
Design and Analysis of an Effective Architecture for Machine Learning Based Intrusion Detection Systems


Abstract
1. Introduction
- A novel centralized network architecture based on a multi-model IDS based on traffic load. The model is more realistic since organizations have prime time or specific events.
- In the proposed model, global traffic inspection occurs before traffic is sent to the central server and other sub-networks of the organization.
- We analyze the results of the AdaBoost, Voting, Stacking, Support Vector Machine, Random Forest, and XGBoost 3.0.0 models on the datasets CIC-MalMem-2022, CIC-IDS-2018, and CIC-IDS- 2017.
- We compare the best models with existing IDSs.
2. Literature Review
2.1. Intrusion Detection Systems
2.2. Machine Learning
2.3. Related Work
2.3.1. Information-Based Learning Techniques
2.3.2. Similarity-Based Learning Techniques
2.3.3. Probability-Based Learning Techniques
2.3.4. Error-Based Learning Techniques
2.3.5. Hybrid Models
2.3.6. SDN Models
2.4. Summary
- Hybrid models: The Stacking classifier and the Voting classifier enable different estimators to predict the result.
- Information-based learning techniques: AdaBoost is a powerful and versatile meta-algorithm particularly useful for cybersecurity applications as it can handle imbalanced and noisy datasets [47]. Random Forest is the most used in related studies, and XGBoost is one of the most powerful gradient-boosting algorithms available [48]. Generally, tree-based algorithms such as RF, AdaBoost, and XGbbost have demonstrated high efficiency and effectiveness in handling binary and categorical data and identifying complex feature relationships. Various ML applications use these algorithms, such as classification, regression, and anomaly detection.
- Error-based learning techniques: Support Vector Machine: Researchers commonly use SVM algorithms because of their versatility, robustness, and capability to handle complex data. They are particularly good at handling classification problems but can also be used for regression and anomaly detection.
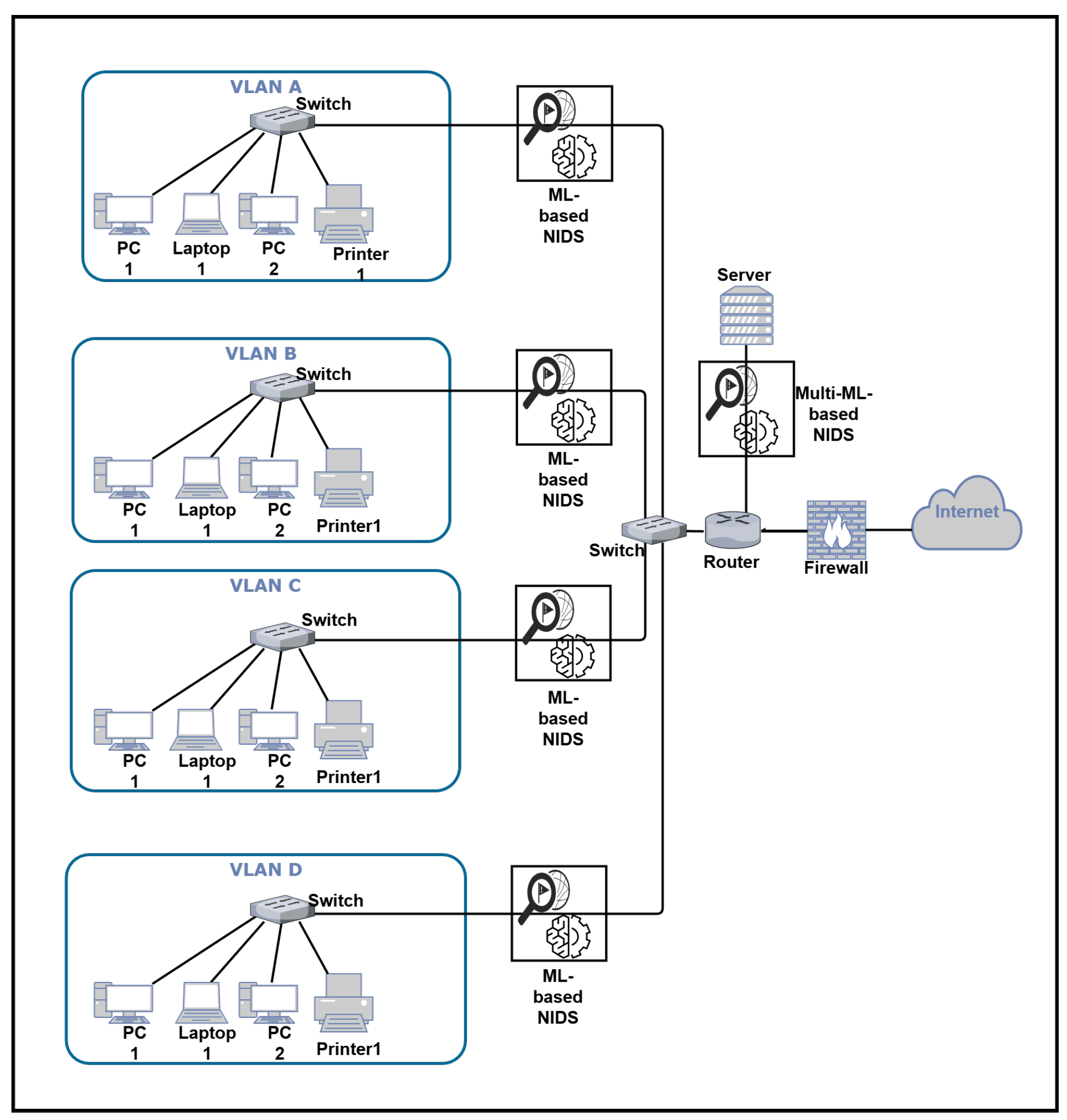
3. Proposed Architecture: Multi-Model IDS Based on Traffic Load
3.1. Proposed Architecture Components
- Firewalls: Firewalls can be configured to block traffic from malicious IP addresses by manually adding these addresses to the firewalls’ blocklist; this can be accomplished by configuring the firewalls to block traffic from malicious IP addresses via an IPS (intrusion prevention system).
- Routers and switches: Configured to collect and report statistics on network traffic. Identifying the amount and type of traffic passing through these devices may help determine the volume and type of traffic on the network. In addition, the routers are configured with a threshold value for network traffic.
- Multi-model ML-based NIDS (first layer): This ensures a centralized global view and inspection of the incoming traffic at the different organization servers and contains two types of ML-based IDSs: the first model focuses on the fast inspection of traffic, and the second model focuses on high accuracy.
- ML-based NIDS (second layer): This model is highly accurate. It inspects all traffic before it is distributed to the server that requests it.
3.2. Proposed Architecture Data Flow
| Algorithm 1 Assess network traffic. |
|
| Algorithm 2 Select the best model. |
|
3.3. Motivation Behind Using Centralized Network Architecture Approach
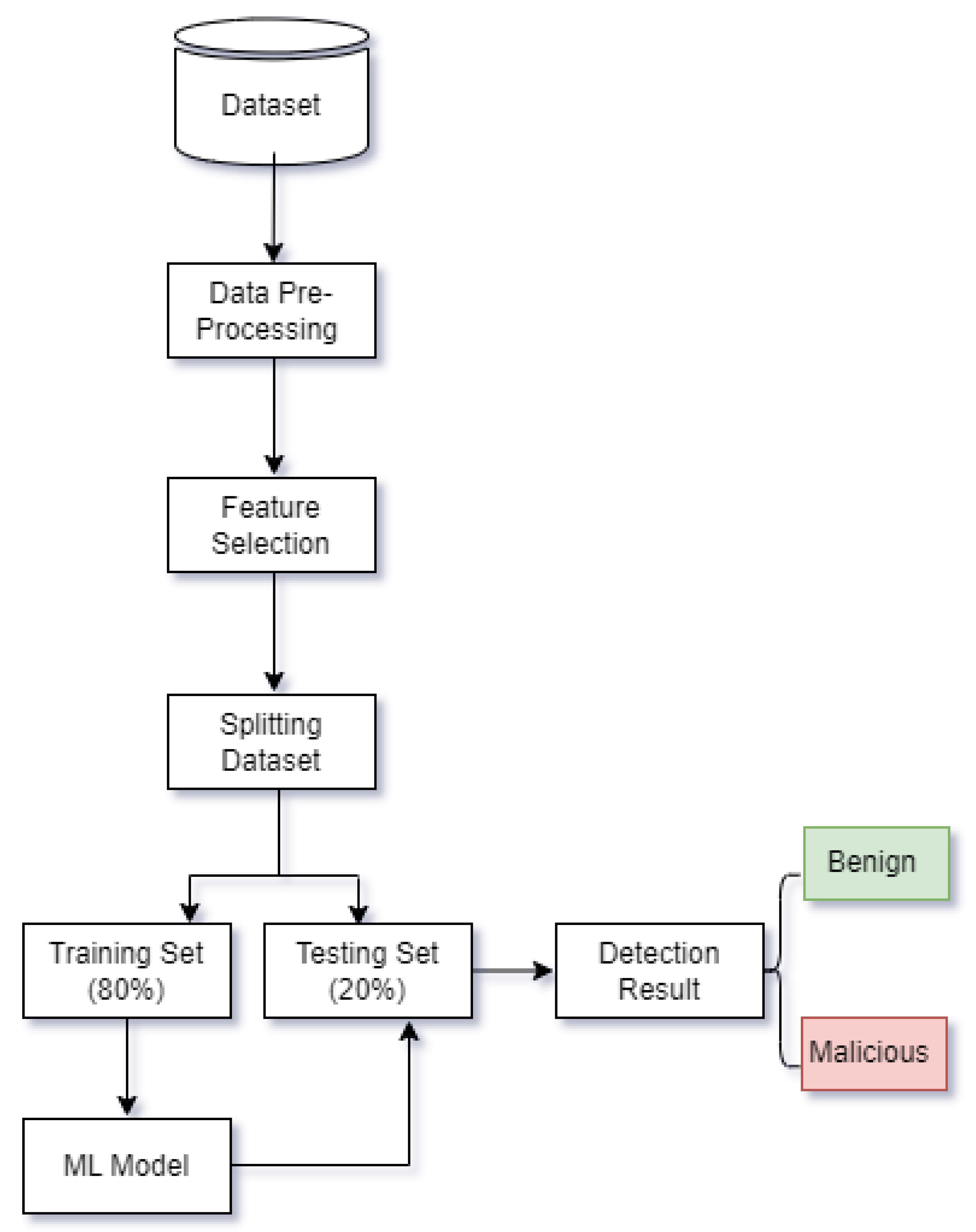
3.4. Benchmark Dataset
3.5. Data Preprocessing
3.5.1. Data Cleaning
3.5.2. Feature Engineering
- The data type for the timestamp column was converted into the DateTime type, and three new columns, namely, day, month, and year, were added to the dataset. In these three new columns, the value from the timestamp column was taken, and then the timestamp column was dropped.
- The dataset was split into features and the target, and the data types of all feature columns that are objects were converted to numeric. The values of the features were set to 0 if the value was infinite to improve code execution speed without affecting accuracy.
3.5.3. Random Undersampling or Oversampling
3.5.4. LabelEencoder for Target
3.5.5. Data Normalization
3.6. Feature Selection
- Univariate feature selection: SelectKBest uses a statistical test to determine the top-K features. Many types of statistical tests are available, including chi-squared, F-tests, mutual information tests, and others. By selecting the first K features with the highest scores from the input dataset, SelectKBest retains them [61]. SelectKbest uses a univariate feature selection method to determine the strength of the relationship between a response variable and a feature. This method offers a greater understanding of data because of its simplicity and ease of use (though it could be optimized for better generalization because of the simplicity and ease of use of these methods). SelectKBest simplifies the modeling process when working with many features by identifying the most essential features needed to make accurate predictions [61].
- Removing features with low variance: In the VarianceThreshold algorithm, features with variances that do not meet a certain threshold are removed from the analysis. By default, all zero-variance features, which have the same value across all samples, are removed. Variance is typically calculated as the squared distance from the mean divided by the average squared value [62]. The variance of binary data (values of 0 and 1) can be calculated by using the following formula:where p indicates the proportion of 1s in the dataset.
- Improved prediction accuracy: As a result of focusing on the most relevant and reliable data, ML algorithms can identify patterns and relationships within the data more accurately, resulting in more accurate predictions [20].
- Minimized computational complexity: Smaller datasets require fewer computational resources, making training and executing ML models more efficient [63].
- Enhanced interpretability: The interpretation of the results is enhanced when fewer features are used, since fewer features make it easier to identify the underlying factors that influence the study’s results [64].
- Reduced overfitting: By reducing the dimensionality of a model, overfitting can be mitigated by eliminating features that do not contribute significantly to predictive power. By reducing the number of features that contribute little to prediction, dimensionality reduction techniques can assist in mitigating overfitting [20].
3.7. Machine Learning Models
3.8. Performance Evaluation
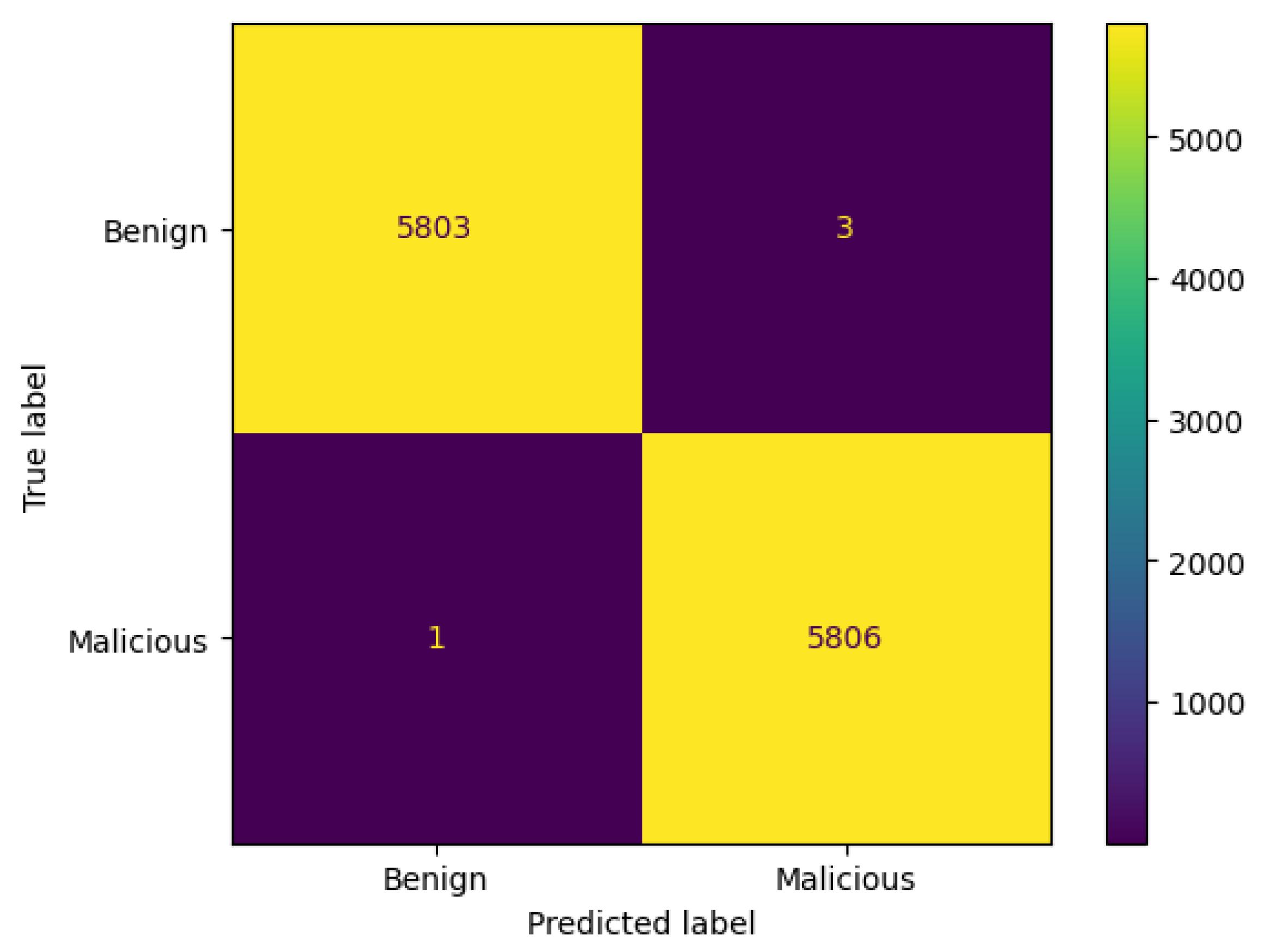
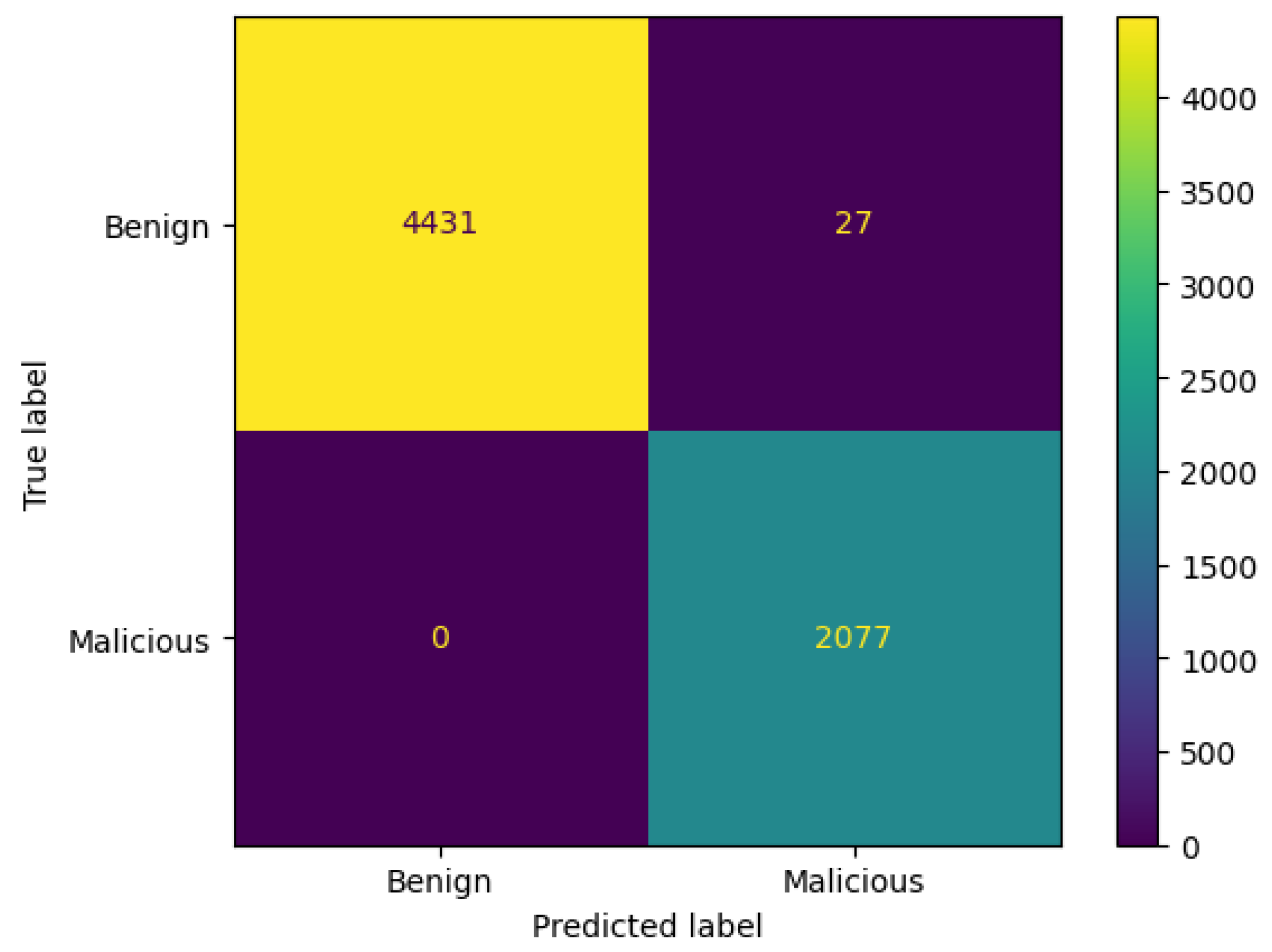
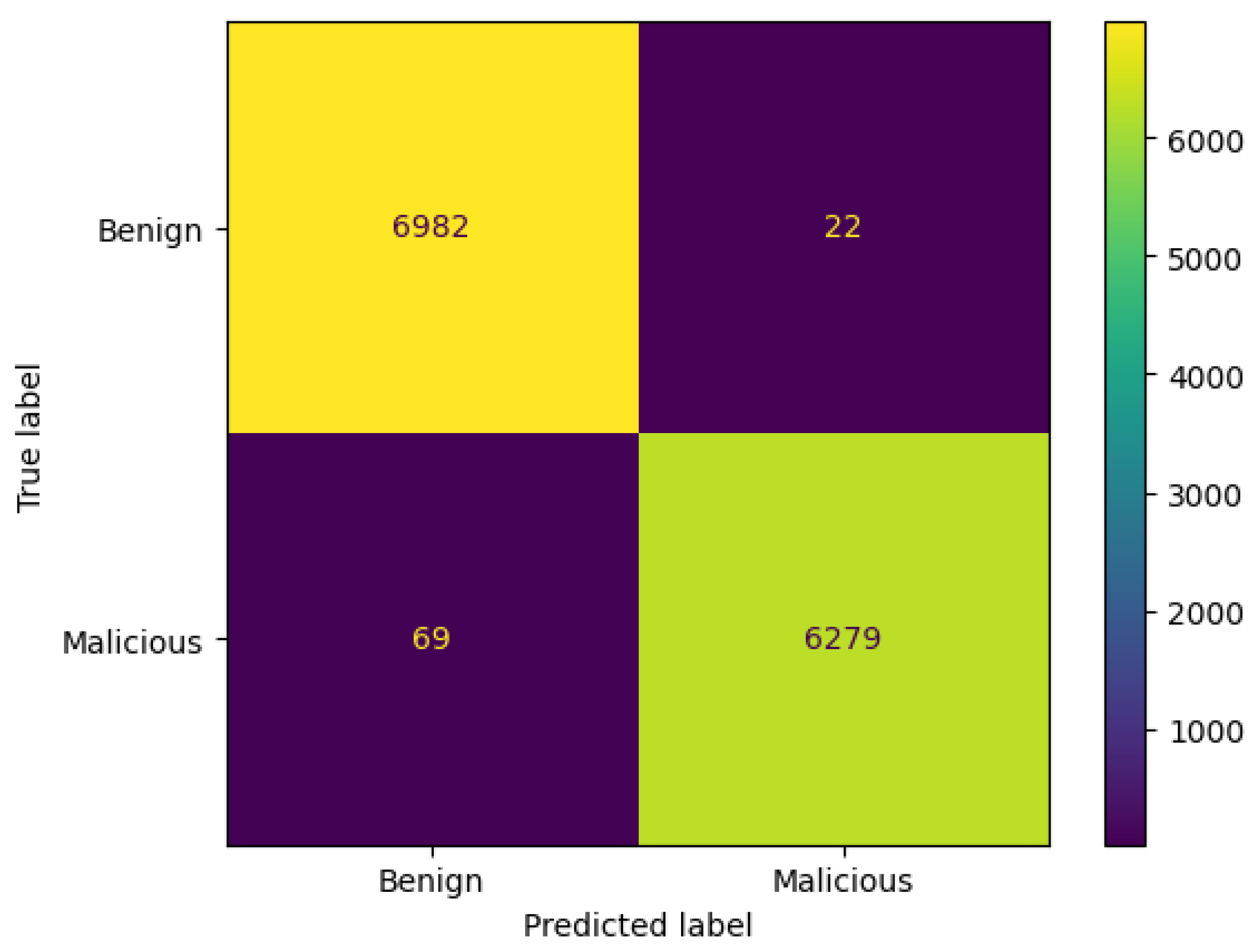
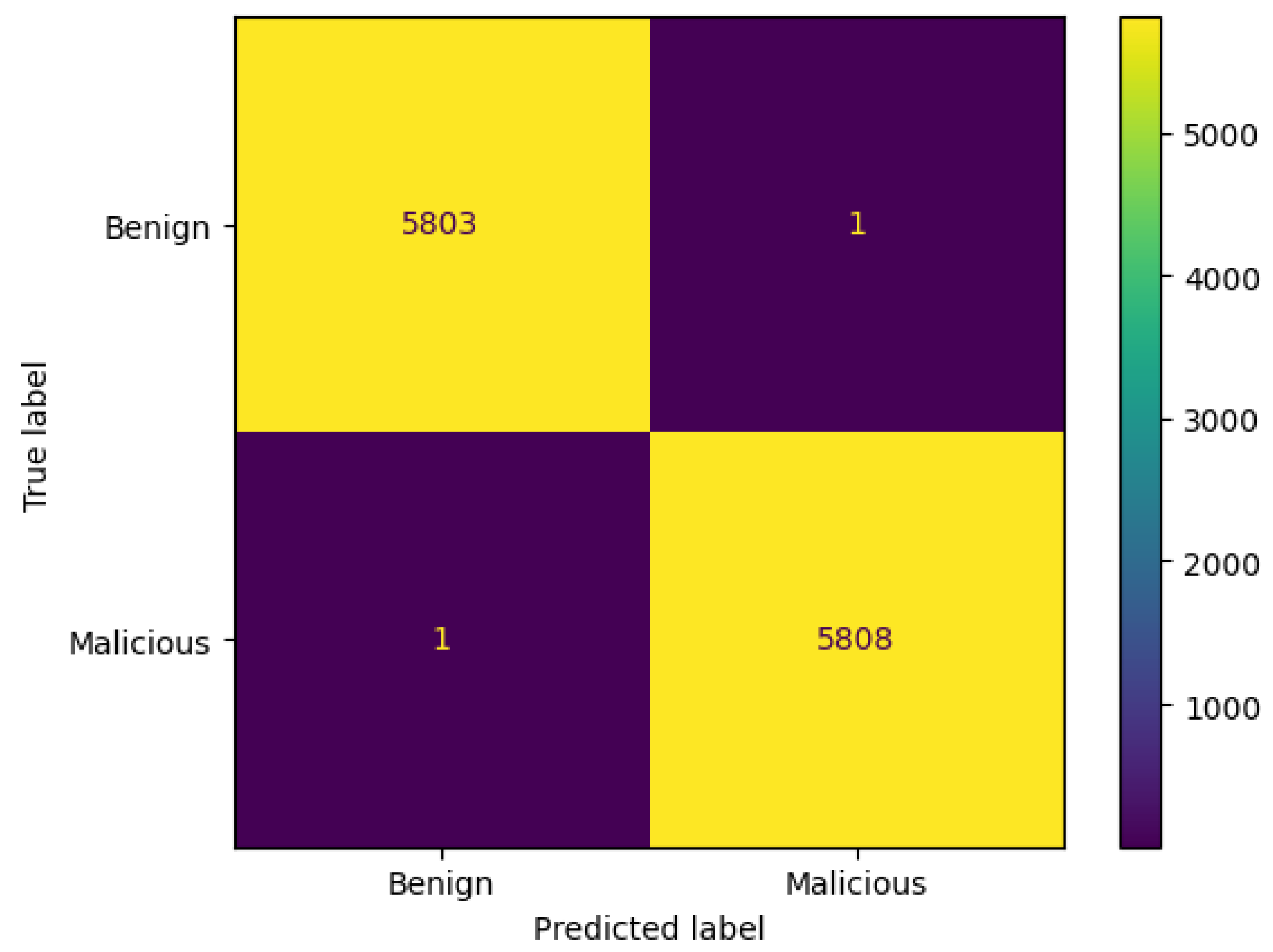
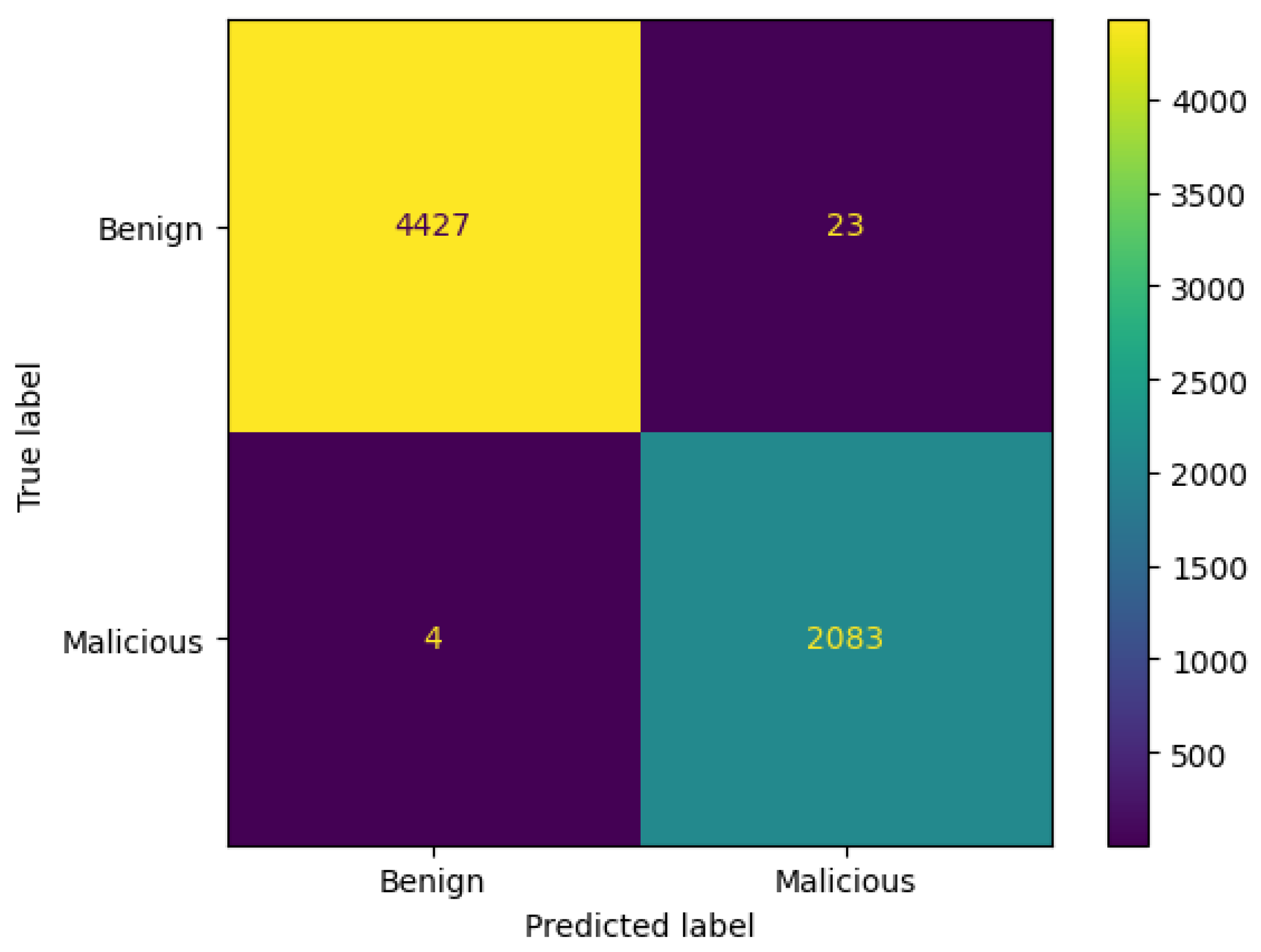
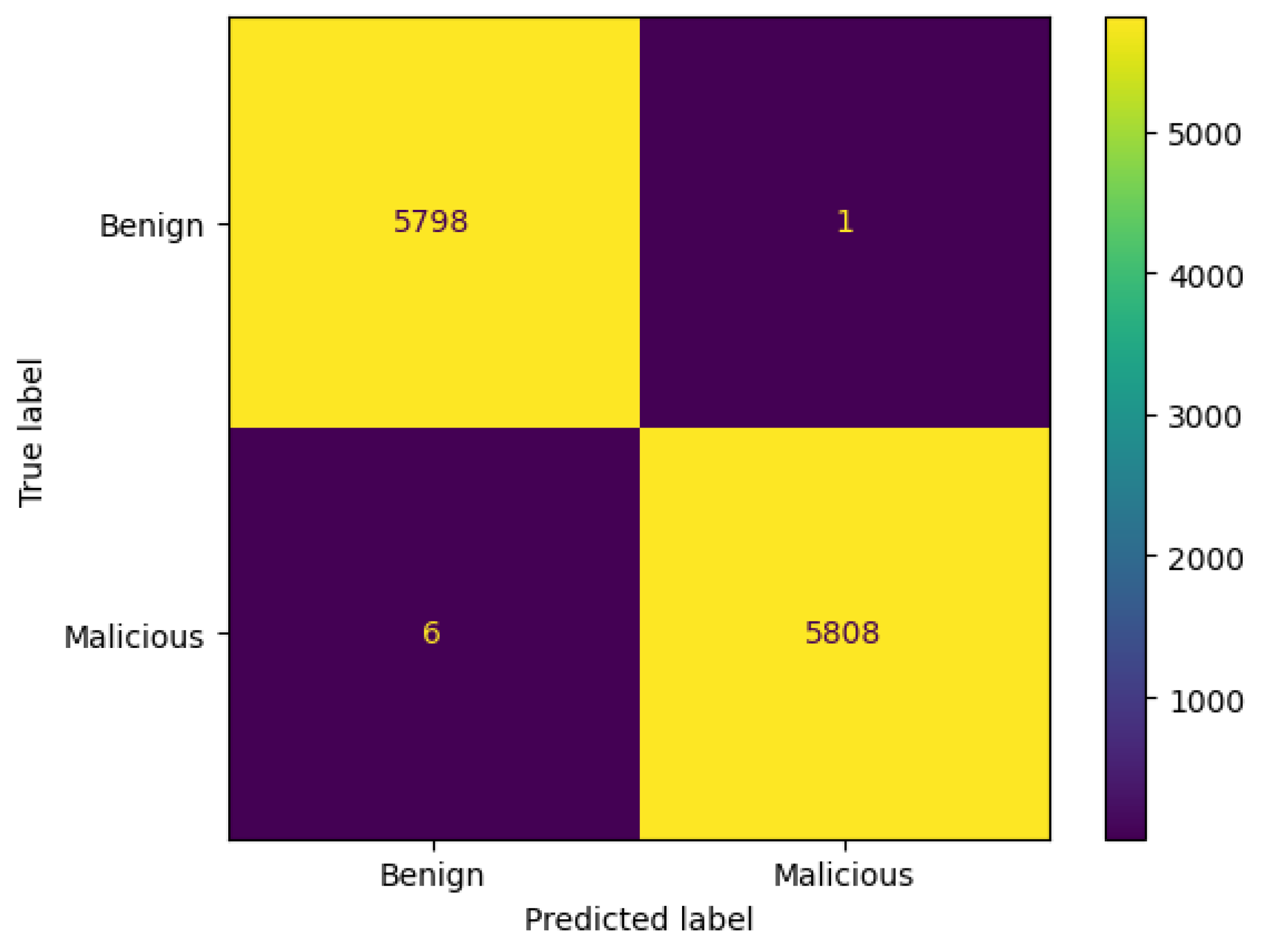
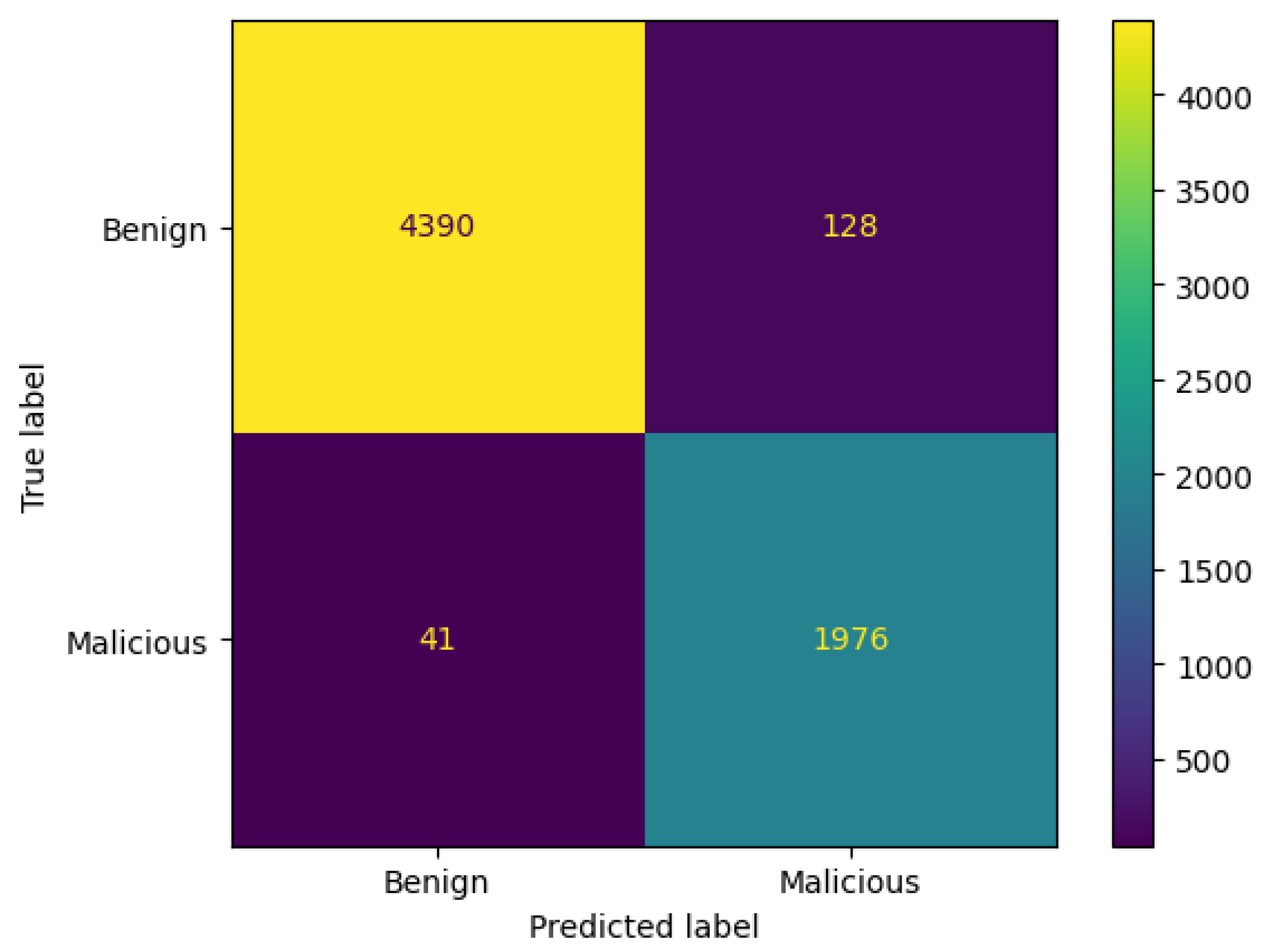
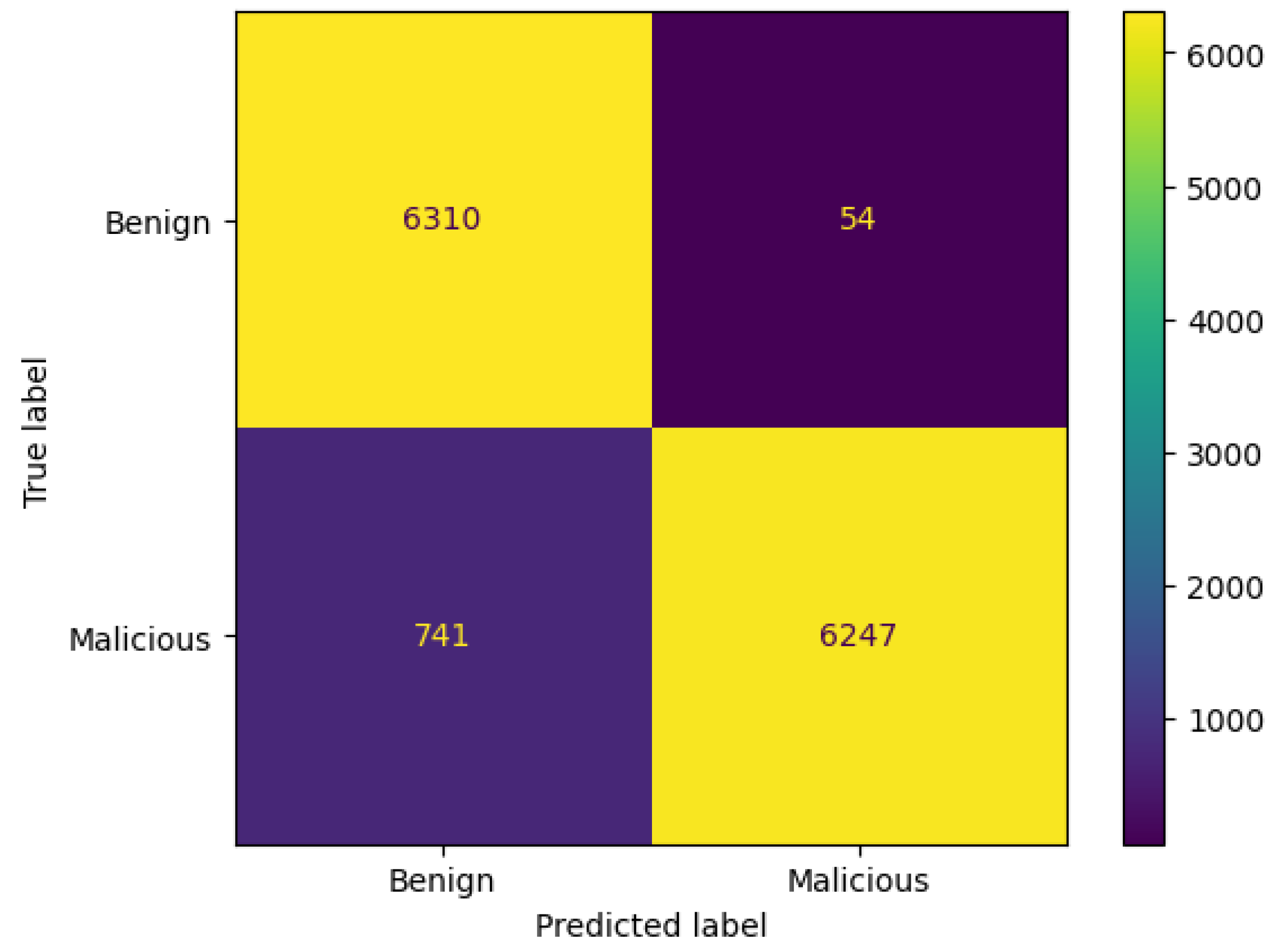
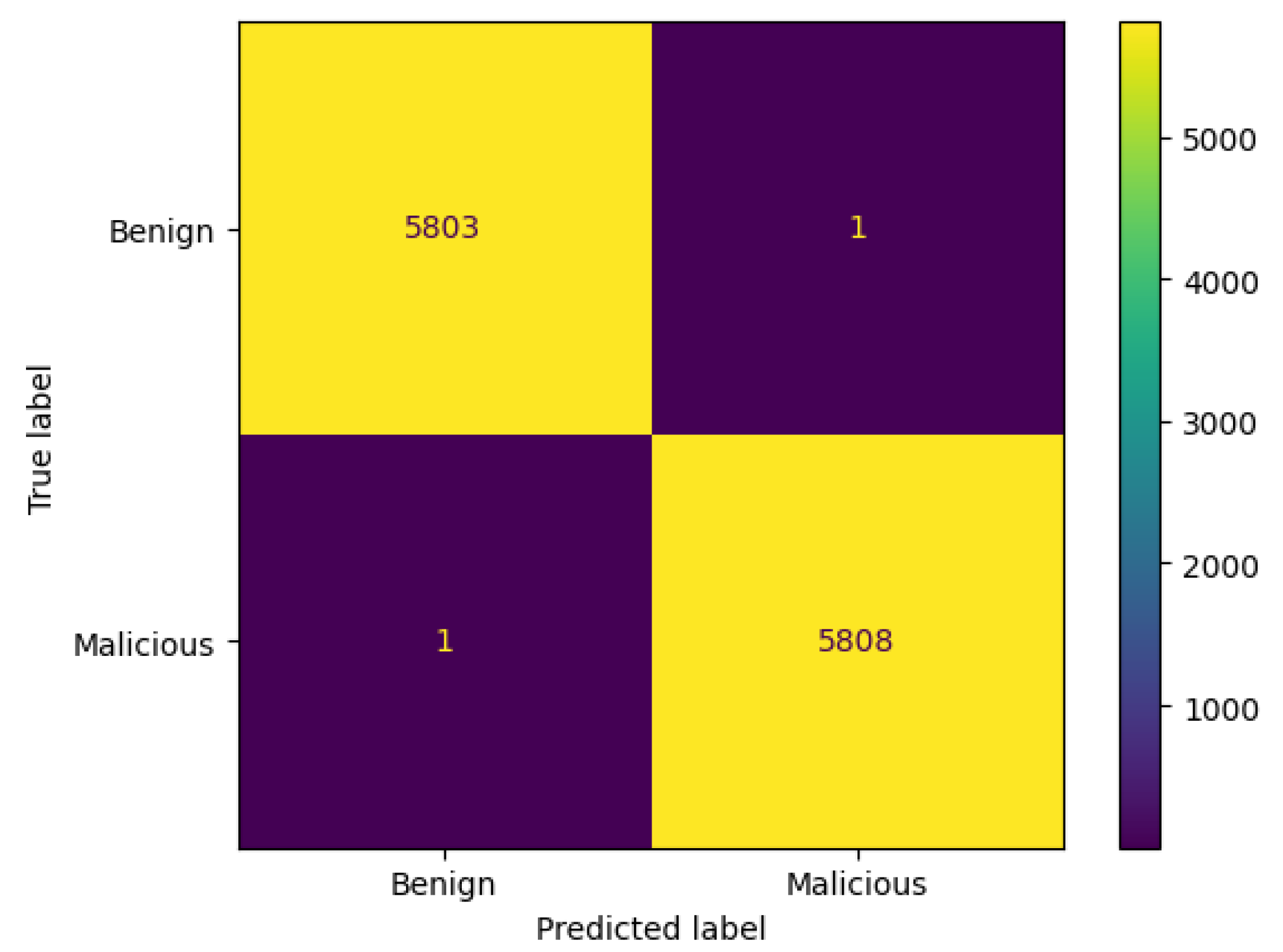
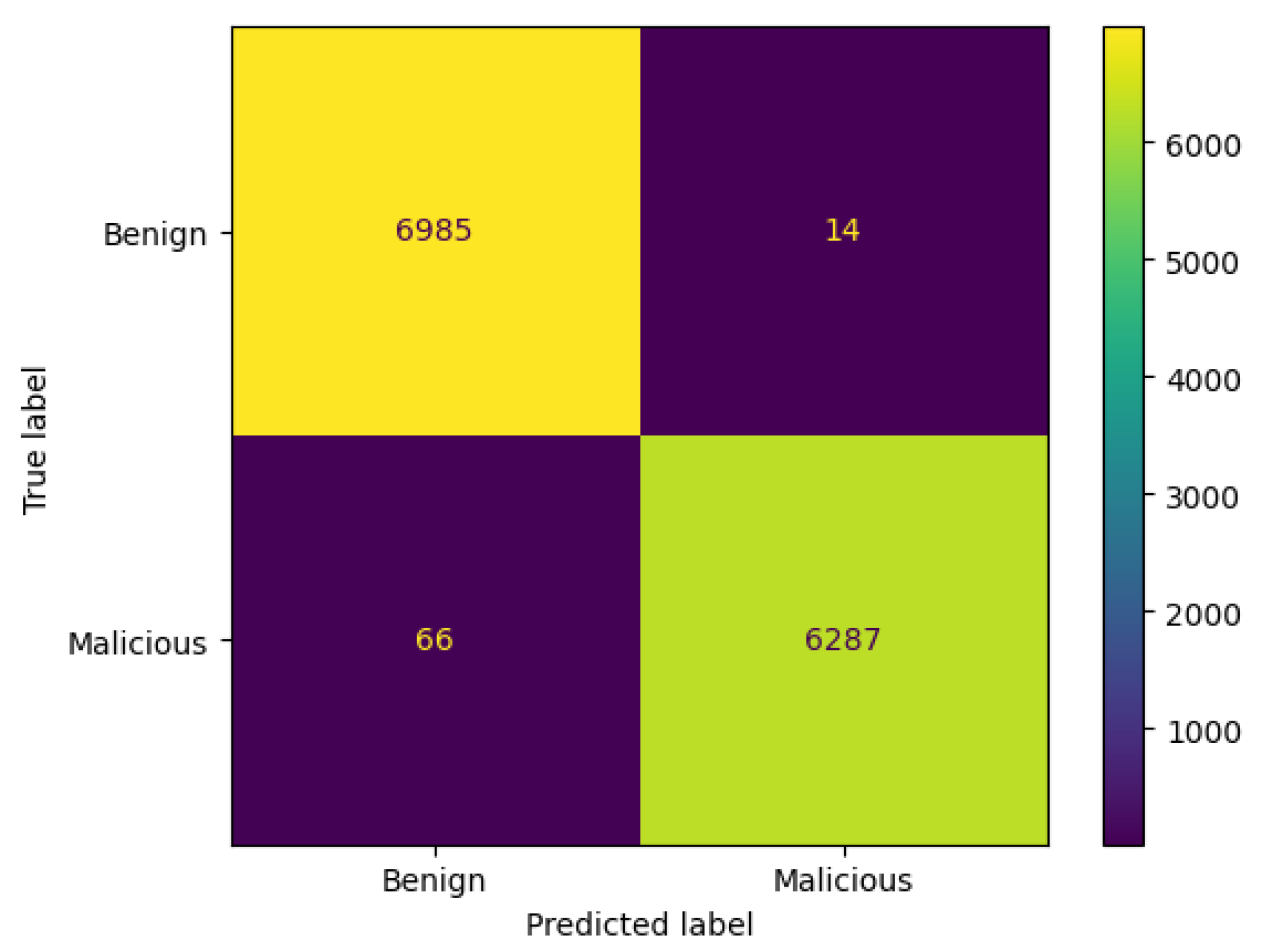
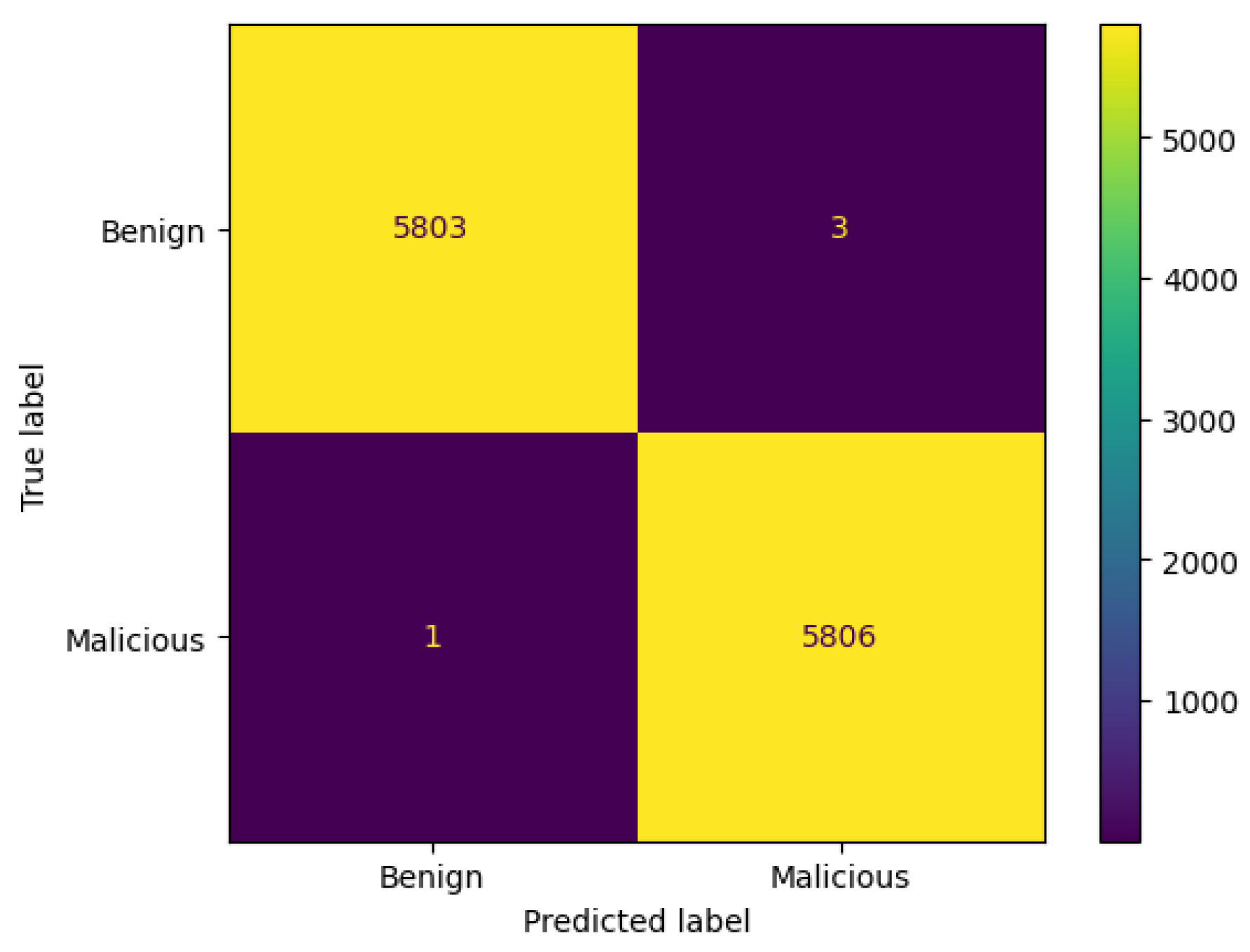
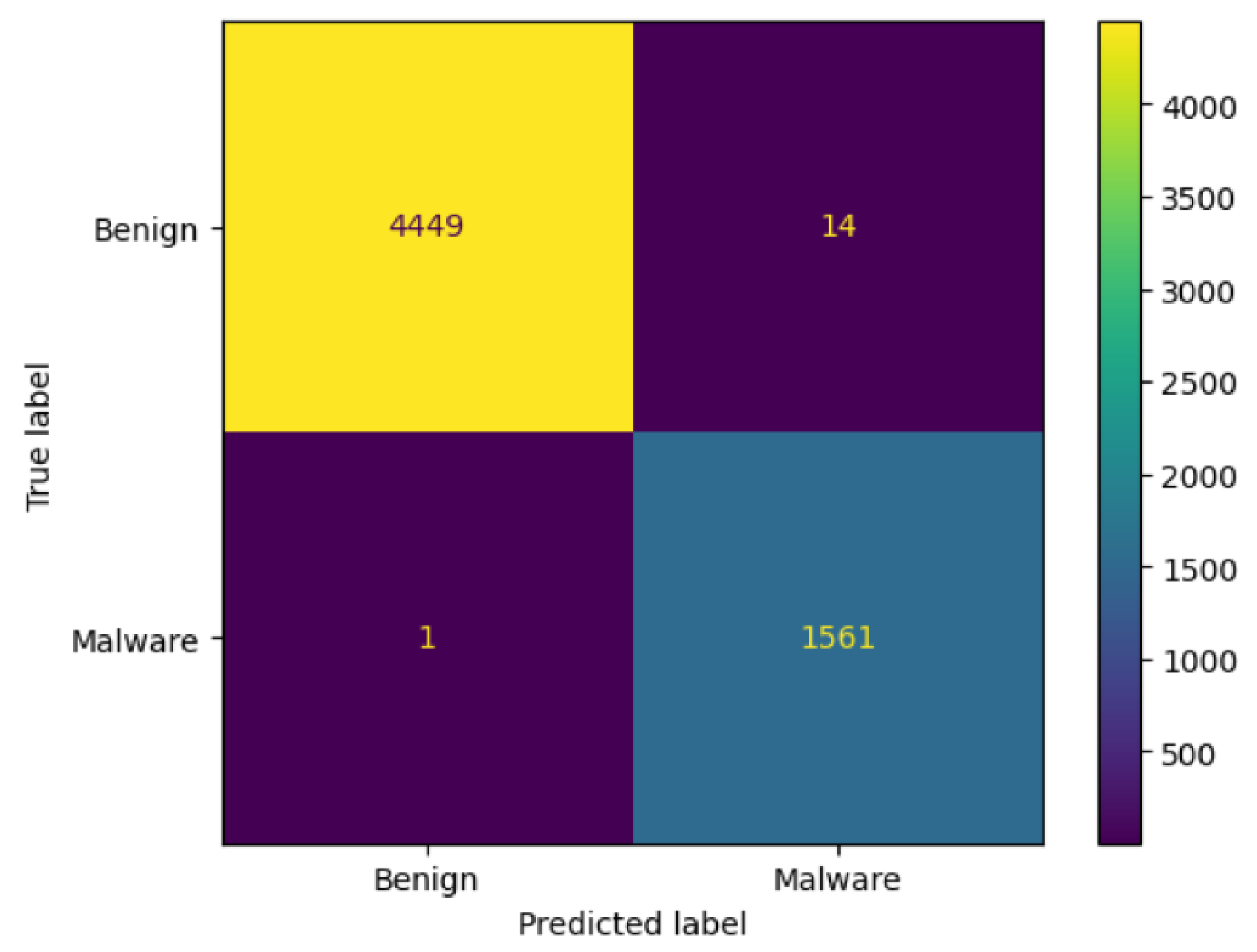
3.8.1. Confusion Matrix
- TN denotes correct prediction for the benign class.
- TP indicates correct prediction for the malicious class.
- FP implies incorrect prediction for the benign class. It is predicted as malicious, but it is actually benign.
- FN represents incorrect prediction for the malicious class. It is predicted as benign, but in reality, it is malicious.
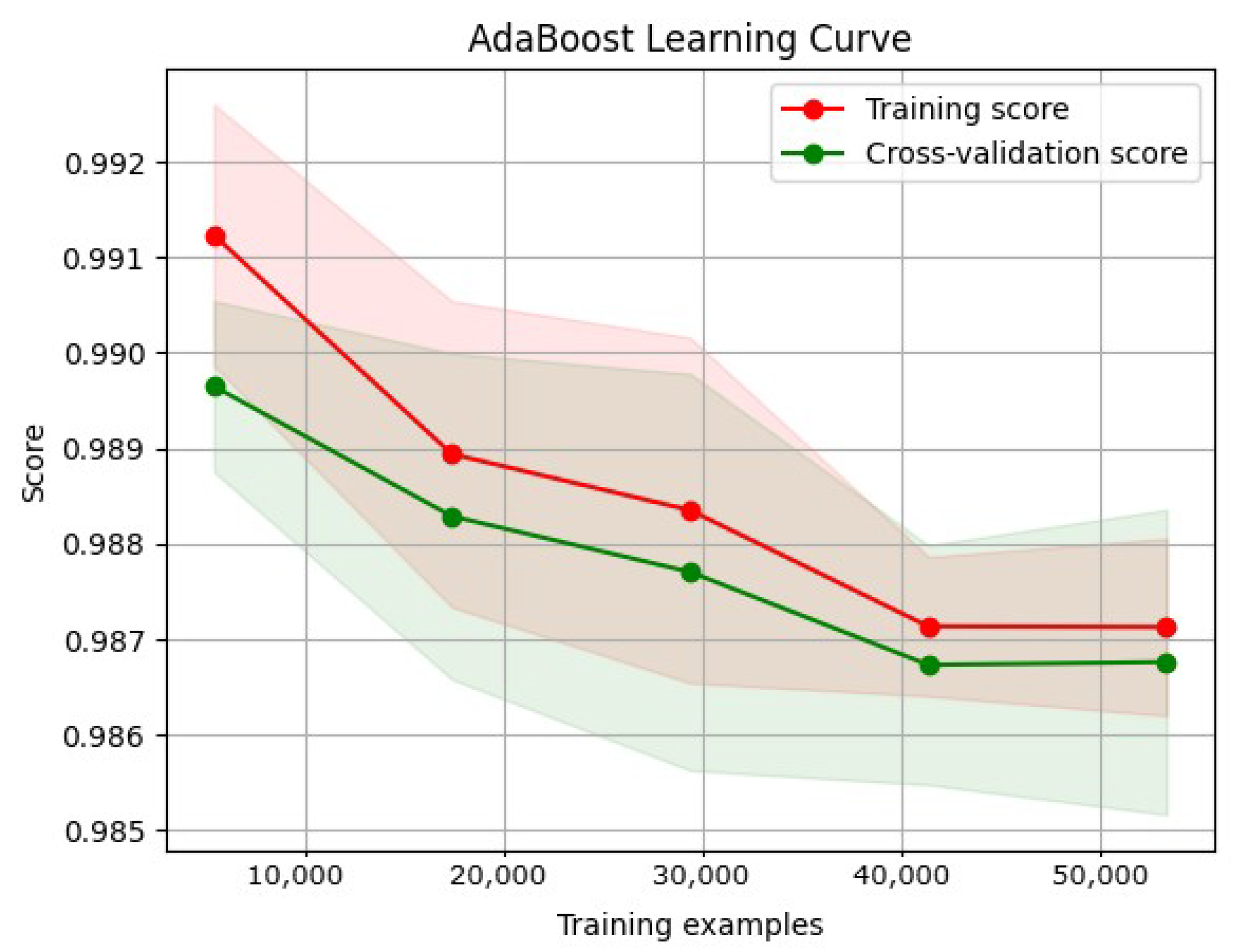
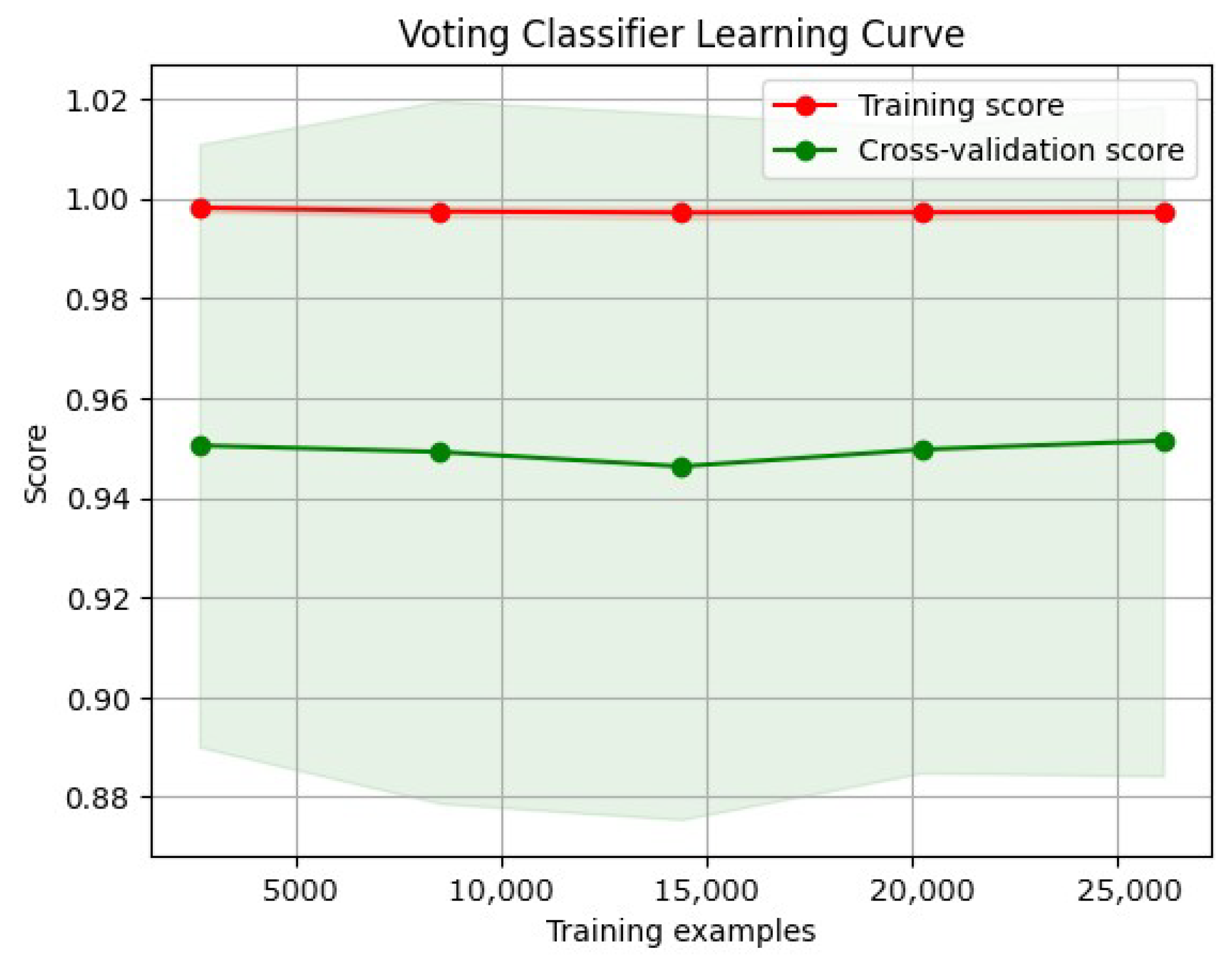
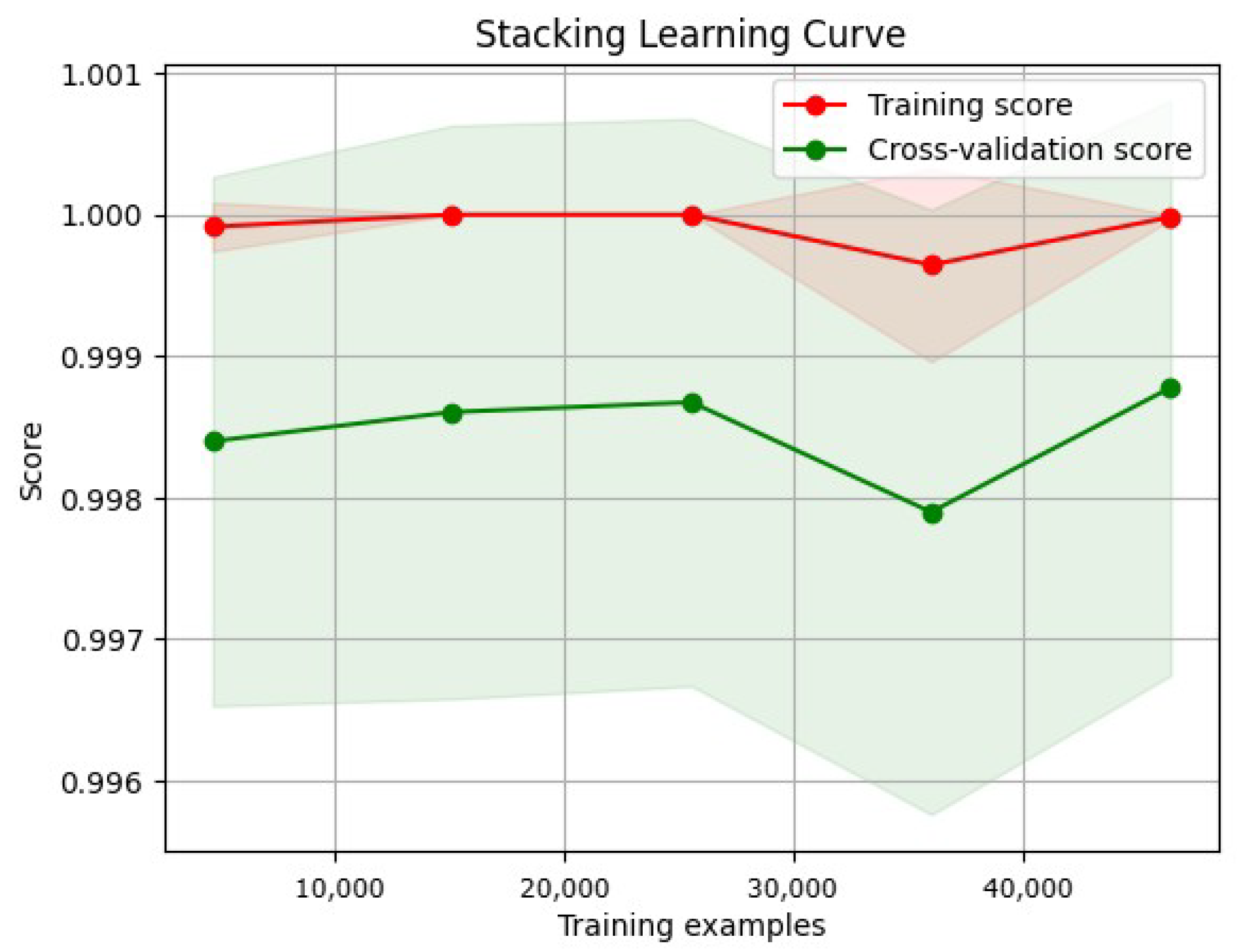
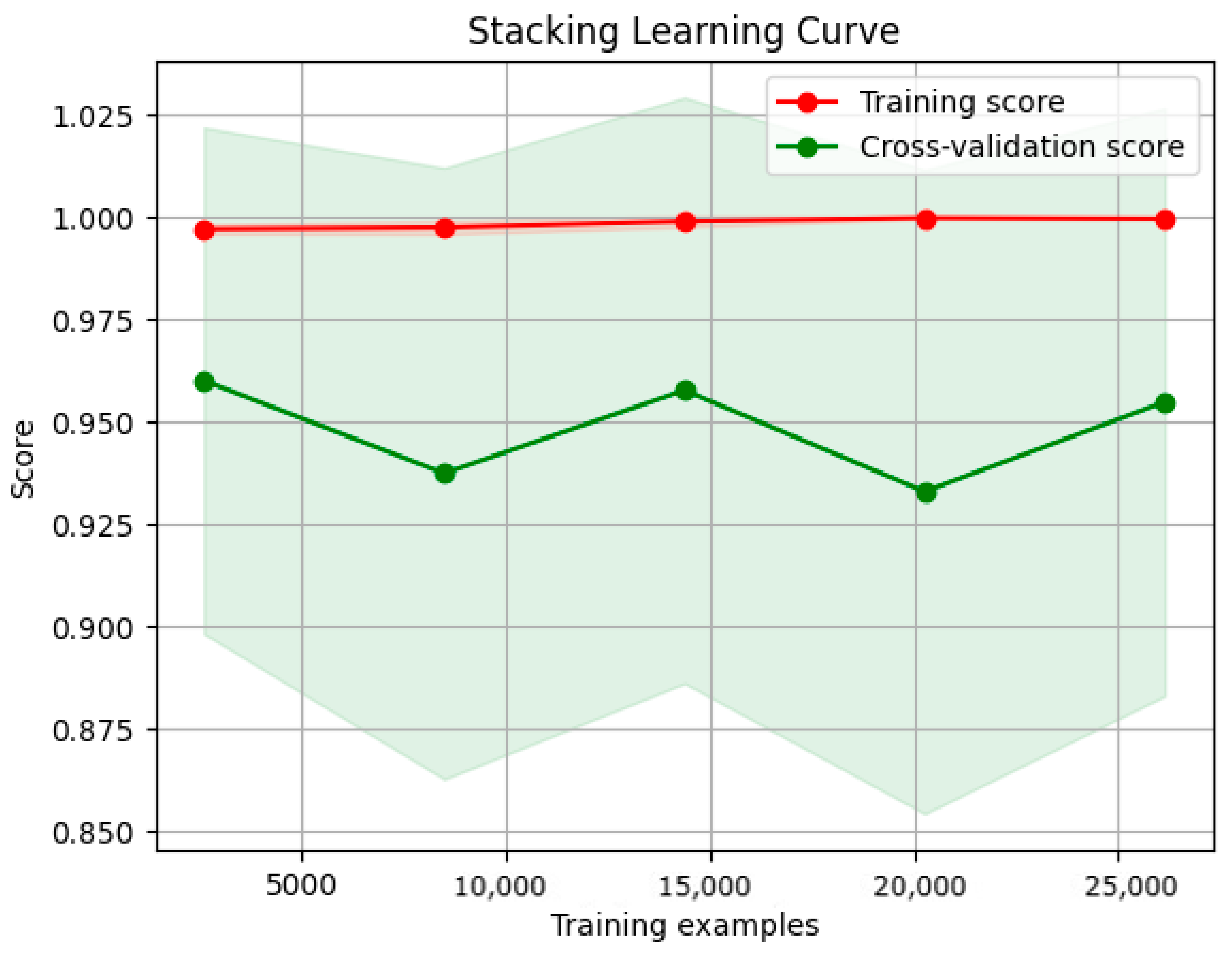
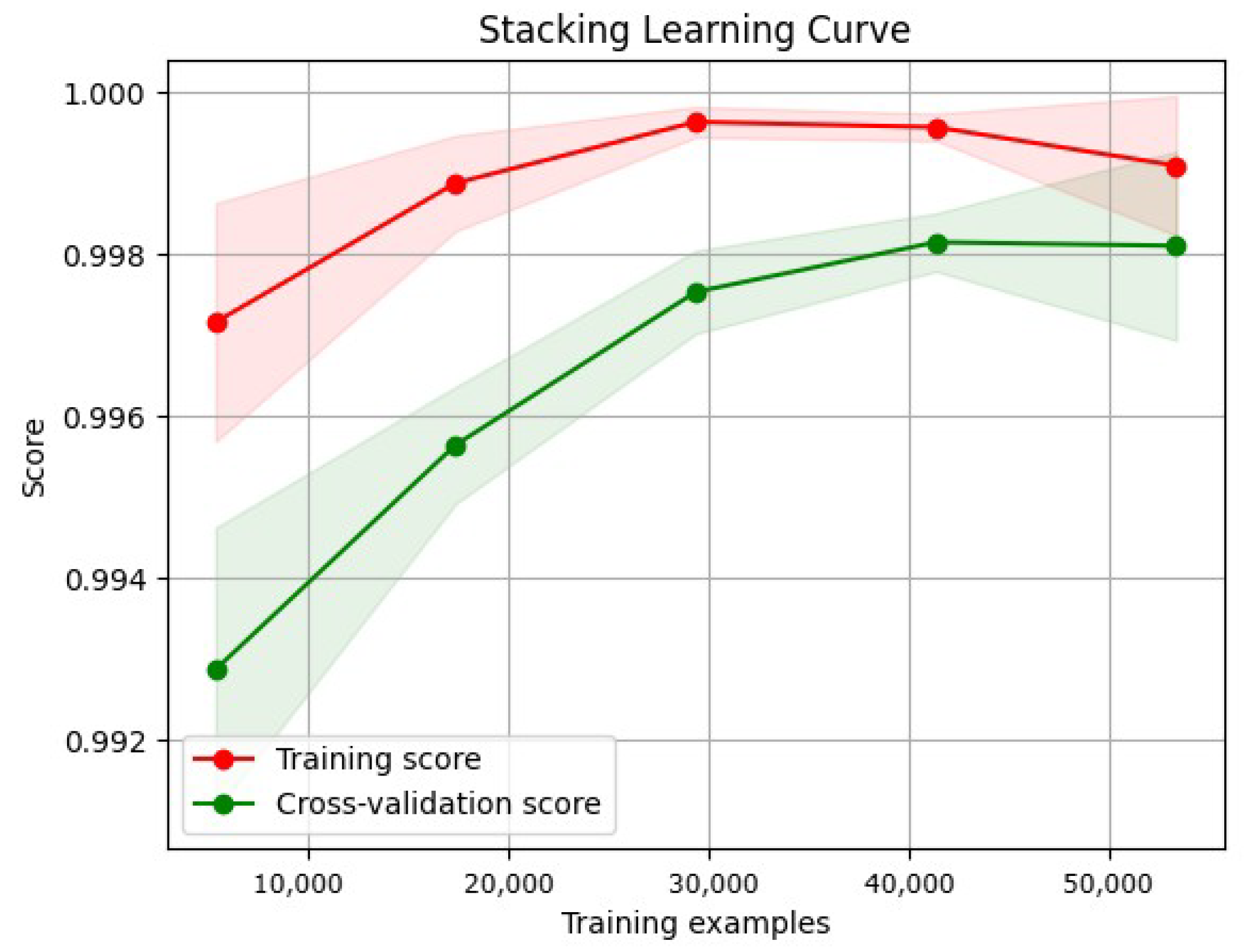
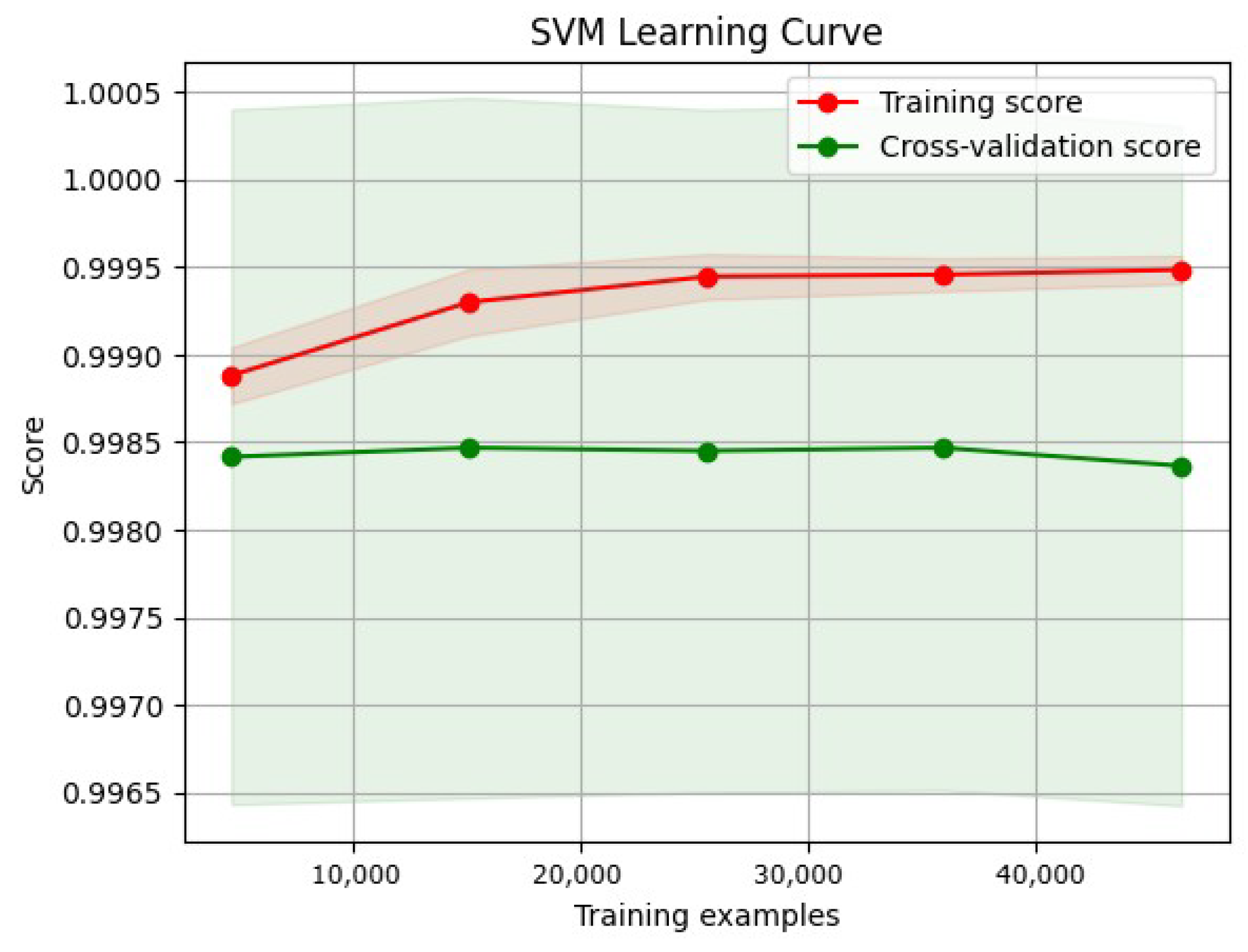
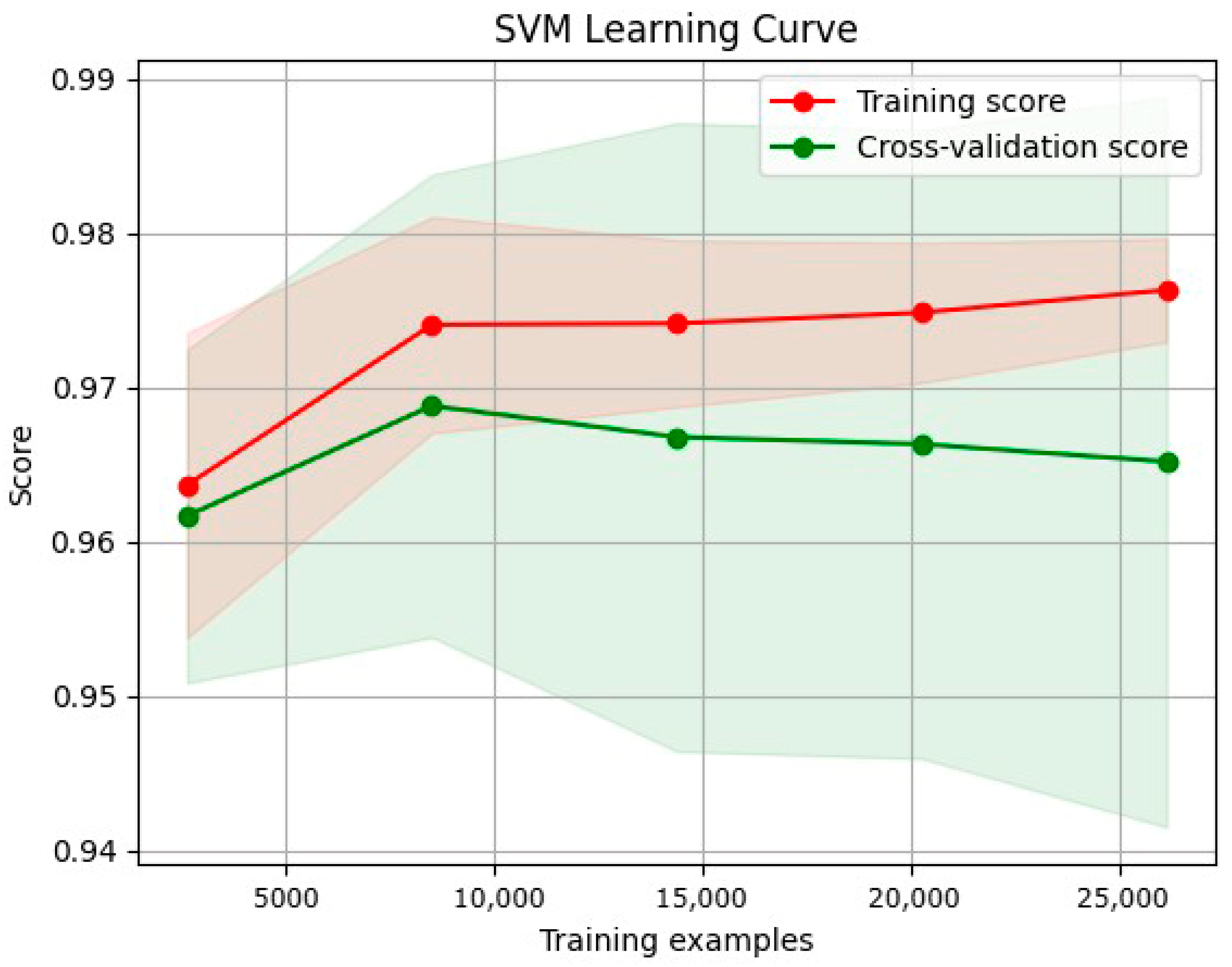
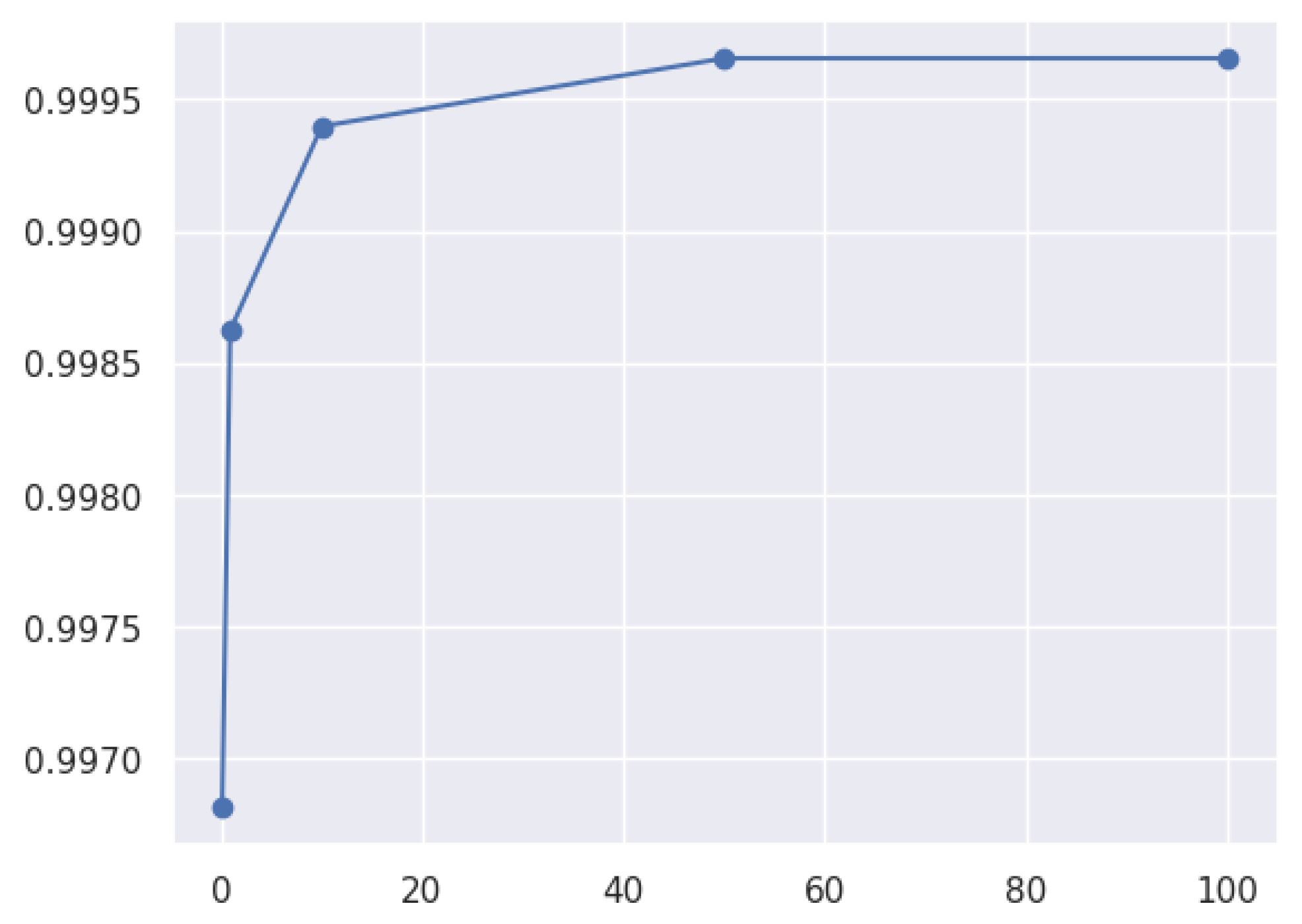
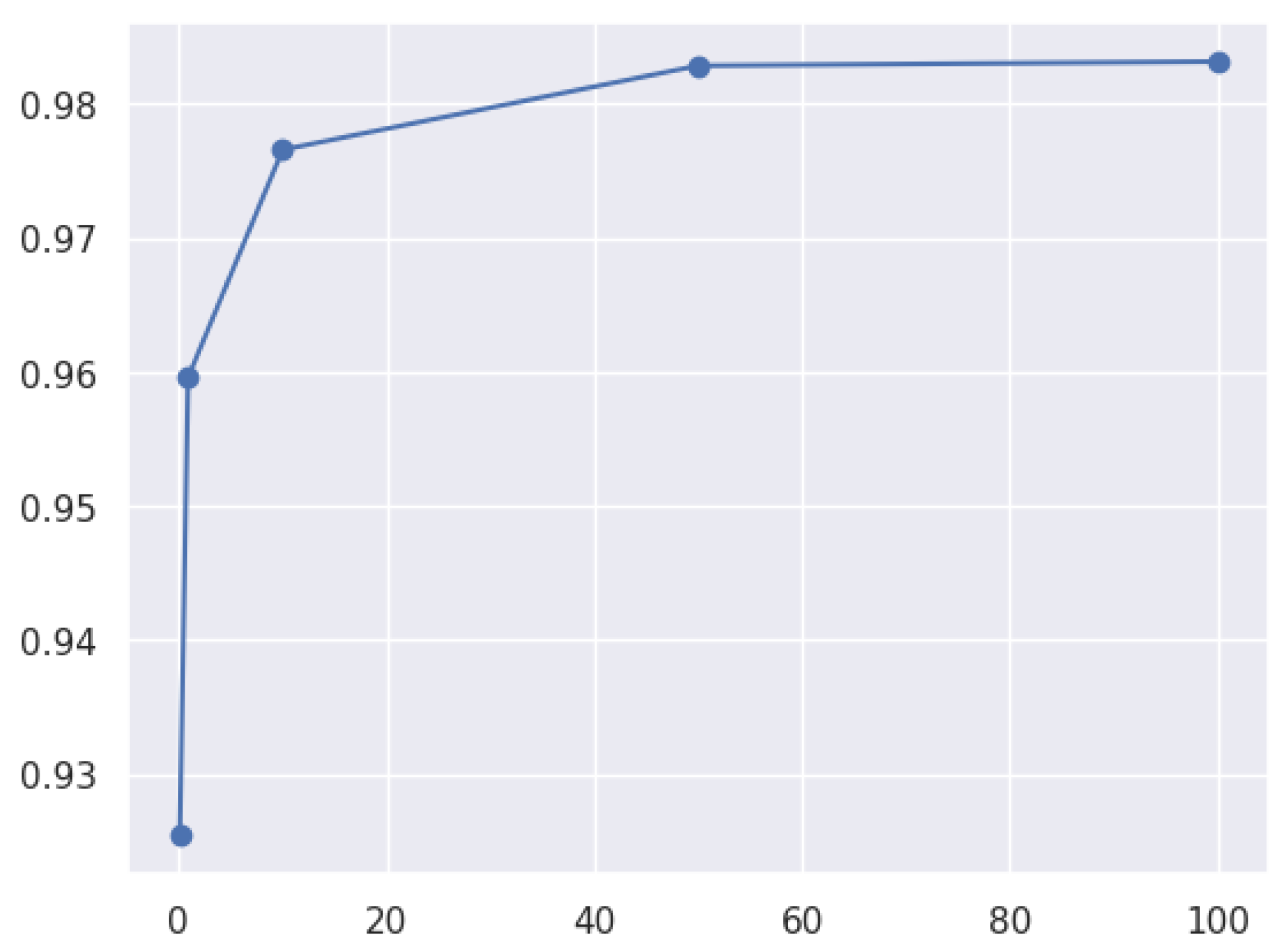
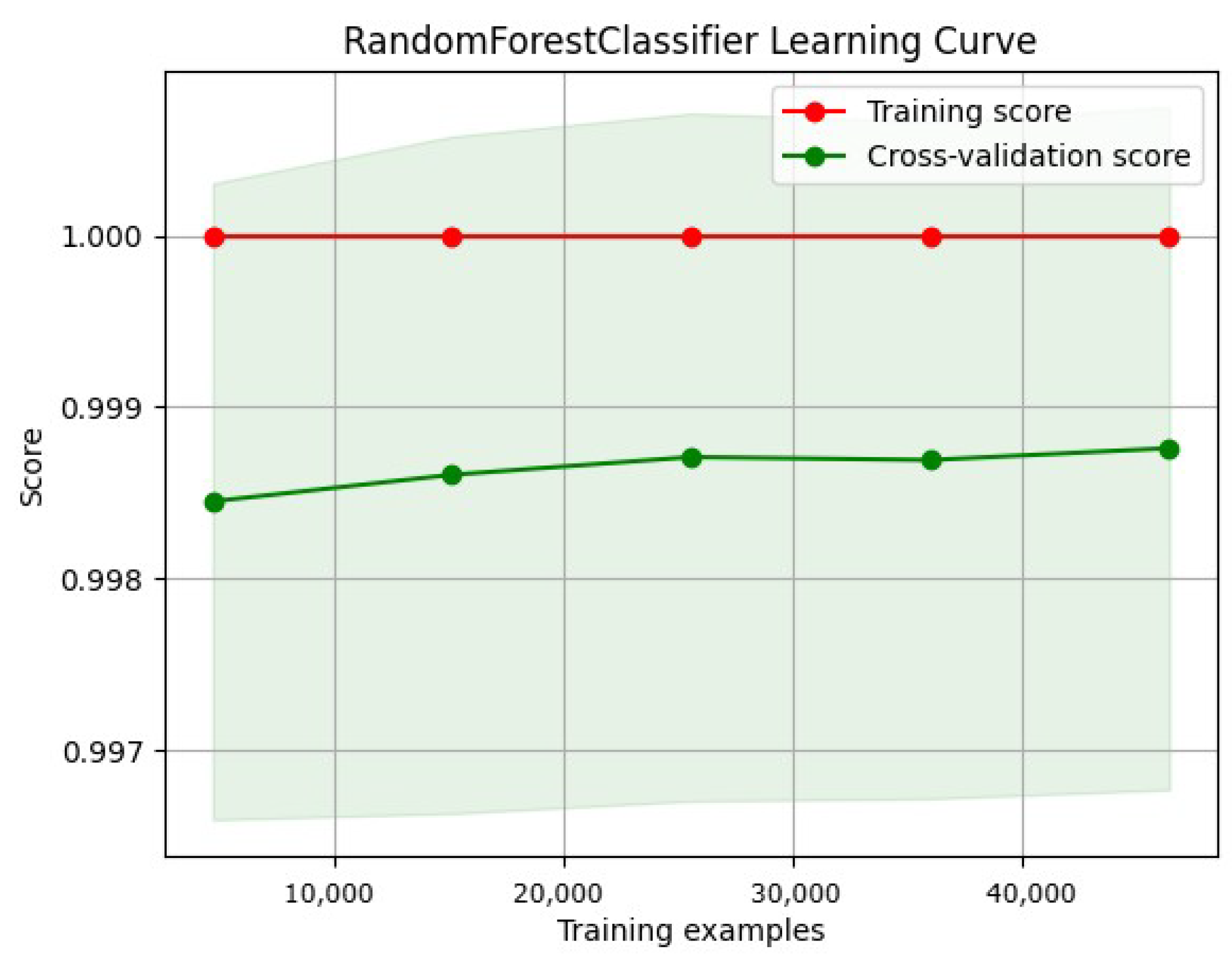
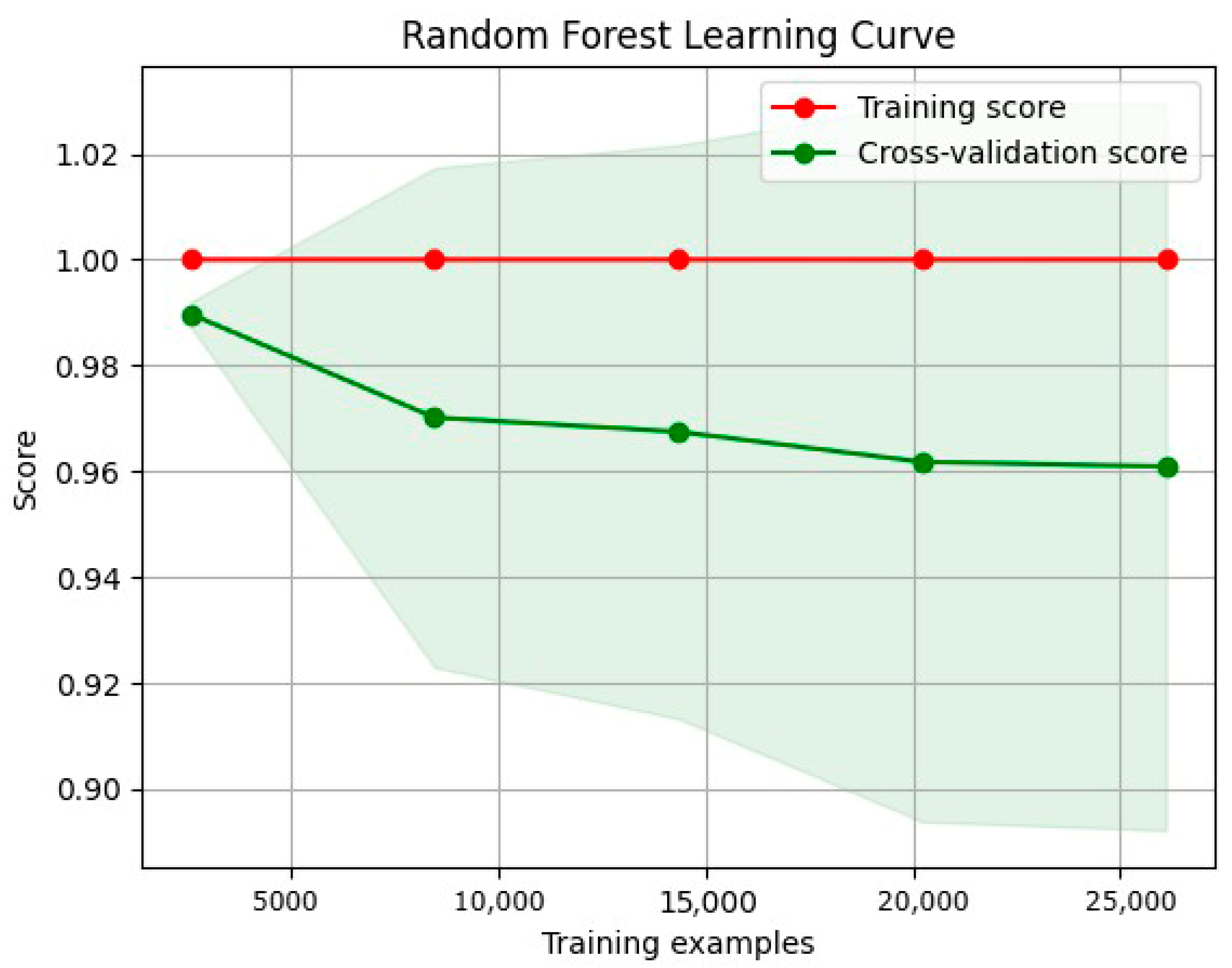
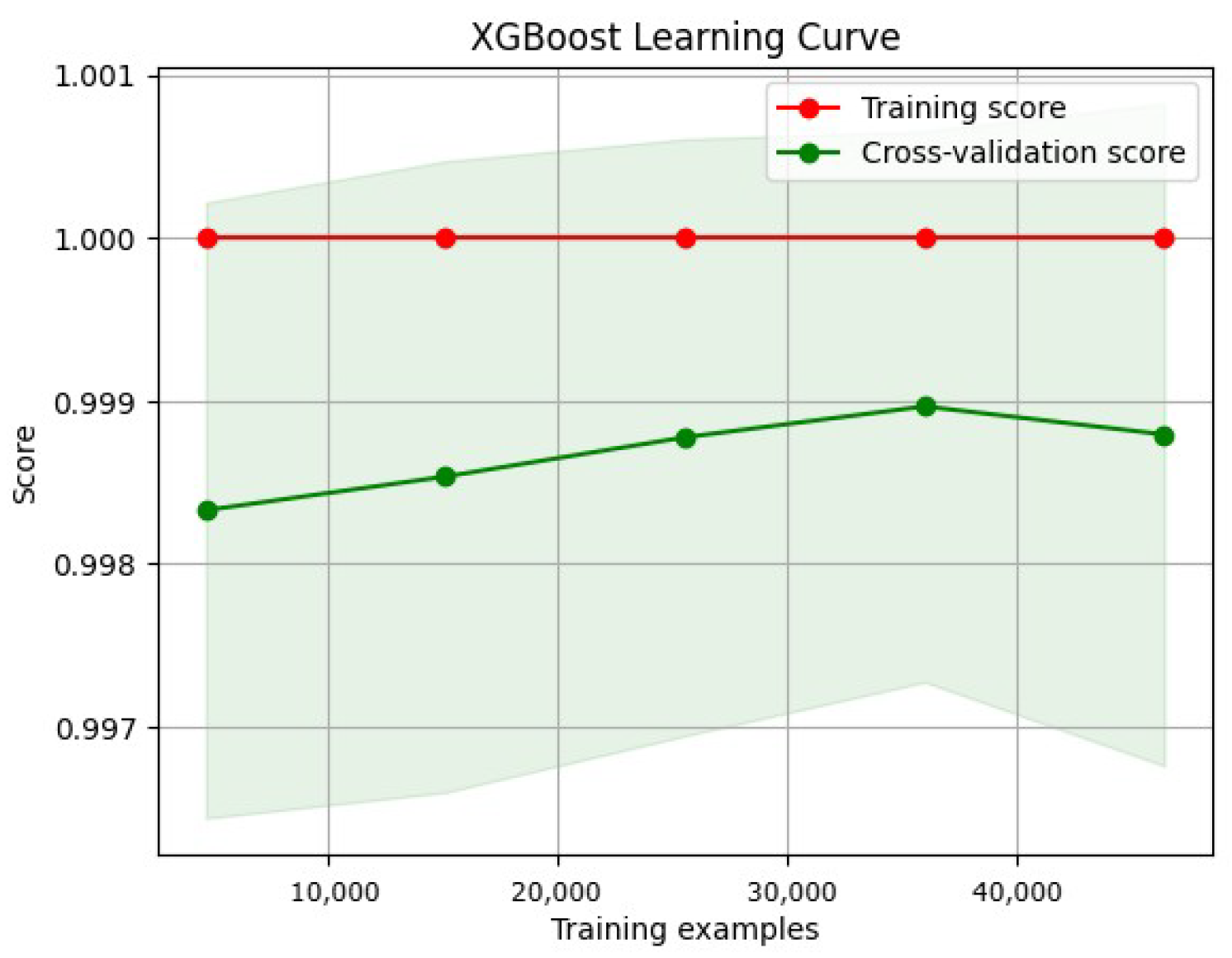
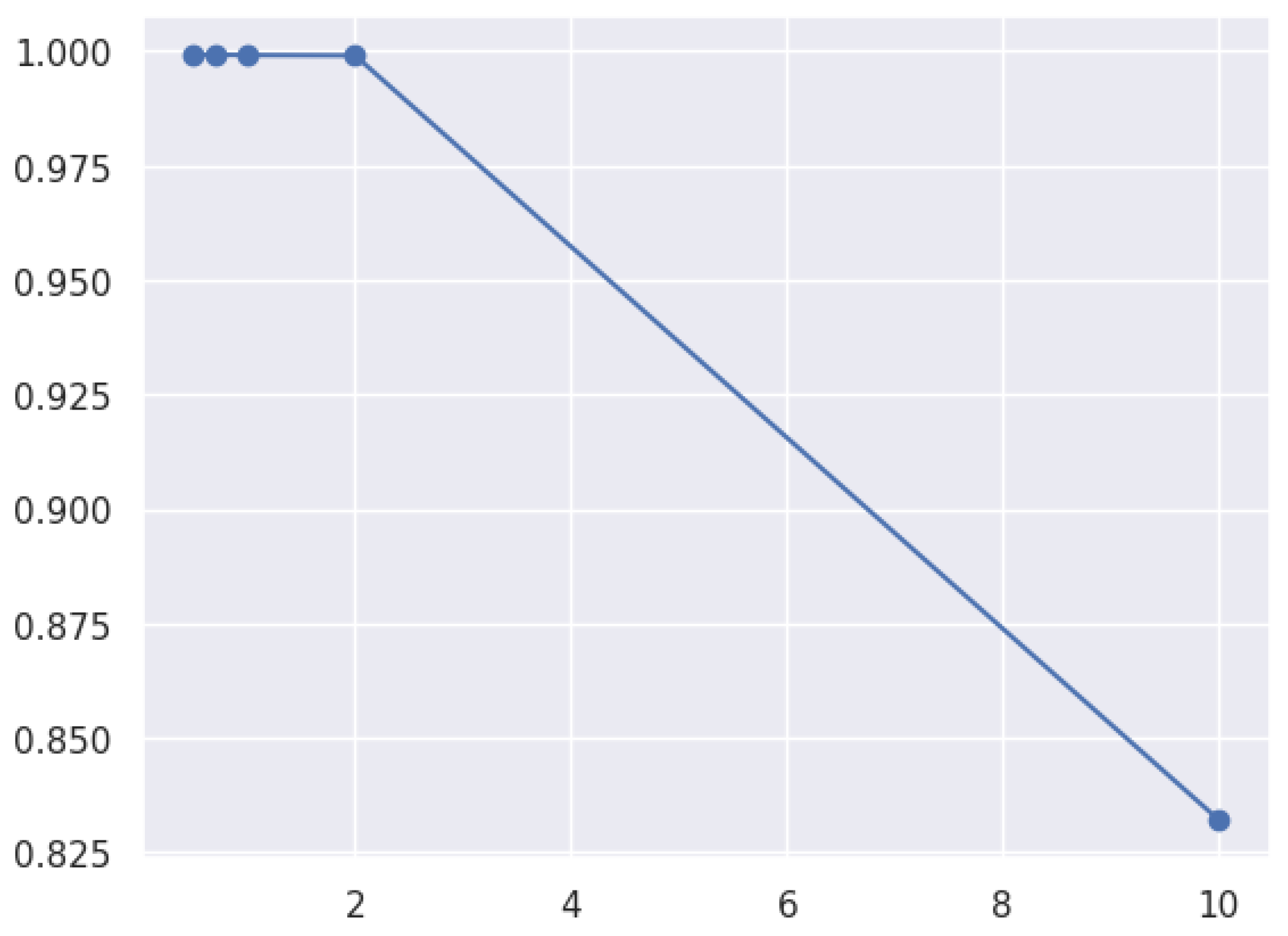
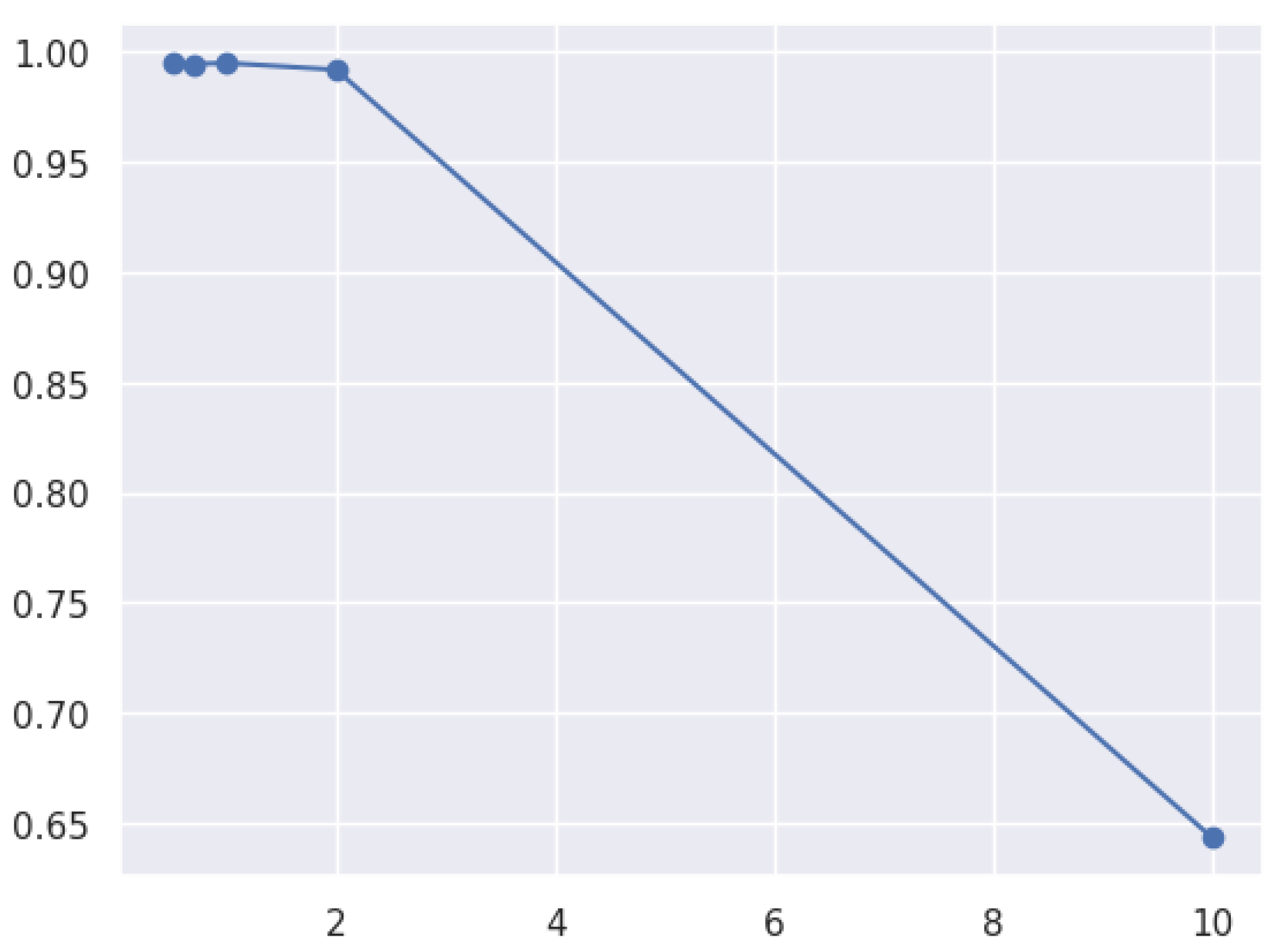
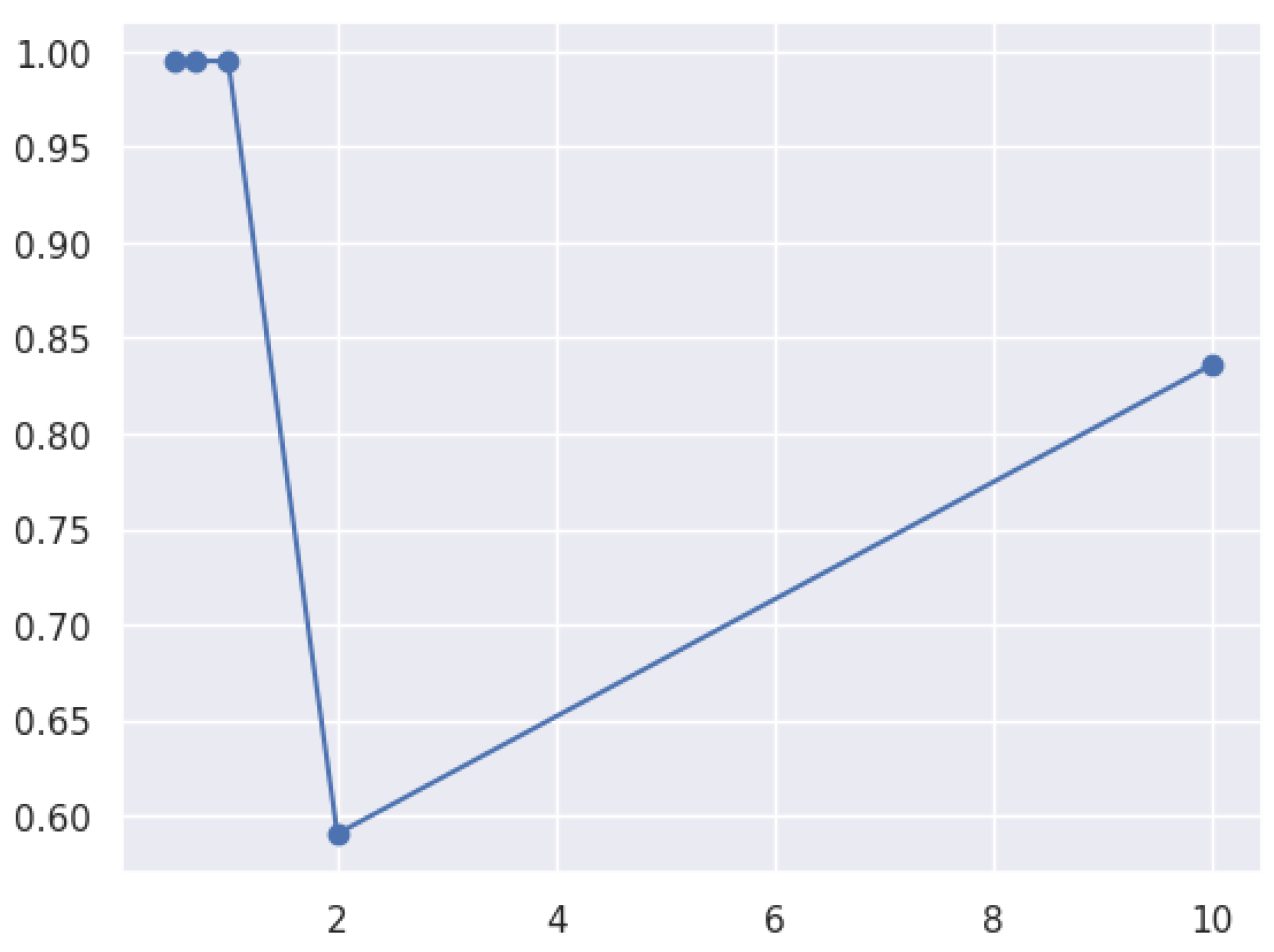
3.8.2. Learning Curve
- Training curve: The training curve shows how the model performs on the training dataset as more training data are presented. Generally, as the model receives more training data, its performance on the training dataset will improve.
- Validation curves illustrate a model’s performance over various validation datasets. These curves can plateau or even worsen after a certain level, indicating that the model has become overfitted.
- Overfitting and underfitting:
- An underfitted model has a high error rate during training and validation due to its oversimplistic nature, which makes it difficult to capture the underlying patterns in the data.
- Overfitted models can learn that the training data contain noise. Consequently, the training error decreases, whereas the validation error increases.
- A low error rate across the training and validation curves is ideal for a model’s generalization to new datasets.
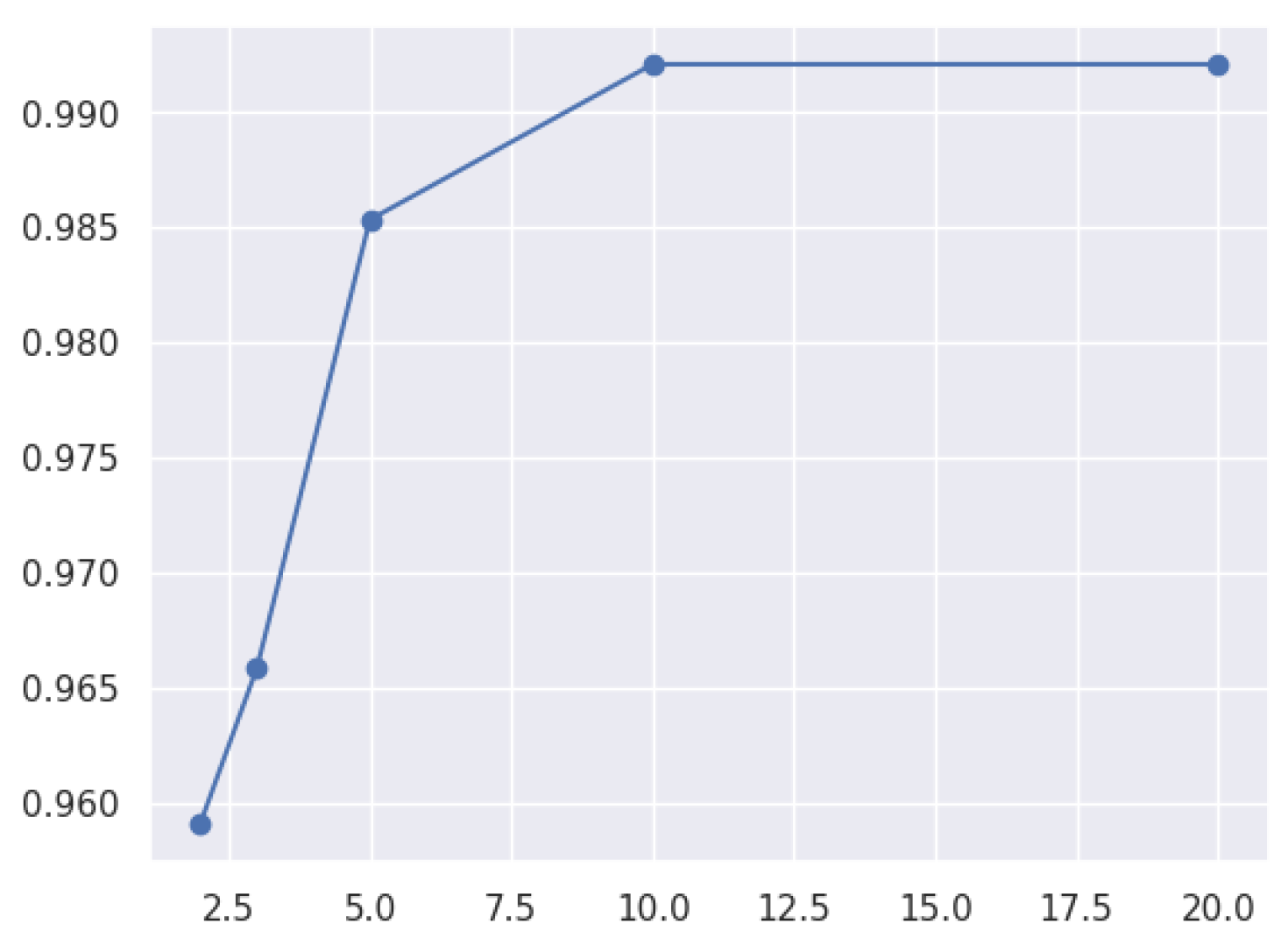
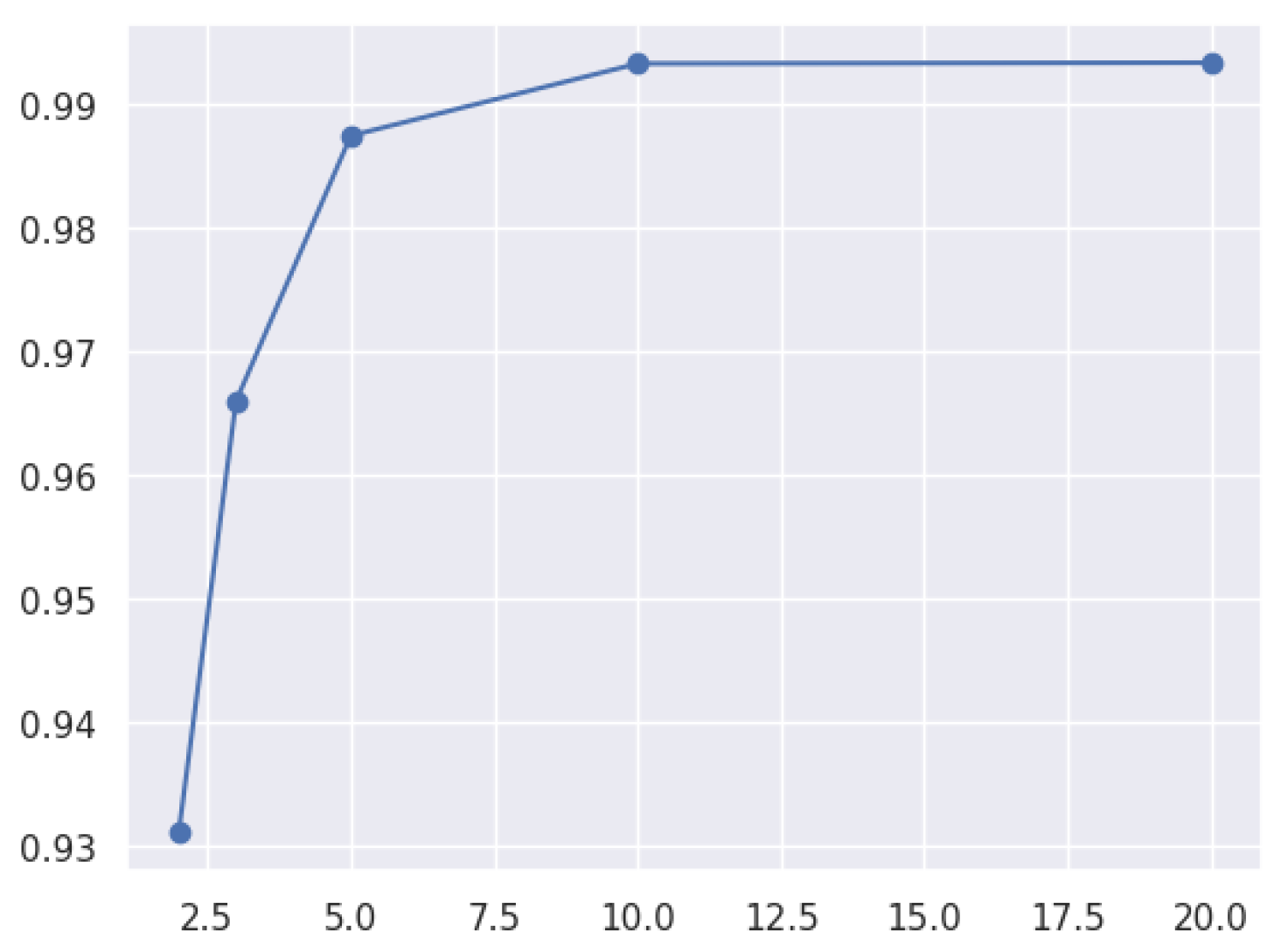
3.8.3. Hyperparameters in the Model
- The following types of hyperparameters can be identified:
- Characteristics specific to a particular model may include the depth of decision trees (DTs) or the number of hidden layers within a neural network, for example.
- Training-specific factors include the learning rate or batch size in gradient descent.
- A hyperparameter tuning approach involves finding the best parameters to optimize a model’s performance on a given task. It can be carried out through grid search, Bayesian optimization, or random search.
- In terms of importance, the following apply:
- Optimizing hyperparameters can significantly improve a model’s performance.
- Controlling overfitting and underfitting can be achieved by altering hyperparameters, such as the regularization parameter.
- The challenge of tuning hyperparameters can be computationally expensive and time-consuming, especially for models with a large number of parameters and complex interactions among them.
4. Results and Discussion
4.1. Results
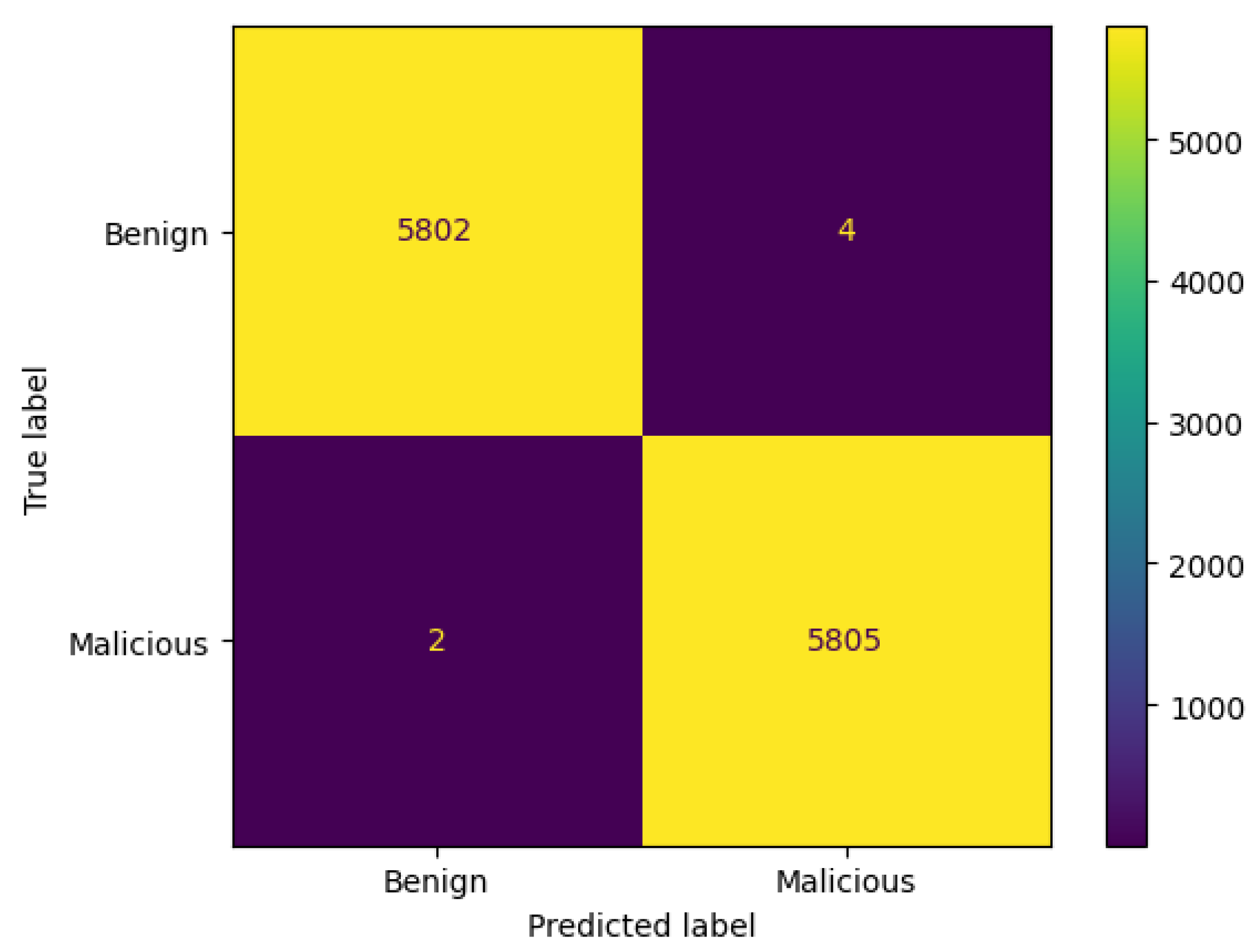
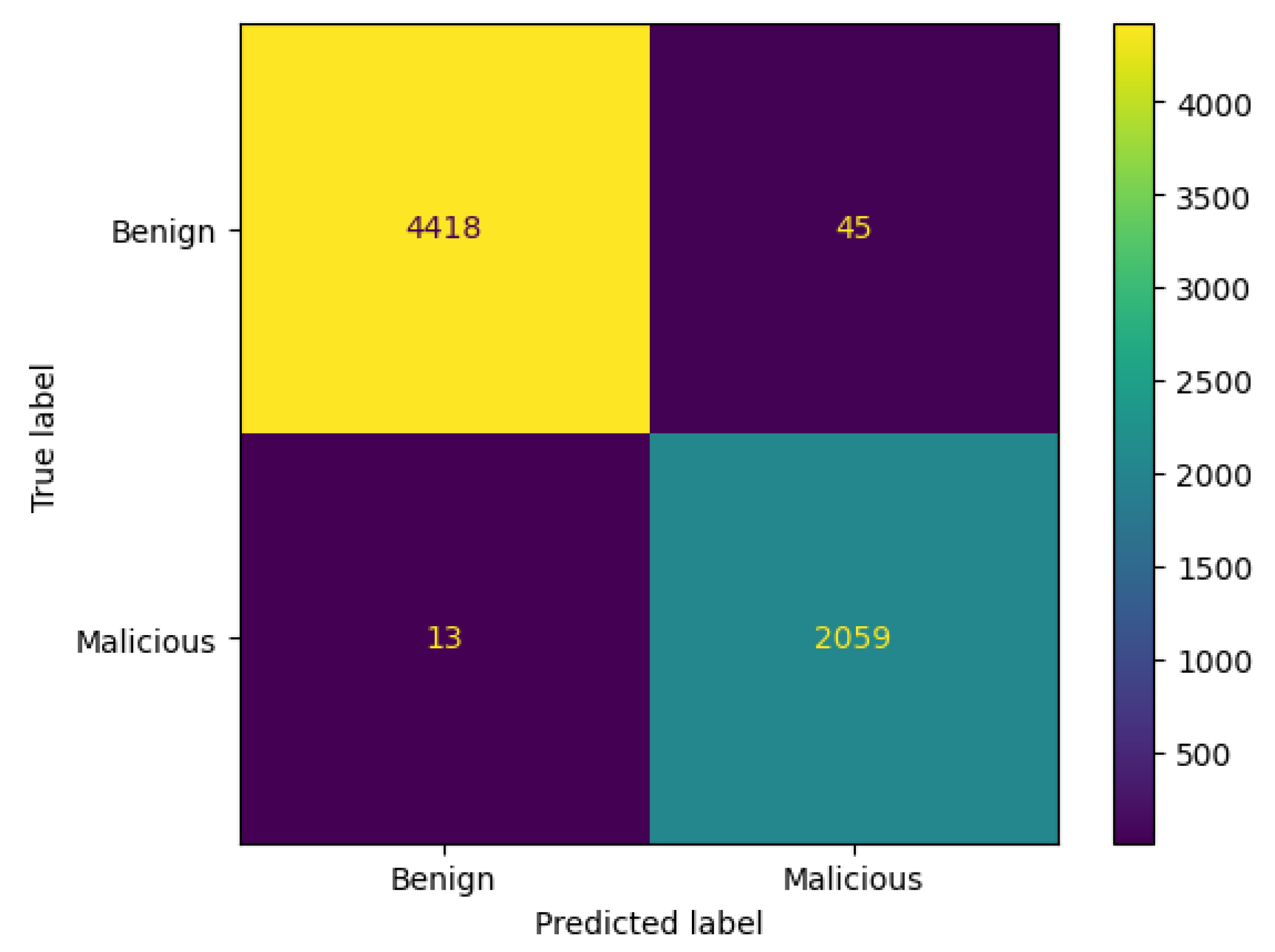
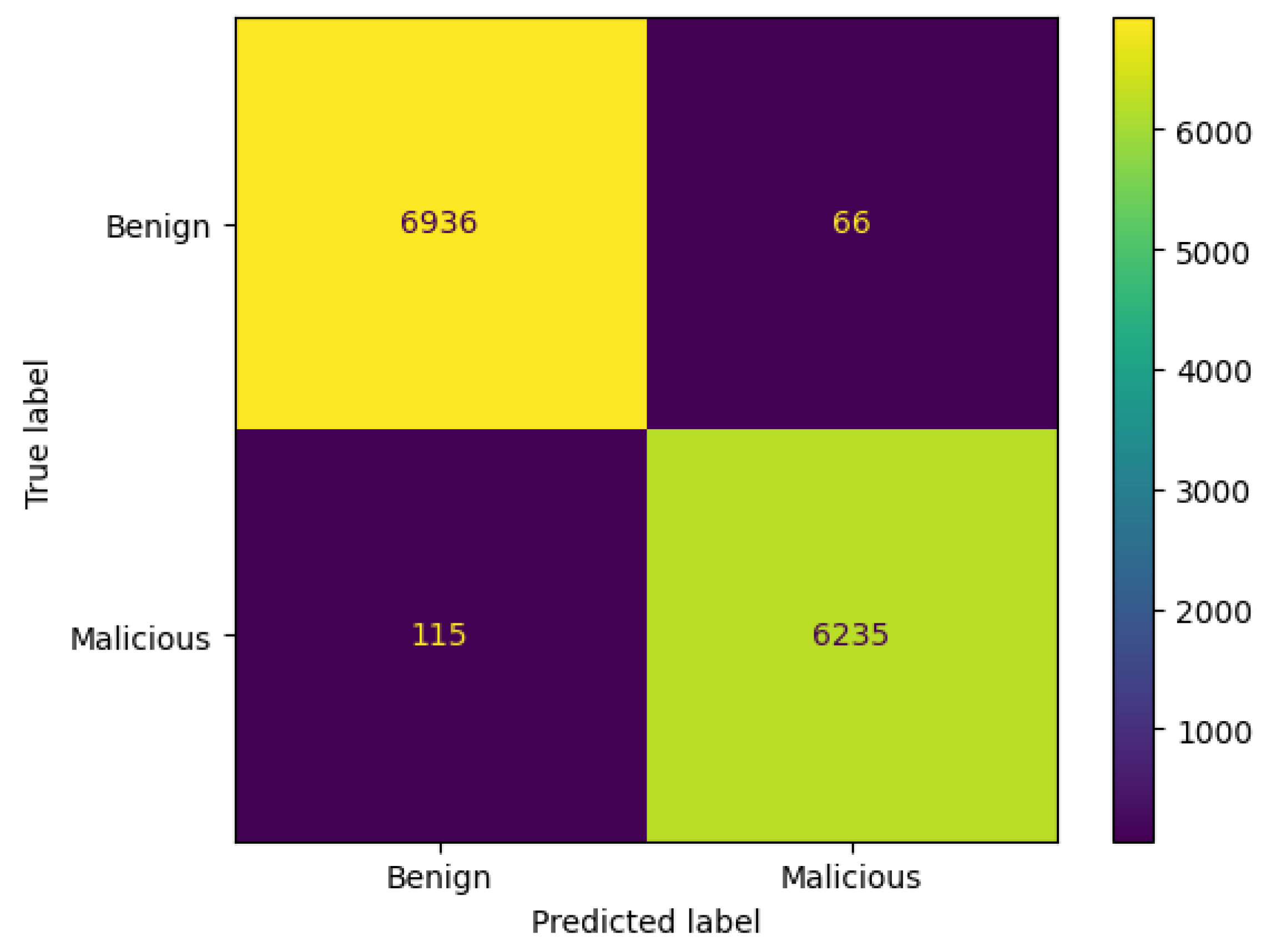
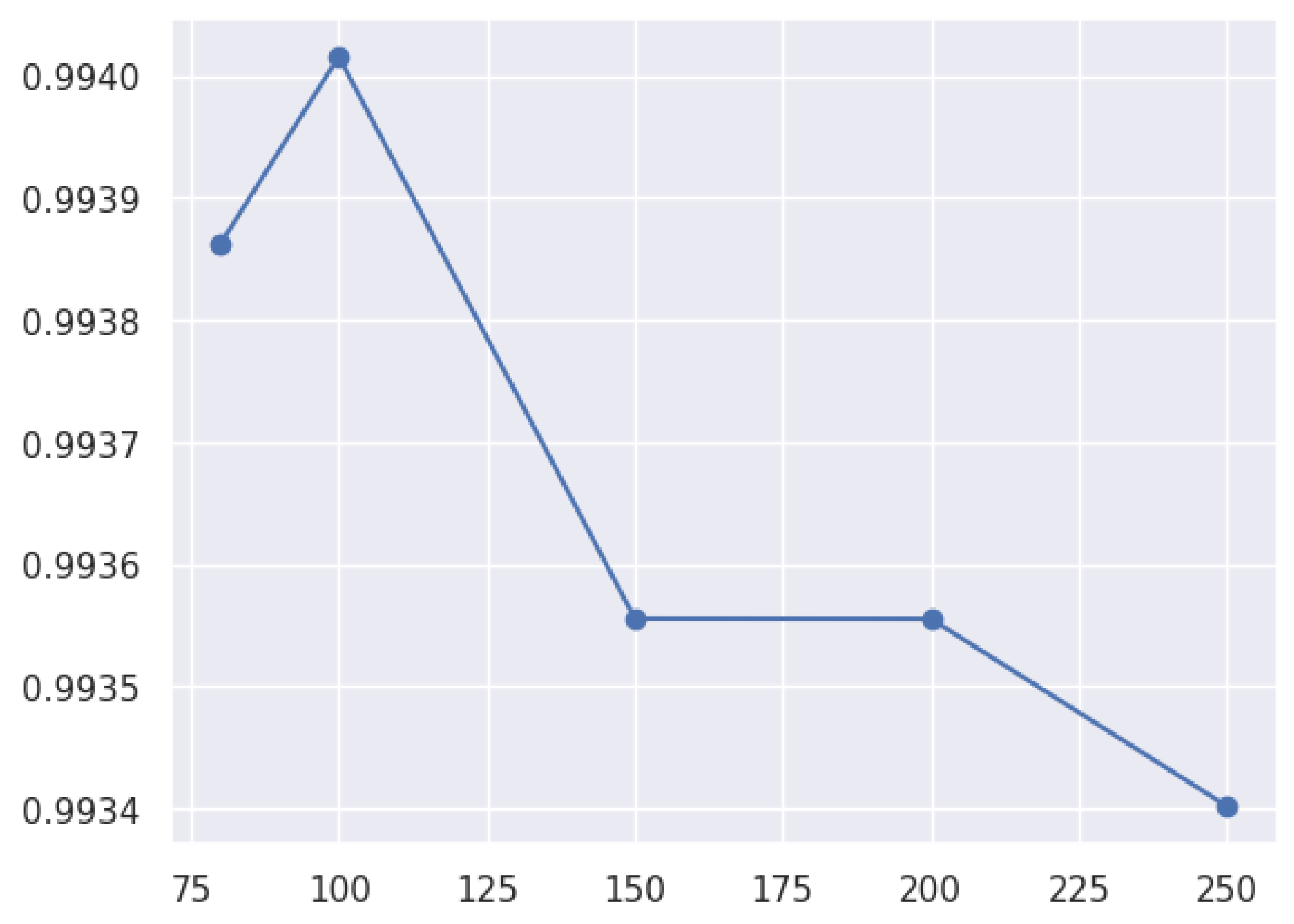
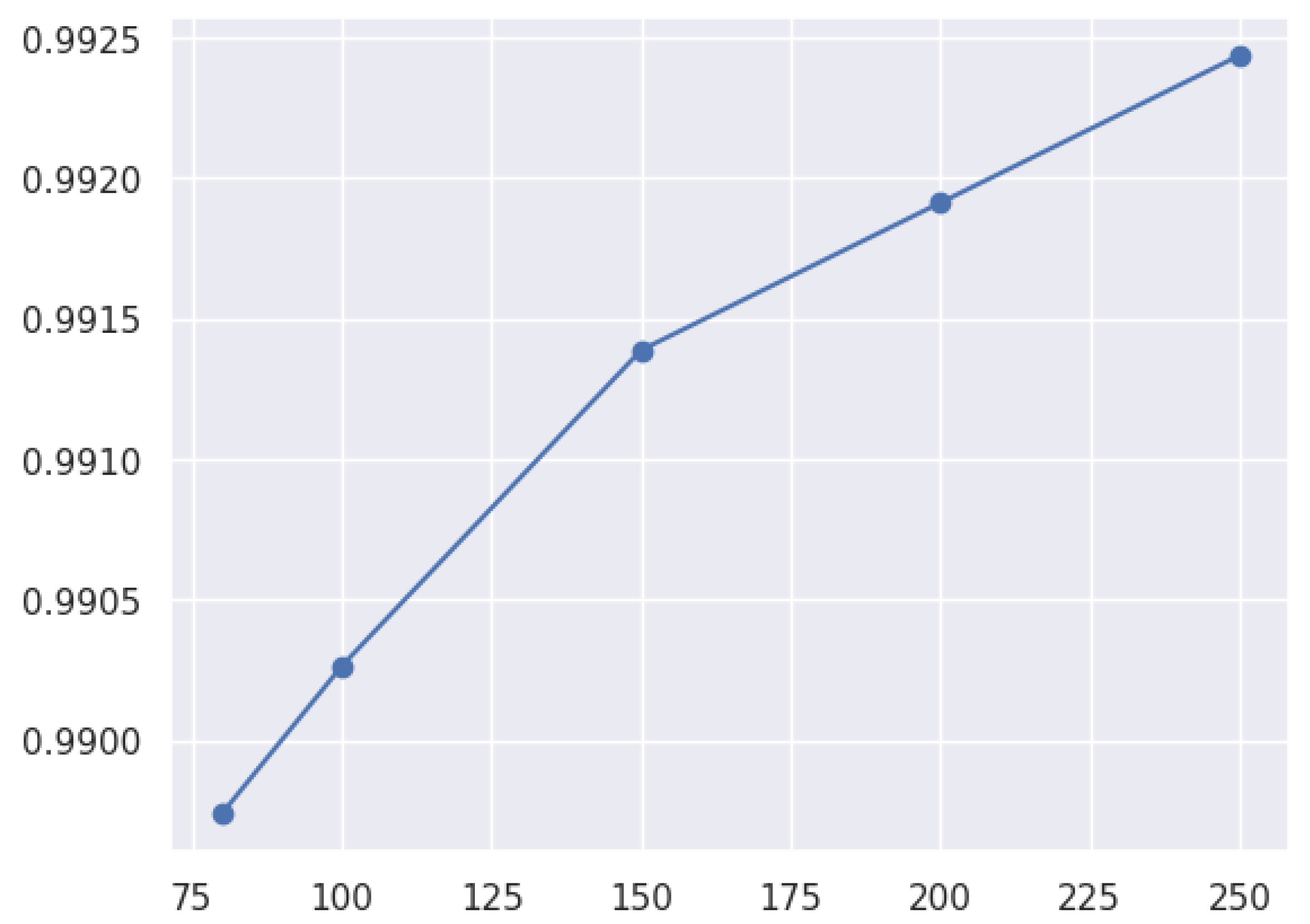
4.1.1. AdaBoost
4.1.2. Voting Classifier
4.1.3. Stacking Classifier
4.1.4. SVM
4.1.5. Random Forest
4.1.6. XGBoost
4.2. Security Analysis Using an Adversarial Attack Model
4.2.1. Adversarial Attack Model
- DoS/DDoS: We simulated high-volume traffic from a single source and multiple sources to disrupt service availability. We used the same features, like packet rate, duration, and protocol type, to mimic attack patterns already existing in the real dataset (CSE-CIC-IDS2018).
- Brute force: We simulated repeated login attempts with varying usernames and passwords to gain unauthorized access to the organization’s network or systems. Also, we used features like failed login attempts and source IP addresses.
- Port scanning: We simulated a port scanning attack by sending packets to multiple ports to identify vulnerabilities in the organization’s network and systems. We used features like port numbers, packet count, and response time.
- Malware: We simulated a malicious payload delivery and execution attack to gain persistent access to or control of the organization’s systems. We used features like file size, execution behavior, and network activity.
4.2.2. Attack Generation and Preprocessing of Generated Attack Data
- Ensure that the simulated adversarial data have the same features as the original dataset. Also, add new features related to new attacks when retraining the model to deal with data changes.
- Apply the same preprocessing steps to the simulated adversarial data as those applied to the original dataset.
- Ensure that the labels in the simulated adversarial data match the encoding used in the original dataset.
- Ensure that the simulated adversarial data follow the same statistical distribution as the original dataset. A significant change in data distribution requires retraining the model.
| Listing 1. DoS/DDos simulated attack. |
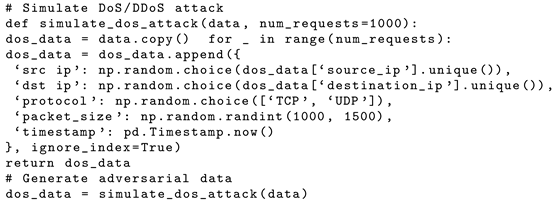 |
| Listing 2. Brute force simulated attack. |
 |
| Listing 3. Port scanning simulated attack. |
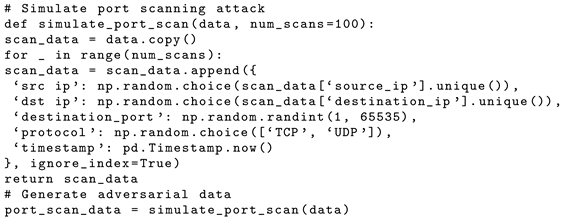 |
| Listing 4. Malware simulated attack. |
 |
4.2.3. Adversarial Model Results and Analysis
4.3. Discussion
Limitations of Proposed Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| IDS | Intrusion Detection System |
| ML | Machine Learning |
References
- Fakieh, A.; Akremi, A. An Effective Blockchain-Based Defense Model for Organizations against Vishing Attacks. Appl. Sci. 2022, 12, 13020. [Google Scholar] [CrossRef]
- Azizan, A.H.; Mostafa, S.A.; Mustapha, A.; Foozy, C.F.M.; Wahab, M.H.A.; Mohammed, M.A.; Khalaf, B.A. A machine learning approach for improving the performance of network intrusion detection systems. Ann. Emerg. Technol. Comput. (AETiC) 2021, 5, 201–208. [Google Scholar] [CrossRef]
- Priyadarsini, M.; Bera, P. Software defined networking architecture, traffic management, security, and placement: A survey. Comput. Netw. 2021, 192, 108047. [Google Scholar] [CrossRef]
- Samantaray, M.; Satapathy, S.; Lenka, A. A Systematic Study on Network Attacks and Intrusion Detection System. In Machine Intelligence and Data Science Applications: Proceedings of MIDAS 2021; Springer: Berlin/Heidelberg, Germany, 2022; pp. 195–210. [Google Scholar]
- Akremi, A.; Sallay, H.; Rouached, M. Intrusion detection systems alerts reduction: New approach for forensics readiness. In Security and Privacy Management, Techniques, and Protocols; IGI Global: Hershey, PA, USA, 2018; pp. 255–275. [Google Scholar]
- Soomro, A.M.; Naeem, A.B.; Ghafoor, M.I.; Senapati, B.; Rajwana, M.A. A Systematic Review of Artificial Intelligence Techniques Used for IDS Analysis. J. Comput. Biomed. Inform. 2023, 5, 52–67. [Google Scholar]
- Jaradat, A.S.; Barhoush, M.M.; Easa, R.B. Network intrusion detection system: Machine learning approach. Indones. J. Electr. Eng. Comput. Sci. 2022, 25, 1151–1158. [Google Scholar] [CrossRef]
- Amanoul, S.V.; Abdulazeez, A.M.; Zeebare, D.Q.; Ahmed, F.Y. Intrusion detection systems based on machine learning algorithms. In Proceedings of the 2021 IEEE International Conference on Automatic Control & Intelligent Systems (I2CACIS), Shah Alam, Malaysia, 26 June 2021; pp. 282–287. [Google Scholar]
- Verma, A.; Ranga, V. Machine learning based intrusion detection systems for IoT applications. Wirel. Pers. Commun. 2020, 111, 2287–2310. [Google Scholar] [CrossRef]
- Mirlekar, S.; Kanojia, K.P. A Study on Taxonomy and State-of-the-Art Intrusion Detection System. In Proceedings of the 2nd International Conference on Advancement in Electronics & Communication Engineering (AECE 2022), Ghaziabad, India, 14–15 July 2022. [Google Scholar]
- Unnisa A, N.; Yerva, M.; Kurian, M.Z. Review on Intrusion Detection System (IDS) for Network Security using Machine Learning Algorithms. Int. Res. J. Adv. Sci. Hub 2022, 4, 67–74. [Google Scholar] [CrossRef]
- Aljanabi, M.; Ismail, M.A.; Ali, A.H. Intrusion detection systems, issues, challenges, and needs. Int. J. Comput. Intell. Syst. 2021, 14, 560–571. [Google Scholar] [CrossRef]
- Alajanbi, M.; Ismail, M.A.; Hasan, R.A.; Sulaiman, J. Intrusion Detection: A Review. Mesopotamian J. Cybersecur. 2021, 2021, 1–4. [Google Scholar] [CrossRef]
- Akremi, A.; Sallay, H.; Rouached, M. An efficient intrusion alerts miner for forensics readiness in high speed networks. Int. J. Inf. Secur. Priv. (IJISP) 2014, 8, 62–78. [Google Scholar] [CrossRef]
- Yan, F.; Wen, S.; Nepal, S.; Paris, C.; Xiang, Y. Explainable machine learning in cybersecurity: A survey. Int. J. Intell. Syst. 2022, 37, 12305–12334. [Google Scholar]
- Jahwar, A.F.; Ameen, S.Y. A review on cybersecurity based on machine learning and deep learning algorithms. J. Soft Comput. Data Min. 2021, 2, 14–25. [Google Scholar]
- Robles Herrera, S.; Ceberio, M.; Kreinovich, V. When is deep learning better and when is shallow learning better: Qualitative analysis. Int. J. Parallel Emergent Distrib. Syst. 2022, 37, 589–595. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine learning: Algorithms, real-world applications and research directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef]
- Demertzis, K.; Kostinakis, K.; Morfidis, K.; Iliadis, L. A comparative evaluation of machine learning algorithms for the prediction of R/C buildings’ seismic damage. arXiv 2022, arXiv:2203.13449. [Google Scholar]
- Kelleher, J.D.; Mac Namee, B.; D’arcy, A. Fundamentals of Machine Learning for Predictive Data Analytics: Algorithms, Worked Examples, and Case Studies; MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Das, S.; Gangwani, P.; Upadhyay, H. Integration of machine learning with cybersecurity: Applications and challenges. In Artificial Intelligence in Cyber Security: Theories and Applications; Springer: Berlin/Heidelberg, Germany, 2023; pp. 67–81. [Google Scholar]
- Attou, H.; Guezzaz, A.; Benkirane, S.; Azrour, M.; Farhaoui, Y. Cloud-Based Intrusion Detection Approach Using Machine Learning Techniques. Big Data Min. Anal. 2023, 6, 311–320. [Google Scholar]
- Saheed, Y.K.; Abiodun, A.I.; Misra, S.; Holone, M.K.; Colomo-Palacios, R. A machine learning-based intrusion detection for detecting internet of things network attacks. Alex. Eng. J. 2022, 61, 9395–9409. [Google Scholar] [CrossRef]
- Seth, S.; Singh, G.; Kaur Chahal, K. A novel time efficient learning-based approach for smart intrusion detection system. J. Big Data 2021, 8, 111. [Google Scholar]
- Ding, H.; Chen, L.; Dong, L.; Fu, Z.; Cui, X. Imbalanced data classification: A KNN and generative adversarial networks-based hybrid approach for intrusion detection. Future Gener. Comput. Syst. 2022, 131, 240–254. [Google Scholar]
- Dini, P.; Saponara, S. Analysis, design, and comparison of machine-learning techniques for networking intrusion detection. Designs 2021, 5, 9. [Google Scholar] [CrossRef]
- Hnamte, V.; Balram, G.; Priyanka, V.; Kolluru, V. Implementation of Naive Bayes Classifier for Reducing DDoS Attacks in IoT Networks. J. Algebr. Stat. 2022, 13, 2749–2757. [Google Scholar]
- Onah, J.O.; Abdullahi, S.M.; Abdullahi, M.; Hassan, I.H.; Al-Ghusham, A. Genetic Algorithm based feature selection and Naïve Bayes for anomaly detection in fog computing environment. Mach. Learn. Appl. 2021, 6, 100156. [Google Scholar]
- Baniasadi, S.; Rostami, O.; Martín, D.; Kaveh, M. A novel deep supervised learning-based approach for intrusion detection in IoT systems. Sensors 2022, 22, 4459. [Google Scholar] [CrossRef] [PubMed]
- Naveed, M.; Arif, F.; Usman, S.M.; Anwar, A.; Hadjouni, M.; Elmannai, H.; Hussain, S.; Ullah, S.S.; Umar, F. A Deep Learning-Based Framework for Feature Extraction and Classification of Intrusion Detection in Networks. Wirel. Commun. Mob. Comput. 2022, 2022, 2215852. [Google Scholar]
- Ponmalar, A.; Dhanakoti, V. An intrusion detection approach using ensemble support vector machine based chaos game optimization algorithm in big data platform. Appl. Soft Comput. 2022, 116, 108295. [Google Scholar]
- Ullah, I.; Mahmoud, Q.H. Design and development of a deep learning-based model for anomaly detection in IoT networks. IEEE Access 2021, 9, 103906–103926. [Google Scholar]
- Hnamte, V.; Hussain, J. DCNNBiLSTM: An Efficient Hybrid Deep Learning-Based Intrusion Detection System. Telemat. Inform. Rep. 2023, 10, 100053. [Google Scholar]
- Talukder, M.A.; Hasan, K.F.; Islam, M.M.; Uddin, M.A.; Akhter, A.; Yousuf, M.A.; Alharbi, F.; Moni, M.A. A dependable hybrid machine learning model for network intrusion detection. J. Inf. Secur. Appl. 2023, 72, 103405. [Google Scholar]
- Balyan, A.K.; Ahuja, S.; Lilhore, U.K.; Sharma, S.K.; Manoharan, P.; Algarni, A.D.; Elmannai, H.; Raahemifar, K. A hybrid intrusion detection model using ega-pso and improved random forest method. Sensors 2022, 22, 5986. [Google Scholar] [CrossRef]
- Akshay Kumaar, M.; Samiayya, D.; Vincent, P.; Srinivasan, K.; Chang, C.Y.; Ganesh, H. A Hybrid Framework for Intrusion Detection in Healthcare Systems Using Deep Learning. Front. Public Health 2022, 9, 824898. [Google Scholar]
- Patil, S.; Varadarajan, V.; Mazhar, S.M.; Sahibzada, A.; Ahmed, N.; Sinha, O.; Kumar, S.; Shaw, K.; Kotecha, K. Explainable artificial intelligence for intrusion detection system. Electronics 2022, 11, 3079. [Google Scholar] [CrossRef]
- Rincy N, T.; Gupta, R. Design and development of an efficient network intrusion detection system using machine learning techniques. Wirel. Commun. Mob. Comput. 2021, 2021, 9974270. [Google Scholar]
- Dutta, V.; Choraś, M.; Kozik, R.; Pawlicki, M. Hybrid model for improving the classification effectiveness of network intrusion detection. In Proceedings of the 13th International Conference on Computational Intelligence in Security for Information Systems (CISIS 2020), Burgos, Spain, 24–26 June 2020; Springer: Berlin/Heidelberg, Germany, 2021; pp. 405–414. [Google Scholar]
- Liu, C.; Gu, Z.; Wang, J. A hybrid intrusion detection system based on scalable K-Means+ random forest and deep learning. IEEE Access 2021, 9, 75729–75740. [Google Scholar]
- Aldallal, A.; Alisa, F. Effective intrusion detection system to secure data in cloud using machine learning. Symmetry 2021, 13, 2306. [Google Scholar] [CrossRef]
- Elsayed, R.A.; Hamada, R.A.; Abdalla, M.I.; Elsaid, S.A. Securing IoT and SDN systems using deep-learning based automatic intrusion detection. Ain Shams Eng. J. 2023, 14, 102211. [Google Scholar]
- Chaganti, R.; Suliman, W.; Ravi, V.; Dua, A. Deep Learning Approach for SDN-Enabled Intrusion Detection System in IoT Networks. Information 2023, 14, 41. [Google Scholar] [CrossRef]
- Alzahrani, A.O.; Alenazi, M.J. Designing a network intrusion detection system based on machine learning for software defined networks. Future Internet 2021, 13, 111. [Google Scholar] [CrossRef]
- Javeed, D.; Gao, T.; Khan, M.T.; Ahmad, I. A hybrid deep learning-driven SDN enabled mechanism for secure communication in Internet of Things (IoT). Sensors 2021, 21, 4884. [Google Scholar] [CrossRef]
- Perez-Diaz, J.A.; Valdovinos, I.A.; Choo, K.K.R.; Zhu, D. A flexible SDN-based architecture for identifying and mitigating low-rate DDoS attacks using machine learning. IEEE Access 2020, 8, 155859–155872. [Google Scholar]
- Alharbi, A.; Alsubhi, K. Botnet detection approach using graph-based machine learning. IEEE Access 2021, 9, 99166–99180. [Google Scholar]
- Wang, X.; Zhu, T.; Xia, M.; Liu, Y.; Wang, Y.; Wang, X.; Zhuang, L.; Zhong, D.; Weng, S.; Zhu, J.; et al. Predicting the Prognosis of Patients in the Coronary Care Unit via Machine Learning Using XGBoost. Front. Front. Cardiovasc. Med. 2021, 9, 1–13. [Google Scholar]
- Urrea, C.; Benítez, D. Software-defined networking solutions, architecture and controllers for the industrial internet of things: A review. Sensors 2021, 21, 6585. [Google Scholar] [CrossRef] [PubMed]
- Shetabi, M.; Akbari, A. SAHAR: A control plane architecture for high available software-defined networks. Int. J. Commun. Netw. Distrib. Syst. 2020, 24, 409–440. [Google Scholar]
- Valdovinos, I.A.; Pérez-Díaz, J.A.; Choo, K.K.R.; Botero, J.F. Emerging DDoS attack detection and mitigation strategies in software-defined networks: Taxonomy, challenges and future directions. J. Netw. Comput. Appl. 2021, 187, 103093. [Google Scholar]
- Ahmad, S.; Mir, A.H. Scalability, consistency, reliability and security in SDN controllers: A survey of diverse SDN controllers. J. Netw. Syst. Manag. 2021, 29, 9. [Google Scholar]
- Khan, K.; Mehmood, A.; Khan, S.; Khan, M.A.; Iqbal, Z.; Mashwani, W.K. A survey on intrusion detection and prevention in wireless ad-hoc networks. J. Syst. Archit. 2020, 105, 101701. [Google Scholar]
- Chen, S.; Wu, Z.; Christofides, P.D. Cyber-security of centralized, decentralized, and distributed control-detector architectures for nonlinear processes. Chem. Eng. Res. Des. 2021, 165, 25–39. [Google Scholar]
- Helmy, A.; Nayak, A. Centralized vs. decentralized bandwidth allocation for supporting green fog integration in next-generation optical access networks. IEEE Commun. Mag. 2020, 58, 33–39. [Google Scholar]
- Louk, M.H.L.; Tama, B.A. Tree-Based Classifier Ensembles for PE Malware Analysis: A Performance Revisit. Algorithms 2022, 15, 332. [Google Scholar] [CrossRef]
- Qazi, E.U.H.; Faheem, M.H.; Zia, T. HDLNIDS: Hybrid Deep-Learning-Based Network Intrusion Detection System. Appl. Sci. 2023, 13, 4921. [Google Scholar] [CrossRef]
- Hassan, I.H.; Abdullahi, M.; Aliyu, M.M.; Yusuf, S.A.; Abdulrahim, A. An improved binary manta ray foraging optimization algorithm based feature selection and random forest classifier for network intrusion detection. Intell. Syst. Appl. 2022, 16, 200114. [Google Scholar]
- Killamsetty, K.; Sivasubramanian, D.; Ramakrishnan, G.; Iyer, R. Glister: Generalization based data subset selection for efficient and robust learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 8110–8118. [Google Scholar]
- Pudjihartono, N.; Fadason, T.; Kempa-Liehr, A.W.; O’Sullivan, J.M. A review of feature selection methods for machine learning-based disease risk prediction. Front. Bioinform. 2022, 2, 927312. [Google Scholar]
- Izquierdo, C.; Casas, G.; Martin-Isla, C.; Campello, V.M.; Guala, A.; Gkontra, P.; Rodríguez-Palomares, J.F.; Lekadir, K. Radiomics-based classification of left ventricular non-compaction, hypertrophic cardiomyopathy, and dilated cardiomyopathy in cardiovascular magnetic resonance. Front. Cardiovasc. Med. 2021, 8, 764312. [Google Scholar]
- Brownlee, J. Data Preparation for Machine Learning: Data Cleaning, Feature Selection, and Data Transforms in Python; Machine Learning Mastery: Melbourne, Australia, 2020. [Google Scholar]
- Zhang, Y.; Wang, H.; Chen, W.; Zeng, J.; Zhang, L.; Wang, H.; Weinan, E. DP-GEN: A concurrent learning platform for the generation of reliable deep learning based potential energy models. Comput. Phys. Commun. 2020, 253, 107206. [Google Scholar]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable ai: A review of machine learning interpretability methods. Entropy 2020, 23, 18. [Google Scholar] [CrossRef] [PubMed]
- Verma, R.; Nagar, V.; Mahapatra, S. Introduction to supervised learning. In Data Analytics in Bioinformatics: A Machine Learning Perspective; John Wiley & Sons: Hoboken, NJ, USA, 2021; pp. 1–34. [Google Scholar]
- Ren, J.; Zhang, M.; Yu, C.; Liu, Z. Balanced mse for imbalanced visual regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7926–7935. [Google Scholar]
- Vázquez, F.I.; Hartl, A.; Zseby, T.; Zimek, A. Anomaly detection in streaming data: A comparison and evaluation study. Expert Syst. Appl. 2023, 233, 120994. [Google Scholar]
- Mohr, F.; van Rijn, J.N. Learning Curves for Decision Making in Supervised Machine Learning—A Survey. arXiv 2022, arXiv:2201.12150. [Google Scholar]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2022. [Google Scholar]
- Hamida, S.; El Gannour, O.; Cherradi, B.; Ouajji, H.; Raihani, A. Optimization of machine learning algorithms hyper-parameters for improving the prediction of patients infected with COVID-19. In Proceedings of the 2020 IEEE 2nd International Conference on Electronics, Control, Optimization and Computer Science (ICECOCS), Kenitra, Morocco, 2–3 December 2020; pp. 1–6. [Google Scholar]
- Yu, T.; Zhu, H. Hyper-parameter optimization: A review of algorithms and applications. arXiv 2020, arXiv:2003.05689. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ML Family | Description | Algorithms |
|---|---|---|
| Information-based learning | Building models based on information theory concepts. | Random Tree, Random Forest, J48, HoeffdingTree, REPTree, and Decision Stump |
| Similarity-based learning | Comparing known and unknown things or measuring the degree of similarity between past and future events. | k-NN and k-means (Simple k-means, Canopy, and Hierarchical) |
| Probability-based learning | Developing a model based on measuring the probability of an event occurring. | Naïve Bayes |
| Error-based learning | Building a model that minimizes the total error by using a set of training instances. | SVM, Logistic Regression, Perceptron, Winnow, and deep learning |
| ML Family | Advantages | Disadvantages |
|---|---|---|
| Information-based learning |
|
|
| Similarity-Based learning |
|
|
| Probability-based learning |
|
|
| Error-based learning |
|
|
| Ref. | Year | Domain | Method | Algorithms | Dataset | Feat. Sel. | Acc. | Limitations |
|---|---|---|---|---|---|---|---|---|
| Attou et al. [22] | 2023 | CC | Information | RF | BoT-IoT | Graphic Vis. | 99.99% | Only Bot-IoT/NSL-KDD datasets. No cloud model examination. No ML algorithm comparison |
| Hnamte and Hussain [33] | 2023 | N/A | Hybrid | CNN, BiLSTM, and DNN | CICIDS2018 | CNN | 100% | Substantial training time required. High computational costs. Increased attack complexity. |
| Chaganti et al. [43] | 2023 | SDN-IoT | SDN | LSTM | SDN-IoT | t-SNE | 97.1% | Needs large number of labeled data for real-time attack detection. |
| Talukder et al. [34] | 2023 | N/A | Hybrid | RF | CIC-MalMem-2022 | XGBoost | 100% | Does not consider environmental factors like network traffic. |
| Saheed et al. [23] | 2022 | IoT | Information | XGBoost | UNSW-NB15 | PCA | 99.99% | Uses only one dataset. |
| Baniasadi et al. [29] | 2022 | IoT | Error | DCNN | BoT-IoT | NSBPSO | 98.86% | High computational costs. IoT systems lack data. |
| Balyan et al. [35] | 2022 | N/A | Hybrid | IRF | NSL-KDD | EGA-PSO | 99.97% | Uses only one dataset. |
| Naveed et al. [30] | 2022 | Network Traffic | Error | DNN | NSL-KDD | Chi-squared, ANOVA, and PCA | 99.73% | Data imbalance may cause incorrect classification. |
| Ding et al. [25] | 2022 | N/A | Similarity | KNN | CIC-IDS-2017 | N/A | 95.86% | High computational impact on efficiency and scalability. |
| Hnamte et al. [27] | 2022 | IoT | Probability | Naïve Bayes | IoT Sentinel | DSC | 89.7% | Scalability, robustness, and overhead concerns. Needs large number of labeled data. |
| Ponmalar and Dhanakoti [31] | 2022 | Big Data | Error | SVM | UNSW-NB15 | CGO | 96.29% | Requires costly labeled data acquisition. |
| Akshay Kumaar et al. [36] | 2022 | N/A | Hybrid | ImmuneNet | CIC Bell DNS 2021 | All Features | 99.19% | Model requires significant time for learning. |
| Patil et al. [37] | 2022 | N/A | Hybrid | Voting | CIC-IDS-2017 | Correlation Heatmap | 96.25% | Single-dataset limitations. |
| Dini and Saponara [26] | 2021 | LAN | Similarity | KNN | LAN traffic (USAF) | MDS | 99.57% | Limited ML model comparison. |
| Rincy N and Gupta [38] | 2021 | Network | Hybrid | NB, RF, J48, and CFS | NSL-KDD20% | CAPPER | 99.90% | Untested on recent attack datasets. |
| Dutta et al. [39] | 2021 | N/A | Hybrid | DNN | UNSW-NB15 | CAE | 99.979% | Single dataset. High computational cost. |
| Ullah and Mahmoud [32] | 2021 | IoT | Error | CNN | MQTT-IoT-IDS2020 | RFE | 99.99% | Latency/processing power challenges. |
| Alzahrani and Alenazi [44] | 2021 | SDN | SDN | XGBoost | NSL-KDD | N/A | 95.95% | Single dataset used. |
| Javeed et al. [45] | 2021 | SDN-IoT | SDN | Cu-BLSTM and Cu-DNNGRU | CIC-IDS-2018 | N/A | 99.87% | Single-dataset limitation. |
| Liu et al. [40] | 2021 | N/A | Hybrid | K-means, RF, LSTM, and CNN | CIC-IDS-2017 | N/A | 99.91% | Lacks recent attack data. |
| Aldallal and Alisa [41] | 2021 | CC | Hybrid | SVM | KDD CUP 99 | GA | 99.3% | Outdated dataset used. |
| Onah et al. [28] | 2021 | Fog | Probability | Naïve Bayes | NSL-KDD | GA Wrapper | 99.73% | Dataset recency issues. |
| Seth et al. [24] | 2021 | IoT | Information | LightGBM | CIC-IDS-2018 | RF and PCA | 97.73% | Single-dataset limitation. |
| Perez-Diaz et al. [46] | 2020 | SDN | SDN | MLP | CIC DoS | N/A | 95% | Dataset recency issues. |
| Network Type | Advantages | Disadvantages |
|---|---|---|
| Centralized |
|
|
| Decentralized |
|
|
| Dataset | Number of Samples | Classes |
|---|---|---|
| CIC-MalMem-2022 | 58,596 | Benign, Trojan horse, Ransomware, and Spyware |
| CIC-IDS-2018 | 16,232,943 | Benign, botnet, DDoS, brute force, DoS, Infiltration, Web Attack, brute force SSH, and Heartbleed |
| CIC-IDS-2017 | 2,830,743 | Benign, Infiltration, port scanning, DoS, Web Attack, brute force, and bots |
| Index | Feature Name | Reason |
|---|---|---|
| 1 | _bwd_psh_flags | Contains constant values |
| 2 | _bwd_urg_flags | Contains constant values |
| 3 | fwd_avg_bytes_bulk | Contains constant values |
| 4 | _fwd_avg_packets_bulk | Contains constant values |
| 5 | _fwd_avg_bulk_rate | Contains constant values |
| 6 | _bwd_avg_bytes_bulk | Contains constant values |
| 7 | _bwd_avg_packets_bulk | Contains constant values |
| 8 | _bwd_avg_bulk_rate | Contains constant values |
| 9 | _fwd_urg_flags | Contains constant values |
| 10 | _cwe_flag_count | Contains constant values |
| 11 | _rst_flag_count | Contains constant values |
| 12 | _ece_flag_count | Contains constant values |
| Class/Prediction | Benign | Malicious |
|---|---|---|
| Benign | TN | FP |
| Malicious | FN | TP |
| ML Algorithm | Hyperparameter | Values |
|---|---|---|
| AdaBoost | n_estimators | 80, 100, 150, 200, 250 |
| Voting | voting | Hard, soft |
| Stacking | passthrough | True, False |
| SVM | Regularization parameter (C) | 0.1, 0.9, 10.0, 50.0, 100.0 |
| RF | max_depth | 2, 3, 5, 10, 20 |
| XGBoost | Learning rate | 0.5, 0.7, 1, 2, 10 |
| Adversarial Attack | Accuracy | Test Time |
|---|---|---|
| DoS/DDoS | 99.61% | 0.02 s |
| Brute force | 99.57% | 0.03 s |
| Port scanning | 99.63% | 0.02 s |
| Malware | 99.63% | 0.02 s |
| Adversarial Attacks | Accuracy | Test Time |
|---|---|---|
| Combined data | 99.75% | 0.03 s |
| Algorithm | Accuracy | Precision | Recall | F1-Score | Test Time |
|---|---|---|---|---|---|
| AdaBoost | 99.94% | 99.96% | 99.93% | 99.94% | 0.10 s |
| Voting | 99.96% | 99.98% | 99.94% | 99.96% | 2.27 s |
| Stacking | 99.98% | 99.98% | 99.98% | 99.98% | 2.90 s |
| SVM | 99.93% | 99.89% | 99.98% | 99.93% | 0.44 s |
| RF | 99.98% | 99.98% | 99.98% | 99.98% | 0.11 s |
| XGBoost | 99.96% | 99.98% | 99.94% | 99.96% | 0.01 s |
| Algorithm | Accuracy | Precision | Recall | F1-Score | Test Time |
|---|---|---|---|---|---|
| AdaBoost | 99.11% | 99.37% | 97.86% | 98.61% | 0.08 s |
| Voting | 99.58% | 100% | 98.71% | 99.35% | 2.20 s |
| Stacking | 99.61% | 99.66% | 99.13% | 99.40% | 1.64 s |
| SVM | 97.41% | 97.96% | 93.91% | 95.89% | 1.56 s |
| RF | 99.64% | 99.90% | 98.99% | 99.44% | 0.10 s |
| XGBoost | 99.73% | 99.95% | 99.23% | 99.59% | 0.03 s |
| Algorithm | Accuracy | Precision | Recall | F1-Score | Test Time |
|---|---|---|---|---|---|
| AdaBoost | 98.64% | 98.18% | 98.95% | 98.56% | 0.11 s |
| Voting | 99.31% | 98.91% | 99.65% | 99.28% | 4.66 s |
| Stacking | 99.86% | 99.66% | 99.74% | 99.85% | 2.93 s |
| SVM | 94.04% | 89.39% | 99.14% | 94.01% | 9.81 s |
| RF | 99.40% | 98.96% | 98.96% | 99.36% | 0.18 s |
| XGBoost | 99.84% | 99.88% | 99.79% | 99.84% | 0.04 s |
| Author | Feature Selection | Algorithm | Selected Features | Accuracy | Test Time |
|---|---|---|---|---|---|
| [34] | XGBoost | RF | 20 | 100% | 0.09 s |
| This study | SelectKBest | XGBoost | 25 | 99.96% | 0.01 s |
| Author | Feature Selection | Algorithm | Selected Features | Accuracy | Test Time |
|---|---|---|---|---|---|
| [24] | RF and PCA | LightGBM | 37 | 97.73% | 17.94 s |
| This study | VarianceThreshold | XGBoost | 72 | 99.73% | 0.03 s |
| Author | Feature Selection | Algorithm | Selected Features | Accuracy | Test Time |
|---|---|---|---|---|---|
| [37] | Correlation Heatmap | Voting classifier | 10 | 96.25% | 15.86 s |
| This study | SelectKBest | XGBoost | 30 | 99.84% | 0.04 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alromaihi, N.; Rouached, M.; Akremi, A. Design and Analysis of an Effective Architecture for Machine Learning Based Intrusion Detection Systems. Network 2025, 5, 13. https://doi.org/10.3390/network5020013
Alromaihi N, Rouached M, Akremi A. Design and Analysis of an Effective Architecture for Machine Learning Based Intrusion Detection Systems. Network. 2025; 5(2):13. https://doi.org/10.3390/network5020013
Chicago/Turabian StyleAlromaihi, Noora, Mohsen Rouached, and Aymen Akremi. 2025. "Design and Analysis of an Effective Architecture for Machine Learning Based Intrusion Detection Systems" Network 5, no. 2: 13. https://doi.org/10.3390/network5020013
APA StyleAlromaihi, N., Rouached, M., & Akremi, A. (2025). Design and Analysis of an Effective Architecture for Machine Learning Based Intrusion Detection Systems. Network, 5(2), 13. https://doi.org/10.3390/network5020013