Comparative Assessment of Hierarchical Clustering Methods for Grouping in Singular Spectrum Analysis



Abstract
:1. Introduction
2. Theoretical Background
2.1. Review of Basic SSA
- Step 1:
- Embedding. In this step, the time series is transformed into the matrix , whose columns comprise , where and . The matrix is called the trajectory matrix. This matrix is a Hankel matrix in the sense that all the elements on the anti-diagonals are equal. The embedding step only has one parameter L, which is called the window length or embedding dimension. The window length is commonly chosen such that where N is the length of the time series .
- Step 2:
- Decomposition. In this step, the trajectory matrix is decomposed into a sum of rank-one matrices using the conventional singular value decomposition (SVD) procedure. The eigenvalues of were denoted by in decreasing order of magnitude and by , the eigenvectors of the matrix corresponding to these eigenvalues. If , then the SVD of the trajectory matrix can be written aswhere and (). The collection () is called the ith eigentriple of the SVD.
- Step 3:
- Grouping. The aim of this step is to group the components of (1). Let be the subset of indices . Then, the resultant matrix corresponding to the group I is defined as , that is, summing the matrices within each group. With the SVD of , the split of the set of indices into the m disjoint subsets corresponds to the following decomposition:If , for , then the corresponding grouping is called elementary.
- Step 4:
- Diagonal Averaging. The main goal of this step is to transform each matrix of the grouped matrix decomposition (2) into a Hankel matrix, which can subsequently be converted into a new time series of length N. Let be an matrix with elements , . By diagonal averaging, the matrix is transferred into the Hankel matrix with the elements over the anti-diagonals using the following formula:where and denotes the number of elements in the set . By applying diagonal averaging (3) to all the matrix components of (2), the following expansion is obtained: where , . This is equivalent to the decomposition of the initial series into a sum of m series: , where corresponds to the matrix .
2.2. Hierarchical Clustering Methods
| Algorithm 1 Auto-grouping using clustering methods. |
|
- Divisive. In this approach, an initial single cluster of objects is divided into two clusters such that the objects in one cluster are far from the objects in the other cluster. The process proceeds by splitting the clusters into smaller and smaller clusters until each object forms a separate cluster [20,21]. We implemented this method in our research via the function diana from the cluster package [22] of the freely available statistical R software [23].
- Agglomerative. In this approach, the individual objects are initially treated as a cluster, and then the most similar clusters are merged according to their similarities. This procedure proceeds by successive fusions until a single cluster is eventually obtained containing all the objects [20,21]. Several agglomerative hierarchical clustering methods are employed in this paper including single, complete, average, mcquitty, median, centroid and Ward. There are two algorithms ward.D and ward.D2 for the Ward method, which are available in R packages such as stats and NbClust [24]. By implementing the ward.D2 algorithm, the dissimilarities are squared before the cluster updates.
2.3. Cluster Validation Measure
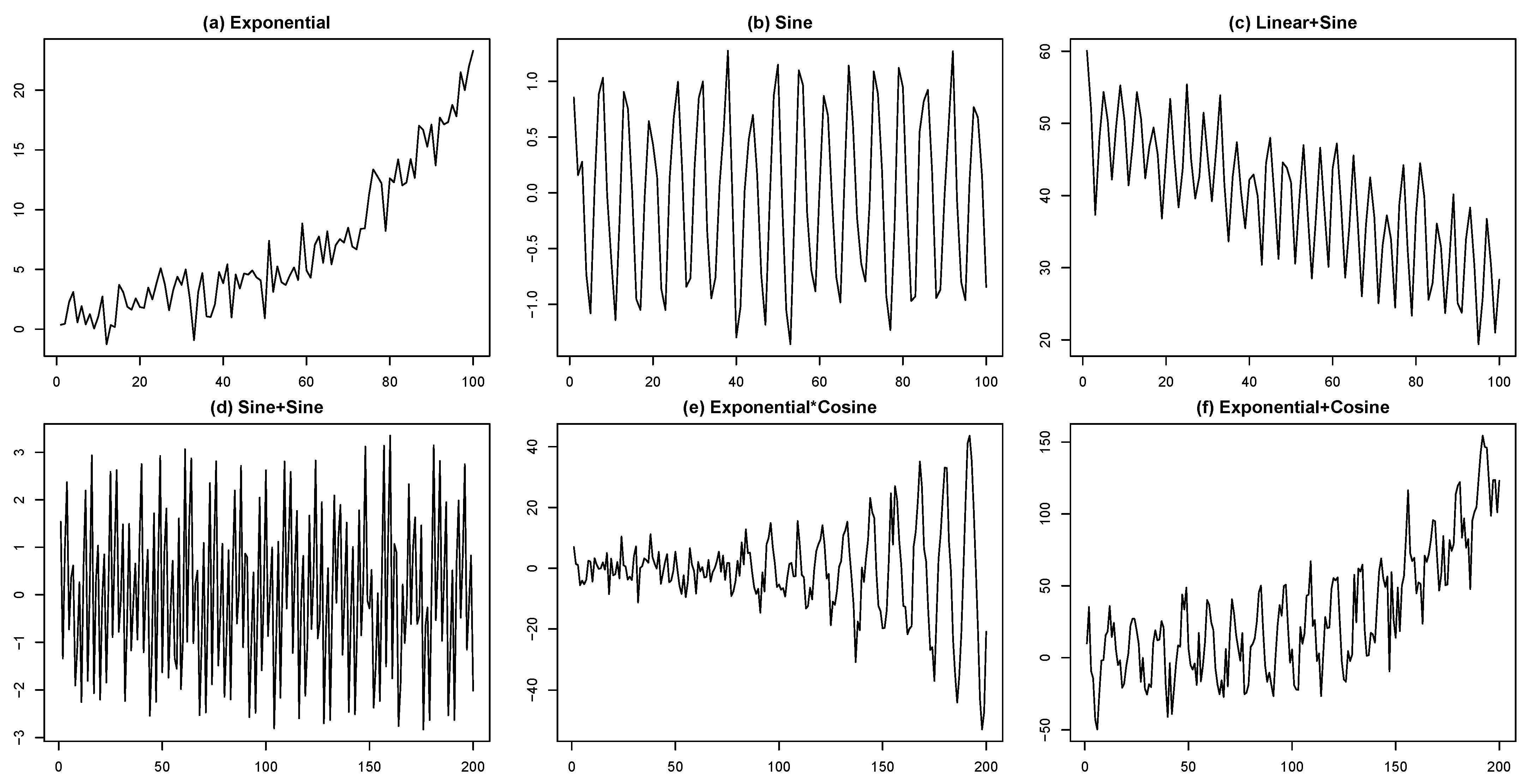
3. Simulation Study
- (a)
- Exponential:
- (b)
- Sine:
- (c)
- Linear + Sine:
- (d)
- Sine + Sine:
- (e)
- Exponential × Cosine:
- (f)
- Exponential + Cosine:
4. Case Studies
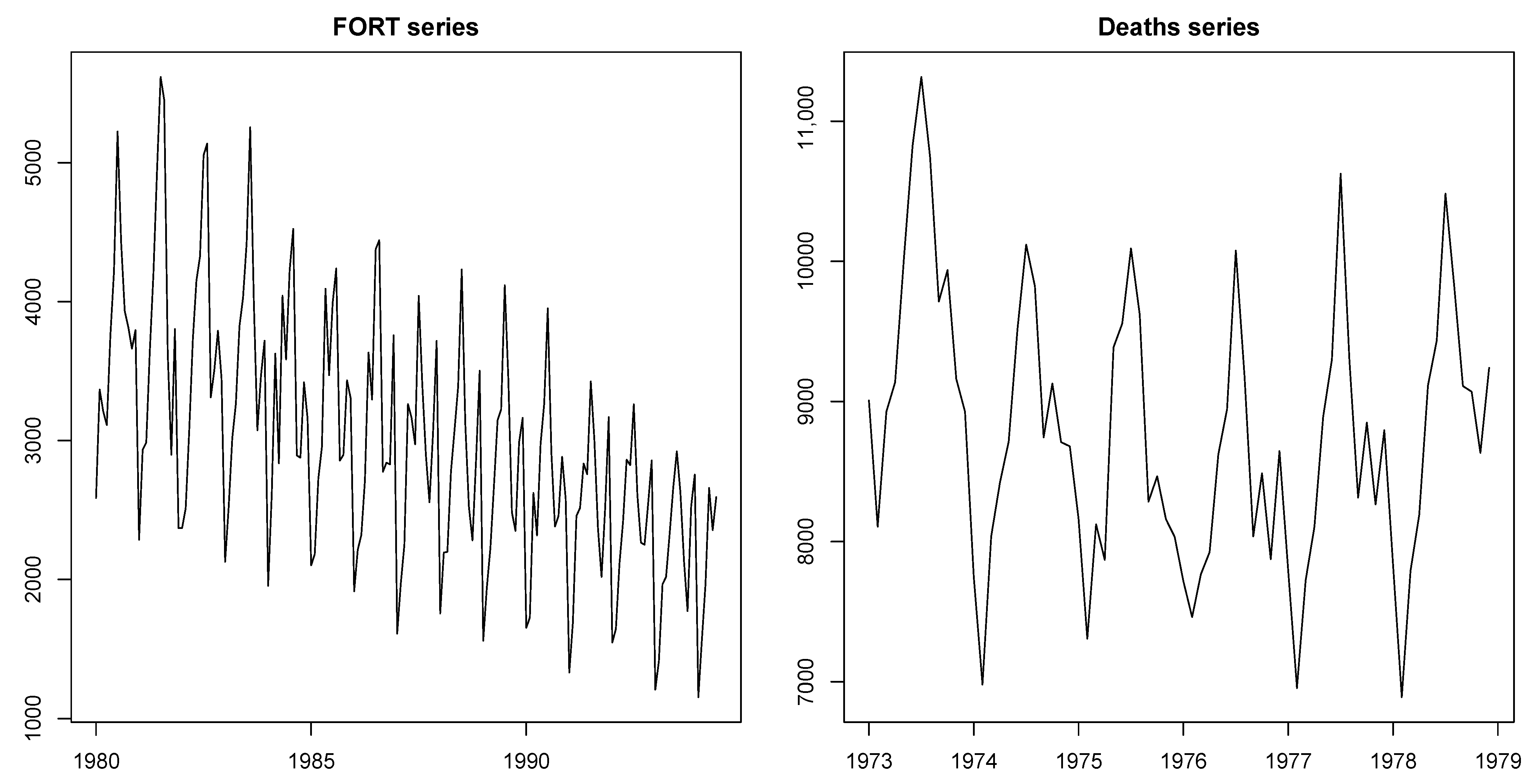
- FORT series: Monthly Australian fortified wine sales (abbreviated to “FORT”) in thousands of liters from January 1980 to July 1995 with 187 observations [14,31]. This time series is part of the dataset AustralianWine from R package Rssa. Each of the seven variables of the full dataset contains 187 points. Since the data were missing values after June 1994, we used the first 174 points.
- Deaths series: Monthly accidental deaths in the USA from 1973 to 1978 including a total of 72 observations. This well-known time series dataset has been used by many authors and can be found in many time series books (as can be seen, for example, [32]). In this study, the USAccDeaths data of R package datasets were used.
- Step 1:
- Choosing the window lengthOne of the most important parameters in SSA is the window length (L). This parameter plays a pivotal role in SSA because the outputs of reconstruction and forecasting are affected by changing this parameter. There are some general recommendations for the choice of the window length L. It should be sufficiently large and the most detailed decomposition is achieved when L is close to the half of time series length () [10]. Furthermore, in order to extract the periodic components of a time series with the known period P, the window lengths divisible by the period P provide better separability [14].In the FORT time series, which is periodic with the period , meets these recommendations, since 84 is close to and . Furthermore, the Deaths time series is periodic with the period . Therefore, satisfies these recommendations, because 36 is equal to and .
- Step 2:
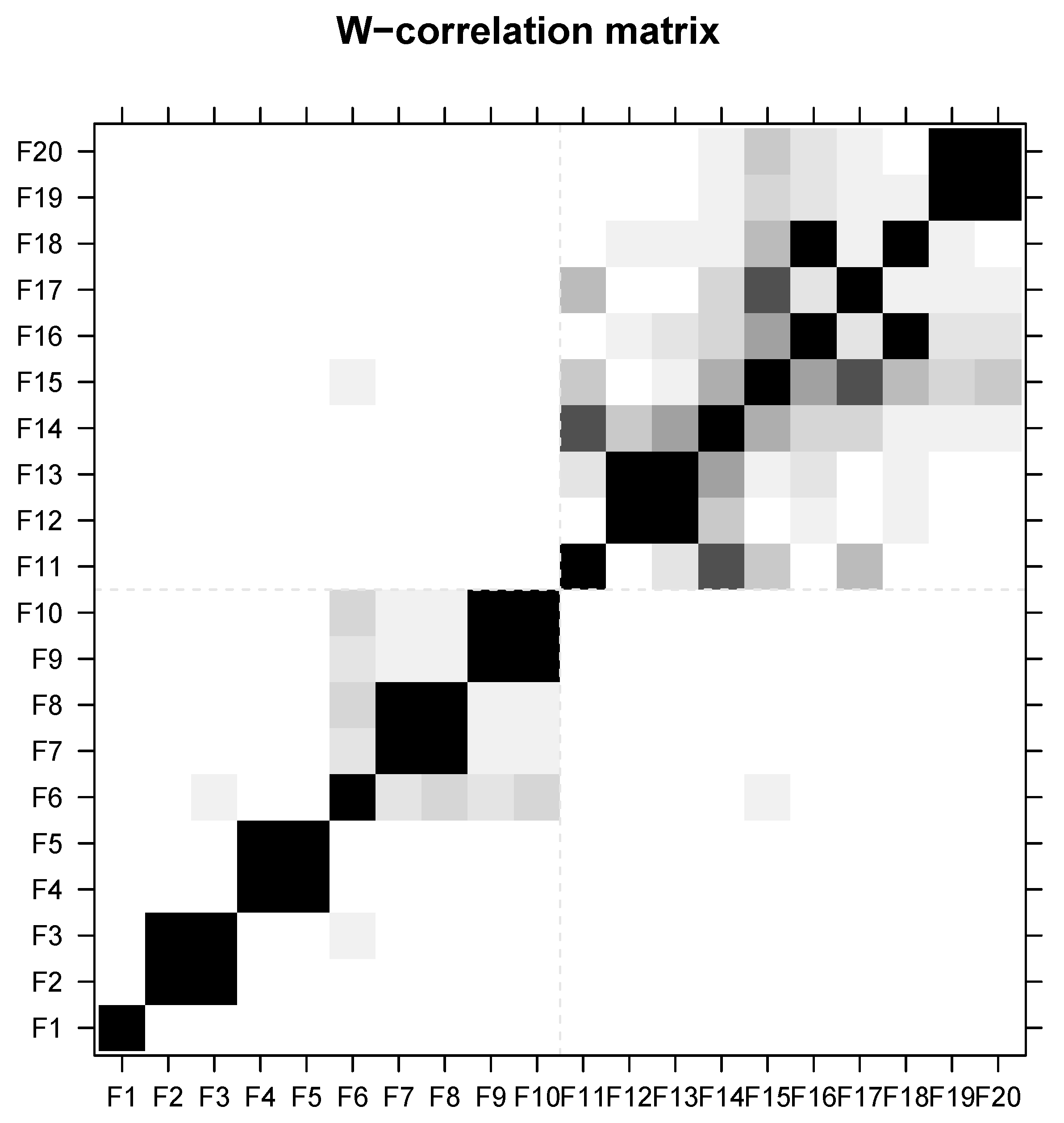
- Determining the number of clustersAn important step in hierarchical clustering is the decision on where to cut the dendrogram. Similar to the simulation study proposed in Section 3, here, we use the number of clusters as a cutting rule of the dendrogram. If the purpose of time series analysis extracts the signal from noise, determining the number of clusters is quite straightforward; it is sufficient to set the number of clusters to equal two. However, if we want to retrieve different components concealed in a time series such as the trend and periodic components, determining the number of clusters requires more information. In this case, we recommend using the w-correlation matrix owing to utilizing it to measure the distance matrix of hierarchical clustering.Figure 9 shows the matrix of absolute values of w-correlations between the 30 leading elementary reconstructed components of FORT series. The matrix of absolute values of w-correlations between the 36 elementary reconstructed components of Deaths series is depicted in Figure 10. In these figures, the white color corresponds to zero and the black color corresponds to the absolute values equal to one. Highly correlated elementary reconstructed components can be easily found by looking at the w-correlation matrix and then we can place these components into the same cluster.It can be deduced from Figure 9 that the components of the FORT series can be partitioned into eight groups: . Furthermore, in order to separate signal from noise, the components can be split into two groups: signal () and noise ().Using the information provided in Figure 10, the components of Deaths series can be partitioned into seven groups: . Additionally, in order to separate signal from noise, the components can be split into two groups: signal () and noise ().
- Step 3:
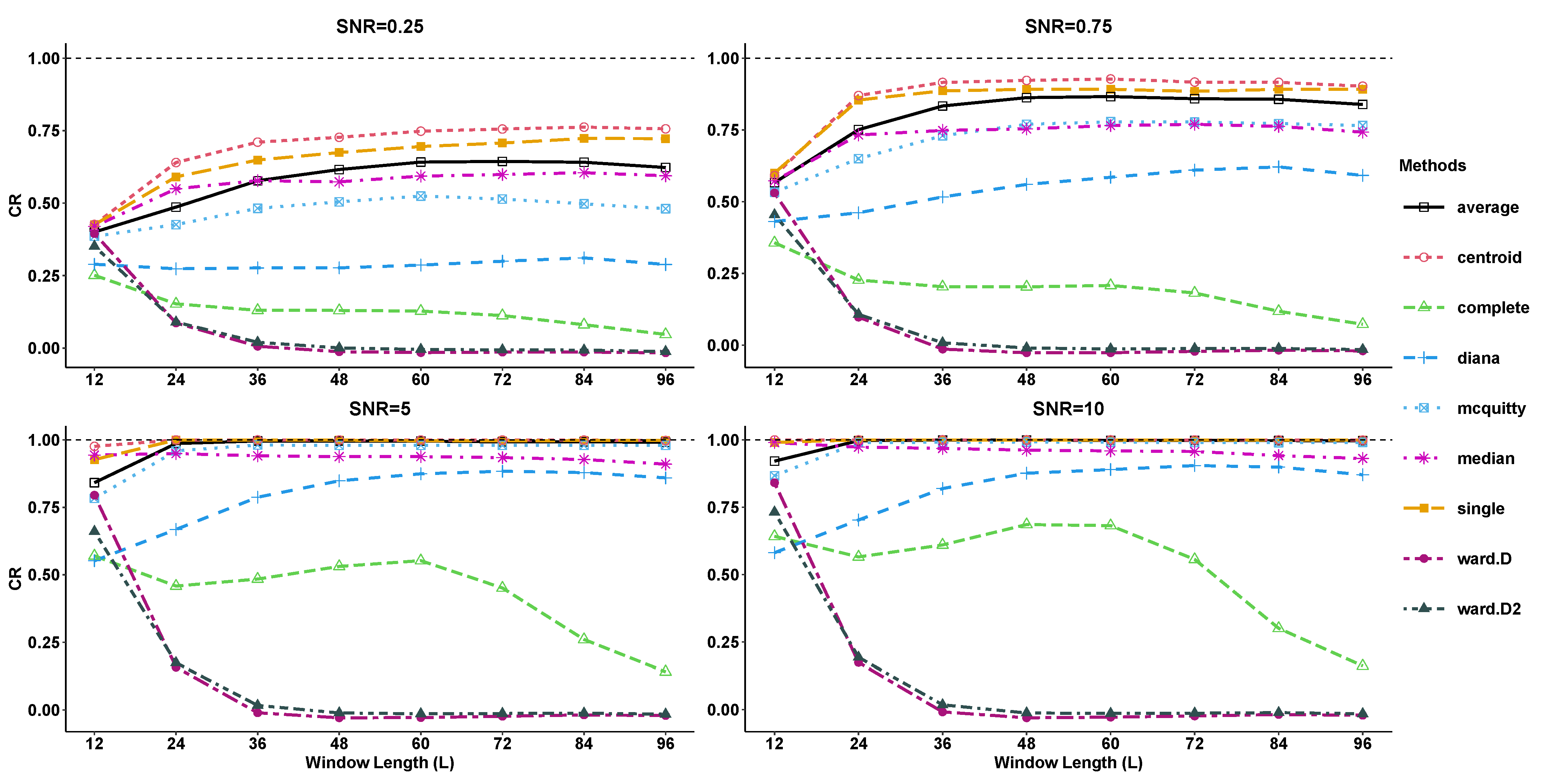
- Selecting a proper linkageAlthough a proper linkage can be selected using the findings of the simulation study given in Section 3, we compared the different linkages based on the CR index for FORT and Deaths series. The outputs of clustering are reported in Table 4 and Table 5, when it is assumed that the correct groups are those mentioned in Step 2. The results reported in these tables show that the single, median and centroid linkages can exactly identify the correct groups in FORT series (expressed in boldface). However, only the centroid linkage can exactly identify the correct groups in Deaths series (expressed in boldface). Based on the CR index reported in Table 4 and Table 5, it can be concluded that the ward.D and ward.D2 linkages have the worst performance both in FORT and Deaths series. These findings are in good agreement with the simulation results obtained in Section 3.Figure 11 shows the dendrogram of the single linkage for our FORT series. The dendrogram of the centroid linkage for the Deaths series is depicted in Figure 12. The reconstruction of the FORT series with the help of the first 13 eigentriples is presented in Figure 13. Furthermore, Figure 14 shows the plot of the signal reconstruction of the Deaths series based on the first 10 eigentriples.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
References
- Atikur Rahman Khan, M.; Poskitt, D.S. Forecasting stochastic processes using singular spectrum analysis: Aspects of the theory and application. Int. J. Forecast. 2017, 33, 199–213. [Google Scholar] [CrossRef]
- Arteche, J.; Garcia-Enriquez, J. Singular Spectrum Analysis for signal extraction in Stochastic Volatility models. Econom. Stat. 2017, 1, 85–98. [Google Scholar] [CrossRef]
- Hassani, H.; Yeganegi, M.R.; Silva, E.S. A New Signal Processing Approach for Discrimination of EEG Recordings. Stats 2018, 1, 155–168. [Google Scholar] [CrossRef] [Green Version]
- Safi, S.M.; Mohammad Pooyan, M.; Nasrabadi, A.M. Improving the performance of the SSVEP-based BCI system using optimized singular spectrum analysis (OSSA). Biomed. Signal Process. Control. 2018, 46, 46–58. [Google Scholar] [CrossRef]
- Mahmoudvand, R.; Rodrigues, P.C. Predicting the Brexit Outcome Using Singular Spectrum Analysis. J. Comput. Stat. Model. 2018, 1, 9–15. [Google Scholar]
- Lahmiri, S. Minute-ahead stock price forecasting based on singular spectrum analysis and support vector regression. Appl. Math. Comput. 2018, 320, 444–451. [Google Scholar] [CrossRef]
- Saayman, A.; Klerk, J. Forecasting tourist arrivals using multivariate singular spectrum analysis. Tour. Econ. 2019, 25, 330–354. [Google Scholar] [CrossRef]
- Hassani, H.; Rua, A.; Silva, E.S.; Thomakos, D. Monthly forecasting of GDP with mixed-frequency multivariate singular spectrum analysis. Int. J. Forecast. 2019, 35, 1263–1272. [Google Scholar] [CrossRef] [Green Version]
- Poskitt, D.S. On Singular Spectrum Analysis and Stepwise Time Series Reconstruction. J. Time Ser. Anal. 2020, 41, 67–94. [Google Scholar] [CrossRef] [Green Version]
- Golyandina, N.; Nekrutkin, V.; Zhigljavsky, A. Analysis of Time Series Structure: SSA and Related Techniques; Chapman & Hall/CRC: Boca Raton, FL, USA, 2001. [Google Scholar]
- Golyandina, N.; Zhigljavsky, A. Singular Spectrum Analysis for Time Series, 2nd ed.; Springer Briefs in Statistics; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Sanei, S.; Hassani, H. Singular Spectrum Analysis of Biomedical Signals; Taylor & Francis/CRC: Boca Raton, FL, USA, 2016. [Google Scholar]
- Hassani, H.; Mahmoudvand, R. Singular Spectrum Analysis Using R; Palgrave Pivot: London, UK, 2018. [Google Scholar]
- Golyandina, N.; Korobeynikov, A.; Zhigljavsky, A. Singular Spectrum Analysis with R; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Golyandina, N. Particularities and commonalities of singular spectrum analysis as a method of time series analysis and signal processing. WIREs Comput. Stat. 2020, 12, e1487. [Google Scholar] [CrossRef]
- Bilancia, M.; Campobasso, F. Airborne particulate matter and adverse health events: Robust estimation of timescale effects. In Classification as a Tool for Research; Locarek-Junge, H., Weihs, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 481–489. [Google Scholar]
- Korobeynikov, A. Computation- and space-efficient implementation of SSA. Stat. Its Interface 2010, 3, 257–368. [Google Scholar] [CrossRef] [Green Version]
- Golyandina, N.; Korobeynikov, A. Basic Singular Spectrum Analysis and forecasting with R. Comput. Stat. Data Anal. 2014, 71, 934–954. [Google Scholar] [CrossRef] [Green Version]
- Golyandina, N.; Korobeynikov, A.; Shlemov, A.; Usevich, K. Multivariate and 2D Extensions of Singular Spectrum Analysis with the Rssa Package. J. Stat. Softw. 2015, 67, 1–78. [Google Scholar] [CrossRef] [Green Version]
- Johnson, R.A.; Wichern, D.W. Applied Multivariate Statistical Analysis, 6th ed.; Pearson Education Ltd: London, UK, 2013. [Google Scholar]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; Wiley: New York, NY, USA, 1990. [Google Scholar]
- Maechler, M.; Rousseeuw, P.; Struyf, A.; Hubert, M.; Hornik, K. Cluster: Cluster Analysis Basics and Extensions. R Package Version 2021, 2, 56. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021; Available online: https://www.R-project.org/ (accessed on 23 October 2021).
- Charrad, M.; Ghazzali, N.; Boiteau, V.; Niknafs, A. NbClust: An R Package for Determining the Relevant Number of Clusters in a Data Set. J. Stat. Softw. 2014, 61, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Gordon, A.D. Classification, 2nd ed.; Chapman & Hall: Boca Raton, FL, USA, 1999. [Google Scholar]
- Contreras, P.; Murtagh, F. Hierarchical Clustering. In Handbook of Cluster Analysis; Henning, C., Meila, M., Murtagh, F., Rocci, R., Eds.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2016; pp. 103–123. [Google Scholar]
- Hennig, C.; fpc: Flexible Procedures for Clustering. R Package Version 2.2-9. 2020. Available online: https://CRAN.R-project.org/package=fpc. (accessed on 15 September 2021).
- Hubert, L.; Arabie, P. Comparing partitions. J. Classif. 1985, 2, 193–218. [Google Scholar] [CrossRef]
- Gates, A.J.; Ahn, Y.Y. The impact of random models on clustering similarity. J. Mach. Learn. Res. 2017, 18, 1–28. [Google Scholar]
- Vinh, N.X.; Epps, J.; Bailey, J. Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance. J. Mach. Learn. Res. 2010, 11, 2837–2854. [Google Scholar]
- Hyndman, R.J. Time Series Data Library. Available online: http://data.is/TSDLdemo (accessed on 10 May 2021).
- Brockwell, P.J.; Davis, R.A. Introduction to Time Series and Forecasting, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ⋯ | sums | ||||
| ⋯ | |||||
| ⋯ | |||||
| ⋮ | ⋮ | ⋮ | ⋱ | ⋮ | ⋮ |
| ⋯ | |||||
| sums | ⋯ |
| Simulated Series | Correct Groups | The Number of Clusters |
|---|---|---|
| Exponential | 2 | |
| Sine | 2 | |
| Linear+sine | 3 | |
| Sine+Sine | 3 | |
| Exponential×Cosine | 2 | |
| Exponential+Cosine | 3 |
| Simulated Series | Proper Linkages |
|---|---|
| Exponential | average, centroid, diana, mcquitty, median, single |
| Sine | average, centroid, mcquitty, median, single |
| Linear + sine | average, centroid, mcquitty, median, single |
| Sine + Sine | average, centroid, mcquitty, median, single |
| Exponential × Cosine | average, single, mcquitty |
| Exponential + Cosine | average, centroid, single |
| Linkage | CR | Clustering Output |
|---|---|---|
| average | 0.491 | |
| centroid | 1.000 | |
| complete | 0.280 | |
| diana | 0.462 | |
| mcquitty | 0.491 | |
| median | 1.000 | |
| single | 1.000 | |
| ward.D | 0.028 | |
| ward.D2 | 0.024 | |
| Linkage | CR | Clustering Output |
|---|---|---|
| average | 0.389 | |
| centroid | 1.000 | |
| complete | 0.158 | |
| diana | 0.353 | |
| mcquitty | 0.389 | |
| median | 0.761 | |
| single | 0.914 | |
| ward.D | 0.056 | |
| ward.D2 | 0.111 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassani, H.; Kalantari, M.; Beneki, C. Comparative Assessment of Hierarchical Clustering Methods for Grouping in Singular Spectrum Analysis. AppliedMath 2021, 1, 18-36. https://doi.org/10.3390/appliedmath1010003
Hassani H, Kalantari M, Beneki C. Comparative Assessment of Hierarchical Clustering Methods for Grouping in Singular Spectrum Analysis. AppliedMath. 2021; 1(1):18-36. https://doi.org/10.3390/appliedmath1010003
Chicago/Turabian StyleHassani, Hossein, Mahdi Kalantari, and Christina Beneki. 2021. "Comparative Assessment of Hierarchical Clustering Methods for Grouping in Singular Spectrum Analysis" AppliedMath 1, no. 1: 18-36. https://doi.org/10.3390/appliedmath1010003
APA StyleHassani, H., Kalantari, M., & Beneki, C. (2021). Comparative Assessment of Hierarchical Clustering Methods for Grouping in Singular Spectrum Analysis. AppliedMath, 1(1), 18-36. https://doi.org/10.3390/appliedmath1010003