
Gradient-Free Neural Network Training via Synaptic-Level Reinforcement Learning


Abstract
:1. Introduction
- Frame the fundamental RL agent as the synapse rather than the neuron.
- Train and apply the same synaptic RL policy on all synapses.
- Set the action space for each synapse to consist of a small increment, a small decrement, and null action on the synapse weight.
- Represent synapse state as the last n synapse actions and rewards.
- Use a universal binary reward at each time step representing whether MLP training loss increased or decreased between the two-most-recent iterations.
2. Materials and Methods
2.1. Synaptic Reinforcement Learning
- Actions: Each synapse can either increment, decrement, or maintain its value by some small synaptic learning rate .Weight update for a given synapse k in neuron i and layer j is thus given as:
- Reward: Reward is defined in terms of the training loss at the previous two time steps. Decreased loss is rewarded while increased or equivalent loss is penalized.
- State: Each synapse “remembers” its previous actions and the previous two global network rewards.In this work, the previous two action-and-reward pairs were used as the synapse state after empirical testing.
- Policy: The Q function gives the expected total reward of a given state–action pair assuming that all future actions correspond to the highest Q-value for the given future state [24]. The epsilon-greedy synaptic policy returns the action with the highest Q-value with probability . Otherwise, a random action is returned [19]. The epsilon-greedy method was selected to add stochasticity to the system, a property that appears to benefit biological information processing [30,31].where is the discount for future reward and is the “exploration probability” of the policy. If the Q function is accurate, then will return the optimal action subject to discount factor . Since the state and action spaces in this formulation have low dimensionality, the Q function (and by extension the policy ) can be implemented as lookup tables of finite size.
2.2. Training
| Algorithm 1: Synaptic RL Training Algorithm. |
 |
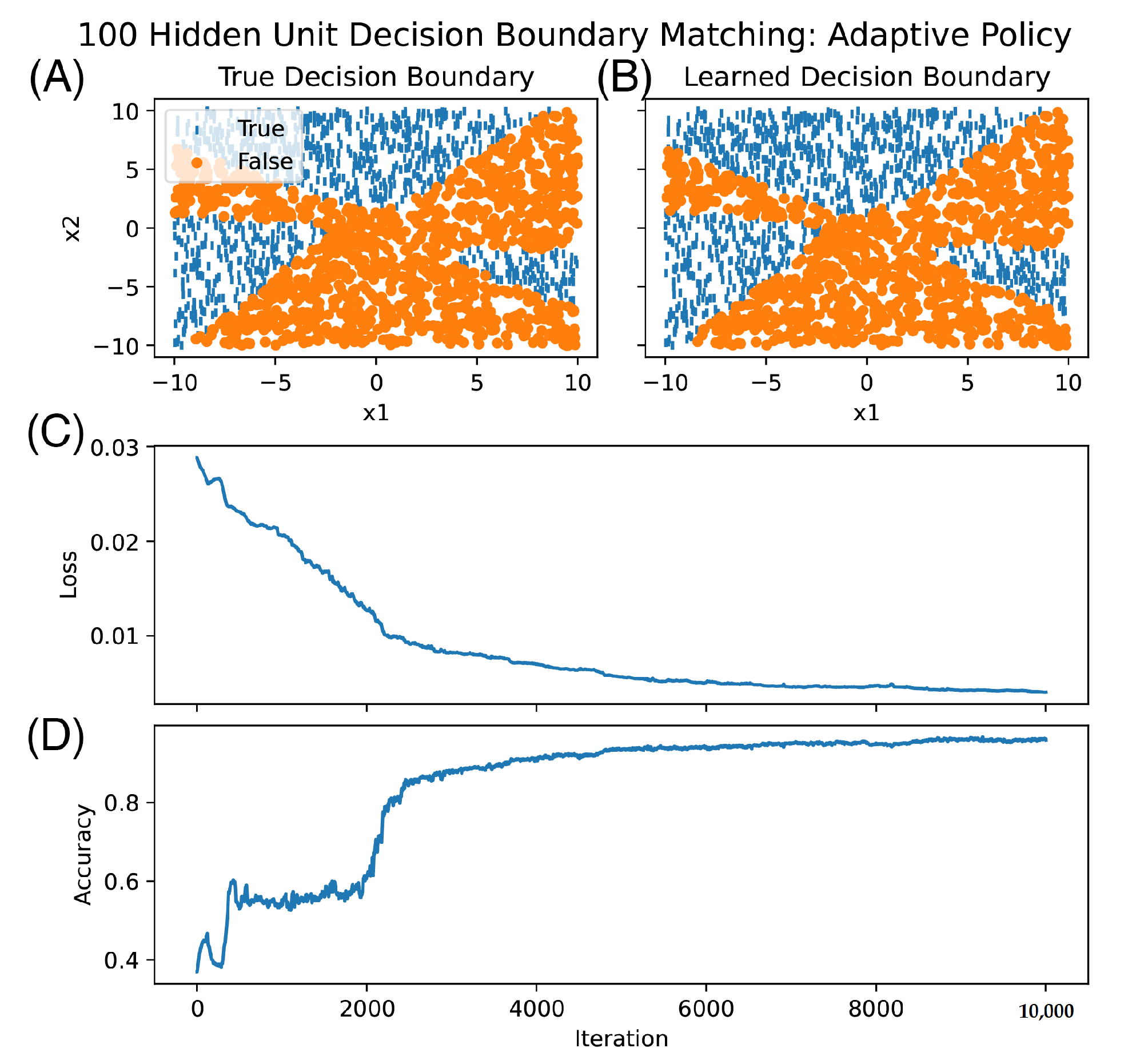
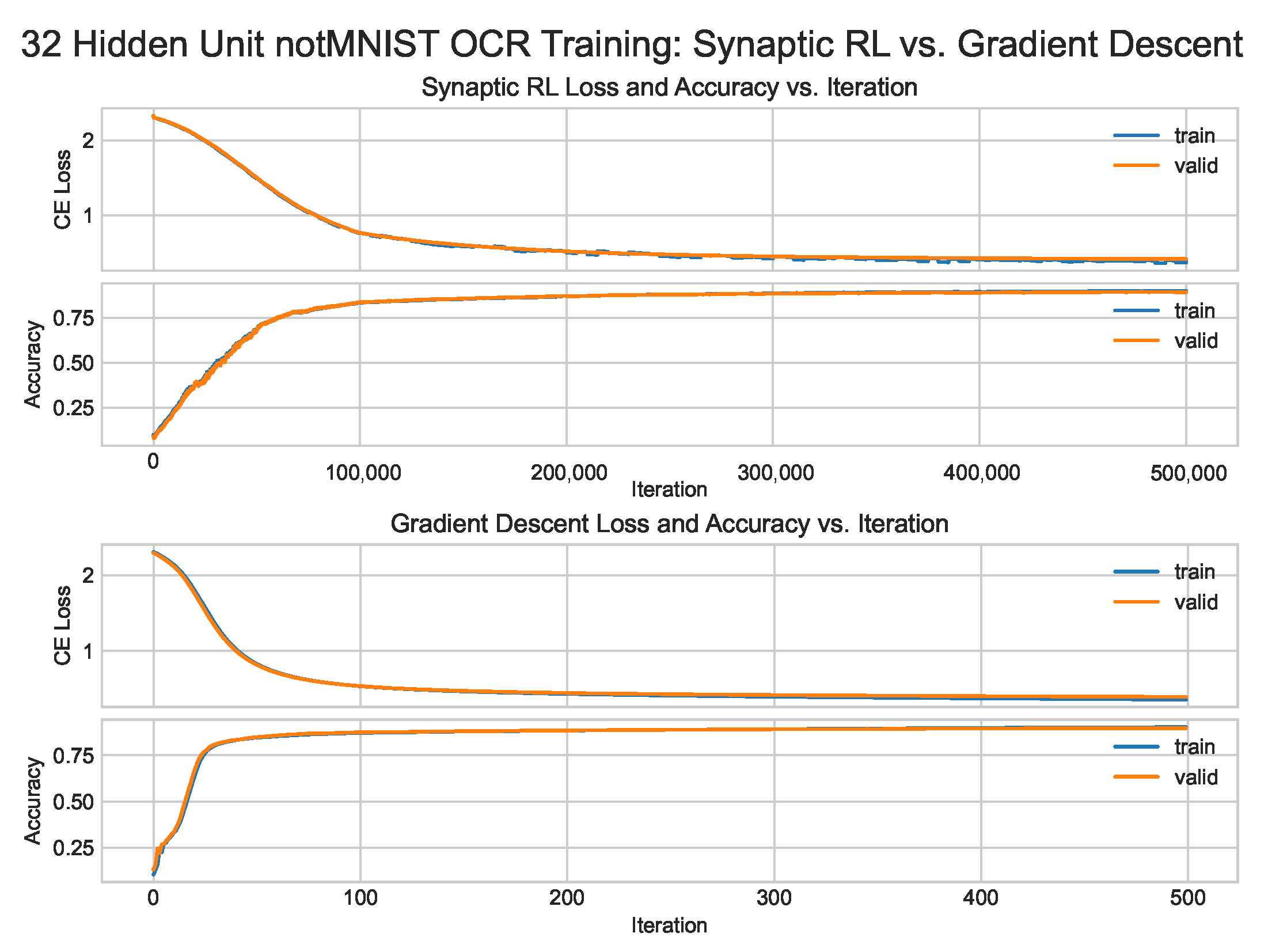
3. Results
4. Discussion
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Adolphs, R. The unsolved problems of neuroscience. Trends Cogn. Sci. 2015, 19, 173–175. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Whittington, J.C.; Bogacz, R. Theories of Error Back-Propagation in the Brain. Trends Cogn. Sci. 2019, 23, 235–250. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Su, L.; Gomez, R.; Bowman, H. Analysing neurobiological models using communicating automata. Form. Asp. Comput. 2014, 26, 1169–1204. [Google Scholar] [CrossRef]
- Rubin, J.E.; Vich, C.; Clapp, M.; Noneman, K.; Verstynen, T. The credit assignment problem in cortico-basal ganglia-thalamic networks: A review, a problem and a possible solution. Eur. J. Neurosci. 2021, 53, 2234–2253. [Google Scholar] [CrossRef]
- Mink, J.W. The basal ganglia: Focused selection and inhibition of competing motor programs. Prog. Neurobiol. 1996, 50, 381–425. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Cownden, D.; Tweed, D.B.; Akerman, C.J. Random synaptic feedback weights support error backpropagation for deep learning. Nat. Commun. 2016, 7, 13276. [Google Scholar] [CrossRef]
- Lansdell, B.J.; Prakash, P.R.; Kording, K.P. Learning to solve the credit assignment problem. arXiv 2019, arXiv:1906.00889. [Google Scholar]
- Ott, J. Giving Up Control: Neurons as Reinforcement Learning Agents. arXiv 2020, arXiv:2003.11642. [Google Scholar]
- Wang, Z.; Cai, M. Reinforcement Learning applied to Single Neuron. arXiv 2015, arXiv:1505.04150. [Google Scholar]
- Chalk, M.; Tkacik, G.; Marre, O. Training and inferring neural network function with multi-agent reinforcement learning. bioRxiv 2020, 598086. [Google Scholar] [CrossRef] [Green Version]
- Ohsawa, S.; Akuzawa, K.; Matsushima, T.; Bezerra, G.; Iwasawa, Y.; Kajino, H.; Takenaka, S.; Matsuo, Y. Neuron as an Agent. In Proceedings of the ICLR 2018: International Conference on Learning Representations 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Gold, J.I.; Shadlen, M.N. The Neural Basis of Decision Making. Annu. Rev. Neurosci. 2007, 30, 535–574. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Parent, A.; Hazrati, L.N. Functional anatomy of the basal ganglia. I. The cortico-basal ganglia-thalamo-cortical loop. Brain Res. Rev. 1995, 20, 91–127. [Google Scholar] [CrossRef]
- Daw, N.D.; O’Doherty, J.P.; Dayan, P.; Seymour, B.; Dolan, R.J. Cortical substrates for exploratory decisions in humans. Nature 2006, 441, 876–879. [Google Scholar] [CrossRef] [PubMed]
- Lee, A.M.; Tai, L.H.; Zador, A.; Wilbrecht, L. Between the primate and ‘reptilian’brain: Rodent models demonstrate the role of corticostriatal circuits in decision making. Neuroscience 2015, 296, 66–74. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- D’Angelo, E.; Solinas, S.; Garrido, J.; Casellato, C.; Pedrocchi, A.; Mapelli, J.; Gandolfi, D.; Prestori, F. Realistic modeling of neurons and networks: Towards brain simulation. Funct. Neurol. 2013, 28, 153. [Google Scholar] [PubMed]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef] [Green Version]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Citri, A.; Malenka, R.C. Synaptic plasticity: Multiple forms, functions, and mechanisms. Neuropsychopharmacology 2008, 33, 18–41. [Google Scholar] [CrossRef] [Green Version]
- Eluyode, O.; Akomolafe, D.T. Comparative study of biological and artificial neural networks. Eur. J. Appl. Eng. Sci. Res. 2013, 2, 36–46. [Google Scholar]
- Caporale, N.; Dan, Y. Spike timing–dependent plasticity: A Hebbian learning rule. Annu. Rev. Neurosci. 2008, 31, 25–46. [Google Scholar] [CrossRef] [Green Version]
- Bengio, Y.; Bengio, S.; Cloutier, J. Learning a Synaptic Learning Rule. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.22.779&rep=rep1&type=pdf (accessed on 1 March 2021).
- Russell, S. Artificial Intelligence: A Modern Approach; Prentice Hall: Upper Saddle River, NJ, USA, 2010. [Google Scholar]
- Hawkins, J.; Ahmad, S. Why Neurons Have Thousands of Synapses, a Theory of Sequence Memory in Neocortex. Front. Neural Circuits 2016, 10, 23. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bulatov, Y. notMNIST Dataset. 8 September, 2011. Available online: http://yaroslavvb.blogspot.com/2011/09/notmnist-dataset.html (accessed on 15 February 2021).
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McKenna, T.M.; Davis, J.L.; Zornetzer, S.F. Single Neuron Computation; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 15 February 2021).
- Kadmon, J.; Timcheck, J.; Ganguli, S. Predictive coding in balanced neural networks with noise, chaos and delays. Adv. Neural Inf. Process. Syst. 2020, 33, 16677–16688. [Google Scholar]
- Hunsberger, E.; Scott, M.; Eliasmith, C. The competing benefits of noise and heterogeneity in neural coding. Neural Comput. 2014, 26, 1600–1623. [Google Scholar] [CrossRef] [PubMed]
- Abu-Mostafa, Y.S.; Magdon-Ismail, M.; Lin, H.T. Learning from Data; AMLBook: New York, NY, USA, 2012; Volume 4. [Google Scholar]
- Schmidt-Hieber, J. Nonparametric regression using deep neural networks with ReLU activation function. Ann. Stat. 2020, 48, 1875–1897. [Google Scholar]
- Rezaei, M.R.; Gillespie, A.K.; Guidera, J.A.; Nazari, B.; Sadri, S.; Frank, L.M.; Eden, U.T.; Yousefi, A. A comparison study of point-process filter and deep learning performance in estimating rat position using an ensemble of place cells. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 4732–4735. [Google Scholar]
- Aloysius, N.; Geetha, M. A review on deep convolutional neural networks. In Proceedings of the 2017 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 6–8 April 2017; pp. 0588–0592. [Google Scholar]
- Pfeiffer, M.; Pfeil, T. Deep learning with spiking neurons: Opportunities and challenges. Front. Neurosci. 2018, 12, 774. [Google Scholar] [CrossRef] [Green Version]
- Lipton, Z.C.; Berkowitz, J.; Elkan, C. A critical review of recurrent neural networks for sequence learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Hasanzadeh, N.; Rezaei, M.; Faraz, S.; Popovic, M.R.; Lankarany, M. Necessary conditions for reliable propagation of slowly time-varying firing rate. Front. Comput. Neurosci. 2020, 14, 64. [Google Scholar] [CrossRef]
- Ding, C.; Liao, S.; Wang, Y.; Li, Z.; Liu, N.; Zhuo, Y.; Wang, C.; Qian, X.; Bai, Y.; Yuan, G.; et al. Circnn: Accelerating and compressing deep neural networks using block-circulant weight matrices. In Proceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture, Cambridge, MA, USA, 14–18 October 2017; pp. 395–408. [Google Scholar]
- Rezaei, M.R.; Popovic, M.R.; Lankarany, M. A Time-Varying Information Measure for Tracking Dynamics of Neural Codes in a Neural Ensemble. Entropy 2020, 22, 880. [Google Scholar] [CrossRef] [PubMed]
- Wolfram, S. A New Kind of Science; Wolfram Media: Champaign, IL, USA, 2002. [Google Scholar]
- Conway, J. The game of life. Sci. Am. 1970, 223, 4. [Google Scholar]
- Dennett, D.C. Real Patterns. J. Philos. 1991, 88, 27–51. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Experiment | Min | Max | Mean | Stdev | Est. Runtime | Params |
|---|---|---|---|---|---|---|
| Syn. RL 32 HU | 87.88% | 89.12% | 88.45% | 0.60% | 5.5 h | 25,450 |
| Grad. Desc. 32 HU | 88.57% | 90.00% | 89.56% | 0.52% | 20 min | 25,450 |
| Syn. RL 0 HU | 87.65% | 88.84% | 88.28% | 0.41% | 1.5 h | 7850 |
| Grad. Desc. 0 HU | 86.11% | 86.73% | 86.42% | 0.22% | 5 min | 7850 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bhargava, A.; Rezaei, M.R.; Lankarany, M. Gradient-Free Neural Network Training via Synaptic-Level Reinforcement Learning. AppliedMath 2022, 2, 185-195. https://doi.org/10.3390/appliedmath2020011
Bhargava A, Rezaei MR, Lankarany M. Gradient-Free Neural Network Training via Synaptic-Level Reinforcement Learning. AppliedMath. 2022; 2(2):185-195. https://doi.org/10.3390/appliedmath2020011
Chicago/Turabian StyleBhargava, Aman, Mohammad R. Rezaei, and Milad Lankarany. 2022. "Gradient-Free Neural Network Training via Synaptic-Level Reinforcement Learning" AppliedMath 2, no. 2: 185-195. https://doi.org/10.3390/appliedmath2020011
APA StyleBhargava, A., Rezaei, M. R., & Lankarany, M. (2022). Gradient-Free Neural Network Training via Synaptic-Level Reinforcement Learning. AppliedMath, 2(2), 185-195. https://doi.org/10.3390/appliedmath2020011