
Design and Performance Analysis of Hardware Realization of 3GPP Physical Layer for 5G Cell Search
Electronics and Communications Department, Indraprastha Institute of Information Technology Delhi, Delhi 110020, India
*
Author to whom correspondence should be addressed.
Chips 2023, 2(4), 223-242; https://doi.org/10.3390/chips2040014
Submission received: 16 June 2023
/
Revised: 20 August 2023
/
Accepted: 31 August 2023
/
Published: 7 October 2023
Abstract
:5G Cell Search (CS) is the first step for user equipment (UE) to initiate communication with the 5G node B (gNB) every time it is powered ON. In cellular networks, CS is accomplished via synchronization signals (SS) broadcasted by gNB. 5G 3rd generation partnership project (3GPP) specifications offer a detailed discussion on the SS generation at gNB, but a limited understanding of their blind search and detection is available. Unlike 4G, 5G SS may not be transmitted at the center of carrier frequency, and their frequency location is unknown to UE. In this work, we demonstrate the 5G CS by designing 3GPP compatible hardware realization of the physical layer (PHY) of the gNB transmitter and UE receiver. The proposed SS detection explores a novel down-sampling approach resulting in a 60% reduction in on-chip memory and 50% lower search time. Via detailed performance analysis, we analyze the functional correctness, computational complexity, and latency of the proposed approach for different word lengths, signal-to-noise ratio (SNR), and down-sampling factors. We demonstrate end-to-end 5G CS using GNU Radio-based RFNoC framework on the USRP-FPGA platform and achieve 66% faster SS search compared to software. The 3GPP compatibility and demonstration on hardware strengthen the commercial significance of the proposed work.
1. Introduction
In a cellular network, user equipment (UE) performs initial access (IA) to establish communication with the base station (BS) every time it is powered ON [1,2,3,4,5,6]. The IA comprises the downlink and uplink synchronizations. The downlink synchronization involves the cell search (CS), and acquisition of minimum system information (MSI) at the UE [2,7,8,9]. The first step, CS, allows the UE to obtain cell identity and synchronize with the BS in terms of symbol, slot, subframe, and frame timings [7,8,9]. After the CS, MSI acquisition provides information such as access type (barred, restricted, or unrestricted), carrier frequency and bandwidth, cell selection information (minimum receiver level), scheduling information, downlink/uplink configurations, etc. [2,10,11,12]. The uplink synchronization, via physical random access channel (PRACH), allows the base station to locate and instruct the UE to fine-tune the uplink timings such that uplink transmissions from multiple UEs are aligned in time irrespective of their distances from base-station [10,13,14]. In [15], CS is moved from UE to BS via code-book-based approach. However, this approach is not compatible with existing 3GPP standards.
The CS is the first and foremost step of the 5G IA and the focus of the work presented in this paper. It is accomplished via synchronization signals (SS) broadcasted by 5G node B (gNB). 5G 3rd generation partnership project (3GPP) specifications offer a detailed discussion on the SS generation at gNB, but limited understanding about their blind search and detection at UE is available [7,8,9,10,16,17,18]. Historically, it is left to be designed by equipment manufacturers.
The CS in 5G substantially evolved from 4G Long Term Evolution (LTE) [19,20,21,22,23]. The significant difference is the location of SS in the frequency domain. In 4G LTE, the SS is transmitted over the subcarriers in the middle of the carrier [19]. In 5G, the location is not fixed and is unknown, which means the UE needs to blindly search the SS over the entire carrier bandwidth [10]. To simplify the blind search, 3GPP introduced Global Synchronization Channel Number (GSCN) in 5G, which pre-defines possible positions where gNB can transmit SS. The SS bandwidth and overall transmission bandwidth in 5G are significantly wider; hence, SS detection requires multiple large-size correlators [4]. This makes the blind search computationally complex and time-consuming. Deep learning for CS may not be suitable for low latency applications [24]. Other blocks of the CS physical layer (PHY), including message generators, channel encoders, data modulators, scramblers, interleaves, and their counterparts in the receivers, are redesigned in 5G [25,26]. Thus, efficient design of 5G CS and in-depth performance analysis are essential to understand computational complexity and identify the limitations for future standard releases.
The work presented in this paper aims to innovate algorithms and architecture for accurate and reliable 5G CS. The proposed 5G CS PHY is based on the Release 16 of the 3GPP standards [16,17,18]. The main contributions of the paper are summarized as follows:
- We develop and integrate various building blocks of the 5G CS PHY of the gNB transmitter and UE receiver for realization on hardware. Along with the conventional baseband PHY operations, we design the gNB scheduler to broadcast the SS signals as per the 3GPP specifications.
- We demonstrate the design and FPGA implementation of signal processing blocks such as primary SS (PSS) and secondary SS (SSS) detection, demodulation reference signal (DMRS) detection, and cell identity (CI) estimation at UE as per 3GPP standard. Multiple instances of the detected PSS, SSS, and DMRS signals are used to detect the frame, sub-frame, and symbol boundaries in the received signal.
- To speed up the blind SS search, we propose a new PSS detection approach that explores a novel down-sampling approach resulting in a 60% reduction in on-chip memory and 50% lower search time.
- Via detailed performance analysis, we analyze the functional correctness, computational complexity, and latency of the proposed approach for different word lengths, signal-to-noise ratio (SNR), and down-sampling factors.
- We demonstrate the functionality of the proposed end-to-end 5G CS PHY on the GNU Radio and Universal Software Radio Peripheral (USRP) based radio frequency network-on-chip (RFNoC) platform from Ettus Research [27,28]. We demonstrate the 66% reduction in SS search time by efficiently utilizing the Field-Programmable Gate Array (FPGA) available on USRP compared to conventional GNU Radio-based software implementation.
The proposed demonstration on hardware and 3GPP compatibility strengthens the commercial significance of the proposed work. Please refer here (https://tinyurl.com/A2AIIITD (accessed on 12 August 2023)) for source codes and supporting tutorials. The list of abbreviations used in the paper is given in Table 1.
The rest of the paper is organized as follows. We discuss the 3GPP specifications for 5G CS and review the relevant works in Section 2. The downlink transmitter and receiver physical layer architectures are presented in Section 3 and Section 4, respectively. The experimental results and complexity analysis is done in Section 5. In Section 6, we discuss the realization of CS using GNU Radio based RFNoC framework followed by experimental results. Section 7 concludes the paper.
2. Specifications of 5G CS and Literature Review
In this section, we discuss the 3GPP specifications for 5G CS PHY and review the works related to the hardware implementation of CS PHY.
2.1. 5G CS PHY
We consider the n78 frequency band (3300–3800 MHz) in the frequency range 1, i.e., FR1 (410–7125 MHz) as it is being widely chosen for initial deployment of the 5G networks [5,6]. As per the 3GPP specifications, the maximum transmission bandwidth in the n78 band is 100 MHz, and sub-carriers (SC) spacing (SCS) is fixed to 30 kHz for SS [17]. Thus, the maximum number of SC in the n78 band is 3276. In 5G, a resource block (RB) is the smallest bandwidth unit for resource allocation and 1 RB consists of 12 SCs. Thus, the maximum number of RBs available in the n78 band is 273.
The 5G PHY is based on orthogonal frequency division multiplexing (OFDM) based waveform modulation [25]. Each OFDM symbol consists of the number of SCs which must be a power of two due to IFFT/FFT operations. This results in 4096 SCs per OFDM symbol in n78 [17]. In the time domain, each frame duration is 10 ms, and it consists of 10 sub-frames. Each sub-frame consists of 2 slots, and each slot consists of 14 OFDM symbols. Then, a single frame of 10 ms comprises 280 OFDM symbols. Then, the symbol duration is 33.33 s with a cyclic prefix size of 2.86 s for the first symbol of each slot and 2.34 s for the remaining 13 symbols. Different size of cyclic prefix allows a common frame structure for multiple SCS newly introduced in 5G [5,25].
The SS signals are transmitted in a burst, known as SS burst (SSB), and the size, duration, and periodicity of the SSB depend on the operating frequency range. For n78, SSB is transmitted in every other frame, and each SSB comprises 8 SS [7,8,9,10,16,18]. In a frame, the starting OFDM symbol of the SS is {4,8,16,20,32,36,44,48}. The duration of each SS is 4 OFDM symbols which means SSB spans over 52 OFDM symbols in a frame of 280 symbols.
Each SS consists of 240 sub-carriers (SC) in the frequency domain, i.e., 20 resource blocks (RBs) and 4 OFDM symbols in the time domain [7,8,9,10,16,18]. As shown in Figure 1, the middle 127 SC of the first and third OFDM symbols are occupied by PSS and SSS, respectively. Since PSS and SSS are the first signals detected by UE during IA, they are carefully designed to enable blind detection with high reliability. 3GPP has adopted m-sequences to generate PSS and SSS , [16]. The rest of the 113 SCs of the first symbol are fixed to zero. The PSS and SSS allow the UE to detect the physical cell ID (PCI). In 5G, there are 3 candidate PSS sequences and 336 candidate SSS sequences which means the PCI range is from 0 to 1007 [16,18]. In the third symbol, there are 7 upper and 6 lower SC adjacent to the SSS fixed to zero, and the remaining SCs are occupied by a physical broadcast control channel (PBCH) carrying MIS and DMRS. The DMRS occupies 25% of the remaining SC, i.e., 144 SC. Since DMRS is quadrature phase shift keying (QPSK) demodulated, it consists of 288 bits which are generated using 3GPP defined pseudo-random sequence generator using two parameters: (1) PCI, , and (2) SS index, , of the SS in SSB, [16,18]. At UE, DMRS is detected after PSS and SSS detections which means DMRS allows estimation of the SS index which is critical for a frame, sub-frame, slot, and symbol synchronization. DMRS also allows channel estimation for MIS reception via PBCH [11,12,23].
The location of all SS in SSB among 4096 SCs is not fixed in 5G and it is decided by the GSCN value. Furthermore, gNB can dynamically change the GSCN of the SSB. As per 3GPP specifications, there is a one-to-one mapping between the GSCN value and corresponding SSB center frequency [16,18]. In n78, the GSCN range is from 7711–8051 and the frequency resolution is 1.44 MHz. For example, the carrier frequency of 3305.28 Mhz is assigned a GSCN of 7711. Then, the GSCN of 7712 corresponds to the carrier frequency of 3305.28 + 1.44 = 3306.72 MHz. The last GSCN of the n78 band is 8051 and it corresponds to 3794.88 MHZ [16,18]. Such a GSCN raster of 1.44 MHz resolution allows UE to quickly detect SS by limiting the search over a limited number of center frequencies compared to the search over carrier frequencies with a channel raster of 15 kHz resolution.
2.2. Review: Mapping of 5G CS PHY on Hardware
The design, theoretical analysis, and simulation-based performance evaluation of 5G PHY have been an active research topic in the last few years [7,8,9,13,14,29,30]. Various works on the design and optimization of PHY sub-blocks such as channel encoders [31,32,33,34], OFDM modulator [35,36], beamforming [37,38] and channel estimation [39,40,41] have been explored to improve the PHY performance compared to 4G PHY. However, only a few works have focused on 3GPP standards and further improvements without compromising the compatibility with existing and previous standards [7,8,13,14,19,30]. From 5G CS perspectives, works in [8,9] provide an in-depth understanding of the SS generation while [7] offers an innovative intelligence-based CS approach. However, these works do not highlight the challenges in SS detection and applications of SS detection for timing synchronization. The work presented in this paper aims to bridge this gap.
Another important aspect of 5G PHY deployment is an efficient implementation on the software and hardware platforms. Compared to 4G, there are numerous scenarios that have resulted in the split of PHY depending on positions of radio, distribution, and centralized units [42,43,44]. This demands hardware-software co-design of the PHY. In [45,46], authors have explored the hardware-software co-design of IEEE 802.11 PHY on Zynq system-on-chip (SoC) platform. In [35,47], authors have explored reconfigurable OFDM waveform with dynamically controlled out-of-band emission. In [48], authors have proposed reconfigurable OFDM-based PHY to support multi-standard operations. However, none of these works consider 3GPP compatible 5G PHY. The work in [26] is limited to OFDM-based transceivers but does not consider various control and data channels in 5G while the work in [49] is limited to software-based CS implementation using USRP. In this work, we design software and hardware IP cores of 3GPP compatible 5G PHY and demonstrate the 5G CS operations by developing the receiver PHY. We also demonstrate end-to-end 5G CS PHY using RFNoC based USRP-FPGA platform.
3. Downlink Transmitter PHY for CS
In this section, we present the design details and architecture of the downlink transmitter PHY for CS. As shown in Figure 2, the PHY consists of multiple scheduling and baseband signal processing tasks such as frame scheduler, SS scheduler, SS generation, 4096-IFFT, CP addition, and windowing or filtering. Among them, the last three blocks perform convectional OFDM modulation and are designed using FFT and filter IPs shared publicly by AMD-Xilinx. As discussed in Section 2, the CP size depends on the location of the OFDM symbol in a slot, and hence, slot and OFDM symbol indexes are given as input to the CP addition block.
SS scheduler is the most important unit of the CS PHY and it is responsible for generating the stream of OFDM symbols with embedded SS signals at the desired time and frequency locations as shown in Figure 1. The SS scheduler mainly consists of a frame scheduler, generation blocks for PSS, SSS, DMRS, and PBCH, memory to store one instance of SS and a resource mapper. The output of the SS scheduler is modulated using OFDM modulation. The 5G frame scheduler block is designed to generate multiple signals to keep track of frame, sub-frame, slot, and OFDM boundaries. This is done using a modulus-4096 counter which is configured by the MAC layer. At the end of each cycle of this counter, the OFDM symbol index is incremented by 1. OFDM symbol index is tracked using the Modulus-14 counter and at the end of its cycle, the slot index is incremented by 1. In this way, slot index, sub-frame index, and frame index are generated using modulus-2, modulus-10, and modulus-1024 counters, respectively. The frame scheduler also generates the SS index, , to generate appropriate SS signals and keep track of active SS transmission. The is calculated using the OFDM symbol and frame indices as discussed in Section 2. The final task of the frame scheduler is to generate the address generator so that 960 symbols corresponding to an upcoming instance of SS are stored in the memory. It is designed using a modulus-960 counter as shown in Figure 2. Though each counter is shown as an independent unit in Figure 2, all counters are carefully implemented to maximize the shared hardware reuse and counters are synchronized so that the signals are generated as per the 3GPP timing requirements.
For SS generation, PCI and GSCN values are configured by the MAC layer in the internal register via the AXI-Lite interface. The first sub-block is the PSS generator which outputs a 127-length binary phase shift key (BPSK) modulated sequence for a given PCI. It is based on the 3GPP specification in [16] and given by
where
Here, = {1,1,1,0,1,1,0}. The first step is to obtain a reference PSS binary sequence, of 127 length, using the first seven fixed bits. As shown in (1), th bit of the depends on the th and th bits. Since is fixed, we can pre-calculate it and store it in the memory as shown in Figure 3. Thereafter, PSS is obtained by reading the reference PSS sequence in the particular order, and this order is based on the input PCI, as shown in Figure 3. For instance, when , PSS is BPSK modulated version of since and for , PSS is BPSK modulated version of 1-bit shifted version of the since . Also, the modulus by three operations indicates that there are three different PSS sequences.
Similarly, SSS is also a 127-length BPSK modulated sequence, and one of the 336 candidate sequences is chosen using the input PCI, , as shown in Figure 4. In SSS generation, two reference 127-lengths sequences, and , are stored in the memory, and they are calculated as
Here, = = {0,0,0,0,0,0,1}. These reference sequences are read in a particular order followed by element-wise multiplication to obtain SSS. Mathematically, SSS is calculated as [16],
where
The DMRS is 144-length Quadrature Phase Shift Keying (QPSK) modulated sequence generated using the PCI, and SS index, as shown in Figure 5. Due to dependence on the value of , the DMRS is different for each SS in a SS burst. The DMRS generation involves pseudo-random binary sequence (PRBS) generation of length 288 which is then QPSK modulated to obtain the final DMRS. The PRBS generation is based on length-31 Gold sequence and it needs the initial seed, , which is calculated using the PCI, and SS index, [16].
Using the , of length 288 is generated using length-31 gold sequences [16]. The detailed steps and algorithm for PRBS generation have been discussed in [16] and the corresponding proposed hardware architecture is given in Figure 5. The final step in SS generation is the PBCH. Since it is not needed for the first phase of CS, we have randomly generated 432 complex symbols that are placed on the resources allocated for PBCH.
The generated SS block, i.e., four OFDM symbols each of 240 complex symbols, is then stored in the memory. The resource mapper block generates the stream of OFDM symbols of size 4096 SCs with an embedded SS at the desired time and frequency location. The frequency location is controlled by the GSCN configured by the MAC layer while the time location is as per the 3GPP specifications discussed in Section 2: Figure 1. Next, the design of the downlink or UE receiver PHY is presented.
4. UE Receiver PHY for CS
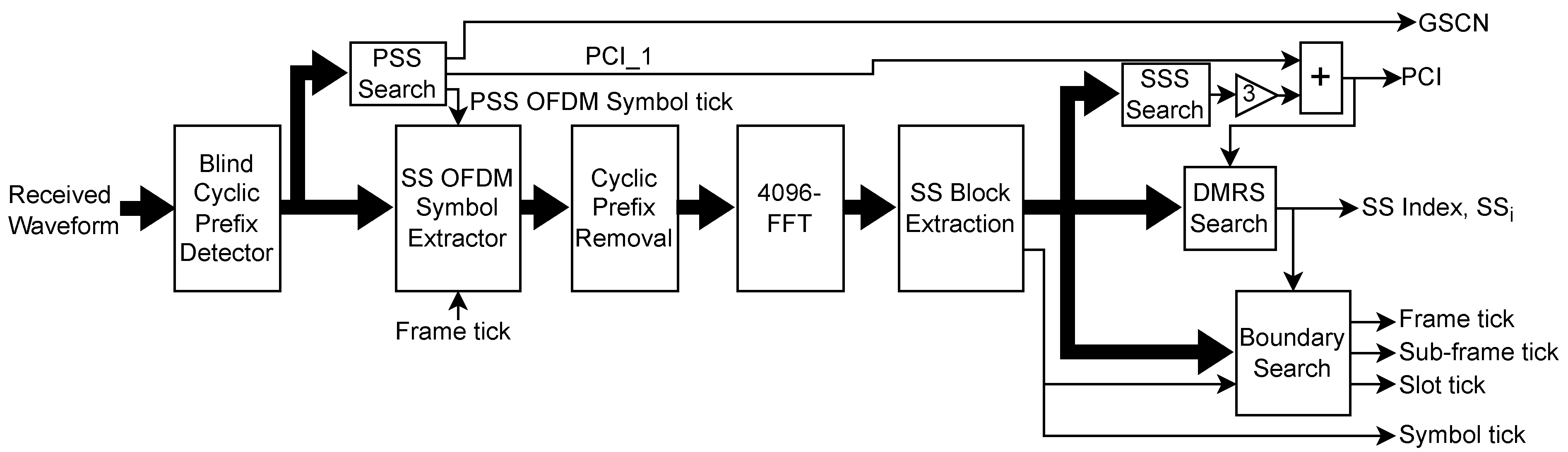
The downlink, i.e., UE, receiver PHY for CS needs to blindly detect the SS and identify the transmitted PCI, , and the index of the detected SS block, . It also helps the UE to locate the starting sample of each frame, sub-frame, slot, and symbol which is critical for receiving the MSI and establishing the uplink communication with the gNB.
The block diagram of the receiver PHY is shown in Figure 6. The first step is to identify the presence of CP so that the receiver can group the received samples in a packet of 4096 samples comprising a single OFDM symbol. In this work, we assume ideal synchronization between BS and UE [50]. This is done via a conventional auto-correlation-based approach where the received signal is auto-correlated with its delayed version since CP is the initial section of the OFDM symbol appended at the end. The CP detection enables the identification of symbol boundaries so that 4096 complex symbols corresponding to a single OFDM symbol are extracted for the PSS search task. Since CP detection is a well-known task in wireless PHY, we skip the discussion on its architecture. Note that the CP detection is an optional step in CS PHY but it helps to reduce the number of samples to be processed by the PSS search block thereby speeding up the PSS search. The CP detection may fail when SNR is poor and in such cases, all the samples are forwarded to the PSS search block.
The next step is to identify the OFDM symbols containing the SS block. Though SS is transmitted in pre-defined OFDM symbols, the receiver is not aware of the index of the detected OFDM symbol, and hence, blind detection of SS is needed. We first detect the presence of the PSS using the PSS Search block and identify the detected PSS sequence, PCI_2 . The PSS detection also enables the extraction of symbol boundaries whenever CP detection fails. The OFDM symbol containing PSS can also be detected using the signal generated by the boundary search block. However, in the beginning, signal may not be available and hence, accurate and fast detection of PSS is critical for CS PHY. The SS OFDM Symbol Extractor block extracts the four OFDM symbols containing one instance of SS and forwards them to the OFDM demodulator containing the CP removal and 4096-FFT. After FFT, 960 symbols of the detected SS instance are extracted. Among them, samples belonging to SSS in the third OFDM symbol are sent to the SSS search block to identify the SSS sequence, PCI_1 . Using the PSS and SSS search, we can estimate the PCI as 3*PCI_1 + PCI_2. The extracted 144 DMRS symbols are forwarded to the DMRS search unit to identify the SS index, . In the end, the boundary search block exploits the timing information of the multiple SS blocks to identify the frame, sub-frame, and slot boundaries. Next, we present the architecture of the PSS search, SSS search, DMRS search, and boundary search blocks of the receiver CS PHY.
4.1. PSS Search
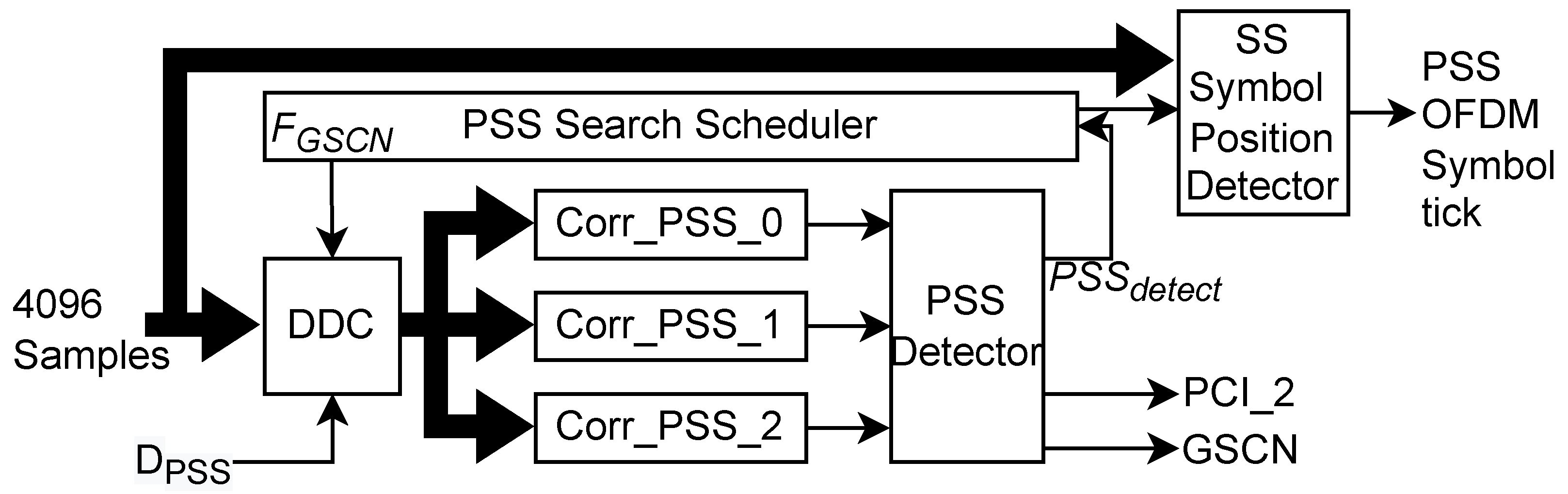
The PSS Search is the most important part of CS PHY as it helps the receiver to identify the presence of the SS block. The challenges in the PSS search are unknown symbol boundary, multiple locations since GSCN is unknown, and large transmission bandwidth of 100 MHz out of which SS occupies only 7.2 MHz resulting in large-size correlators.
To detect the transmitted PSS index, , the cross-correlation is performed between the three reference PSS signals and the received signal. Since the location or GSCN of the received PSS is unknown and SS bandwidth is small compared to total transmission bandwidth, direct cross-correlation between the received signal and reference PSS is computationally complex and time-consuming. Furthermore, generating separate PSS reference signals for each of the 340 different GSCN needs huge on-chip memory. To address these challenges, we propose a novel architecture for PSS search as shown in Figure 7. In the proposed architecture, instead of generating reference PSS for every GSCN, we generate three reference PSS with the lowest GSCN, i.e., 7711. Thus, the received signal need to be down-converted to the lowest GSCN so that cross-correlation can be performed to detect the presence of the PSS. Since the GSCN of the received signal is not known, we need to perform down-conversion for all possible GSCN values and hence, a scheduler is used to generate appropriate down-conversion frequency, , sequentially till the PSS is detected. Since PSS occupies only 7.2 MHz bandwidth, the size of correlators can be reduced by downsampling reference as well as received signals. We have achieved these operations via a digital down converter (DDC) which downconverts the received signal to the GSCN value selected by the scheduler followed by the low-pass filtering to remove aliasing and down-sampling by the chosen factor, . Since the downsampling results in a loss of signal and may affect the detection probability of the PSS, it should be chosen carefully based on the received signal-to-noise ratio (SNR). Empirically, higher SNR allows the use of larger which in turn leads to faster PSS search and lower memory requirement. The final task after the PSS detection is to locate the starting sample of the OFDM symbol containing the PSS and generate an appropriate tick signal for further synchronization. This is done using the location of the correlation peak for the detected PSS and corresponding GSCN value.
4.2. SSS Search
In SSS Search, the received 240 samples extracted from the third OFDM symbol of the detected SS are correlated with 336 reference SSS sequences to detect the . Instead of storing all reference sequences, we have used the SSS generator in Figure 4 to generate the desired sequence. Since PCI is not known, the scheduler is used to cycle through all possible SSS sequences. The sequential SSS search architecture is shown in Figure 8. Depending on the given resource and latency constraints, we can explore serial-parallel architecture by using multiple SSS generators and correlation blocks in parallel.
4.3. DMRS Search
The DMRS search block identifies the by correlating the 144 samples of received DMRS with eight candidate reference DMRS generated using the PCI detected by PSS and SSS search blocks. There are two ways to realize the DMRS search architecture: (1) Use the DMRS generator in Figure 5 to generate reference DMRS, and (2) Store all possible DMRS, i.e., 1008*8 = 8064 sequences each consisting of 144 QPSK modulated samples which demand 9.3 MegaBytes of on-chip memory. Due to memory constraints on ZSoC, we have selected the first option and the corresponding architecture is shown in Figure 9. Similar to the SSS search, we can explore serial-parallel architecture by using multiple DMRS generators and correlation blocks in parallel.
4.4. Boundary Search
The aim of this block is to generate various time reference tick signals to locate the starting samples of the OFDM symbol, slot, sub-frame, and frame. These are critical for MSI reception and uplink synchronization. Such signals are also needed in 5G repeaters to accurately extract the data samples for re-transmission.
Since the SS signals are transmitted at fixed OFDM symbols and the DMRS search block has already identified the index of the detected SS signal, we can directly infer the OFDM symbol number for a detected Symbol_tick by PSS search and SS Block extraction blocks. Since each slot, sub-frame, and frame consists of a certain number of OFDM symbols, corresponding ticks are appropriately generated as shown in Figure 10. For instance, the detection of corresponds to OFDM symbol number of 8 for PSS which lies in slot 0 of the even frame. Using this information, Slot_tick is detected which goes high after OFDM symbols from the detected PSS. Similarly, the detection of corresponds to the OFDM symbol number of 16 for PSS which lies in slot 1 of the even frame. Using this information, Slot_tick is detected which goes high after OFDM symbols from the detected PSS. Thereafter, Slot_tick is generated after the interval of every 14 OFDM symbols. For every two low-to-high transitions of the Slot_tick, Sub-frame_tick is generated and for every 10 low-to-high transitions of the Sub-frame_tick, Frame_tick is generated.
5. Performance and Complexity Analysis
In this section, we present the functional correctness and complexity analysis of the proposed architecture for different SNR, WL, and PSS down-sampling factors. We specifically focus on the PSS Search, SSS Search, and DMRS Search blocks using the data samples generated by the transmit PHY. We consider the wireless PHY with specifications in Section II.A and Additive White Gaussian Noise (AWGN) channel between BS and UE. For comparison, we use reference 3GPP 5G CS PHY with and floating-point WL.
5.1. PSS Search
The main task of the PSS Search is to identify the PCI_2 and GSCN. Since the identification of PCI_2 also confirms the correct identification of the GSCN, we limit the discussion on the probability of detection of PCI_2 for different SNRs and . It is referred to as . In Figure 11, obtained from the experimental results on single-precision floating-point (SPFL) architecture for SNR ranging from −16 dB to 8 dB and are shown. It can be observed that increases with the increase in SNR and . The degradation in the is not significant for even at low SNR when compared to PSS Search without any downsampling, i.e., . At SNR higher than 5 dB, it is possible to perform PSS Search with of 14 as well. Experimental results show that PSS Search fails for due to the insufficient number of samples available for correlation with reference PSS.
Next, we analyze the effect of WL of the PSS search architecture on the . We consider two fixed-point architectures with a total WL of 32 and 24 bits. The WL of 32 bits is selected to keep the number of bits the same as that of SPFL architecture. Experimental results showed that the PSS detection fails for any WL lower than 24 bits and hence, second architecture with a WL of 24 bits is selected. In each fixed-point architecture, the number of bits allocated to integer and fractional parts is carefully selected to maximize the probability of detection. In Figure 12, we compare the difference in for SPFL and fixed-point 24-bit architecture for SNR ranging from -16 dB to 8 dB and . It can be observed that the error is small and negligible for even at low SNR.
The architecture with lower WL and higher offers significant savings in resource utilization and execution time. In Table 1, we first compare the execution time in milliseconds (ms). It can be observed that the execution time decreases with the increase in the . Also, fixed-point architectures offer a 2–3 factor reduction in the execution time over SPFL architecture. Similarly, higher leads to lower utilization of on-chip memory, i.e., FPGA block RAM, due to a few samples of the received and reference PSS. The use of lower WL also offers a further reduction in on-chip memory. Interestingly, the effect of on the number of embedded multipliers and FPGA LUTs is not significant since the correlation block is realized in a sequential manner due to the limited number of memory ports. However, lower WL offers further savings in multipliers and LUTs since the size of multipliers and accumulators is smaller for lower WL. Overall, the proposed approach offers a 60% reduction in on-chip memory and 50% lower latency, i.e., PSS search time. To summarize, the appropriate selection of and WL is important to meet the desired execution time, functional accuracy, and resource utilization constraints. For such analysis, the proposed work of mapping complete transmit and receiver PHY on the SoC is critical.
5.2. SSS Search
The main task of the SSS Search is to identify the PCI_1 which along with PCI_2 from PSS Search gives PCI. The SSS Search is computationally less complex than PSS Search due to the small correlation size and hence, there is no need for down-sampling. We analyze the effect of WL on the probability of detection of PCI_1, referred to as , for different SNRs. We consider four different WL as shown in Figure 13 and corresponding execution time and resource utilization results are given in Table 2. It can be observed that SPFL, half-precision floating-point (HPFL) and fixed point architecture with 24 bits offer nearly identical detection performance. On the other hand, execution time decreases by half as we move from SPFL to fixed-point architecture. In addition, there are significant savings in resource utilization as well. Further savings in resource utilization is possible using a fixed-point architecture with WL of 16 bits but it incurs slight degradation in detection performance. When compared to PSS search, SSS search is significantly faster and requires lower on-chip memory due to a smaller correlation size. The higher number of DSP48s and LUTs is due to the serial-parallel realization of correlators as a complete SSS search involves 336 correlation operations compared to 3 in the PSS search.
5.3. DMRS Search
Similar to PSS and SSS search, we compare the probability of detection of SS index, referred to as , for different WL and SNRs. As shown in Figure 14, we can observe that WL of 16 offers nearly identical performance to that of SPFL and HPFL architecture. As shown in Table 3, DMRS search architecture with WL of 16 offers 33% reductions in execution time along with significant savings in resource utilization as well.
For all the results presented in this section, we have used the transmitter PHY with a WL of 16. This is done by observing the power spectral density of the transmitter output and performance of PSS search with SPFL WL for different WLs of transmitter PHY. Corresponding results are not included here to avoid repetition of results.
6. PHY Deployment on RFNoC Platform
In academia as well as industry, GNU Radio is widely used for prototyping wireless systems and integration with the radio front-end of the USRP platform for demonstration in a real-radio environment. Since the GNU Radio tool is deployed on the host processor, the performance of signal processing algorithms is limited due to its sequential nature. To address this issue, Ettus Research developed the RFNoC tool that enables the acceleration of GNU Radio algorithms on hardware such as USRP FPGA [27,28]. It offers a seamless tight interface between GNU Radio software and FPGA for data transfer thus enabling hardware-software co-design between a host processor and FPGA. Like GNU Radio, RFNoC is free and open-source software.
In this work, we design complete software realization of the CS transmitter and receiver PHY using GNU Radio. Next, we have modified the AXI-Stream compatible hardware IPs discussed in Section 3 and Section 4 for different building blocks of the CS transmitter and receiver PHY, respectively, into the custom RFNoC hardware IPs. Then, we have verified the functional correctness of these IPs using custom test benches and an out-of-tree module-based approach which allows integration and verification of RFNoC blocks in GNU Radio. For instance, one of the configurations with CS transmitter PHY in GNU Radio and CS receiver PHY on USRP FPGA is shown in Figure 15. As per the requirement of the RFNoC framework, the proposed receiver PHY hardware IP with AXI-stream interface is integrated with the AXI wrapper and network-on-chip (NoC) shell. This integrated IP is capable of transmitting and receiving data packets from GNU Radio over an Ethernet interface using the RFNoC framework. The NoC shell decodes the received packets from the transmitter to extract the data samples, which are then forwarded to receiver PHY along with appropriate control signals via the settings bus. The processed data is then returned to GNU Radio via another packet using the NoC shell. Similarly, multiple blocks in GNU Radio can be moved to USRP FPGA to improve the execution time via parallel processing on the FPGA.
In Table 4, we compare the execution time of the PSS search block on GNU Radio and RFNoC platforms. We have selected SPFL WL for a fair comparison between both platforms. Like Table 1, the execution time decreases with the increase in . It can be observed that the RFNoC-based acceleration offers an improvement in execution time by a factor of 2 or higher. Similar to Table 1, higher and lower WL offer savings in resource utilization on the RFNoc platform, and corresponding results are skipped to avoid repetition of discussion.
Next, we consider the end-to-end execution time, which involves the data communication overhead between GNU Radio and USRP. We consider around two frames of data which corresponds to around 2000 data packets. As shown in Figure 16, RFNoC-based architecture outperforms the GNU Radio based architecture with around 66% faster SS search time. In addition, variation in the execution time of packets is lower in RFNoC compared to GNU Radio, thereby offering stable and reliable performance.
7. Conclusions and Future Works
In this work, we studied and designed hardware IP cores for 5G cell search (CS) as per the third-generation partnership project (3GPP) specifications. Our contributions include the design of CS transmitter PHY consisting of synchronization signal (SS) generation, resource mapping, scheduler, and orthogonal frequency division multiplexing (OFDM) modulation and receiver PHY consisting of blind primary SS search, OFDM demodulation, secondary SS (SSS) search, a demodulation reference signal (DMRS) search, and boundary detection for the frame, sub-frame, slot, and symbols. We have proposed a novel down-sampling approach for PSS search, which offers a substantial reduction in execution time and resource utilization. We have demonstrated the functional correctness and superiority of the proposed approach via the RFNoC framework. Future works include extending the proposed architecture for physical broadcast channel (PBCH) detection, physical random access channel (PRACH) generation, and detection.
Author Contributions
Conceptualization, S.J.D.; methodology, K.L. and J.C.; software, K.L., D.S. and J.C.; validation, K.L., D.S., J.C. and S.J.D.; writing—original draft preparation, S.J.D.; writing—S.J.D.; supervision, S.J.D.; project administration, S.J.D.; funding acquisition, S.J.D. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the funding received from core research grant (CRG) awarded to Sumit J. Darak from DST-SERB, GoI.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| 3GPP | 3rd Generation Partnership Project |
| AXI | ARM Extensible Interface |
| BPSK | Binary Phase Shift Keying |
| BS | Base Station |
| CI | Cell Identity |
| CS | Cell Search |
| DMRS | Demodulation Reference Signal |
| DPFL | Double Precision Floating Point |
| FFT | Fast Fourier Transform |
| FPGA | Field Programmable Gate Array |
| GSCN | Global Synchronization Channel Number |
| HPFL | Half Precision Floating Point |
| IA | Initial Access |
| LTE | Long Term Evolution |
| MAC | Medium Access Control |
| MSI | Minimum System Information |
| OFDM | Orthogonal Frequency Division Multiplexing |
| PBCH | Physical Broadcast Control Channel |
| PCI | Physical Cell ID |
| PHY | Physical Layer |
| PRACH | Physical Random Access Channel |
| PRBS | Pseudo-random Binary Sequence |
| PSS | Primary Synchronization Signal |
| QPSK | Quadrature Phase Shift Keying |
| RB | Resource Block |
| RFNoC | Radio Frequency Network on Chip |
| SCS | Sub-carrier Spacing |
| SNR | Signal to Noise Ratio |
| SoC | System on Chip |
| SPFL | Single Precision Floating Point |
| SS | Synchronization Signal |
| SSB | Synchronization Signal Burst |
| SSS | Secondary Synchronization Signal |
| UE | User Equipment |
| USRP | Universal Software Radio Peripheral |
| WL | Word Length |
| ZSoC | Zynq System on Chip |
References
- Won, S.; Choi, S.W. Three Decades of 3GPP Target Cell Search through 3G, 4G, and 5G. IEEE Access 2020, 8, 116914–116960. [Google Scholar] [CrossRef]
- Lien, S.Y.; Shieh, S.L.; Huang, Y.; Su, B.; Hsu, Y.L.; Wei, H.Y. 5G New Radio: Waveform, Frame Structure, Multiple Access, and Initial Access. IEEE Commun. Mag. 2017, 55, 64–71. [Google Scholar] [CrossRef]
- Dahlman, E.; Parkvall, S. NR—The New 5G Radio-Access Technology. In Proceedings of the 2018 IEEE 87th Vehicular Technology Conference (VTC Spring), Porto, Portugal, 3–6 June 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Jeon, J. NR Wide Bandwidth Operations. IEEE Commun. Mag. 2018, 56, 42–46. [Google Scholar] [CrossRef]
- Zaidi, A.A.; Baldemair, R.; Moles-Cases, V.; He, N.; Werner, K.; Cedergren, A. OFDM Numerology Design for 5G New Radio to Support IoT, eMBB, and MBSFN. IEEE Commun. Stand. Mag. 2018, 2, 78–83. [Google Scholar] [CrossRef]
- Lin, X.; Li, J.; Baldemair, R.; Cheng, J.F.T.; Parkvall, S.; Larsson, D.C.; Koorapaty, H.; Frenne, M.; Falahati, S.; Grovlen, A.; et al. 5G New Radio: Unveiling the Essentials of the Next Generation Wireless Access Technology. IEEE Commun. Stand. Mag. 2019, 3, 30–37. [Google Scholar] [CrossRef]
- Won, S.; Choi, S.W. A Tutorial on 3GPP Initial Cell Search: Exploring a Potential for Intelligence Based Cell Search. IEEE Access 2021, 9, 100223–100263. [Google Scholar] [CrossRef]
- Chakrapani, A. On the Design Details of SS/PBCH, Signal Generation and PRACH in 5G-NR. IEEE Access 2020, 8, 136617–136637. [Google Scholar] [CrossRef]
- Omri, A.; Shaqfeh, M.; Ali, A.; Alnuweiri, H. Synchronization Procedure in 5G NR Systems. IEEE Access 2019, 7, 41286–41295. [Google Scholar] [CrossRef]
- Dahlman, E.; Parkvall, S.; Sköld, J. Chapter 16—Initial Access. In 5G NR: The Next Generation Wireless Access Technology; Dahlman, E., Parkvall, S., Sköld, J., Eds.; Academic Press: Cambridge, MA, USA, 2018; pp. 311–334. [Google Scholar] [CrossRef]
- Zhang, C.; Wu, Q.; Zhao, X.; Bai, J.; Wang, Z. A Scheme for improving 5G Cell Search Performance. In Proceedings of the 2023 5th International Conference on Communications, Information System and Computer Engineering (CISCE), Guangzhou, China, 14–16 April 2023; pp. 141–145. [Google Scholar] [CrossRef]
- Wang, S.D.; Wang, H.M.; Wang, W.; Leung, V.C.M. Detecting Intelligent Jamming on Physical Broadcast Channel in 5G NR. IEEE Commun. Lett. 2023, 27, 1292–1296. [Google Scholar] [CrossRef]
- Zhang, Z. Novel PRACH Scheme for 5G Networks Based on Analog Bloom Filter. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Schreiber, G.; Tavares, M. 5G New Radio Physical Random Access Preamble Design. In Proceedings of the 2018 IEEE 5G World Forum (5GWF), Silicon Valley, CA, USA, 9–11 July 2018; pp. 215–220. [Google Scholar] [CrossRef]
- Yin, J.L.; Lee, M.C.; Hsiao, W.H.; Huang, C.C. A Novel Network Resolved and Mobile Assisted Cell Search Method for 5G Cellular Communication Systems. IEEE Access 2022, 10, 75331–75342. [Google Scholar] [CrossRef]
- 3GPP. NR: Physical Channels and Modulation; Technical Specification (TS) 36.211, Version 17.0; 3rd Generation Partnership Project (3GPP): Valbonne, France, 2022. [Google Scholar]
- 3GPP. NR: Physical Layer: General Description; Technical Specification (TS) 36.201, Version 17.0.0; 3rd Generation Partnership Project (3GPP): Valbonne, France, 2022. [Google Scholar]
- 3GPP. NR: Physical Layer Procedures for Control; Technical Specification (TS) 36.213, Version 17.2.0; 3rd Generation Partnership Project (3GPP): Valbonne, France, 2022. [Google Scholar]
- Zhang, Z.; Liu, J.; Long, K. Low-Complexity Cell Search With Fast PSS Identification in LTE. IEEE Trans. Veh. Technol. 2012, 61, 1719–1729. [Google Scholar] [CrossRef]
- Dahlman, E.; Parkvall, S.; Sköld, J. Chapter 5—NR Overview. In 5G NR: The Next Generation Wireless Access Technology; Dahlman, E., Parkvall, S., Sköld, J., Eds.; Academic Press: Cambridge, MA, USA, 2018; pp. 57–71. [Google Scholar] [CrossRef]
- Dahlman, E.; Parkvall, S.; Sköld, J. Chapter 4—LTE—An Overview. In 5G NR: The Next Generation Wireless Access Technology; Dahlman, E., Parkvall, S., Sköld, J., Eds.; Academic Press: Cambridge, MA, USA, 2018; pp. 39–55. [Google Scholar] [CrossRef]
- Enescu, M.; Yuk, Y.; Vook, F.; Ranta-aho, K.; Kaikkonen, J.; Hakola, S.; Farag, E.; Grant, S.; Manolakos, A. PHY Layer. In 5G New Radio: A Beam-Based Air Interface; John Wiley & Sons: Hoboken, NJ, USA, 2020; pp. 95–260. [Google Scholar] [CrossRef]
- Chong, D.; Ko, G.; Kim, B.K.; Do, J.H.; Lee, J. Efficient PBCH DMRS Sequence Detection for Fast Synchronization Process of 5G NR Systems. In Proceedings of the 2021 IEEE 94th Vehicular Technology Conference (VTC2021-Fall), Norman, OK, USA, 27–30 September 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Wang, M.; Hu, D.; He, L.; Wu, J. Deep-Learning-Based Initial Access Method for Millimeter-Wave MIMO Systems. IEEE Wirel. Commun. Lett. 2022, 11, 1067–1071. [Google Scholar] [CrossRef]
- Ahmadi, S. Chapter 3—New Radio Access Physical Layer Aspects (Part 1). In 5G NR; Ahmadi, S., Ed.; Academic Press: Cambridge, MA, USA, 2019; pp. 285–409. [Google Scholar] [CrossRef]
- Bishop, J.; Chareau, J.M.; Bonavitacola, F. Implementing 5G NR Features in FPGA. In Proceedings of the 2018 European Conference on Networks and Communications (EuCNC), Ljubljana, Slovenia, 18–21 June 2018; pp. 373–379. [Google Scholar] [CrossRef]
- Braun, M.; Pendlum, J. A flexible data processing framework for heterogeneous processing environments: RF Network-on-Chip™. In Proceedings of the 2017 International Conference on FPGA Reconfiguration for General-Purpose Computing (FPGA4GPC), Hamburg, Germany, 9–10 May 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Reddy, K.M.; Darak, S.J.; Praveen, M.D. Novel Framework for Enabling Hardware Acceleration in GNU Radio. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Seville, Spain, 12–14 October 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Vook, F.W.; Ghosh, A.; Diarte, E.; Murphy, M. 5G New Radio: Overview and Performance. In Proceedings of the 2018 52nd Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 28–31 October 2018; pp. 1247–1251. [Google Scholar] [CrossRef]
- Lagen, S.; Wanuga, K.; Elkotby, H.; Goyal, S.; Patriciello, N.; Giupponi, L. New Radio Physical Layer Abstraction for System-Level Simulations of 5G Networks. In Proceedings of the ICC 2020–2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Ji, W.; Wu, Z.; Zheng, K.; Zhao, L.; Liu, Y. Design and Implementation of a 5G NR System Based on LDPC in Open Source SDR. In Proceedings of the 2018 IEEE Globecom Workshops (GC Wkshps), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Henarejos, P.; Ángel Vázquez, M. Decoding 5G-NR Communications VIA Deep Learning. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3782–3786. [Google Scholar] [CrossRef]
- Sybis, M.; Wesolowski, K.; Jayasinghe, K.; Venkatasubramanian, V.; Vukadinovic, V. Channel Coding for Ultra-Reliable Low-Latency Communication in 5G Systems. In Proceedings of the 2016 IEEE 84th Vehicular Technology Conference (VTC-Fall), Montreal, QC, Canada, 18–21 September 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Gamage, H.; Rajatheva, N.; Latva-aho, M. Channel coding for enhanced mobile broadband communication in 5G systems. In Proceedings of the 2017 European Conference on Networks and Communications (EuCNC), Oulu, Finland, 12–15 June 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Tewari, A.; Singh, N.; Darak, S.J.; Kizheppatt, V.; Jafri, M.S. Reconfigurable Wireless PHY with Dynamically Controlled Out-of-Band Emission on Zynq SoC. In Proceedings of the 65TH IEEE International Midwest Symposium on Circuits and Systems (MWSCAS 2022), Fukuoka, Japan, 7–10 August 2022; pp. 1–6. [Google Scholar]
- Zhang, L.; Ijaz, A.; Xiao, P.; Molu, M.M.; Tafazolli, R. Filtered OFDM Systems, Algorithms, and Performance Analysis for 5G and Beyond. IEEE Trans. Commun. 2018, 66, 1205–1218. [Google Scholar] [CrossRef]
- Hong, W.; Choi, J.; Park, D.; Kim, M.s.; You, C.; Jung, D.; Park, J. mmWave 5G NR Cellular Handset Prototype Featuring Optically Invisible Beamforming Antenna-on-Display. IEEE Commun. Mag. 2020, 58, 54–60. [Google Scholar] [CrossRef]
- Herranz, C.; Zhang, M.; Mezzavilla, M.; Martin-Sacristán, D.; Rangan, S.; Monserrat, J.F. A 3GPP NR Compliant Beam Management Framework to Simulate End-to-End MmWave Networks. In Proceedings of the 21st ACM International Conference on Modeling, Analysis and Simulation of Wireless and Mobile Systems, New York, NY, USA, 28 October–2 November 2018; pp. 119–125. [Google Scholar] [CrossRef]
- Mehrabi, M.; Mohammadkarimi, M.; Ardakani, M.; Jing, Y. Decision Directed Channel Estimation Based on Deep Neural Network k-Step Predictor for MIMO Communications in 5G. IEEE J. Sel. Areas Commun. 2019, 37, 2443–2456. [Google Scholar] [CrossRef]
- He, H.; Wen, C.K.; Jin, S.; Li, G.Y. Deep Learning-Based Channel Estimation for Beamspace mmWave Massive MIMO Systems. IEEE Wirel. Commun. Lett. 2018, 7, 852–855. [Google Scholar] [CrossRef]
- Chun, C.J.; Kang, J.M.; Kim, I.M. Deep Learning-Based Channel Estimation for Massive MIMO Systems. IEEE Wirel. Commun. Lett. 2019, 8, 1228–1231. [Google Scholar] [CrossRef]
- Larsen, L.M.P.; Checko, A.; Christiansen, H.L. A Survey of the Functional Splits Proposed for 5G Mobile Crosshaul Networks. IEEE Commun. Surv. Tutor. 2019, 21, 146–172. [Google Scholar] [CrossRef]
- Koutsopoulos, I. The Impact of Baseband Functional Splits on Resource Allocation in 5G Radio Access Networks. In Proceedings of the IEEE INFOCOM 2021—IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021; pp. 1–10. [Google Scholar] [CrossRef]
- Rony, R.I.; Lopez-Aguilera, E.; Garcia-Villegas, E. Optimization of 5G Fronthaul Based on Functional Splitting at PHY Layer. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Drozdenko, B.; Zimmermann, M.; Dao, T.; Leeser, M.; Chowdhury, K. High-level hardware-software co-design of an 802.11a transceiver system using Zynq SoC. In Proceedings of the 2016 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), San Francisco, CA, USA, 10–14 April 2016; pp. 682–683. [Google Scholar]
- Drozdenko, B.; Zimmermann, M.; Dao, T.; Chowdhury, K.; Leeser, M. Hardware-Software Codesign of Wireless Transceivers on Zynq Heterogeneous Systems. IEEE Trans. Emerg. Top. Comput. 2018, 6, 566–578. [Google Scholar] [CrossRef]
- Garg, S.; Agrawal, N.; Darak, S.J.; Sikka, P. Spectral coexistence of candidate waveforms and DME in air-to-ground communications: Analysis via hardware software co-design on Zynq SoC. In Proceedings of the 2017 IEEE/AIAA 36th Digital Avionics Systems Conference (DASC), St. Petersburg, FL, USA, 17–21 September 2017; pp. 1–6. [Google Scholar]
- Pham, T.H.; Fahmy, S.A.; McLoughlin, I.V. An End-to-End Multi-Standard OFDM Transceiver Architecture Using FPGA Partial Reconfiguration. IEEE Access 2017, 5, 21002–21015. [Google Scholar] [CrossRef]
- Drozdova, V.G.; Kalachikov, A.A. SDR Based Evaluation of the Initial Cell Search In 5G NR OpenAirInterface Implementation. In Proceedings of the 2021 XV International Scientific-Technical Conference on Actual Problems of Electronic Instrument Engineering (APEIE), Novosibirsk, Russia, 19–21 November 2021; pp. 248–251. [Google Scholar] [CrossRef]
- Yoneda, S.; Sawahashi, M.; Nagata, S. Comparisons of Physical Cell ID Detection Methods with Carrier Frequency Offset Compensation for Millimeter-Wave Bands. In Proceedings of the 2022 IEEE 96th Vehicular Technology Conference (VTC2022-Fall), London, UK, 26–29 September 2022; pp. 1–6. [Google Scholar] [CrossRef]
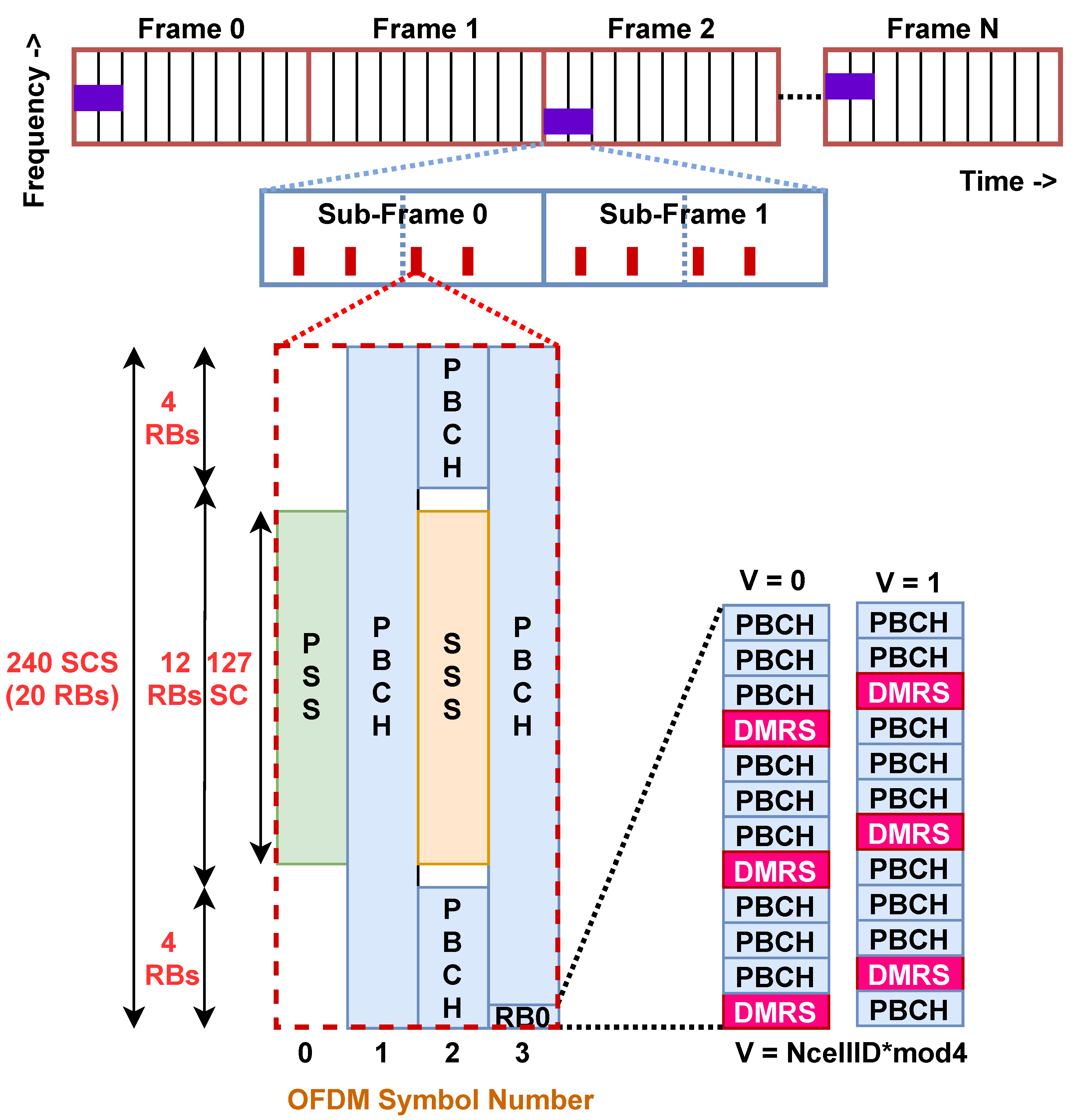
Figure 2.
Block diagram of CS transmitter PHY.
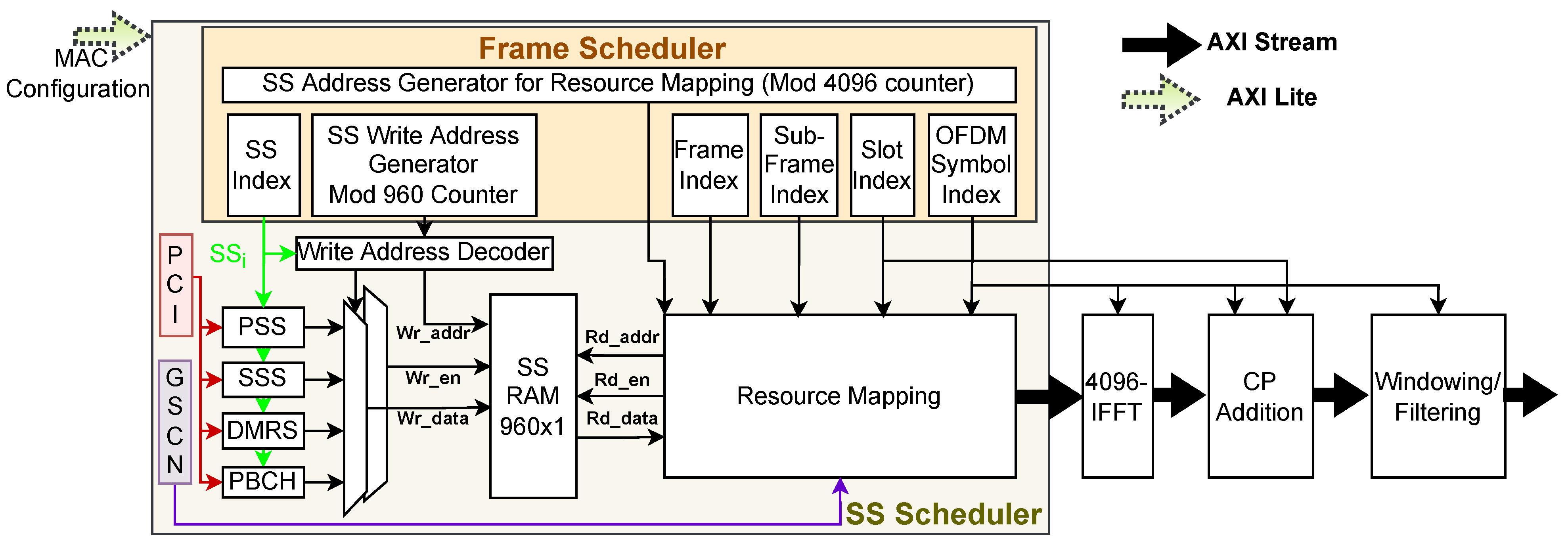
Figure 3.
Architecture for generating the 3GPP PSS.
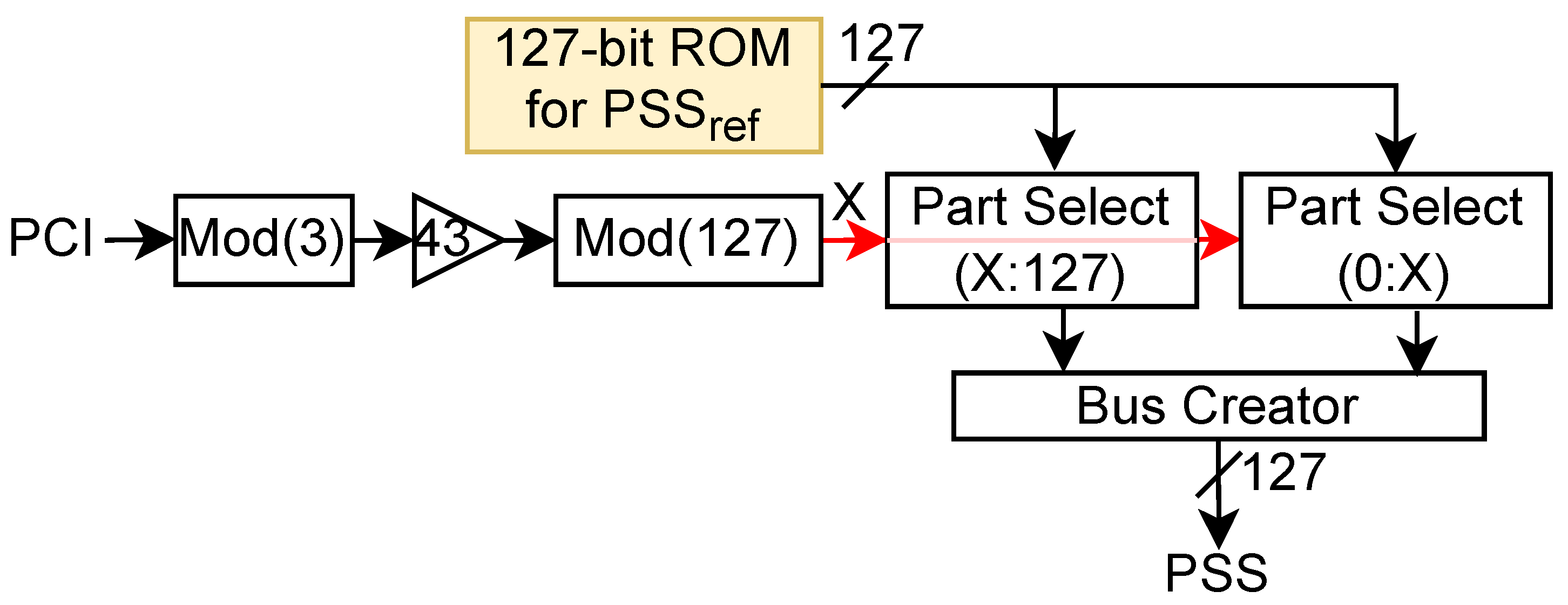
Figure 4.
Architecture for generating the 3GPP SSS.
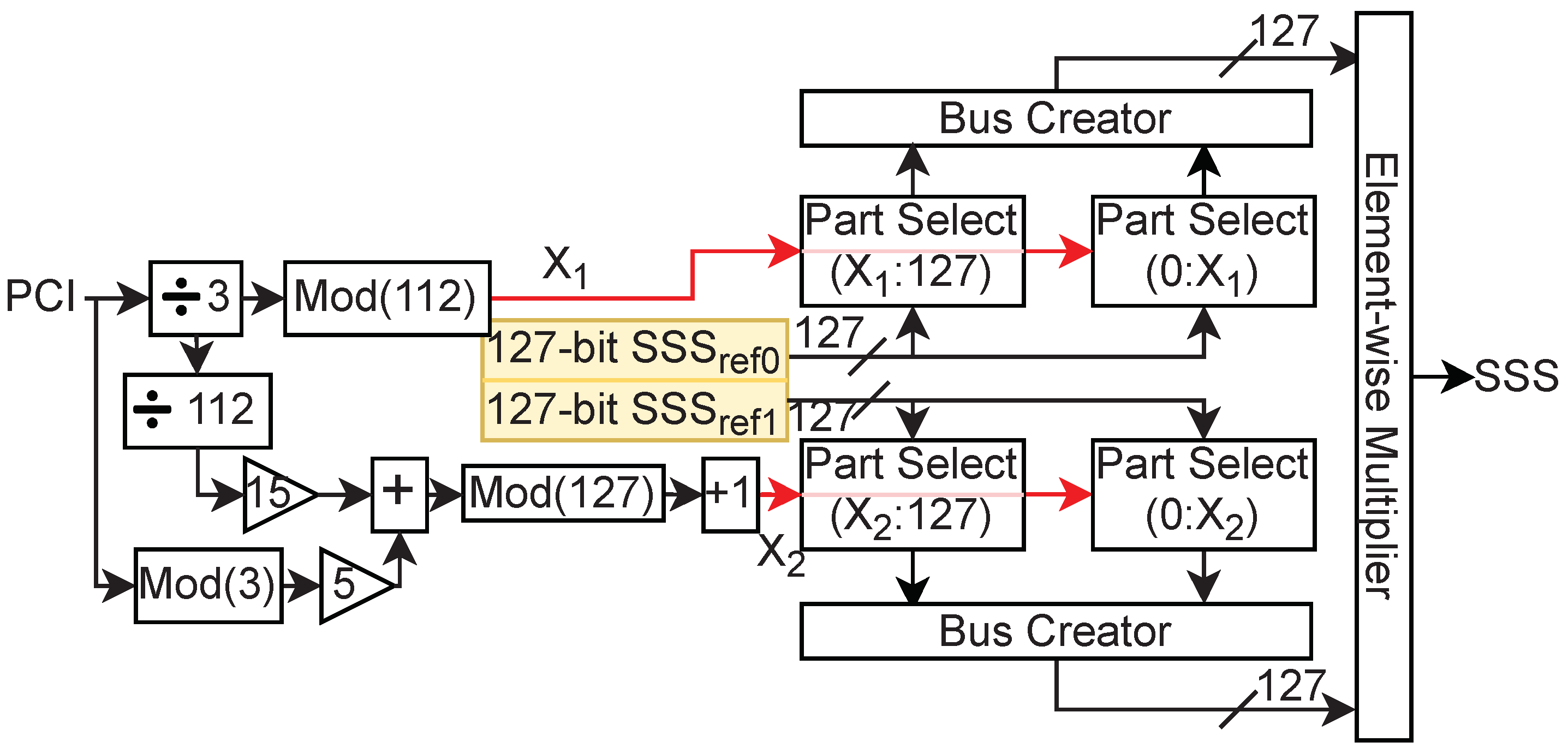
Figure 5.
Architecture for generating the 3GPP PBCH-DMRS.
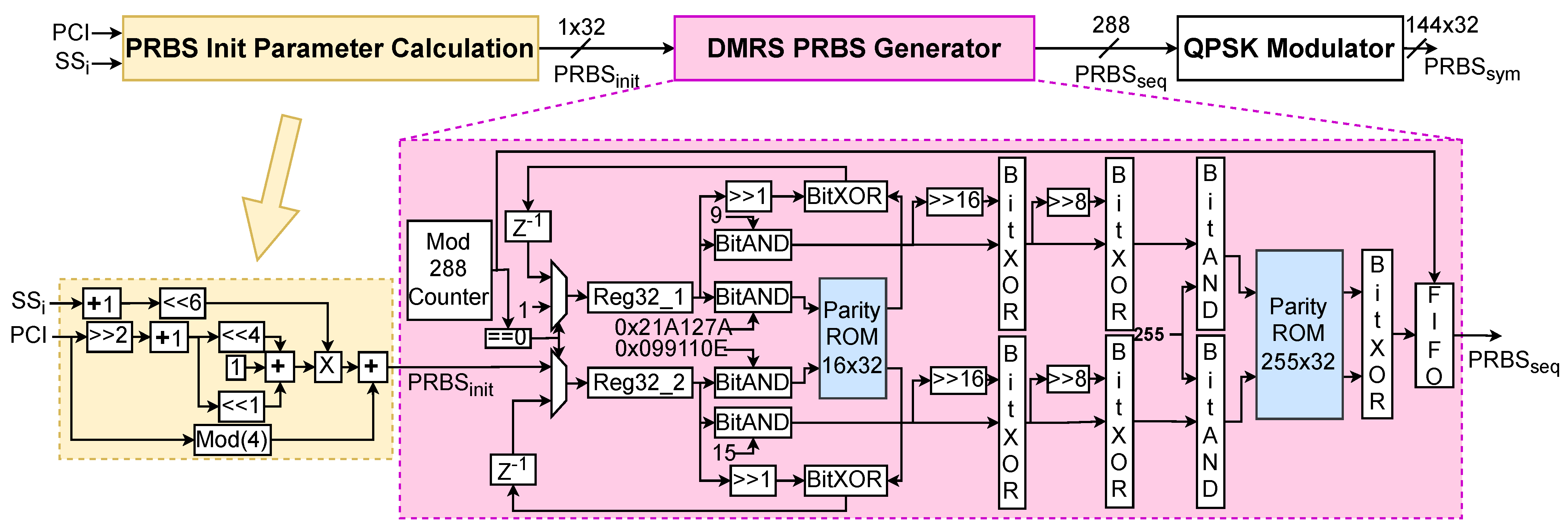
Figure 6.
Block diagram of the CS receiver PHY.
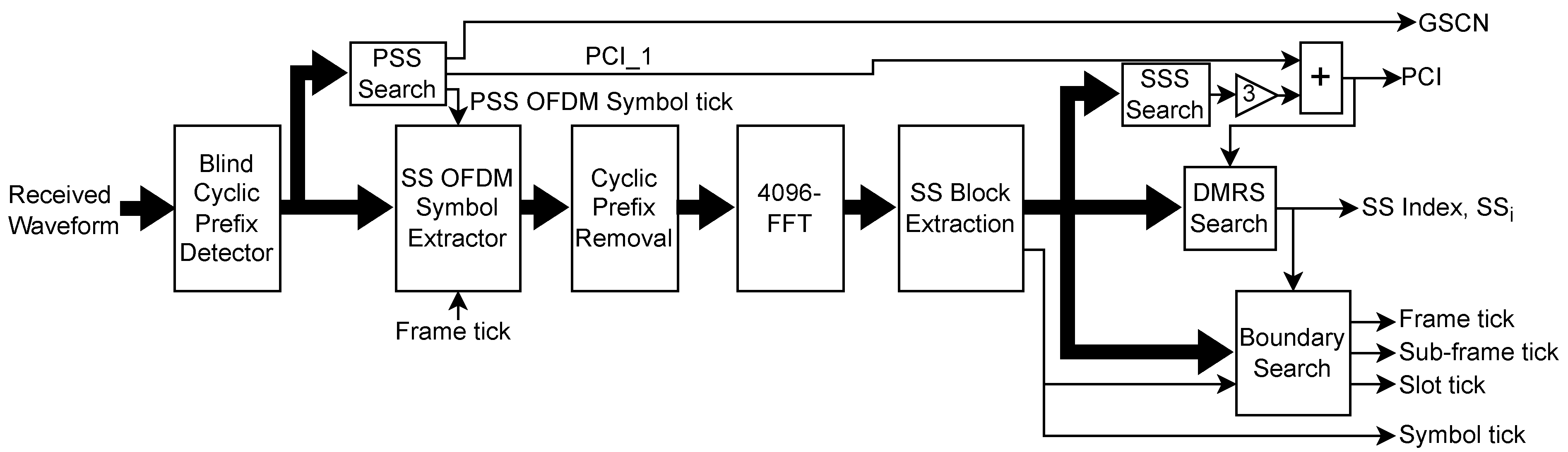
Figure 7.
PSS Search Architecture.
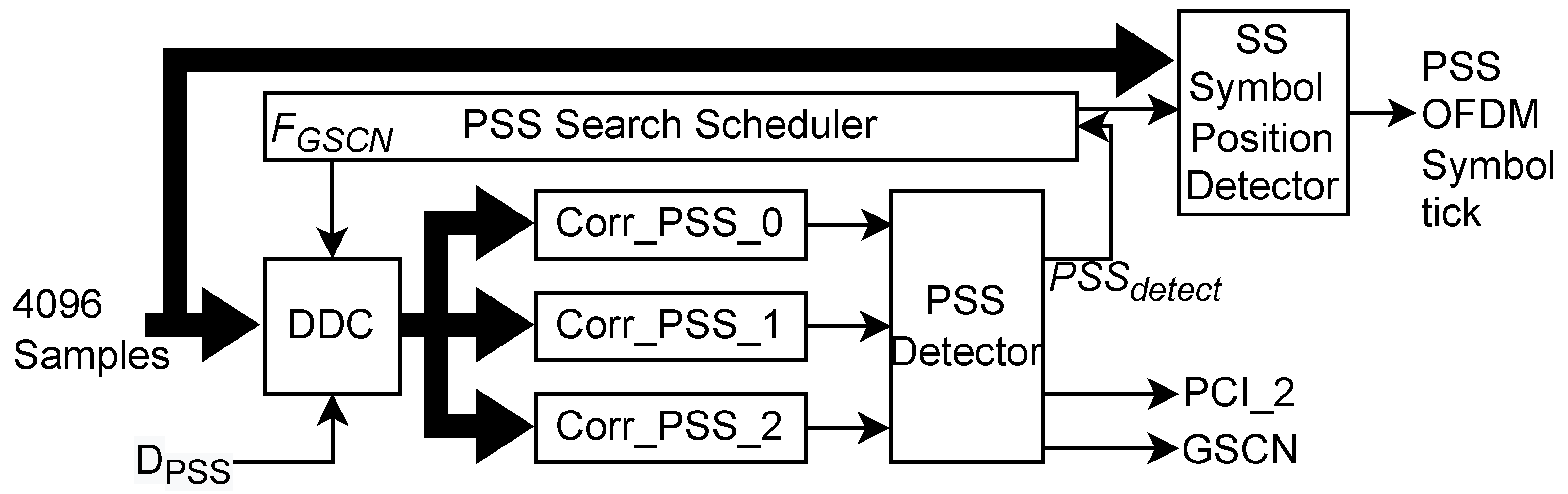
Figure 8.
SSS Search Architecture.
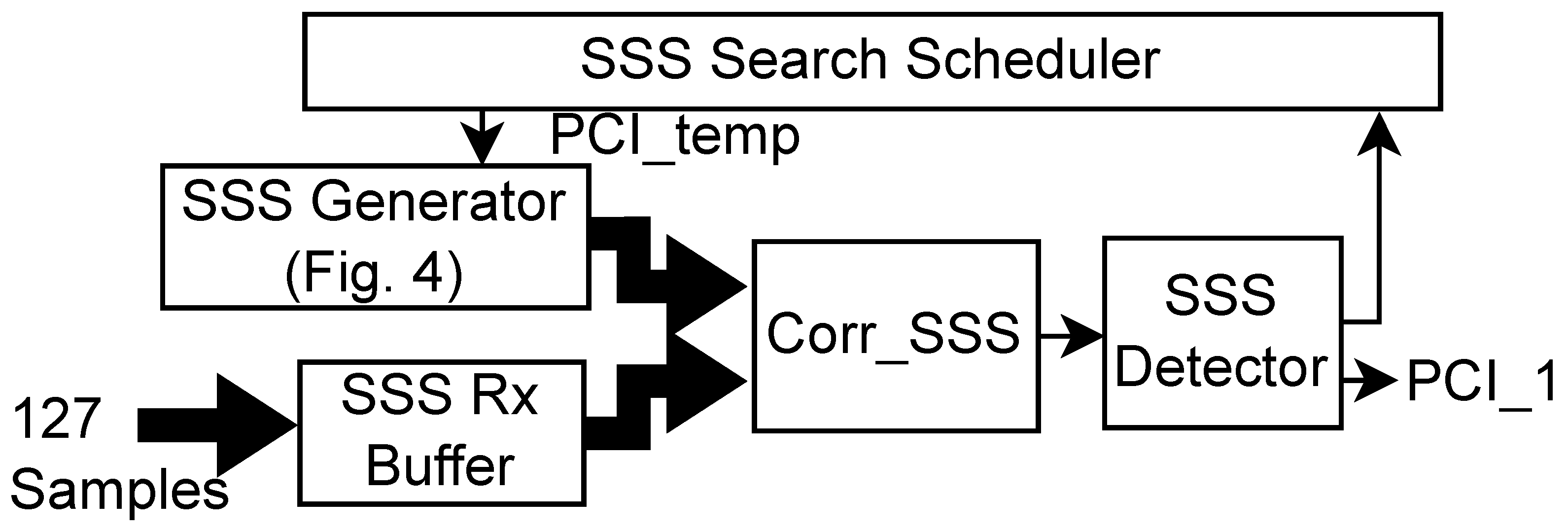
Figure 9.
DMRS Search Architecture.
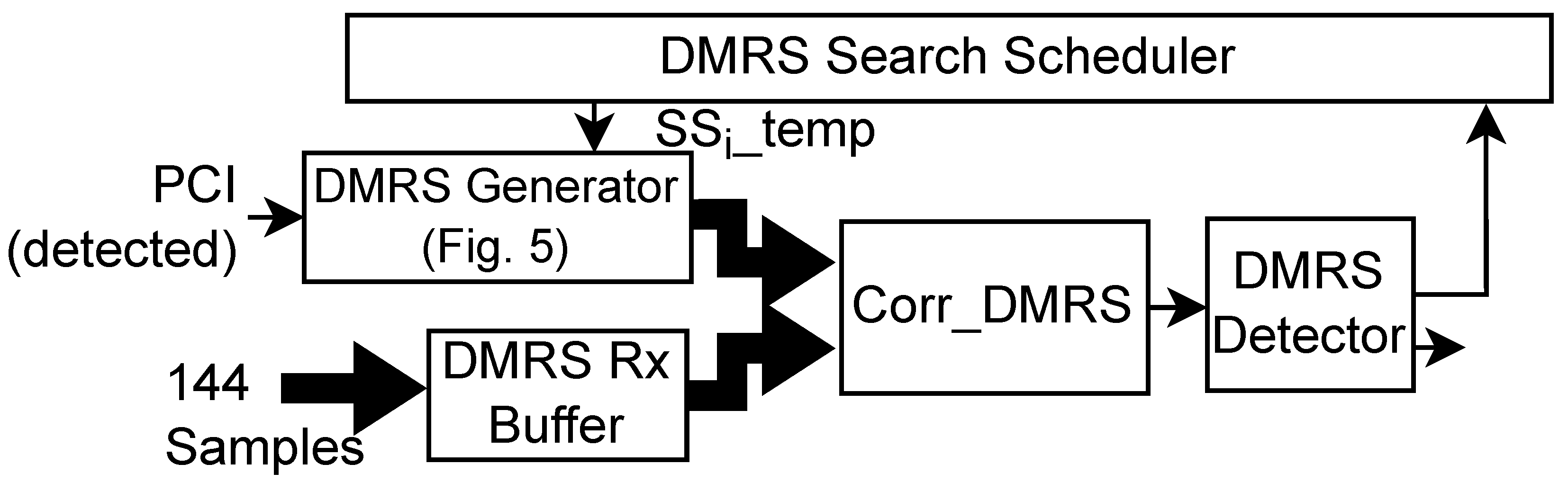
Figure 10.
Boundary Search Architecture.
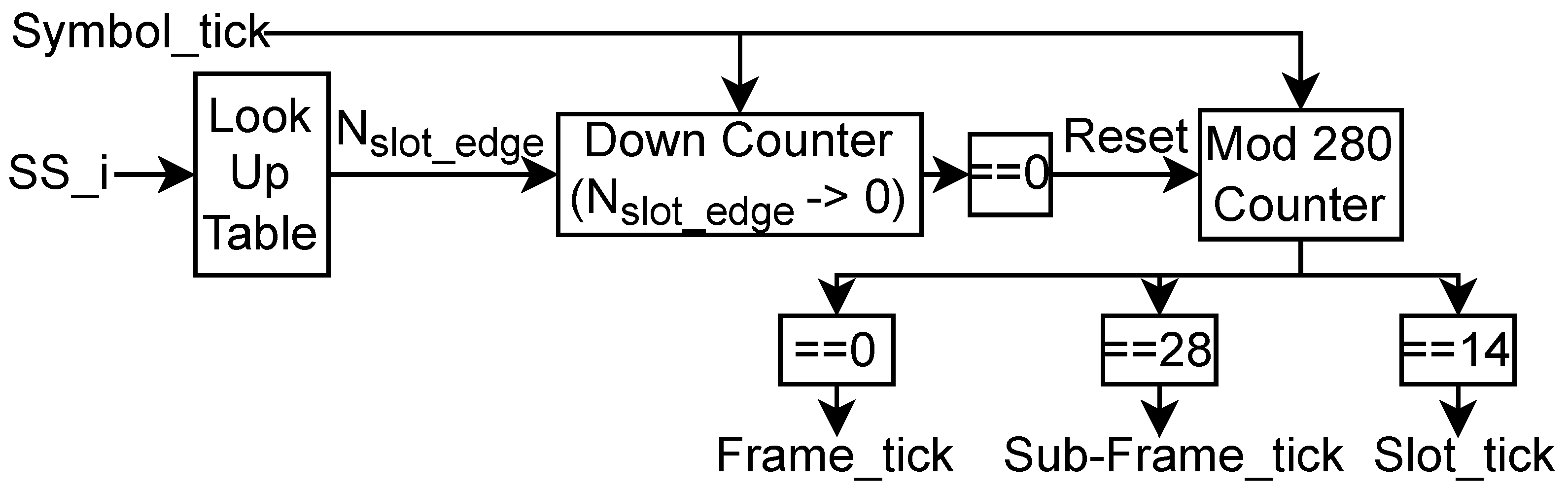
Figure 11.
Effect of SNR and on the probability of detection, , for PSS search architecture.
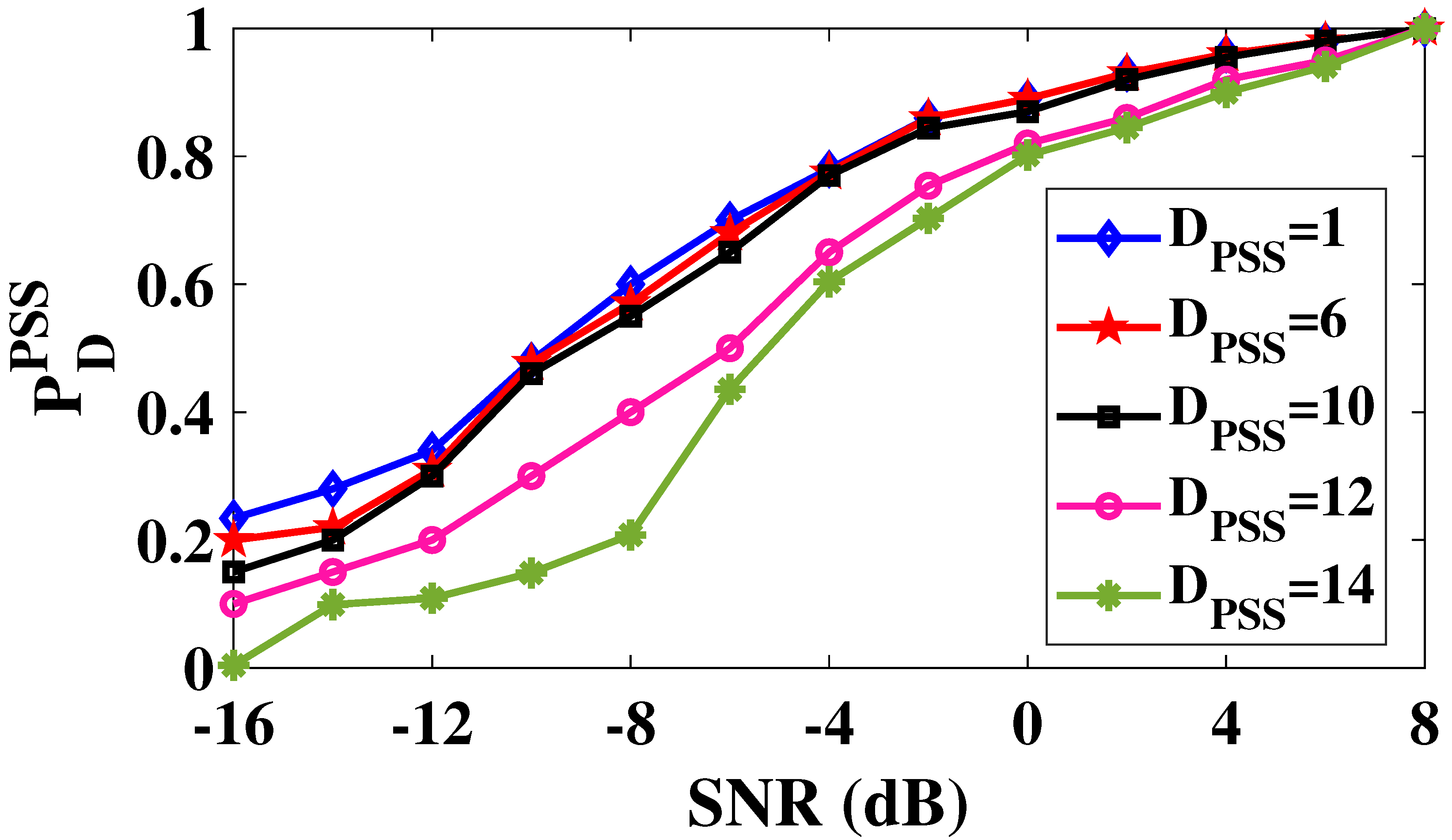
Figure 12.
Effect of WL on the probability of detection, , for PSS search architecture.
Figure 13.
Effect of WL on the probability of detection, , for SSS search architecture.
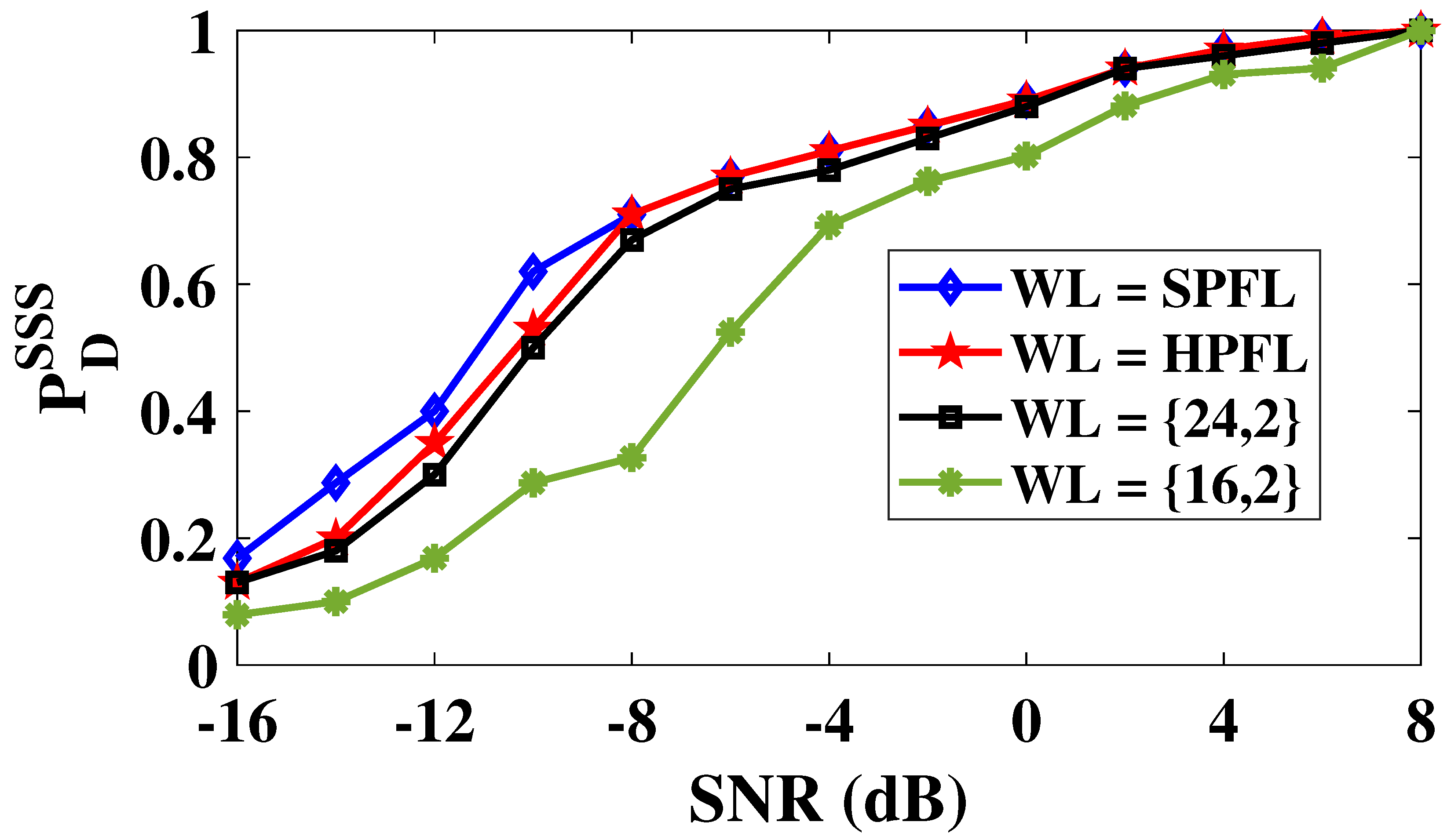
Figure 14.
Effect of WL on the probability of detection, , for DMRS search architecture.
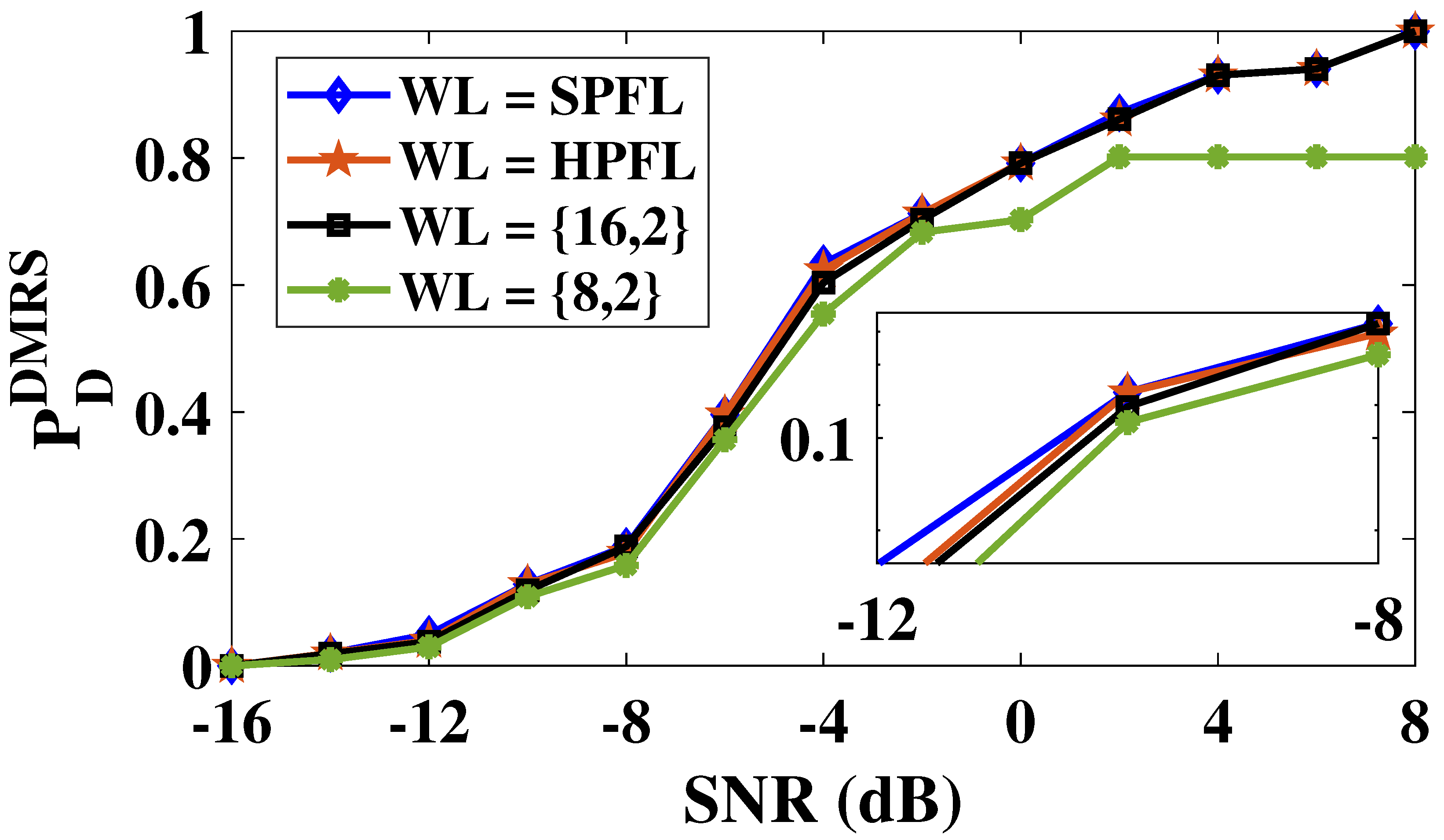
Figure 15.
Realization of the CS transmitter and receiver PHY using GNU Radio based RFNoC framework on X310 USRP platform.
Figure 15.
Realization of the CS transmitter and receiver PHY using GNU Radio based RFNoC framework on X310 USRP platform.
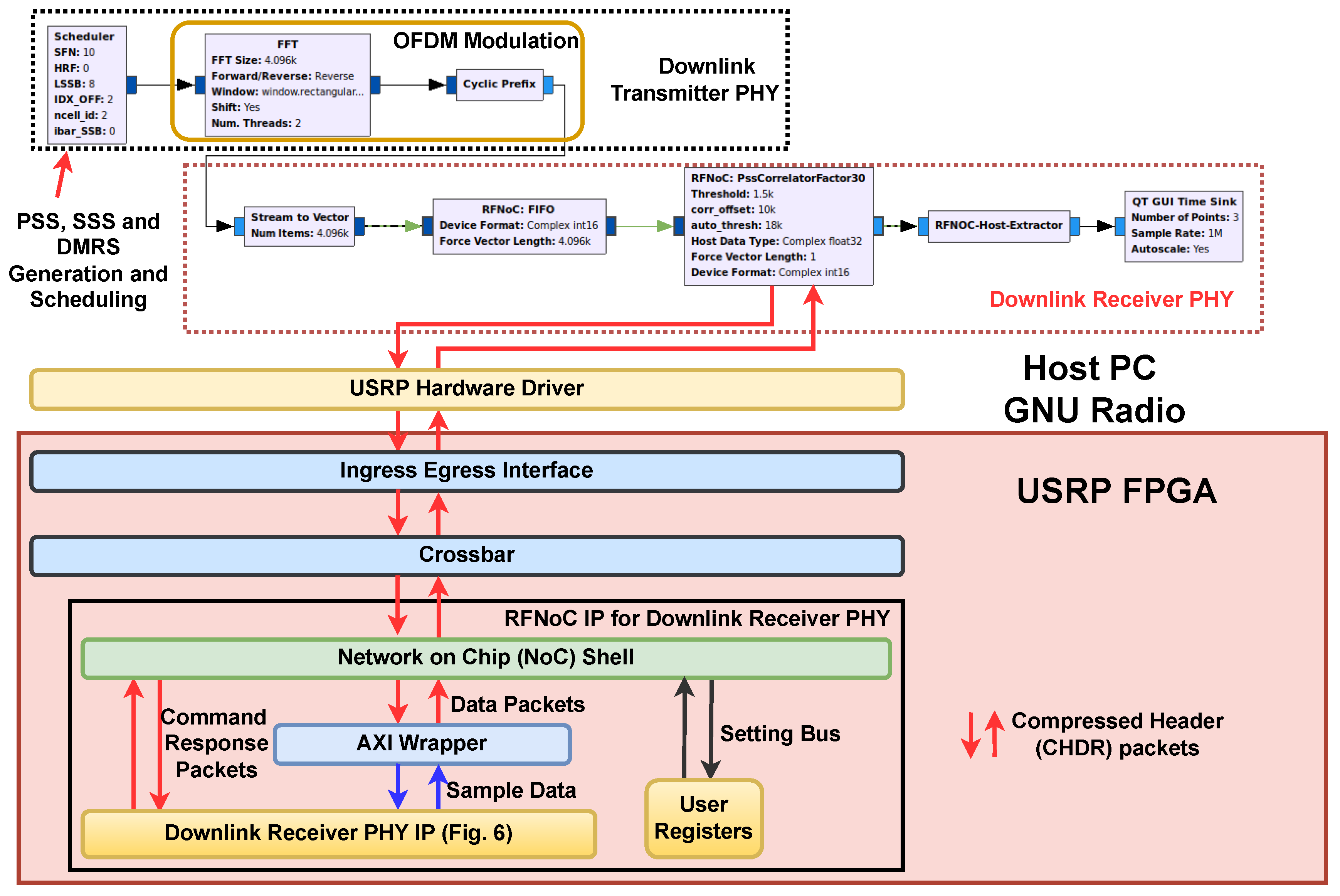
Figure 16.
Execution time comparison for PSS detection on GNU Radio and RFNoC for different downsampling factors. Here we consider single SS burst comprising of 8 SS signals over two frames.
Figure 16.
Execution time comparison for PSS detection on GNU Radio and RFNoC for different downsampling factors. Here we consider single SS burst comprising of 8 SS signals over two frames.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Execution Time and Resource Utilization Comparison for PSS Search.
| Parameters | Word Length | |||
|---|---|---|---|---|
| 1 | 6 | 10 | ||
| Execution Time (ms) | SPFL (32 bits) | 29.3 | 19.2 | 19.1 |
| Fixed Point {32,2} | 13.3 | 6.9 | 6.85 | |
| Fixed Point {24,2} | 13.3 | 6.8 | 6.84 | |
| On Chip Memory (18 KB BRAMs) | SPFL (32 bits) | 156 | 108 | 100 |
| Fixed Point {32,2} | 144 | 106 | 96 | |
| Fixed Point {24,2} | 108 | 82 | 80 | |
| Embedded Multipliers (DSP48s) | SPFL (32 bits) | 137 | 137 | 137 |
| Fixed Point {32,2} | 107 | 107 | 107 | |
| Fixed Point {24,2} | 104 | 104 | 104 | |
| 6-input Look-Up-Table (LUT) | SPFL (32 bits) | 42.7 K | 42.6 K | 42.6 K |
| Fixed Point {32,2} | 41.5 K | 41.3 K | 41.3 K | |
| Fixed Point {24,2} | 31.1 K | 30.9 K | 30.9 K | |
Table 2.
Execution Time and Resource Utilization Comparison for SSS Search.
| Parameters | SPFL | HPFL | Fixed Point {24,2} | Fixed Point {16,2} |
|---|---|---|---|---|
| Execution Time (μs) | 33.4 | 18.8 | 16.6 | 16.6 |
| On Chip Memory (18 KiloBytes BRAMs) | 58 | 49 | 44 | 31 |
| Embedded Multipliers (DSP48s) | 651 | 573 | 573 | 558 |
| 6-input Look-Up-Table (LUT) | 84,052 | 33,696 | 32,574 | 28,878 |
Table 3.
Execution Time and Resource Utilization Comparison for DMRS Search.
| Parameters | SPFL | HPFL | Fixed Point {16,2} | Fixed Point {8,2} |
|---|---|---|---|---|
| Execution Time (μs) | 6.7 | 6.1 | 2.1 | 1.9 |
| On Chip Memory (18 KiloBytes BRAMs) | 83 | 60 | 60 | 42 |
| Embedded Multipliers (DSP48s) | 85 | 71 | 70 | 66 |
| 6-input Look-Up-Table (LUT) | 50,311 | 39,956 | 38,933 | 28,069 |
Table 4.
Execution time of the PSS search IP in milliseconds (ms).
| Platform | ||||
|---|---|---|---|---|
| 1 | 6 | 10 | 14 | |
| GNU Radio | 27.6 | 17.9 | 15.3 | 13.6 |
| RFNoC | 9.54 | 8 | 7.2 | 6.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Lodhi, K.; Chhillar, J.; Darak, S.J.; Sharma, D. Design and Performance Analysis of Hardware Realization of 3GPP Physical Layer for 5G Cell Search. Chips 2023, 2, 223-242. https://doi.org/10.3390/chips2040014
AMA Style
Lodhi K, Chhillar J, Darak SJ, Sharma D. Design and Performance Analysis of Hardware Realization of 3GPP Physical Layer for 5G Cell Search. Chips. 2023; 2(4):223-242. https://doi.org/10.3390/chips2040014
Chicago/Turabian StyleLodhi, Khalid, Jayant Chhillar, Sumit J. Darak, and Divisha Sharma. 2023. "Design and Performance Analysis of Hardware Realization of 3GPP Physical Layer for 5G Cell Search" Chips 2, no. 4: 223-242. https://doi.org/10.3390/chips2040014