However, the main interest lies in modeling the number of days between publication and update of vulnerabilities. Since 26 vulnerabilities sampled from 2022 have coinciding publication and update dates, these were removed from the sample.
Two modeling approaches seemed worthwhile to explore. One consisted of using all data for the fitting, and the other, using the subsample without the extreme outliers (364 in total), with the aim of making the statistical analysis more robust. The results obtained with each approach will be compared later on with each other, and also with the findings for the 2021 sample, to establish which modeling strategy is the most adequate in this framework.
6.2.1. Modeling the Data
Statistics for the sample (sample size
) are given in
Table 6, with some representations of the data being displayed in
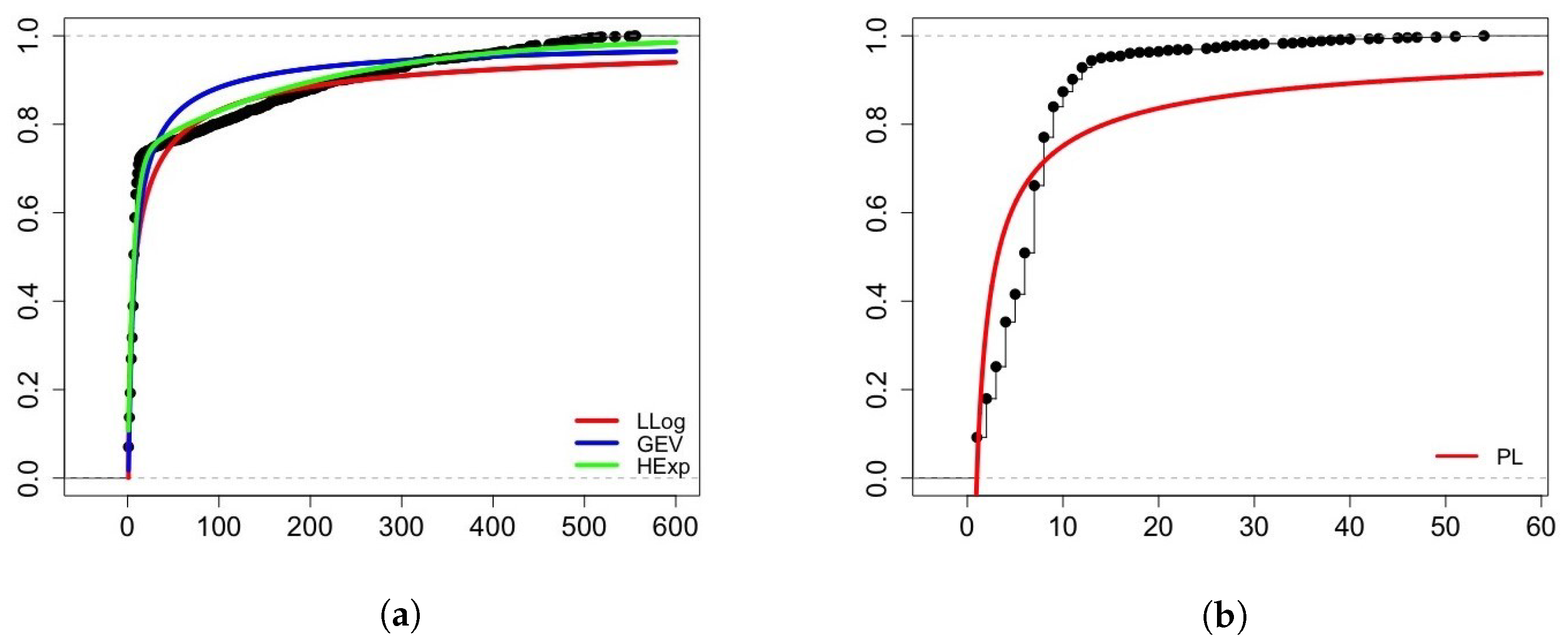
Figure 9. Note that the bin width of the histogram in
Figure 9a is
days (this ensures that all intervals have non-null frequencies). It is also worth mentioning that 72.6% of the vulnerabilities sampled were updated within the first two weeks after publication (50.5% within the first week and 11.6% in exactly 7 days).
In order to establish the power law signature, the procedure used for the 2021 sample was applied here. In this case,
x is the midpoint of an interval of width
, and
is the ratio between the relative frequency of the
x’s interval and 14. By plotting
against
(see
Figure 10), a linear signature is observed when
; that is, if
. Therefore, to fit a power law model to the data, a subsample of
values that are smaller than or equal to 54 should be considered.
The recalculated statistics for the censored data are shown in
Table 7, and
Figure 11 exhibits a plot of the data.
Table 8 shows the results obtained for the heavy-tailed model fits and
Table 9 for the hyperexponential fit for
.
Table 8 shows that the GEV fit is supported by both the AD and CvM tests, and the log-logistic fit just by the CvM test. None of the other model fits are supported by any goodness-of-fit test. For all fits that pass at least one test (GEV and log-logistic), the lowest AIC is obtained with the log-logistic. Although the generalized Pareto has the smallest AIC (note that the power law fit is not under consideration), it should not be considered because it is not supported by any test. Moreover, when comparing the values of the KS test statistic, it is interesting to see again that the smallest value is achieved with GEV, despite the fact that the KS test does not support this model or any other for that matter. As for the power law itself, the results clearly show an inadequate fit.
On the other hand, the results for the hyperexponential model (see
Table 9) reveal that there is some evidence in favor of it being a good fit for both
and
(only with the CvM test). There is not much gain when considering the case
, because its last two exponential components have rates that are indistinguishable to three decimal places. Additionally, when comparing the AIC for the hyperexponential for
with the AIC of GEV and of the log-logistic, a better fit is achieved with the log-logistic. Note, however, that for all models considered, the hyperexponential is the model that requires more parameters to be estimated, three for
and five for
, which may explain, to a certain extent, the bigger AIC value compared with the log-logistic one. It is a well-known fact that the AIC (and the BIC) penalize models with more parameters. Nonetheless, the hyperexponential fit with
has a smaller AIC than the GEV fit.
Figure 12 shows the EDF, comparing it with the investigated fits that are supported by at least one goodness-of-fit test. The power law case is shown again separately, with the lack of fit to the censored data being quite striking.
From the above results, the log-logistic and hyperexponential (
) are the two strongest candidates to model the data. If the choice were to be made solely based on AIC, the log-logistic would be selected. However,
Figure 12a seems to reveal that the hyperexponential provides a more adequate fit, since it more closely follows the EDF towards the center to the right of the empirical data distribution. To better justify the choice between these two models, once again, the Vuong test can be helpful.
Comparing the log-logistic and hyperexponential () models, () and p-value = 0.023, and, therefore, there is some evidence in favor of the log-logistic having a better fit. Note, however, that if the decision is to be made using a significance level of 1%, the conclusion would be that there is some evidence (although weak) in favor of both models being equivalent.
6.2.2. Modeling the Data without Extreme Outliers
As mentioned earlier, the second modeling approach consists of considering a subsample of the 2022 sample without the extreme outliers (sample size
). Statistics for this subsample are given in
Table 10, with some representations of the data being shown in
Figure 13 (the bin width of the histogram is
since all intervals have non-null frequencies).
The procedure described before to establish the power law signature was applied again to this subsample (see
Figure 14). In this case, a linear signature is observed when
, or if
, with exactly the same condition obtained when working with the whole 2022 sample. Therefore, the results for the power law fit are identical in this context to those shown in
Table 8, and for this reason will not be replicated here. The results for the other model fits are given in
Table 11 and
Table 12.
This modeling approach leads to some different conclusions from those when modeling with all the data. The log-normal, GEV, and Cauchy are potential model candidates, all being supported by both the AD and CvM tests. The hyperexponential is also a potential model candidate, but is only supported by the CvM test. Again there is no gain in using the hyperexponential model compared with the model. Curiously, the evidence in favor of the log-logistic model is no longer supported by any goodness-of-fit test, although the p-value of the CvM test is close to the significance level of 5%.
On the other hand, the GEV fit is the one that has the smallest AIC of all the fits, as well as the lowest value for the KS test statistic. Therefore, if the choice of a model is to be made solely on the AIC, the GEV model is clearly the winner, and the log-normal the runner up (it has the second smallest AIC). The different conclusions from the ones obtained before might be somewhat explained by the fact that the subsample used has a skewness of 3.53, as opposed to 2.29 for the whole sample, which introduces some changes in the characteristics of the data and, therefore, of the underlying data distribution.
Figure 15 displays the EDF, comparing it with the log-normal, GEV, Cauchy, and hyperexponential (
) fits. Observe that, despite the fact that the hyperexponential has the third lowest AIC of the four models, its fit again follows quite closely the EDF towards the center to the right of the empirical data distribution.
With the GEV and the log-normal models being the two strongest model candidates, it is advisable once again to use the Vuong test to support a choice. Comparing these two models, () and p-value = 0; hence, there is strong evidence in favor of GEV having a better fit here.
On the other hand, and out of curiosity, when comparing the GEV and hyperexponential () fits with the Vuong test, as (), and the p-value , when the choice is between GEV and the hyperexponential, the test’s results clearly suggest the first model. However, one must remember that the AIC (and the BIC) is an overall measure of goodness-of-fit, which may explain why a better fit is achieved with GEV.
The analysis of the number of days from publication to update of vulnerabilities using a systematic sample (
) from 2021 and a simple random sample (
) from 2022 led to consistent results, both with respect to the basic sample statistics (
Table 1,
Table 2,
Table 6,
Table 7, and
Table 10) and with respect to the choice of statistical models, with a clear indication that an extreme value (either GEV, in the classical setting of the maxima of IID random variables, or log-logistic in the context of geometrically thinned sequences of IID random variables, or a hyperexponential mixture of two exponential variables) provided the best fit.
Observe that to be on the safe side, the analysis was performed for the sets of all data and for the censored sets cleaned of extreme outliers, as indicated in the boxplot diagrams. But the adequacy of the hyperexponential fit seems to indicate that the data considered as outliers in the exploratory data analysis phase are data coming from the second component of the hyperexponential population.
There is some evidence, in view of the hyperexponential fit and of the sample statistics seen in
Table 1,
Table 2,
Table 6,
Table 7, and
Table 10, that it is reasonable to split the data into two subsets at the three weeks threshold. This provides a naive indication of the weights of the first and second components of the hyperexponential fit, as shown in
Table 13.
A sensible conjecture is that hackers maintain interest in one-third of high-risk vulnerabilities during a longer period, while for medium-risk and critical-risk vulnerabilities (in this last case possibly because vendors prioritize patching investment and discourage hackers) only one-fifth have a long update period. With respect to low-risk vulnerabilities, the one-eighth of those taking a long update period is even smaller. Observe that there was a subsample of only 23 low-risk vulnerabilities, which seems negligible in a sample of size
(1.18%). The split sample statistics are indicated in
Table 14.
The close coincidence of values is striking. Concerning the quick update component, the median time is about one week, for the 3rd quartile, 8 days, and (although artificial) this slowly increases to the maximum time to update of 3 weeks.
With regard to the long updating vulnerabilities, around 25% of the vulnerabilities are updated up to 3 months, the median time to update is approximately 6 months, and the 3rd quartile is approximately 10 months.
This may inspire some ways of forecasting a dynamic CVSS score. Instead of the temporal metrics equation
(see
Appendix A and
Section 2), a multiplier
can be used to obtain a time-dependent dynamic base score as
where
is computed twice: for the fast updating component and for the slow updating component of the hyperexponential fit. This will necessarily produce two lines showing the probable evolution of the severity score of the vulnerability, assuming that the multiplier
appropriately reflects the behavior of hackers and vendors.
Adequate choices of the multiplier depend on a fuller understanding of hackers’ behavior, and empirical evaluation must take into account its effect on the number of changes over time from medium to high, from high to critical, and vice versa, and, concomitantly, the time intervals in which these changes occur. These are informal indicators of the effectiveness of the R multipliers in boosting the CVSS.
An example, assuming that the interest of hackers in the vulnerability increases steadily until the 1st quartile and also between the 1st quartile and the median (
), and that, in most cases, they will loose interest in the vulnerability (eventually, since the vendors invest in patching), is
Figure 16 exhibits the above multiplier function, as well as the evolution of a vulnerability with score 7.4 over time.
Although the initial aim of this research was to change the static status of the CVSS, the development of the work led to some reflections on the past and expected evolution of the measurement concept.
Just as the law of large numbers and the central limit theorem became non-physical measurement aids, and regression made it possible to measure one variable to evaluate another (for instance, an instrument to measure the glucose level on a daily basis explains in the technical description of the device that it effectively measures the angle of refraction of light in the blood deposited on the strip, and transforms this measurement into the “measurement” of glucose), the digital transition will eventually lead metrology to evolve towards encompassing other non-physical auxiliary means of measurement, such as metrics and CVSS indices and machine learning algorithms, such as those that evaluate EPSS (the theme of the 2022 World Metrology Day was ’Metrology in the Digital Era’).
In the case of assessing the severity of vulnerabilities or the likelihood of risk of exploitation, it will imply hard work in the harmonization process and eventually a desirable evolution towards standardization. However, the situation is far from satisfactory. For example, with a file containing the vulnerabilities that in April 2021 to March 2022 were rated ’Functional’ or ’High’ with respect to the metric exploit code maturity (which is a collection of data, not a random sample), searching the CVE-ID in other databases to obtain CTI and EPSS, the unpleasant surprise was to find that the empirical correlations were , and , indicating that they are uncorrelated scores. Thus, as prioritization guides in the urgency of patching vulnerabilities, while they are often concordant, they do not offer the comfortable sense of security to which such an economically sensitive area aspires.

 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















