3.4. Application to the Mathematics of Quantum Mechanics
3.4.1. Interpreting Superposition Is the Key
The mathematics of QM is quite distinctive and different from the math of classical physics in that states are vectors in a vector space (so addition of vectors gives new ‘superposition’ states) and observables are operators (whose eigenvalues and eigenvectors gives quantization of values). QM math is different for a reason; it has to describe a different kind of reality that is not contemplated in classical physics—the reality of superposition states. To see this, we will focus on just the math of QM, not the physics. For instance, Planck’s constant h (or the limit as ) will not be discussed in the analysis.
How is the mathematics of partitions relevant? The thesis is that the math of QM is the Hilbert space version of the math of partitions, or put the other way around, the math of partitions is a very schematic or skeletonized version of QM math. For instance, in a superposition state, there is a linear combination of eigenstates like , but if we throw away the complex coefficients and along with the vector space sum, then we are left with the underlying support set, which is just a ‘superposition subset’ or just without the Dirac notation. That is the skeletonized version of the quantum superposition state and those are the superposition subsets or blocks dealt with in partition math.
The exposition strategy is to develop a side-by-side dictionary of partition math and the corresponding QM math so that one can easily see how the QM math is the Hilbert space version of the partition math. And since we know how to interpret the partition math, e.g., non-singleton blocks or equivalence classes as superposition subsets, we can then see how to interpret the corresponding QM math.
The idea that superposition is the key non-classical concept in QM and that quantum superpositions are indefinite states is not new, so this approach through partitions is corroborating some rather common views held in quantum mechanics. For instance, the philosopher of science, Mario Bunge, makes these points (where he calls a quantum particle, a “quanton”).
Another surprising peculiarity of quantons is that they are blurry or fuzzy rather than neat or sharp. Whereas in classical physics all properties are sharp, in quantum physics only a few are: most are blunt or smudged….
The reason for this fuzziness is that ordinarily an isolated quanton is in a “coherent” state, that is, the combination or superposition (weighted sum) of two or more basic states (or eigenfunctions). The superposition or “ entanglement” of states is a hallmark of quantum mechanics.
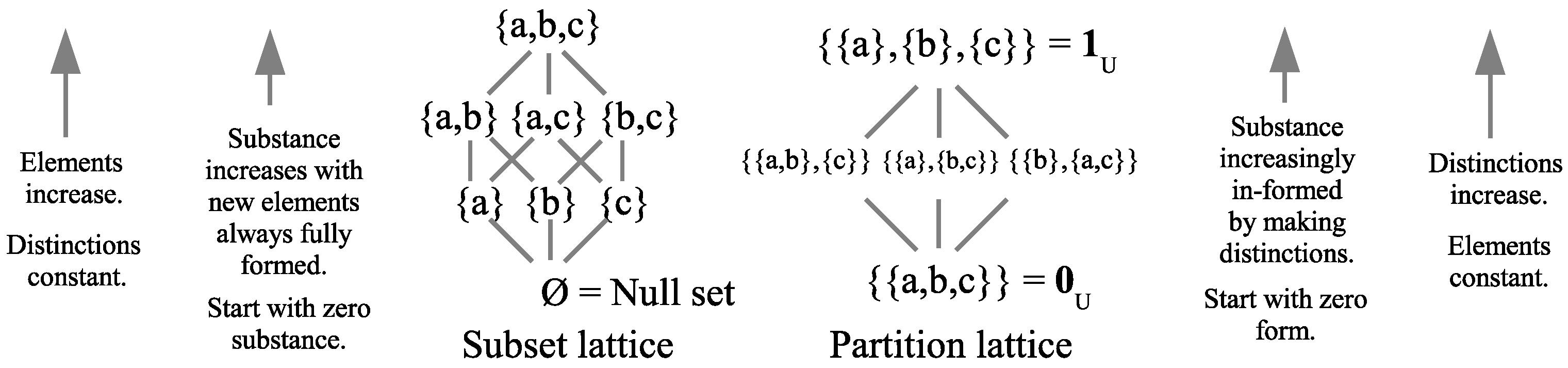
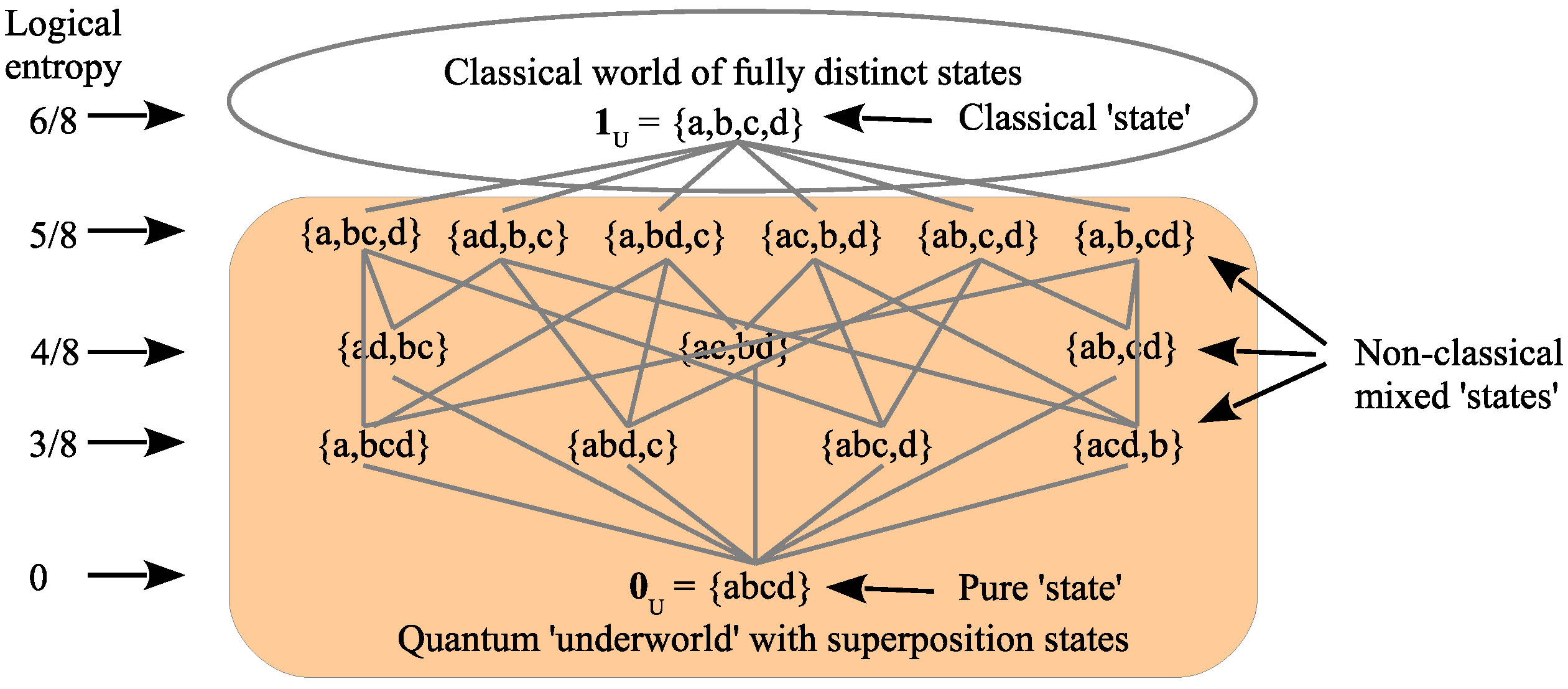
There is only one partition on a set that contains no superposition blocks (non-singleton blocks) and that is the discrete partition , where all the states are fully distinguished as singleton blocks. Leibniz used the Principle of Identity of Indistinguishables (PII) as a characterization of classical reality. Accordingly, the discrete partition (and only that partition) satisfies the partition logic version of the PII:
Thus, we can divide the partition lattice in the classical part (tip of the iceberg) and the quantum part (rest of the iceberg), where all the states include a superposition state, as illustrated in
Figure 7 (with logical entropies based on an equiprobable assumption).
We begin building up the side-by-side dictionary by developing the set versions of the key QM concepts of quantum observables, quantum states, and quantum measurement.
3.4.2. Quantum Observables
We use a semi-algorithmic procedure to relate set concepts with the corresponding vector space concepts, where, for our purposes, the vector space is a Hilbert space. Such a procedure might be called a “yoga” [
39] (p. 251). The key is to consider a set
U first as just a set of elements at the set level and then as a basis set at the vector space level.
For instance, when a subset taken as a subset of a basis set, then it generates a subspace of the Hilbert space and the cardinality of the subset correlates with the dimension of the subspace. Technically, the Yoga can be considered as an embellishment of the functor from the category of to the category of vector spaces over a given field, in our case the complex numbers . Given the vectors in a vector space represented in a certain basis U, the underlying set functor would take to the support .
If we start with a partition on U, then applying that to a basis set of V, each block generates a subspace and the collection of subspaces is a direct-sum decomposition or DSD of V, where DSD is defined as a set of subspaces so that each non-zero vector in the space can be uniquely represented as a sum of non-zero vectors from the subspaces in the set. Hence, a set partition correlates with a vector space DSD in our side-by-side dictionary. Indeed, we could have given a DSD-type definition of a set partition on U as a set of non-empty subsets such that every subset is uniquely represented as a union of non-empty subsets of the ’s. If the union of the ’s did not exhaust U, then would have no representation, and if , then that overlap would not have a unique representation. Hence, the DSD-type definition is equivalent to the usual definition as a set of non-empty subsets that exhaust U and are mutually disjoint.
In QM, the observables are Hermitian (or self-adjoint) operators , which have all eigenvalues as real numbers. The set correlate is a real-valued numerical attribute . Given such a numerical attribute, the Yoga defines a Hermitian operator F by on U as a basis set which then extends linearly to . The numerical attribute has an inverse-image partition and, by the Yoga, this generates the DSD of eigenspaces of F, where . Given a Hermitian operator with an orthonormal (ON) basis U of eigenvectors, the numerical attribute f is recovered as the eigenvalue function that assigns each eigenvector in the basis to its eigenvalue. Thus, the set level correlate of an eigenvalue is a value of a real-valued numerical attribute.
What is the set level notion of an eigenvector? If we take “” to stand for “r is the value on the subset S”, then “” (where is f restricted to S) is the set version of the eigenvalue-eigenvector equation . Then the set level eigenvectors are just the constant sets of f, the subsets on which f is constant (with some value r). The set level correlate of the eigenspace is the set of all constant subsets (where we include ∅ as an honorary ‘eigenvector’).
Characteristic functions , where if , and 0 otherwise, define projection operators , which have only 0 or 1 eigenvalues. A Hermitian operator F, with eigenvalue function f, has a spectral decomposition as: , and the eigenvalue function or numerical attribute also has a ‘spectral decomposition’, where characteristic functions are substituted for the correlated projection operators, i.e., . Furthermore, given two sets U and , we may form the set notion of the product . Considering U and as a basis set for vector spaces V and , we may apply the Yoga and the ordered pairs (written as bilinearly generate the tensor product .
We collect together these side-by-side correlates in partition math and QM math in
Table 3.
3.4.3. Quantum States
In ordinary mathematics. a real-valued random variable is a function , where is an outcome set with point probabilities . But it will be noted that probabilities played no role in the above treatment of quantum observables or their set correlates as real-valued numerical attributes. This is because in the comparison with real-valued random variables, quantum mechanics splits the two aspects between quantum observables (with no probabilities) and the quantum states which carry the probability information.
Hence, to build up the side-by-side correlates between partition math and QM math for quantum states, we begin with a universe set
but with positive point probabilities
(so
U is an outcome space), and then we build the partition version of the quantum state. In QM math, there are two ways to represent a quantum state, as a state vector or as a density matrix. For our purposes, the density matrix [
40] is far superior since the elements of the set level
density matrix can be one-to-one correlated with the distinctions and indistinctions of a partition in
.
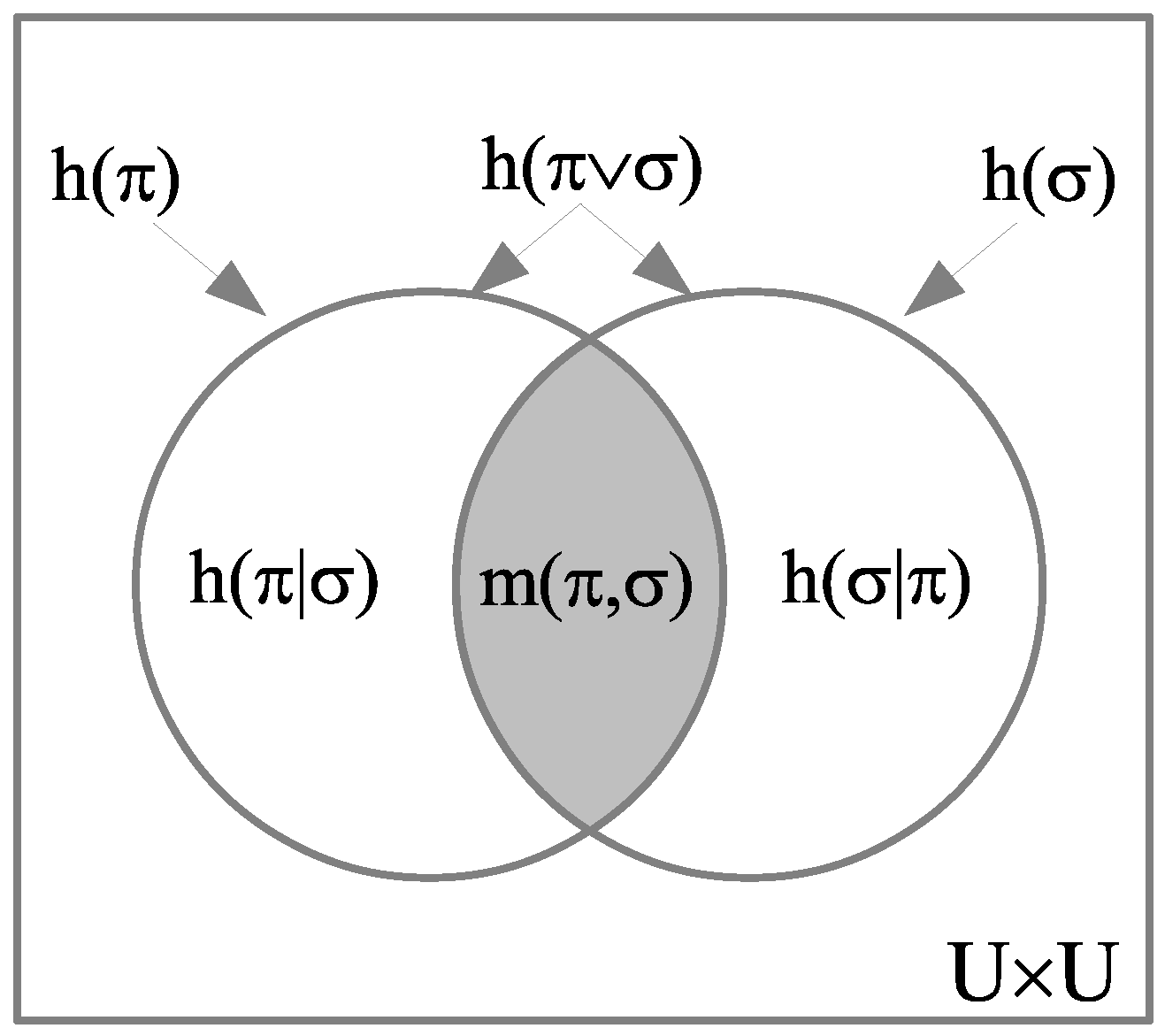
For a subset or event , consider the column vector whose -entry is if , and otherwise 0. Taking as the row vector transpose of the normalized , we define the density matrix representation of the event S as the outer product:
Density matrices are called pure if , and otherwise mixed. Since is normalized, the inner product is so , so it is a pure state density matrix. The off-diagonal elements are if and 0 otherwise. This corresponds to the interpretation of S as a superposition subset since the non-zero off-diagonal elements indicate that the associated elements and are blurred, blobbed, or cohered together in a superposition. In QM math, the non-zero off-diagonal elements are called “coherences” indicating superposition, and, since superposition states are the characteristic non-classical states in QM, they account for the characteristic interference effects in QM.
For this reason, the off-diagonal terms of a density matrix… are often called “quantum coherences” because they are responsible for the interference effects typical of quantum mechanics that are absent in classical dynamics.
At the set level, plays the role of the state vector or the so-called “wave function” even though there are no waves in sight in partition math.
It should be noted that the set version of the Born rule already appears since . It might be said that the Born rule was simply built into the definition of , but it still appears if we start with simply a pure state density matrix . Since density matrices are positive and Hermitian, the eigenvalues of any density matrix are non-negative and sum to 1. The eigenvalues of a pure state density matrix are one 1 with the rest 0’s. If is the normalized eigenvector associated with the eigenvalue 1, then it is the same as our previously defined (up to sign), and the spectral decomposition of is . Empirically, the Born rule does give the probability .
We now consider a partition on U and define the pure state density matrices by taking with then denoted . Then, the set level density matrix for is the probabilistic sum of the matrices:
which is a mixed state density matrix except in the case
which is pure. All the properties of the partition
are now expressed in a density matrix form at the set level. For instance, the entries in
are
if
and 0 otherwise. Thus, the non-zero entries represent the indistinctions of
and the zero entries represents the distinctions. The point probabilities are along the diagonal of
and the
n eigenvalues of
are the
m block probabilities
and
0’s and the associated ON eigenvectors are the
m vectors and
other ON vectors; so, the spectral decomposition is:
. Since the blocks of
are disjoint, the normalized vectors
are mutually orthogonal, so
.
Now that we have converted the set level machinery of partition math into a density matrix format, the rest of the argument that QM math is just the Hilbert space version of the partition math is trivial. In a (
n-dimensional) Hilbert space, an arbitrary density matrix
has an orthonormal basis of eigenvectors
with
n non-negative eigenvalues
, which sum to 1 and the spectral decomposition is:
. These and the correlations for pure state density matrices
are given in
Table 4.
3.4.4. Quantum Measurement
A quantum measurement (always projective) can be described at the quantum level by the Lüders mixture operation ([
42,
43]). Given an observable
with projections
to the eigenspaces
with an ON basis of eigenvectors
U, the result of measuring a quantum state given by a density matrix
, expressed in the measurement basis
U, is the post-measurement density matrix
given by:
The Lüders mixture operation creates a mixed state, a set of states, one of which occurs with the probabilities given by the Born rule. That process is overall described as the infamous ‘quantum jump’.
We have already built up the side-by-side correlation tables between partition math and QM math, so we know how to formulate the set level version of the Lüders mixture operation. Given a numerical attribute with the inverse-image partition playing the role of the observable and the state playing the role of the state being measured, we can compute the effect of the set level measurement. Let be the projection matrix, which is a diagonal matrix with the diagonal entries being . Then, the Lüders mixture operation at the set level is:
What is the result of measuring the partition-based state by the numerical attribute f which defines the partition ? It is easily shown that:
Thus, the effect of (projective) measurement at the set level is to go from a state given by
to the more refined state
. The increase in logical entropy is:
(as one can see from the Venn diagram of
Figure 2 with
. Moreover, that difference can be read off of the difference between the pre-measurement
and the post-measurement
. Logical entropy is the value of product measure
on the ditsets and the ditsets are given by the zeros in the density matrices. Hence, we consider all the indits given by non-zero entries
in
that were turned into dits (i.e., zeroed) in
. The squares
of all those zeroed entries is the value of the product measure
on the additional dits created in the measurement, which is just
. The analogous theorem holds for quantum logical entropy for the projective measurement process in QM math ([
1,
28]).
This completes the argument that the QM math of quantum states, quantum observables, and quantum measurement is just the Hilbert space version of the math of partitions. The results are given in the side-by-side dictionary of
Table 5.
A numerical example. These results can be illustrated with a simple example. Let with the point probabilities , , and . We first construct the density matrix for the partition . Then, we have:
so that the two pure state density matrices are:
Then, is the probabilistic sum:
With , we have: , which corresponds to the five non-zero entries in —and thus the zero entries correspond to the ditset: .
The orthogonal eigenvectors of are:
the non-zero eigenvalues are the block probabilities
and
, and the eigenvectors for those non-zero eigenvalues normalize to
and
.
Let be the numerical attribute where and ; so, the inverse-image partition is . The projection matrices for the blocks are:
so, the set version of the Lüders mixture operation is:
The first thing to check is ? The join is:
Then, it is clear that since there are no non-zero off-diagonal elements indicating no superpositions in the partition, i.e., the discrete partition . Furthermore, we can check that the increase in logical entropy from to is equal to the sum of the squares of the ‘coherence’ entries that were ‘decohered’, i.e., zeroed in the measurement. The logical entropy of is:
The logical entropy of is:
so, the increase in logical entropy due to the measurement is:
In the transition from to , there were two non-zero coherence terms with the value of which were zeroed (i.e., those indits were decohered into dits), so the sum of their squares is: . ✓
3.4.5. ‘Quantum Mechanics’ Over Sets
Now that we have established a basic dictionary to translate between partition math and QM math, we can start to use the partition math to help explain in relatively simple and intuitive terms, some of the more vexing aspects of QM. But there is one aspect of QM math that we have not yet given a set-based version for, and that is the existence of different bases since the QM math is formulated in a vector space.
The solution is that the set-based math can also be formulated in the vector space, where the vectors stand for subsets, name vector spaces over
. Addition modulo two is like normal addition except that
. To represent the subsets of
U in vector space terms, we may work in
, where the vectors are
column vectors with
entries and modulo two addition of components. The canonical basis vectors are the column vectors
with a 1 in the
place and otherwise 0’s; so, a subset
would be represented on this basis by the column vector
with the
entry
. Given the vector
for
, the sum
would have cancellation on the overlap
; so, the sum is the vector for the
symmetric difference so,
. By associating the canonical basis vectors
with the singletons
, we can transfer the vector space structure on
to
, where the subset addition operation in
as a vector space is
; so, we have an isomorphism of vector spaces
. In this manner, we can build up a toy or pedagogical model of QM called “Quantum Mechanics over Sets” or QM/Sets ([
1,
44]).
To keep matters simple, let us take and then the singletons , , and are a basis set for the vectors in the 3-dimensional vector space —a basis that we can treat as the computational basis. Now, there are other basis sets, such as , where , , and . The vectors form a basis since:
,
, and .
Table 6 lists the eight vectors expressed in three different bases, where each row represents the same abstract vector or “ ket”, so it is a ket table.
3.4.6. A Pedagogical Model of the Two-Slit Experiment
One simple application of this set level framework is to build a pedagogical model of the two-slit experiment, an experiment that Richard Feynman said “ has in it the heart of quantum mechanics” and the “only mystery” [
45] (Section 1-1). We have already seen how quantum measurement looks at the set level. The transition of an isolated system in QM without any measurements (state reductions) is described as a unitary transformation, which is a linear transformation that preserves inner products and thus maps an ON basis to an ON basis. There are no inner products in vector spaces over finite fields, so the corresponding type of transformation would just be a non-singular one that transforms a basis into a basis, e.g., transforms the
U-basis into the
-basis. Indeed, in our model of the two-slit experiment, we will assume that ‘dynamics’ for each time period, i.e.,
,
, and
. There are three (equiprobable) states of
that a particle can have which are the vertical positions as pictured in
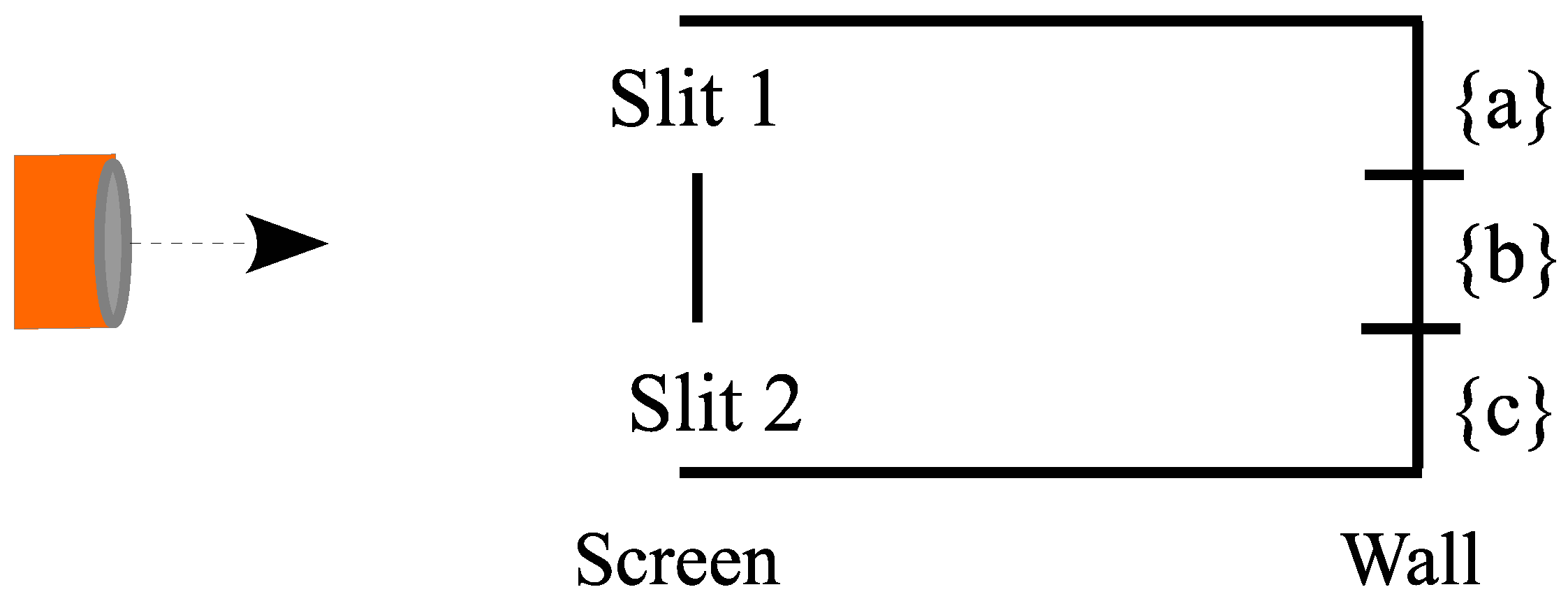
Figure 9 for the initial setup for the experiment. We could think of the vertical positions as having numerical values 3, 2, and 1, respectively, but the letters will suffice for a pedagogical model.
The two slits are in the screen at positions and , and the detection wall can record a particle hitting at positions , , or . A particle emerges at the source on the left at and in one time period evolves to the state . The particle in that superposition state has its first state reduction at the screen. If it hits the screen at , then it does not proceed on to the detection wall. Otherwise, the particle is reduced to the superposition state at the screen, i.e., a superposition of Slit 1 and Slit 2.
Starting with the superposition at the screen, we need to consider two cases: Case 1 where there are detectors at the slits so there is a state reduction to or with equal probability, or Case 2 where there is no detection at the screen.
Case 1: Starting with at the screen, with detectors, there is a half-half probability of the particle being detected at each of the slits and then it evolves according to the dynamics to the detection wall. If it went through Slit 1 at , then it evolves to and hits the detection wall with equal probability at or . If it went through Slit 2 at , then it evolves to and hits the detection wall with equal probability at or . Then, we add up the final probabilities at the detection wall as follows:
;
; and
.
Hence, Case 1 of detectors at the screen, gives the probability distribution pictured in
Figure 10.
The partition lattice for
provides an
anschaulich or intuitive picture of these processes where
at the screen reduces (i.e., “quantum jumps”) to the classical states
or
, i.e., the particle goes through Slit 1 or through Slit 2, and evolves to either
or
, as illustrated in
Figure 11.
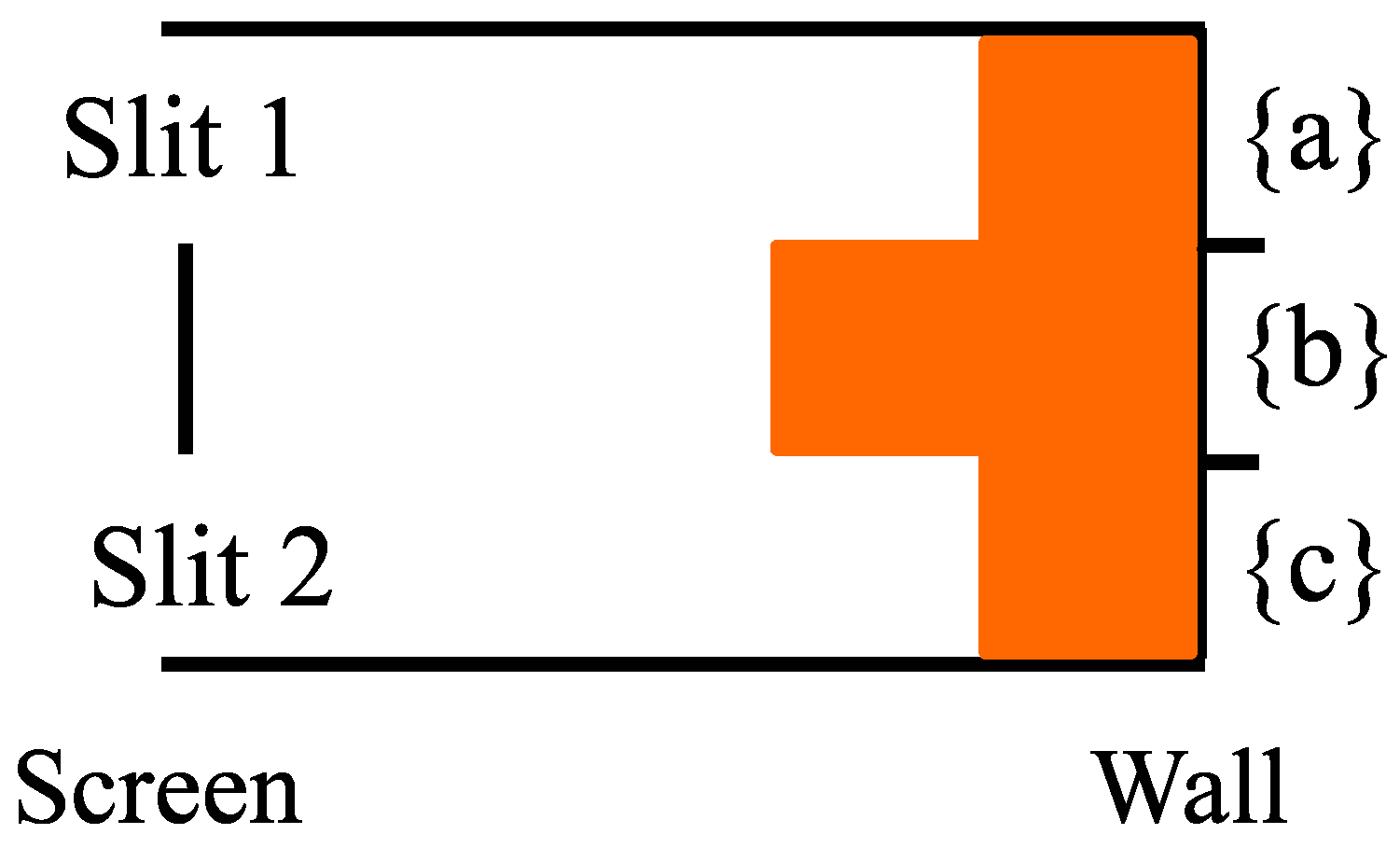
Case 2: Starting with the superposition at the screen, if there are not detectors at the slits, then the superposition evolves linearly according to the dynamics:
Then, the probabilities at the detection wall are:
;
; and
.
Hence, Case 2 of no detectors at the screen, gives the probability distribution pictured in
Figure 12.
Figure 12 shows the probability stripes characteristic of the full QM two-slit experiments with no detectors at the slits. The stripes are due to the interference in the evolving superposition state, i.e.,
, where the
’s destructively interfere in the modulo two addition of the model. Since there were no state reductions (or ‘measurements’) at the screen, the evolution was from the superposition state
to the superposition state
, all at the non-classical quantum level, as illustrated in
Figure 13–not at the classical level that is crossed out.
One of the important ‘takeaways’ of the partition analysis is that there are different levels of reality (
Figure 7), and yet our intuitions only see reality in classical terms as fully definite. Thus, in case two, there is no state reduction at the screen (since there are no detectors), so the evolution of the superposition takes place
at a non-classical level (
Figure 13) without ever achieving the definiteness of “going through Slit 1” or “going through Slit” as in Case 1.
The great sticking point in the “mystery” of the two-slit experiment is that question: “Which slit did the particle do through to get to the detection wall in the case of no detectors?” This is the question that has gone unanswered for a century. The implicit classical assumption is that evolution has to be at the fully definite (“It has to go through one slit or the other”) classical level. Feynman stated that intuitive assumption as: “Proposition A: Either an electron goes through hole No. 1 or it goes through hole No. 2”. And then he showed that “Proposition A is false” [
46] (pp. 139–140). If the particle did go through one slit or the other, then there would be no interference effects.
Nobel laureate Anthony Leggett, when addressing physics departments, would refer to the two-slit experiment with its Slit 1 (or path A) and Slit 2 (path B) and then ask for a vote on the negative statement “that it is not the case that each individual atom of the relevant ensemble chooses either path A or path B.” And he reports that “I almost invariably get a large majority in favor” [
47] (pp. 154–155). Thus, it would seem that most physicists realize that the particle’s evolution does not rise to the classical level of having to go through one slit or the other; it has to take place at the quantum level of evolving non-classical superpositions as illustrated in the skeletal model of
Figure 13.
3.4.7. Commuting, Non-Commuting, and Conjugate Observables
One of the distinctive features of QM math is the non-commuting and even conjugate observables, such as position and momentum. What light can the partition math throw on that feature? Given two or more numerical attributes defined on the
same set
U, their join is always another (more refined) partition on
U. The join of two such partitions is formed by taking as blocks all the non-empty intersections of their blocks. Since a direct-sum decomposition of a vector space is the QM version of a partition, we might make a similar join-like operation of two or more DSDs. Given two DSDs
and
of eigenspaces of two observables
, we consider all the non-zero spaces
, which would consist of the eigenvectors common to
F and
G, i.e., simultaneous eigenvectors. Let
be the subspace of
V spanned by those non-zero subspaces
of simultaneous eigenvectors. The difference with the set case is that
may not be the whole space. Commutativity is usually defined in terms of the commutator linear operator
being the zero operator. But as a linear operator, the commutator
has a kernel (the subspace of vectors taken to the zero vector by the operator) and it can be shown [
1] that:
Since commutativity is equivalent to , we can characterize commutativity by , and it is only in that case that the join-like operation of forming the intersections can be called the join of commuting operators. Moreover, it is then clear that conjugacy can be characterized as the case (the zero space), i.e., the case where there are no simultaneous eigenvectors. Moreover, we can use QM/Sets to construct canonical examples of conjugate operators in for even .
Example: take as the computational U-basis in . The basis for a ‘conjugate’ attribute is , where the “hat” means leave out that state of the U-basis, so ,…, . Then, we can define two linear operators in by: with and , and by by and . Then, the two operators define two DSDs. For f, the DSD has two subspaces:
For g, the DSD also has two subspaces:
But to take intersections of the subspaces in the DSDs, we need to first express the DSD in terms of the computational basis:
Then, when we take all the four cross-intersections between the two DSDs, we see that the zero vector ∅ is only a common subset, so the two operators defined by f and g are conjugate operators. Any eigenvector of one operator, such as or , is a superposition of eigenvectors for the other operator, such as and , and vice versa in this Fourier-like transform, since and .
It was previously noted in our treatment of coding and partitions that a sequence of partition joins can eventually characterize each distinct element. This provides one of the excellent cases where the partition math and QM math are just word-for-word translations of each other. Two or more numerical attributes are said to be compatible if defined on the same set.
Set case: A set of compatible numerical attributes is said to be complete if their join is the partition with all subsets of cardinality 1. In that case of a Complete Set of Compatible Attributes (CSCA), each element of U is uniquely characterized by the ordered set of its attribute values.
And then a word-for-word translation, using the Yoga-generated translation dictionary, gives the quantum case emphasized by Dirac.
Quantum case: A set of commuting observables
is said to be
complete if their join is the DSD with all subspaces of dimension 1. In that case of a
Complete Set of Commuting Observables (CSCO) [
48] (p. 57), each simultaneous eigenvector in the basis is uniquely characterized by the ordered set of its eigenvalues.
3.4.8. Von Neumann’s Type I and II Processes and the Feynman Rules
Quantum processes were divided by John von Neumann (vN) into Type I and Type II [
49]. The Type I processes were the state reductions (or measurements), which, as we have seen, make distinctions, e.g., in the set case, adding the distinctions of
to the distinctions of
. The Type II processes are those that evolve by Schrödinger’s Equation. That equation seems to have no connection to partitions, so let us consider how Type II processes might otherwise be characterized. Since Type I processes make distinctions, perhaps Type II processes should be those that do not make distinctions. In QM math, the distinctness or indistinctness of two quantum states is measured by their inner product, e.g., if the inner product is zero, then they have zero indistinctness or overlap so are fully distinct or orthogonal. Hence, the analysis in terms of distinctions indicates that Type II processes would be naturally characterized as those processes that preserve inner products, i.e., by unitary transformations. The connection to the solutions to the Schrödinger equation is then supplied mathematically by Stone’s Theorem [
50]. The two types of fundamental processes in quantum mechanics are illustrated in
Figure 14.
Classical mechanics has only one type of fundamental process, the evolution of definite states to definite states. There has been some questioning of how QM can have two basic processes unlike classical mechanics.
Even if the notion of “measurement” were somehow given a clear and precise meaning—even if, that is, a sharp boundary were somehow drawn between “measurements” and “non-measurements” so that it became unambiguous when to apply which part of the quantum formalism—there would still be something unbelievable about the idea that there are these two fundamentally distinct types of processes.
Figure 14 also helps to explain that difference between quantum and classical mechanics. The classical worldview is based on completely distinct states and those states are represented in the partition lattices of
Figure 14 as the states in the discrete partitions
and
. But at that classical level of full definiteness, there are no more Type I processes of becoming more definite; so, there is then only one type of fundamental process, the evolution at the same level of indefiniteness, i.e., the evolution of definite states to definite states as in classical mechanics.
Moreover, the sought-after boundary between “measurements” and “non-measurements” is given in the Feynman rules as the boundary between the distinguishable and indistinguishable cases. One of the important connections made by this partitional analysis in terms of distinctions is to connect the two vN processes characterized in terms of making more distinctions or preserving the level of distinctness with the two cases in the Feynman rules based on distinguishability or indistinguishability. As early as 1951 [
52], and later in his Lectures, Richard Feynman made that point about the two cases in considering a quantum process that has an initial and a final state.
If you could, in principle, distinguish the alternative final states (even though you do not bother to do so), the total, final probability is obtained by calculating the probability for each state (not the amplitude) and then adding them together. If you cannot distinguish the final states even in principle, then the probability amplitudes must be summed before taking the absolute square to find the actual probability.
It might be noted that those two cases can be read off of the skeletal model of
Figure 13; the case 1 where the alternatives are distinguished by detection at the slits so probabilities are added and the case 2 where there is no distinguishing at the slits so the superposition does not rise to the classical level and, thus, it evolves unitarily, which involves the interference effects. This analysis has been further explained by John Stachel.
Feynman’s approach is based on the contrast between processes that are distinguishable within a given physical context and those that are indistinguishable within that context. A process is distinguishable if some record of whether or not it has been realized results from the process in question; if no record results, the process is indistinguishable from alternative processes leading to the same end result.
Feynman avoided the anthropomorphic language of “measurement” in stating his rules, but John Stachel has cleared up that language problem. “Using a registration apparatus is commonly called making a measurement” [
53] (p. 290).
In my terminology, a registration of the realization of a process must exist for it to be a distinguishable alternative. In the two-slit experiment, for example, passage through one slit or the other is only a distinguishable alternative if a counter is placed behind one of the slits; without such a counter, these are indistinguishable alternatives. Classical probability rules apply to distinguishable processes. Nonclassical probability amplitude rules apply to indistinguishable processes.
In short, over-simplified terms,
Feynman’s Distinguishable Case = vN Type I state reductions, and
Feynman’s Indistinguishable Case = vN Type II unitary evolution.
In both cases, the key analytical concepts are distinctions and indistinctions, which at the set level are modeled by partitions (or equivalence relations).
Nobel laureate Anton Zeilinger described the Feynman rule using the notion of information-as-distinctions of any sort.
In other words, the superposition of amplitudes … is only valid if there is no way to know, even in principle, which path the particle took. It is important to realize that this does not imply that an observer actually takes note of what happens. It is sufficient to destroy the interference pattern, if the path information is accessible in principle from the experiment or even if it is dispersed in the environment and beyond any technical possibility to be recovered, but in principle is still “out there”. The absence of any such information is the essential criterion for quantum interference to appear.
Incidentally, it might also be noted that Zeilinger and Brukner [
55] have also suggested the formula for logical entropy as being superior for analysis than the Shannon entropy.
Feynman uses ([
45] (Section 3-3); [
56] (pp. 17–18)) an example of a neutron starting at point
A and then scattering off the atoms in a crystal to finally reach a point
B. If there was no distinction made as to which atom it scattered off of (the indistinguishability case), then the amplitudes of getting from
A to
B by scattering off the different atoms would be added, and then the absolute square would give the probability of the transition. However, it might be that a distinction was made, say, by all the atoms having spin down and the neutron with spin up and the scattering would exchange the spin. Then, there was a distinction made as to which atom did the scattering (the distinguishability or “registration of a record” case), so the probabilities (not amplitudes) of scattering off the different atoms must be added to obtain the final
A to
B probability.
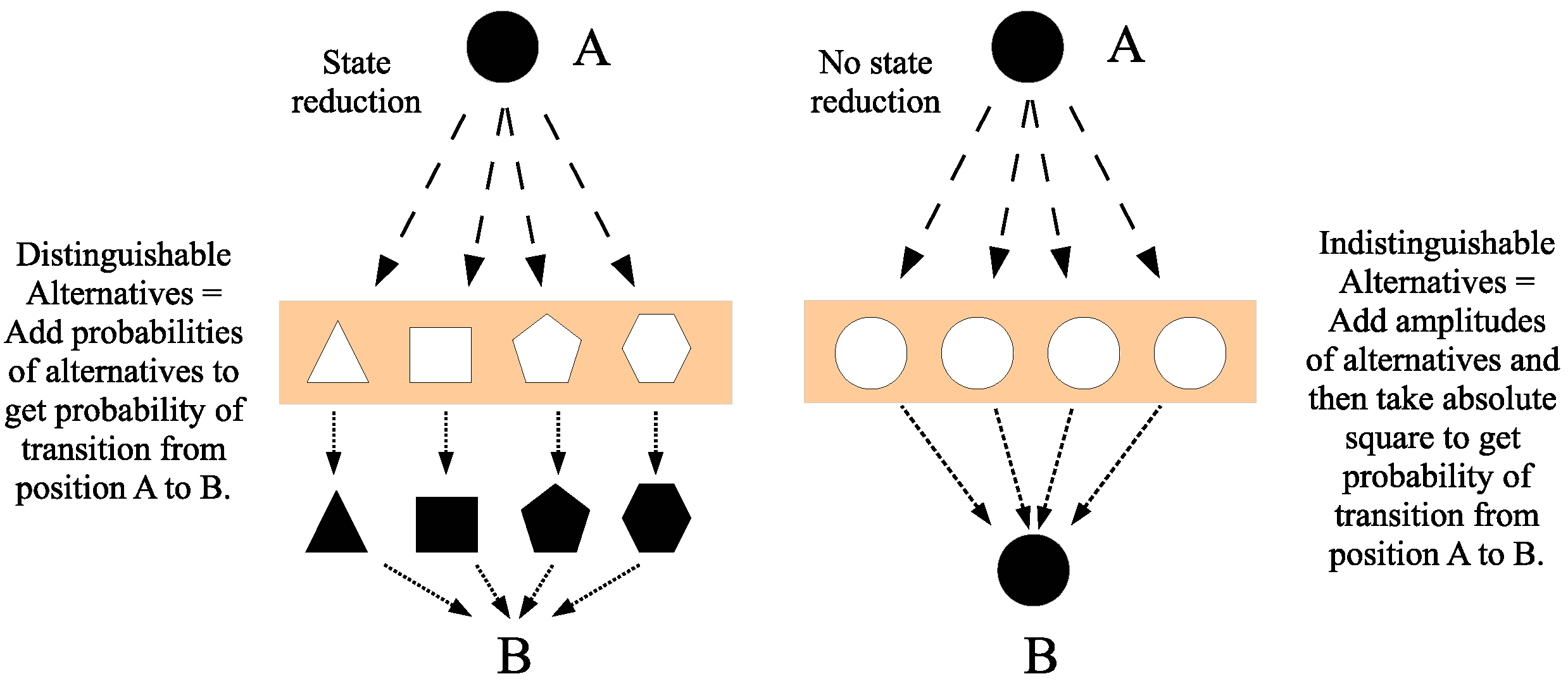
Hermann Weyl, in his informal writing about quantum mechanics, used the notion of a grating or sieve and implicitly used the Yoga to liken an equivalence relation on a set to a direct-sum decomposition of a vector space as two types of gratings [
57] (p. 256). Then, a measurement of a state would be the application of a grating. In
Figure 15, the grating metaphor for state reduction or measurement is used to illustrate the Feynman rules, where the ‘ball of dough’ black circle is like the superposition of the polygon-shapes, and when it passes through the distinguishing grating (left side of the figure), it reduces to one of the polygon shapes. On the right-side of the figure is the non-distinguishing grating so the amplitudes to go through each round hole are added to get the amplitude of going from
A to
B, and then the absolute square gives the probability.
Thus, the partitional analysis, in terms of making distinctions or not, is realized in the Feynman rules based on distinguishability or indistinguishability. In the two-slit experiment, case 1 is the distinguishable case (in Feynman’s terms), where there were detectors at the slits, and case 2 is the indistinguishable case, with no detectors at the slits. In Feynman’s example, the measurement is entirely at the quantum level with no macroscopic apparatus. Hence, the Feynman analysis undermines the approach trying to analyze measurement in term of the “decoherence” induced by a macroscopic measuring devices (e.g., [
58]) as well as the literature about the “von Neumann cut” [
49] (or “Heisenberg cut”) also involving macroscopic measuring devices. With virtual certainty that the state reductions take place at the quantum level, the literature about the ‘problems’ arising from extending Schrödinger’s equation to the macroscopic level (e.g., his eponymous cat) are pseudo-problems. Naturally, humans need some amplification of the quantum level physical result in the distinguishable case to know the result, but such macroscopic considerations have no role in quantum
theory.
3.4.9. Summing up about Quantum Mechanics
Even though the Hermitian observables have real eigenvalues, quantum mechanics could not be formulated in vector spaces over the reals since the reals are not algebraically complete. Only in the algebraically complete extension of the reals, the complex numbers, could the Hermitian operators have a full set of eigenvectors [
59] (p. 67, fn. 7). But the complex numbers are
also the natural mathematics to express waves; in the polar representation, each complex number has an amplitude and a phase. But that turned out to be a major false clue about the nature of quantum reality. Now, it is widely accepted that the so-called “wave function” is only a computational device to compute probabilities by the Born rule, not a part of physical reality. Einstein’s famous quip that “The Lord is subtle, but not malicious” may need to be nuanced. If not malicious, He is at least a trickster. The mathematics of complex-valued vectors is not wrong, but it is certainly misleading if taken as a description of quantum reality.
That interpretive problem with waves was compounded by the misinterpretation of superposition, the key non-classical notion in QM. Superposition was misinterpreted as being like the classical addition of water waves or electromagnetic waves. Here, the approach by partitions or equivalence relations offered an alternative interpretation of superposition; the idea is that a superposition of definite states is indefinite on where the states differ and is only definite on commonalities. That is why superposition states are indefinite, blurry, blobby, or smeared-out, unlike the whole idea of superposition as the addition of physical waves. That basic wave-misinterpretation of superposition is compounded in the classroom ripple tank demonstration of the two-slit experiment. Again, it is not the math of complex numbers that is wrong but the interpretation of “probability waves” as matter waves like the water waves in a ripple tank. The partition approach was also helpful in building the pedagogical model of QM/Sets, which we used to model the two-slit experiment. In that model, using operations in a vector space over , there was superposition and interference effects, but no waves.
The indefiniteness interpretation of superposition is certainly not new but it has been expressed in the language of “potentialities” by Werner Heisenberg [
60], Abner Shimony [
61], Gregg Jaeger [
62], and many others, where indefinite states were described as being potentially any of a set of actualized definite states. But the notion of “potentiality” or “possibility” should be construed only as a manner of speaking (like “the thrown die has the potentiality of landing with six up”) instead of as a different ontological category of reality. There is only one type of reality but it can be in indefinite superposition states or definite eigenstates. Others, such as Henry Margenau [
63] and R. I. G. Hughes [
64], held similar views but used the word “latency” instead of “potentiality.” Many other quantum theorists have emphasized objective or ontic indefiniteness, such as Peter Mittelstaedt, “objective indeterminateness” [
65] (p. 178), Paul Feyerabend, “inherent indefiniteness is a universal and objective property of matter” [
66] (p. 202), and Fritz Rohrlich who saw “blurring as a fundamental ontic feature” [
67] (p. 380). Thus, the partitional approach corroborates and clarifies this widespread acceptance of quantum reality as featuring objective indefiniteness. If quantum philosophers call any view of the nature of quantum reality an “interpretation”, then this might be called the “objective indefiniteness interpretation of quantum mechanics”.







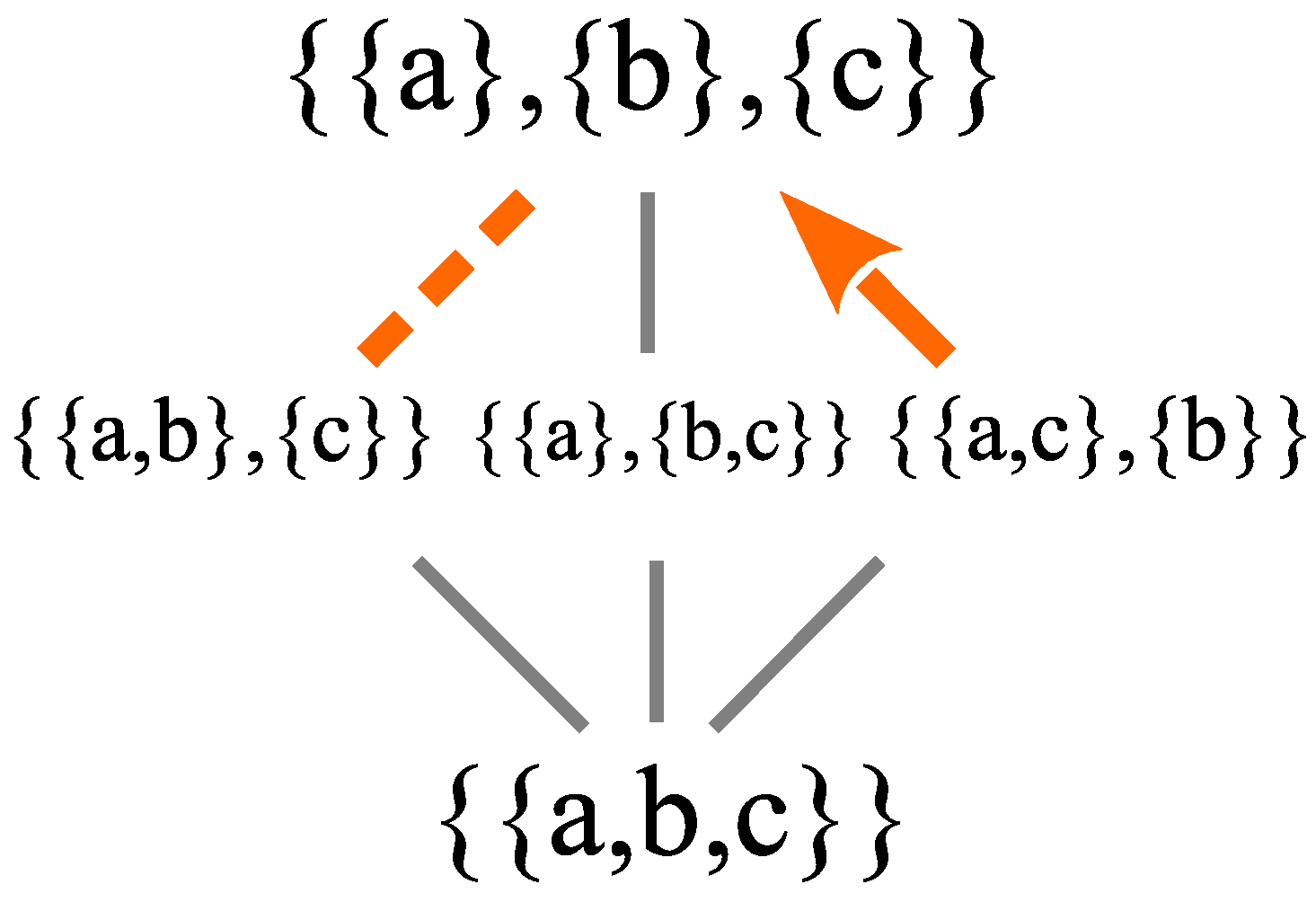





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}