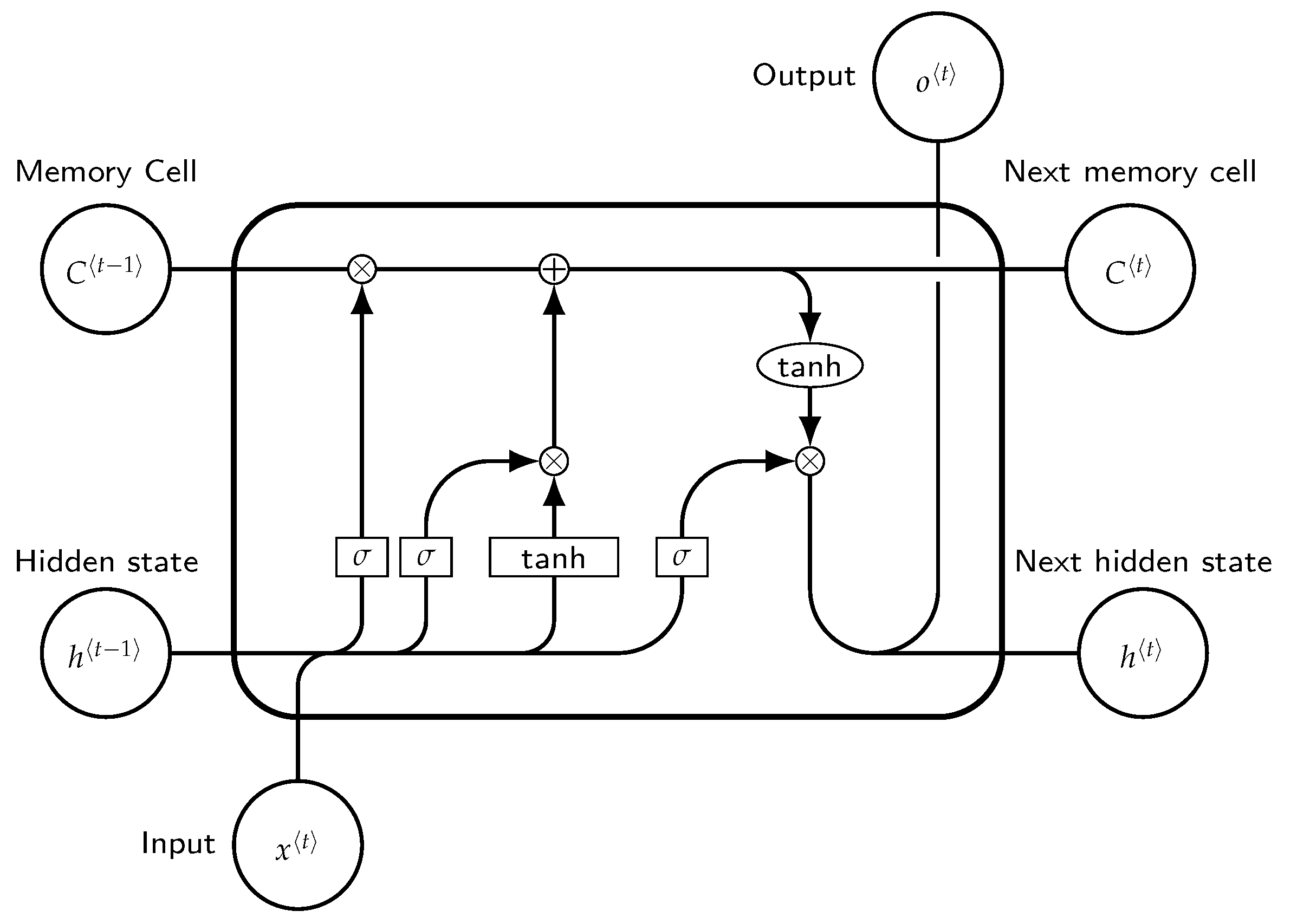
Figure 1.
Block of long short term memory at any timestamp t.
Figure 1.
Block of long short term memory at any timestamp t.
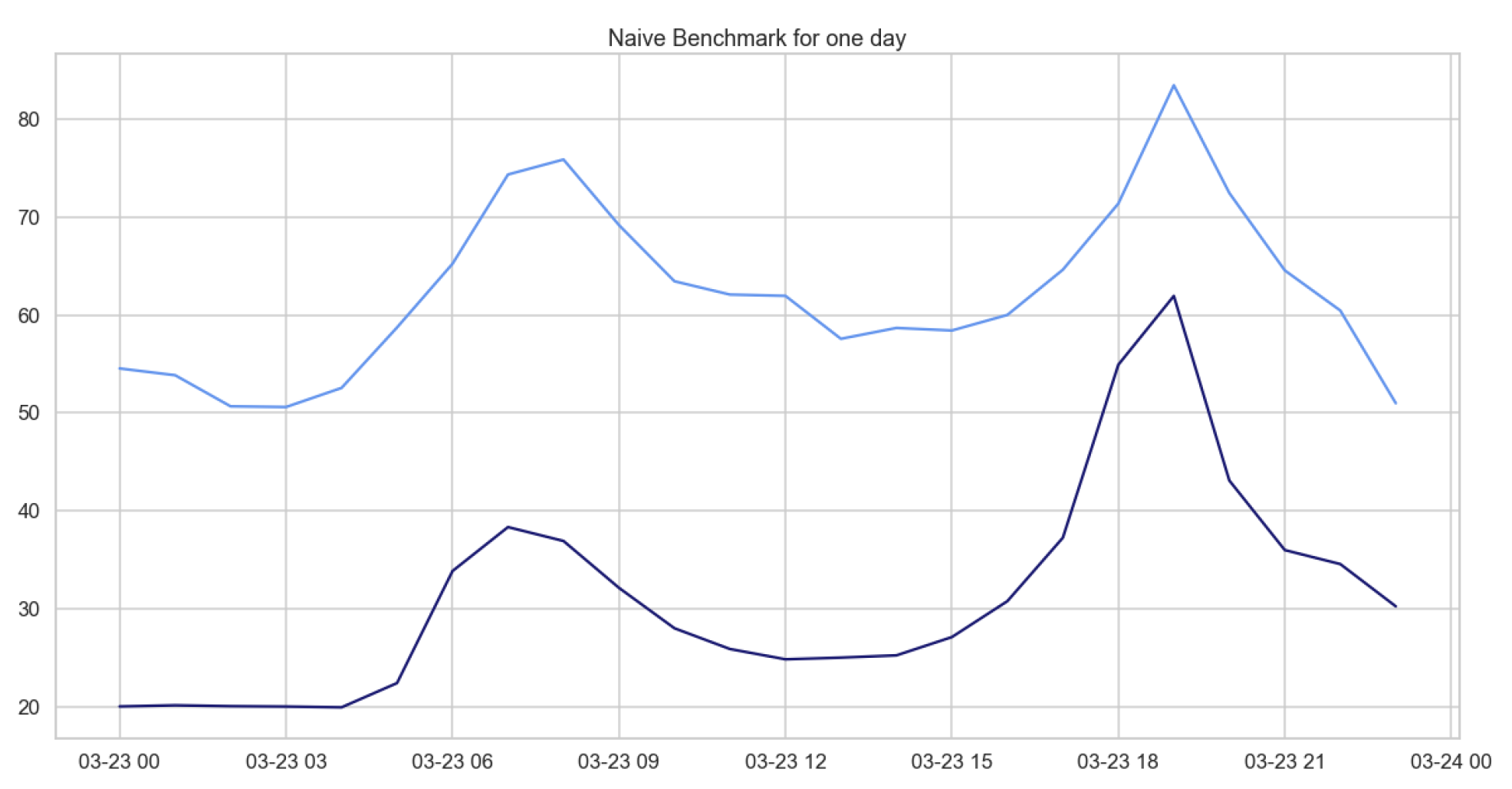
Figure 2.
Comparison of target and forecast values for one day with the naive benchmark model for daily hourly prices on 23 March for the years 2020 and 2021.
Figure 2.
Comparison of target and forecast values for one day with the naive benchmark model for daily hourly prices on 23 March for the years 2020 and 2021.
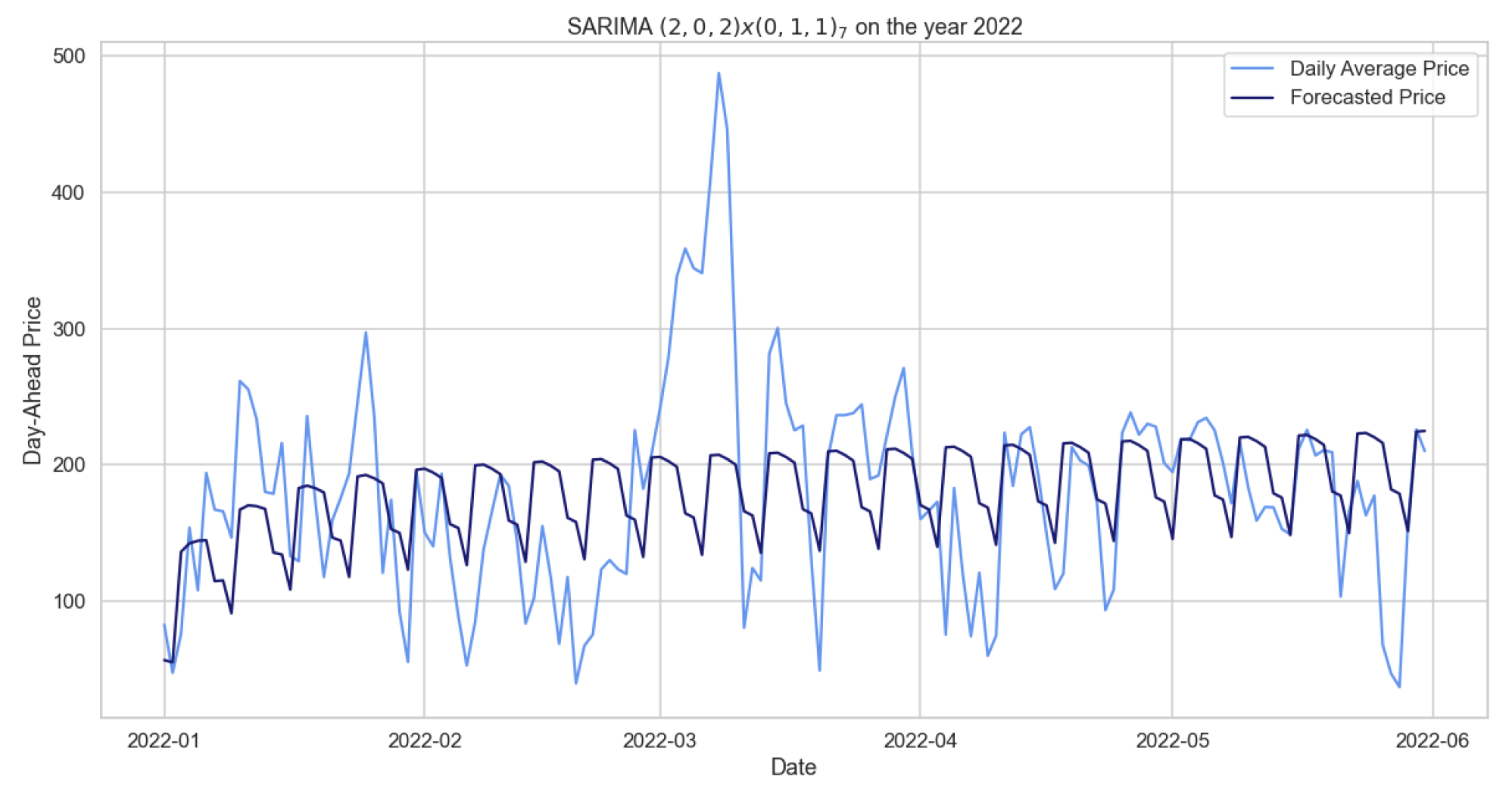
Figure 3.
Comparison of target and forecast values for mid-2022 using 2020–2021 as the training set with for daily average prices.
Figure 3.
Comparison of target and forecast values for mid-2022 using 2020–2021 as the training set with for daily average prices.
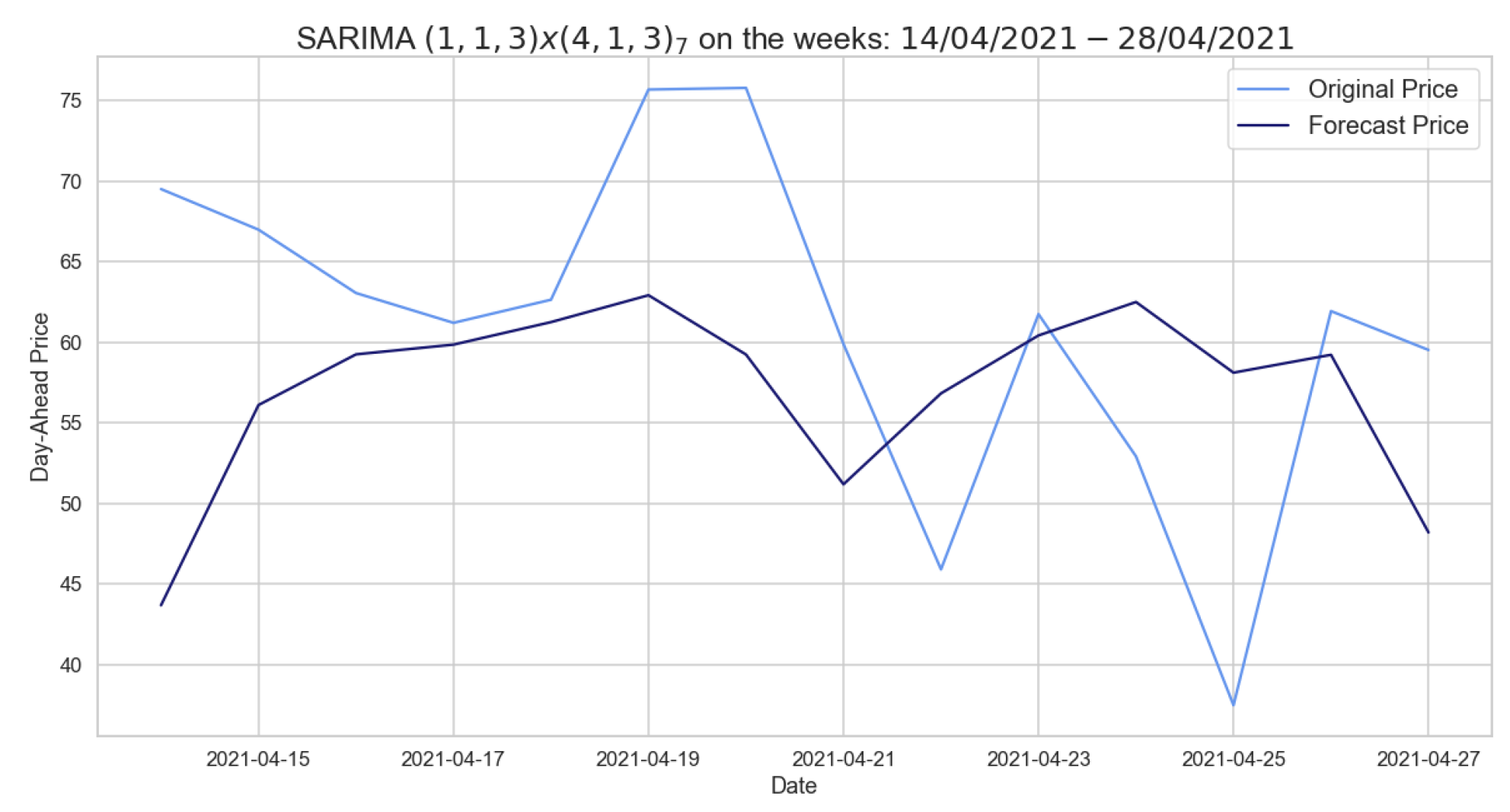
Figure 4.
Comparison of target and forecast values for two weeks in 2021 using autumn–winter 2020–2021 as the training set with on daily average prices.
Figure 4.
Comparison of target and forecast values for two weeks in 2021 using autumn–winter 2020–2021 as the training set with on daily average prices.
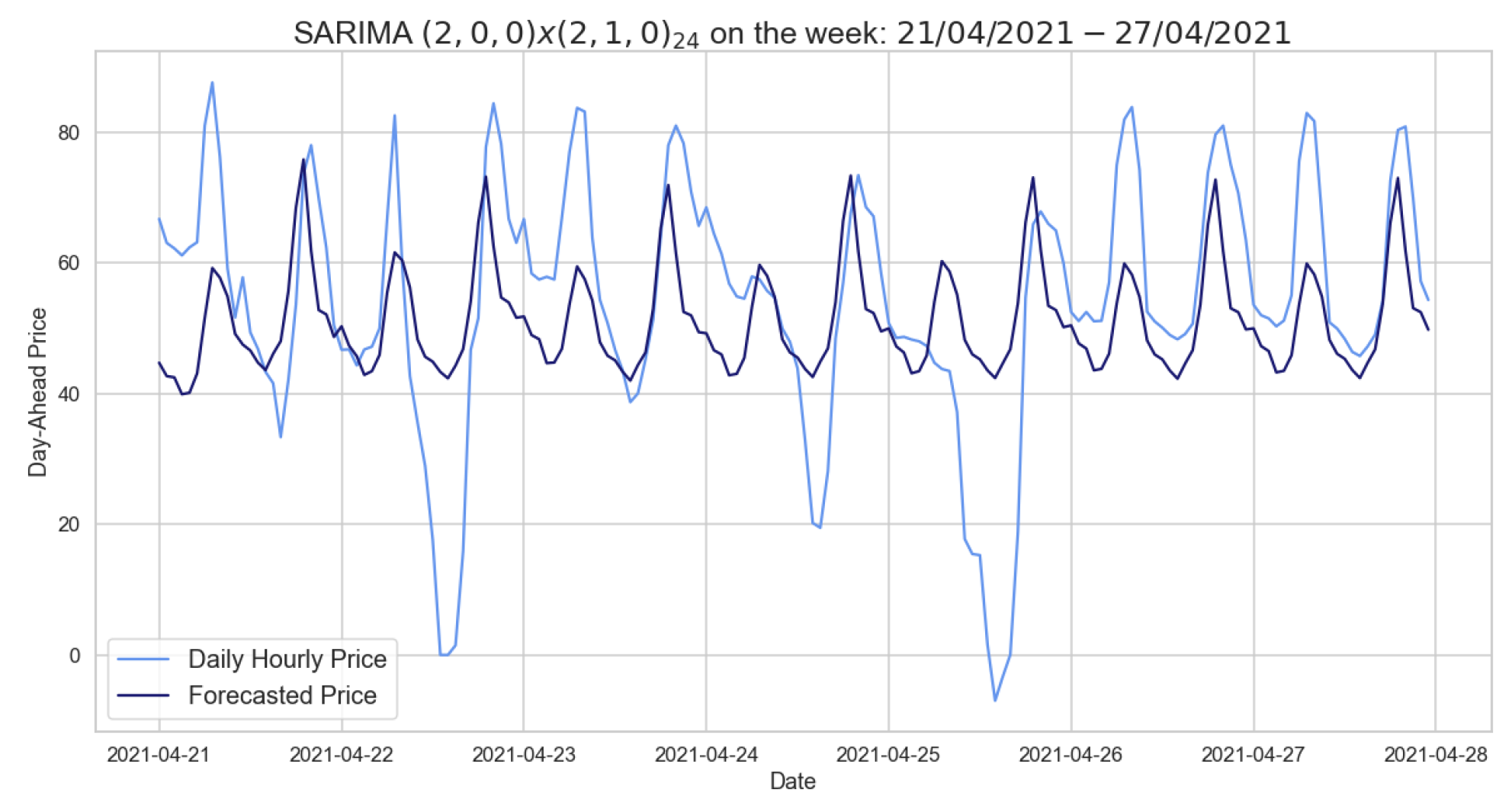
Figure 5.
Comparison of target and forecast values for one week in 2021 using autumn–winter as the training set with .
Figure 5.
Comparison of target and forecast values for one week in 2021 using autumn–winter as the training set with .
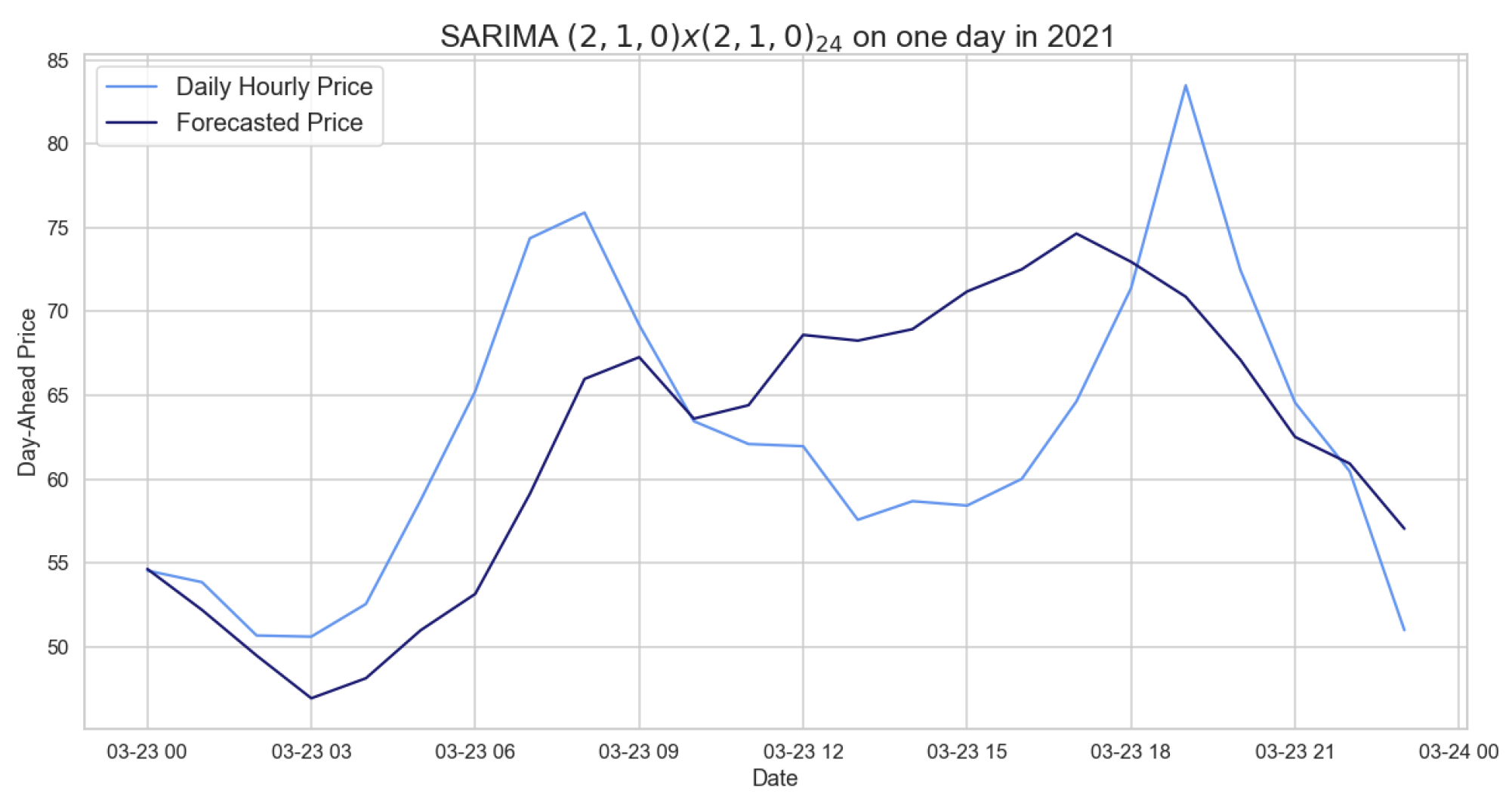
Figure 6.
Comparison of target and forecast values for one day in 2021 using 2020 as the training set with .
Figure 6.
Comparison of target and forecast values for one day in 2021 using 2020 as the training set with .
Figure 7.
Figure of the long trend seasonal component (LTSC) based on wavelets , , and for the daily average prices.
Figure 7.
Figure of the long trend seasonal component (LTSC) based on wavelets , , and for the daily average prices.
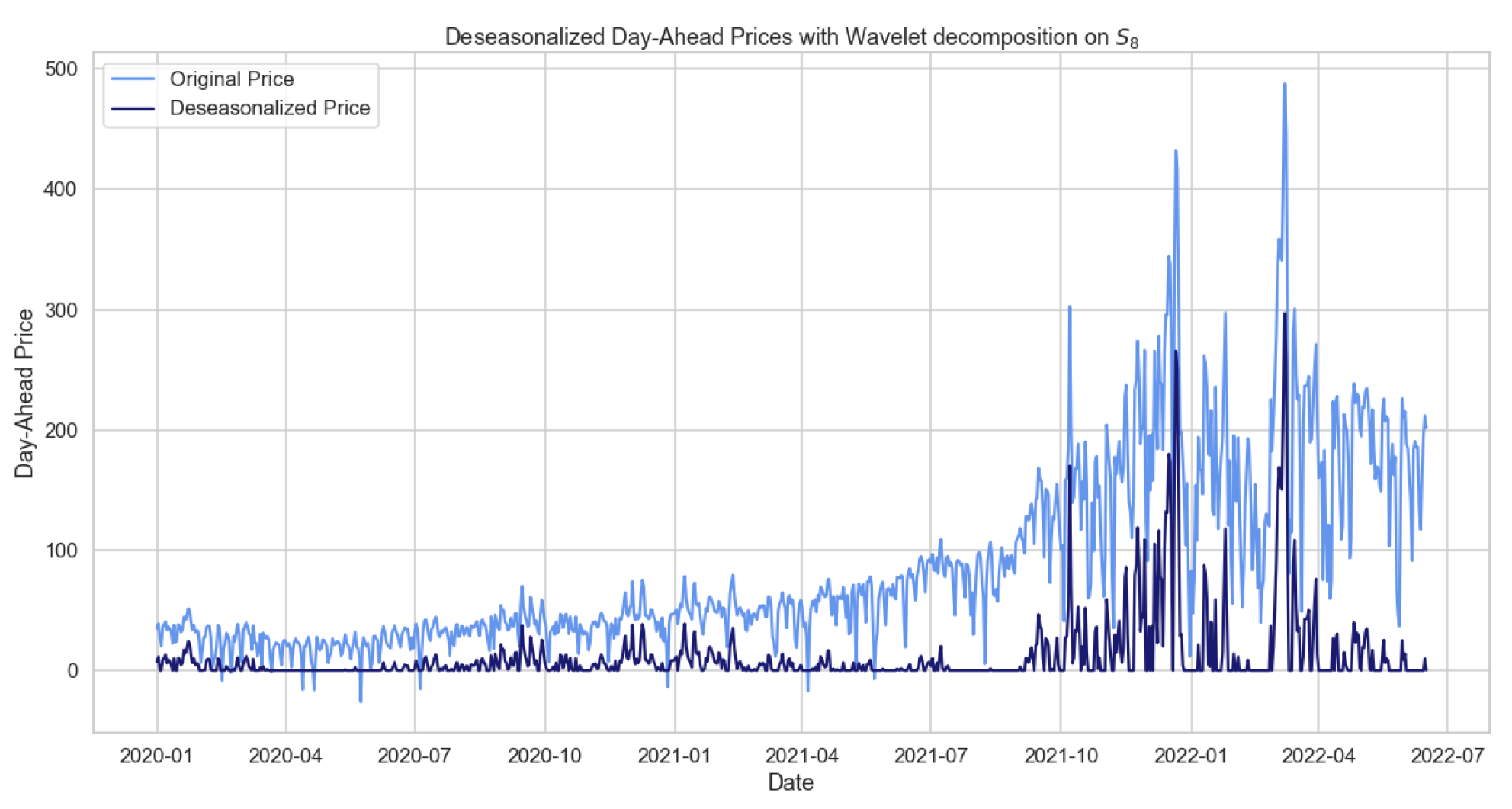
Figure 8.
Figure showing the deseasonalized prices based on wavelet for the daily average prices.
Figure 8.
Figure showing the deseasonalized prices based on wavelet for the daily average prices.
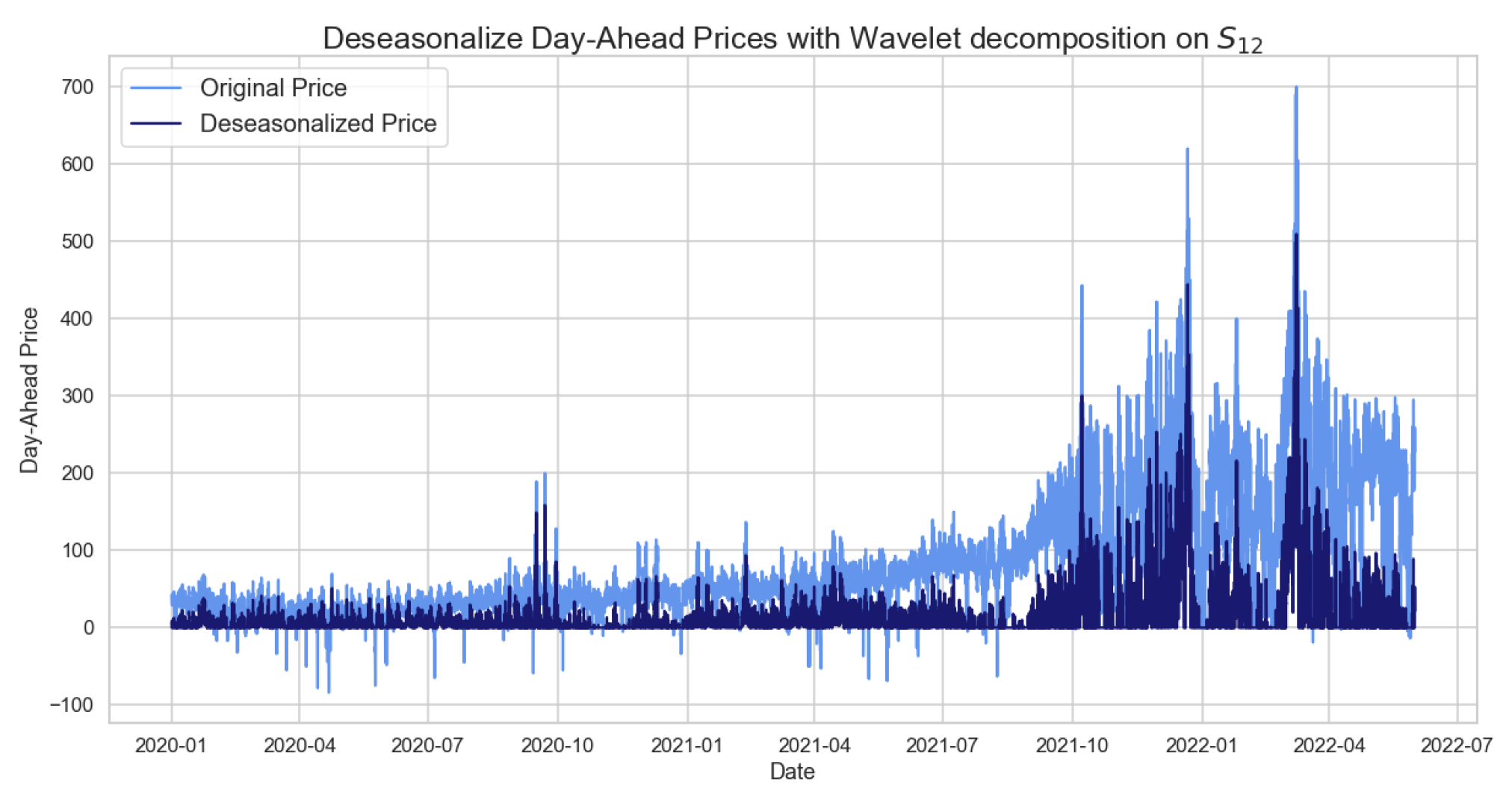
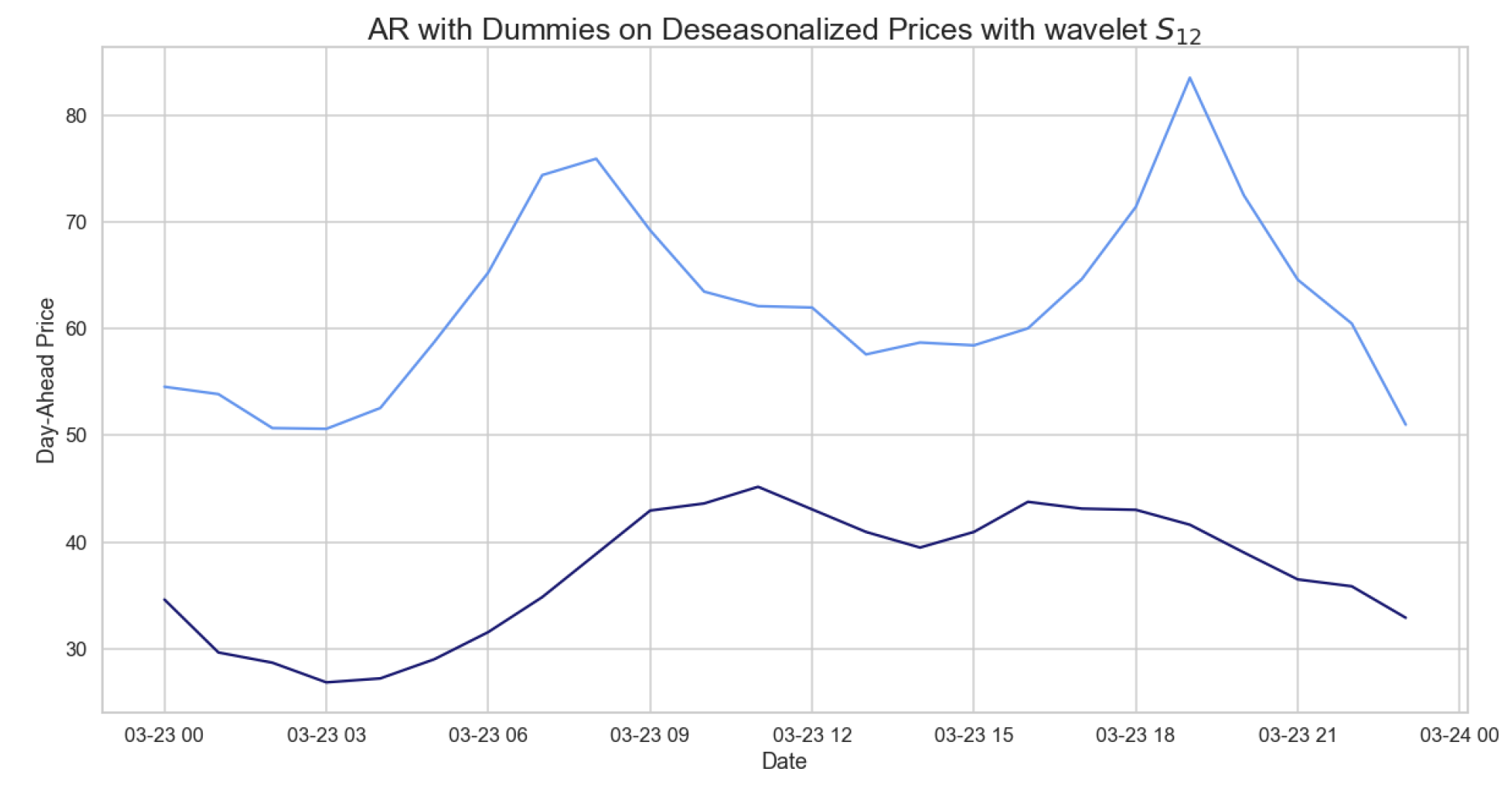
Figure 9.
Figure showing the deseasonalized prices based on wavelet for the daily hourly prices.
Figure 9.
Figure showing the deseasonalized prices based on wavelet for the daily hourly prices.
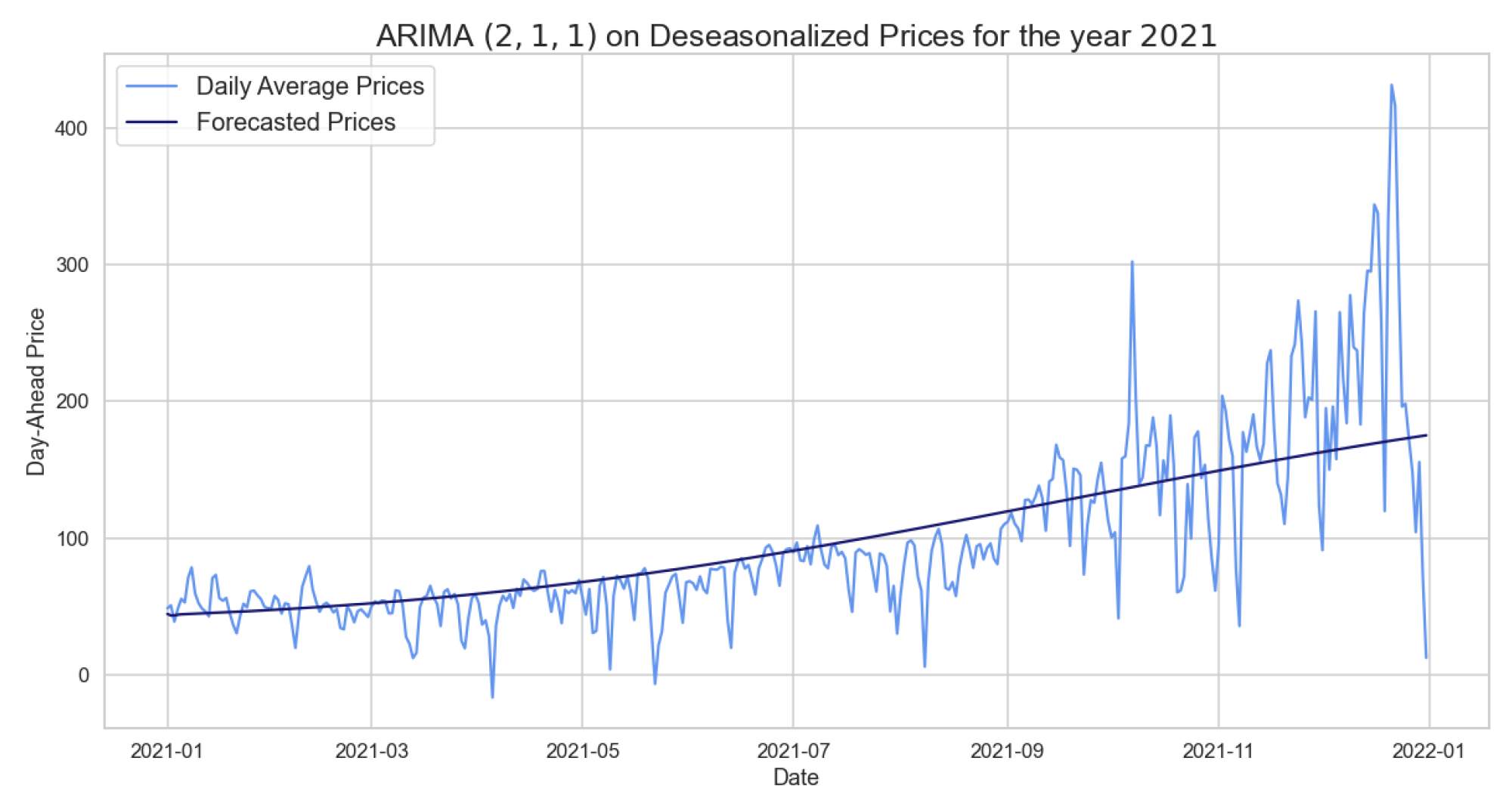
Figure 10.
Comparison of target and forecast values for 2021 using 2020 as training set with for daily average prices.
Figure 10.
Comparison of target and forecast values for 2021 using 2020 as training set with for daily average prices.
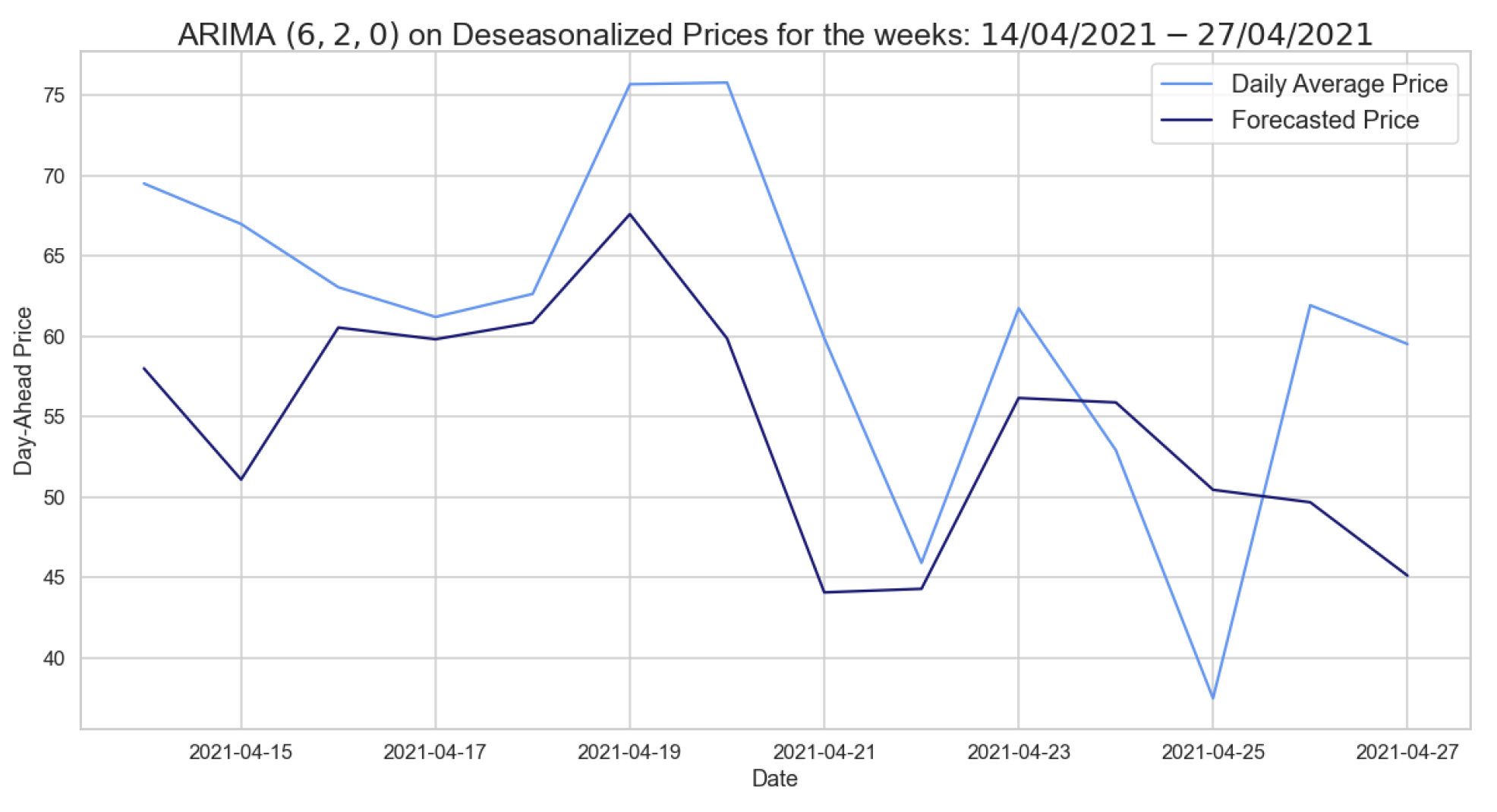
Figure 11.
Comparison of target and forecast values for two weeks in 2021 using spring–summer as the training set with ARIMA for the deseasonalized daily average prices.
Figure 11.
Comparison of target and forecast values for two weeks in 2021 using spring–summer as the training set with ARIMA for the deseasonalized daily average prices.
Figure 12.
Comparison of target and forecast values for one week using 2020 as the training set with for daily hourly prices.
Figure 12.
Comparison of target and forecast values for one week using 2020 as the training set with for daily hourly prices.
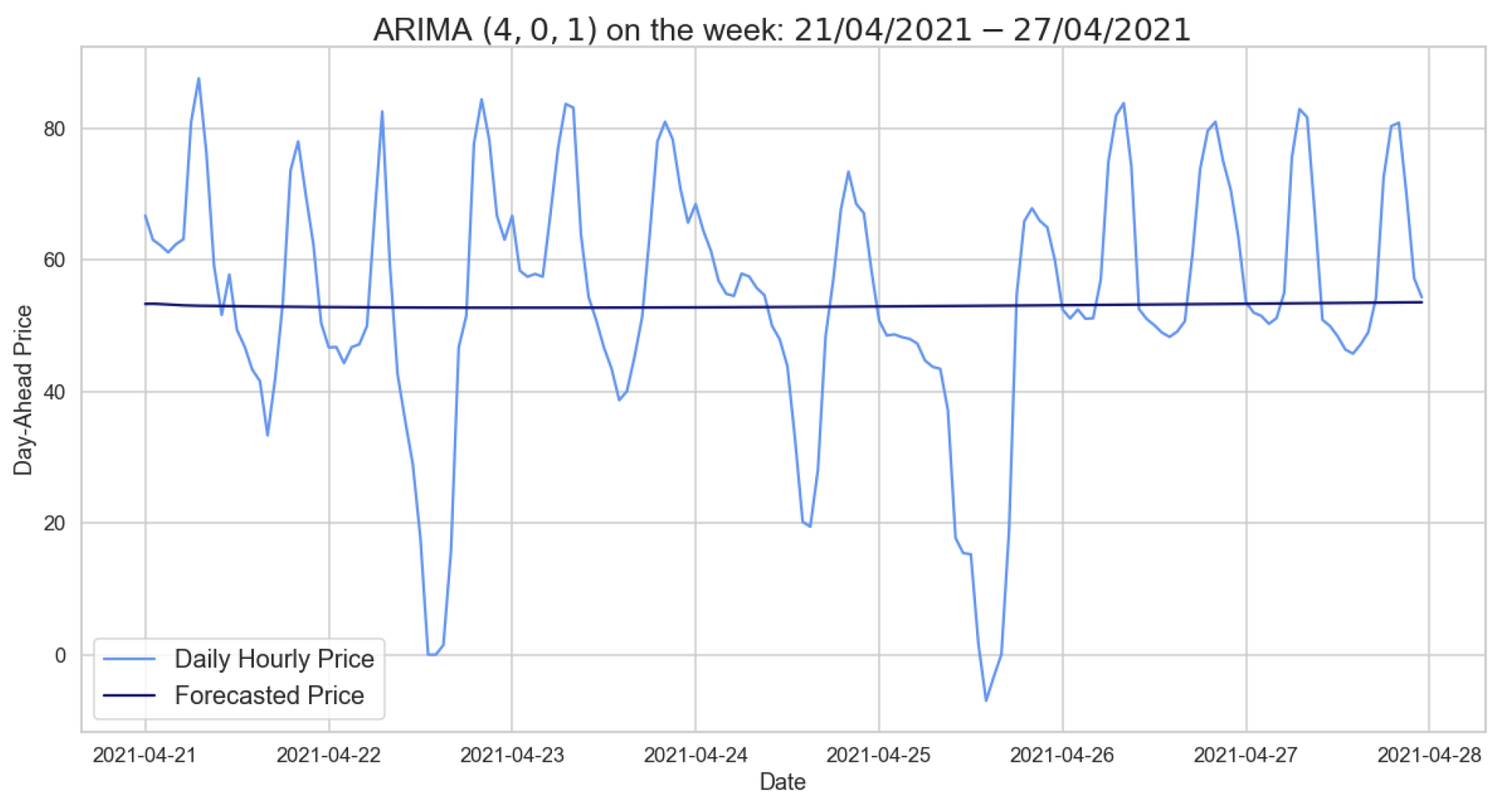
Figure 13.
Comparison of target and forecast values with AR dummies for one day in 2021 using 2020 as training set on daily hourly prices.
Figure 13.
Comparison of target and forecast values with AR dummies for one day in 2021 using 2020 as training set on daily hourly prices.
Figure 14.
Feature importance of the XGBoost on daily average prices for two weeks using the autumn–winter period as the training set.
Figure 14.
Feature importance of the XGBoost on daily average prices for two weeks using the autumn–winter period as the training set.
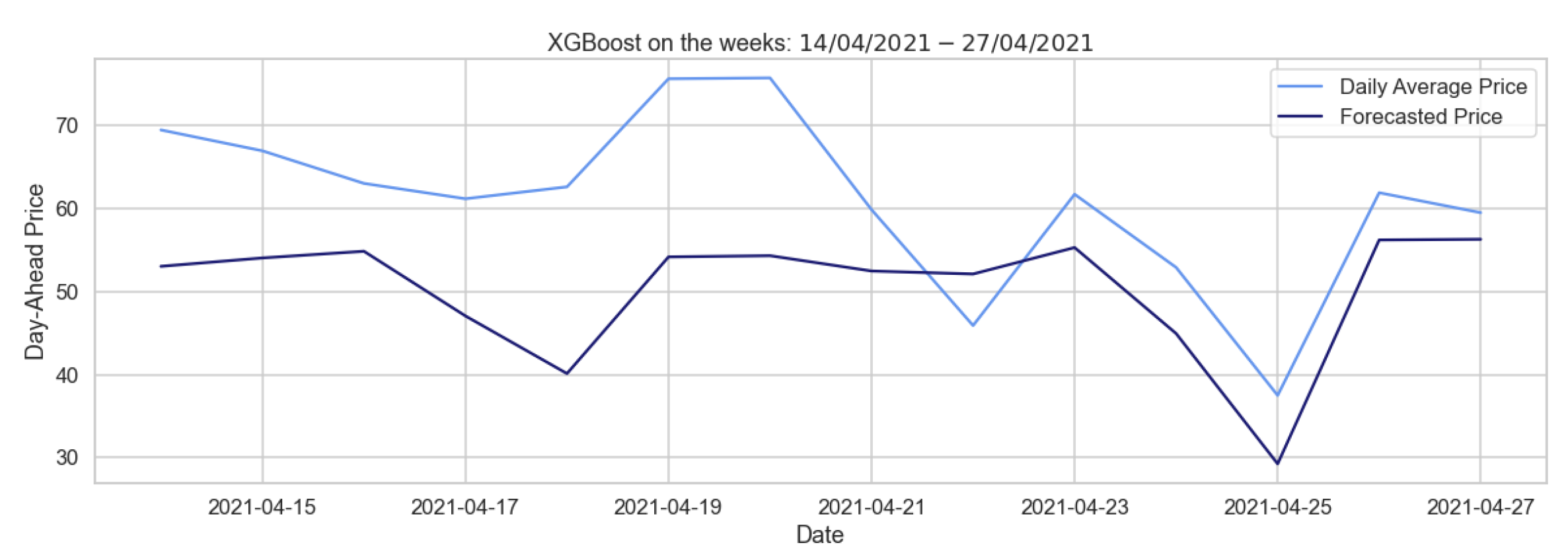
Figure 15.
Comparison of target and forecast with XGBoost on daily average prices for two weeks using autumn–winter as the training set.
Figure 15.
Comparison of target and forecast with XGBoost on daily average prices for two weeks using autumn–winter as the training set.
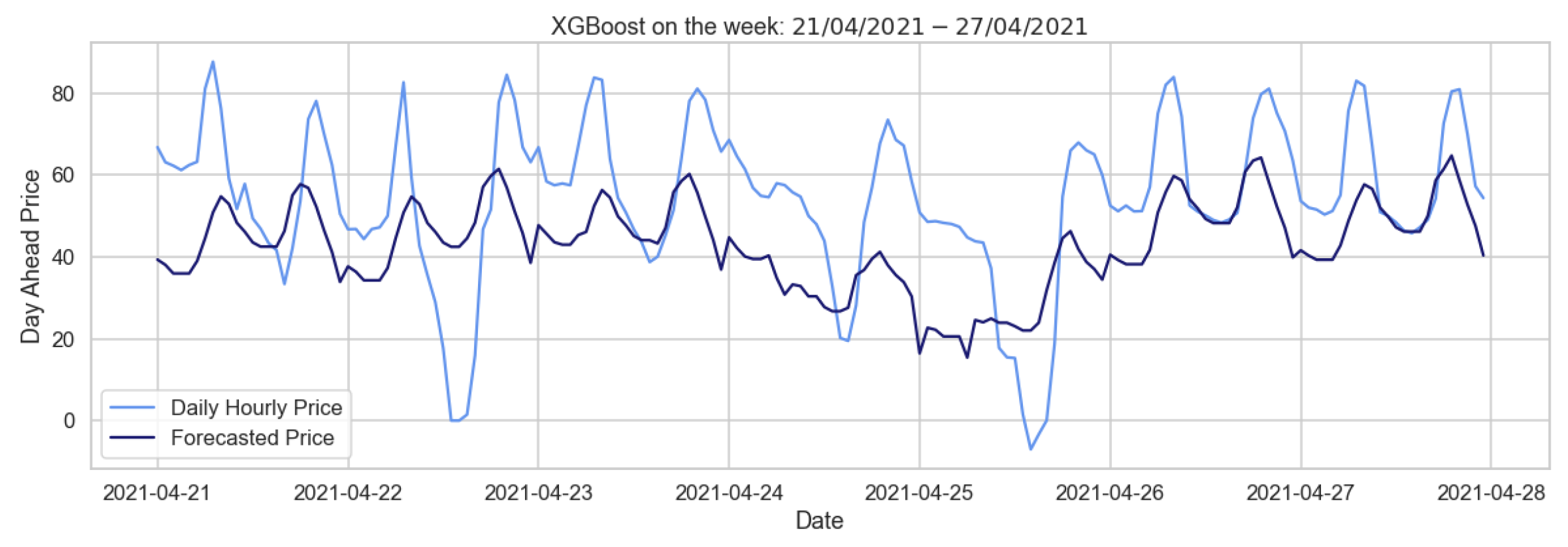
Figure 16.
Comparison of target and forecast values for one week using autumn–winter as the training set with the XGBoost model on daily hourly prices.
Figure 16.
Comparison of target and forecast values for one week using autumn–winter as the training set with the XGBoost model on daily hourly prices.
Figure 17.
Comparison of target and forecast values for the year 2021 using 2020 as the training set with the LSTM model on daily average prices.
Figure 17.
Comparison of target and forecast values for the year 2021 using 2020 as the training set with the LSTM model on daily average prices.
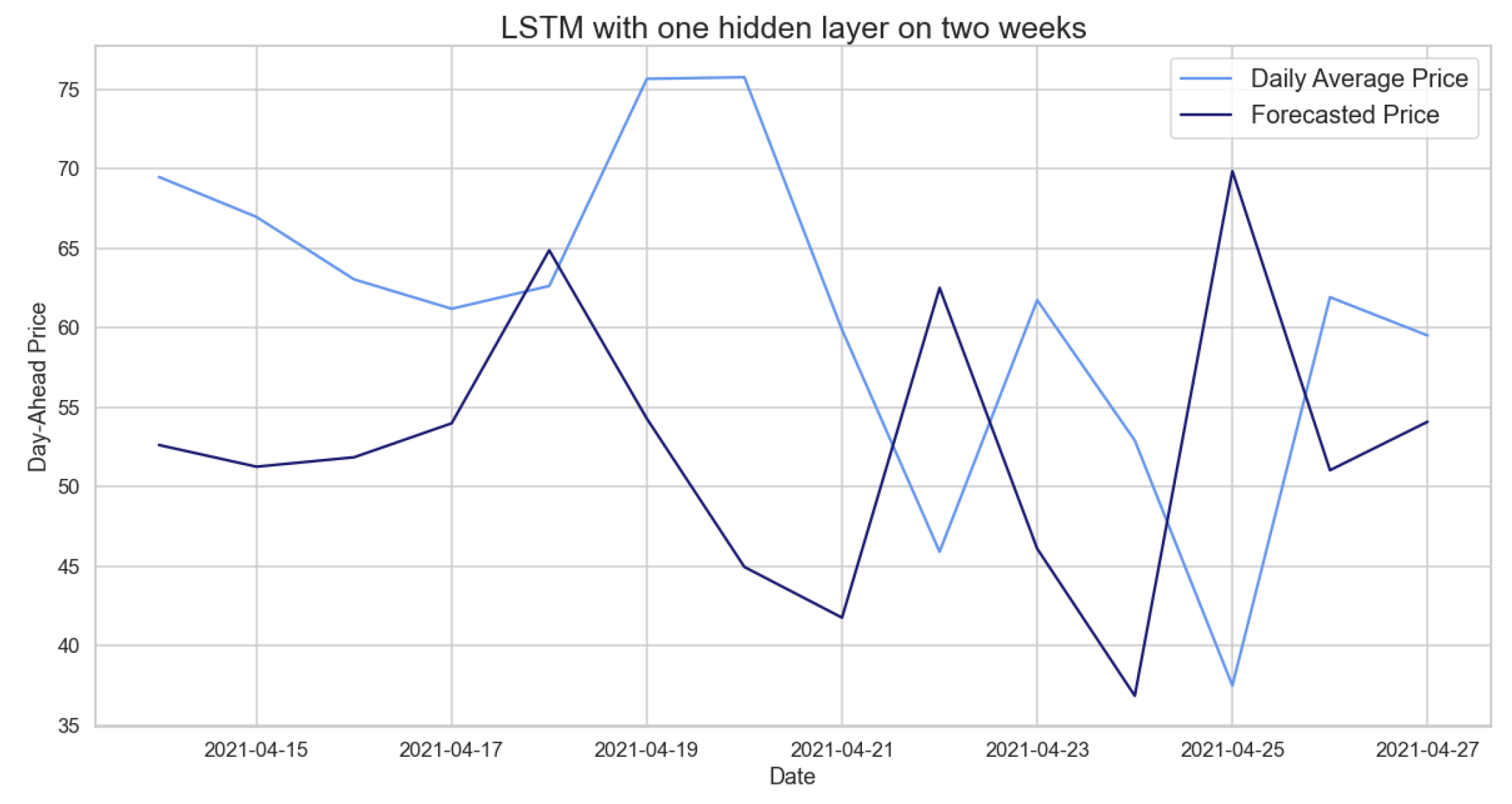
Figure 18.
Comparison of target and forecast values for two weeks using 2020 as the training set with the LSTM model on daily average prices.
Figure 18.
Comparison of target and forecast values for two weeks using 2020 as the training set with the LSTM model on daily average prices.
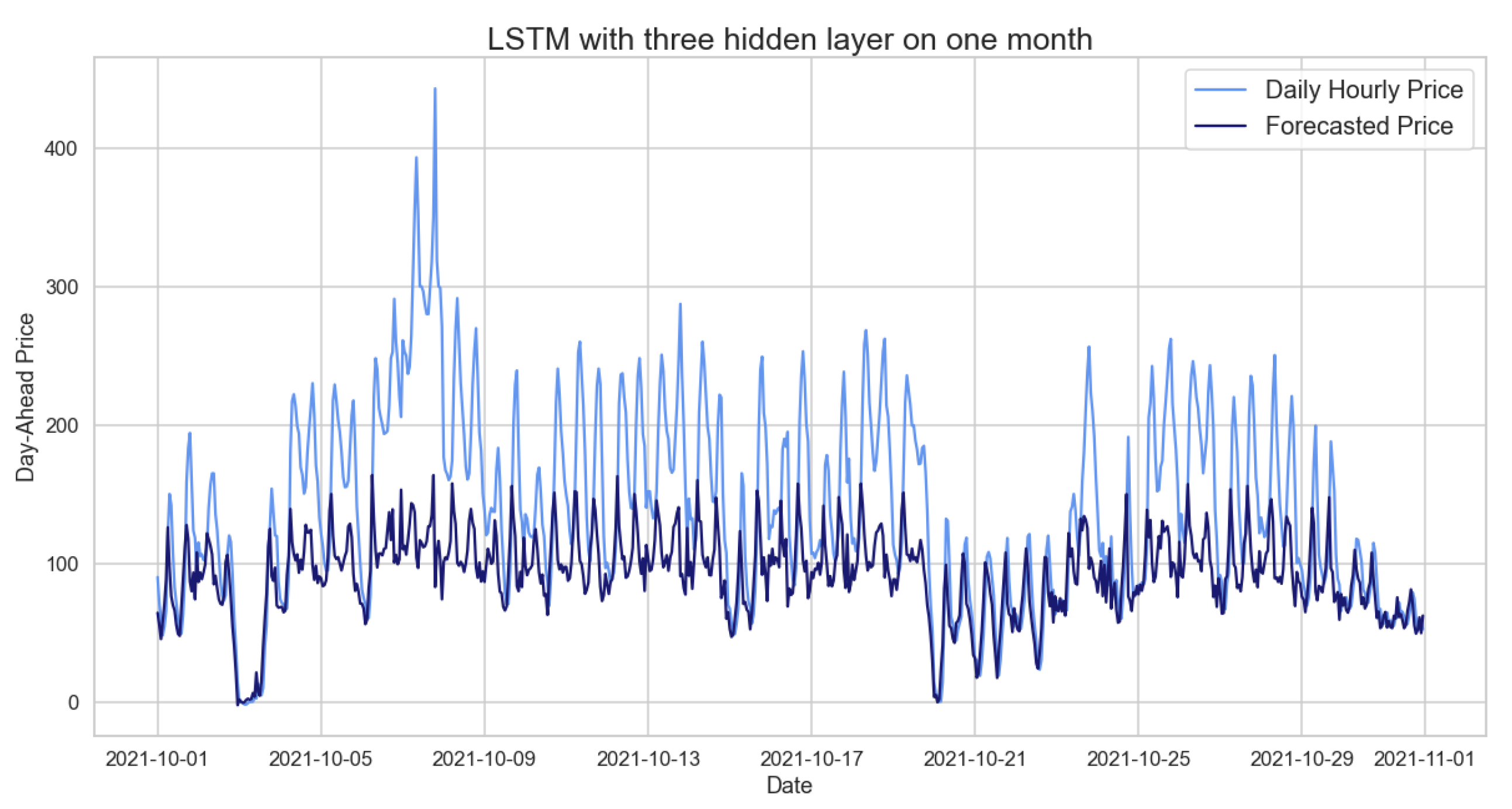
Figure 19.
Comparison of target and forecast values for one month using 2020 as the training set with the LSTM model on daily hourly prices.
Figure 19.
Comparison of target and forecast values for one month using 2020 as the training set with the LSTM model on daily hourly prices.
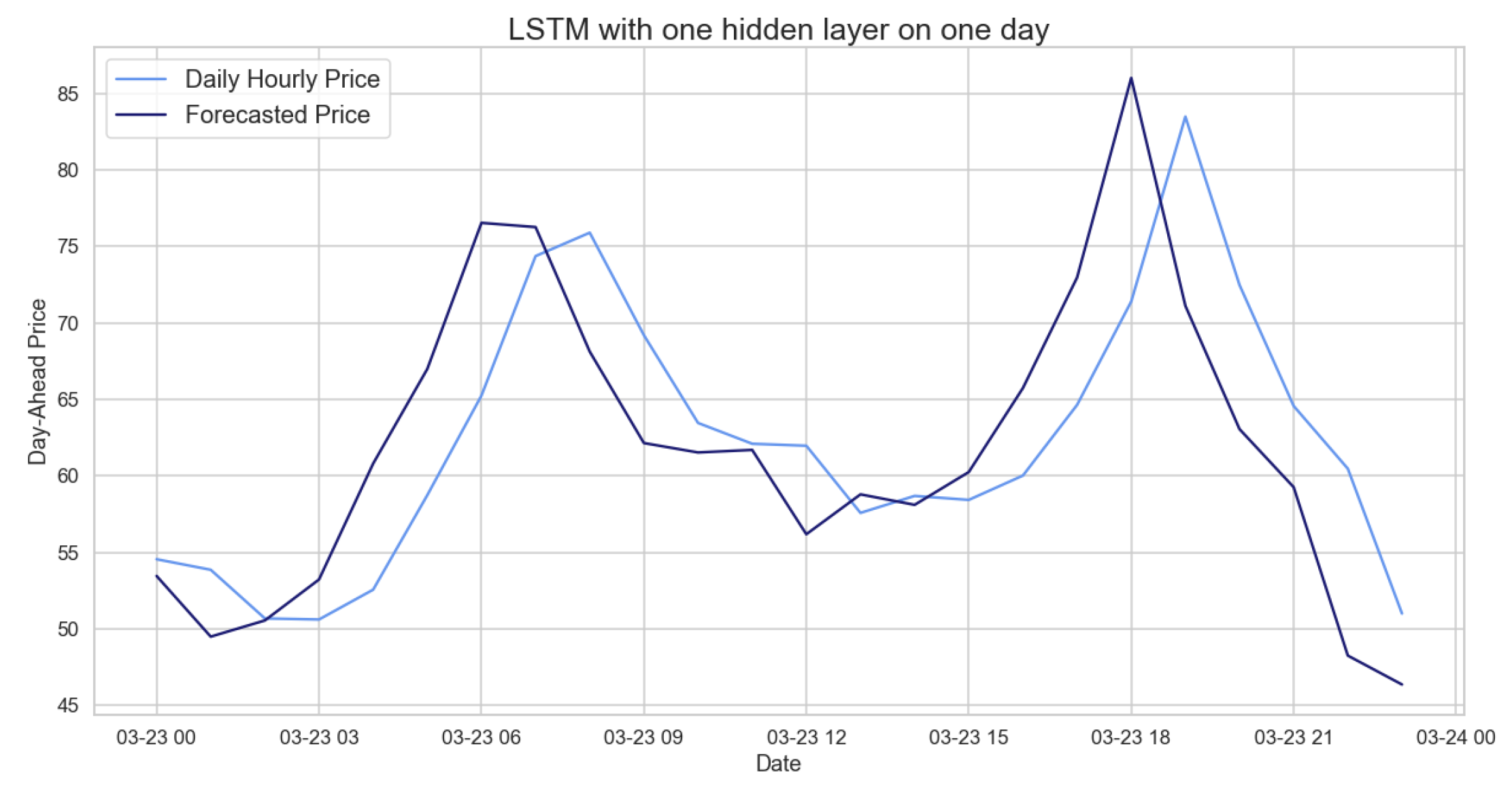
Figure 20.
Comparison of target and forecast values for one day using 2020 as the training set with the LSTM model on daily hourly prices.
Figure 20.
Comparison of target and forecast values for one day using 2020 as the training set with the LSTM model on daily hourly prices.
Table 1.
RMSE of naive benchmark on different training and test periods for daily average prices.
Table 1.
RMSE of naive benchmark on different training and test periods for daily average prices.
| Naive Benchmark |
|---|
| Training Period | Test Period | RMSE |
| 2020 | 2021 | 91.0102 |
| 2020–2021 | 2022 | 150.4029 |
| two weeks in 2020 | two weeks in 2021 | 56.0675 |
Table 2.
RMSE of the naive benchmark model on different training and test periods for daily hourly prices.
Table 2.
RMSE of the naive benchmark model on different training and test periods for daily hourly prices.
| Naive Benchmark |
|---|
| Training Period | Test Period | RMSE |
| one month in 2020 | one month in 2021 | 123.8230 |
| one week in 2020 | one week in 2021 | 51.5851 |
| one day in 2020 | one day in 2021 | 31.6256 |
Table 3.
RMSE of the SARIMA model of 2020–2021 for testing mid-2022 for the daily average prices.
Table 3.
RMSE of the SARIMA model of 2020–2021 for testing mid-2022 for the daily average prices.
| SARIMA (2, 0, 2) × (0, 1, 1) |
|---|
| Training Period | RMSE |
| 2020–2021 | 77.6600 |
Table 4.
RMSE of the SARIMA model trained on different time windows for testing two weeks.
Table 4.
RMSE of the SARIMA model trained on different time windows for testing two weeks.
| RMSE of Two Weeks of Testing in 2021 |
|---|
| Training Period | | RMSE |
| 2020 | | 23.3416 |
| Spring–Summer | | 17.1818 |
| Autumn–Winter | | 12.2135 |
Table 5.
The p-values of the Ljung–Box test for the SARIMA model for 2 weeks of testing.
Table 5.
The p-values of the Ljung–Box test for the SARIMA model for 2 weeks of testing.
| Ljung–Box Test |
|---|
| Training Period | -Value | Null Hypothesis |
| 2020 | 0.93 | not rejected |
| Spring–Summer | 0.87 | not rejected |
| Autumn–Winter | 0.69 | not rejected |
Table 6.
The p-values of the Ljung–Box test for the SARIMA model of a one-month test.
Table 6.
The p-values of the Ljung–Box test for the SARIMA model of a one-month test.
| Ljung–Box Test |
|---|
| Training Period | -Value | Null Hypothesis |
| 2020 | 0.33 | not rejected |
| Spring–Summer | 0.92 | not rejected |
| Autumn–Winter | 0.96 | not rejected |
Table 7.
RMSE of the SARIMA model of different time windows for testing one month in 2021.
Table 7.
RMSE of the SARIMA model of different time windows for testing one month in 2021.
| RMSE of One Month of Testing in 2021 |
|---|
| Training Period | | RMSE |
| 2020 | | 118.8870 |
| Spring–Summer | | 107.9992 |
| Autumn–Winter | | 110.7636 |
Table 8.
RMSE of the SARIMA model of different time windows for testing one week.
Table 8.
RMSE of the SARIMA model of different time windows for testing one week.
| RMSE of One Week of Testing in 2021 |
|---|
| Training Period | SARIMA (p, d, q) × (P, D, Q) | RMSE |
| 2020 | | 41.7355 |
| Spring–Summer | | 19.6915 |
| Autumn–Winter | | 16.5124 |
Table 9.
RMSE of the SARIMA model of different time windows for testing one day for the hourly prices.
Table 9.
RMSE of the SARIMA model of different time windows for testing one day for the hourly prices.
| RMSE of One Day of Testing in 2021 |
|---|
| Training Period | | RMSE |
| 2020 | | 7.8986 |
| Spring–Summer | | 16.9000 |
| Autumn–Winter | | 12.1786 |
Table 10.
RMSE of the ARIMA model of 2020 for testing 2021 on the daily average deseasonalized prices.
Table 10.
RMSE of the ARIMA model of 2020 for testing 2021 on the daily average deseasonalized prices.
| ARIMA |
|---|
| Training Period | RMSE |
| 2020 | 43.4172 |
Table 11.
RMSE of the SARIMA model of 2020 for testing 2021 for the daily average prices.
Table 11.
RMSE of the SARIMA model of 2020 for testing 2021 for the daily average prices.
| SARIMA (3, 1, 3) × (1, 1, 1) |
|---|
| Training Period | RMSE |
| 2020 | 85.3509 |
Table 12.
RMSE of ARIMA on 2020–2021 for testing mid-2022 on daily average deseasonalized prices.
Table 12.
RMSE of ARIMA on 2020–2021 for testing mid-2022 on daily average deseasonalized prices.
| ARIMA |
|---|
| Training Period | RMSE |
| 2020–2021 | 77.6933 |
Table 13.
RMSE of the ARIMA model for testing two weeks on daily average deseasonalized prices.
Table 13.
RMSE of the ARIMA model for testing two weeks on daily average deseasonalized prices.
| RMSE of Two Weeks of Testing in 2021 |
|---|
| Training Period | | RMSE |
| 2020 | | 11.1749 |
| Spring–Summer | | 10.4634 |
| Autumn–Winter | | 11.2119 |
Table 14.
The p-values of the Ljung–Box test for the ARIMA model on a two-week test.
Table 14.
The p-values of the Ljung–Box test for the ARIMA model on a two-week test.
| Ljung–Box Test on a Two-Weeks Test |
|---|
| Training Period | -Value | Null Hypothesis |
| 2020 | 0.83 | not rejected |
| Spring–Summer | 0.24 | not rejected |
| Autumn–Winter | 0.95 | not rejected |
Table 15.
RMSE of the ARIMA model on different training sets for testing one month on the hourly deseasonalized prices.
Table 15.
RMSE of the ARIMA model on different training sets for testing one month on the hourly deseasonalized prices.
| RMSE of One Month of Testing in 2021 |
|---|
| Training Period | | RMSE |
| 2020 | | 71.1059 |
| Spring–Summer | | 71.0840 |
| Autumn–Winter | | 71.3371 |
Table 16.
The p-values of the Ljung–Box test for the ARIMA models on a one-month test.
Table 16.
The p-values of the Ljung–Box test for the ARIMA models on a one-month test.
| Ljung–Box Test on One Month of Test |
|---|
| Training Period | -Value | Null Hypothesis |
| 2020 | 0.97 | not rejected |
| Spring–Summer | 0.99 | not rejected |
| Autumn–Winter | 1 | not rejected |
Table 17.
RMSE of the ARIMA model on different training sets for testing one week on the hourly deseasonalized prices.
Table 17.
RMSE of the ARIMA model on different training sets for testing one week on the hourly deseasonalized prices.
| RMSE of One Week of Testing in 2021 |
|---|
| Training Period | | RMSE |
| 2020 | | 19.1394 |
| Spring–Summer | | 19.2664 |
| Autumn–Winter | | 19.2074 |
Table 18.
RMSE of the ARIMA model of different training sets for testing one day on the hourly deseasonalized prices.
Table 18.
RMSE of the ARIMA model of different training sets for testing one day on the hourly deseasonalized prices.
| RMSE of One Day of Testing in 2021 |
|---|
| Training Period | | RMSE |
| 2020 | | 16.8249 |
| Spring–Summer | | 16.6854 |
| Autumn–Winter | | 14.2826 |
Table 19.
RMSE of the AR with the dummies model of different training sets for testing one day on the hourly deseasonalized prices.
Table 19.
RMSE of the AR with the dummies model of different training sets for testing one day on the hourly deseasonalized prices.
| AR with Dummies |
|---|
| Training Period | RMSE |
| 2020 | 26.1521 |
| Spring–Summer | 43.4731 |
| Autumn–Winter | 39.1706 |
Table 20.
RMSE of XGBoost model on different training and test periods for the daily average prices.
Table 20.
RMSE of XGBoost model on different training and test periods for the daily average prices.
| XGBoost |
|---|
| Training Period | Test Period | RMSE |
| 2020 | 2021 | 90.1138 |
| 2020–2021 | 2022 | 148.2663 |
Table 21.
RMSE of the XGBoost model on different training periods for testing two weeks in 2021 on the daily average prices.
Table 21.
RMSE of the XGBoost model on different training periods for testing two weeks in 2021 on the daily average prices.
| XGBoost |
|---|
| Training Period | Test Period | RMSE |
| 2020 | two weeks in 2021 | 46.6614 |
| Spring–Summer | two weeks in 2021 | 47.8949 |
| Autumn–Winter | two weeks in 2021 | 13.2064 |
Table 22.
RMSE of the XGBoost model of one month in 2021 for the daily hourly prices.
Table 22.
RMSE of the XGBoost model of one month in 2021 for the daily hourly prices.
| XGBoost |
|---|
| Training Period | Test Period | RMSE |
| 2020 | one month in 2021 | 122.8169 |
| Spring–Summer | one month in 2021 | 114.8268 |
| Autumn–Winter | one month in 2021 | 123.3496 |
Table 23.
RMSE of the XGBoost model of different training periods for testing one week in 2021 on the daily hourly prices.
Table 23.
RMSE of the XGBoost model of different training periods for testing one week in 2021 on the daily hourly prices.
| XGBoost |
|---|
| Training Period | Test Period | RMSE |
| 2020 | one week in 2021 | 42.4270 |
| Spring–Summer | one week in 2021 | 41.3770 |
| Autumn–Winter | one week in 2021 | 19.7381 |
Table 24.
RMSE of the XGBoost model of different training periods for testing one day in 2021.
Table 24.
RMSE of the XGBoost model of different training periods for testing one day in 2021.
| XGBoost |
|---|
| Training Period | Test Period | RMSE |
| 2020 | one day in 2021 | 40.3105 |
| Spring–Summer | one day in 2021 | 40.9339 |
| Autumn–Winter | one day in 2021 | 7.7653 |
Table 25.
RMSE of the LSTM of training period 2020 for testing one year on the daily average prices.
Table 25.
RMSE of the LSTM of training period 2020 for testing one year on the daily average prices.
| LSTM with One Hidden Layer |
|---|
| Training Period | Epochs | RMSE |
| 2020 | 250 | 34.0001 |
Table 26.
RMSE of LSTM of training period 2020–2021 for testing mid-2022 on the daily average prices.
Table 26.
RMSE of LSTM of training period 2020–2021 for testing mid-2022 on the daily average prices.
|
LSTM with Two Hidden Layers |
|---|
| Training Period | Epochs | RMSE |
| 2020–2021 | 250 | 57.8398 |
Table 27.
RMSE of the LSTM model of different training periods for testing two weeks in 2021 on daily average prices.
Table 27.
RMSE of the LSTM model of different training periods for testing two weeks in 2021 on daily average prices.
| LSTM with One Hidden Layer |
|---|
| Training Period | Hidden Layers | Epochs | RMSE |
| 2020 | 400 units | 300 | 11.0914 |
| Spring–Summer | 400 units | 300 | 9.5359 |
| Autumn–Winter | 400 units | 300 | 13.8709 |
Table 28.
RMSE of the LSTM model of different training periods for testing one month in 2021.
Table 28.
RMSE of the LSTM model of different training periods for testing one month in 2021.
| LSTM with Different Number of Hidden Layers |
|---|
| Training Period | Epochs | LSTM Layers | RMSE |
| 2020 | 300 | 3 | 67.5297 |
| Spring–Summer | 300 | 2 | 75.1064 |
| Autumn–Winter | 300 | 3 | 74.7541 |
Table 29.
RMSE of the LSTM model of different training periods for testing one week in 2021.
Table 29.
RMSE of the LSTM model of different training periods for testing one week in 2021.
| LSTM with Different Numbers of Hidden Layers |
|---|
| Training Period | Epochs | RMSE |
| 2020 | 300 | 11.3126 |
| Spring–Summer | 150 | 14.3904 |
| Autumn–Winter | 250 | 12.6480 |
Table 30.
RMSE of the LSTM model for different training periods for testing one day in 2021.
Table 30.
RMSE of the LSTM model for different training periods for testing one day in 2021.
| LSTM with Different Numbers of Hidden Layers |
|---|
| Training Period | Epochs | RMSE |
| 2020 | 250 | 7.2073 |
| Spring–Summer | 250 | 8.2753 |
| Autumn–Winter | 250 | 8.2147 |


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}