023. [Google Scholar]
- ASCON Team. Ascon C Repository.
- Rezaeezade, A.; Basurto-Becerra, A.; Weissbart, L.; Perin, G. One for all, all for ascon: Ensemble-based deep learning side-channel analysis. In Proceedings of the International Conference on Applied Cryptography and Network Security, Abu Dhabi, United Arab Emirates, 5–8 March 2024; Springer: Cham, Switherland, 2024; pp. 139–157. [Google Scholar]
- You, S.C.; Kuhn, M.G.; Sarkar, S.; Hao, F. Low trace-count template attacks on 32-bit implementations of ASCON AEAD. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2023, 2023, 344–366. [Google Scholar]
- Ramezanpour, K.; Ampadu, P.; Diehl, W. SCARL: Side-channel analysis with reinforcement learning on the ascon authenticated cipher. arXiv 2020, arXiv:2006.03995. [Google Scholar]
- Goubin, L.; Patarin, J. DES and differential power analysis the “Duplication” method. In Proceedings of the Cryptographic Hardware and Embedded Systems: First InternationalWorkshop, CHES’99, Worcester, MA, USA, 12–13 August 1999; Proceedings 1. Springer: Berlin/Heidelberg, Germany, 1999; pp. 158–172. [Google Scholar]
- Herbst, C.; Oswald, E.; Mangard, S. An AES smart card implementation resistant to power analysis attacks. In Proceedings of the International Conference on Applied Cryptography and Network Security, Singapore, 6–9 June 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 239–252. [Google Scholar]
- Clavier, C.; Coron, J.S.; Dabbous, N. Differential power analysis in the presence of hardware countermeasures. In Proceedings of the Cryptographic Hardware and Embedded Systems—CHES 2000: Second International Workshop, Worcester, MA, USA, 17–18 August 2000; Proceedings 2. Springer: Berlin/Heidelberg, Germany, 2000; pp. 252–263. [Google Scholar]
- Groß, H.; Mangard, S.; Korak, T. Domain-oriented masking: Compact masked hardware implementations with arbitrary protection order. Cryptol. ePrint Arch. 2016. [Google Scholar] [CrossRef]
- Bilgin, B.; Daemen, J.; Nikov, V.; Nikova, S.; Rijmen, V.; Van Assche, G. Efficient and first-order DPA resistant implementations of Keccak. In Proceedings of the Smart Card Research and Advanced Applications: 12th International Conference, CARDIS 2013, Berlin, Germany, 27–29 November 2013; Revised Selected Papers 12. Springer: Cham, Switherland, 2014; pp. 187–199. [Google Scholar]
- Groß, H.; Wenger, E.; Dobraunig, C.; Ehrenhöfer, C. Suit up!–made-to-measure hardware implementations of ASCON. In Proceedings of the 2015 Euromicro Conference on Digital System Design, Madeira, Portugal, 26–28 August 2015; pp. 645–652. [Google Scholar]
- Gross, H.; Wenger, E.; Dobraunig, C.; Ehrenhöfer, C. Ascon hardware implementations and side-channel evaluation. Microprocess. Microsyst. 2017, 52, 470–479. [Google Scholar]
- Groß, H.; Mangard, S. Reconciling masking in hardware and software. In Proceedings of the International Conference on Cryptographic Hardware and Embedded Systems, Taipei, Taiwan, 25–28 September 2017; Springer: Cham, Switherland, 2017; pp. 115–136. [Google Scholar]
- Belaïd, S.; Benhamouda, F.; Passelègue, A.; Prouff, E.; Thillard, A.; Vergnaud, D. Randomness complexity of private circuits for multiplication. In Proceedings of the Advances in Cryptology–EUROCRYPT 2016: 35th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Vienna, Austria, 8–12 May 2016; Proceedings, Part II 35. Springer: Berlin/Heidelberg, Germany, 2016; pp. 616–648. [Google Scholar]
- Barthe, G.; Dupressoir, F.; Faust, S.; Grégoire, B.; Standaert, F.X.; Strub, P.Y. Parallel implementations of masking schemes and the bounded moment leakage model. In Proceedings of the Advances in Cryptology–EUROCRYPT 2017: 36th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Paris, France, 30 April–4 May 2017; Proceedings, Part I 36. Springer: Berlin/Heidelberg, Germany, 2017; pp. 535–566. [Google Scholar]
- Groß, H.; Iusupov, R.; Bloem, R. Generic low-latency masking in hardware. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2018, 2018, 1–21. [Google Scholar]
- Nagpal, R.; Gigerl, B.; Primas, R.; Mangard, S. Riding the waves towards generic single-cycle masking in hardware. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2022, 2022, 693–717. [Google Scholar]
- Prasad, S.H.; Mendel, F.; Schläffer, M.; Nagpal, R. Efficient low-latency masking of ascon without fresh randomness. Cryptol. ePrint Arch. 2023. [Google Scholar]






| Design Strategy | Effect | Optimization |
|---|---|---|
| Permutation-based design | → No key schedule required | • No hidden setup costs when changing keys |
| → Online plaintext and ciphertext processing | • Supports real-time encryption and decryption | |
| → Reuse of core component | • Same permutation used by encryption and decryption | |
| Simple initialization and finalization | → Low overhead | • Efficient for short messages |
| Small-state | → Low memory footprint | • Fits in CPU registers, reducing cache reloads and attacks |
| → Efficient memory usage | • Faster and simpler HW implementation | |
| → Platform adaptability | • Supports a wide range of architectures | |
| Bit-sliced S-boxes | → Prevents cache-timing attacks | • Low-cost side-channel countermeasures |
| Low algebraic degree of S-box | → Compact implementation | • Easy first- and higher-order protection via masking |
| 64 bit words, simple bitwise operations | → Efficient linear and nonlinear layers | • SIMD acceleration and dedicated HW implementations |
| Constant: | 0xf0 | 0xe1 | 0xd2 | 0xc3 | 0xb4 | 0xa5 | 0x96 | 0x87 | 0x78 | 0x69 | 0x5a | 0x4b |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| p12 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| p8 | – | – | – | – | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| p6 | – | – | – | – | – | – | 0 | 1 | 2 | 3 | 4 | 5 |
| Bit Size | Perm. Rounds | ||||
|---|---|---|---|---|---|
| Variant | Algorithm | Key K | Rate r | ||
| AED | ASCON-128 | 128 | 64 | 12 | 6 |
| ASCON-128a | 128 | 128 | 12 | 8 | |
| ASCON-80pq | 160 | 64 | 12 | 6 | |
| Hash | ASCON-HASH | - | 64 | 12 | 12 |
| ASCON-HASHa | - | 64 | 12 | 8 | |
| XOF | ASCON-XOF | - | 64 | 12 | 12 |
| ASCON-XOFa | - | 64 | 12 | 8 | |
| MAC | ASCON-MAC | 128 | 256/128 | 12 | - |
| PRF | ASCON-PRF | 128 | 256/128 | 12 | - |
| ASCON-PRFshort | 128 | 128 | 12 | - | |
| Cipher Variants | Bit Size of | Rounds | ||||||
|---|---|---|---|---|---|---|---|---|
| State () | Rate () | Capacity () | Key () | Nonce () | Tag () | |||
| ASCON-128 | 320 | 64 | 256 | 128 | 128 | 128 | 12 | 6 |
| ASCON-128a | 320 | 128 | 192 | 128 | 128 | 128 | 12 | 8 |
| Byte7 | Byte6 | Byte5 | Byte4 | Byte3 | Byte2 | Byte1 | Byte0 | |
|---|---|---|---|---|---|---|---|---|
| x0 | IV[7] | IV[6] | IV[5] | IV[4] | IV[3] | IV[2] | IV[1] | IV[0] |
| x1 | K[15] | K[14] | K[13] | K[12] | K[11] | K[10] | K[9] | K[8] |
| x2 | K[7] | K[6] | K[5] | K[4] | K[3] | K[2] | K[1] | K[0] |
| x3 | N[15] | N[14] | N[13] | N[12] | N[11] | N[10] | N[9] | N[8] |
| x4 | N[7] | N[6] | N[5] | N[4] | N[3] | N[2] | N[1] | N[0] |
| Device | Work | Freq [MHz] | Area | Thr. [Mbps] | Thr./Area | Power [mW] | Energy [nJ/bit] | |
|---|---|---|---|---|---|---|---|---|
| Best area | FPGA | [28]—serial (one-bit-per-cycle version) | 232.6 | LUTs: 1030 | 6.5 | 0.006 Mbps/LUTs | 57 | 10.25 |
| ASIC | [35] | 100 | 5246.3 | 66.7 | 0.0127 Mbps/ | 0.715 | ||
| Best thr. | FPGA | [40] | 92.59 | LUTs: 2958, FFs: 595 | 5925.9 | 2.01 | n.d | n.d |
| ASIC | [37] | 667 | 67,600 | 5926 | 0.0877 Mbps/ | 1.9 | ||
| Best power | FPGA | [36] | 107 | LUTs: 1330, FFs: 870 | 457 | 0.343 Mbps/LUTs | 31 | n.d. |
| ASIC | [35] | 100 | 5246.3 | 66.7 | 0.0127 Mbps/ | 0.715 | ||
| Best energy per bit | FPGA | [43] | 100 | LUTs: 1437, FFs: 366 | 884.1 | 0.615 Mbps/LUTs | n.d. | 0.0385 |
| ASIC | [37] | 667 | 67,600 | 5926 | 0.0877 Mbps/ | 1.9 |
| Algebraic Expression | Equivalent Expression | |
|---|---|---|
| Work | ASCON Implementation | FPGA/MCU | Freq [MHz] | SCA Workstation | Attack Strategy | Template Dataset | SR = 1 | |
|---|---|---|---|---|---|---|---|---|
| Board | Oscilloscope | |||||||
| [48] | AEAD (ASCON-128) SW optimized for ARMv7-M | STM32F4 ARM Cortex-M4 | 7.37 | ChipWhisperer Lite | Integrated 8 bit oscilloscope | Deep learning SCA with a Bayesian-optimized neural network | 60 k traces, 772 samples each | Unprotected: ∼1 k traces Protected: first-order, partial key recovery |
| [50] | AEAD (ASCON-128) SW optimized for ARMv7-M | STM32F4 ARM Cortex-M4 | 7.37 | ChipWhisperer Lite | Integrated 8 bit oscilloscope | Ensemble deep learning SCA; tested MLP and CNN architectures | 60 k traces unprotected, 772 samples protected: 1408 samples | Unprotected: ∼1 k traces with CNN ensemble ∼100 traces with MLP ensemble Protected: First-order, ∼3 k traces with MLP ensemble |
| [51] | Weatherley’s ASCON-128 on ARMv7-M | STM32F4 ARM Cortex-M4 | 7.37 | ChipWhisperer Lite | PXIe-5160 (2.5 GHz, 500 PPC) | Pre-processing for highest leakage points; fragment template attack (modified LDA); SASCA + key enumeration | 16 k cycles selected; 64 k traces for templates | Unprotected: Compiled with U-0s, single-trace with <220 key search Compiled with U-03s, ∼10 traces with <227 key search Protected: First-order compiled with M-0s, ∼5 traces with <236 key search |
| Work | Masking Scheme | Technology | Architecture | Protection Order | Area | Randomness | Latency | Max Freq. | Throughput | T/A | Power | Energy |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| [kGE] | [bit/cycle] | [cycles/round] | [MHz] | [Gbps] | [Gbps/GE] | [μW] | [μJ/B] | |||||
| [58] | Unmasked implementation for comparison | 90 nm UMC | ASCON with single S-box instance | unprotected | 3.75 | 0 | 0 | 168 | 0.014 | 3.73 | 15 | 1397 |
| ASCON with 64 S-box instances | unprotected | 7.95 | 0 | 0 | 1035 | 5.524 | 694.84 | 43 | 33 | |||
| [58] | Threshold Implementation (TI) | 90 nm UMC | ASCON-fast-TI 1-round unrolled | 1-order | 30.42 | 4 | 2 | 708 | 3.77 | 124 | 183 | 137.25 |
| ASCON-fast-TI 2-round unrolled | 1-order | 49.13 | 8 | 3 | 590 | 6.29 | 128 | 315 | 119.7 | |||
| ASCON-fast-TI 3-round unrolled | 1-order | 68.27 | 12 | 4 | 446 | 7.14 | 105 | 447 | 111.75 | |||
| ASCON-fast-TI 6-round unrolled | 1-order | 125.19 | 24 | 7 | 282 | 9.02 | 72 | 830 | 107.9 | |||
| ASCON-x-low-TI single S-box | 1-order | 9.19 | 4/64 | 128 | 180 | 0.015 | 1.6 | 45 | 17,280 | |||
| [60] | Unified Masking Approach (UMA) | 90 nm UMC | ASCON DOM with single S-box instance | 1-order | 10.8 | 5 | 192 | 864 | 0.048 | 4.4 | n.d. | n.d. |
| 2-order | 16.5 | 15 | 192 | 846 | 0.047 | 2.85 | n.d. | n.d. | ||||
| 5-order | 32.0 | 75 | 192 | 828 | 0.046 | 1.44 | n.d. | n.d. | ||||
| ASCON UMA with single S-box | 1-order | 10.8 | 5 | 192 | 864 | 0.048 | 4.44 | n.d. | n.d. | |||
| 2-order | 16.4 | 10 | 192 | 846 | 0.047 | 2.87 | n.d. | n.d. | ||||
| 5-order | 33.0 | 55 | 448 | 1932 | 0.046 | 1.44 | n.d. | n.d. | ||||
| ASCON DOM with 64 parallel S-box | 1-order | 28.89 | 320 | 3 | 632.8 | 2.25 | 77.88 | n.d. | n.d. | |||
| 2-order | 53.0 | 960 | 3 | 537.19 | 1.91 | 36.04 | n.d. | n.d. | ||||
| 5-order | 161.87 | 4800 | 3 | 523.13 | 1.86 | 11.49 | n.d. | n.d. | ||||
| ASCON UMA with 64 parallel S-box | 1-order | 27.18 | 320 | 3 | 632.81 | 2.25 | 82.78 | n.d. | n.d. | |||
| 2-order | 125.0 | 640 | 3 | 514.69 | 1.83 | 14.64 | n.d. | n.d. | ||||
| 5-order | 220.01 | 3520 | 7 | 557.81 | 0.85 | 3.86 | n.d. | n.d. | ||||
| [64] | Self-synchronized masking | 65 nm UMC | ASCON with 64 S-box instances | 1-order | 50.4 | 320 | 1 | 408.3 | 4.35 | 79.8 | n.d. | n.d. |
| 2-order | 102.39 | 960 | 1 | 377.1 | 4.02 | 39.3 | n.d. | n.d. | ||||
| 5-order | 357.65 | 4800 | 1 | 312.9 | 3.34 | 9.3 | n.d. | n.d. | ||||
| [63] | Generic low-latency masking | 90 nm UMC | ASCON with 64 S-box instances | 1-order | 42.75 | 2048 | 1 | 43.29 | 2.77 | 64.8 | n.d. | n.d. |
| 2-order | 90.94 | 4608 | 1 | 52.19 | 3.34 | 52.19 | n.d. | n.d. | ||||
| 5-order | 339.82 | 18432 | 1 | 46.7 | 2.99 | 8.8 | n.d. | n.d. | ||||
| [65] | DOM AND gate with Changing of the Guards | lsi_10k library, node size undefined | ASCON permutation with 64 S-box | 1-order | 26.1 | 0 | 2 | n.d. | n.d. | n.d. | n.d. | n.d. |
| 2-order | 52.63 | 0 | 2 | n.d. | n.d. | n.d. | n.d. | n.d. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mirigaldi, M.; Piscopo, V.; Martina, M.; Masera, G. The Quest for Efficient ASCON Implementations: A Comprehensive Review of Implementation Strategies and Challenges. Chips 2025, 4, 15. https://doi.org/10.3390/chips4020015
Mirigaldi M, Piscopo V, Martina M, Masera G. The Quest for Efficient ASCON Implementations: A Comprehensive Review of Implementation Strategies and Challenges. Chips. 2025; 4(2):15. https://doi.org/10.3390/chips4020015
Chicago/Turabian StyleMirigaldi, Mattia, Valeria Piscopo, Maurizio Martina, and Guido Masera. 2025. "The Quest for Efficient ASCON Implementations: A Comprehensive Review of Implementation Strategies and Challenges" Chips 4, no. 2: 15. https://doi.org/10.3390/chips4020015
APA StyleMirigaldi, M., Piscopo, V., Martina, M., & Masera, G. (2025). The Quest for Efficient ASCON Implementations: A Comprehensive Review of Implementation Strategies and Challenges. Chips, 4(2), 15. https://doi.org/10.3390/chips4020015