
Designing Possibilistic Information Fusion—The Importance of Associativity, Consistency, and Redundancy



Abstract
:1. Introduction
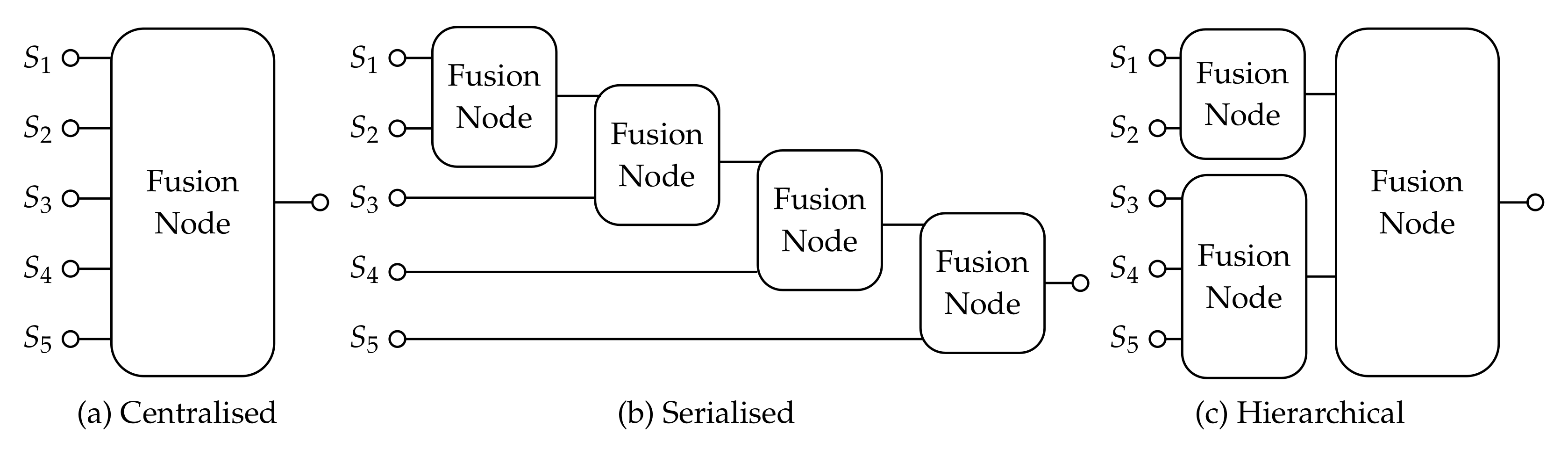
2. Fusion Topology Design in Related Work
3. Fusion within Possibility Theory
- Possibilistic Pooling Fusion has mainly been advanced by Dubois et al. [4,48]. The aim of possibilistic pooling is to find the possibility degree for each alternative x. Hence, operators work on the grades of possibilities (by applying fuzzy norms). Inside this framework, the choice of fusion rules is most often based on the state of knowledge about the reliability of the information sources involved. Depending on reliability and available knowledge, fusion operators are distinguished into conjunctive, disjunctive, and trade-off modes [32].
- Possibilistic Estimation Fusion was mainly devised and advanced by Yager [54]. In contrast to pooling, estimation operators are based on Zadeh’s extension principle [55], which defines the use of mappings to fuzzy inputs. The goal of estimation concerns itself with finding the result that is the most compatible with all information items. Operators apply averaging functions on the frame of discernment X.
- Majority-guided Fusion identifies majority subsets—often based on consistency measures—and aggregates information from these subsets either exclusively or prioritised—similar to a voting procedure. Majority-guided fusion deliberately violates the fairness principle. It finds application in situations in which it is explicitly known that sources produce consistent readings, e.g., in redundantly engineered technical sensor systems [23]. The operators for majority-guided fusion are often based upon either pooling or fuzzy estimation as is shown in detail in the following.
3.1. Possibilistic Pooling Fusion
3.2. Possibilistic Estimation Fusion
3.3. Majority-Guided Fusion
4. Approach towards Topology Design
- Modularity: A fusion node outputs a fused information item, which qualifies as a possibility distribution π (see Section 3), i.e., π is normal. This property allows self-contained intermediate results in a topology and makes fusion nodes modular. This increases the transparency of the distributed fusion topology.
- Self-Reproducing: Given a single input, a fusion node reproduces this input. It preserves its identity, i.e., .
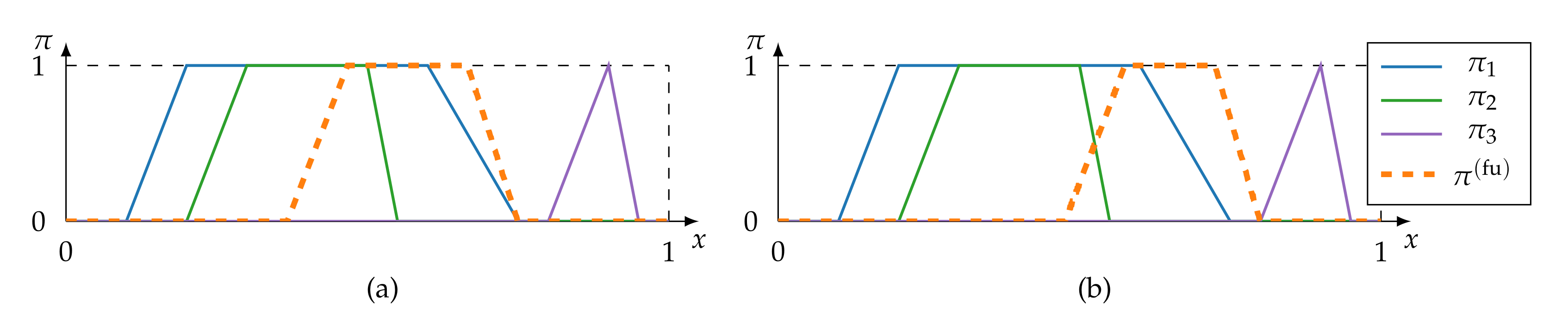
4.1. Associativity
4.1.1. Pooling Fusion
4.1.2. Estimation and Majority-Guided Fusion
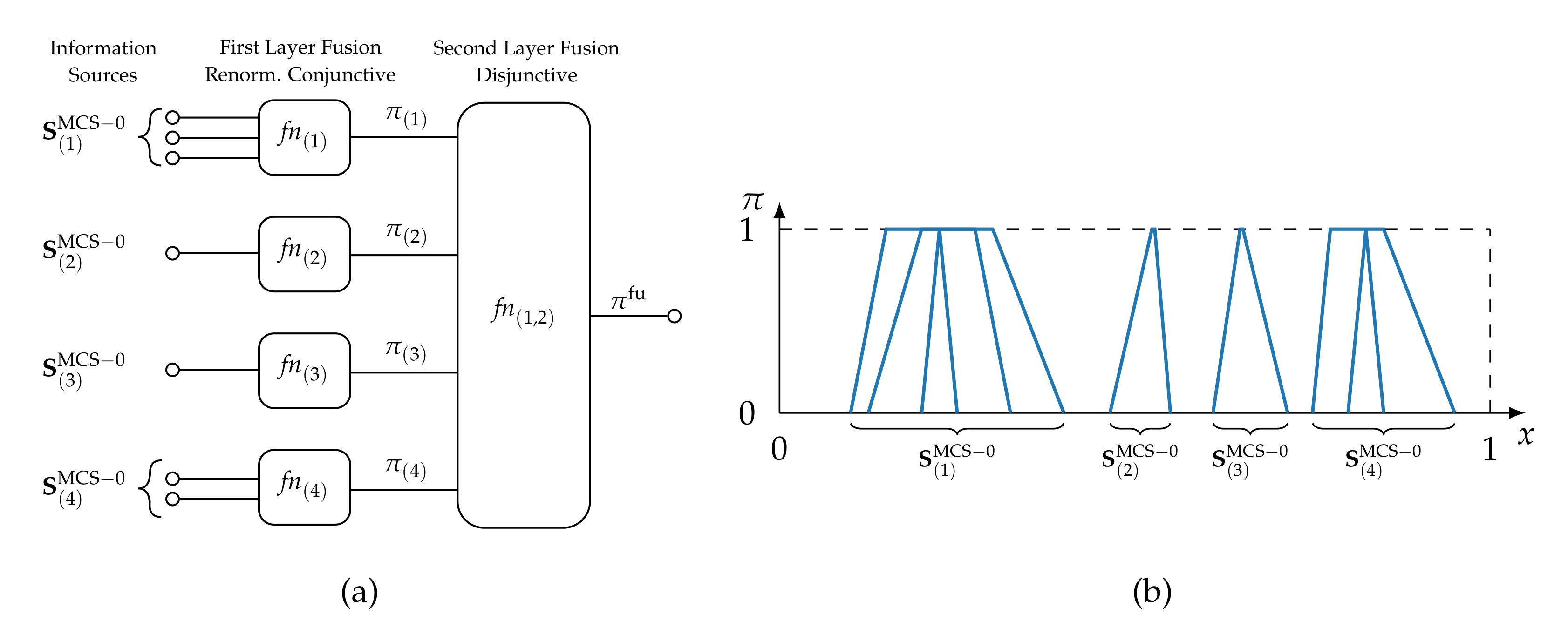
4.2. MCS-Based Topology Design
| Algorithm 1: Fast algorithm for finding subsets of information sources, which are consistent at least to degree on every instance of training data. Each subset is assigned to fusion node . The algorithm relies on finding MCS of information items as defined by Dubois et al. [58,61]. |
 |
4.3. Robustness
- First, incomplete information and epistemic uncertainty in the training data may lead to assessing a group of sources as consistent prematurely. Information sources may produce different (in)consistent behaviours depending on the training data’s true value and its position on the frame of discernment. Take, for example, a condition-monitoring scenario of a technical system in which sensors state the condition on a discrete frame of discernment . Two sensors may both detect two of the conditions (e.g., error1, normal); however, only one is able to detect the third condition (error2). If training data does not include data regarding error2, then with Algorithm 1, both sensors are falsely identified as consistent and grouped into a fusion node. If error2 occurs later, then the sensors behave unexpectedly inconsistently. This problem relates to spurious correlations in probability theory [70], which describes that, in large datasets, it is particularly likely that correlations are found between variables incorrectly.
- Second, defective sources are a cause of unexpected inconsistent behaviour. Defective sources are sources that are trustworthy and therefore have a high reliability but nonetheless start to supply incorrect information [71]. Source defects appear in different forms: Information can change suddenly, drift continuously or incrementally, or can be characterised by an increasing number of outliers [72,73]. Countermeasures are majority-guided fusion rules as applied by Ehlenbröker et al. and Holst and Lohweg [21,23]. This requires redundant and reliable sources in a fusion node.
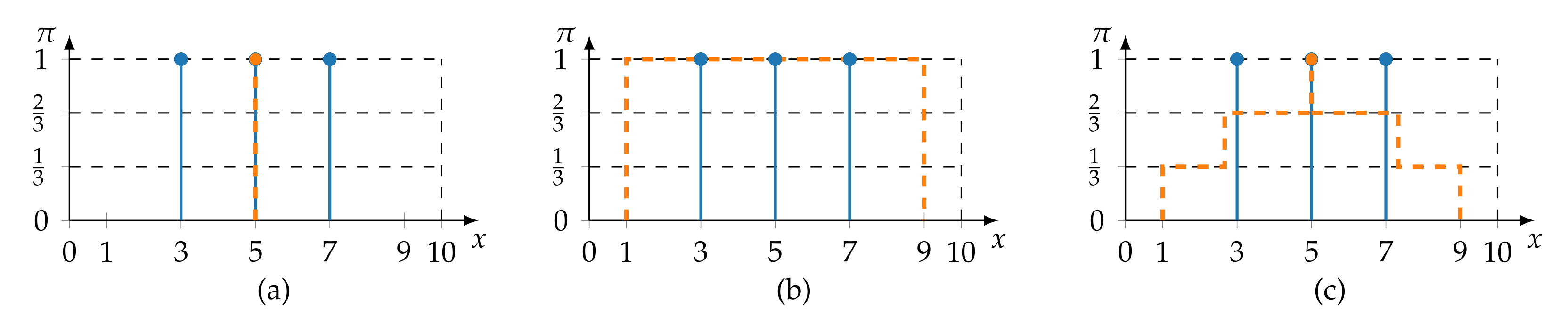
- Redundancy-Driven Topology Design: To counteract non-representative training data, it must be ensured that information sources are not prematurely deemed to be consistent. For this, it must be analysed whether the consistent behaviour between sources extends over the entire frame of discernment. Therefore, instead of the consistency metric used in (16), the redundancy metric originally proposed in previous works [38,39] is adopted, which ensures that the complete frame of discernment is considered.
- Discounting Defective Sources: Grouping the information sources by consistency (or redundancy) eases the detection of defects [23,24]. Items detected as defective are discounted in the fusion node so that they have less influence on the output of the node. This requires an adjustment of the fusion rule (previously minimum or maximum operator) in the nodes. This defect detection step explicitly exploits the distributed topology to its advantage. This deliberately dismisses the associativity of the overall fusion.
- Estimation-fusion-based Nodes: Averaging information is a natural way to favour opinions of the majority. Adopting estimation fusion in nodes results in more robust behaviour against defects—such as outliers—compared to purely conjunctive fusion as applied in (6).
4.3.1. Redundancy-Driven Topology Design
- Upper bound: If , then and .
- Lower bound: if , i.e., all possibility distributions are identical.
- Boundaries: A redundancy metric should be able to model complete redundancy and complete non-redundancy. It follows that ρ is minimally and maximally bounded. It is proposed that .
- Identity relation: An information source is fully redundant with identical copies of itself: . Note that sources can be redundant without necessarily being identical.
- Symmetry: The metric ρ is a symmetric function in all its arguments, i.e.,for any permutation p on .
- If information sources are redundant, then they provide redundant information items. Consequently, increases as the redundancy of information items increase.
- Redundant information items do no necessitate that their information sources are also redundant. Due to cases of incomplete information, redundant information items may be a case of spurious redundancy (similar to spurious correlation).
| Algorithm 2: Algorithm that searches for redundancy-based fusion nodes based on found by Algorithm 1. The algorithm iterates over and searches all , for sets meeting the redundancy criterion . |
 |
4.3.2. Discounting Defective Sources
- Information preservation: If , then the information must not be changed but instead preserved. Let be a modified possibility distribution based on π. If , then .
- Neutral element: If , then I needs to have no effect on the fusion. The item I needs to act as a neutral element on fusion operator , i.e., .
- Monotonicity: For increasing , I needs to have a monotonic increasing effect on .
4.3.3. Estimation-Based Fusion Nodes
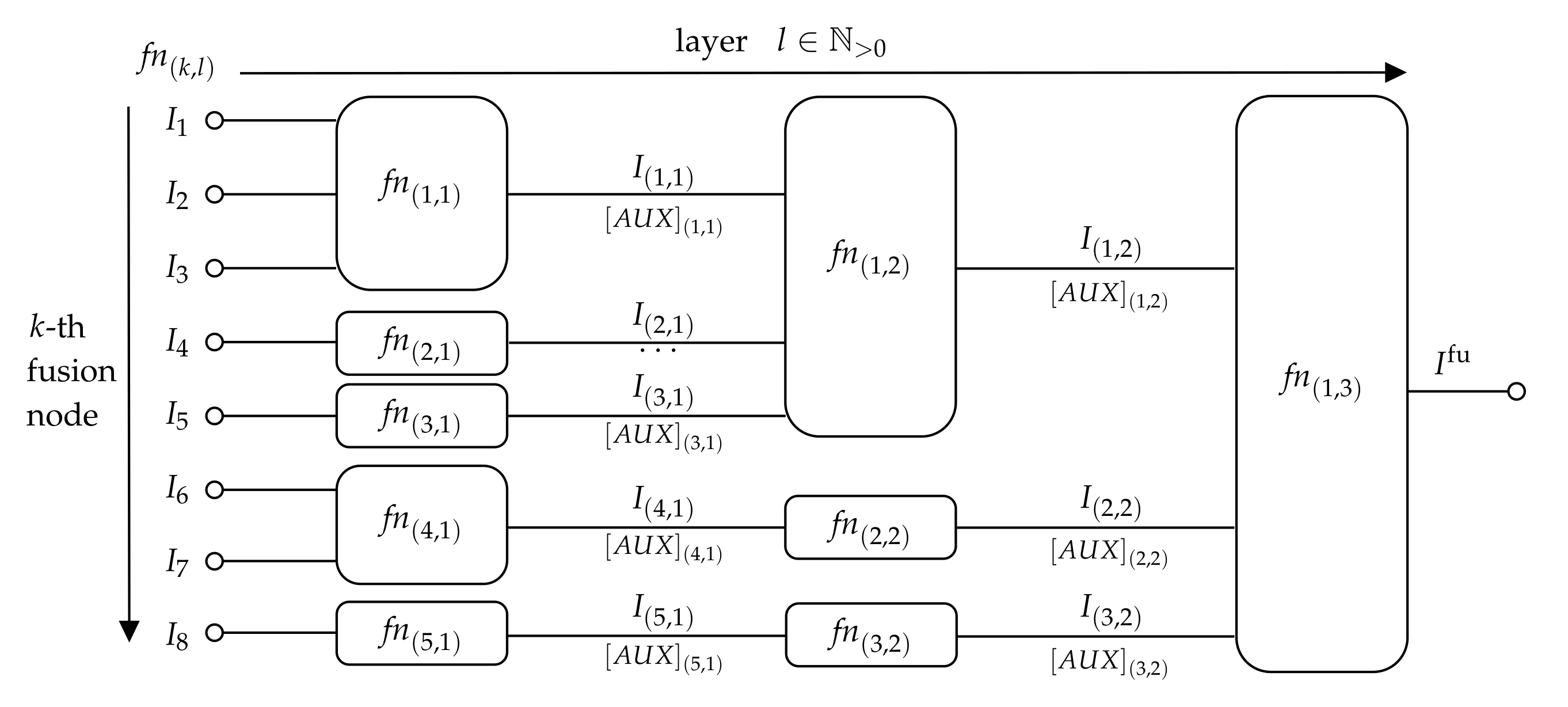
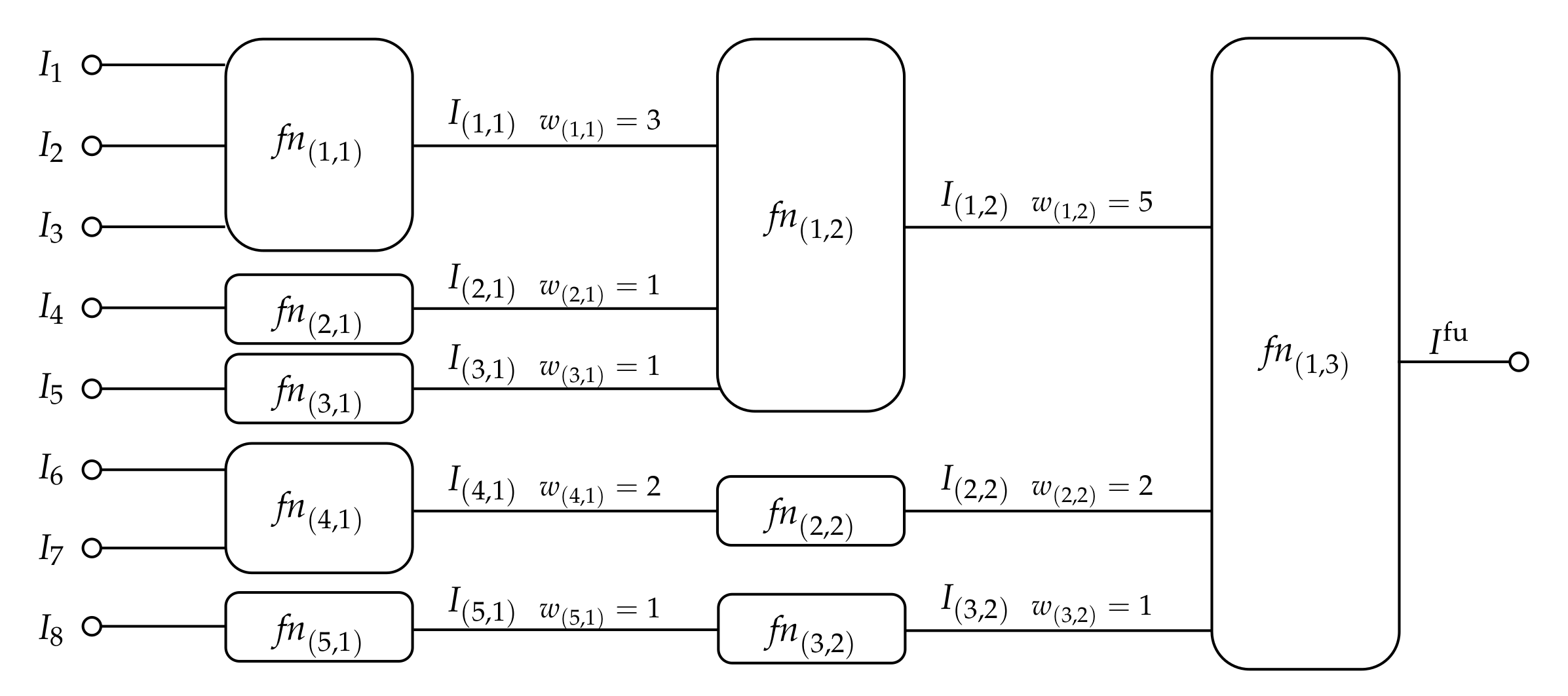
4.4. Remark on Multi-Level Fusion by Splitting Nodes
5. Evaluation
5.1. Computational Complexity
5.1.1. Fusion Rules
5.1.2. Fusion Topology Algorithms
5.2. Robustness
5.2.1. Data Preprocessing
- If data are singular values or probability distributions, they are transferred into possibility distributions first. For this step, singular values x are interpreted as probability distributions with and . Transformation is conducted by the truncated triangular probability-possibility transformation [49,77,78] resulting in .
- Second, sources providing noisy data are regarded as partially unreliable. Their possibility distribution are modified using (25) accordingly. Unreliability values for information sources are determined heuristically.
- Third, modified possibility distributions are mapped to a common, shared frame of discernment. This X is based on fuzzy memberships , i.e., . This requires a fuzzy class to be defined to which indicates the degree of membership of x. The class membership function can either be provided by an expert or trained automatically [18,38,39]. Here, is trained by a parametric unimodal potential function proposed proposed by Lohweg et al. [79]:with being the arithmetic mean of given training data . The parameters are determined as follows: , , and , . and are often determined empirically [21,80]. A training routine for and based on density estimations is given by Mönks et al. [81].The possibility distribution is then mapped to via the extension principle as follows:
5.2.2. Nonrepresentative Training Data
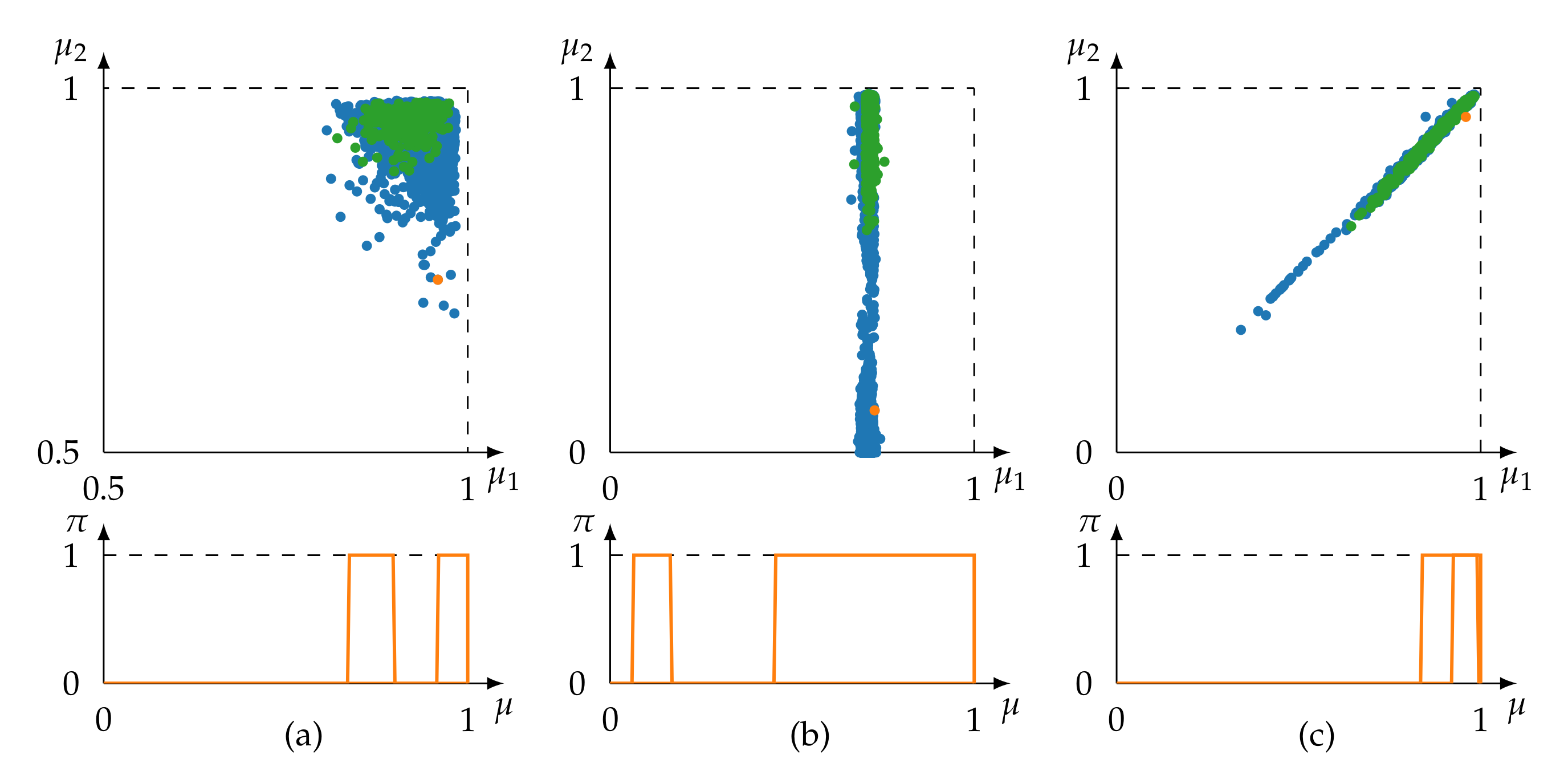
- For the consistency-based approach, fusion nodes trained on complete data are expected to be smaller or of equal size compared with nodes trained on reduced data. More specifically, because (16) requires consistencies of all data instances to be above the threshold .
- Sources grouped by the redundancy-based approach are expected to always be a subset of at least one consistency-based found group , i.e., because the redundancy metric (18) is more restrictive than pure consistency. The additional range information (22) prevents sources being added to a fusion node when it is not known that they behave consistently over the complete frame of discernment.
5.2.3. Defective Sources
- with ,
- with , and
- with .
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Specificity as a Measure of Information Content
- 1.
- in the case of total ignorance, i.e., .
- 2.
- in the case of complete knowledge, i.e., only one unique event is totally possible and all other events are impossible.
- 3.
- A specificity measure de- and increases with the maximum value of , i.e., let be the k-th largest possibility degree in , then .
- 4.
- , i.e., the specificity decreases as the possibilities of other values approach the maximum value of .
Appendix B. Proofs of (Non-)Associativity of Fusion Rules


References
- Hall, D.L.; Llinas, J.; Liggins, M.E. (Eds.) Handbook of Multisensor Data Fusion: Theory and Practice, 2nd ed.; The Electrical Engineering and Applied Signal Processing Series; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Ayyub, B.M.; Klir, G.J. Uncertainty Modeling and Analysis in Engineering and the Sciences; Chapman & Hall/CRC: Boca Raton, FL, USA, 2006. [Google Scholar]
- Dubois, D.; Prade, H. On the use of aggregation operations in information fusion processes. Fuzzy Sets Syst. 2004, 142, 143–161. [Google Scholar] [CrossRef] [Green Version]
- Dubois, D.; Prade, H. Possibility theory in information fusion. In Proceedings of the Third International Conference on Information Fusion, Paris, France, 10–13 July 2000; Volume 1, pp. PS6–PS19. [Google Scholar] [CrossRef]
- Dubois, D.; Everaere, P.; Konieczny, S.; Papini, O. Main issues in belief revision, belief merging and information fusion. In A Guided Tour of Artificial Intelligence Research: Volume I: Knowledge Representation, Reasoning and Learning; Marquis, P., Papini, O., Prade, H., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 441–485. [Google Scholar] [CrossRef]
- Dubois, D.; Liu, W.; Ma, J.; Prade, H. The basic principles of uncertain information fusion. An organised review of merging rules in different representation frameworks. Inf. Fusion 2016, 32, 12–39. [Google Scholar] [CrossRef]
- Varshney, P.K. Multisensor data fusion. Electron. Commun. Eng. J. 1997, 9, 245–253. [Google Scholar] [CrossRef]
- Mitchell, H.B. (Ed.) Multi-Sensor Data Fusion: An Introduction; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar] [CrossRef]
- Castanedo, F.; Ursino, D.; Takama, Y. A review of data fusion techniques. Sci. World J. 2013, 2013, 704504. [Google Scholar] [CrossRef] [PubMed]
- Bakr, M.A.; Lee, S. Distributed multisensor data fusion under unknown correlation and data inconsistency. Sensors 2017, 17, 2472. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Durrant-Whyte, H.F. Sensor models and multisensor integration. Int. J. Robot. Res. 1988, 7, 97–113. [Google Scholar] [CrossRef]
- Elmenreich, W. An Introduction to Sensor Fusion; Technical Report; Vienna University of Technology: Vienna, Austria, 2002. [Google Scholar]
- Elmenreich, W. A review on system architectures for sensor fusion applications. In Software Technologies for Embedded and Ubiquitous Systems; Obermaisser, R., Nah, Y., Puschner, P., Rammig, F.J., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 547–559. [Google Scholar] [CrossRef] [Green Version]
- Ben Ayed, S.; Trichili, H.; Alimi, A.M. Data fusion architectures: A survey and comparison. In Proceedings of the 2015 15th International Conference on Intelligent Systems Design and Applications (ISDA), Marrakech, Morocco, 14–16 December 2015; pp. 277–282. [Google Scholar] [CrossRef]
- Sidek, O.; Quadri, S.A. A review of data fusion models and systems. Int. J. Image Data Fusion 2012, 3, 3–21. [Google Scholar] [CrossRef]
- Raz, A.K.; Wood, P.; Mockus, L.; DeLaurentis, D.A.; Llinas, J. Identifying interactions for information fusion system design using machine learning techniques. In Proceedings of the 2018 21st International Conference on Information Fusion (FUSION), Cambridge, UK, 10–13 July 2018; pp. 226–233. [Google Scholar] [CrossRef]
- Luo, R.C.; Kay, M.G. Multisensor integration and fusion in intelligent systems. IEEE Trans. Syst. Man Cybern. 1989, 19, 901–931. [Google Scholar] [CrossRef]
- Mönks, U. Information Fusion Under Consideration of Conflicting Input Signals. In Technologies for Intelligent Automation; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar] [CrossRef]
- Fritze, A.; Mönks, U.; Holst, C.A.; Lohweg, V. An approach to automated fusion system design and adaptation. Sensors 2017, 17, 601. [Google Scholar] [CrossRef] [Green Version]
- Rescher, N.; Manor, R. On inference from inconsistent premisses. Theory Decis. 1970, 1, 179–217. [Google Scholar] [CrossRef]
- Ehlenbröker, J.F.; Mönks, U.; Lohweg, V. Sensor defect detection in multisensor information fusion. J. Sensors Sens. Syst. 2016, 5, 337–353. [Google Scholar] [CrossRef]
- Holst, C.A.; Lohweg, V. A conflict-based drift detection and adaptation approach for multisensor information fusion. In Proceedings of the 2018 IEEE 23rd International Conference on Emerging Technologies and Factory Automation (ETFA), Turin, Italy, 4–9 September 2018; pp. 967–974. [Google Scholar] [CrossRef]
- Holst, C.A.; Lohweg, V. Improving majority-guided fuzzy information fusion for Industry 4.0 condition monitoring. In Proceedings of the 2019 22nd International Conference on Information Fusion (FUSION), Ottawa, ON, Canada, 2–5 July 2019. [Google Scholar]
- Holst, C.A.; Lohweg, V. Feature fusion to increase the robustness of machine learners in industrial environments. Automation 2019, 67, 853–865. [Google Scholar] [CrossRef]
- Mönks, U.; Lohweg, V.; Dörksen, H. Conflict measures and importance weighting for information fusion applied to Industry 4.0. In Information Quality in Information Fusion and Decision Making; Bossé, É., Rogova, G.L., Eds.; Information Fusion and Data Science; Springer International Publishing: Cham, Switzerland, 2019; pp. 539–561. [Google Scholar] [CrossRef]
- Fritze, A.; Mönks, U.; Lohweg, V. A support system for sensor and information fusion system design. Procedia Technol. 2016, 26, 580–587. [Google Scholar] [CrossRef]
- Fritze, A.; Mönks, U.; Lohweg, V. A concept for self-configuration of adaptive sensor and information fusion systems. In Proceedings of the IEEE 21st International Conference on Emerging Technologies and Factory Automation (ETFA), Berlin, Germany, 6–9 September 2016. [Google Scholar] [CrossRef]
- Boury-Brisset, A.C. Ontology-based approach for information fusion. In Proceedings of the Sixth International Conference of Information Fusion, Cairns, QLD, Australia, 8–11 July 2003; pp. 522–529. [Google Scholar] [CrossRef]
- Martí, E.; García, J.; Molina, J.M. Adaptive sensor fusion architecture through ontology modeling and automatic reasoning. In Proceedings of the 2015 18th International Conference on Information Fusion (Fusion), Washington, DC, USA, 6–9 July 2015; pp. 1144–1151. [Google Scholar]
- Steinberg, A.N.; Bowman, C.L. Revisions to the JDL Data Fusion Model. In Handbook of Multisensor Data Fusion; Hall, D.L., Llinas, J., Eds.; The Electrical Engineering and Applied Signal Processing Series; CRC Press: Boca Raton, FL, USA, 2001; pp. 2-1–2-19. [Google Scholar]
- Smoleń, M.; Augustyniak, P. Assisted living system with adaptive sensor’s contribution. Sensors 2020, 20, 5278. [Google Scholar] [CrossRef] [PubMed]
- Solaiman, B.; Bossé, É. Possibility Theory for the Design of Information Fusion Systems; Information Fusion and Data Science; Springer International Publishing: Cham, Switzerland, 2019. [Google Scholar]
- Waltz, E.; Llinas, J. Multisensor Data Fusion; Artech House: Boston, MA, USA, 1990; Volume 685. [Google Scholar]
- Grabisch, M.; Prade, H. The correlation problem in sensor fusion in a possibilistic framework. Int. J. Intell. Syst. 2001, 16, 1273–1283. [Google Scholar] [CrossRef] [Green Version]
- Ayoun, A.; Smets, P. Data association in multi-target detection using the transferable belief model. Int. J. Intell. Syst. 2001, 16, 1167–1182. [Google Scholar] [CrossRef]
- Schubert, J. Clustering belief functions based on attracting and conflicting metalevel evidence using Potts spin mean field theory. Inf. Fusion 2004, 5, 309–318. [Google Scholar] [CrossRef]
- Schubert, J. Clustering decomposed belief functions using generalized weights of conflict. Int. J. Approx. Reason. 2008, 48, 466–480. [Google Scholar] [CrossRef] [Green Version]
- Holst, C.A.; Lohweg, V. A redundancy metric based on the framework of possibility theory for technical systems. In Proceedings of the 2020 25th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Vienna, Austria, 8–11 September 2020. [Google Scholar] [CrossRef]
- Holst, C.A.; Lohweg, V. A redundancy metric set within possibility theory for multi-sensor systems. Sensors 2021, 21, 2508. [Google Scholar] [CrossRef]
- Kamal, A.T.; Bappy, J.H.; Farrell, J.A.; Roy-Chowdhury, A.K. Distributed multi-target tracking and data association in vision networks. IEEE Trans. Pattern Anal. Mach. 2016, 38, 1397–1410. [Google Scholar] [CrossRef] [Green Version]
- Yoon, K.; Du Kim, Y.; Yoon, Y.C.; Jeon, M. Data association for multi-object tracking via deep neural networks. Sensors 2019, 19, 559. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khaleghi, B.; Khamis, A.; Karray, F.O.; Razavi, S.N. Multisensor data fusion: A review of the state-of-the-art. Inf. Fusion 2013, 14, 28–44. [Google Scholar] [CrossRef]
- Lohweg, V.; Voth, K.; Glock, S. A possibilistic framework for sensor fusion with monitoring of sensor reliability. In Sensor Fusion; Thomas, C., Ed.; IntechOpen: Rijeka, Croatia, 2011. [Google Scholar] [CrossRef] [Green Version]
- Zadeh, L.A. Fuzzy sets as a basis for a theory of possibility. Fuzzy Sets Syst. 1978, 1, 3–28. [Google Scholar] [CrossRef]
- Denœux, T.; Dubois, D.; Prade, H. Representations of uncertainty in artificial intelligence: Probability and possibility. In A Guided Tour of Artificial Intelligence Research: Volume I: Knowledge Representation, Reasoning and Learning; Marquis, P., Papini, O., Prade, H., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 69–117. [Google Scholar] [CrossRef]
- Salicone, S.; Prioli, M. Measuring Uncertainty within the Theory of Evidence; Springer Series in Measurement Science and Technology; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Dubois, D.; Prade, H. Representation and combination of uncertainty with belief functions and possibility measures. Comput. Intell. 1988, 4, 244–264. [Google Scholar] [CrossRef]
- Dubois, D.; Prade, H. Possibility theory and data fusion in poorly informed environments. Control Eng. Pract. 1994, 2, 811–823. [Google Scholar] [CrossRef]
- Dubois, D.; Foulloy, L.; Mauris, G.; Prade, H. Probability-possibility transformations, triangular fuzzy sets, and probabilistic inequalities. Reliab. Comput. 2004, 10, 273–297. [Google Scholar] [CrossRef]
- Yager, R.R. On ordered weighted averaging aggregation operators in multicriteria decisionmaking. IEEE Trans. Syst. Man Cybern. 1988, 18, 183–190. [Google Scholar] [CrossRef]
- Yager, R.R. On the specificity of a possibility distribution. Fuzzy Sets Syst. 1992, 50, 279–292. [Google Scholar] [CrossRef]
- Yager, R.R. Measures of specificity. In Computational Intelligence: Soft Computing and Fuzzy-Neuro Integration with Applications; Kaynak, O., Zadeh, L.A., Türkşen, B., Rudas, I.J., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; pp. 94–113. [Google Scholar]
- Yager, R.R. Measures of specificity over continuous spaces under similarity relations. Fuzzy Sets Syst. 2008, 159, 2193–2210. [Google Scholar] [CrossRef]
- Yager, R.R. Aggregation operators and fuzzy systems modeling. Fuzzy Sets Syst. 1994, 67, 129–145. [Google Scholar] [CrossRef]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning—II. Inf. Sci. 1975, 8, 301–357. [Google Scholar] [CrossRef]
- Klement, E.P. Triangular Norms; Springer eBook Collection Mathematics and Statistics; Springer: Dordrecht, Germany, 2000; Volume 8. [Google Scholar] [CrossRef]
- Benferhat, S.; Dubois, D.; Prade, H. Reasoning in inconsistent stratified knowledge bases. In Proceedings of the 26th IEEE International Symposium on Multiple-Valued Logic (ISMVL’96), Compostela, Spain, 29–31 May 1996; pp. 184–189. [Google Scholar] [CrossRef]
- Dubois, D.; Fargier, H.; Prade, H. Multi-source information fusion: A way to cope with incoherences. In Proceedings of the French Days on Fuzzy Logic and Applications (LFA), Paris, France, 21 October 2000; pp. 123–130. [Google Scholar]
- Liu, W.; Qi, G.; Bell, D.A. Adaptive merging of prioritized knowledge bases. Fundam. Inform. 2006, 73, 389–407. [Google Scholar]
- Hunter, A.; Liu, W. A context-dependent algorithm for merging uncertain information in possibility theory. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2008, 38, 1385–1397. [Google Scholar] [CrossRef]
- Destercke, S.; Dubois, D.; Chojnacki, E. Possibilistic information fusion using maximal coherent subsets. IEEE Trans. Fuzzy Syst. 2009, 17, 79–92. [Google Scholar] [CrossRef] [Green Version]
- Yager, R.R. Aggregating evidence using quantified statements. Inf. Sci. 1985, 36, 179–206. [Google Scholar] [CrossRef]
- Dubois, D.; Prade, H.; Testemale, C. Weighted fuzzy pattern matching. Fuzzy Sets Syst. 1988, 28, 313–331. [Google Scholar] [CrossRef]
- Oussalah, M.; Maaref, H.; Barret, C. From adaptive to progressive combination of possibility distributions. Fuzzy Sets Syst. 2003, 139, 559–582. [Google Scholar] [CrossRef]
- Yager, R.R. A general approach to the fusion of imprecise information. Int. J. Intell. Syst. 1997, 12, 1–29. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Glock, S.; Voth, K.; Schaede, J.; Lohweg, V. A framework for possibilistic multi-source data fusion with monitoring of sensor reliability. In Proceedings of the World Conference on Soft Computing, San Francisco, CA, USA, 23–26 May 2011. [Google Scholar]
- Larsen, H.L. Efficient importance weighted aggregation between min and max. In Proceedings of the ninth Conference on Information Processing and Management of Uncertainty in Knowledge-based Systems, Annecy, France, 1–5 July 2002; pp. 1203–1208. [Google Scholar]
- Oussalah, M. Study of some algebraical properties of adaptive combination rules. Fuzzy Sets Syst. 2000, 114, 391–409. [Google Scholar] [CrossRef]
- Calude, C.; Longo, G. The deluge of spurious correlations in big data. Found. Sci. 2017, 22, 595–612. [Google Scholar] [CrossRef] [Green Version]
- Delmotte, F.; Borne, P. Modeling of reliability with possibility theory. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 1998, 28, 78–88. [Google Scholar] [CrossRef]
- Žliobaitė, I. Learning under concept drift: An overview. arXiv 2010, arXiv:1010.4784. [Google Scholar] [CrossRef]
- Ramírez-Gallego, S.; Krawczyk, B.; García, S.; Woźniak, M.; Herrera, F. A survey on data preprocessing for data stream mining: Current status and future directions. Neurocomputing 2017, 239, 39–57. [Google Scholar] [CrossRef]
- Dubois, D.; Del Cerro, L.F.; Herzig, A.; Prade, H. An ordinal view of independence with application to plausible reasoning. In Uncertainty Proceedings 1994; Mantaras, R.L.d., Poole, D., Eds.; Morgan Kaufmann: Burlington, MA, USA, 1994; pp. 195–203. [Google Scholar] [CrossRef] [Green Version]
- Yager, R.R.; Kelman, A. Fusion of fuzzy information with considerations for compatibility, partial aggregation, and reinforcement. Int. J. Approx. Reason. 1996, 15, 93–122. [Google Scholar] [CrossRef] [Green Version]
- Knuth, D.E. Big omicron and big omega and big theta. ACM Sigact News 1976, 8, 18–24. [Google Scholar] [CrossRef]
- Lasserre, V.; Mauris, G.; Foulloy, L. A simple possibilistic modelisation of measurement uncertainty. In Uncertainty in Intelligent and Information Systems; Bouchon-Meunier, B., Yager, R.R., Zadeh, L.A., Eds.; World Scientific Publishing Co. Pte. Ltd.: Singapore, 2000; Volume 20, pp. 58–69. [Google Scholar] [CrossRef]
- Mauris, G.; Lasserre, V.; Foulloy, L. Fuzzy modeling of measurement data acquired from physical sensors. IEEE Trans. Instrum. Meas. 2000, 49, 1201–1205. [Google Scholar] [CrossRef]
- Lohweg, V.; Diederichs, C.; Müller, D. Algorithms for hardware-based pattern recognition. EURASIP J. Appl. Signal Process. 2004, 2004, 1912–1920. [Google Scholar] [CrossRef] [Green Version]
- Voth, K.; Glock, S.; Mönks, U.; Lohweg, V.; Türke, T. Multi-sensory machine diagnosis on security printing machines with two-layer conflict solving. In Proceedings of the SENSOR+TEST Conference 2011, Nuremberg, Germany, 7–9 June 2011; pp. 686–691. [Google Scholar] [CrossRef]
- Mönks, U.; Petker, D.; Lohweg, V. Fuzzy-Pattern-Classifier training with small data sets. In Information Processing and Management of Uncertainty in Knowledge-Based Systems. Theory and Methods; Hüllermeier, E., Kruse, R., Hoffmann, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 426–435. [Google Scholar] [CrossRef]
- Paschke, F.; Bayer, C.; Bator, M.; Mönks, U.; Dicks, A.; Enge-Rosenblatt, O.; Lohweg, V. Sensorlose Zustandsüberwachung an Synchronmotoren. In 23. Workshop Computational Intelligence; Hoffmann, F., Hüllermeier, E., Mikut, R., Eds.; KIT Scientific Publishing: Karlsruhe, Germany, 2013; Volume 46, pp. 211–225. [Google Scholar]
- Lessmeier, C.; Enge-Rosenblatt, O.; Bayer, C.; Zimmer, D. Data acquisition and signal analysis from measured motor currents for defect detection in electromechanical drive systems. In Proceedings of the PHM Society European Conference, Nantes, France, 8–10 July 2014. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA, 2020; Available online: http://archive.ics.uci.edu/ml (accessed on 14 March 2022).
- Charfi, A.; Bouhamed, S.A.; Bossé, É.; Kallel, I.K.; Bouchaala, W.; Solaiman, B.; Derbel, N. Possibilistic similarity measures for data science and machine learning applications. IEEE Access 2020, 8, 49198–49211. [Google Scholar] [CrossRef]
- Higashi, M.; Klir, G.J. Measures of uncertainty and information based on possibility distributions. Int. J. Gen. Syst. 1982, 9, 43–58. [Google Scholar] [CrossRef]
- Higashi, M.; Klir, G.J. On the notion of distance representing information closeness: Possibility and probability distributions. Int. J. Gen. Syst. 1983, 9, 103–115. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
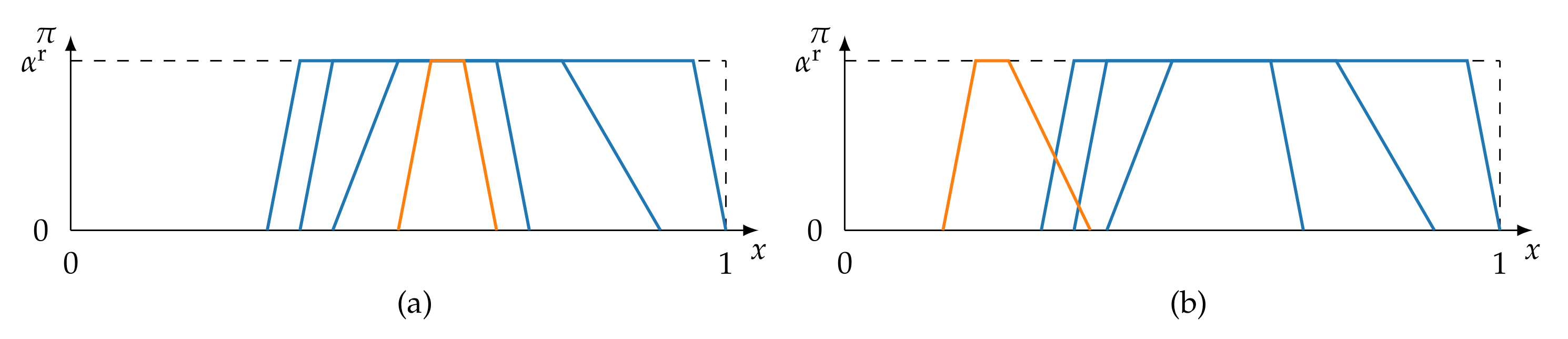{kind=link}
{kind=link}
{kind=link}
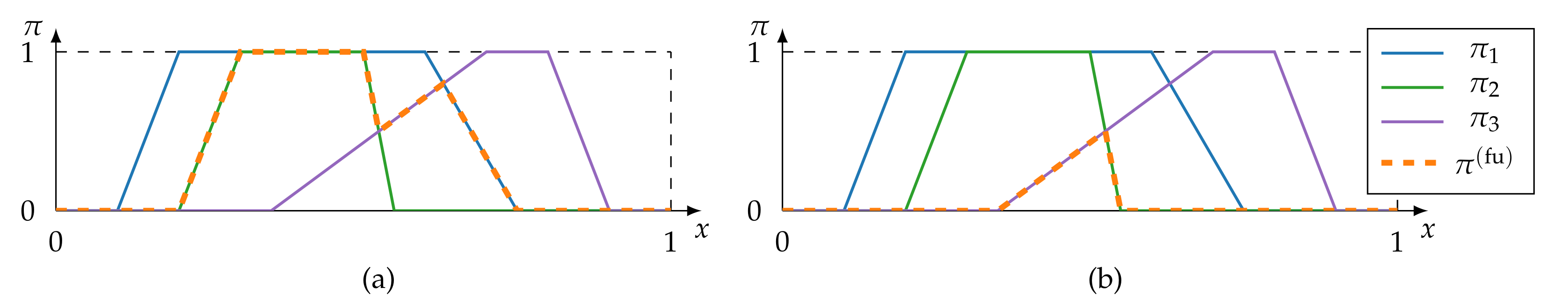{kind=link}
{kind=link}
| Fusion Rule | Equation(s) | Associative | Proof of Associativity | Quasi-Associative | Proof of Quasi-Associativity |
|---|---|---|---|---|---|
| Conjunctive | (3) | yes | Inherited from t-norm | yes | See Proposition 2 |
| Renormalised Conjunctive | (4) | Dependent on t-norm | Proof for nonassociativity in the case of minimum-norm and associativity in the case of product-norm given by Dubois and Prade [47] | yes | and |
| Disjunctive | (5) | yes | Inherited from s-norm | yes | See Proposition 2 |
| MCS fusion | (6) | no | [61] | no | [61] |
| Quantified | (7) | no | Proof given in Appendix B | no | Similar to MCS fusion |
| Adaptive | (8), (9) | no | [69] | no | [69] |
| Progressive | (9), (10) | no | Inherited from adaptive fusion | no | Inherited from adaptive fusion |
| Estimation | (13) | yes (with restrictions) | See Proposition 3 | yes (with restrictions) | See Propositions 2 and 3 |
| MOGPFR | (14) | no | Proof given in Appendix B | no | OWA operator prevents quasi-associativity |
| Node | Reduced Training Data | Complete Training Data | ||||||
|---|---|---|---|---|---|---|---|---|
| , | , | |||||||
| 0 | 0 | |||||||
| 0 | 0 | |||||||
| 0 | 0 | |||||||
| 0 | 0 | |||||||
| 0 | 0 | |||||||
| 0 | 0 | |||||||
| 0 | 0 | |||||||
| 0 | 0 | |||||||
| 0 | 0 | |||||||
| 0 | 0 | |||||||
| 0 | 0 | |||||||
| 0 | 0 | |||||||
| 0 | - | - | - | - | ||||
| 0 | - | - | - | - | ||||
| 0 | - | - | - | - | ||||
| 0 | - | - | - | - | ||||
| 0 | - | - | - | - | ||||
| 0 | - | - | - | - | ||||
| 0 | - | - | - | - | ||||
| 0 | - | - | - | - | ||||
| Node | Reduced Training Data | Complete Training Data | ||||||
|---|---|---|---|---|---|---|---|---|
| , | , | |||||||
| 0 | 0 | |||||||
| 0 | 0 | |||||||
| 0 | 0 | |||||||
| 0 | 0 | |||||||
| 0 | 0 | |||||||
| 0 | 0 | |||||||
| 0 | 0 | |||||||
| 0 | 0 | |||||||
| 0 | - | - | - | - | ||||
| 0 | - | - | - | - | ||||
| 0 | - | - | - | - | ||||
| 0 | - | - | - | - | ||||
| 0 | - | - | - | - | ||||
| 0 | - | - | - | - | ||||
| 0 | - | - | - | - | ||||
| Fusion Approach | Similarity (32) | Similarity (32) | ||||
|---|---|---|---|---|---|---|
| min | mean | max | min | mean | max | |
| Renormalised Conjunctive (15) | 1 | 1 | ||||
| Discounted Renormalised Conjunctive (15), (23), (25) | 0 | 1 | 1 | |||
| Estimation (13) | 1 | 1 | ||||
| Weighted Estimation (27) | 1 | 1 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Holst, C.-A.; Lohweg, V. Designing Possibilistic Information Fusion—The Importance of Associativity, Consistency, and Redundancy. Metrology 2022, 2, 180-215. https://doi.org/10.3390/metrology2020012
Holst C-A, Lohweg V. Designing Possibilistic Information Fusion—The Importance of Associativity, Consistency, and Redundancy. Metrology. 2022; 2(2):180-215. https://doi.org/10.3390/metrology2020012
Chicago/Turabian StyleHolst, Christoph-Alexander, and Volker Lohweg. 2022. "Designing Possibilistic Information Fusion—The Importance of Associativity, Consistency, and Redundancy" Metrology 2, no. 2: 180-215. https://doi.org/10.3390/metrology2020012
APA StyleHolst, C.-A., & Lohweg, V. (2022). Designing Possibilistic Information Fusion—The Importance of Associativity, Consistency, and Redundancy. Metrology, 2(2), 180-215. https://doi.org/10.3390/metrology2020012