



Partially Ordered Sets in Socio-Economic Data Analysis


{kind=link}
{kind=link}
{kind=link}
Definition
1. Introduction
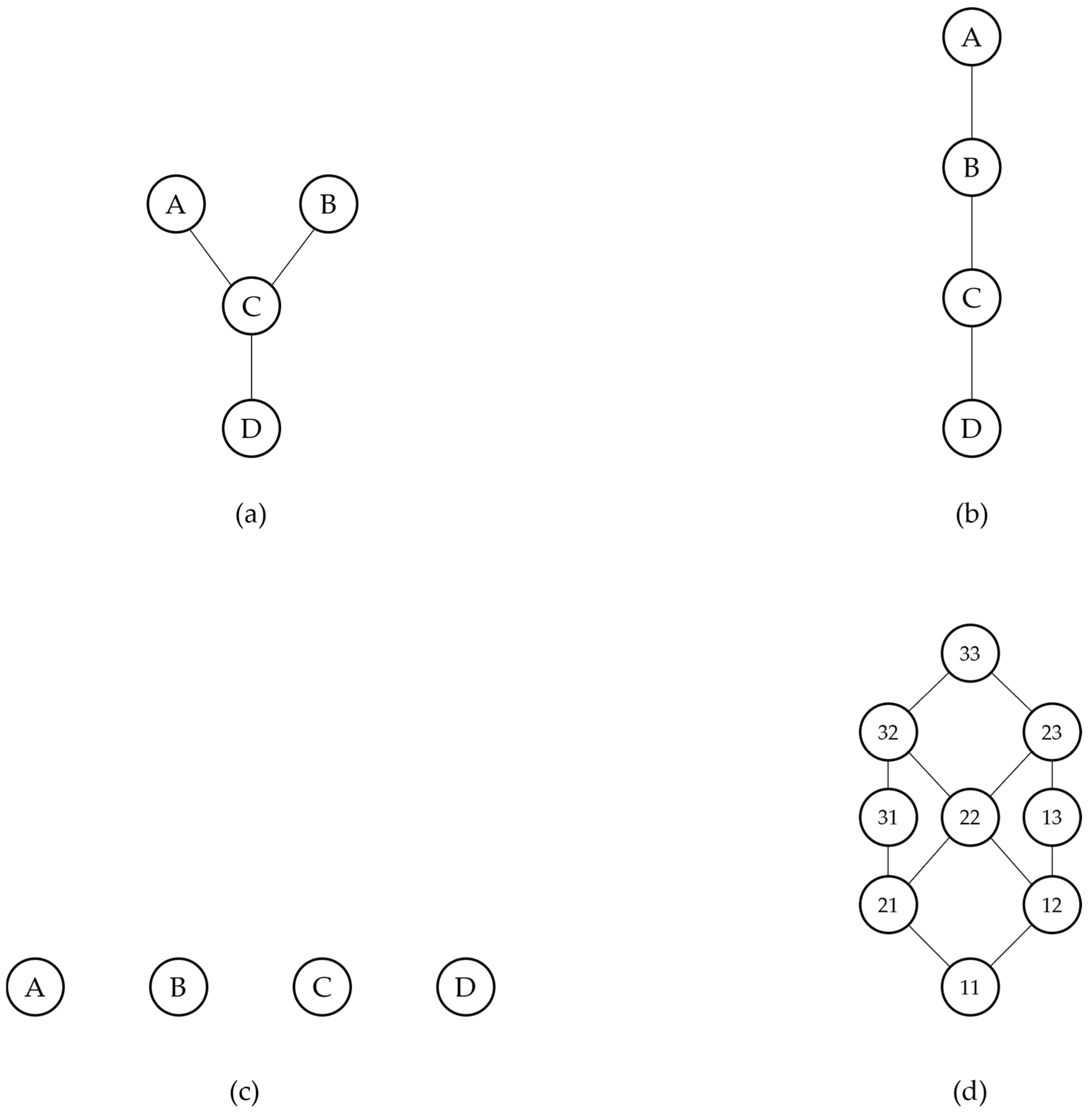
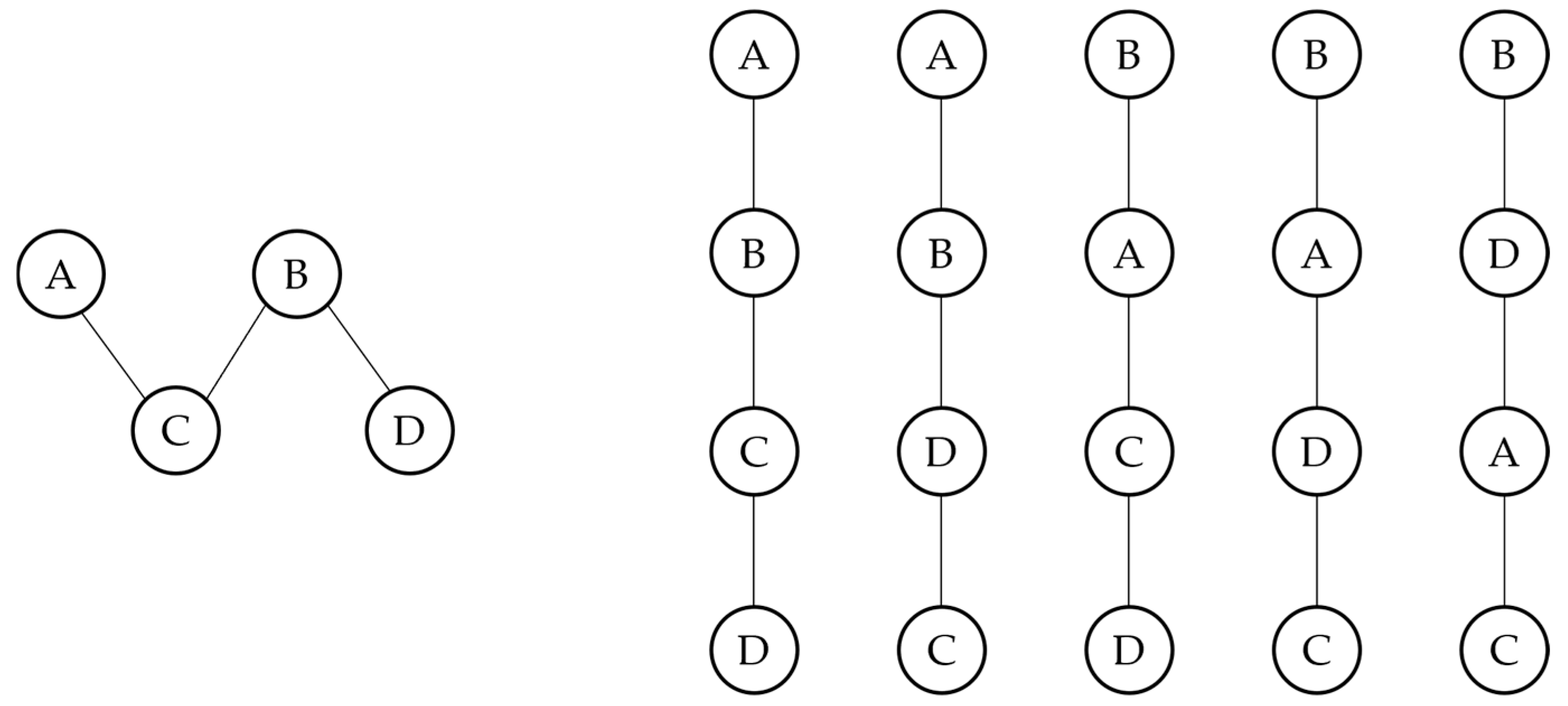
2. Some Essential Concepts on Posets and Order Relations
- x ≤ x, for all x ∈ X (reflexivity).
- x ≤ y and y ≤ x ⇒ x = y (anti-symmetry).
- x ≤ y and y ≤ z ⇒ x ≤ z (transitivity).
3. Applications of Posets and Order Theory to Data Analysis and Social Sciences
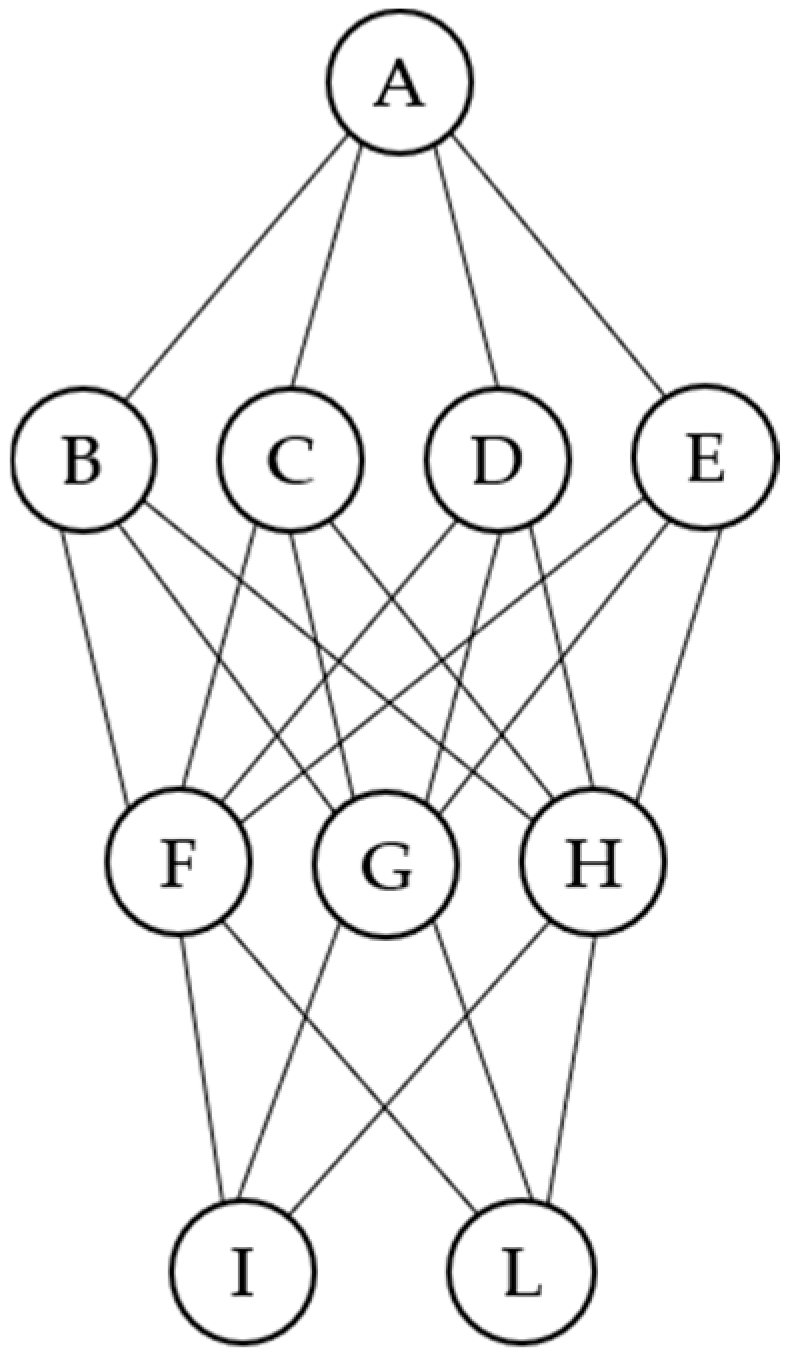
3.1. Scoring and Ranking on Multi-Indicator Systems
- The set of all possible profiles, over the input variables, is structured as a component-wise lattice, and to each profile its observed frequency in the input dataset is attached.
- A scoring function over the lattice is built, exploiting only its order structure. The scoring function can be seen as a way to quantify the degree of dominance between profiles, even when they are incomparable.
- Each statistical unit is assigned a synthetic score by summing up its degree of dominance over the other units, based on their respective profiles.
- Synthetic scores can then be used to compare and rank statistical units (possibly with ties).
3.2. Multi-Criteria Decision-Making and Evaluation Procedures
3.3. Multidimensional Frequency Distribution Comparison
3.4. Formal Concept Analysis
3.5. Examples of Applications to the Social Sciences
- Multidimensional poverty measurement and material deprivation assessment [6,11]. As already mentioned, the shift from a unidimensional (monetary) to a multidimensional perspective on poverty measurement leads to the need to describe the different facets of deprivation and its nuances, which are naturally represented using posets, as somehow suggested also by Amartya Sen in his book on inequality [12]. In this perspective, the posetic approach overcomes the limitations of so-called counting approaches, which in the end deliver a black-and-white picture of deprivation, providing instead a fuzzy view of it, which effectively fits its multi-faceted nature. Due to computational issues, the posetic approach was initially mainly of theoretical interest; recent advances in analytical results and algorithmic implementations are now making it an effective tool in concrete applications.
- Life satisfaction and individual and societal well-being [13,14,15]. Along similar lines as in the case of poverty, posetic tools have been employed in studies on life satisfaction, subjective well-being, and quality of life to assess them and to build rankings at the individual and societal/territorial levels.
- Sustainability and human development [16,17,18,19,20,21]. In more recent years, posets have attracted the attention of researchers in sustainability and, interestingly, in human development studies. In the perspective of Sen’s Capability Approach, posets can in fact accommodate different criteria, points of view, and references to diverse “informational spaces”, avoiding too restricted normative approaches to the evaluation of the flourishing of human beings and societies.
3.6. Open Problems in Posetic Data Analysis
- Cluster analysis on multidimensional ordinal indicator systems and component-wise lattices. The development of consistent and effective procedures for the hierarchical clustering of ordinal data is still an open issue in the statistical literature. Available algorithms follow a similarity-based approach, involving some metrics defined on the ordinal score configurations (profiles) of the statistical units, analogously to what is performed with numerical data. This way, however, the component-wise order of the input data is by no means taken into account. As the input units’ profiles are partially ordered, so the final clusters (that can be considered as “macro” units) should be partially ordered as well. Therefore, the clustering algorithm should produce clusters, together with an order relation defined on them, somehow inherited from the input component-wise order. Lattice theory provides the proper way to pursue this goal, through the concept of lattice congruences [34], i.e., of equivalence relations compatible with the input component-wise order. Usual hierarchical clustering can be seen as a process producing a chain of equivalence relations on the set of inputs. In the component-wise case, the chain must be instead restricted to the set of lattice congruences, so assuring the final clusters to constitute a lattice as well. However, this poses some relevant computational issues, since building congruences is not a trivial task. Current research is exploring ways to search the space of congruences in a computationally efficient manner.
- Measuring multidimensional ordinal inequality/polarization. While the theory of inequality/polarization measurement on cardinal variables is well-established, the multidimensional ordinal case is still open, and just a few attempts to address it can be found in the literature [35]. Interestingly, in more or less explicit ways, these attempts rely on posets, which have so made their appearance in this research area. In this perspective, the use of order theory is promising. It allows us to abstract the structure of unidimensional inequality/polarization indexes away from their unidimensional context, reformulating them in posetic terms as functionals over distributions on component-wise lattices, and naturally leading to their multidimensional generalization.
- Visualization of multidimensional ordinal data systems. Many dimensionality reduction algorithms exist in statistical literature to optimally approximate multidimensional numerical data systems in spaces of lower dimension. In the multidimensional ordinal case, just one tool (called POSAC [36]) is currently available. The POSAC has been developed in the context of facet theory and is a numerical algorithm designed to optimally map and approximate generic posets in the Euclidean plane, ordered component-wise. More specific partially ordered structures should, however, deserve better-tuned algorithms, capable of exploiting their properties and easing the interpretation of the final results. Currently, research is focusing on the bidimensional visualization of component-wise lattices built from systems of binary ordinal variables (called Boolean lattices). The mathematical properties of this class of lattices, in fact, make the bidimensional embedding computationally feasible for a number of variables up to 10, or even more. The resulting visualization not only approximates in an optimal way the input lattice but also unveils the dependence structure of the input variables, providing richer information than the generic POSAC embedding.
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| FCA | Formal Concept Analysis |
| mrp | mutual ranking probability |
| POSAC | Partial Order Scalogram Analysis with Base Coordinates |
| Poset | partially ordered set |
References
- Davey, B.A.; Priestley, A. Introduction to Lattices and Order, 2nd ed.; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Gratzer, G. General Lattice Theory; Academic Press, Inc.: New York, NY, USA, 1978. [Google Scholar]
- De Loof, K. Efficient Computation of Rank Probabilities in Posets. Ph.D. Thesis, University of Ghent, Ghent, Belgium, 2010. [Google Scholar]
- Schroeder, B.S.W. Ordered Stes: An Introduction; Birkhaser: Boston, MA, USA, 2002. [Google Scholar]
- Fattore, M.; De Capitani, L.; Avellone, A. A fuzzy posetic toolbox for multi-criteria evaluation on ordinal data systems. Ann. Oper. Res. 2024. [Google Scholar] [CrossRef]
- Fattore, M.; Arcagni, A. A reduced posetic approach to the measurement of multidimensional ordinal deprivation. Soc. Indic. Res. 2018, 136, 1053–1070. [Google Scholar] [CrossRef]
- Patil, G.P.; Taillie, C. Multiple indicators, partially ordered sets, and linear extensions: Multi-criterion ranking and prioritization. Environ. Ecol. Stat. 2004, 11, 199–228. [Google Scholar] [CrossRef]
- Arcagni, A.; Fattore, M.; Avellone, A. Complexity reduction and approximation of multidomain systems of partially ordered data. Comput. Stat. Data. An. 2022, 173, 107520. [Google Scholar] [CrossRef]
- Rimoldi, S.M.L.; Arcagni, A.; Fattore, M.; Barbiano di Belgiojoso, E. Targeting policies for multidimensional poverty and social fragility relief among migrants in Italy, using F-FOD analysis. Soc. Indic. Res. 2021, 157, 57–75. [Google Scholar] [CrossRef]
- Fattore, M.; Arcagni, A. F-FOD: Fuzzy first order dominance analysis and populations ranking over ordinal multi-indicators system. Soc. Indic. Res. 2019, 144, 1–29. [Google Scholar] [CrossRef]
- Ivaldi, E.; Ciacci, A.; Soliani, R. Urban deprivation in Argentina: A POSET analysis. Pap. Reg. Sci. 2020, 99, 1723–1747. [Google Scholar] [CrossRef]
- Sen, A. Inequality Reexamined; Clarendon Press: Oxford, UK, 1992. [Google Scholar]
- Caperna, G.; Boccuzzo, G. Use of poset theory with big datasets: A new proposal applied to the analysis of life satisfaction in Italy. Soc. Indic. Res. 2018, 136, 1071–1088. [Google Scholar] [CrossRef]
- Cavalletti, B.; Corsi, M. Beyond GDP Effects on National Subjective Well-Being of OECD Countries. Soc. Indic. Res. 2018, 136, 931–966. [Google Scholar] [CrossRef]
- della Queva, S. Analysis of Social Participation: A Multidimensional Approach Based on the Theory of Partial Ordering. In Partial Order Concepts in Applied Sciences; Fattore, M., Bruggemann, R., Eds.; Springer: Cham, Switzerland, 2017; pp. 151–160. [Google Scholar]
- Alaimo, L.S.; Ciacci, A.; Ivaldi, E. Measuring Sustainable Development by Non-aggregative Approach. Soc. Indic. Res. 2021, 157, 101–122. [Google Scholar] [CrossRef]
- Alaimo, L.S.; Maggino, F. Sustainable Development Goals Indicators at Territorial Level: Conceptual and Methodological Issues–The Italian Perspective. Soc. Indic. Res. 2020, 147, 383–419. [Google Scholar] [CrossRef]
- Comim, F. A Poset-Generalizability Method for Human Development Indicators. Soc. Indic. Res. 2021, 158, 1179–1198. [Google Scholar] [CrossRef]
- Comin, F.; Abreu, M.; Guinesi Mattos Borges, C. Defining left behind places: An international comparative poset analysis. Camb. J. Reg. Econ. Soc. 2024, 17, 163–180. [Google Scholar] [CrossRef]
- Hilckmann, A.; Bach, V.; Bruggemann, R.; Ackermann, R.; Finkbeiner, M. Partial order analysis of the government dependence of the sustainable development performance in Germany’s federal states. In Partial Order Concepts in Applied Sciences; Fattore, M., Bruggemann, R., Eds.; Springer: Cham, Switzerland, 2017; pp. 219–228. [Google Scholar]
- Hirai, T.; Comim, F. Measuring the sustainable development goals: A poset analysis. Ecol. Indic. 2022, 145, 109605. [Google Scholar] [CrossRef]
- Di Brisco, A.; Farina, P. Measuring gender gap from a poset perspective. Soc Indic. Res. 2018, 136, 1109–1124. [Google Scholar] [CrossRef]
- Carlsen, L.; Bruggemann, R. Gender equality in Europe: The development of the sustainable development goal No. 5 illustrated by exemplary cases. Soc. Indic. Res. 2021, 158, 1127–1151. [Google Scholar] [CrossRef]
- Levy, S. Partial order analysis of crime indicators. Soc. Indic. Res. 1985, 16, 195–199. [Google Scholar] [CrossRef]
- Raveh, A.; Landau, S.F. Partial Order Scalogram Analysis with Base Coordinates (POSAC): Its Application to Crime Patterns in all the states in the United States. J. Quant. Criminol. 1993, 9, 83–99. [Google Scholar] [CrossRef]
- Canter, D. A Partial Order Scalogram Analysis of Criminal Network Structures. Behaviormetrika 2004, 31, 131–152. [Google Scholar] [CrossRef]
- Bachtrogler, J.; Badinger, H.; de Clairfontaine, A.F.; Reuter, W.H. Summarizing data using partially ordered set theory: An application to fiscal frameworks in 97 countries. Stat. J. IAOS 2016, 32, 383–402. [Google Scholar] [CrossRef]
- Badinger, H.; Reuter, W.H. Measurement of Fiscal Rules: Introducing the Application of Partially Ordered Set (POSET) Theory. J. Macroecon. 2015, 43, 108–123. [Google Scholar] [CrossRef]
- Sorensen, P.B.; Bruggemann, R.; Carlsen, L.; Mogensen, B.B.; Kreuger, J.; Pudenz, S. Analysis of monitoring data of pesticide residues in surface waters using partial order ranking theory. Environ. Tox. Chem. 2003, 22, 661–670. [Google Scholar] [CrossRef]
- Voigt, K.; Welzl, G.; Bruggemann, R. Data analysis of environmental air pollutant monitoring systems in Europe. Environmetrics 2004, 15, 577–596. [Google Scholar] [CrossRef]
- Voigt, K.; Bruggemann, R. Water contamination with pharmaceuticals: Data availability and evaluation approach with Hasse diagram technique and METEOR. MATCH Commun. Math. Comput. Chem. 2005, 54, 671–689. [Google Scholar]
- Bruggemann, R.; Carlsen, L. (Eds.) Partial Order in Environmental Sciences and Chemistry; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Voigt, K. Bruggemann R, Ranking of pharmaceuticals detected in the environment: Aggregation and weighting procedures. Combin. Chem. High Through. Screen. 2008, 11, 770–782. [Google Scholar] [CrossRef]
- Gratzer, G. The Congruences of a Finite Lattices: A Proof-by-Picture Approach; Birkhauser: Cham, Switzerland, 2005. [Google Scholar]
- Kobus, M.; Kurek, R. Multidimensional polarization for ordinal data. J. Econ. Inequal. 2019, 17, 301–317. [Google Scholar] [CrossRef]
- Shye, S. Multiple Scaling: The Theory and Application of Partial Order Scalogram Analysis (POSAC); North Holland: Amsterdam, The Netherlands, 1985. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fattore, M.; De Capitani, L. Partially Ordered Sets in Socio-Economic Data Analysis. Encyclopedia 2025, 5, 100. https://doi.org/10.3390/encyclopedia5030100
Fattore M, De Capitani L. Partially Ordered Sets in Socio-Economic Data Analysis. Encyclopedia. 2025; 5(3):100. https://doi.org/10.3390/encyclopedia5030100
Chicago/Turabian StyleFattore, Marco, and Lucio De Capitani. 2025. "Partially Ordered Sets in Socio-Economic Data Analysis" Encyclopedia 5, no. 3: 100. https://doi.org/10.3390/encyclopedia5030100
APA StyleFattore, M., & De Capitani, L. (2025). Partially Ordered Sets in Socio-Economic Data Analysis. Encyclopedia, 5(3), 100. https://doi.org/10.3390/encyclopedia5030100