1. Introduction
It is a common task in numerous disciplines (e.g., physics, chemistry, biology, economics, robotics, and engineering, social, and medical sciences) to construct a mathematical model with some parameters for an observed system which gives an observable response to an observable external effect. The unknown parameters of the mathematical model are determined so that the difference between the observed and the simulated system responses of the mathematical model for the same external effect is minimized (see e.g., [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11]). This problem leads to finding the zero of a residual function (difference between observed and simulated responses). The rapidly accelerating computational tools and the increasing complexity of mathematical models with more and more efficient numerical algorithms provide a chance for better understanding and control of the surrounding nature.
As referenced above, root-finding methods are essential for solving a great class of numerical problems, such as data fitting problems with
sampled data
(
) and
adjustable parameters
(
) with
. This leads to the problem of least-squares solving of an over-determined system of nonlinear equations,
(
and
(
)), where the solution
minimizes the difference
between the data
and a computational model function
. The system of simultaneous multi-variable nonlinear Equation (
1) can be solved by Newton’s method when the derivatives of
are available analytically and a new iterate,
that follows
can be determined, where
is the function value and
is the Jacobian matrix of
at
in the
iteration step. Newton’s method is one of the most widely used algorithm, with very attractive theoretical and practical properties and with some limitations. The computational costs of Newton’s method is high, since the Jacobian
and the solution to the linear system (
3) must be computed at each iteration. In many cases, explicit formulae for the function
are not available (
can be a residual function between a system model response and an observation of that system response) and the Jacobian
can only be approximated. The classic Newton’s method can be modified in many different ways. The partial derivatives of the Jacobian may be replaced by suitable difference quotients (discretized Newton iteration, see [
12,
13]),
,
with
additional function value evaluations, where
is the
Cartesian unit vector. However, it is difficult to choose the stepsize
. If any
is too large, then Expression (
4) can be a bad approximation to the Jacobian, so the iteration converges much more slowly if it converges at all. On the other hand, if any
is too small, then
, and cancellations can occur which reduce the accuracy of the difference quotients (
4) (see [
14]). The suggested procedure (“T-Secant”) may resemble the discretized Newton iteration, but it uses a systematic procedure to determine suitable stepsizes for the Jacobian approximates. Another modification is the inexact Newton approach, where the nonlinear equation is solved by an iterative linear solver (see [
15,
16,
17]).
It is well-known that the local convergence of Newton’s method is q-quadratic if the initial trial approximate
is close enough to the solution
,
is non-singular, and
satisfies the Lipschitz condition
for all
close enough to
. However, in many cases, the function
is not an analytical function, the partial derivatives are not known, and Newton’s method cannot be applied. Quasi-Newton methods are defined as the generalization of Equation (
3) as
and
where
is the iteration step length and
is expected to be the approximate to the Jacobian matrix
without computing derivatives in most cases. The new iterate is then given as
and
is updated to
according to the specific quasi-Newton method. Martinez [
18] has made a thorough survey on practical quasi-Newton methods. The iterative methods of the form (
6) that satisfy the equation
for all
are called “quasi-Newton” methods, and Equation (
10) is called the fundamental equation of quasi-Newton methods (“quasi-Newton condition” or “secant equation”). However, the quasi-Newton condition does not uniquely specify the updated Jacobian approximate
, and further constraints are needed. Different methods offer their own specific solution. One new quasi-Newton approximate
will never allow for a full-rank update of
because it is an
matrix and only
components can be determined from the Secant equation, making it an under-determined system of equations for the elements
if
.
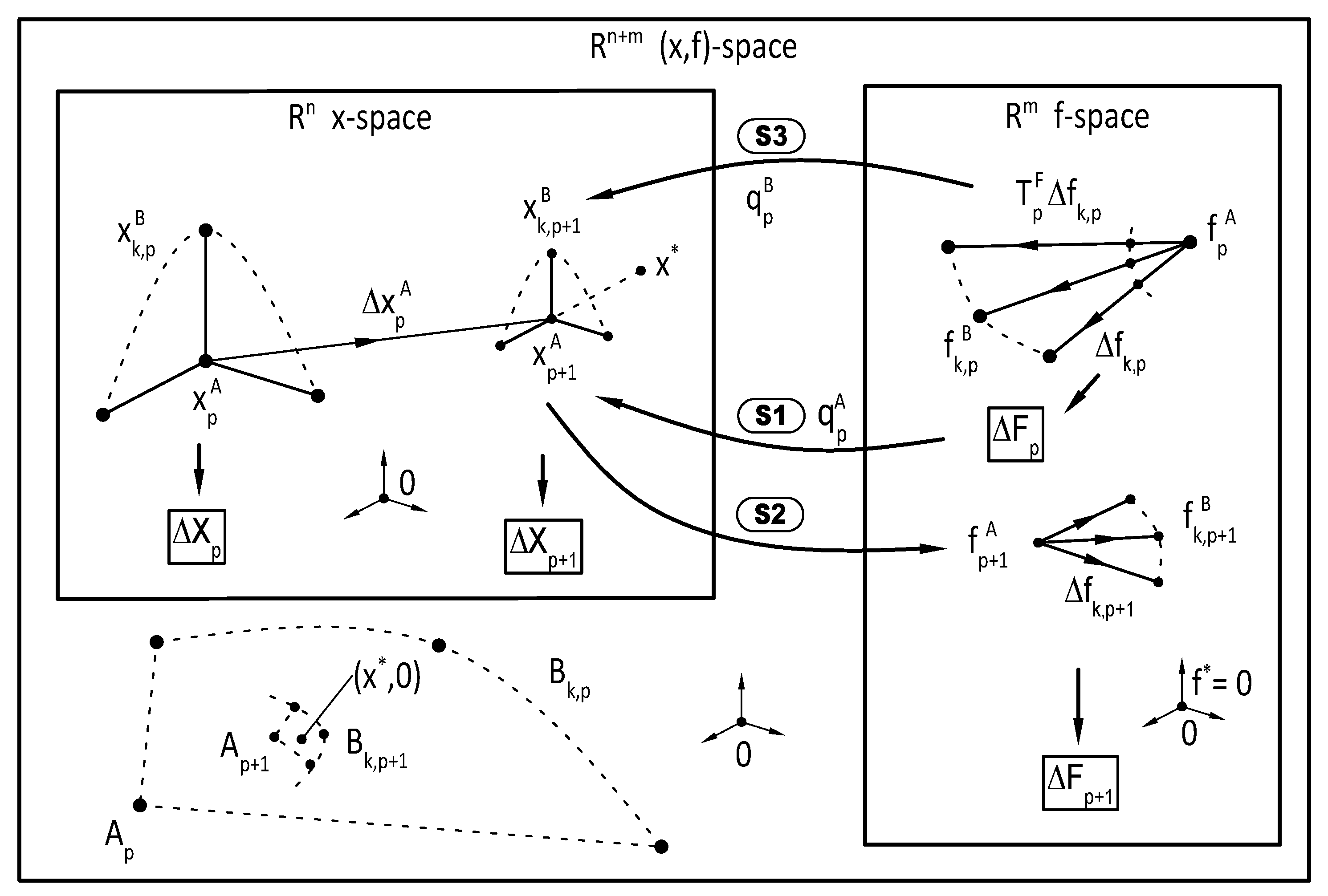
The suggested new strategy is based on Wolfe’s [
19] formulation of a generalized Secant method. The function
is locally replaced by linear interpolation through
interpolation base points
,
. The variables
and the function values
are separated into two equations and an auxiliary variable
is introduced. Then the Jacobian approximate matrix
is split into a variable difference
and a function value difference
matrix, and the zero
of the
interpolation plane is determined from the quasi-Newton condition (
7) as
where
The auxiliary variable
is determined from the second row of Equation (
12), and the new quasi-Newton approximate
comes from the first row of this equation. Popper [
20] made further generalization for functions
and suggested the use of a pseudo-inverse solution for the over-determined system of linear equations (where
is the number of unknowns and
is the number of function values). The auxiliary variable
is determined from the second row of Equation (
12) as
where
stands for the pseudo-inverse, and the new quasi-Newton approximate
comes from the first row of this equation as
The new iteration continues with
new base points
,
. Details are given in
Section 3.
Ortega and Rheinboldt [
12] stated that a necessary condition of convergence is that the interpolation base points should be linearly independent and they have to be “in general position” through the whole iteration process. Experiences show that the low-rank update procedures often lead to a dead end because this condition is not satisfied. The purpose of the suggested new iteration strategy is to determine linearly independent base points providing that the Ortega and Rheinboldt condition is satisfied. The basic idea of the procedure is that another new approximate
is determined from the previous approximate
and a new system of
linearly independent base points is generated. The basic equations of the Wolfe–Popper formulation (Equation (
12)) were modified as
where
and
The auxiliary variable
is determined from the second row of Equation (
17) as
and the new quasi-Newton approximate
comes from the first row of Equation (
17) as
. The details of the proposed new strategy (“T-Secant method”) are given in
Section 4. It is different from the traditional Secant method in that all interpolation base points
and
are updated in each iteration (full-rank update), providing
new base points
and
for the next iteration. The key idea of the method is very simple. The function value
(that can be determined from the new Secant approximate
) measures the “distance” of the approximate
from the root
(if
, then the distance is zero and
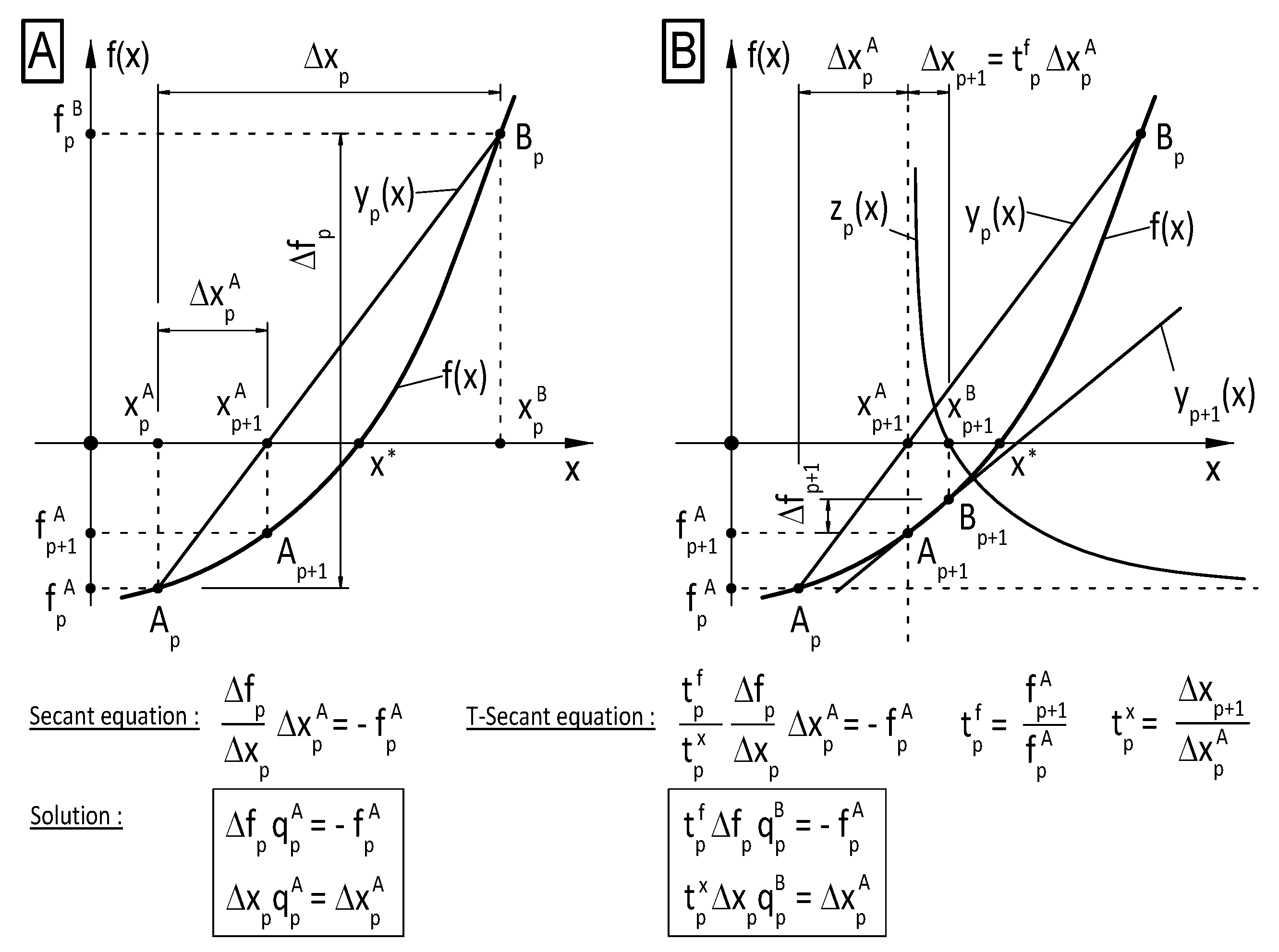
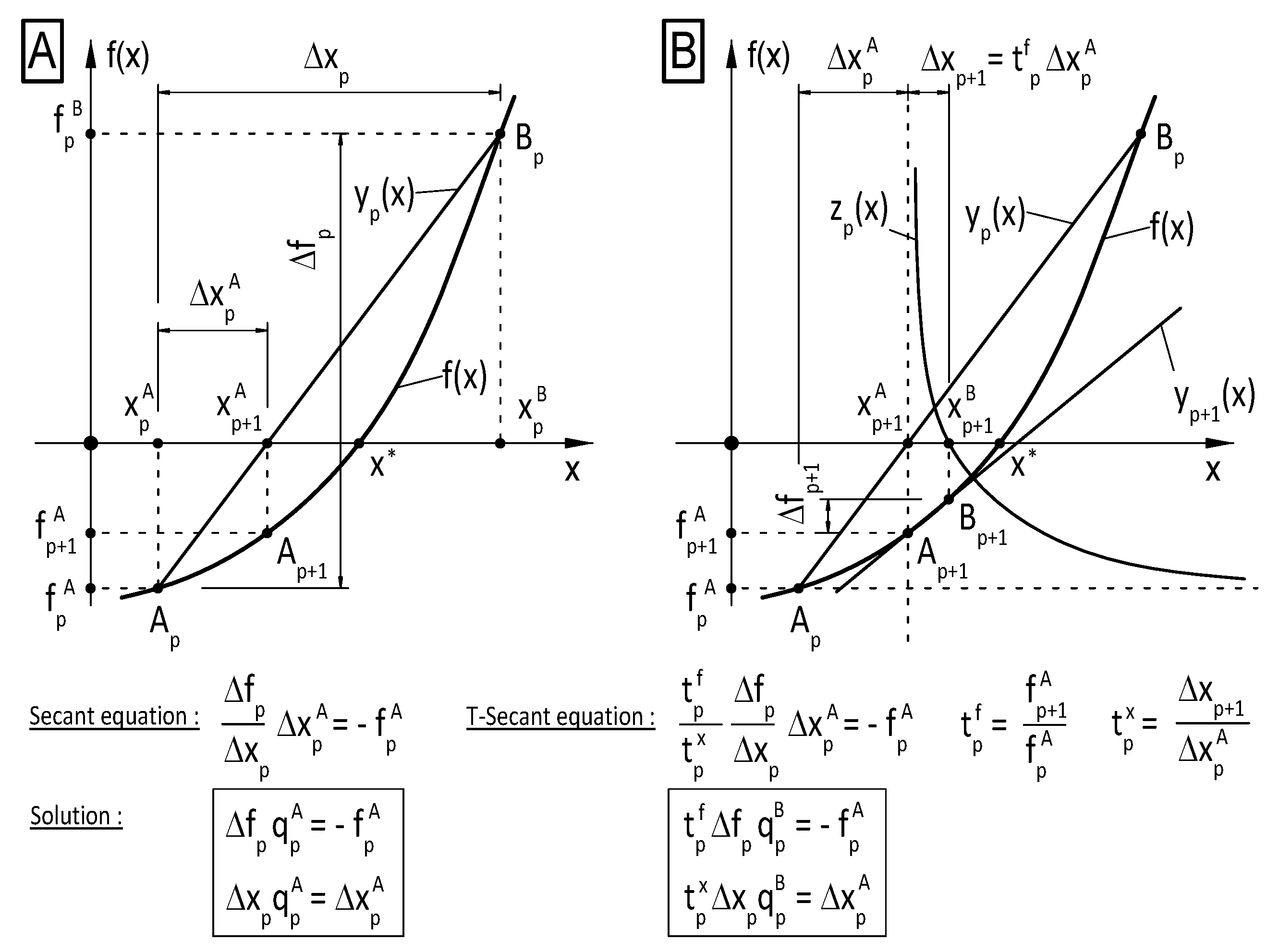
). The T-Secant method uses this information so that the basic equations of the Secant method are modified by a scaling transformation
, and an additional new estimate
is determined. Then, the new approximates
and
are used to construct the
new interpolation base points
and
.
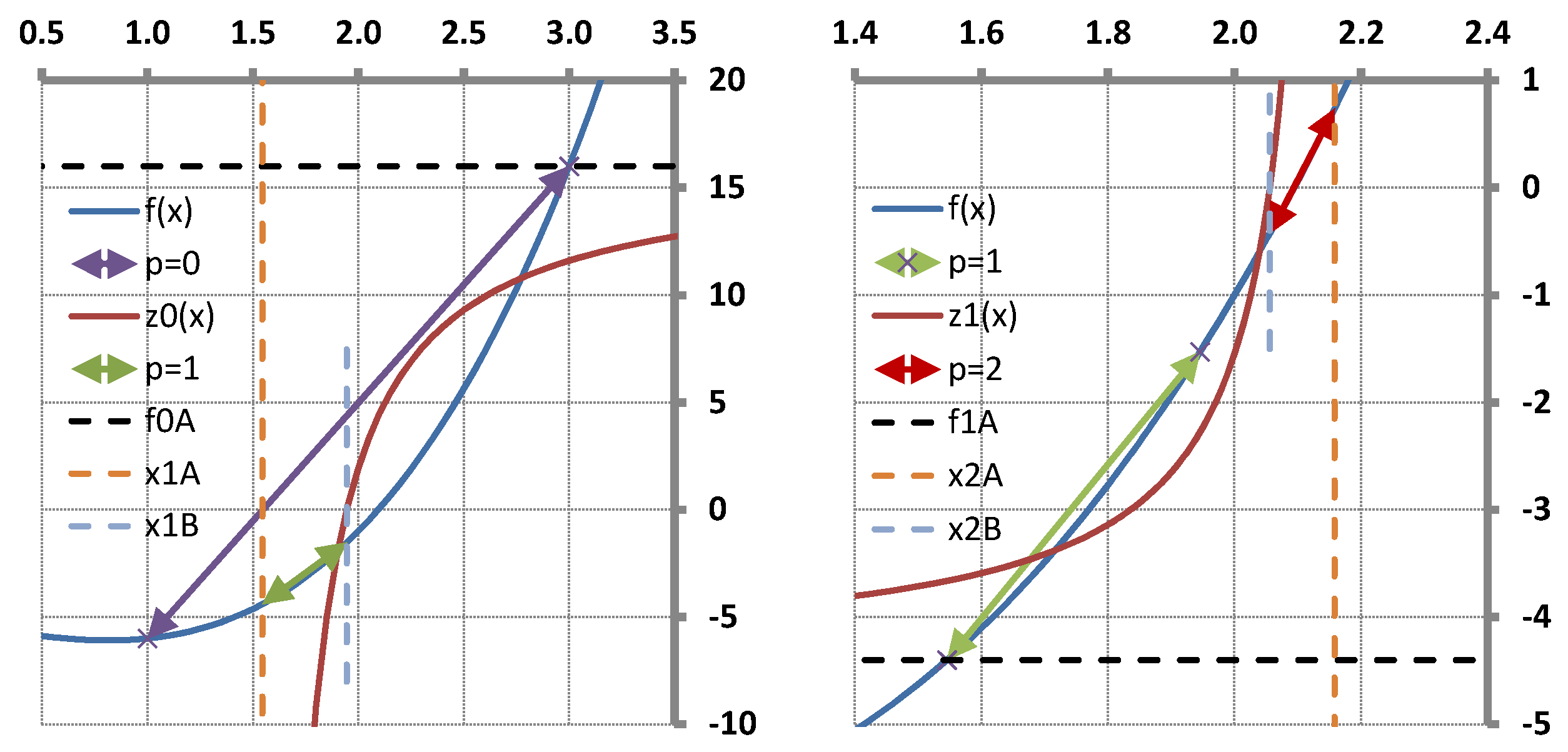
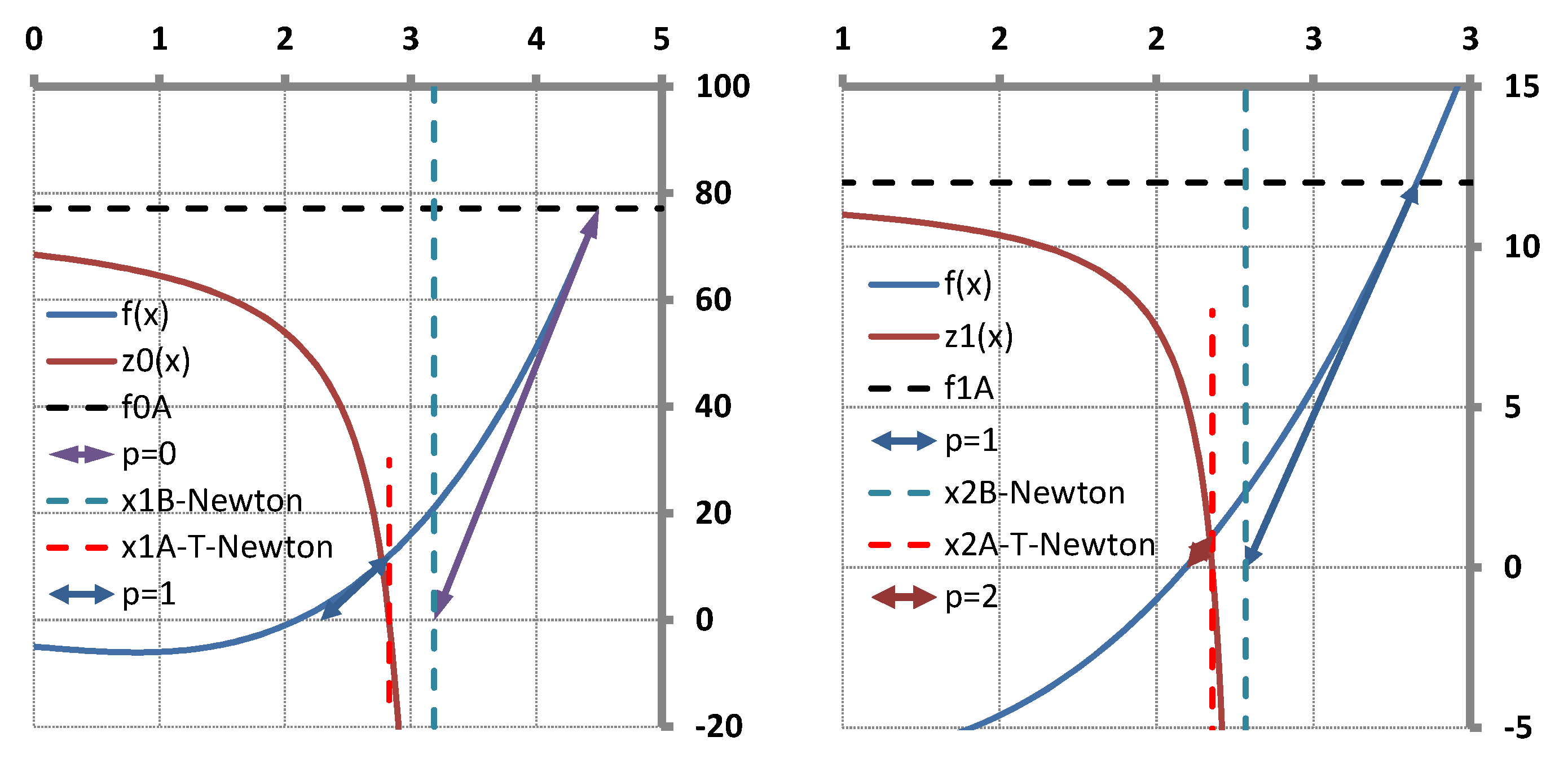
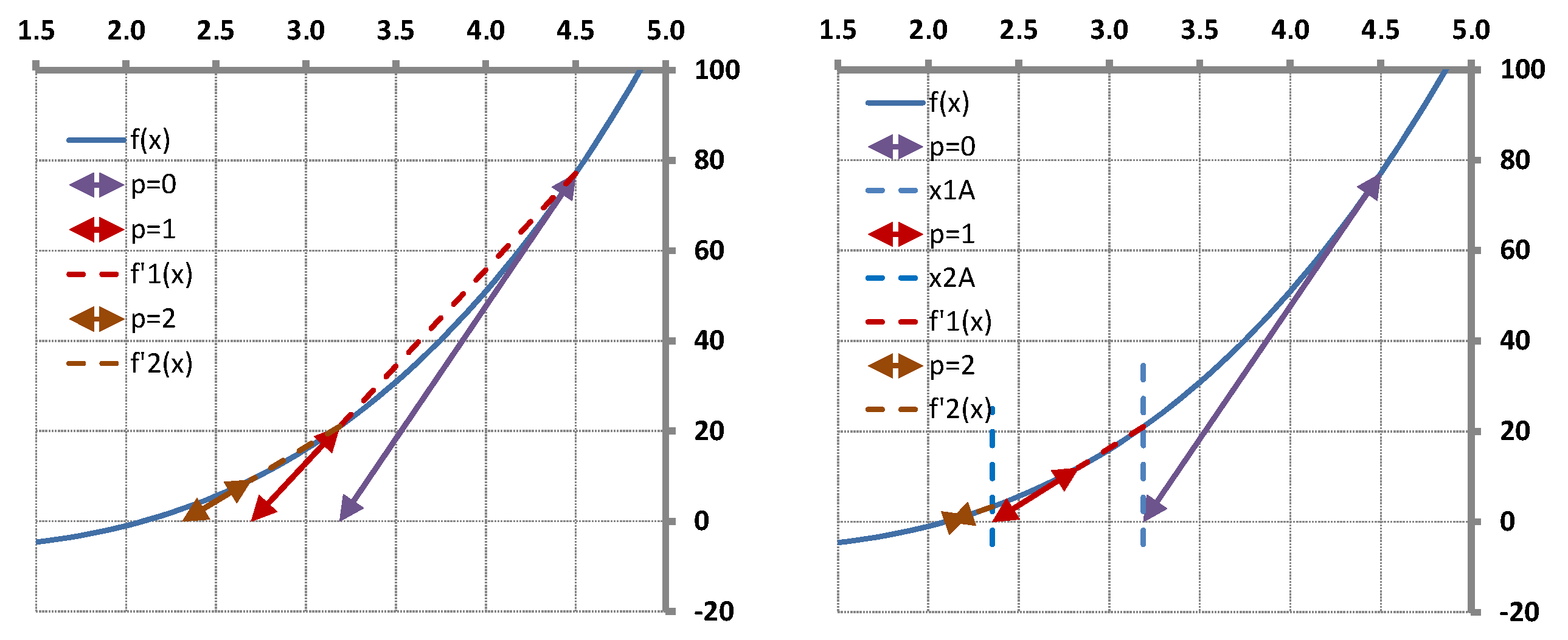
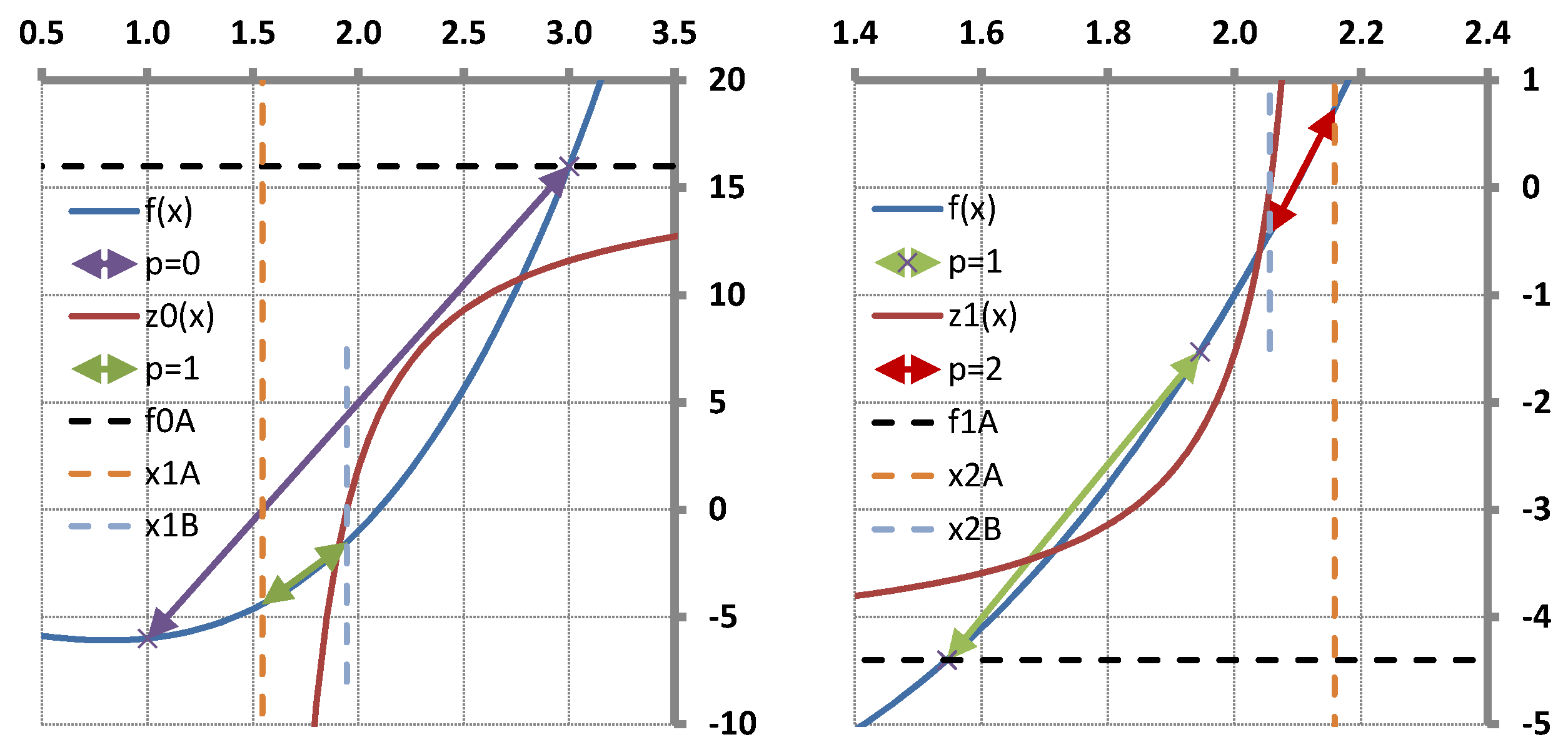
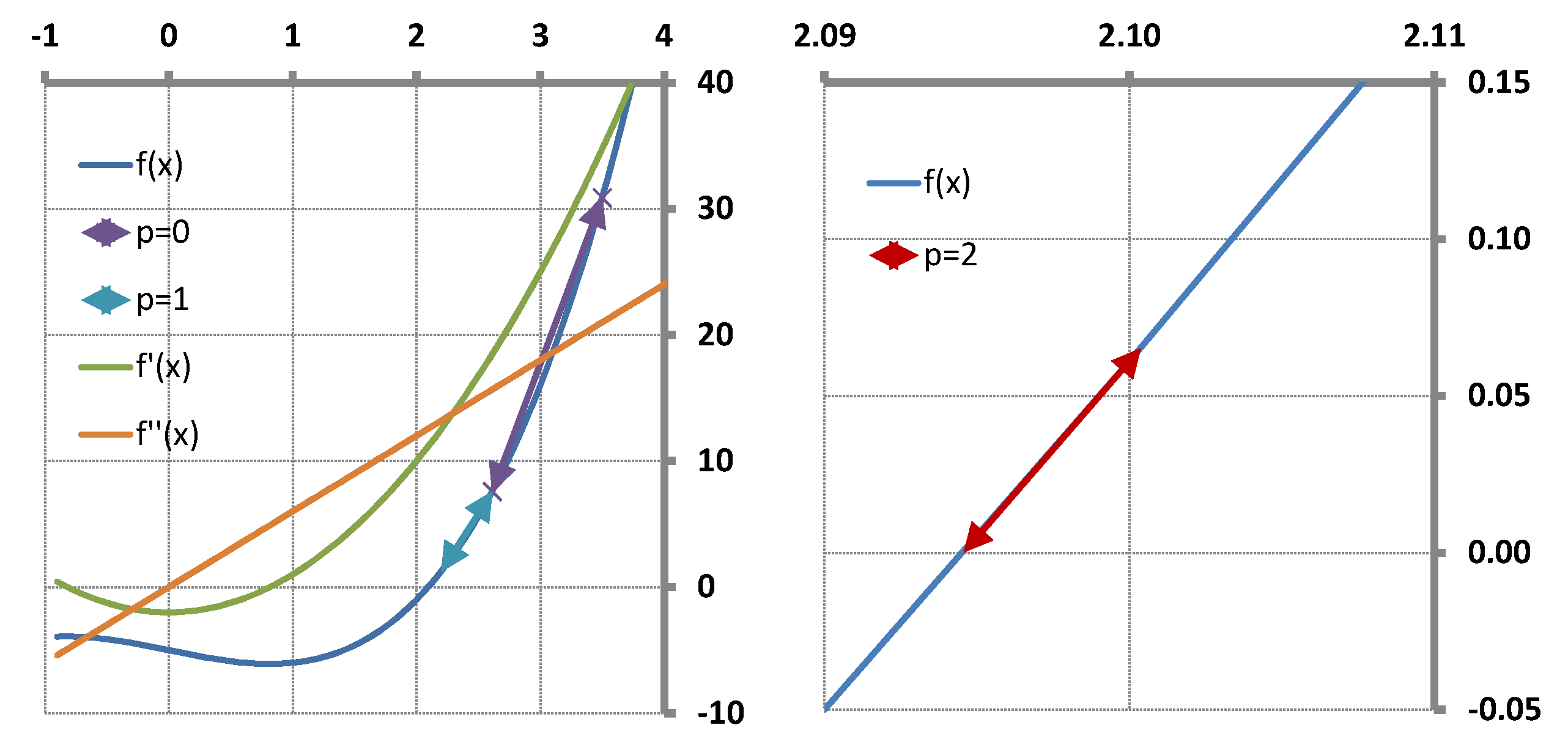
The T-Secant procedure has been worked out for solving multi-variable problems. It can also be applied for solving single-variable ones, however. The geometrical representation of the latter provides a good view with which to explain the mechanism of the procedure as shown in
Section 5. It is a surprising result that the T-Secant modification corresponds to a hyperbolic function
the zero of which gives the second approximate
in the single-variable case. A vector space interpretation is also given for the multvariable case in this section.
The general formulations of the proposed method are given in
Section 6 and compared with the basic formula of classic quasi-Newton methods. It follows from Equation (
16) that
where
is the Jacobian approximate of the traditional Secant method. It follows from the first and second rows of Equation (
17) of the T-Secant method and from the Definition (
25) of
that
is the modified Secant equation, where
It is well known that the single-variable Secant method has asymptotic convergence for sufficiently good initial approximates
and
if
does not vanish in
and
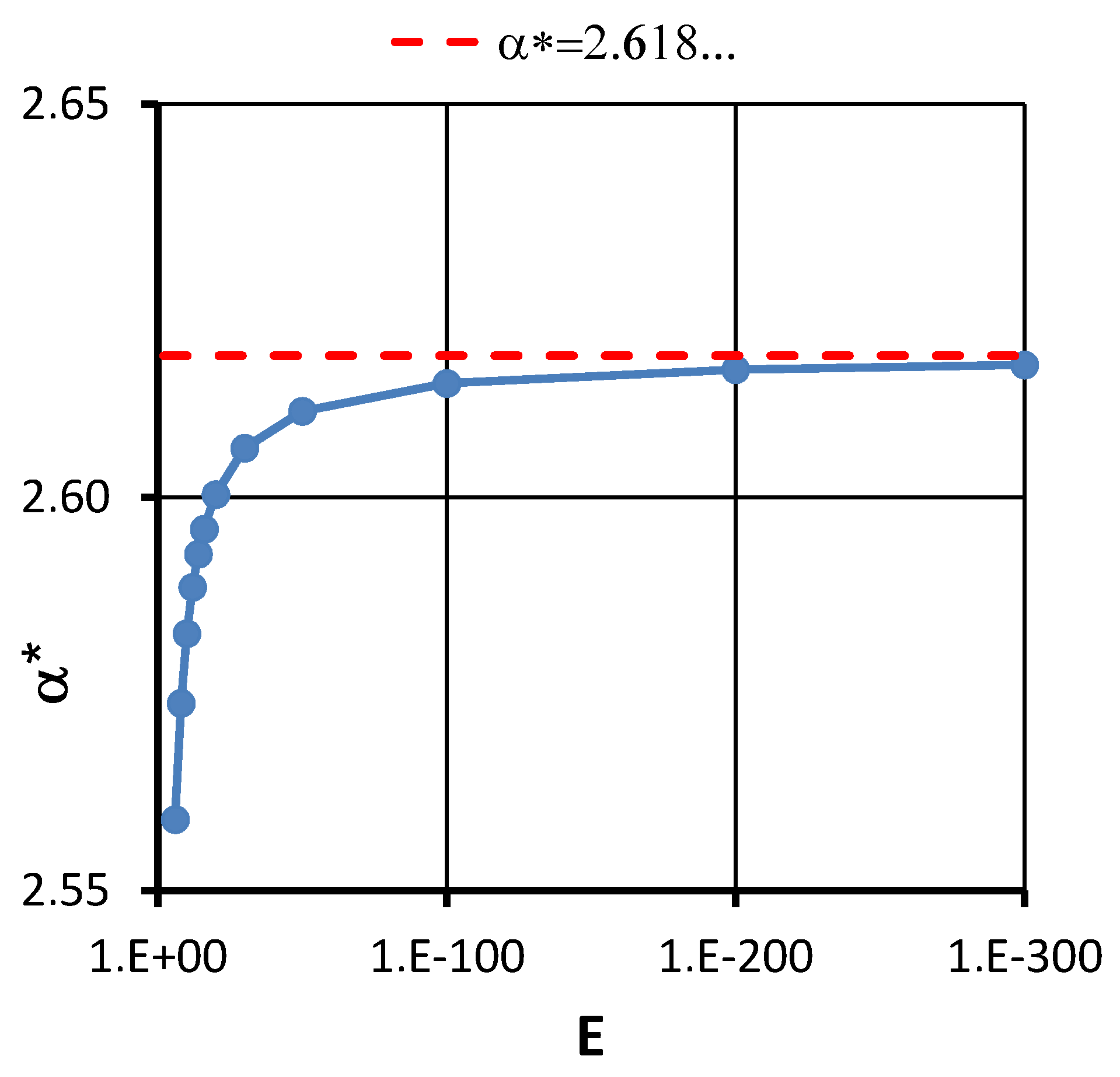
is continuous at least in a neighborhood of the zero
. The super-linear convergence property has been proved in different ways, and it is known that the order of convergence is
(where
is the golden ratio). The convergence order of the proposed method is determined in
Section 7, and it is shown that it has super-quadratic convergence with rate
in the single variable case. It is also shown for the multi-variable case in this section that the second approximate
will always be in the vicinity of the classic Secant approximate
, providing that the solution
will evenly be surrounded by the
new trial approximates and matrix
will be well-conditioned.
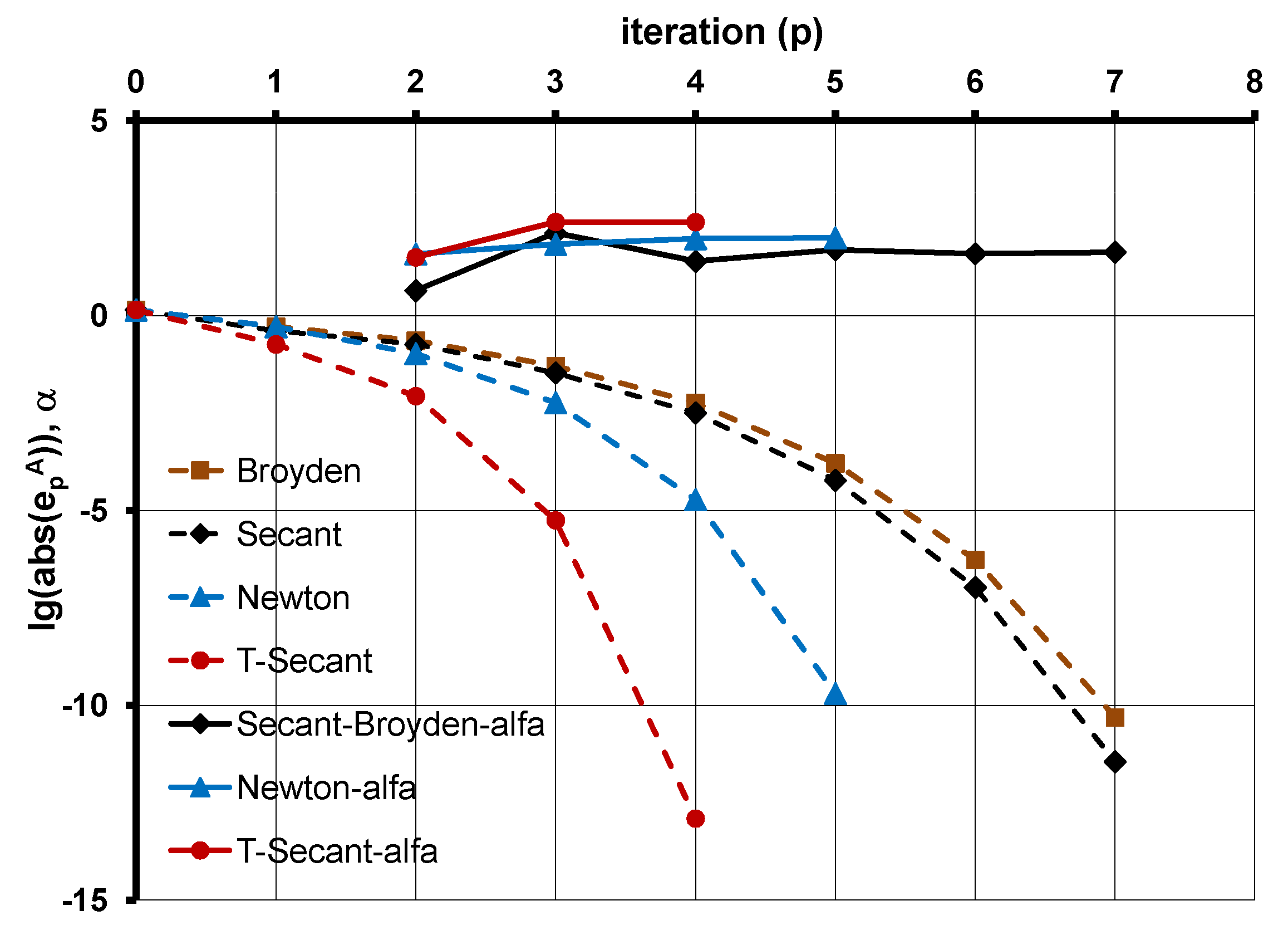
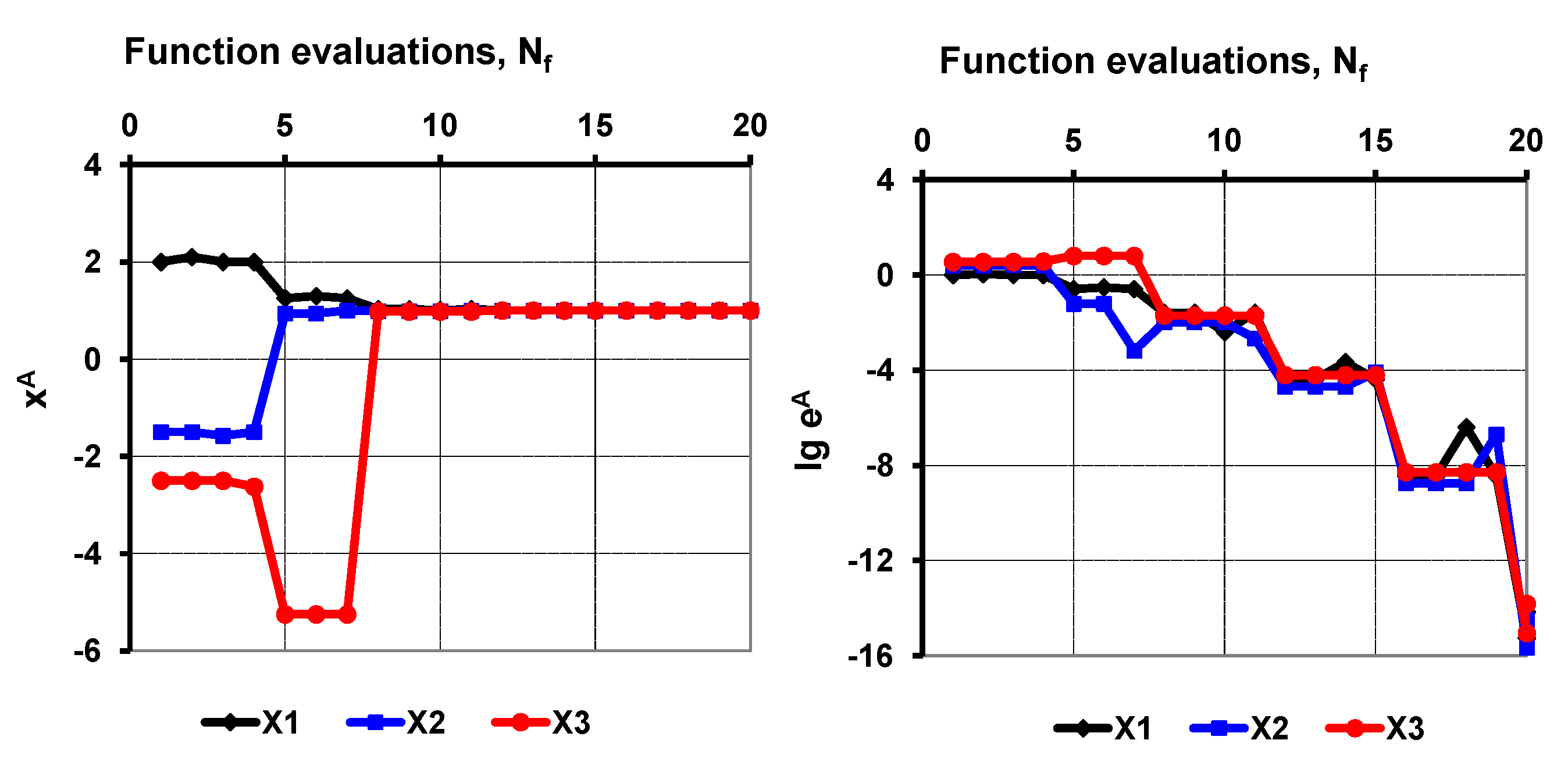
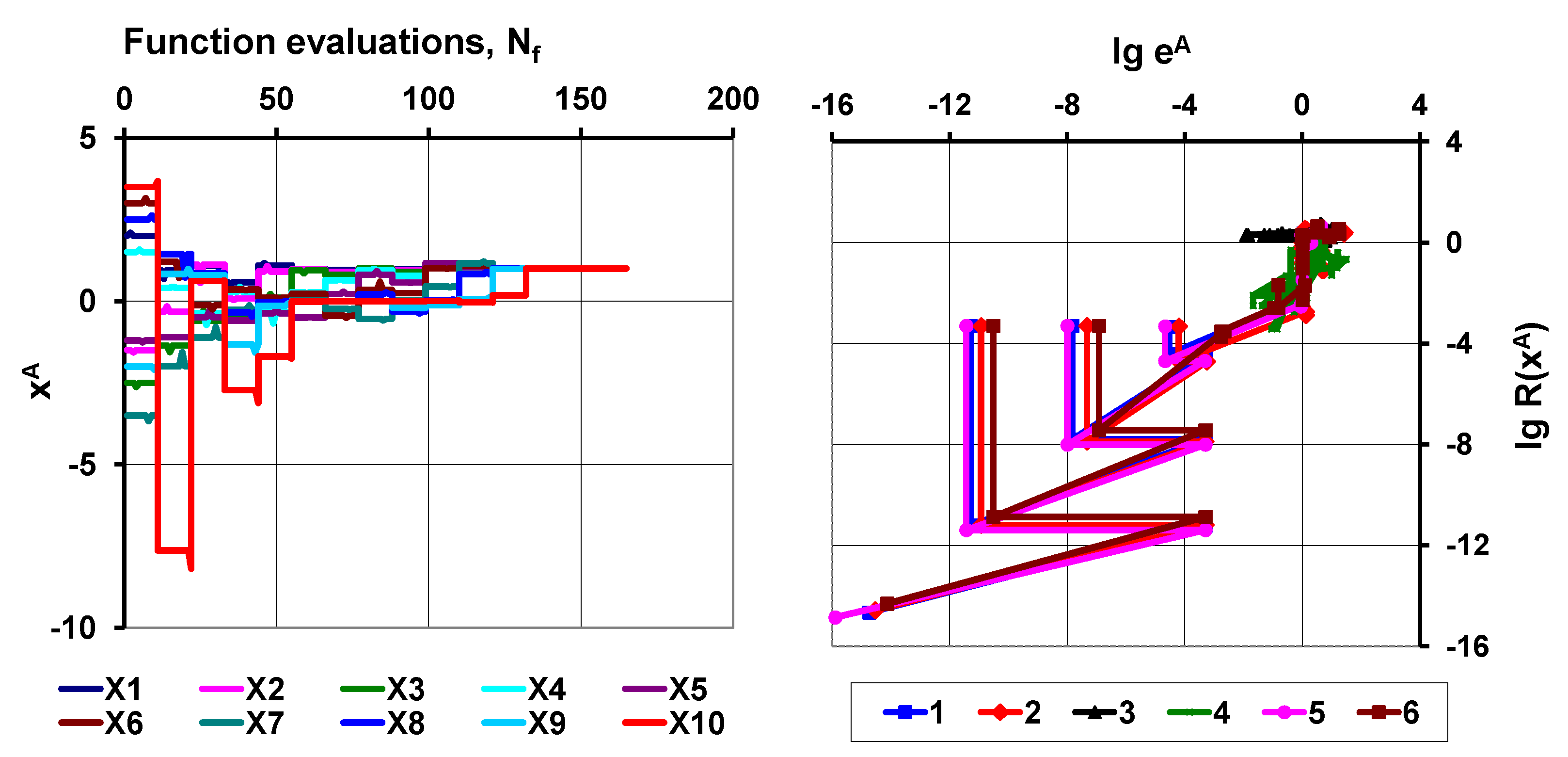
A step-by-step algorithm is given in
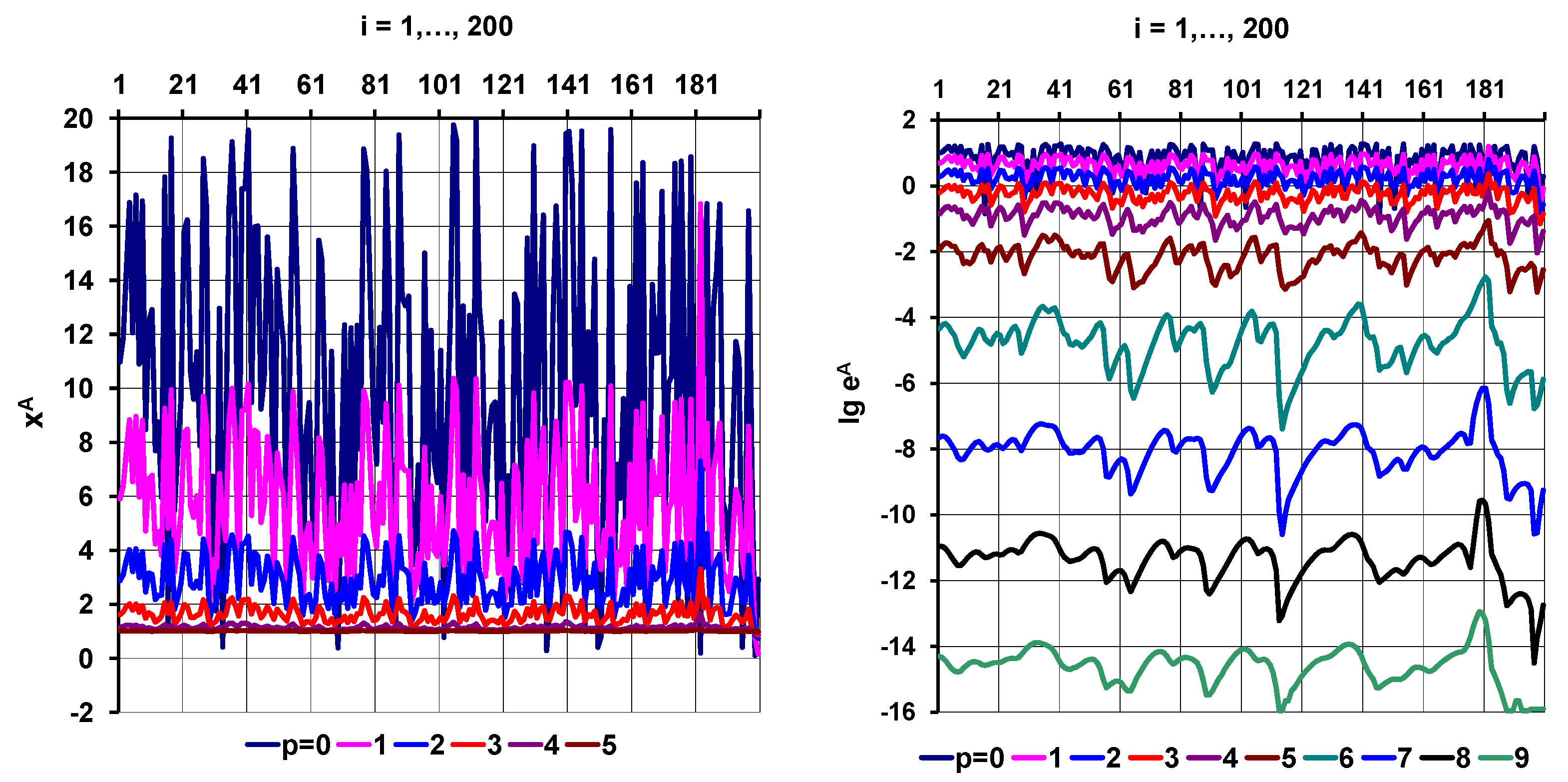
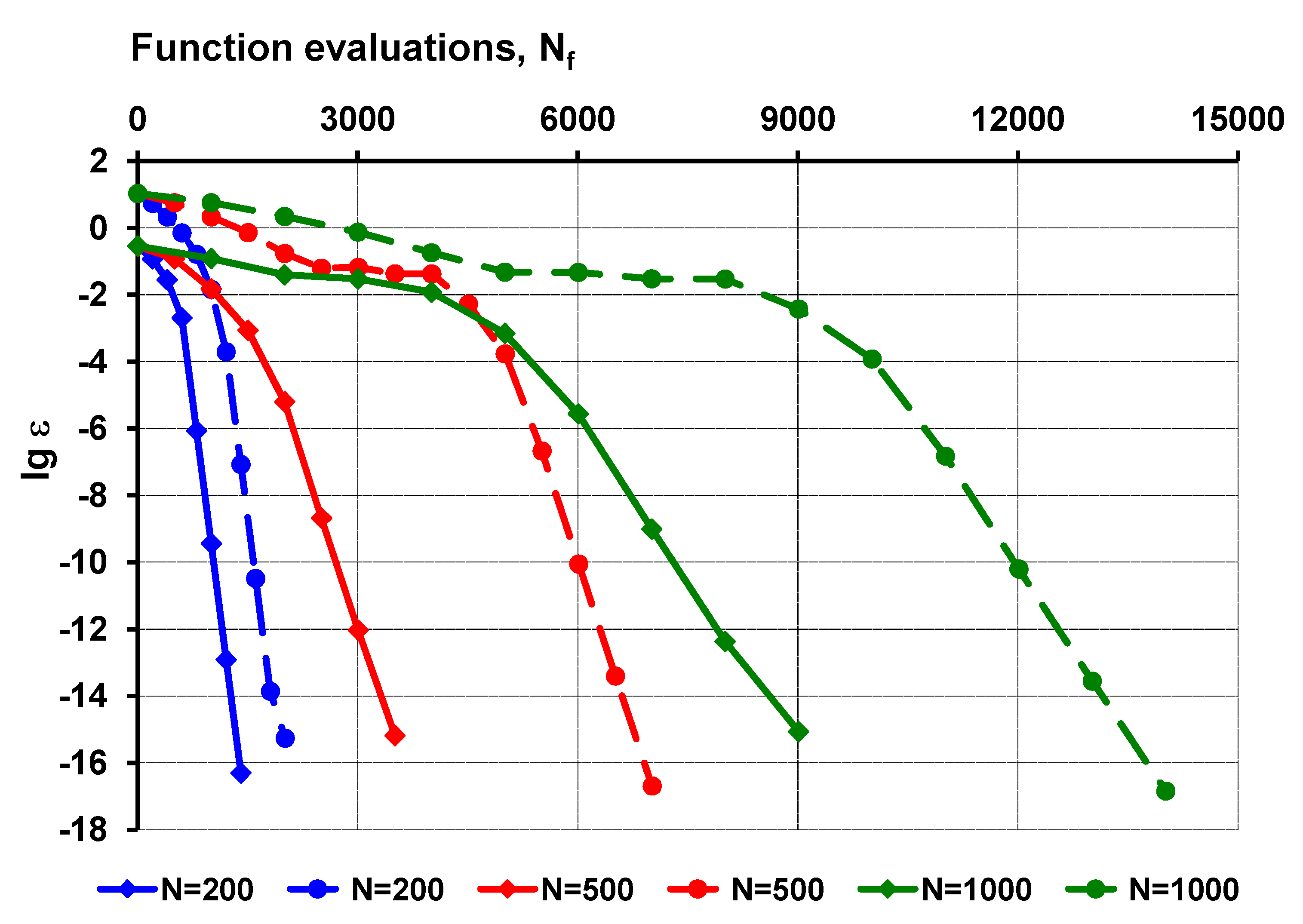
Section 8, and the results of numerical tests with a Rosenbrock-type test function demonstrates the stability of the proposed strategy in
Section 9 for up to 1000 unknown variables. The Broyden-type efficiency (mean convergence rate) of the proposed method is studied in a multi-variable case in
Section 10, and it is compared with other classic rank-one update and line-search methods on the basis of available test data. It is shown in
Section 11 how the new procedure can be used to improve the convergence of other classic multi-variable root finding methods (Newton–Raphson and Broyden methods). Concluding remarks are summarized in
Section 12. Among others, the method has been used for the identification of vibrating mechanical systems (foundation pile driving [
21,
22], percussive drilling [
23]) and found to be very stable and efficient even in cases with a large number of unknowns.
The proposed method needs function value evaluations in each iteration, and it is not using the derivative information of the function like the Newton–Raphson method is doing. On the other hand, it needs more function evaluations than the traditional secant method needs in each iteration. However, this is an apparent disadvantage, as the convergence rate considerably increases (). Furthermore, the stability and the efficiency of the procedure has been greatly improved.
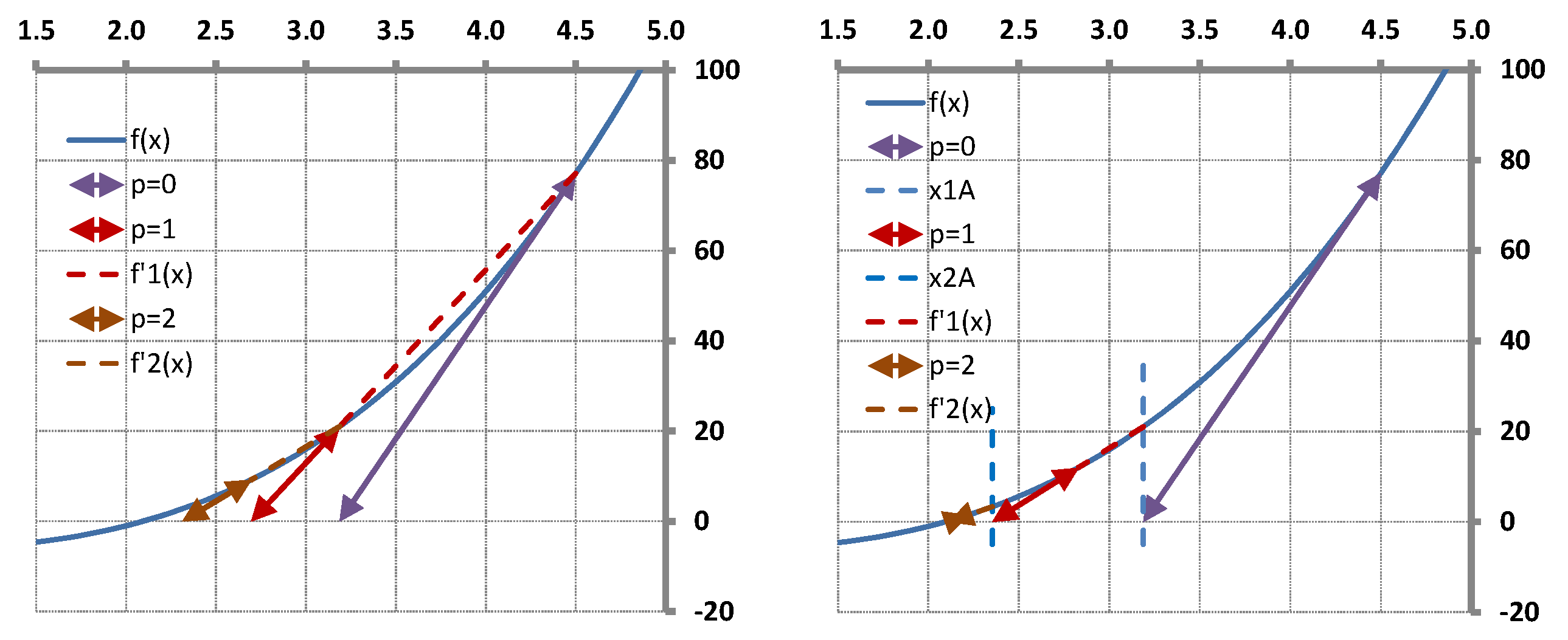
3. Secant Method
The history of the Secant method in single-variable cases is several thousands of years old, its origin was found in ancient times. The idea of finding the scalar root
of a scalar nonlinear function
by successive local replacement of the function by linear interpolation (secant line) gives a simple and efficient numerical procedure. It has the advantage that it does not need the calculation of function derivatives, it only uses function values, and the order of asymptotic convergence is super-linear with a convergence of rate
.
The function
is locally replaced by linear interpolation (secant line) through interpolation base points
and
, and the zero
of the Secant line is determined as an approximate to the zero
of the function. The next iteration continues with new base points, selected from available old ones. Wolfe [
19] extended the scalar procedure to multidimensional
and Popper [
20] made a further generalization
and suggested use of pseudo-inverse solution for the over-determined system of linear equations (where
is the number of unknowns and
is the number of function values).
The zero
of the nonlinear function
has to be found, where
and
. Let
be the initial trial for the zero
, and let the function
be linearly interpolated through
interpolation base points
and
and be approximated/replaced by the interpolation “plane”
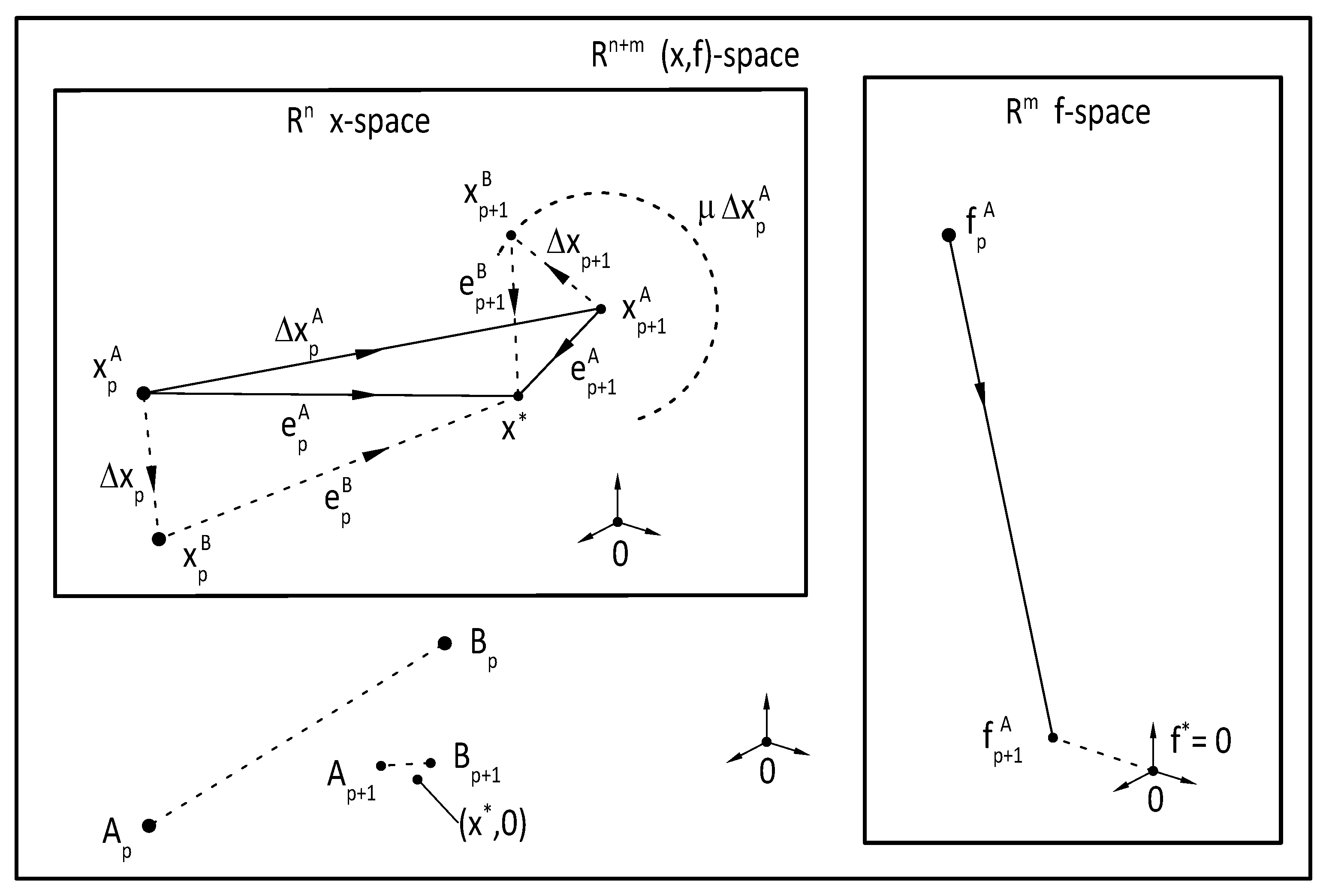
near
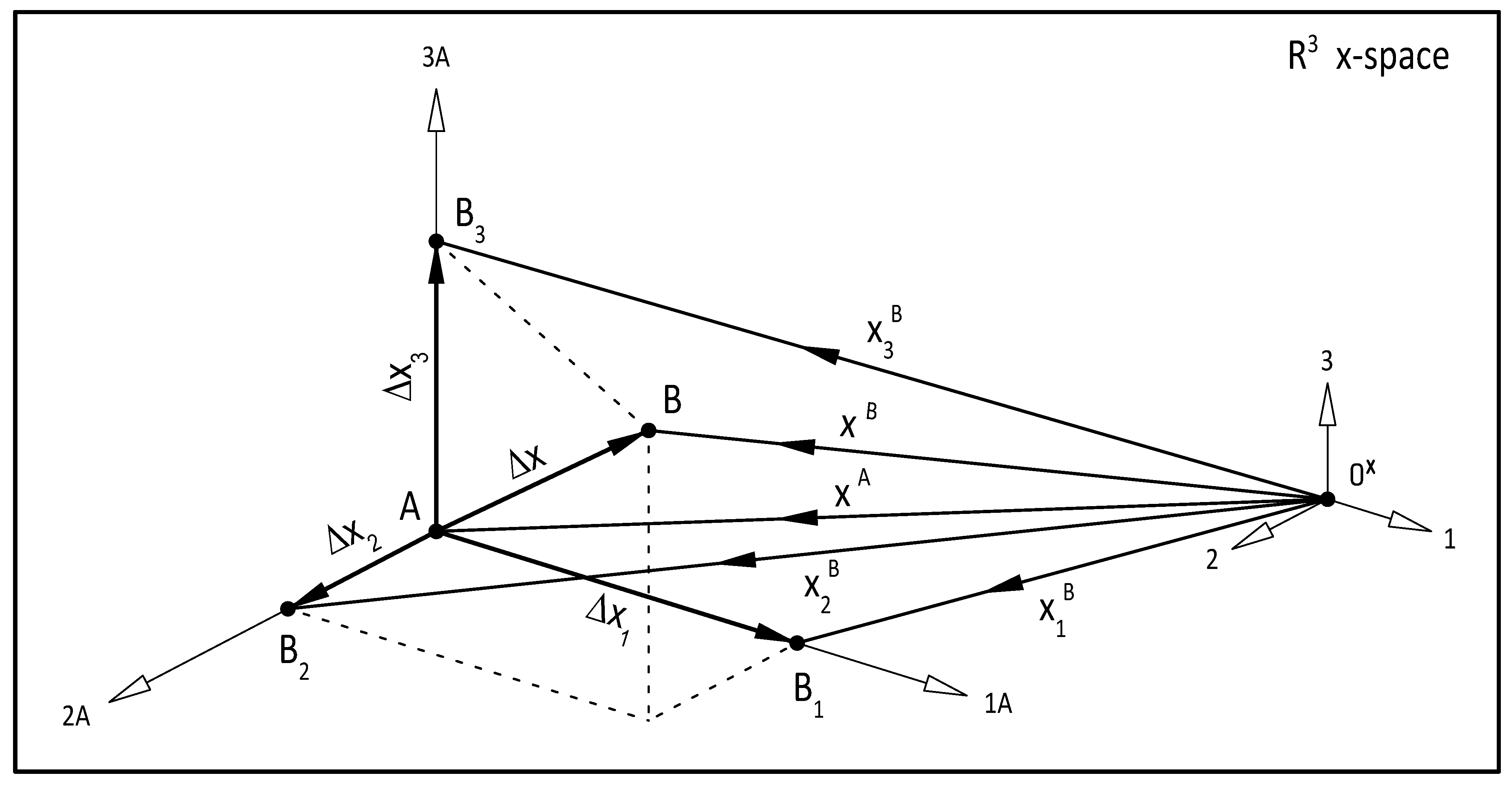
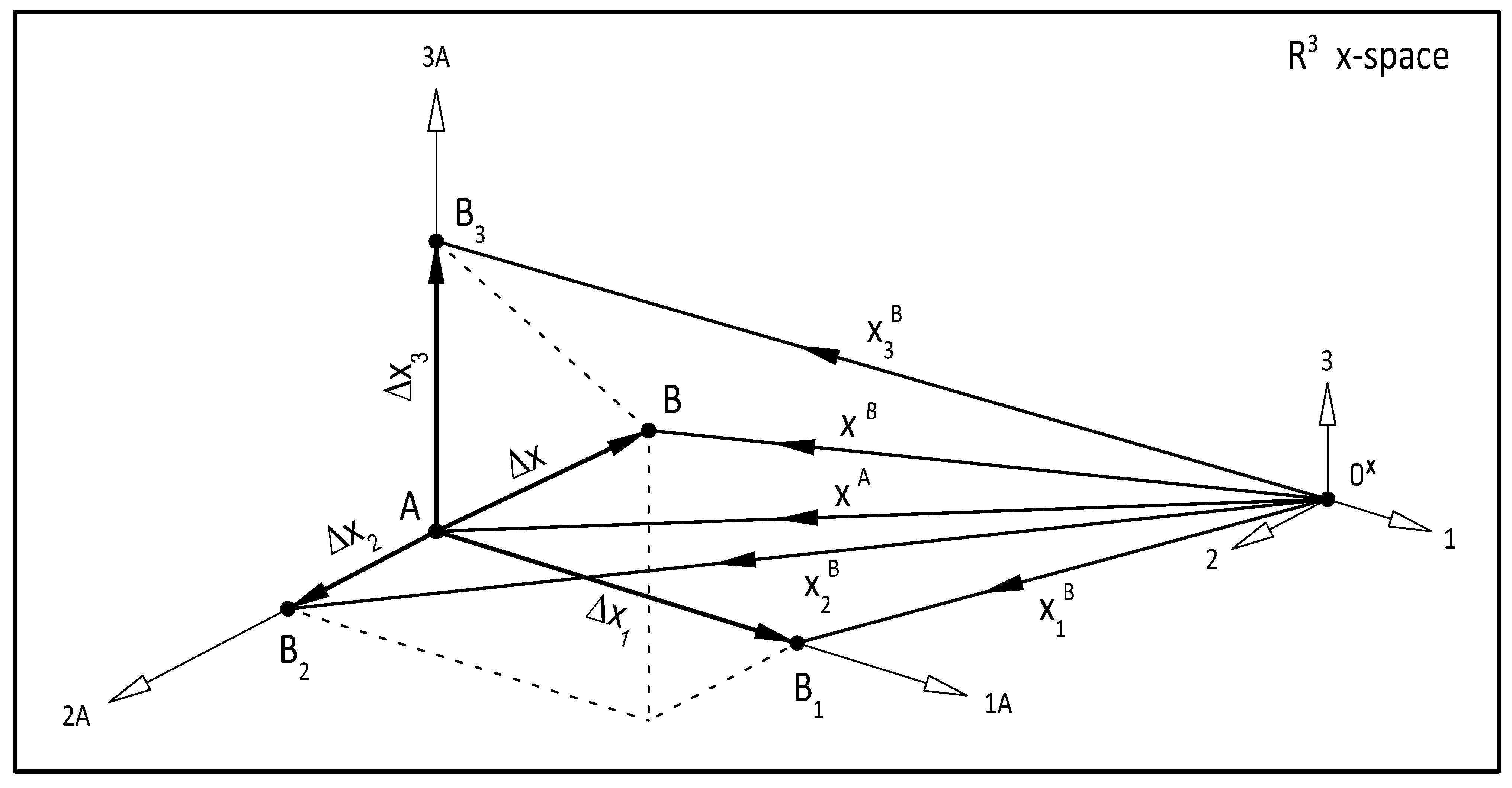
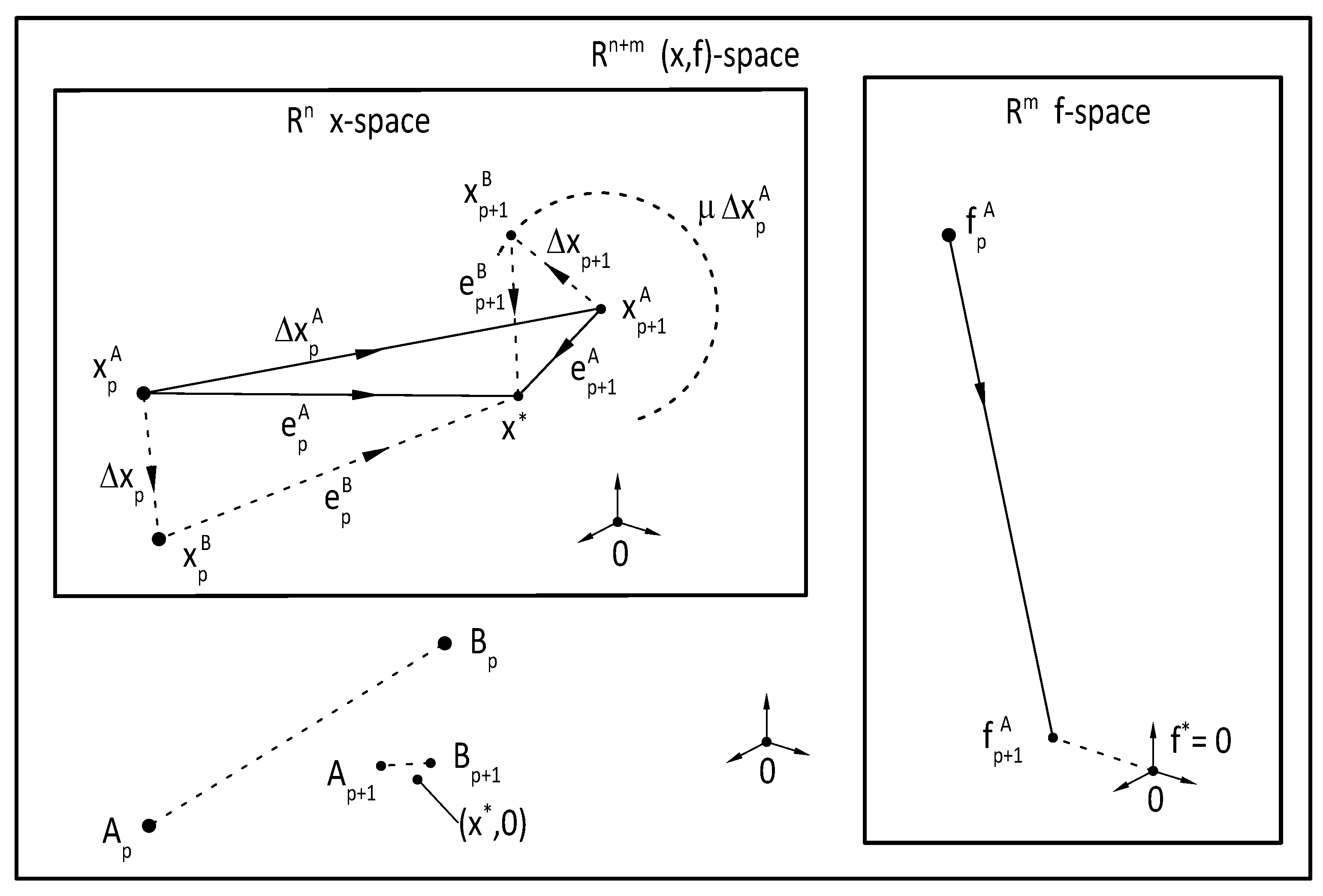
. One of the key ideas of the suggested numerical procedure is that interpolation base points
are constructed by individually incrementing the coordinates
of the initial trial
by an “initial trial increment” value
as
or in vector form as
where
is the
Cartesian unit vector, as shown in
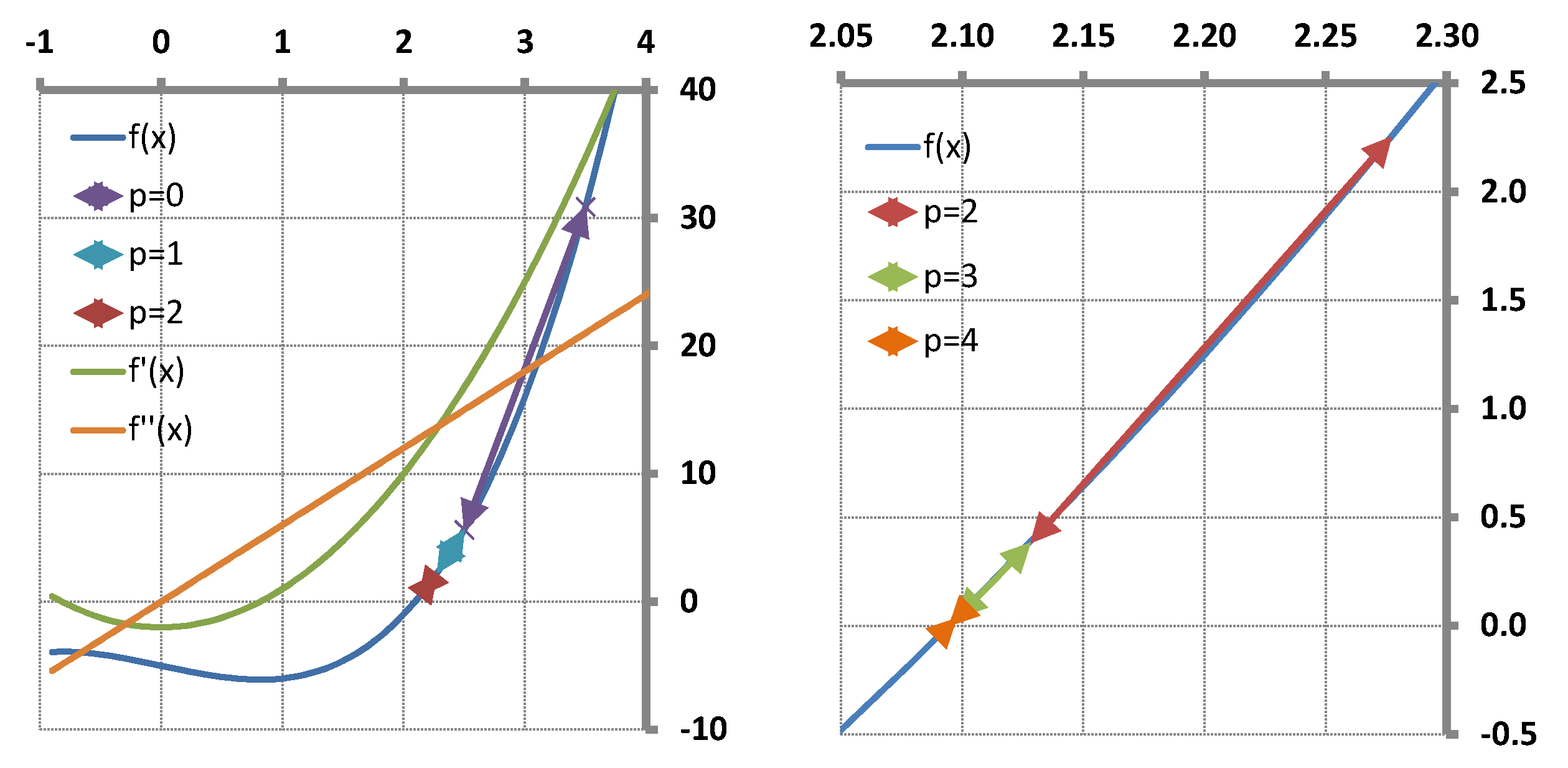
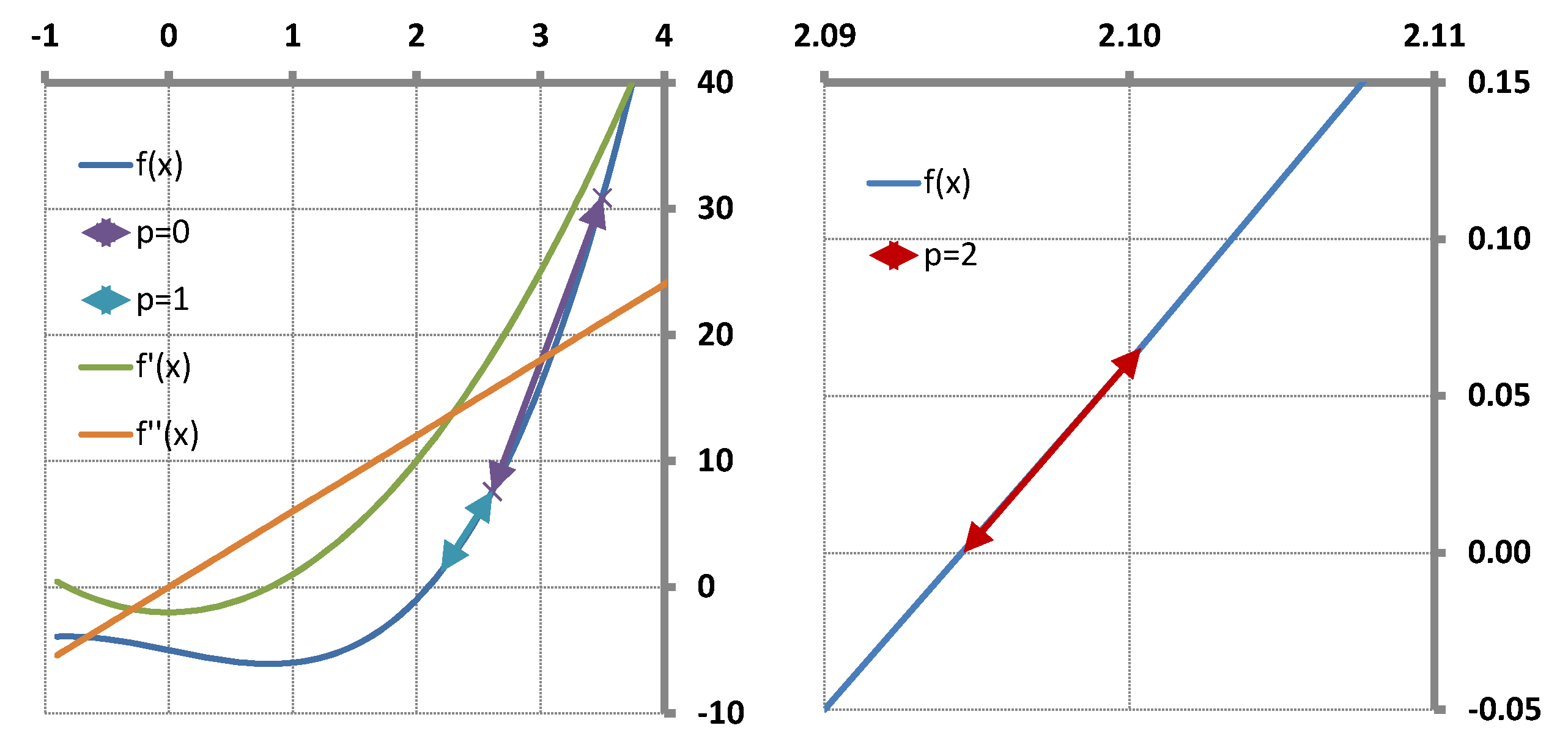
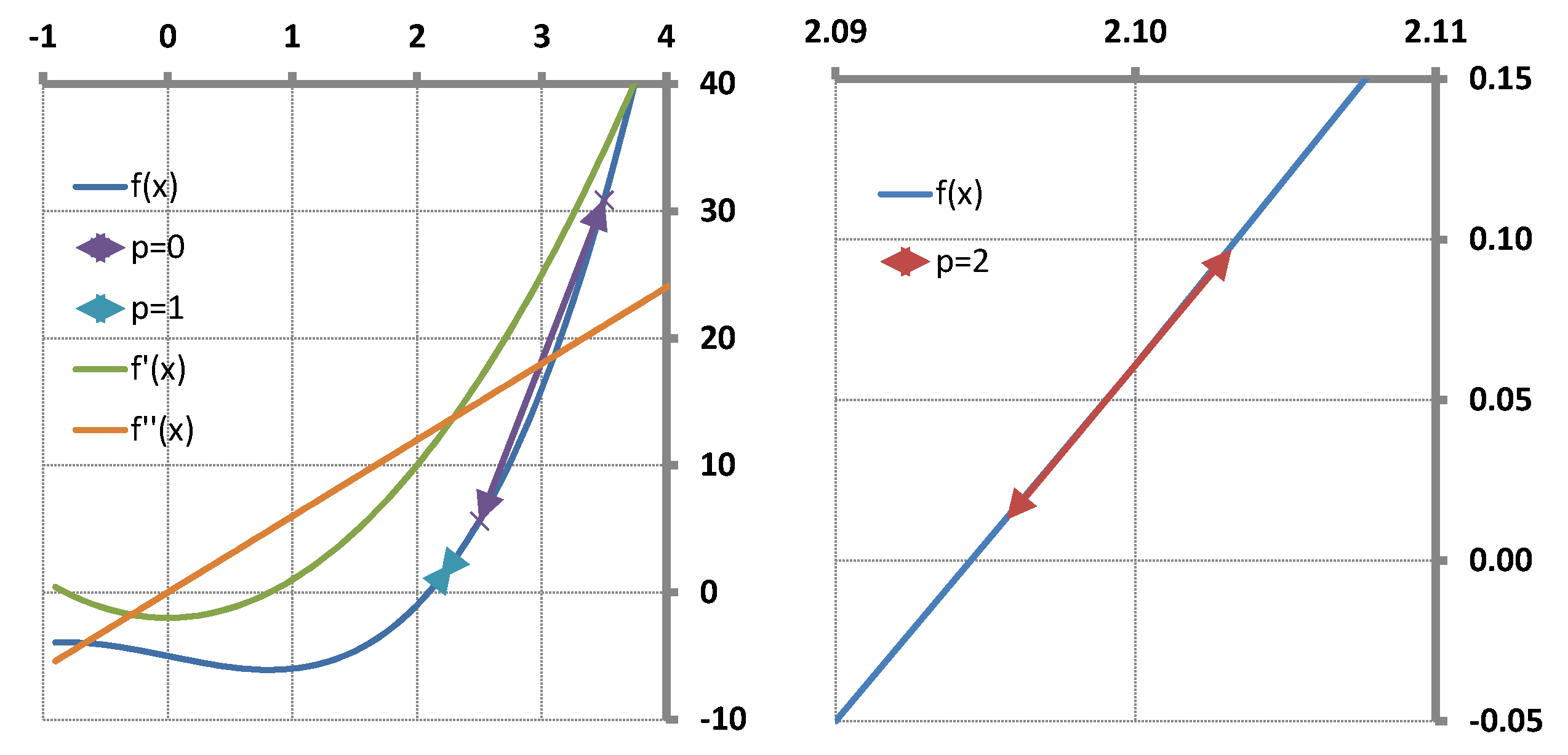
Figure 1.
It follows from this special construction of the initial trials
that
for
and
for
providing that
is the “initial trial increment vector”. Let
. Any point on the
dimensional interpolation plane
can be expressed as
where
,
is a vector with
scalar multipliers
, and as a consequence of Equation (
32),
is a diagonal matrix that has great computational advantage. It also follows from Definition (
34) that
Let
be the zero of the n-dimensional interpolation plane
with interpolation base points
and
in the
iteration. Then, it follows from the zero condition that
and from the second row of Equation (
35) that
and the vector
of multipliers
can be expressed as
where
stands for the pseudo-inverse. Let
be the iteration stepsize of the Secant method; then, it follows from the first row of Equation (
35) and from Equation (
42) that
and from Definition (
43), it follows that
and the new Secant approximate
can be expressed from Equation (
44) as
A new base point
can than be determined for the next iteration. In a single-variable case
with interpolation base points
and
, Equation (
42) will have the form
and the new Secant approximate
can be determined according to Equation (
46). The procedure then continues with new interpolation base points
and
.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}