1. Introduction
RNA combinatorics is one of the mathematical fields used for RNA sequence analysis and prediction [
1,
2,
3]. This relatively new field combines topics from molecular biology, enumerative combinatorics, and bioinformatics. In this paper, we will interpret and analyze RNA secondary structures using various combinatorial techniques such as analyzing RNA arrays as combinatorial matrices, manipulating generating functions, solving recurrence relations, counting certain linear trees and lattice walks, and establishing explicit bijections. The main motivation for the bijections is that the given combinatorial objects may provide insight into the prediction of optimal RNA secondary structures. These bijections will allow RNA researchers to find and model optimal folding patterns that otherwise would be hard to observe and discover. Finding optimal structures may lead to more biological functionality for certain RNAs. Note that no RNA secondary structure prediction or folding was performed for this paper. Evans [
4] used lattice walks to predict optimal RNA secondary folds of microRNAs related to tumor growth and cancer. This paper contributes to the literature on finding bijections between various combinatorial objects and RNA structures. See the following references [
1,
2,
5,
6,
7,
8,
9,
10] for other bijections between certain trees and RNA secondary structures.
Before we move on to the main results of the paper, we introduce Ribonucleic Acid (RNA) structures, RNA arrays, and the combinatorial objects presented in this paper. RNA plays a vital role in biological processes such as coding, decoding, regulation, and the expression of genes [
11]. A single-stranded RNA molecule consists of a sequence of four nucleotides or bases, namely Adenine (A), Cytosine (C), Guanine (G), and Uracil (U). A sequence can be considered as a string of letters defined over
where
A linear RNA sequence of such bases is a one-dimensional structure called a primary structure. The RNA sequence in
Figure 1 is an example of a specific one-dimensional structure.
When RNA molecules fold onto themselves, some nucleotides form base pairs through the creation of hydrogen bonds between complementary bases, where A pairs with U, U pairs with A, G pairs with C, and C pairs with G. These pairings are identified as Watson–Crick base pairs and this folding creates a two-dimensional structure. Uncommon cases where G pairs with U and U pairs with G are identified as non-Watson–Crick base pairs, called wobble pairs. The presence of GU (or UG) pairs occurs in the region of electronegative potential, which is proposed as the recognition site for the binding of metal ions and other positively charged ligands [
12]. Molecules formed by the two-dimensional folding of RNA molecules are known as secondary structures. Those formed through the three-dimensional folding of RNA molecules are known as tertiary structures. For more information on RNA secondary structures and molecular biology, see the following references [
11,
13]. Note that if the nucleotide Uracil (U) is replaced by the nucleotide Thymine (T), then from the four nucleotides we obtain a Deoxyribonucleic Acid (DNA) molecule. DNA molecules are only mentioned in
Section 5.
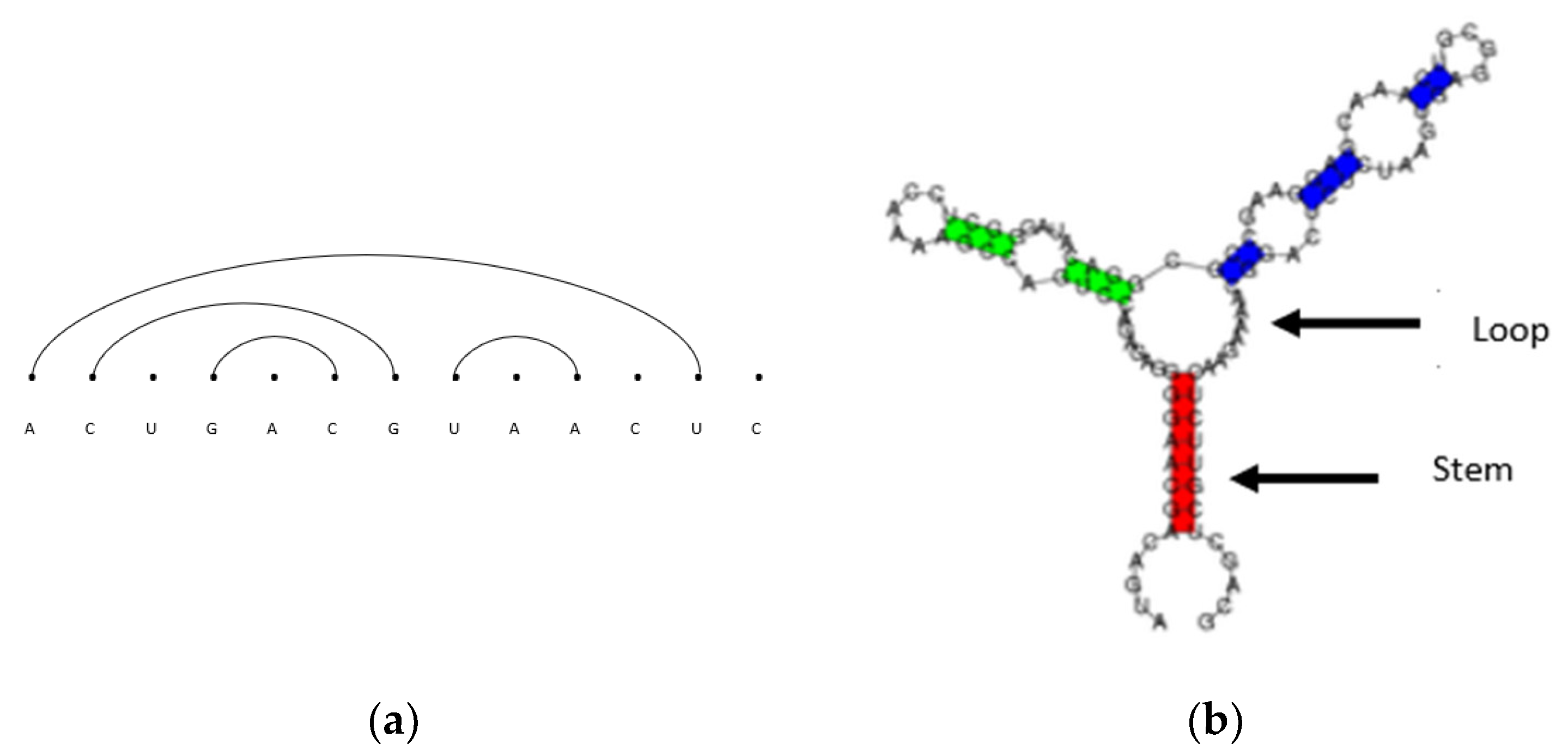
There are various ways to visually represent RNA secondary structures, such as biplanar graphs, arc diagrams, conventional diagrams, bracket notation, and tree representations [
14]. As an example of arc diagrams, which are used most often throughout this paper, we start with the primary structure given above in
Figure 1. A primary structure is first written along a horizontal line as depicted in
Figure 1. Base pairs are represented as non-intersecting chords to form secondary structures.
Figure 2 shows examples of two-dimensional RNA secondary structures represented by (a) non-intersecting arc diagrams and a conventional representation where, in (b), the stems are regions of stacked base pairs and the loops are identified as gaps between the stems. RNA secondary structures and RNA sequences are used interchangeably in this paper. Note that pseudoknot RNA secondary structures represented by intersecting arc diagrams are not considered in this paper.
In a non-biological context, secondary structures are of vital consideration in RNA computing, prediction, and analysis since the pattern of base pairs ultimately determine the overall structure of a molecule. Knowing a biomolecule’s precise structure is one of the foremost goals of molecular biology [
15]. It is the structure that determines the molecule’s function. Moreover, determining the three-dimensional tertiary structure of RNA has proved to be more difficult [
16]. Such a situation has created an intense search for secondary structure prediction methods: methods that can predict the optimal secondary structure of a molecule based on the folding of its one-dimensional primary structure.
We now consider the two infinite lower triangular arrays
and
—which we call RNA arrays I and II, respectively—that are associated with RNA secondary structures. The first few entries are listed below in
Figure 3. The leftmost column entries of the arrays count the sequence of integers {1, 1, 1, 2, 4, 8, 17, …} known as the RNA numbers [
17]. Focusing on the leftmost columns, note that the leading ‘1’ in the sequence is not included in
. The RNA numbers are also called generalized Catalan numbers [
17]. See the following references [
18,
19,
20] for background information on the construction and development of
and
.
These two lower triangular RNA arrays (or combinatorial matrices) were first introduced by Nkwanta [
18,
19,
20,
21]. It is also known that the RNA arrays are proper Riordan arrays [
18,
19,
20]. Riordan arrays form a special subset of infinite lower triangular arrays that are typically used as tools for proving combinatorial identities [
22]. The definition of Riordan array is given in
Section 4.1. The method used to produce combinatorial interpretations of Riordan arrays and to solve combinatorial recurrence relations related to Riordan arrays is called the Riordan matrix method. Some parts of the method are introduced in this paper. See [
7,
20,
23] for more information on the Riordan matrix method.
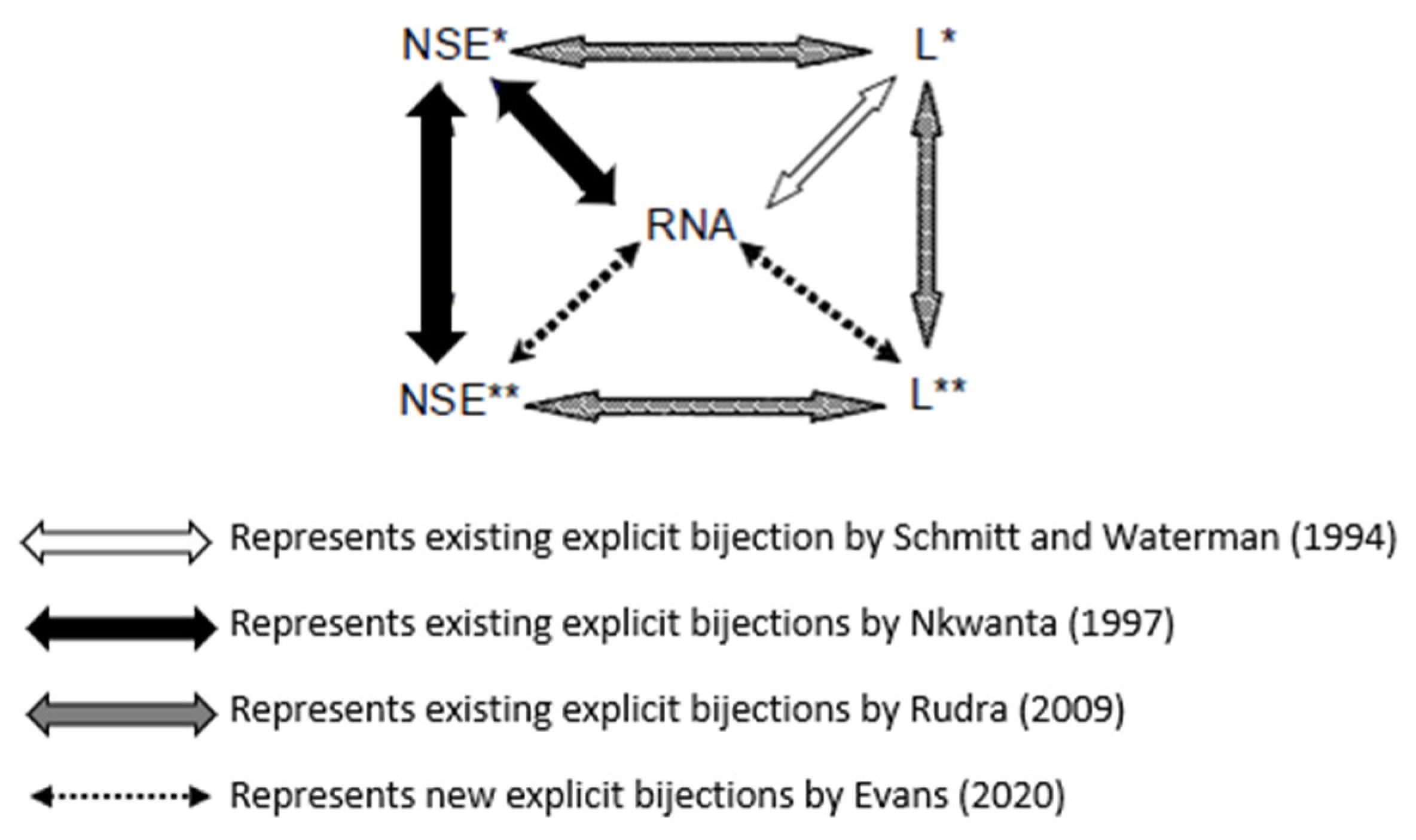
We will now explore well-established explicit bijections between RNA secondary structures and the various combinatorial objects, as illustrated in
Figure 4.
In 1994, Schmitt and Waterman [
24] established an explicit bijection between the set of all secondary structures of a given length with a fixed number of base pairs and a particular set of plane trees. In 1997, Nkwanta [
19] introduced a lattice walk interpretation of RNA array I, denoted by
, by showing that the entries of the array count the number of a certain subset of lattice walks of length
ending at height
, denoted by
. Consequently, this led to establishing an explicit bijection between
lattice walks and RNA secondary structures. Additionally, also in 1997, Nkwanta established another bijection between another subclass of unit-step lattice walks of length
n ending at height
denoted by
and the
lattice walks. The
lattice walks were given as a combinatorial interpretation of RNA array II, denoted by
. Then in 2009, motivated by Nkwanta and Schmitt and Waterman’s correspondences, Rudra [
25] established an explicit bijection between the
lattice walks and a certain subclass of linear trees denoted by
. By establishing another subclass of linear trees denoted by
, Rudra introduced an additional bijection between the
lattice walks and
linear trees. In addition, Rudra established a correspondence between
linear trees and
linear trees. In 2020, Evans [
4] resolved two open problems presented by Rudra [
25] by establishing explicit bijections among
linear trees,
lattice walks, and RNA secondary structures. See the following references [
1,
2,
5,
6,
7,
8,
9,
10] for other bijections between certain trees and RNA secondary structures. The motivation for the bijections is that the given combinatorial objects may provide insight into the prediction of RNA secondary structures. Note that no RNA secondary structure prediction or folding was performed in this paper.
This paper is organized as follows. In
Section 2, a brief introduction describes the combinatorial objects presented in the paper. The new explicit bijections by Evans are proved in
Section 3. The motivation for the bijections is that the
lattice walks and/or linear trees may provide some insight into the folding (modeling) of RNA secondary structures [
26]. In
Section 4, we propose an interesting generalized interpretation of
. We do this by taking
-copies of
, denoted by
, and proving that the entries of the array count the number of
-colored
lattice walks, of length
, ending at height
. This result is not obvious and exhibits a nice pattern of the formation rules of the column entries of the higher dimensional arrays. In
Section 5, we combinatorially interpret
in terms of RNA base-point mutations and wobble base pairs. We denote
as the number of RNA secondary structures of length
with
base-point mutations that have
wobble base pairs. Since the entries of
count
lattice walks as well as RNA secondary structures with
base-point mutations where
of the structures contain wobble base pairs, a new explicit bijection is established between these two combinatorial structures. Recall that the definition of wobble base pairs is given earlier in this section. Mutations are defined later in
Section 5. For more details on the new results presented in this paper, see reference [
4].
3. New Explicit Bijections
The following theorem gives a new explicit bijection between the set of lattice walks and a certain subset of RNA secondary structures.
Theorem 1. There is an explicit bijection between the set of unit-step lattice walks of length ending at height and the set of RNA secondary structures of length .
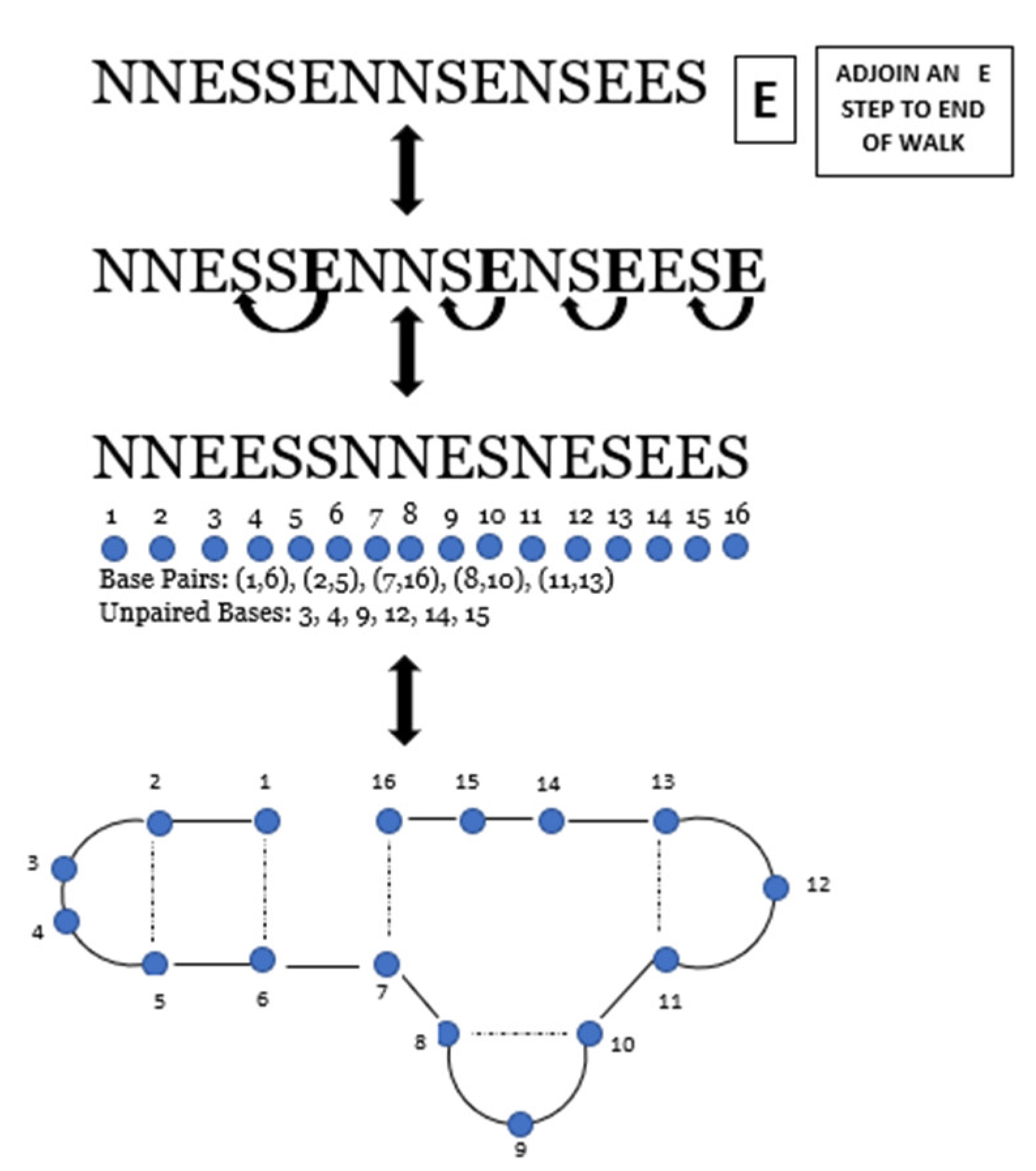
Proof. To establish the required correspondence, let be an arbitrary unit-step lattice walk of length ending at height . Since is an lattice walk, there are no SN steps in the walk. To form an RNA secondary structure of length , we use the rules described below.
Given , insert an additional th step at the end of the walk, restricting this step to an E step only. Beginning with the th step and moving left through the sequence, we move every E step we encounter positions to the left, where is the number of consecutive S steps directly to the left of the E step. E steps can only move if there is a S step to the left of it. Note that some E steps will be fixed depending upon the walk structure of (i.e., if there are no S steps to the left of the E step). In this construction: (1) Walks never go below the -axis; (2) there is no pairing between S and N steps; and (3) since walks are of height k = 0, there is always an E step or a sequence of E steps between consecutive N and S steps.
Next, we form an RNA secondary structure of length
and height
k = 0. We label corresponding NS steps as
th base pairs and they become bonded bases of RNA following the Watson–Crick base pairing rules. We label E steps as
th unpaired bases. Additionally, note that the nested innermost NS steps are paired first to avoid base pairs from crossing. Then, we number the positions of the steps of
from one to
and pair position
with position
to form the base pairs
. Recall that the E steps are unpaired bases. Via the bijection between the
walks and RNA secondary structures [
19], we obtain a
walk of length
The trivial case of the correspondence is when there are only E steps in the walk, so the appended step does not move left. Therefore, an RNA structure of length
is formed. The correspondence is constructed, and reversing the process illustrated in
Figure 7 produces the outline of the proof of the reverse map. As a consequence of the reverse map, by following the Watson–Crick base pairing rules and the way the lattice walk steps are assigned to a walk, no consecutive S and N steps are possible. We move through the example of reversing the steps as follows: let
be an arbitrary RNA secondary structure of length
and height
. We write
in its linear form as a sequence of bases, denoted by integers, increasing in order from left to right along a horizontal axis with
bases. We identify paired and unpaired bases and arcs are drawn between paired bases. By the correspondence, if an arc links integers
and
with
, we then label the
th pairing members as (N,S) steps. If a base is unpaired, label the
kth unpaired base as an E (east) step. Moving through the sequence from left to right, we move every E step we encounter
positions to the right where
is the number of consecutive S steps directly to the right of the E step. Lastly, we remove the right most E step resulting in an
lattice walk of length
at height
. Thus, the correspondence is one-to-one, and the theorem is proved. □
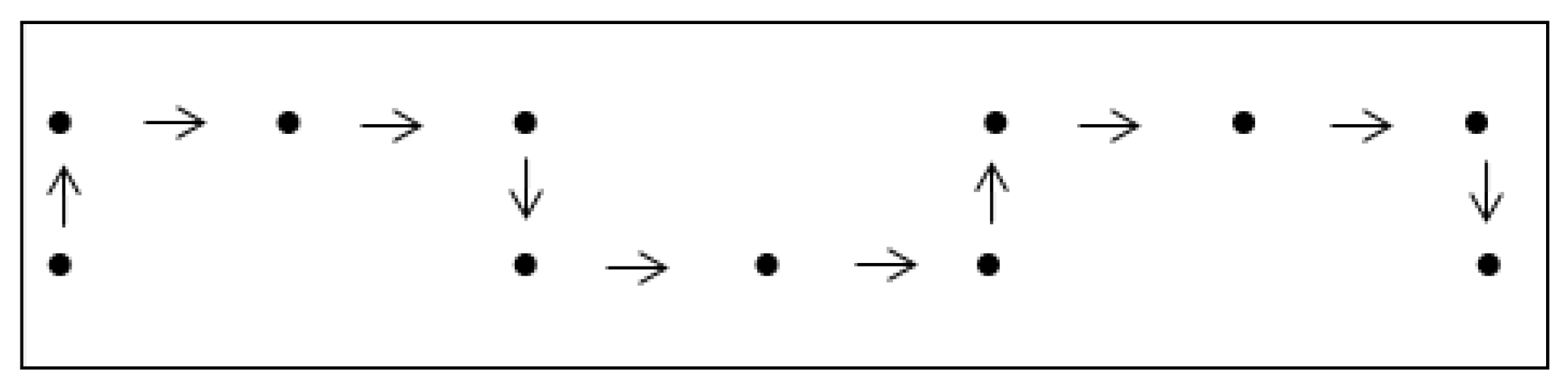
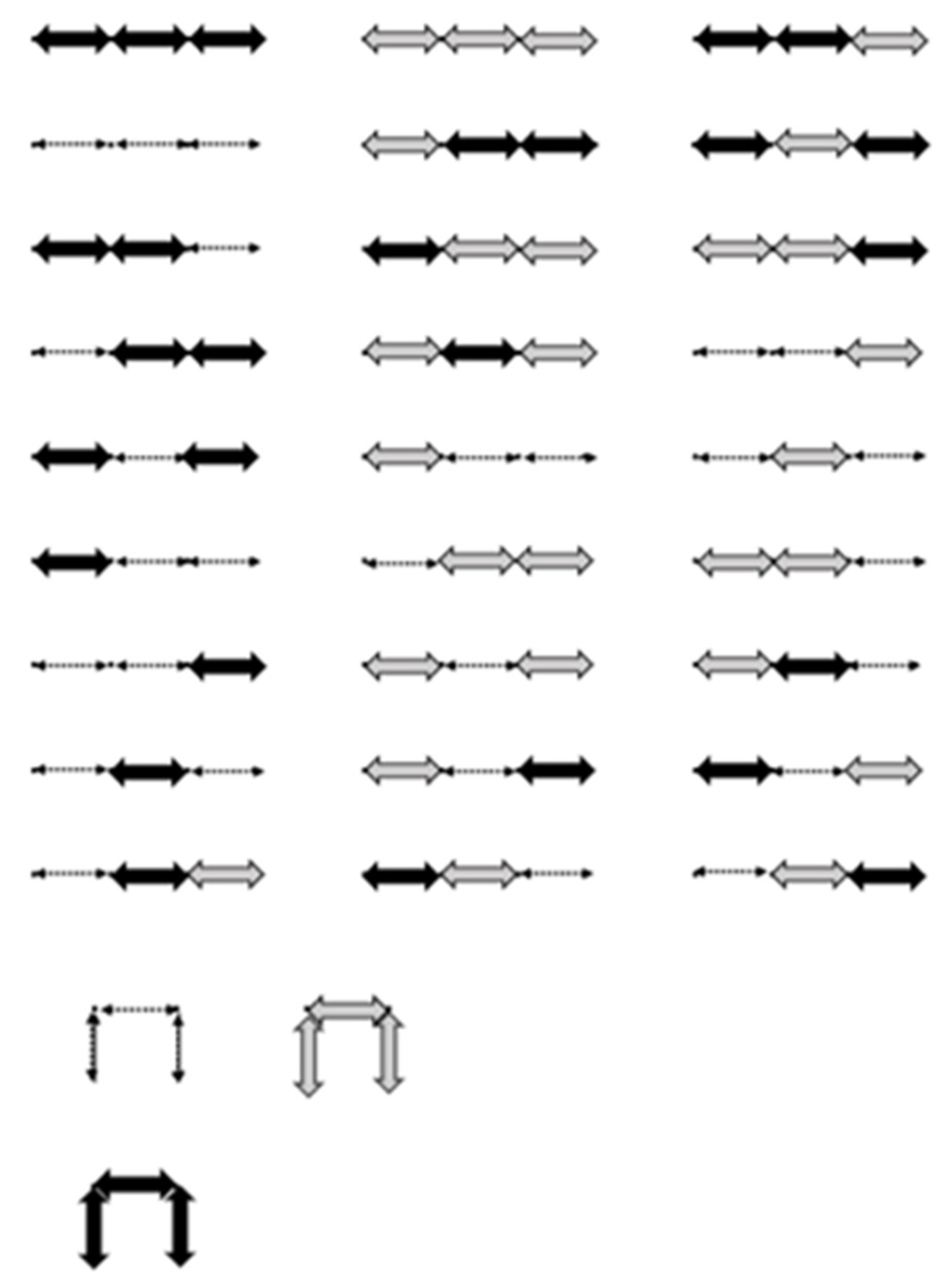
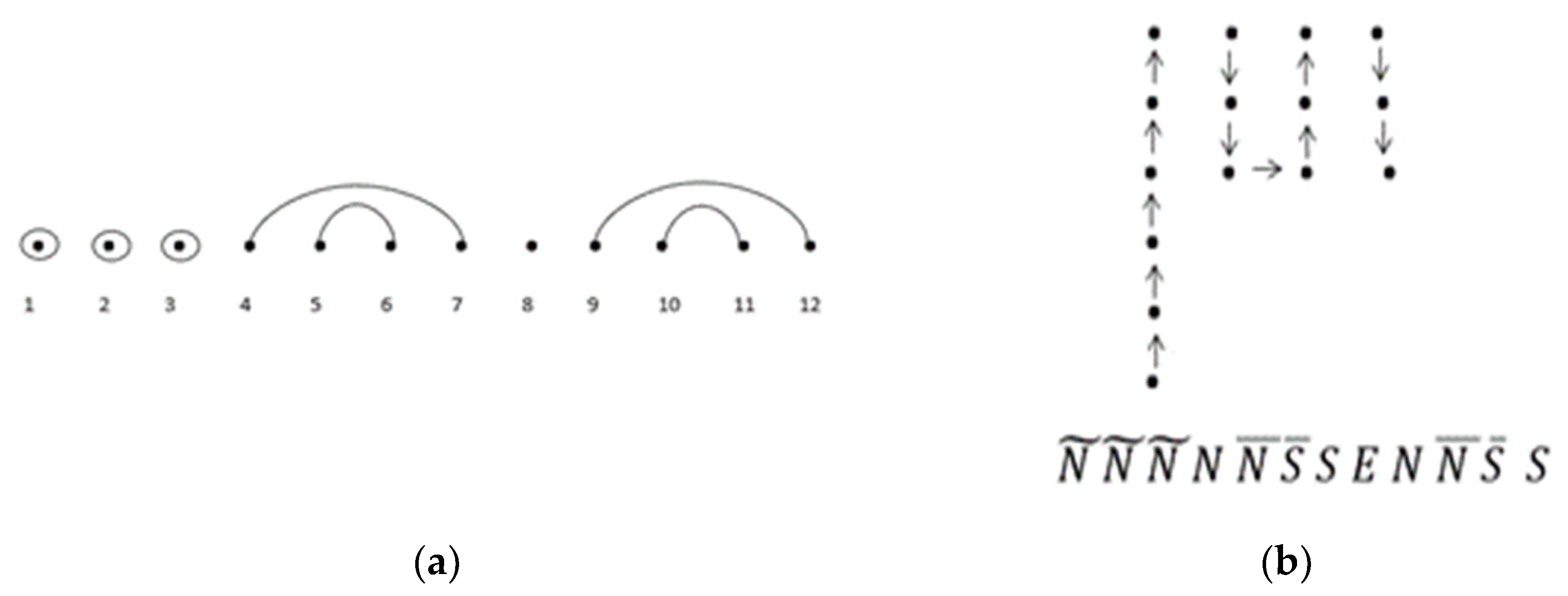
As an example of the correspondence, consider the unit step
walk
of length. By the rules of the correspondence, a possible RNA secondary structure of length 16 is obtained in the following figure.
Figure 7.
One-to-one correspondence between and a possible RNA sequence. Dashed lines represent paired bases.
Figure 7.
One-to-one correspondence between and a possible RNA sequence. Dashed lines represent paired bases.
Now, before we move on to the next new theorem, we will discuss the labeling of the linear tree
, which we now denote by
. Recall that the linear tree
was given earlier in
Section 2.2. Thus, the linear tree
is a modified version of
described as follows. Each vertex has a level, ranging from 0 down to level
, with exactly one root vertex, which is at level 0. All adjacent vertices differ by exactly one level and each vertex at level
is adjacent to exactly one vertex at level h.
are labeled linear trees with a linear ordering on the set of children of each vertex in the tree. Vertices are labeled consecutively by searching depth first from left to right, starting with 0 at the root. Vertices are labeled only when they are first encountered and last encountered, thus resulting in each vertex in a linear tree being labeled by two integers. However, there is an exception to the rules of labeling. Children with the same parent vertex will always have every other sibling labeled with one integer. The descriptions for terminal and non-terminal vertices are given in the proof for Theorem 2.
Recall that the notion of bijectivity is an equivalence relation on sets. Since there are explicit bijections between RNA secondary structures and linear trees, and between linear trees and linear trees, there exists an explicit bijection between RNA secondary structures and the set of linear trees, with , given by the following theorem.
Theorem 2. For all there is an explicit bijection between the set of linear trees
with
vertices,
of which are non-terminal, and
of which are terminal vertices that are labeled by two consecutive integers and the set of RNA secondary structures
of length
that have
base pairs.
Proof. Suppose and is a rooted labeled linear tree with vertices, of which are non-terminal, and of the terminal vertices are labeled by two consecutive integers. To establish the required correspondence, we begin by considering each vertex at level of , starting at level 0 and moving to the lowest level in the tree. We consider the following cases:
- (a)
If the vertex at level is non-terminal, then the vertex remains unchanged.
- (b)
If the vertex at level is terminal and
- (i)
labeled with two consecutive integers, then a child vertex (terminal) is inserted at the endpoint. This new child will be on level
- (ii)
labeled with one integer, then the child vertex remains unchanged, except in the case that the vertex is positioned between two vertices that are labeled by two integers, in which case the child vertex (terminal) is removed from in between the vertices. Note that this vertex will be labeled with one integer.
Next, after reconstructing the new linear tree by deleting and/or adding vertices, we remove all labels from . The linear tree receives new labeling rules by a depth-first search moving left to right around the tree. We relabel the vertices as they are encountered by consecutive integers (starting with 0 at the root); however, we label internal vertices only when they are first and last encountered. Note that these will be the non-terminal vertices that are labeled by two integers. Terminal vertices are labeled by one integer. As we leave the linear tree form, we now represent the tree as an RNA secondary structure. The resulting pairs of labels on the non-terminal vertices of the linear tree correspond to the paired bases of the structure. Following the Watson–Crick pairing rules, the unpaired labels on the terminal vertices of the linear tree are associated with the unpaired bases of a secondary structure.
The following properties are observed in the above construction: (i) The length of the RNA secondary structure is composed of all vertices of , in addition to all vertices that are labeled by two integers (paired integers). This includes non-terminal (internal) vertices and terminal vertices that are labeled by two consecutive integers. Therefore, we obtain an RNA secondary structure of length . (ii) The number of base pairs in the RNA secondary structure is composed of all internal vertices of , in addition to all terminal vertices that are labeled by two consecutive integers. Therefore, we obtain an RNA secondary structure that has base pairs. (iii) We also observe that the unpaired bases of the RNA secondary structure correspond to .
Therefore, an RNA secondary structure of length with base pairs is formed and denoted by ). The correspondence is constructed and reversible. Thus, the theorem is proved. □
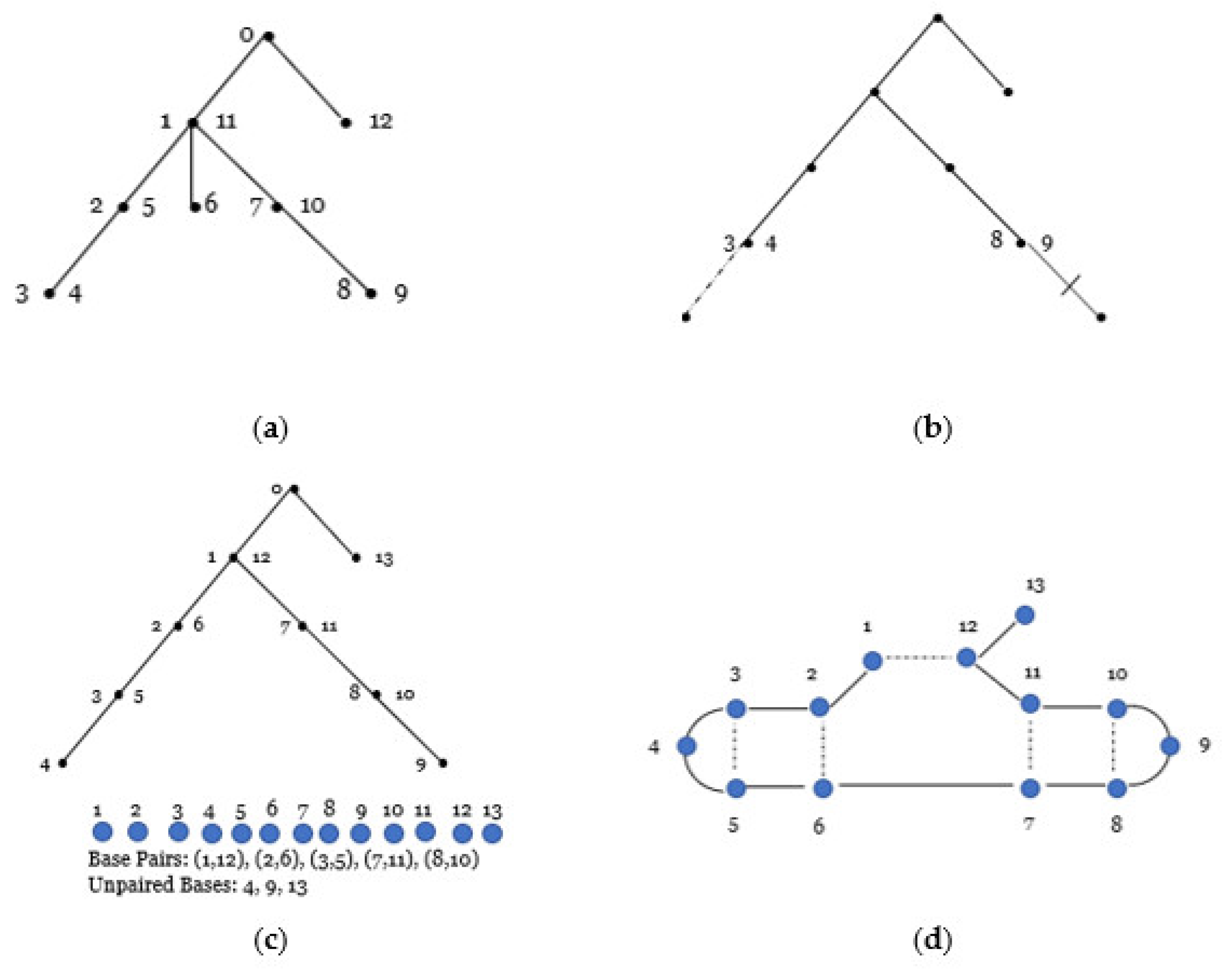
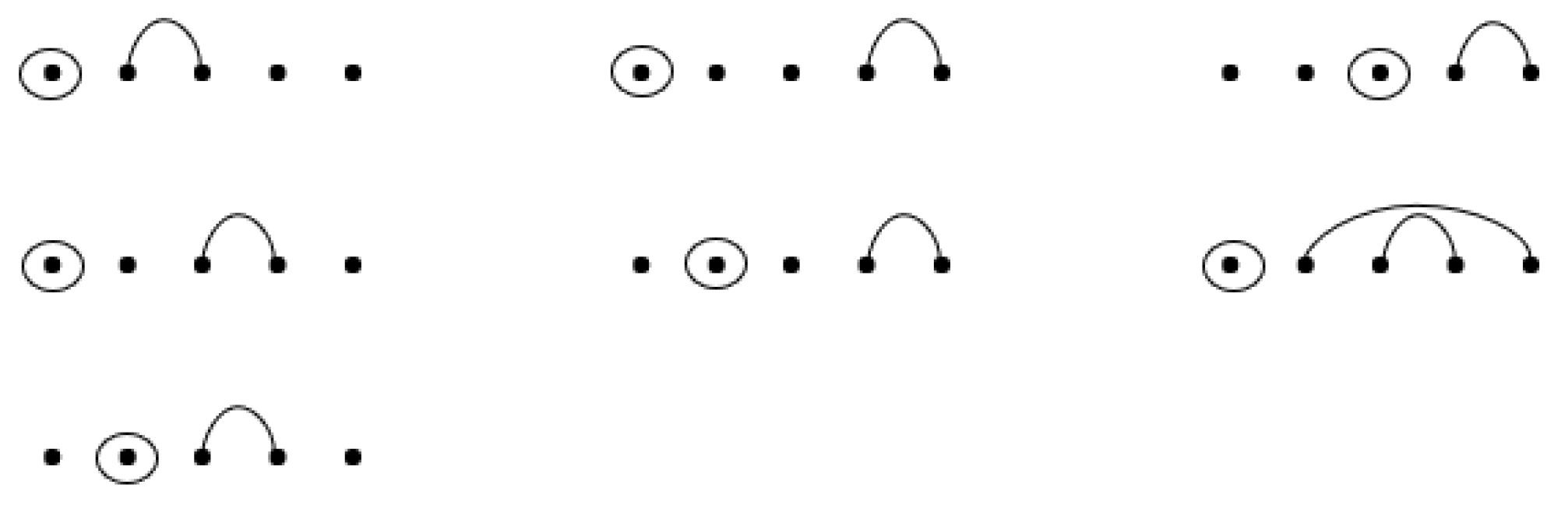
As an example of the correspondence, consider
for
and
as in
Figure 8 below. To construct an RNA secondary structure, we consider each vertex at level
of
. Starting at the highest level 0 and moving to the lowest level:
Level 0 has one non-terminal vertex 0 (the root), so according to the rules, the vertex remains unchanged.
Level 1 has one non-terminal vertex (1, 11) and one terminal vertex (12) labeled with one integer. According to the rules of the bijection, both vertices remain unchanged.
Level 2 has one terminal vertex (6) positioned between two vertices {(2, 5), (7, 10)} that are labeled by two integers; therefore, we remove the terminal vertex (6) from in between the vertices.
Level 3 has two terminal vertices {(3, 4), (8, 9)}, both labeled with two consecutive integers, so we add a terminal vertex at the end of (3, 4) and at the end of (8, 9).
Next, starting with the root, we move around the tree starting with a depth-first search and relabel vertices using consecutive integers where only non-terminal (internal) vertices are labeled with two integers. Internal vertices are labeled as they are first and last encountered. We ignore the root as we move to form the secondary structure. As a result of relabeling the vertices, vertices labeled by two integers form the set of base pairs {(1, 12), (2, 6), (3, 5), (7, 11), (8, 10)} and vertices labeled by a single integer form the set of unpaired bases {4, 9, 13} for the secondary structure (13, 5) of length 13 with five base pairs.
We note when for we obtain which is the set of unlabeled linear trees that have vertices and of which are non-terminal.
5. RNA Interpretation of and Bijection
In this section, we give two RNA combinatorial interpretations of . One interpretation is given in terms of RNA secondary structures with mutations and wobble pairs, and the other is in terms of RNA secondary structures with mutations and structures with wobble pairs and non-wobble pairs. Before deriving the interpretations of , we define what we mean by RNA mutation.
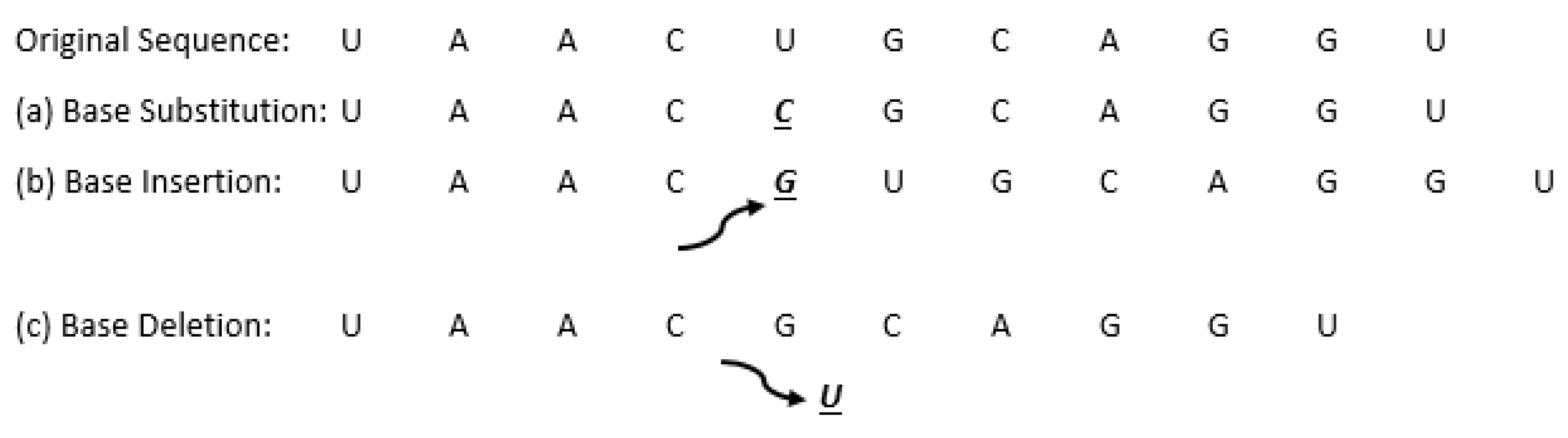
In biology, mutations are defined as random changes/alternations in the genomes in a cell, either in DNA or RNA. Mutations occur due to exposure to ultraviolet (UV) light, replication errors, or the degradation of bonds in DNA. Alternations that happen during the DNA replication of a single nucleotide (base) where a base may be substituted, inserted, or deleted are defined as point mutations. The consequences of these mutations lead to protein composition, production, and functionality. Point mutations include several types [
33]:
- (a)
Substitution—when one or more nucleotides (bases) in the sequence are replaced by the same number of bases (for example, a cytosine substituted for an adenine).
- (b)
Insertion—when one or more nucleotides (bases) are added to the sequence.
- (c)
Deletion—when one or more nucleotides (bases) are removed from the sequence.
Figure 11 below shows an example of various point mutations of an RNA sequence, where each mutation is underlined and in bold print.
5.1. RNA Mutations and Wobble Base Pairs
Recall that Rudra proposes an RNA combinatorial interpretation of
in terms of RNA structures with mutations in [
25]. We now propose, in this subsection, an RNA combinatorial interpretation of
in terms of RNA structures with mutations where
of the structures contain wobble base pairs. A combinatorial meaning of wobble base pairs is given in terms of arc diagrams. This is completed by labeling consecutive G and U base pairs as G–U pairs and U and G base pairs as U–G pairs. We call the G–U (U–G) pairs ‘wobble base pairs.’ Wobble base pairs are connected by arcs of consecutive base pairs at positions
and
of an RNA sequence. Recall that RNA sequences and RNA structures are used interchangeably. Wobble pairs are restricted to not allowing consecutive G–U (U–G) base pairs. This means there are no sequences with GUGU (UGUG, UGGU, GUUG) bases. Generally, we mention here that in the biological literature, wobble pairs are not necessarily labeled as G–U (U–G) pairs [
34]. In this paper, base-point mutations are represented by ⊙ and restricted to the following conditions:
- (a)
They do not occur under an arc of two paired bases

.
- (b)
They do not occur as a point of a base pair

.
- (c)
They do not occur to the right of any wobble base pairing, whether that pairing is isolated or nested under an additional base pair that is connected by an arc diagram

.
Proposition 1 below gives a combinatorial interpretation of
in terms of RNA secondary structures with mutations that contain wobble base pairs. See
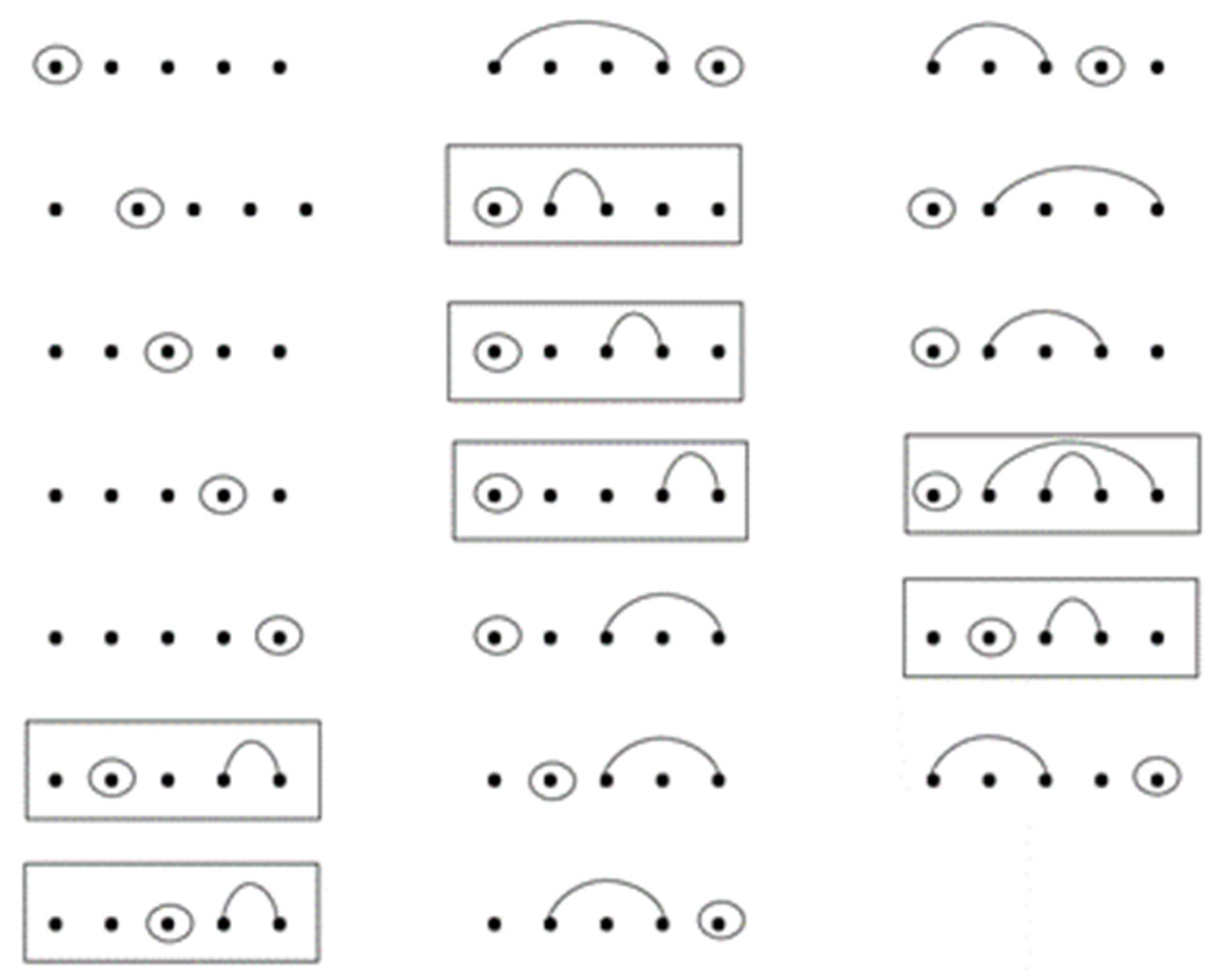
Figure 12 for an example where seven RNA sequences contain base-point mutations and wobble base pairs.
Proposition 1. Given the initial conditions ,
, and
, for
and 0, satisfies the following recurrence relation for all column entries of except for the leftmost columnwhere
counts the number of RNA secondary structures of length
with
mutations that contain wobble pairs.
See
Figure 13 below for an example of the construction of the seven sequences with base-point mutations and wobble base pairs given by
Figure 12. By the recursion, the entry associated with w(4, 2) of R** is computed by
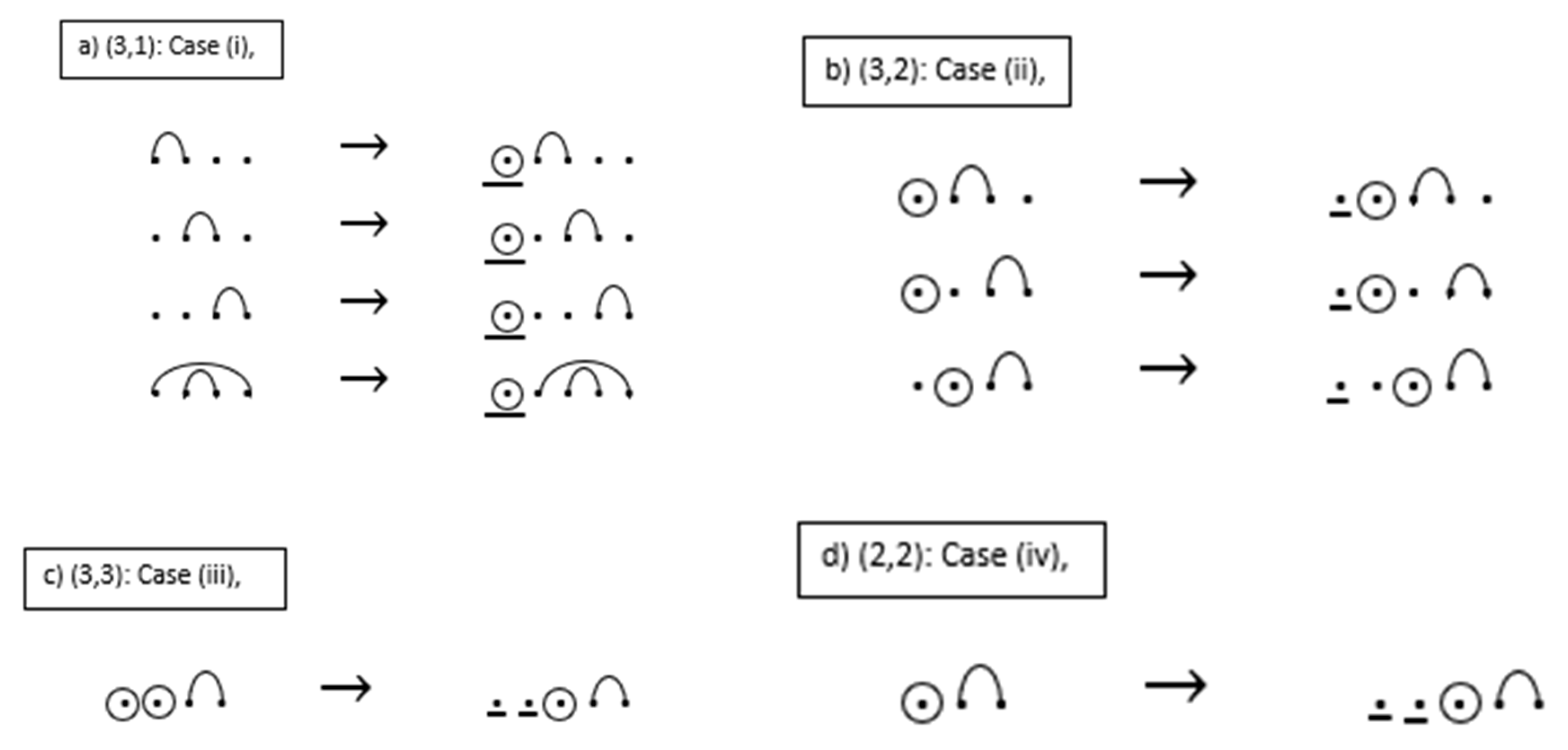
The outline of the proof of Proposition 1 is illustrated by the cases given in the example below. For the given RNA sequences: Case (i) insert one base-point mutation to the leftmost position of the sequence; Case (ii) insert one unpaired base point (base point without a mutation) to the leftmost position of the sequence; Case (iii) delete one base-point mutation from the sequence, starting with the leftmost base-point mutation, substitute the deleted mutation with an unpaired base point at this position in the sequence, then insert an additional unpaired base point at the very beginning of the sequence; Case (iv) insert two unpaired base points to the leftmost position of the sequence. In addition, Proposition 1 and Theorem 4 have the same recurrence relations; thus, the proof of Proposition 1 is similar to the proof for Theorem 4. The proof for Theorem 4 is given after the example.
Thus, the lower triangular RNA array is interpreted as the number of RNA secondary structures with base-point mutations that contain wobble base pairs. Recall that wobble base pairs represent all entries of except for the entries of the leftmost column. Since the combinatorial arguments in the proof for Proposition 1 are similar to the combinatorial arguments in the proof of Theorem 4, we omit a formal proof for Proposition 1.
Let
where
counts RNA structures of length
that have
mutations and contain wobble base pairs. Let
denote the set of RNA secondary structures of length
with
base-point mutations, where
of the RNA sequences contain wobble base pairs. Before proving Theorem 4, as given below, we give the example
= 20 which is illustrated in
Figure 14, which has secondary structures with lengths of five and one base-point mutation. Of the twenty RNA sequences, seven sequences contain wobble base pairs and thirteen sequences do not contain wobble base pairs.
Proposition 1, given above, confirms that ω is the entry of that counts the number of RNA secondary structures with mutations that contain wobble base pairs. The entry of w is associated with the entry of . We now give a combinatorial interpretation of in terms of RNA mutations with wobble pairs and non-wobble pairs.
Theorem 4. Given the initial condition and the condition
, then for
and
,
satisfies the following recurrence relations
- (a)
- (b)
where (a) is defined for the leftmost column of
, (b) is defined for the other columns of
, and
counts RNA secondary structures of length
with
base point mutations where
of the structures contain wobble base pairs.
Proof. Condition = 1 follows the definition of the restrictions placed on base-point mutations and wobble base pairs, and the way the entries are formed of . By convention, there is only one possibility for the condition . Suppose we have an RNA sequence of length with base-point mutations where of the sequences contain wobble pairs. Then, to form a new sequence of length with base-point mutations where of the structures contain wobble base pairs, we consider the following cases to prove recursion (b).
Case (i): If the given sequence has length with base-point mutations and of the sequences contain wobble pairs, where then there is one choice: to insert one base-point mutation to the leftmost position of the sequence with base-point mutations where of the sequences contain wobble pairs. In this case, all sequences whose leftmost point is a base-point mutation where ω of the sequences contain wobble pairs are counted by .
Case (ii): If the given sequence has length with base-point mutations and of the sequences contain wobble pairs, where then there is one choice: to insert one unpaired base point (base point without a mutation) to the leftmost position of the sequence with k base-point mutations where of the sequences contain wobble pairs. In this case, all sequences whose leftmost point is an unpaired base point where of the sequences contain wobble pairs are counted by .
Case (iii): If the given sequence has length with base-point mutations and of the sequences contain wobble pairs, where then there is one choice: to delete one base-point mutation from the sequence, starting with the leftmost base-point mutation. We substitute the deleted mutation with an unpaired base point at this position in the sequence. Then, we insert an additional unpaired base point at the very beginning of the sequence. We form an arc between the two new base points if they are not successive, and if they are successive, we do not form an arc. Note that from the construction of the sequence, no base-point mutations occur under an arc. In this case, all sequences with a substitution of a base-point mutation where of the sequences contain wobble pairs are counted by .
Case (iv): If the given sequence has a length of and base-point mutations and of the sequences contain wobble pairs, where then there is one choice: to insert two unpaired base points to the leftmost position of the sequence with k base-point mutations. In this case, all sequences whose two leftmost successive points are unpaired base points (base points without a mutation) where ω of the sequences contain wobble pairs are counted by .
Note that in Case (iii) there is an over count and Case (iv) accounts for an over count. This over count occurs in Case (iii) because we are deleting a base-point mutation and this produces, in some cases, the same structure as in Case (ii). Therefore, all sequences are removed from the count by Combining all of the cases accounts for all possible ways of forming where Applying the addition principle concludes that the recurrence relation (b) is proved. By similar reasoning we can prove part (a). □
This provides an elegant connection between RNA array I and RNA array II by the equation
where
counts the RNA secondary structures of length
with
mutations given by
[
25]. Thus, as a consequence of
and
counts the number of RNA structures that contain non-wobble base pairs.
5.2. Bijection between Modified Walks and
Recall that
are the lattice walks identified by Definition 4(b). In this subsection, we present modified unit-step
lattice walks. Modified
lattice walks consist of
lattice walks with three different kinds of north steps denoted by N,
, and
, and two different kinds of south steps denoted by S and
. These steps are subsequently described in the proof of Theorem 5. Since
counts RNA secondary structures with
base-point mutations where
of the sequences contain wobble pairs and modified unit-step
lattice walks, there exists an explicit bijection between these sets of combinatorial objects. See
Figure 15 below for an example of the bijection. We now state and prove the following theorem.
Theorem 5. There exists an explicit bijection between the set of modified unit-step lattice walks of length
ending at height
with consecutive north and south steps and the set of RNA secondary structures of length
with
base-point mutations where
of the sequences contain wobble pairs.
Proof. To establish the required correspondence, let be an arbitrary secondary structure of length with base-point mutations where of the sequences contain wobble pairs. We write in its linear form as a sequence of bases, denoted by integers, increasing in order from left to right along a horizontal axis with n bases where the base-point mutations are denoted by ⊙. Arcs are drawn between two paired bases, allowing consecutive and non-consecutive bases to be paired. The arcs joining consecutive bases are wobble pairs.
Now, we will form a modified unit-step lattice walk as follows. Consider each ⊙ (i.e., base-point mutation) as an unpaired N (north) step, denoted by of the modified unit-step lattice walk. If a base is unpaired, label the base as an E (east) step. If an arc links non-consecutive integers and with , then label the th pairing members as non-consecutive (N, S) steps (non-wobble pairs). If an arc links consecutive integers and with , then label the th pairing members as consecutive (, ) steps (wobble pairs). Using the definition of , we confirm that the modified unit-step NSE** walks do not have consecutive south and north steps of any type of height and no two arcs intersect. Thus, there are no lattice walks with SN, N, S, or steps. However, S steps are allowed for lattice walks ending at height . To form a modified unit-step walk, we now have the following mappings: steps maps to N steps, (N, S) maps to unconsecutive N and S steps to form unconsecutive NS base pairs, (, ) maps to consecutive and steps to form consecutive steps, and E steps map to E steps. Note that (, ) and (N, S) steps will have the same number of and and N and S steps, respectively. The number of base-point mutations correspond to the height of modified unit-step lattice walks. From , we can obtain from the th entry of . The correspondence is constructed and reversible. Thus, the correspondence is one-to-one, and the theorem is proved. □
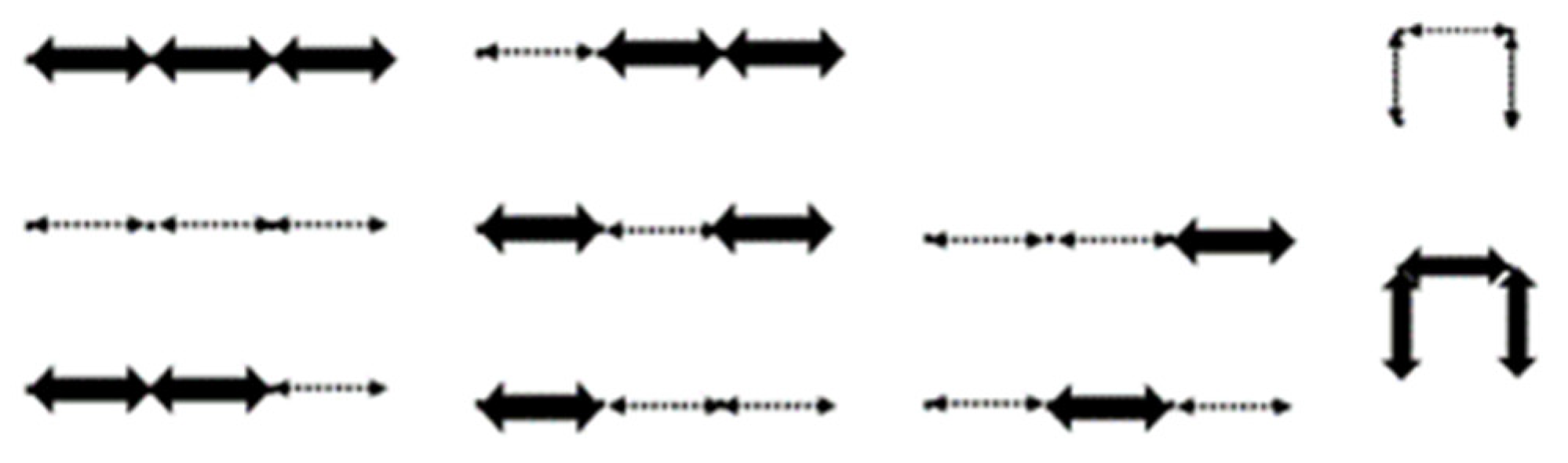
See
Figure 7 for an example of a lattice walk ending at height
. As an example of the bijection of a lattice walk ending at height
(Theorem 5), consider one of the sequences of
in
Figure 15a below, where
= w(11, 4) = 2307 is an entry of
. Let
be one secondary structure of length 12 with three base-point mutations. Of the structures, 2307 contain wobble base pairs. Applying the mapping, the integers are assigned as follows: 1
, 2
, 3
, 4
N, 5
, 6
, 7
S, 8
E, 9
N, 10
, 11
, 12
S. We can then apply the rules of the correspondence to obtain one of the possible modified unit-step
lattice walks with a length of 12, a height of three, and consecutive north and south steps given by
Figure 15b.
Figure 15.
(a) One representation of ; (b) corresponding modified unit-step NSE** lattice walk with a length of 12, a height of three, and consecutive north and south steps.
Figure 15.
(a) One representation of ; (b) corresponding modified unit-step NSE** lattice walk with a length of 12, a height of three, and consecutive north and south steps.








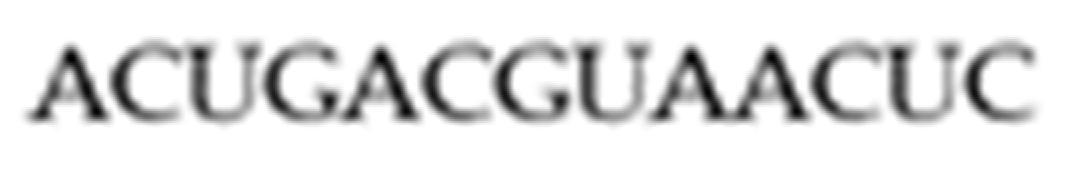{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













