

Age of Information Minimization in Vehicular Edge Computing Networks: A Mask-Assisted Hybrid PPO-Based Method




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- To fully utilize vehicular computing resources, we consider a VEC network in which vehicles can offload computational tasks to the RSU as well as vehicles with idle computational resources. To effectively optimize the characteristic of information timeliness, an optimization problem that aims to minimize the Aol by jointly optimizing task offloading ratios, service node selection strategies, and subcarrier resource allocation schemes is formulated.
- Due to the time-varying channel and the coupling of continuous and discrete optimization variables, a mask-assisted hybrid proximal policy optimization (MHPPO)-based DRL method is proposed, which the mixed action space is designed to handle the challenge coupling of the continuous and discrete optimization variables. Moreover, within the MHPPO method, an action masking mechanism is employed to filter the invalid actions.
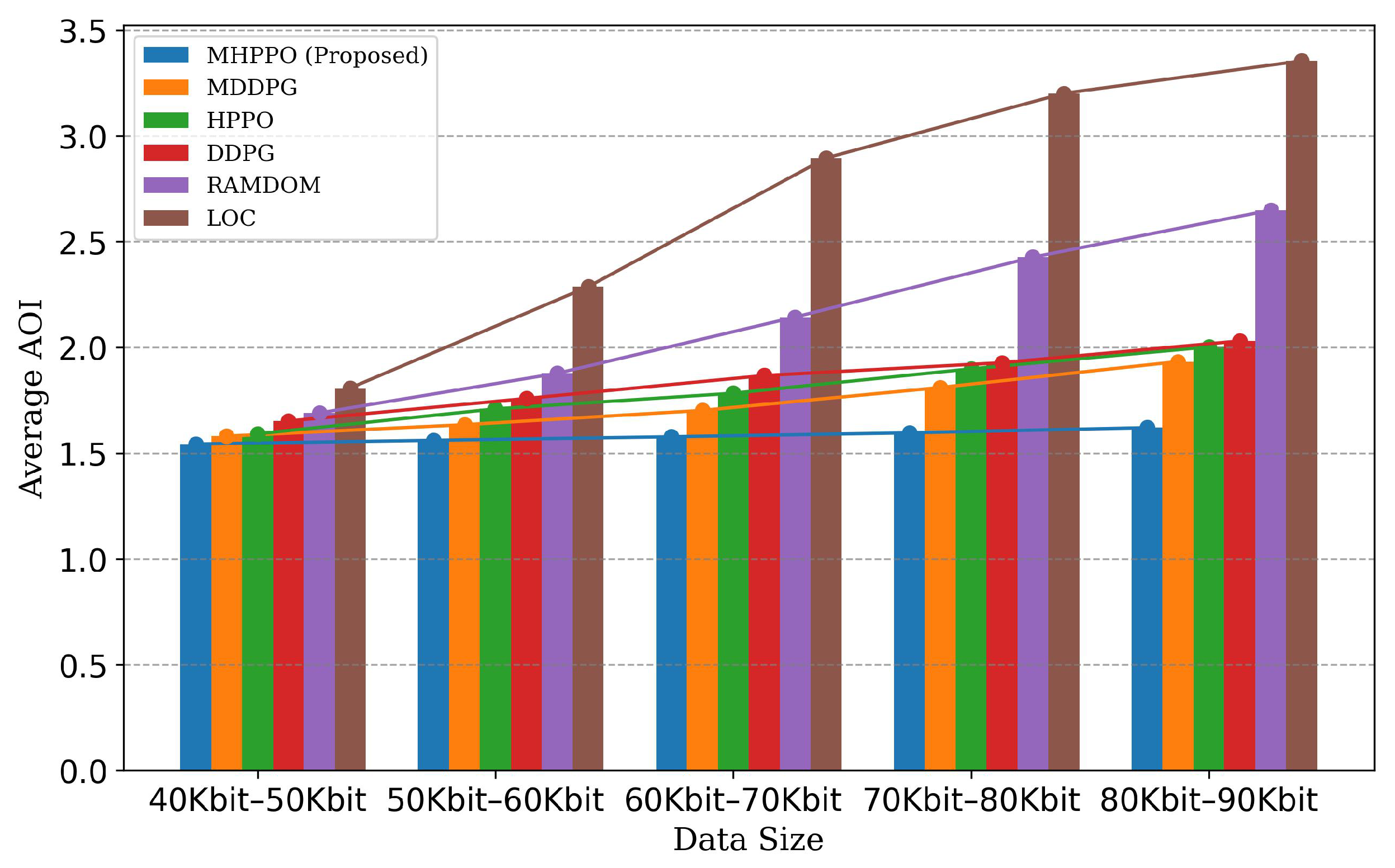
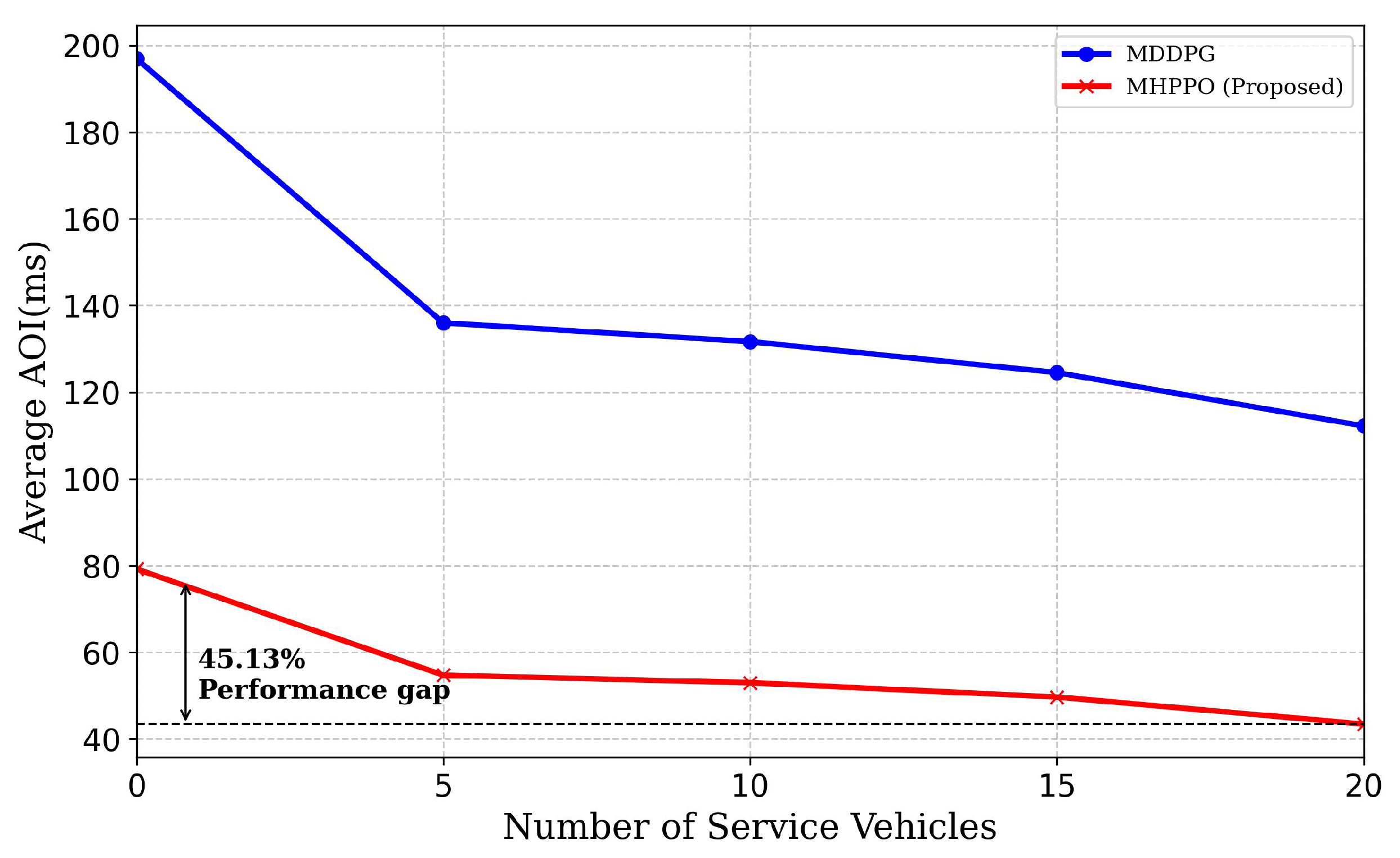
- Simulation results show that the proposed MHPPO method can achieve much lower average AoI and outperforms other benchmark methods. Specifically, the proposed MHPPO method reduces AoI by approximately 28.9% compared with the HPPO method, and by about 23% and 38.2% compared with the mask-assisted deep deterministic policy gradient (MDDPG) and the conventional DDPG method.
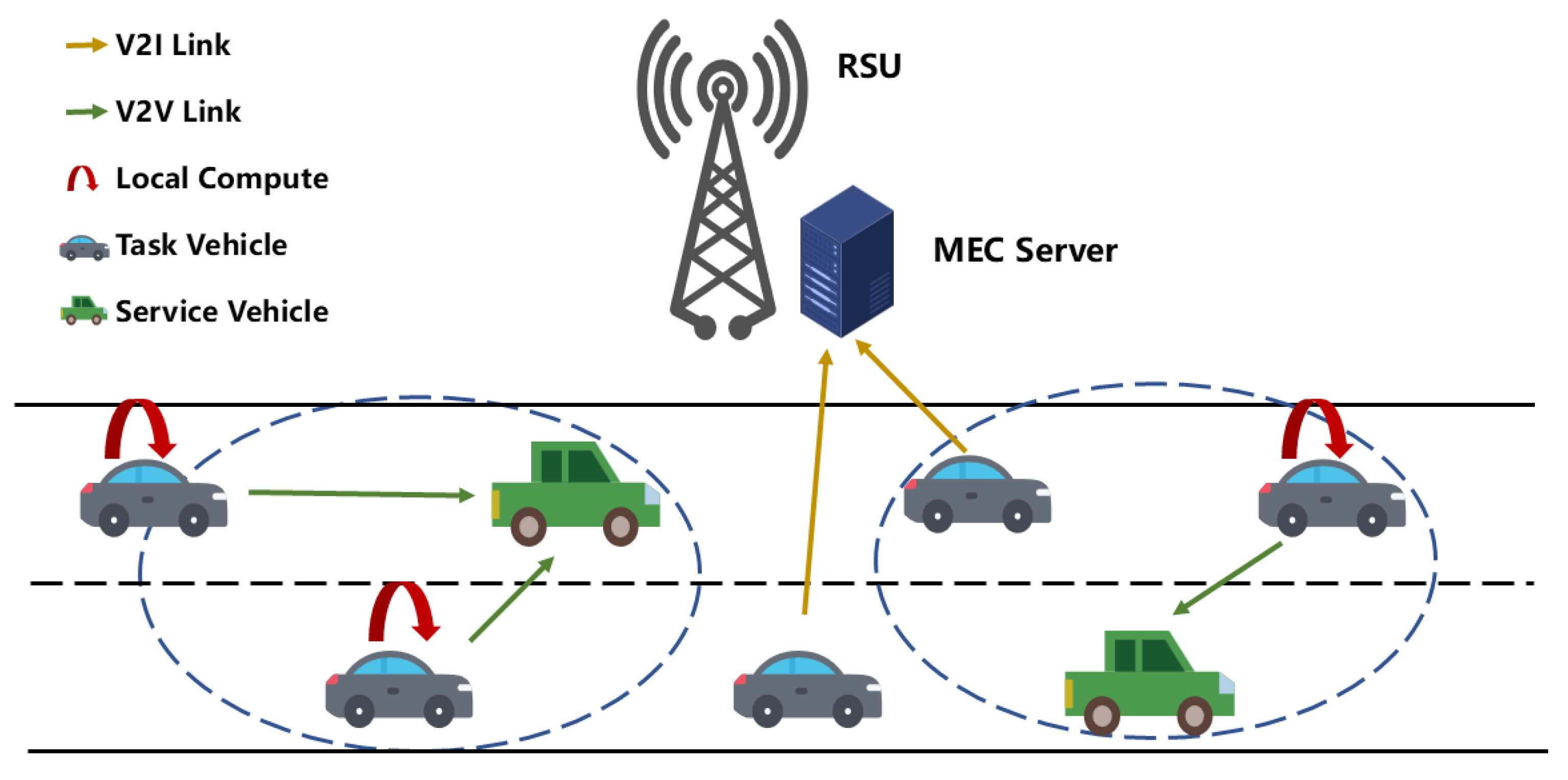
2. System Model
2.1. Communication Model
2.2. Computation Model
2.3. AoI Model
3. Problem Formulation
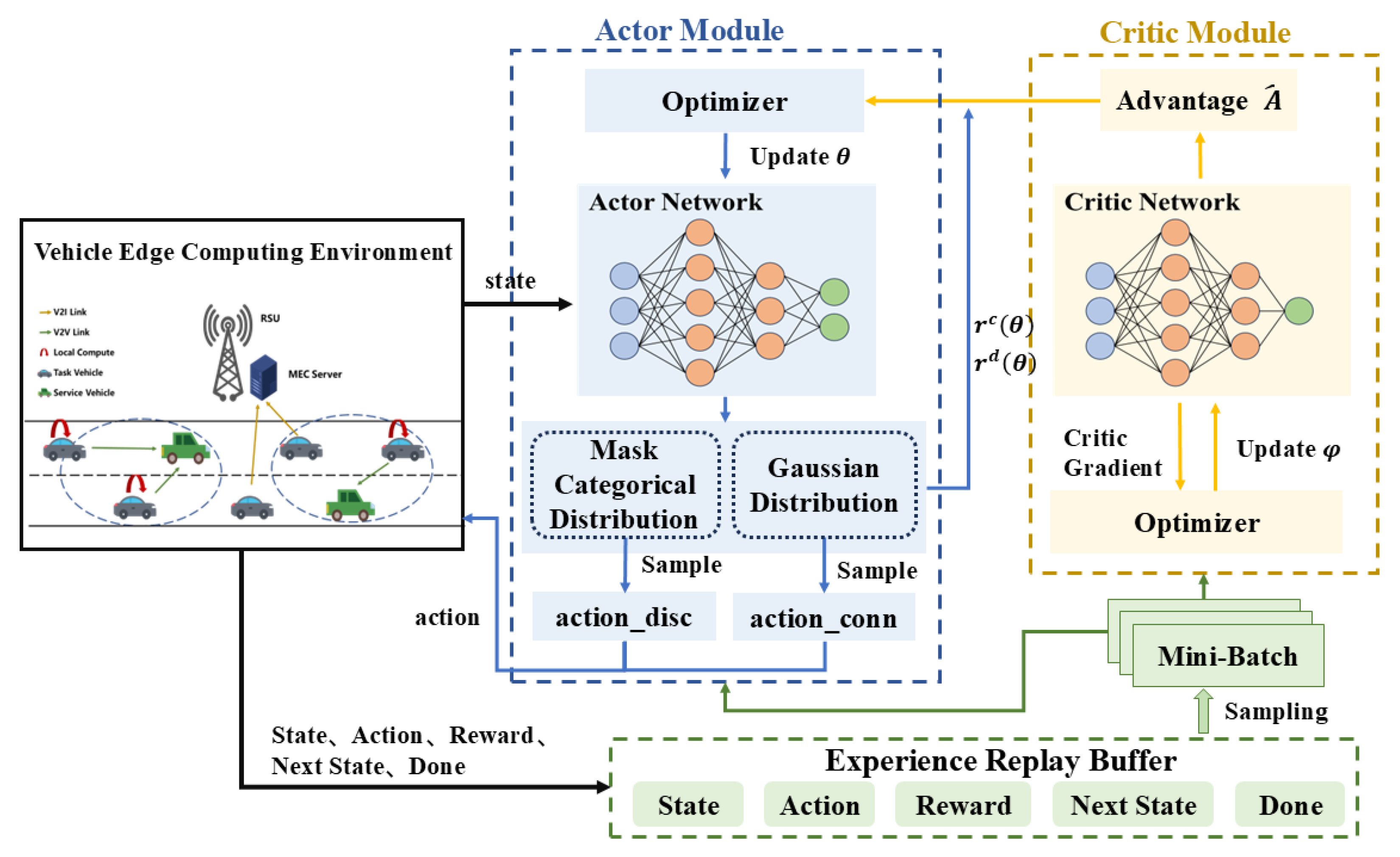
4. Proposed PPO-Based Method
4.1. MDP Formulation
4.2. MHPPO-Based Solution Strategy
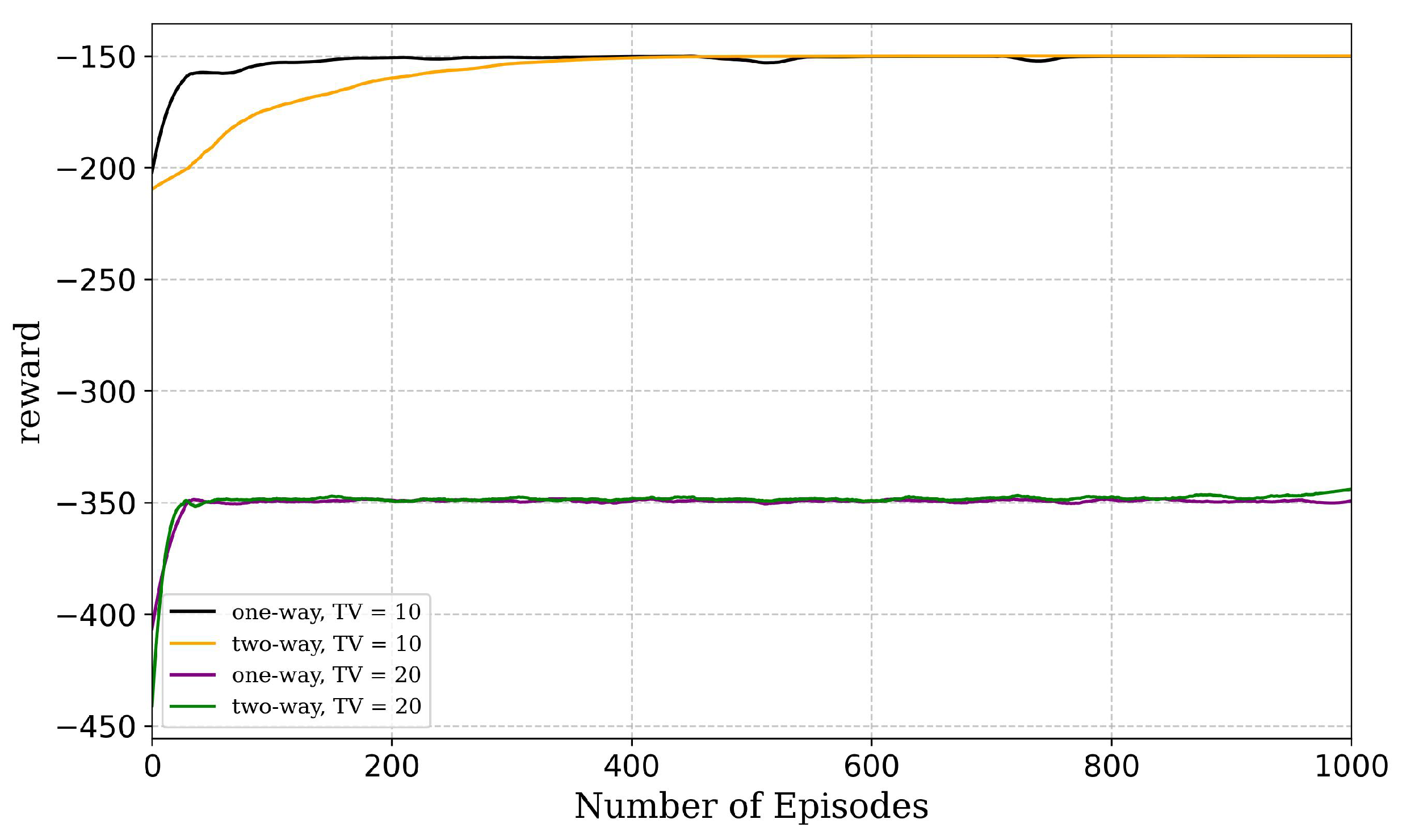
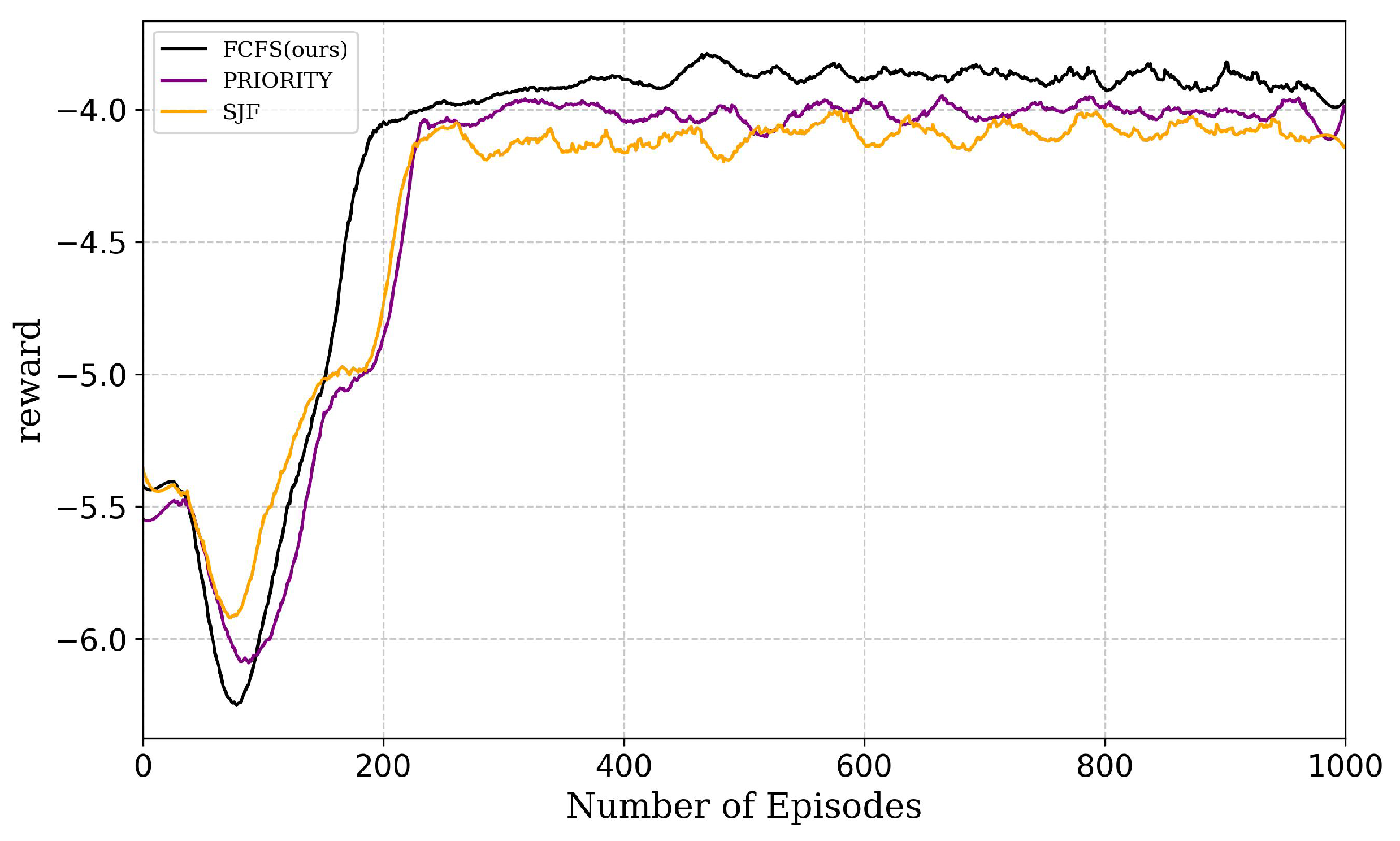
5. Results and Discussion
5.1. Simulation Settings
5.2. Simulation Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xu, Y.; Gui, G.; Gacanin, H.; Adachi, F. A Survey on Resource Allocation for 5G Heterogeneous Networks: Current Research, Future Trends, and Challenges. IEEE Commun. Surv. Tutor. 2021, 23, 668–695. [Google Scholar] [CrossRef]
- Pham, X.Q.; Nguyen, T.D.; Nguyen, V.; Huh, E.N. Joint node selection and resource allocation for task offloading in scalable vehicle-assisted multi-access edge computing. Symmetry 2019, 11, 58. [Google Scholar] [CrossRef]
- Cui, T.; Hu, Y.; Shen, B.; Chen, Q. Task offloading based on lyapunov optimization for mec-assisted vehicular platooning networks. Sensors 2019, 19, 4974. [Google Scholar] [CrossRef]
- Bréhon-Grataloup, L.; Kacimi, R.; Beylot, A.L. Mobile edge computing for V2X architectures and applications: A survey. Comput. Netw. 2022, 206, 108797. [Google Scholar] [CrossRef]
- Shi, J.; Du, J.; Shen, Y.; Wang, J.; Yuan, J.; Han, Z. DRL-Based V2V Computation Offloading for Blockchain-Enabled Vehicular Networks. IEEE Trans. Mob. Comput. 2023, 22, 3882–3897. [Google Scholar] [CrossRef]
- Zeng, F.; Zhang, Z.; Wu, J. Task offloading delay minimization in vehicular edge computing based on vehicle trajectory prediction. Digit. Commun. Netw. 2024, in press. [CrossRef]
- Nie, X.; Yan, Y.; Zhou, T.; Chen, X.; Zhang, D. A delay-optimal task scheduling strategy for vehicle edge computing based on the multi-agent deep reinforcement learning approach. Electronics 2023, 12, 1655. [Google Scholar] [CrossRef]
- Lv, W.; Yang, P.; Zheng, T.; Yi, B.; Ding, Y.; Wang, Q.; Deng, M. Energy consumption and qos-aware co-offloading for vehicular edge computing. IEEE Internet Things J. 2022, 10, 5214–5225. [Google Scholar] [CrossRef]
- Cho, H.; Cui, Y.; Lee, J. Energy-efficient cooperative offloading for edge computing-enabled vehicular networks. IEEE Trans. Wirel. Commun. 2022, 21, 10709–10723. [Google Scholar] [CrossRef]
- Liu, Z.; Jia, Z.; Pang, X. DRL-based hybrid task offloading and resource allocation in vehicular networks. Electronics 2023, 12, 4392. [Google Scholar] [CrossRef]
- Li, P.; Xiao, Z.; Wang, X.; Huang, K.; Huang, Y.; Gao, H. EPtask: Deep Reinforcement Learning Based Energy-Efficient and Priority-Aware Task Scheduling for Dynamic Vehicular Edge Computing. IEEE Trans. Intell. Veh. 2024, 9, 1830–1846. [Google Scholar] [CrossRef]
- Dai, Y.; Xu, D.; Maharjan, S.; Zhang, Y. Joint Load Balancing and Offloading in Vehicular Edge Computing and Networks. IEEE Internet Things J. 2019, 6, 4377–4387. [Google Scholar] [CrossRef]
- Sun, J.; Gu, Q.; Zheng, T.; Dong, P.; Valera, A.; Qin, Y. Joint optimization of computation offloading and task scheduling in vehicular edge computing networks. IEEE Access 2020, 8, 10466–10477. [Google Scholar] [CrossRef]
- Feng, W.; Zhang, N.; Li, S.; Lin, S.; Ning, R.; Yang, S.; Gao, Y. Latency Minimization of Reverse Offloading in Vehicular Edge Computing. IEEE Trans. Veh. Technol. 2022, 71, 5343–5357. [Google Scholar] [CrossRef]
- Cong, Y.; Xue, K.; Wang, C.; Sun, W.; Sun, S.; Hu, F. Latency-Energy Joint Optimization for Task Offloading and Resource Allocation in MEC-Assisted Vehicular Networks. IEEE Trans. Veh. Technol. 2023, 72, 16369–16381. [Google Scholar] [CrossRef]
- Li, Y.; Li, L.; Fan, P. Mobility-Aware Computation Offloading and Resource Allocation for NOMA MEC in Vehicular Networks. IEEE Trans. Veh. Technol. 2024, 73, 11934–11948. [Google Scholar] [CrossRef]
- Nan, Z.; Zhou, S.; Jia, Y.; Niu, Z. Joint Task Offloading and Resource Allocation for Vehicular Edge Computing with Result Feedback Delay. IEEE Trans. Wirel. Commun. 2023, 22, 6547–6561. [Google Scholar] [CrossRef]
- Xia, Y.; Zhang, H.; Zhou, X.; Yuan, D. Location-Aware and Delay-Minimizing Task Offloading in Vehicular Edge Computing Networks. IEEE Trans. Veh. Technol. 2023, 72, 16266–16279. [Google Scholar] [CrossRef]
- Tang, Z.; Mou, F.; Lou, J.; Jia, W.; Wu, Y.; Zhao, W. Multi-User Layer-Aware Online Container Migration in Edge-Assisted Vehicular Networks. IEEE/ACM Trans. Netw. 2024, 32, 1807–1822. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, X.; Xu, Y.; Li, D.; Yuen, C.; Xue, Q. Partial Offloading and Resource Allocation for MEC-Assisted Vehicular Networks. IEEE Trans. Veh. Technol. 2024, 73, 1276–1288. [Google Scholar] [CrossRef]
- Fan, W.; Su, Y.; Liu, J.; Li, S.; Huang, W.; Wu, F.; Liu, Y. Joint Task Offloading and Resource Allocation for Vehicular Edge Computing Based on V2I and V2V Modes. IEEE Trans. Intell. Transp. Syst. 2023, 24, 4277–4292. [Google Scholar] [CrossRef]
- Huang, M.; Shen, Z.; Zhang, G. Joint Spectrum Sharing and V2V/V2I Task Offloading for Vehicular Edge Computing Networks Based on Coalition Formation Game. IEEE Trans. Intell. Transp. Syst. 2024, 25, 11918–11934. [Google Scholar] [CrossRef]
- Wu, C.; Huang, Z.; Zou, Y. Delay Constrained Hybrid Task Offloading of Internet of Vehicle: A Deep Reinforcement Learning Method. IEEE Access 2022, 10, 102778–102788. [Google Scholar] [CrossRef]
- Li, S.; Sun, W.; Ni, Q.; Sun, Y. Road Side Unit-Assisted Learning-Based Partial Task Offloading for Vehicular Edge Computing System. IEEE Trans. Veh. Technol. 2024, 73, 5546–5555. [Google Scholar] [CrossRef]
- Xue, J.; Yu, Q.; Wang, L.; Fan, C. Vehicle task offloading strategy based on DRL in communication and sensing scenarios. Ad Hoc Netw. 2024, 159, 103497. [Google Scholar] [CrossRef]
- Zhang, X.; Xiong, K.; Chen, W.; Fan, P.; Ai, B.; Ben Letaief, K. Minimizing AoI in High-Speed Railway Mobile Networks: DQN-Based Methods. IEEE Trans. Intell. Transp. Syst. 2024, 25, 20137–20150. [Google Scholar] [CrossRef]
- Ge, Y.; Xiong, K.; Wang, Q.; Ni, Q.; Fan, P.; Letaief, K.B. AoI-Minimal Power Adjustment in RF-EH-Powered Industrial IoT Networks: A Soft Actor-Critic-Based Method. IEEE Trans. Mob. Comput. 2024, 23, 8729–8741. [Google Scholar] [CrossRef]
- Shen, Y.; Luo, W.; Wang, S.; Huang, X. Average AoI minimization for data collection in UAV-enabled IoT backscatter communication systems with the finite blocklength regime. Ad Hoc Netw. 2023, 145, 103164. [Google Scholar] [CrossRef]
- Yiyang, G.; Ke, X.; Rui, D.; Yang, L.; Pingyi, F.; Gang, Q. Age of information based user scheduling and data assignment in multi-user mobile edge computing networks: An online algorithm. China Commun. 2024, 21, 153–165. [Google Scholar] [CrossRef]
- Ma, X.; Zhou, A.; Sun, Q.; Wang, S. Freshness-Aware Information Update and Computation Offloading in Mobile-Edge Computing. IEEE Internet Things J. 2021, 8, 13115–13125. [Google Scholar] [CrossRef]
- Narayanasamy, I.; Rajamanickam, V. A Cascaded Multi-Agent Reinforcement Learning-Based Resource Allocation for Cellular-V2X Vehicular Platooning Networks. Sensors 2024, 24, 5658. [Google Scholar] [CrossRef]
- Han, Z.; Yang, Y.; Wang, W.; Zhou, L.; Nguyen, T.N.; Su, C. Age Efficient Optimization in UAV-Aided VEC Network: A Game Theory Viewpoint. IEEE Trans. Intell. Transp. Syst. 2022, 23, 25287–25296. [Google Scholar] [CrossRef]
- Xiao, Y.; Lin, Z.; Cao, X.; Chen, Y.; Lu, X. AoI-Energy-Efficient Edge Caching in UAV-Assisted Vehicular Networks. IEEE Internet Things J. 2025, 12, 6764–6774. [Google Scholar] [CrossRef]
- Jiang, Y.; Liu, J.; Humar, I.; Chen, M.; AlQahtani, S.A.; Hossain, M.S. Age-of-Information-Based Computation Offloading and Transmission Scheduling in Mobile-Edge-Computing-Enabled IoT Networks. IEEE Internet Things J. 2023, 10, 19782–19794. [Google Scholar] [CrossRef]
- Liu, L.; Qin, X.; Zhang, Z.; Zhang, P. Joint Task Offloading and Resource Allocation for Obtaining Fresh Status Updates in Multi-Device MEC Systems. IEEE Access 2020, 8, 38248–38261. [Google Scholar] [CrossRef]
- Xiao, L.; Lin, Y.; Zhang, Y.; Li, J.; Shu, F. AoI-Aware Energy-Efficient Vehicular Edge Computing Using Multi-Agent Reinforcement Learning with Actor-Attention-Critic. In Proceedings of the 2024 IEEE 99th Vehicular Technology Conference (VTC2024-Spring), Singapore, 24–27 June 2024; pp. 1–6. [Google Scholar]
- Xiong, K.; Zhang, Y.; Fan, P.; Yang, H.C.; Zhou, X. Mobile Service Amount Based Link Scheduling for High-Mobility Cooperative Vehicular Networks. IEEE Trans. Veh. Technol. 2017, 66, 9521–9533. [Google Scholar] [CrossRef]
- Garcia, M.H. Castañeda and Molina-Galan, Alejandro and Boban, Mate and Gozalvez, Javier and Coll-Perales, Baldomero and Şahin, Taylan and Kousaridas, Apostolos A Tutorial on 5G NR V2X Communications. IEEE Commun. Surv. Tutor 2021, 23, 1972–2026. [Google Scholar] [CrossRef]
- Xiong, K.; Liu, Y.; Zhang, L.; Gao, B.; Cao, J.; Fan, P.; Letaief, K.B. Joint Optimization of Trajectory, Task Offloading, and CPU Control in UAV-Assisted Wireless Powered Fog Computing Networks. IEEE Trans. Green Commun. Netw. 2022, 6, 1833–1845. [Google Scholar] [CrossRef]
- Li, H.; Xiong, K.; Lu, Y.; Gao, B.; Fan, P.; Letaief, K.B. Distributed Design of Wireless Powered Fog Computing Networks with Binary Computation Offloading. IEEE Trans. Mobile Comput. 2023, 22, 2084–2099. [Google Scholar] [CrossRef]
- Meng, C.; Xiong, K.; Chen, W.; Gao, B.; Fan, P.; Letaief, K.B. Sum-Rate Maximization in STAR-RIS-Assisted RSMA Networks: A PPO-Based Algorithm. IEEE Internet Things J. 2024, 11, 5667–5680. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, X.; Zhang, Z.; Meng, C.; Dong, R.; Xiong, K.; Fan, P. Age of Information Minimization in Vehicular Edge Computing Networks: A Mask-Assisted Hybrid PPO-Based Method. Network 2025, 5, 12. https://doi.org/10.3390/network5020012
Qin X, Zhang Z, Meng C, Dong R, Xiong K, Fan P. Age of Information Minimization in Vehicular Edge Computing Networks: A Mask-Assisted Hybrid PPO-Based Method. Network. 2025; 5(2):12. https://doi.org/10.3390/network5020012
Chicago/Turabian StyleQin, Xiaoli, Zhifei Zhang, Chanyuan Meng, Rui Dong, Ke Xiong, and Pingyi Fan. 2025. "Age of Information Minimization in Vehicular Edge Computing Networks: A Mask-Assisted Hybrid PPO-Based Method" Network 5, no. 2: 12. https://doi.org/10.3390/network5020012
APA StyleQin, X., Zhang, Z., Meng, C., Dong, R., Xiong, K., & Fan, P. (2025). Age of Information Minimization in Vehicular Edge Computing Networks: A Mask-Assisted Hybrid PPO-Based Method. Network, 5(2), 12. https://doi.org/10.3390/network5020012