1. Introduction
Coronavirus disease, also known as COVID-19, is an infectious disease that is caused by a virus called severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) from the family of viruses that cause illnesses in humans and animals. It is believed that SARS-CoV-2 officially originated in bats and spread to humans through a host known as the pangolin [
1]. It became a pandemic as it spread, affecting the world in a destructive way and causing unrestrained infections and deaths globally. Ever since the pandemic started affecting the world, the United Kingdom (UK) was severely hit by the impact of the virus, with millions of cases and a high mortality rate, causing millions of deaths compared to other European countries, with a mortality rate of 1.46% up until 3 April 2023 [
2]. The significant risk factor that was primarily identified as causing severe illness and death from COVID-19 is primarily age, as well as older individuals and others who have other health conditions who are also known to be at higher risk. Other factors like insufficient medical resources and personnels have contributed to the rapid spread of the disease in the UK, which has pressurized its healthcare system. The UK government sought out and implemented various control measures as intervention strategies to control the transmission of the disease, such as face masking, social distancing, lockdowns, and vaccination.
Over the years, mathematical modeling has played a major role in predicting incidence and mortality rates for infectious diseases such as COVID-19 [
3]. Mathematical modeling has been shown to be a very effective technique for tracking and managing many diseases, such as tuberculosis, [
4], malaria, and smoking-related diseases, suggesting possible government interventions [
5,
6]. Epidemiological and statistical modeling and analysis have been used for predicting incidence and mortality rates and to consider the impact that non-pharmaceutical intervention (NPI) control measures such as lockdowns, social distancing, and travel bans have had. The Response Team of Imperial College formulated a COVID-19 model that was used to predict the mortality rate of COVID-19 in the UK [
7]. It was found that the NPI control measures, although very effective in reducing mortality rates, were only short term. The model was then used to predict the likely occurrence of a second wave of the disease in the UK and a possible significant increase in mortality rates without the implementation of adequate and effective control measures. One of the most effective measures for controlling the mortality rates of COVID-19 in the UK was vaccination, which was made available to all adults. The UK government ensured that people were vaccinated since it had been shown to be a more effective strategy for reducing illnesses and mortality rates from COVID-19 in the UK. Policymakers are responsible for ensuring the implementation of the most effective control measures for mitigating COVID-19 transmission.
Factors that underline the increase in health problems in the UK are gender and age; these have been seen to increase the rate of mortality in the UK. In the world, the UK is known to have one of the highest COVID-19 mortality rates. In total, 126,000 deaths have occurred from COVID-19 cases since inception as of March 2021 [
8]. Various studies were carried out in the UK on modeling the rates of mortality from COVID-19; for instance, Ref. [
9] estimated the cases and number of deaths from COVID-19 in the UK by using the Bayesian model. The authors research shows that implementing NPI control measures like face masking and social distancing reduces the number of deaths. Ref. [
10] used a cohort study design to investigate some factors, such as males and older age, being responsible for the high rate of mortality in the UK. The authors study pointed out that such factors have worsened health problems such as obesity and diabetes and increased the rate of mortality from COVID-19. During the first wave of the COVID-19 pandemic, non-pharmaceutical interventions (NPIs) were very effective in reducing the transmission of COVID-19.
The Imperial College Response Team on COVID-19 researched and found that NPIs, such as school closures and social distancing, were used as effective control measures in reducing COVID-19 spread in the UK. In their study, they used a mathematical model to estimate the NPIs’ impact on the reproductive number,
, of the COVID-19 virus and found that without NPIs, the
value would have been excessively higher [
11]. Ref. [
11] used a mathematical model to estimate the effect of vaccination on COVID-19 cases in the UK and their hospitalization. Vaccines were found to be highly significant and effective in reducing COVID-19 cases. The London School of Hygiene in [
12] performed a study that used mathematical modeling to estimate how school closures impacted the spread and reduction of the value
of the virus. Although, in their study, they found out that school closures impacted the spread and reduction of the value
of the virus, it was not enough for the value of
to be less than 1. The Scientific Pandemic Influenza Group on Modeling (SPI-M) in [
13] performed a study using mathematical modeling to estimate and find out the impact that the value
of the Delta variant had on COVID-19 transmission. They found out that the value of
caused a higher risk of hospitalization in the Delta variant. The University of Warwick, Ref. [
14] carried out a study to understand the impact of the COVID-19 pandemic on the rate of mortality in the UK and discovered that the pandemic has had a highly significant impact on the rate of mortality in the UK, particularly among older adults. Their study estimated the excess rate of mortality in the UK through a mathematical model. They discovered that the mortality rate was highest among those aged 85 and over.
In [
15], the authors developed a deterministic transmission model to describe the prevalence of individuals who are PCR positive for SARS-CoV-2 in some states in the United States. Our work is an extension of the model developed in [
15] by taking into account vaccination and the number of deaths in the population. We also used the idea in [
16] by partitioning the data into before and after vaccination started in the UK, which helps to understand the dynamics of the disease at these different phases. We want to be able to explain the dynamics of the disease’s spread from the beginning of the pandemic in the UK until July 2022 by considering different phases in the epidemic curve. Also, we used both mathematical (a non-linear differential equation model) and statistical (time series modeling on a moving window) models to understand the COVID-19 pandemic in the UK. To the best of our knowledge, the use of this hybrid modeling approach is new and has not been used to understand the dynamics of the COVID-19 outbreak in the UK from the beginning of the pandemic up until July 2022, a period which is a combination of different phases of the pandemic.
The reminder of the article is divided as follows: in
Section 2, we present the materials and methods used in this work; in
Section 3, we calculate the basic reproduction number of the model developed and extensively study this important threshold parameter; in
Section 4, we present the numerical simulation results; in
Section 5, we present the statistical modeling approach, its analysis, and results obtained from using the method; and finally, in
Section 6, we discuss the results and some key conclusions from our analysis.
2. Materials and Methods
2.1. Materials
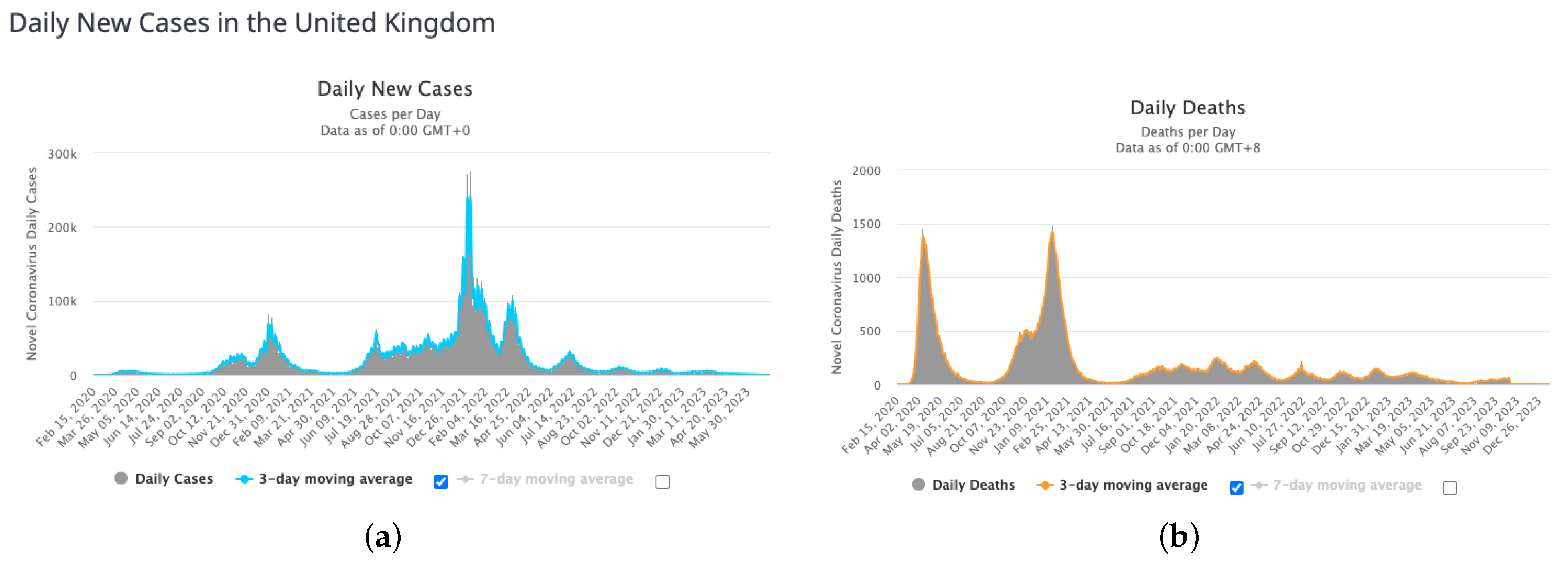
In this Section, we provide insight into the data that we will be using to analyze the motivation of this study. First, we present the daily new cases and deaths of COVID-19 outbreak in the UK adapted from [
17] as of year 2023 with a 3-day moving average (in blue) in
Figure 1 and the cumulative cases and deaths with their moving average as at July 2022 in
Figure 2.
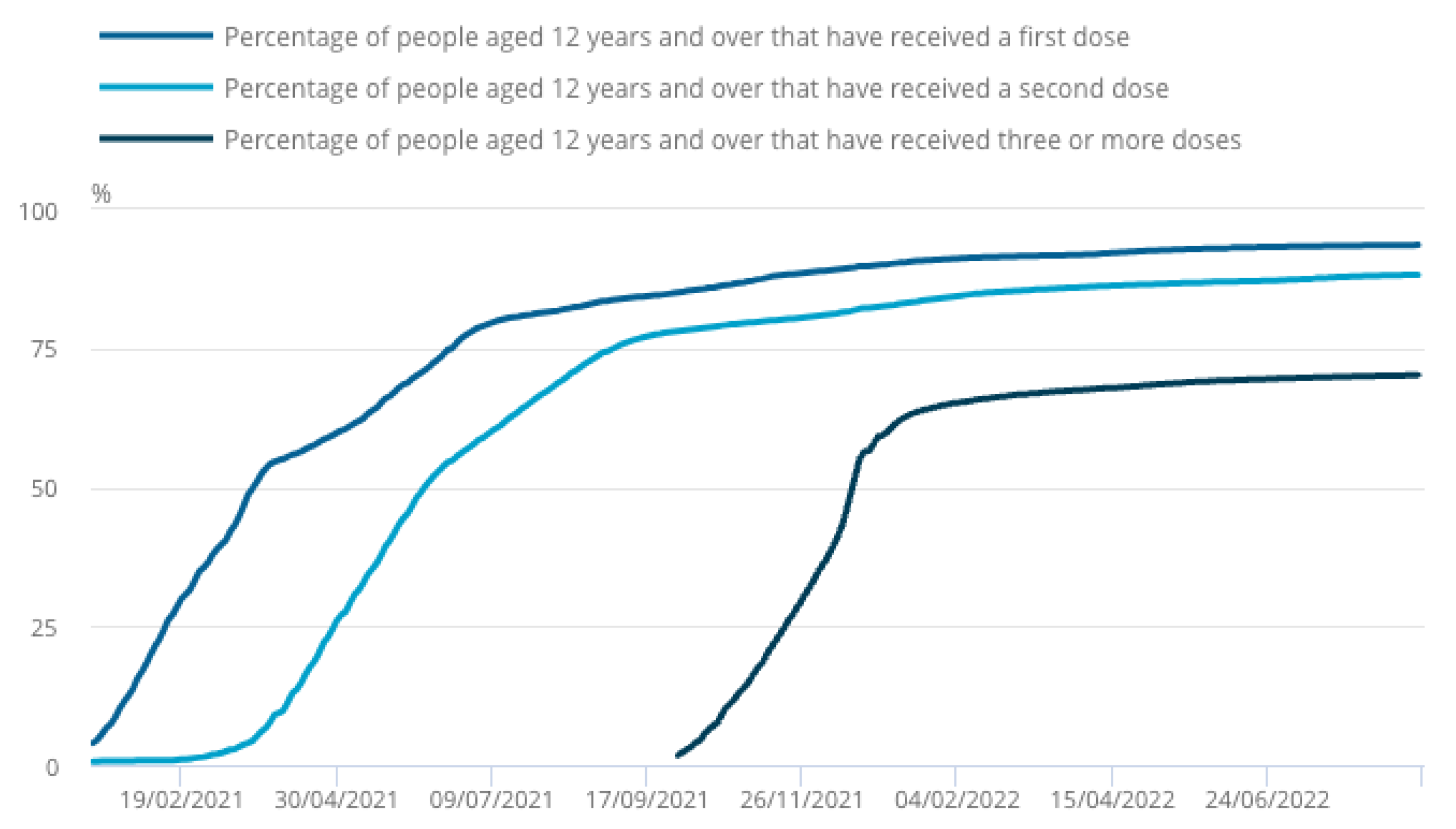
Secondly, we present in
Figure 3 the vaccination drive in the UK in the year 2021 to 2022, which shows that nearly 9 in 10 people aged 12 years and over in the UK have received two doses of a COVID-19 vaccine. This will help the part of our analysis that involves vaccination in our modeling approach to better understand the influence of vaccination in the disease dynamics.
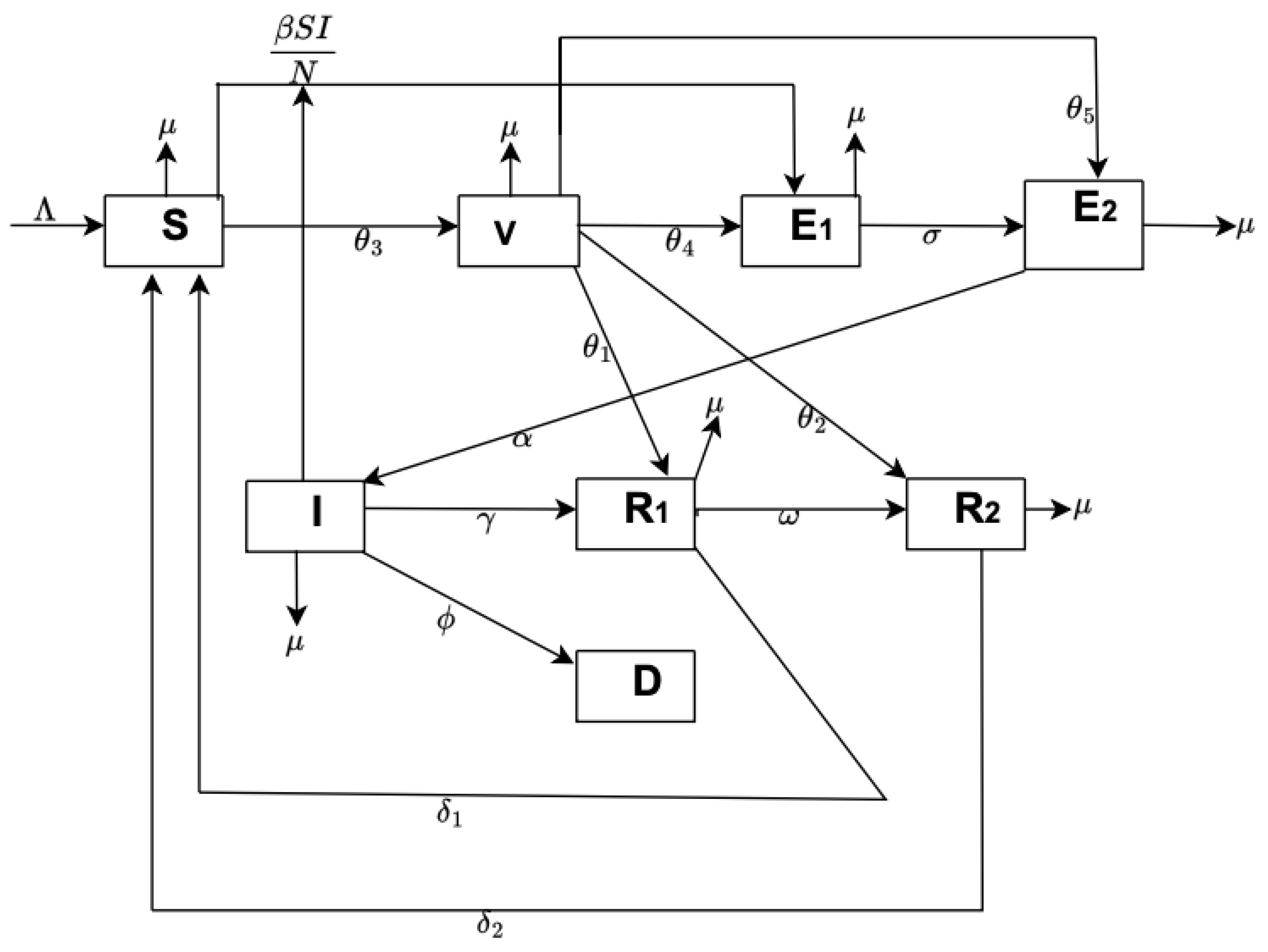
2.2. Mathematical Model Formulation
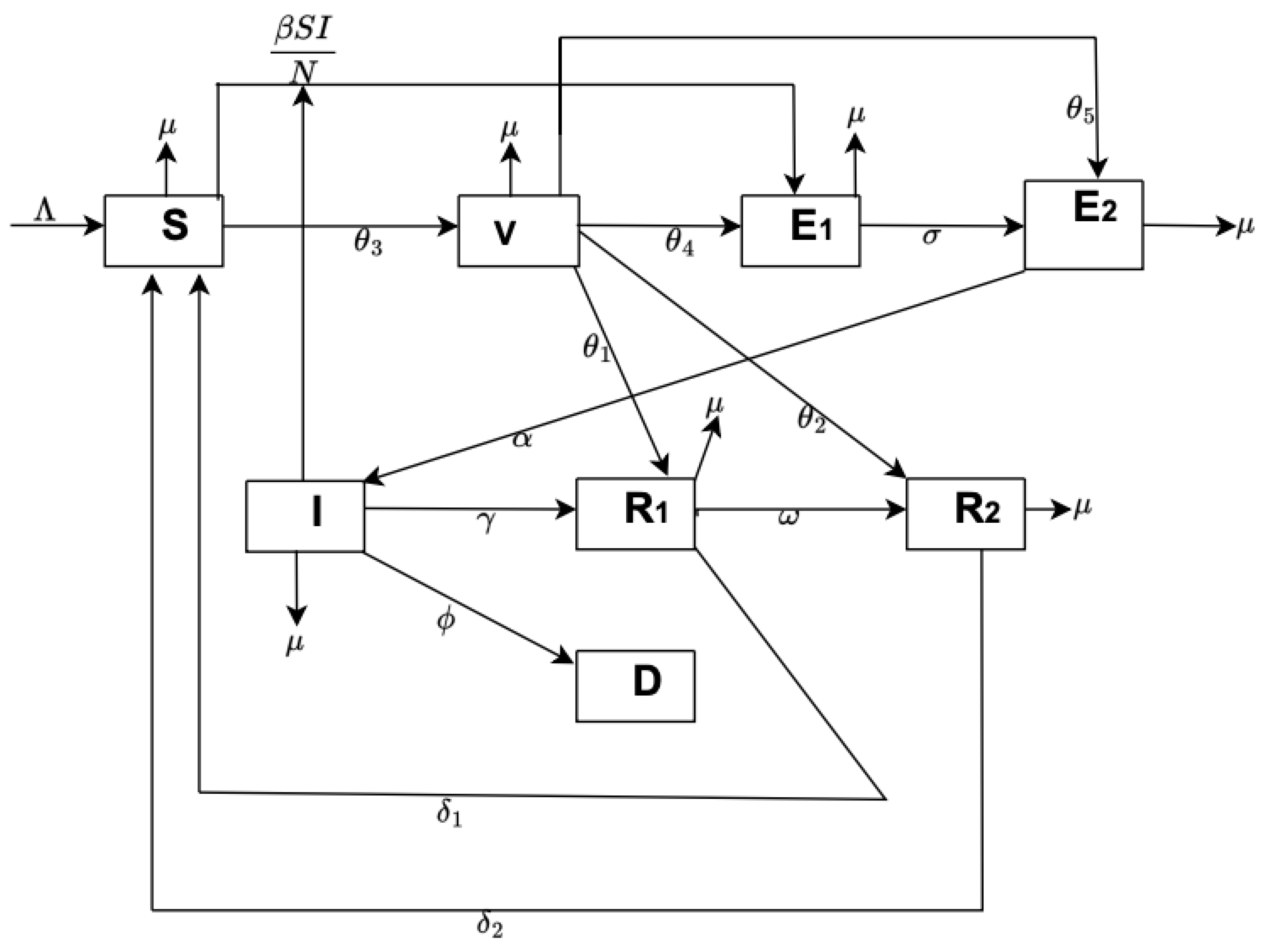
In this section, we propose a mathematical compartmental transmission model for the spread of the COVID-19 outbreak in the UK, consisting of susceptible
, vaccinated
, exposed unreported
, exposed reported
, infected
, recovered unreported
, recovered reported
, and death
. The total population (
) is assumed to be very large and open (natural deaths and exit rates are included). Recruitment into susceptible is at rate
is the effective contact rate, and
is the force of infection. We assumed the entire population (N) had no prior immunity against COVID-19 regardless of their vaccination status and that they can be re-infected. We also assume that some proportion of the vaccinated population can be exposed to the disease and not be reported because they assume that the vaccine makes them immune to the disease. Other parameters are defined in
Table 1, and the schematic diagram of the model Equation (
1) we developed can be seen in
Figure 4. The system of non-linear differential equations for our model is as follows:
where time
with the initial conditions
,
,
,
,
,
,
,
.
The mathematical analysis of model (1) such as the positivity, stability, and equilibrium points are presented in
Appendix A.
2.3. Statistical Fitting of Model (1)
We used data from a public database from the beginning of the pandemic to July 2022 in the United Kingdom. We used initial values (choice guided by information from [
8])
for susceptible, vaccinated, exposed unreported, exposed reported, infected, recovered unreported, recovered reported, and recovered individuals in the population, and the values of parameters are in
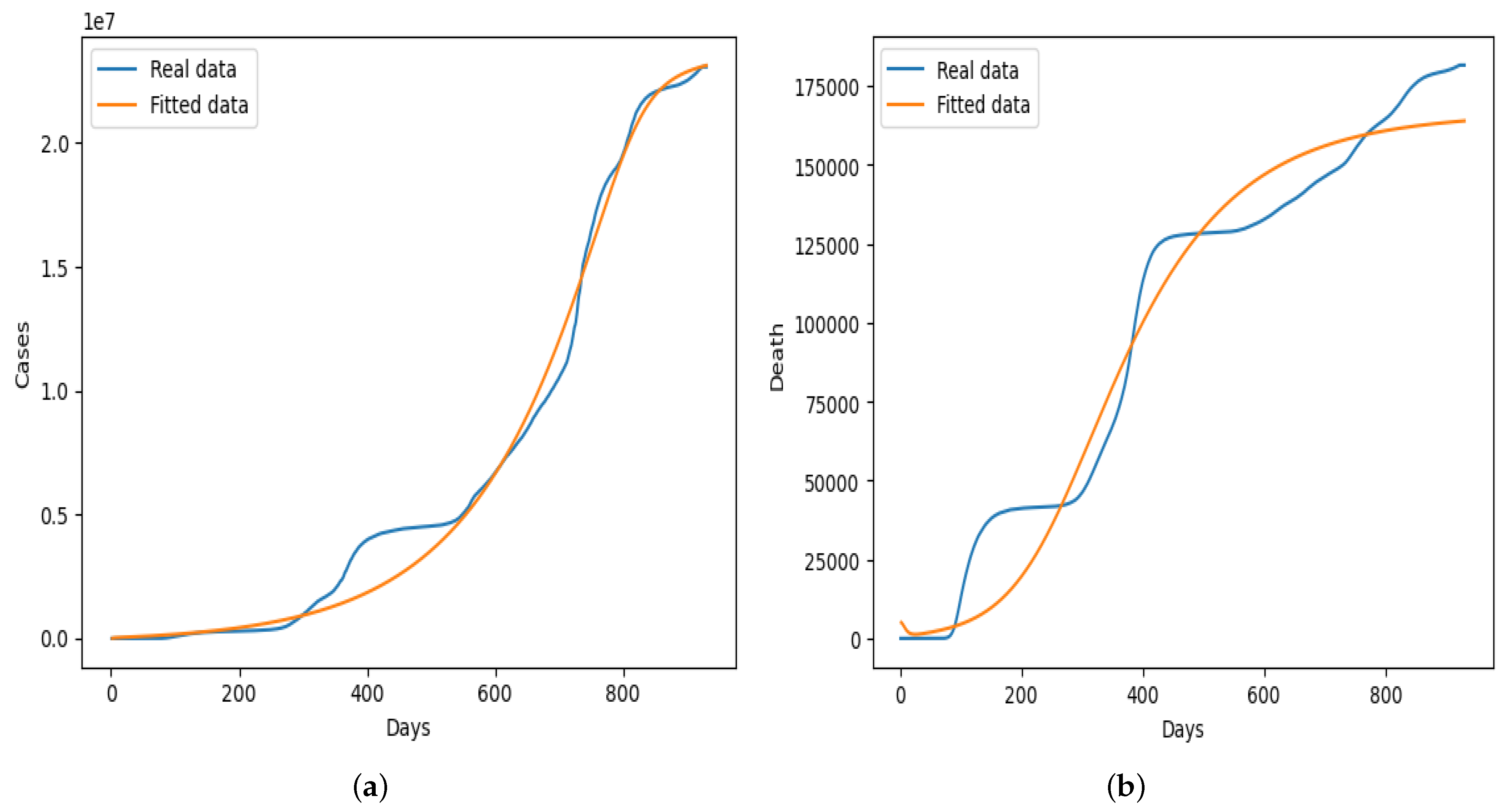
Table 2. Some of the parameters were fitted in order to obtain the optimal parameters, while others were assumed or taken from existing literature. The nonlinear least squares curve fitting technique was used to fit the model to empirical daily case and death data from the UK using the Python programming language, and the graphical result obtained is presented in
Figure 5. The result in
Figure 5 shows that our model fit the real daily case data better throughout the different phases of the epidemic curve, unlike the fitting presented in
Figure 5b in which the dynamics of the fitted data did not capture the real data properly. We also test our model using different partitions of the data before and after vaccination started in the UK, the results of which we did not present in this section. In general, our model fit the daily cases from the beginning of the pandemic up to July 2022 better, as shown in
Figure 5a.
2.4. Statistical Predictors and Principal Component Analysis (PCA)
Principal component analysis (PCA) is a technique widely used for dimensionality reduction, feature extraction, and data visualization [
19] commonly used in the field of machine learning and statistics. It is used to transform high-dimensional data into a lower-dimensional representation while retaining as much of the original data’s variability as possible. PCA achieves this by finding a set of orthogonal axes, called principal components, along which the data varies the most. The principal component analysis can be applied in the statistical modeling of infectious diseases to help analyze and understand complex datasets related to disease dynamics, transmission patterns, and other epidemiological factors [
20]. The first principal component explains the most variance in the data, the second principal component explains the second most, and so on. The
principal component of a data (for instance UK COVID-19 cases) vector
can therefore be given as a score
=
in the transformed coordinates or as the corresponding vector in the space of the original variables,
, where
is the
eigenvector of
[
21].
The distribution of data along its principal components is known as skewness. The distributional characteristics of this data require appropriate preprocessing steps to ensure that PCA results accurately capture the underlying structure of the data. If data contains significant outliers or skewness that cannot be easily addressed through data preprocessing, one might consider using robust PCA techniques that are less sensitive to extreme values and skewed distributions.
Kurtosis, on the other hand, in the context of principal component analysis (PCA), refers to the distribution of data points in terms of their peakedness or the presence of heavy tails in the data’s probability distribution. It measures the degree to which the data deviates from a normal distribution (Gaussian distribution). There are several different measures of kurtosis, but they all essentially assess the tails of the distribution relative to a normal distribution. Kurtosis can have an impact on PCA in the following ways: interpretability of principal components, robustness to outliers, data transformation, and so on. If your data exhibits high kurtosis due to extreme outliers, you might consider using robust PCA techniques that are less sensitive to outliers and heavy-tailed distributions. In as much as kurtosis can impact the results of PCA by affecting the distributional characteristics of the data, appropriate data preprocessing techniques and transformations can help address these issues and lead to more reliable and interpretable principal components.
In summary, skewness and kurtosis are both important measures of a distribution’s shape. Skewness measures the asymmetry of a distribution, while kurtosis measures the heaviness of a distribution’s tails relative to a normal distribution [
22].
The coefficient of variation (CV) is a statistic used to measure the relative variability or spread of data points in a dataset. It is expressed as a percentage and is calculated as the ratio of the standard deviation () to the mean () of the data, multiplied by . The coefficient of variation is often used to compare the variation in datasets with different units or scales. A higher CV indicates greater relative variability, while a lower CV indicates less relative variability. The coefficient of variation can be a helpful tool in the context of PCA for data preprocessing, feature selection, and interpreting the significance of individual variables in the principal components. It helps ensure that PCA is applied appropriately, especially when dealing with datasets with varying scales and levels of variability.
In PCA, the concept from information theory that measures the uncertainty or randomness in a dataset or information source is known as entropy. It is used to gain and interpret information and is also useful in making decisions about splitting data at each node in the (decision trees/forests).
In the broader context of data analysis and preprocessing, especially when assessing the normality of data distributions, the
Kolmogorov–Smirnov (KS) test is a statistical test used to compare the distribution of a sample data set with a known distribution or to compare two sample data sets. It assesses whether a sample is drawn from a particular distribution, such as a normal distribution [
23]. While the KS test itself is not typically used directly within principal component analysis (PCA). It can be used to identify potential outliers.
The first principal component explains the most variance, the second explains the second most, and so on. Measures of variance, such as the eigenvalues of the covariance matrix, are crucial for understanding the importance of each principal component. The measures of dispersion (dispersion index (ID)), particularly variance and explained variance, play a crucial role in the technique of PCA. PCA aims to maximize the variance of the data along its principal components, and the analysis often involves assessing how much variance is retained or explained by each component to make informed decisions about dimensionality reduction.
Further mathematical formulation of these statistical predictors and PCA can be found in [
24,
25].
4. Numerical Simulation
We used the homotopy perturbation method (HPM) for the numerical simulation of model (1). The description and the analytical solution of the method are presented in the
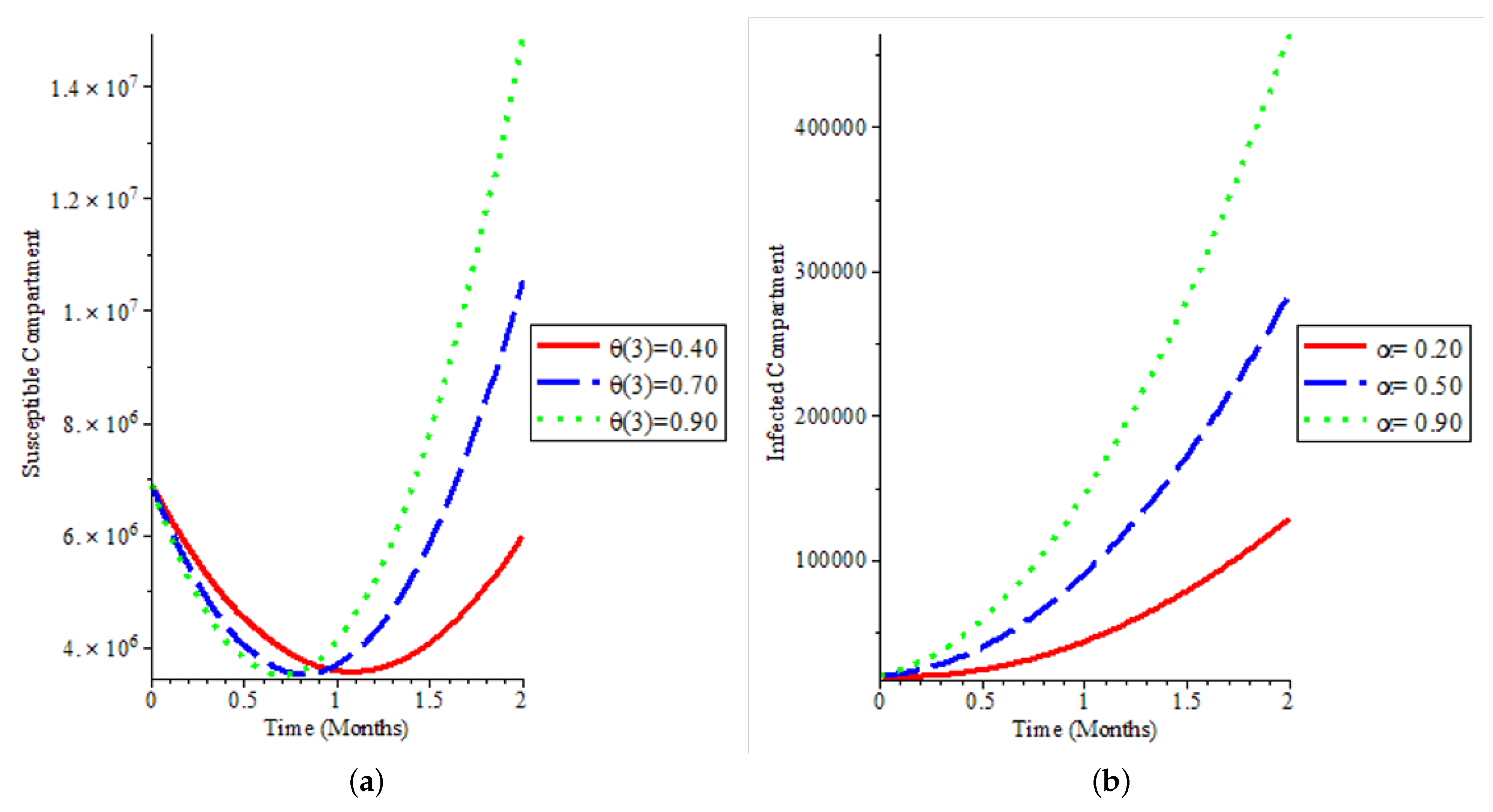
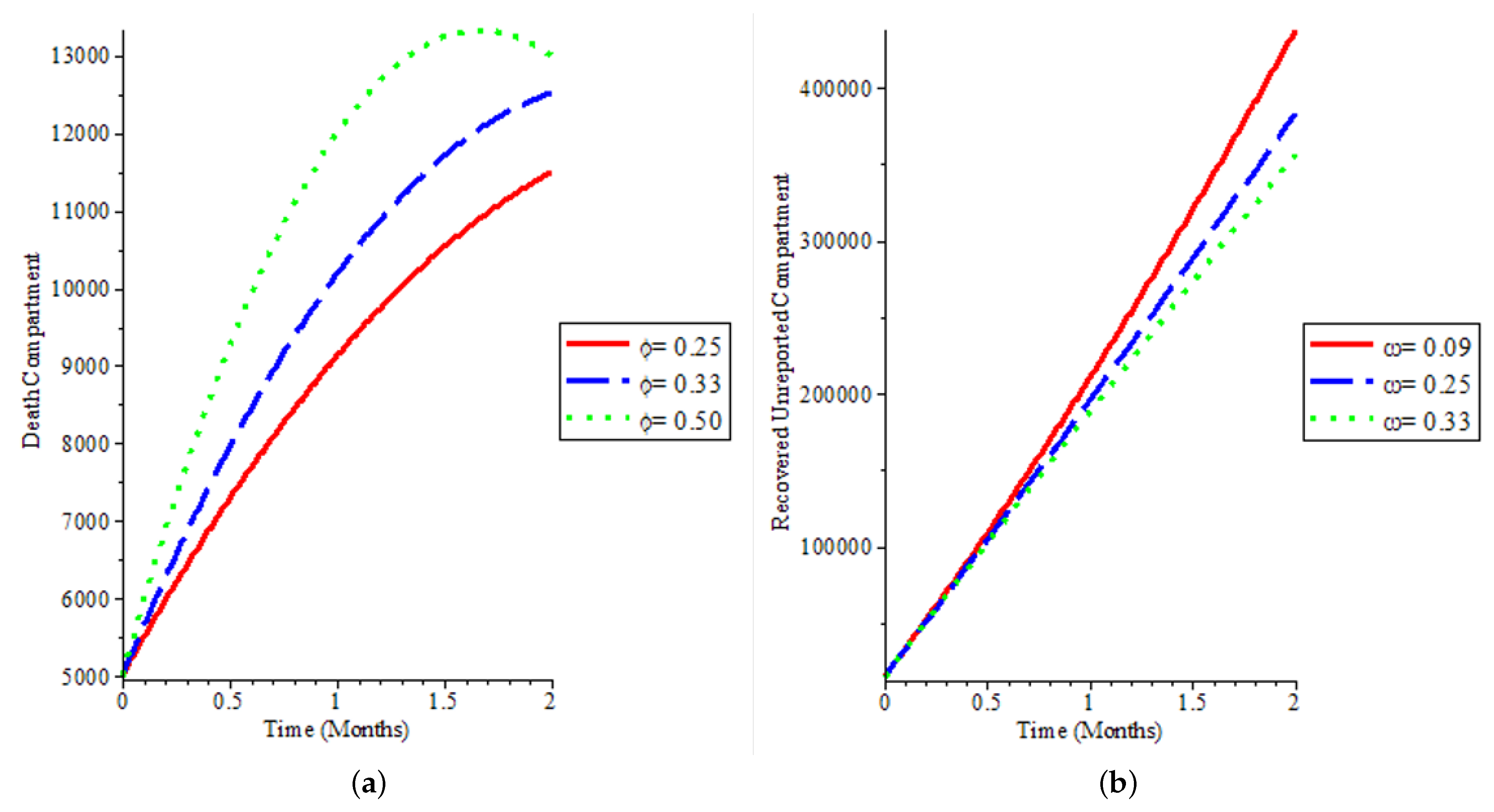
Appendix A. We present the numerical simulation of our mathematical model by varying some of the model parameters to see the behaviour of the epidemic curve over an 8-week period. The visualisation of the results of the simulation with varying parameters is presented in
Figure 8,
Figure 9,
Figure 10 and
Figure 11.
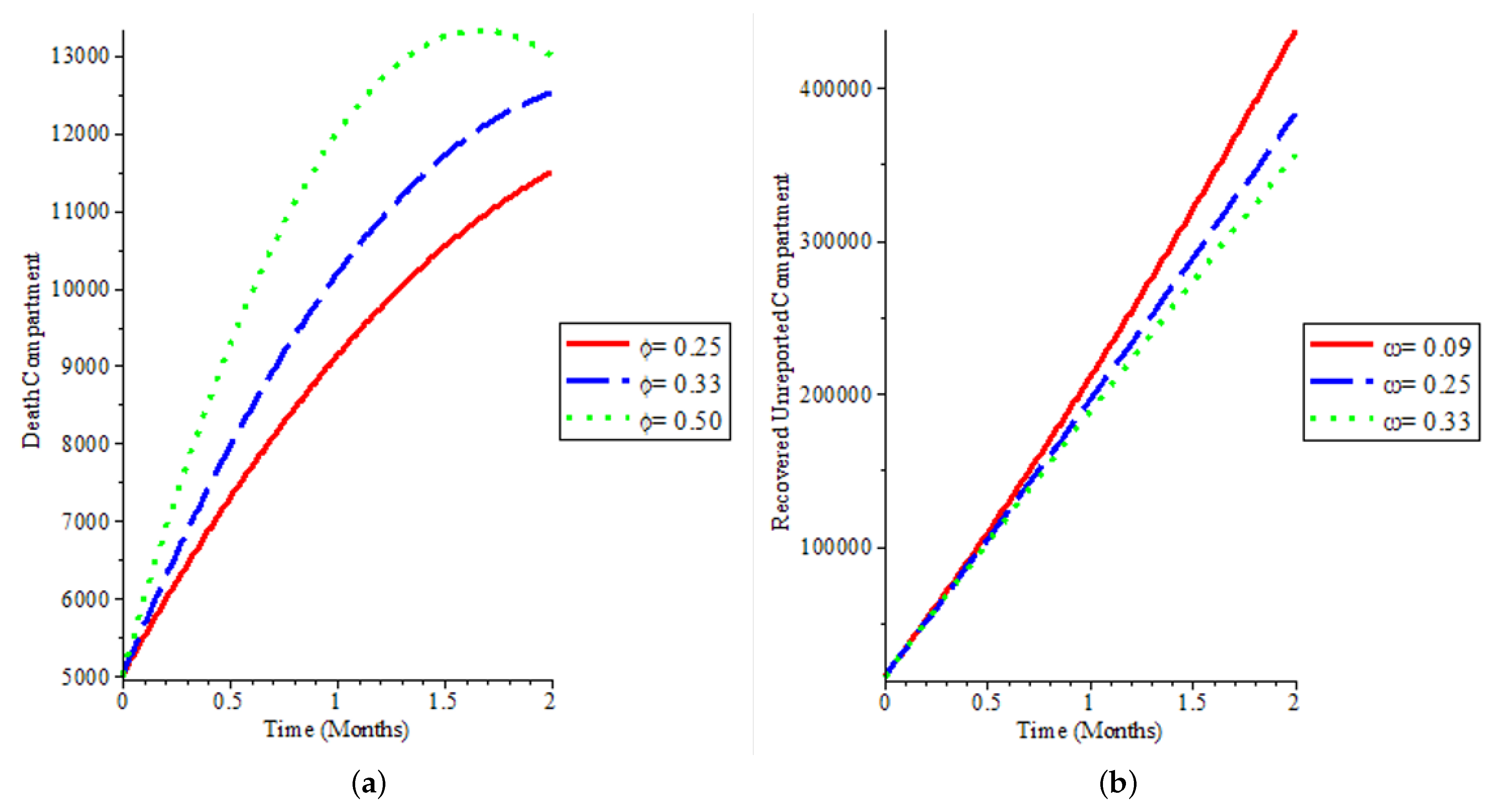
Figure 8a shows that even if we have a high vaccination rate, it does not change the fact that the population is not still susceptible to the COVID-19 virus. It affirms that individuals are not immune to the disease and can be reinfected, which has been the case with COVID-19 dynamics. In
Figure 8b, we could say that if more people are exposed to the disease and are infectious, there will be exponential growth in the infected population, which will lead to rapid spread within the population.
Figure 9a explains how deaths can be reduced in the population, and our model was able to capture low death rates as observed in the real data of COVID-19 spread in the UK and by extension globally. We demonstrate in
Figure 9a that after a time period, most especially when vaccination starts, it can reduce death due to the disease as can be seen in the green line demonstrating a sharp reduction in the death population if we increase the time step.
Figure 9b and
Figure 10 show that more people recover, whether it is reported or not, if there is an aggressive vaccination campaign leading to more people being vaccinated in the population. This leads to what we have observed in the global COVID-19 recovery count: we have more people recovering from the disease, which is also observed in the UK.
Figure 11a shows that more vaccinated individuals are exposed to the disease and they are unreported, affirming that most COVID-19 cases are unreported while a smaller proportion of the population that is vaccinated and exposed to the disease is reported as shown in
Figure 11b.
5. Statistical Modeling and Analysis
5.1. Statistical Analysis of the Entire Dataset
In this section, we present some time-series modeling that is statistically predictive of the evolution of the spread of the COVID-19 outbreak in the UK.
These statistical predictor indicators calculated in a moving window of 14 days are the coefficient of variation (CV), the entropy of the stationary empirical measure, the third and fourth standardized moments of the empirical distribution (respectively, skewness and kurtosis), the uniformity index, which is the index of dispersion (ID), and the normality index, which is the Kolmogorov–Smirnov test (KStest) of adequacy to the normal distribution, showing, respectively, expectation and standard deviation. We normalized the index of dispersion (normalized ID) to remove outliers. Using the principal component analysis (PCA), a score is built from these statistical indicators, and the prediction performance is estimated from the ability to predict the epidemic exponential growth phase.
All the predictor indicators are calculated in the same moving window, respecting the following rules:
Choose the same length of moving window for the predictor indicator calculation (14 days).
Use the same time step as for moving the window (1 day).
Move the window from the start to the end of the COVID-19 outbreak observed between January 2020 and July 2022 for both daily cases and daily deaths.
A way to obtain an important score is to use the first principal component of the principal component analysis (PCA), which explains in general a sufficient percentage of the variance of the daily new cases and deaths from the UK COVID-19 data empirical distribution. In
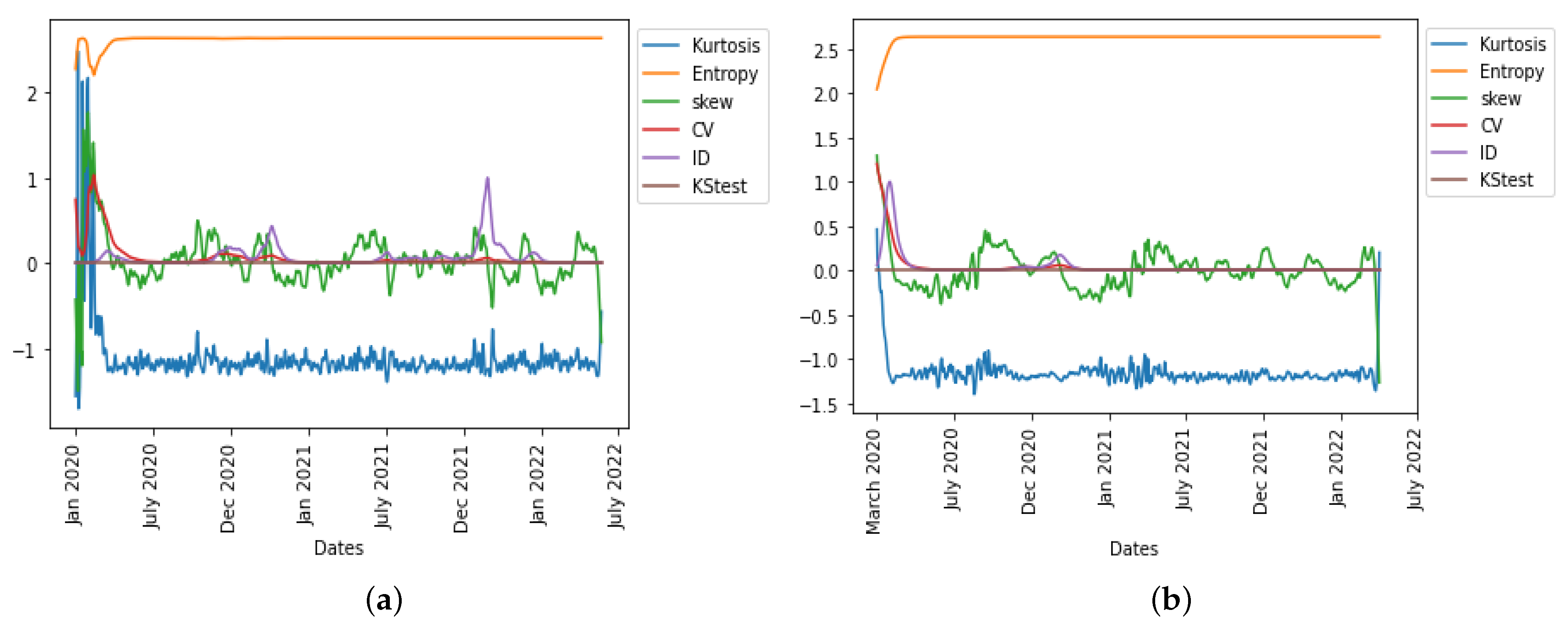
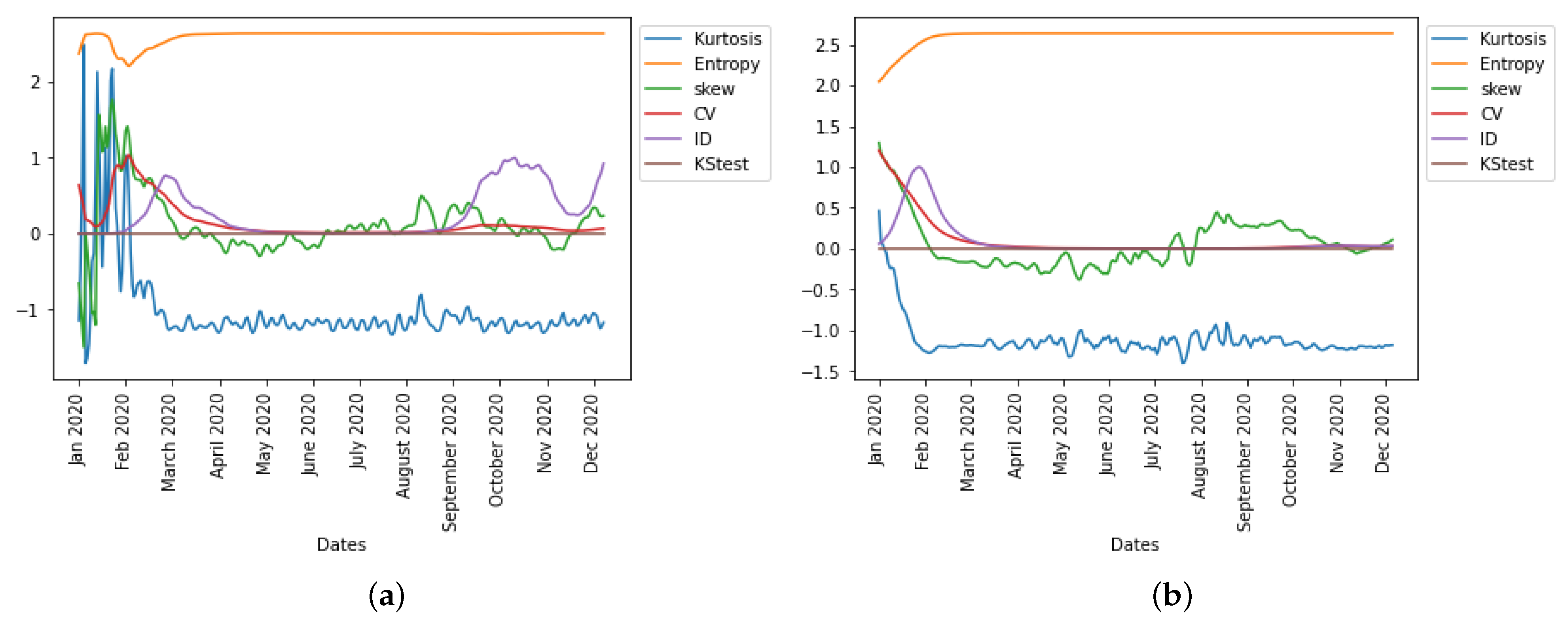
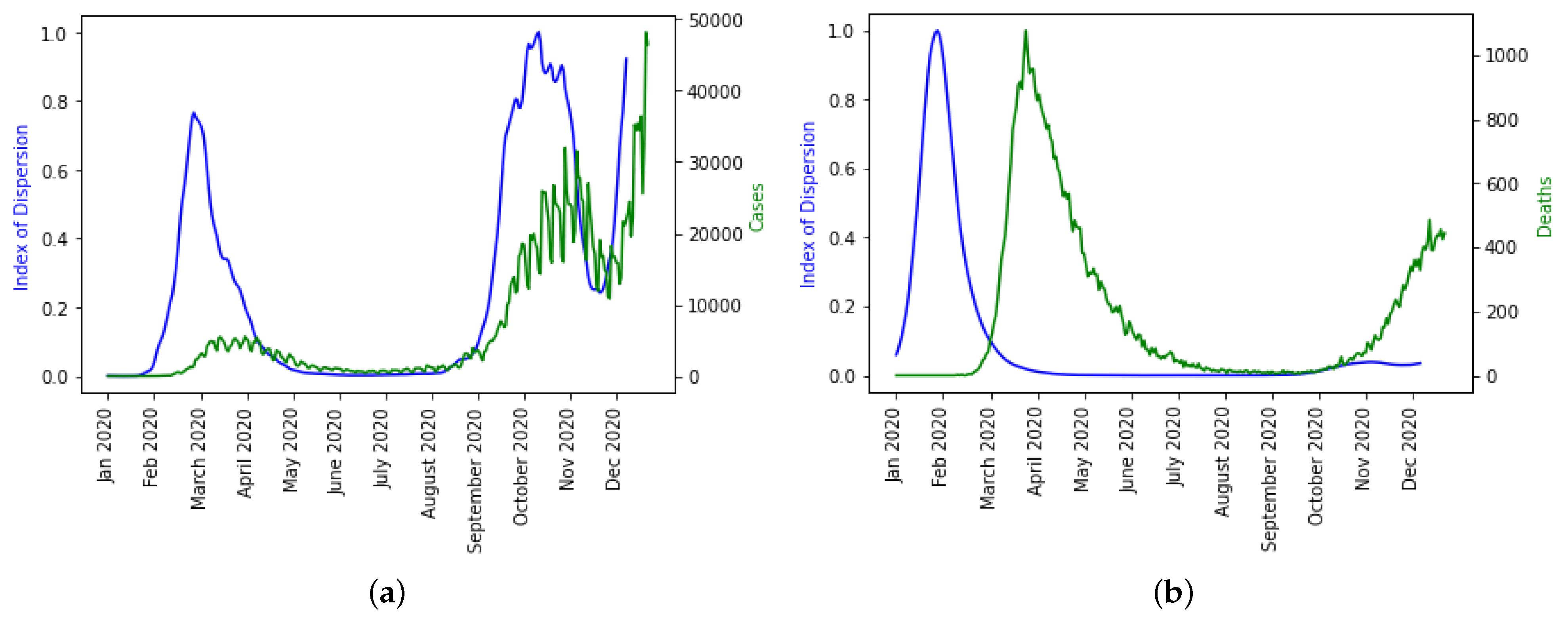
Figure 12, we observe in the UK the evolution of all six statistical predictor indicators for daily new cases and deaths data.
The precision of the forecasting character of both the first PCA principal component, PC0, and the index of dispersion (see
Figure 12) can be easily explained by the fact that the ID is often the main weight in the linear combination expressing PC0 on the breakdown coefficients, as calculated for example for the first moving window in the UK daily new cases during early January 2020, the breaking coefficients calculated for the first moving windows of 14 days in
Table 4, and the breakdown of principal components (PCs) in
Table 5.
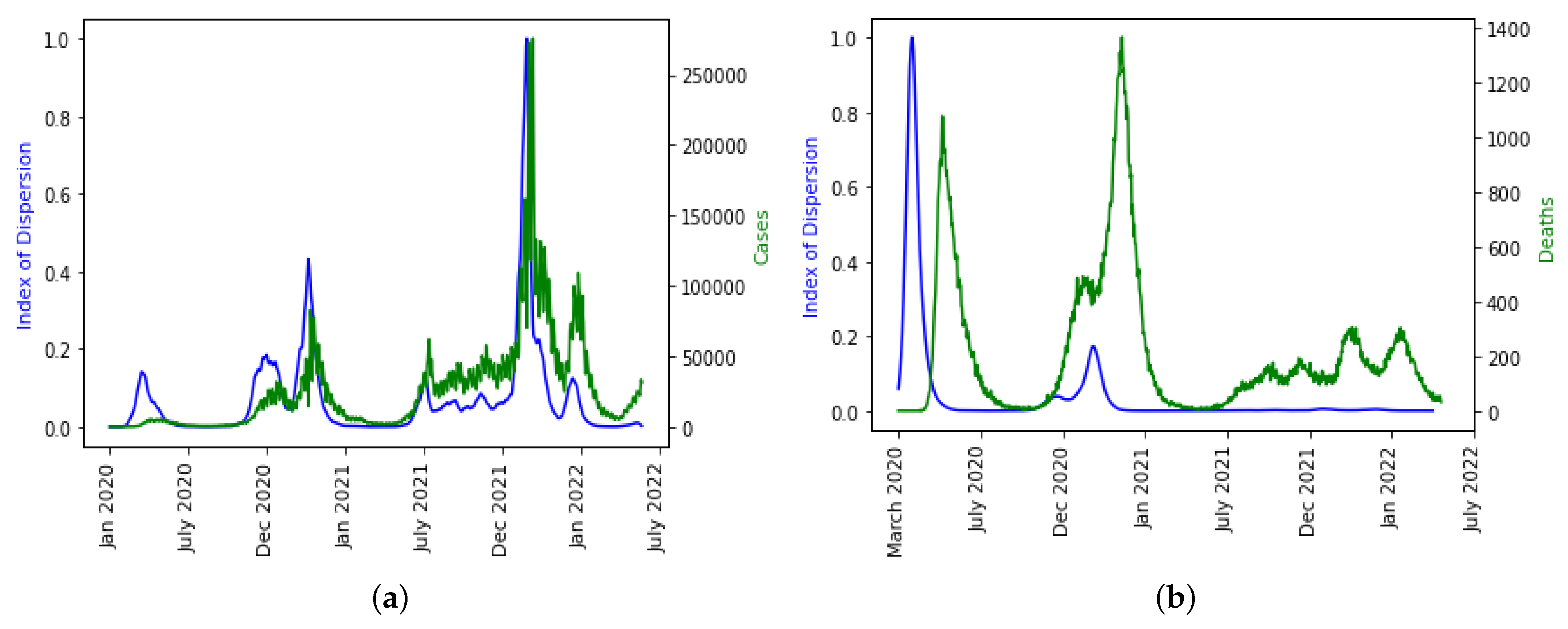
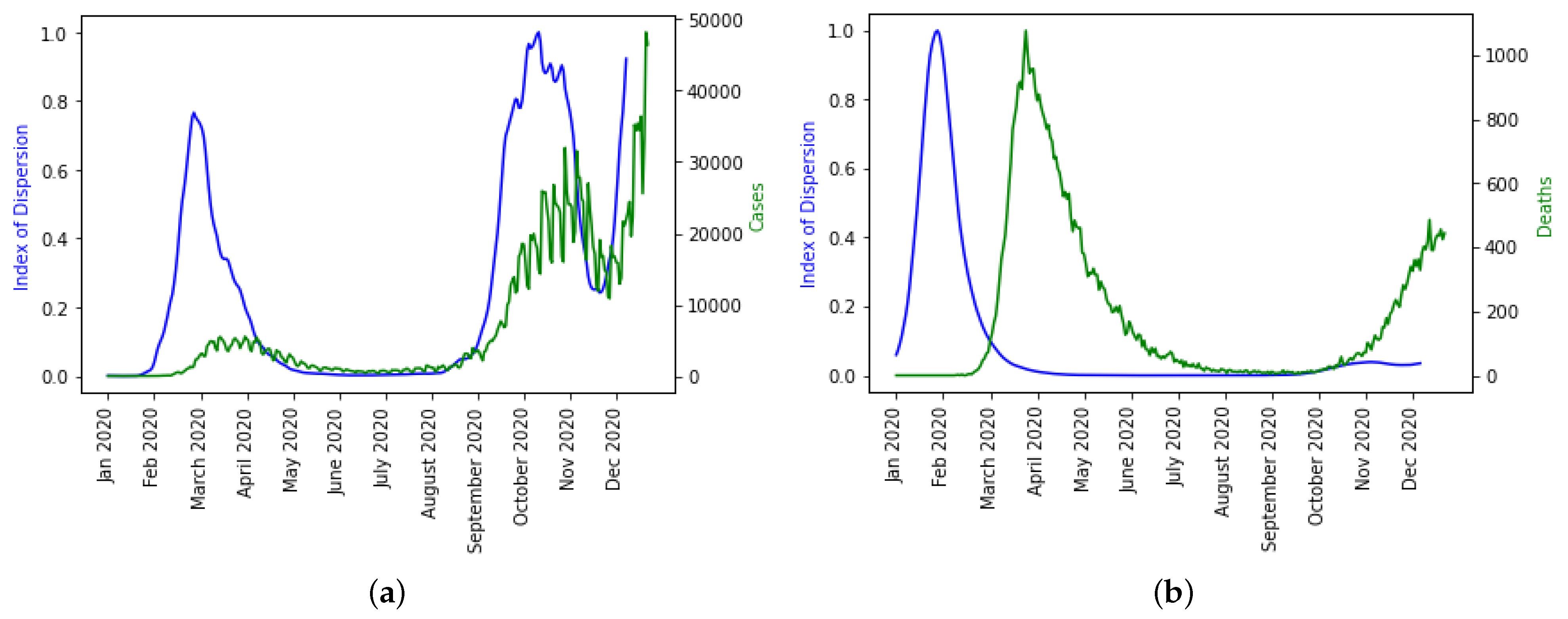
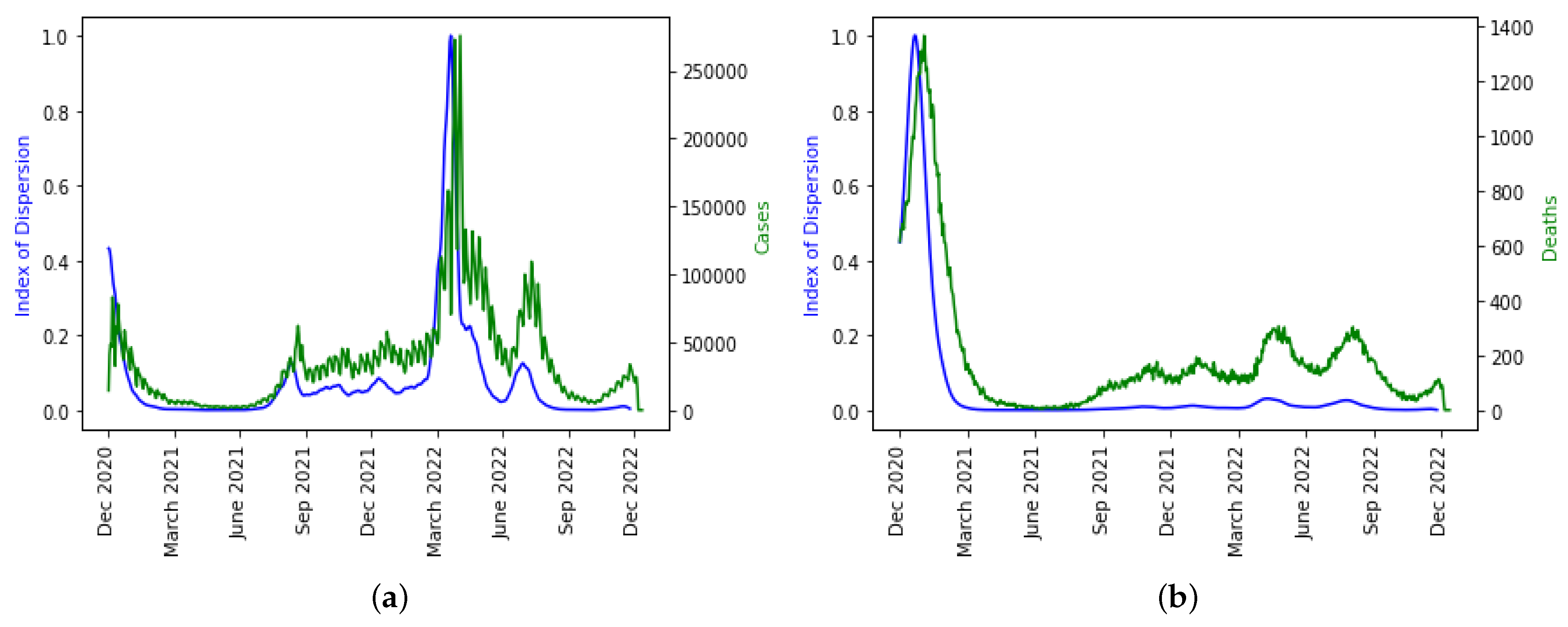
We plotted ID separately over the daily new cases and deaths because it is the only indicator that captured the disease spread dynamics well as seen in
Figure 13a even though there is a shift in the daily death dynamics as shown in
Figure 13b. It is not surprising that higher moments like skewness and kurtosis are not capturing the disease dynamics well and have smaller weights in the linear combination of PC0 because it has been statistically proven that higher moments are not good predictor variables.
The epidemic peaks are consistently preceded by the PC0 minima and ID maxima, and therefore it makes sense that the empirical distribution of the new cases has changed (losing stationarity). The index of dispersion ID is, in fact, the logarithm of the ratio between the second and first (mean) moments of the empirical distribution of new cases. Variations in the index of dispersion ID show the loss of stationarity prior to an exponential growth of new cases, which is one of the primary characteristics of the early dynamics of an epidemic peak. The statistical predictors used exhibit the same predicted behavior with PC0. Index of dispersion ID waves take place out of phase with PC0, but they also accurately predict future cases.
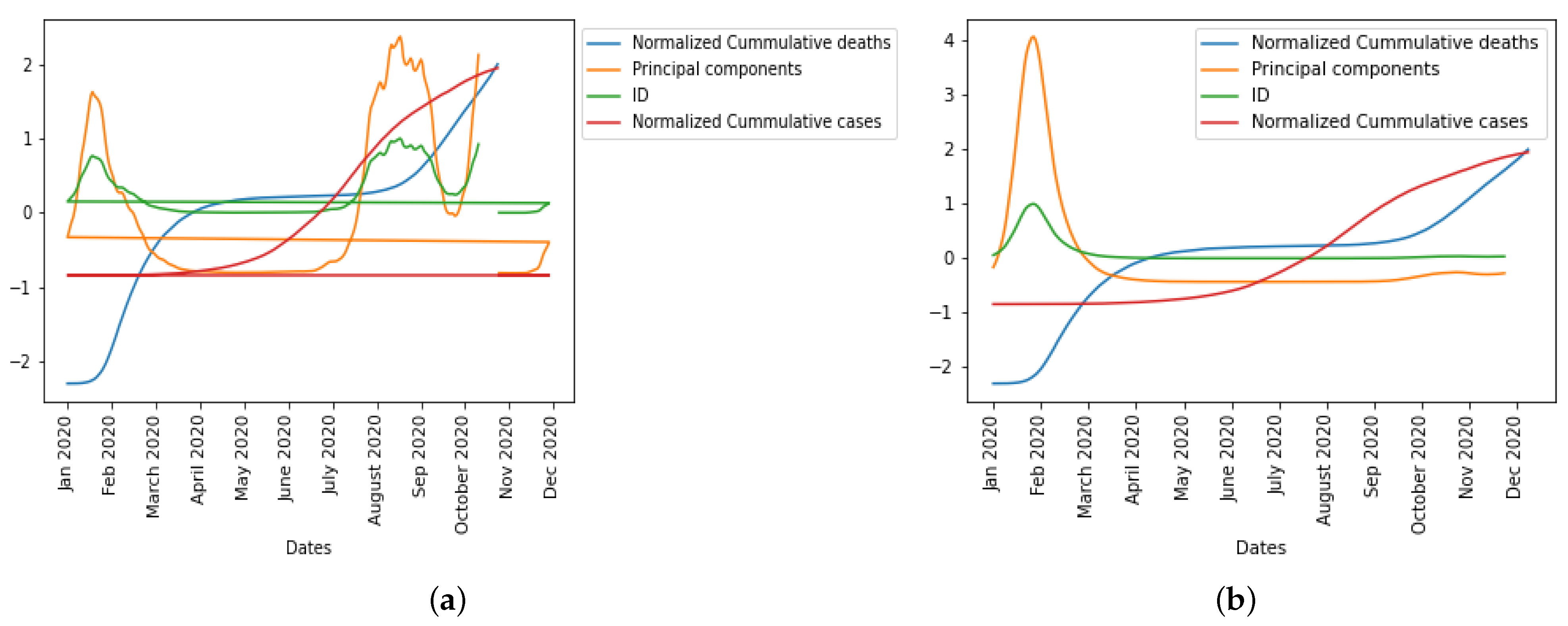
5.2. Statistical Analysis before Vaccination Started
In this section, we present the epidemic dynamics of how these statistical predictor indicators behave before the introduction of vaccination in the population.
In
Figure 14, we observe in the UK the evolution of all six statistical predictor indicators for daily new cases and deaths data before vaccination was introduced to the population.
The index of dispersion captured the disease spread dynamics and peaks in the epidemic curve well as seen in
Figure 15a even though there is a shift for the daily deaths dynamics as shown in
Figure 15b.
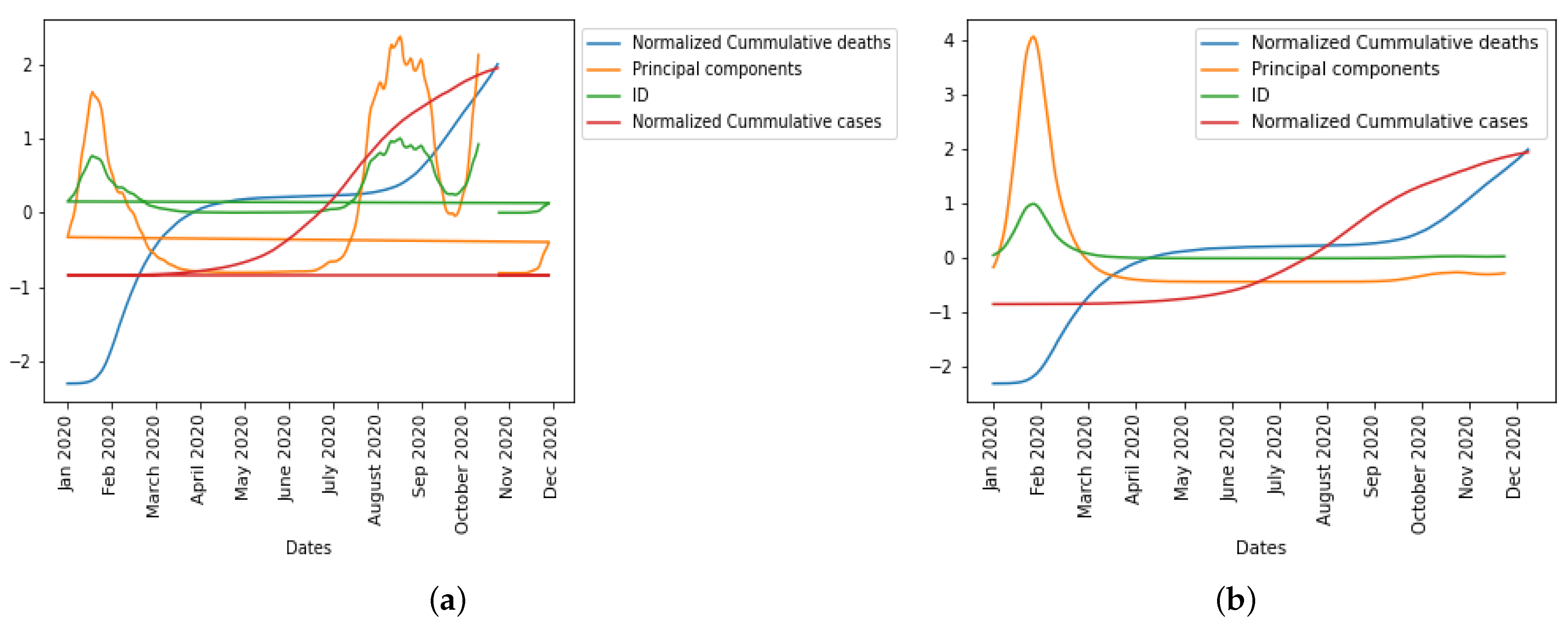
In
Figure 16, we normalized the cumulative cases and deaths so as to be on the same scale with first principal component and index of dispersion when considering daily new cases and daily deaths before vaccination, respectively, which will help us compare the epidemic waves in the different curves.
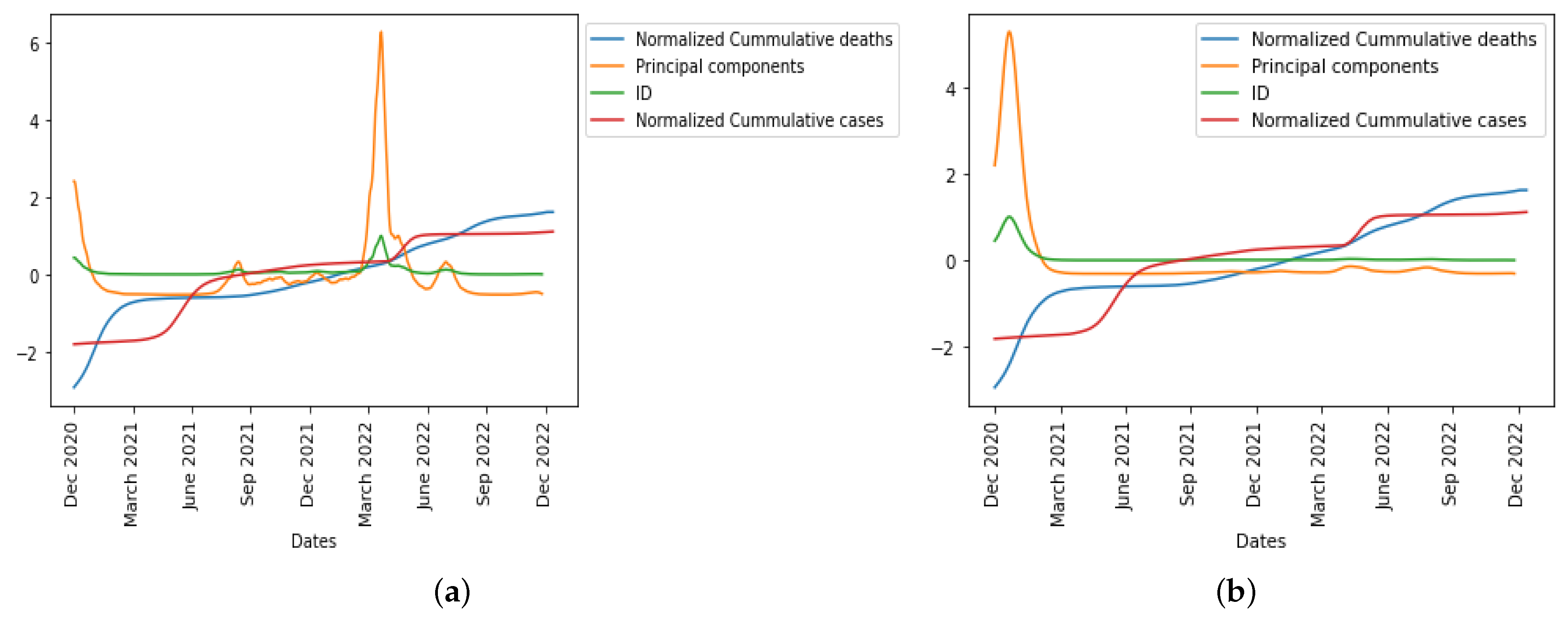
5.3. Statistical Analysis after Vaccination Has Started
Here, we present the epidemic dynamics of how these statistical predictor indicators behave after vaccination started in the UK.
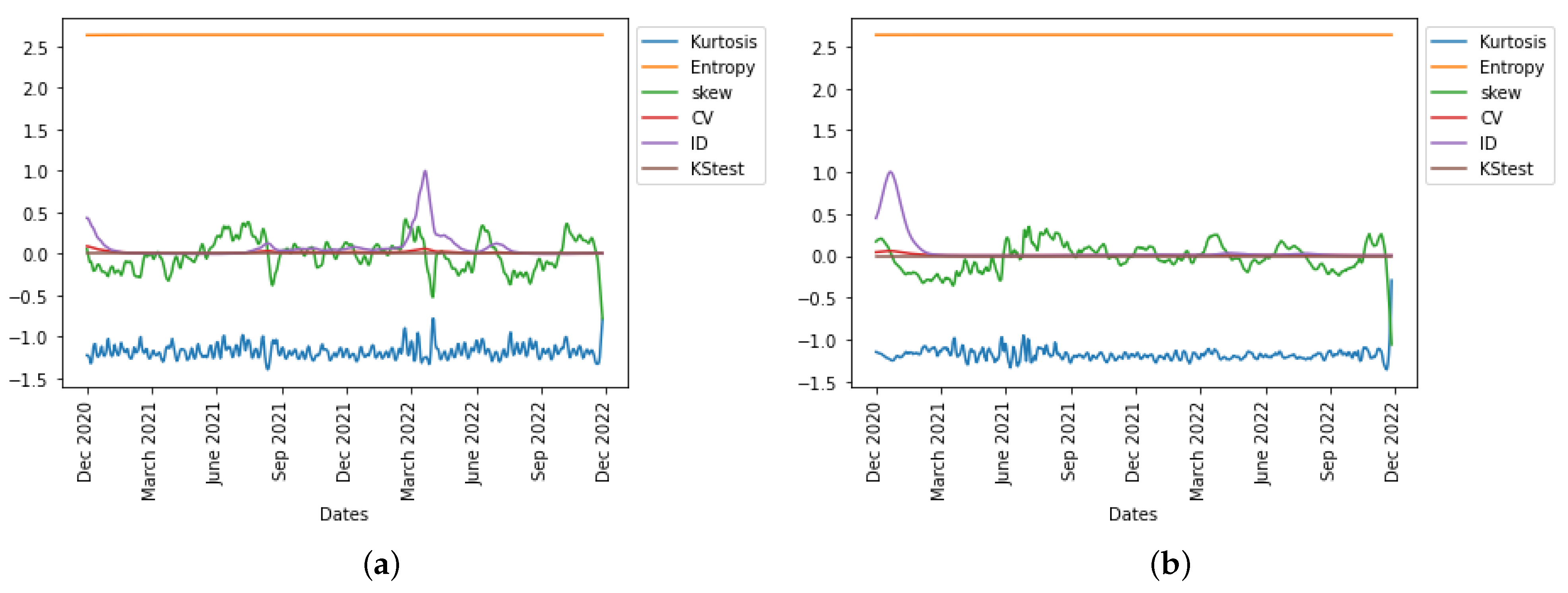
In
Figure 17, we observe in the UK the evolution of all six statistical predictor indicators for daily new cases and deaths data after vaccination was introduced in the population.
The index of dispersion captured the disease spread dynamics and peaks in the epidemic curve well as seen in
Figure 18 for both the daily cases and daily deaths. This phenomenon observed in this case might be due to the effect of the vaccination of the population, which enables this statistical predictor indicator to better capture the disease dynamics appropriately.
In
Figure 19, we normalized the cumulative cases and deaths so as to be on the same scale with first principal component and index of dispersion when considering daily new cases and daily deaths after vaccination, respectively, which will help us compare the epidemic waves in the different curves.
6. Concluding Remarks
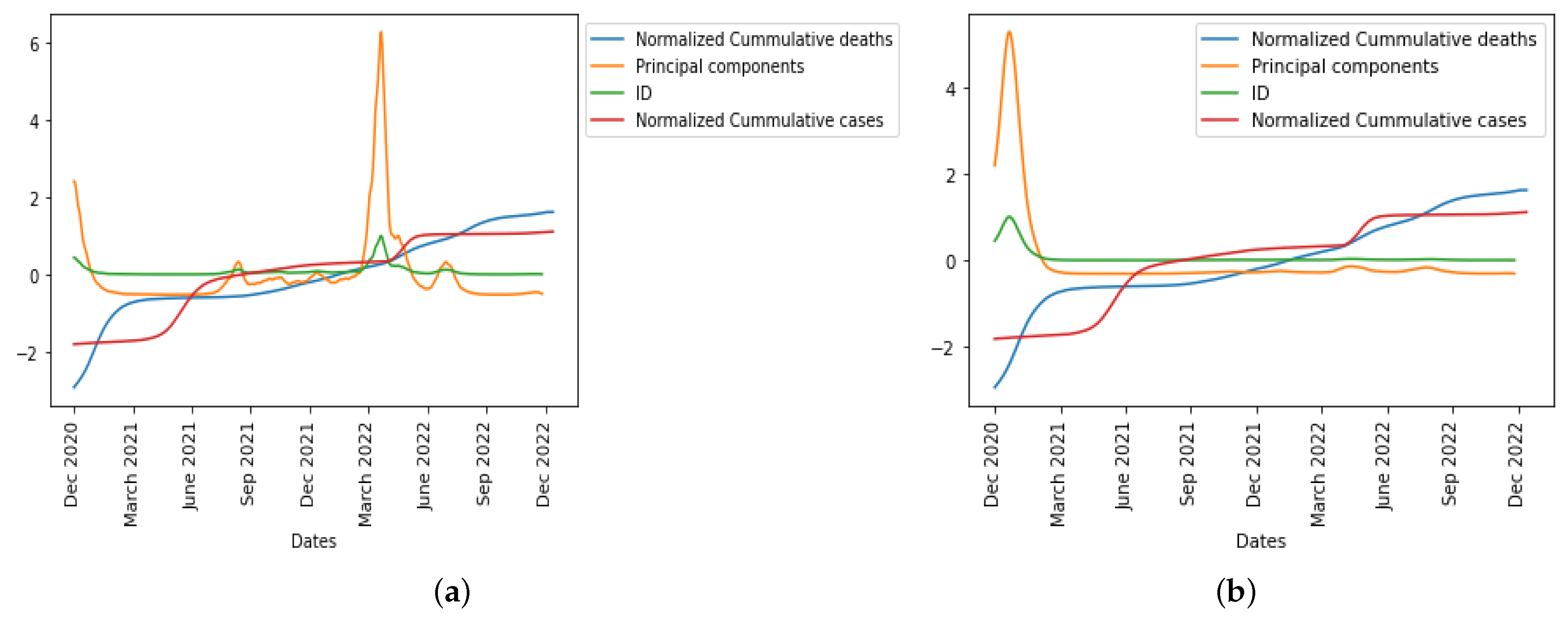
We have shown the nexus between the two approaches we used in this research by predicting the COVID-19 cases and deaths from the beginning of the pandemic in the UK up until July 2022 using a hybrid (mathematical and statistical) model demonstrating high predictive power that shows an alignment with the empirical COVID-19 case and deaths data. The prediction from the fitting of the mathematical model to real data (
Figure 5), the simulated results (
Figure 8b) that simulated 8 weeks of the epidemic trend, the first principal component curve, and the index of dispersion (see
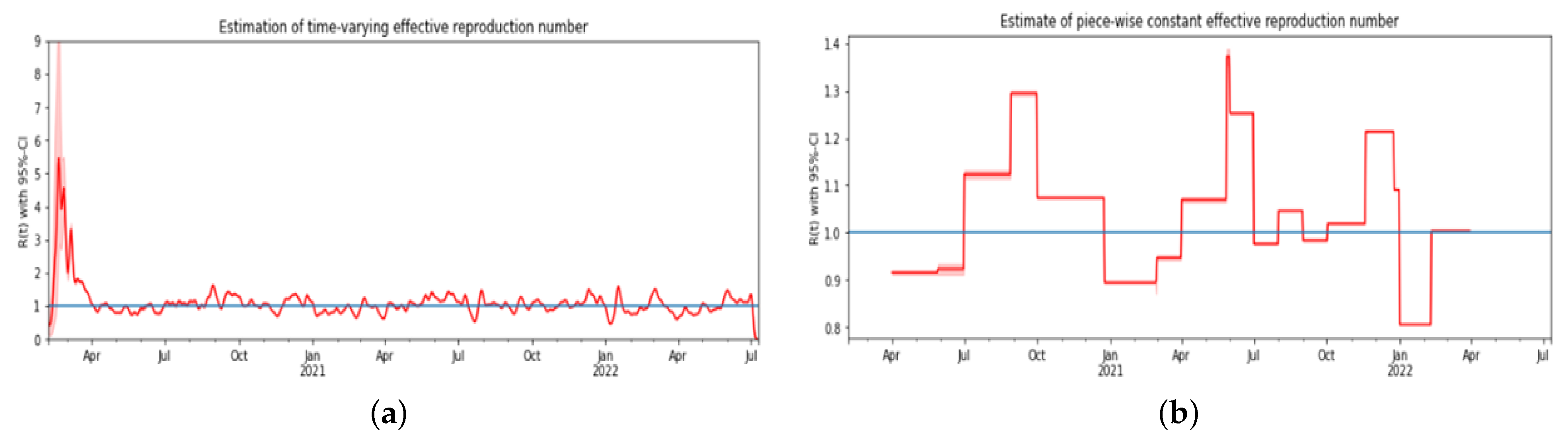
Figure 6b) captured the dynamics of the disease across different exponential and endemic phases in the epidemic curve, showing similarity in trends.
Also, comparing the vaccination trend (see
Figure 3) with the results we presented in
Figure 17,
Figure 18 and
Figure 19 explains the influence of vaccination on the epidemic waves (both daily new cases and deaths) after vaccines were introduced to the population.
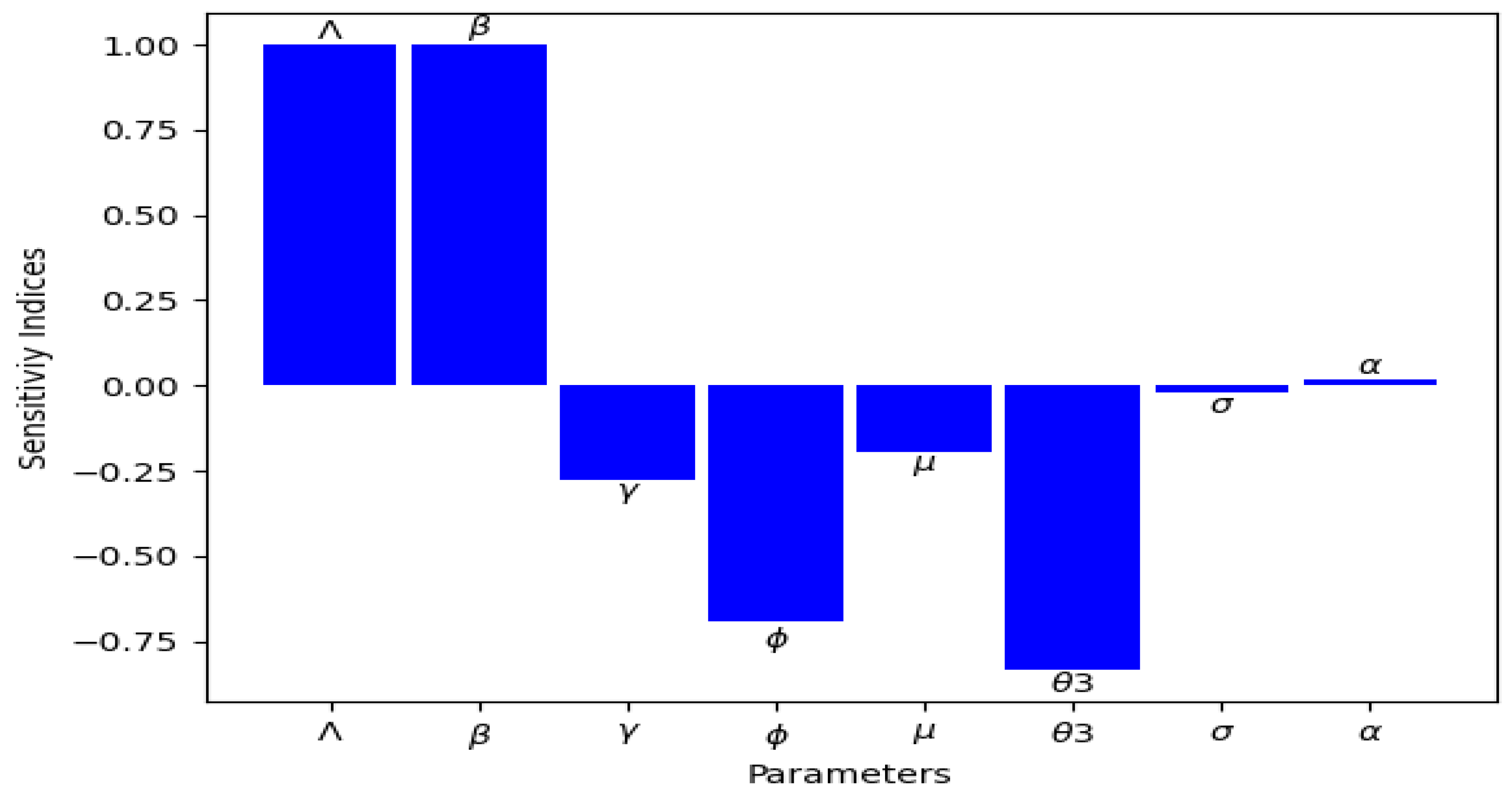
In this paper, we have been able to use a nonlinear mathematical model to perform some mathematical analysis, fit the model to real data, and also perform some numerical simulation by varying some epidemic parameters. We also calculated the threshold parameter () and the time-varying across the pandemic period we considered. We showed the importance of vaccinating individuals in the population, which will help increase recovery among those infected with the virus. Furthermore, we used some statistical predictor indicators to infer how the index of dispersion fit well with the observed data from the UK, used PCA to generate scores, and then used the first principal component, which is the most important in principal component analysis, to capture the trends in the epidemic curve. Our hybrid modeling approach and the consideration of a long epidemic period allow us to demonstrate the robustness of our results, which will be useful for modelers and researchers.
To conclude, the COVID-19 pandemic has been a transformative event with profound implications for global health, society, and the economy. It has challenged us in unprecedented ways but has also brought out our resilience and capacity for innovation. By learning from this experience, we can build a stronger, more equitable world that is better equipped to confront future epidemics. From this paper, we know that integrating mathematical and statistical models with daily empirical case and death data is a valuable approach to understanding and modeling the spread of COVID-19. By combining these two components, researchers and policymakers can gain insights into the dynamics of the disease, enhance the accuracy of models, allow for the estimation of key parameters, predict future trends, evaluate intervention strategies, and facilitate the development of monitoring systems. A future research direction could be considering the age stratification in the UK with the number of doses of vaccine shots received by individuals in the population using a spatial modeling approach at a small spatial scale, which will enable us to understand the local or community spread of the disease and to understand how to deploy resources to mitigate its spread. Another future work could be to look at the disease variants during different peaks of the pandemic and align this with the demographic structure of the population.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}