
A Multilevel Monte Carlo Approach for a Stochastic Optimal Control Problem Based on the Gradient Projection Method


Abstract
1. Introduction
2. Stochastic Optimal Control Problem
3. Review of Gradient Projection Method and MLMC Method
3.1. Gradient Projection Method
3.2. MLMC Method
3.2.1. Scalar-Valued Quantities of Output
3.2.2. Function Valued Quantities of Output
4. MLMC Method Based on Gradient Projection
4.1. Classic Monte Carlo Method
4.2. Multilevel Monte Carlo Method
4.3. Gradient Projection Based on Optimization
4.4. MLMC Gradient Projection Algorithm
| Algorithm 1: MLMC gradient projection based optimization |
1: input , , , , 2: for i = 1, do 3: estimate 4: estimate 5: if then 6: return 7: end if 8: if or then 9: or 10: else 11: 12: end if 13: end for |
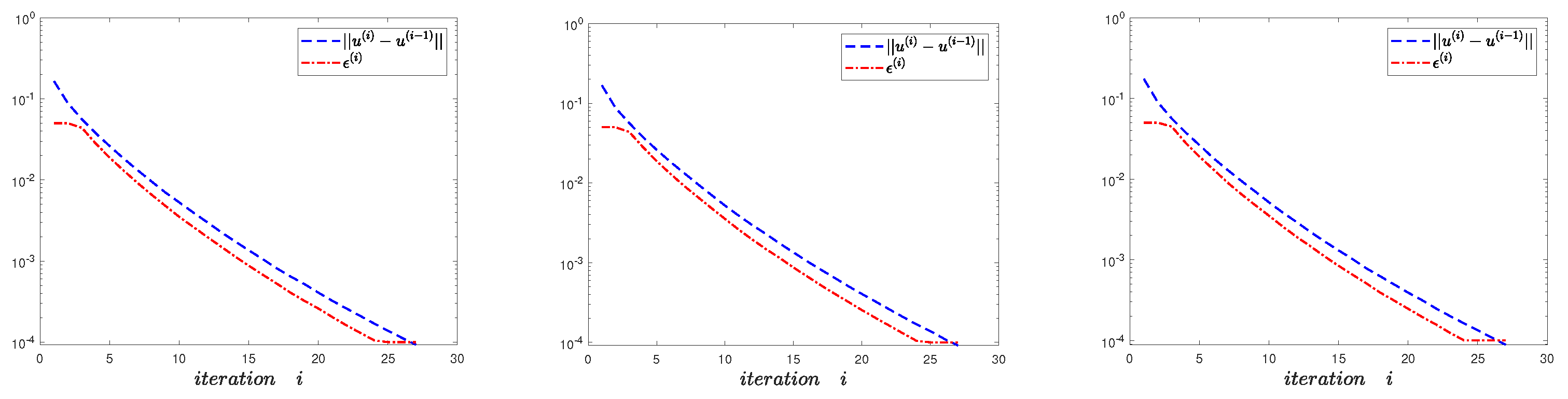
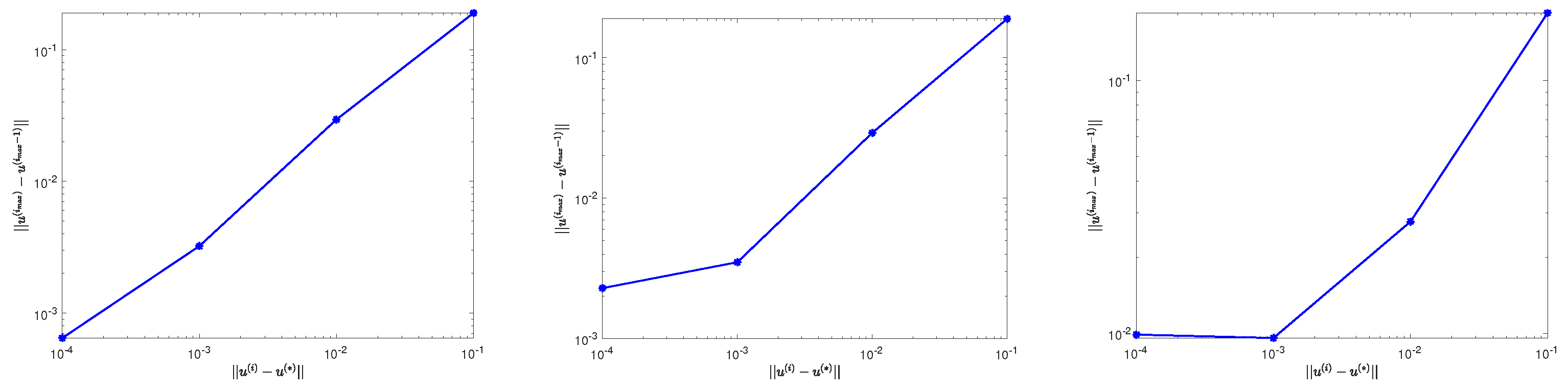
4.5. Convergence Analysis of the Algorithm
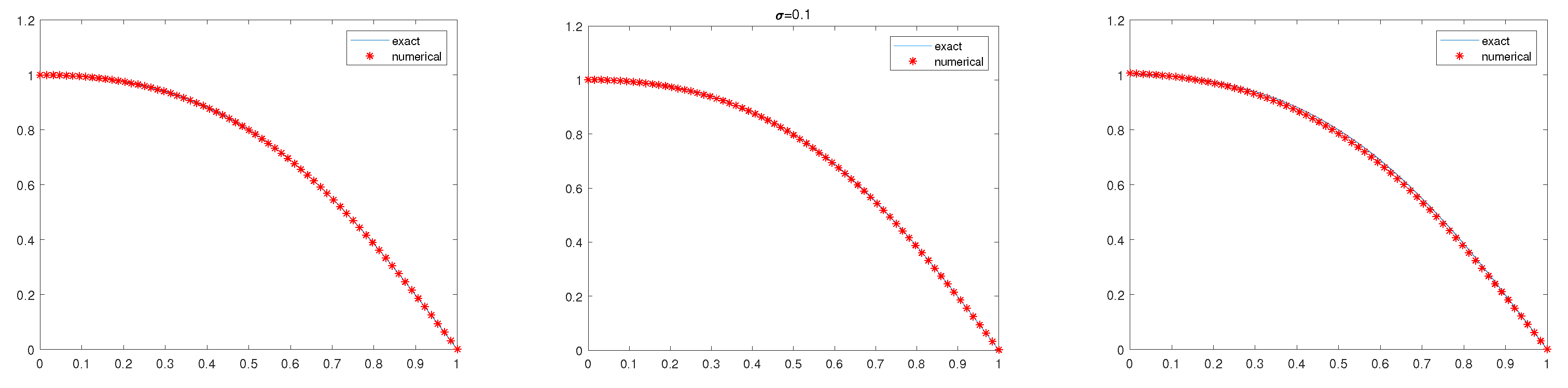
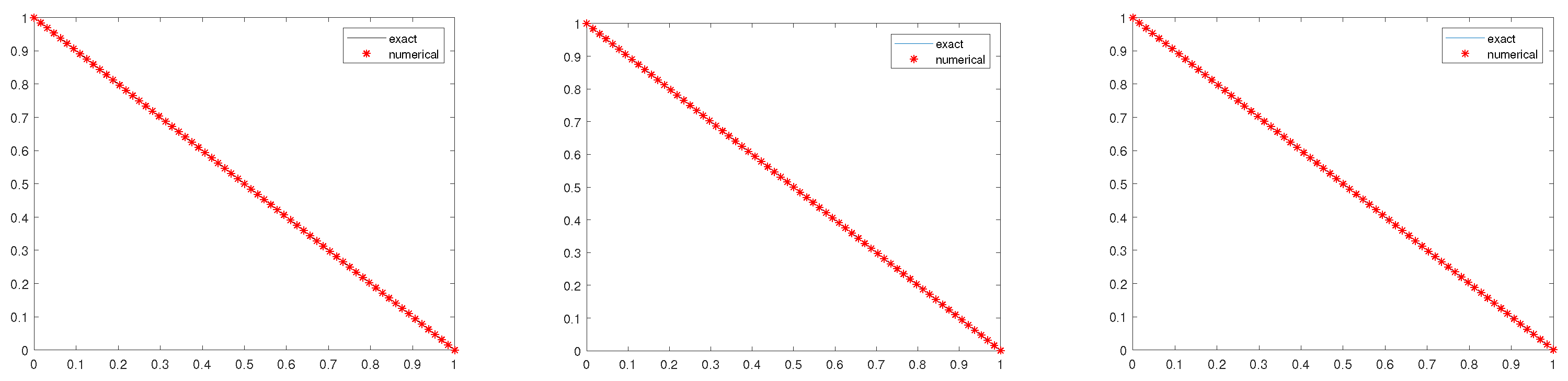
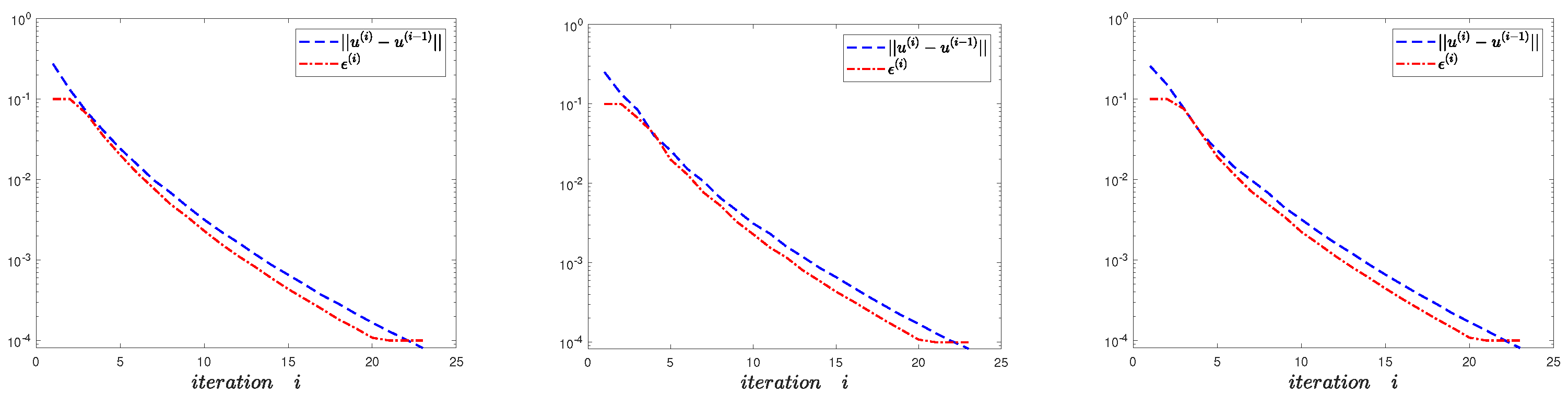
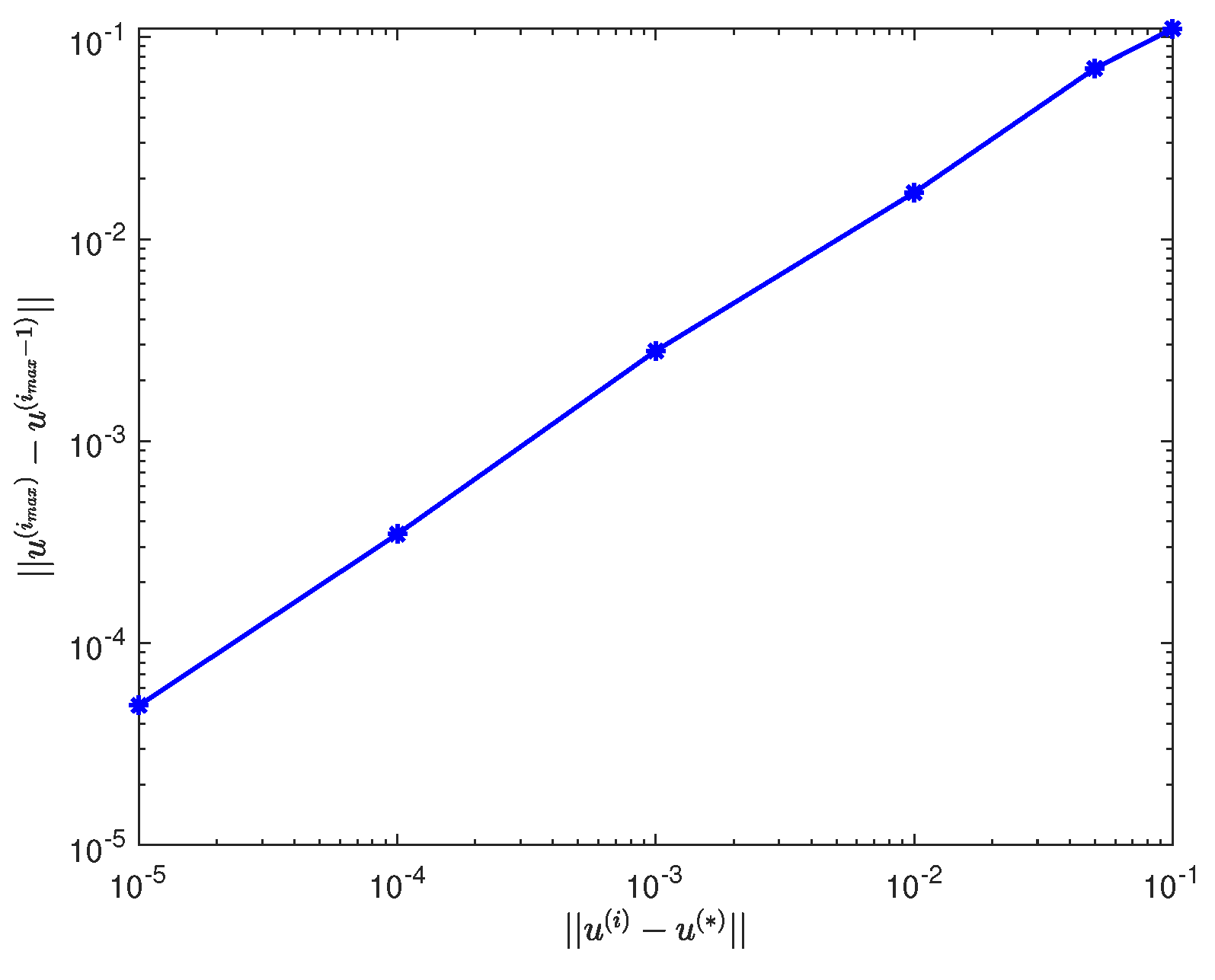
5. Numerical Experiments
5.1. Example 1
5.2. Example 2
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cerone, V.; Regruto, D.; Abuabiah, M.; Fadda, E. A kernel- based nonparametric approach to direct data-driven control of LTI systems. IFAC-PapersOnLine 2018, 51, 1026–1031. [Google Scholar] [CrossRef]
- Hinze, M.; Pinnau, R.; Ulbrich, M.; Ulbrich, S. Optimization with PDE Constraints; Springer: New York, NY, USA, 2009. [Google Scholar]
- Liu, W.; Yan, N. Adaptive Finite Element Methods: Optimal Control Governed by PDEs; Science Press: Beijing, China, 2008. [Google Scholar]
- Luo, X. A priori error estimates of Crank-Nicolson finite volume element method for a hyperbolic optimal control problem. Numer. Methods Partial Differ. Equ. 2016, 32, 1331–1356. [Google Scholar] [CrossRef]
- Luo, X.; Chen, Y.; Huang, Y.; Hou, T. Some error estimates of finite volume element method for parabolic optimal control problems. Optim. Control Appl. Methods 2014, 35, 145–165. [Google Scholar] [CrossRef]
- Luo, X.; Chen, Y.; Huang, Y. A priori error estimates of finite volume element method for hyperbolic optimal control problems. Sci. China Math. 2013, 56, 901–914. [Google Scholar] [CrossRef]
- Ali, A.A.; Ullmann, E.; Hinze, M. Multilevel Monte Carlo analysis for optimal control of elliptic PDEs with random coefficients. SIAM/ASA J. Uncertain. Quantif. 2016, 5, 466–492. [Google Scholar] [CrossRef]
- Borzi, A.; Winckel, G. Multigrid methods and sparse-grid collocation techniques for parabolic optimal control problems with random coefficients. SIAM J. Sci. Comput. 2009, 31, 2172–2192. [Google Scholar] [CrossRef]
- Sun, T.; Shen, W.; Gong, B.; Liu, W. A priori error estimate of stochastic Galerkin method for optimal control problem governed by random parabolic PDE with constrained control. J. Sci. Comput. 2016, 67, 405–431. [Google Scholar] [CrossRef]
- Archibald, R.; Bao, F.; Yong, J.; Zhou, T. An efficient numerical algorithm for solving data driven feedback control problems. J. Sci. Comput. 2020, 85, 51. [Google Scholar] [CrossRef]
- Haussmann, U.G. Some examples of optimal stochastic controls or: The stochastic maximum principle at work. SIAM Rev. 1981, 23, 292–307. [Google Scholar] [CrossRef]
- Kushner, H.J.; Dupuis, P. Numerical Methods for Stochastic Control Problems in Continuous Time, 2nd ed.; Springer: New York, NY, USA, 2001. [Google Scholar]
- Korn, R.; Kraft, H. A stochastic control approach to portfolio problems with stochastic interest rates. SIAM J. Control Optim. 2001, 40, 1250–1269. [Google Scholar] [CrossRef]
- Archibald, R.; Bao, F.; Yong, J. A stochastic gradient descent approach for stochastic optimal control. East Asian J. Appl. Math. 2020, 10, 635–658. [Google Scholar] [CrossRef]
- Du, N.; Shi, J.; Liu, W. An effective gradient projection method for stochastic optimal control. Int. J. Numer. Anal. Model. 2013, 10, 757–774. [Google Scholar]
- Gong, B.; Liu, W.; Tang, T. An efficient gradient projection method for stochastic optimal control problems. SIAM J. Numer. Anal. 2017, 55, 2982–3005. [Google Scholar] [CrossRef]
- Wang, Y. Error analysis of a discretization for stochastic linear quadratic control problems governed by SDEs. IMA J. Math. Control Inf. 2021, 38, 1148–1173. [Google Scholar] [CrossRef]
- Barel, A.V.; Vandewalle, S. Robust optimization of PDEs with random coefficients using a multilevel Monte Carlo method. SIAM/ASA J. Uncertain. Quantif. 2017, 7, 174–202. [Google Scholar] [CrossRef]
- Cliffe, K.A.; Giles, M.B.; Scheichl, R.; Teckentrup, A.L. Multilevel Monte Carlo methods and applications to elliptic PDEs with random coefficients. Comput. Vis. Sci. 2011, 14, 3–15. [Google Scholar] [CrossRef]
- Giles, M.B. Multilevel Monte Carlo Path Simulation. Oper. Res. 2008, 56, 607–617. [Google Scholar] [CrossRef]
- Giles, M.B. Multilevel Monte Carlo methods. Acta Numer. 2015, 24, 259–328. [Google Scholar] [CrossRef]
- Kornhuber, R.; Schwab, C.; Wolf, M.W. Multilevel Monte Carlo finite element methods for stochastic elliptic variational inequalities. SIAM J. Numer. Anal. 2014, 52, 1243–1268. [Google Scholar] [CrossRef]
- Li, M.; Luo, X. An MLMCE-HDG method for the convection diffusion equation with random diffusivity. Comput. Math. Appl. 2022, 127, 127–143. [Google Scholar] [CrossRef]
- Li, M.; Luo, X. Convergence analysis and cost estimate of an MLMC-HDG method for elliptic PDEs with random coefficients. Mathematics 2021, 9, 1072. [Google Scholar] [CrossRef]
- Ikeda, N.; Watanabe, S. Stochastic Differential Equations and Diffusion Processes, 2nd ed.; North-Holland Publishing Company: New York, NY, USA, 1989. [Google Scholar]
- Ma, J.; Yong, J. Forward-Backward Stochastic Differential Equations and their Applications; Springer: Berlin/Heidelberg, Germany, 2007; pp. 51–79. [Google Scholar]
- Peng, S. Backward stochastic differential equations and applications to optimal control. Appl. Math. Optim. 1993, 27, 125–144. [Google Scholar] [CrossRef]
- Brenner, S.C.; Scott, L.R. The Mathematical Theory of Finite Element Methods, 3rd ed.; Springer: New York, NY, USA, 2007. [Google Scholar]
- Li, T.; Vanden-Eijnden, E. Applied Stochastic Analysis; AMS: Providengce, RI, USA, 2019. [Google Scholar]
- Lord, G.J.; Powell, C.E.; Shardlow, T. An Introduction to Computational Stochastic PDEs; Cambridge University Press: New York, NY, USA, 2014. [Google Scholar]
- Alaya, M.B.; Hajji, K.; Kebaier, A. Adaptive importance sampling for multilevel Monte Carlo Euler method. Stochastics 2022. [Google Scholar] [CrossRef]
- Kebaier, A.; Lelong, J. Coupling importance sampling and multilevel Monte Carlo using sample average approximation. Methodol. Comput. Appl. Probab. 2018, 20, 611–641. [Google Scholar] [CrossRef]
- Giles, M.B.; Waterhouse, B.J. Multilevel quasi-Monte Carlo path simulation. In Advanced Financial Modeling; Albrecher, H., Runggaldier, W.J., Schachermayer, W., Eds.; de Gruyter: New York, NY, USA, 2009; pp. 165–181. [Google Scholar]
- Kuo, F.Y.; Schwab, C.; Sloan, I.H. Multi-level quasi-Monte Carlo finite element methods for a class of elliptic partial differential equation with random coefficients. Found. Comput. Math. 2015, 15, 411–449. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| i | ||||||||
|---|---|---|---|---|---|---|---|---|
| 3 | 178 | 3 | 1 | 0.08 | ||||
| 7 | 4273 | 55 | 10 | 0.09 | ||||
| 11 | 53,203 | 749 | 126 | 0.20 | ||||
| 15 | 508,312 | 6715 | 1181 | 254 | 1.70 | |||
| 19 | 3,816,292 | 51,158 | 8526 | 1880 | 463 | 11.63 | ||
| 23 | 23,879,767 | 321,838 | 54,732 | 11,887 | 2892 | 67.07 |
| i | |||||||
|---|---|---|---|---|---|---|---|
| 3 | 2785 | 19 | 3 | 0.05 | |||
| 7 | 329,983 | 2050 | 267 | 0.56 | |||
| 11 | 6,642,693 | 42,434 | 5277 | 9.23 | |||
| 15 | 85,982,855 | 549,800 | 69,370 | 119.30 | |||
| 19 | 821,441,011 | 5,264,257 | 656,891 | 82,911 | 1160.74 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, C.; Luo, X. A Multilevel Monte Carlo Approach for a Stochastic Optimal Control Problem Based on the Gradient Projection Method. AppliedMath 2023, 3, 98-116. https://doi.org/10.3390/appliedmath3010008
Ye C, Luo X. A Multilevel Monte Carlo Approach for a Stochastic Optimal Control Problem Based on the Gradient Projection Method. AppliedMath. 2023; 3(1):98-116. https://doi.org/10.3390/appliedmath3010008
Chicago/Turabian StyleYe, Changlun, and Xianbing Luo. 2023. "A Multilevel Monte Carlo Approach for a Stochastic Optimal Control Problem Based on the Gradient Projection Method" AppliedMath 3, no. 1: 98-116. https://doi.org/10.3390/appliedmath3010008
APA StyleYe, C., & Luo, X. (2023). A Multilevel Monte Carlo Approach for a Stochastic Optimal Control Problem Based on the Gradient Projection Method. AppliedMath, 3(1), 98-116. https://doi.org/10.3390/appliedmath3010008