
A Deep Contextual Bandit-Based End-to-End Slice Provisioning Approach for Efficient Allocation of 5G Network Resources


Abstract
:1. Introduction
- A NS scenario is modeled as a Contextual Bandit problem, and an attempt is made to solve such a problem using a Deep Reinforcement Learning approach. Moreover, a network slicing agent (NSA) is developed and trained to perform slice creation for each Network Slice Request (NSR). For each NSR sent to the network, the agent is trained to select the best possible network slice from options. Accordingly, the state of the network determines the agent’s action and the reward it receives. Furthermore, the proposed work uses the Upper Confidence Bound (UCB) strategy to solve the exploration vs. exploitation dilemma in reinforcement learning, encouraging the agent to balance exploration and exploitation, resulting in more options for each NSR.
- Network theory is used to model the 5G network and its components. The modeling process is done through a graph-based approach that includes mapping, attribute definition, association, and path estimation of network nodes. The node degree and betweenness centrality, which are essential values for identifying appropriate nodes, are calculated for node selection. In addition, a link mapping method based on the Edmonds–Karp method to calculate the maximum flow is proposed.
- Network states are defined for the simulation as the basis for reward calculation. This work also considers the network’s current computing capability, bandwidth, node utilization, and the length of every candidate network slice as Reward Influencing Factors (RIF). Additionally, weights are assigned to each RIF to determine how they influence the reward for each action based on the current state of the network.
2. Review of Related Works
2.1. Resource Allocation in 5G Networks
2.2. Network Slicing Solutions in 5G Networks
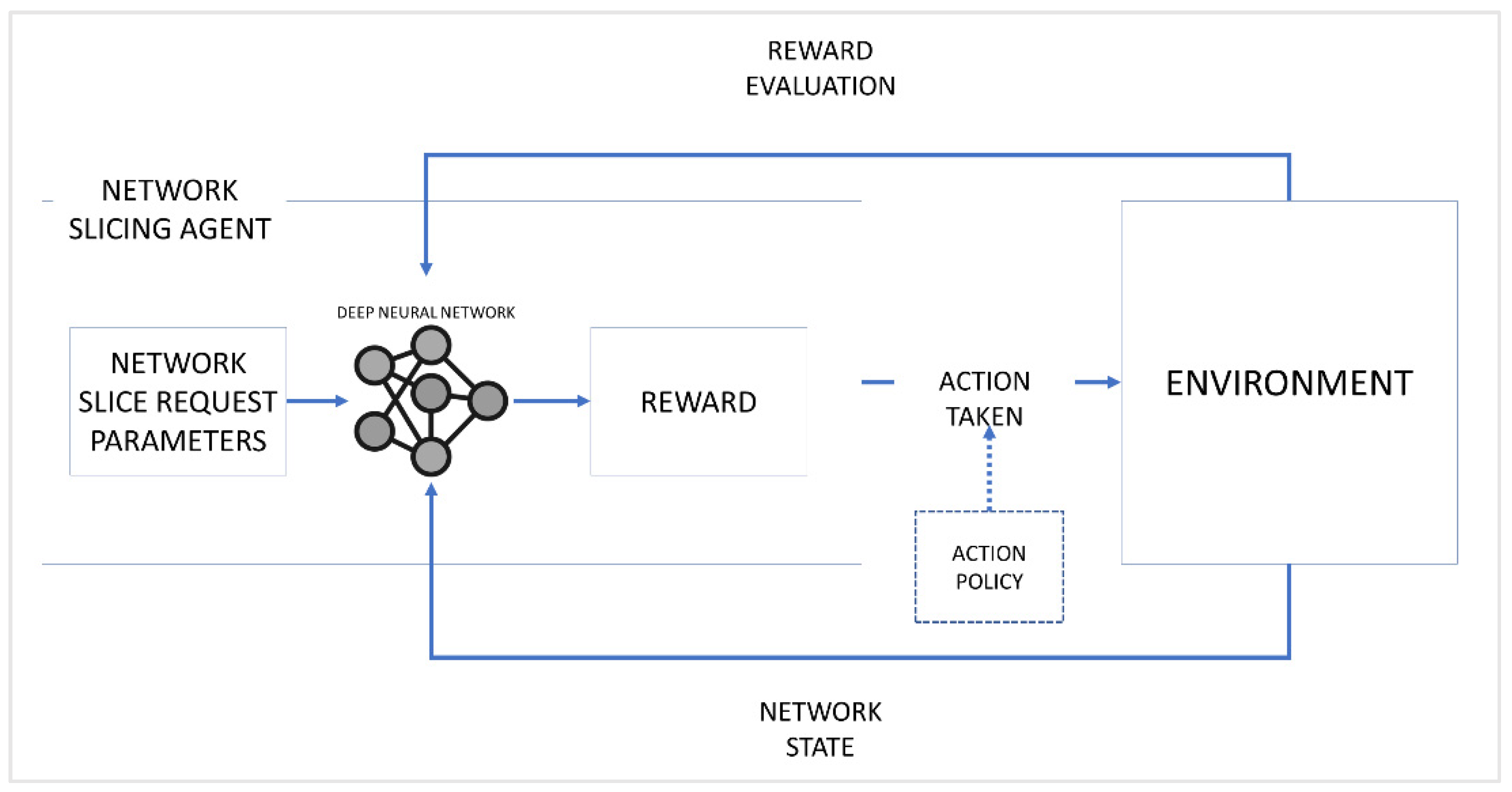
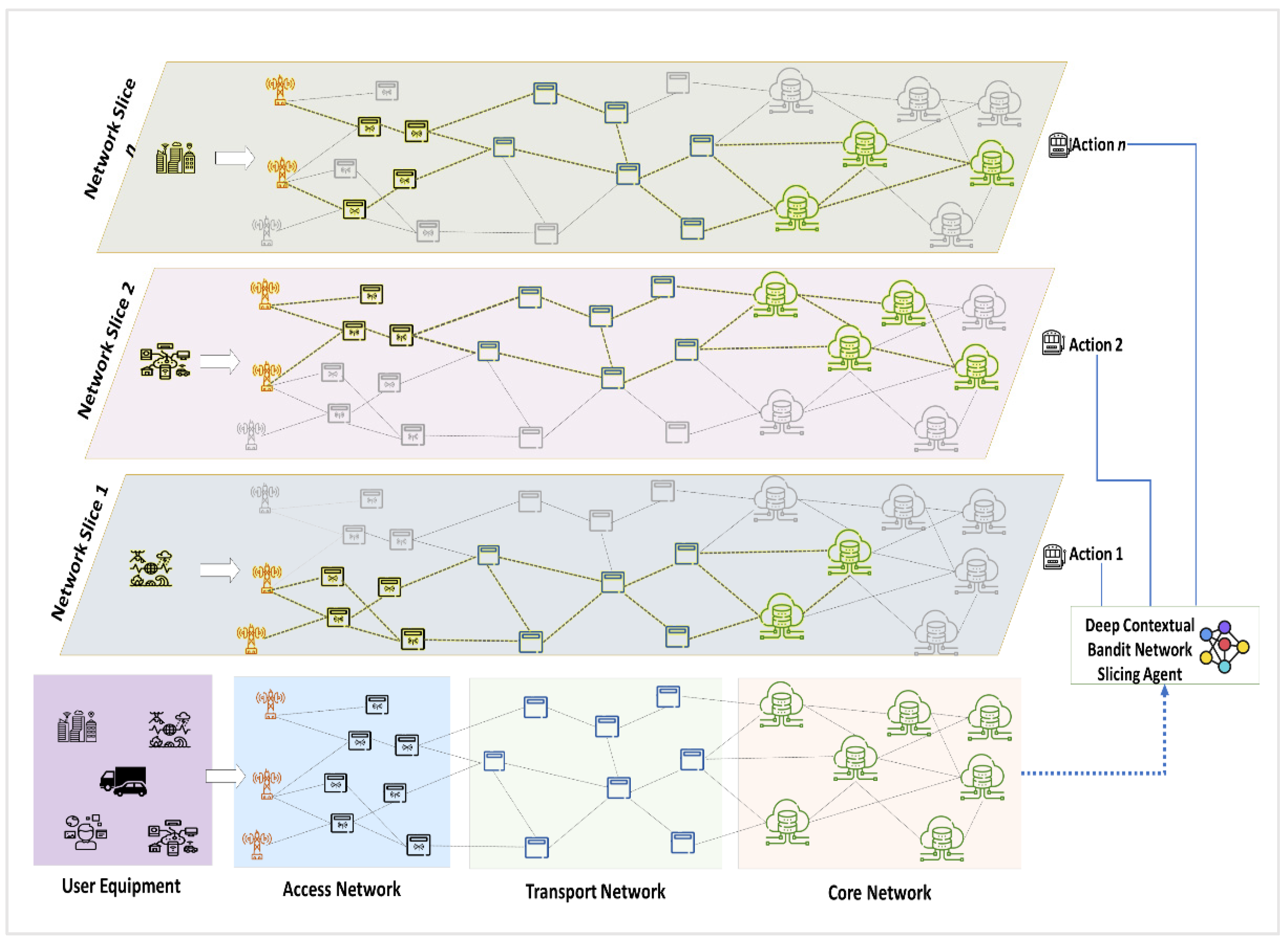
3. Proposed Work
3.1. System Architecture
3.2. Network Slice Request Model
3.3. Node Selection and Slice Mapping Model
| Algorithm 1. NSR Node Selection Method. | |
| 1: | initialize , , , , , and x values |
| 2: | for each node i with : |
| 3: | calculate node degree (Equation (3)) |
| 4: | calculate node betweenness centrality (Equation (4)) |
| 5: | calculate node viability value (Equation (5)) |
| 6: | save of node to NVA |
| 7: | sort NVA values in descending order |
| 8: | for each : |
| 9: | input x value as the number of nodes to select from NVA |
| 10: | while : |
| 11: | retrieve from NVA |
| 12: | return and perform node mapping (Algorithm 2) |
| Algorithm 2. NSR Link Mapping Method. | |
| 1: | initialize flow value |
| 2: | for each value from NVA: |
| 3: | select source node and initialize node of as target node |
| 4: | let be a path with the minimum number of edges |
| 5: | perform Breadth-First Search for to |
| 6: | for each in : |
| 7: | calculate for residual flow |
| 8: | , for forward edges |
| 9: | , if otherwise |
| 10: | if Equations (6)–(8) = true: |
| 11: | store to augmenting path array |
| 12: | select with highest from as NSR path |
| 13: | return |
3.4. Deep Contextual Bandit Network Slicing Scheme
- 1.
- The total path length is the sum of all paths from to . This value provides the agent with the candidate slice topology information.
- 2.
- The computing capacity utilization denoted as provides information regarding the computing capacity allocated for at time . This value also helps determine the remaining computing capacity for the network’s physical infrastructure at the specified time step.where refers to the total remaining computing capacity for all physical infrastructure nodes.
- 3.
- The bandwidth utilization reflects the network’s total bandwidth utilized at time . This bandwidth utilization is also affected by other NSRs served at the specified time step.where is the allocated link capacity for and is the total remaining link capacity for all nodes from the physical infrastructure.
- 4.
- Node utilization represents the percentage of network nodes serving all existing NSRs at time . It also verifies whether the network can allocate the nodes needed by the NSR.where is the number of allocated nodes for at time and is the total remaining number of physical infrastructure nodes.
- 1.
- Network State 1 () represents a normal network state, meaning that the total available computing capacity , link capacity , the number of usable nodes , and total path length are at 81–100%.
- 2.
- Network State 2 () indicates that , , , and are at 50–80% capacity or availability. Such a state requires that succeeding NSRs should not exceed the remaining capacity of available network resources.
- 3.
- Network State 3 () signals that all network resources are below 50% capacity or availability. This state indicates either that the network is currently serving many NSRs or the NSRs currently served are utilizing a large amount of resource capacity.
| Algorithm 3. Proposed Deep Contextual Bandit Network Slicing Scheme. | |
| 1: | initialize , , , |
| 2: | perform Node Selection (Algorithm 1) |
| 3: | for x in NVA: |
| 4: | perform Node Mapping (Algorithm 2) |
| 5: | add mapped nodes to candidate slices array |
| 6: | check for network state |
| 7: | while : |
| 8: | select action a candidate slice from Slices[] as action |
| 9: | calculate action value (Equation (10)) |
| 10: | calculate reward (Equation (16)) |
| 11: | calculate total estimated value (Equation (17)) |
| 12: | calculate Upper Confidence Bound (Equation (18)) |
| 13: | if = 1: |
| 14: | set of as the max UCB |
| 15: | select new action , repeat steps 8–12 |
| 16: | else: Compare values for all actions performed |
| 17: | if of current action is highest: |
| 18 | set of that action as max UCB (exploit) |
| 19: | else: select new action and repeat from step 8 (explore) |
| 20: | select action with the highest from all actions performed in |
| 21: | implement selected action as network slice for |
| 22: | return |
4. Simulation Environment and Performance Metrics
4.1. Simulation Environment Configuration
4.2. Performance Metrics
5. Results and Discussions
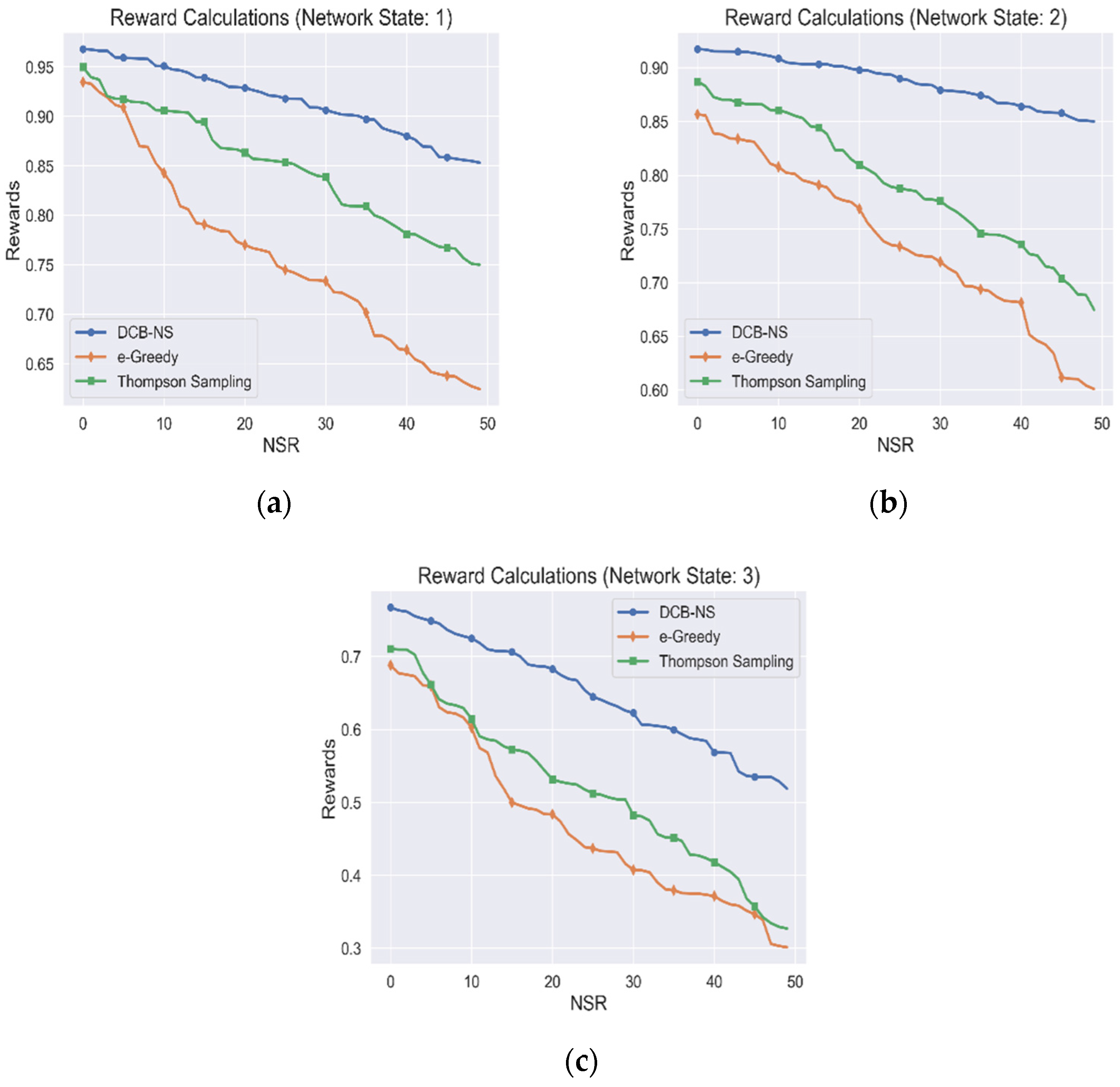
5.1. Agent Rewards Accumulation
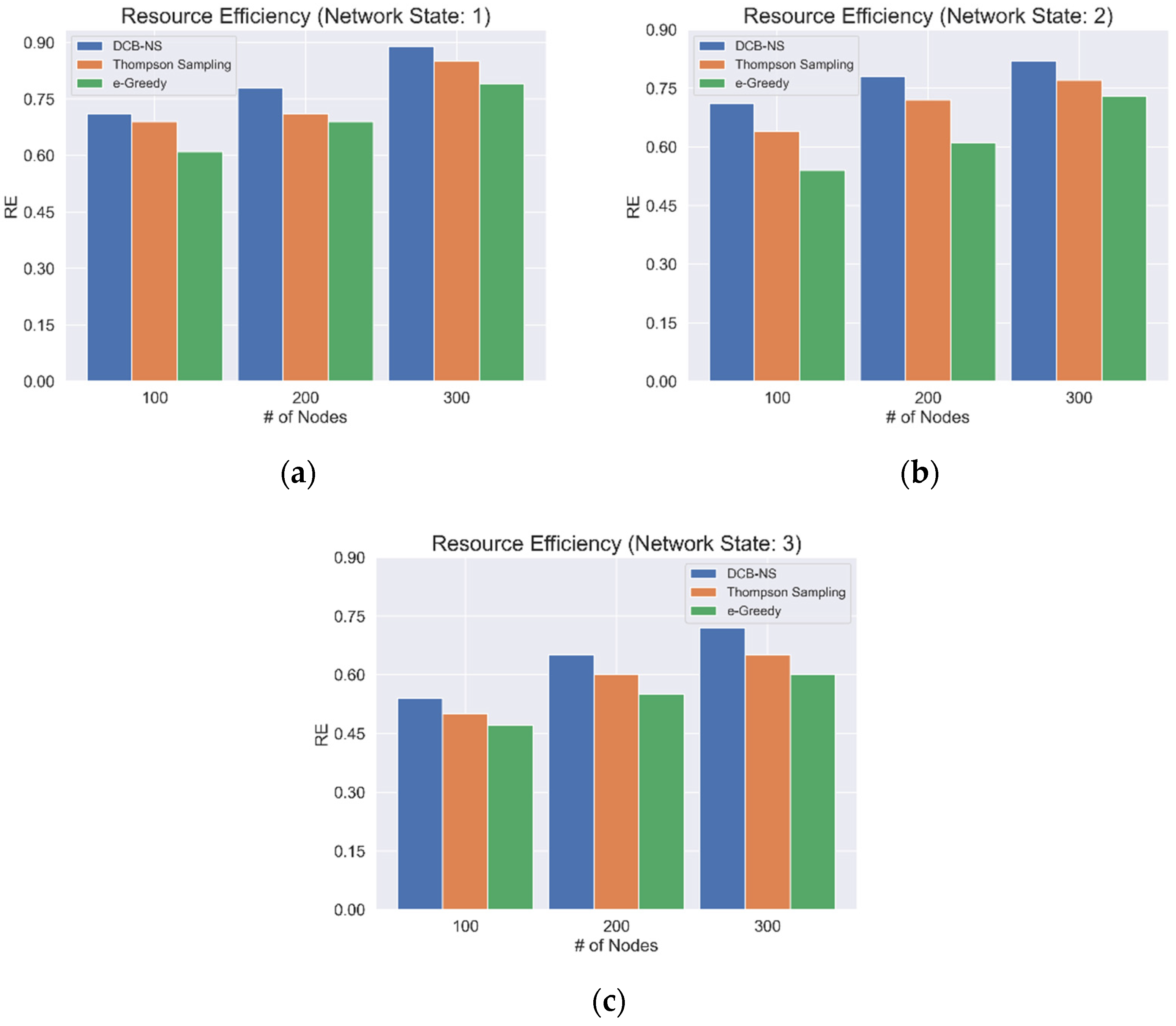
5.2. Network Resource Efficiency
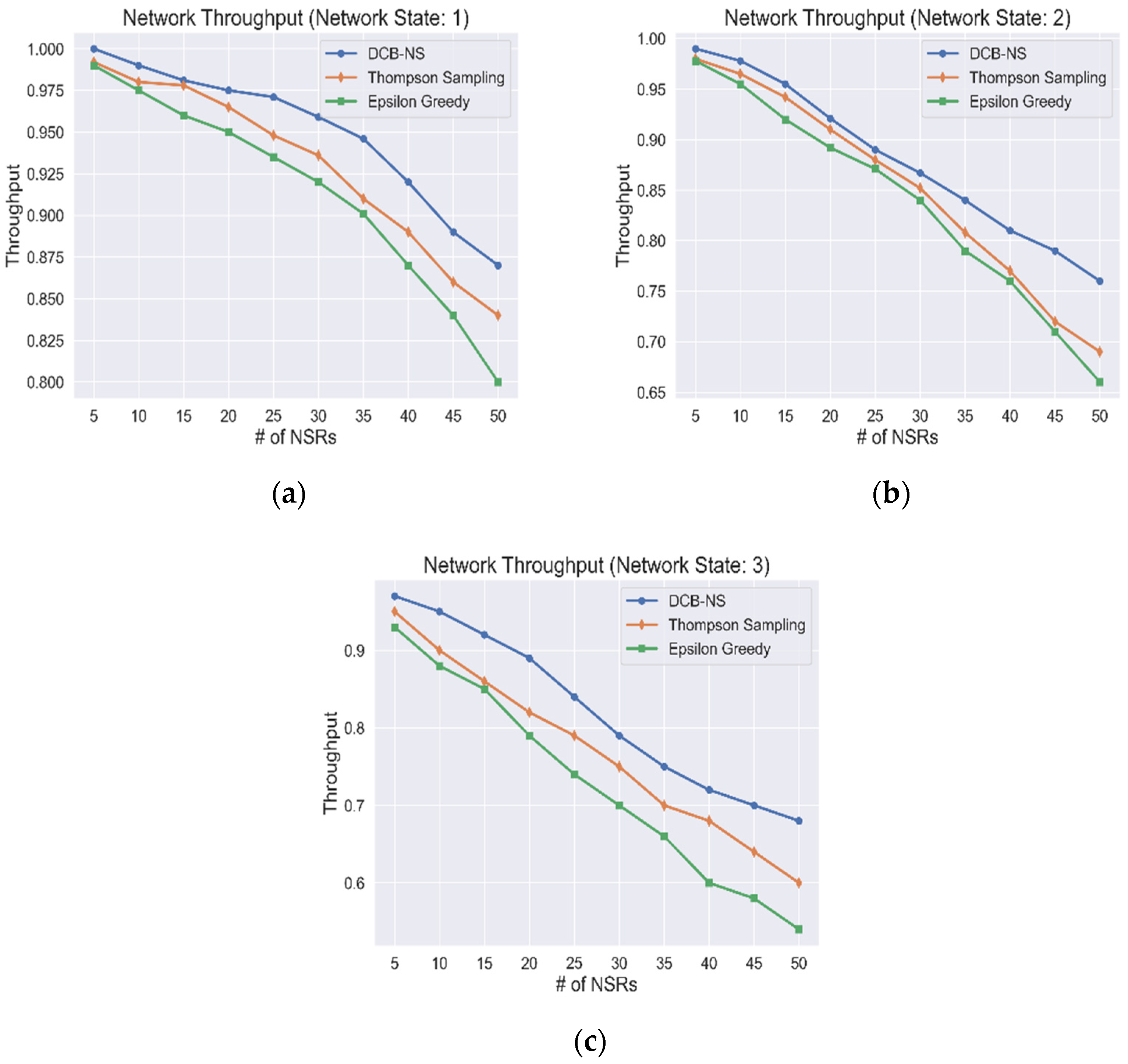
5.3. Network Throughput
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Henry, S.; Alsohaily, A.; Sousa, E.S. 5G is Real: Evaluating the Compliance of the 3GPP 5G New Radio System with the ITU IMT-2020 Requirements. IEEE Access 2020, 8, 42828–42840. [Google Scholar] [CrossRef]
- Jain, A.; Lopez-Aguilera, E.; Demirkol, I. User association and resource allocation in 5G (AURA-5G): A joint optimization framework. Comput. Netw. 2021, 192, 108063. [Google Scholar] [CrossRef]
- Fantacci, R.; Picano, B. When Network Slicing Meets Prospect Theory: A Service Provider Revenue Maximization Framework. IEEE Trans. Veh. Technol. 2020, 69, 3179–3189. [Google Scholar] [CrossRef]
- Tadros, C.N.; Rizk, M.R.M.; Mokhtar, B.M. Software Defined Network-Based Management for Enhanced 5G Network Services. IEEE Access 2020, 8, 53997–54008. [Google Scholar] [CrossRef]
- Mei, C.; Liu, J.; Li, J.; Zhang, L.; Shao, M. 5G network slices embedding with sharable virtual network functions. J. Commun. Netw. 2020, 22, 415–427. [Google Scholar] [CrossRef]
- Papageorgiou, A.; Fernández-Fernández, A.; Siddiqui, S.; Carrozzo, G. On 5G network slice modelling: Service, resource, or deployment-driven? Comput. Commun. 2020, 149, 232–240. [Google Scholar] [CrossRef]
- Subedi, P.; Alsadoon, A.; Prasad, P.W.C.; Rehman, S.; Giweli, N.; Imran, M.; Arif, S. Network slicing: A next generation 5G perspective. EURASIP J. Wirel. Commun. Netw. 2021, 2021, 1–26. [Google Scholar] [CrossRef]
- Kourtis, M.-A.; Sarlas, T.; Xilouris, G.; Batistatos, M.C.; Zarakovitis, C.C.; Chochliouros, I.P.; Koumaras, H. Conceptual Evaluation of a 5G Network Slicing Technique for Emergency Communications and Preliminary Estimate of Energy Trade-off. Energies 2021, 14, 6876. [Google Scholar] [CrossRef]
- Chagdali, A.; Elayoubi, S.; Masucci, A. Slice Function Placement Impact on the Performance of URLLC with Multi-Connectivity. Computers 2021, 10, 67. [Google Scholar] [CrossRef]
- Alotaibi, D. Survey on Network Slice Isolation in 5G Networks: Fundamental Challenges. Procedia Comput. Sci. 2021, 182, 38–45. [Google Scholar] [CrossRef]
- Sohaib, R.; Onireti, O.; Sambo, Y.; Imran, M. Network Slicing for Beyond 5G Systems: An Overview of the Smart Port Use Case. Electronics 2021, 10, 1090. [Google Scholar] [CrossRef]
- Ojijo, M.O.; Falowo, O.E. A Survey on Slice Admission Control Strategies and Optimization Schemes in 5G Network. IEEE Access 2020, 8, 14977–14990. [Google Scholar] [CrossRef]
- Ye, Q.; Li, J.; Qu, K.; Zhuang, W.; Shen, X.S.; Li, X. End-to-End Quality of Service in 5G Networks: Examining the Effectiveness of a Network Slicing Framework. IEEE Veh. Technol. Mag. 2018, 13, 65–74. [Google Scholar] [CrossRef]
- Thantharate, A.; Paropkari, R.; Walunj, V.; Beard, C. DeepSlice: A Deep Learning Approach towards an Efficient and Reliable Network Slicing in 5G Networks. In Proceedings of the 2019 IEEE 10th Annual Ubiquitous Computing, Electronics and Mobile Communication Conference, UEMCON 2019, New York, NY, USA, 10–12 October 2019; pp. 762–767. [Google Scholar] [CrossRef]
- Thantharate, A.; Paropkari, R.; Walunj, V.; Beard, C.; Kankariya, P. Secure5G: A Deep Learning Framework Towards a Secure Network Slicing in 5G and Beyond. In Proceedings of the 2020 10th Annual Computing and Communication Workshop and Conference, CCWC 2020, Las Vegas, NV, USA, 6–8 January 2020; pp. 852–857. [Google Scholar] [CrossRef]
- Abbas, K.; Afaq, M.; Khan, T.A.; Mehmood, A.; Song, W.-C. IBNSlicing: Intent-Based Network Slicing Framework for 5G Networks using Deep Learning. In Proceedings of the APNOMS 2020–2020 21st Asia-Pacific Network Operations and Management Symposium: Towards Service and Networking Intelligence for Humanity, Daegu, Korea, 22–25 September 2020; pp. 19–24. [Google Scholar] [CrossRef]
- Sharma, N.; Kumar, K. Resource allocation trends for ultra-dense networks in 5G and beyond networks: A classification and comprehensive survey. Phys. Commun. 2021, 48, 101415. [Google Scholar] [CrossRef]
- Ejaz, W.; Sharma, S.K.; Saadat, S.; Naeem, M.; Anpalagan, A.; Chughtai, N. A comprehensive survey on resource allocation for CRAN in 5G and beyond networks. J. Netw. Comput. Appl. 2020, 160, 102638. [Google Scholar] [CrossRef]
- Pereira, R.; Lieira, D.; Silva, M.; Pimenta, A.; Da Costa, J.; Rosário, D.; Villas, L.; Meneguette, R. RELIABLE: Resource Allocation Mechanism for 5G Network using Mobile Edge Computing. Sensors 2020, 20, 5449. [Google Scholar] [CrossRef]
- Guan, W.; Wen, X.; Wang, L.; Lu, Z.; Shen, Y. A service-oriented deployment policy of end-to-end network slicing based on complex network theory. IEEE Access 2018, 6, 19691–19701. [Google Scholar] [CrossRef]
- Sciancalepore, V.; Zanzi, L.; Costa-Perez, X.; Capone, A. ONETS: Online Network Slice Broker From Theory to Practice. IEEE Trans. Wirel. Commun. 2022, 21, 121–134. [Google Scholar] [CrossRef]
- Abidi, M.H.; Alkhalefah, H.; Moiduddin, K.; Alazab, M.; Mohammed, M.K.; Ameen, W.; Gadekallu, T.R. Optimal 5G network slicing using machine learning and deep learning concepts. Comput. Stand. Interfaces 2021, 76, 103518. [Google Scholar] [CrossRef]
- Li, X.; Guo, C.; Gupta, L.; Jain, R. Efficient and Secure 5G Core Network Slice Provisioning Based on VIKOR Approach. IEEE Access 2019, 7, 150517–150529. [Google Scholar] [CrossRef]
- Fossati, F.; Moretti, S.; Perny, P.; Secci, S. Multi-Resource Allocation for Network Slicing. IEEE/ACM Trans. Netw. 2020, 28, 1311–1324. [Google Scholar] [CrossRef]
- Sun, Y.; Qin, S.; Feng, G.; Zhang, L.; Imran, M.A. Service Provisioning Framework for RAN Slicing: User Admissibility, Slice Association and Bandwidth Allocation. IEEE Trans. Mob. Comput. 2021, 20, 3409–3422. [Google Scholar] [CrossRef]
- Li, T.; Zhu, X.; Liu, X. An End-to-End Network Slicing Algorithm Based on Deep Q-Learning for 5G Network. IEEE Access 2020, 8, 122229–122240. [Google Scholar] [CrossRef]
- Jungnickel, D. Graphs, Networks, and Algorithms, 2nd ed.; Springer: New York, NY, USA, 2005. [Google Scholar]
- Li, X.; Guo, C.; Xu, J.; Gupta, L.; Jain, R. Towards Efficiently Provisioning 5G Core Network Slice Based on Resource and Topology Attributes. Appl. Sci. 2019, 9, 4361. [Google Scholar] [CrossRef] [Green Version]
- Van Steen, M. Graph Theory and Complex Networks: An Introduction; University of Twente: Enschede, The Netherlands, 2010. [Google Scholar]
- Slivkins, A. Introduction to Multi-Armed Bandits. arXiv 2019, arXiv:1904.07272. Available online: http://arxiv.org/abs/1904.07272 (accessed on 3 March 2022).
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Singh, A. Reinforcement Learning Based Empirical Comparison of UCB, Epsilon-Greedy, and Thompson Sampling. Int. J. Aquat. Sci. 2021, 12, 1–9. Available online: http://www.journal-aquaticscience.com/article_134653_449d479986f2096f94b09b7227ae8a2d.pdf (accessed on 24 March 2022).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref | Objective | Proposed Solution | Performance Metrics |
|---|---|---|---|
| [14] | Optimal slice selection and prediction for mobile devices and adaptive slice assignments in the case of network failures | A Deep Learning and machine learning-based network slicing scheme that analyzes and predicts network traffic patterns for optimal resource allocation |
|
| [15] | Secure network slicing for user equipment access | A neural network-based network slicing model for proactive threat detection and elimination |
|
| [16] | Efficient slice management and resource allocation for RAN and CN | An intent-based network slicing framework for upper-level slice configuration and orchestration |
|
| [19] | Integration of Mobile Edge Computing (MEC) for efficient allocation of idle 5G mobile network resources in urban settings | A MEC-based 5G network resource allocation framework for aggregated idle network resources |
|
| [20] | Service-oriented network E2E slice mapping and deployment | A complex network theory-based slice mapping and creation with slice deployment policy formulation for eMBB, mMTC, and uRLLC use-cases |
|
| [21] | Efficient online service request-to-network slice brokering while considering network resource availability | A multi-armed bandit-based slice brokering method for budgeted resource lock-up for 5G network tenants |
|
| [22] | Efficient network slicing using machine learning and AI techniques | A Deep Belief Network and Neural Network-based network slice classification scheme with Glowworm Swarm-based parameter weight optimization |
|
| [23] | Implementation of MCDM-based node ranking for effective slice provisioning | A VIKOR algorithm-based core-network-slice-provisioning approach to secure network slicing |
|
| [24] | multi-resource allocation while considering resource usage fairness and system efficiency | A multi-resource allocation framework based on the Ordered Weighted Average (OWA) operator for resource availability and user demand information aggregation |
|
| [25] | Efficient slice deployment through cost and network energy reduction | A dynamic slice deployment through a prediction-assisted adaptive network slice algorithm using Holt–Winters (HW) prediction |
|
| [26] | Service provisioning in RAN slices while ensuring QoS and optimal resource utilization | A unified RAN slice provisioning framework for maximization of bandwidth utilization with user QoS guarantee |
|
| [27] | RAN and CN resource allocation through E2E NS while considering access rate and delay service requirements | A proposed Deep Q-Network algorithm for E2E wireless resource allocation and service link mapping on 5G network slices |
|
| | ||||
|---|---|---|---|---|
| 0.50 | 0.75 | 0.75 | 0.50 | |
| 0.50 | 1 | 1 | 0.75 | |
| 1 | 1 | 1 | 1 |
| Parameter | Range |
|---|---|
| Physical Network: | |
| Access network nodes | 20, 40, 80 |
| Transport network nodes | 30, 60, 120 |
| Core network nodes | 50, 100, 200 |
| Node computing capacity | U [20, 50] |
| Node link capacity | U [20, 50] |
| Network Slice Requests: | |
| Number of nodes per NSR | 15 |
| Maximum number of NSRs | 20 |
| NSR node computing capacity | U [5, 25] |
| NSR link capacity | U [5, 25] |
| Transmission Delay | T [0.05, 1] |
| NSR Lifetime | T [10, 50] |
| Algorithm | Rewards | RE | Throughput |
| DCB-NS | 90% | 77% | 85% |
| Thompson Sampling | 86% | 63% | 83% |
| Epsilon-Greedy | 77% | 60% | 80% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dayot, R.V.J.; Ra, I.-H.; Kim, H.-J. A Deep Contextual Bandit-Based End-to-End Slice Provisioning Approach for Efficient Allocation of 5G Network Resources. Network 2022, 2, 370-388. https://doi.org/10.3390/network2030023
Dayot RVJ, Ra I-H, Kim H-J. A Deep Contextual Bandit-Based End-to-End Slice Provisioning Approach for Efficient Allocation of 5G Network Resources. Network. 2022; 2(3):370-388. https://doi.org/10.3390/network2030023
Chicago/Turabian StyleDayot, Ralph Voltaire J., In-Ho Ra, and Hyung-Jin Kim. 2022. "A Deep Contextual Bandit-Based End-to-End Slice Provisioning Approach for Efficient Allocation of 5G Network Resources" Network 2, no. 3: 370-388. https://doi.org/10.3390/network2030023
APA StyleDayot, R. V. J., Ra, I.-H., & Kim, H.-J. (2022). A Deep Contextual Bandit-Based End-to-End Slice Provisioning Approach for Efficient Allocation of 5G Network Resources. Network, 2(3), 370-388. https://doi.org/10.3390/network2030023