
Domain Specific Abstractions for the Development of Fast-by-Construction Dataflow Codes on FPGAs


Abstract
1. Introduction
- Description of how custom dataflow computing machines can enable large-scale theoretical concurrency compared to the imperative Von Neumann model, and an Application Specific Dataflow Machine (ASDM)-based conceptual execution model.
- Exploration of an appropriate set of programming abstractions and language semantics enabling the convenient expression of high-level declarative algorithms that can be transformed into a dataflow architecture.
- Demonstration that a declarative language, using our abstractions and presenting the progression of time as a first-class concern, delivers comparable, sometimes better, performance to state-of-the-art approaches whilst being significantly simpler to program.
2. Motivation: The Challenges with Von Neumann
3. Embracing Computational Concurrency via Custom Dataflow Machines
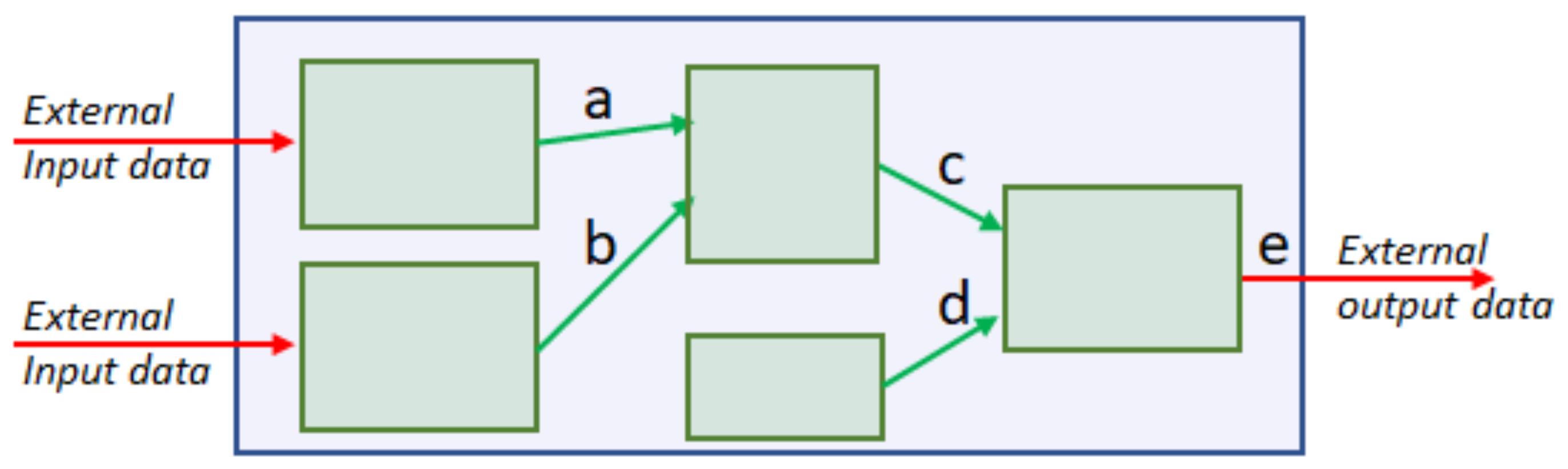
- An architecture with significant amounts of raw concurrency.
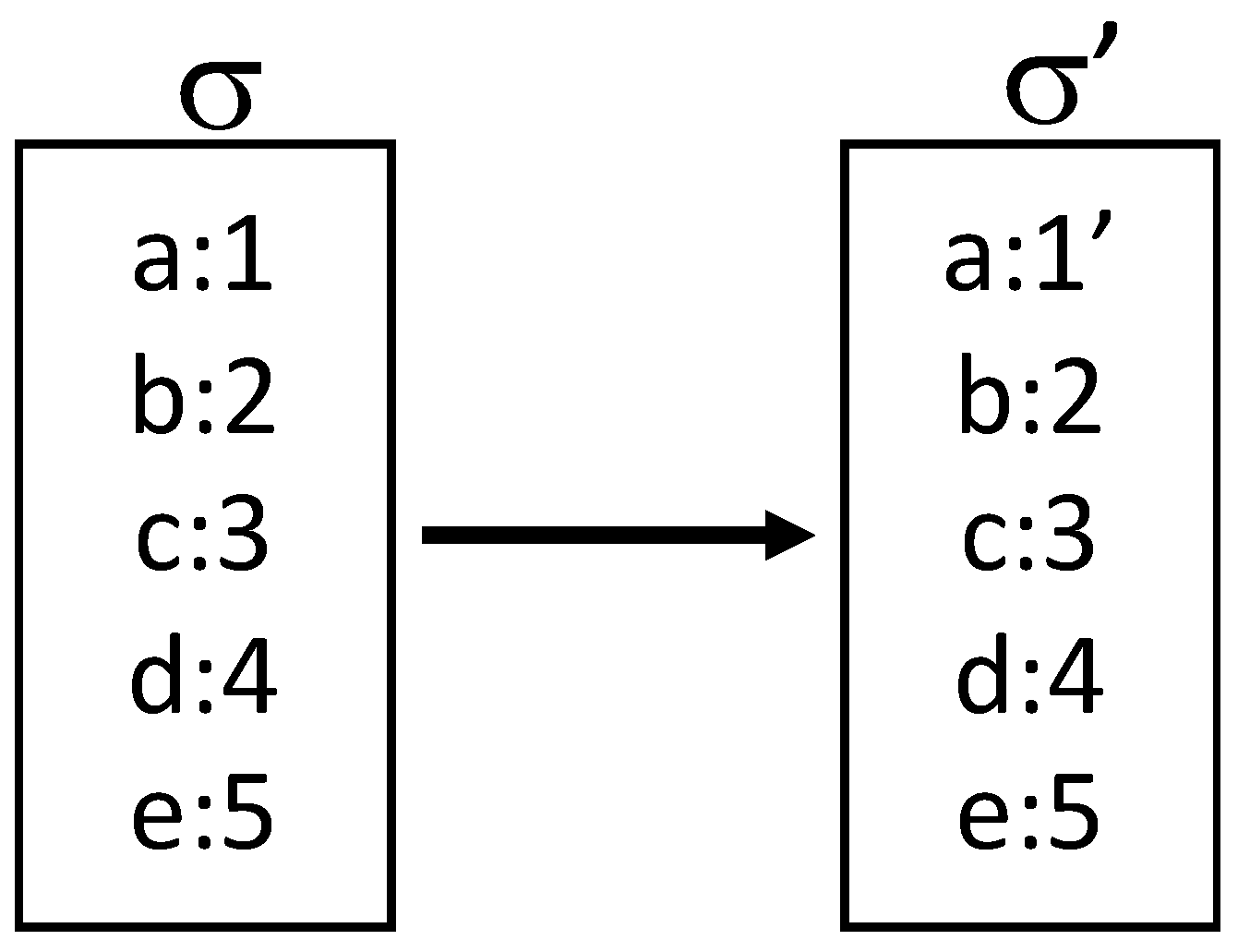
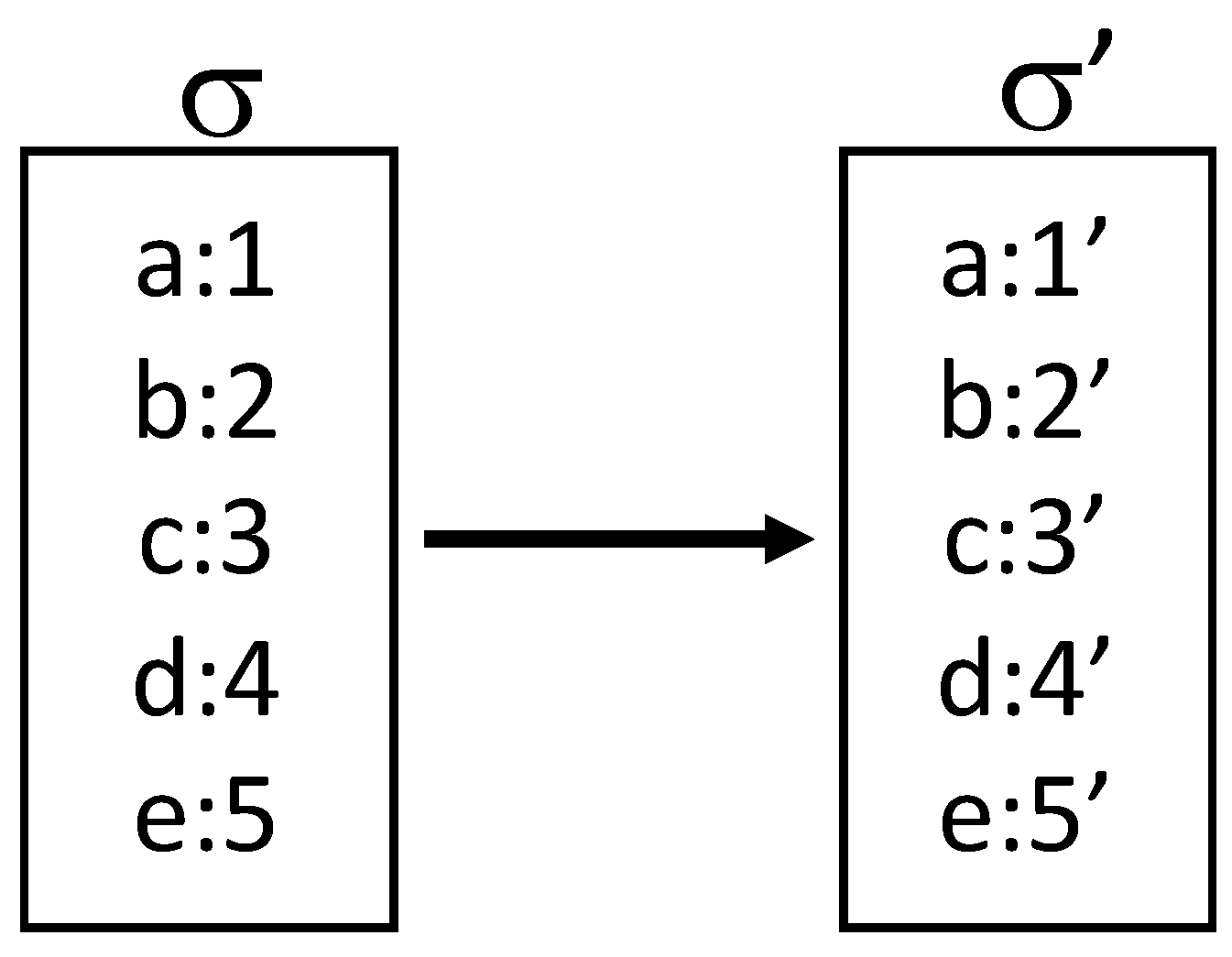
- A way of representing the state that supports efficient concurrent updates.
- Programming abstractions that provide consistency across concurrent updates and avoid interference between them.
3.1. Application Specific Dataflow Machine Execution Model
3.2. Building upon the Foundations of Lucid
4. The Lucent Dataflow Language
4.1. Filters
| Listing 1. Lucent filter that streams out 12 infinitely. |
|
| Listing 2. Example of working with input streams, calling a filter, and conditionals. |
|
4.2. Manipulating Values over Time
4.2.1. Intermediate Dataflow Operators
| Listing 3. Lucent implementation of the as-soon-as filter. |
|
4.3. Nested Time via Time Dimensions
| Listing 4. Example of time dimension applied to factorial filter. |
|
4.4. Exploiting the Type System
| Listing 5. Type system to specialise data representation. |
|
| Listing 6. The multistream type enables a filter to stream out multiple sub-streams. |
|
4.4.1. The List Type
| Listing 7. Example of the list type and operators. |
|
| Listing 8. Concurrency via list vectorisation. |
|
4.4.2. Generics
| Listing 9. Examples of generics in Lucent. |
|
5. 2D Jacobi: Bringing the Concepts Together
| Listing 10. Illustration of solving LaPlace’s equation for diffusion in 2D using Jacobi iteration. |
|
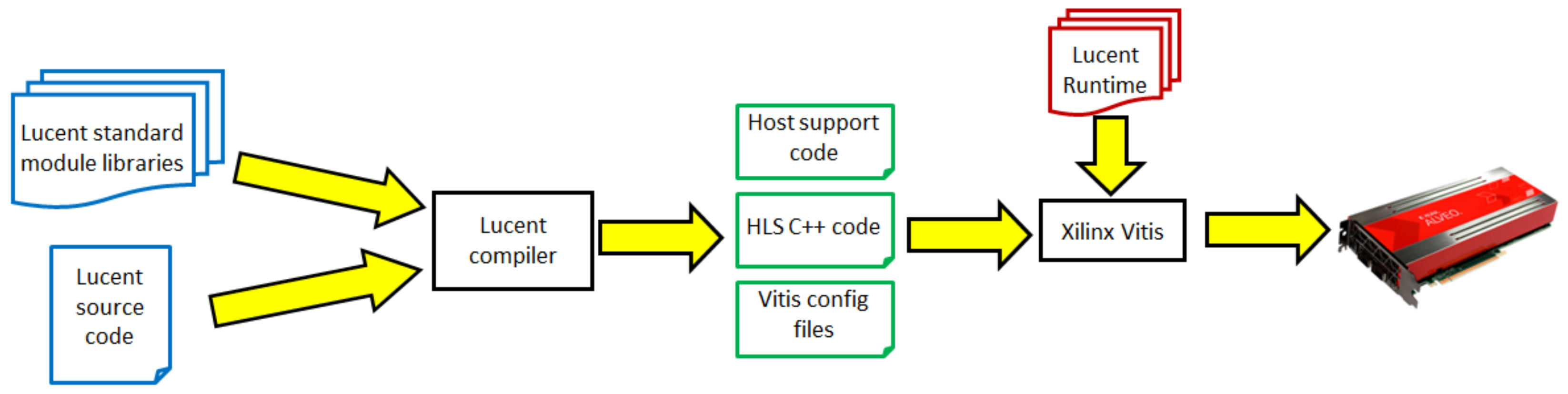
6. Language Implementation
- Bind generic filters and types to actual values, bind filters passed as arguments and resolve overloaded filters. These all result in separate filters in the DAG, one for each permutation in the user’s code, enabling independent type-specific optimisations and transformations to be applied in later phases.
- Work at the individual operation level, resolving information such as storage location based on annotations to types and whether filter calls are across time dimensions. Also, determine how some operations should be implemented, for instance, maintaining minimal data copying whilst providing the immutability property for lists.
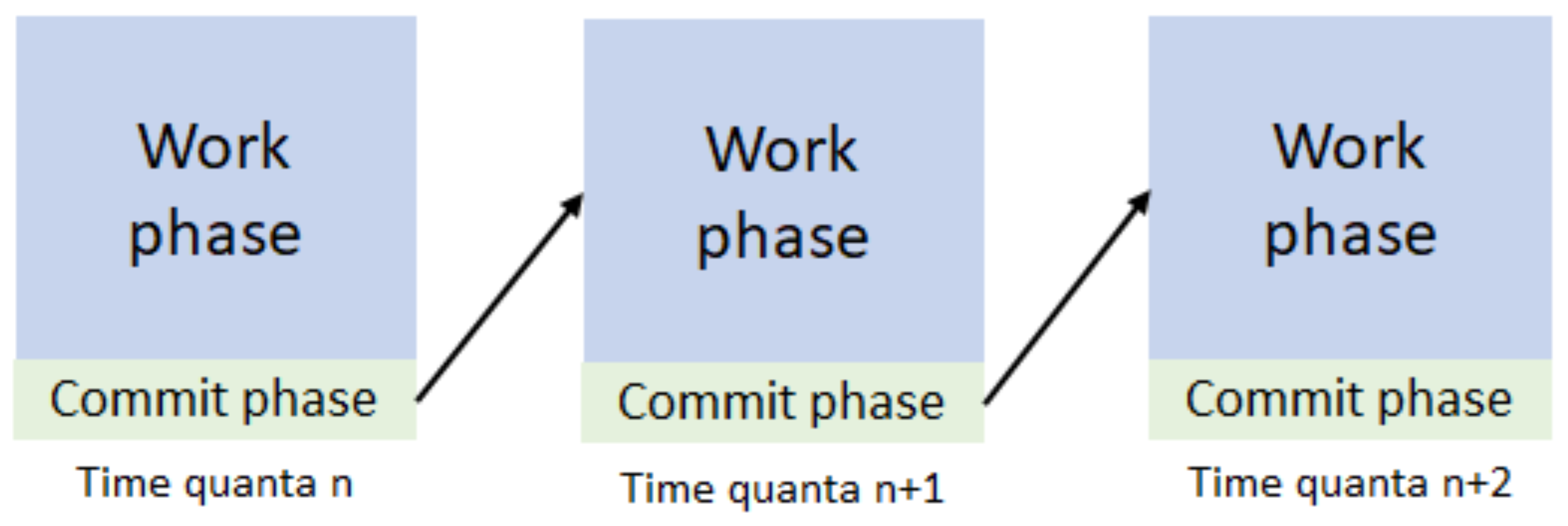
- Inter-operation transformation and optimisation, for example, to identify spatial dependencies or conflicts on memory ports. Reorganisation of the DAG’s structure is undertaken if appropriate and a check is inserted to ensure that the time quantum’s split between the work and commit phase is consistent. There is no explicit synchronisation point for this split, but instead, if this phase determines the interaction of operations results in inconsistencies it adds a temporary value.
- C++ HLS code is generated for the constituent parts and these are linked by transforming into an Intermediate Representation (IR) that represents the individual dataflow regions, connections between them and specific HLS configuration settings. This represents the concrete C++ code for each individual part, combined with an abstract view of how the different parts of the dataflow algorithm will be connected.
7. Performance and Productivity Evaluation
7.1. Foundational BLAS Operations
| Listing 11. Dot product Lucent code (scalar version). |
|
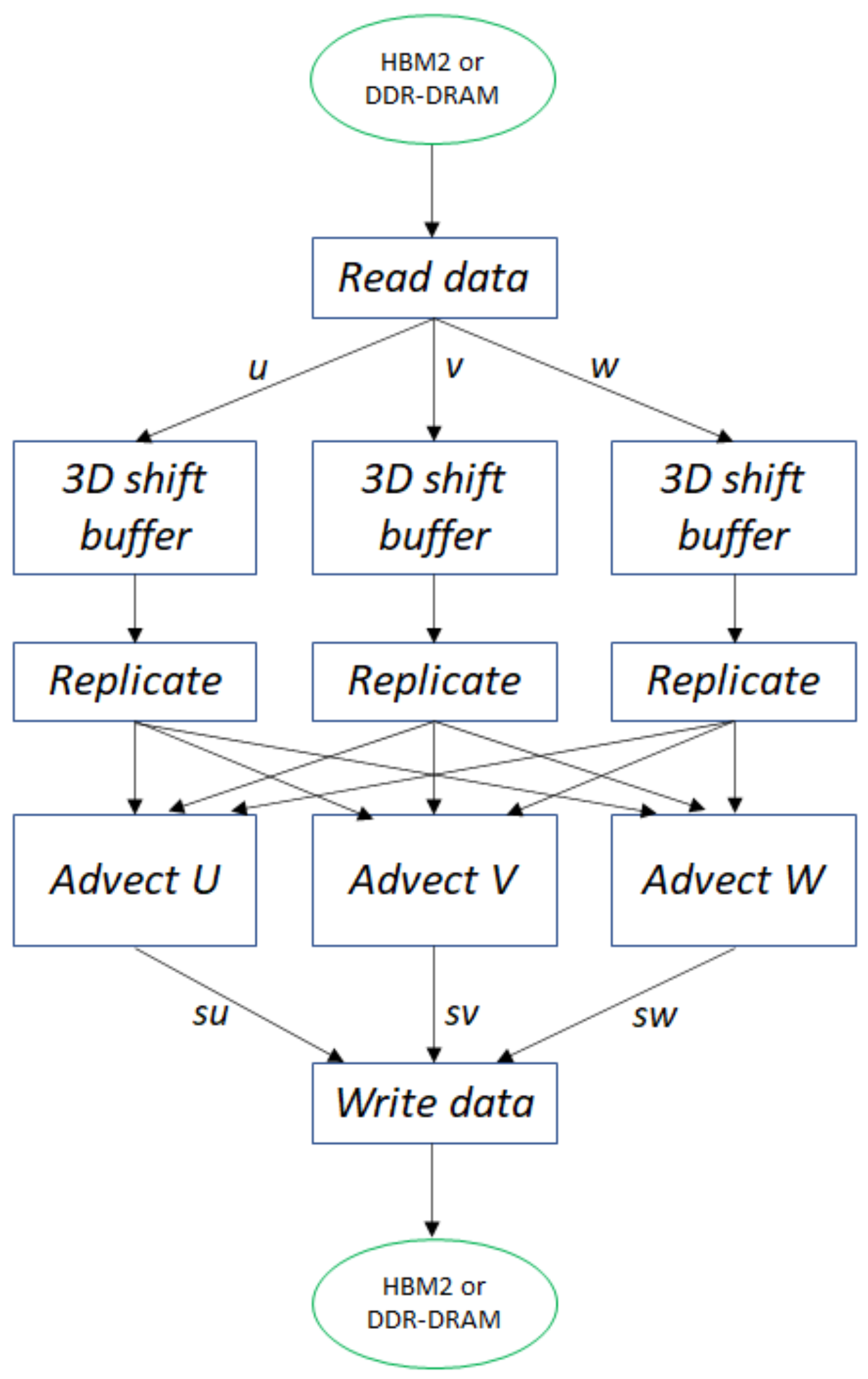
7.2. Application Case Study: Atmospheric Advection
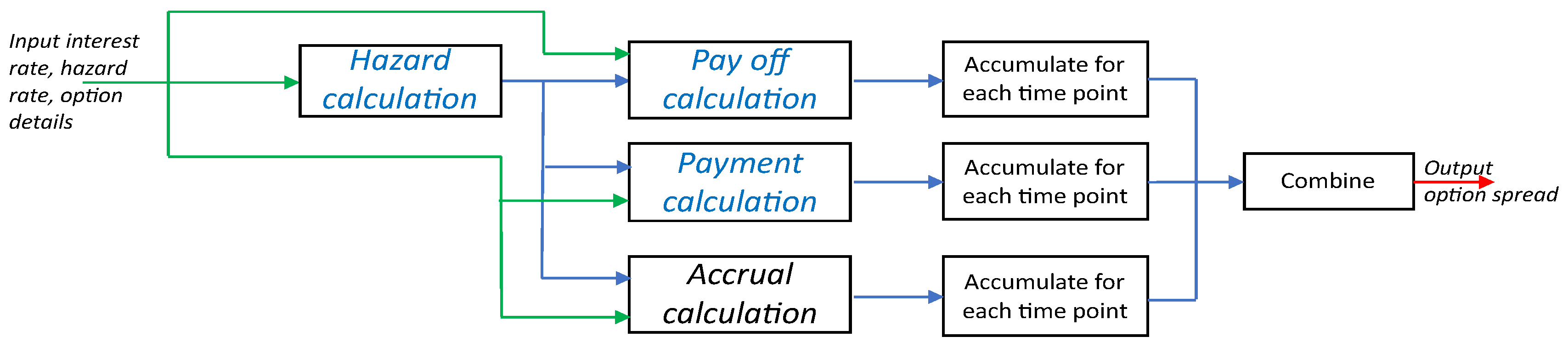
7.3. Application Case Study: Credit Default Swap
7.4. Limitations
8. Related Work
9. Conclusions and Future Work
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| HPC | High Performance Computing |
| FPGA | Field Programmable Gate Array |
| HLS | High Level Synthesis |
| ASDM | Application Specific Dataflow Machine |
| CPU | Central Processing Unit |
| GPU | Graphical Processing Unit |
| AST | Abstract Syntax Tree |
| DAG | Directed Acyclical Graph |
| IR | Intermediate Representation |
| BLAS | Basic Linear Algebras Subprograms |
| CDS | Credit Default Swap |
| SDFG | Stateful DataFlow multiGraph |
References
- Brown, N. Exploring the acceleration of Nekbone on reconfigurable architectures. In Proceedings of the 2020 IEEE/ACM International Workshop on Heterogeneous High-performance Reconfigurable Computing (H2RC), Atlanta, GA, USA, 13 November 2020; pp. 19–28. [Google Scholar]
- Brown, N. Accelerating advection for atmospheric modelling on Xilinx and Intel FPGAs. In Proceedings of the 2021 IEEE International Conference on Cluster Computing (CLUSTER), Portland, OR, USA, 7–10 September 2021; pp. 767–774. [Google Scholar]
- Karp, M.; Podobas, A.; Kenter, T.; Jansson, N.; Plessl, C.; Schlatter, P.; Markidis, S. A High-Fidelity Flow Solver for Unstructured Meshes on Field-Programmable Gate Arrays. In Proceedings of the 2022 International Conference on High Performance Computing in Asia-Pacific Region, Virtual Event, Japan, 11–14 January 2022; pp. 125–136. [Google Scholar]
- Ma, Y.; Cao, Y.; Vrudhula, S.; Seo, J.S. Optimizing loop operation and dataflow in FPGA acceleration of deep convolutional neural networks. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017; pp. 45–54. [Google Scholar]
- Firmansyah, I.; Changdao, D.; Fujita, N.; Yamaguchi, Y.; Boku, T. Fpga-based implementation of memory-intensive application using opencl. In Proceedings of the 10th International Symposium on Highly-Efficient Accelerators and Reconfigurable Technologies, Nagasaki, Japan, 6–7 June 2019; pp. 1–4. [Google Scholar]
- Xilinx. Vitis Unified Software Platform Documentation. Available online: https://docs.amd.com/v/u/2020.2-English/ug1416-vitis-documentation (accessed on 28 September 2024).
- Intel. Intel FPGA SDK for OpenCL Pro Edition: Best Practices Guide. Available online: https://www.intel.com/content/www/us/en/programmable/documentation/mwh1391807516407.html (accessed on 28 September 2024).
- de Fine Licht, J.; Blott, M.; Hoefler, T. Designing scalable FPGA architectures using high-level synthesis. In Proceedings of the 23rd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, Vienna, Austria, 24–28 February 2018; pp. 403–404. [Google Scholar]
- Cong, J.; Fang, Z.; Kianinejad, H.; Wei, P. Revisiting FPGA acceleration of molecular dynamics simulation with dynamic data flow behavior in high-level synthesis. arXiv 2016, arXiv:1611.04474. [Google Scholar]
- Fraser, N.J.; Lee, J.; Moss, D.J.; Faraone, J.; Tridgell, S.; Jin, C.T.; Leong, P.H. FPGA implementations of kernel normalised least mean squares processors. ACM Trans. Reconfigurable Technol. Syst. (TRETS) 2017, 10, 1–20. [Google Scholar] [CrossRef]
- Ben-Nun, T.; de Fine Licht, J.; Ziogas, A.N.; Schneider, T.; Hoefler, T. Stateful dataflow multigraphs: A data-centric model for performance portability on heterogeneous architectures. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Denver, CO, USA, 17–22 November 2019; pp. 1–14. [Google Scholar]
- Tech, M. Multiscale Dataflow Programming; Technical Report; Maxeler Technologies: London, UK, 2015. [Google Scholar]
- Veen, A.H. Dataflow machine architecture. ACM Comput. Surv. (CSUR) 1986, 18, 365–396. [Google Scholar] [CrossRef]
- Wadge, W.W.; Ashcroft, E.A. Lucid, the Dataflow Programming Language; Academic Press: London, UK, 1985; Volume 303. [Google Scholar]
- Halbwachs, N.; Caspi, P.; Raymond, P.; Pilaud, D. The synchronous data flow programming language LUSTRE. Proc. IEEE 1991, 79, 1305–1320. [Google Scholar] [CrossRef]
- Berry, G. A hardware implementation of pure Esterel. Sadhana 1992, 17, 95–130. [Google Scholar] [CrossRef]
- Brown, N. Porting incompressible flow matrix assembly to FPGAs for accelerating HPC engineering simulations. In Proceedings of the 2021 IEEE/ACM International Workshop on Heterogeneous High-performance Reconfigurable Computing (H2RC), St. Louis, MO, USA, 15 November 2021; pp. 9–20. [Google Scholar]
- Faustini, A.A.; Jagannathan, R. Multidimensional Problem Solving in Lucid; SRI International, Computer Science Laboratory: Tokyo, Japan, 1993. [Google Scholar]
- Ashcroft, E.A.; Faustini, A.A.; Wadge, W.W.; Jagannathan, R. Multidimensional Programming; Oxford University Press on Demand: Oxford, UK, 1995. [Google Scholar]
- Lawson, C.L.; Hanson, R.J.; Kincaid, D.R.; Krogh, F.T. Basic linear algebra subprograms for Fortran usage. ACM Trans. Math. Softw. (TOMS) 1979, 5, 308–323. [Google Scholar] [CrossRef]
- Xilinx. Vitis Libraries. Available online: https://github.com/Xilinx/Vitis_Libraries (accessed on 28 September 2024).
- Xilinx. Vitis—Optimising Performance. Available online: https://docs.amd.com/v/u/2020.1-English/ug1416-vitis-documentation (accessed on 28 September 2024).
- Brown, N.; Lepper, A.; Weil, M.; Hill, A.; Shipway, B.; Maynard, C. A directive based hybrid met office nerc cloud model. In Proceedings of the Second Workshop on Accelerator Programming Using Directives, Online, 16 November 2015; p. 7. [Google Scholar]
- Brown, N. Exploring the acceleration of the Met Office NERC cloud model using FPGAs. In Proceedings of the International Conference on High Performance Computing, Frankfurt, Germany, 16–20 June 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 567–586. [Google Scholar]
- Dempster, M.A.H.; Kanniainen, J.; Keane, J.; Vynckier, E. High-Performance Computing in Finance: Problems, Methods, and Solutions; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Hull, J.; Basum, S. Options, Futures and Other Derivatives; Prentice Hall: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- Brown, N.; Klaisoongnoen, M.; Brown, O.T. Optimisation of an FPGA Credit Default Swap engine by embracing dataflow techniques. In Proceedings of the 2021 IEEE International Conference on Cluster Computing (CLUSTER), Portland, OR, USA, 7–10 September 2021; pp. 775–778. [Google Scholar]
- Cong, J.; Huang, M.; Pan, P.; Wang, Y.; Zhang, P. Source-to-source optimization for HLS. In FPGAs for Software Programmers; Springer: Cham, Switzerland, 2016; pp. 137–163. [Google Scholar] [CrossRef]
- Lattner, C.; Amini, M.; Bondhugula, U.; Cohen, A.; Davis, A.; Pienaar, J.; Riddle, R.; Shpeisman, T.; Vasilache, N.; Zinenko, O. MLIR: A compiler infrastructure for the end of Moore’s law. arXiv 2020, arXiv:2002.11054. [Google Scholar]
- Ye, H.; Hao, C.; Cheng, J.; Jeong, H.; Huang, J.; Neuendorffer, S.; Chen, D. ScaleHLS: A New Scalable High-Level Synthesis Framework on Multi-Level Intermediate Representation. arXiv 2021, arXiv:2107.11673. [Google Scholar]
- Rodriguez-Canal, G.; Brown, N.; Jamieson, M.; Bauer, E.; Lydike, A.; Grosser, T. Stencil-HMLS: A multi-layered approach to the automatic optimisation of stencil codes on FPGA. In Proceedings of the SC’23 Workshops of The International Conference on High Performance Computing, Network, Storage, and Analysis, Denver, CO, USA, 12–17 November 2023; pp. 556–565. [Google Scholar]
- Brown, N.; Jamieson, M.; Lydike, A.; Bauer, E.; Grosser, T. Fortran performance optimisation and auto-parallelisation by leveraging MLIR-based domain specific abstractions in Flang. In Proceedings of the SC’23 Workshops of The International Conference on High Performance Computing, Network, Storage, and Analysis, Denver, CO, USA, 12–17 November 2023; pp. 904–913. [Google Scholar]
- Bisbas, G.; Lydike, A.; Bauer, E.; Brown, N.; Fehr, M.; Mitchell, L.; Rodriguez-Canal, G.; Jamieson, M.; Kelly, P.H.; Steuwer, M.; et al. A shared compilation stack for distributed-memory parallelism in stencil DSLs. In Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, San Diego, CA, USA, 27 April–1 May 2024; Volume 3, pp. 38–56. [Google Scholar]
- Gysi, T.; Müller, C.; Zinenko, O.; Herhut, S.; Davis, E.; Wicky, T.; Fuhrer, O.; Hoefler, T.; Grosser, T. Domain-specific multi-level IR rewriting for GPU: The Open Earth compiler for GPU-accelerated climate simulation. ACM Trans. Archit. Code Optim. (TACO) 2021, 18, 1–23. [Google Scholar] [CrossRef]
- Ziogas, A.N.; Schneider, T.; Ben-Nun, T.; Calotoiu, A.; De Matteis, T.; de Fine Licht, J.; Lavarini, L.; Hoefler, T. Productivity, portability, performance: Data-centric Python. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, St. Louis, MO, USA, 14–19 November 2021; pp. 1–13. [Google Scholar]
- de Fine Licht, J.; Hoefler, T. hlslib: Software engineering for hardware design. arXiv 2019, arXiv:1910.04436. [Google Scholar]
- Maxeler. N-Body Simulation. Available online: https://github.com/maxeler/NBody (accessed on 28 September 2024).
- Baaij, C.; Kooijman, M.; Kuper, J.; Boeijink, A.; Gerards, M. C? ash: Structural descriptions of synchronous hardware using haskell. In Proceedings of the 2010 13th Euromicro Conference on Digital System Design: Architectures, Methods and Tools, Lille, France, 1–3 September 2010; pp. 714–721. [Google Scholar]
- Cox, D. Where Lions Roam: RISC-V on the VELDT. Available online: https://github.com/standardsemiconductor/lion (accessed on 28 September 2024).
- Bjesse, P.; Claessen, K.; Sheeran, M.; Singh, S. Lava: Hardware design in Haskell. ACM Sigplan Not. 1998, 34, 174–184. [Google Scholar] [CrossRef]
- Kapre, N.; Bayliss, S. Survey of domain-specific languages for FPGA computing. In Proceedings of the 2016 26th International Conference on Field Programmable Logic and Applications (FPL), Lausanne, Switzerland, 29 August–2 September 2016; pp. 1–12. [Google Scholar]
- Kamalakkannan, K.; Mudalige, G.R.; Reguly, I.Z.; Fahmy, S.A. High-level FPGA accelerator design for structured-mesh-based explicit numerical solvers. In Proceedings of the 2021 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Portland, OR, USA, 17–21 May 2021; pp. 1087–1096. [Google Scholar]
- Stewart, R.; Duncan, K.; Michaelson, G.; Garcia, P.; Bhowmik, D.; Wallace, A. RIPL: A Parallel Image processing language for FPGAs. ACM Trans. Reconfigurable Technol. Syst. (TRETS) 2018, 11, 1–24. [Google Scholar] [CrossRef]
- Gaide, B.; Gaitonde, D.; Ravishankar, C.; Bauer, T. Xilinx adaptive compute acceleration platform: Versaltm architecture. In Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, CA, USA, 24–26 February 2019; pp. 84–93. [Google Scholar]
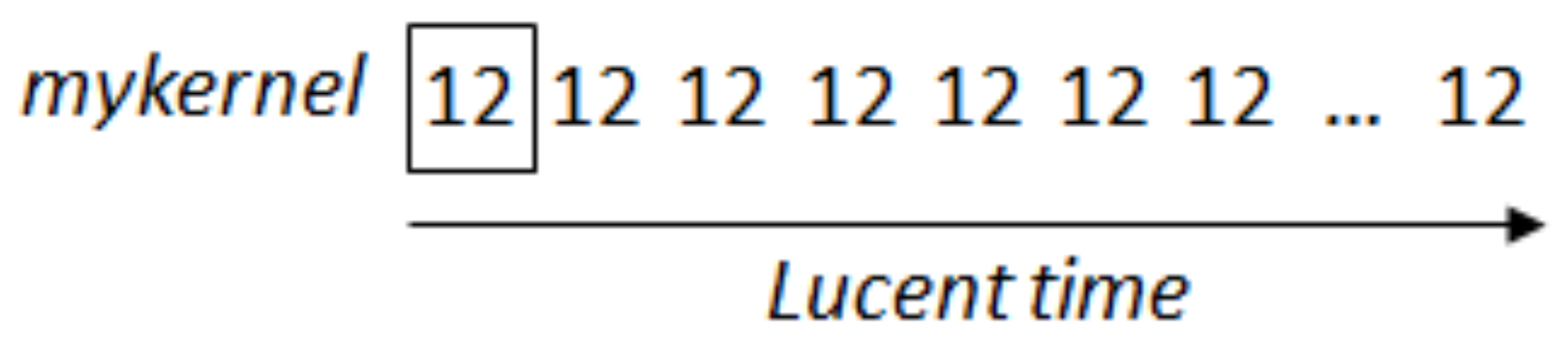
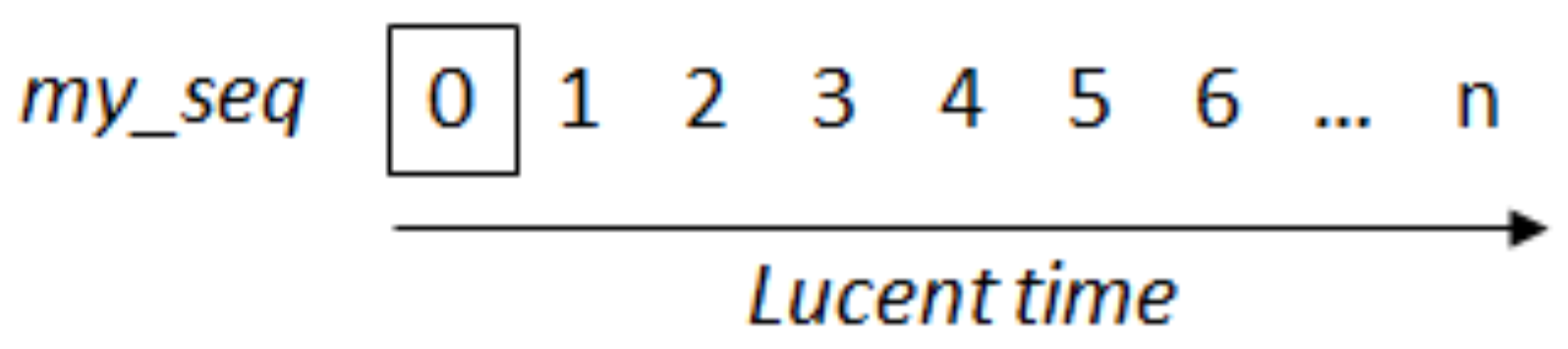



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Routine | Naive (ms) | DaCe (ms) | Vitis Library (ms) | Lucent (ms) | ||
|---|---|---|---|---|---|---|
| Scalar | Vect | Scalar | Vect | |||
| dot product | 286.15 | 167.25 | 265.65 | 31.84 | 87.42 | 15.31 |
| axpy | 61.52 | 34.13 | 259.64 | 38.45 | 41.92 | 8.32 |
| l2norm | 247.37 | 167.04 | 136.75 | 19.83 | 56.96 | 18.96 |
| gemv | 422.41 | 83.90 | 401.25 | 55.76 | 154.65 | 31.56 |
| gemm | 2598.84 | 42.63 | 2187.49 | 173.74 | 356.32 | 65.32 |
| Routine | Naive (J) | DaCe (J) | Vitis Library (J) | Lucent (J) | ||
|---|---|---|---|---|---|---|
| Scalar | Vect | Scalar | Vect | |||
| dot product | 4.83 | 4.83 | 7.52 | 0.95 | 2.56 | 0.46 |
| axpy | 1.76 | 0.95 | 7.37 | 1.09 | 1.13 | 0.25 |
| l2norm | 7.01 | 4.69 | 3.40 | 0.59 | 1.65 | 0.54 |
| gemv | 12.12 | 2.42 | 11.79 | 1.57 | 4.45 | 0.88 |
| gemm | 75.63 | 1.25 | 63.66 | 5.14 | 10.26 | 1.94 |
| Routine | Naive | DaCe | Vitis Library | Lucent | ||||
|---|---|---|---|---|---|---|---|---|
| BRAM | LUTs | BRAM | LUTs | BRAM | LUTs | BRAM | LUTs | |
| dot product | 0.17% | 0.31% | 0.45% | 0.88% | 0.54% | 0.42% | 0.86% | 0.71% |
| axpy | 0.17% | 0.32% | 0.56% | 1.27% | 0.51% | 0.33% | 0.89% | 0.45% |
| l2norm | 0.38% | 0.11% | 0.69% | 1.05% | 0.11% | 0.56% | 0.72% | 0.95% |
| gemv | 0.23% | 0.25% | 0.94% | 2.21 % | 0.56% | 0.50% | 0.93% | 1.72% |
| gemm | 0.76% | 3.21% | 5.37% | 7.28% | 1.27% | 9.69% | 3.45% | 6.55% |
| Description | GFLOPs (Single) | GFLOPs (Entire) | Lines of Code |
|---|---|---|---|
| Xeon Platinum CPU | 2.09 | 15.20 | 21 |
| Naive HLS | 0.018 | - | 32 |
| hand-optimised HLS | 14.50 | 80.22 | 598 |
| Lucent | 14.02 | 67.19 | 23 |
| Description | LUT Usage (Single) | BRAM Usage (Single) | LUT Usage (Entire) | BRAM Usage (Entire) |
|---|---|---|---|---|
| Naive HLS | 2.55% | 8.65% | - | - |
| hand-optimised HLS | 3.78% | 14.40% | 22.68% | 86.42% |
| Lucent | 5.23% | 16.51% | 26.15% | 82.55% |
| Description | Single | Entire | ||
|---|---|---|---|---|
| Power (Watts) | Efficiency (GFLOPs/Watt) | Power (Watts) | Efficiency (GFLOPs/Watt) | |
| Xeon Platinum CPU | 65.55 | 0.03 | 172.56 | 0.09 |
| Naive HLS | 32.56 | 0.0006 | - | - |
| hand-optimised HLS | 33.39 | 0.43 | 46.54 | 1.72 |
| Lucent | 33.55 | 0.42 | 44.23 | 1.52 |
| Description | Options/sec (Single) | Options/sec (Entire) | Lines of Code |
|---|---|---|---|
| Xeon Platinum CPU | 8738 | 75,823 | 102 |
| AMD Xilinx’s Vitis library | 3462 | 16,071 | 252 |
| hand-optimised HLS | 27,675 | 114,115 | 742 |
| Lucent | 26,854 | 107,801 | 83 |
| Description | Single | Entire | ||
|---|---|---|---|---|
| Power (Watts) | Efficiency (Options/Watt) | Power (Watts) | Efficiency (Options/Watt) | |
| Xeon Platinum CPU | 65.98 | 132 | 175.39 | 432 |
| AMD Xilinx’s Vitis library | 35.72 | 97 | 38.09 | 422 |
| hand-optimised HLS | 35.86 | 771 | 37.38 | 3052 |
| Lucent | 35.26 | 762 | 39.88 | 2703 |
| Description | LUT Usage (Single) | BRAM Usage (Single) | LUT Usage (Entire) | BRAM Usage (Entire) |
|---|---|---|---|---|
| AMD Xilinx’s Vitis library | 9.16% | 2.54% | 54.96% | 15.23% |
| hand-optimised HLS | 9.52% | 2.54% | 56.86% | 15.23% |
| Lucent | 10.01% | 2.73% | 60.6% | 16.38% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Brown, N. Domain Specific Abstractions for the Development of Fast-by-Construction Dataflow Codes on FPGAs. Chips 2024, 3, 334-360. https://doi.org/10.3390/chips3040017
Brown N. Domain Specific Abstractions for the Development of Fast-by-Construction Dataflow Codes on FPGAs. Chips. 2024; 3(4):334-360. https://doi.org/10.3390/chips3040017
Chicago/Turabian StyleBrown, Nick. 2024. "Domain Specific Abstractions for the Development of Fast-by-Construction Dataflow Codes on FPGAs" Chips 3, no. 4: 334-360. https://doi.org/10.3390/chips3040017
APA StyleBrown, N. (2024). Domain Specific Abstractions for the Development of Fast-by-Construction Dataflow Codes on FPGAs. Chips, 3(4), 334-360. https://doi.org/10.3390/chips3040017