
Overview of STEM Science as Process, Method, Material, and Data Named Entities


Abstract
1. Introduction
2. Background
3. Related Work: Scientific Named Entity Recognition (NER) Formalisms
3.1. Computer Science NER (CS NER)
3.2. Biomedical NER (BioNER)
3.3. Chemistry NER (ChemNER)
4. Materials and Methods
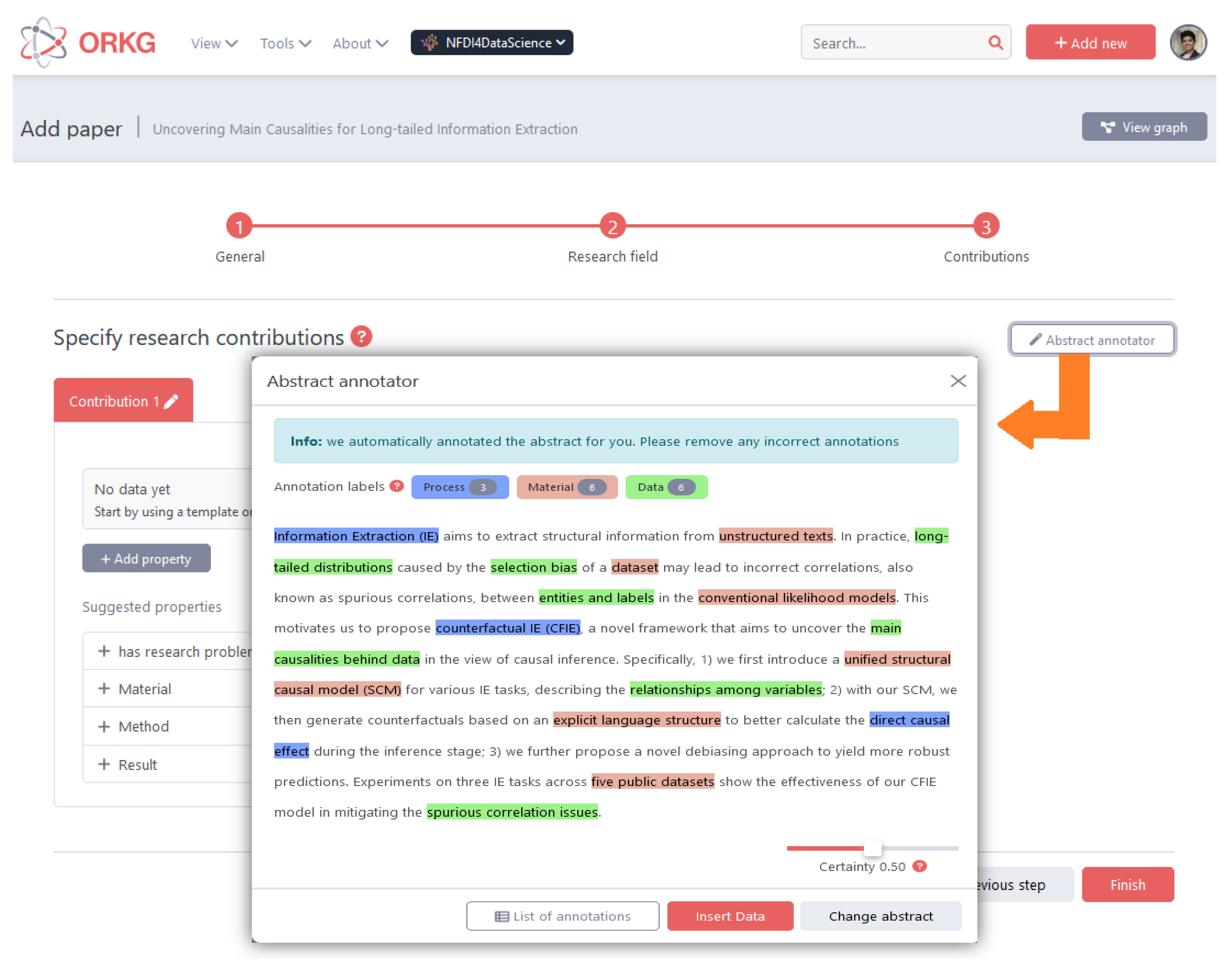
4.1. Our STEM-NER-60k Corpus
4.1.1. Concept Definitions
- Process. Natural phenomenon, or independent/dependent activities. For example, growing (bio), cured (ms), flooding (es).
- Method. A commonly used procedure that acts on entities. For example, powder X-ray (chem), the PRAM analysis (cs), magnetoencephalography (med).
- Material. A physical or digital entity used for scientific experiments. For example, soil (agri), the moon (ast), the set (math).
- Data. The data themselves, or quantitative or qualitative characteristics of entities. For example, rotational energy (eng), tensile strength (ms), vascular risk (med).
4.1.2. Corpus Creation
4.1.3. Corpus Insights
STEM scientific terms as process
STEM scientific terms as method
STEM scientific terms as material
STEM scientific terms as data
Discovered STEM scientific research trends based on the terminology of our corpus
Agriculture domain
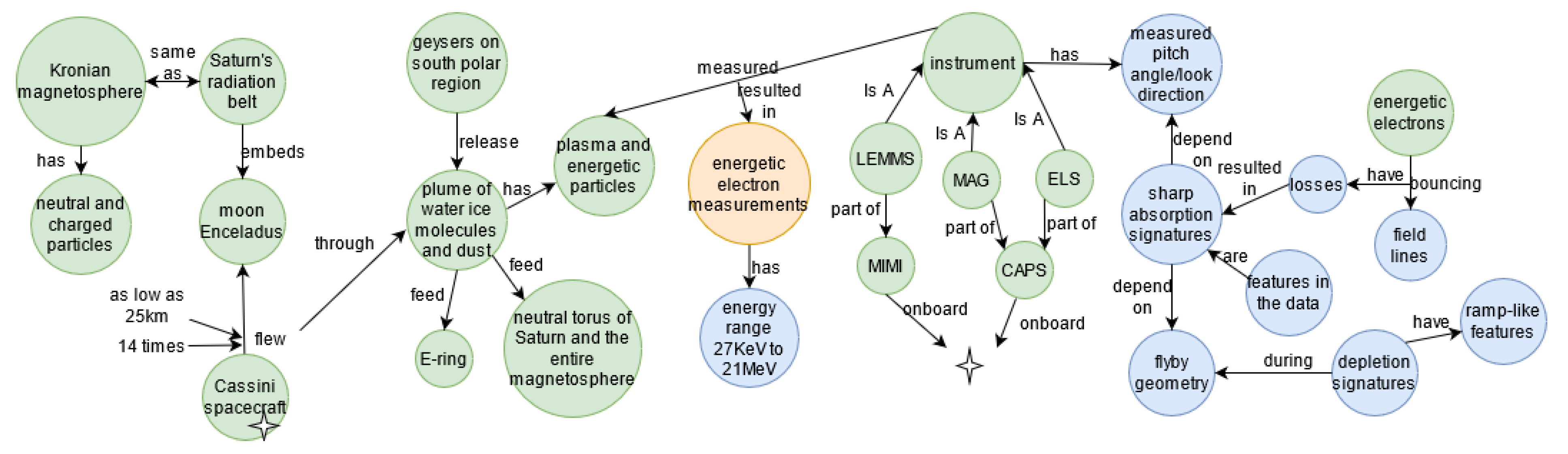
Astronomy domain
Biology domain
Chemistry domain
Computer Science domain
Earth Science domain
Engineering domain
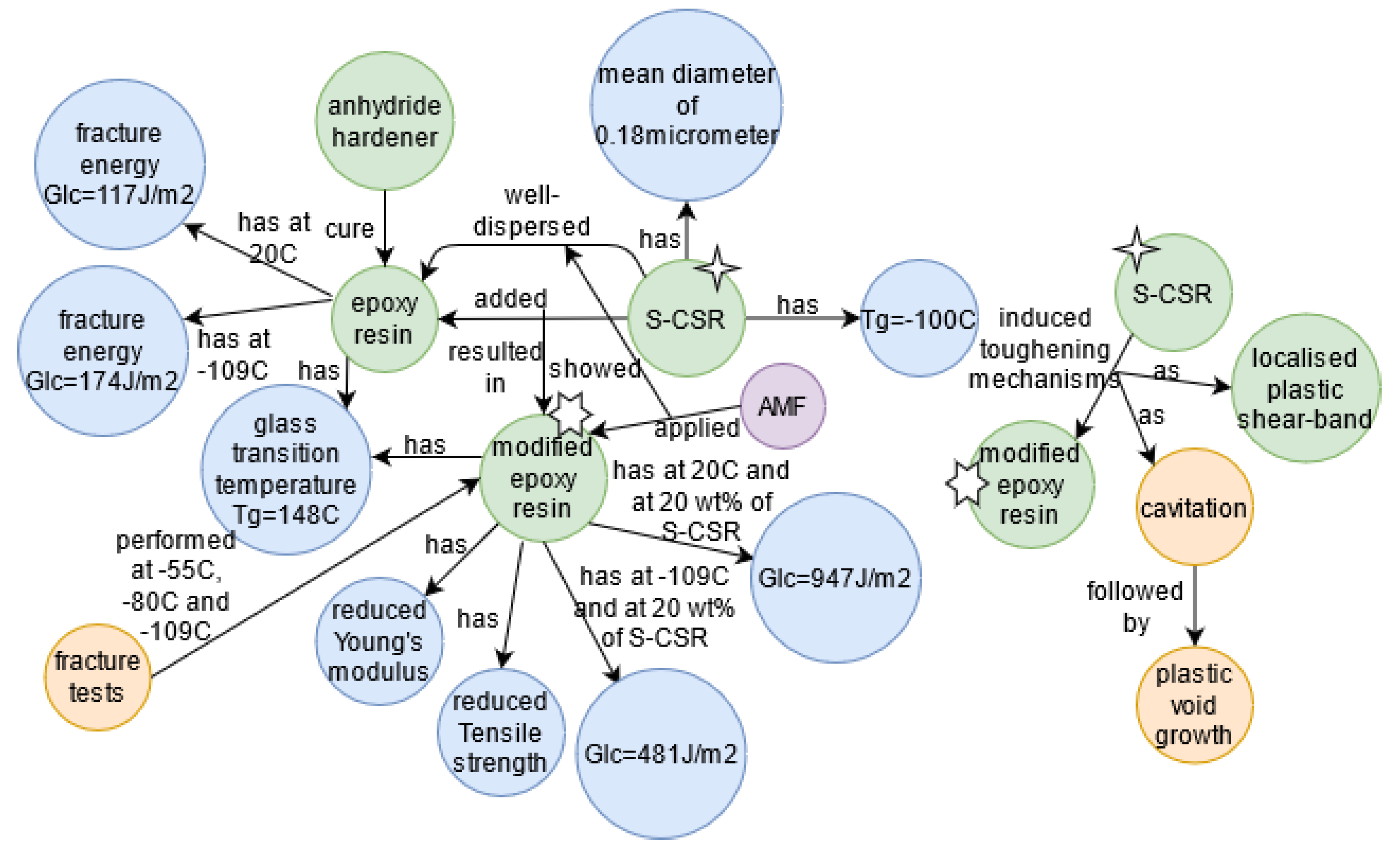
Material Science domain
Mathematics domain
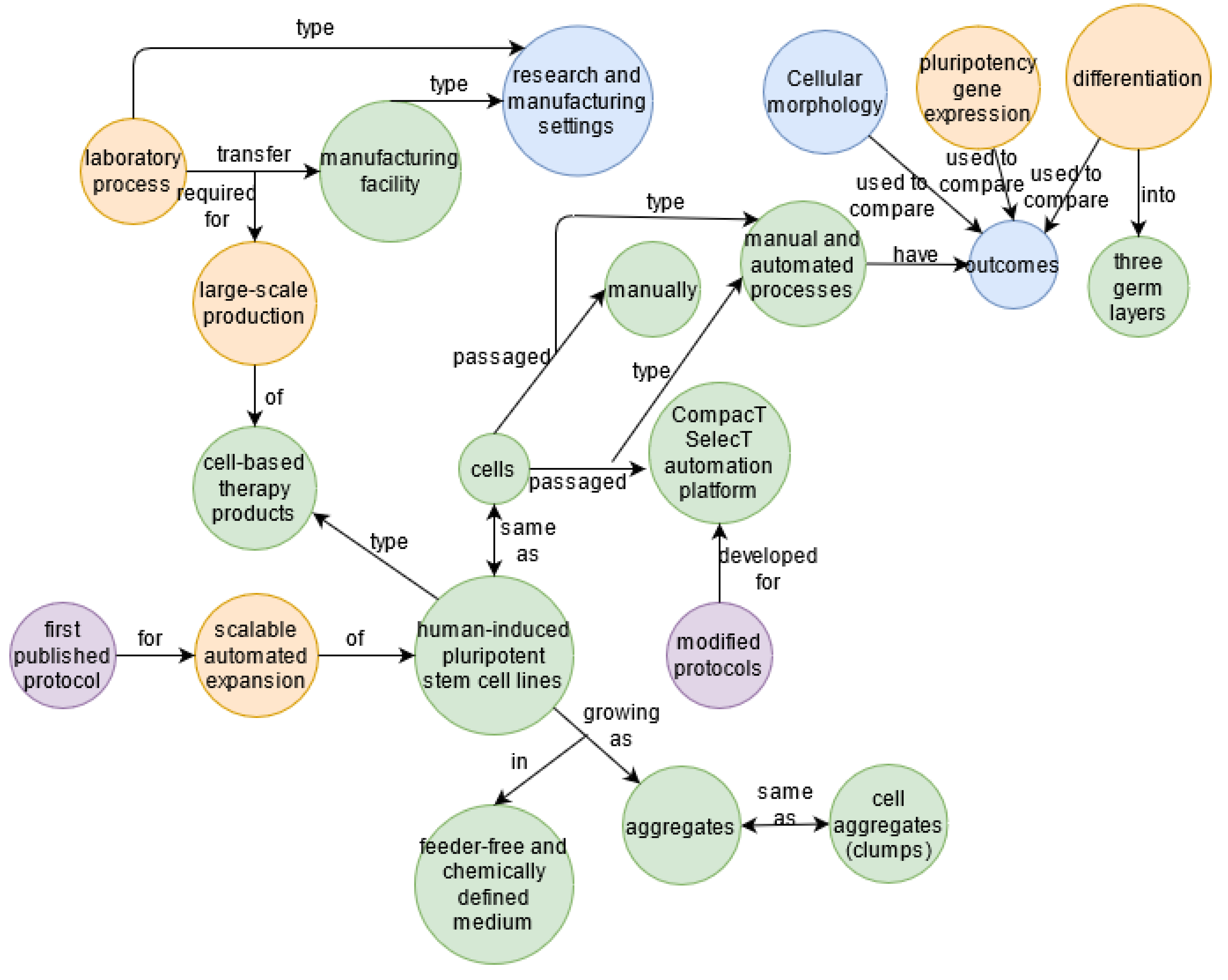
Medicine domain
5. Results
STEM Entities Recommendation Service in the Open Research Knowledge Graph
6. Discussion
Knowledge Graph Construction for Fine-Grained Structured Search
7. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A









References
- Schubert, L. Turing’s dream and the knowledge challenge. In Proceedings of the National Conference on Artificial Intelligence, Boston, MA, USA, 16–20 June 2006; Volume 21, p. 1534. [Google Scholar]
- Moro, A.; Cecconi, F.; Navigli, R. Multilingual Word Sense Disambiguation and Entity Linking for Everybody. In Proceedings of the ISWC, Downtown Seattle, WA, USA, 13–17 September 2014; pp. 25–28. [Google Scholar]
- Mendes, P.N.; Jakob, M.; García-Silva, A.; Bizer, C. DBpedia spotlight: Shedding light on the web of documents. In Proceedings of the 7th International Conference on Semantic Systems, Graz, Austria, 7–9 September 2011; ACM: New York, NY, USA, 2011; pp. 1–8. [Google Scholar]
- Mitchell, T.; Cohen, W.; Hruschka, E.; Talukdar, P.; Yang, B.; Betteridge, J.; Carlson, A.; Dalvi, B.; Gardner, M.; Kisiel, B.; et al. Never-ending learning. Commun. ACM 2018, 61, 103–115. [Google Scholar] [CrossRef]
- Gangemi, A.; Presutti, V.; Recupero, D.R.; Nuzzolese, A.G.; Draicchio, F.; Mongiovi, M. Semantic Web Machine Reading with FRED. Semant. Web 2017, 8, 873–893. [Google Scholar] [CrossRef]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [PubMed]
- Birkle, C.; Pendlebury, D.A.; Schnell, J.; Adams, J. Web of Science as a data source for research on scientific and scholarly activity. Quant. Sci. Stud. 2020, 1, 363–376. [Google Scholar] [CrossRef]
- Wang, K.; Shen, Z.; Huang, C.; Wu, C.H.; Dong, Y.; Kanakia, A. Microsoft academic graph: When experts are not enough. Quant. Sci. Stud. 2020, 1, 396–413. [Google Scholar] [CrossRef]
- Auer, S. Towards an Open Research Knowledge Graph. Ser. Libr. 2018, 76, 35–41. [Google Scholar] [CrossRef]
- Auer, S.; Oelen, A.; Haris, M.; Stocker, M.; D’Souza, J.; Farfar, K.E.; Vogt, L.; Prinz, M.; Wiens, V.; Jaradeh, M.Y. Improving access to scientific literature with knowledge graphs. Bibl. Forsch. Und Prax. 2020, 44, 516–529. [Google Scholar] [CrossRef]
- Fricke, S. Semantic scholar. J. Med Libr. Assoc. 2018, 106, 145. [Google Scholar] [CrossRef]
- Brack, A.; D’Souza, J.; Hoppe, A.; Auer, S.; Ewerth, R. Domain-independent extraction of scientific concepts from research articles. In Proceedings of the European Conference on Information Retrieval, Lisbon, Portugal, 14–17 April 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 251–266. [Google Scholar]
- D’Souza, J.; Hoppe, A.; Brack, A.; Jaradeh, M.Y.; Auer, S.; Ewerth, R. The STEM-ECR Dataset: Grounding Scientific Entity References in STEM Scholarly Content to Authoritative Encyclopedic and Lexicographic Sources. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 13–15 May 2020; pp. 2192–2203. [Google Scholar]
- Kim, S.N.; Medelyan, O.; Kan, M.Y.; Baldwin, T. Semeval-2010 task 5: Automatic keyphrase extraction from scientific articles. In Proceedings of the 5th International Workshop on Semantic Evaluation, Uppsala, Sweden, 15–17 July 2010; pp. 21–26. [Google Scholar]
- Moro, A.; Navigli, R. Semeval-2015 task 13: Multilingual all-words sense disambiguation and entity linking. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, CO, USA, 4–5 June 2015; pp. 288–297. [Google Scholar]
- Augenstein, I.; Das, M.; Riedel, S.; Vikraman, L.; McCallum, A. SemEval 2017 Task 10: ScienceIE—Extracting Keyphrases and Relations from Scientific Publications. In Proceedings of the SemEval@ACL, Vancouver, BC, Canada, 3–4 August 2017. [Google Scholar]
- Gábor, K.; Buscaldi, D.; Schumann, A.K.; QasemiZadeh, B.; Zargayouna, H.; Charnois, T. Semeval-2018 Task 7: Semantic relation extraction and classification in scientific papers. In Proceedings of the SemEval, New Orleans, LA, USA, 5–6 June 2018; pp. 679–688. [Google Scholar]
- D’Souza, J.; Auer, S.; Pedersen, T. SemEval-2021 Task 11: NLPContributionGraph-Structuring Scholarly NLP Contributions for a Research Knowledge Graph. In Proceedings of the 15th International Workshop on Semantic Evaluation (SemEval-2021), Bangkok, Thailand, 5–6 August 2021; pp. 364–376. [Google Scholar]
- D’Souza, J.; Auer, S. Pattern-based acquisition of scientific entities from scholarly article titles. In Proceedings of the International Conference on Asian Digital Libraries, Virtual Event, 1–3 December 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 401–410. [Google Scholar]
- Hou, Y.; Jochim, C.; Gleize, M.; Bonin, F.; Ganguly, D. Identification of Tasks, Datasets, Evaluation Metrics, and Numeric Scores for Scientific Leaderboards Construction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5203–5213. [Google Scholar] [CrossRef]
- Jain, S.; van Zuylen, M.; Hajishirzi, H.; Beltagy, I. SciREX: A Challenge Dataset for Document-Level Information Extraction. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7506–7516. [Google Scholar] [CrossRef]
- Kabongo, S.; D’Souza, J.; Auer, S. Automated mining of leaderboards for empirical ai research. In Proceedings of the International Conference on Asian Digital Libraries, Virtual Event, 1–3 December 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 453–470. [Google Scholar]
- QasemiZadeh, B.; Schumann, A.K. The ACL RD-TEC 2.0: A language resource for evaluating term extraction and entity recognition methods. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portoroz, Slovenia, 23–28 May 2016; pp. 1862–1868. [Google Scholar]
- Gupta, S.; Manning, C. Analyzing the Dynamics of Research by Extracting Key Aspects of Scientific Papers. In Proceedings of the 5th International Joint Conference on Natural Language Processing, Chiang Mai, Thailand, 8–23 November 2011; Asian Federation of Natural Language Processing: Chiang Mai, Thailand, 2011; pp. 1–9. [Google Scholar]
- Luan, Y.; He, L.; Ostendorf, M.; Hajishirzi, H. Multi-Task Identification of Entities, Relations, and Coreference for Scientific Knowledge Graph Construction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3219–3232. [Google Scholar]
- Mondal, I.; Hou, Y.; Jochim, C. End-to-End Construction of NLP Knowledge Graph. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 1885–1895. [Google Scholar] [CrossRef]
- Färber, M.; Albers, A.; Schüber, F. Identifying used methods and datasets in scientific publications. In Proceedings of the Workshop on Scientific Document Understanding: Co-located with 35th AAAI Conference on Artificial Inteligence (AAAI 2021), Online, 9 February 2021. [Google Scholar]
- D’Souza, J.; Auer, S. Computer Science Named Entity Recognition in the Open Research Knowledge Graph. In Proceedings of the International Conference on Asian Digital Libraries, Hybrid Event, 30 November–2 December 2022; Springer: Berlin/Heidelberg, Germany, 2021; pp. 35–45. [Google Scholar] [CrossRef]
- Tanabe, L.; Xie, N.; Thom, L.H.; Matten, W.; Wilbur, W.J. GENETAG: A tagged corpus for gene/protein named entity recognition. BMC Bioinform. 2005, 6, S3. [Google Scholar] [CrossRef]
- Collier, N.; Kim, J.D. Introduction to the Bio-entity Recognition Task at JNLPBA. In Proceedings of the International Joint Workshop on Natural Language Processing in Biomedicine and its Applications (NLPBA/BioNLP), Geneva, Switzerland, 28–29 August 2004; pp. 73–78. [Google Scholar]
- Kim, J.D.; Ohta, T.; Tateisi, Y.; Tsujii, J. GENIA corpus—A semantically annotated corpus for bio-textmining. Bioinformatics 2003, 19, i180–i182. [Google Scholar] [CrossRef]
- Doğan, R.I.; Leaman, R.; Lu, Z. NCBI disease corpus: A resource for disease name recognition and concept normalization. J. Biomed. Inform. 2014, 47, 1–10. [Google Scholar] [CrossRef]
- Bada, M.; Eckert, M.; Evans, D.; Garcia, K.; Shipley, K.; Sitnikov, D.; Baumgartner, W.A.; Cohen, K.B.; Verspoor, K.; Blake, J.A.; et al. Concept annotation in the CRAFT corpus. BMC Bioinform. 2012, 13, 161. [Google Scholar] [CrossRef] [PubMed]
- Mohan, S.; Li, D. MedMentions: A Large Biomedical Corpus Annotated with UMLS Concepts. In Proceedings of the Automated Knowledge Base Construction (AKBC), San Diego, CA, USA, 17 June 2016. [Google Scholar]
- Ashburner, M.; Ball, C.A.; Blake, J.A.; Botstein, D.; Butler, H.; Cherry, J.M.; Davis, A.P.; Dolinski, K.; Dwight, S.S.; Eppig, J.T.; et al. Gene ontology: Tool for the unification of biology. Nat. Genet. 2000, 25, 25–29. [Google Scholar] [CrossRef]
- Bodenreider, O. The Unified Medical Language System (UMLS): Integrating biomedical terminology. Nucleic Acids Res. 2004, 32, D267. [Google Scholar] [CrossRef] [PubMed]
- Schoch, C.L.; Ciufo, S.; Domrachev, M.; Hotton, C.L.; Kannan, S.; Khovanskaya, R.; Leipe, D.; Mcveigh, R.; O’Neill, K.; Robbertse, B.; et al. NCBI Taxonomy: A comprehensive update on curation, resources and tools. Database 2020, 2020, baaa062. Available online: https://academic.oup.com/database/article-pdf/doi/10.1093/database/baaa062/33570620/baaa062.pdf (accessed on 12 December 2022). [CrossRef]
- Chatr-Aryamontri, A.; Ceol, A.; Palazzi, L.M.; Nardelli, G.; Schneider, M.V.; Castagnoli, L.; Cesareni, G. MINT: The Molecular INTeraction database. Nucleic Acids Res. 2007, 35, D572–D574. [Google Scholar] [CrossRef] [PubMed]
- Kerrien, S.; Alam-Faruque, Y.; Aranda, B.; Bancarz, I.; Bridge, A.; Derow, C.; Dimmer, E.; Feuermann, M.; Friedrichsen, A.; Huntley, R.; et al. IntAct—Open source resource for molecular interaction data. Nucleic Acids Res. 2007, 35, D561–D565. [Google Scholar] [CrossRef]
- Bader, G.D.; Cary, M.P.; Sander, C. Pathguide: A pathway resource list. Nucleic Acids Res. 2006, 34, D504–D506. [Google Scholar] [CrossRef]
- Camon, E.; Magrane, M.; Barrell, D.; Lee, V.; Dimmer, E.; Maslen, J.; Binns, D.; Harte, N.; Lopez, R.; Apweiler, R. The Gene Ontology Annotation (GOA) Database: Sharing knowledge in Uniprot with Gene Ontology. Nucleic Acids Res. 2004, 32, D262. [Google Scholar] [CrossRef]
- Krallinger, M.; Leitner, F.; Rodriguez-Penagos, C.; Valencia, A. Overview of the protein-protein interaction annotation extraction task of BioCreative II. Genome Biol. 2008, 9, S4. [Google Scholar] [CrossRef]
- Krallinger, M.; Vazquez, M.; Leitner, F.; Salgado, D.; Chatr-Aryamontri, A.; Winter, A.; Perfetto, L.; Briganti, L.; Licata, L.; Iannuccelli, M.; et al. The Protein-Protein Interaction tasks of BioCreative III: Classification/ranking of articles and linking bio-ontology concepts to full text. BMC Bioinform. 2011, 12, S3. [Google Scholar] [CrossRef]
- Krallinger, M.; Izarzugaza, J.M.; Rodriguez-Penagos, C.; Valencia, A. Extraction of human kinase mutations from literature, databases and genotyping studies. BMC Bioinform. 2009, 10, S1. [Google Scholar] [CrossRef] [PubMed]
- Krallinger, M.; Leitner, F.; Valencia, A. Analysis of biological processes and diseases using text mining approaches. Bioinform. Methods Clin. Res. 2010, 341–382. [Google Scholar]
- Kim, J.D.; Ohta, T.; Pyysalo, S.; Kano, Y.; Tsujii, J. Extracting bio-molecular events from literature—The BIONLP’09 shared task. Comput. Intell. 2011, 27, 513–540. [Google Scholar] [CrossRef]
- Herrero-Zazo, M.; Segura-Bedmar, I.; Martínez, P.; Declerck, T. The DDI corpus: An annotated corpus with pharmacological substances and drug–drug interactions. J. Biomed. Inform. 2013, 46, 914–920. [Google Scholar] [CrossRef]
- Krallinger, M.; Rabal, O.; Leitner, F.; Vazquez, M.; Salgado, D.; Lu, Z.; Leaman, R.; Lu, Y.; Ji, D.; Lowe, D.M.; et al. The CHEMDNER corpus of chemicals and drugs and its annotation principles. J. Cheminform. 2015, 7, S2. [Google Scholar] [CrossRef]
- Li, J.; Sun, Y.; Johnson, R.J.; Sciaky, D.; Wei, C.H.; Leaman, R.; Davis, A.P.; Mattingly, C.J.; Wiegers, T.C.; Lu, Z. BioCreative V CDR task corpus: A resource for chemical disease relation extraction. Database 2016, 2016, baw068. [Google Scholar] [CrossRef]
- Krallinger, M.; Miranda, A.; Mehryary, F.; Luoma, J.; Pyysalo, S.; Valencia, A. DrugProt Shared Task (BioCreative VII track 1-2021) Text Mining Drug-Protein/Gene Interactions (DrugProt) Shared Task. 2021. Available online: https://biocreative.bioinformatics.udel.edu/tasks/biocreative-vii/track-1/ (accessed on 13 October 2022).
- Corbett, P.; Batchelor, C.; Teufel, S. Annotation of chemical named entities. In Proceedings of the Biological, Translational, and Clinical Language Processing, Prague, Czech Republic, 7–10 June 2007; pp. 57–64. [Google Scholar]
- Islamaj, R.; Leaman, R.; Kim, S.; Kwon, D.; Wei, C.H.; Comeau, D.C.; Peng, Y.; Cissel, D.; Coss, C.; Fisher, C.; et al. NLM-Chem, a new resource for chemical entity recognition in PubMed full text literature. Sci. Data 2021, 8, 91. [Google Scholar] [CrossRef]
- Shah, P.K.; Perez-Iratxeta, C.; Bork, P.; Andrade, M.A. Information extraction from full text scientific articles: Where are the keywords? BMC Bioinform. 2003, 4, 20. [Google Scholar] [CrossRef]
- Adel, H. Deep Learning Methods for Knowledge Base Population. Ph.D. Thesis, LMU Munchen, Munchen, Germany, 2018. [Google Scholar]
- Unger, C.; Forascu, C.; Lopez, V.; Ngomo, A.C.N.; Cabrio, E.; Cimiano, P.; Walter, S. Question Answering over Linked Data (QALD-4). 2014. Available online: https://pub.uni-bielefeld.de/record/2763516 (accessed on 13 October 2022).
- Beltagy, I.; Lo, K.; Cohan, A. SciBERT: A pretrained language model for scientific text. In Proceedings of the EMNLP-IJCNLP, Hong Kong, China, 3–7 November 2019; pp. 3606–3611. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Ma, X.; Hovy, E.H. End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF. arXiv 2016, arXiv:1603.01354. [Google Scholar]
- Cover, T.M. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 1999. [Google Scholar]
- Ammar, W.; Groeneveld, D.; Bhagavatula, C.; Beltagy, I.; Crawford, M.; Downey, D.; Dunkelberger, J.; Elgohary, A.; Feldman, S.; Ha, V.; et al. Construction of the Literature Graph in Semantic Scholar. In Proceedings of the NAACL-HLT (3), New Orleans, LA, USA, 1–6 June 2018. [Google Scholar]
- D’Souza, J.; Auer, S. Sentence, phrase, and triple annotations to build a knowledge graph of natural language processing contributions—A trial dataset. J. Data Inf. Sci. 2021, 6, 6–34. [Google Scholar] [CrossRef]
- Auer, S.; Kovtun, V.; Prinz, M.; Kasprzik, A.; Stocker, M.; Vidal, M.E. Towards a knowledge graph for science. In Proceedings of the 8th International Conference on Web Intelligence, Mining and Semantics, Novi Sad, Serbia, 25–27 June 2018; pp. 1–6. [Google Scholar]
- Jaradeh, M.Y.; Oelen, A.; Farfar, K.E.; Prinz, M.; D’Souza, J.; Kismihók, G.; Stocker, M.; Auer, S. Open Research Knowledge Graph: Next Generation Infrastructure for Semantic Scholarly Knowledge. In Proceedings of the 10th International Conference on Knowledge Capture, New York, NY, USA, 19–21 November 2019; pp. 243–246. [Google Scholar] [CrossRef]
- Chen, J.; Kinloch, A.; Sprenger, S.; Taylor, A. The mechanical properties and toughening mechanisms of an epoxy polymer modified with polysiloxane-based core-shell particles. Polymer 2013, 54, 4276–4289. [Google Scholar] [CrossRef]
- Soares, F.A.; Chandra, A.; Thomas, R.J.; Pedersen, R.A.; Vallier, L.; Williams, D.J. Investigating the feasibility of scale up and automation of human induced pluripotent stem cells cultured in aggregates in feeder free conditions. J. Biotechnol. 2014, 173, 53–58. [Google Scholar] [CrossRef] [PubMed]
- Haution, O. Integrality of the Chern character in small codimension. Adv. Math. 2012, 231, 855–878. [Google Scholar] [CrossRef]
- Kender, S.; Stephenson, M.H.; Riding, J.B.; Leng, M.J.; Knox, R.W.; Peck, V.L.; Kendrick, C.P.; Ellis, M.A.; Vane, C.H.; Jamieson, R. Marine and terrestrial environmental changes in NW Europe preceding carbon release at the Paleocene–Eocene transition. Earth Planet. Sci. Lett. 2012, 353, 108–120. [Google Scholar] [CrossRef]
- Krupp, N.; Roussos, E.; Kollmann, P.; Paranicas, C.; Mitchell, D.; Krimigis, S.; Rymer, A.; Jones, G.; Arridge, C.; Armstrong, T.; et al. The Cassini Enceladus encounters 2005–2010 in the view of energetic electron measurements. Icarus 2012, 218, 433–447. [Google Scholar] [CrossRef]
- Martin, S.L.; Mooney, S.J.; Dickinson, M.J.; West, H.M. Soil structural responses to alterations in soil microbiota induced by the dilution method and mycorrhizal fungal inoculation. Pedobiologia 2012, 55, 271–281. [Google Scholar] [CrossRef]
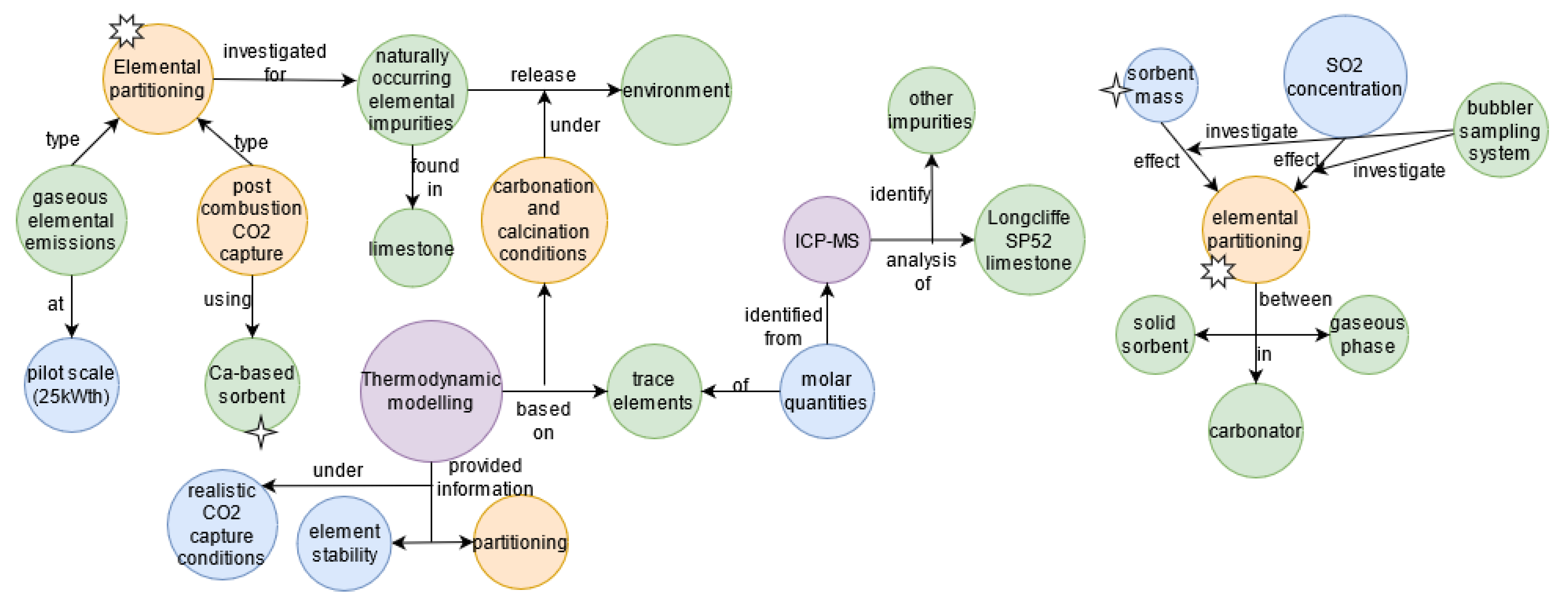
- Cotton, A.; Patchigolla, K.; Oakey, J.E. Minor and trace element emissions from post-combustion CO2 capture from coal: Experimental and equilibrium calculations. Fuel 2014, 117, 391–407. [Google Scholar] [CrossRef]
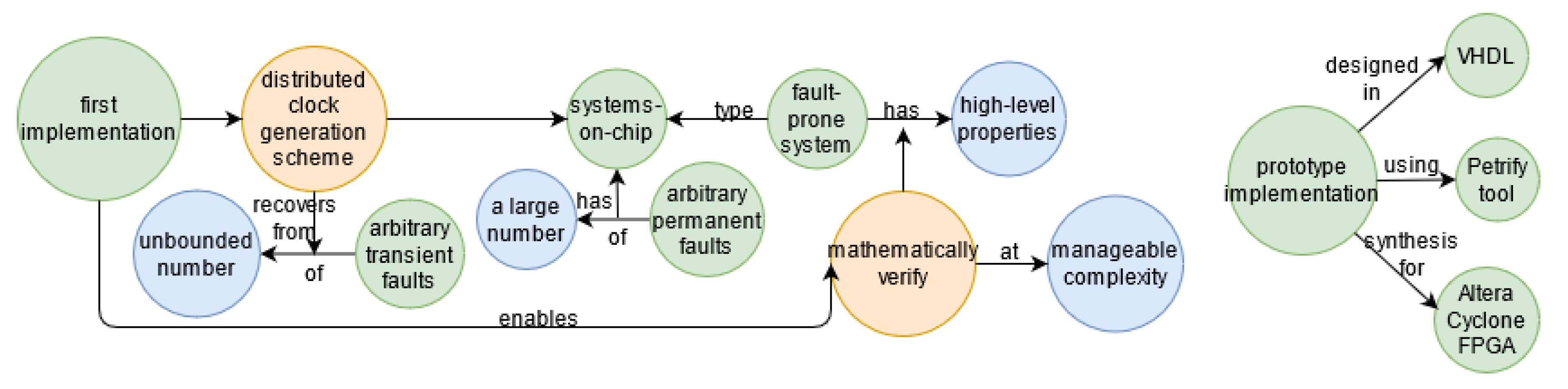
- Dolev, D.; Függer, M.; Posch, M.; Schmid, U.; Steininger, A.; Lenzen, C. Rigorously modeling self-stabilizing fault-tolerant circuits: An ultra-robust clocking scheme for systems-on-chip. J. Comput. Syst. Sci. 2014, 80, 860–900. [Google Scholar] [CrossRef]
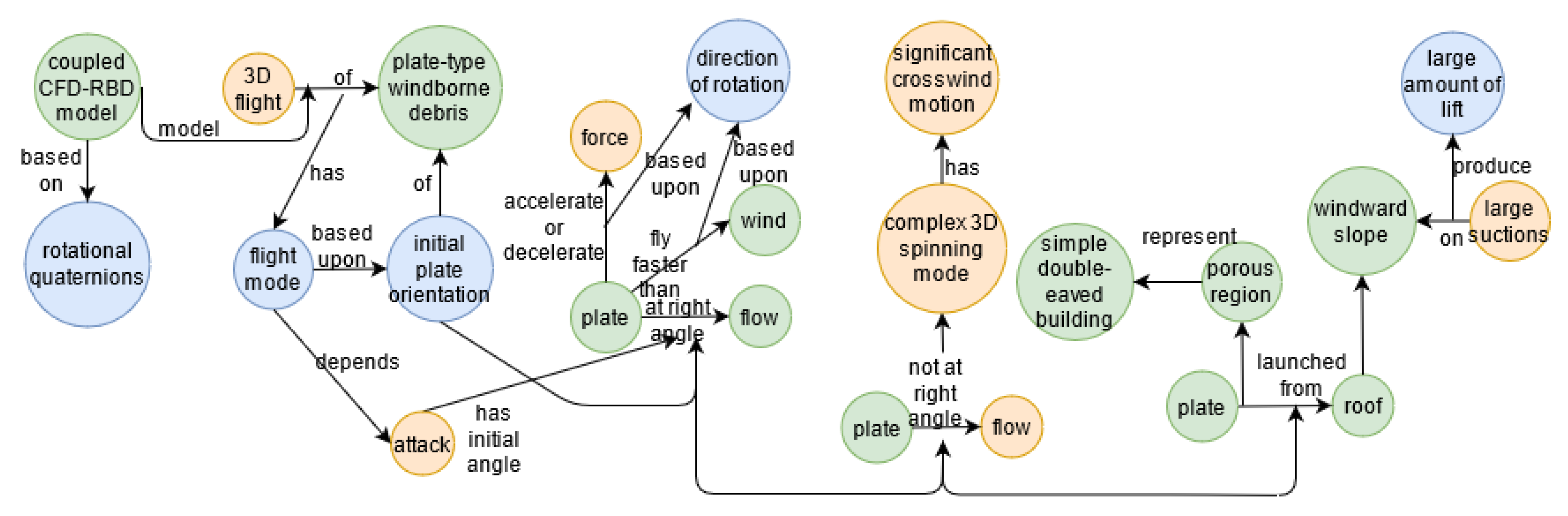
- Kakimpa, B.; Hargreaves, D.; Owen, J. An investigation of plate-type windborne debris flight using coupled CFD–RBD models. Part II: Free and constrained flight. J. Wind. Eng. Ind. Aerodyn. 2012, 111, 104–116. [Google Scholar] [CrossRef]
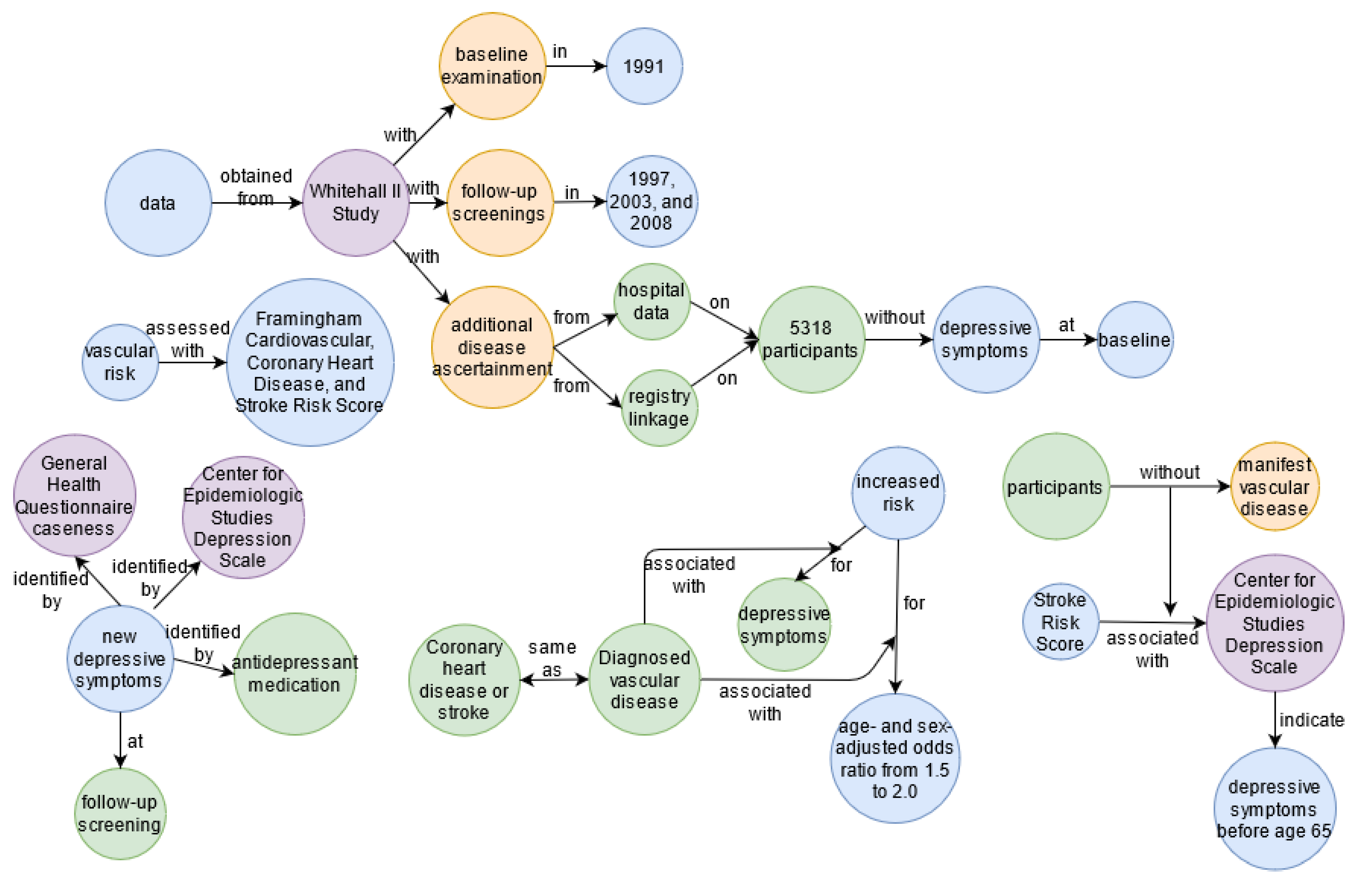
- Kivimäki, M.; Shipley, M.J.; Allan, C.L.; Sexton, C.E.; Jokela, M.; Virtanen, M.; Tiemeier, H.; Ebmeier, K.P.; Singh-Manoux, A. Vascular risk status as a predictor of later-life depressive symptoms: A cohort study. Biol. Psychiatry 2012, 72, 324–330. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Articles | Process | Method | Material | Data | |
|---|---|---|---|---|---|
| agriculture (agri) | 4944 | 20,532 | 3252 | 62,043 | 33,608 |
| astronomy (ast) | 15,003 | 31,104 | 10,423 | 55,753 | 97,011 |
| biology (bio) | 9038 | 54,029 | 6777 | 100,454 | 43,418 |
| chemistry (chem) | 5232 | 18,185 | 6044 | 48,779 | 30,596 |
| computer science (cs) | 5389 | 17,014 | 13,650 | 35,554 | 33,575 |
| earth science (es) | 4363 | 28,432 | 5129 | 56,571 | 50,211 |
| engineering (eng) | 2441 | 12,705 | 3293 | 24,633 | 24,238 |
| material science (ms) | 2144 | 10,102 | 2437 | 23,054 | 16,981 |
| mathematics (math) | 1765 | 8002 | 1941 | 11,381 | 15,631 |
| medicine (med) | 15,054 | 89,637 | 19,580 | 148,059 | 134,249 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
D’Souza, J. Overview of STEM Science as Process, Method, Material, and Data Named Entities. Knowledge 2022, 2, 735-754. https://doi.org/10.3390/knowledge2040042
D’Souza J. Overview of STEM Science as Process, Method, Material, and Data Named Entities. Knowledge. 2022; 2(4):735-754. https://doi.org/10.3390/knowledge2040042
Chicago/Turabian StyleD’Souza, Jennifer. 2022. "Overview of STEM Science as Process, Method, Material, and Data Named Entities" Knowledge 2, no. 4: 735-754. https://doi.org/10.3390/knowledge2040042
APA StyleD’Souza, J. (2022). Overview of STEM Science as Process, Method, Material, and Data Named Entities. Knowledge, 2(4), 735-754. https://doi.org/10.3390/knowledge2040042